1. Introduction
It is proposed that autonomous vehicles (AVs) can significantly reduce the number of traffic accidents by minimizing the impact of human factors on collision probabilities. Real-time experiments related to AVs are conducted worldwide, and a recent survey performed by [
1] predicts that by 2025, the US market will achieve a target of around 8 million customers who will be using AVs for their day-to-day activities. The use of AVs has many potential advantages like minimizing the number of road accidents; avoiding long waiting traffic jams caused by congestion of vehicles, thus saving energy to a great extent; reducing parking problems; and helping customers, who do not know how to drive a manual vehicle, to easily access the AV [
2]. The same study also predicts that by the end of 2040, around 33 million people will be accustomed to using AVs, indicating the importance of AVs. Though the statistics provide the importance and need for AVs in the future, more analysis is required to ensure against safety hazards to the customers using AV.
To prevent accidents caused by AVs, these vehicles must make instant and accurate decisions when encountering roadside events. Contextual information that AVs see has to be unambiguous and precise to ensure accurate decision making. The systems that perceive their environment information need to be highly accurate, providing a comprehensive understanding of the surroundings and functioning effectively even in adverse conditions, in particular when specific sensors malfunction or break. The collection of environmental- and vehicle-related data relies on fully operational sensor systems. However, the data collected from various devices, including sensors, thermal cameras, and radars, exhibit heterogeneous multimodal features, posing challenges to achieving accurate perception. More consideration should be given to data preparation tasks like data cleansing and multimodal fusion to improve the contextual awareness of self-driving vehicles.
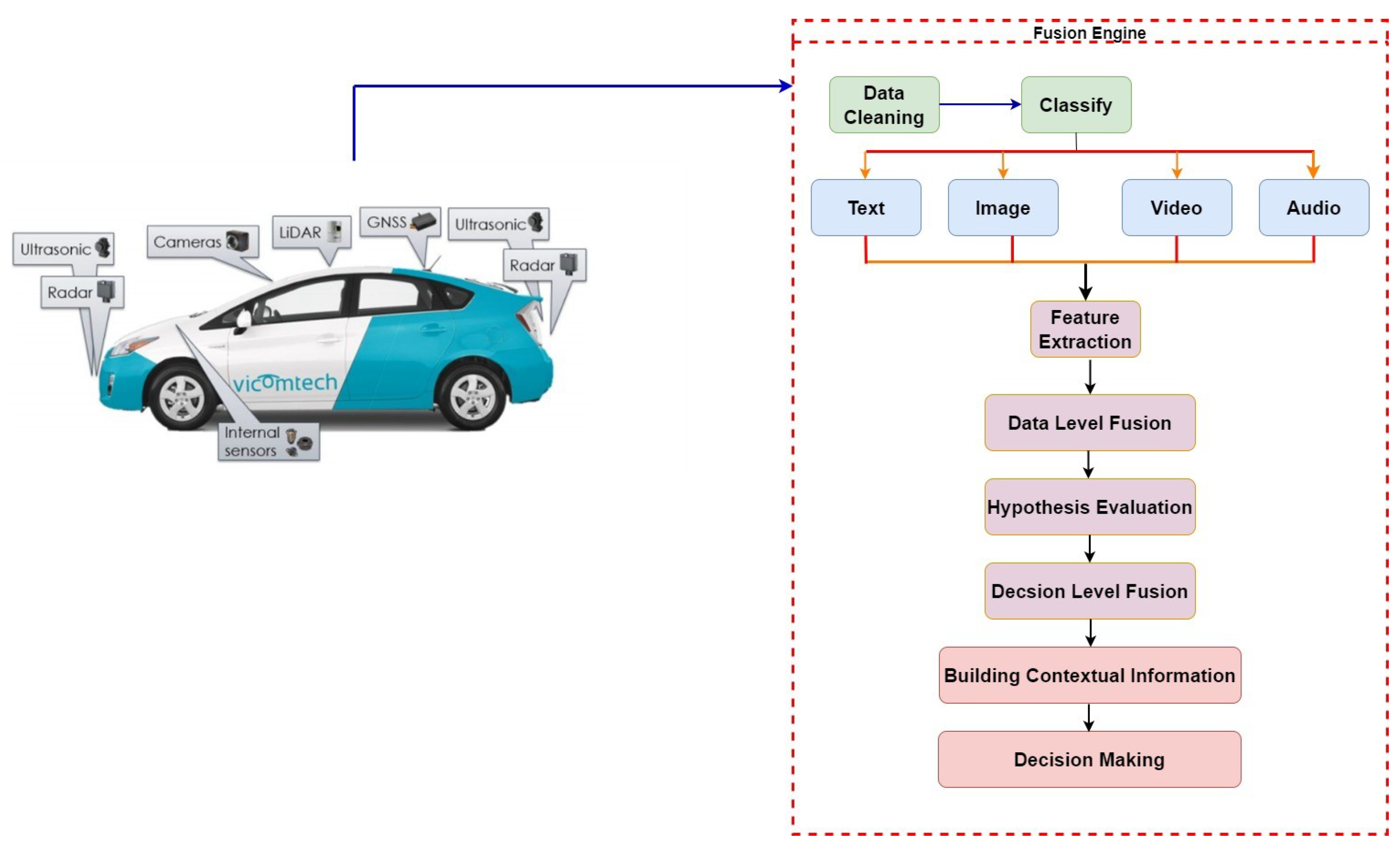
For environmental data collection and situational awareness [
3], AVs depend on inside as well as outdoor sensors, including LiDAR, radar, ultrasonic, stereo, and thermal cameras to create the perceived perception of the AV. The gathered vehicle data, however, may be in various formats, including text, image, video, and audio, and may include errors like insignificant information, inaccurate information, anomalies, and repetitions. Images and audio data, for instance, may both contain fuzzily-defined information. Pre-processing the sensory input is essential as a result of increasing its accuracy. Although data cleaning has received a lot of attention, this proposal focuses on data fusion, the second step in the data pre-treatment process. A powerful architecture to integrate data must be designed and developed to combine disparate data into a solitary structure and improve its precision for additional analysis since sensory information can display multi-functional properties. This study primarily focuses on the information gathered from state-of-the-art sensors like RADAR, Velodyne, and LiDAR, with a specific emphasis on image fusion due to the predominance of visual data from these sensors. However, the upcoming research will solely concentrate on the proposed models for fusing text, audio, and video data.
