
An Alternative Estimation Method for Time-Varying Parameter Models


Abstract
:1. Introduction
2. Model
2.1. Basic State-Space Model of the Class of TV-AR Models
2.2. Model Matrix Formulation of the State-Space Model
2.3. Likelihood Function
3. Estimation of the TV-AR Models
3.1. Regression Lemma and Kalman Smoothing
3.2. Equivalence of the GLS-Based Estimator and Kalman Smoother
3.3. GLS in Practice
- Step 1. We estimate model (10) by OLS and obtain the estimate of by OLS, . From the OLS residuals, and , we construct the first-step estimates of and :Then, to construct the estimates of H and Q, denoted as and , respectively, we set and to assume that the variances of and are time-invariant. This assumption is undesirable because a number of studies of TV-VAR models have focused on stochastic volatility models, which require , for example. However, thanks to this assumption, H and Q are always invertible, and those inverses are readily computed. The simulations in the next section will reveal how severely this assumption affects our estimation when stochastic volatility is present. With and , the log-likelihood is computed by (A6) or (5).
- Step 2 (1FGLS). Given and , we apply FGLS to obtain , which is the FGLS or 1FGLS estimate of . We also compute the estimates of H and Q, denoted as and , respectively, in the same way as we computed and in the first step. Then, the value of the log-likelihood function is computed.
- Step 3 (2FGLS). We repeat Step 2, computing , which is the (second-time) FGLS or 2FGLS of . More precisely, we use the FGLS residuals in Step 2 to construct and to obtain . Then, the value of the log-likelihood function is computed. If the likelihood ratio (from OLS to 1FGLS or from 1FGLS to 2FGLS) cannot be computed or is extraordinarily large, such as greater than 1e+10, we disregard the 1FGLS and 2FGLS estimators because both indicate that the variance–covariance matrix is not precisely estimated (degenerated). In such a case, we only record OLS. In addition, we define 2FGLS’ as GLS using and in place of and , respectively, to compute and , where and are the corresponding elements of 1FGLS, . The reason why we use , which denotes 2FGLS’, is that it is expected to ameliorate the effects arising