
Semi-Metric Portfolio Optimization: A New Algorithm Reducing Simultaneous Asset Shocks

Abstract
:1. Introduction
1.1. Overview of Portfolio Optimization
1.2. Overview of Change Point Detection Methods
1.3. Overview of Semi-Metrics
1.4. Motivation and Structure of This Paper
2. Proposed Semi-Metric Change Point Optimization Framework
- Covariance is computed as an expectation , which is an average (integral) over an entire probability space. In a financial context, this computes an average over time; in modern financial markets, especially since the global financial crisis, most time periods are bull markets, with most assets performing quite well together. As such, assets that rise together in a bull market but actually exhibit distinct dynamics may be erroneously identified as similar.
- Covariance fails to capture dissimilarity between time series during periods of market crisis and erratic behavior. Investors are often particularly concerned with the robustness of their portfolio during such times. Portfolios that are optimized using covariance as a risk measure fail to determine the impact of various asset combinations during times of market crisis. For instance, if two assets are simultaneously acting erratically, they may actually be negatively correlated during this time. If they are both included in a portfolio, this would increase rather than reduce erratic behavior. Structural breaks herald erratic behavior, so using distances between breaks in the objective function may better separate out erratic behavior in a portfolio.
- Investors are also interested in peak-to-trough measures of asset performance, that is, the size of a drop in returns from a local maximum to a local minimum. Optimization algorithms using covariance measures fail to identify and minimize peak-to-trough behavior. However, distances between sets of structural breaks (in the mean, variance, and other stochastic quantities) are better equipped to identify how similar two time series are with respect to peak-to-trough measures. Thus, they may suitably allocate weights to minimize these precipitous drops.
- While various methods of portfolio optimization target downside risk directly, we believe that structural breaks may be a kind of “root cause” of the greatest erratic behavior and simultaneous downside risk, and thus are of the greatest priority to diversify away from.
3. Theoretical Properties
4. Simulation Study
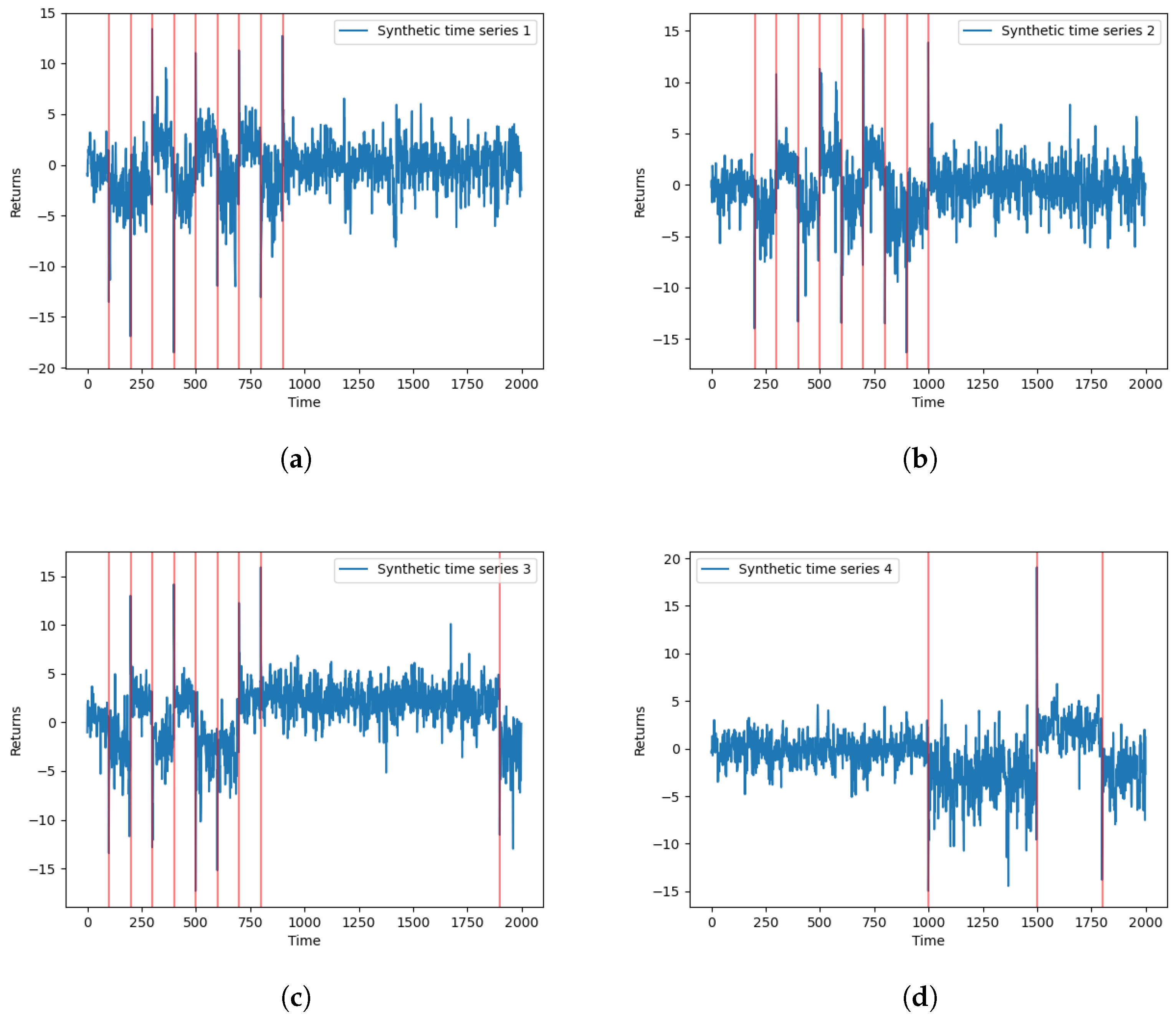
4.1. Synthetic Data Simulation
4.2. Synthetic Data: Portfolio Optimization Experiments
5. Real Data Results
- We train our algorithm over a relatively long period to estimate the true dynamics between various assets’ structural breaks as precisely as possible. Training the algorithm on longer periods provides a more accurate assessment of similarity in varying market dynamics.
- However, there is a balance between going back far enough to learn appropriate dynamics between asset classes and using too much history that relationships between assets no longer behave the way in which they were estimated. The behavior of individual asset classes and their relationships may change over time.
- The period from January 2018–June 2019 is a suitable out-of-sample period to test the algorithm, due to the varied market conditions. Most of 2018 provided relatively buoyant equity market returns, with a sharp drop in December 2018, followed by a prolonged recovery until June 2019. We wish to examine how candidate portfolios will perform in various market conditions, particularly in the presence of large drawdowns. In addition, we do not wish to test our algorithm during a period that is too similar to the training interval, as performance could be artificially strong. Thus, this is a suitable period to compare the optimization algorithms’ performance.
- We did not include the COVID-19 market crisis in our test data to ensure that our training data have broadly similar dynamics to the out-of-sample data set. We include a targeted analysis of the COVID-19 crisis in Section 5.3.
- The role of asset allocation is often guided by an investment policy statement that provides upper and lower bounds for capital allocation decisions. This is captured in the candidate weights’ constraints. During pronounced bull and bear markets, institutional asset allocators may not have the flexibility to implement global optimization solutions. For example, if two asset classes had significantly higher returns and lower volatility than the remainder of candidate investments, the unconstrained solution would allocate all portfolio weight into these two assets. Investment weighting constraints prevent these contrived scenarios from occurring. For our constraints, we place a minimum 5% and maximum 25% of portfolio assets in any candidate investment. This is one of several typical constraints imposed in real-world policy statements—indeed, investment policy statements may include this as their only constraint (Coffey 2016). As mentioned in Section 3, we may impose additional constraints by combining with other optimization methods cited in Section 1.
