
A Machine Learning Approach to Solve the Network Overload Problem Caused by IoT Devices Spatially Tracked Indoors

Abstract
:1. Introduction
- RQ1—Would the modeling used be able to predict routes that avoid obstacles in closed environments?
- RQ2—How much can latency be increased without loss of performance from ML algorithms?
- RQ3—What is the impact of the amount of data on the performance of ML algorithms?
2. Related Work
3. Dataset
4. Methodology
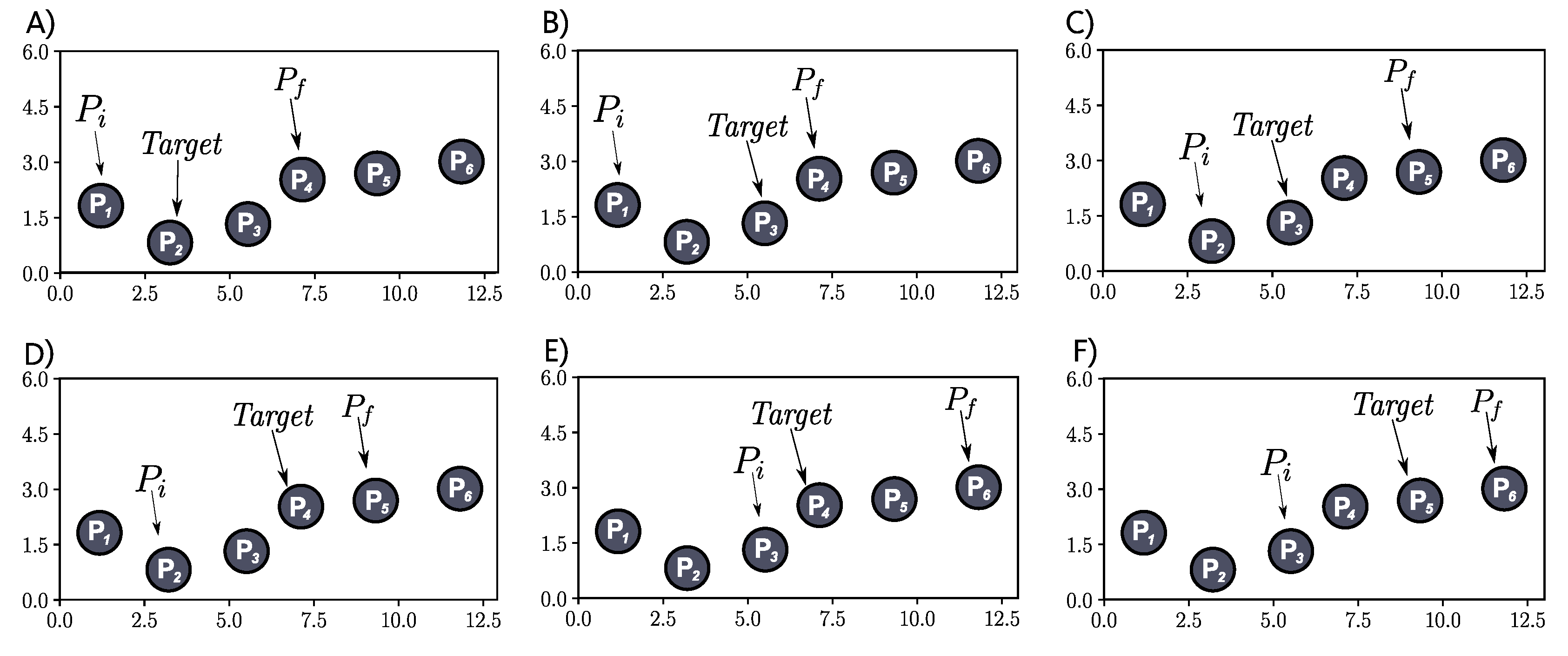
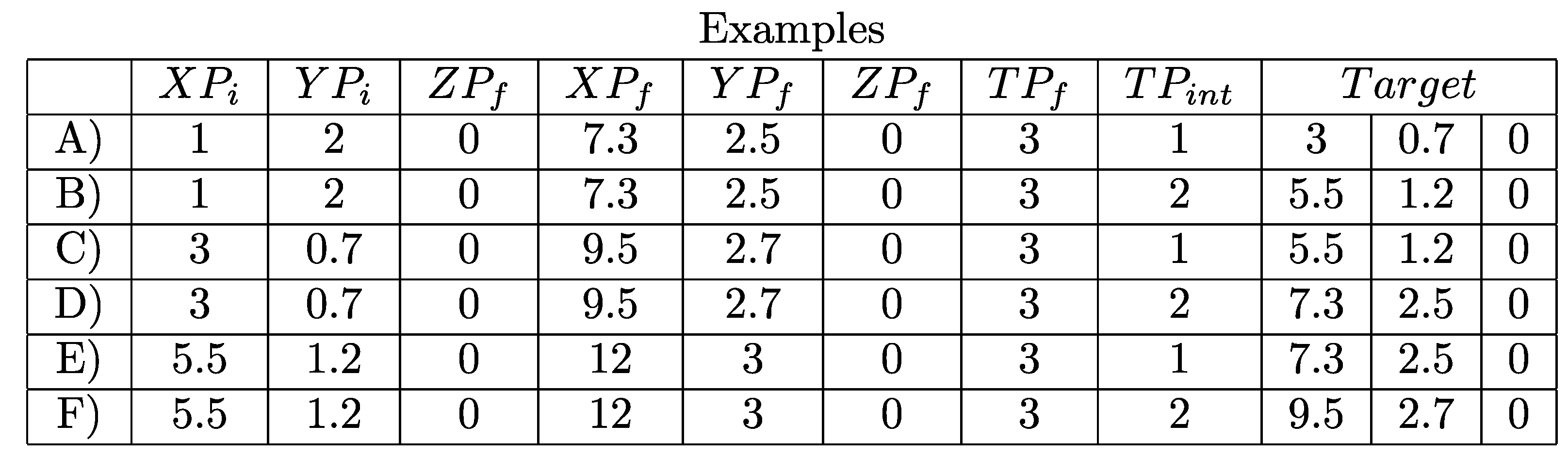
4.1. Feature Modeling
- Starting point of a path (), composed of X, Y, and Z coordinates;
- End point of a path (), also composed of the coordinates X, Y, and Z;
- Relative time at which the end point was recorded (). The value of is calculated by adding the number of points from to multiplied by the latency. It is important to mention that the time of is a reference value, so it is always 0; thus it is not necessary to use it as a feature;
- Relative time at which the intermediate point is to be predicted () with n being the indicator of chronological order of the point. For example, if you want to predict only one point between e , then there will be an observation with . If we want to predict m intermediate points, then we will have an observation with , and another with before finally reaching the last point to be predicted ().
4.2. Setting Up and Running ML Algorithms
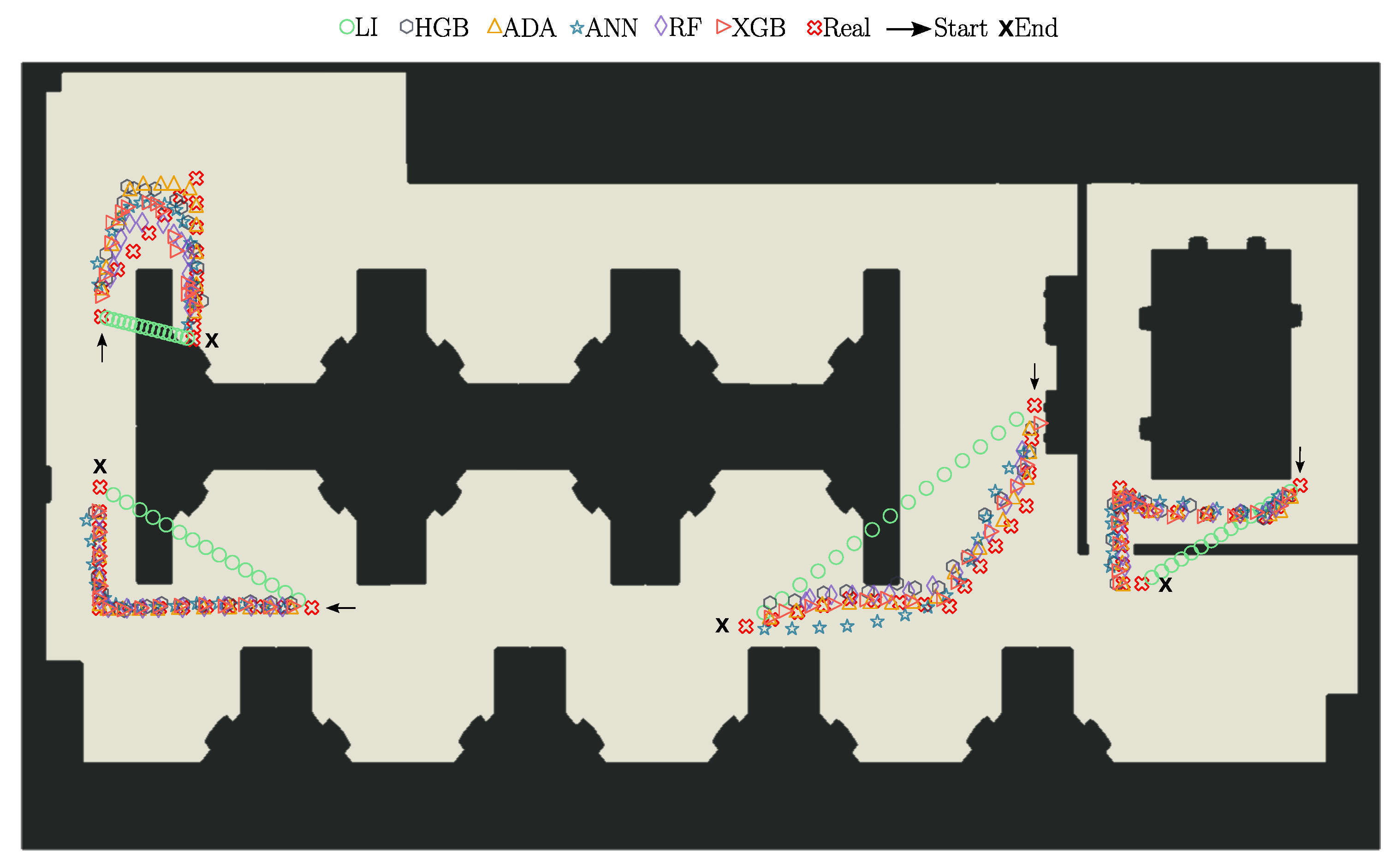
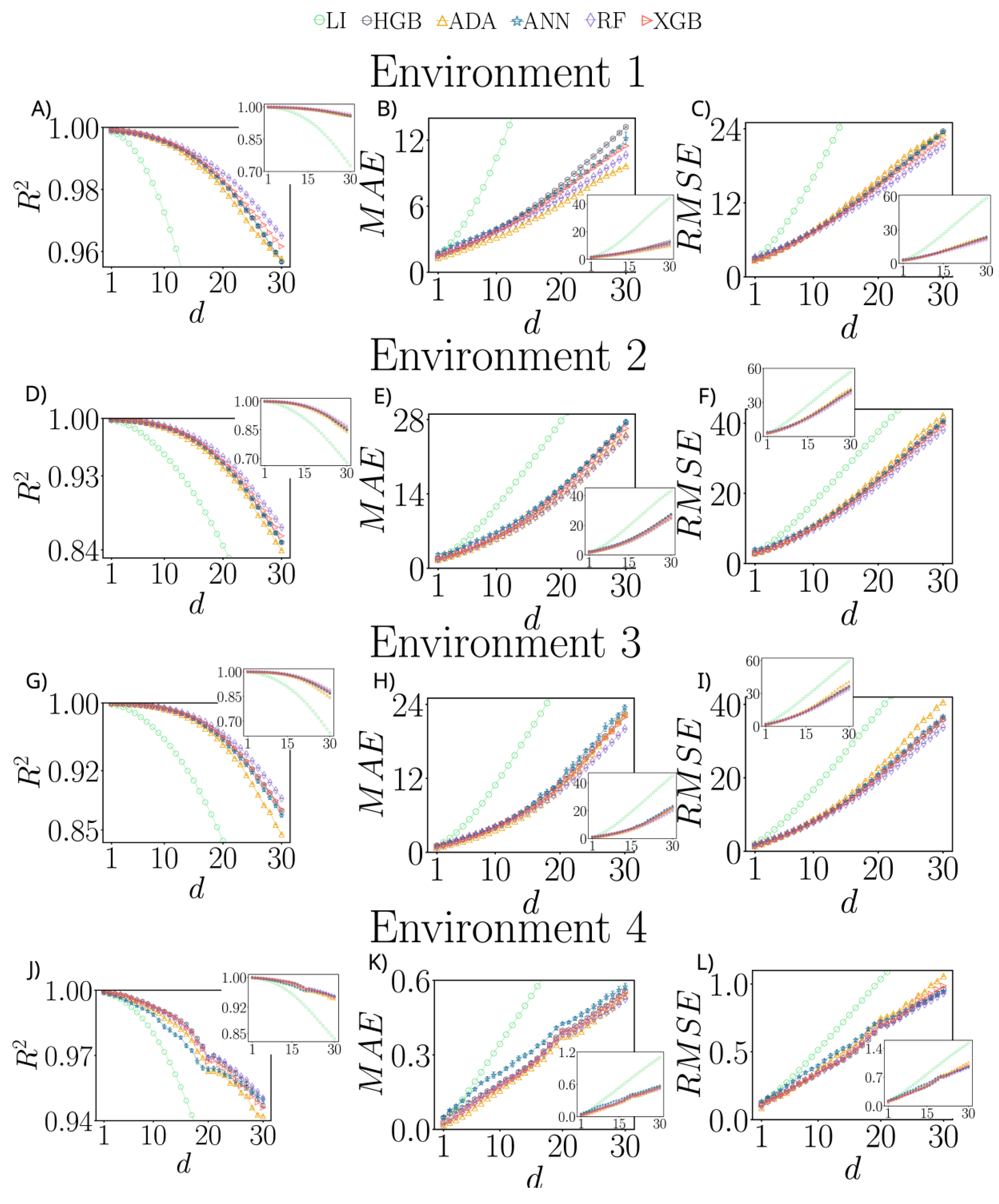
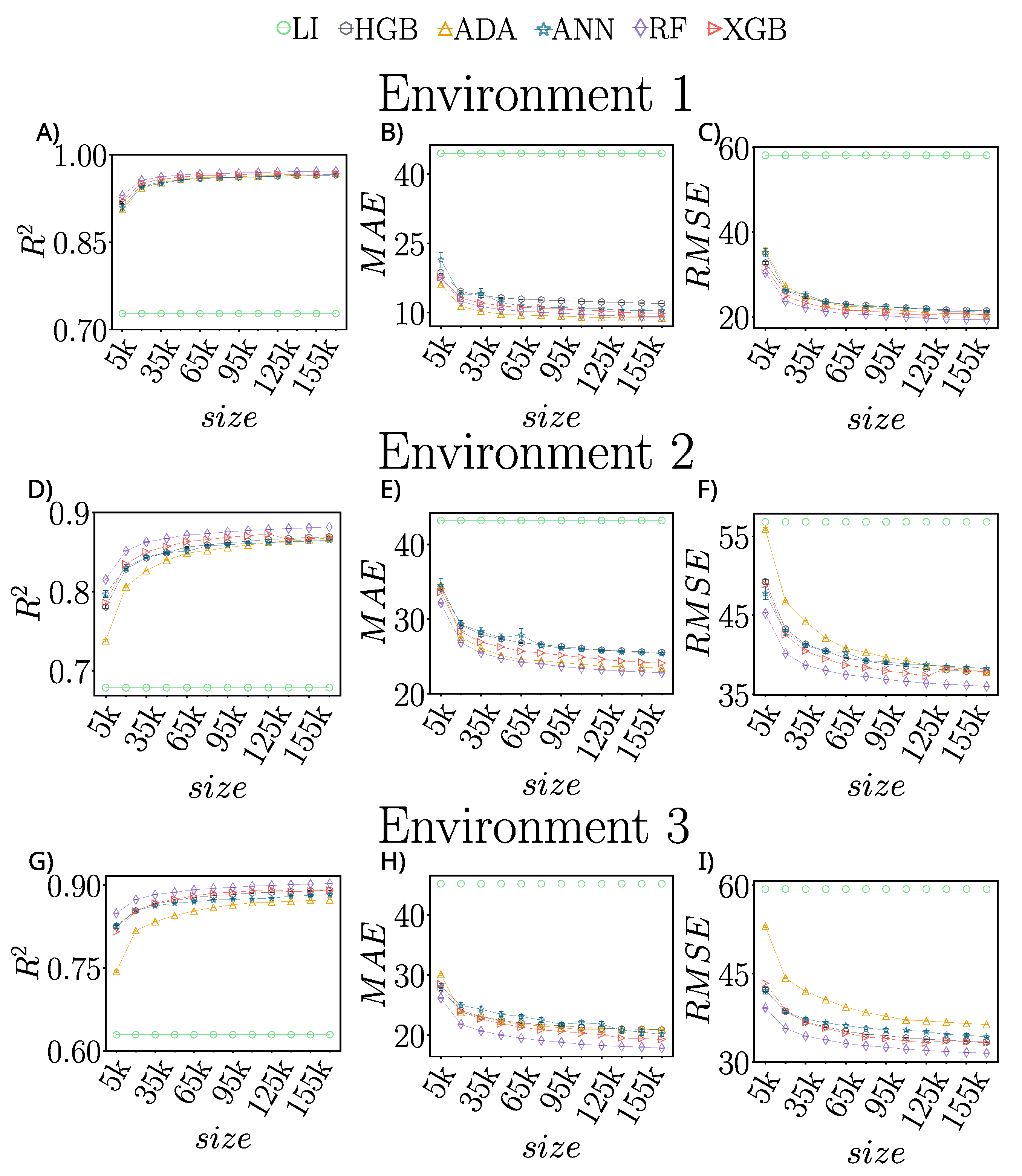
5. Results
