Exploiting Virtual Machine Commonality for Improved Resource Allocation in Edge Networks




Abstract
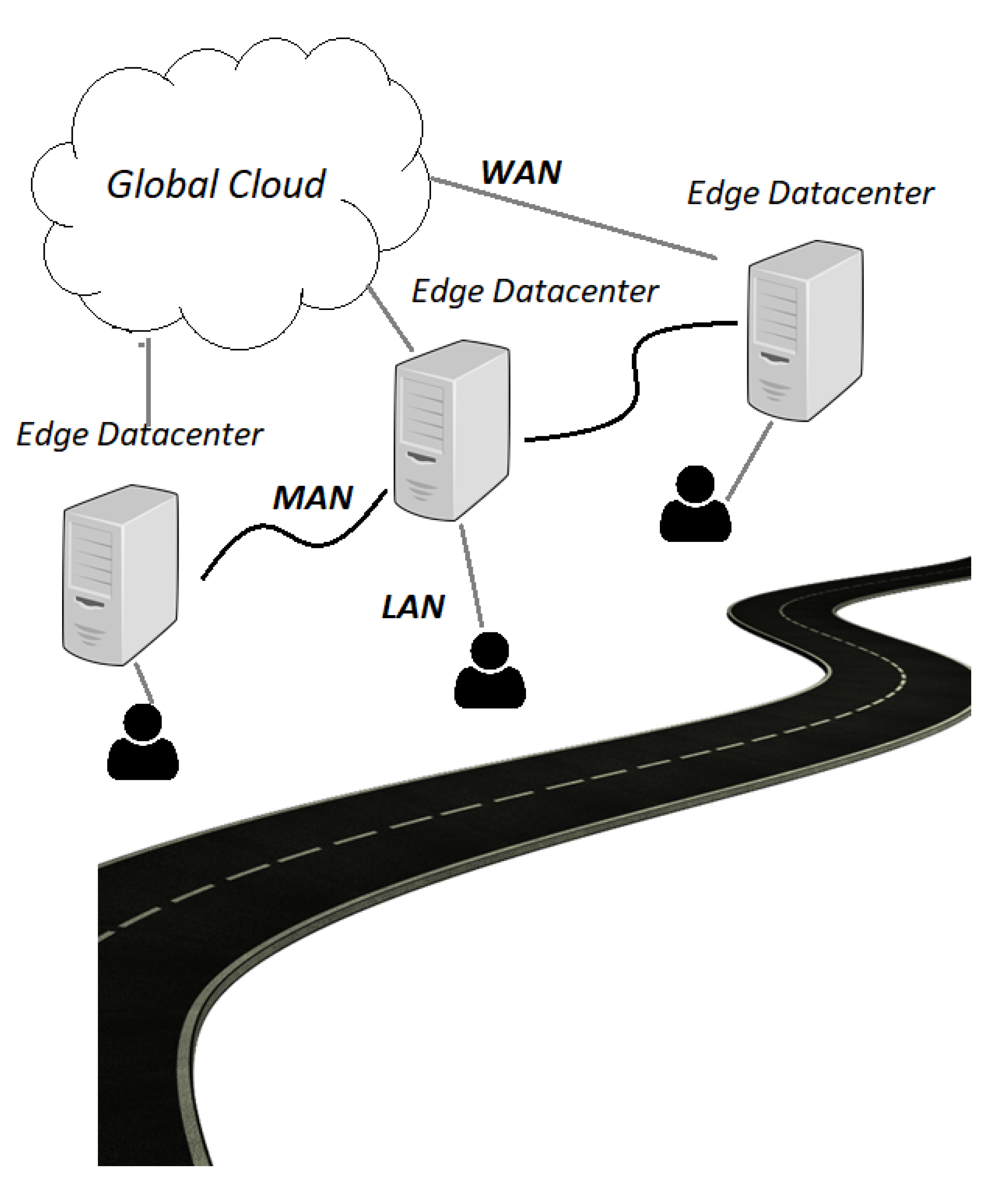
:1. Introduction
- Identify the main contributors to the delay in MEC environments and formulate a pragmatic mathematical model for E2E delay experienced by mobile users.
- Propose dynamic VM allocation policies to achieve minimal resources provisioning for VMs while satisfying the delay constraints defined for the service.
