
Building Multivariate Time-Varying Smooth Transition Correlation GARCH Models, with an Application to the Four Largest Australian Banks


Abstract
:1. Introduction
2. The MTV Model
3. The Three Stages of Model Building
4. Specification of the MTV Model
4.1. Specification of the Univariate Variance Equations
4.2. Specification of Time-Varying Correlations
5. Estimation of the MTV Model
- AN1.
- In (4), , either and or and , , and for .
- AN2.
- The parameter subspaces , , are compact, the whole space is compact, and the true parameter value is an interior point of .
- AN3.
- iid.
6. Evaluation of the MTV Model
7. Big Four Results
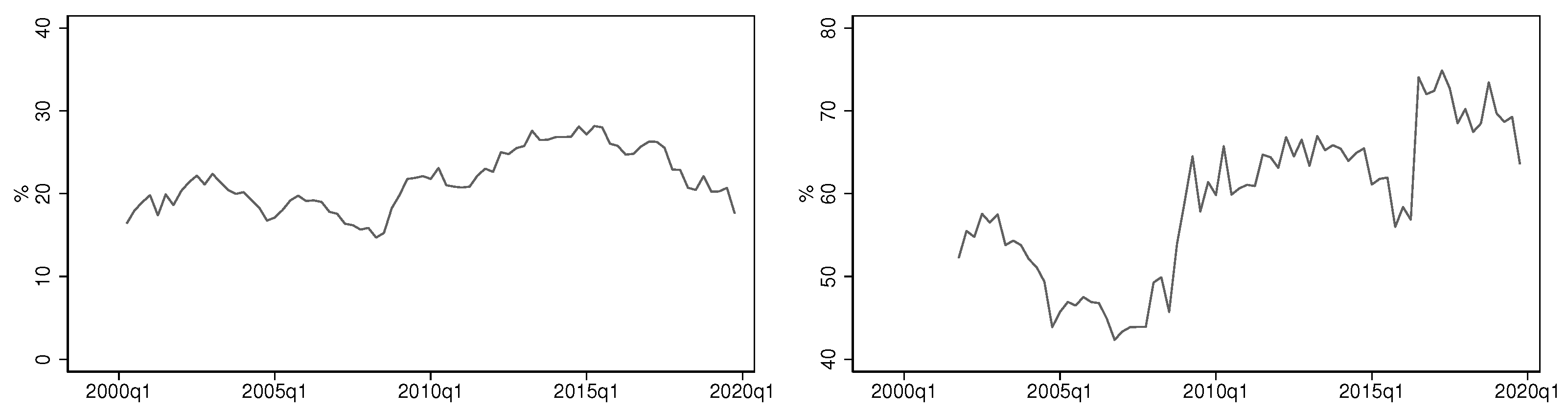
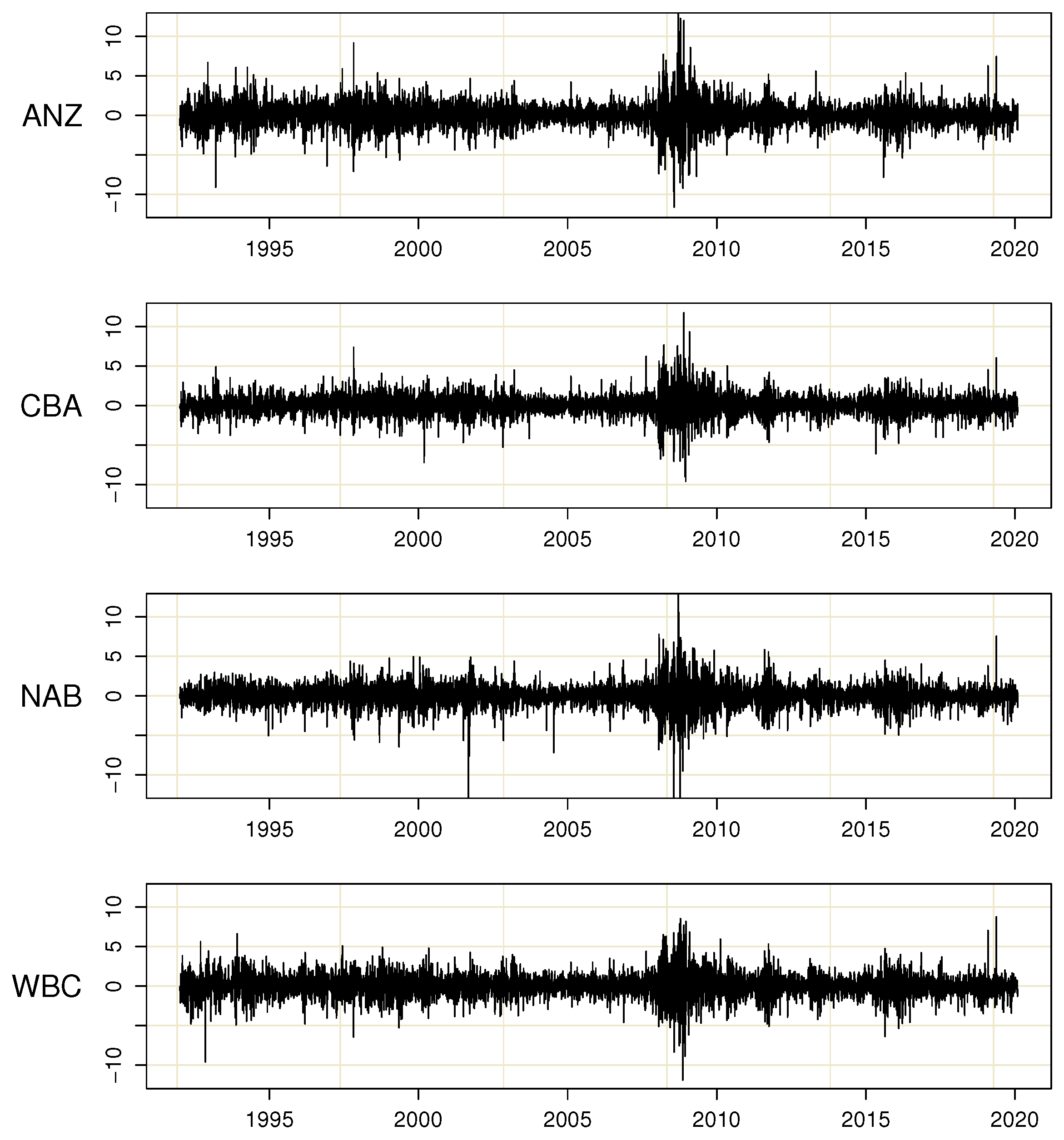
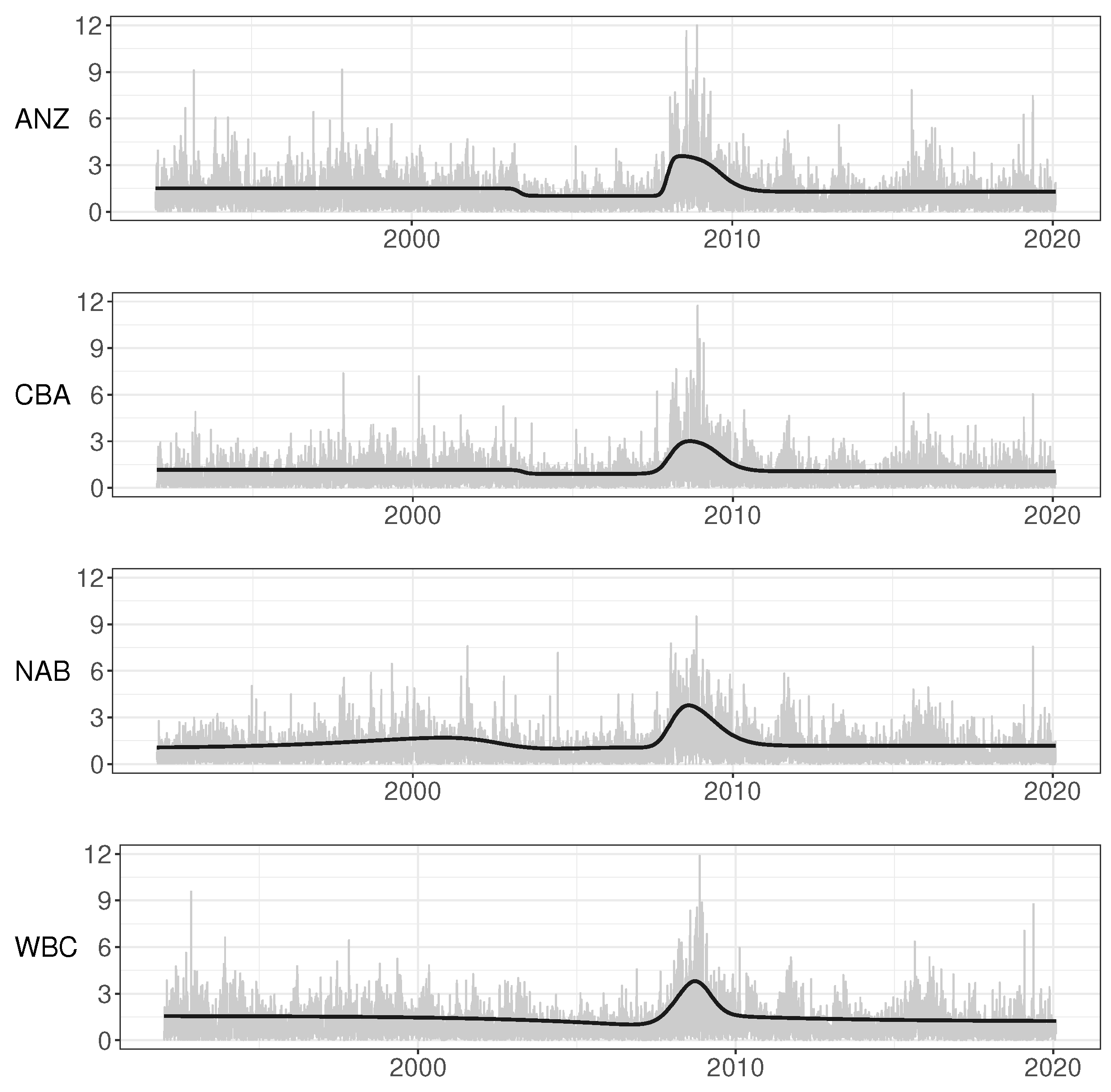
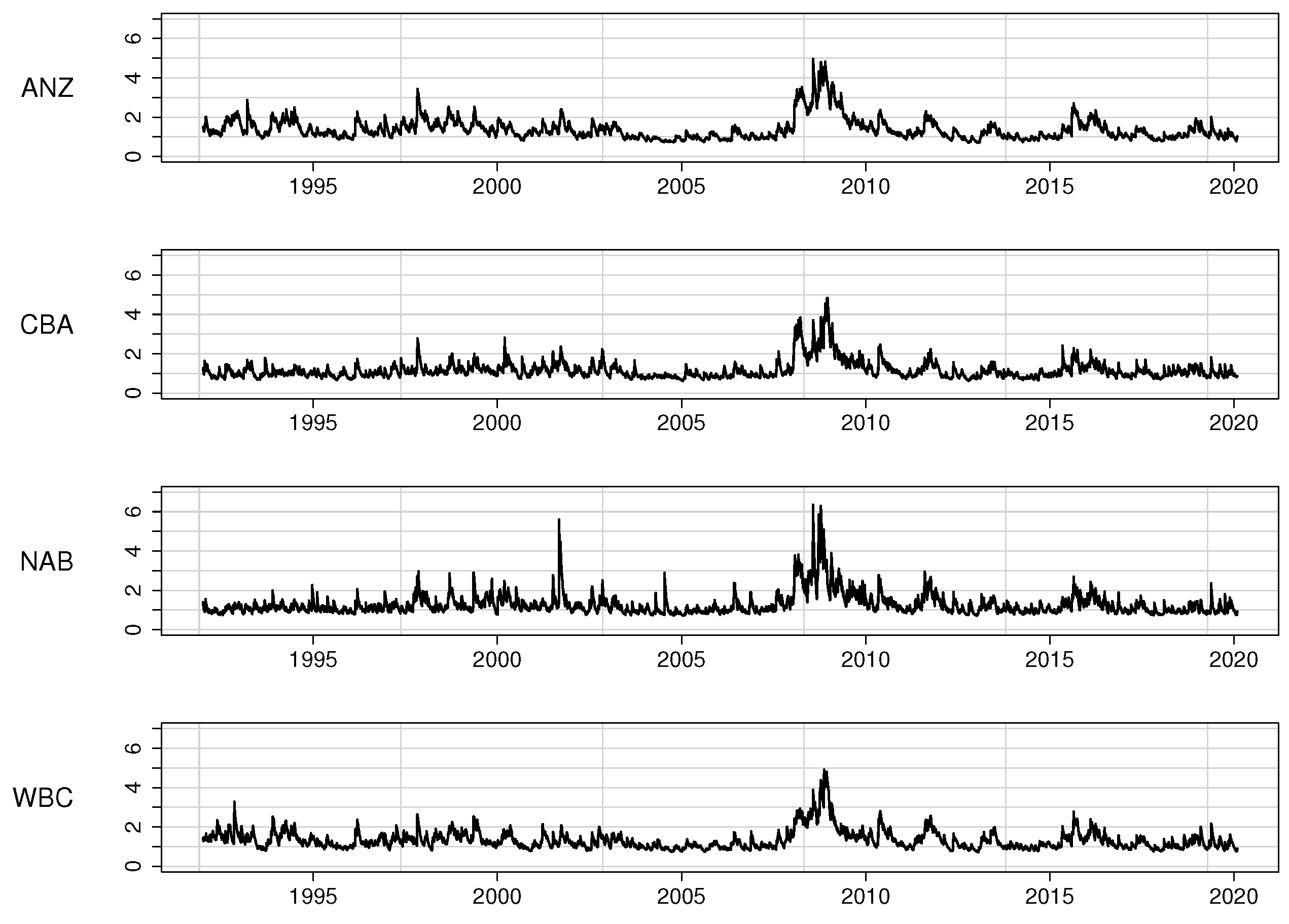
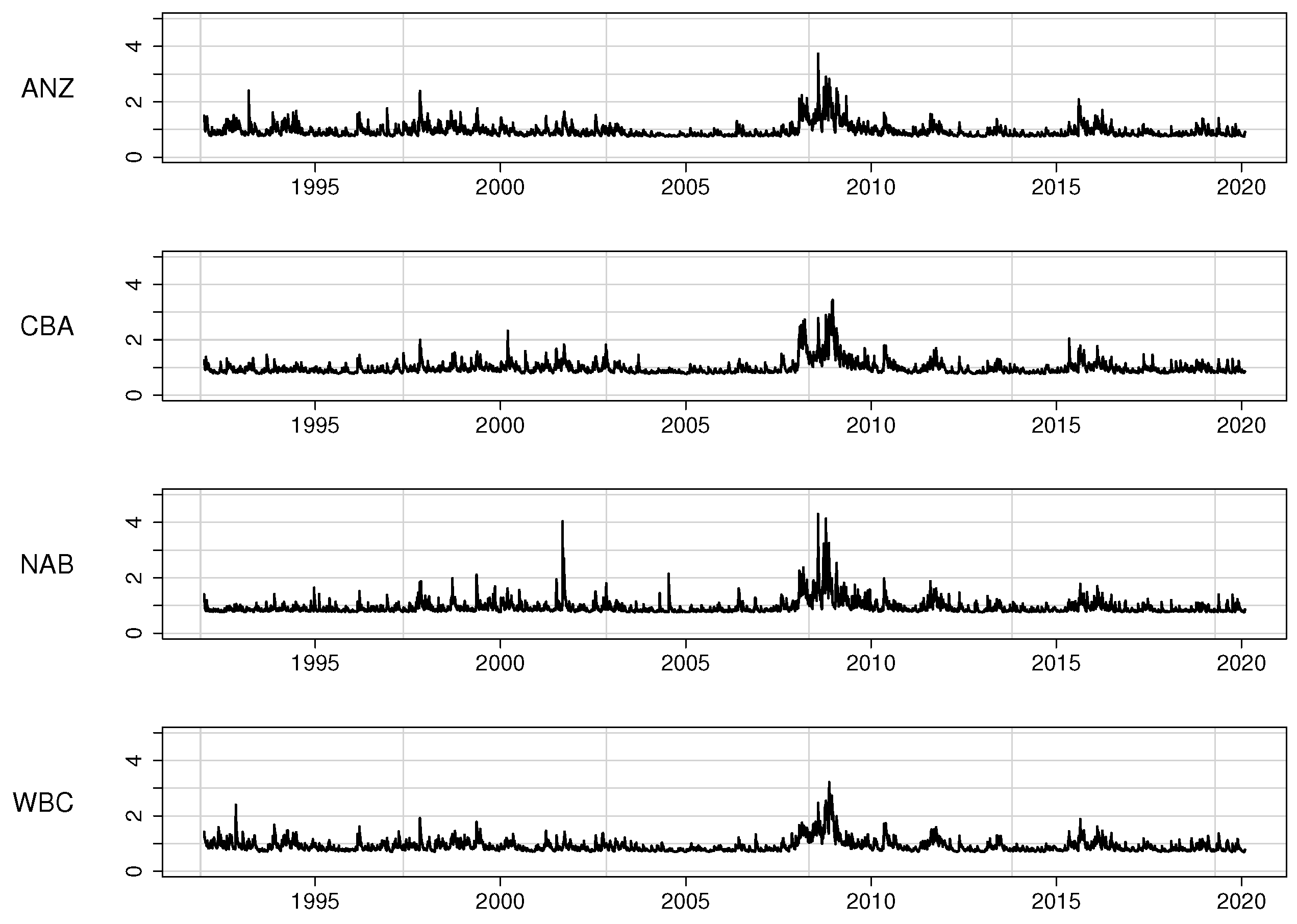
7.1. Main Features of the Australian Banking Sector 1990–2020
7.2. Modelling the Error Variances
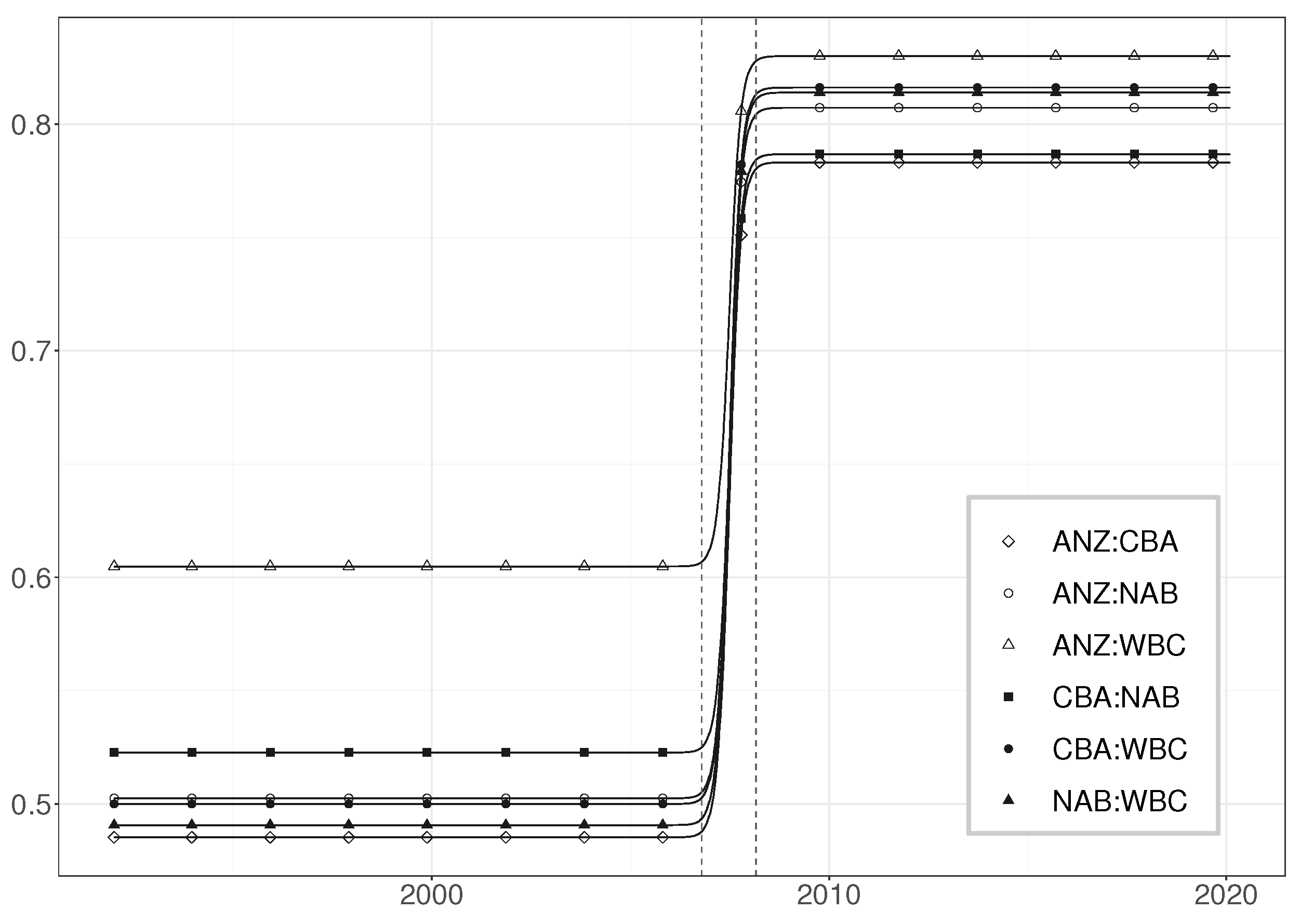
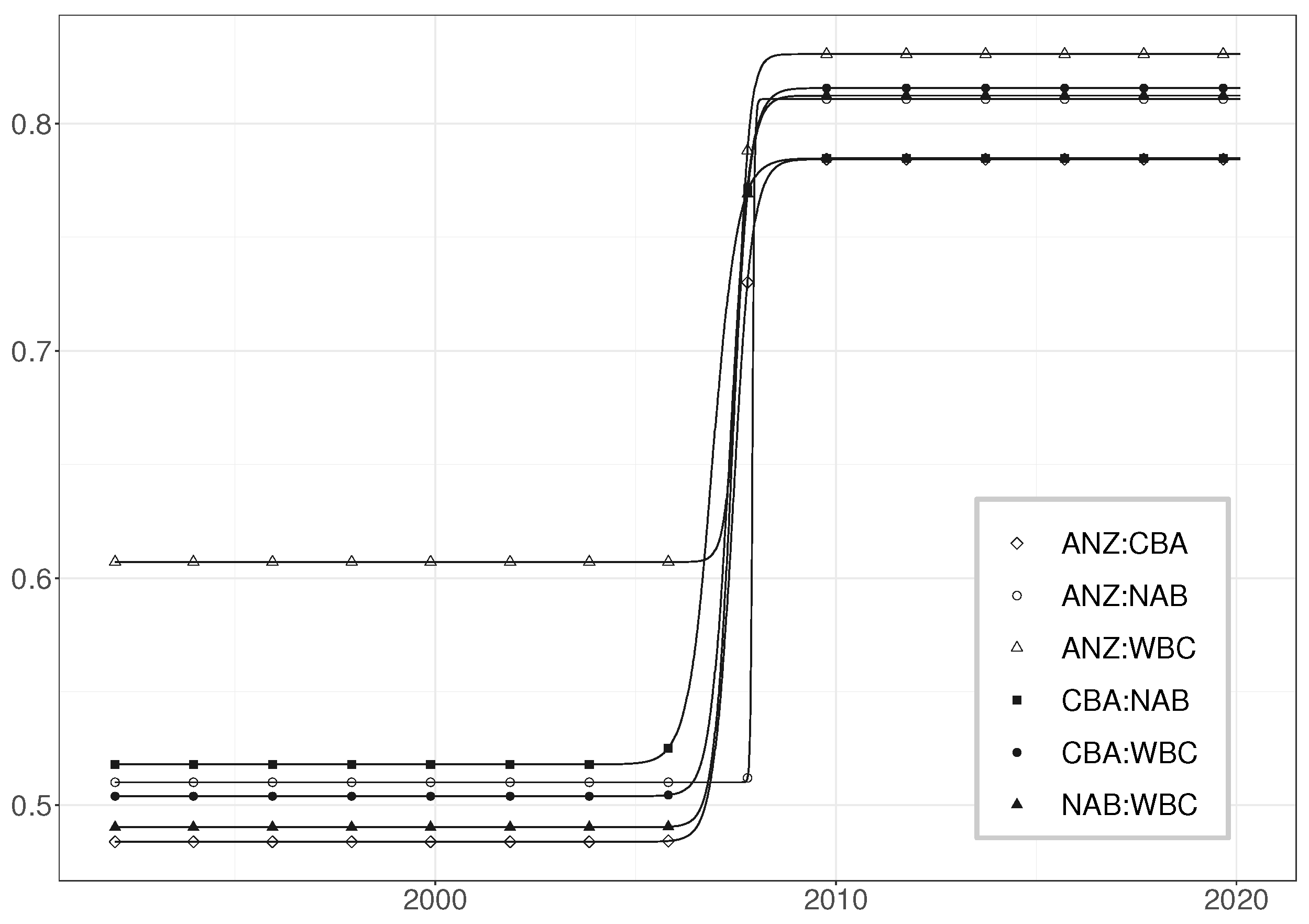
7.3. Modelling the Error Correlations
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Test Statistics
Appendix A.1. Test Statistic for TVV-Model Specification
Appendix A.2. Test Statistic for MTV-GARCH Model Evaluation
- Compute the .
- Regress on , and form the sum of squared residuals .
- Compute the test statistic .
- Regress on and obtain residuals . When has more than one variable, run the regression for each of them separately and, thereby, obtain a set of residuals .
- Regress on and form the sum of squared residuals .
- Compute the test statistic .