Image fusion is a technique that creates a single image with more information than any of the individual images by combining data from various images of the same scene. Though extensive research and contributions are still in progress in this domain, indeed, there are a few challenges and drawbacks associated with the existing solutions. The datasets, evaluation metrics, and fusion methods utilized in image fusion research are not standardized. This makes evaluating the effectiveness of various fusion methods challenging. Numerous image fusion techniques in use today were developed for particular uses like remote sensing or medical imaging. Other applications, such as autonomous vehicles which need real-time processing and robustness to noise and other environmental conditions, might not be compatible with these techniques. A lot of image fusion methods concentrate on combining information from different sensors that belong to the same modality, such as different cameras or different heat sensors. However, the data from numerous sensors, including LiDAR, radar, and cameras, as well as sensors from other modalities, is often used by autonomous cars. It is necessary to use fusion approaches that can handle multimodal data. Many currently used image fusion algorithms may not be appropriate for real-time processing since they need a lot of computation [
4]. This is a big barrier for autonomous vehicles since they need to evaluate sensor data quickly and effectively to make judgments in real time. Several fusion methods are not resistant to noisy or imperfect data. When it comes to autonomous vehicles, elements like weather or sensor failures may have an impact on the sensor data, resulting in noisy or missing data. We need fusion methods that can withstand such influences. Moreover, there has been minimal effort to integrate the multispectral environmental data collected from advanced sensing devices [
5]. Adaptable architectures integrated with revolutionary algorithms and predictive modeling techniques are required to fuse multidimensional image data.
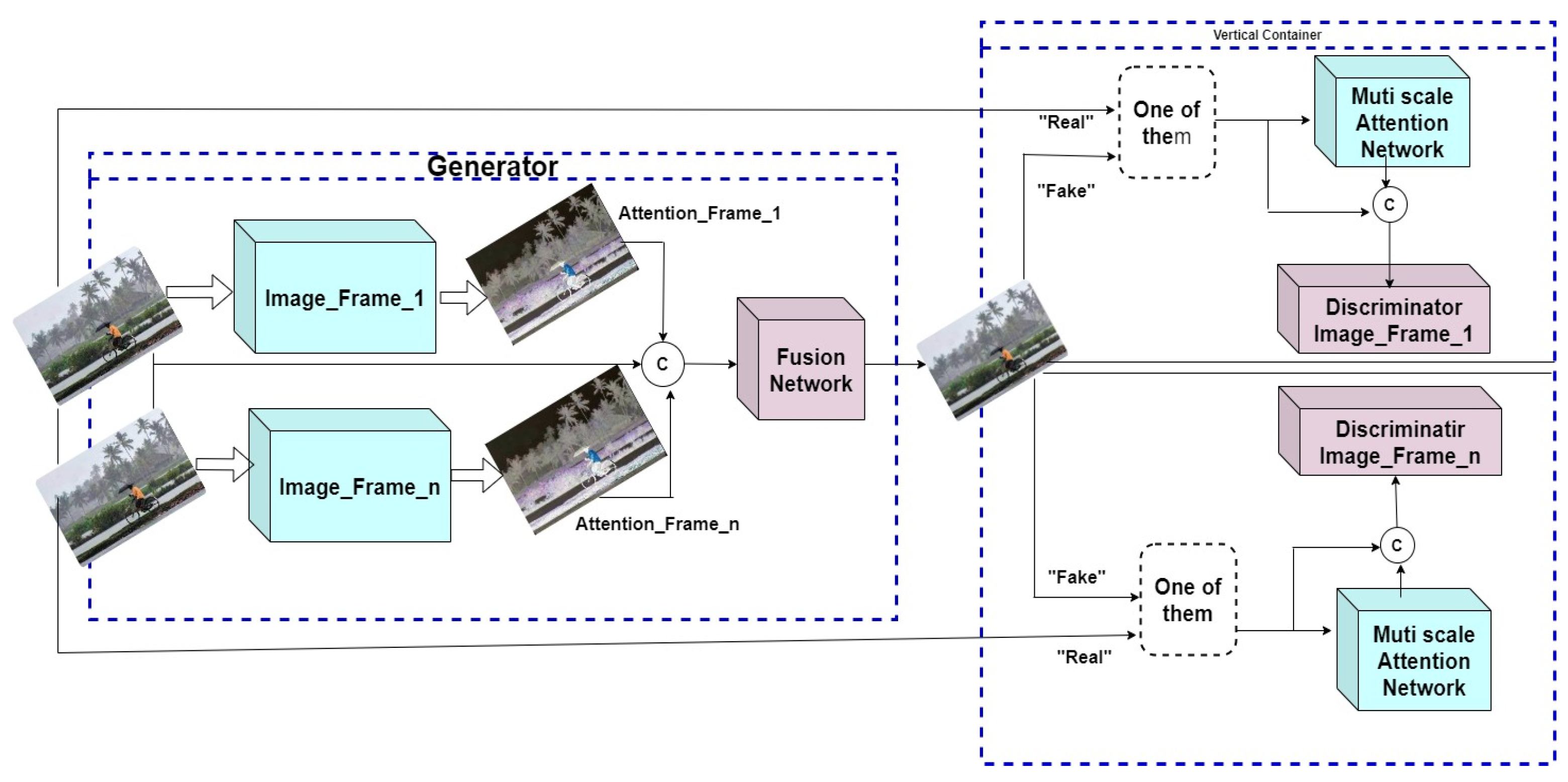
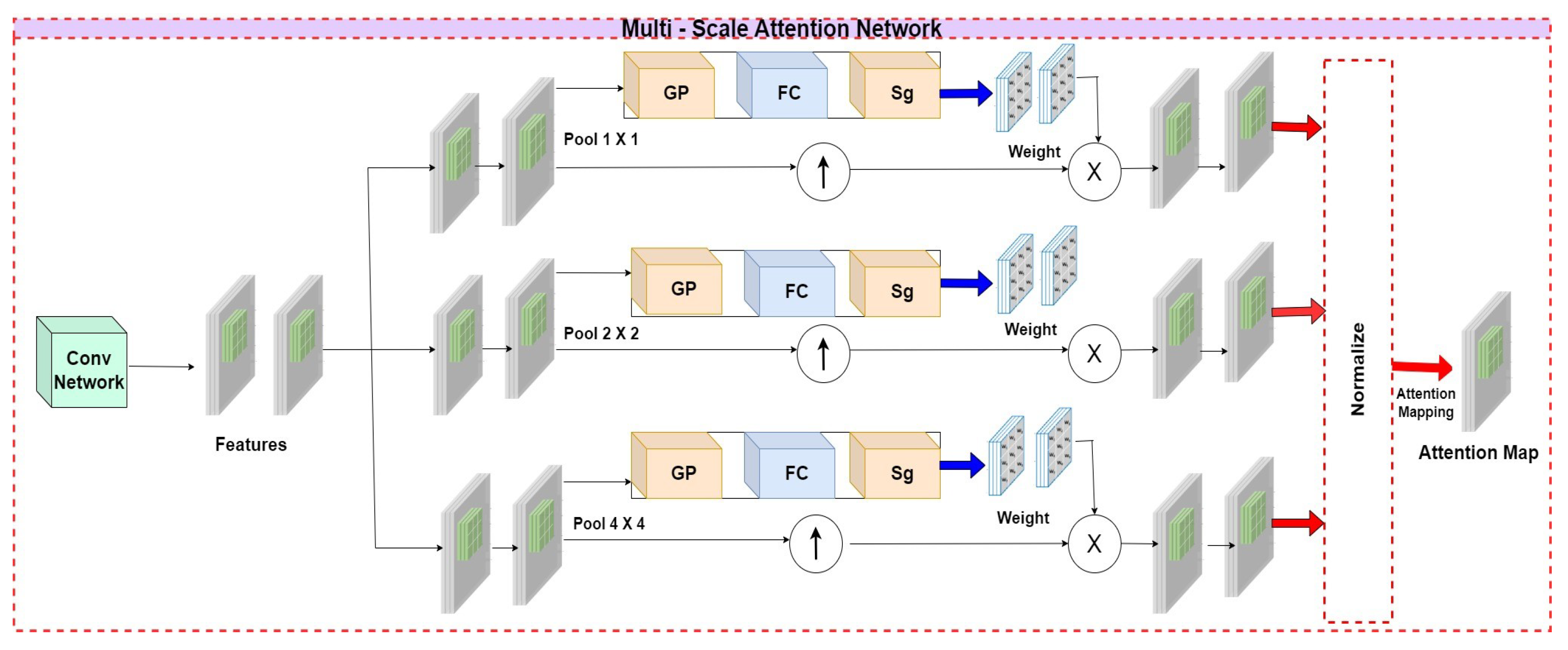
Given the disadvantages listed above, this study suggests a hybrid fusion paradigm, which combines an advanced deep residual network (ResNet) model that focuses on feature extraction and low-vision image restoration tasks, with the proposed advanced GAN model, collectively called Image Fusion GAN (IFGAN). In addition to capturing detailed spatial information to assist the generator in focusing on the foreground and background information of the images, the multiscale attention mechanism also seeks to limit the discriminators’ focus to the focused areas rather than the complete input picture. The IFGAN model is an advanced CNN model that consists of two important functional layers: one for obtaining the attention map of the images generated from the ResNet, and the other to fuse the collected images to obtain the actual information.