2. Related Works
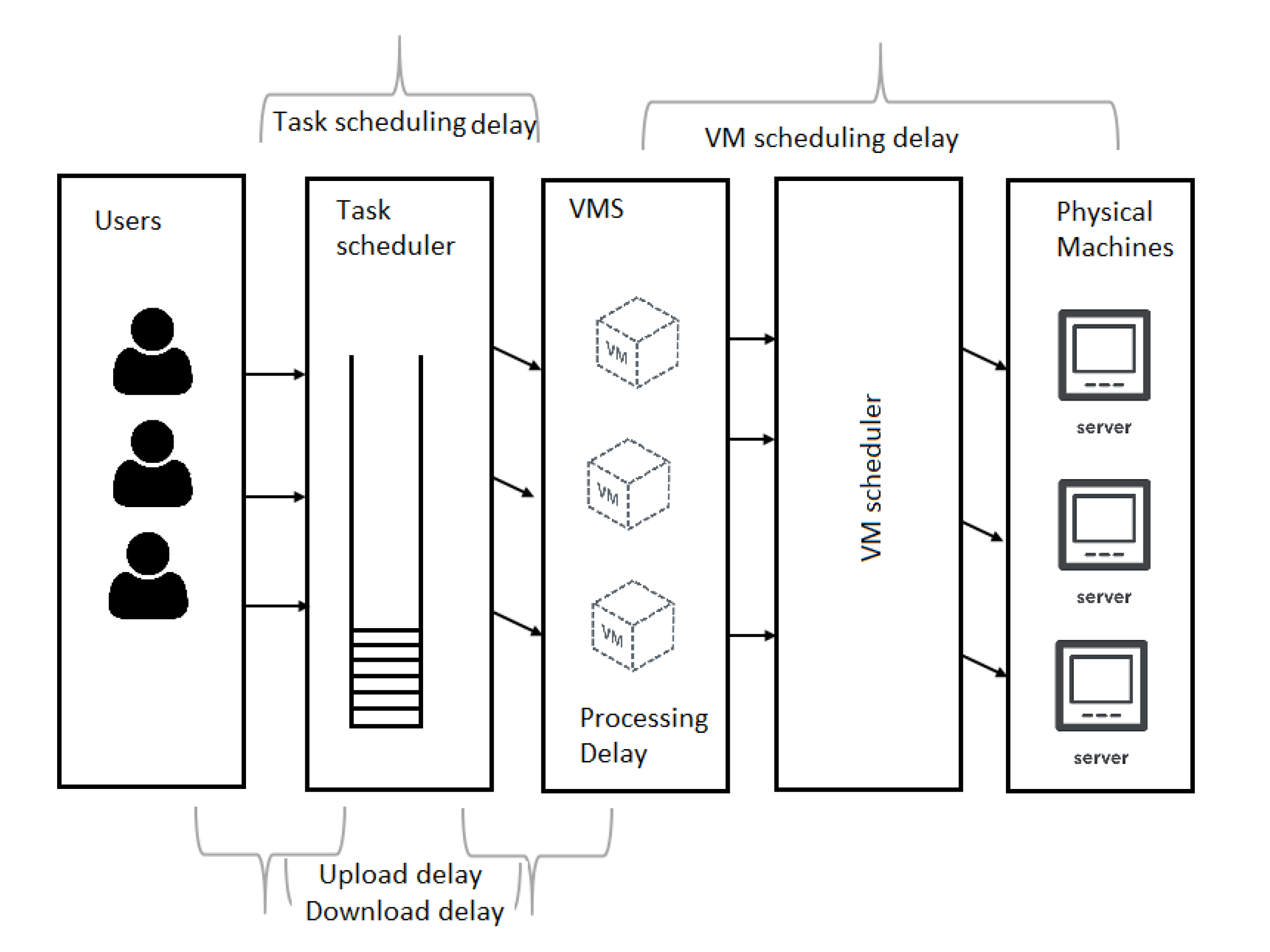
3. User Experienced Delay Modeling
3.1. Communication Delay Modeling
3.2. Processing Delay Modeling
3.3. Scheduling Delay Modeling
- Condition 1: Less than 50 pages were dirtied during the last pre-copy iteration.
- Condition 2: 29 pre-copy iterations have been realized.
- Condition 3: More than 3 times the total amount of RAM provisioned to the VM has been copied to the target node.
