
Biases in the Maximum Simulated Likelihood Estimation of the Mixed Logit Model


Abstract
:1. Introduction
2. Maximum Simulated Likelihood Estimator
3. Materials and Methods
3.1. Random Utility Maximization
3.2. Multinomial Logit (MNL) Model
3.3. Mixed Logit (MIXL) Model
3.4. Simulated Likelihood Function of MIXL
4. Results
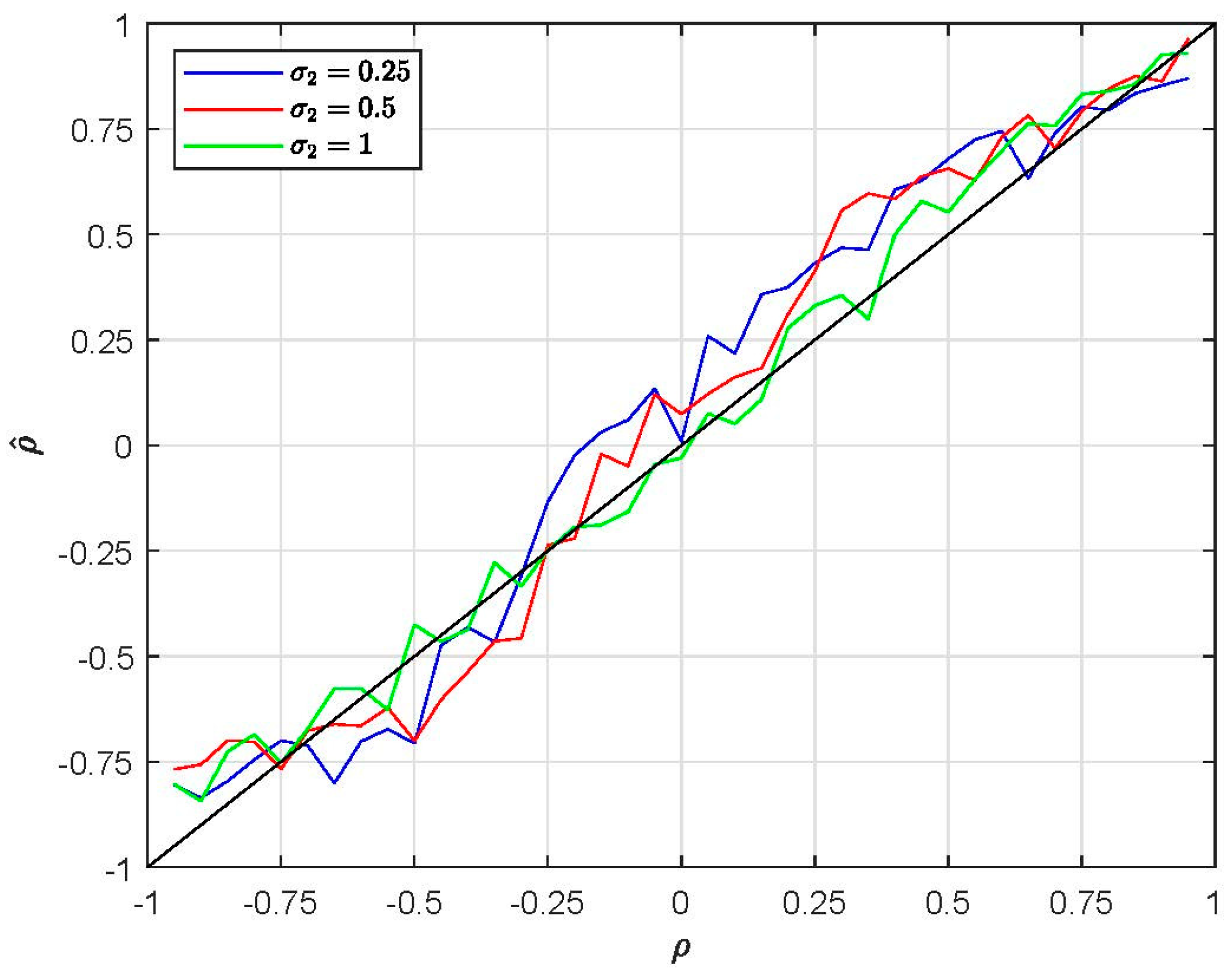
4.1. Taste Patterns: EC1 Simulation Evidence
4.2. Substitution Patterns: EC2 Simulation Evidence
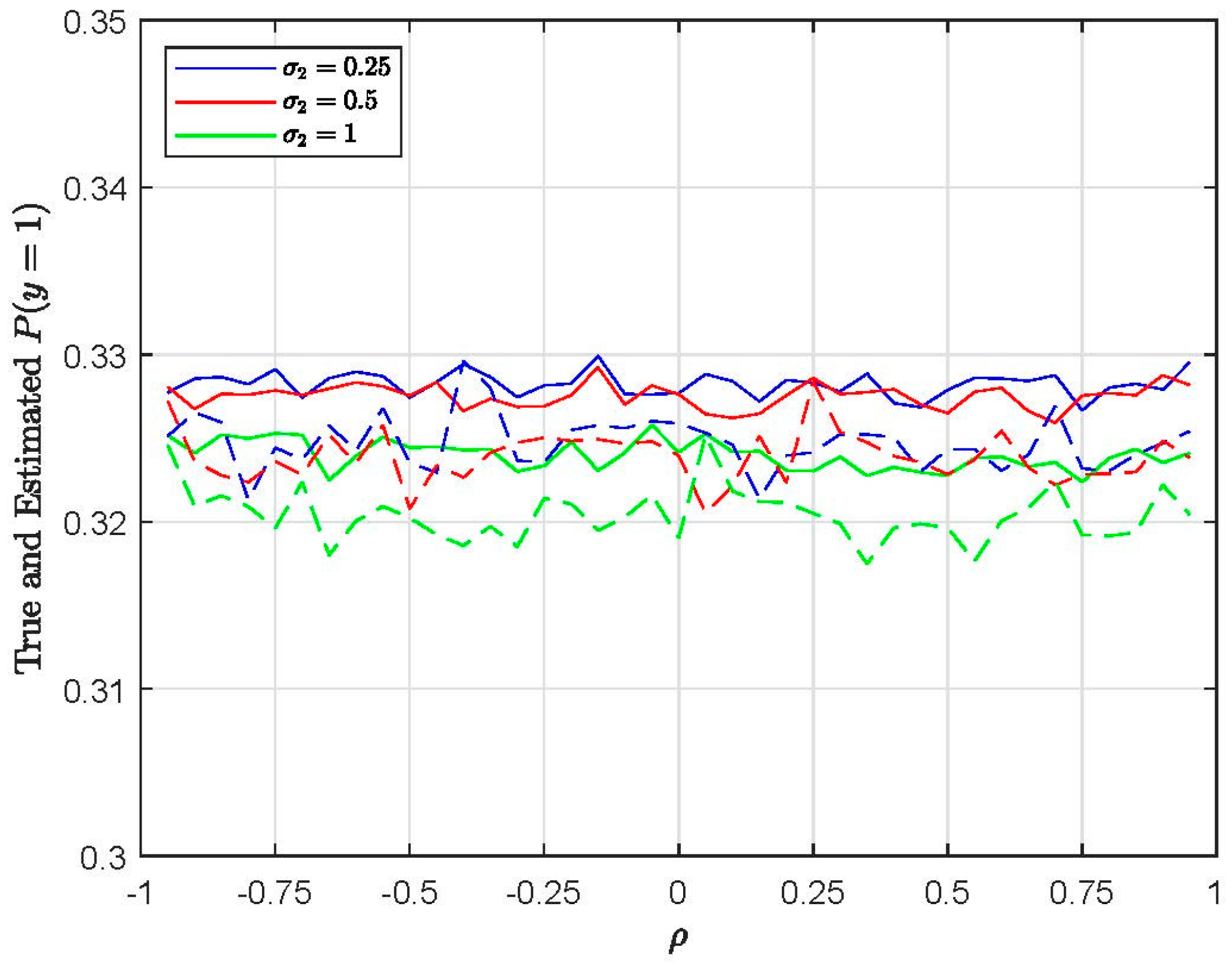
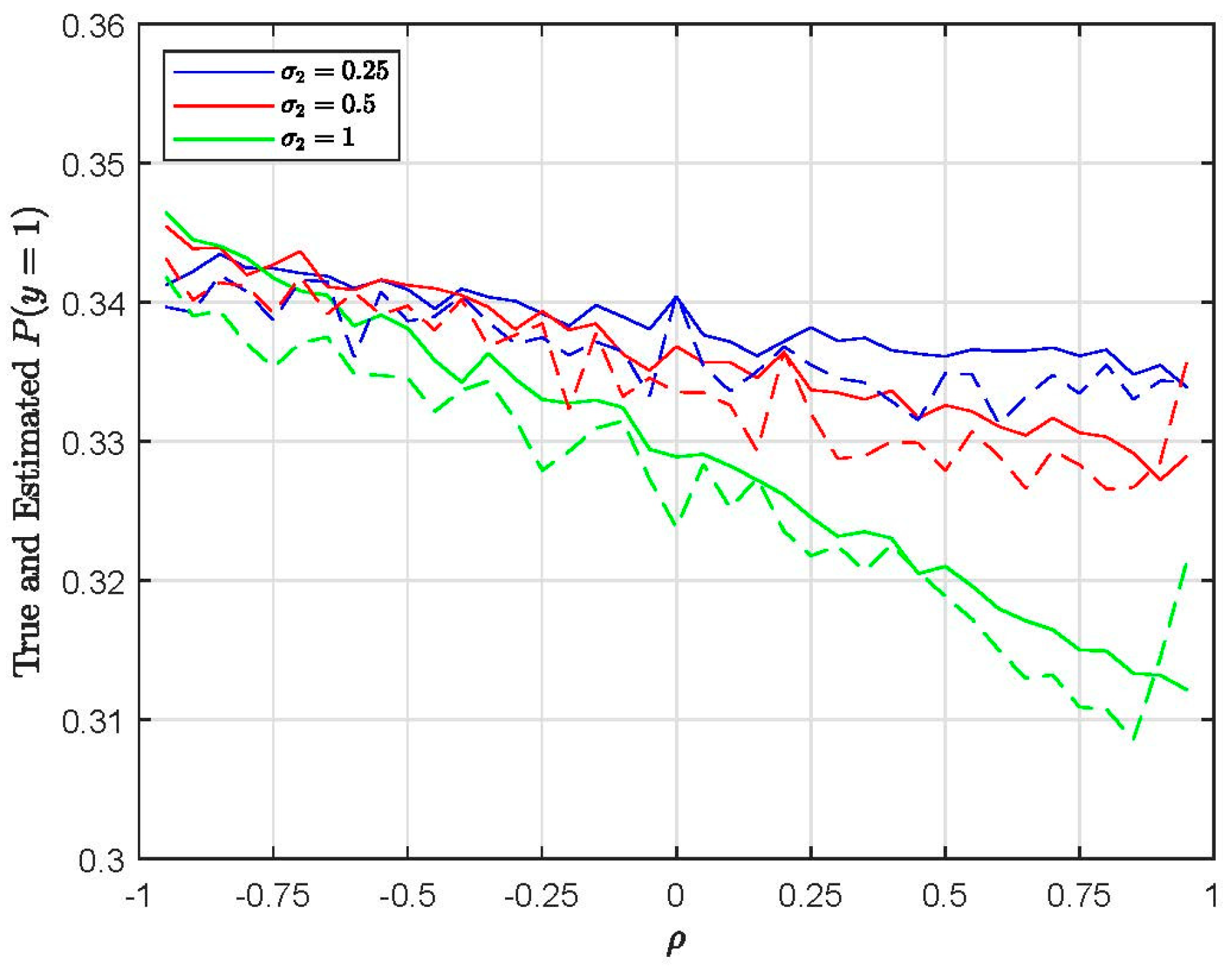
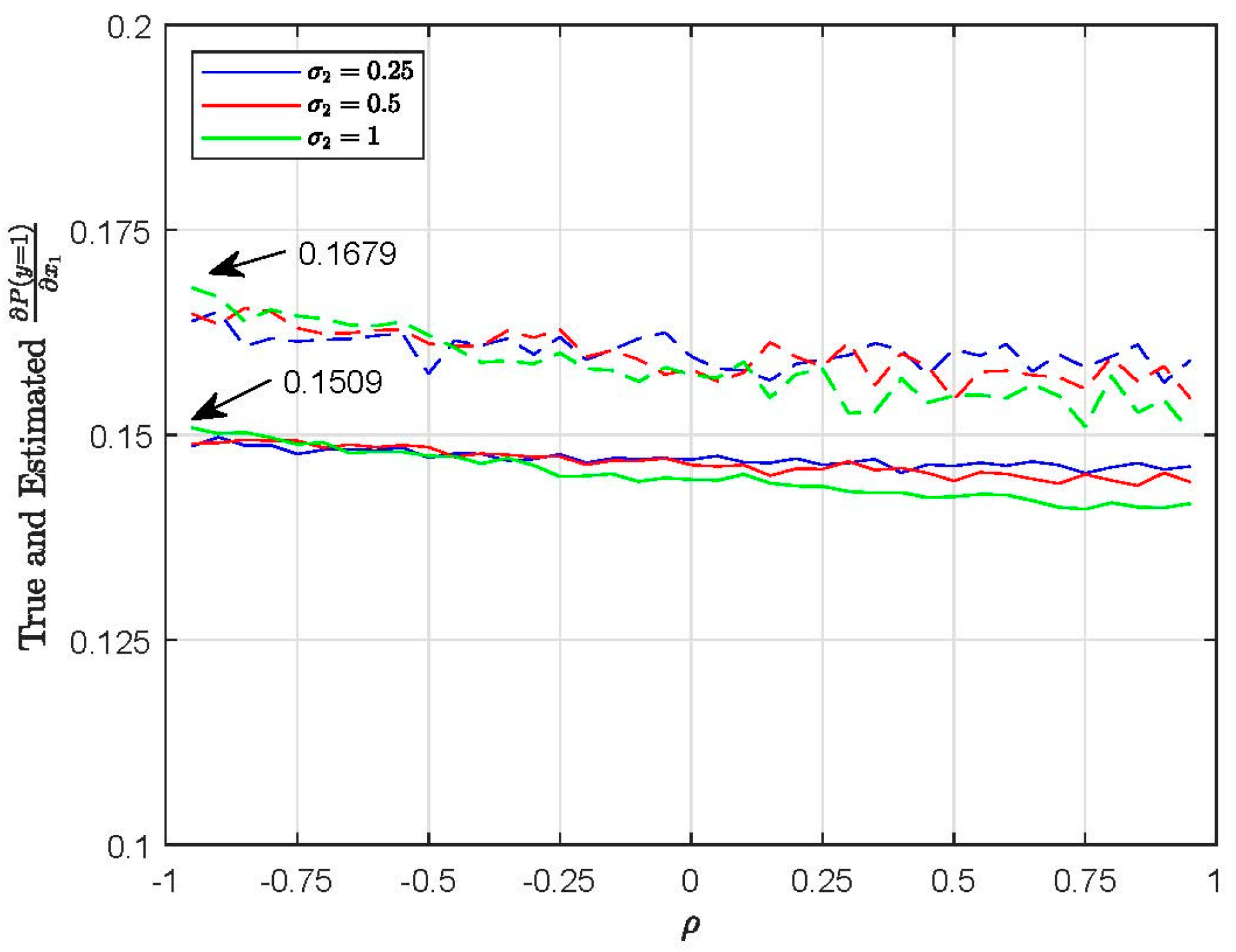
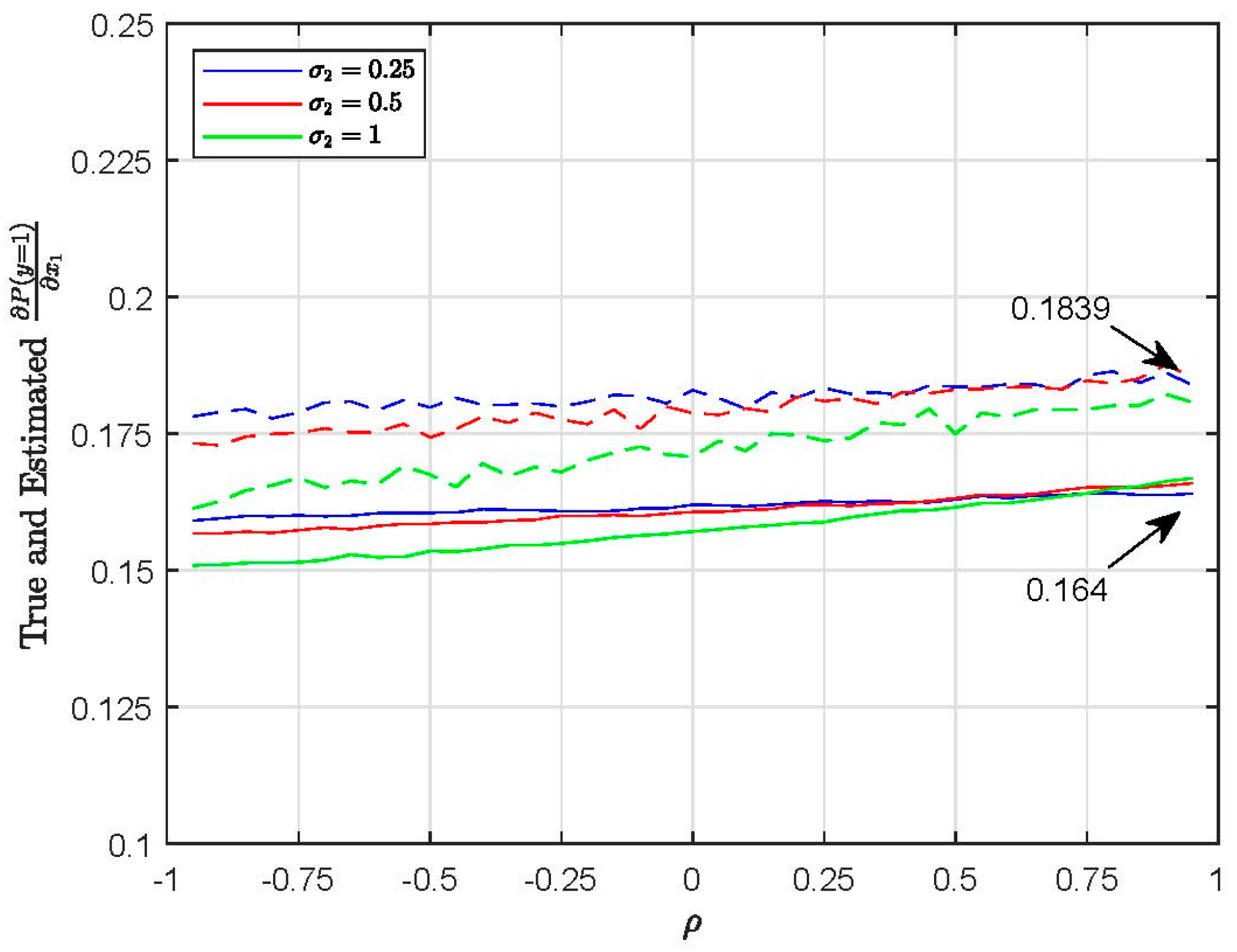
4.3. Choice Probabilities and Marginal Effects
5. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Bastin, Fabian, and Cinzia Cirillo. 2010. Reducing simulation bias in mixed logit model estimation. Journal of Choice Modelling 3: 71–88. [Google Scholar] [CrossRef]
- Ben-Akiva, Moshe, Denis Bolduc, and Mark Bradley. 1993. Estimation of travel choice models with randomly distributed values of time. Transportation Research Record 1413: 88–97. [Google Scholar]
- Bhat, Chandra. 1998. Accommodating flexible substitution patterns in multidimensional choice modeling: Formulation and application to travel mode and departure time choice. Transportation Research Part B: Methodological 32: 455–66. [Google Scholar] [CrossRef]
- Bhat, Chandra. 2000. Incorporating observed and unobserved heterogeneity in urban work travel mode choice modeling. Transportation Science 34: 228–38. [Google Scholar] [CrossRef]
- Bhat, Chandra. 2001. Quasi-random maximum simulated likelihood estimation of the mixed multinomial logit model. Transportation Research Part B: Methodological 35: 677–93. [Google Scholar] [CrossRef]