Additionally, this research has introduced adaptable kernel functions designed for all machine learning models utilized across various tasks. The GAN model has undergone customization of its layers, with Layer-1 dedicated to feature extraction, Layer-2 responsible for the initial fusion of 2D/3D images using the previously suggested Hybrid Image Fusion model [
6], Layer-3 focused on transforming the fused 2D/3D data into a 3D point cloud data format, Layer-4 designed for executing discriminator tasks, and Layer-5 designated for the final stage of image fusion. Moreover, a novel loss function has been introduced to assess the accuracy of image fusion. Within the GAN model, two discriminators have been integrated to capture spatial and spectral information. The proposed IFGAN model employs a dual-fold fusion approach, combining the inherent features of the earlier proposed Hybrid Image Fusion model [
6] with the novel IFGAN model, thereby aiming to enhance the precision of image fusion.
The rest of this paper is organized in the following manner:
Section 2 provides an introduction to sensor technology, outlines the significance of data fusion in enhancing data accuracy, and presents an overview of the topic.
Section 3 explores the existing literature in this field, highlighting its limitations that inspired our research proposal.
Section 4 constitutes the central component of the paper, where detailed explanations are provided regarding the design, development, and implementation of the proposed models. The evaluation of these models and the resulting outcomes are discussed in
Section 5. Finally,
Section 6 concludes the paper by summarizing the overall findings, discussing their implications, and suggesting avenues for future research.
2. Background and Motivation—GAN and ResNet Models: State of the Art
The suggested research presents an effective GAN model designed to merge various image data formats, specifically focusing on 3D point cloud image sensor data. Due to the model’s reliance on extensive mathematical computations and sophisticated matrix and vector transformations, an in-depth understanding of GAN models is crucial. This paragraph emphasizes key aspects of essential features in advanced machine learning-driven image fusion models, notably GAN and ResNet. Hybrid transform-based image fusion algorithms, which combine both the spatial domain and transform domain, are becoming more and more prominent in the field of image fusion since picture distortion and insufficient spatial continuity are common problems with transform domain-based image fusion methods. As mentioned above, the proposed approach integrates two efficient models to fuse image data: one is ResNet to extract the image feature, and the other is an advanced GAN model to fuse the extracted feature. The upcoming paragraphs briefly describe the salient features of ResNet and GAN models. Researchers at Microsoft Research developed ResNet (Residual Network), a deep learning model, in 2015. It is designed to address the problem of vanishing gradients, which occurs when training very deep neural networks, by introducing a “shortcut” or “skip connection” that allows the gradient to flow directly through the network.
