
Model Validation and DSGE Modeling

Abstract
:1. Introduction
“The main failing of most macroeconometric models is in not taking macroeconomic theory seriously enough with the result that little or nothing is learned about key parameter values, a fault no amount of econometric sophistication will compensate for”.(p. 1637)
“Over the last 20 years dynamic stochastic general equilibrium (DSGE) models have become more detailed and complex and numerous features have been added to the original real business cycle core. Still, even the best practice DSGE model is likely to be misspecified; either because features, such as heterogeneities in expectations, are missing or because researchers leave out aspects deemed tangential to the issues of interest”.
2. Empirical Model Validation
2.1. Macroeconometric Models
“...an important component of Kydland and Prescott’s advocacy of calibration is based on a criticism of the probability approach....In sum, the use of calibration exercises as a means for facilitating the empirical implementation of DSGE models arose in the aftermath of the demise of system of equations analyses”.(p. 257)
2.2. Structural vs. Statistical Models
- (i)
- Rendering the distribution of the sample as well as the likelihood function erroneous.
- (ii)
- Distorting the relevant sampling distribution, of any statistic (estimator, test, predictor), that underlies the inference in question since:
- (iii)
- Undermining the reliability of inference procedures by belying their optimality and inducing sizeable discrepancies between the actual and the nominal (the ones assuming the validity of ) error probabilities. Applying a 0.05 significance level (nominal) test when the actual type I error is greater than will lead an inference astray. This unreliability affects not just testing and estimation but also goodness-of-fit and prediction measures rendering them highly misleading. Statistical adequacy secures the reliability of inference by securing the optimality of inference and ensuring that the actual error probabilities approximate closely the nominal ones. As shown in (Spanos and McGuirk 2001), such discrepancies can easily arise for what are often considered ‘minor’ statistical misspecifications.
3. Revisiting DSGE Modeling
3.1. Smets and Wouters 2007 DSGE Model
- (i)
