
An Efficient Gait Abnormality Detection Method Based on Classification


 , ,
, , 
Abstract
:1. Introduction
- We designed and implemented machine learning models to detect and classify the gait patterns between healthy controls and gait disorders.
- We employed machine learning techniques for robust identification of affected anatomical regions due to gait impairment.
- We investigated in detail about the automated classification of several functional gait disorders solely based on GRF data
- We investigated classifying a more detailed localization of primary impairments through the help of GRF data.
2. Background Study
- Time-consuming data collection
- High acquisition and maintenance costs
- Requirement of highly qualified staff
3. Methods
3.1. Dataset
3.2. CSV Information
- Calculate the COP only if vertical force reaches 80 N. This is done to avoid inaccuracies in COP calculation at small force values.
- The medio-lateral COP coordinates were mean-centered and anterior–posterior coordinates zero-centered.
- The processed force signals were filtered using a second order low-pass filter with a cut-of frequency of 20 Hz to reduce noise.
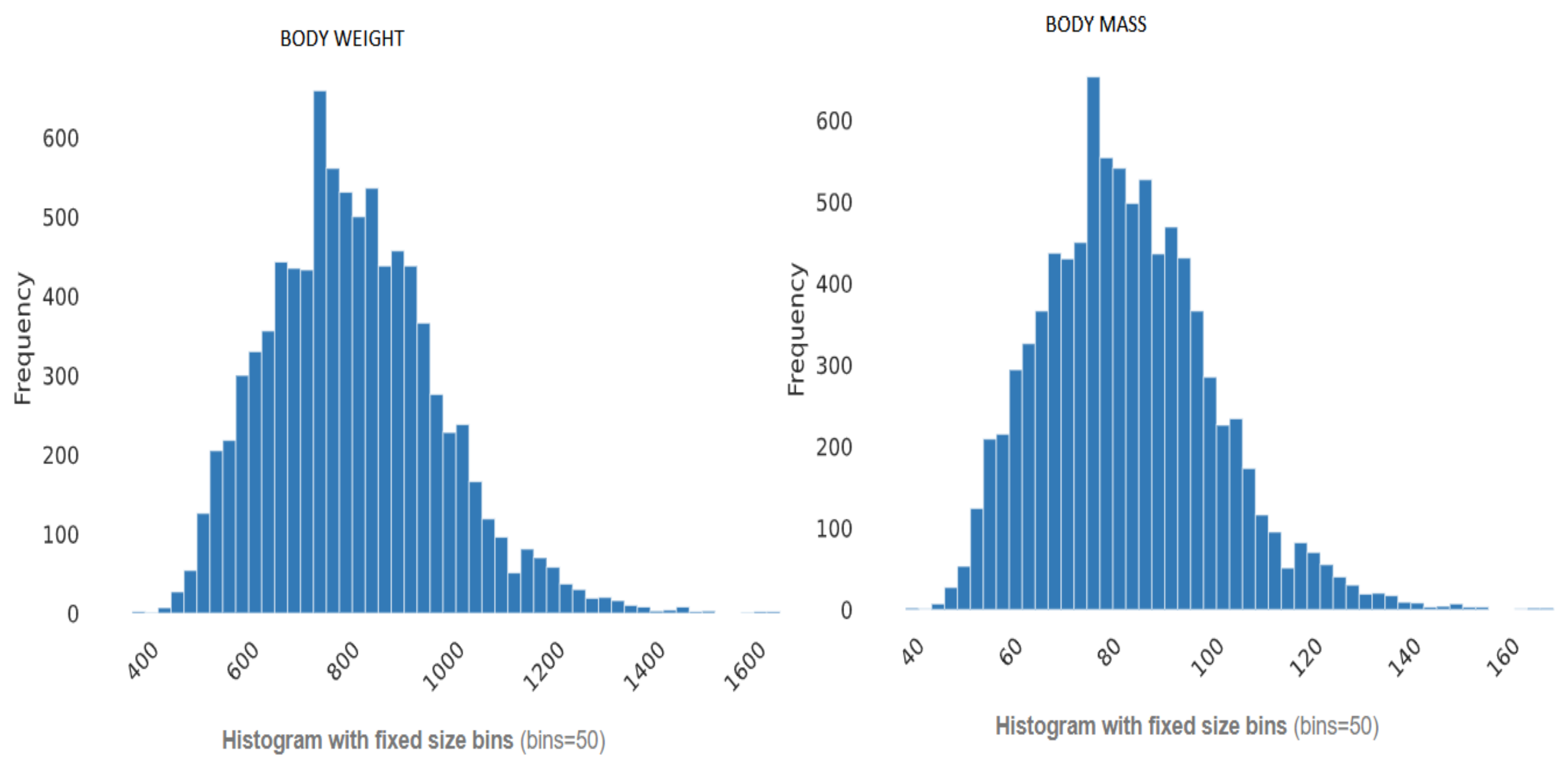
- Amplitude values of the three force components were expressed as a multiple of body weight (BW) by dividing the force by the product of body mass times acceleration due to gravity (g).
- Outliers are eliminated to further refine the dataset.
3.3. Exploratory Data Analysis (EDA)
3.4. Exploratory Data Analysis and Metadata
- (1)
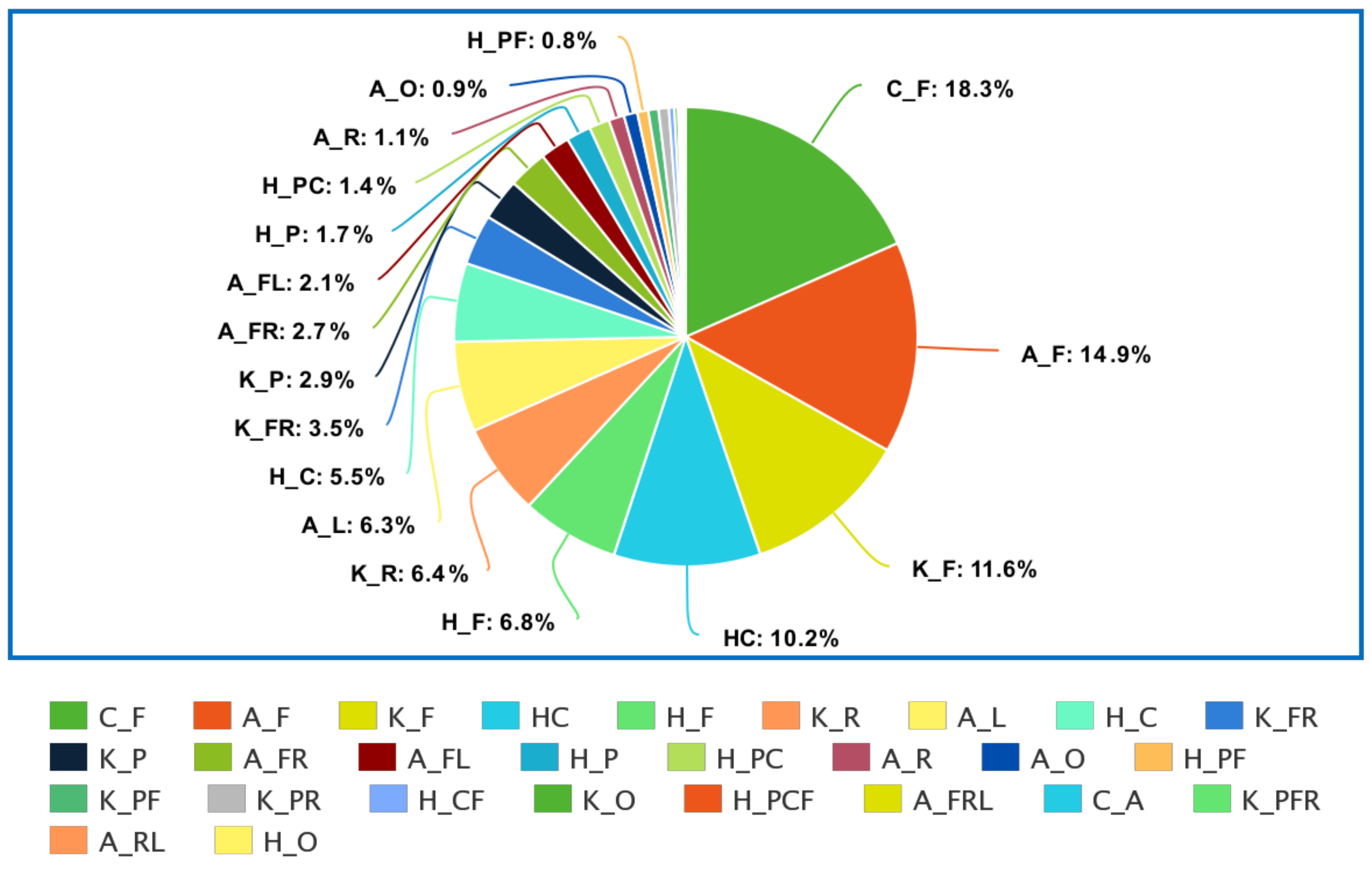
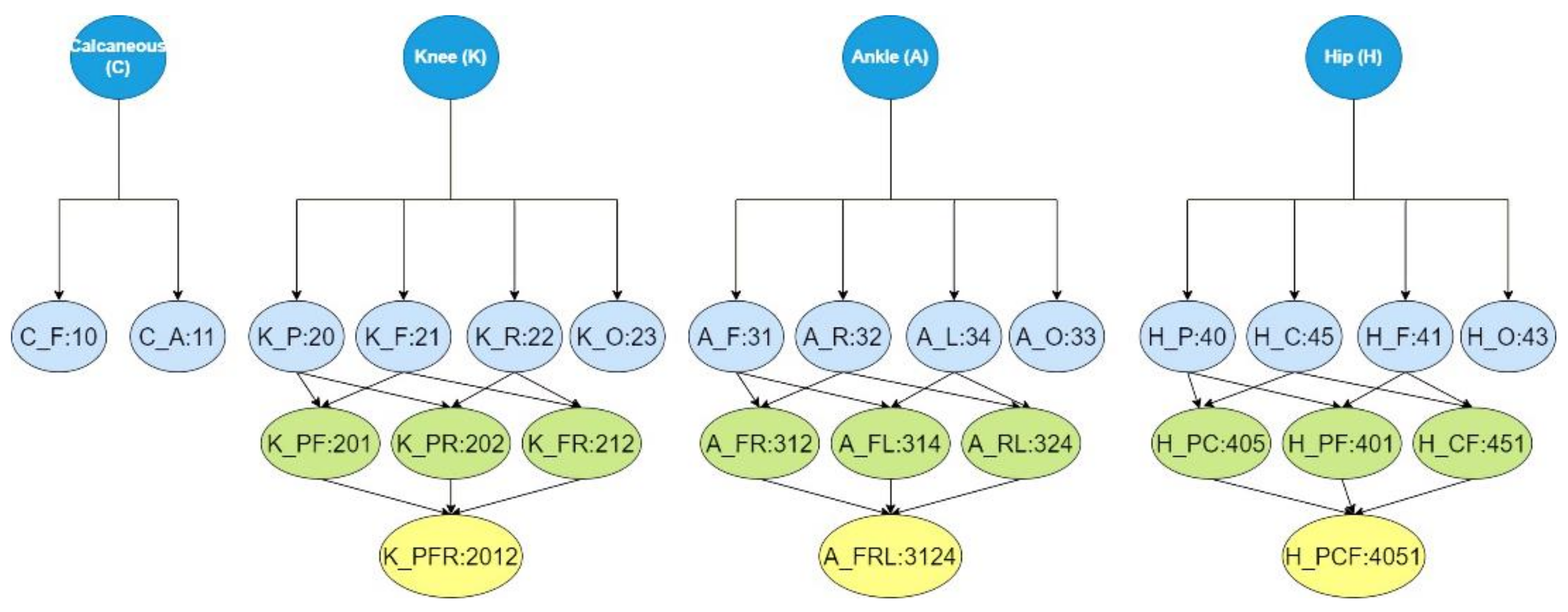
- “CLASS LABEL” contains the general anatomical joint level at which the orthopaedic impairment was located, i.e., at the hip (H), knee (K), ankle (A), calcaneus (C), or healthy (HC).
