


Fast Multi-User Searchable Encryption with Forward and Backward Private Access Control

 , and
, and 
Abstract
:1. Introduction
- Type I backward privacy leakage: When a search for a keyword w is carried out, Type I schemes reveal how many updates were made to w, what type of updates were made, and when each update was made.
- Type II backward privacy leakage: As well as the leakage at the first level, the second level may also reveal the times at which all updates associated with the keyword were made.
- Type III backward privacy leakage: The last level is considered the weakest, as it reveals the deletion of a previously added keyword, in addition to the leakage at the above levels.
- We propose a multi-user searchable symmetric encryption scheme that uses symmetric keys, thus significantly reducing the computation cost of the scheme.
- Our scheme is shown to be secure in multi-user scenarios via theoretical analyses of forward privacy and user security. Several experiments are also carried out to demonstrate that our design is efficient from the perspectives of computation and storage.
- Our scheme achieves reverse privacy: search queries should not reveal deleted files, because the updating key is changed when each search query is finished. This type of privacy is lacking in most similar constructions.
- We employ an optimized indexing system that marks and subsequently removes accessed entries, as the access pattern inadvertently reveals these results, and their encryption similarly exposes them.
2. Previous Work
3. Problem Statement
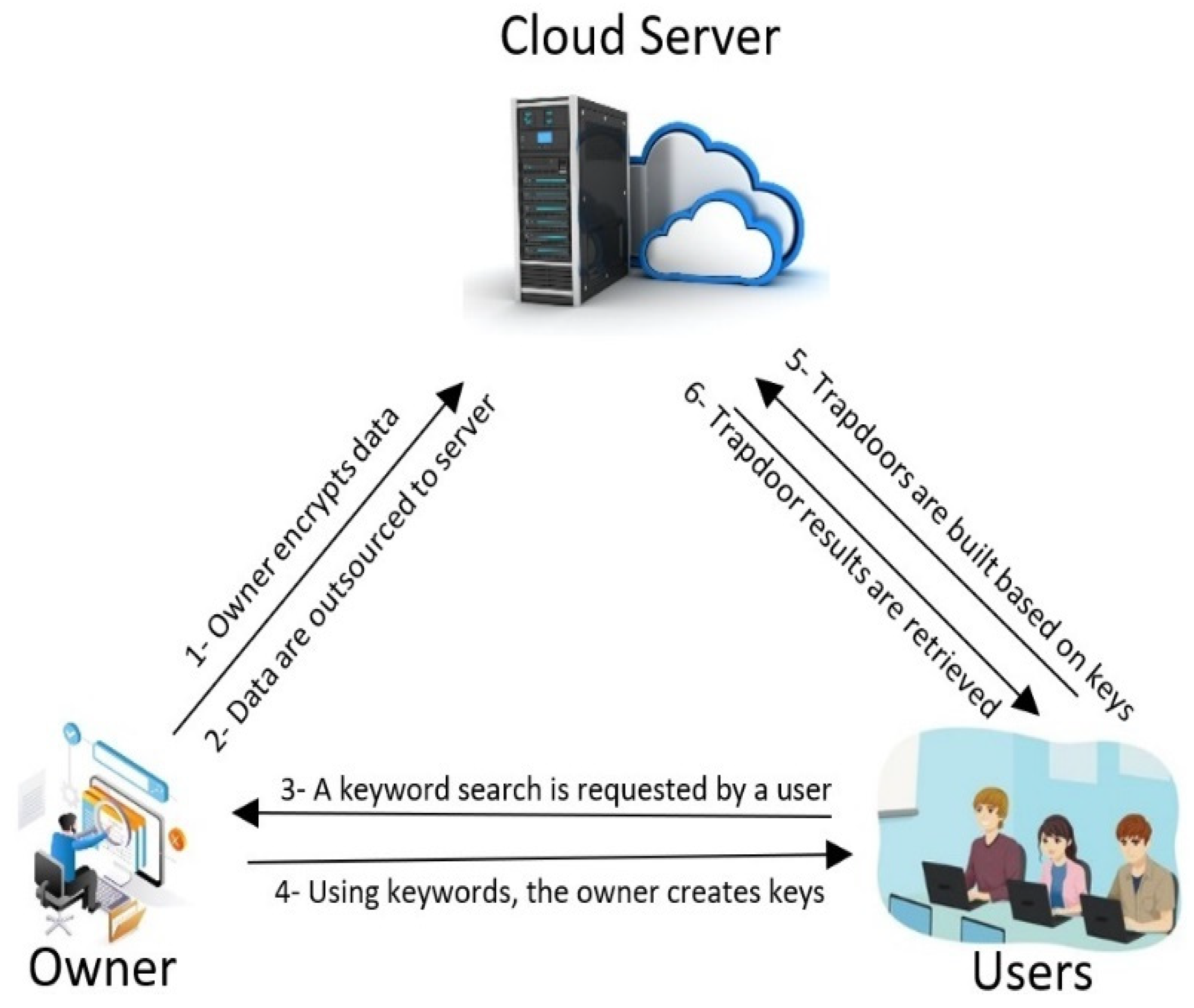
3.1. System Model
- Data owners bear responsibility for the maintenance of the system and resolving issues. They play a pivotal role in the allocation and distribution of access tokens to users. Data owners are tasked with generating encryption keys, modifying databases, and creating keys for users upon request, particularly when users initiate search operations.
