
Safe Data-Driven Lane Change Decision Using Machine Learning in Vehicular Networks

Abstract
:1. Introduction
2. Related Work
- Architecture: Depending on where it is located within the vehicular network, the architecture of an LC module can be categorized as either centralized or decentralized. The LC module can be installed in a Road Side Unit (RSU) in a centrally controlled architecture. For trajectory planning and lane-changing choices, a centralized controller can combine data from Onboard Units (OBUs). Additionally, the controller may advise an OBU [38] to change lanes or recommend state changes, such as path or velocity [44]. It has been discovered that centralized controllers perform better while accomplishing cooperative objectives [45]. The difficulty of scaling the RSU, based on traffic fluctuations, is however a drawback of the centralized architecture. On the other hand, The LC module can be added to individual OBUs to execute the decentralized design. An autonomous controller can be created using the LC module, perception module, and vehicle control module. When gathering data from other vehicles for trajectory planning and lane change choices, these autonomous controllers can communicate through V2V communications or via the network infrastructure [46]. Based on traffic demands, this method can greatly enhance the module’s scalability. Nevertheless, reaching consensus among numerous vehicles in a decentralized architecture is a major difficulty [46].
- Automation penetration ratio: An environment with mixed levels of connectivity and automation is important to consider when designing a lane change module [47]. Due to the slow pace of autonomous vehicles adoption, significant market penetration is only anticipated to occur starting from 2040 [48]. Therefore, it is likely that autonomous vehicles and human driven vehicles will coexist in the near future [47], and it is important to take mixed traffic into account while designing an effective LC module. Creating a perspective of the surroundings in mixed traffic can be a challenging issue [48]. Additionally, the performance analysis of the module in mixed traffic with a varied autonomous vehicles penetration rate can offer a useful estimate of the minimal vehicles penetration needed for the module to function properly [49].
- Delay evaluation: Lane change decision is a critical real-time process that should be taken in a tight time window. Therefore, a special concern should be devoted to evaluate the performance of the lane change. Mathematical modeling based on queuing theory is an efficient tool that may be adopted to assess the average delay of the control traffic needed to take the decision.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | AI Method | Architecture | Penetration Ratio | Delay Evaluation |
|---|---|---|---|---|
| [43] | DQN | Decentralized | No | No |
| [37] | DQN | Decentralized | No | No |
| [38] | GNN and DQN | Centralized | Yes | No |
| [49] | GCN and ACN | Centralized | Yes | No |
| [37] | ACN | Decentralized | Yes | No |
| [50] | Fedeterated Leraning | Decentralized | Yes | No |
- –
- Mobility models should simulate the real behavior of vehicular traffic, whilst it is critical to assess lane change decision modules for vehicle ad hoc networks. In fact, the vehicles distribution on highways is captured by the mobility model, which also affects vehicle trajectory. Performance results retrieved from simulations may not accurately reflect performance in an actual deployment in case a realistic mobility model is not used. Therefore, we adopt an authentic car-following mobility model to validate our lane change decision module in light of this understanding. The suggested module’s performance results demonstrate its advantages and demonstrate that it outperforms competing machine learning algorithms.
- –
- Research projects dealing with automatic lane switching adopt functions based on rule-based models; while these models may function well under typical common circumstances, they may be vulnerable to failure in the event of unforeseen conditions. Based on this knowledge, we develop a Reinforcement Federated Machine Learning based platform. The platform’s major goal is to train the vehicle agent to learn an automated lane change behavior so that it can lane shift intelligently in unforeseen situations. To calculate the total return, which is an accumulation of rewards across a lane shifting process, we specifically treat both state space and action space as continuous and construct a special format of Q-function approximator.
- –
- Lane change decision is a critical process that should be performed timely. Therefore, we perform a mathematical modelling of the downlink traffic at the Road Side Unit (RSU), using a M/GI/1 multiclass preemptive queue. The modelling is crucial to assess the real time feature of the lane change process.
3. Studied Lane Change Assistance Platform
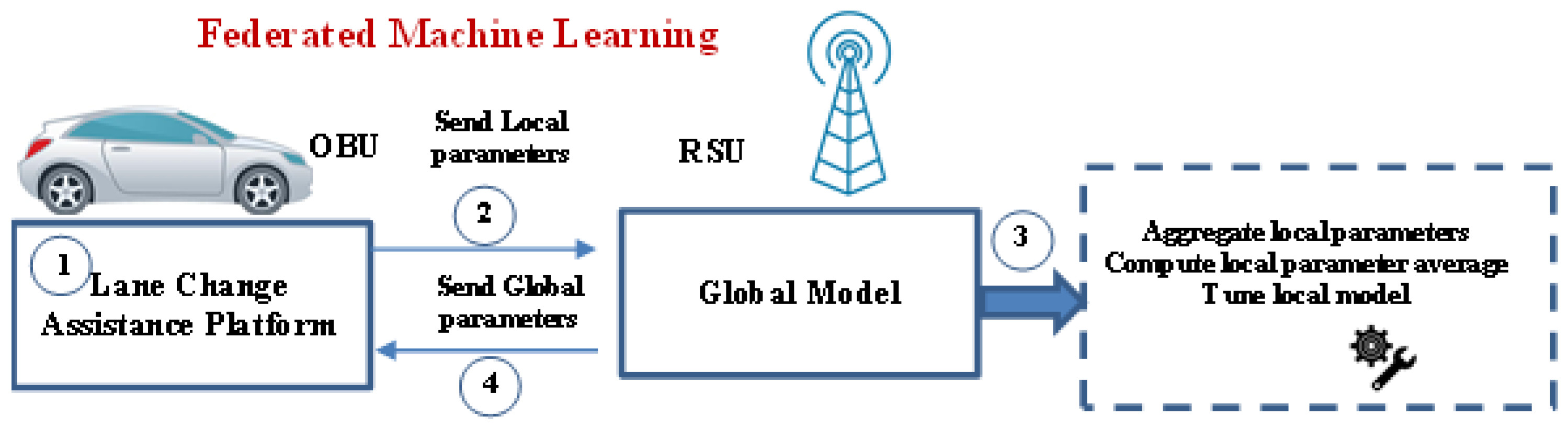
3.1. Global Federated Machine Learning Architecture
- –
- In a first stage, the OBUs apply a local lane change assistance platform which is extensively detailed in next subsection. In this context, OBUs exchange local ML model parameters with RSU.