- Our method provides an advantage over the simple correlation measure by addressing all three limitations in Section 2. One possible drawback to our proposed method, however, is that to learn meaningful relationships between assets’ structural breaks, a long time series history is needed, preferably with many structural breaks observed.
- When considering portfolio risk in an optimization framework, investors have a variety of measures they may choose to optimize over. Standard deviation, , downside deviation, and tracking error are just several of these. Our CPO model introduces a mathematical framework that addresses peak-to-trough (drawdown) losses and erratic behavior as a measure of risk. Specifically, the model captures simultaneous asset shocks and aims to minimize the size of drawdowns by creating a uniform spread of change points across all portfolio holdings. We are unaware of any existing measure with these properties.
5.1. Training and Validation Procedure
5.2. Out-of-Sample Performance and Distributional Properties
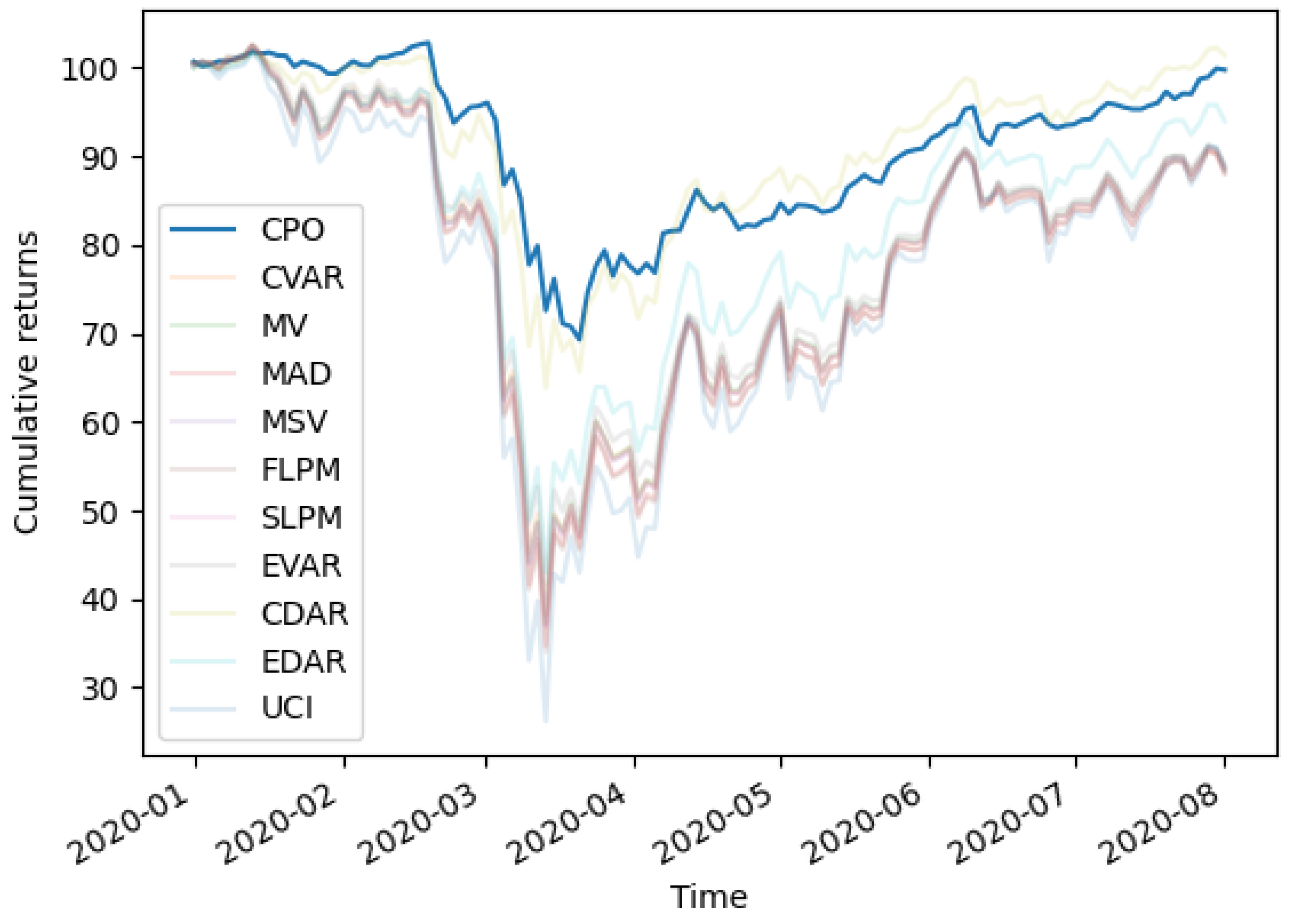
5.3. Performance during COVID-19
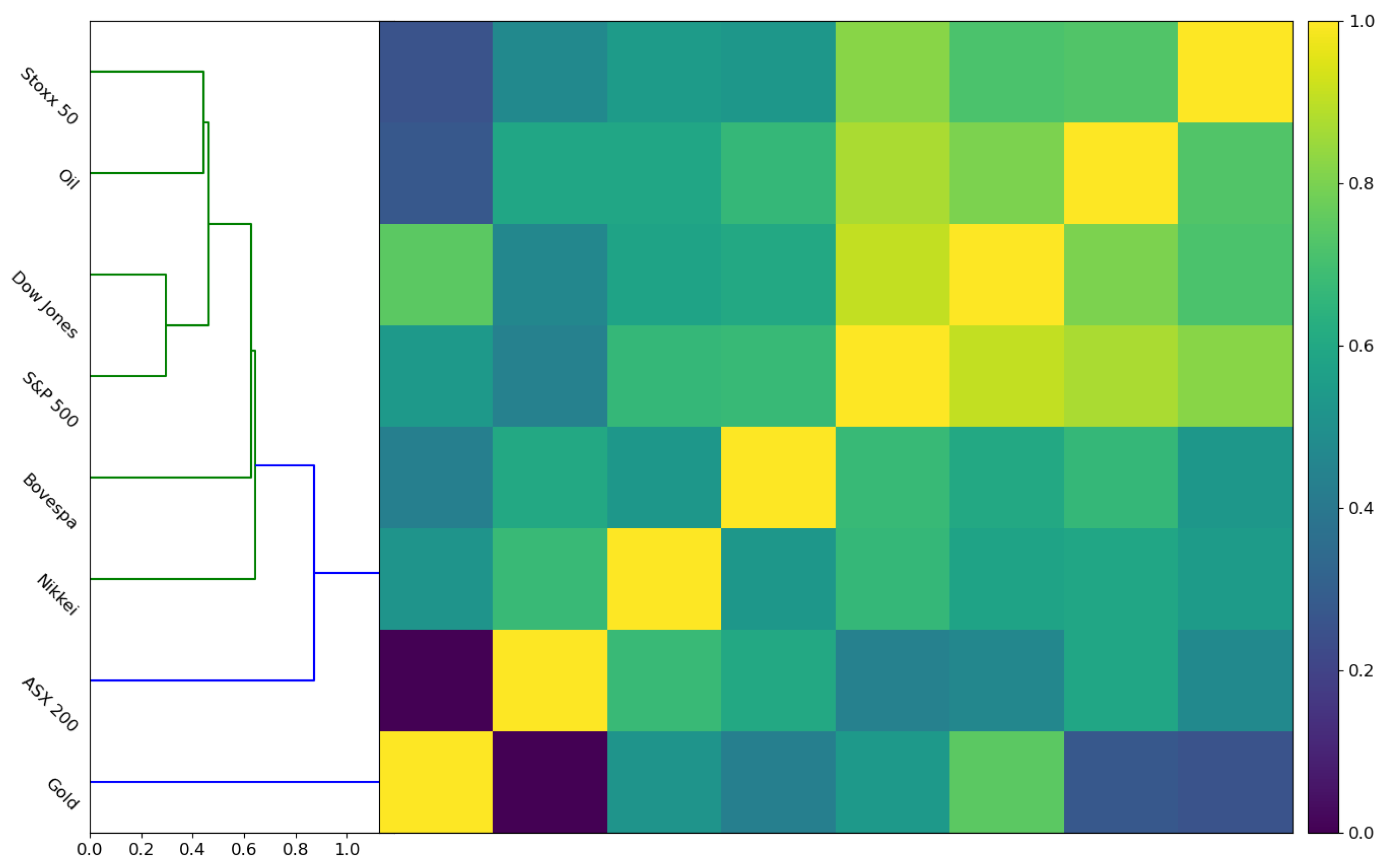
5.4. Sampling Study of Structural Breaks between Countries’ Financial Indices
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CPO | Change point optimization method |
| MVO | Mean–variance optimization |
| MSV | Mean–semivariance |
| MAD | Mean absolute deviation |
| FLPM | First lower partial moment |
| SLPM | Second lower partial moment |
| CVAR | Conditional value at risk |
| EVAR | Entropic value at risk |
| CDAR | Conditional drawdown at risk |
| UCI | Ulcer index |
| CPM | Change point model |
Appendix A. Change Point Detection Algorithm
Appendix A.1. Batch Detection (Phase I)
Appendix A.2. Sequential Detection (Phase II)
Appendix B. Overview and Properties of Distances between Sets
Appendix B.1. Overview of Metrics
- , with equality if and only if ;
- ;
- .