from poorly estimated . That is perhaps due to misspecified H and Q. When those matrices are not correctly estimated, may be far from its true value; hence, the residuals computed from should not be used for further FGLS because the repeated use of the wrong variance–covariance matrices may make the estimator worse. In such a case, it may make sense to obtain as it does not repeat the same type of misspecification.
4. Simulations
4.1. Data-Generating Process
4.1.1. Non-Gaussian Errors
4.1.2. Stochastic Volatility and Autoregressive Stochastic Volatility
4.1.3. Eliminating Outliers
4.2. Mean and Variance of the Estimated and Likelihood
4.3. Simulation Results 1: The SNR, Sample Size and Estimation Precision
4.4. Simulation Results 2: The Effects of Non-i.i.d. and Non-Gaussian Errors
4.5. Discussion: The Pile-Up Problem
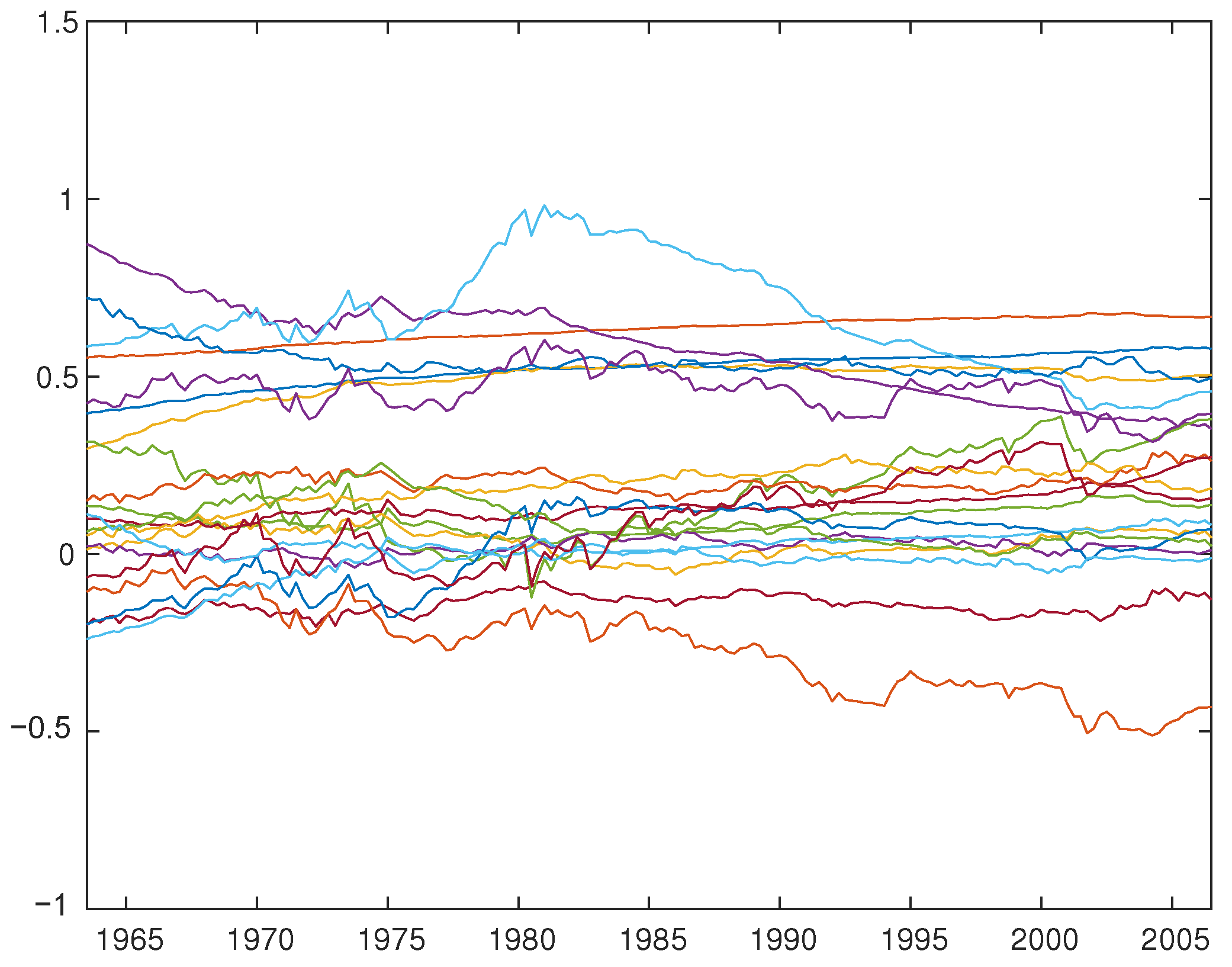
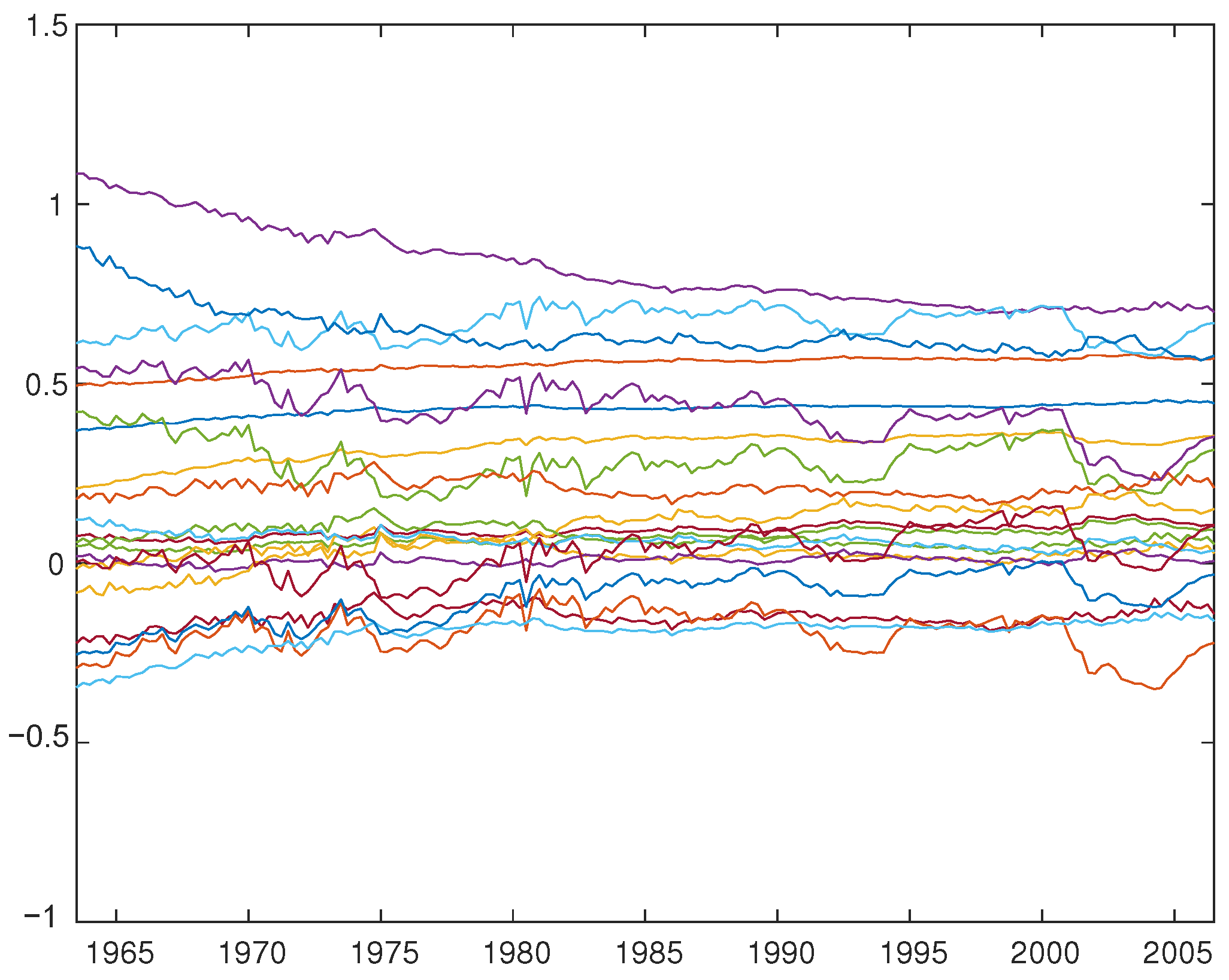
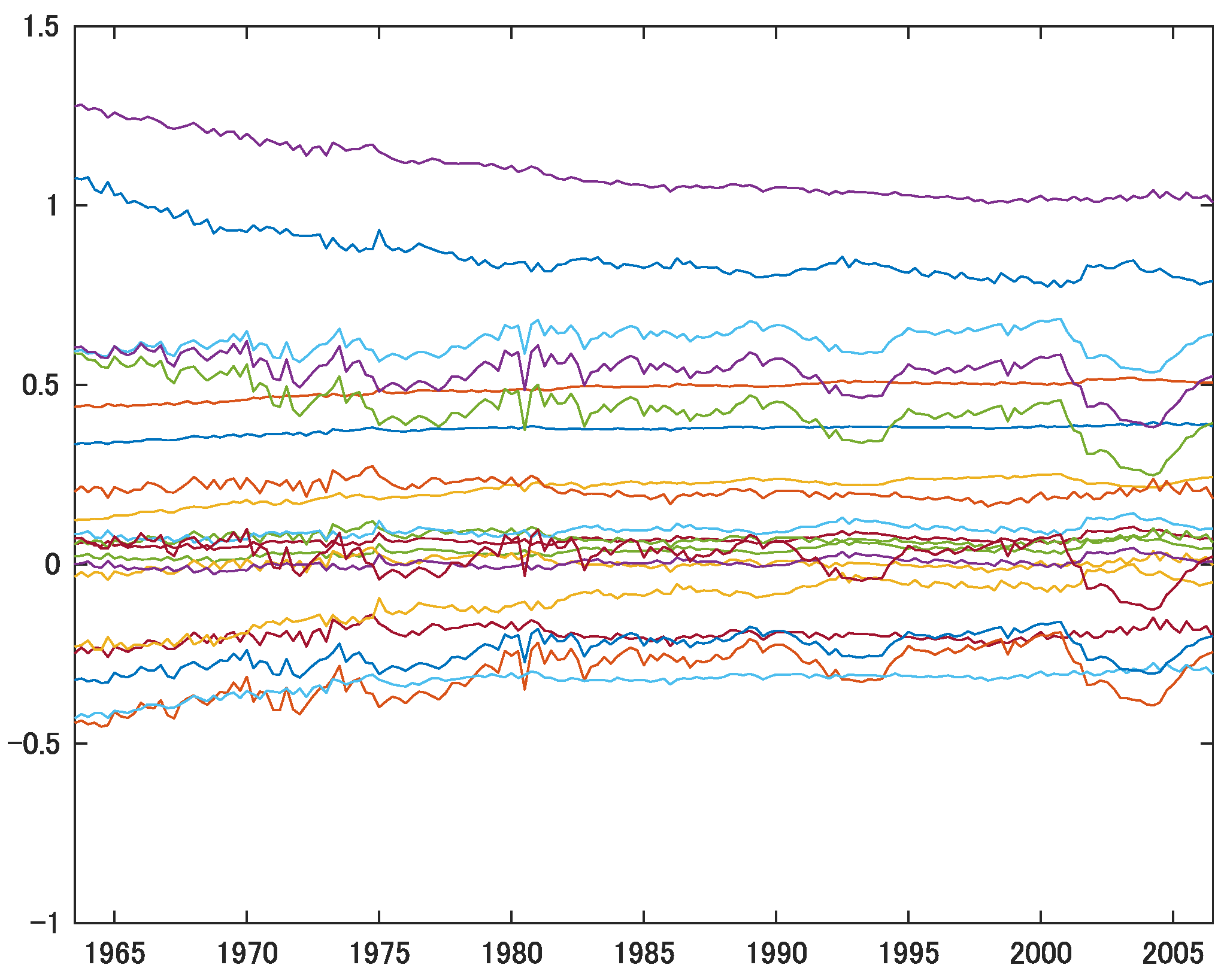
5. Application to the TV-VAR(2) Model with Interest Rates, Inflation, and Unemployment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FGLS | Feasible generalized least squares |
| GLS | Generalized least squares |
| MCMC | Markov Chain Monte Carlo |
| ML | Maximum likelihood |
| MSE | Mean squared error |
| OLS | Ordinary least squares |
| SNR | Signal-to-noise ratio |
| TV-AR | time-varying autoregressive |
| TV-VAR | time-varying vector autoregressive |
| TV-VEC | time-varying vector error correction |
| VAR | Vector autoregressive |
Appendix A. The Summary of GLS-Kalman Smoother Equivalence
Appendix B. Model with Time-Invariant Intercepts
Appendix B.1. The GLS Estimator under the Presence of Time-Invariant Intercepts
Appendix B.2. Detailed Proof of Propositions A2
- (i)
- (ii)
- Therefore,
- (iii)
- (iv)
Appendix C. TV-VAR(2) with Time-Varying Intercepts
VAR(2) Case: p = 2 (i.e., 2 Lags) and k = 3 (i.e., 3 Variables)
| 1 | An alternative to those two methods is the approach presented by Cooley and Prescott (1976), who use the likelihood method to estimate the unknown parameters rather than Kalman filtering. |
