1. Introduction
Since the seminal work of Mandelbrot [
1] and Fama [
2], the stable Paretian distribution for modeling financial asset returns has generated increasing interest, as computer power required for its computation became commonplace, and given its appealing theoretical properties of (i) summability (as can be used for portfolio analysis; see [
3,
4,
5], and the references therein); (ii) its heavy tails and asymmetry that are ubiquitously characteristic of financial asset returns; and (iii) it being the limiting distribution of sums of various independent identically distributed (i.i.d.) random variables,
i.e., such sums are in the domain of attraction of a stable law; see, e.g., Geluk and De Haan [
6] and the references therein. McCulloch [
7], Rachev and Mittnik [
8], Borak
et al. [
9], and Nolan [
10] offer extensive accounts of the stable distribution and its wide applicability in finance, while Samorodnitsky and Taqqu [
11] provides a more technical development including the multivariate setting. Extensions and compliments to the use of the stable Paretian include the tempered stable (see e.g., [
12,
13], and the references therein) and the geometric stable (see, e.g., [
14,
15,
16], and the numerous references therein).
As asset returns measured at the weekly, daily, or higher frequency exhibit the near-immutable property of conditional heteroskedasticity, GARCH-type models are employed when interest centers on short-term density and risk prediction. While such models, driven by Gaussian innovations, result in a heavy-tailed process (see [
17,
18,
19,
20]; and the references therein), the residuals themselves are still highly non-Gaussian, and numerous suggestions have been made for replacing the Gaussian distribution with a leptokurtic one, the seminal article being Bollerslev [
21] with the use of a Student’s
t. Owing to computational advances, the stable distribution was subsequently used; see [
22,
23,
24] for details of this model, its computation based on maximum likelihood, and the stationarity conditions.
In this paper, we propose two estimation methods. The first is based on traditional use of the MLE, and focuses on a new, efficient, vectorized evaluation of the stable density. The second is a very different and new estimation methodology for the stable-GARCH model that is extremely fast, as it does not require evaluation of the likelihood or numerical optimization methods.
Given (i) the appealing theoretical properties of the stable distribution; (ii) the fact that the expected shortfall (ES) risk measure, as a left tail partial first moment (
, where
c is the VaR), is potentially highly dependent on the distributional assumption (see [
25,
26], and the references therein); and (iii) that ES is not elicitable and thus more difficult to empirically test compared to VaR (see [
27]), one is motivated to test the validity of the stable Paretian assumption as the innovations sequence for a GARCH-type model used for risk prediction or asset allocation.
Testing the stable Paretian distribution has been considered by several authors. Koutrouvelis and Meintanis [
28], Meintanis [
29], and Matsui and Takemura [
30] use the empirical characteristic function to develop testing procedures in the symmetric stable case. Fama and Roll [
31], Lau and Lau [
32], and Paolella [
33,
34] consider the change in the estimated tail index,
α, as the data are summed: If the data are stable, then the value of
α should not change, whereas for many alternatives outside the stable class, the classic central limit theorem will be at work, and the values of
α will tend to increase towards two as the data are summed. McCulloch and Percy [
35] propose a set of composite (unknown parameter case) tests for, among others, the symmetric stable distribution and are able to reject the null in their applications, though they attribute this primarily to the presence of asymmetry.
Paolella [
34] also proposes a test based on the difference of two consistent estimators of the tail index
α, and combines this with a new summability test, termed
, yielding a test that is (i) size correct; (ii) often substantially more powerful than either of its two constituents and much more powerful than the test based on the empirical characteristic function; (iii) easily computed, without the need for the density or maximum likelihood (ML) estimation of the stable distribution; (iv) applicable in the asymmetric case; and (v) also delivers an approximate
p-value.
Our second interest in this paper is to use some of these tests applied to the filtered innovations sequences of stable-GARCH models, in an effort to determine the applicability of the stable assumption as the underlying distribution. While the literature is rich in proposing various GARCH-type models with a variety of distributional assumptions on the innovations process, there is not as much work dedicated to testing such assumptions. Klar
et al. [
36] propose use of a characteristic function based test applied to the filtered residuals and use a bootstrap to assess small-sample properties; and also contains references to some earlier literature for GARCH distributional testing.
Of interest in such a testing framework are the results of Sun and Zhou [
37], which demonstrate that, as the normal-GARCH process approaches the IGARCH border, the filtered innovation sequence could exhibit artificially heavier tails. Recall that, in classic time series literature, it is known that, if an AR(1) model is misspecified and the true process contains time-varying parameters or structural breaks, then, as the sample size increases, the probability of unit-root tests not rejecting the null of a unit root often increases; see, e.g., Kim
et al. [
38] and the references therein. Similarly, in a GARCH context, under certain types of misspecification, as the sample size increases, the fitted GARCH model will tend to the IGARCH border as the sample size increases. We attempt to counteract this phenomenon by (i) using short windows of data; (ii) fit the rather flexible stable-APARCH model, as opposed to appealing to quasi-maximum likelihood, which uses a normality assumption on the error term in the GARCH process; and (iii) investigate results when imposing a fixed APARCH structure which is not close to the IGARCH border; see
Section 5.3 below, and, in particular, the discussion of the use of (18). In this way, the (in general, highly relevant) findings of Sun and Zhou [
37] are less applicable to our setting.
Anticipating our empirical results below, we find that, for most stocks and numerous segments of time, the assumption of the innovation process driving a GARCH-type process being i.i.d. asymmetric stable Paretian cannot be rejected. However, when viewing all the resulting p-values, they follow more of an exponential-type distribution rather than a uniform, and thus there is substantial evidence against the stable as the correct distribution for all stocks and time periods.
The remainder of this paper is structured as follows.
Section 2 discusses and refutes the common argument against using the stable distribution for modeling financial asset returns.
Section 3 briefly introduces the stable distribution and methods for its computation and estimation, while
Section 4 details the tests for the symmetric and asymmetric stable Paretian assumption.
Section 5 discusses two new methods for estimating a stable-APARCH process and also provides a comparison with the competitive method of estimation based on the characteristic function, in the i.i.d. setting.
Section 6 provides simulation evidence under the true model and some deviations from it, to illustrate the behavior of the model parameter estimates and test statistics.
Section 7 provides an empirical illustration, applying the tests to the filtered innovations sequences of the fitted stable-APARCH process to the constituents of the DJIA-30 and the 100 largest market-cap stocks from the S&P500 index.
Section 8 provides concluding remarks concerning distributional choices for modeling asset returns and the role of testing.
2. Critique of the Stable Paretian Assumption
The primary argument invoked by some against use of the stable Paretian distribution in a financial context is that (except in the special case of the Gaussian), the second moment,
i.e., the variance, does not exist. We wish to dismantle this concern. There indeed exists literature, influential papers including Loretan and Phillips [
39], that provide evidence of the existence of second moments in financial data. The problem with all such attempts at inference in this regard is that the determination of the maximally existing moment of a set of data is notoriously difficult; see McCulloch [
40], Mittnik
et al. [
41], McNeil
et al. [
42], Heyde and Kou [
43], and the references therein for critique of such studies.
It should be noted that non-existence of variance cannot be claimed if a fitted stable distribution has a tail index, α, whose confidence interval (easily computed nowadays via a parametric or nonparametric bootstrap) does not contain the upper value of two. The flaw is that, first, an entire parametric assumption is being placed on the density, whereas interest centers only on the tails; and second, this particular parametric structure enforces non-existence of variance except in the measure-zero case of normality. As an example, using a reasonably sized set of simulated Student’s t data with degrees of freedom (implying the supremum of the existing moments is four) and fitting a (location-scale) stable distribution will result in an estimated tail index of around , and whose confidence intervals do not include two. The conclusion that the variance does not exist is false.
Going the other way, if simulated stable Paretian data with are fit with a (location-scale) Student’s t model, the estimated degrees of freedom will be around 4, and such that confidence intervals often do not extend below two. The conclusion that the variance exists is false. This disparity of the actual tail index, when estimated via a parametric structure, is, again, an artefact of imposing a parametric heavy tailed density such that the tail index is bound between 0 and 2, and at two, the distribution becomes the Gaussian. This mapping is continuous (e.g., for α close to 2, the density is indeed “close to” Gaussian, except in the extreme tails). As such, the use of these and related parametric models is not justified for inference about the maximally existing moment in the absence of a strict parametric assumption.