3.4. E2E Influential Factors
4. Resource Provisioning-Aware VM Allocation
4.1. Common Notations
4.2. Use-Based Problem Formulation
4.3. Distance-Based Problem Formulation
4.4. Volume-Based Problem Formulation
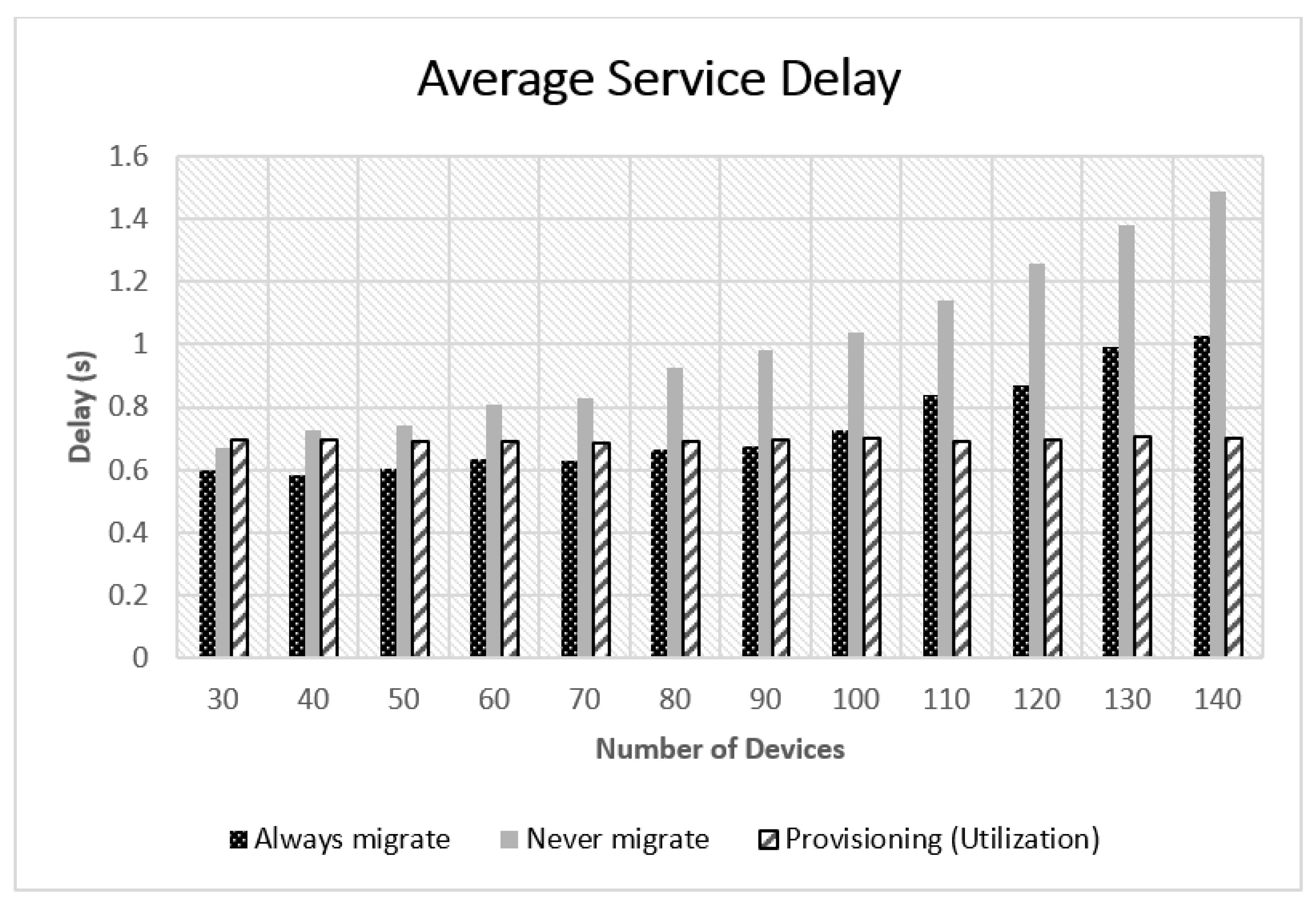
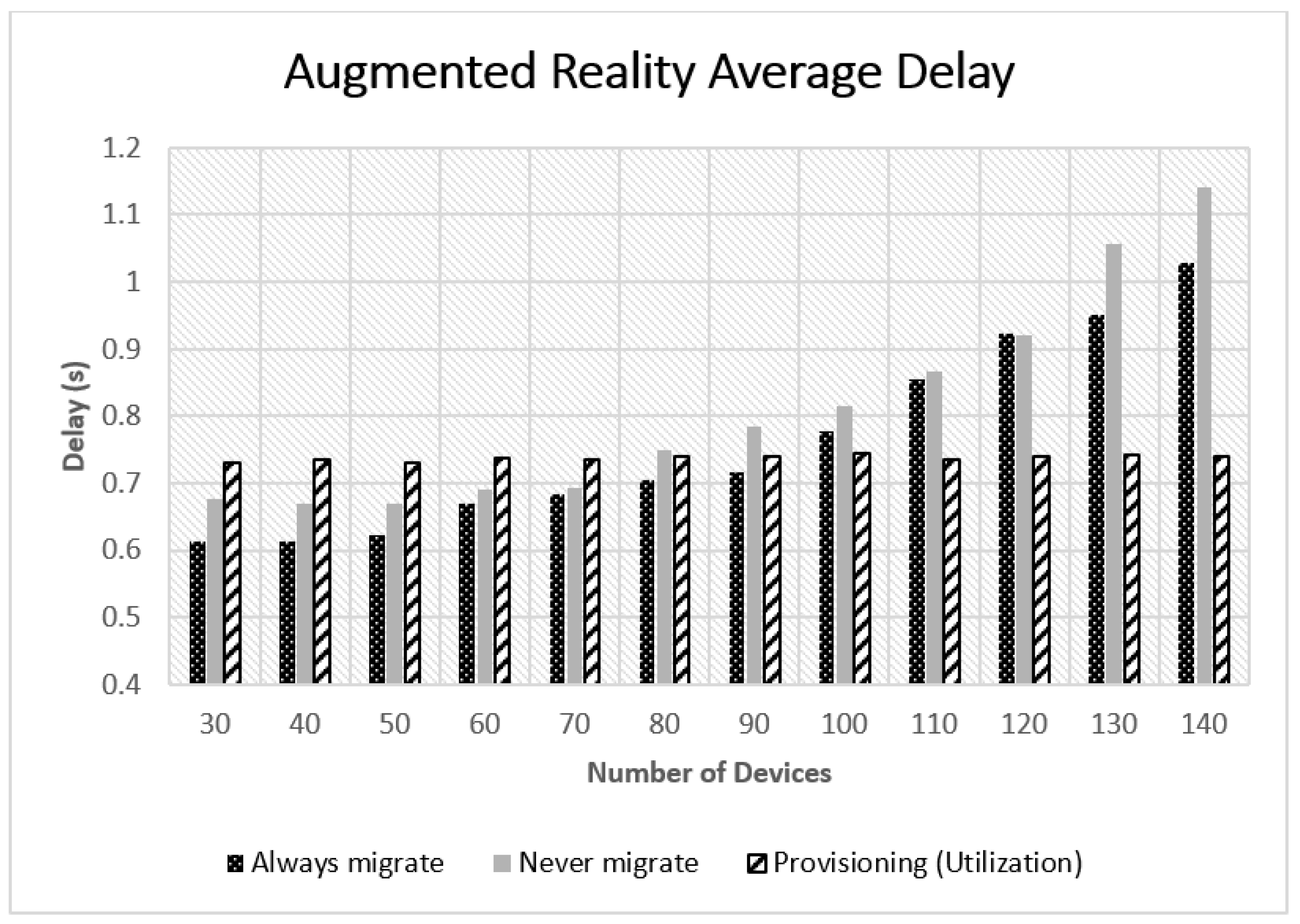
5. Evaluation
5.1. Experimental Setup
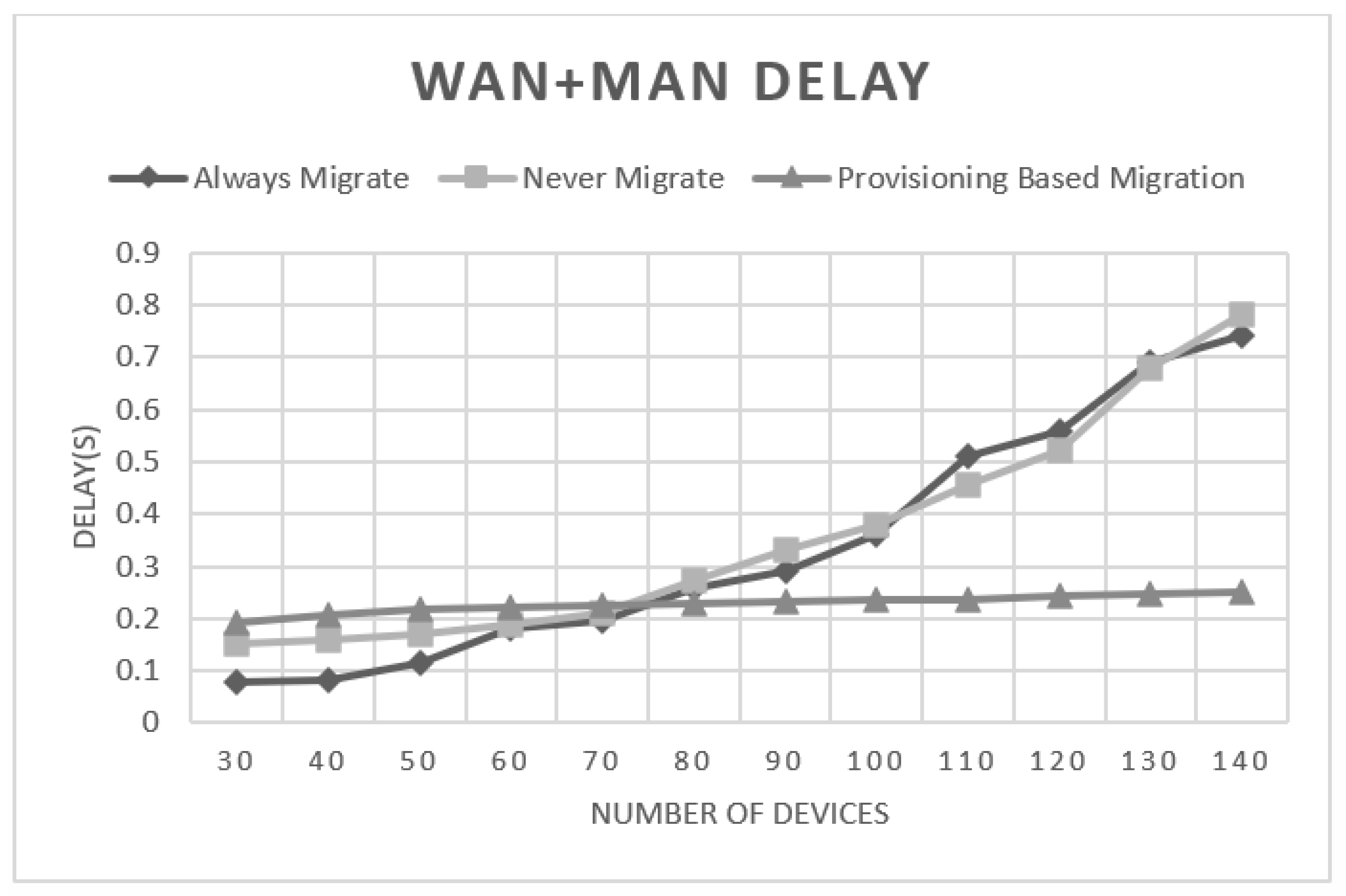
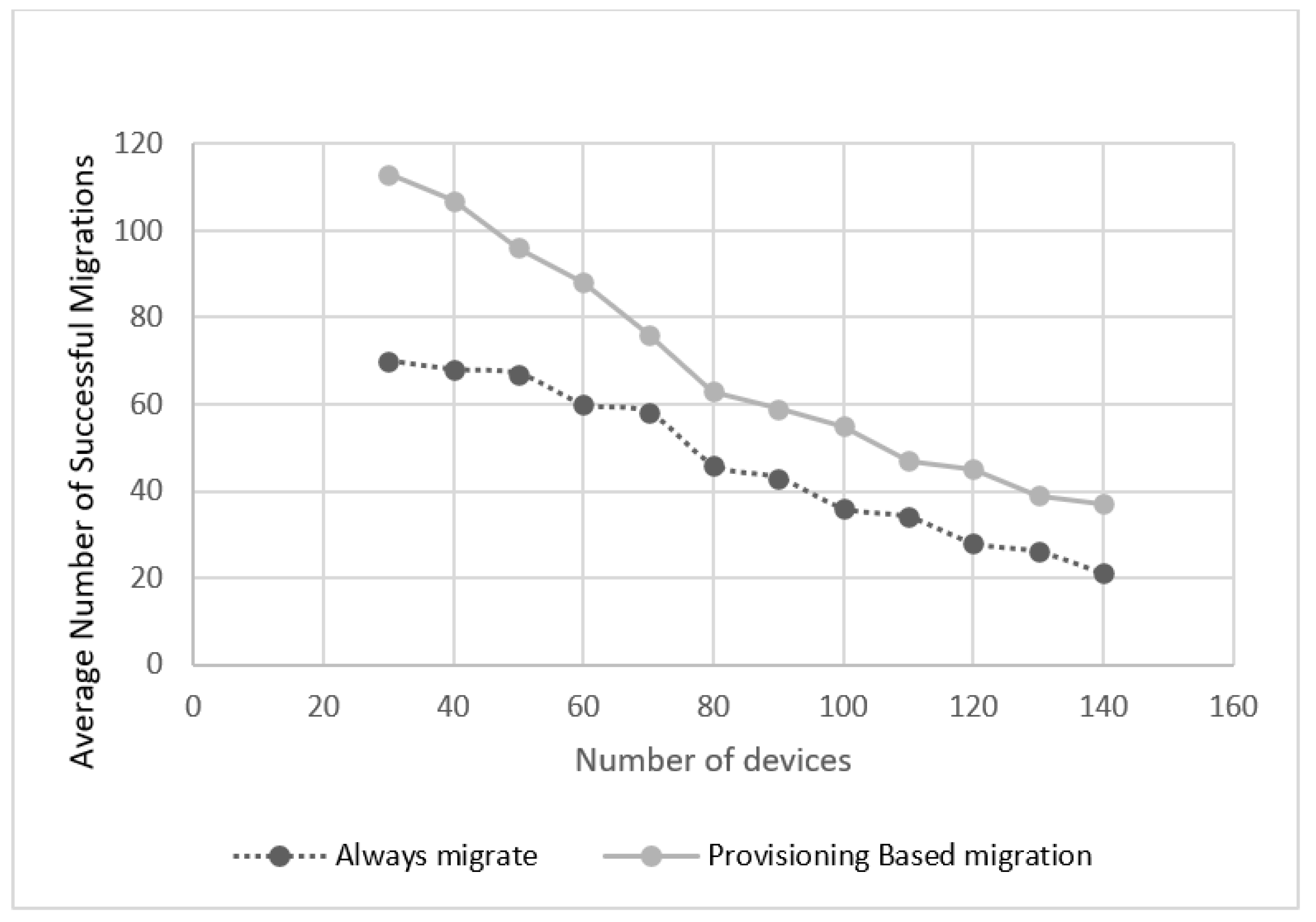
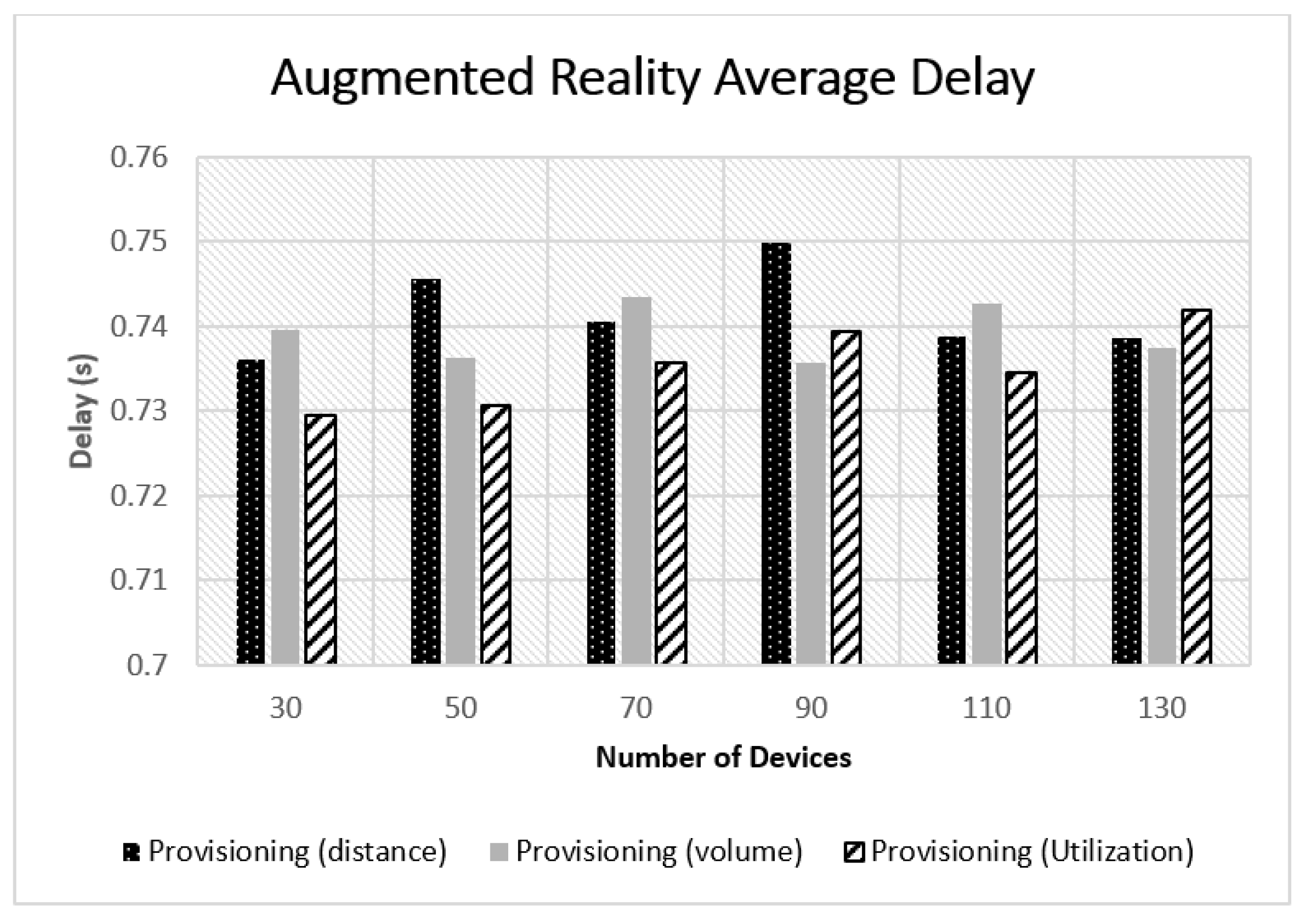
5.2. Experimental Results
| Algorithm 1: Migration Strategies Algorithms. |
 |
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Kikuchi, J.; Wu, C.; Ji, Y.; Murase, T. Mobile edge computing based VM migration for QoS improvement. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), Nagoya, Japan, 24–27 October 2017; pp. 1–5. [Google Scholar]
- Yunoki, K.; Shinbo, H. Carry-on state service handover between edge hosts for latency strict applications in mobile networks. In Proceedings of the 2018 21st International Symposium on Wireless Personal Multimedia Communications (WPMC), Chiang Rai, Thailand, 25–28 November 2011; pp. 472–477. [Google Scholar]
- Kikuchi, J.; Wu, C.; Ji, Y.; Murase, T. VM Migration in Mobile Edge Computing for QoS Improvement with Wireless Multi-Hop Access Networks. In Proceedings of the 12th International Conference on Ubiquitous Information Management and Communication, Langkawi, Malaysia, 5–7 January 2018; pp. 1–8. [Google Scholar]