| 2 | Related to our approach of not using Kalman filtering, McCausland et al. (2011) develop and propose a new simulation smoothing approach which is more computationally efficient than the approach based on Kalman filtering. While we pay little attention to computational efficiency in this paper, evaluating computation costs along with estimation accuracy should be further investigated in later studies. |
| 3 | Ito et al. (2014, 2016) do not formally prove that their regression-based approach generates estimates that are equivalent to Kalman-smoothed estimates. |
| 4 | As our model include unknown parameters such as the variances of the error terms, we must rely on feasible GLS (FGLS), which may not be equivalent to GLS. |
| 5 | In this paper, we focus on the case where and are mutually uncorrelated. Relaxing this assumption poses a great challenge. |
| 6 | This assumption does not change our conclusions below. The main difference is that and . An exception is when the diffuse prior is used and the likelihood function is computed excluding the first few observations. In such a case, the estimates of the unknown intercept parameters under the two approaches would differ. |
| 7 | By contrast, Duncan and Horn (1972) assume that matrix F is known, which renders their estimation impractical. The original form of Maddala and Kim (1998, pp. 469–70) is similar to ours, but it is a general form for a scalar . Hence, it does not aim to deal with the autoregressive part of time-varying parameter models nor consider vector processes. |
| 8 | For the Bayesian approach, we focus on the posterior mean from MCMC. Since our simulations are based on Primiceri’s (2005) model, we use the same priors as his. The Matlab codes provided by D. Korobilis are used, which can be downloaded from: https://drive.google.com/file/d/1pYNP96FeGgBH1KpnDEEdXGqZ62ZPw_PQ/view, accessed on 14 March 2022. |
| 9 | In addition, we can compute the values of the log-likelihood function to evaluate whether the repeated use of FGLS improves estimation accuracy. Our simulation tends to show that 2FGLS has a higher likelihood value than 1FGLS. |
| 10 | |
| 11 | Throughout this simulation study, we use bold numbers to highlight the best (the smallest median and the median closest to one) estimation method of the four approaches (OLS, 1FGLS, 2FGLS, 2FGLS’ and Primiceri). |
| 12 | We use the data and MATLAB codes provided by Koop and Korobilis (2010). |