Appendix A.3. Test of Constant Correlations
Appendix A.4. Test for an Additional Transition in the Correlations
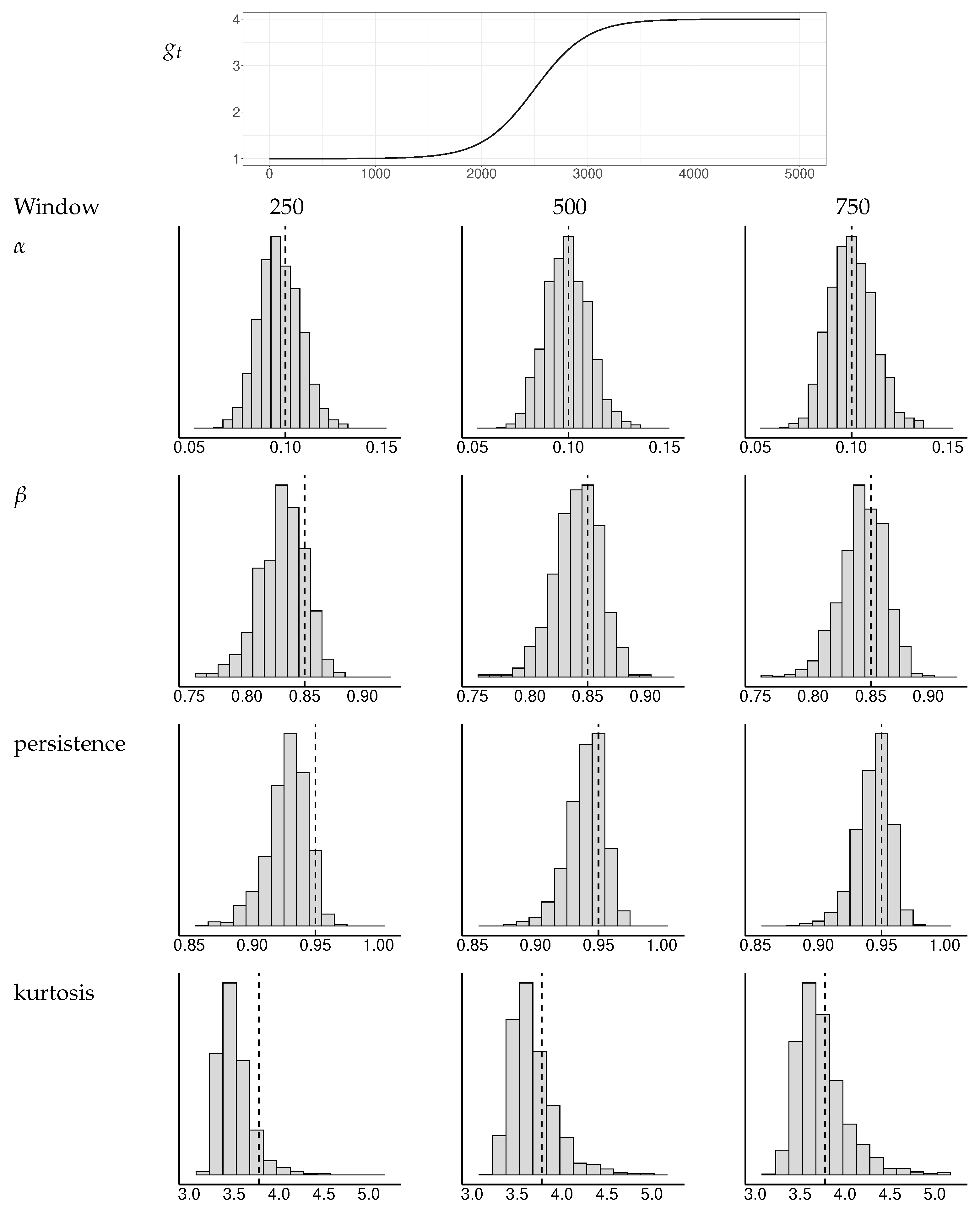
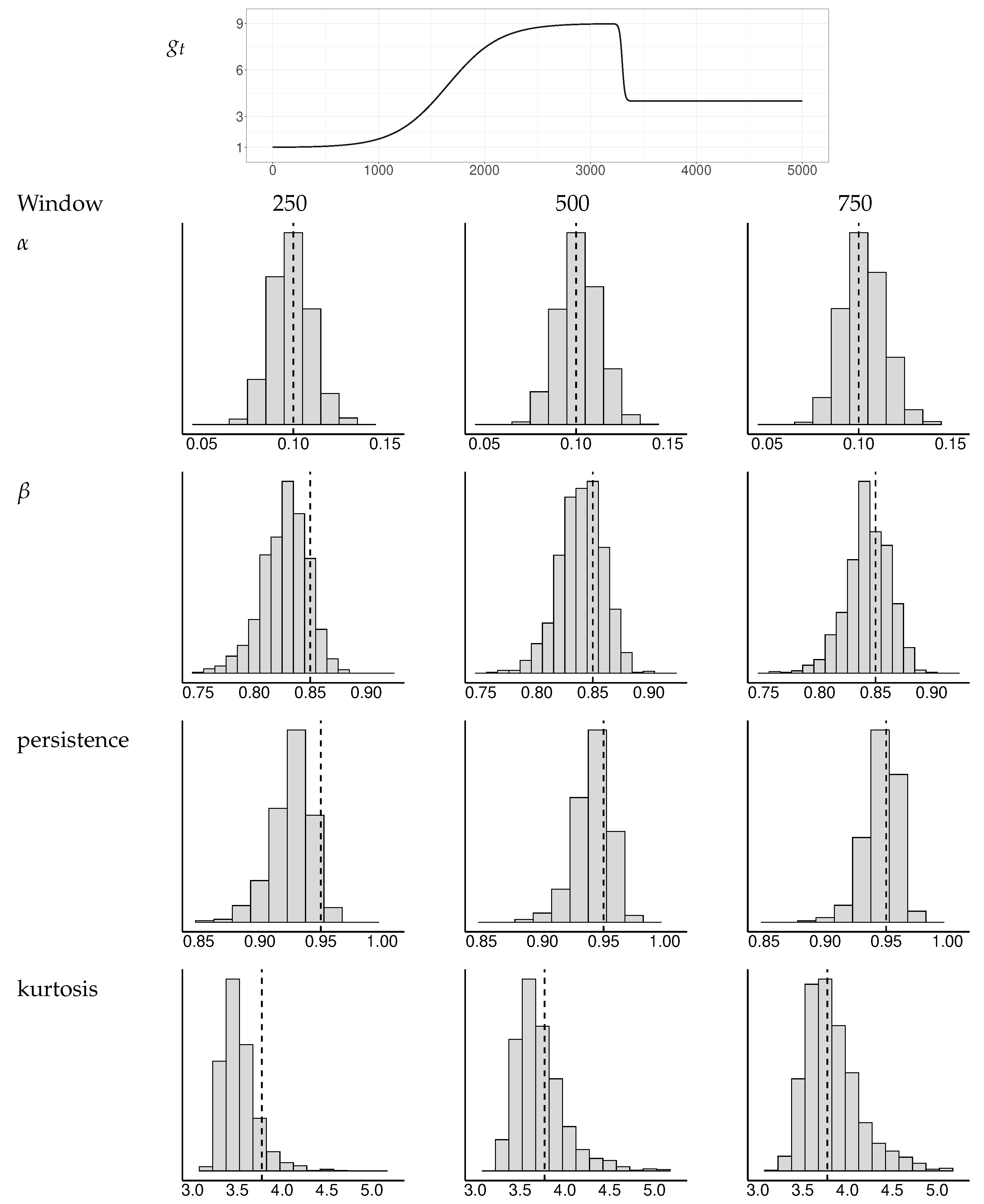
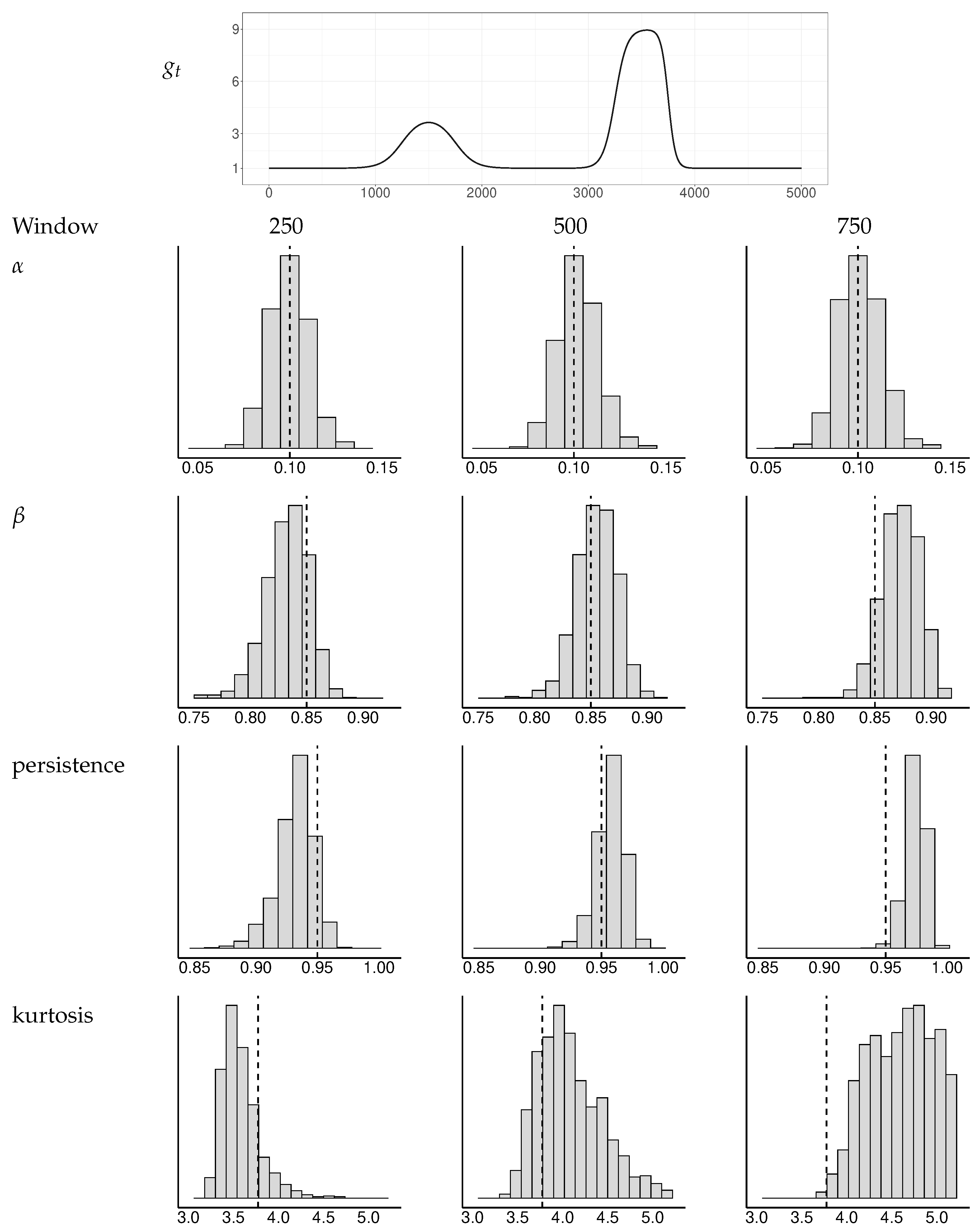
Appendix B. Simulations of Test Statistics
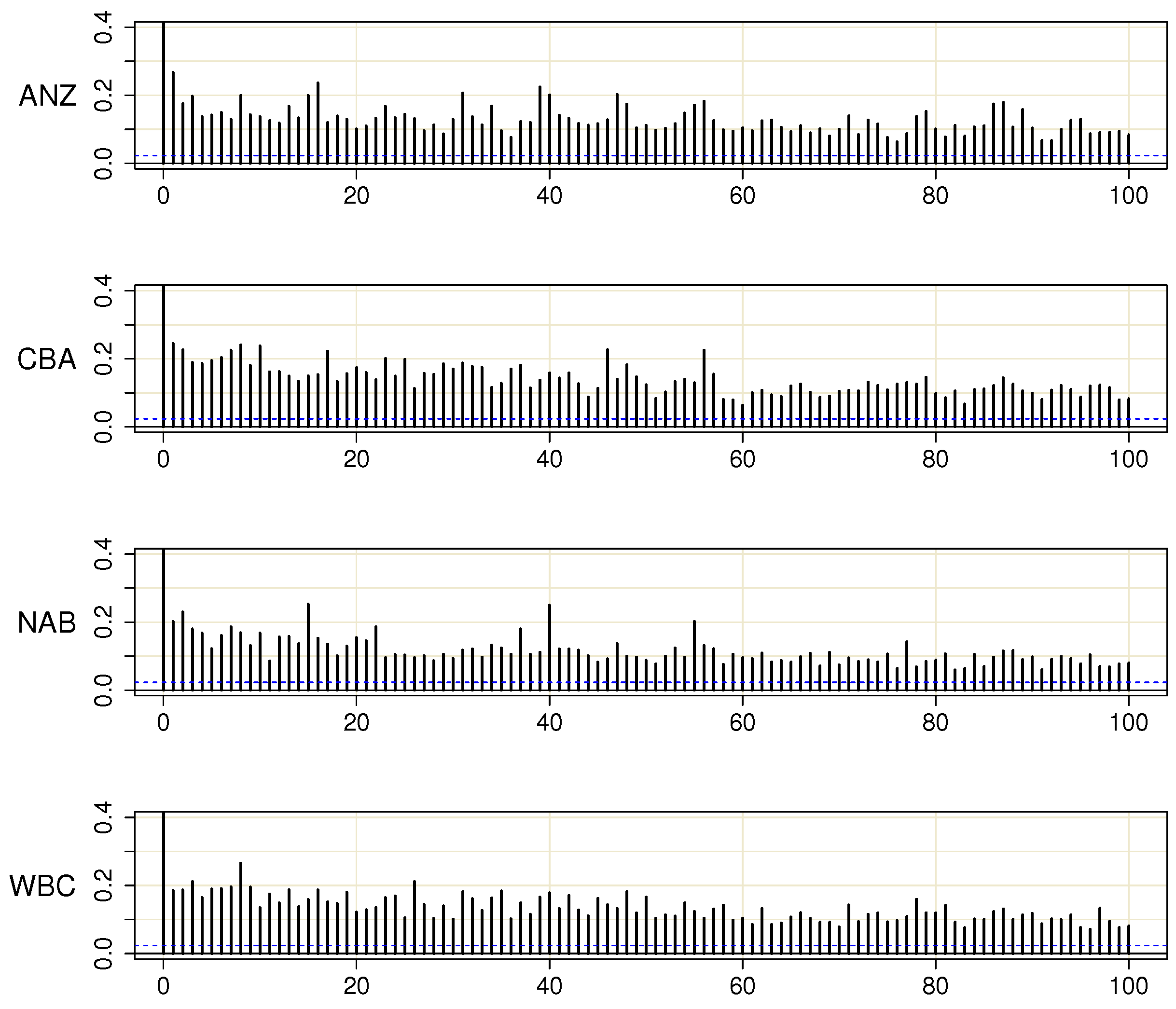
Appendix B.1. Tests of GARCH Equations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Persistence | Kurtosis | ||||
|---|---|---|---|---|---|
| Rolling window 400 | ANZ | 0.090 | 0.836 | 0.926 | 3.38 |
| CBA | 0.087 | 0.850 | 0.937 | 3.43 | |
| NAB | 0.095 | 0.817 | 0.912 | 3.36 | |
| WBC | 0.085 | 0.858 | 0.943 | 3.45 | |
| Calm period | ANZ | 0.073 | 0.852 | 0.925 | 3.24 |
| CBA | 0.081 | 0.842 | 0.923 | 3.29 | |
| NAB | 0.066 | 0.829 | 0.896 | 3.14 | |
| WBC | 0.091 | 0.806 | 0.897 | 3.28 | |
| Entire period GARCH only | ANZ | 0.065 | 0.927 | 0.992 | 6.40 |
| CBA | 0.089 | 0.890 | 0.979 | 4.83 | |
| NAB | 0.104 | 0.867 | 0.971 | 4.85 | |
| WBC | 0.075 | 0.911 | 0.986 | 5.08 | |
| Entire period TV-GARCH | ANZ | 0.078 | 0.880 | 0.957 | 3.50 |
| CBA | 0.091 | 0.860 | 0.950 | 3.61 | |
| NAB | 0.107 | 0.825 | 0.931 | 3.62 | |
| WBC | 0.084 | 0.878 | 0.962 | 3.70 |



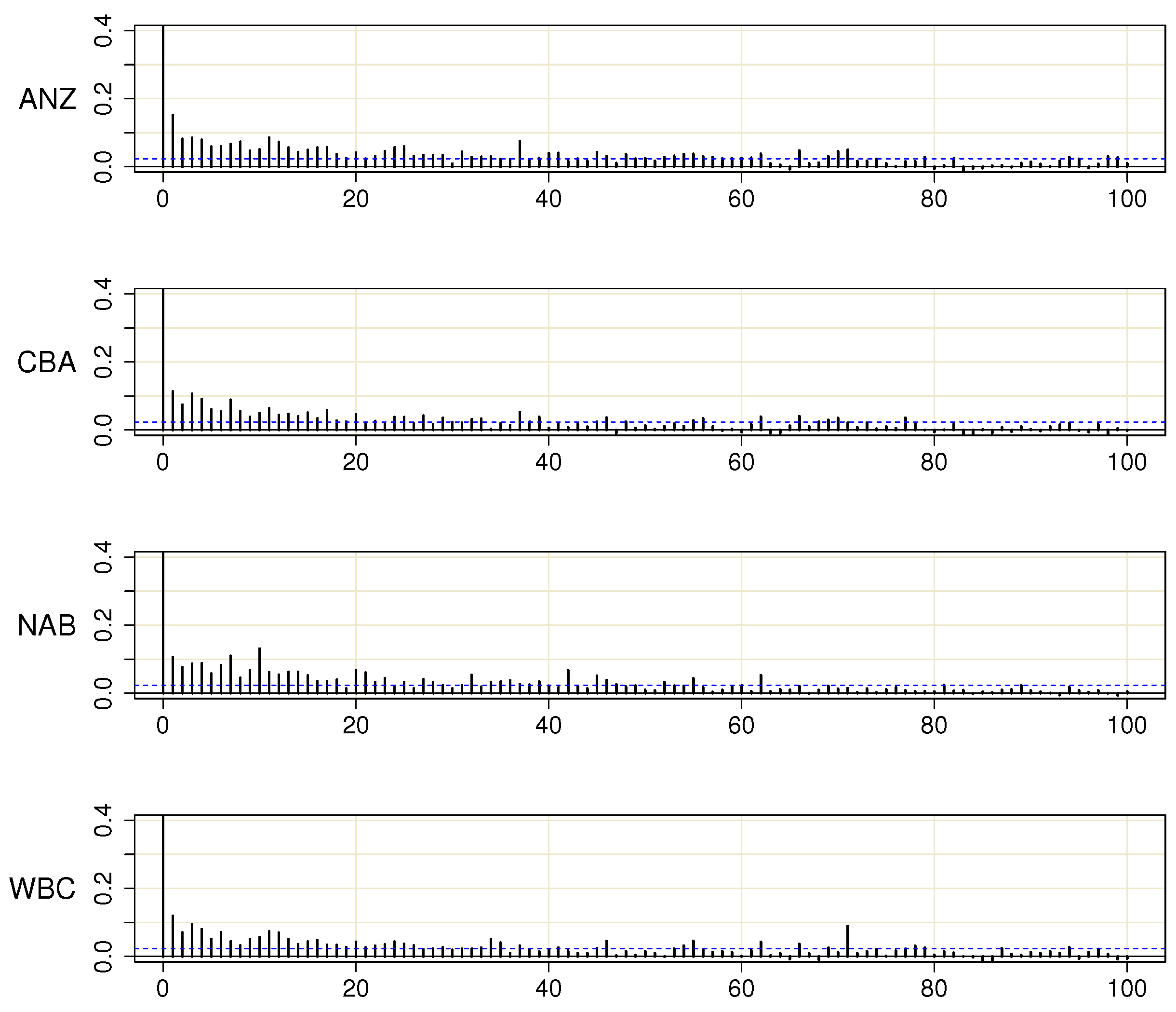
Appendix B.2. Evaluation Tests of GARCH Equations
- First step
- The individual TVGARCH models are estimated, assuming the series are uncorrelated.
- Second step
- Estimate the correlation model conditional on the volatility model estimates from the previous step. Then, estimate the TVGARCH models conditional on the correlation estimates.
| Standard | Robust | ||||||
|---|---|---|---|---|---|---|---|
| 10% | 5% | 1% | 10% | 5% | 1% | ||
| CCC two-step | MS1 | 0.146 | 0.085 | 0.020 | 0.132 | 0.074 | 0.016 |
| MS2-a | 0.122 | 0.064 | 0.012 | 0.101 | 0.048 | 0.013 | |
| MS2-b | 0.143 | 0.080 | 0.017 | 0.108 | 0.051 | 0.008 | |
| MS3 | 0.125 | 0.061 | 0.010 | 0.104 | 0.054 | 0.010 | |
| STCC two-step | MS1 | 0.134 | 0.074 | 0.023 | 0.121 | 0.055 | 0.015 |
| MS2-a | 0.123 | 0.059 | 0.015 | 0.101 | 0.045 | 0.013 | |
| MS2-b | 0.122 | 0.062 | 0.019 | 0.087 | 0.044 | 0.010 | |
| MS3 | 0.115 | 0.058 | 0.015 | 0.100 | 0.050 | 0.011 | |
| CCC multi-step | MS1 | 0.145 | 0.083 | 0.022 | 0.133 | 0.073 | 0.014 |
| MS2-a | 0.116 | 0.062 | 0.015 | 0.097 | 0.052 | 0.009 | |
| MS2-b | 0.133 | 0.069 | 0.018 | 0.100 | 0.046 | 0.010 | |
| MS3 | 0.120 | 0.062 | 0.016 | 0.107 | 0.060 | 0.014 | |
| STCC multi-step | MS1 | 0.147 | 0.084 | 0.023 | 0.135 | 0.068 | 0.012 |