- –
- At a second stage, a global model of a machine learning algorithm is maintained by an RSU. In fact, after receiving the local model parameters sent by each OBU, the RSU calculates model averaging across vehicles, fine-tunes these parameters, and then feeds back the global model to the OBUs. This will collaboratively and accurately detect lane change erroneous decisions and reduces collisions caused by lane changes.
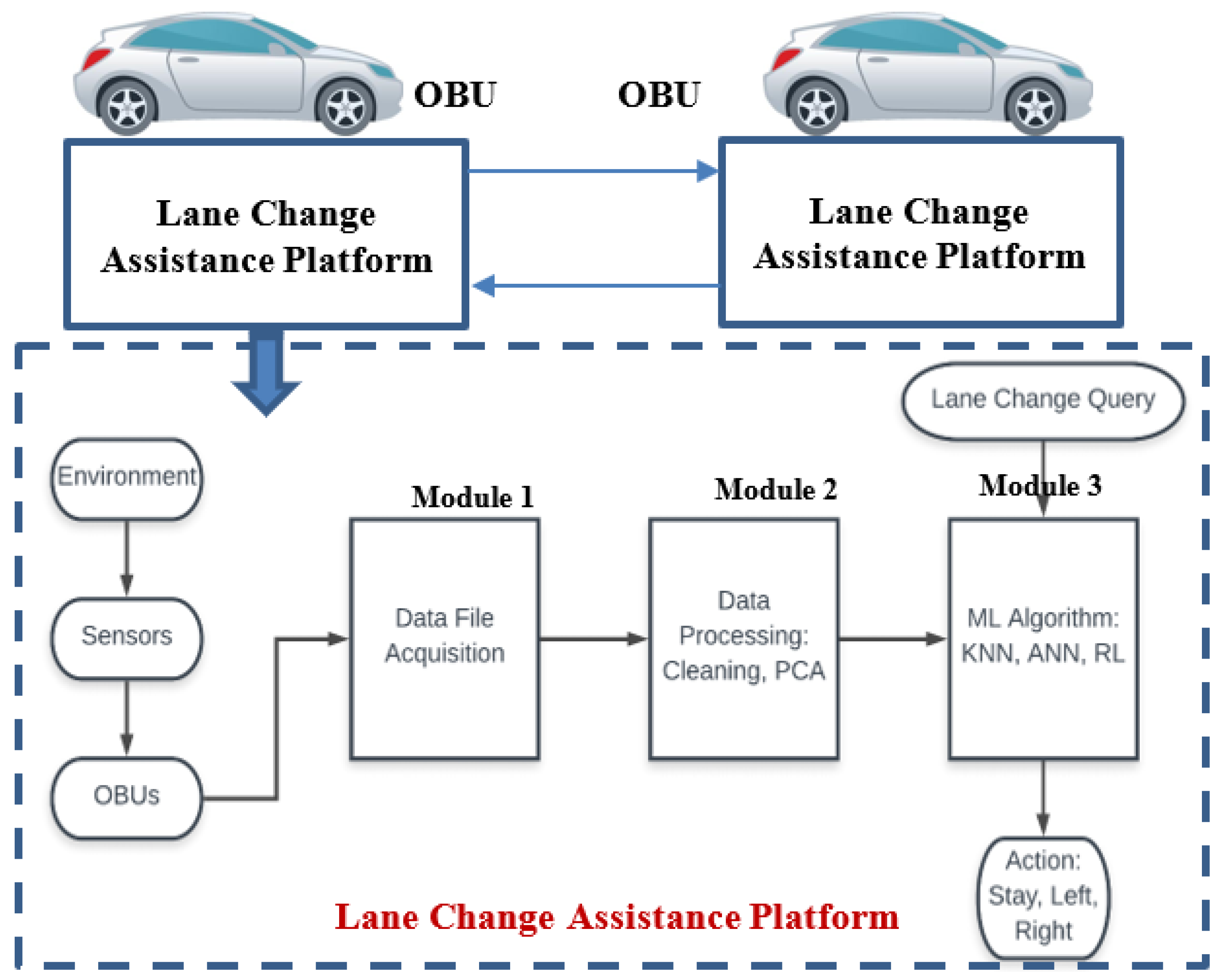
3.2. Local Lane Change Assistance Platform
- –
- Module 1: Data file acquisition
- –
- Module 2: Data processing
- –
- Module 3: Lane Change Decision Module
3.2.1. Module 1: Data File Acquisition
- –
- Time-step at which the data was collected;
- –
- Detected risk (−1 if no risk detected, else equal to the risky lane ID);
- –
- Ego vehicle variables: X position, Y position, lane ID, velocity, acceleration;
- –
- Neighboring vehicles variables: car ID, X position, Y position, lane ID, velocity, acceleration, distance to ego vehicle;
- –
- Action taken by ego (stay in lane, go left, or go right).