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Andreev, S.; Galinina, O.; Pyattaev, A.; Gerasimenko, M.; Tirronen, T.; Torsner, J.; Sachs, J.; Dohler, M.; Koucheryavy, Y. Understanding the IoT connectivity landscape: A contemporary M2M radio technology roadmap. IEEE Commun. Mag. 2015, 53, 32–40. [Google Scholar] [CrossRef] [Green Version]
- Leppänen, T.; Savaglio, C.; Lovén, L.; Russo, W.; Fatta, G.D.; Riekki, J.; Fortino, G. Developing agent-based smart objects for IoT edge computing: Mobile crowdsensing use case. In Proceedings of the International Conference on Internet and Distributed Computing Systems, Tokyo, Japan, 11–13 October 2018; pp. 235–247. [Google Scholar]
- Voggu, A.R.; Vazhayily, V.; Ra, M. Decimeter Level Indoor Localisation with a Single WiFi Router Using CSI Fingerprinting. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–5. [Google Scholar]
- Zafari, F.; Gkelias, A.; Leung, K.K. A survey of indoor localization systems and technologies. IEEE Commun. Surv. Tutor. 2019, 21, 2568–2599. [Google Scholar] [CrossRef] [Green Version]
- Ponte, C.; Caminha, C.; Bomfim, R.; Moreira, R.; Furtado, V. A temporal clustering algorithm for achieving the trade-off between the user experience and the equipment economy in the context of IoT. In Proceedings of the 2019 8th Brazilian Conference on Intelligent Systems (BRACIS), Salvador, Brazil, 15–18 October 2019; pp. 604–609. [Google Scholar]
- Samie, F.; Bauer, L.; Henkel, J. IoT technologies for embedded computing: A survey. In Proceedings of the 2016 International Conference on Hardware/Software Codesign and System Synthesis (CODES+ ISSS), Pittsburgh, PA, USA, 2–7 October 2016; pp. 1–10. [Google Scholar]
- Campbell, M. Smart Edge: The Effects of Shifting the Center of Data Gravity Out of the Cloud. Computer 2019, 52, 99–102. [Google Scholar] [CrossRef]