- (2)
- “DETAILED CLASS LABEL” contains more detailed localization and is joint-dependent. i.e., H_P, where H represents Hip Joint and P represents Pelvis. There can be a combination of two or more anatomical areas as well, i.e., H_PC where H is the hip joint and PC is the pelvis and coxa region.
3.5. Preprocessing
- For HIP (H): pelvis (P), the femur (F), coxa (C), and other diagnoses (O) as 0, 1, 5, and 3 respectively.
- For Calcaneus (C): fracture (F) or arthrodesis (A) as 0 and 1, respectively.
- For Knee (K): patella (P), tibia (F), rupture of ligaments or the menisci (R) and other diagnoses (O) as 0, 1, 2, and 3, respectively.
4. Experimental Analysis
4.1. Splitting the Dataset into Train and Test Set While Maintaining Target Label Balance
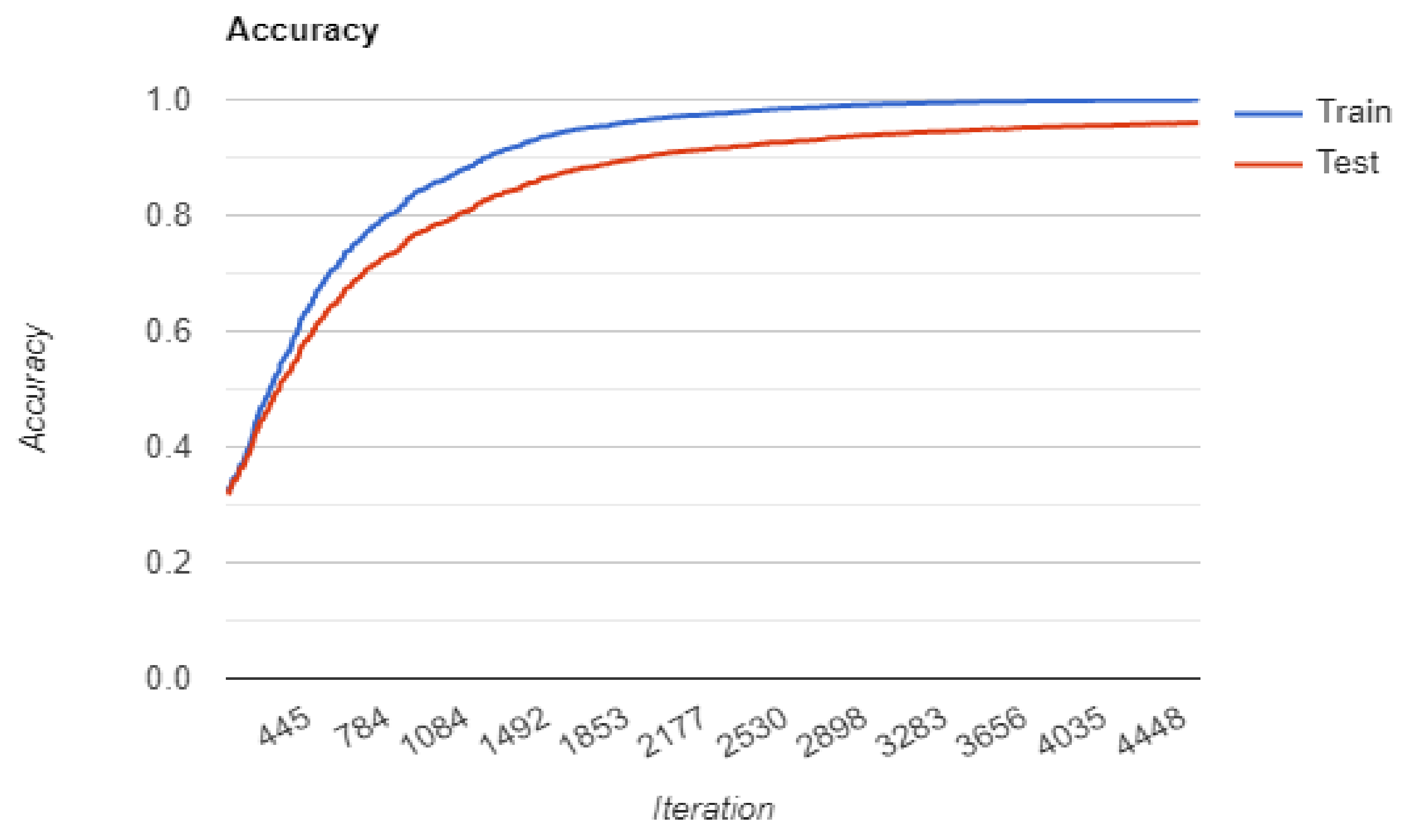
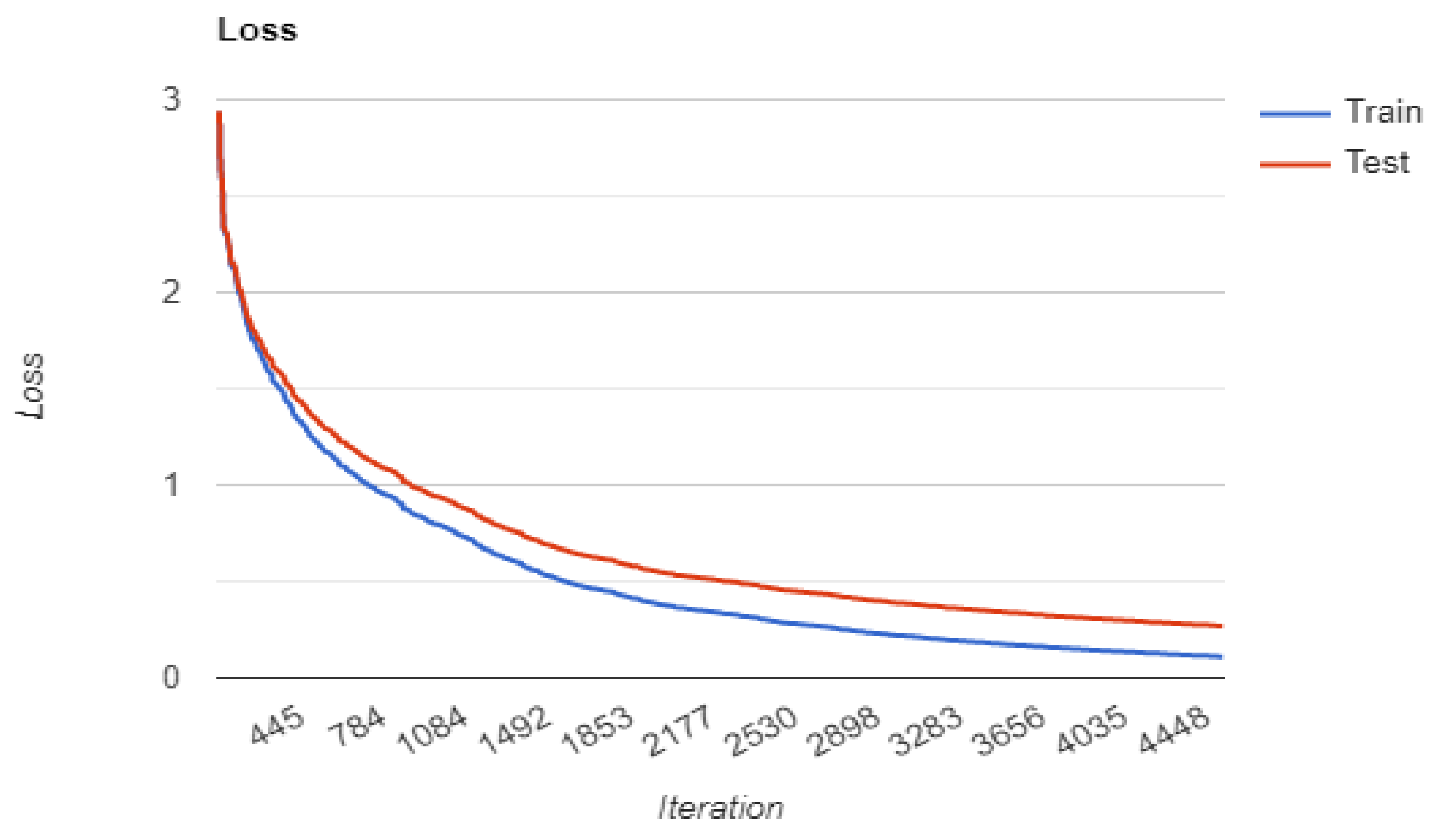
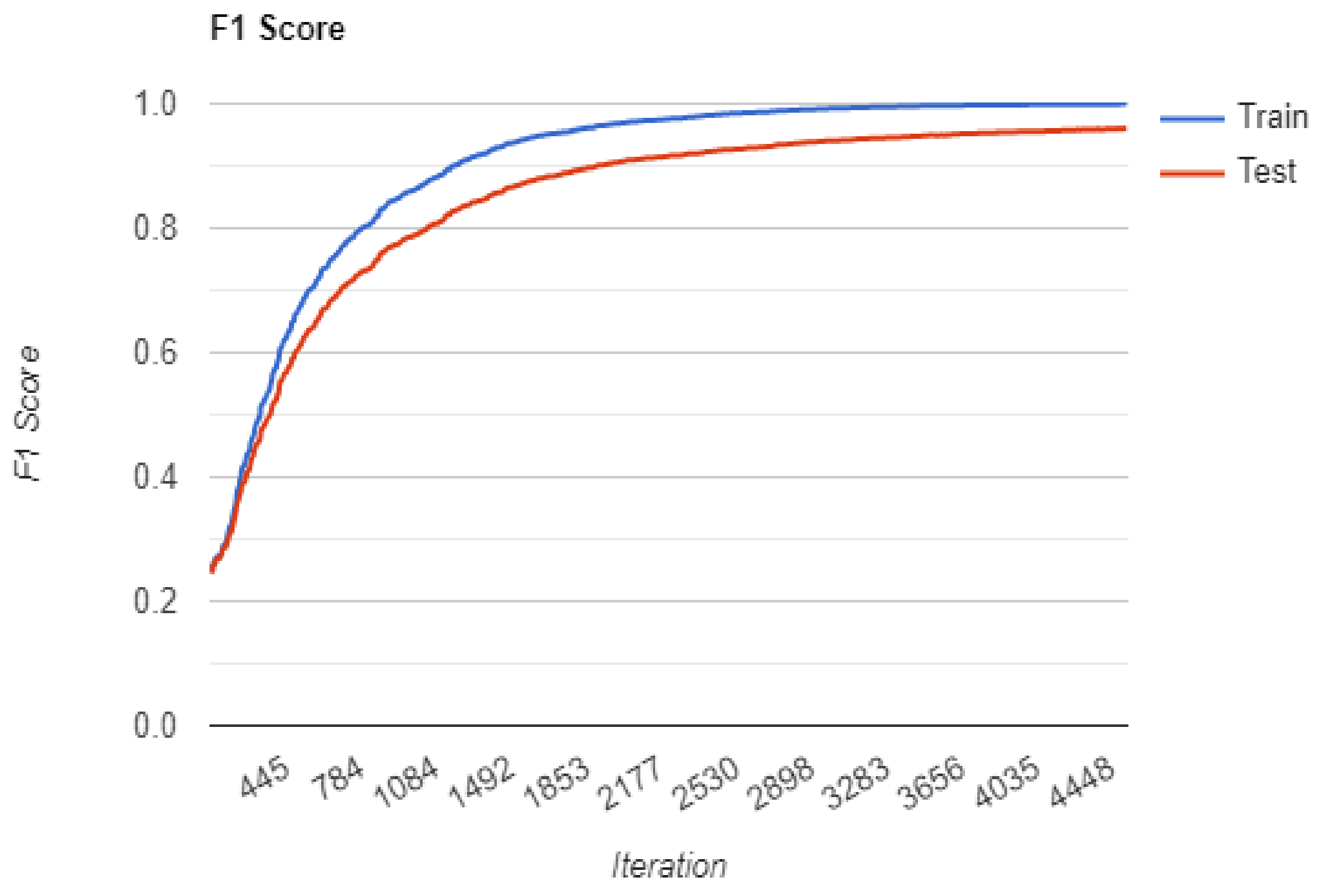
4.2. Training Multiple Base Models
4.3. Loss Function
4.4. Classifiers
- (i)
- Decision Tree
- (1)
- Start the tree with a root node (R), containing the entire dataset;
- (2)
- Find the attribute from the dataset which minimizes the loss function using ASM the most;
- (3)
- Split the root node into subsets using ASM containing the value of the best attribute;
- (4)
- Create a decision node using the best attribute values;
- (5)
- Using the subsets of the dataset root node generated in step 3, recursively create a new decision tree below it. Continue this recursive process of splitting the best attribute and generating a decision node until we reach a stage where there is no split possible; a place where the loss function value of ASM is the least is called the leaf node.
- (ii)
- Gradient Boosting
- (A)
- CatBoost
- Ordered Boosting Technique
- 2.