| MS2-a | 0.130 | 0.059 | 0.011 | 0.103 | 0.046 | 0.006 | |
| MS2-b | 0.120 | 0.067 | 0.016 | 0.090 | 0.039 | 0.005 | |
| MS3 | 0.112 | 0.055 | 0.012 | 0.104 | 0.047 | 0.009 | |
Appendix B.3. Tests of Correlations
| CEC33 | CEC67 | CTC50 | CTC90 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | T | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% |
| 2 | 25 | 0.023 | 0.076 | 0.132 | 0.022 | 0.069 | 0.128 | 0.024 | 0.074 | 0.130 | 0.022 | 0.070 | 0.126 |
| 50 | 0.015 | 0.063 | 0.116 | 0.016 | 0.064 | 0.115 | 0.016 | 0.064 | 0.115 | 0.015 | 0.062 | 0.109 | |
| 100 | 0.011 | 0.056 | 0.104 | 0.010 | 0.054 | 0.102 | 0.011 | 0.056 | 0.103 | 0.010 | 0.051 | 0.101 | |
| 250 | 0.012 | 0.055 | 0.108 | 0.010 | 0.054 | 0.107 | 0.011 | 0.055 | 0.106 | 0.009 | 0.053 | 0.108 | |
| 500 | 0.010 | 0.051 | 0.097 | 0.009 | 0.049 | 0.097 | 0.010 | 0.050 | 0.096 | 0.009 | 0.050 | 0.094 | |
| 1000 | 0.010 | 0.048 | 0.099 | 0.010 | 0.048 | 0.095 | 0.010 | 0.046 | 0.097 | 0.010 | 0.049 | 0.092 | |
| 5 | 100 | 0.011 | 0.054 | 0.112 | 0.011 | 0.053 | 0.110 | 0.011 | 0.056 | 0.112 | 0.011 | 0.053 | 0.111 |
| 250 | 0.014 | 0.054 | 0.099 | 0.012 | 0.051 | 0.099 | 0.013 | 0.053 | 0.100 | 0.012 | 0.051 | 0.101 | |
| 500 | 0.010 | 0.050 | 0.104 | 0.010 | 0.053 | 0.106 | 0.009 | 0.052 | 0.101 | 0.010 | 0.054 | 0.105 | |
| 1000 | 0.010 | 0.056 | 0.102 | 0.010 | 0.052 | 0.103 | 0.009 | 0.053 | 0.100 | 0.008 | 0.053 | 0.103 | |
| 10 | 250 | 0.013 | 0.055 | 0.112 | 0.013 | 0.057 | 0.112 | 0.013 | 0.057 | 0.110 | 0.012 | 0.054 | 0.115 |
| 500 | 0.009 | 0.049 | 0.101 | 0.010 | 0.049 | 0.104 | 0.008 | 0.053 | 0.103 | 0.010 | 0.050 | 0.103 | |
| 1000 | 0.011 | 0.052 | 0.102 | 0.011 | 0.054 | 0.105 | 0.011 | 0.053 | 0.099 | 0.012 | 0.056 | 0.103 | |
| 20 | 1000 | 0.012 | 0.056 | 0.106 | 0.012 | 0.057 | 0.106 | 0.013 | 0.056 | 0.103 | 0.012 | 0.056 | 0.107 |
| CEC33 | CEC67 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| kurtosis = 4 | kurtosis = 6 | kurtosis = 4 | kurtosis = 6 | |||||||||||
| Persistence | N | T | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% |
| 0.95 | 2 | 500 | 0.012 | 0.056 | 0.108 | 0.016 | 0.056 | 0.106 | 0.016 | 0.070 | 0.122 | 0.016 | 0.092 | 0.122 |
| 2 | 1000 | 0.009 | 0.044 | 0.103 | 0.009 | 0.042 | 0.097 | 0.011 | 0.045 | 0.093 | 0.009 | 0.044 | 0.097 | |
| 2 | 2000 | 0.008 | 0.042 | 0.094 | 0.007 | 0.042 | 0.090 | 0.010 | 0.052 | 0.099 | 0.009 | 0.046 | 0.092 | |