Appendix B.2. Distances between Sets
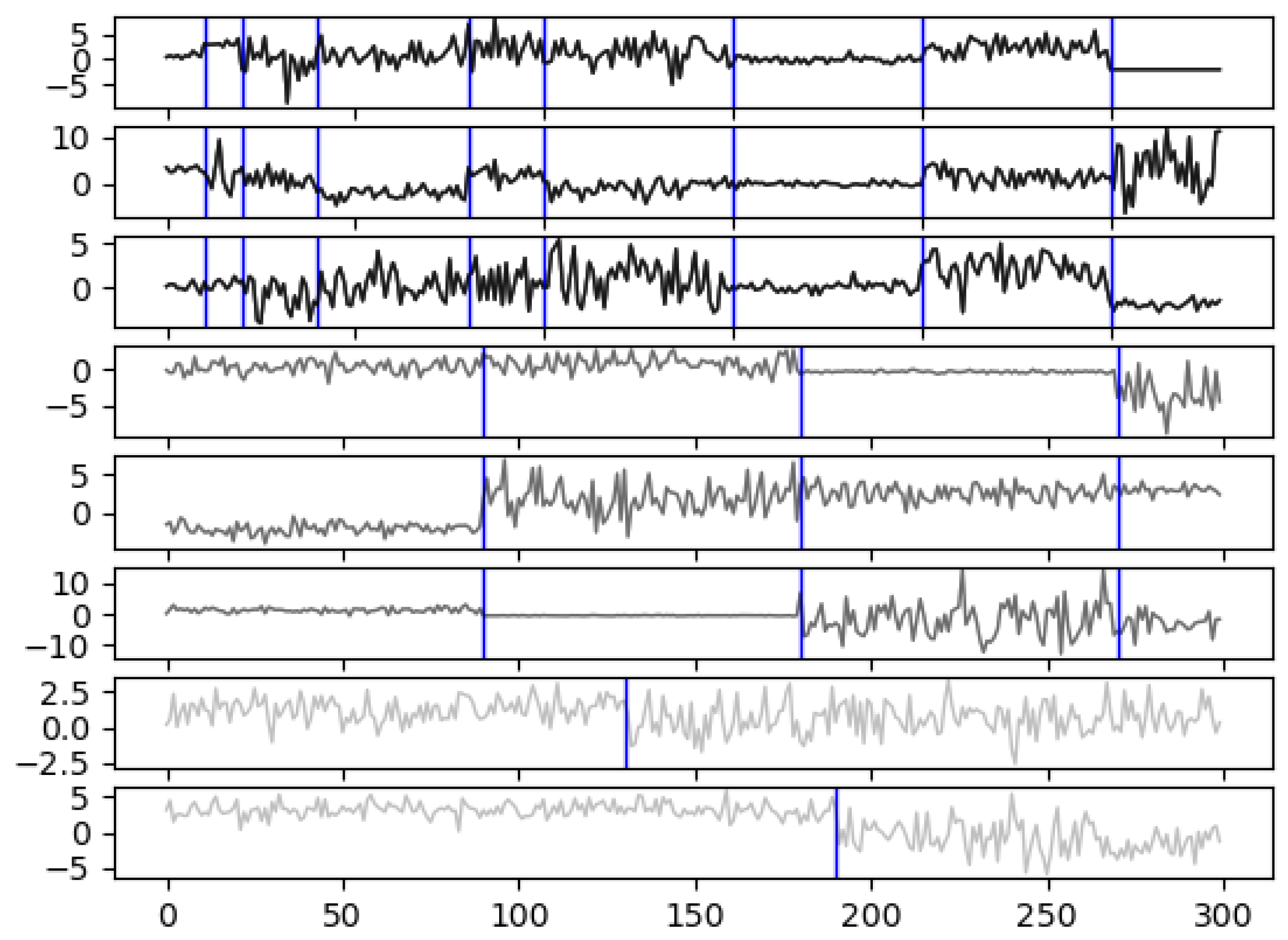
Appendix B.3. Illustration Study of Different (Semi-)Metrics


References
- Adams, Ryan Prescott, and David J. C. MacKay. 2007. Bayesian online changepoint detection. arXiv arXiv:0710.3742. [Google Scholar]
- Akhtaruzzaman, Md, Sabri Boubaker, and Ahmet Sensoy. 2020. Financial contagion during COVID–19 crisis. Finance Research Letters 38: 101604. [Google Scholar] [CrossRef] [PubMed]
- Akoglu, Leman, Hanghang Tong, and Danai Koutra. 2014. Graph based anomaly detection and description: A survey. Data Mining and Knowledge Discovery 29: 626–88. [Google Scholar] [CrossRef] [Green Version]
- Alexander, Gordon J., and Alexandre M. Baptista. 2002. Economic implications of using a mean-VaR model for portfolio selection: A comparison with mean-variance analysis. Journal of Economic Dynamics and Control 26: 1159–93. [Google Scholar] [CrossRef]
- Almahdi, Saud, and Steve Y. Yang. 2017. An adaptive portfolio trading system: A risk-return portfolio optimization using recurrent reinforcement learning with expected maximum drawdown. Expert Systems with Applications 87: 267–79. [Google Scholar] [CrossRef]
- Alves, Luiz G. A., Higor Y. D. Sigaki, Matjaž Perc, and Haroldo V. Ribeiro. 2020. Collective dynamics of stock market efficiency. Scientific Reports 10: 21992. [Google Scholar] [CrossRef] [PubMed]
- Ammar, E., and H. A. Khalifa. 2003. Fuzzy portfolio optimization a quadratic programming approach. Chaos, Solitons & Fractals 18: 1045–54. [Google Scholar] [CrossRef]
- Anagnostopoulos, K. P., and G. Mamanis. 2011. The mean–variance cardinality constrained portfolio optimization problem: An experimental evaluation of five multiobjective evolutionary algorithms. Expert Systems with Applications 38: 14208–17. [Google Scholar] [CrossRef]
- Atallah, Mikhail J. 1983. A linear time algorithm for the Hausdorff distance between convex polygons. Information Processing Letters 17: 207–9. [Google Scholar] [CrossRef] [Green Version]
- Atallah, Mikhail J., Celso C. Ribeiro, and Sergio Lifschitz. 1991. Computing some distance functions between polygons. Pattern Recognition 24: 775–81. [Google Scholar] [CrossRef] [Green Version]
- Baddeley, A. J. 1992. Errors in binary images and an Lp version of the Hausdorff metric. Nieuw Archief voor Wiskunde 10: 157–83. [Google Scholar]
- Ballestero, Enrique. 2005. Mean-semivariance efficient frontier: A downside risk model for portfolio selection. Applied Mathematical Finance 12: 1–15. [Google Scholar] [CrossRef]
- Barry, Daniel, and J. A. Hartigan. 1993. A Bayesian analysis for change point problems. Journal of the American Statistical Association 88: 309. [Google Scholar] [CrossRef]
- Basalto, Nicolas, Roberto Bellotti, Francesco De Carlo, Paolo Facchi, Ester Pantaleo, and Saverio Pascazio. 2007. Hausdorff clustering of financial time series. Physica A: Statistical Mechanics and Its Applications 379: 635–44. [Google Scholar] [CrossRef] [Green Version]
- Basalto, Nicolas, Roberto Bellotti, Francesco De Carlo, Paolo Facchi, Ester Pantaleo, and Saverio Pascazio. 2008. Hausdorff clustering. Physical Review E 78: 046112. [Google Scholar] [CrossRef] [Green Version]
- Bhansali, Vineer. 2007. Putting economics (back) into quantitative models. The Journal of Portfolio Management 33: 63–76. [Google Scholar] [CrossRef]
- Boasson, Vigdis, Emil Boasson, and Zhao Zhou. 2011. Portfolio optimization in a mean-semivariance framework. Investment Management and Financial Innovations 8: 58–68. [Google Scholar]
- Bongini, L., M. Degli Esposti, C. Giardinà, and A. Schianchi. 2002. Portfolio optimization with short-selling and spin-glass. The European Physical Journal B - Condensed Matter 27: 263–72. [Google Scholar] [CrossRef]
- Braione, Manuela, and Nicolas Scholtes. 2016. Forecasting value-at-risk under different distributional assumptions. Econometrics 4: 3. [Google Scholar] [CrossRef] [Green Version]
- Brass, Peter. 2002. On the nonexistence of Hausdorff-like metrics for fuzzy sets. Pattern Recognition Letters 23: 39–43. [Google Scholar] [CrossRef] [Green Version]
- Bridges, Robert A., John P. Collins, Erik M. Ferragut, Jason A. Laska, and Blair D. Sullivan. 2015. Multi-level anomaly detection on time-varying graph data. Paper presented at the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2015, Paris, France, August 25–28; pp. 579–83. [Google Scholar] [CrossRef] [Green Version]
- Bun, Joel, Jean-Philippe Bouchaud, and Marc Potters. 2017. Cleaning large correlation matrices: Tools from random matrix theory. Physics Reports 666: 1–109. [Google Scholar] [CrossRef]
- Calvo, Clara, Carlos Ivorra, and Vicente Liern. 2014. Fuzzy portfolio selection with non-financial goals: Exploring the efficient frontier. Annals of Operations Research 245: 31–46. [Google Scholar] [CrossRef]
- Campbell, Rachel, Ronald Huisman, and Kees Koedijk. 2001. Optimal portfolio selection in a value-at-risk framework. Journal of Banking & Finance 25: 1789–804. [Google Scholar] [CrossRef]