| 13 | Note that the impulse responses of Primiceri’s (2005) VAR vary largely over time. This is not because the time-varying parameters () are very volatile over time, but mainly because the variance of the shocks are time-dependent and vary greatly, as shown in Figure 1 of Primiceri (2005, p. 832) and as discussed in the conclusion thereof. |
References
- Bernanke, Ben S., and Ilian Mihov. 1998. Measuring monetary policy. Quarterly Journal of Economics 113: 869–902. [Google Scholar] [CrossRef] [Green Version]
- Chan, Joshua C. C., and Ivan Jeliazkov. 2009. Efficient simulation and integrated likelihood estimationin state space models. International Journal of Mathematical Modelling and Numerical Optimisation 1: 101–20. [Google Scholar] [CrossRef]
- Cogley, Timothy F., and Thomas J. Sargent. 2001. Evolving post-world war II u.s. inflation dynamics. NBER Macroeconomics Annual 16: 331–73. [Google Scholar] [CrossRef]
- Cogley, Timothy F., and Thomas J. Sargent. 2005. Drifts and volatilities: Monetary policies and outcomes in the post WWII US. Review of Economic Dynamics 8: 262–302. [Google Scholar] [CrossRef] [Green Version]
- Cogley, Timothy F., and Edward C. Prescott. 1976. Estimation in the presence of stochastic parameter variation. Econometrica 44: 167–84. [Google Scholar]
- Duncan, David B., and Susan D. Horn. 1972. Linear dynamic recursive estimation from the viewpoint of regression analysis. Journal of the American Statistical Association 67: 815–21. [Google Scholar] [CrossRef]
- Durbin, James, and Siem J. Koopman. 2012. Time Series Analysis by State Space Methods, 2nd ed. Oxford: Oxford University Press. [Google Scholar]
- Hamilton, James D. 1989. A new approach to the economic analysis of nonstationary time series and the business cycle. Econometrica 57: 357–84. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 1992. Testing for parameter instability in linear models. Journal of Policy Modeling 14: 517–33. [Google Scholar] [CrossRef]
- Harvey, Andrew C. 1989. Forecasting, Structural Time Series Models and the Kalman Filter. Cambridge and New York: Cambridge University Press. [Google Scholar]