- Boyd, Hayden, and Robert Mellman. 1980. The effect of fuel economy standards on the U.S. automotive market: An hedonic demand analysis. Transportation Research Part A: General 14: 367–78. [Google Scholar] [CrossRef]
- Brownstone, David, and Kenneth Train. 1998. Forecasting new product penetration with flexible substitution patterns. Journal of Econometrics 89: 109–29. [Google Scholar] [CrossRef]
- Cardell, Scott, and Frederick Dunbar. 1980. Measuring the societal impacts of automobile downsizing. Transportation Research Part A: General 14: 423–34. [Google Scholar] [CrossRef]
- Czajkowski, Mikołaj, and Wiktor Budziński. 2019. Simulation error in maximum likelihood estimation of discrete choice models. Journal of Choice Modelling 31: 73–85. [Google Scholar] [CrossRef]
- Debreu, Gerard. 1960. Review of Duncan Luce, Individual Choice Behavior: A theoretical analysis. American Economic Review 50: 186–88. [Google Scholar]
- Elshiewy, Ossama, German Zenetti, and Yasemin Boztug. 2017. Differences between classical and Bayesian estimates for mixed logit models: A replication study. Journal of Applied Econometrics 32: 470–76. [Google Scholar] [CrossRef]
- Fiebig, Denzil, Michael Keane, Jordan Louviere, and Nada Wasi. 2010. The generalized multinomial logit model: Accounting for scale and coefficient heterogeneity. Marketing Science 29: 393–421. [Google Scholar] [CrossRef]
- Gourieroux, Christian, and Alain Monfort. 1990. Simulation based inference in models with heterogeneity. Annales d’Economie et de Statistique 20/21: 69–107. [Google Scholar] [CrossRef]
- Gourieroux, Christian, and Alain Monfort. 1996. Simulation-Based Econometric Methods. New York: Oxford University Press. [Google Scholar]
- Greene, William, and David Hensher. 2010. Does scale heterogeneity across individuals matter? An empirical assessment of alternative logit models. Transportation 37: 413–28. [Google Scholar] [CrossRef]