- Handling Categorical Dataset
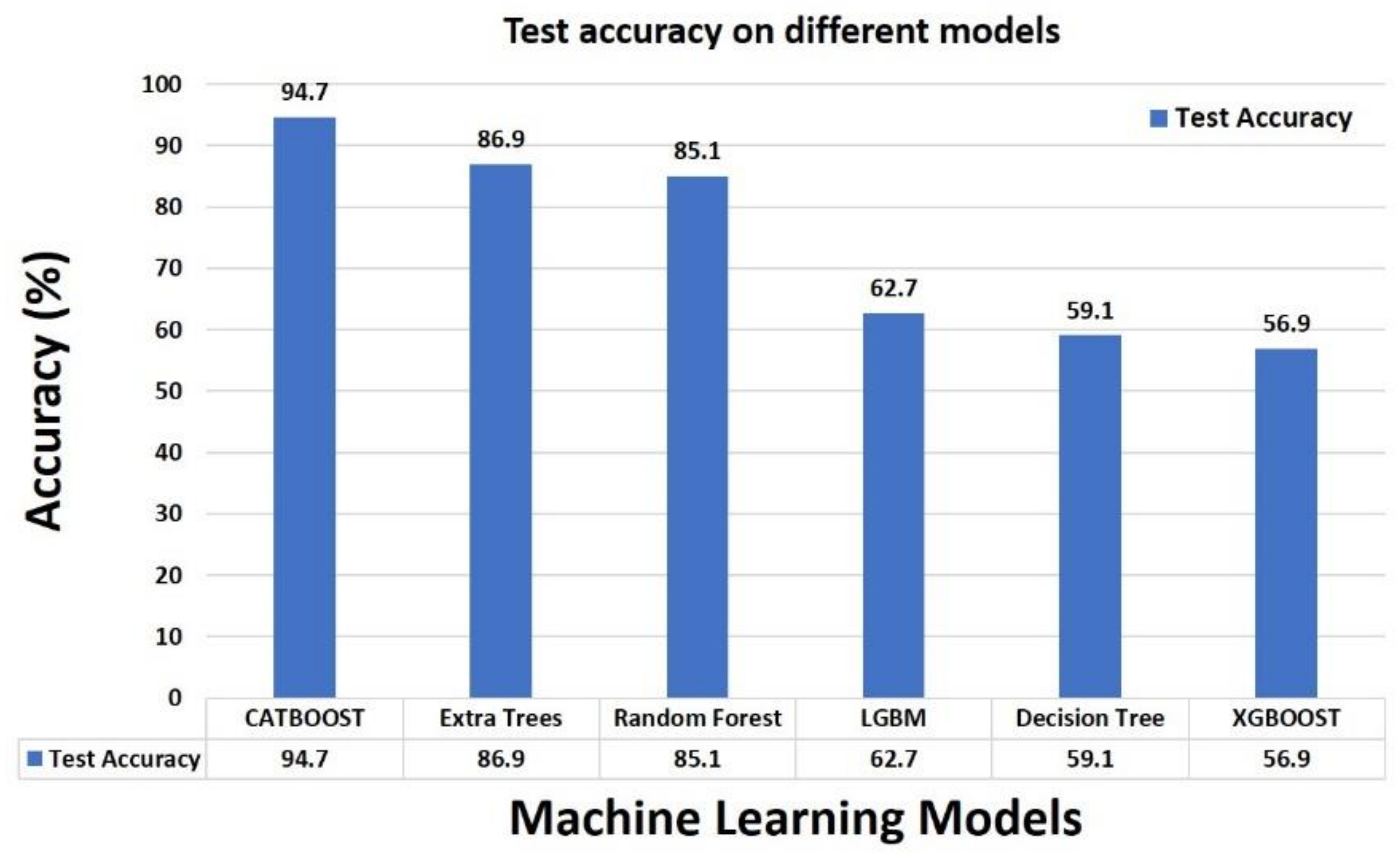
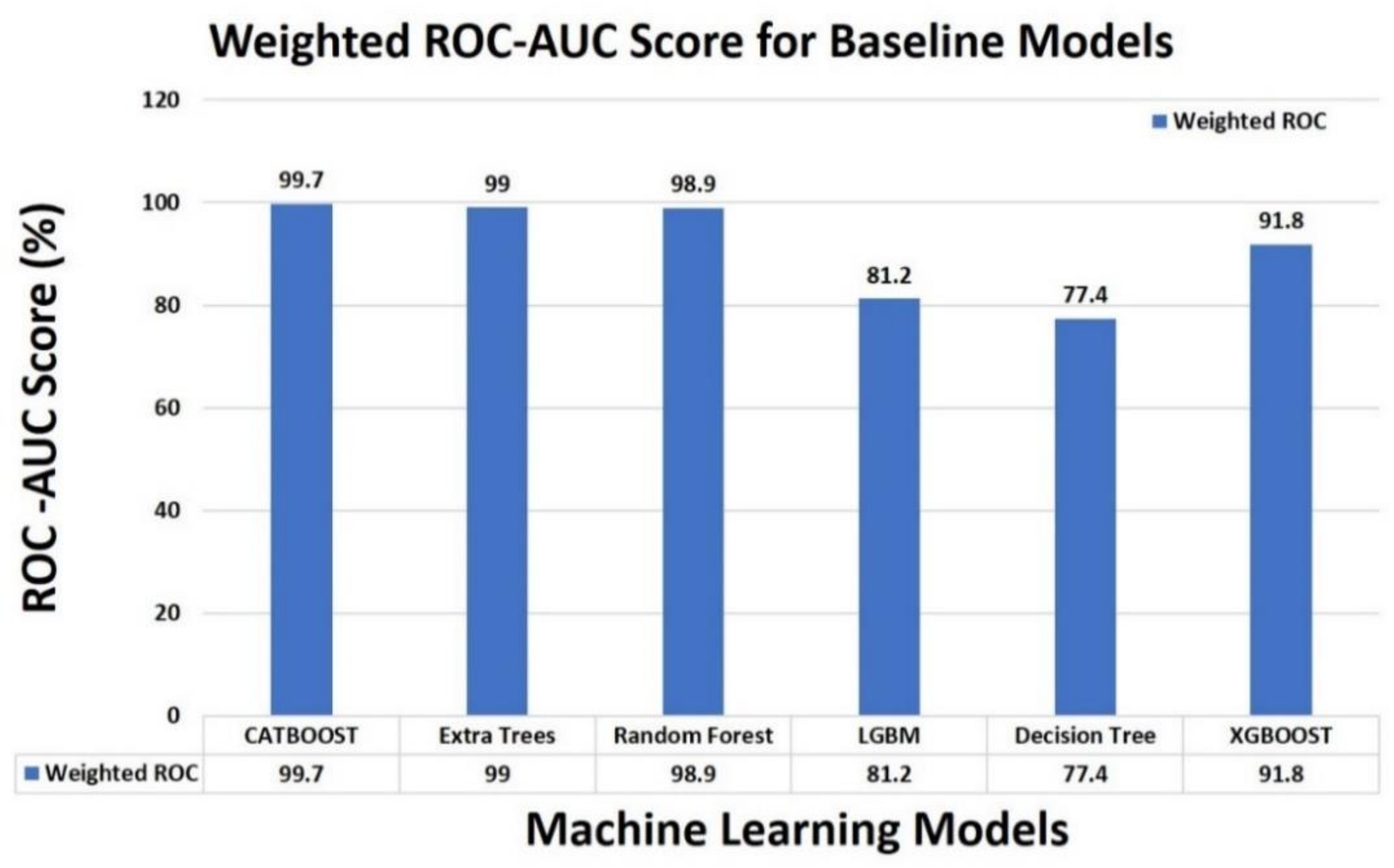
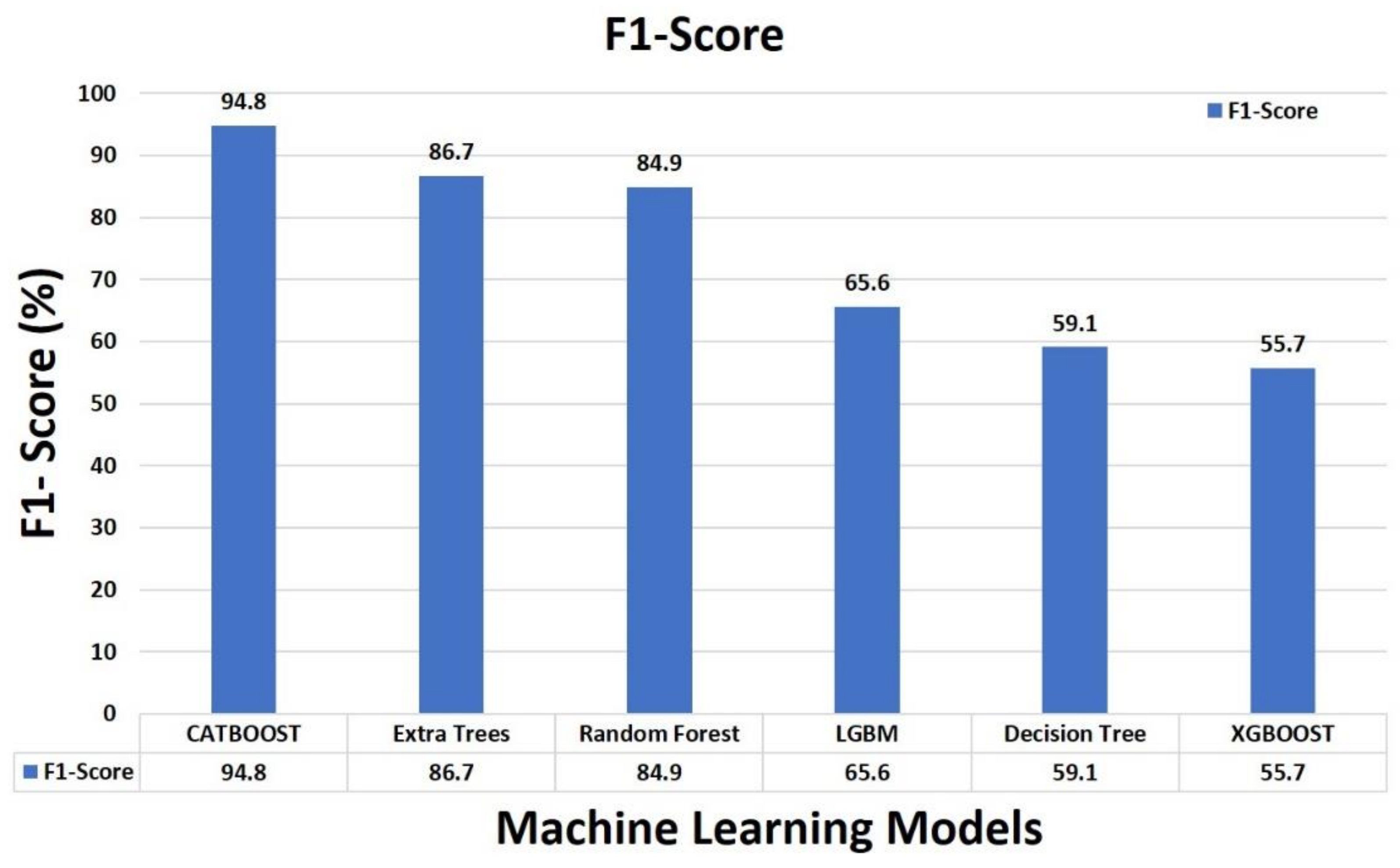
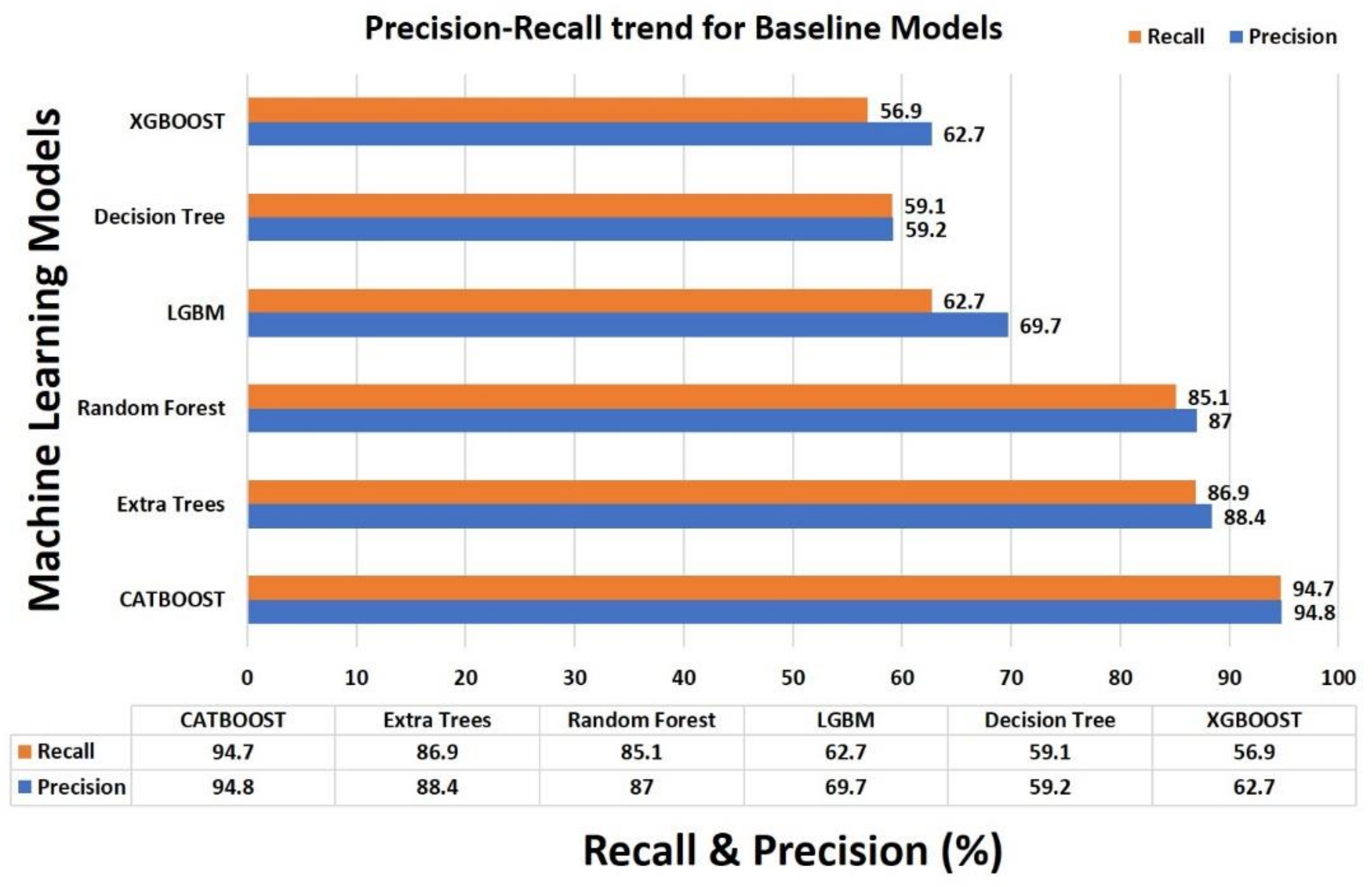
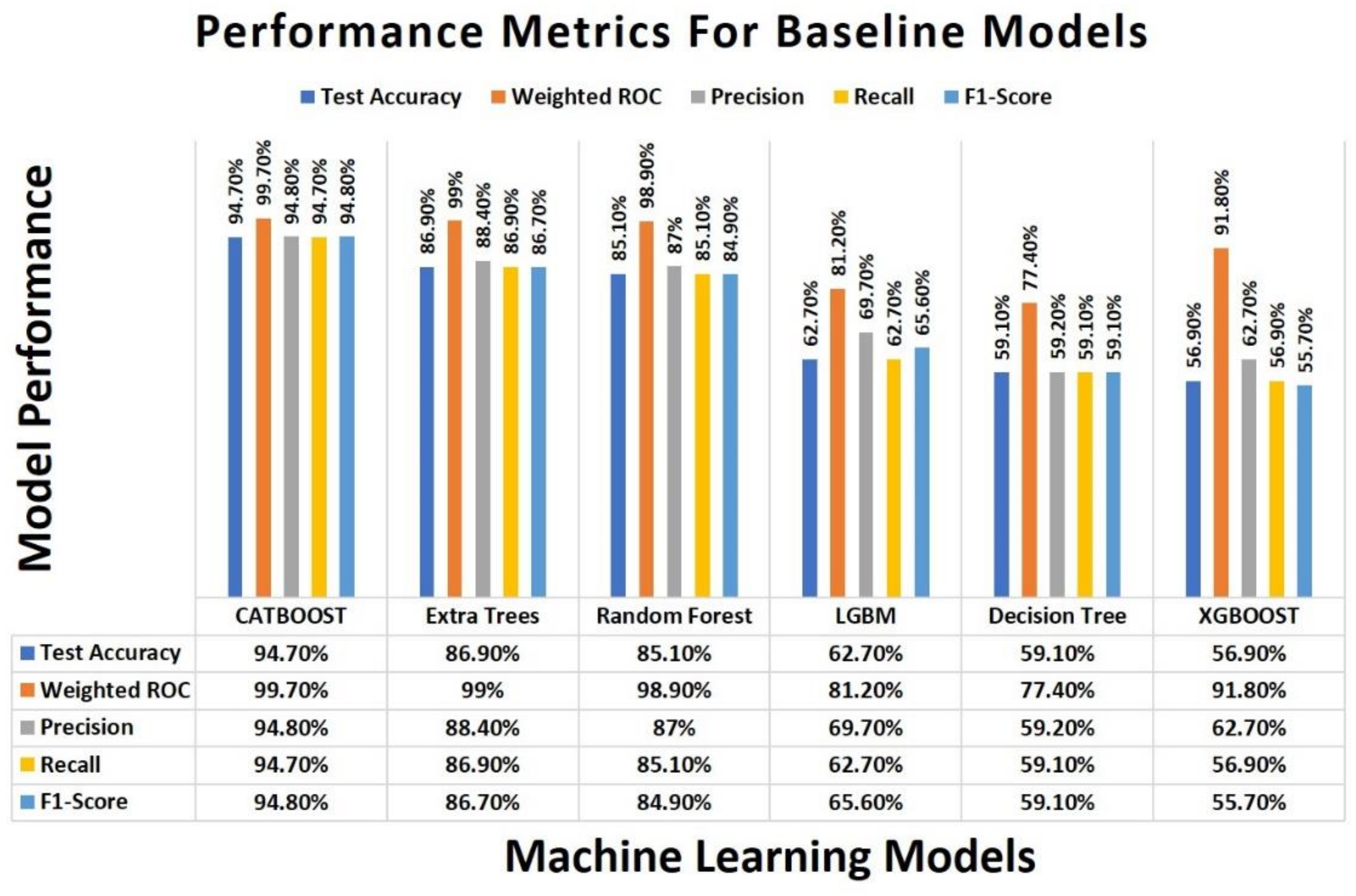
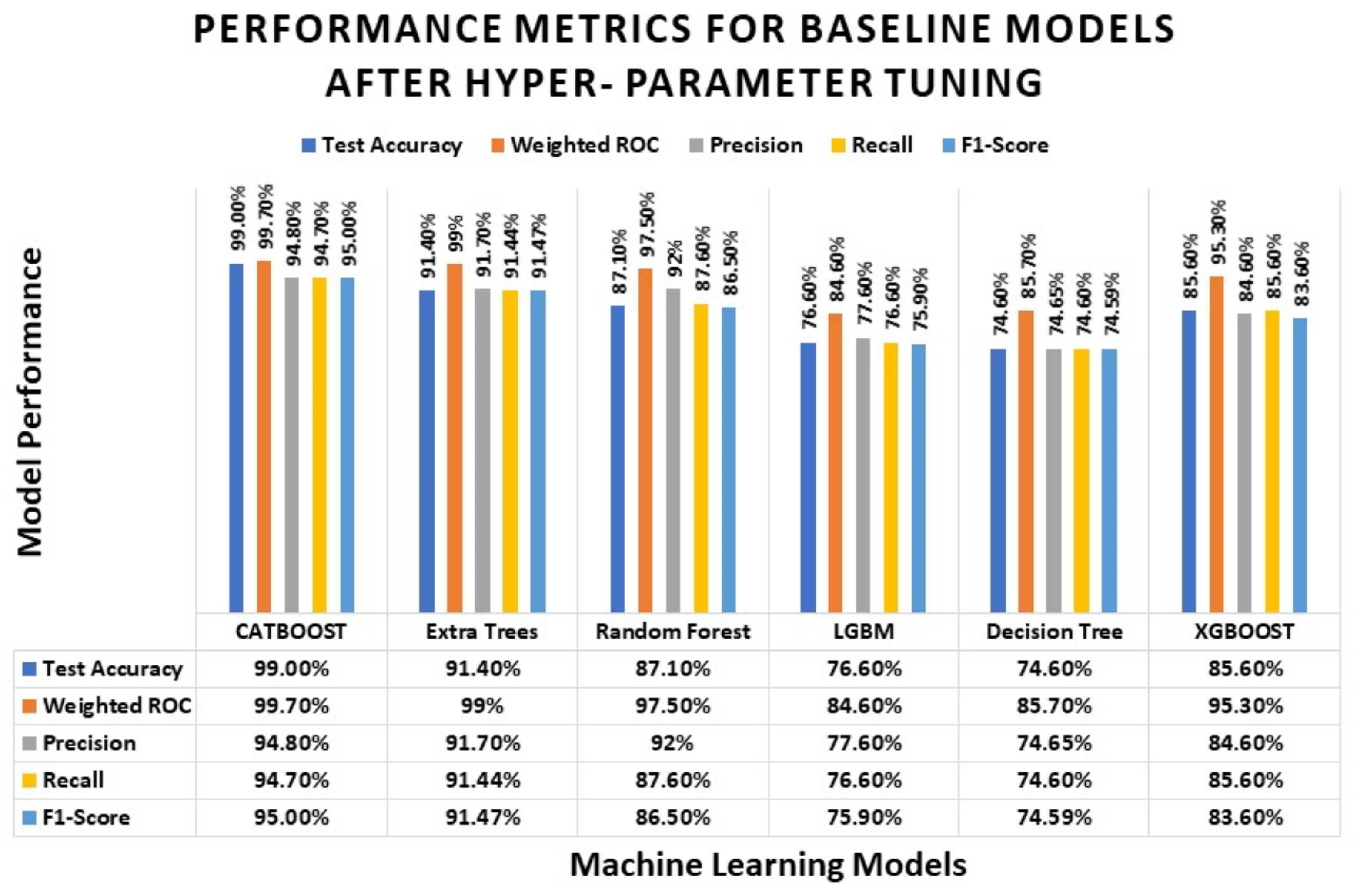
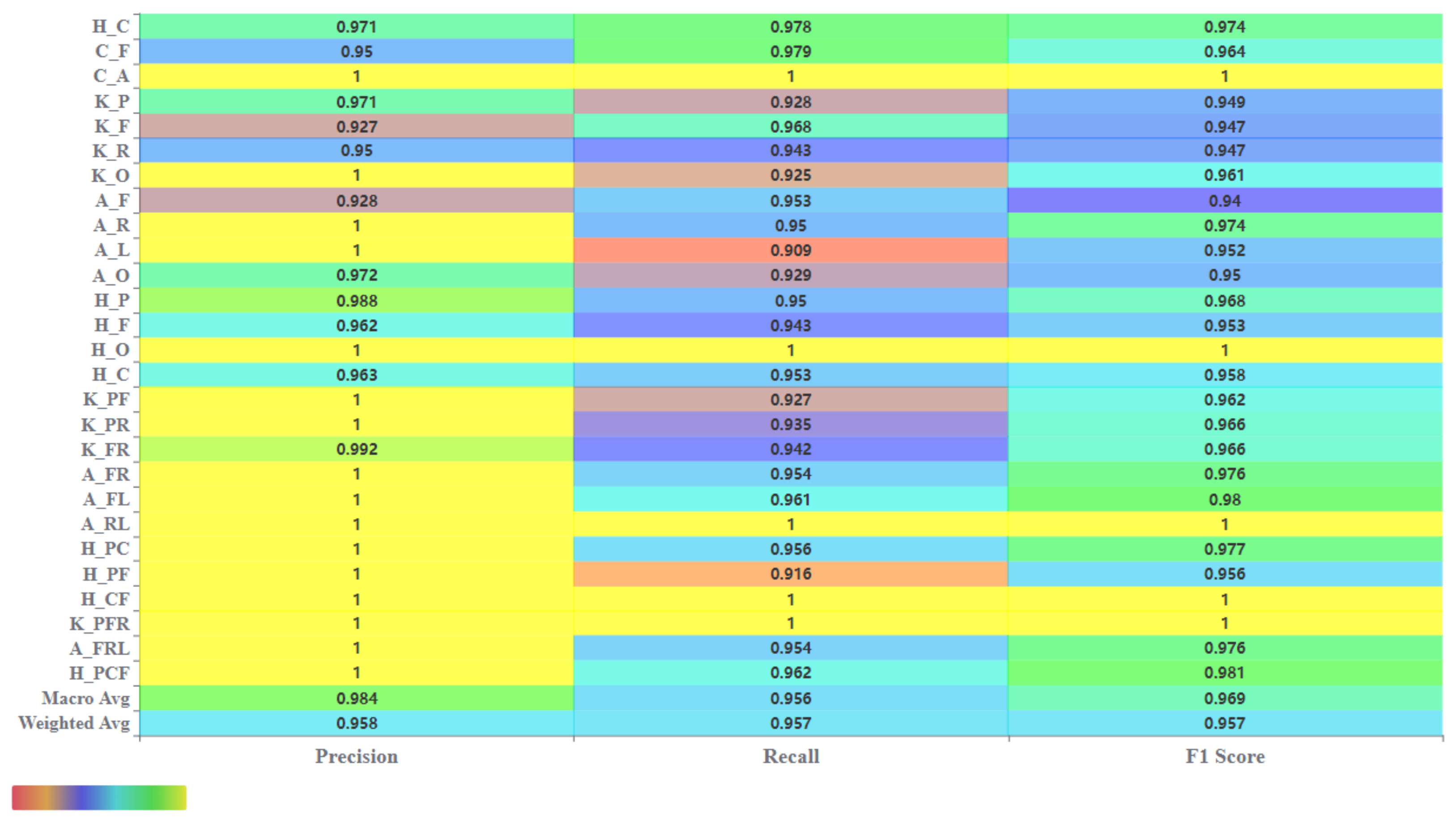
4.5. Result Comparison of Base Classifiers
5. Discussion
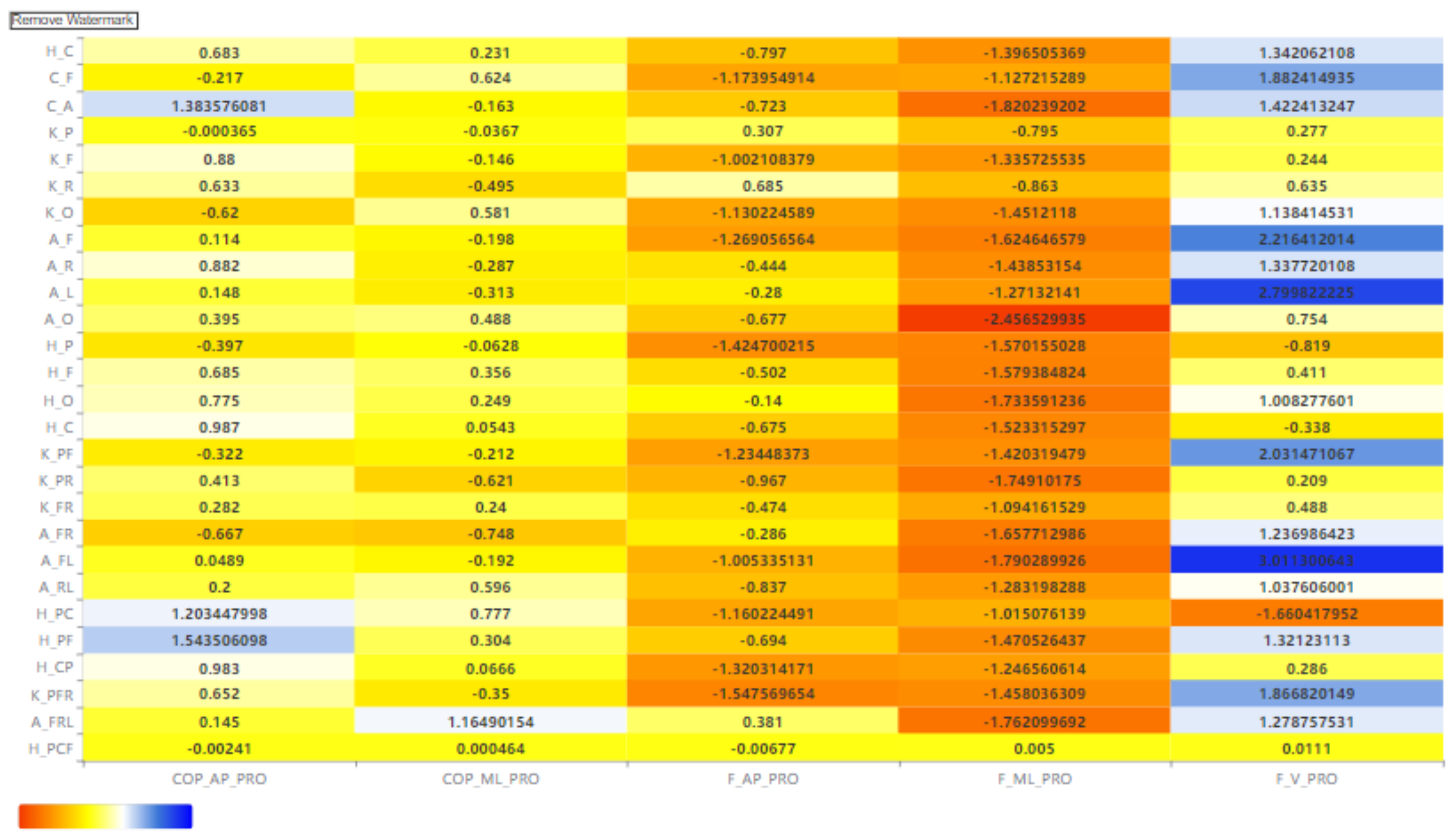
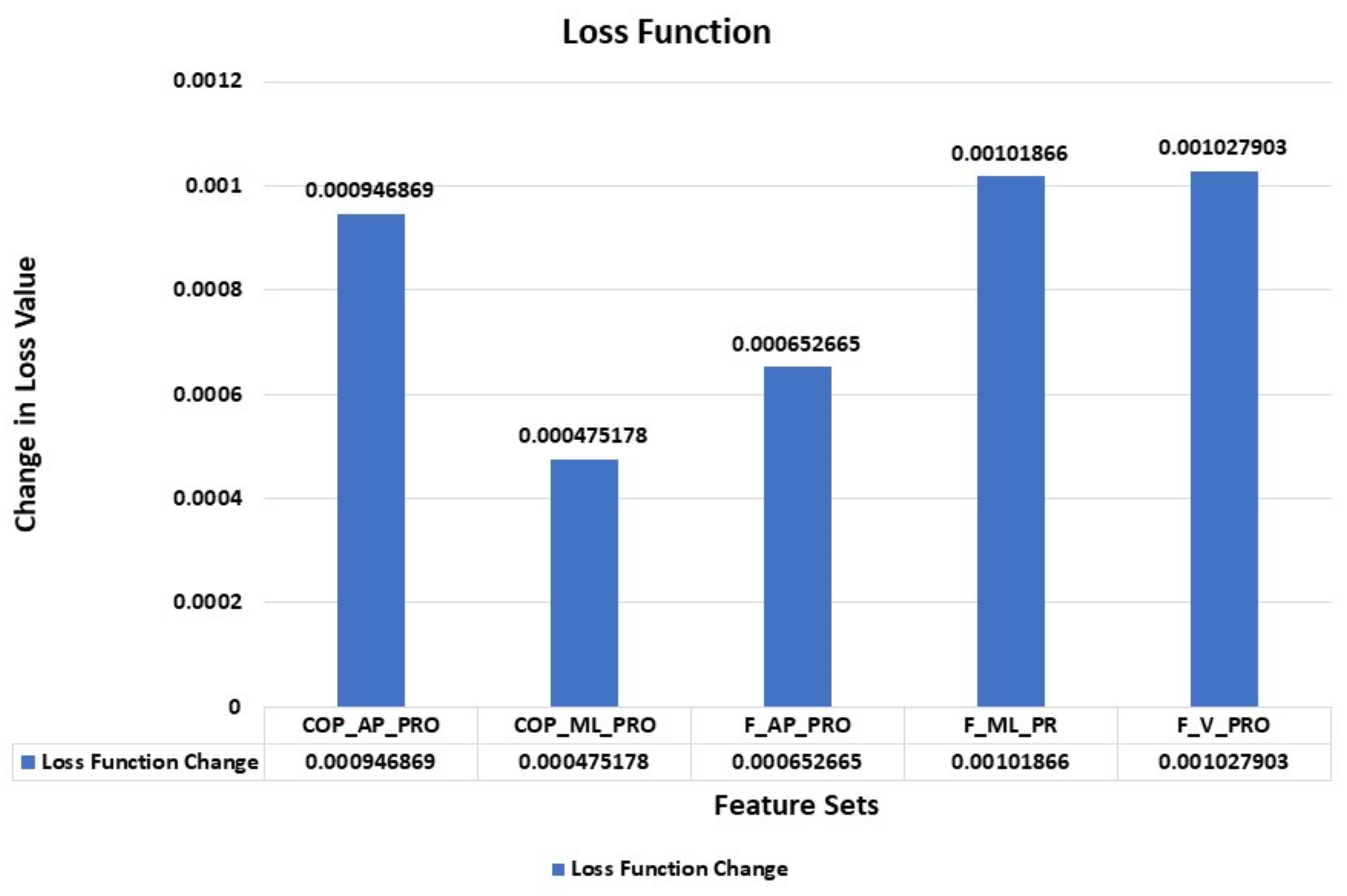
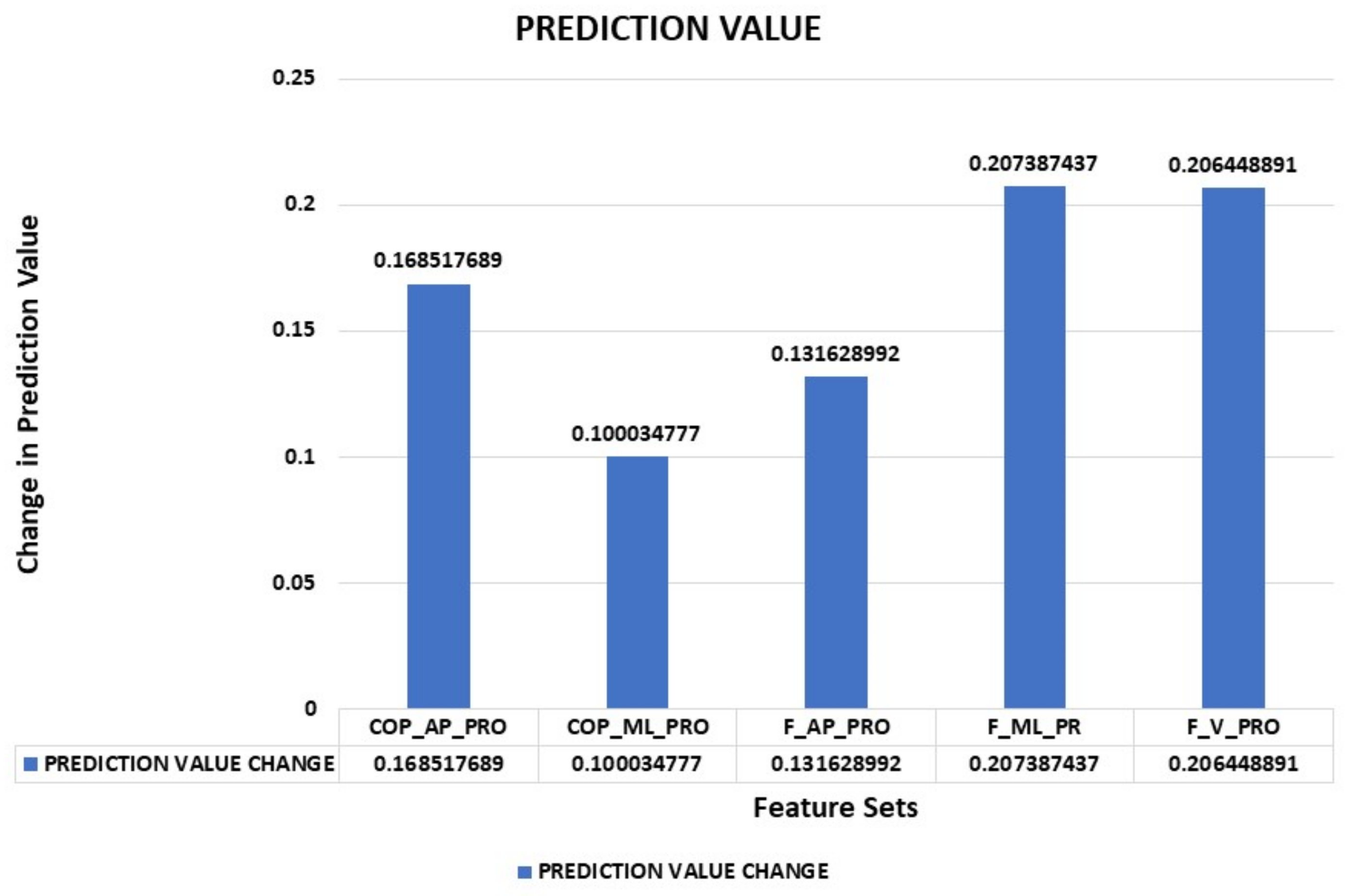
5.1. Feature Importance
5.1.1. Prediction Value Change
5.1.2. Loss Function Change
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Chau, T. A review of analytical techniques for gait data. Part 1: Fuzzy, statistical and fractal methods. Gait Posture 2001, 13, 49–66. [Google Scholar] [CrossRef]
- Lozano-Ortiz, C.A.; Muniz, A.M.S.; Nadal, J. Human gait classification after lower limb fracture using artificial neural networks and principal component analysis. In Proceedings of the 2010 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Buenos Aires, Argentina, 31 August–4 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1413–1416. [Google Scholar]
- Zeng, W.; Liu, F.; Wang, Q.; Wang, Y.; Ma, L.; Zhang, Y. Parkinson’s disease classification using gait analysis via deterministic learning. Neurosci. Lett. 2016, 633, 268–278, Erratum in IEEE J. Biomed. Health Inform. 2017, 9. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Wang, J.; Liu, L. Feature extraction via KPCA for classification of gait patterns. Hum. Mov. Sci. 2007, 26, 393–411. [Google Scholar] [CrossRef] [PubMed]