- Cappelli, Carmela, Roy Cerqueti, Pierpaolo D’Urso, and Francesca Di Iorio. 2021. Multiple breaks detection in financial interval-valued time series. Expert Systems with Applications 164: 113775. [Google Scholar] [CrossRef]
- Coffey, Greg. 2016. Investment Policy Statement: Elements of a Clearly Defined IPS for Non-Profits. Russell Investments Research. April. Available online: https://russellinvestments.com/-/media/files/us/insights/institutions/non-profit/elements-of-a-clearly-defined-ips-for-non-profits-an-update (accessed on 30 June 2022).
- Conci, A., and C. Kubrusly. 2017. Distances between sets—A survey. Advances in Mathematical Sciences and Applications 26: 1–18. [Google Scholar]
- del Barrio, Eustasio, Evarist Giné, and Carlos Matrán. 1999. Central limit theorems for the Wasserstein distance between the empirical and the true distributions. The Annals of Probability 27: 1009–71. [Google Scholar] [CrossRef]
- Deza, Michel Marie, and Elena Deza. 2013. Encyclopedia of Distances. Berlin and Heidelberg: Springer. [Google Scholar] [CrossRef]
- Dose, Christian, and Silvano Cincotti. 2005. Clustering of financial time series with application to index and enhanced index tracking portfolio. Physica A: Statistical Mechanics and Its Applications 355: 145–51. [Google Scholar] [CrossRef]
- Drożdż, Stanisław, Jarosław Kwapień, and Paweł Oświęcimka. 2021. Complexity in economic and social systems. Entropy 23: 133. [Google Scholar] [CrossRef]
- Drożdż, Stanisław, Jarosław Kwapień, Paweł Oświęcimka, Tomasz Stanisz, and Marcin Wątorek. 2020a. Complexity in economic and social systems: Cryptocurrency market at around COVID-19. Entropy 22: 1043. [Google Scholar] [CrossRef]
- Drożdż, Stanisław, Ludovico Minati, Paweł Oświęcimka, Marek Stanuszek, and Marcin Wątorek. 2019. Signatures of the crypto-currency market decoupling from the forex. Future Internet 11: 154. [Google Scholar] [CrossRef] [Green Version]
- Drożdż, Stanisław, Ludovico Minati, Paweł Oświęcimka, Marek Stanuszek, and Marcin Wątorek. 2020b. Competition of noise and collectivity in global cryptocurrency trading: Route to a self-contained market. Chaos: An Interdisciplinary Journal of Nonlinear Science 30: 023122. [Google Scholar] [CrossRef] [Green Version]
- Drożdż, Stanislaw, Robert Gębarowski, Ludovico Minati, Pawel Oświęcimka, and Marcin Wątorek. 2018. Bitcoin market route to maturity? Evidence from return fluctuations, temporal correlations and multiscaling effects. Chaos: An Interdisciplinary Journal of Nonlinear Science 28: 071101. [Google Scholar] [CrossRef] [Green Version]
- Dubuisson, M.-P., and A. K. Jain. 1994. A modified Hausdorff distance for object matching. Paper presented at 12th International Conference on Pattern Recognition, Jerusalem, Israel, October 9–13; pp. 566–68. [Google Scholar] [CrossRef]
- Duffie, Darrell, and Jun Pan. 1997. An overview of value at risk. The Journal of Derivatives 4: 7–49. [Google Scholar] [CrossRef] [Green Version]
- Eisler, Zoltán, and János Kertész. 2006. Scaling theory of temporal correlations and size-dependent fluctuations in the traded value of stocks. Physical Review E 73: 046109. [Google Scholar] [CrossRef] [Green Version]
- Eiter, Thomas, and Heikki Mannila. 1997. Distance measures for point sets and their computation. Acta Informatica 34: 109–33. [Google Scholar] [CrossRef]
- Fama, Eugene F. 1965. The behavior of stock-market prices. The Journal of Business 38: 34–105. [Google Scholar] [CrossRef] [Green Version]
- Fastrich, B., S. Paterlini, and P. Winker. 2014. Constructing optimal sparse portfolios using regularization methods. Computational Management Science 12: 417–34. [Google Scholar] [CrossRef]
- Fister, Dušan, Matjaž Perc, and Timotej Jagrič. 2021. Two robust long short-term memory frameworks for trading stocks. Applied Intelligence 51: 7177–95. [Google Scholar] [CrossRef]
- Fujita, Osamu. 2013. Metrics based on average distance between sets. Japan Journal of Industrial and Applied Mathematics 30: 1–19. [Google Scholar] [CrossRef] [Green Version]
- Gardner, Andrew, Jinko Kanno, Christian A. Duncan, and Rastko Selmic. 2014. Measuring distance between unordered sets of different sizes. Paper presented at Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, June 23–28; pp. 137–43. [Google Scholar] [CrossRef] [Green Version]
- Gilchrist, Warren. 2000. Statistical Modelling with Quantile Functions. Boca Raton: Chapman and Hall/CRC. [Google Scholar] [CrossRef]
- Gopikrishnan, P., M. Meyer, L. A. N. Amaral, and H. E. Stanley. 1998. Inverse cubic law for the distribution of stock price variations. The European Physical Journal B 3: 139–40. [Google Scholar] [CrossRef]
- Gustafsson, Fredrik. 2001. Adaptive Filtering and Change Detection. New York: John Wiley & Sons, Ltd. [Google Scholar] [CrossRef]