- Choi, H.W.; Kwak, H.; Sohn, A.; Chung, K. Autonomous learning for efficient resource utilization of dynamic VM migration. In Proceedings of the 22nd Annual International Conference on Supercomputing, Island of Kos, Greece, 7–12 June 2008; pp. 185–194. [Google Scholar]
- Seth, S.; Singh, N. Dynamic threshold-based dynamic resource allocation using multiple VM migration for cloud computing systems. In International Conference on Information, Communication and Computing Technology; Springer: Singapore, 2017; pp. 106–116. [Google Scholar]
- Feng, Y.; Li, B.; Li, B. Bargaining towards maximized resource utilization in video streaming datacenters. In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 1134–1142. [Google Scholar]
- Farahnakian, F.; Pahikkala, T.; Liljeberg, P.; Plosila, J.; Tenhunen, H. Utilization prediction aware VM consolidation approach for green cloud computing. In Proceedings of the 2015 IEEE 8th International Conference on Cloud Computing, New York, NY, USA, 27 June–2 July 2015; pp. 381–388. [Google Scholar]
- Bazarbayev, S.; Hiltunen, M.; Joshi, K.; Sanders, W.H.; Schlichting, R. Content-based scheduling of virtual machines (VMs) in the cloud. In Proceedings of the 2013 IEEE 33rd International Conference on Distributed Computing Systems, Philadelphia, PA, USA, 8–11 July 2013; pp. 93–101. [Google Scholar]
- Lawton, K.P.; Vlaovic, S. Using Memory Equivalency Across Compute Clouds for Accelerated Virtual Memory Migration And Memory De-Duplication. U.S. Patent Application 12/368,247, 13 August 2009. [Google Scholar]
- Sapuntzakis, C.P.; Chandra, R.; Pfaff, B.; Chow, J.; Lam, M.S.; Rosenblum, M. Optimizing the migration of virtual computers. ACM SIGOPS Oper. Syst. Rev. 2002, 36, 377–390. [Google Scholar] [CrossRef] [Green Version]
- Bozek, J.J.; Hansson, N.P.J.; Suffern, E.S.; Wooldridge, J.L. Virtual Machine Placement to Improve Memory Utilization. U.S. Patent 8,490,091, 16 July 2013. [Google Scholar]
- Waldspurger, C.; Colbert, O.K.; Chen, X.; Venkatasubramanian, R. Page Signature Disambiguation for Increasing the Efficiency of Virtual Machine Migration in Shared-Page Virtualized Computer Systems. U.S. Patent 7,925,850, 12 April 2011. [Google Scholar]
- Wood, T.; Tarasuk-Levin, G.; Shenoy, P.; Desnoyers, P.; Cecchet, E.; Corner, M.D. Memory buddies: Exploiting page sharing for smart colocation in virtualized data centers. ACM SIGOPS Oper. Syst. Rev. 2009, 43, 27–36. [Google Scholar] [CrossRef]
