5.1. Results about the Classification
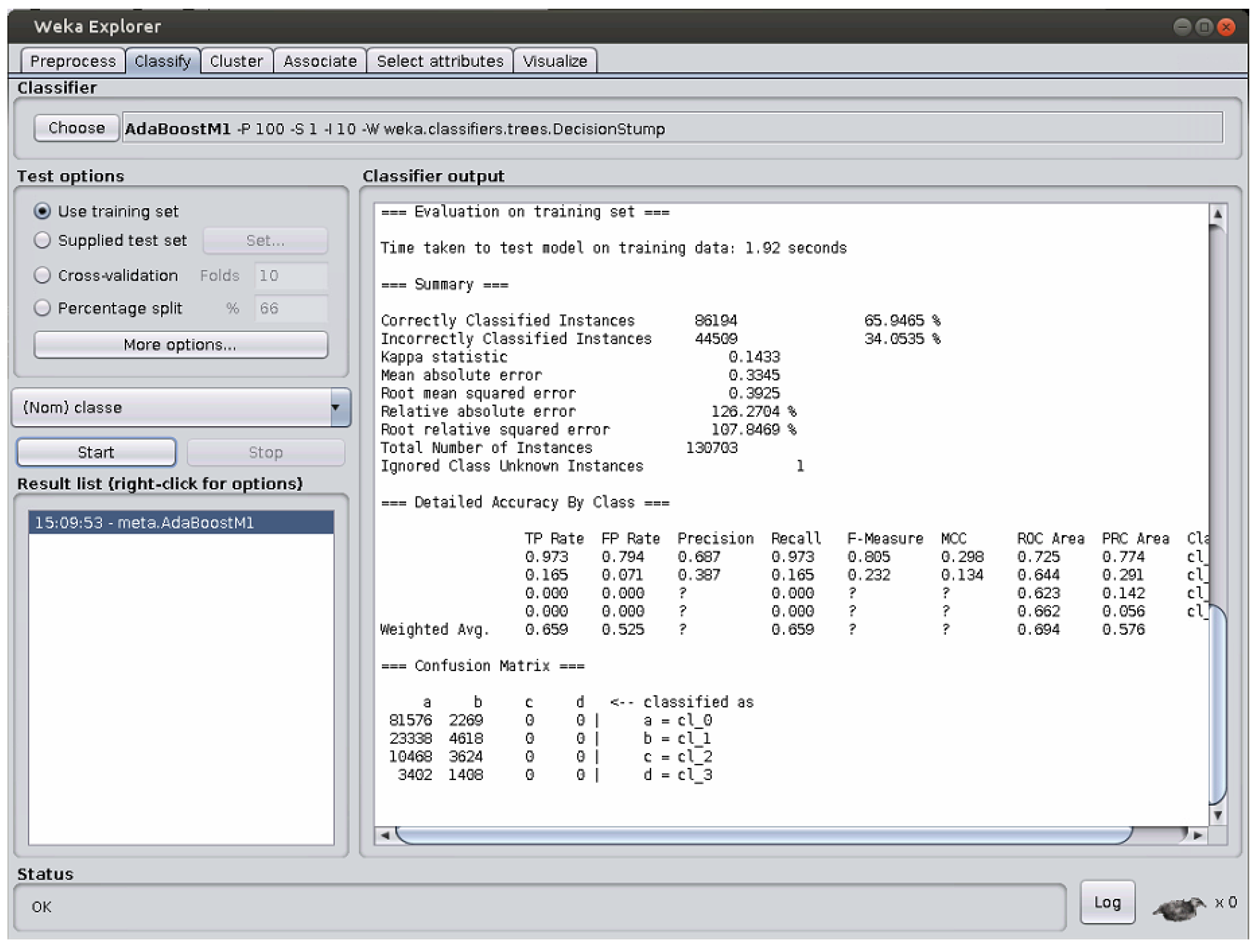
Table 3 shows the results obtained by each algorithm over the training set and the testing set in terms of the five parameters defined above. The best result obtained over each parameter is reported in bold.