3.2.2. Module 2: Data Processing
- –
- Task1: Extract relevant data
- –
- Task 2: Fill NA (not assigned) values
- –
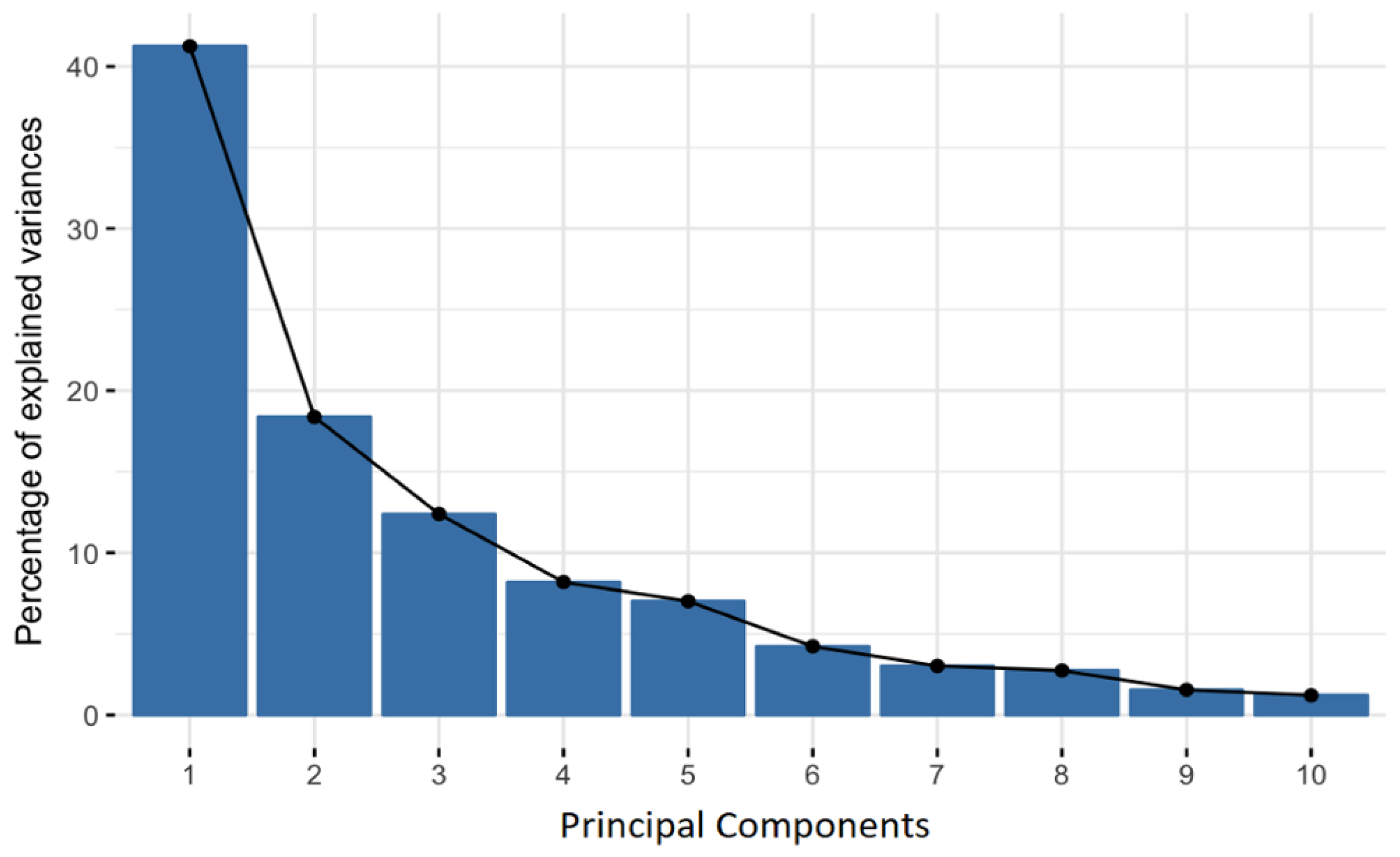
- Task 3: Reduce data dimension
- –
- Y position, velocity, acceleration for the ego vehicle
- –
- Y position, velocity, acceleration, distance to ego for each of the neighboring vehicles
- –
- Action taken by ego vehicle (stay in lane, go left, or go right).
- –
- At the highway entrance, where the ego vehicle does not have any followers in any lane.
- –
- At the highway exit, where the ego vehicle does not have any leaders.
- –
- At the right-most lane, where there are no right-side followers or leaders.
- –
- At the left-most lane, where there are no left-side followers or leaders.
3.2.3. Module 3: Lane Change Decision Module
- –
- Input layer: Within the input layer, we considered 11 input neurons with the ReLU activation function.
- –
- Hidden layers:
- *
- With the first architecture, we adopted 5 hidden layers with 20 neurons each, and a ReLu activation function
- *
- The second architecture relies on 5 hidden layers with 200 neurons each, and a ReLu activation function
- *
- With the third architecture, we adopted 12 hidden layers with 20 neurons each, and a ReLu activation function
- –
- Output Layer: Within the output layer, we considered 3 output neurons with the SoftMax activation function.Performance tests show that the first architecture exhibits the best prediction accuracy (0.89673).
- *
- Positive reward equal to the distance driven with no collisions:
- *
- Negative reward:where:
- •
- , , and are negative rewards.
- •
- is the collision ratio sent by the RSU.
- •
- is the probability that the distance, separating two following vehicles, is less than the safety distance.
- •
- is the probability that an emergency brake occurs.
- •
- is the probability that a lane change takes place.
- *
- Total reward: R = + −1
4. End to End Delay Analysis
- Class 1: Safety related message sent by the RSU; This message contains the collision ratio required for the RL utility function.
- Class 2: Global update sent by the RSU related to the OBU local update required for the federated machine learning.
- Queuing delay at the RSU,
- RSU-to-vehicle propagation delay,
4.1. Propagation Delay
4.2. Queuing Delay at the RSU Side
- : the occupation rate of a class-i request;
- : the arrival rate of a class-i request;
- : the mean service time at the drone of a class-i request;
- : the mean waiting time in the queue of a class-i request;
- : the mean residual service time of a class-i request;
- : the mean sojourn time of a class-i request, note that ;
- : the average number of requests of class i waiting in the queue.
4.2.1. Mean Waiting Time of High Priority Requests
4.2.2. Mean Waiting Time of Low Priority Requests
5. Lane Change Assistance Platform Validation
5.1. Simulation Scenario
- Computing the safety speed of vehicle i, , required to maintain a safety distance from its leading vehicle.
- Determining the desired new speed of vehicle i, , which is equal to the current speed plus the increment determined by the uniform acceleration, upper bounded by the maximum safe speeds.
- Determining the actual speed of the vehicle i, , by adding some randomness, due to driver’s imperfection using the measure of a maximum percentage of the highest achievable speed increment . is a random variable uniformly distributed in [0, 1].