- Faragher, R.; Harle, R. An analysis of the accuracy of bluetooth low energy for indoor positioning applications. In Proceedings of the 27th International Technical Meeting of The Satellite Division of the Institute of Navigation (ION GNSS+ 2014), Tampa, FL, USA, 8–12 September 2014; pp. 201–210. [Google Scholar]
- Ruiz, A.R.J.; Granja, F.S. Comparing ubisense, bespoon, and decawave uwb location systems: Indoor performance analysis. IEEE Trans. Instrum. Meas. 2017, 66, 2106–2117. [Google Scholar] [CrossRef]
- Coronel, P.; Furrer, S.; Schott, W.; Weiss, B. Indoor location tracking using inertial navigation sensors and radio beacons. In The Internet of Things; Springer: Berlin/Heidelberg, Germany, 2008; pp. 325–340. [Google Scholar]
- Lee, S.K.; Bae, M.; Kim, H. Future of IoT Networks: A survey. Appl. Sci. 2017, 7, 1072. [Google Scholar] [CrossRef]
- Li, X.; Liu, Y.; Ji, H.; Zhang, H.; Leung, V.C. Optimizing resources allocation for fog computing-based internet of things networks. IEEE Access 2019, 7, 64907–64922. [Google Scholar] [CrossRef]
- Cruz, L.A.; Zeitouni, K.; da Silva, T.L.C.; de Macedo, J.A.F.; da Silva, J.S. Location prediction: A deep spatiotemporal learning from external sensors data. Distrib. Parallel Databases 2021, 39, 259–280. [Google Scholar] [CrossRef]
- Wiest, J.; Hoffken, M.; Kresel, U.; Dietmayer, K. Probabilistic trajectory prediction with Gaussian mixture models. In Proceedings of the 2012 IEEE Intelligent Vehicles Symposium, Alcala de Henares, Spain, 3–7 June 2012. [Google Scholar] [CrossRef]
- Hunter, T.; Herring, R.; Abbeel, P.; Bayen, A. Path and travel time inference from GPS probe vehicle data. NIPS Anal. Netw. Learn. Graphs 2009, 12, 2. [Google Scholar]