It is important to emphasize that, if the data are non-Gaussian stable, then the traditional measures of asymmetry and heavy-tails vis sample skewness
(as the scale-standardized third central moment) and kurtosis
(as the fourth), respectively, are not valid, because their theoretical counterparts do not exist. As such, while an empirically computed sample kurtosis will be large, the law of large numbers is not applicable, and it will not converge as the sample size increases. This is not the case with Student’s
t data with degrees of freedom,
v, larger than four. In that case, the sample kurtosis is informative for estimation of
v. For example, Singh [
44] proposed an estimator of
v, assuming
, as
.
It is noteworthy that there do exist periods of stock returns and indexes, particularly during crisis periods, such that not only is the tail index of the stable far less than two, but also
even the Student’s t fit yields estimated tail indices below two. While this is still not a formal test of non-existence of second moments, it does provide strong evidence that that existence of the variance can be questioned. Observe that traditional methods of portfolio optimization, which make use of the sample variance-covariance matrix of returns data, would then be invalid; see, e.g., Gamba [
3]. This is addressed, for example, in Giacometti
et al. [
4], Doganoglu
et al. [
5], Paolella [
45], Paolella and Polak [
46], and the references therein.
The existence of moments is determined from the asymptotic tail behavior, but in practical applications, there are never enough data points to accurately characterize the tail. This point is forcefully made in Heyde and Kou [
43]. This helps explain why models using distributions with completely different tail behaviors all can perform very well in terms of value at risk (VaR) forecasting, this being a left-tail quantile of the predictive returns distribution of a portfolio of assets.
For example, Haas
et al. [
47], Alexander and Lazar [
48], Haas
et al. [
49], Haas and Paolella [
50] and Haas
et al. [
51] use discrete normal mixture (MixN) GARCH models, with the MixN being a short-tailed distribution; Broda and Paolella [
52] use a normal inverse Gaussian (NIG) structure, this having so-called semi-heavy tails (and existence of a moment generating function); several authors, including Mittnik and Paolella [
53], Kuester
et al. [
54], and Krause and Paolella [
55] use an asymmetric Student’s
t distribution (this having heavy tails but such that the tail index lies in
); Mittnik and Paolella [
56] and Broda
et al. [
57] use the asymmetric stable and mixtures of symmetric stable, respectively, these having heavy tails such that the tail index lies in
. The fact that all of these methods can deliver highly accurate VaR forecasts confirms that the choice of asymptotic tail behavior and the (non-)existence of the second moment are not highly relevant for risk forecasting, but rather the use of a leptokurtic, asymmetric, bell-shaped distribution, in conjunction with a GARCH-type process.
5. Estimation of the Stable-APARCH Process
After introducing the model in
Section 5.1,
Section 5.2 and
Section 5.3 detail the new, faster estimation procedures, with the first one being related to use of profile likelihood, while the second one does not require any evaluation of the likelihood and is nearly instantaneous. Finally,
Section 5.4 examines the use of an alternative estimation procedure that is also fast and accurate.
5.1. Model
Daily stock returns are obviously not i.i.d., but use of a GARCH-type model can be effectively used to model and filter the time-varying scale term, yielding a sequence of underlying estimated innovation terms that are close to being i.i.d., though from a distribution with heavier tails than the normal.
The earliest GARCH-type model with stable innovations appears to be that of McCulloch [
95], which can be viewed as a precursor of the Bollerslev [
17] Gaussian-based GARCH model or the Bollerslev [
21] Student’s
t-based GARCH model or, for that matter, the Taylor [
96] power-one GARCH model, as well as the integrated GARCH model of Engle and Bollerslev [
18]. It amounts to a power-one, integrated GARCH(1,1) process, without a constant term, driven by conditional S
αS innovations and, as such, with regard to use of non-Gaussian distributions, was ahead of its time.
Subsequently proposed models address the benefit (to VaR and density forecasts) of allowing asymmetry in the innovations distribution, as well as asymmetric effects of shocks on volatility, as shown in Mittnik and Paolella [
53], Bao
et al. [
97], Kuester
et al. [
54], and the references therein. Importantly, Kuester
et al. [
54] demonstrate that use of asymmetric GARCH models with asymmetric (and heavy-tailed) distributions yield imputed innovations sequences that are closer to i.i.d., as required for the application of our testing procedures.
We use the lag-one asymmetric power ARCH (APARCH) model from Ding
et al. [
98], coupled with an asymmetric stable Paretian innovation sequence, hereafter
-APARCH, for the percentage log returns sequence
, given by
, where the evolution of scale term
takes the form
with
,
,
, and, to ensure stationarity (see [
24]),
. We fix
, as it is typically estimated with large standard errors, and fixing it to any value in
has very little effect on the performance of density and VaR forecasts. Observe that
for any
and any
(see [
65] (Section 8.3) for details), so that
.
5.2. Model Estimation: Likelihood-Based
To estimate the parameters of the
-APARCH model, one could conduct full MLE for all seven parameters jointly. This entails being able to effectively compute the pdf of the (asymmetric) stable Paretian distribution. This approach, in a GARCH context, was first pursued by Liu and Brorsen [
22], using an integral expression for the stable density at a given point. Those authors advocate fixing
in (
15), in which case,
does not exist, but is precisely on the “knife edge” border, as
exists for
, and not otherwise. Mittnik
et al. [
23,
99] and Mittnik and Paolella [
56] use an FFT-based approach for evaluating the stable density, this being much faster than pointwise evaluation of the pdf, and also constrain
. An alternative method in the symmetric case that is competitive with use of the FFT in terms of computational time, and is more accurate, is to use the vectorized expression (
5).
In this paper, we consider two new ways, both of which are much faster, and numerically very reliable. This section discusses the first. The idea is to estimate only the four APARCH parameters, based on the likelihood, using a generic multivariate optimization routine, and such that, for any fixed set of these four values, estimates of
,
α and
β are obtained from an alternative method, discussed now, and referred to as the “stable-table estimator”, or, in short, STE. In particular, following the same method as introduced in Krause and Paolella [
55], the location term is obtained via a trimmed mean procedure such that the trimming amount is optimal for the estimated value of tail index
α. For example, if
, then the median should be used, while if
, the mean should be used; the optimal values for
were pre-determined via simulation.
Then, based on the location-standarized and APARCH scale-filtered data, the estimates of
α and
β are determined from a table-lookup procedure based on sample and pre-tabulated quantiles. In particular, for return series
, we compute
where STE refers to use of the stable-table method of estimation, but only for parameters
,
α and
β;
L is the likelihood
is the time series of location-standardized, APARCH-filtered values using the notation in (14), with typical element , and are the APARCH parameters from (15).
The benefit of this procedure is that the generic optimizer only needs to search in three or four dimensions, for the APARCH parameters (three if is fixed in (15), as it tends to be erratic for small samples), conveying a speed benefit, and also more numeric reliability. For a particular θ (as chosen by a generic multivariate optimization algorithm), the STE method quickly delivers estimates of , α and β. However, the likelihood of the model still needs to be computed, and this requires the evaluation of the stable pdf, for which we use the fast spline approximation available in the Nolan Stable toolbox. As such, the proposed method is related to the use of profile likelihood, enabling a partition of the parameter set for estimation. As the STE method is not likelihood-based, the resulting estimator is not the MLE, but enjoys similar properties of the MLE such as consistency, and can actually outperform the MLE, first in terms of numeric reliability and speed, as already mentioned, but also in terms of mean squared error (MSE), as discussed next.
Observe that the STE method utilizes the simple notion of pre-computing and the availability of large memory on modern personal computers to save enormous amounts of processor time. It entails tabulating a large set of quantiles for a tight grid of α and β values, and then using table lookup based on sample quantiles to select the optimal and . While the initial construction of the table takes many hours, and requires megabytes of storage, once available, its use for estimation is virtually instantaneous, does not require computation of the stable density and use of optimization algorithms, and (depending on the granularity of the table and the choice of quantiles), delivers estimates of α and β that are on par with the MLE, and, for small sample sizes, can outperform the MLE in terms of mean squared error. The estimator is necessarily consistent, as the table lookup procedure is based on sample and theoretical quantiles, and appealing to the Glivenko-Cantelli theorem, i.e., the empirical cdf converges almost surely to its theoretical counterpart uniformly, and the fact that the cdf embodies all information about the random variable.