5.2. Risk Modelling
5.3. Performance Parameters
5.4. Performance Analysis
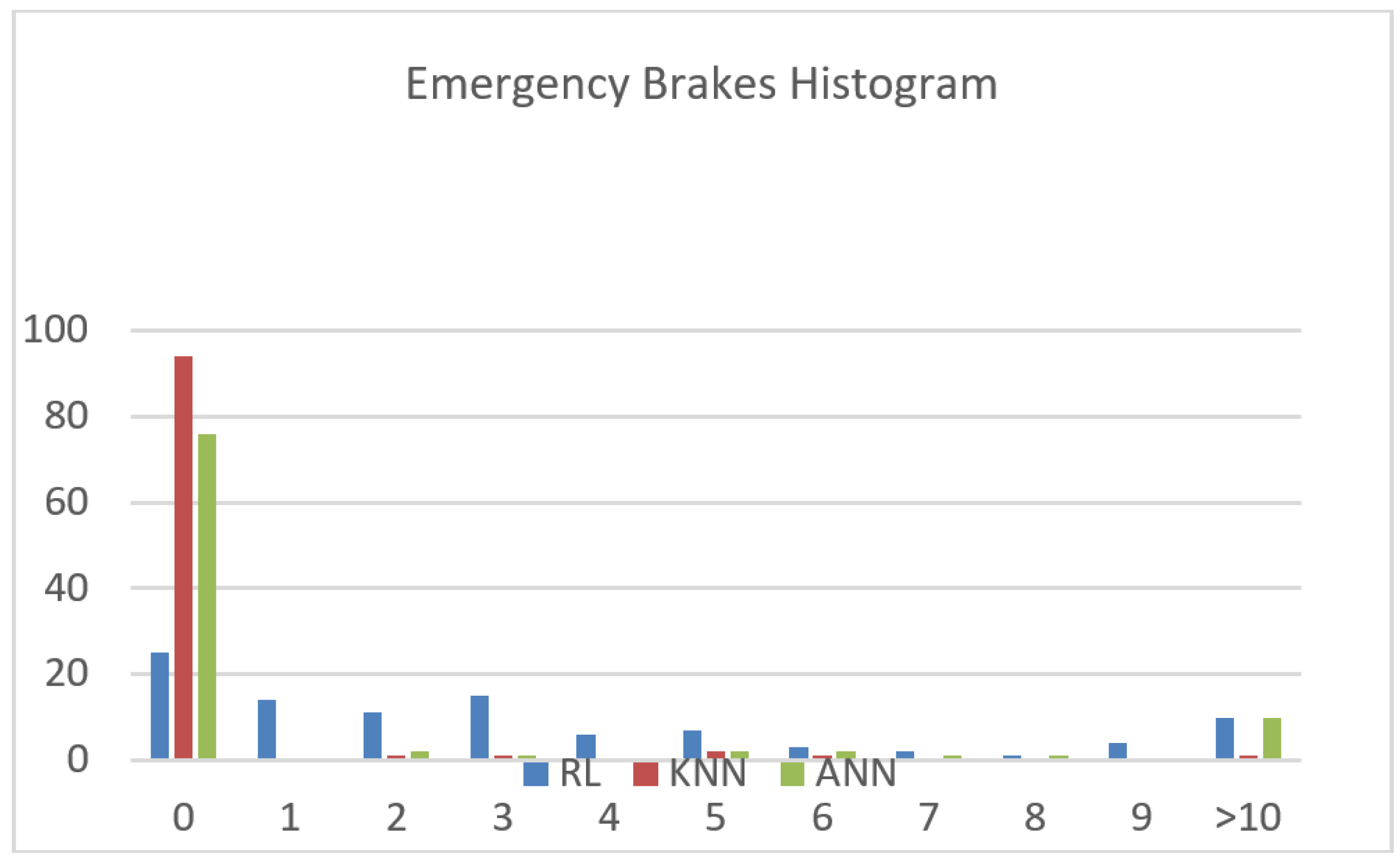
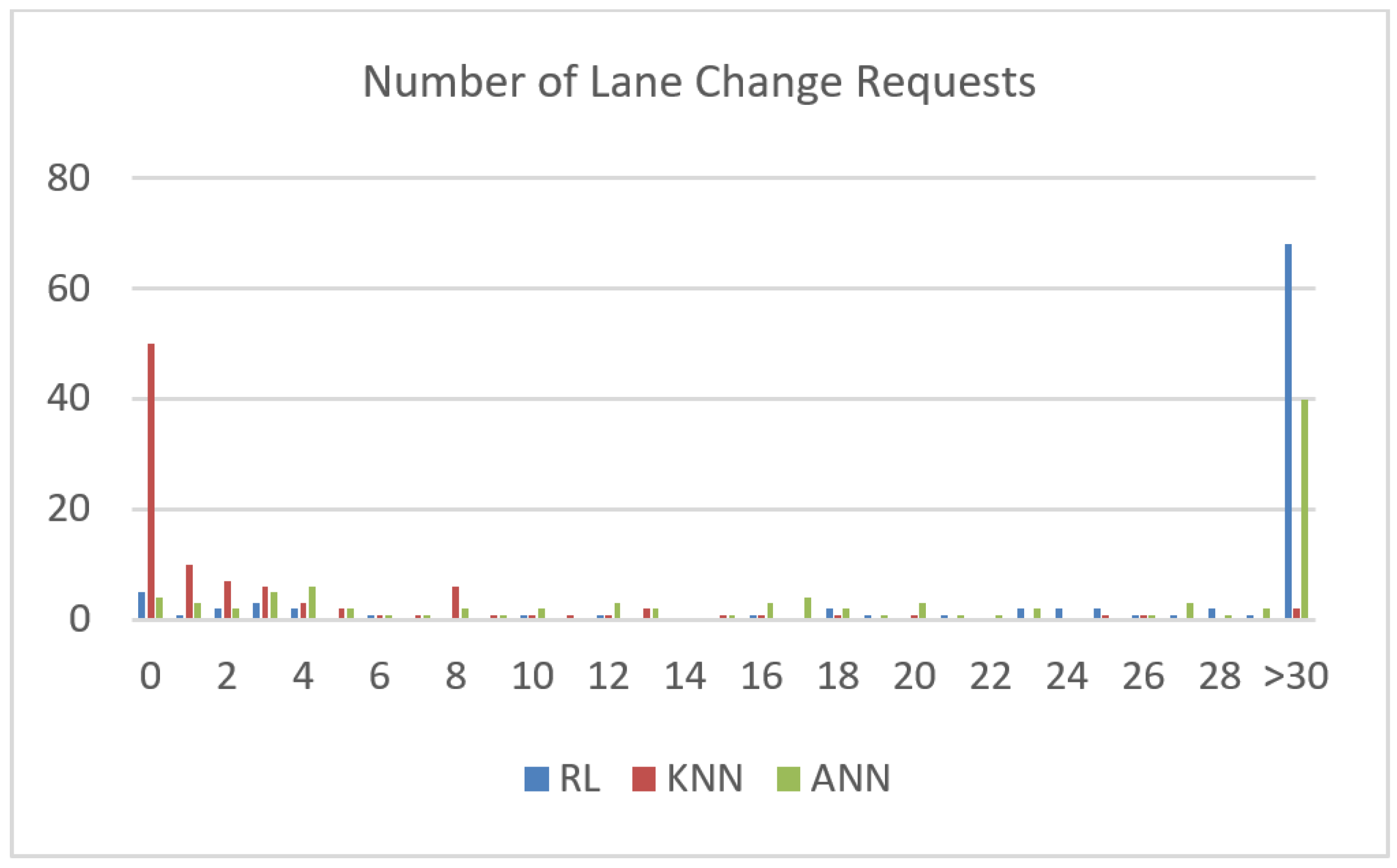
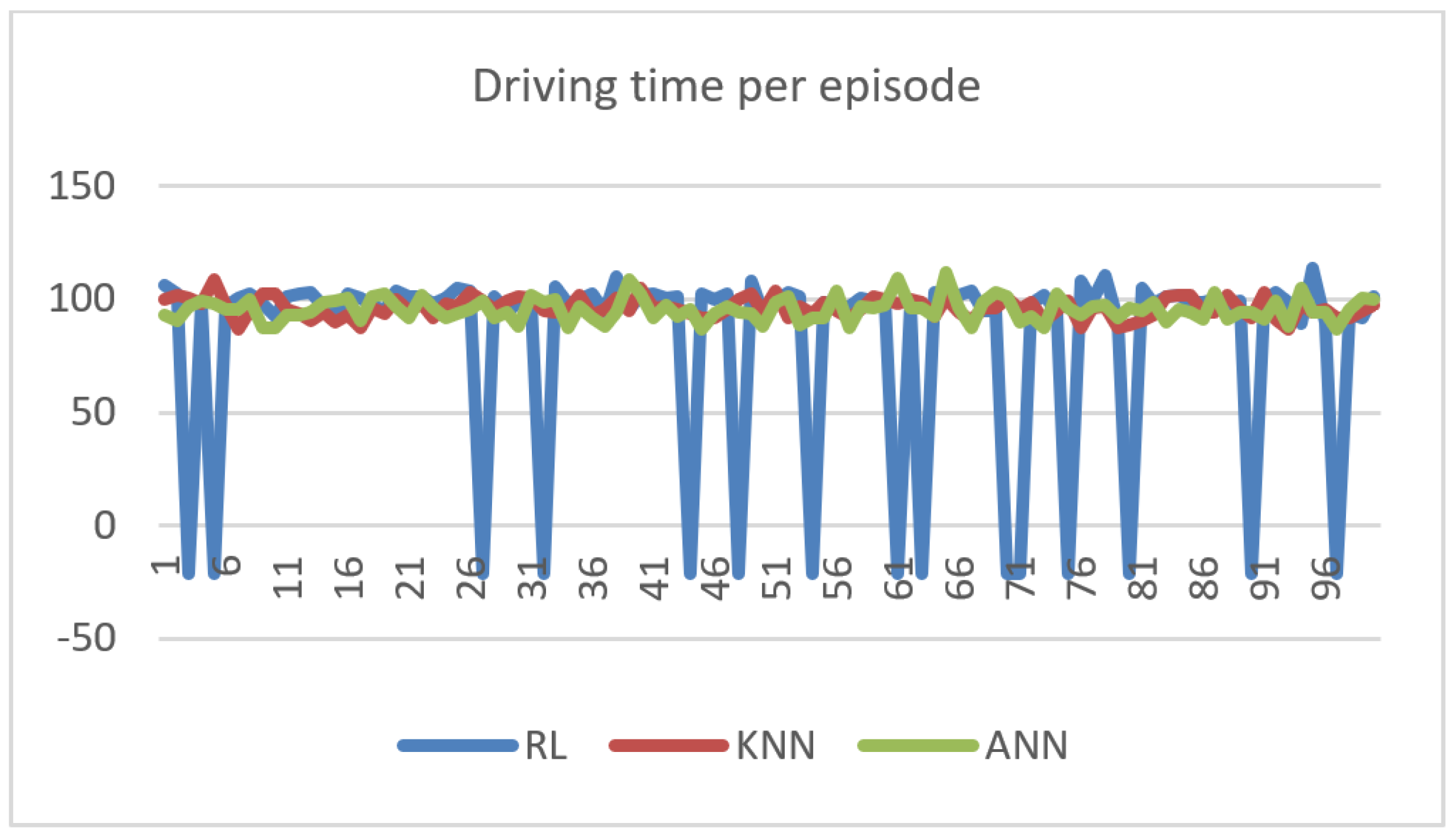
- The RL agent performs poorly. In fact, RL algorithms require relatively more training than regular algorithms, as they start learning from random data. Different tuning of reward and penalty points might also impact the speed of convergence of the algorithm.