- Users have the authority to upload their own data to the cloud and to perform searches across documents uploaded by other users. Access tokens, which are furnished by data owners, enable users to formulate access policies when uploading documents. Users can only access documents for which their access tokens align with the access policies, thus ensuring secure access during query execution.
- Cloud servers within the SSE system are equipped with advanced computational and storage capabilities, thereby facilitating robust data processing and storage. When a user uploads ciphertext accompanied by its associated index, the cloud server assumes responsibility for data processing. In cases where a user dispatches a search token to the cloud server, it initiates the search operation and subsequently returns the corresponding ciphertext results. The functionality of this server is crucial in terms of ensuring the security and efficiency of the system’s search operations.
3.2. Security Assumptions
3.3. Design Objectives
- The owner has the exclusive capability to generate tokens from a master primitive key, which can subsequently be entrusted to authorized users as necessary. Subsequently, these users can perform queries on an encrypted database by utilizing the securely stored keywords at their disposal.
- A multi-user environment is provided. Using the access tokens assigned to each user, the cloud server allows them to outsource their documents on behalf of all users and to search for outsourced documents that other users have contributed.
- The computational cost is low. In our scheme, access control is implemented using only symmetric encryption. We contend that our proposed scheme will be less computationally expensive than previous schemes.
- Forward and backward privacy are preserved. To achieve privacy, we use a counter based on keywords and a random number that is modified after each search to generate fresh keys. For these reasons, the cloud server cannot establish a connection between new documents that have been uploaded and previous search tokens.
4. Preliminaries
4.1. Notation
4.2. Forward and Backward Privacy and Leakage Functions
- () and
- () and
- () and
- In this case, and represent a stateless function.
5. Proposed Forward and Backward Multi-User Scheme
5.1. Overview
| Owner: | |
| 1: | |
| 2: | |
| 3: | |
| 4: | Send To the Server side. |