5.3. Model Estimation: Nearly Instantaneous Method
We can improve upon the previous profile-likelihood type of estimation method in terms of speed and also accuracy by forgoing the calculation of (16) and the necessity of evaluating the stable pdf in (17) by using a fixed set of APARCH parameters
θ that is determined by finding the compromise values which optimize the sum of log-likelihoods of (16) for numerous typical daily financial return series. The reason this works is statistically motivated in Krause and Paolella [
55]. This is nothing but an (extreme) form of shrinkage estimation, and, as demonstrated in Krause and Paolella [
55], often leads to better VaR forecasts than when estimating
θ separately for each return series. A similar analysis as done in Krause and Paolella [
55] leads to the choice of
θ as
This idea, reminiscent of the suggestion in the 1994 RiskMetrics technical document, often results in (perhaps surprisingly) higher accuracy, and nearly instantaneous estimation of the -APARCH model. In the empirical section below, we will primarily use (16), and briefly show how the results change when using (18).
5.4. Model Estimation: Characteristic Function Method
There exist other methods for the estimation of the four stable parameters in the i.i.d. setting, most notably that of McCulloch [
82], which, as already mentioned, is extraordinarily fast. Here, we are concerned with the method of Kogon and Williams [
83], hereafter KW, which also avoids calculation of the stable density, instead making use of the empirical and theoretical characteristic function.
2 It is also fast, consistent, asymptotically normal, and generally outperforms the method of McCulloch [
82]. The drawback of either of these methods is that, in our context of a stable APARCH model, these methods are not immediately applicable, but, like the STE method, could be used analogously to the setup in (16). However, the primary benefit of the STE method is that it is designed to deal with the
parameter as the location term of (14), which is not the same as the location parameter of an i.i.d. stable framework. Nevertheless, for completeness, we contrast the STE and KW methods in an i.i.d. setting.
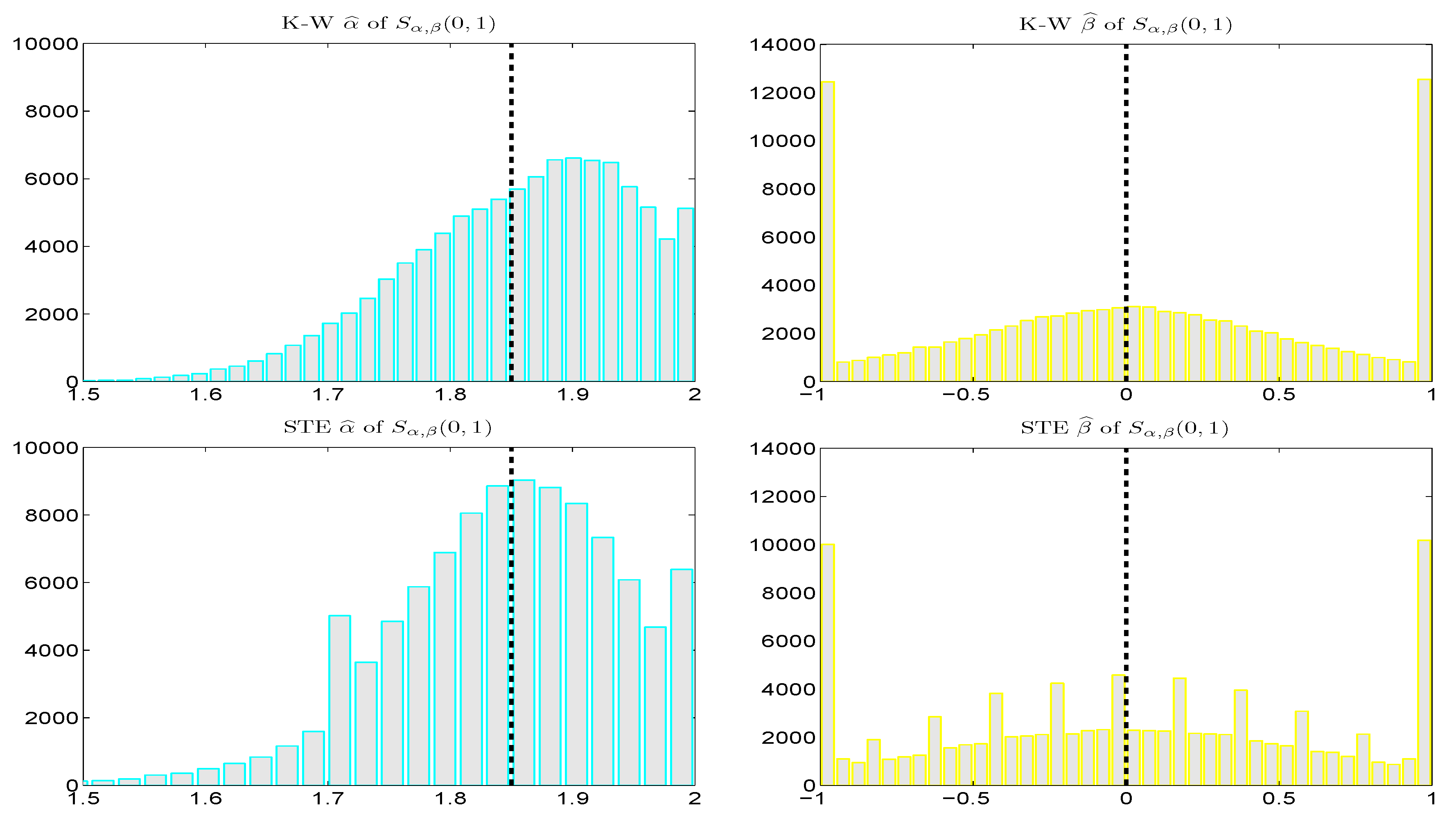
Figure 4 shows the small sample properties of the KW and STE estimators from a simulation study, using true values of
α and
β that are typical for the conditional innovations process in an
-APARCH model, as revealed in
Section 7.1 below. For tail index parameter
α, we see that the mode of
is virtually at the true value, while that of
is upward biased. For asymmetry parameter
β,
exhibits less pile-up at the endpoints of the support than does
. The graininess of the former results from the nature of the table lookup. While both methods are vastly faster than use of the MLE, the STE method is about five times faster than KW, thus conveying it yet a further advantage. The empirically computed mean squared error values are, to two significant digits,
,
,
, and
.
Thus, in addition to comparable, if not slightly better small-sample performance, the STE method is also much faster. However, as mentioned, its real benefit is its handling of parameter in (14). Much admirable work has been done over the years to enable estimation of the i.i.d. stable model. However, the use of the i.i.d. model in modern, genuine applications is rather limited—once an i.i.d. model is estimated, possibly with an estimator that yields slightly more accuracy in the third significant digit, then what? Our concern is (ultra-) fast estimation of a -APARCH model, given the obvious prominence of GARCH-type effects in financial returns data, with, first, the intent of testing the stability assumption, and secondly, the goal of computing tail risk measures, such as VaR and ES.
As mentioned in
Section 3.1, the STE method has been extended to also provide the VaR and ES, based on pre-computation. These otherwise laborious calculations are reduced to essentially instantaneous delivery, and thus can be used for routine calculation by large financial institutions that require reporting the VaR and/or ES on potentially tens of thousands of client portfolios. Moreover, given the near instantaneous calculation of the (parameters, as well as the) VaR and ES for a particular time series under the
-APARCH model assumption, the methodology can be used for mean-ES portfolio optimization via the univariate collapsing method; see, e.g., Paolella [
45], and thus in the context of risk
management. Finally, computation of confidence intervals for these measures are nontrivial and inaccurate using the usual delta-method in conjunction with the sample covariance matrix of the model parameters, rendering the asymptotic distributional behavior of such estimators of little value. Instead, bootstrap methods are required for obtaining accurate confidence intervals of tail risk measures, and thus only consistency (as fulfilled by the STE) is formally required, but practically, also speed, for which the STE method shines.
Remark:
The method of Kogon and Williams [
83] has been extended to the stable-power-GARCH class of models by Francq and Meintanis [
100]. They propose an estimation method based on the integrated weighted squared distance between the characteristic function of the stable distribution and an empirical counterpart computed from the GARCH residuals. Under fairly standard conditions, the estimator is shown to be consistent. Future work could consider the efficacy of such an approach compared to the one proposed herein.