- Pecher, P.; Hunter, M.; Fujimoto, R. Data-Driven Vehicle Trajectory Prediction. In Proceedings of the 2016 ACM SIGSIM Conference on Principles of Advanced Discrete Simulation, Banff, AB, Canada, 15–18 May 2016; SIGSIM-PADS ’16. Association for Computing Machinery: New York, NY, USA, 2016; pp. 13–22. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Liu, C.; Luo, Q.; Ni, L.M.; Krishnan, R. Calibrating Large Scale Vehicle Trajectory Data. In Proceedings of the 2012 IEEE 13th International Conference on Mobile Data Management, Bengaluru, India, 23–26 July 2012; pp. 222–231. [Google Scholar] [CrossRef]
- Malan, S.A.; Brevi, E.D.; Pacella, E.F.; Mancini, A. Vehicle Path Prediction for Safety Enhancement of Autonomous Driving. Master’s Thesis, Politecnico di Torino, Turin, Italy, 2021. [Google Scholar]
- Kennedy, M.; Spachos, P.; Taylor, G.W. BLE Beacon Indoor Localization Dataset; Scholars Portal Dataverse: Toronto, ON, Canada, 2019. [Google Scholar] [CrossRef]
- Akima, H. A new method of interpolation and smooth curve fitting based on local procedures. J. ACM 1970, 17, 589–602. [Google Scholar] [CrossRef]
- Meijering, E. A chronology of interpolation: From ancient astronomy to modern signal and image processing. Proc. IEEE 2002, 90, 319–342. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.C.; Hsu, K.L.; Liu, Y.; Hong, C.Y.; Chow, C.W.; Yeh, C.H.; Liao, X.L.; Lin, K.H.; Chen, Y.Y. Using Linear Interpolation to Reduce the Training Samples for Regression Based Visible Light Positioning System. IEEE Photonics J. 2020, 12, 1–5. [Google Scholar] [CrossRef]