The ResNet architecture consists of a series of residual blocks, each containing one or more convolutional layers followed by shortcut connections that bypass the convolutional layers. These shortcut connections allow information to flow more easily through the network and enable the network to learn deeper and more complex features. On a variety of computer vision tasks, such as picture categorization, detecting objects, and segmentation using semantics, ResNet has demonstrated cutting-edge performance. The architecture has been extended and adapted in many ways, such as the introduction of “bottleneck” layers to make the model’s complex computations less difficult, and ResNeXt, which improves performance by introducing a new type of connectivity between residual blocks. Overall, ResNet models prove to be a robust resource in the realm of computer vision tasks, thanks to their adaptability and ability to scale, rendering them well suited for a broad range of intricate applications [
7]. Convolutional neural networks (CNNs) have gained significant prominence in the field of image processing due to their adeptness at efficiently extracting crucial visual information [
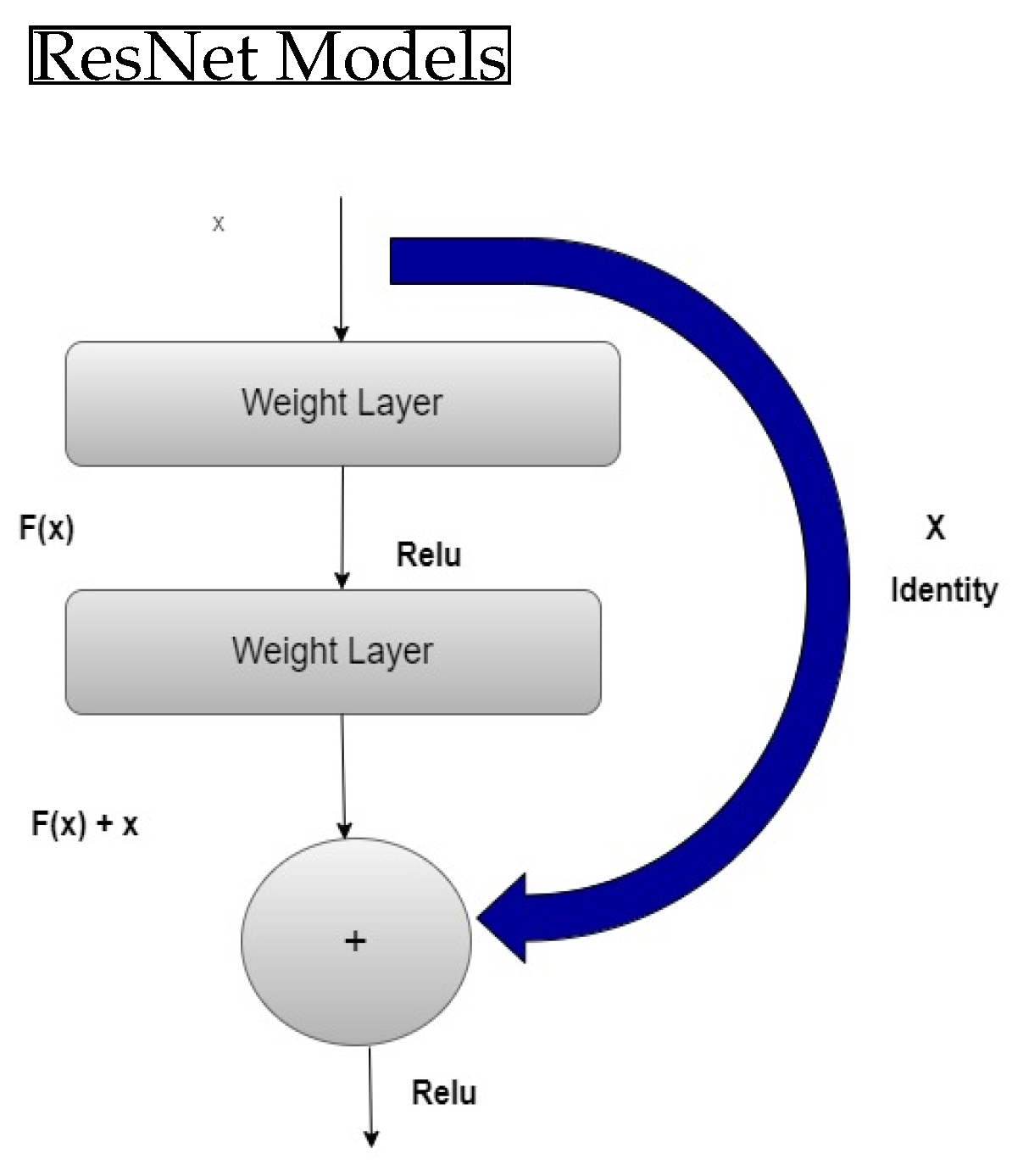
8]. While shallow networks can only learn basic local features, increasing the number of network layers enables the creation of detailed characteristics, like intricate surfaces, which has to be explored further. However, as the assortment of layers rises, deeper networks may become challenging to train, resulting in the issue of disappearing gradients and declining training performance. To address these issues, the profound remnant architect was proposed in the literature, which consists of residual blocks. This approach enables the learning of deep features while mitigating the issues related to disappearing slopes, further improving the model’s training performance. The layout of the remaining component is shown in
Figure 1. Assuming that the underlying mapping that a CNN is expected to learn is denoted as
, yet another assignment
is fitted using stacked nonlinear layers. This changes the format of the connection to
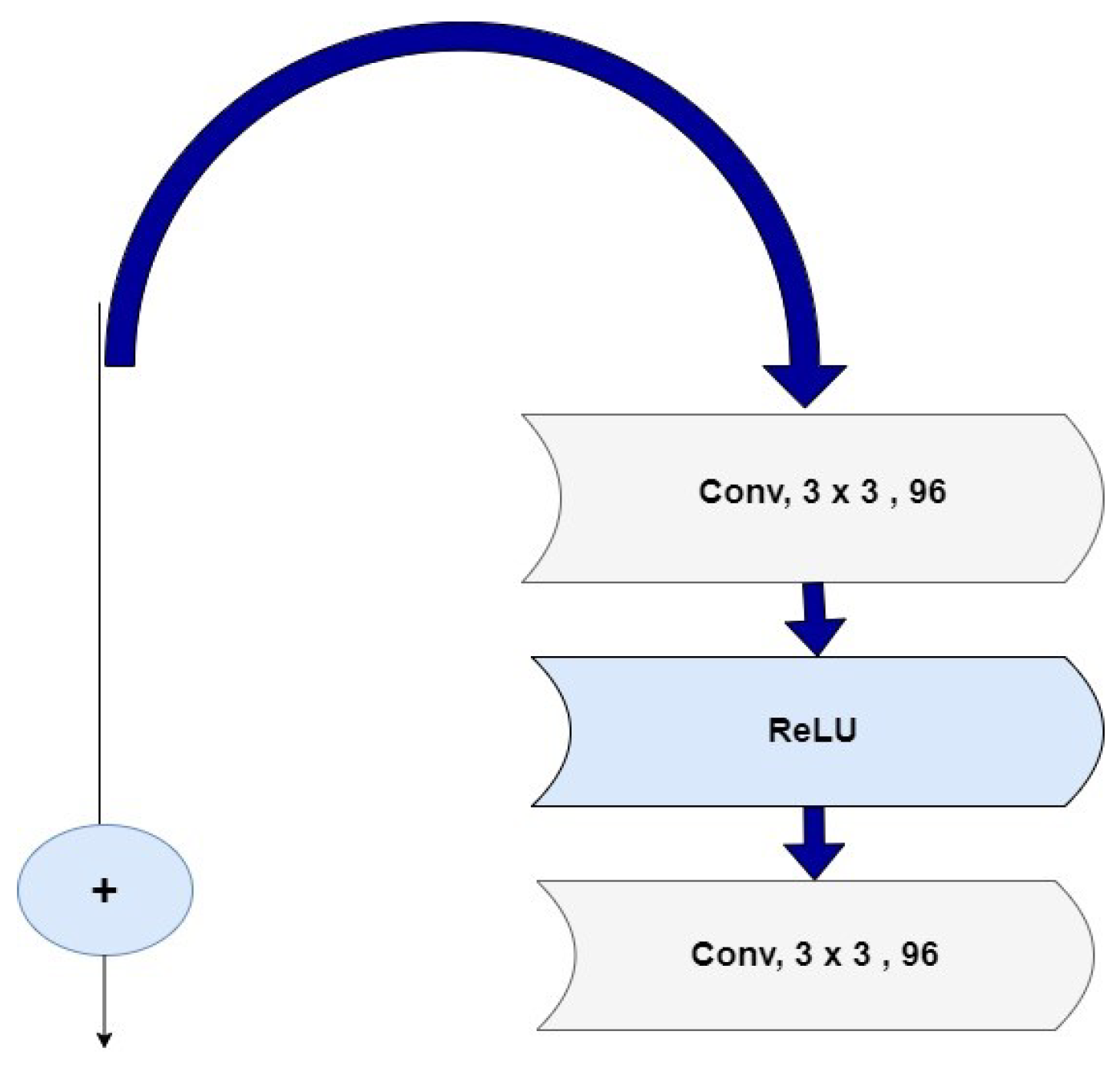
. The addition of this residue component to the system allows for improved visualization of networks while extending the network’s depth to achieve improved training outcomes. As a result, a residue component is integrated into the system to matriculate asymmetric pattern translation. The residue components’ structure is demonstrated in
Figure 2. Many edge-maintaining filters, such as bilateral filters and guided filtering, have been proposed by many researchers. However, these filters frequently overlook the precise impact of scale illusion on the retention of picture edges. To tackle this challenge, Zhang and colleagues [
9] introduced the concept of a rolling guidance filter. This innovative approach incorporates a multi-scale edge-preserving filter to safeguard the edges of an image, achieved by applying edge-preserving filters at various scales. Additionally, each iteration of the filter uses the image resulting from the previous filtering step as the guiding image. Owing to its impressive ability to preserve image edges, the rolling guidance filter has gained widespread adoption in the field of image fusion.
Generative Adversarial Networks, often termed as GAN, is another extension of the neural networks (NN) model. GAN has two parts, namely (i) Generator and (ii) Discriminator. The generator gains the ability to generate credible data, which the discriminator uses as negative training examples. The discriminator gains the skill to differentiate fabricated data from authentic data generated by the generator. It penalizes the generator for creating unrealistic outcomes. At the start of the training, the generator generates noticeably artificial data, prompting the discriminator to rapidly discern its falseness. As the training advances, the generator moves towards generating output that can deceive the discriminator. Ultimately, with successful generator training, the discriminator’s ability to differentiate between genuine and fake diminishes. It begins to classify fake data as real, leading to a decline in its accuracy. The generator and discriminator function as NN. The generator’s output directly links to the discriminator’s input. Utilizing backpropagation, the discriminator’s classification offers a signal used by the generator to adjust its weights [