- Hawkins, Douglas M. 1977. Testing a sequence of observations for a shift in location. Journal of the American Statistical Association 72: 180–86. [Google Scholar] [CrossRef]
- Hawkins, Douglas M., and K. D. Zamba. 2005. A change-point model for a shift in variance. Journal of Quality Technology 37: 21–31. [Google Scholar] [CrossRef]
- Hawkins, Douglas M., Peihua Qiu, and Chang Wook Kang. 2003. The changepoint model for statistical process control. Journal of Quality Technology 35: 355–66. [Google Scholar] [CrossRef]
- Imbert, Fred, and Thomas Franck. 2020. Dow plunges 10% amid coronavirus fears for its worst day since the 1987 market crash. CNBC, March 12. [Google Scholar]
- Iorio, Carmela, Gianluca Frasso, Antonio D’Ambrosio, and Roberta Siciliano. 2018. A P-spline based clustering approach for portfolio selection. Expert Systems with Applications 95: 88–103. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2021a. A new measure between sets of probability distributions with applications to erratic financial behavior. Journal of Statistical Mechanics: Theory and Experiment 2021: 123404. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2021b. Association between COVID-19 cases and international equity indices. Physica D: Nonlinear Phenomena 417: 132809. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2021c. Efficiency of communities and financial markets during the 2020 pandemic. Chaos: An Interdisciplinary Journal of Nonlinear Science 31: 083116. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2022a. Collective correlations, dynamics, and behavioural inconsistencies of the cryptocurrency market over time. Nonlinear Dynamics 107: 4001–17. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2022b. Dual-domain analysis of gun violence incidents in the United States. Chaos: An Interdisciplinary Journal of Nonlinear Science 32: 111101. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2022c. Estimating a continuously varying offset between multivariate time series with application to COVID-19 in the United States. The European Physical Journal Special Topics 231: 3419–26. [Google Scholar] [CrossRef] [PubMed]
- James, Nick, and Max Menzies. 2022d. Global and regional changes in carbon dioxide emissions: 1970–2019. Physica A: Statistical Mechanics and Its Applications 608: 128302. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2022e. Optimally adaptive Bayesian spectral density estimation for stationary and nonstationary processes. Statistics and Computing 32: 45. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2022f. Spatio-temporal trends in the propagation and capacity of low-carbon hydrogen projects. International Journal of Hydrogen Energy 47: 16775–84. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2023a. Distributional trends in the generation and end-use sector of low-carbon hydrogen plants. Hydrogen 4: 174–89. [Google Scholar] [CrossRef]
- James, Nick, and Max Menzies. 2023b. Equivalence relations and Lp distances between time series with application to the Black Summer Australian bushfires. Physica D: Nonlinear Phenomena 448: 133693. [Google Scholar] [CrossRef]
- James, Nick, Max Menzies, and Georg A Gottwald. 2022. On financial market correlation structures and diversification benefits across and within equity sectors. Physica A: Statistical Mechanics and Its Applications 604: 127682. [Google Scholar] [CrossRef]
- James, Nick, Max Menzies, and Howard Bondell. 2021. Understanding spatial propagation using metric geometry with application to the spread of COVID-19 in the United States. EPL (Europhysics Letters) 135: 48004. [Google Scholar] [CrossRef]
- James, Nick, Max Menzies, and Howard Bondell. 2022. In search of peak human athletic potential: A mathematical investigation. Chaos: An Interdisciplinary Journal of Nonlinear Science 32: 023110. [Google Scholar] [CrossRef] [PubMed]
- James, Nick, Max Menzies, and Jennifer Chan. 2021. Changes to the extreme and erratic behaviour of cryptocurrencies during COVID-19. Physica A: Statistical Mechanics and Its Applications 565: 125581. [Google Scholar] [CrossRef]
- James, Nick, Max Menzies, and Kevin Chin. 2022. Economic state classification and portfolio optimisation with application to stagflationary environments. Chaos, Solitons & Fractals 164: 112664. [Google Scholar] [CrossRef]
- James, Nick, Max Menzies, James Chok, Aaron Milner, and Cas Milner. 2023. Geometric persistence and distributional trends in worldwide terrorism. Chaos, Solitons & Fractals 169: 113277. [Google Scholar] [CrossRef]
- James, Nick, Max Menzies, Lamiae Azizi, and Jennifer Chan. 2020. Novel semi-metrics for multivariate change point analysis and anomaly detection. Physica D: Nonlinear Phenomena 412: 132636. [Google Scholar] [CrossRef]
- Jin, Yan, Rong Qu, and Jason Atkin. 2016. Constrained portfolio optimisation: The state-of-the-art Markowitz models. Paper presented at the 5th the International Conference on Operations Research and Enterprise Systems, Rome, Italy, February 23–25; pp. 388–95. [Google Scholar] [CrossRef] [Green Version]