- Observables -consumption, -investment, -output, -labor hour, -inflation rate, -real wage rate, and -interest rate.
- (ii)
- Latent variables -capital utilization rate, -current value of the capital stock, -current capital services used in production, -installed capital, -rental rate of capital, -price mark-up, -wage mark-up.
- (iii)
- Latent shocks (Table 3):
3.2. Traditional Model Quantification
- Purely backward (or purely predetermined) variables: Those that appear only at the current and past periods in the model, but not at any future period.
- Purely forward variables: Those that appear only at the current, and future periods in the model, but not at past periods.
- Mixed variables: Those that appear at current, past, and future periods in the model.
- Static variables: Those that appear only at current, not past and future periods in the model.
3.3. Confronting the DSGE Model with Data
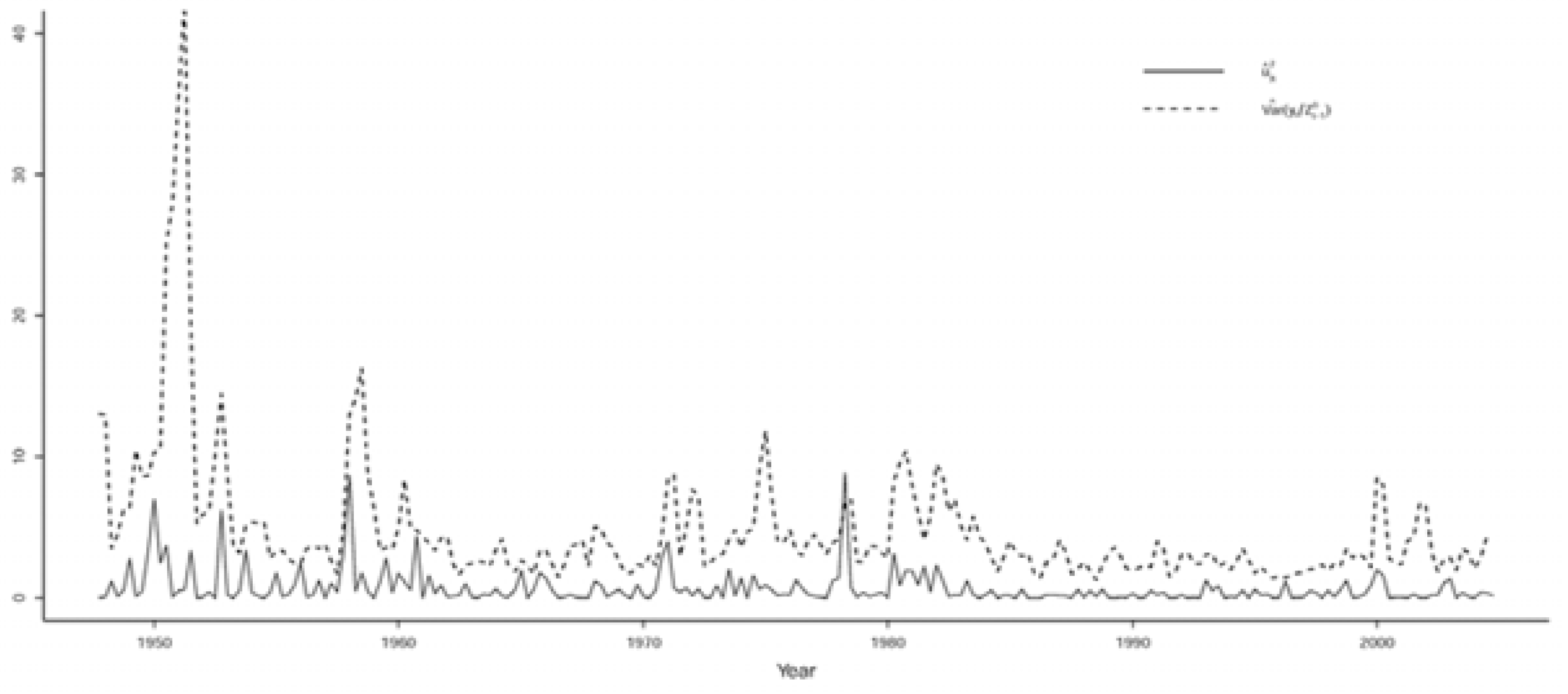
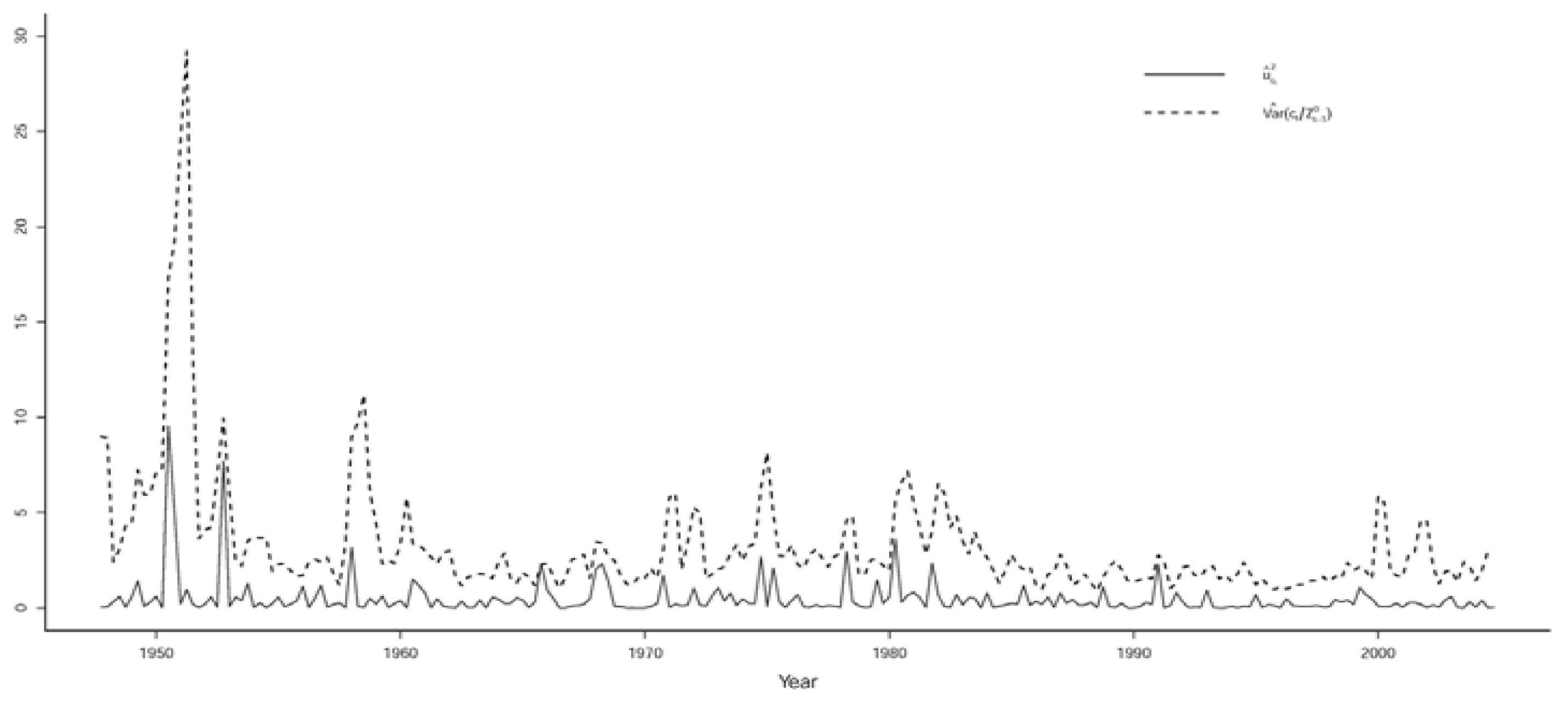
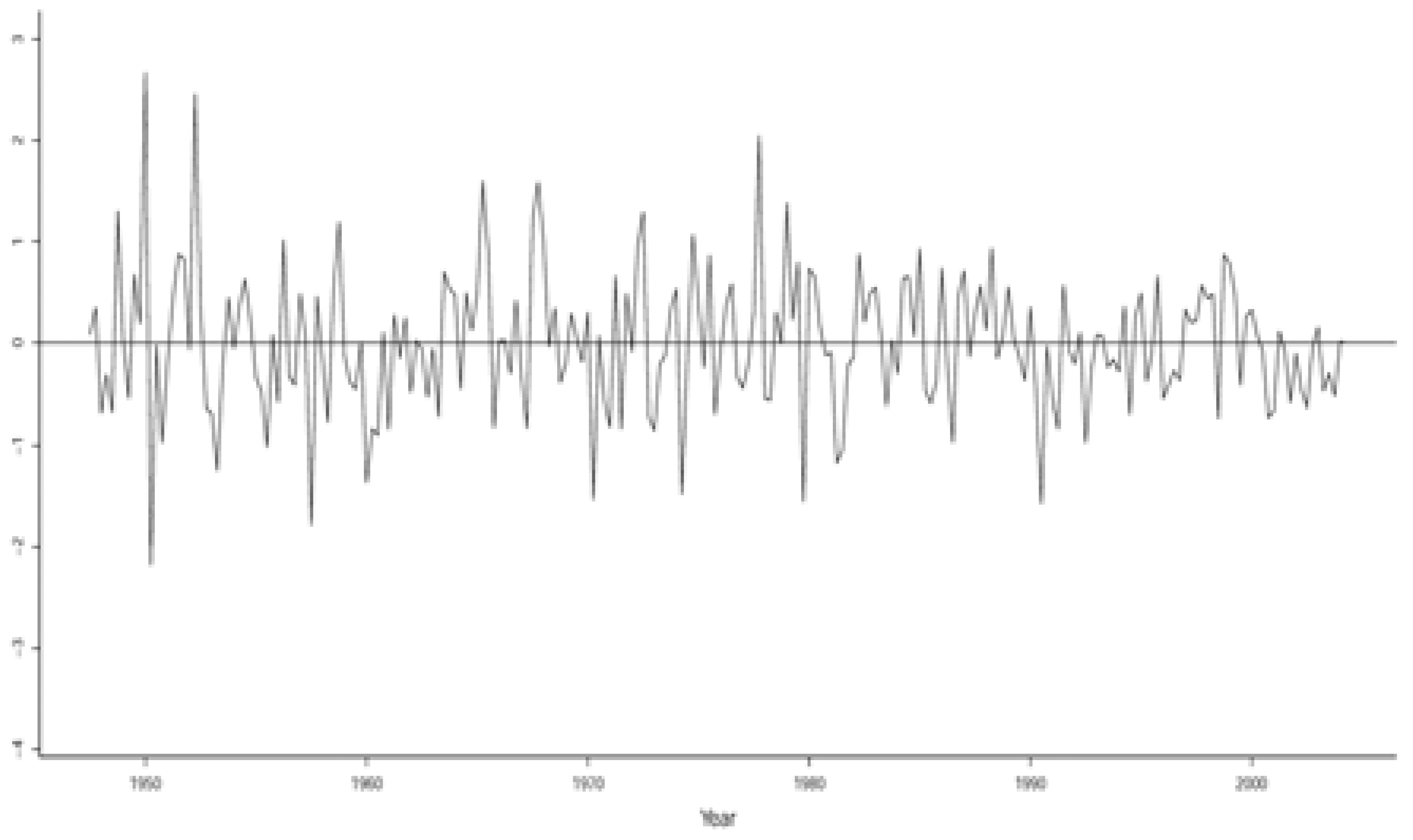
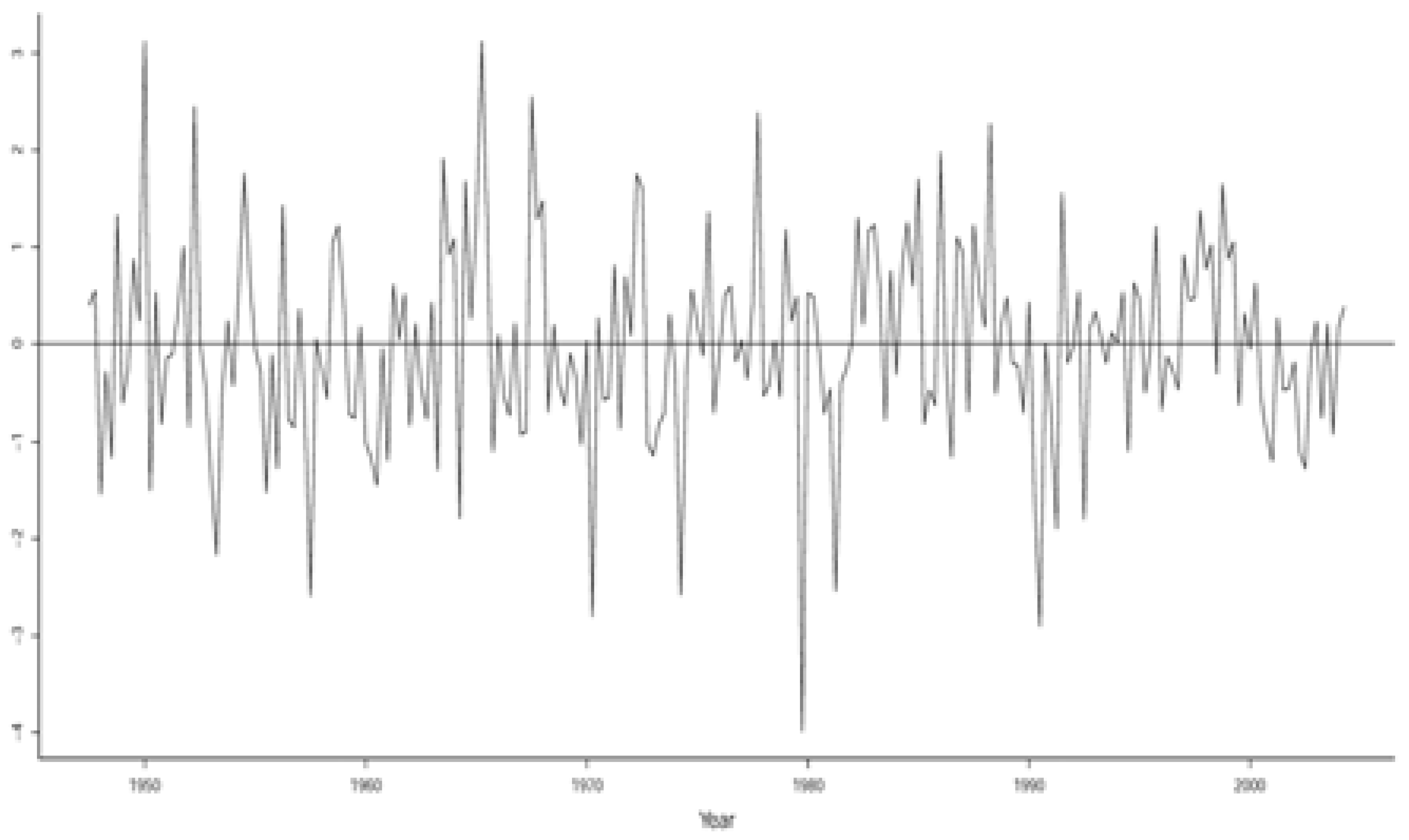
3.3.1. Evaluating the Validity of the Implicit Statistical Model
3.3.2. Respecifying the Implicit Statistical Model