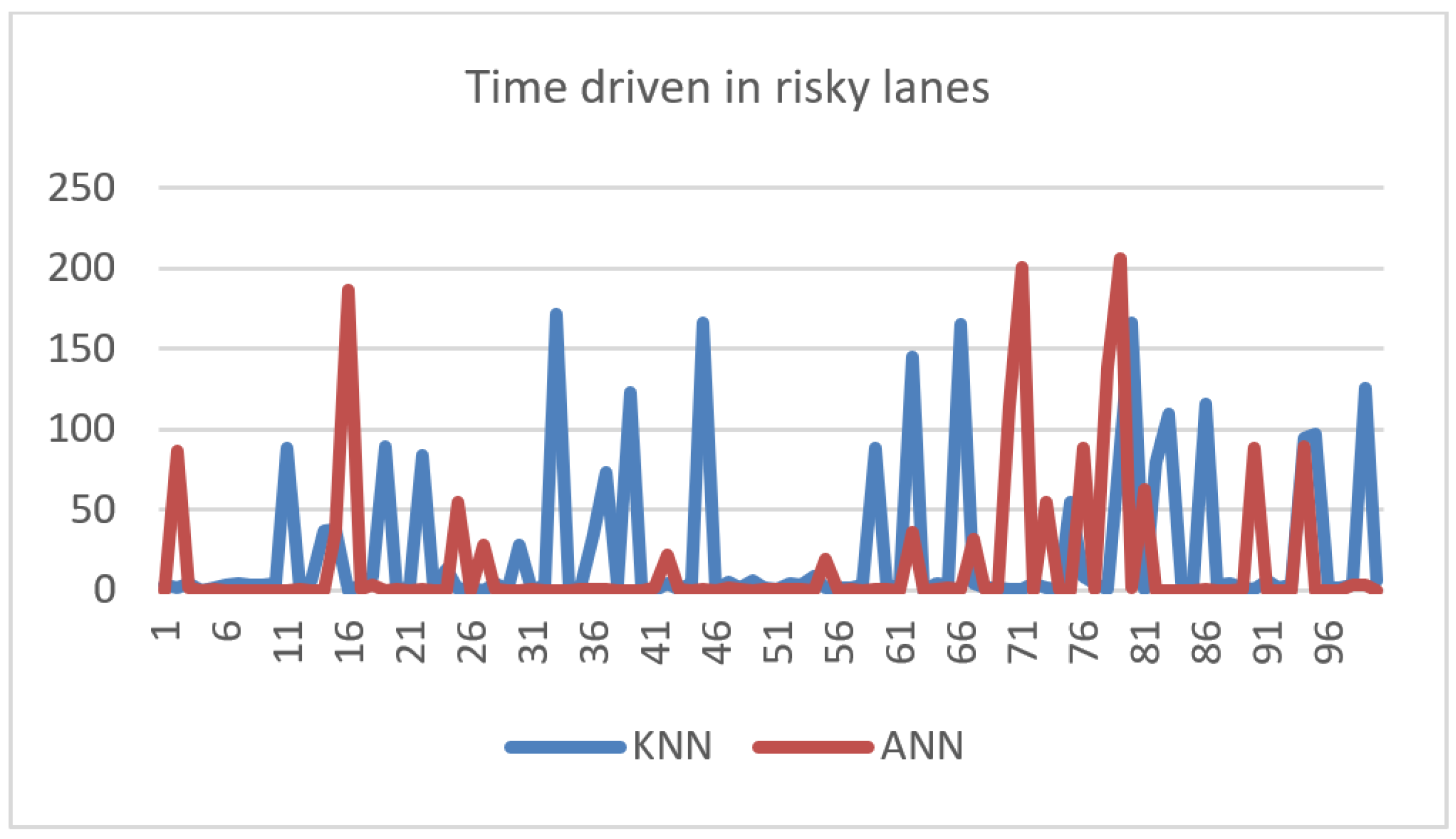
- The KNN agent performs best out of the proposed algorithms, as it induces zero collision rate and the lowest emergency brake frequency. We note that this performance was a consequence of the bias of KNN towards staying in the same lane.
- The ANN agent presents relative satisfying performance, with zero collision rates. It is to be noted that ANN tends to cause higher emergency brakes due to the higher frequency of approved lane change requests. As a conclusion, the machine learning parameter models need to be dynamic and should adapt to the traffic fluctuation. This issue is under study in our future research work.
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Deng, L.; Ni, W.; Zhou, T.; Yu, Y.; Zhai, L. Analysis of Vehicle Assisted Lane Change System and Autonomous Lane Change Model. In Proceedings of the 2022 Fourth International Conference on Emerging Research in Electronics, Computer Science and Technology (ICERECT), Mandya, India, 26–27 December 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Ranjan, A.; Sharma, S.; Goyal, H.R.; Kumar, K.C.N. Vehicle Collision Avoidance System During Lane Change using Internet-of-Things. In Proceedings of the 2023 International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT), Bengaluru, India, 5–7 January 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Ouyang, K.; Wang, Y.; Li, Y.; Zhu, Y. Lane change decision planning for autonomous vehicles. In Proceedings of the IEEE Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 6277–6281. [Google Scholar] [CrossRef]
- Sun, M.; Chen, Z.; Li, H.; Fu, B. Cooperative Lane-Changing Strategy for Intelligent Vehicles. In Proceedings of the IEEE Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 6022–6027. [Google Scholar] [CrossRef]
- Institute of Electrical and Electronics Engineers. IEEE Standard for Information Technology—Telecommunications and Information Exchange between Systems—Local and Metropolitan Area Networks—Specific Requirements Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications; Institute of Electrical and Electronics Engineers: Piscataway, NJ, USA, 2007. [Google Scholar]
- ETSI 302665; Intelligent Transport Systems (ITS). Communications Architecture, 2010.