- Frank, S.; Baron, A. Hashing Storage Images of a Virtual Machine. U.S. Patent 8,701,106, 15 April 2014. [Google Scholar]
- Taleb, T.; Ksentini, A. Follow me cloud: Interworking federated clouds and distributed mobile networks. IEEE Netw. 2013, 27, 12–19. [Google Scholar] [CrossRef]
- Rodrigues, T.G.; Suto, K.; Nishiyama, H.; Kato, N. Hybrid method for minimizing service delay in edge cloud computing through VM migration and transmission power control. IEEE Trans. Comput. 2016, 66, 810–819. [Google Scholar] [CrossRef]
- Zhang, J.; Ren, F.; Lin, C. Delay guaranteed live migration of virtual machines. In Proceedings of the IEEE INFOCOM 2014-IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 574–582. [Google Scholar]
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Ge, J.; He, Q.; Fang, Y. Cloud computing task scheduling strategy based on improved differential evolution algorithm. In AIP Conference Proceedings; AIP Publishing: Melvile, NY, USA, 2017; Volume 1834, p. 040038. [Google Scholar]
- Cho, K.M.; Tsai, P.W.; Tsai, C.W.; Yang, C.S. A hybrid meta-heuristic algorithm for VM scheduling with load balancing in cloud computing. Neural Comput. Appl. 2015, 26, 1297–1309. [Google Scholar] [CrossRef]