- Upchurch, P.; Gardner, J.; Pleiss, G.; Pless, R.; Snavely, N.; Bala, K.; Weinberger, K. Deep Feature Interpolation for Image Content Changes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Petschnigg, G.; Szeliski, R.; Agrawala, M.; Cohen, M.; Hoppe, H.; Toyama, K. Digital photography with flash and no-flash image pairs. ACM Trans. Graph. 2004, 23, 664–672. [Google Scholar] [CrossRef]
- Joblove, G.H.; Greenberg, D. Color spaces for computer graphics. In Proceedings of the 5th Annual Conference on Computer Graphics and Interactive Techniques, Atlanta, GA, USA, 23–25 August 1978; pp. 20–25. [Google Scholar]
- Li, Z.; Shi, Y.; Wang, C.; Wang, Y. Accurate calibration method for a structured light system. Opt. Eng. 2008, 47, 053604. [Google Scholar] [CrossRef]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82, 35–45. [Google Scholar] [CrossRef] [Green Version]
- Vikranth, S.; Sudheesh, P.; Jayakumar, M. Nonlinear tracking of target submarine using extended kalman filter (ekf). In Proceedings of the International Symposium on Security in Computing and Communication, Jaipur, India, 21–24 September 2016; pp. 258–268. [Google Scholar]
- Patel, H.A.; Thakore, D.G. Moving object tracking using kalman filter. Int. J. Comput. Sci. Mob. Comput. 2013, 2, 326–332. [Google Scholar]
- Seng, K.Y.; Chen, Y.; Chai, K.M.A.; Wang, T.; Fun, D.C.Y.; Teo, Y.S.; Tan, P.M.S.; Ang, W.H.; Lee, J.K.W. Tracking body core temperature in military thermal environments: An extended Kalman filter approach. In Proceedings of the 2016 IEEE 13th International Conference on Wearable and Implantable Body Sensor Networks (BSN), San Francisco, CA, USA, 14–17 June 2016; pp. 296–299. [Google Scholar]