| 5 | 500 | 0.006 | 0.062 | 0.118 | 0.006 | 0.070 | 0.114 | 0.018 | 0.076 | 0.140 | 0.018 | 0.082 | 0.146 | |
| 5 | 1000 | 0.016 | 0.060 | 0.119 | 0.016 | 0.061 | 0.112 | 0.016 | 0.059 | 0.115 | 0.018 | 0.060 | 0.112 | |
| 5 | 2000 | 0.010 | 0.058 | 0.108 | 0.008 | 0.051 | 0.102 | 0.016 | 0.060 | 0.116 | 0.010 | 0.052 | 0.098 | |
| 10 | 500 | 0.016 | 0.058 | 0.118 | 0.020 | 0.064 | 0.114 | 0.020 | 0.068 | 0.116 | 0.024 | 0.080 | 0.128 | |
| 10 | 1000 | 0.018 | 0.053 | 0.104 | 0.015 | 0.051 | 0.101 | 0.014 | 0.061 | 0.111 | 0.017 | 0.063 | 0.110 | |
| 10 | 2000 | 0.014 | 0.072 | 0.126 | 0.012 | 0.060 | 0.112 | 0.018 | 0.082 | 0.142 | 0.013 | 0.062 | 0.118 | |
| 0.97 | 2 | 500 | 0.010 | 0.056 | 0.114 | 0.012 | 0.054 | 0.118 | 0.020 | 0.072 | 0.114 | 0.014 | 0.068 | 0.120 |
| 2 | 1000 | 0.011 | 0.043 | 0.102 | 0.011 | 0.044 | 0.103 | 0.012 | 0.047 | 0.107 | 0.013 | 0.048 | 0.103 | |
| 2 | 2000 | 0.009 | 0.046 | 0.094 | 0.007 | 0.042 | 0.089 | 0.010 | 0.056 | 0.108 | 0.012 | 0.050 | 0.093 | |
| 5 | 500 | 0.004 | 0.066 | 0.124 | 0.012 | 0.056 | 0.104 | 0.012 | 0.088 | 0.152 | 0.018 | 0.086 | 0.164 | |
| 5 | 1000 | 0.015 | 0.063 | 0.113 | 0.014 | 0.067 | 0.114 | 0.018 | 0.063 | 0.121 | 0.019 | 0.060 | 0.125 | |
| 5 | 2000 | 0.010 | 0.060 | 0.110 | 0.008 | 0.050 | 0.100 | 0.015 | 0.060 | 0.118 | 0.012 | 0.050 | 0.101 | |
| 10 | 500 | 0.012 | 0.062 | 0.108 | 0.016 | 0.070 | 0.112 | 0.016 | 0.072 | 0.112 | 0.022 | 0.086 | 0.148 | |
| 10 | 1000 | 0.016 | 0.053 | 0.100 | 0.015 | 0.056 | 0.107 | 0.015 | 0.063 | 0.113 | 0.018 | 0.057 | 0.110 | |
| 10 | 2000 | 0.015 | 0.074 | 0.132 | 0.014 | 0.058 | 0.108 | 0.016 | 0.088 | 0.142 | 0.010 | 0.063 | 0.112 | |
| CTC50 | CTC90 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| kurtosis = 4 | kurtosis = 6 | kurtosis = 4 | kurtosis = 6 | |||||||||||
| Persistence | N | T | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% |
| 0.95 | 2 | 500 | 0.010 | 0.064 | 0.102 | 0.010 | 0.070 | 0.106 | 0.018 | 0.094 | 0.136 | 0.026 | 0.088 | 0.146 |
| 2 | 1000 | 0.009 | 0.041 | 0.097 | 0.011 | 0.042 | 0.103 | 0.014 | 0.053 | 0.096 | 0.020 | 0.062 | 0.104 | |
| 2 | 2000 | 0.008 | 0.044 | 0.096 | 0.009 | 0.044 | 0.090 | 0.017 | 0.066 | 0.120 | 0.014 | 0.048 | 0.098 | |
| 5 | 500 | 0.006 | 0.062 | 0.118 | 0.010 | 0.058 | 0.114 | 0.020 | 0.120 | 0.212 | 0.050 | 0.134 | 0.210 | |
| 5 | 1000 | 0.014 | 0.060 | 0.112 | 0.018 | 0.064 | 0.113 | 0.027 | 0.076 | 0.134 | 0.034 | 0.093 | 0.144 | |
| 5 | 2000 | 0.011 | 0.057 | 0.110 | 0.008 | 0.052 | 0.105 | 0.020 | 0.075 | 0.142 | 0.018 | 0.058 | 0.110 | |