6. Simulation Study Under True Model and Variations
First we wish to consider the behavior of the parameter estimates and the
p-values of the combined
test (this being more powerful than either of its two constituent tests) when the simulated model is
-APARCH with
,
,
, and APARCH parameters as given in (18). The choice of
α is based on the empirical evidence shown in
Figure 5, associated with the empirical exercise below in
Section 7.
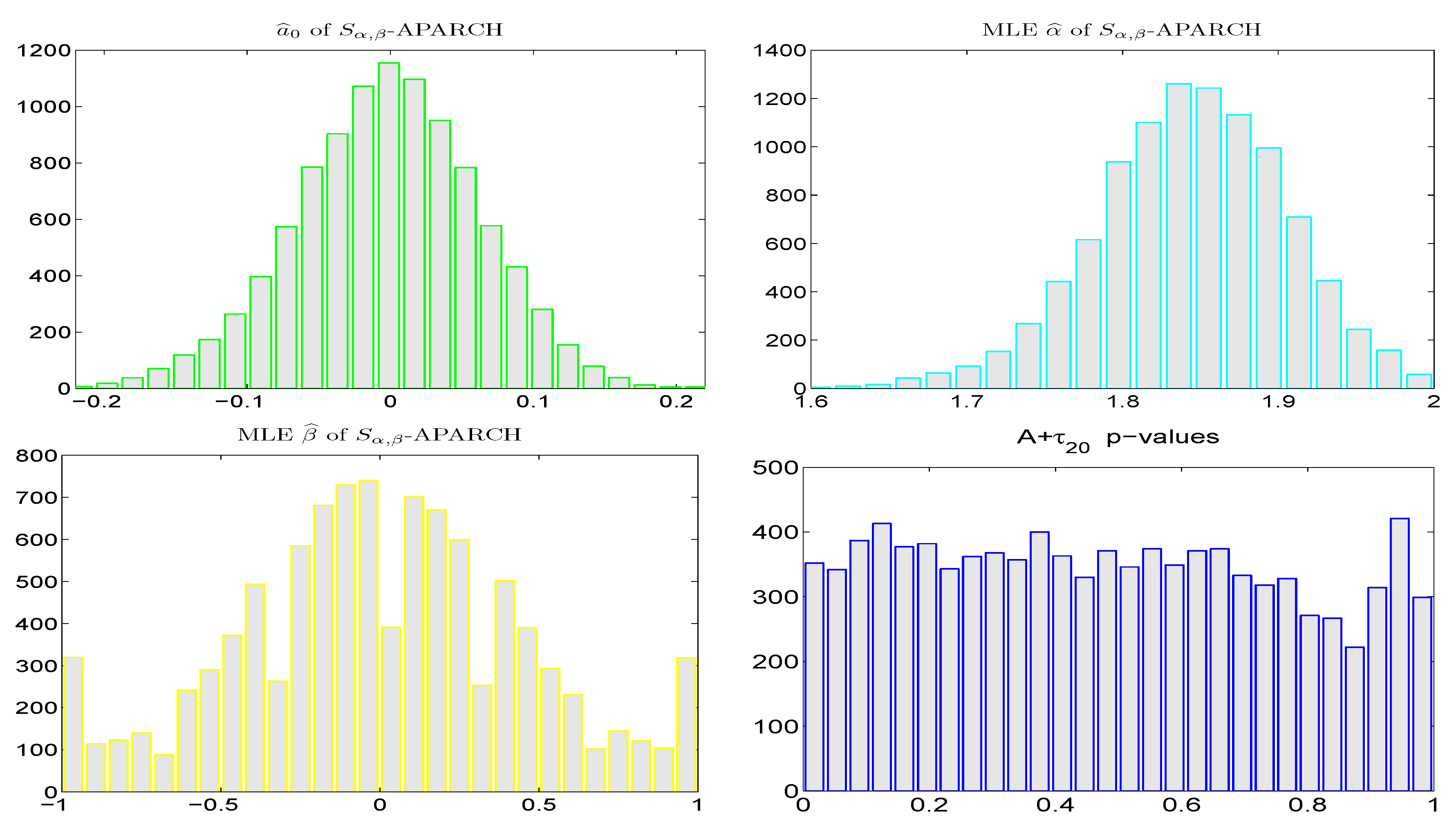
Figure 6 shows the results, based on 10,000 replications with sample size
, using the fixed APARCH parameters (18) and the trimmed mean technique for
and the fast table lookup method for the two stable shape parameters. Unsurprisingly, given that the true APARCH structure is used, and given the high accuracy of the trimmed mean and table lookup methods, the modes of the histograms of the parameter estimates are at their true values and the shapes of the histograms are very nearly Gaussian (though observe that occasionally, the values of
are at the extremes of its parameter space), and the
p-values of the
test are very close to being uniform.
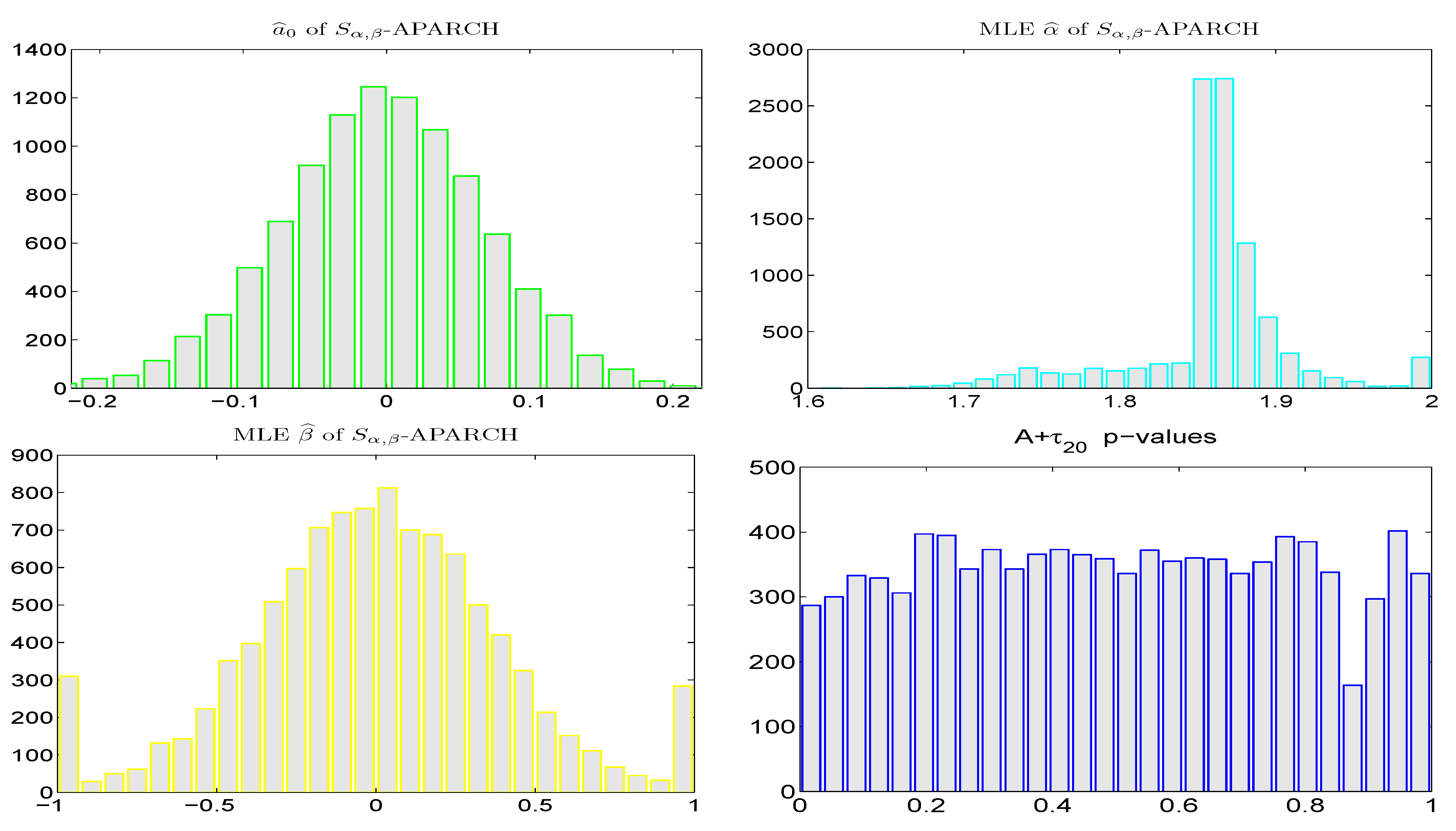
Figure 7 is similar, but having used the jointly computed MLE of all seven model parameters. The results are very similar, including the pileup at the extremes for
, though for
, its empirical distribution is far from Gaussian. To inspect this in more detail, various starting values were used for
(and not just the true value), and the results were always the same. We suspect the reason for this oddly-shaped behavior stems from the use of the fast spline approximation to the stable density used for the MLE calculation. Confirmation could be done using slower but more accurate methods for the calculation of the stable density, but the computing time would then become extensive; and in our context, it is not the primary issue under study.