- Naja, R. Wireless Vehicular Networks for Car Collision Avoidance; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Wan, F.; Li, M. Research on Coordinated Processing Scheme of Intelligent Transportation under Big Data Structure. In Proceedings of the IEEE 5th International Conference on Electromechanical Control Technology and Transportation (ICECTT), Nanchang, China, 15–17 May 2020; pp. 628–631. [Google Scholar] [CrossRef]
- Zhu, L.; Yu, F.R.; Wang, Y.; Ning, B.; Tang, T. Big Data Analytics in Intelligent Transportation Systems: A Survey. IEEE Trans. Intell. Transp. Syst. 2019, 20, 383–398. [Google Scholar] [CrossRef]
- Sliwa, B.; Adam, R.; Wietfeld, C. Client-Based Intelligence for Resource Efficient Vehicular Big Data Transfer in Future 6G Networks. IEEE Trans. Veh. Technol. 2021, 70, 5332–5346. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, C.; Zhang, H.; Ren, Y.; Han, Z.; Chen, K.; Hanzo, L. Machine Learning Paradigms for Next-Generation Wireless Networks. IEEE Wirel. Commun. 2017, 24, 98–105. [Google Scholar] [CrossRef] [Green Version]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F. Traffic Flow Prediction With Big Data: A Deep Learning Approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Ye, H.; Li, G.Y.; Juang, B.H.F. Deep Reinforcement Learning Based Resource Allocation for V2V Communications. IEEE Trans. Veh. Technol. 2019, 68, 3163–3173. [Google Scholar] [CrossRef] [Green Version]
- Khan Tayyaba, S.; Khattak, H.A.; Almogren, A.; Shah, M.A.; Ud Din, I.; Alkhalifa, I.; Guizani, M. 5G Vehicular Network Resource Management for Improving Radio Access Through Machine Learning. IEEE Access 2020, 8, 6792–6800. [Google Scholar] [CrossRef]
- Afify, A.A.; Mokhtar, B. Machine Learning-based Services Provisioning for Intelligent Internet of Vehicles. In Proceedings of the 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14 June–31 July 2021; pp. 51–54. [Google Scholar] [CrossRef]
- Aljeri, N.; Boukerche, A. A Novel Online Machine Learning Based RSU Prediction Scheme for Intelligent Vehicular Networks. In Proceedings of the 2019 IEEE/ACS 16th International Conference on Computer Systems and Applications (AICCSA), Abu Dhabi, United Arab Emirates, 3–7 November 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, X.; Liu, J.; Qiu, T.; Mu, C.; Chen, C.; Zhou, P. A Real-Time Collision Prediction Mechanism With Deep Learning for Intelligent Transportation System. IEEE Trans. Veh. Technol. 2020, 69, 9497–9508. [Google Scholar] [CrossRef]
- Zheng, Q.; Zheng, K.; Zhang, H.; Leung, V. Delay-optimal virtualized radio resource scheduling in software-defined vehicular networks via stochastic learning. IEEE Trans. Veh. Technol. 2016, 65, 7857–7867. [Google Scholar] [CrossRef]
- Ahmed, K. Modeling Drivers’ Acceleration and Lane Changing Behavior. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2005. [Google Scholar]
- Julian, E.; Damerow, F. Complex Lane Change Behavior in the Foresighted Driver Model. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 1747–1754. [Google Scholar]
- Nilsson, J.; Silvlin, J.; Brännström, M.; Coelingh, E.; Fredriksson, J. If, When, and How to Perform Lane Change Maneuvers on Highways. IEEE Intell. Transp. Syst. Mag. 2016, 8, 68–78. [Google Scholar] [CrossRef]
- Ulbrich, S.; Maurer, M. Towards Tactical Lane Change Behavior Planning for Automated Vehicles. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 989–995. [Google Scholar] [CrossRef] [Green Version]
- Sunberg, Z.; Ho, C.; Kochenderfer, M. The value of inferring the internal state of traffic participants for autonomous freeway driving. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017; pp. 3004–3010. [Google Scholar]
- Treiber, M.; Hennecke, A.; Helbing, D. Congested Traffic States in Empirical Observations and Microscopic Simulations. Phys. Rev. E 2000, 62, 1805–1824. [Google Scholar] [CrossRef] [Green Version]
- Kesting, A.; Treiber, M.; Helbing, D. General Lane-Changing Model MOBIL for Car-Following Models. Transp. Res. Rec. 2007, 1999, 86–94. [Google Scholar] [CrossRef] [Green Version]
- Hoel, C.; Wolff, K.; Laine, L. Automated Speed and Lane Change Decision Making using Deep Reinforcement Learning. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Zhou, J.; Zheng, H.; Wang, J.; Wang, Y.; Zhang, B.; Shao, Q. Multiobjective Optimization of Lane-Changing Strategy for Intelligent Vehicles in Complex Driving Environments. IEEE Trans. Veh. Technol. 2020, 69, 1291–1308. [Google Scholar] [CrossRef]
- Hegde, B.; Bouroche, M. Design of AI-based lane changing modules in connected and autonomous vehicles: A survey. In Proceedings of the 2022 Workshop Agents in Traffic and Transportation, Vienna, Austria, 25 July 2022. [Google Scholar]
- Bermejo, S.; Cabestany, J. Adaptive soft k-nearest-neighbour classifiers. Pattern Recognit. 2000, 33, 1999–2005. [Google Scholar] [CrossRef]
- McCulloch, W.; Pitts, W.A. Alogical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rosenblatt, F. Principles of Neurodynamics: Perceptions and the Theory of Brain Mechanism; Spartan Books: Washington, DC, USA, 1961; Volume 5. [Google Scholar]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Tong, W.; Hussain, A.; Bo, W.; Maharjan, S. Artificial Intelligence for Vehicle-to-Everything: A Survey. IEEE Access 2019, 7, 10823–10843. [Google Scholar] [CrossRef]
- Veres, M.; Moussa, M.A. Deep Learning for Intelligent Transportation Systems: A Survey of Emerging Trends. IEEE Trans. Intell. Transp. Syst. 2020, 21, 3152–3168. [Google Scholar] [CrossRef]