| Owner: | |
| 1: | |
| 2: | |
| 3: | |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 8: | Send {} to server |
| Server: | |
| 9: | |
| 1: | User asks the owner to search for keyword |
| Owner: | |
| 2: | |
| 3: | |
| 4: | |
| 5: | Send to user |
| User Uk: | |
| 6: | |
| 7: | |
| 8: | |
| 9: | Send {} to Server |
| Server: | |
| 10: | , Res={} |
| 11: | Res |
| 12: | |
| 14: | |
| 15: | Delete |
| Send {} to User | |
| User Uk: | |
| 16: | |
| 17: | |
| 18: | |
| 19: | Res Res |
| 20: | Else |
| 21: | Res Res |
| 22: | Send { Res} to Server |
| Server: | |
| 23: | |
5.2. Security Analysis
6. Experimental Evaluation
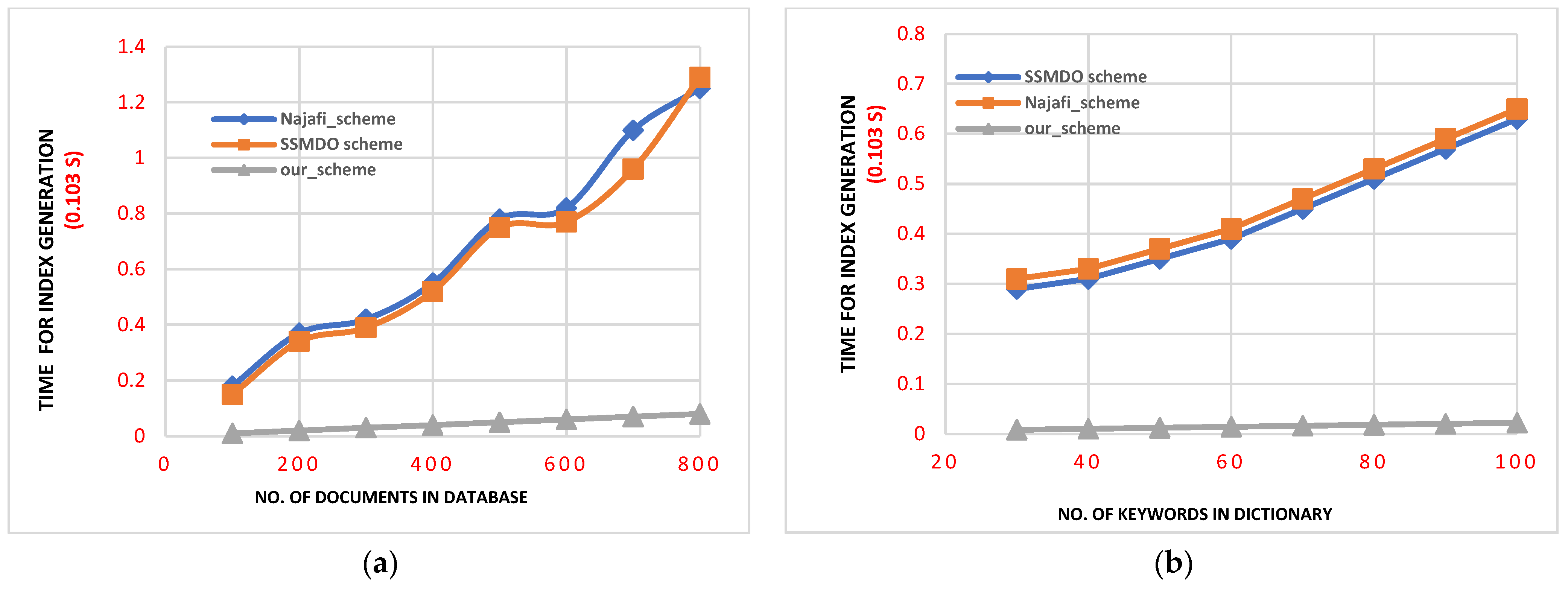
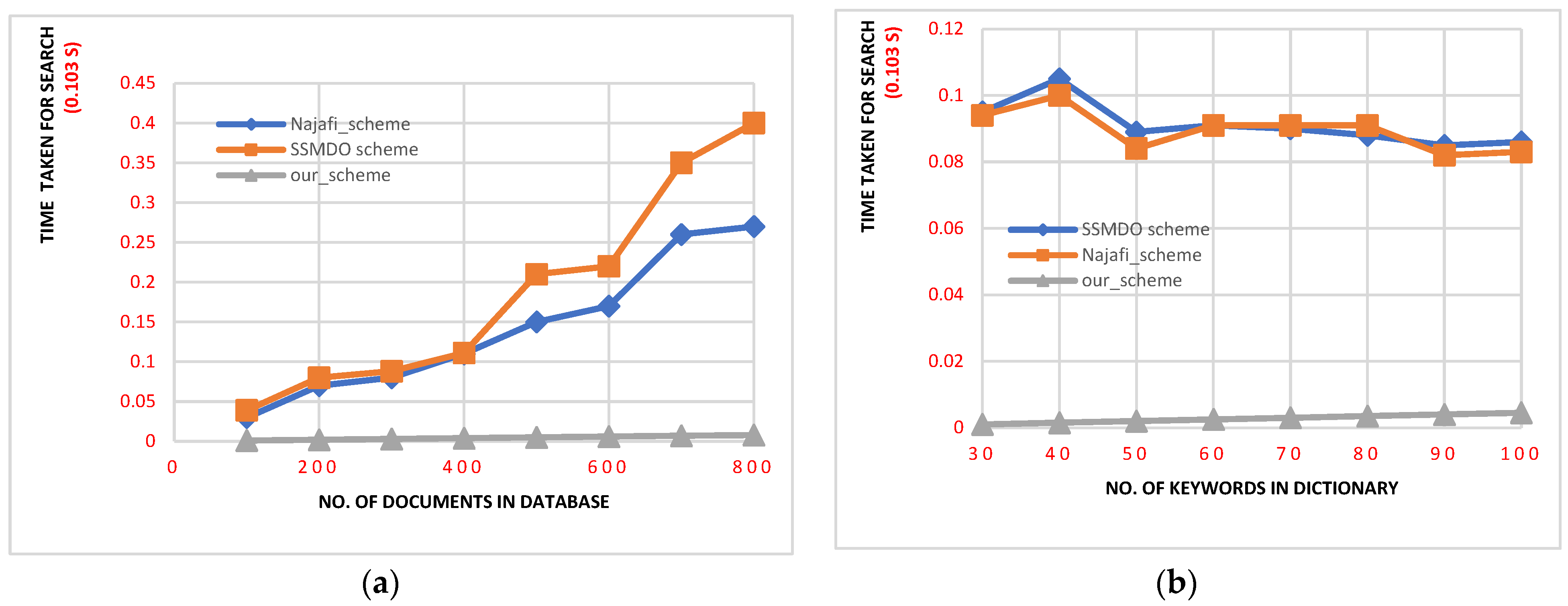
6.1. Comparison of the Performance of Our Scheme
- . In this hybrid, it deals with the real system , as shown in the following figure.
| 1: | |
| 2: | |
| 3: | |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 11: | |
| 12: | |
| 1: | |
| 2: | |
| 3: | |
| 4: | |
| 5: | |
| 6: | |
| 7: | |
| 11: | |
| 12: | |
6.2. Performance Evaluation

7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Al Sibahee, M.A.; Lu, S.; Abduljabbar, Z.A.; Liu, X.; Abdalla, H.B.; Hussain, M.A.; Hussien, Z.A.; Ghrabat, M.J.J. Lightweight secure message delivery for E2E S2S communication in the IoT-cloud system. IEEE Access 2020, 8, 218331–218347. [Google Scholar] [CrossRef]
- Abduljabbar, Z.A.; Jin, H.; Ibrahim, A.; Hussien, Z.A.; Hussain, M.A.; Abbdal, S.H.; Zou, D. Secure Biometric Image Retrieval in IoT-Cloud. In Proceedings of the 2016 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Hong Kong, China, 5–8 August 2016; pp. 1–6. [Google Scholar]
- Hussain, M.A.; Hussien, Z.A.; Abduljabbar, Z.A.; Ma, J.; Al Sibahee, M.A.; Hussain, S.A.; Nyangaresi, V.O.; Jiao, X. Provably throttling SQLI using an enciphering query and secure matching. Egypt. Inform. J. 2022, 23, 145–162. [Google Scholar] [CrossRef]
- Abduljabbar, Z.A.; Jin, H.; Ibrahim, A.; Hussien, Z.A.; Hussain, M.A.; Abbdal, S.H.; Zou, D. Sepim: Secure and efficient private image matching. Appl. Sci. 2016, 6, 213. [Google Scholar] [CrossRef]
- Song, D.X.; Wagner, D.; Perrig, A. Practical Techniques for Searches on Encrypted Data. In Proceedings of the 2000 IEEE Symposium on Security and Privacy, S&P 2000, Berkeley, CA, USA, 14–17 May 2000; pp. 44–55. [Google Scholar]