- Khraibani, Hussein, Bilal Nehme, and Olivier Strauss. 2018. Interval estimation of value-at-risk based on nonparametric models. Econometrics 6: 47. [Google Scholar] [CrossRef] [Green Version]
- Kocadağlı, Ozan, and Rıdvan Keskin. 2015. A novel portfolio selection model based on fuzzy goal programming with different importance and priorities. Expert Systems with Applications 42: 6898–912. [Google Scholar] [CrossRef]
- Koutra, Danai, Neil Shah, Joshua T. Vogelstein, Brian Gallagher, and Christos Faloutsos. 2016. Delta-Con: Principled massive-graph similarity function with attribution. ACM Transactions on Knowledge Discovery from Data 10: 1–43. [Google Scholar] [CrossRef]
- Krause, Jochen, and Marc Paolella. 2014. A fast, accurate method for value-at-risk and expected shortfall. Econometrics 2: 98–122. [Google Scholar] [CrossRef] [Green Version]
- Laloux, Laurent, Pierre Cizeau, Jean-Philippe Bouchaud, and Marc Potters. 1999. Noise dressing of financial correlation matrices. Physical Review Letters 83: 1467–70. [Google Scholar] [CrossRef] [Green Version]
- Lam, Weng Siew, Weng Hoe Lam, and Saiful Hafizah Jaaman. 2021. Portfolio optimization with a mean-absolute deviation-entropy multi-objective model. Entropy 23: 1266. [Google Scholar] [CrossRef]
- Lamoureux, Christopher G., and William D. Lastrapes. 1990. Persistence in variance, structural change, and the GARCH model. Journal of Business & Economic Statistics 8: 225–34. [Google Scholar] [CrossRef]
- León, Diego, Arbey Aragón, Javier Sandoval, Germán Hernández, Andrés Arévalo, and Jaime Niño. 2017. Clustering algorithms for risk-adjusted portfolio construction. Procedia Computer Science 108: 1334–43. [Google Scholar] [CrossRef]
- Li, Bo, and Ranran Zhang. 2021. A new mean-variance-entropy model for uncertain portfolio optimization with liquidity and diversification. Chaos, Solitons & Fractals 146: 110842. [Google Scholar] [CrossRef]
- Li, Jiahan. 2015. Sparse and stable portfolio selection with parameter uncertainty. Journal of Business & Economic Statistics 33: 381–92. [Google Scholar] [CrossRef]
- Liagkouras, K., and K. Metaxiotis. 2015. Efficient portfolio construction with the use of multiobjective evolutionary algorithms: Best practices and performance metrics. International Journal of Information Technology & Decision Making 14: 535–64. [Google Scholar] [CrossRef]
- Liagkouras, K., and K. Metaxiotis. 2018. Handling the complexities of the multi-constrained portfolio optimization problem with the support of a novel MOEA. Journal of the Operational Research Society 69: 1609–27. [Google Scholar] [CrossRef]
- Liu, Yanhui, Parameswaran Gopikrishnan, Pierre Cizeau, Martin Meyer, Chung-Kang Peng, and H. Eugene Stanley. 1999. Statistical properties of the volatility of price fluctuations. Physical Review E 60: 1390–400. [Google Scholar] [CrossRef] [Green Version]
- Long, H. Viet, H. Bin Jebreen, I. Dassios, and D. Baleanu. 2020. On the statistical GARCH model for managing the risk by employing a fat-tailed distribution in finance. Symmetry 12: 1698. [Google Scholar] [CrossRef]
- Lwin, Khin, Rong Qu, and Graham Kendall. 2014. A learning-guided multi-objective evolutionary algorithm for constrained portfolio optimization. Applied Soft Computing 24: 757–72. [Google Scholar] [CrossRef]
- Magdon-Ismail, M., A. Atiya, A. Pratap, and Y. Abu-Mostafa. 2003. The maximum drawdown of the Brownian motion. Paper presented at 2003 IEEE International Conference on Computational Intelligence for Financial Engineering, Hong Kong, China, March 20–23; pp. 243–47. [Google Scholar] [CrossRef] [Green Version]
- Mandelbrot, Benoit. 1963. The variation of certain speculative prices. The Journal of Business 36: 394–419. [Google Scholar] [CrossRef]
- Mansour, Nabil, Mohamed Sadok Cherif, and Walid Abdelfattah. 2019. Multi-objective imprecise programming for financial portfolio selection with fuzzy returns. Expert Systems with Applications 138: 112810. [Google Scholar] [CrossRef]
- Mantegna, Rosario N., H. Eugene Stanley, and Neil A. Chriss. 2000. An introduction to econophysics: Correlations and complexity in finance. Physics Today 53: 70. [Google Scholar] [CrossRef] [Green Version]
- Markowitz, Harry. 1952. Portfolio selection. The Journal of Finance 7: 77. [Google Scholar] [CrossRef]
- Meghwani, Suraj S., and Manoj Thakur. 2017. Multi-criteria algorithms for portfolio optimization under practical constraints. Swarm and Evolutionary Computation 37: 104–25. [Google Scholar] [CrossRef]
- Milhomem, Danilo Alcantara, and Maria José Pereira Dantas. 2020. Analysis of new approaches used in portfolio optimization: A systematic literature review. Production 30: e20190144. [Google Scholar] [CrossRef]