- Haan, Peter, Daniel Kemptner, and Arne Uhlendorff. 2015. Bayesian procedures as a numerical tool for the estimation of an intertemporal discrete choice model. Empirical Economics 49: 1123–41. [Google Scholar] [CrossRef]
- Hajivassiliou, Vassilis, Daniel McFadden, and Paul Ruud. 1996. Simulation of multivariate normal rectangle probabilities and their derivatives theoretical and computational results. Journal of Econometrics 72: 85–134. [Google Scholar] [CrossRef]
- Hensher, David, and William Greene. 2003. The mixed logit model: The state of practice. Transportation 30: 133–76. [Google Scholar] [CrossRef]
- Hensher, David, John Rose, and William Greene. 2005. Applied Choice Analysis: A Primer. Cambridge: Cambridge University Press. [Google Scholar]
- Hess, Stephane, and John Rose. 2012. Can scale and coefficient heterogeneity be separated in random coefficients models? Transportation 39: 1225–39. [Google Scholar] [CrossRef]
- Hess, Stephane, and Kenneth Train. 2017. Correlation and scale in mixed logit models. Journal of Choice Modelling 23: 1–8. [Google Scholar] [CrossRef]
- Hess, Stephane, Michel Bierlaire, and John Polak. 2005. Estimation of value of travel-time savings using mixed logit models. Transportation Research Part A: Policy and Practice 39: 221–36. [Google Scholar] [CrossRef]
- Huber, Joel, and Kenneth Train. 2001. On the similarity of classical and Bayesian estimates of individual mean partworths. Marketing Letters 12: 259–69. [Google Scholar] [CrossRef]
- Jumamyradov, Maksat, and Murat Munkin. 2021. Biases in maximum simulated likelihood estimation of bivariate models. Journal of Econometric Methods 11: 55–70. [Google Scholar] [CrossRef]