- Lam, C.H.; Ng, P.C.; She, J. Improved distance estimation with BLE beacon using Kalman filter and SVM. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Li, G.; Geng, E.; Ye, Z.; Xu, Y.; Lin, J.; Pang, Y. Indoor positioning algorithm based on the improved RSSI distance model. Sensors 2018, 18, 2820. [Google Scholar] [CrossRef] [Green Version]
- Hirakawa, T.; Yamashita, T.; Tamaki, T.; Fujiyoshi, H.; Umezu, Y.; Takeuchi, I.; Matsumoto, S.; Yoda, K. Can AI predict animal movements? Filling gaps in animal trajectories using inverse reinforcement learning. Ecosphere 2018, 9, e02447. [Google Scholar] [CrossRef]
- Chai, X.; Tang, G.; Wang, S.; Lin, K.; Peng, R. Deep learning for irregularly and regularly missing 3-D data reconstruction. IEEE Trans. Geosci. Remote. Sens. 2020, 59, 6244–6265. [Google Scholar] [CrossRef]
- Chen, Y.; Huang, W.; Zhang, D.; Chen, W. An open-source Matlab code package for improved rank-reduction 3D seismic data denoising and reconstruction. Comput. Geosci. 2016, 95, 59–66. [Google Scholar] [CrossRef]
- Kang, M.; Ichii, K.; Kim, J.; Indrawati, Y.M.; Park, J.; Moon, M.; Lim, J.H.; Chun, J.H. New gap-filling strategies for long-period flux data gaps using a data-driven approach. Atmosphere 2019, 10, 568. [Google Scholar] [CrossRef] [Green Version]
- AlHajri, M.I.; Ali, N.T.; Shubair, R.M. Classification of indoor environments for IoT applications: A machine learning approach. IEEE Antennas Wirel. Propag. Lett. 2018, 17, 2164–2168. [Google Scholar] [CrossRef]
- Silva, I.D.; Spatti, D.H.; Flauzino, R.A. Redes Neurais Artificiais para Engenharia e Ciências Aplicadas, 2nd ed.; Artliber Editora Ltda: São Paulo, SP, Brazil, 2016. [Google Scholar]