3.3.3. Evaluating the Statistical Adequacy of the St-VAR(2) Model
“...large changes tend to be followed by large changes-of either sign-and small changes tend to be followed by small changes”.(p. 418)
4. Evaluating the Smets and Wouters DSGE Model
4.1. Testing the Over-Identifying Restrictions
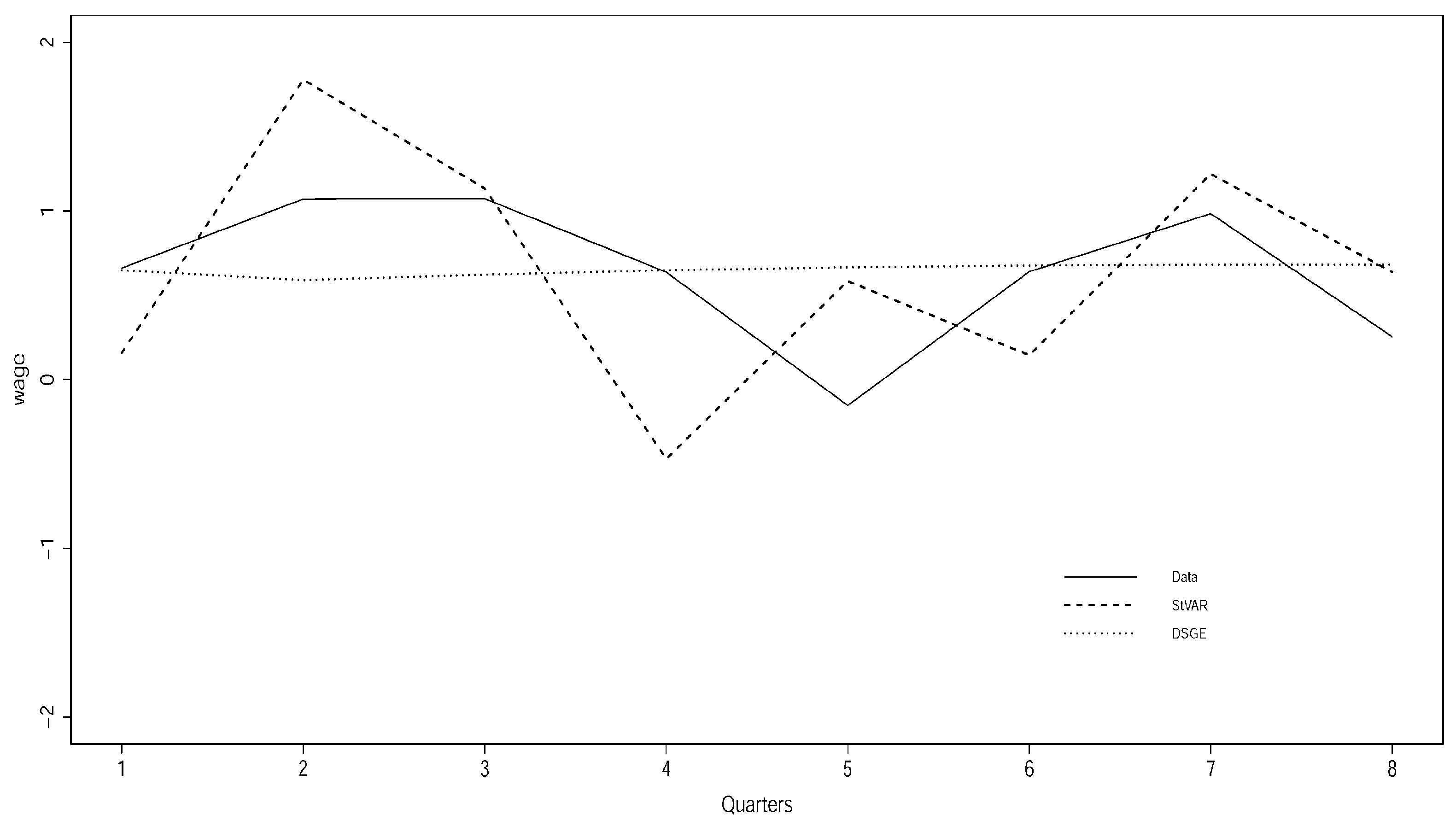
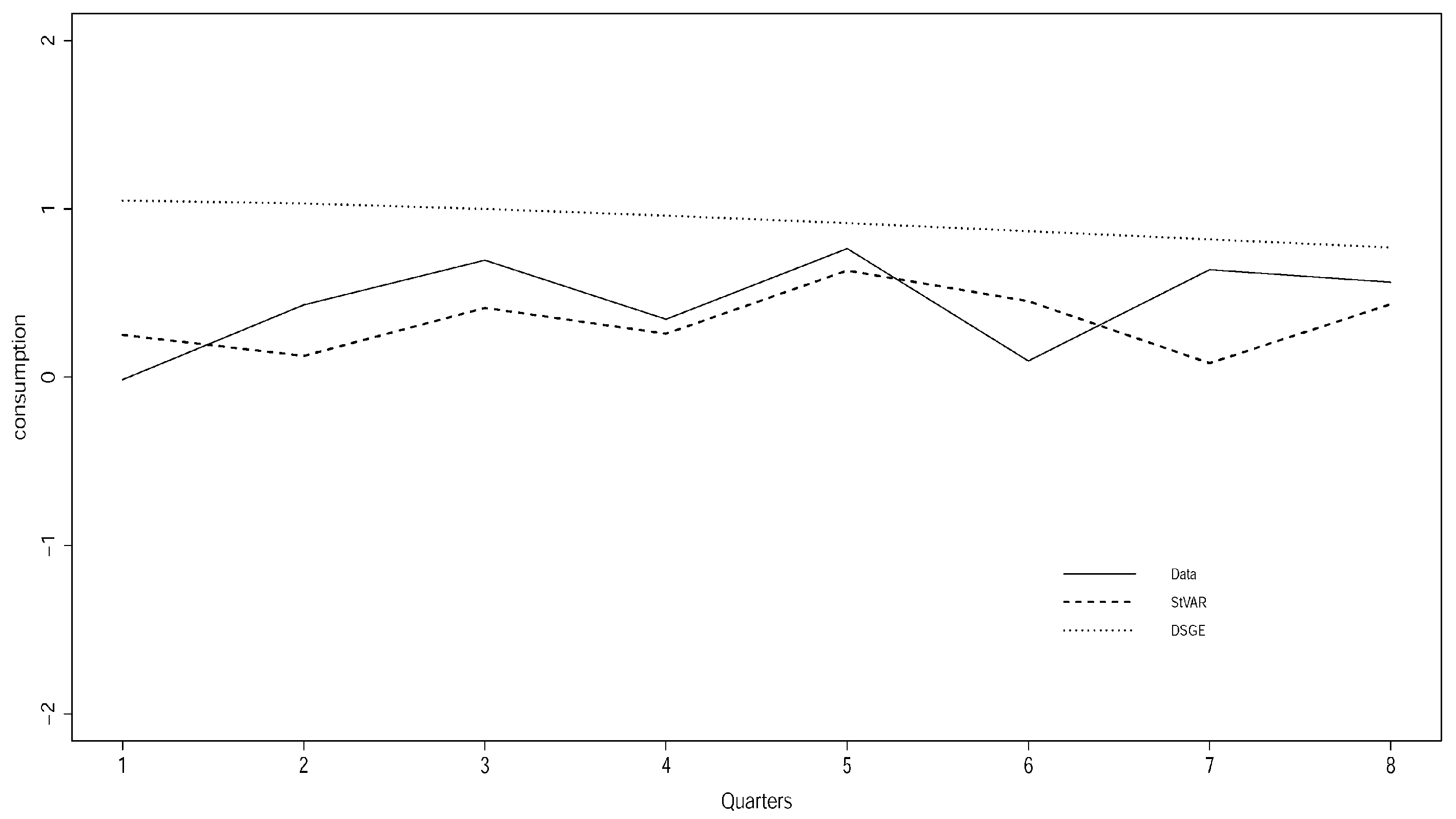
4.2. Forecasting Performance
“...we find that the benchmark estimated medium scale DSGE model forecasts inflation and GDP growth very poorly, although statistical and judgemental forecasts do equally poorly”.(Edge and Gurkaynak 2010, p. 209)
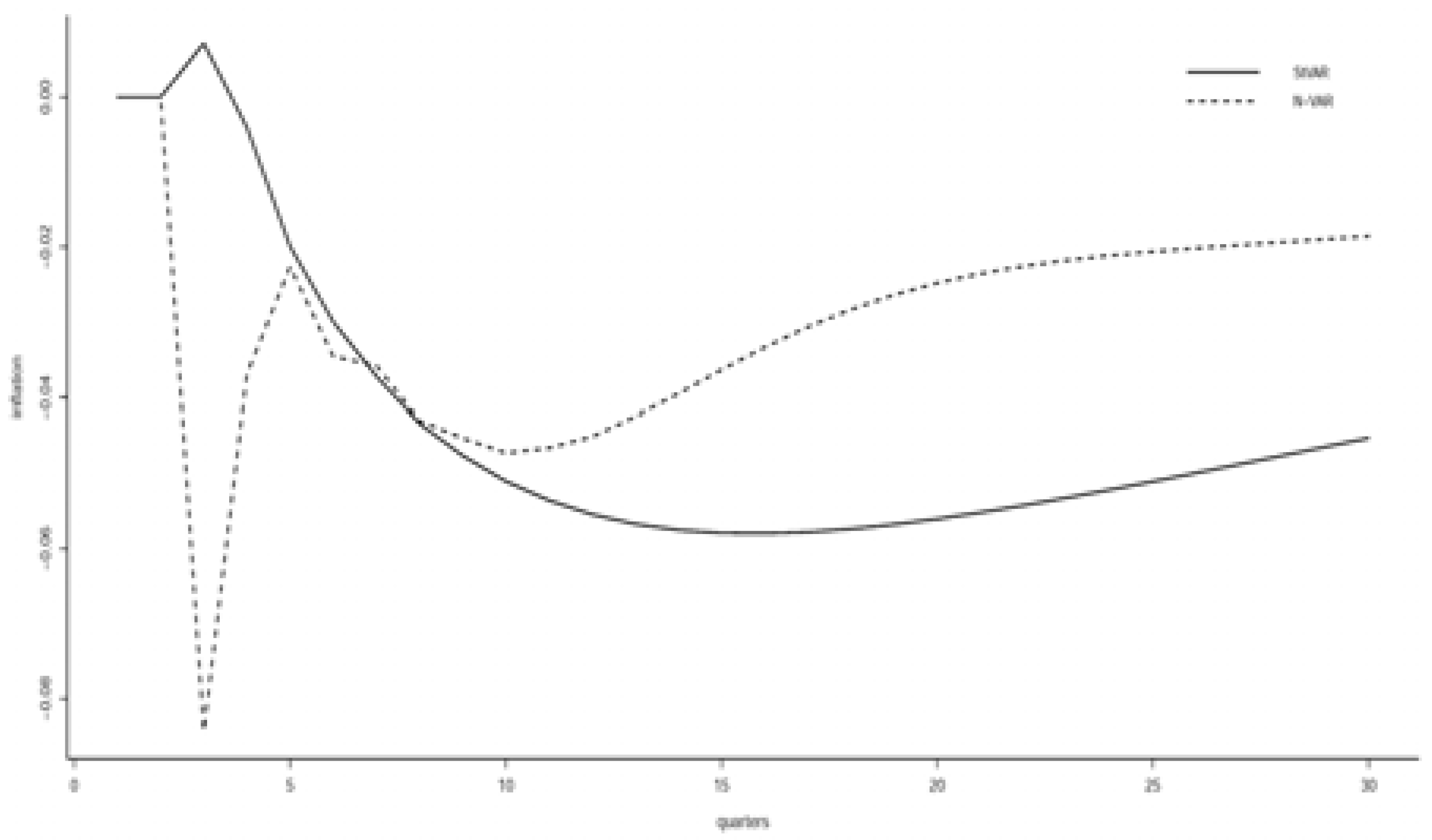
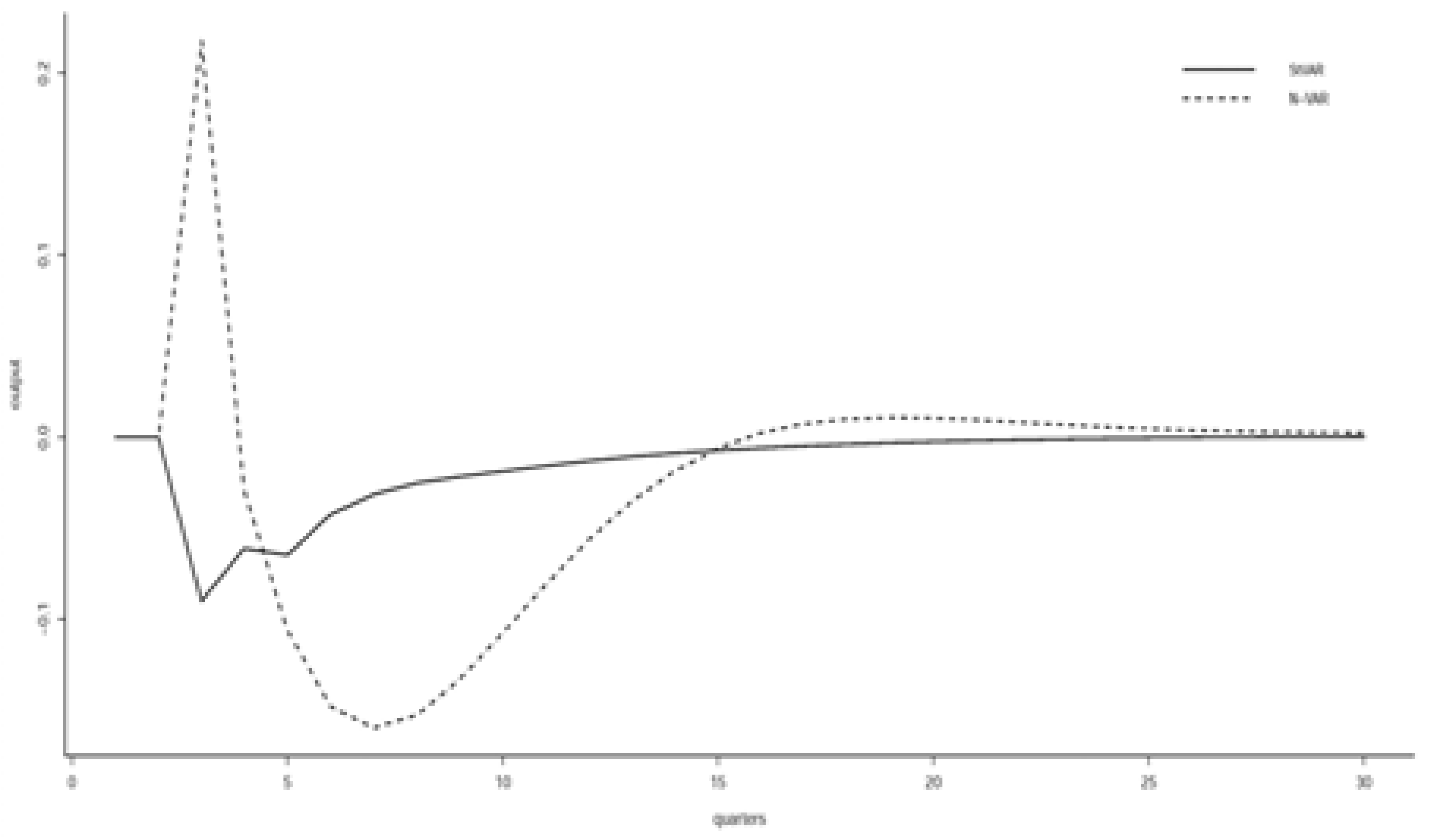
4.3. Potentially Misleading Impulse Response Analysis
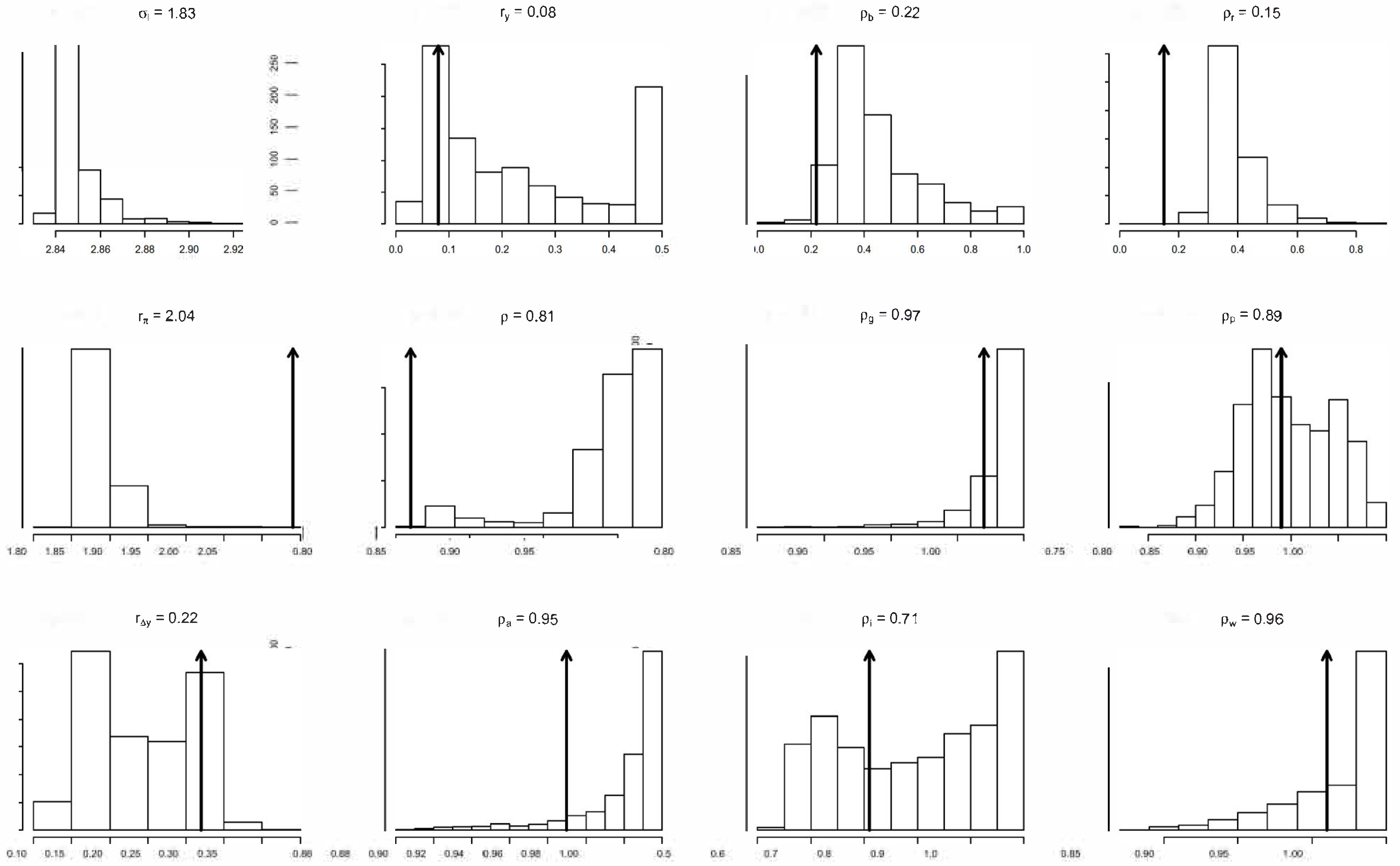
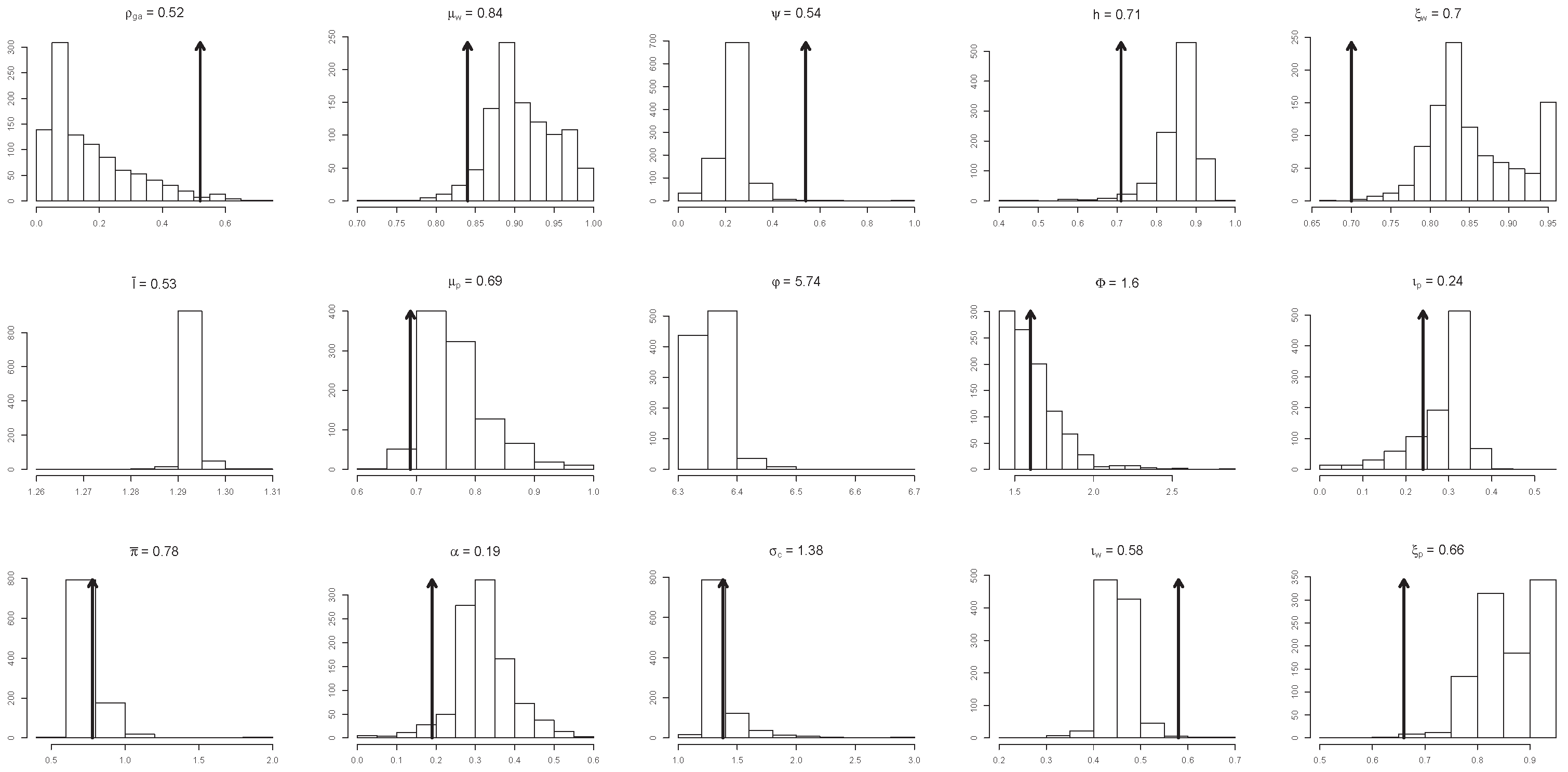
4.4. Identification of the ‘Deep’ Structural Parameters
4.5. Substantive vs. Statistical Adequacy
“This implication is not a tract for mindless modeling of data in the absence of economic analysis, but instead suggests formulating more general initial models that embed the available economic theory as a special case, consistent with our knowledge of the institutional framework, historical record, and the data properties...Applied econometrics cannot be conducted without an economic theoretical framework to guide its endeavors and help interpret its findings. Nevertheless, since economic theory is not complete, correct, and immutable, and never will be, one also cannot justify an insistence on deriving empirical models from theory alone”.(pp. 56–57)
5. Summary and Conclusions
- (a)
- (b)
- When a DSGE model is estimated directly, the statistical reliability of any inferences drawn is questionable. Before any reliable inferences can be drawn, the modeler needs to test the validity of the assumptions of the statistical model.
- (c)
- When the statistical model is found to be misspecified, the modeler needs to respecify it to account for the statistical information in the data. Only when the statistical adequacy of is established, one should proceed to the inference stage.
- (d)
- The evaluation of the empirical validity of the structural model begins with testing the validity of the over-identifying restrictions in the context of a statistically adequate .