- Keane, Michael, and Nada Wasi. 2013. Comparing alternative models of heterogeneity in consumer choice behavior. Journal of Applied Econometrics 28: 1018–45. [Google Scholar] [CrossRef]
- Lee, Lung-Fei. 1995. Asymptotic bias in simulated maximum likelihood estimation of discrete choice models. Econometric Theory 11: 437–83. [Google Scholar] [CrossRef]
- Lerman, Steven, and Charles Manski. 1980. On the use of simulated frequencies to approximate choice probabilities. In Structural Analysis of Discrete Data with Econometric Applications. Edited by Charles Manski and Daniel McFadden. Cambridge: MIT Press, pp. 305–19. [Google Scholar]
- Louviere, Jordan, Deborah Street, Leonie Burgess, Nada Wasi, Towhidul Islam, and Anthony Marley. 2008. Modeling the choices of individual decision-makers by combining efficient choice experiment designs with extra preference information. Journal of Choice Modelling 1: 128–64. [Google Scholar] [CrossRef]
- Louviere, Jordan, Deborah Street, Richard Carson, Andrew Ainslie, Jay DeShazo, Trudy Cameron, David Hensher, Robert Kohn, and Tony Marley. 2002. Dissecting the random component of utility. Marketing Letters 13: 177–93. [Google Scholar] [CrossRef]
- Louviere, Jordan, Robert Meyer, David Bunch, Richard Carson, Benedict Dellaert, Michael Hanemann, David Hensher, and Julie Irwin. 1999. Combining sources of preference data for modeling complex decision processes. Marketing Letters 10: 205–17. [Google Scholar] [CrossRef]
- McFadden, Daniel. 1974. Conditional logit analysis of qualitative choice behavior. In Frontiers in Econometrics. Edited by Paul Zarambka. New York: Academic Press, pp. 105–42. [Google Scholar]
- McFadden, Daniel. 2001. Economic choices. American Economic Review 91: 351–78. [Google Scholar] [CrossRef]
- McFadden, Daniel, and Kenneth Train. 2000. Mixed mnl models for discrete response. Journal of Applied Econometrics 15: 447–70. [Google Scholar] [CrossRef]