- Li, K.; Xu, G.; Zhao, G.; Dong, Y.; Wang, D. Cloud task scheduling based on load balancing ant colony optimization. In Proceedings of the 2011 Sixth Annual ChinaGrid Conference, Liaoning, China, 22–23 August 2011; pp. 3–9. [Google Scholar]
- Bian, S.; Huang, X.; Shao, Z. Online task scheduling for fog computing with multi-resource fairness. In Proceedings of the 2019 IEEE 90th Vehicular Technology Conference (VTC2019-Fall), Honolulu, HI, USA, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Little, J.D. A proof for the queuing formula: L = λ W. Oper. Res. 1961, 9, 383–387. [Google Scholar] [CrossRef]
- Sztrik, J. Basic queueing theory. Univ. Debrecen, Fac. Inform. 2012, 193, 60–67. [Google Scholar]
- Clark, C.; Fraser, K.; Hand, S.; Hansen, J.G.; Jul, E.; Limpach, C.; Pratt, I.; Warfield, A. Live migration of virtual machines. In Proceedings of the 2nd Conference on Symposium on Networked Systems Design & Implementation, Boston, MA, USA, 2–4 May 2005; USENIX Association: Berkeley, CA, USA; Volume 2, pp. 273–286. [Google Scholar]
- VMware Inc. VMware VirtualCenter—Centralized Management, Automation and Optimization for IT Infrastructure; Product Datasheet, VMware Inc.: Palo Alto, CA, USA; Available online: https://www.vmware.com/pdf/vc_datasheet.pdf (accessed on 30 September 2019).