- Alaqtash, M.; Sarkodie-Gyan, T.; Yu, H.; Fuentes, O.; Brower, R.; Abdelgawad, A. Automatic classification of pathological gait patterns using ground reaction forces and machine learning algorithms. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 453–457. [Google Scholar]
- Ferrarin, M.; Bovi, G.; Rabuffetti, M.; Mazzoleni, P.; Montesano, A.; Pagliano, E.; Marchi, A.; Magro, A.; Marchesi, C.; Pareyson, D.; et al. Gait pattern classification in children with Charcot–Marie–Tooth disease type 1A. Gait Posture 2012, 35, 131–137. [Google Scholar] [CrossRef] [Green Version]
- Ruhe, A.; Fejer, R.; Walker, B. The test–retest reliability of centre of pressure measures in bipedal static task conditions—A systematic review of the literature. Gait Posture 2010, 32, 436–445. [Google Scholar] [CrossRef] [Green Version]
- Mezghani, N.; Husse, S.; Boivin, K.; Turcot, K.; Aissaoui, R.; Hagemeister, N.; de Guise, J. Automatic Classification of Asymptomatic and Osteoarthritis Knee Gait Patterns Using Kinematic Data Features and the Nearest Neighbor Classifier. IEEE Trans. Biomed. Eng. 2008, 55, 1230–1232. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Giakas, G.; Baltzopoulos, V. Time and frequency domain analysis of ground reaction forces during walking: An investigation of variability and symmetry. Gait Posture 1997, 5, 189–197. [Google Scholar] [CrossRef]
- Lafuente, R.; Belda, J.; Sánchez-Lacuesta, J.; Soler, C.; Prat, J. Design and test of neural networks and statistical classifiers in computer-aided movement analysis: A case study on gait analysis. Clin. Biomech. 1998, 13, 216–229. [Google Scholar] [CrossRef]
- Soares, D.P.; de Castro, M.P.; Mendes, E.A.; Machado, L. Principal component analysis in ground reaction forces and center of pressure gait waveforms of people with transfemoral amputation. Prosthet. Orthot. Int. 2016, 40, 729–738. [Google Scholar] [CrossRef]