- Ito, Mikio, Akihiko Noda, and Tatsuma Wada. 2014. International stock market efficiency: A non-bayesian time-varying model approach. Applied Economics 46: 2744–754. [Google Scholar] [CrossRef] [Green Version]
- Ito, Mikio, Akihiko Noda, and Tatsuma Wada. 2016. The evolution of stock market efficiency in the us: A non-bayesian time-varying model approach. Applied Economics 48: 621–35. [Google Scholar] [CrossRef] [Green Version]
- Ito, Mikio, Akihiko Noda, and Tatsuma Wada. 2021. Time-varying comovement of foreign exchange markets: A GLS-based time-varying model approach. Mathematics 9: 849. [Google Scholar] [CrossRef]
- Koop, Gary, and Dimitris Korobilis. 2010. Bayesian multivariate time series methods for empirical macroeconomics. Foundations and Trends in Econometrics 3: 267–358. [Google Scholar] [CrossRef]
- Koopman, Siem J. 1997. Exact initial kalman filtering and smoothing for nonstationary time series models. Journal of the American Statistical Association 92: 1630–638. [Google Scholar] [CrossRef]
- Maddala, Gangadharrao S., and In-Moo Kim. 1998. Unit Roots, Cointegration, and Structural Change. Cambridge, New York: Cambridge University Press. [Google Scholar]
- McCausland, William J., Shirley Miller, and Denis Pelletier. 2011. Simulation smoothing for state-space models: A computational efficiency analysis. Computational Statistics & Data Analysis 55: 199–212. [Google Scholar]
- Perron, Pierre. 1989. The great crash, the oil price shock, and the unit root hypothesis. Econometrica 57: 1361–401. [Google Scholar] [CrossRef]
- Perron, Pierre, and Tatsuma Wada. 2009. Let’s take a break: Trends and cycles in us real gdp. Journal of Monetary Economics 56: 749–65. [Google Scholar] [CrossRef]
- Primiceri, Giorgio E. 2005. Time varying structural vector autoregressions and monetary policy. Review of Economic Studies 72: 821–52. [Google Scholar] [CrossRef]
- Sant, Donald T. 1977. Generalized least squares applied to time varying parameter models. Annals of Economic and Social Measurement 6: 301–14. [Google Scholar]
- Sargan, Dennis J., and Alok Bhargava. 1983. Maximum likelihood estimation of regression models with first order moving average errors when the root lies on the unit circle. Econometrica 51: 799–820. [Google Scholar] [CrossRef]