As a preliminary note, whenever the question mark “?” is reported in the tables, this means that the problem described in
Figure 1 took place, so that a correct computation of the corresponding parameter could not be carried out. NT, instead, means that the run did not end before the one-week timeout set.
If we take into account the results obtained over the train set, we can see that both IBk and Random Forest perform perfectly, as they both achieve the highest value on any parameter considered here.
When, instead, the test set containing previously unseen items is considered, the results show that Random Forest is the algorithm with the best performance in terms of four parameters, i.e., accuracy , precision , sensitivity , and F-score . Naive Bayes, instead, has the best performance in terms of specificity .
These results obtained by IBk, excellent over training set and lower performance over the testing set, imply that, for this classification task, IBk suffers from overfitting. With this term, we mean that IBk has learned too much from the train set items, while not understanding the general mechanisms underlying this data set to be used for new, previously unseen items as those contained in the test set.
On the contrary, the results for Naive Bayes, quite bad over the training set and much better over the testing set, reveal that this algorithm does not suffer from overfitting for this classification task. Rather, it has been able to understand the mechanisms underlying the data set, as can be proven by its value over the previously unseen items of the data set, which is the highest from among those of all the algorithms considered here.
In conclusion, the use of Random Forest is preferable when facing this data set.
Once it is seen that Random Forest is the best-performing algorithm, we wish to closely examine its behavior over this data set.
Table 4 shows the confusion matrix for Random Forest over the Training set, whereas
Table 5 contains the same information with reference to the Testing Set. For the sake of space, we have represented in the tables the classes with numbers: NT stands for normotension, PT for pre-hypertension, HT1 for hypertension at stage 1, and HT2 for hypertension at stage 2.
Table 4 shows that no item is wrongly classified, as non–zero values are contained only in the cells on the main diagonal of the confusion matrix.
Table 5, instead, shows that a relatively low amount of items are wrongly classified, as non–zero values are contained in all the cells of the confusion matrix.
Going into details class by class, 96.23% of the normotension items are correctly classified, and the high majority of the erroneously classified items are considered as prehypertension, which is the least possible classification error for these items.
For the prehypertension items, instead, 51.83% are correctly classified, while the vast majority of the errors consists in an item of this class being considered as a pormotension item (42.15% of the cases). This type of error is quite normal, as the differences between the two classes are, in many cases, minimal and fuzzy. Only a few items are assigned to the other two classes, which is a good result.
For the items representing Hypertension at Stage 1, just 36.32% of them are correctly classified. However, the vast majority of them are assigned to prehypertension (45.04% of the cases). Only very few cases are assigned to the other classes.
Finally, for the items representing Hypertension at Stage 2, 48.05% of them are correctly classified. A fraction of them, equal to 34.17%, is assigned to the neighboring Hypertension at Stage 1 class. Minor fractions are assigned to the farther classes.
As a summary, very seldom are normotensive cases seen as Hypertensive at Stages 1 and 2, and the same holds true for Hypertensive cases of Stage 2, which are very rarely considered as normotensive. All these findings are good, and confirm the quality of the Random Forest in correctly classifying over this data set.
5.2. Discussion about Risk Stratification
It is interesting to investigate the behavior of the classification algorithms in terms of risk stratification. This means to consider the discrimination ability provided by an algorithm at different levels of granularity into which the data set can be divided, as reported in, e.g., ref. [
4,
11,
12].
In the medical literature, three different such levels are usually considered when hypertension is investigated:
discrimination ability between normotensive events and pre-hypertensive ones
discrimination ability between normotensive events and hypertensive ones
discrimination ability between normotensive and pre-hypertensive events considered together as opposed to hypertensive events.
Each of these above levels corresponds to a two-class classification problem. In our data set, the hypertensive events are divided into two classes (type 1 and type 2). Therefore, in order to investigate this issue, we have to group the items belonging to these two classes into a unique class containing all the hypertensive events. Once this is done, we can run all the experiments related to these three different classification problems for all the algorithms considered in this paper.