10,
11].
Compared to fusing other data types, image fusion and audio fusion pose greater complexity. Image data fusion generally involves three levels: (i) pixel-level fusion, which provides detailed image data that cannot be obtained at any other level; (ii) feature-level fusion, serving as an intermediary for data caching and compression; and (iii) decision-level fusion, the most advanced and intricate level, relying less on the image registration process. A variety of techniques are commonly employed for image data fusion, including recurrent strategies, Multiplicative Algorithms, PCA, High Postfilter, the Brovey transform image fusion technique, the Color rotated technique, and the Discrete Wavelet Transformation. These techniques consider key image features such as color, corners, SIFT, SURF, blobs, and edges.
Table 1 delineates the operational principles of prominent image fusion models based on machine learning, along with their advantages and disadvantages. The subsequent section delves deeper into the existing literature on this topic.
3. Related Work
A thorough investigation of the various picture, video, and audio data fusion strategies put forth by distinguished academics is provided to pinpoint their key contributions and any current shortcomings. The information acquired will serve as a springboard for developing this research further to close any gaps that may still exist.
3.1. Hybrid Image Fusion Models
B. Shahian Jahromi et al. [
12] designed and developed an adaptable composite multi-sensor fusion pipeline framework, especially for self-driving cars. Road segmentation, obstacle recognition, and surveillance are just a few of the environment perception tasks that this architecture accomplishes. The fusion framework incorporates an encoder–decoder-based Fully Convolutional Neural Network (FCNx) and a standard Extended Kalman Filter (EKF) nonlinear state estimator approach. Additionally, the fusion system optimizes the camera, LiDAR, and radar sensors configured for each specific fusion strategy. The primary goal of this hybrid architecture is to create a cost effective, lightweight, adaptable, and resilient fusion system that can withstand sensor failures. While preserving real-time effectiveness on embedded processors for self-driving cars, the FCNx methodology used in this framework improves road recognition accuracy beyond the benchmark models. D. Jia et al. [
13] introduced a hybrid Spatiotemporal Fusion (STF) method centered around a deep learning model called Hybrid Deep Learning-based Spatiotemporal Fusion Model (HDLSFM). This method aims to reliably fuse morphological and physiological data to better understand the physical properties of the Earth’s surface. The proposed technique combines regressive deep learning-based related radiometric normalization, deep learning-based super resolution, and linear-based fusion to handle radiation discrepancies among different satellite images. The HDLSFM framework demonstrates its ability to predict phenological and land-cover changes compared to the benchmark Fit-FC method. Moreover, HDLSFM stays resistant to emission differences between various images acquired from various satellite data and periods between prediction and baseline dates, guaranteeing its efficacy in merging data obtained from time series events.