- Moody, J., and M. Saffell. 2001. Learning to trade via direct reinforcement. IEEE Transactions on Neural Networks 12: 875–89. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moreno, Sebastian, and Jennifer Neville. 2013. Network hypothesis testing using mixed kronecker product graph models. Paper presented at IEEE 13th International Conference on Data Mining, Dallas, TX, USA, December 7–10; pp. 1163–68. [Google Scholar] [CrossRef] [Green Version]
- Müllner, Daniel. 2013. Fastcluster: Fast hierarchical, agglomerative clustering routines forRandPython. Journal of Statistical Software 53: 1–18. [Google Scholar] [CrossRef] [Green Version]
- Okorie, David Iheke, and Boqiang Lin. 2020. Stock markets and the COVID-19 fractal contagion effects. Finance Research Letters 38: 101640. [Google Scholar] [CrossRef]
- Peel, Leto, and Aaron Clauset. 2015. Detecting change points in the large-scale structure of evolving networks. Paper presented at Twenty-Ninth AAAI Conference on Artificial Intelligence, AAAI’15, Austin, TX, USA, January 25–30; pp. 2914–20. [Google Scholar]
- Pessa, Arthur A. B., Matjaz Perc, and Haroldo V. Ribeiro. 2023. Age and market capitalization drive large price variations of cryptocurrencies. Scientific Reports 13. [Google Scholar] [CrossRef]
- Podobnik, Boris, Davor Horvatic, Alexander M. Petersen, and H. Eugene Stanley. 2009. Cross-correlations between volume change and price change. Proceedings of the National Academy of Sciences of the United States of America 106: 22079–84. [Google Scholar] [CrossRef] [Green Version]
- Prakash, Arjun, Nick James, Max Menzies, and Gilad Francis. 2021. Structural clustering of volatility regimes for dynamic trading strategies. Applied Mathematical Finance 28: 236–74. [Google Scholar] [CrossRef]
- Pun, Chi Seng, and Hoi Ying Wong. 2019. A linear programming model for selection of sparse high-dimensional multiperiod portfolios. European Journal of Operational Research 273: 754–71. [Google Scholar] [CrossRef]
- Ranshous, Stephen, Shitian Shen, Danai Koutra, Steve Harenberg, Christos Faloutsos, and Nagiza F. Samatova. 2015. Anomaly detection in dynamic networks: A survey. Wiley Interdisciplinary Reviews: Computational Statistics 7: 223–47. [Google Scholar] [CrossRef]
- Rosenfeld, Azriel. 1985. Distances between fuzzy sets. Pattern Recognition Letters 3: 229–33. [Google Scholar] [CrossRef]
- Ross, Gordon J. 2014. Sequential change detection in the presence of unknown parameters. Statistics and Computing 24: 1017–30. [Google Scholar] [CrossRef] [Green Version]
- Ross, Gordan J. 2015. Parametric and nonparametric sequential change detection in R: The cpm package. Journal of Statistical Software, Articles 66: 1–20. [Google Scholar] [CrossRef] [Green Version]
- Ross, Gordon J., and Niall M. Adams. 2012. Two nonparametric control charts for detecting arbitrary distribution changes. Journal of Quality Technology 44: 102–16. [Google Scholar] [CrossRef]
- Ross, Gordon J., Dimitris K. Tasoulis, and Niall M. Adams. 2013. Sequential monitoring of a Bernoulli sequence when the pre-change parameter is unknown. Computational Statistics 28: 463–79. [Google Scholar] [CrossRef]
- Rudin, Walter. 1976. Principles of Mathematical Analysis. New York: McGraw-Hill. [Google Scholar]
- Sagi, Omer, and Lior Rokach. 2018. Ensemble learning: A survey. WIREs Data Mining and Knowledge Discovery 8: e1249. [Google Scholar] [CrossRef]
- Salah, Hanen Ben, Jan G. De Gooijer, Ali Gannoun, and Mathieu Ribatet. 2018. Mean–variance and mean–semivariance portfolio selection: A multivariate nonparametric approach. Financial Markets and Portfolio Management 32: 419–36. [Google Scholar] [CrossRef]
- Sharpe, William F. 1966. Mutual fund performance. The Journal of Business 39: 119–38. [Google Scholar] [CrossRef]
- Shaw, Dong X., Shucheng Liu, and Leonid Kopman. 2008. Lagrangian relaxation procedure for cardinality-constrained portfolio optimization. Optimization Methods and Software 23: 411–20. [Google Scholar] [CrossRef]
- Shen, Weiwei, Bin Wang, Jian Pu, and Jun Wang. 2019. The kelly growth optimal portfolio with ensemble learning. Proceedings of the AAAI Conference on Artificial Intelligence 33: 1134–41. [Google Scholar] [CrossRef] [Green Version]
- Shonkwiler, R. 1989. An image algorithm for computing the Hausdorff distance efficiently in linear time. Information Processing Letters 30: 87–89. [Google Scholar] [CrossRef]
- Sigaki, Higor Y. D., Matjaž Perc, and Haroldo V. Ribeiro. 2019. Clustering patterns in efficiency and the coming-of-age of the cryptocurrency market. Scientific Reports 9: 1440. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soleimani, Hamed, Hamid Reza Golmakani, and Mohammad Hossein Salimi. 2009. Markowitz-based portfolio selection with minimum transaction lots, cardinality constraints and regarding sector capitalization using genetic algorithm. Expert Systems with Applications 36: 5058–63. [Google Scholar] [CrossRef]
- Sortino, Frank A., and Robert van der Meer. 1991. Downside risk. The Journal of Portfolio Management 17: 27–31. [Google Scholar] [CrossRef]