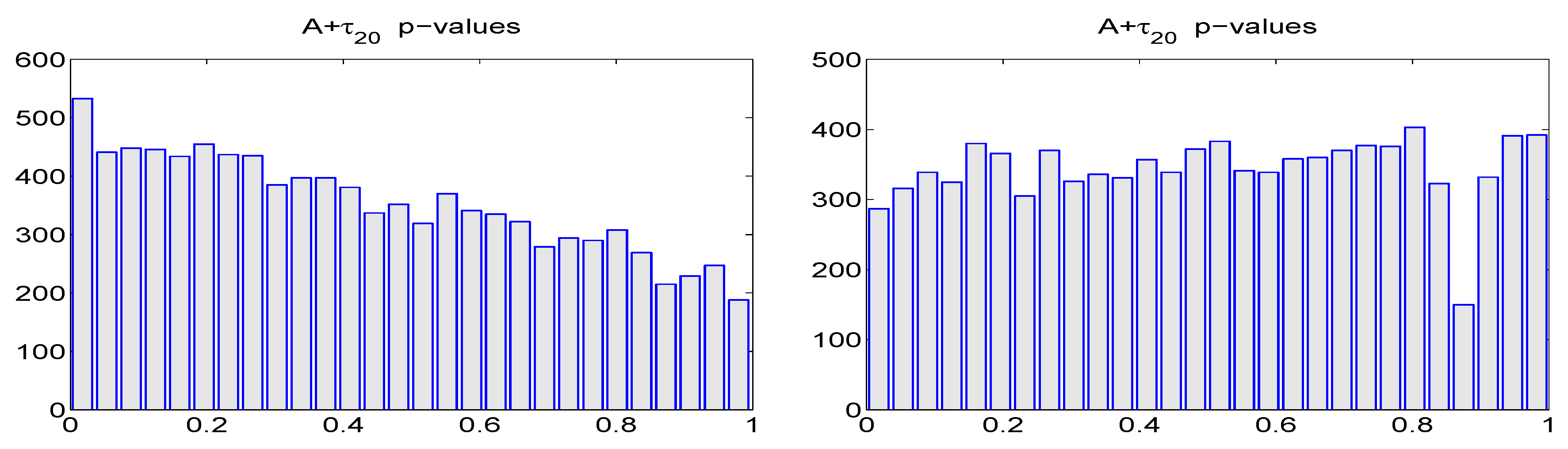
There are obviously infinite ways of modifying the true, simulated data generating process.
Figure 8 shows the effect on the
p-value of the combined
test, under the fixed APARCH and MLE settings, when taking
and
(and the remaining parameters as before), this choice being such that the volatility persistence is higher, but the stationarity condition (as a function of
,
,
α and
β, plus
) is about the same; see Mittnik and Paolella [
53] (p. 316) for calculation of the stationarity border in the APARCH case for various distributions. As expected, the
p-values of the
test tend more towards zero when using the fixed, incorrect values of the APARCH parameters (18), while those based on the MLE are still nearly uniform. Further experiments reveal that modifying the true parameter
has little effect on the uniformity of the
p-values under the
fixed APARCH specification (18) (and of course no effect on the MLE-based counterparts), while modifying parameter
has a large impact on the former, as well as the parameter estimates of
α and
β.
7. Empirical Illustration
We apply the above methodology for estimating the
-APARCH model to various sequences of asset returns, primarily using the estimation method in (16), given the previous simulation results in
Section 6, though we briefly compare the resulting
p-values to the use of fixed APARCH parameters in (18).
7.1. Detailed Analysis for Four Stocks from the DJIA Index
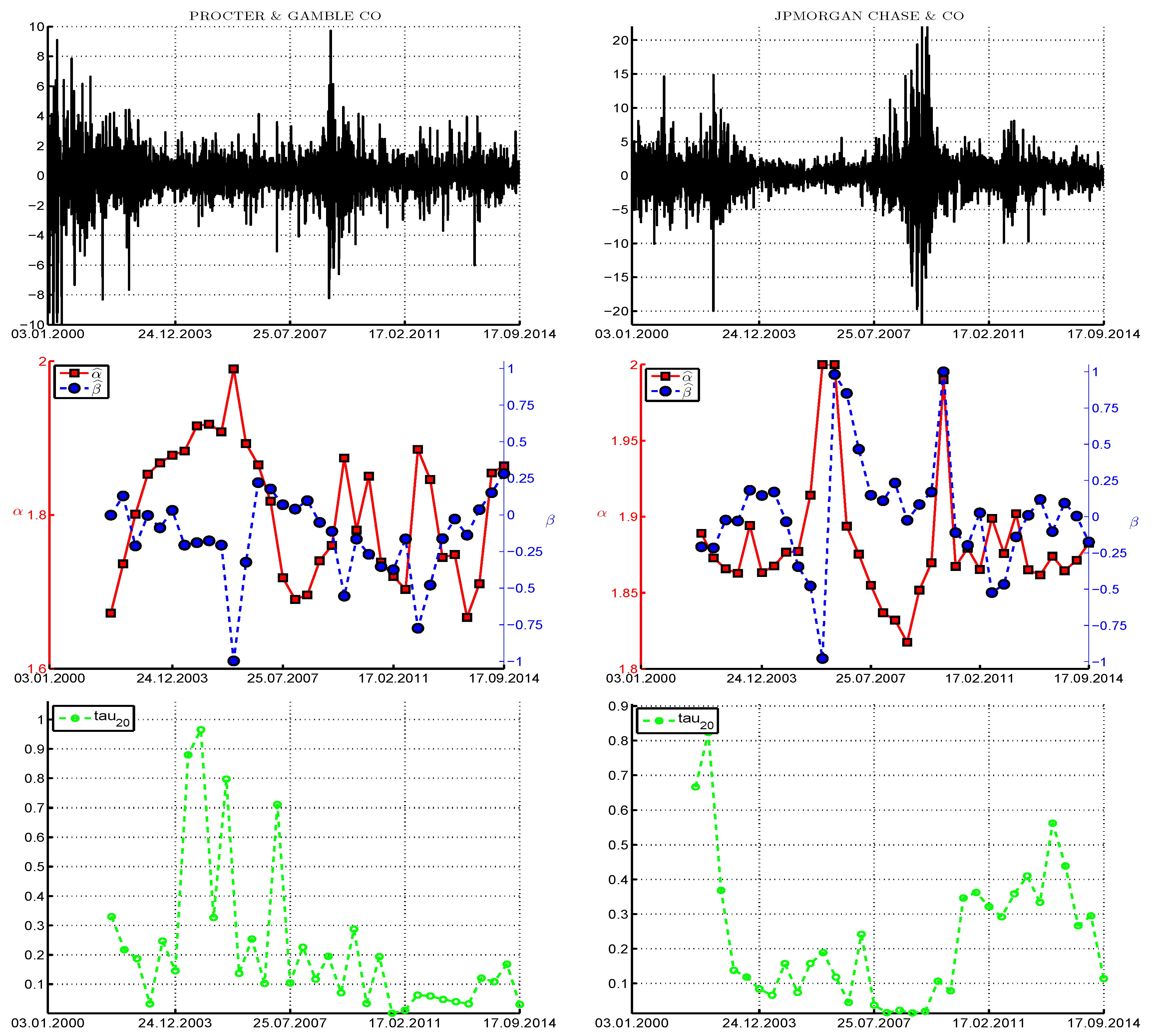
We first show the testing results for four daily (log percentage) return series associated with the DJIA index, from 3rd January 2000 to 17 September 2014, using:
moving windows of length and moving the window ahead by 100 days (resulting in 33 windows of data for each return series);
moving windows of length and moving the window ahead by 250 days (resulting in 12 windows of data for each return series);
the full data set.