- Peng, Z.; Cao, C.; Liu, Q.; Pan, W. Human Walking Pattern Recognition Based on KPCA and SVM with Ground Reflex Pressure Signal. Math. Probl. Eng. 2013, 2013, 1–12. [Google Scholar] [CrossRef]
- Goh, K.; Lim, K.; Gopalai, A.; Chong, Y. Multilayer perceptron neural network classification for human vertical ground reaction forces. In Proceedings of the 2014 IEEE Conference on Biomedical Engineering and Sciences, Miri, Malaysia, 8–10 December 2014; pp. 536–540. [Google Scholar]
- Xu, Y.; Zhang, D.; Jin, Z.; Li, M.; Yang, J.-Y. A fast kernel-based nonlinear discriminant analysis for multi-class problems. Pattern Recognit. 2006, 39, 1026–1033. [Google Scholar] [CrossRef]
- Horsak, B.; Slijepcevic, D.; Raberger, A.-M.; Schwab, C.; Worisch, M.; Zeppelzauer, M. GaitRec, a large-scale ground reaction force dataset of healthy and impaired gait. Sci. Data 2020, 7, 1–8. [Google Scholar] [CrossRef]
- Muniz, A.; Nadal, J. Application of principal component analysis in vertical ground reaction force to discriminate normal and abnormal gait. Gait Posture 2009, 29, 31–35. [Google Scholar] [CrossRef]
- LeMoyne, R.; Kerr, W.; Mastroianni, T.; Hessel, A. Implementation of machine learning for classifying hemiplegic gait disparity through use of a force plate. In Proceedings of the 2014 13th International Conference on Machine Learning and Applications, Detroit, MI, USA, 3–5 December 2014; pp. 379–382. [Google Scholar]
- Williams, G.; Lai, D.; Schache, A.; Morris, M.E. Classification of Gait Disorders Following Traumatic Brain Injury. J. Head Trauma Rehabilitation 2015, 30, E13–E23. [Google Scholar] [CrossRef]