- (e)
- In cases where the overidentifying restrictions are rejected, the modeler needs to return to in order to respecify it substantively, to account for the statistical regularities summarized by the statistically adequate . The misspecification/respecification scenarios proposed by (Del Negro et al. 2007) and (Del Negro and Schorfeide 2009) enter the modeling at this stage, and not before.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Miscellaneous Results
Appendix A.1. Derivation of Reduced Form Structural Model
Appendix A.2. Multivariate Student’s t
Appendix A.3. Software
References
- Anderson, Theodore Wilbur, and Donald Allan Darling. 1952. Asymptotic Theory of Certain “Goodness of Fit” Criteria Based on Stochastic Processes. The Annals of Mathematical Statistics 23: 193–212. [Google Scholar] [CrossRef]
- Blanchard, Olivier Jean, and Charles Kahn. 1980. The solution of linear difference models under rational expectations. Econometrica 48: 1305–11. [Google Scholar] [CrossRef]
- Bodkin, Ronald, Lawrence Robert Klein, and Kanta Marwah. 1991. A History of Macroeconometric Model-Building. Altershot: Edward Elgar. [Google Scholar]
- Canova, Fabio. 2007. Methods for Applied Macroeconomic Research. Hoboken: Princeton Unversity Press. [Google Scholar]
- Canova, Fabio. 2009. How Much Structure in Empirical Models. In Palgrave Handbook of Econometrics. Edited by Terence C. Mills and Kerry D. Patterson. Vol. 2: Applied Econometrics. Basingstoke: Palgrave MacMillan, pp. 68–97. [Google Scholar]
- Chang, Yongsung, Taeyoung Doh, and Frank Schorfheide. 2007. Non-stationary Hours in a DSGE Model. Journal of Money, Credit, and Banking 39: 1357–73. [Google Scholar] [CrossRef]
- Consolo, Agostino, Carlo A. Favero, and Alessia Paccagnini. 2009. On the statistical identification of DSGE models. Journal of Econometrics 150: 99–115. [Google Scholar] [CrossRef] [Green Version]
- DeJong, David N., and Chetan Dave. 2011. Structural Macroeconometrics, 2nd ed. Hoboken: Princeton Unversity Press. [Google Scholar]
- Del Negro, Marco, and Frank Schorfeide. 2009. Monetary Policy Analysis with Potentially Misspecified Models. The American Economic Review 99: 1415–50. [Google Scholar] [CrossRef] [Green Version]
- Del Negro, Marco, Frank Schorfheide, Frank Smets, and Rafael Wouters. 2007. On the Fit of New Keynesian Models. Journal of Business & Economic Statistics 25: 123–43. [Google Scholar]
- Edge, Rochelle M., and Refet S. Gurkaynak. 2010. How Useful are Estimated DSGE Model Forecasts for Central Bankers? Brookings Papers 2010: 209–44. [Google Scholar] [CrossRef] [Green Version]
- Favero, Carlo A. 2001. Applied Macroeconometrics. Oxford: Oxford University Press. [Google Scholar]
- Fernández-Villaverde, Jesus, and Juan F. Rubio-Ramírez. 2007. Estimating macroeconomic models: A likelihood approach. The Review of Economic Studies 74: 1059–87. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Villaverde, Jesus, Juan F. Rubio-Ramírez, Thomas John Sargent, and Mark W. Watson. 2007. ABCs (and Ds) of Understanding VARs. The American Economic Review 97: 1021–26. [Google Scholar] [CrossRef] [Green Version]
- Galí, Jordi, Frank Smets, and Rafael Wouters. 2011. Unemployment in an Estimated New Keynesian Model. NBER Macroeconomics Annual 26: 329–60. [Google Scholar] [CrossRef] [Green Version]
- Granger, Clive William John, and Paul Newbold. 1986. Forecasting Economic Time Series, 2nd ed. London: Academic Press. [Google Scholar]
- Gregory, Allan W., and Gregor W. Smith. 1993. Statistical aspects of calibration in macroeconomics. In Handbook of Statistics. Edited by Gangadharrao Soundalyarao (G.S.) Maddala, Calyampudi Radhakrishna (C.R.) Rao and Hrishikesh D. Vinod. Amsterdam: Elsevier, vol. 2. [Google Scholar]
- Harvey, Andrew C., and Albert Jaeger. 1993. Detrending, Stylized Facts and the Business Cycle. Journal of Applied Econometrics 8: 231–47. [Google Scholar] [CrossRef] [Green Version]
- Hashimzade, Nigar, and Michael Alan Thornton, eds. 2013. Handbook of Research Methods and Applications in Empirical Macroeconomics. Altershot: Edward Elgar. [Google Scholar]
- Heer, Burkhard, and Alfred Maussner. 2009. Dynamic General Equilibrium Modeling, 2nd ed. New York: Springer. [Google Scholar]
- Hendry, David Forbes. 2009. The Methodology and Philosophy of Applied Econometrics. In New Palgrave Handbook of Econometrics. Edited by Terence C. Mills and Kerry D. Patterson. vol. 2: Applied Econometrics. London: MacMillan, pp. 3–67. [Google Scholar]
- Ireland, Peter N. 2004. Technology Shocks in the New Keynesian Model. The Review of Economics and Statistics 86: 923–36. [Google Scholar] [CrossRef] [Green Version]
- Ireland, Peter N. 2011. A new Keynesian perspective on the great recession. Journal of Money, Credit and Banking 43: 31–54. [Google Scholar] [CrossRef] [Green Version]
- Iskrev, Nikolay. 2010. Local identification in DSGE models. Journal of Monetary Economics 57: 189–202. [Google Scholar] [CrossRef] [Green Version]
- Kim, Kiwhan, and Adrian Rodney Pagan. 1994. The Econometric Analysis of Calibrated Macroeconomic Models. In Handbook of Applied Econometrics. Edited by Hashem Mohammad Pesaran and Michael R. Wickens. vol. I: Macroeconomics. Oxford: Blackwell. [Google Scholar]
- Klein, Paul. 2000. Using the generalized Schur form to solve a multivariate linear rational expectations model. Journal of Economic Dynamics and Control 24: 1405–23. [Google Scholar] [CrossRef]
- Kydland, Finn Erling, and Edward Christian Prescott. 1982. Time to built and aggregate fluctuations. Econometrica 50: 1345–70. [Google Scholar] [CrossRef]
- Kydland, Finn Erling, and Edward Christian Prescott. 1991. The Econometrics of the General Equilibrium Approach to the Business Cycles. The Scandinavian Journal of Economics 93: 161–78. [Google Scholar] [CrossRef]
- Lucas, Robert Emerson. 1976. Econometric Policy Evaluation: A Critique. In The Phillips Curve and Labour Markets. Edited by Karl Brunner and Allan M. Metzer. Carnegie-Rochester Conference on Public Policy I. Amsterdam: North-Holland, pp. 19–46. [Google Scholar]
- Lucas, Robert Emerson. 1980. Methods and Problems in Business Cycle Theory. Journal of Money, Credit and Banking 12: 696–715. [Google Scholar] [CrossRef]
- Lucas, Robert Emerson. 1987. Models of Business Cycles. Oxford: Blackwell. [Google Scholar]
- Lutkepohl, Helmut. 2005. New Introduction to Multiple Time Series Analysis. New York: Springer. [Google Scholar]
- Mandelbrot, Benoit. 1963. The variation of certain speculative prices. Journal of Business 36: 394–419. [Google Scholar] [CrossRef]