Y. Wang et al. [
14] have put forward an integrated fusion method that considers the geographical and temporal attributes of sensory data related to roadside events. They achieved this by employing Cmage, a notation based on images that encapsulate both physical and social data from sensors, specifying the state of specific visual concepts (e.g., “crowdedness”, “inhabitants parading”). The authors introduced a fusion model that integrates spatial relationships among sensor data and community information, event signals from multiple modalities, Bayesian methods, and incomplete sensor data using a Gaussian process based on the acquired Cmage representation. A. V. Malawade et al. [
15] have developed an architecture for targeted sensor fusion called HydraFusion that learns to understand the driving context in use before combining the right combination of sensing devices to increase resilience without reducing economy. To change both how and when fusion is used, HydraFusion is the initial way to propose continuous switching within an early fusion, late fusion, and variants in between. The authors demonstrate that HydraFusion outperforms both initial and final fusion approaches by 13.66% and 14.54%, respectively, using the industry-standard Nvidia Drive PX2 AV hardware platform without raising computational complexity or energy usage. The authors suggest and assess both fixed and deep-learning-based context detection techniques.
The advancement of these techniques signifies a transition from supervised to unsupervised approaches, with a continued emphasis on generating precise logical maps. Liu et al. [
16] made use of a CNN model to distinguish between zones with and without focus, creating an integrative judgment map to fuse the data. They used a personally generated judgment map as reference data for supervised training, which is important to note, aiming to improve classification accuracy. Du et al. [
17] introduced an innovative strategy for multi-focus image fusion using image segmentation, where decision map detection involves segmenting the source images into focused and defocused regions. While this fragmenting approach enhances the efficiency of the decision map’s boundary lines, to some extent it might cause impairment in specifics. Guo et al. [
18] suggested the use of conditional GAN for multi-focus image fusion, but this method still requires labeled images for supervised training of the network. Ma et al. [
19] introduced an unsupervised network that creates the fusion judgment map to overcome the above-mentioned challenge. However, even with ground truth available for reference, these approaches may not produce an optimal decision map solely relying on the ANN’s capacity to acquire knowledge. Therefore, they often require post-processing techniques like consistency verification or guided filtering, which do not fully exploit the potential of NNs. Contrarily, our suggested IFGAN is an unsupervised approach that eliminates the need for post-processing.
Multi-focus blending of image techniques now in use have advanced significantly; however, additional progress is needed to improve their performance. Firstly, current approaches often rely on manually created guidelines for fusion and intensity measuring, which reduces their efficiency as it is challenging to account for all pertinent elements in a single manual approach. Secondly, many methods treat multi-focus image fusion as a classification problem focused on sharpness detection and decision map generation. However, accurately classifying regions of focus and defocus that are close to the boundaries remains a challenge for these methods. Thirdly, while creating decision maps, the majority of deep learning-based techniques demand additional processing activities like coherence tests, which adds complexity to the methods. Additionally, these methods often use human decision map generation as the basis for network training, which further limits their application.
3.2. Feature Extraction Models (Image Data)
P. Tiede et al. [
20] have introduced an innovative method called Variational Image Domain Analysis (VIDA) for universal image feature extraction in a broad spectrum of VLBI image reconstructions. VIDA can be used for any picture reconstruction, regardless of the order, in contrast to earlier methods. This strategy provides valuable insights into effectively extracting essential picture attributes such as color and edges. The utilization of CNN as a feature extraction tool for images is preferred since it is difficult to successfully combine classifiers and imagery. The primary advantage of CNNs as feature extractors lies in their ability to acquire a greater number of distinctive attributes in comparison to alternative approaches. In their study, Govindaswamy et al. [
21] investigated the use of a CNN for predicting physician gaze. The authors specifically focused on comparing hand-crafted features with features extracted by a CNN, and they also examined the impact of completely connected layers over the feature selection strategy of the model.
Similarly, Wang et al. [
22] put forth a proposal to integrate the CNN and the extreme learning machine (ELM) algorithm for the recognition of synthetic aperture radar (SAR) images. The CNN model was employed as the feature extractor, leveraging its remarkable ability to extract intricate features from images while maintaining invariance to various forms of image deformation. On the other hand, the ELM served as the recognizer. The experimental findings illustrated that this model efficiently alleviated the problem of overfitting, thus accelerating the convergence of the network, leading to a reduction in the total experimentation time. Liu et al. [
23] utilized a dataset consisting of 61 COVID-19 and 27 general pneumonia CT images. A total of 34 quantitative textural traits were retrieved and compared to the performance of the Ensemble-based bagged trees classification model with four eminent classifiers: Linear Regression, Support Vector Machine, Decision Tree, and k-Nearest Neighbors (KNN). The classification accuracy reached its peak at 94.16% with the ensemble of bagged tree classifiers. Ozkaya et al. [
24] employed the same dataset as the previous study [
6] and divided it into two subsets: Subset-1 (16 × 16) and Subset-2 (32 × 32). They utilized a convolutional neural network architecture to extract features from the images and classified them using SVM. Subset-2 yielded an accuracy of 98.27%. In the research conducted by Kassani et al. [
25], a method was proposed for feature extraction using various pre-trained deep learning networks. For classification, they employed Random Forest, XGBoost, Decision Tree, AdaBoost, LightGBM, and Bagging Classifiers. Employing features collected with DenseNet121 and categorized with the Bagging tree classifier, the best accuracy of 99% was attained.