- Tanaka, Hideo, Peijun Guo, and I.Burhan Türksen. 2000. Portfolio selection based on fuzzy probabilities and possibility distributions. Fuzzy Sets and Systems 111: 387–97. [Google Scholar] [CrossRef]
- Tsay, Ruey S. 2010. Analysis of Financial Time Series. Wiley Series in Probability and Statistics; Hoboken: John Wiley & Sons, Inc. [Google Scholar] [CrossRef]
- Ullah, Malik Zaka, Fouad Othman Mallawi, Mir Asma, and Stanford Shateyi. 2022. On the conditional value at risk based on the Laplace distribution with application in GARCH model. Mathematics 10: 3018. [Google Scholar] [CrossRef]
- Ünlü, Ramazan, and Petros Xanthopoulos. 2021. A reduced variance unsupervised ensemble learning algorithm based on modern portfolio theory. Expert Systems with Applications 180: 115085. [Google Scholar] [CrossRef]
- Valenti, Davide, Giorgio Fazio, and Bernardo Spagnolo. 2018. Stabilizing effect of volatility in financial markets. Physical Review E 97: 062307. [Google Scholar] [CrossRef] [Green Version]
- Vercher, Enriqueta, José D. Bermúdez, and José Vicente Segura. 2007. Fuzzy portfolio optimization under downside risk measures. Fuzzy Sets and Systems 158: 769–82. [Google Scholar] [CrossRef]
- Wang, Fengzhong, Kazuko Yamasaki, Shlomo Havlin, and H. Eugene Stanley. 2006. Scaling and memory of intraday volatility return intervals in stock markets. Physical Review E 73: 026117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Shaojie, Shaobo He, Amin Yousefpour, Hadi Jahanshahi, Robert Repnik, and Matjaž Perc. 2020. Chaos and complexity in a fractional-order financial system with time delays. Chaos, Solitons & Fractals 131: 109521. [Google Scholar] [CrossRef]
- Wątorek, Marcin, Stanisław Drożdż, Jarosław Kwapień, Ludovico Minati, Paweł Oświęcimka, and Marek Stanuszek. 2021. Multiscale characteristics of the emerging global cryptocurrency market. Physics Reports 901: 1–82. [Google Scholar] [CrossRef]
- Xuan, Xiang, and Kevin Murphy. 2007. Modeling changing dependency structure in multivariate time series. Paper presented at the 24th International Conference on Machine Learning—ICML ’07, Corvalis, OR, USA, June 20–24; pp. 1055–62. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Pan, and Qingxian Xiao. 2016. Portfolio selection problem with liquidity constraints under non-extensive statistical mechanics. Chaos, Solitons & Fractals 82: 5–10. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
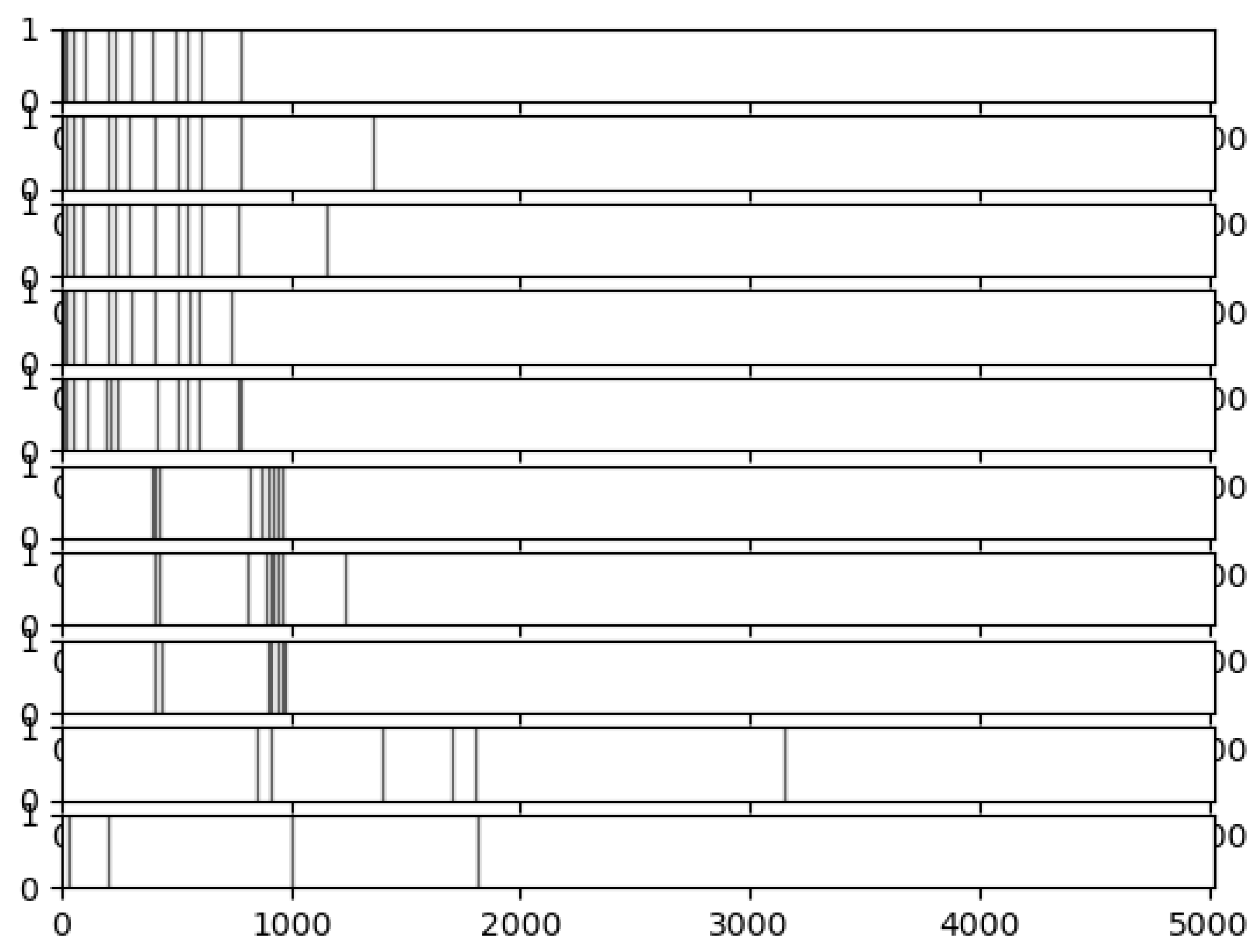
| Asset | Number of Change Points | Weights |
|---|---|---|
| Asset | 8 | 6.9% |
| Asset | 8 | 6.9% |
| Asset | 8 | 6.9% |
| Asset | 3 | 5% |
| Asset | 3 | 5% |
| Asset | 3 | 5% |
| Asset | 1 | 33.49% |
| Asset | 1 | 30.7% |
| Method | Cumulative Returns | Standard Deviation | Sharpe Ratio | Drawdown | Kurtosis |
|---|---|---|---|---|---|
| CPO | 107.04 | 0.0045 | 0.99 | 8.83 | 1.06 |
| MVO | 98.64 | 0.0060 | - | 17.08 | 1.54 |
| MSV | 105.76 | 0.0055 | 0.66 | 6.61 | 1.61 |
| MAD | 102.28 | 0.0068 | 0.21 | 13.03 | 2.38 |
| FLPM | 101.82 | 0.0063 | 0.18 | 11.05 | 0.90 |
| SLPM | 102.26 | 0.0062 | 0.23 | 10.59 | 0.90 |
| CVAR | 72.32 | 0.0061 | - | 29.23 | 0.90 |
| EVAR | 148.55 | 0.0053 | 5.77 | 27.17 | 1.57 |
| CDAR | 100.66 | 0.0066 | 0.063 | 14.22 | 2.25 |
| UCI | 100.60 | 0.0055 | 0.069 | 12.47 | 1.61 |
| Method | Cumulative Returns | Standard Deviation | Drawdown | Kurtosis |
|---|---|---|---|---|
| CPO | 99.76 | 0.018 | 33.55 | 8.55 |
| MVO | 88.82 | 0.036 | 65.13 | 15.48 |
| MSV | 88.69 | 0.036 | 65.54 | 15.60 |
| MAD | 88.06 | 0.038 | 67.71 | 15.99 |
| FLPM | 88.08 | 0.038 | 68.39 | 16.11 |
| SLPM | 88.69 | 0.036 | 65.51 | 15.60 |
| CVAR | 88.45 | 0.035 | 64.41 | 15.54 |
| EVAR | 89.12 | 0.033 | 60.99 | 14.90 |
| CDAR | 101.43 | 0.025 | 38.38 | 9.49 |
| UCI | 88.40 | 0.045 | 75.58 | 17.15 |
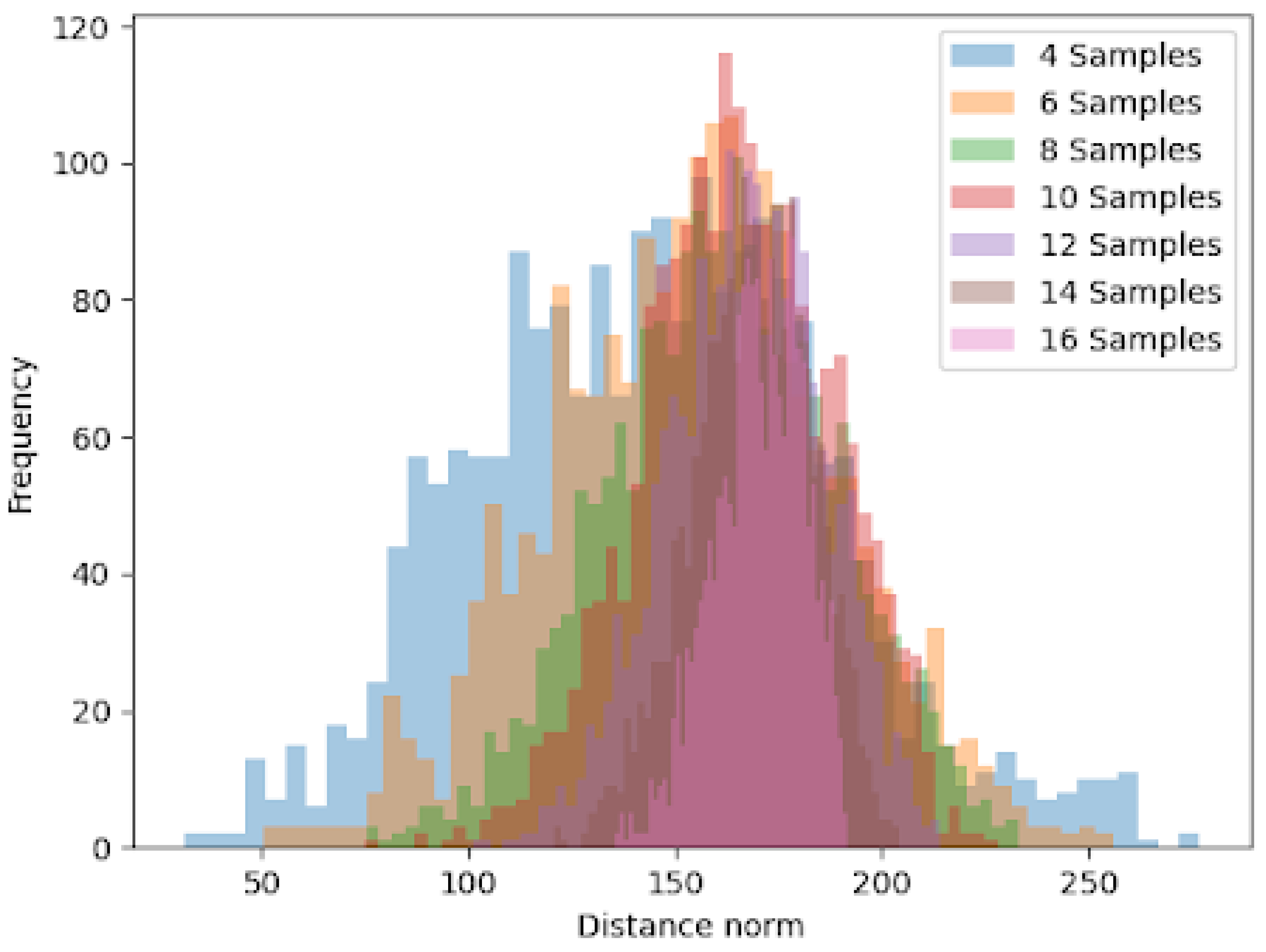
| Sample Size | Lower Limit | Upper Limit |
|---|---|---|
| 4 | 72.99 | 213.17 |
| 6 | 100.70 | 210.92 |
| 8 | 113.35 | 208.32 |
| 10 | 127.02 | 201.08 |
| 12 | 135.86 | 196.36 |
| 14 | 143.81 | 191.59 |
| 16 | 151.42 | 186.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
James, N.; Menzies, M.; Chan, J. Semi-Metric Portfolio Optimization: A New Algorithm Reducing Simultaneous Asset Shocks. Econometrics 2023, 11, 8. https://doi.org/10.3390/econometrics11010008
James N, Menzies M, Chan J. Semi-Metric Portfolio Optimization: A New Algorithm Reducing Simultaneous Asset Shocks. Econometrics. 2023; 11(1):8. https://doi.org/10.3390/econometrics11010008
Chicago/Turabian StyleJames, Nick, Max Menzies, and Jennifer Chan. 2023. "Semi-Metric Portfolio Optimization: A New Algorithm Reducing Simultaneous Asset Shocks" Econometrics 11, no. 1: 8. https://doi.org/10.3390/econometrics11010008
APA StyleJames, N., Menzies, M., & Chan, J. (2023). Semi-Metric Portfolio Optimization: A New Algorithm Reducing Simultaneous Asset Shocks. Econometrics, 11(1), 8. https://doi.org/10.3390/econometrics11010008