- Bonaccorso, G. Machine Learning Algorithms; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Carvalho, D.; Sullivan, D.; Almeida, R.; Caminha, C. A Machine Learning Approach to Interpolating Indoors Trajectories. In Proceedings of the Anais do IX Symposium on Knowledge Discovery, Mining and Learning, Rio de Janeiro, Brazil, 4–8 October 2021; pp. 145–152. [Google Scholar]
- Juliani, A.; Berges, V.P.; Teng, E.; Cohen, A.; Harper, J.; Elion, C.; Goy, C.; Gao, Y.; Henry, H.; Mattar, M.; et al. Unity: A general platform for intelligent agents. arXiv 2018, arXiv:1809.02627. [Google Scholar]
- Kennedy, B.; Taylor, G.W.; Spachos, P. Ble beacon based patient tracking in smart care facilities. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athens, Greece, 19–23 March 2018; pp. 439–441. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rätsch, G.; Onoda, T.; Müller, K.R. Soft margins for AdaBoost. Mach. Learn. 2001, 42, 287–320. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference On Knowledge Discovery And Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chi, Y.; Wang, H.; Yu, P.S.; Muntz, R.R. Moment: Maintaining closed frequent itemsets over a stream sliding window. In Proceedings of the Fourth IEEE International Conference on Data Mining (ICDM’04), Brighton, UK, 1–4 November 2004; pp. 59–66. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K. Xgboost: Extreme Gradient Boosting; R Package Version 0.4-2 1; 2015; pp. 1–4. Available online: https://mran.microsoft.com/snapshot/2015-11-30/web/packages/xgboost/index.html (accessed on 30 March 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | Contribution |
|---|---|
| Lam et al. (2018) [31] and Li et al. (2018) [32] | Proposed a combination of KF and a ML model is used in order to denoisify and correct trajectory data |