- Cash, D.; Jarecki, S.; Jutla, C.; Krawczyk, H.; Roşu, M.-C.; Steiner, M. Highly-Scalable Searchable Symmetric Encryption with Support for Boolean Queries. In Proceedings of the Advances in Cryptology–CRYPTO 2013: 33rd Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; Proceedings, Part I. Springer: Berlin/Heidelberg, Germany, 2013; pp. 353–373. [Google Scholar]
- Lai, S.; Patranabis, S.; Sakzad, A.; Liu, J.K.; Mukhopadhyay, D.; Steinfeld, R.; Sun, S.-F.; Liu, D.; Zuo, C. Result Pattern Hiding Searchable Encryption for conjunctive Queries. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 745–762. [Google Scholar]
- Abduljabbar, Z.A.; Ibrahim, A.; Hussain, M.A.; Hussien, Z.A.; Al Sibahee, M.A.; Lu, S. EEIRI: Efficient encrypted image retrieval in IoT-cloud. KSII Trans. Internet Inf. Syst. (TIIS) 2019, 13, 5692–5716. [Google Scholar]
- Sun, S.-F.; Zuo, C.; Liu, J.K.; Sakzad, A.; Steinfeld, R.; Yuen, T.H.; Yuan, X.; Gu, D. Non-interactive multi-client searchable encryption: Realization and implementation. IEEE Trans. Dependable Secur. Comput. 2020, 19, 452–467. [Google Scholar] [CrossRef]
- Huaze, L.; Kaiping, X.; David, S.L.W.; Ruidong, L. An efficient multi-user multi-keyword fuzzy search scheme over encrypted cloud storage. J. Univ. Sci. Technol. China 2021, 51, 1361–1382. [Google Scholar]
- Sun, S.-F.; Liu, J.K.; Sakzad, A.; Steinfeld, R.; Yuen, T.H. An Efficient Non-Interactive Multi-Client Searchable Encryption with Support for Boolean Queries. In European Symposium on Research in Computer Security; Springer: Berlin/Heidelberg, Germany, 2016; pp. 154–172. [Google Scholar]
- Du, L.; Li, K.; Liu, Q.; Wu, Z.; Zhang, S. Dynamic multi-client searchable symmetric encryption with support for boolean queries. Inf. Sci. 2020, 506, 234–257. [Google Scholar] [CrossRef]
- Al Sibahee, M.A.; Lu, S.; Abduljabbar, Z.A.; Ibrahim, A.; Hussien, Z.A.; Mutlaq KA, A.; Hussain, M.A. Efficient encrypted image retrieval in IoT-cloud with multi-user authentication. Int. J. Distrib. Sens. Netw. 2018, 14, 1550147718761814. [Google Scholar] [CrossRef]
- Kamara, S.; Papamanthou, C. Parallel and Dynamic Searchable Symmetric Encryption. In International Conference on Financial Cryptography and Data Security; Springer: Berlin/Heidelberg, Germany, 2013; pp. 258–274. [Google Scholar]
- Kamara, S.; Papamanthou, C.; Roeder, T. Dynamic Searchable Symmetric Encryption. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 965–976. [Google Scholar]