| 10 | 500 | 0.012 | 0.070 | 0.120 | 0.016 | 0.080 | 0.128 | 0.040 | 0.114 | 0.172 | 0.078 | 0.150 | 0.230 | |
| 10 | 1000 | 0.012 | 0.049 | 0.100 | 0.013 | 0.051 | 0.102 | 0.019 | 0.078 | 0.127 | 0.032 | 0.089 | 0.147 | |
| 10 | 2000 | 0.019 | 0.072 | 0.127 | 0.014 | 0.059 | 0.111 | 0.033 | 0.110 | 0.178 | 0.018 | 0.077 | 0.140 | |
| 0.97 | 2 | 500 | 0.014 | 0.066 | 0.114 | 0.018 | 0.068 | 0.116 | 0.016 | 0.082 | 0.134 | 0.030 | 0.104 | 0.164 |
| 2 | 1000 | 0.009 | 0.044 | 0.101 | 0.008 | 0.042 | 0.099 | 0.016 | 0.051 | 0.112 | 0.022 | 0.063 | 0.119 | |
| 2 | 2000 | 0.010 | 0.050 | 0.102 | 0.009 | 0.044 | 0.092 | 0.024 | 0.070 | 0.120 | 0.015 | 0.052 | 0.100 | |
| 5 | 500 | 0.014 | 0.056 | 0.128 | 0.008 | 0.074 | 0.130 | 0.024 | 0.134 | 0.208 | 0.052 | 0.160 | 0.256 | |
| 5 | 1000 | 0.013 | 0.059 | 0.112 | 0.016 | 0.066 | 0.123 | 0.022 | 0.082 | 0.157 | 0.037 | 0.102 | 0.164 | |
| 5 | 2000 | 0.014 | 0.062 | 0.112 | 0.010 | 0.052 | 0.101 | 0.028 | 0.086 | 0.145 | 0.020 | 0.066 | 0.116 | |
| 10 | 500 | 0.018 | 0.080 | 0.128 | 0.022 | 0.088 | 0.130 | 0.040 | 0.114 | 0.172 | 0.100 | 0.188 | 0.278 | |
| 10 | 1000 | 0.012 | 0.054 | 0.105 | 0.013 | 0.054 | 0.107 | 0.019 | 0.078 | 0.127 | 0.030 | 0.104 | 0.181 | |
| 10 | 2000 | 0.016 | 0.072 | 0.132 | 0.016 | 0.062 | 0.110 | 0.033 | 0.110 | 0.178 | 0.026 | 0.089 | 0.150 | |
Appendix C. Details of Maximisation by Parts
- Assume , , and estimate parameters , , equation by equation, assuming . Denote the estimate . This means that the deterministic components have been estimated once, including the intercept in (2).
- Re-estimate assuming . This yields . Then, re-estimate given . Iterate until convergence. Let the result after iterations be and . The resulting estimates are maximum likelihood ones under the assumption .
- Estimate from using . This is a standard multivariate conditional correlation GARCH estimation step as in Bollerslev (1990), because is fixed and does not affect the maximum and is known. In total, steps 1–4 form the first iteration of the maximisation algorithm. Denote the estimate .
- Estimate from keeping and fixed. This step is analogous to the first part of Step 3. The difference is that . Denote the estimator .
- Estimate given and . Denote the estimator . Iterate until convergence, iterations. The result: and .
- Estimate from using ( is fixed). The result: . This completes the second full iteration.
- Repeat steps 5–7 and iterate until convergence.