- Shephard, Neil G., and Andrew C. Harvey. 1990. On the probability of estimating a deterministic component in the local level model. Journal of Time Series Analysis 11: 339–347. [Google Scholar] [CrossRef]
- Tanaka, Katsuto. 2017. Time Series Analysis: Nonstationary and Noninvertible Distribution Theory, 2nd ed. Hoboken: John Wiley & Suns, Inc. [Google Scholar]
- Taylor, Stephen J. 2007. Modelling Financial Time Series, 2nd ed. Hackensack: World Scientific. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| H | Q | True | OLS | 1FGLS | 2FGLS | 2FGLS’ | Primiceri | |
|---|---|---|---|---|---|---|---|---|
| median m | −0.006 | −0.001 | 0.000 | 0.001 | 0.001 | 0.000 | ||
| median s | 0.086 | 0.033 | 0.016 | 0.019 | 0.010 | 0.000 | ||
| median | 0.129 | 0.141 | 0.164 | 0.193 | 0.273 | |||
| median | 0.416 | 0.206 | 0.252 | 0.124 | 0.006 | |||
| median m | −0.002 | −0.003 | −0.003 | −0.003 | 0.001 | 0.002 | ||
| median s | 0.087 | 0.135 | 0.084 | 0.048 | 0.031 | 0.000 | ||
| median | 0.164 | 0.131 | 0.120 | 0.122 | 0.273 | |||
| = | median | 1.759 | 1.078 | 0.609 | 0.397 | 0.006 | ||
| 1 | median m | −0.001 | −0.009 | −0.009 | −0.006 | −0.005 | −0.003 | |
| median s | 0.087 | 0.287 | 0.291 | 0.297 | 0.104 | 0.000 | ||
| median | 0.272 | 0.277 | 0.278 | 0.135 | 0.273 | |||
| = | median | 3.761 | 3.812 | 3.904 | 1.339 | 0.005 |
| H | Q | True | OLS | 1FGLS | 2FGLS | 2FGLS’ | Primiceri | |
|---|---|---|---|---|---|---|---|---|
| median m | −0.007 | −0.003 | −0.002 | −0.001 | 0.002 | 0.002 | ||
| median s | 0.156 | 0.110 | 0.076 | 0.059 | 0.022 | 0.024 | ||
| median | 0.103 | 0.126 | 0.150 | 0.263 | 0.348 | |||
| = | median | 0.718 | 0.494 | 0.392 | 0.159 | 0.173 | ||
| median m | −0.004 | −0.006 | −0.006 | −0.005 | 0.002 | 0.003 | ||
| median s | 0.156 | 0.201 | 0.150 | 0.105 | 0.061 | 0.048 | ||
| median | 0.153 | 0.128 | 0.120 | 0.144 | 0.341 | |||
| = | median | 1.379 | 1.013 | 0.692 | 0.408 | 0.337 | ||
| 1 | median m | −0.002 | −0.003 | −0.004 | −0.005 | −0.002 | 0.003 | |
| median s | 0.156 | 0.321 | 0.320 | 0.317 | 0.135 | 0.030 | ||
| median | 0.243 | 0.243 | 0.243 | 0.114 | 0.341 | |||
| = | median | 2.285 | 2.282 | 2.265 | 0.922 | 0.208 |
| T | Q | True | OLS | 1FGLS | 2FGLS | 2FGLS’ | Primiceri | |
|---|---|---|---|---|---|---|---|---|