- Palma, Marco, Dmitry Vedenov, and David Bessler. 2020. The order of variables, simulation noise, and accuracy of mixed logit estimates. Empirical Economics 58: 2049–83. [Google Scholar] [CrossRef]
- Quandt, Richard. 1970. The Demand for Travel: Theory and Measurement. Lexington: Heath and Company. [Google Scholar]
- Regier, Dean A., Mandy Ryan, Euan Phimister, and Carlo A. Marra. 2009. Bayesian and classical estimation of mixed logit: An application to genetic testing. Journal of Health Economics 28: 598–610. [Google Scholar] [CrossRef] [PubMed]
- Revelt, David, and Kenneth Train. 1998. Mixed logit with repeated choices: Households’ choices of appliance efficiency level. The Review of Economics and Statistics 80: 647–57. [Google Scholar] [CrossRef]
- Train, Kenneth. 2009. Discrete Choice Methods with Simulation. New York: Cambridge University Press. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 250 Draws | 500 Draws | 1000 Draws | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| M0 | −0.307 | −0.299 | −0.299 | −0.299 | −0.301 | −0.303 | −0.308 | −0.298 | −0.308 | |
| (0.008) | (0.009) | (0.009) | (0.008) | (0.009) | (0.009) | (0.008) | (0.009) | (0.009) | ||
| −0.349 | −0.342 | −0.273 | −0.349 | −0.342 | −0.296 | −0.348 | −0.344 | −0.289 | ||
| (0.010) | (0.009) | (0.011) | (0.009) | (0.010) | (0.012) | (0.010) | (0.010) | (0.011) | ||
| 1.131 | 1.122 | 1.163 | 1.133 | 1.141 | 1.154 | 1.132 | 1.137 | 1.159 | ||
| (0.011) | (0.011) | (0.012) | (0.012) | (0.012) | (0.012) | (0.011) | (0.011) | (0.012) | ||
| 1.248 | 1.197 | 1.070 | 1.265 | 1.241 | 1.136 | 1.245 | 1.220 | 1.120 | ||
| (0.013) | (0.013) | (0.017) | (0.013) | (0.019) | (0.027) | (0.013) | (0.014) | (0.025) | ||
| 0.413 | 0.569 | 0.885 | 0.439 | 0.662 | 0.930 | 0.405 | 0.566 | 0.897 | ||