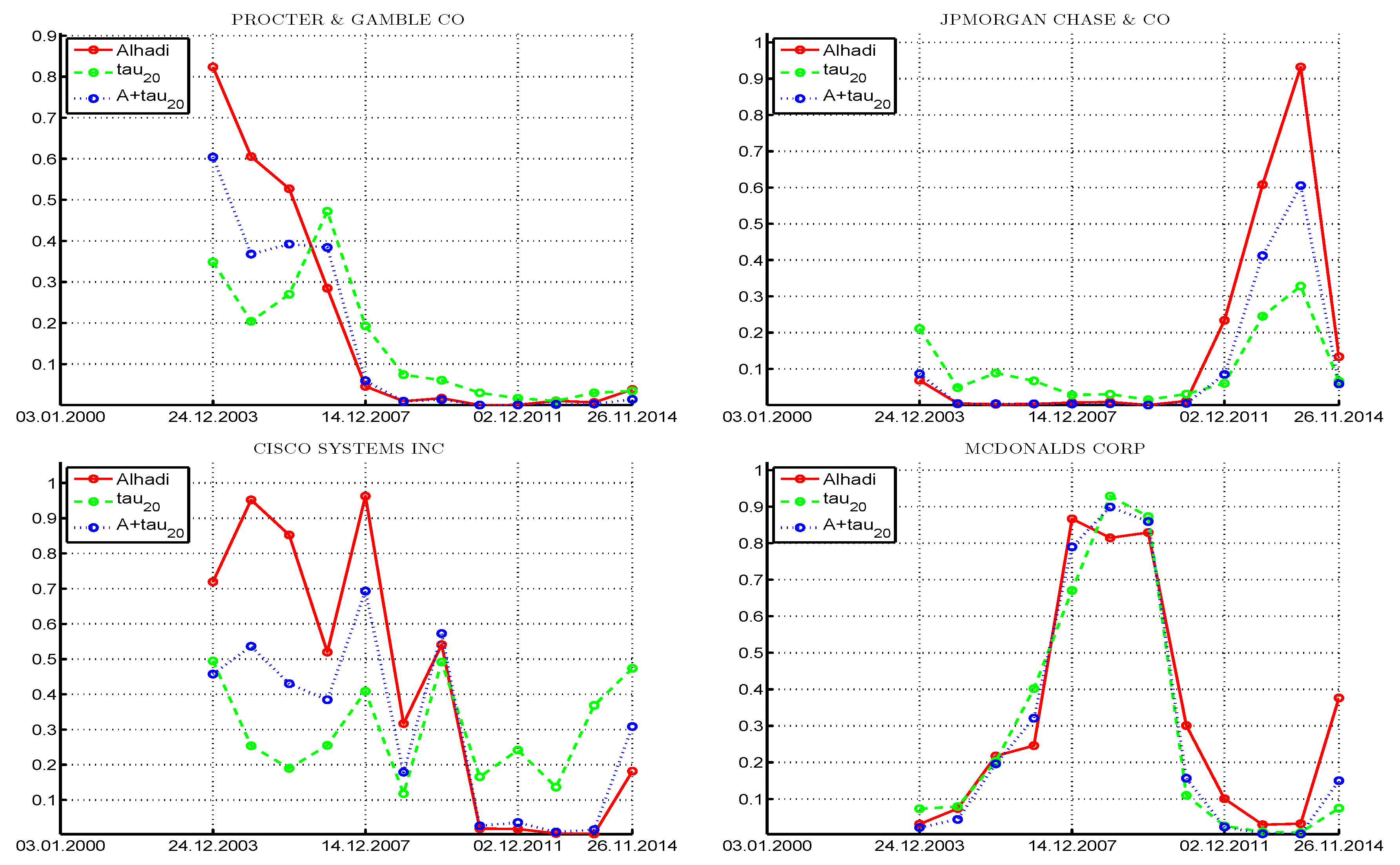
Consider use of the
test and ignoring the asymmetry in the returns, recalling that it approximately preserves its size for mildly asymmetric stable Paretian data. To each window, we fit the
-APARCH model as discussed above, and conduct the
test on the filtered innovation sequence. The left panels of
Figure 9 pertain to the Procter & Gamble company, and show the returns data (top), followed by the estimated values of tail index
α (and
β, when we consider the tests under asymmetry below), and, in the third panel, the
p-values of the
test (ignoring asymmetry). (Observe that there is overlap in the data sets used to generate the 33 windows, so that the
test
p-values are not independent.) Under the null hypothesis (irrespective of the fact that they are not independent) we would expect that their values are uniform on
, and expect one to two of the 33
p-values to lie below 0.05 and about three of them to lie below 0.10. This is clearly not the case, with the vast majority below 0.5, eight values below 0.05, and 13 below 0.10. We conclude, particularly for recent times, that the symmetric stable distribution can be rejected for this model.
Now consider the asymmetric case. The bottom panel shows the p-values from the three tests, , ALHADI, and , based on fitting the -APARCH model and use of the (12) transform. Comparing the results from the symmetric case, we see, as expected, less rejections when asymmetry is accounted for (as the power decreases), but the results are qualitatively the same. The combined test , which we recall has higher power than its constituent parts, delivers p-values around the region of 2011–2012 very close to zero, providing strong evidence against the stable hypothesis for that time period. With respect to the and values, observe that, for three windows, , but in two of those cases, is nearly two, in which case, parameter β has no meaning (and is very difficult to estimate). When is close to two, the ALHADI test does not deliver a statistic, which explains the missing value in the p-value plot.
The right panels of
Figure 9 pertain to the JP Morgan Chase company. Similar conclusions hold in the sense that there are periods of data for which the stable hypothesis is clearly rejected, particularly from the combined
test. It is noteworthy for this data set that, after about 2011, for only one window can the stable hypothesis be rejected.
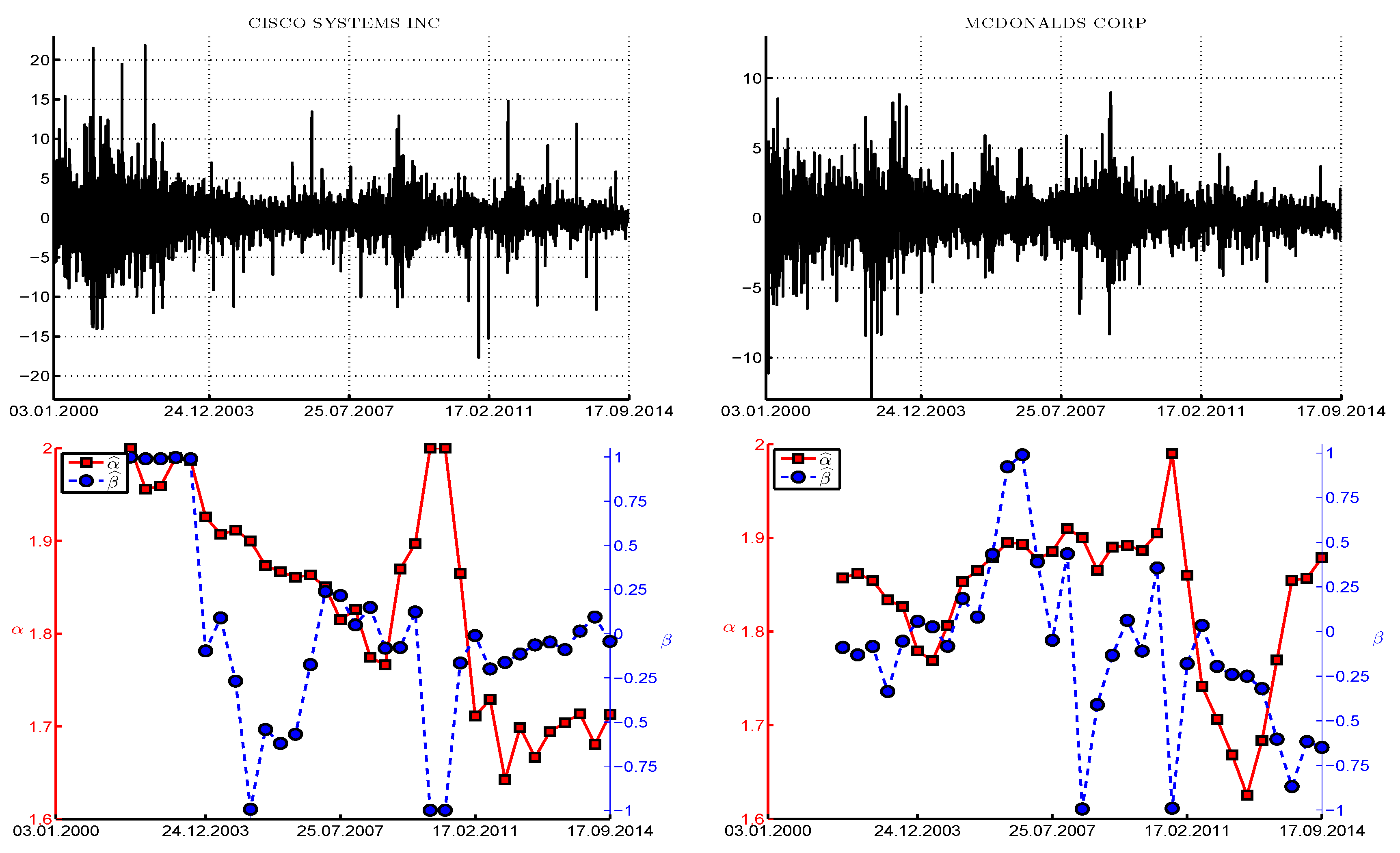
Figure 10 is the same as
Figure 9, having used two different stocks, Cisco Systems Inc., and McDonalds Corporation. From the plot of
for Cisco, it appears that, since the year 2003, the risk (as measured by the conditional tail index) increased over much of the time (except for about two years after the high point of the liquidity crisis in 2007), and since about 2011,
is relatively constant around 1.7, and
around zero. Use of the
test under the assumption of symmetry would suggest that the assumption of stability is tenable for this stock, with rejection at the 10% level only two times out of 33. However, under asymmetry, all three tests reject more frequently with approximately the same proportion. McDonalds yields the interesting observation that, when
decreases, the tests tend to reject the stable assumption.