- Schöllhorn, W.; Nigg, B.; Stefanyshyn, D.; Liu, W. Identification of individual walking patterns using time discrete and time continuous data sets. Gait Posture 2001, 15, 180–186. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Slijepcevic, D.; Zeppelzauer, M.; Gorgas, A.-M.; Schwab, C.; Schüller, M.; Baca, A.; Breiteneder, C.; Horsak, B. Automatic Classification of Functional Gait Disorders. IEEE J. Biomed. Health Inform. 2017, 22, 1653–1661. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z. An Efficient Automatic Gait Anomaly Detection Method Based on Semi-Supervised Clustering. Comput. Intell. Neurosci. 2021, 2021, 8840156. [Google Scholar] [CrossRef]
- Vijayvargiya, A.; Prakash, C.; Kumar, R. Human knee abnormality detection from imbalanced sEMG data. Biomed. Signal Process. Control 2021, 66, 102406. [Google Scholar] [CrossRef]
- Veer, K.; Pahuja, S.K. Gender based assessment of gait rhythms during dual-task in Parkinson’s disease and its early detection. Biomed. Signal Process. Control 2022, 72, 103346. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 2017, 30, 1–9. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS’18), Montreal, QC, Canada, 3–8 December 2018; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 6639–6649. [Google Scholar]
- Sciuto, G.L.; Capizzi, G.; Shikler, R.; Napoli, C. Organic solar cells defects classification by using a new feature extraction algorithm and an EBNN with an innovative pruning algorithm. Int. J. Intell. Syst. 2021, 36, 2443–2464. [Google Scholar] [CrossRef]
- Sciuto, G.L.; Capizzi, G.; Caramagna, A.; Famoso, F.; Lanzafame, R.; Woźniak, M. Failure Classification in High Concentration Photovoltaic System (HCPV) by using Probabilistic Neural Networks. Int. J. Appl. Eng. Res. 2017, 12, 16039–16046. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Disorder Classes | Anatomical Regions | Combinations |