- Mayo, Deborah G. 1996. Error and the Growth of Experimental Knowledge. Chicago: The University of Chicago Press. [Google Scholar]
- Mayo, Deborah G., and Aris Spanos. 2004. Methodology in Practice: Statistical Misspecification Testing. Philosophy of Science 71: 1007–25. [Google Scholar] [CrossRef]
- McCarthy, Michael D. 1972. The Wharton Quarterly Econometric Forecasting Model Mark III. Philadelphia: University of Pennsylvania. [Google Scholar]
- Nelson, Charles R. 1972. The Prediction Performance of the F.R.B. -M.I.T.-PENN model of the U.S. Economy. American Economic Review 62: 902–17. [Google Scholar]
- Prescott, Edward Christian. 1986. Theory Ahead of Business Cycle Measurement. Federal Reserve Bank of Minneapolis, Quarterly Review 10: 9–22. [Google Scholar]
- Primiceri, Alejandro, and Giorgio E. Justiniano. 2008. The Time Varying Volatility of Macroeconomic Fluctuations. The American Economic Review 98: 604–41. [Google Scholar]
- Rao, Calyampudi Radhakrishna (C.R.), and Sujit Kumar Mitra. 1972. Generalized Inverse of Matrices and Its Applications. New York: Wiley. [Google Scholar]
- Saijo, Hikaru. 2013. Estimating DSGE models using seasonally adjusted and unadjusted data. Journal of Econometrics 173: 22–35. [Google Scholar] [CrossRef]
- Smets, Frank, and Rafael Wouters. 2003. An estimated Dynamic Stochastic General Equilibrium Model of the Euro Area. Journal of the European Economic Association 1: 1123–75. [Google Scholar] [CrossRef] [Green Version]
- Smets, Frank, and Rafael Wouters. 2005. Comparing Shocks and Frictions in US and Euro Area Business Cycles: A Bayesian DSGE Approach. Journal of Applied Econometrics 20: 161–83. [Google Scholar] [CrossRef] [Green Version]
- Smets, Frank, and Rafael Wouters. 2007. Shocks and Frictions in US Business Cycles: A Bayesian DSGE Approach. The American Economic Review 97: 586–606. [Google Scholar] [CrossRef] [Green Version]
- Spanos, Aris. 1986. Statistical Foundations of Econometric Modelling. Cambridge: Cambridge University Press. [Google Scholar]
- Spanos, Aris. 1990. The Simultaneous Equations Model revisited: Statistical adequacy and identification. Journal of Econometrics 44: 87–108. [Google Scholar] [CrossRef]
- Spanos, Aris. 1994. On Modeling Heteroskedasticity: The Student’s t and Elliptical Linear Regression Models. Econometric Theory 10: 286–315. [Google Scholar] [CrossRef]
- Spanos, Aris. 2006a. Revisiting the omitted variables argument: Substantive vs. statistical adequacy. Journal of Economic Methodology 13: 179–218. [Google Scholar] [CrossRef]
- Spanos, Aris. 2006b. Where Do Statistical Models Come From? Revisiting the Problem of Specification. In Optimality: The Second Erich L. Lehmann Symposium. Edited by Javier Rojo. Lecture Notes-Monograph Series; Beachwood: Institute of Mathematical Statistics, vol. 49, pp. 98–119. [Google Scholar]
- Spanos, Aris. 2009a. Statistical Misspecification and the Reliability of Inference: The simple t-test in the presence of Markov dependence. The Korean Economic Review 25: 165–213. [Google Scholar]
- Spanos, Aris. 2009b. The Pre-Eminence of Theory Versus the European CVAR Perspective in Macroeconometric Modeling. Economics: The Open-Access, Open-Assessment E-Journal 3: 2009–10. Available online: http://www.economics-ejournal.org/economics/journalarticles/2009-10 (accessed on 23 March 2022).
- Spanos, Aris. 2010a. Akaike-type Criteria and the Reliability of Inference: Model Selection vs. Statistical Model Specification. Journal of Econometrics 158: 204–20. [Google Scholar] [CrossRef]
- Spanos, Aris. 2010b. Theory Testing in Economics and the Error Statistical Perspective. In Error and Inference. Edited by Deborah G. Mayo and Aris Spanos. Cambridge: Cambridge University Press, pp. 202–46. [Google Scholar]
- Spanos, Aris. 2012. Philosophy of Econometrics. In Philosophy of Economics. Edited by Uskali Maki, Dov Gabbay, Paul Thagard and Jack Woods. Series of Handbook of Philosophy of Science; Amsterdam: Elsevier, pp. 329–93. [Google Scholar]
- Spanos, Aris. 2014. Recurring Controversies about P values and Confidence Intervals Revisited. Ecology 95: 645–51. [Google Scholar] [CrossRef] [Green Version]
- Spanos, Aris. 2018. Mis-Specification Testing in Retrospect. Journal of Economic Surveys 32: 541–77. [Google Scholar] [CrossRef]
- Spanos, Aris. 2019. Probability Theory and Statistical Inference: Empirical Modeling with Observational Data. Cambridge: Cambridge University Press. [Google Scholar]
- Spanos, Aris. 2021. Methodology of Macroeconometrics. In Oxford Research Encyclopedia of Economics and Finance. Edited by Avinash Dixit, Sebastian Edwards and Kenneth Judd. Oxford: Oxford University Press. [Google Scholar]
- Spanos, Aris, and Anya McGuirk. 2001. The Model Specification Problem from a Probabilistic Reduction Perspective. Journal of the American Agricultural Association 83: 1168–76. [Google Scholar] [CrossRef]
- Stock, James Harold, and Mark W. Watson. 2002. Has the Business Cycle Changed and Why? NBER Macroeconomics Annual 17: 159–230. [Google Scholar] [CrossRef]
- Wickens, Michael. 1995. Real Business Cycle Analysis: A Needed Revolution in Macroeconometrics. The Economic Journal 105: 1637–48. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [1] Normality: | , |
| [2] Linearity: | linear in |
| [3] Homosk/city: | free of |
| [4] Independence: | independent process, |
| [5] t-invariance: | do not change with |
| Resource constraint: | |
| Consumption: | |
| Investment: | |
| Arbitrage: | |
| Production: | |
| Capital services: | |
| Capital utilization: | |
| Installed capital: | |
| Price mark-up: | |
| Phillips curve: | |
| Rental rate of capital: | |
| Wage mark-up: | |
| Real wage: | |
| Taylor rule: |
| Exogeneous spending: | |
| Risk premium: | |
| Investment-specific technology: | |
| Total factor productivity: | |
| Price mark-up: | |
| Wage mark-up: | |
| Monetary policy: |
| [1] | Normality: | is Normal, |
| [2] | Linearity: | |
| [3] | Homosked.: | = V is free of |
| [4] | Markov: | is a Markov(p) process, |
| [5] | t-invariance: | are t-invariant for all . |
| Null Hypotheses | |
|---|---|
| [1] Normality (Anderson-Darling) | N |
| [2] Linearity: F(228,1) | : |
| [3] (i) Homoskedasticity: F(228,2) | : |
| [3] (ii) Dynamic Heterosk/sticity: F(228,2) | : |
| [4] Markov (2): F(228,2) | : |
| [5] (i) 1st moment t-invariance: F(228,2) | : |
| [5] (ii) 2nd moment t-invariance: F(228,2) | : |
| Linearity | 0.116[0.734] | 2.963[0.087] | 0.082[0.774] | 3.597[0.059] | 1.653[0.2] | 2.112[0.148] | 0.406[0.525] |
| 1st-depend | 0.045[0.956] | 0.096[0.909] | 0.303[0.739] | 1.404[0.248] | 0.328[0.721] | 0.032[0.968] | 5.520[] |