| (0.026) | (0.023) | (0.038) | (0.030) | (0.033) | (0.054) | (0.025) | (0.022) | (0.050) | ||
| −0.877 | −0.938 | −0.975 | −0.875 | −0.899 | −0.970 | −0.887 | −0.904 | −0.973 | ||
| (0.026) | (0.017) | (0.008) | (0.025) | (0.023) | (0.009) | (0.025) | (0.021) | (0.009) | ||
| M1 | −0.308 | −0.297 | −0.294 | −0.300 | −0.302 | −0.302 | −0.308 | −0.298 | −0.302 | |
| (0.008) | (0.009) | (0.009) | (0.009) | (0.009) | (0.009) | (0.008) | (0.009) | (0.009) | ||
| −0.342 | −0.342 | −0.295 | −0.342 | −0.337 | −0.323 | −0.342 | −0.341 | −0.323 | ||
| (0.010) | (0.010) | (0.011) | (0.010) | (0.010) | (0.012) | (0.010) | (0.010) | (0.012) | ||
| 1.151 | 1.147 | 1.196 | 1.151 | 1.167 | 1.190 | 1.151 | 1.162 | 1.190 | ||
| (0.011) | (0.011) | (0.011) | (0.012) | (0.012) | (0.012) | (0.011) | (0.010) | (0.012) | ||
| 1.250 | 1.227 | 1.179 | 1.261 | 1.254 | 1.264 | 1.249 | 1.239 | 1.263 | ||
| (0.014) | (0.015) | (0.020) | (0.016) | (0.019) | (0.025) | (0.014) | (0.016) | (0.025) | ||
| 0.305 | 0.522 | 1.013 | 0.322 | 0.563 | 1.107 | 0.320 | 0.508 | 1.108 | ||
| (0.033) | (0.036) | (0.042) | (0.035) | (0.039) | (0.049) | (0.031) | (0.032) | (0.048) | ||
| M2 | −0.307 | −0.295 | −0.291 | −0.299 | −0.299 | −0.299 | −0.307 | −0.297 | −0.299 | |
| (0.008) | (0.009) | (0.009) | (0.008) | (0.009) | (0.009) | (0.008) | (0.009) | (0.009) | ||
| −0.348 | −0.354 | −0.315 | −0.348 | −0.349 | −0.341 | −0.348 | −0.352 | −0.340 | ||
| (0.010) | (0.010) | (0.011) | (0.010) | (0.009) | (0.011) | (0.010) | (0.010) | (0.011) | ||
| 1.127 | 1.114 | 1.148 | 1.126 | 1.132 | 1.140 | 1.127 | 1.129 | 1.140 | ||
| (0.011) | (0.011) | (0.011) | (0.012) | (0.012) | (0.012) | (0.011) | (0.010) | (0.012) | ||
| 1.249 | 1.239 | 1.193 | 1.262 | 1.266 | 1.272 | 1.249 | 1.250 | 1.272 | ||