- Chang, Y.-C.; Mitzenmacher, M. Privacy Preserving Keyword Searches on Remote Encrypted Data. In International Conference on Applied Cryptography and Network Security; Springer: Berlin/Heidelberg, Germany, 2005; pp. 442–455. [Google Scholar]
- Bost, R. ∑ oφoς: Forward Secure Searchable Encryption. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 1143–1154. [Google Scholar]
- Stefanov, E.; Papamanthou, C.; Shi, E. Practical Dynamic Searchable Encryption with Small Leakage. Cryptology ePrint Archive 2013. [Google Scholar]
- Etemad, M.; Küpçü, A.; Papamanthou, C.; Evans, D. Efficient dynamic searchable encryption with forward privacy. Proc. Priv. Enhancing Technol. 2018, 2018, 5–20. [Google Scholar] [CrossRef]
- Huang, Y.; Lv, S.; Liu, Z.; Song, X.; Li, J.; Yuan, Y.; Dong, C. Cetus: An efficient symmetric searchable encryption against file-injection attack with SGX. Sci. China Inf. Sci. 2021, 64, 182314. [Google Scholar] [CrossRef]
- Bost, R.; Minaud, B.; Ohrimenko, O. Forward and Backward Private Searchable Encryption from Constrained Cryptographic Primitives. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1465–1482. [Google Scholar]
- Zhang, K.; Wen, M.; Lu, R.; Chen, K. Multi-client sub-linear boolean keyword searching for encrypted cloud storage with owner-enforced authorization. IEEE Trans. Dependable Secur. Comput. 2020, 18, 2875–2887. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, H.; Sun, C.; Wen, Q.; Li, W. Secure multi-keyword ranked search over encrypted cloud data for multiple data owners. J. Syst. Softw. 2018, 137, 380–395. [Google Scholar] [CrossRef]
- Najafi, A.; Bayat, M.; Javadi, H.H.S. Fair multi-owner search over encrypted data with forward and backward privacy in cloud-assisted Internet of Things. Future Gener. Comput. Syst. 2021, 124, 285–294. [Google Scholar] [CrossRef]
- Kim, K.S.; Kim, M.; Lee, D.; Park, J.H.; Kim, W.-H. Forward Secure Dynamic Searchable Symmetric Encryption with Efficient Updates. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1449–1463. [Google Scholar]
- Cash, D.; Tessaro, S. The Locality of Searchable Symmetric Encryption. In Annual International Conference on the Theory and Applications of Cryptographic Techniques; Springer: Berlin/Heidelberg, Germany, 2014; pp. 351–368. [Google Scholar]