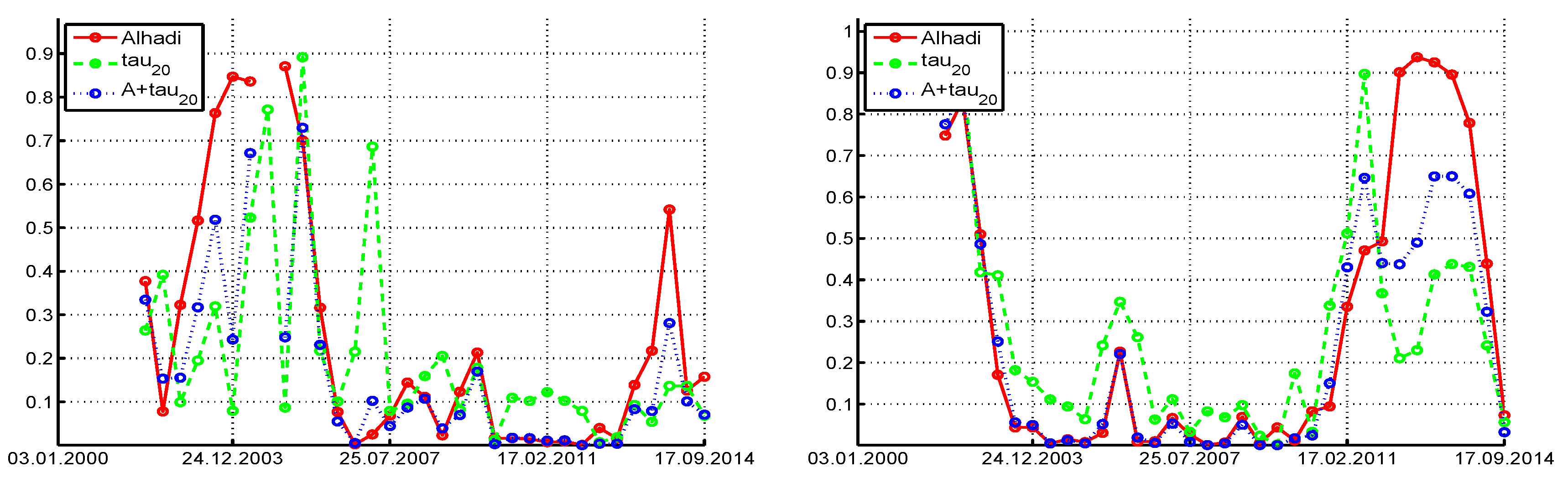
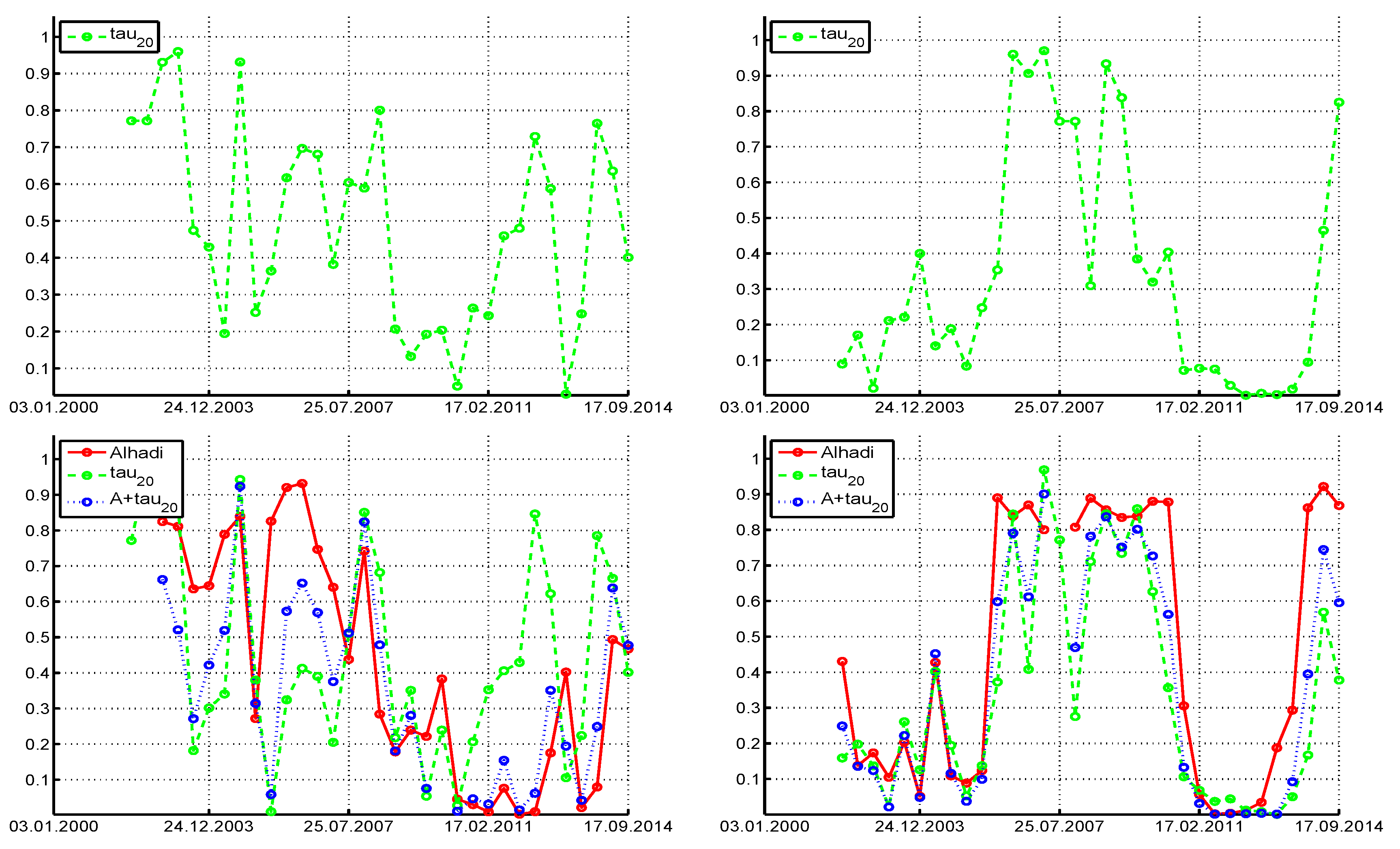
Figure 11 shows the
p-values of the three tests when using a window length of
and step size of 250. Qualitatively, they are similar to the
case. When using the entire series (with length
), the
p-values of the ALHADI test are 0.0011, 0.0070, 0.55, and 0.17, for Procter & Gamble, JPMorgan Chase, Cisco Systems, and McDonalds Corp., respectively, while the
p-values for
are 0.0041, 0.0043, 0.12, and 0.0034.