| (0.012) | (0.014) | (0.017) | (0.013) | (0.016) | (0.024) | (0.012) | (0.014) | (0.024) | ||
| 0.430 | 0.677 | 1.200 | 0.446 | 0.722 | 1.271 | 0.430 | 0.649 | 1.271 | ||
| (0.025) | (0.030) | (0.034) | (0.028) | (0.030) | (0.045) | (0.025) | (0.025) | (0.045) | ||
| 250 Draws | 500 Draws | 1000 Draws | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| M0 | −0.274 | −0.271 | −0.241 | −0.278 | −0.246 | −0.243 | −0.285 | −0.266 | −0.238 | |
| (0.012) | (0.012) | (0.012) | (0.011) | (0.012) | (0.012) | (0.012) | (0.011) | (0.012) | ||
| −0.341 | −0.299 | −0.227 | −0.321 | −0.289 | −0.233 | −0.349 | −0.301 | −0.216 | ||
| (0.011) | (0.013) | (0.012) | (0.014) | (0.015) | (0.014) | (0.014) | (0.013) | (0.012) | ||
| 1.160 | 1.127 | 1.078 | 1.165 | 1.126 | 1.071 | 1.146 | 1.127 | 1.069 | ||
| (0.009) | (0.009) | (0.010) | (0.009) | (0.010) | (0.009) | (0.008) | (0.008) | (0.009) | ||
| 0.258 | 0.469 | 0.892 | 0.284 | 0.484 | 0.874 | 0.252 | 0.442 | 0.853 | ||
| (0.055) | (0.050) | (0.044) | (0.058) | (0.060) | (0.044) | (0.053) | (0.050) | (0.043) | ||
| −0.781 | −0.810 | −0.799 | −0.826 | −0.740 | −0.819 | −0.805 | −0.768 | −0.803 | ||
| (0.040) | (0.034) | (0.036) | (0.037) | (0.039) | (0.033) | (0.034) | (0.035) | (0.036) | ||
| M1 | −0.243 | −0.200 | −0.095 | −0.247 | −0.188 | −0.093 | −0.255 | −0.199 | −0.095 | |
| (0.009) | (0.009) | (0.009) | (0.009) | (0.009) | (0.010) | (0.010) | (0.010) | (0.009) | ||
| −0.285 | −0.241 | −0.161 | −0.292 | −0.244 | −0.171 | −0.312 | −0.247 | −0.161 | ||
| (0.010) | (0.011) | (0.013) | (0.013) | (0.013) | (0.016) | (0.011) | (0.013) | (0.013) | ||
| 1.153 | 1.111 | 1.085 | 1.157 | 1.117 | 1.080 | 1.132 | 1.113 | 1.084 | ||
| (0.010) | (0.009) | (0.011) | (0.009) | (0.011) | (0.012) | (0.008) | (0.010) | (0.011) | ||