| Hirakawa et al. (2018) [33] | Proposed a model that uses reinforcement learning (ML) to fill birds trajectories data gaps in an outdoor environment |
| Chai et al. (2020) [34] | Proposed a model that uses ML to reconstruct missing parts of seismic data |
| Kang et al. (2019) [36] | Proposed a model that uses ML to reconstruct river water flow time series data |
| AlHajri et al. (2018) [37] | Proposed a model that uses ML in combination with FCF and CTF to classify indoors environments |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carvalho, D.; Sullivan, D.; Almeida, R.; Caminha, C. A Machine Learning Approach to Solve the Network Overload Problem Caused by IoT Devices Spatially Tracked Indoors. J. Sens. Actuator Netw. 2022, 11, 29. https://doi.org/10.3390/jsan11020029
Carvalho D, Sullivan D, Almeida R, Caminha C. A Machine Learning Approach to Solve the Network Overload Problem Caused by IoT Devices Spatially Tracked Indoors. Journal of Sensor and Actuator Networks. 2022; 11(2):29. https://doi.org/10.3390/jsan11020029
Chicago/Turabian StyleCarvalho, Daniel, Daniel Sullivan, Rafael Almeida, and Carlos Caminha. 2022. "A Machine Learning Approach to Solve the Network Overload Problem Caused by IoT Devices Spatially Tracked Indoors" Journal of Sensor and Actuator Networks 11, no. 2: 29. https://doi.org/10.3390/jsan11020029
APA StyleCarvalho, D., Sullivan, D., Almeida, R., & Caminha, C. (2022). A Machine Learning Approach to Solve the Network Overload Problem Caused by IoT Devices Spatially Tracked Indoors. Journal of Sensor and Actuator Networks, 11(2), 29. https://doi.org/10.3390/jsan11020029