In the literature, this analysis is in the vast majority of the cases performed by means of the F score indicator; therefore, we will use it here.
Table 6 shows the results obtained for the stratification risk in terms of the F score. The NotT term for an algorithm means that the execution of the algorithm has not terminated within one week. The best performance for each risk level is evidenced in bold.
As a general comment to this table, it can be evidenced that the F score values obtained by all the algorithms are quite high at all the three levels investigated, which witnesses good discrimination ability for them. Hence, any of them could be profitably used to carry out a risk assessment analysis. This is a hint of the fact that the data set was constructed properly.
The analysis of the results shows that the risk level at which the investigated algorithms are, on average, better performing is that related to the discrimination between normotensive events and hypertensive ones: the values of F score are in the range of (0.953–0.994), apart from AdaBoost and OneR that perform worse. This is to be expected, as this usually is the easiest decision a doctor can make.
The level at which, instead, the algorithms obtain the second performance is that related to the discrimination between normotensive and pre-hypertensive events as opposed to hypertensive ones: here, the F score values range within 0.862 and 0.933, and all the algorithms show good discrimination ability. This is usually a case of intermediate difficulty because the pre-hypertensive events could be erroneously considered even by specialists as normotensive or hypertensive.
Finally, the discrimination task between normotensive events and pre-hypertensive ones is the worst in terms of easiness to deal with, as, in this case, the F score values range within 0.704 and 0.857, with the exceptions of AdaBoost and PART that show lower discrimination ability. This latter outcome should be expected, as it is often hard even for skilled doctors to tell whether an event is normotensive or pre-hypertensive. In fact, in many cases, just slight differences can take place in these two situations.
Going into detail, this table proves that Random Forest is the algorithm that better allows discriminating pre-hypertensive events from normotensive ones. Moreover, this algorithm also obtains a higher discrimination ability between normotensive and pre-hypertensive events together as opposed to hypertensive ones.
Naive Bayes, instead, has a higher discrimination ability when the aim is to divide normotensive events from hypertensive ones.
To further discuss these findings, for each of these three risk stratification cases, in the following, we report the confusion matrix obtained by the algorithm that performs best on it.
Let us start with the first discrimination level, i.e., that between normotensive and prehypertensive items.
Table 7 shows the numerical results obtained by Random Forest.
While normotensive cases are well classified, prehypertensive ones are almost shared between the classes, as 55.15% is correctly classified, and the remaining part is wrongly considered as normotensive. This shows that this level of risk stratification is difficult, which is due to the fact that the differences between the two classes are, in many cases, really slight. The normotension class being more populated than the prehypertension one, any algorithm tends to favor the former when building its own internal model.
The second level of stratification risk involves the discrimination of normotensive items as opposed to Hypertensive at both stages considered together. The confusion matrix is shown in
Table 8 with reference to the best-performing algorithm, which is, in this case, Naive Bayes.
In this case, the division between the two cases is extremely good: for each class, a large majority of the items is correctly classified. This should be expected, as we are contrasting very different situations. In fact, many algorithms obtain over this level their best performance with respect to the other two, more difficult, risk stratification levels.
Finally, we take into account the third risk stratification level, in which normotensive and prehypertensive cases are considered together, and are contrasted against the items contained in both Hypertensive classes.
Table 9 shows the findings obtained by Random Forest, which is the best-performing classification algorithm for this risk level.
In this case, we have that the items in the NT + PT group are almost perfectly classified: 98.28% of these items are exactly considered, and just 1.72% of them are wrongly assigned. For the HT group, instead, things are not as good as for the first group, as just 50.80% of them are classified correctly. This is not surprising because the difference between prehypertensive and Hypertensive is, in many cases, low. This has an impact on the results. If we consider the second level of risk stratification, the algorithms could easily discriminate between normotensive and Hypertensive. Adding the prehypertensive to the normotensive, instead makes things much more complicated for all the classification algorithms. This is also favored by the fact that the former group is much more numerous than the second, as it has already been discussed for the first risk stratification level.






{kind=link}