| 100 | median m | −0.002 | −0.002 | −0.003 | −0.002 | −0.005 | −0.001 | |
| RW | median s | 0.086 | 0.289 | 0.295 | 0.298 | 0.103 | 0.000 | |
| median | 0.273 | 0.278 | 0.279 | 0.135 | 0.273 | |||
| median | 3.837 | 3.916 | 3.986 | 1.369 | 0.005 | |||
| 100 | median m | −0.002 | −0.002 | −0.003 | −0.002 | −0.005 | −0.002 | |
| AR | median s | 0.086 | 0.289 | 0.295 | 0.298 | 0.103 | 0.000 | |
| median | 0.273 | 0.278 | 0.279 | 0.135 | 0.273 | |||
| median | 3.837 | 3.916 | 3.986 | 1.369 | 0.005 | |||
| 250 | median m | −0.002 | −0.006 | −0.005 | −0.005 | −0.004 | 0.001 | |
| RW | median s | 0.154 | 0.321 | 0.320 | 0.318 | 0.136 | 0.030 | |
| median | 0.244 | 0.244 | 0.244 | 0.114 | 0.343 | |||
| median | 2.299 | 2.291 | 2.277 | 0.928 | 0.211 | |||
| 250 | median m | −0.002 | −0.008 | −0.008 | -0.009 | −0.005 | 0.002 | |
| AR | median s | 0.154 | 0.322 | 0.321 | 0.318 | 0.137 | 0.030 | |
| median | 0.243 | 0.244 | 0.244 | 0.114 | 0.338 | |||
| median | 2.310 | 2.303 | 2.292 | 0.937 | 0.213 |
| H | Q | True | OLS | 1FGLS | 2FGLS | 2FGLS’ | Primiceri | |
|---|---|---|---|---|---|---|---|---|
| median m | −0.002 | 0.002 | 0.004 | 0.004 | 0.004 | 0.003 | ||
| median s | 0.102 | 0.042 | 0.025 | 0.021 | 0.012 | 0.001 | ||
| median | 0.137 | 0.151 | 0.171 | 0.229 | 0.328 | |||
| median | 0.477 | 0.266 | 0.229 | 0.139 | 0.006 | |||
| median m | −0.001 | −0.004 | −0.003 | −0.003 | 0.006 | 0.007 | ||
| median s | 0.103 | 0.138 | 0.092 | 0.059 | 0.033 | 0.000 | ||
| median | 0.164 | 0.136 | 0.129 | 0.135 | 0.310 | |||
| median | 1.497 | 0.987 | 0.633 | 0.362 | 0.006 | |||
| 1 | median m | −0.002 | −0.007 | −0.007 | −0.007 | −0.007 | 0.000 | |
| median s | 0.105 | 0.277 | 0.281 | 0.284 | 0.099 | 0.000 | ||
| median | 0.259 | 0.264 | 0.265 | 0.135 | 0.319 | |||
| median | 3.068 | 3.112 | 3.139 | 1.066 | 0.005 |
| H | Q | True | OLS | 1FGLS | 2FGLS | 2FGLS’ | Primiceri | |
|---|---|---|---|---|---|---|---|---|
| median m | −0.006 | −0.001 | −0.002 | −0.003 | 0.004 | 0.002 | ||
| median s | 0.181 | 0.132 | 0.101 | 0.083 | 0.030 | 0.045 | ||
| median | 0.109 | 0.130 | 0.153 | 0.291 | 0.388 | |||
| median | 0.738 | 0.554 | 0.460 | 0.183 | 0.268 | |||
| median m | −0.004 | −0.005 | −0.004 | −0.003 | 0.003 | 0.002 | ||
| median s | 0.182 | 0.212 | 0.169 | 0.128 | 0.064 | 0.074 | ||