- Hines, M.R.; Gopalan, K. Post-copy based live virtual machine migration using adaptive pre-paging and dynamic self-ballooning. In Proceedings of the 2009 ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, Washington, DC, USA, 11–13 March 2009; pp. 51–60. [Google Scholar]
- Wood, T.; Ramakrishnan, K.; Shenoy, P.; Van der Merwe, J. CloudNet: Dynamic pooling of cloud resources by live WAN migration of virtual machines. In ACM Sigplan Notices; ACM: New York, NY, USA, 2011; Volume 46, pp. 121–132. [Google Scholar]
- Akoush, S.; Sohan, R.; Rice, A.; Moore, A.W.; Hopper, A. Predicting the performance of virtual machine migration. In Proceedings of the 2010 IEEE International Symposium on Modeling, Analysis and Simulation Of Computer And Telecommunication Systems, Miami Beach, FL, USA, 17–19 August 2010; pp. 37–46. [Google Scholar]
- Xen Project Schedulers. Available online: https://wiki.xenproject.org/wiki/Xen-Project-Schedulers (accessed on 30 September 2019).
- Wood, T.; Shenoy, P.J.; Venkataramani, A.; Yousif, M.S. Black-box and Gray-box Strategies for Virtual Machine Migration. In Proceedings of the NSDI 2007—4th US ENIX Symposiumon Networked Systems Design & Implementat, Cambridge, MA, USA, 11–13 April 2007; Volume 7, p. 17. [Google Scholar]
- Wood, T.; Shenoy, P.; Venkataramani, A.; Yousif, M. Sandpiper: Black-box and gray-box resource management for virtual machines. Comput. Netw. 2009, 53, 2923–2938. [Google Scholar] [CrossRef]
- Mishra, M.; Sahoo, A. On theory of VM placement: Anomalies in existing methodologies and their mitigation using a novel vector based approach. In Proceedings of the IEEE 4th International Conference on Cloud Computing, Washington, DC, USA, 4–9 July 2011; pp. 275–282. [Google Scholar]
- Sonmez, C.; Ozgovde, A.; Ersoy, C. EdgeCloudSim: An environment for performance evaluation of edge computing systems. Trans. Emerg. Telecommun. Technol. 2018, 29, e3493. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity | CPU () | Ram (Gb) | Storage (Gb) | BW (Mbps) | RAM Commonality % | Storage Commonality % |
|---|---|---|---|---|---|---|
| Edge Host | () | 12 | 300 | - | - | |
| Augmented Reality | () | 1.5 | 40 | 40 | 10 | 40 |
| Health App VM | () | 1 | 30 | 30 | 20 | 40 |
| Heavy Computing App VM | () | 2 | 50 | 50 | 30 | 30 |
| Infotainment APP VM | () | 1 | 20 | 25 | 50 | 15 |
| App | Active Period (s) | Idle Period (s) | Avg Data Upload (KB) | Avg Data Download (KB) | Avg Task Length (MI) |
|---|---|---|---|---|---|
| Augmented Reality | 40 | 20 | 1500 | 25 | 3000 |
| Health App | 45 | 90 | 20 | 1250 | 1000 |
| Heavy Computing App | 60 | 120 | 2500 | 200 | 4500 |
| Infotainment App | 30 | 45 | 25 | 1000 | 1500 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdah, H.; Barraca, J.P.; Aguiar, R.L. Exploiting Virtual Machine Commonality for Improved Resource Allocation in Edge Networks. J. Sens. Actuator Netw. 2020, 9, 58. https://doi.org/10.3390/jsan9040058
Abdah H, Barraca JP, Aguiar RL. Exploiting Virtual Machine Commonality for Improved Resource Allocation in Edge Networks. Journal of Sensor and Actuator Networks. 2020; 9(4):58. https://doi.org/10.3390/jsan9040058
Chicago/Turabian StyleAbdah, Hadeel, João Paulo Barraca, and Rui L. Aguiar. 2020. "Exploiting Virtual Machine Commonality for Improved Resource Allocation in Edge Networks" Journal of Sensor and Actuator Networks 9, no. 4: 58. https://doi.org/10.3390/jsan9040058
APA StyleAbdah, H., Barraca, J. P., & Aguiar, R. L. (2020). Exploiting Virtual Machine Commonality for Improved Resource Allocation in Edge Networks. Journal of Sensor and Actuator Networks, 9(4), 58. https://doi.org/10.3390/jsan9040058