| 0.335 | 0.534 | 1.199 | 0.452 | 0.660 | 1.199 | 0.365 | 0.558 | 1.211 | ||
| (0.052) | (0.053) | (0.058) | (0.049) | (0.053) | (0.060) | (0.041) | (0.050) | (0.055) | ||
| M2 | −0.283 | −0.280 | −0.278 | −0.283 | −0.265 | −0.281 | −0.291 | −0.278 | −0.278 | |
| (0.012) | (0.012) | (0.013) | (0.012) | (0.013) | (0.010) | (0.013) | (0.011) | (0.013) | ||
| −0.319 | −0.312 | −0.308 | −0.319 | −0.303 | −0.319 | −0.347 | −0.316 | −0.308 | ||
| (0.013) | (0.015) | (0.016) | (0.016) | (0.017) | (0.019) | (0.015) | (0.016) | (0.016) | ||
| 1.160 | 1.134 | 1.123 | 1.160 | 1.129 | 1.117 | 1.144 | 1.135 | 1.123 | ||
| (0.010) | (0.010) | (0.011) | (0.010) | (0.011) | (0.011) | (0.009) | (0.010) | (0.011) | ||
| 0.235 | 0.452 | 1.027 | 0.223 | 0.449 | 1.058 | 0.222 | 0.451 | 1.028 | ||
| (0.048) | (0.047) | (0.055) | (0.052) | (0.053) | (0.044) | (0.045) | (0.045) | (0.055) | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jumamyradov, M.; Munkin, M.; Greene, W.H.; Craig, B.M. Biases in the Maximum Simulated Likelihood Estimation of the Mixed Logit Model. Econometrics 2024, 12, 8. https://doi.org/10.3390/econometrics12020008
Jumamyradov M, Munkin M, Greene WH, Craig BM. Biases in the Maximum Simulated Likelihood Estimation of the Mixed Logit Model. Econometrics. 2024; 12(2):8. https://doi.org/10.3390/econometrics12020008
Chicago/Turabian StyleJumamyradov, Maksat, Murat Munkin, William H. Greene, and Benjamin M. Craig. 2024. "Biases in the Maximum Simulated Likelihood Estimation of the Mixed Logit Model" Econometrics 12, no. 2: 8. https://doi.org/10.3390/econometrics12020008
APA StyleJumamyradov, M., Munkin, M., Greene, W. H., & Craig, B. M. (2024). Biases in the Maximum Simulated Likelihood Estimation of the Mixed Logit Model. Econometrics, 12(2), 8. https://doi.org/10.3390/econometrics12020008