Appendix D. Estimated Transition Equations
| 1 | Available also in https://econ.au.dk/research/researchcentres/creates/research/creates-research-papers/supplementary-downloads/rp-2012-09, accessed on 26 January 2023. |
| 2 | The operator vecl stacks the subdiagonal elements of its argument matrix. |
| 3 | See Explanatory Statement, Banking (prudential standard) Determination 2007, Nos 5, 12 and 15. https://www.legislation.gov.au/Details/F2007L04593/ (accessed on 26 January 2023), https://www.legislation.gov.au/Details/F2007L04600/ (accessed on 26 January 2023) and https://www.legislation.gov.au/Details/F2007L04603/ (accessed on 26 January 2023). |
References
- Amado, Christina, and Timo Teräsvirta. 2008. Modelling Conditional and Unconditional Heteroskedasticity with Smoothly Time-Varying Structure. SSE/EFI Working Paper Series in Economics and Finance 691. Stockholm: Stockholm School of Economics. [Google Scholar]
- Amado, Cristina, and Timo Teräsvirta. 2013. Modelling volatility by variance decomposition. Journal of Econometrics 175: 153–65. [Google Scholar] [CrossRef]
- Amado, Cristina, and Timo Teräsvirta. 2014. Conditional correlation models of autoregressive conditional heteroscedasticity with nonstationary GARCH equations. Journal of Business and Economic Statistics 32: 69–87. [Google Scholar] [CrossRef]
- Amado, Cristina, and Timo Teräsvirta. 2017. Specification and testing of multiplicative time-varying GARCH models with applications. Econometric Reviews 36: 421–46. [Google Scholar] [CrossRef]
- Amado, Cristina, Annastiina Silvennoinen, and Timo Teräsvirta. 2017. Modelling and forecasting WIG20 daily returns. Central European Journal of Economic Modelling and Econometrics 9: 173–200. [Google Scholar]
- Berben, Robert-Paul, and W. Jos Jansen. 2005. Comovement in international equity markets: A sectoral view. Journal of International Money and Finance 24: 832–57. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1986. Generalized autoregressive conditional heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef]
- Bollerslev, Tim. 1990. Modelling the coherence in short-run nominal exchange rates: A multivariate generalized ARCH model. Review of Economics and Statistics 72: 498–505. [Google Scholar] [CrossRef]
- Box, George E. P., and Gwilym M. Jenkins. 1970. Time Series Analysis, Forecasting Furthermore, Control. San Francisco: Holden-Day. [Google Scholar]
- Chan, Felix, and Billy Theoharakis. 2011. Estimating m-regimes STAR–GARCH model using QMLE with parameter transformation. Mathematics and Computers in Simulation 81: 1385–96. [Google Scholar] [CrossRef]
- Ekner, Line, and Emil Nejstgaard. 2013. Parameter Identification in the Logistic STAR Model. Discussion Paper 13-07. København: Department of Economics, University of Copenhagen. [Google Scholar]
- Engle, Robert F. 2002. Dynamic conditional correlation: A simple class of multivariate generalized autoregressive conditional heteroskedasticity models. Journal of Business and Economic Statistics 20: 339–50. [Google Scholar] [CrossRef]
- Engle, Robert, and Bryan Kelly. 2012. Dynamic equicorrelation. Journal of Business & Economic Statistics 30: 212–28. [Google Scholar]
- Feng, Yuanhua. 2004. Simultaneously modeling conditional heteroskedasticity and scale change. Econometric Theory 20: 563–96. [Google Scholar] [CrossRef]
- Feng, Yuanhua. 2006. A Local Dynamic Conditional Correlation Model. MPRA Paper 1592. Edinburgh: Maxwell Institute for Mathematical Sciences, Heriot-Watt University. [Google Scholar]
- Glosten, Lawrence R., Ravi Jagannathan, and David E. Runkle. 1993. On the relation between the expected value and the volatility of the nominal excess return on stocks. Journal of Finance 48: 1779–801. [Google Scholar] [CrossRef]
- Godfrey, Leslie G. 1988. Misspecification Tests in Econometrics. Cambridge: Cambridge University Press. [Google Scholar]
- Goodwin, Barry K., Matthew T. Holt, and Jeffrey P. Prestemon. 2011. North American oriented strand board markets, arbitrage activity, and market price dynamics: A smooth transition approach. American Journal of Agricultural Economics 93: 993–1014. [Google Scholar] [CrossRef]
- He, Changli, and Timo Teräsvirta. 1999. Properties of moments of a family of GARCH processes. Journal of Econometrics 92: 173–92. [Google Scholar] [CrossRef]
- Kang, Jian, Johan Stax Jakobsen, Annastiina Silvennoinen, Timo Teräsvirta, and Glen Wade. 2022. A parsimonious test of constancy of a positive definite correlation matrix in a multivariate time-varying GARCH model. Econometrics 10: 30. [Google Scholar] [CrossRef]
- Lütkepohl, Helmut. 1996. Handbook of Matrices. Chichester: John Wiley & Sons. [Google Scholar]
- Luukkonen, Ritva, Pentti Saikkonen, and Timo Teräsvirta. 1988. Testing linearity against smooth transition autoregressive models. Biometrika 75: 491–99. [Google Scholar] [CrossRef]
- Silvennoinen, Annastiina, and Timo Teräsvirta. 2005. Multivariate Autoregressive Conditional Heteroskedasticity with Smooth Transitions in Conditional Correlations. SSE/EFI Working Paper Series in Economics and Finance No. 577. Stockholm: Stockholm School of Economics. [Google Scholar]
- Silvennoinen, Annastiina, and Timo Teräsvirta. 2009. Modelling multivariate autoregressive conditional heteroskedasticity with the double smooth transition conditional correlation GARCH model. Journal of Financial Econometrics 7: 373–411. [Google Scholar] [CrossRef]
- Silvennoinen, Annastiina, and Timo Teräsvirta. 2015. Modeling conditional correlations of asset returns: A smooth transition approach. Econometric Reviews 34: 174–97. [Google Scholar] [CrossRef]
- Silvennoinen, Annastiina, and Timo Teräsvirta. 2016. Testing constancy of unconditional variance in volatility models by misspecification and specification tests. Studies in Nonlinear Dynamics and Econometrics 20: 347–64. [Google Scholar] [CrossRef]
- Silvennoinen, Annastiina, and Timo Teräsvirta. 2021. Consistency and asymptotic normality of maximum likelihood estimators of the multiplicative time-varying smooth transition correlation GARCH model. Econometrics and Statistics. in press. [Google Scholar] [CrossRef]
- Song, Peter X.-K., Yanqin Fan, and John D. Kalbfleisch. 2005. Maximization by parts in likelihood inference. Journal of the American Statistical Association 100: 1145–58. [Google Scholar] [CrossRef]
- Teräsvirta, Timo. 1994. Specification, estimation, and evaluation of smooth transition autoregressive models. Journal of the American Statistical Association 89: 208–18. [Google Scholar]
- Teräsvirta, Timo, Dag Tjøstheim, and Clive W. J. Granger. 2010. Modelling Nonlinear Economic Time Series. Oxford: Oxford University Press. [Google Scholar]
- Tse, Yiu Kuen, and Albert K. C. Tsui. 2002. A multivariate generalized autoregressive conditional heteroscedasticity model with time-varying correlations. Journal of Business and Economic Statistics 20: 351–62. [Google Scholar] [CrossRef]









| Persistence | Kurtosis | ||||||
|---|---|---|---|---|---|---|---|
| ANZ | GJR | 0.991 | 3.76 | ||||
| TV-GJR | 0.831 | 3.02 | |||||
| CBA | GJR | 0.977 | 3.66 | ||||
| TV-GJR | 0.867 | 3.06 | |||||
| NAB | GJR | 0.964 | 3.68 | ||||
| TV-GJR | 0.780 | 3.03 | |||||
| WBC | GJR | 0.985 | 3.70 | ||||
| TV-GJR | 0.864 | 3.02 |
| ANZ | CBA | NAB | ANZ | CBA | NAB | |||
| CBA | CBA | |||||||
| NAB | NAB | |||||||
| WBC | WBC | |||||||
| Transition parameters: | c | |||||||
| ANZ | CBA | NAB | ANZ | CBA | NAB | |||
| CBA | CBA | |||||||
| NAB | NAB | |||||||
| WBC | WBC | |||||||
| Transition parameters: | ||||||||
| c | ||||||||
| ANZ | CBA | NAB | ANZ | CBA | NAB | |||
| CBA | CBA | |||||||
| NAB | NAB | |||||||
| WBC | WBC | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hall, A.D.; Silvennoinen, A.; Teräsvirta, T. Building Multivariate Time-Varying Smooth Transition Correlation GARCH Models, with an Application to the Four Largest Australian Banks. Econometrics 2023, 11, 5. https://doi.org/10.3390/econometrics11010005
Hall AD, Silvennoinen A, Teräsvirta T. Building Multivariate Time-Varying Smooth Transition Correlation GARCH Models, with an Application to the Four Largest Australian Banks. Econometrics. 2023; 11(1):5. https://doi.org/10.3390/econometrics11010005
Chicago/Turabian StyleHall, Anthony D., Annastiina Silvennoinen, and Timo Teräsvirta. 2023. "Building Multivariate Time-Varying Smooth Transition Correlation GARCH Models, with an Application to the Four Largest Australian Banks" Econometrics 11, no. 1: 5. https://doi.org/10.3390/econometrics11010005
APA StyleHall, A. D., Silvennoinen, A., & Teräsvirta, T. (2023). Building Multivariate Time-Varying Smooth Transition Correlation GARCH Models, with an Application to the Four Largest Australian Banks. Econometrics, 11(1), 5. https://doi.org/10.3390/econometrics11010005