- Naveed, M.; Prabhakaran, M.; Gunter, C.A. Dynamic Searchable Encryption via Blind Storage. In 2014 IEEE Symposium on Security and Privacy; IEEE: Berlin/Heidelberg, Germany, 2014; pp. 639–654. [Google Scholar]
- Chatterjee, S.; Puria, S.K.P.; Shah, A. Efficient backward private searchable encryption. J. Comput. Secur. 2020, 28, 229–267. [Google Scholar] [CrossRef]
- Yang, J.; Liu, F.; Luo, X.; Hong, J.; Li, J.; Xue, K. Forward Private Multi-Client Searchable Encryption with Efficient Access Control in Cloud Storage. In GLOBECOM 2022-2022 IEEE Global Communications Conference; IEEE: Berlin/Heidelberg, Germany, 2022; pp. 3791–3796. [Google Scholar]
- Alyousif, A.; Yassin, A.; Abduljabbar, Z.; Xu, K. Improving the performance of searchable symmetric encryption by optimizing locality. J. Basrah Res. 2023, 49, 102–113. [Google Scholar] [CrossRef]
- Enron Email Dataset. Available online: https://www.cs.cmu.edu/~enron/ (accessed on 10 November 2023).



{kind=link}
{kind=link}
{kind=link}
| Scheme | Computation | Communication | BP | Multi-User | ||
|---|---|---|---|---|---|---|
| Search | Update | Search | Update | |||
| [17] | I | |||||
| [17] | III | |||||
| [30] | II | |||||
| [28] | III | |||||
| [24] | III | ✓ | ||||
| [23] | ✓ | |||||
| Ours | II | ✓ | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bulbul, S.S.; Abduljabbar, Z.A.; Najem, D.F.; Nyangaresi, V.O.; Ma, J.; Aldarwish, A.J.Y. Fast Multi-User Searchable Encryption with Forward and Backward Private Access Control. J. Sens. Actuator Netw. 2024, 13, 12. https://doi.org/10.3390/jsan13010012
Bulbul SS, Abduljabbar ZA, Najem DF, Nyangaresi VO, Ma J, Aldarwish AJY. Fast Multi-User Searchable Encryption with Forward and Backward Private Access Control. Journal of Sensor and Actuator Networks. 2024; 13(1):12. https://doi.org/10.3390/jsan13010012
Chicago/Turabian StyleBulbul, Salim Sabah, Zaid Ameen Abduljabbar, Duaa Fadhel Najem, Vincent Omollo Nyangaresi, Junchao Ma, and Abdulla J. Y. Aldarwish. 2024. "Fast Multi-User Searchable Encryption with Forward and Backward Private Access Control" Journal of Sensor and Actuator Networks 13, no. 1: 12. https://doi.org/10.3390/jsan13010012
APA StyleBulbul, S. S., Abduljabbar, Z. A., Najem, D. F., Nyangaresi, V. O., Ma, J., & Aldarwish, A. J. Y. (2024). Fast Multi-User Searchable Encryption with Forward and Backward Private Access Control. Journal of Sensor and Actuator Networks, 13(1), 12. https://doi.org/10.3390/jsan13010012