| 1st-invar | 0.177[0.838] | 0.601[0.549] | 0.067[0.935] | 1.638[0.197] | 0.887[0.413] | 0.150[0.861] | 0.623[0.537] |
| Homosk/city | 5.947[] | 8.005[] | 1.397[0.249] | 2.694[0.070] | 0.265[0.767] | 1.593[0.206] | 0.021[0.979] |
| 2nd-depen | 0.591[0.555] | 0.080[0.923] | 0.068[0.934] | 1.012[0.365] | 0.697[0.499] | 0.696[0.500] | 11.115[] |
| 2nd t-invar | 3.643[0.028] | 3.434[0.034] | 11.428[] | 2.272[0.106] | 8.652[] | 0.218[0.804] | 0.927[0.397] |
| A-D test | 0.960[0.015] | 1.355[] | 0.610[0.111] | 0.435[0.298] | 3.315[] | 1.155[] | 8.053[] |
| Linearity | 0.251[0.617] | 1.994[0.159] | 0.107[0.744] | 1.905[0.169] | 0.699[0.404] | 3.293[0.071] | 0.067[0.796] |
| 1st-dependence | 0.043[0.958] | 0.065[0.937] | 0.522[0.594] | 0.191[0.826] | 0.828[0.439] | 0.057[0.945] | 0.290[0.749] |
| 1st-t-invar | 0.512[0.600] | 0.569[0.567] | 0.437[0.647] | 0.609[0.545] | 0.763[0.467] | 0.074[0.929] | 1.187[0.307] |
| Homosk/city | 8.245[] | 9.869[] | 0.976[0.378] | 2.315[0.101] | 1.757[0.175] | 0.317[0.728] | 0.035[0.966] |
| 2nd-dependence | 1.090[0.338] | 0.242[0.785] | 0.054[0.948] | 0.960[0.384] | 3.080[0.048] | 0.637[0.530] | 5.940[] |
| 2nd-t-invar | 3.595[0.029] | 2.102[0.125] | 1.547[] | 1.856[0.159] | 8.613[] | 0.477[0.621] | 0.842[0.432] |
| A-Darling test | 0.780[0.042] | 1.113[] | 0.631[0.099] | 0.142[0.972] | 2.423[] | 1.222[] | 7.316[] |
| [1] | Student’s t: | is Student’s t with d.f. |
| [2] | Linearity: | |
| [3] | Heterosk/city.: | = depends on |
| [4] | Markov (p): | is a Markov(p) process |
| [5] | t-invariance: | are constant for . |
| const | 0.832[0.000] | 1.017[0.001] | 0.587[0.000] | 0.004[0.954] | −0.001[0.979] | 0.356[0.000] | −0.043[0.015] |
| t | −0.343[0.397] | −2.006[0.051] | −1.583[0.001] | −0.192[0.326] | 0.098[0.449] | −1.201[0.001] | −0.291[0.000] |
| −0.227[0.000] | −0.022[0.905] | 0.147[0.064] | 0.135[0.014] | 0.104[0.001] | 0.018[0.754] | 0.008[0.468] | |
| 0.025[0.222] | 0.382[0.000] | 0.111[0.000] | 0.040[0.550] | −0.009[0.359] | −0.004[0.837] | 0.016[0.000] | |
| 0.179[0.005] | 0.215[0.239] | −0.056[0.457] | 0.094[0.072] | −0.042[0.179] | 0.044[0.453] | 0.012[0.262] | |
| −0.041[0.669] | −0.319[0.259] | −0.074[0.533] | 1.046[0.000] | 0.008[0.867] | 0.037[0.672] | 0.015[0.386] | |
| −0.369[0.001] | 0.377[0.188] | 0.101[0.451] | 0.167[0.096] | 0.571[0.000] | 0.126[0.246] | 0.043[0.036] | |
| −0.053[0.415] | 0.240[0.214] | −0.067[0.412] | −0.001[0.992] | 0.070[0.039] | 0.013[0.829] | 0.004[0.755] | |
| −0.389[0.219] | 0.036[0.970] | 0.000[0.999] | 0.585[0.035] | 0.330[0.044] | −0.855[0.003] | 0.303[0.000] | |
| 0.010[0.898] | −0.141[0.553] | 0.043[0.667] | −0.052[0.483] | 0.037[0.387] | 0.041[0.602] | −0.020[0.163] | |
| −0.024[0.324] | 0.050[0.488] | −0.021[0.456] | −0.010[0.646] | 0.026[0.050] | −0.007[0.749] | −0.005[0.235] | |
| 0.059[0.411] | −0.331[0.074] | 0.014[0.861] | −0.039[0.516] | −0.057[0.129] | 0.006[0.922] | 0.013[0.288] | |
| 0.007[0.943] | 0.210[0.466] | 0.065[0.588] | −0.080[0.299] | −0.024[0.621] | −0.003[0.970] | −0.007[0.692] | |
| 0.030[0.819] | −0.996[0.003] | −0.262[0.092] | −0.248[0.025] | 0.308[0.000] | −0.129[0.308] | 0.004[0.755] | |
| 0.040[0.550] | −0.210[0.284] | −0.096[0.240] | −0.062[0.275] | 0.054[0.163] | 0.120[0.071] | −0.006[0.657] | |
| −0.441[0.251] | −1.002[0.375] | −1.532[0.001] | −0.540[0.116] | 0.050[0.800] | 0.291[0.393] | −0.206[0.003] |
| const. | 1.101[0.000] | 1.891[0.000] | 0.952[0.000] | 0.161[0.191] | −0.130[0.146] | 0.534[0.000] | −0.003[0.947] |
| −0.398[0.000] | −0.287[0.265] | 0.145[0.179] | 0.072[0.294] | 0.03[0.544] | 0.030[0.685] | 0.029[0.247] | |
| 0.025[0.386] | 0.327[0.000] | 0.053[0.135] | 0.027[0.231] | 0.018[0.262] | −0.010[0.671] | 0.022[0.008] | |
| 0.182[0.024] | 0.245[0.297] | 0.001[0.992] | 0.167[0.008] | 0.003[0.944] | 0.004[0.954] | −0.018[0.429] | |
| 0.196[0.091] | 0.492[0.145] | 0.218[0.124] | 1.083[0.000] | −0.084[0.197] | 0.050[0.606] | 0.050[0.130] | |
| −0.463[0.000] | 0.436[0.227] | 0.192[0.204] | 0.155[0.109] | 0.539[0.000] | 0.060[0.563] | 0.034[0.339] | |
| 0.018[0.849] | 0.360[0.197] | −0.081[0.488] | 0.017[0.817] | 0.084[0.121] | −0.082[0.303] | 0.006[0.837] | |
| −0.585[0.018] | −1.047[0.145] | −0.376[0.212] | 0.090[0.639] | 0.195[0.161] | −0.324[0.115] | 1.093[0.000] | |
| 0.031[0.717] | 0.161[0.519] | 0.117[0.264] | 0.018[0.783] | 0.085[0.079] | 0.095[0.182] | −0.013[0.581] | |
| −0.012[0.650] | 0.004[0.958] | −0.030[0.372] | 0.004[0.832] | 0.026[0.088] | −0.023[0.314] | −0.012[0.121] | |
| 0.068[0.343] | −0.313[0.137] | 0.047[0.591] | 0.026[0.641] | −0.047[0.247] | −0.036[0.546] | 0.017[0.418] | |
| −0.271[0.020] | −0.750[0.027] | −0.281[0.048] | −0.156[0.085] | 0.070[0.282] | −0.007[0.940] | −0.047[0.157] | |
| −0.078[0.555] | −0.944[0.015] | −0.122[0.450] | −0.233[0.025] | 0.243[0.001] | 0.008[0.945] | 0.044[0.242] | |
| 0.001[0.986] | −0.337[0.177] | −0.178[0.090] | −0.169[0.012] | 0.111[0.022] | 0.115[0.108] | −0.008[0.730] | |
| 0.542[0.031] | 0.301[0.681] | −0.043[0.888] | −0.242[0.217] | −0.080[0.572] | 0.207[0.323] | −0.149[0.039] |
| [2] Linearity | 1.598[0.208] | 2.312[0.130] | 0.844[0.359] | 0.003[0.957] | 1.244[0.266] | 0.000[0.986] | 6.337[0.013] |
| [4] 1st depend | 0.316[0.575] | 0.249[0.619] | 0.610[0.436] | 1.888[0.171] | 0.627[0.429] | 0.146[0.703] | 0.905[0.342] |
| [5] 1st-invar | 0.697[0.499] | 1.157[0.316] | 1.398[0.249] | 0.972[0.380] | 1.548[0.215] | 1.268[0.284] | 0.206[0.814] |
| [3] Heterosked | 0.009[0.925] | 0.250[0.617] | 1.320[0.252] | 0.009[0.926] | 3.085[0.080] | 0.009[0.924] | 0.075[0.785] |
| [4] 2nd depend | 0.199[0.820] | 0.748[0.475] | 0.666[0.515] | 0.384[0.682] | 1.308[0.273] | 0.447[0.640] | 0.303[0.739] |
| [5] 2nd t-invar | 0.388[0.679] | 0.153[0.858] | 0.537[0.585] | 0.010[0.990] | 1.706[0.184] | 3.339[0.037] | 5.142[0.010] |
| [1] A-D test | 0.763[0.508] | 0.961[0.378] | 0.823[0.465] | 0.841[0.452] | 1.666[0.141] | 1.130[0.296] | 1.790[0.120] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poudyal, N.; Spanos, A. Model Validation and DSGE Modeling. Econometrics 2022, 10, 17. https://doi.org/10.3390/econometrics10020017
Poudyal N, Spanos A. Model Validation and DSGE Modeling. Econometrics. 2022; 10(2):17. https://doi.org/10.3390/econometrics10020017
Chicago/Turabian StylePoudyal, Niraj, and Aris Spanos. 2022. "Model Validation and DSGE Modeling" Econometrics 10, no. 2: 17. https://doi.org/10.3390/econometrics10020017
APA StylePoudyal, N., & Spanos, A. (2022). Model Validation and DSGE Modeling. Econometrics, 10(2), 17. https://doi.org/10.3390/econometrics10020017