|---|---|---|
| Hip (H) | Pelvis (P) | H_PC |
| Coxa (C) | H_PF | |
| Femur (F) | H_CF | |
| Other (O) | H_PCF | |
| Knee (K) | Patella (P) | K_PF |
| Femur/Tibia (F) | K_PR | |
| Rupture (R) | K_FR | |
| Other (O) | K_PFR | |
| Ankle (A) | Fibula/Tibia (F) | A_FR |
| Rupture (R) | A_FL | |
| Lower Leg Shaft (L) | A_RL | |
| Other (O) | A_FRL | |
| Calcaneous (C) | Fracture (F) | C_F |
| Arthrodesis (A) | C_A |
| SUBJECT ID | SESSION ID | TRIAL ID | AMP 1 | AMP 2 | ... | AMP 101 | |
|---|---|---|---|---|---|---|---|
| 1 | 512 | 413 | 1 | 0.022633 | 0.061113 | ... | 0.022629 |
| 2 | 512 | 413 | 2 | 0.022631 | 0.064086 | ... | 0.022631 |
| 3 | 512 | 413 | 3 | 0.022629 | 0.057981 | ... | 0.022629 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 75,732 | 127 | 345 | 8 | 0.029585 | 0.075245 | ... | 0.019985 |
| Methods | Training Accuracy | Test Accuracy | Weighted ROC-AUC | Precision | Recall | F1-Score |
|---|---|---|---|---|---|---|
| CATBOOST | 0.998 | 0.947 | 0.997 | 0.948 | 0.947 | 0.948 |
| Extra Trees | 1.000 | 0.869 | 0.990 | 0.884 | 0.869 | 0.867 |
| Random Forest | 1.000 | 0.851 | 0.989 | 0.870 | 0.851 | 0.849 |
| Light Gradient Boosting Machine (LGBM) | 0.781 | 0.627 | 0.812 | 0.697 | 0.627 | 0.656 |
| Decision Tree | 1.000 | 0.591 | 0.774 | 0.592 | 0.591 | 0.591 |
| XGBOOST | 0.626 | 0.569 | 0.918 | 0.627 | 0.569 | 0.557 |
| Training Accuracy | Test Accuracy | AUC Score | F1-Score | |
|---|---|---|---|---|
| Optimized CATBOOST Model | 0.990 | 0.960 | 0.990 | 0.950 |
| Name of the Algorithm | Hyperparameters | Values of Hyperparameters |
|---|---|---|
| Decision Trees | criterion | Entropy |
| splitter | Best | |
| min_samples_split | 2 | |