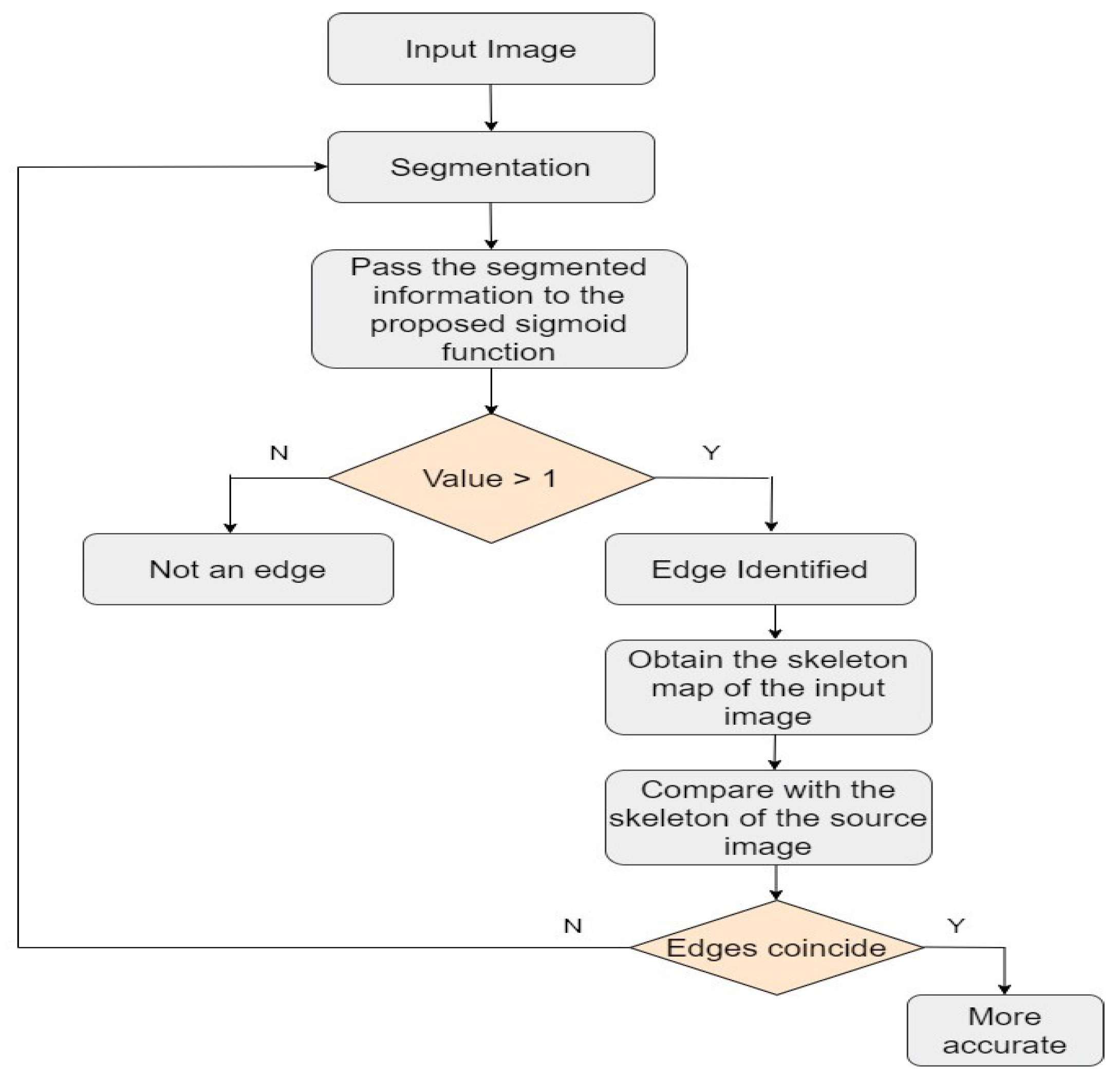
While CNN-based edge detection models have shown significant advancements in computer vision tasks, they are not without their drawbacks. Some of the limitations of CNN-based edge detection models are described in the following paragraph. CNN models heavily rely on large and diverse datasets for training. Without a sufficiently diverse and representative dataset, the model may struggle to generalize well to different edge detection scenarios. CNN models can be sensitive to noise, variations in lighting conditions, and other distortions in the input image. These factors can lead to false positives or missed edges, reducing the overall robustness of the model. CNNs typically operate on fixed-size image patches or windows, which makes it challenging to handle scale variations in edge detection. Detecting edges at different scales requires additional processing steps or modifications to the network architecture. CNN models for edge detection often involve deep architectures with numerous layers. This complexity can make training and inference computationally expensive, requiring significant computational resources. CNNs focus on local image patches and lack extensive contextual understanding. As a result, they may struggle to accurately detect edges in complex scenes with occlusions or overlapping objects. CNN-based edge detection models may be biased towards detecting specific types of edges that are prevalent in the training dataset. Consequently, they may not perform well in detecting unseen or rare edge types. CNN models are often considered black-box models due to their complex architecture and large number of parameters. Interpreting and explaining the decision-making process of CNN-based edge detection models can be challenging. It is important to consider these drawbacks and potential limitations when applying CNN-based edge detection models in practical applications. This research suggests a general data fusion engine to combine various data formats as well as cutting-edge techniques for gathering the key elements of audio and visual data. The work is motivated by the holes that have been discovered.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}