| median | 0.150 | 0.131 | 0.129 | 0.177 | 0.387 | |||
| median | 1.235 | 0.969 | 0.726 | 0.373 | 0.450 | |||
| 1 | median m | −0.002 | −0.006 | −0.006 | −0.006 | −0.007 | 0.000 | |
| median s | 0.181 | 0.318 | 0.317 | 0.329 | 0.138 | 0.063 | ||
| median | 0.228 | 0.229 | 0.239 | 0.127 | 0.385 | |||
| median | 1.918 | 1.906 | 1.961 | 0.795 | 0.373 |
| T | RW/AR | True | OLS | 1FGLS | 2FGLS | 2FGLS’ | Primiceri | |
|---|---|---|---|---|---|---|---|---|
| 100 | RW | median m | −0.002 | −0.010 | −0.010 | −0.008 | −0.008 | −0.004 |
| median s | 0.104 | 0.275 | 0.278 | 0.282 | 0.098 | 0.000 | ||
| median | 0.258 | 0.261 | 0.262 | 0.134 | 0.317 | |||
| median | 3.070 | 3.131 | 3.175 | 1.078 | 0.005 | |||
| AR | median m | −0.002 | −0.010 | −0.010 | −0.008 | −0.008 | −0.004 | |
| median s | 0.104 | 0.275 | 0.278 | 0.282 | 0.098 | 0.000 | ||
| median | 0.258 | 0.261 | 0.262 | 0.134 | 0.317 | |||
| median | 3.070 | 3.130 | 3.177 | 1.078 | 0.005 | |||
| 250 | RW | median m | −0.001 | −0.005 | −0.005 | −0.006 | −0.004 | −0.001 |
| median s | 0.180 | 0.317 | 0.315 | 0.314 | 0.135 | 0.060 | ||
| median | 0.228 | 0.228 | 0.229 | 0.127 | 0.381 | |||
| median | 1.924 | 1.913 | 1.905 | 0.785 | 0.361 | |||
| AR | median m | −0.001 | −0.005 | −0.006 | −0.007 | −0.004 | −0.001 | |
| median s | 0.180 | 0.317 | 0.315 | 0.314 | 0.135 | 0.060 | ||
| median | 0.228 | 0.228 | 0.229 | 0.127 | 0.382 | |||
| median | 1.923 | 1.916 | 1.911 | 0.785 | 0.362 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ito, M.; Noda, A.; Wada, T. An Alternative Estimation Method for Time-Varying Parameter Models. Econometrics 2022, 10, 23. https://doi.org/10.3390/econometrics10020023
Ito M, Noda A, Wada T. An Alternative Estimation Method for Time-Varying Parameter Models. Econometrics. 2022; 10(2):23. https://doi.org/10.3390/econometrics10020023
Chicago/Turabian StyleIto, Mikio, Akihiko Noda, and Tatsuma Wada. 2022. "An Alternative Estimation Method for Time-Varying Parameter Models" Econometrics 10, no. 2: 23. https://doi.org/10.3390/econometrics10020023
APA StyleIto, M., Noda, A., & Wada, T. (2022). An Alternative Estimation Method for Time-Varying Parameter Models. Econometrics, 10(2), 23. https://doi.org/10.3390/econometrics10020023