| min_samples_leaf | 1 | |
| class_weight | Balanced | |
| Extra Trees | n_estimator | 350 |
| criterion | Best | |
| min_samples_split | 9 | |
| class_weight | Balanced | |
| Light Gradient Boosting Machine (LGBM) | objective | Multiclass |
| boosting | Gbdt | |
| num_iterations | 2569 | |
| learning_rate | 0.21 | |
| lambda_l2 | 0.3 | |
| early_stopping | 50 | |
| Random Forest | criterion | Entropy |
| n_estimator | 1756 | |
| min_samples_split | 8 | |
| class_weight | Balanced | |
| Xgboost | Booster | Gbtree |
| Learning_rate | 0.26 | |
| Max_depth | 15 | |
| Reg_lambda | 1.1 | |
| N_estimators | 1657 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jani, D.; Varadarajan, V.; Parmar, R.; Bohara, M.H.; Garg, D.; Ganatra, A.; Kotecha, K. An Efficient Gait Abnormality Detection Method Based on Classification. J. Sens. Actuator Netw. 2022, 11, 31. https://doi.org/10.3390/jsan11030031
Jani D, Varadarajan V, Parmar R, Bohara MH, Garg D, Ganatra A, Kotecha K. An Efficient Gait Abnormality Detection Method Based on Classification. Journal of Sensor and Actuator Networks. 2022; 11(3):31. https://doi.org/10.3390/jsan11030031
Chicago/Turabian StyleJani, Darshan, Vijayakumar Varadarajan, Rushirajsinh Parmar, Mohammed Husain Bohara, Dweepna Garg, Amit Ganatra, and Ketan Kotecha. 2022. "An Efficient Gait Abnormality Detection Method Based on Classification" Journal of Sensor and Actuator Networks 11, no. 3: 31. https://doi.org/10.3390/jsan11030031
APA StyleJani, D., Varadarajan, V., Parmar, R., Bohara, M. H., Garg, D., Ganatra, A., & Kotecha, K. (2022). An Efficient Gait Abnormality Detection Method Based on Classification. Journal of Sensor and Actuator Networks, 11(3), 31. https://doi.org/10.3390/jsan11030031