- Dong, J.; Chen, S.; Li, Y.; Du, R.; Steinfeld, A.; Labi, S. Space-weighted information fusion using deep reinforcement learning: The context of tactical control of lane-changing autonomous vehicles and connectivity range assessment. Transp. Res. Part C Emerg. Technol. 2021, 128, 103192. [Google Scholar] [CrossRef]
- Chen, S.; Dong, J.; Ha, P.; Li, Y.; Labi, S. Graph neural network and reinforcement learning for multi-agent cooperative control of connected autonomous vehicles. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 838–857. [Google Scholar] [CrossRef]
- Hwang, S.; Lee, K.; Jeon, H.; Kum, D. Autonomous Vehicle Cut-In Algorithm for Lane-Merging Scenarios via Policy-Based Reinforcement Learning Nested within Finite-State Machine. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17594–17606. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.; Veness, J.; Bellemare, M.; Graves, A.; Riedmiller, M.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Liao, X.; Zhao, X.; Wang, Z.; Han, K.; Tiwari, P.; Barth, M.J.; Wu, G. Game Theory-Based Ramp Merging for Mixed Traffic with Unity-SUMO Co-Simulation. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 5746–5757. [Google Scholar] [CrossRef]
- Dong, J.; Chen, S.; Li, Y.; Ha, P.Y.J.; Du, R.; Steinfeld, A.; Labi, S. Spatio-weighted information fusion and DRL-based control for connected autonomous vehicles. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Yu, C.; Wang, X.; Xu, X.; Zhang, M.; Ge, H.; Ren, J.; Sun, L.; Chen, B.; Tan, G. Distributed Multiagent Coordinated Learning for Autonomous Driving in Highways Based on Dynamic Coordination Graphs. IEEE Trans. Intell. Transp. Syst. 2020, 21, 735–748. [Google Scholar] [CrossRef]
- Häfner, B.; Bajpai, V.; Ott, J.; Schmitt, G.A. A Survey on Cooperative Architectures and Maneuvers for Connected and Automated Vehicles. IEEE Commun. Surv. Tutor. 2022, 24, 380–403. [Google Scholar] [CrossRef]
- Yang, Y.; Luo, R.; Li, M.; Zhou, M.; Zhang, W.; Wang, J. Mean Field Multi-Agent Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 5571–5580. [Google Scholar]
- Shi, P.; Yan, B. A Survey on Intelligent Control for Multiagent Systems. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 161–175. [Google Scholar] [CrossRef]
- Garg, M.; Johnston, C.; Bouroche, M. Can Connected Autonomous Vehicles really improve mixed traffic efficiency in realistic scenarios? In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 2011–2018. [Google Scholar] [CrossRef]
- Zhou, W.; Chen, D.; Yan, J.; Li, Z.; Yin, H.; Ge, W. Multi-agent reinforcement learning for cooperative lane changing of connected and autonomous vehicles in mixed traffic. Auton. Intell. Syst. 2022, 2, 5. [Google Scholar] [CrossRef]
- Ha, Y.J.; Chen, S.; Dong, J.; Du, R.; Li, Y.; Labi, S. Leveraging the Capabilities of Connected and Autonomous Vehicles and Multi-Agent Reinforcement Learning to Mitigate Highway Bottleneck Congestion. arXiv 2020, arXiv:2010.05436. [Google Scholar]
- Zeng, T.; Semiari, O.; Chen, M.; Saad, W.; Bennis, M. Federated Learning on the Road Autonomous Controller Design for Connected and Autonomous Vehicles. IEEE Trans. Wirel. Commun. 2022, 21, 10407–10423. [Google Scholar] [CrossRef]
- Konecny, J.; McMahan, H.B.; Ramage, D.; Richtarik, P. Federated Optimization: Distributed Machine Learning for On-Device Intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Samarakoon, S.; Bennis, M.; Saad, W.; Debbah, M. Federated Learning for Ultra-Reliable Low-Latency V2V Communications. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018. [Google Scholar]
- Giordani, P. Principal Component Analysis. In Encyclopedia of Social Network Analysis and Mining; Alhajj, R., Rokne, J., Eds.; Springer: New York, NY, USA, 2018; pp. 1831–1844. [Google Scholar] [CrossRef]
- Davies, V. Evaluating Mobility Models within an Ad Hoc Network. Master’s Thesis, Colorado School of Mines, Golden, CO, USA, 2000. [Google Scholar]
- Fiore, M.; Harri, J.; Filali, F.; Bonnet, C. Understanding Vehicular Mobility in Network Simulation. In Proceedings of the IEEE International Conference on Mobile Adhoc and Sensor Systems, Pisa, Italy, 8–11 October 2007; pp. 1–6. [Google Scholar] [CrossRef]









| Arrival Process | Service Time Distribution | |
|---|---|---|
| Safety Message | Poisson | Exponential |
| Global update message | Uniform | Constant |
| Parameters | RL | KNN | ANN |
|---|---|---|---|
| Collision rate | 15 | 0 | 0 |
| Average number of emergency brakes | 3.89 | 0.45 | 2.88 |
| Average number of lane change requests per episode | 38.27 | 3.91 | 31.66 |
| Average sojourn time | 100.0259 | 96.294 | 95.607 |
| KNN | ANN |
|---|---|
| 24.87 | 15.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naja, R. Safe Data-Driven Lane Change Decision Using Machine Learning in Vehicular Networks. J. Sens. Actuator Netw. 2023, 12, 59. https://doi.org/10.3390/jsan12040059
Naja R. Safe Data-Driven Lane Change Decision Using Machine Learning in Vehicular Networks. Journal of Sensor and Actuator Networks. 2023; 12(4):59. https://doi.org/10.3390/jsan12040059
Chicago/Turabian StyleNaja, Rola. 2023. "Safe Data-Driven Lane Change Decision Using Machine Learning in Vehicular Networks" Journal of Sensor and Actuator Networks 12, no. 4: 59. https://doi.org/10.3390/jsan12040059
APA StyleNaja, R. (2023). Safe Data-Driven Lane Change Decision Using Machine Learning in Vehicular Networks. Journal of Sensor and Actuator Networks, 12(4), 59. https://doi.org/10.3390/jsan12040059