Plots associated with the other stocks in the DJIA index were inspected using window lengths and , and reveal similar findings. In particular, there is no stock such that the p-values of the tests appear uniform on (with the somewhat exception of Cisco and use of the test under symmetry), but instead, they tend to be closer to zero than one, and tend to have more than two rejections out of 33 at the 5% level and more than three rejections at the 10% level. Given the rejection rates (and the fact that the tests do not have perfect power), it appears that the assumption of stability is not tenable for all stocks and time periods.
7.2. Summary of p-Values from the 29 DJIA Index Stocks
As a summary, and serving as a heuristic for judging the overall assessment of stability in the (APARCH-filtered innovations of the percentage returns of the) stocks, we show the p-values for all stocks and (i) all windows of length and (ii) based on the entire length of the return sequence, as well as looking at the mean rejection rate of the LRT test of size 0.05.
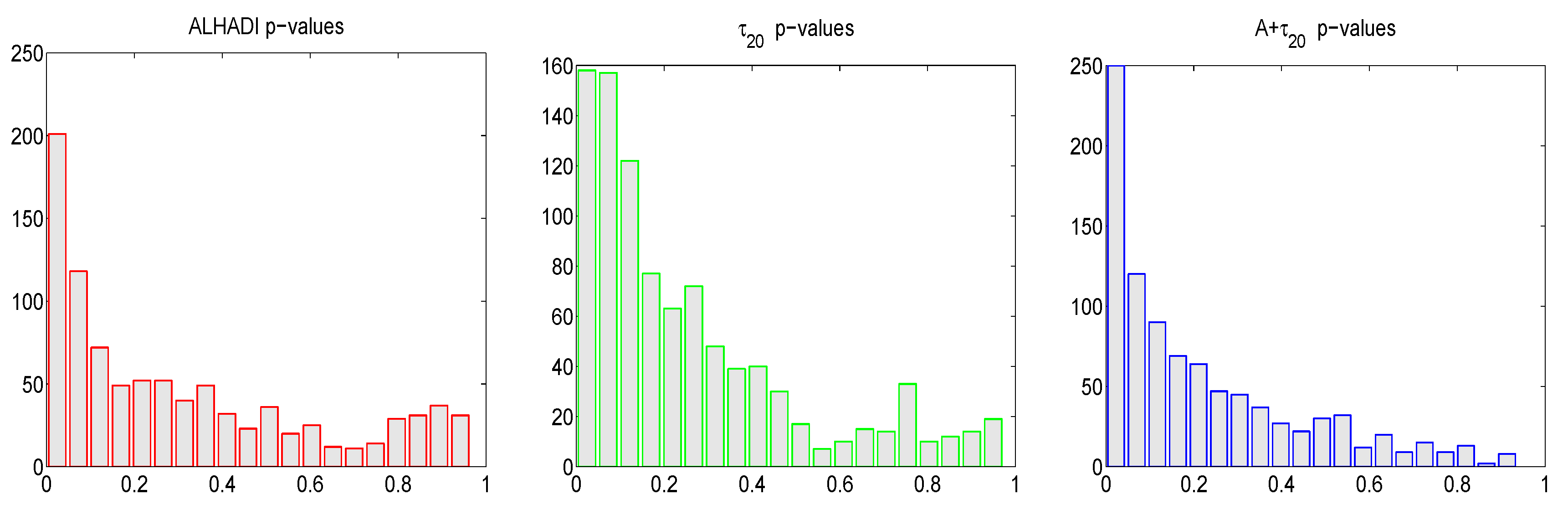
First,
Figure 12 shows histograms of the resulting
p-values, for each of the three tests, resulting from use of all 29 available stocks and 33 windows of length
. (The DJIA Index consists of 30 stocks, but for the dates we use, the Visa company is excluded due to its late IPO in 2008.) As mentioned before, within a stock, the
p-values for a particular test are not independent, as the windows overlap. They are perhaps not independent also across stocks. Nevertheless, if the stable hypothesis were true, then the resulting histograms should be close to uniform
. We see that this is not the case, with the deviation from uniformity (and pile-up towards small values) greatest for the
test, which is precisely the general test with the highest power against numerous alternatives; see Paolella [
34]. The mean number of rejections at the nominal level of 0.05 are 0.17, 0.22, 0.28, for the
, ALHADI, and
tests, respectively.
When conducting this same analysis using moving windows of length
in increments of 250 (resulting in
time series), the resulting mean number of rejections are 0.27, 0.29, and 0.39. This substantial increase in rejection can be attributed to two factors. The first is that the tests are more powerful as the sample size increases. The second factor is that, unfortunately, as the sample size grows, so does the extent of the misspecification of the model (stable-APARCH, with constant parameters), rendering the filtered innovation sequences less likely to be genuinely i.i.d. Even if (heroically) the
-APARCH model assumption were correct at each point in time, then its parameters are changing through time, as observed for the conditional tail index in
Figure 9 and
Figure 10.
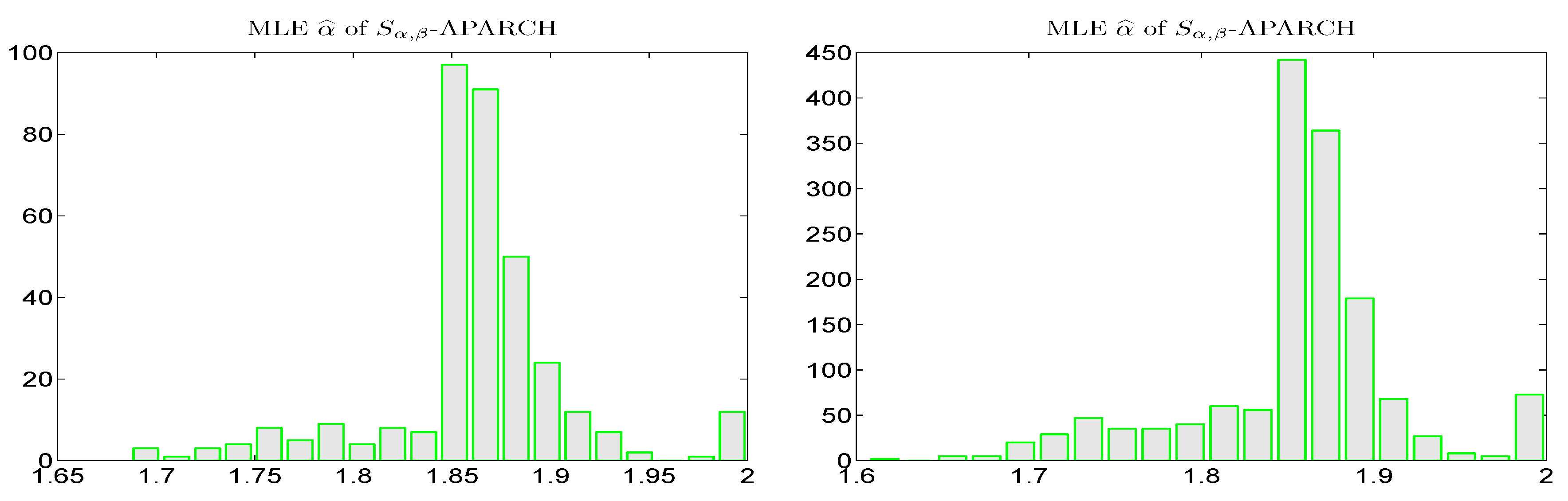
The left panel of
Figure 5 shows the estimates of
α of the fitted
-APARCH process, for the 348 time series of length
from the 29 DJIA stock returns. (The right panel is similar, but applies to the 100 stocks considered in
Section 7.3.) We see that, for both data sets,
clusters between 1.85 and 1.9, so that, conditional on the scale term (as modeled via an APARCH process), the conditional distribution of the return is often not particularly heavy-tailed, though still “far” from Gaussian, as can be seen by comparing the, say, 0.01 quantiles or expected shortfall measures of the stable distribution with tail indexes 1.9 and 2.0.
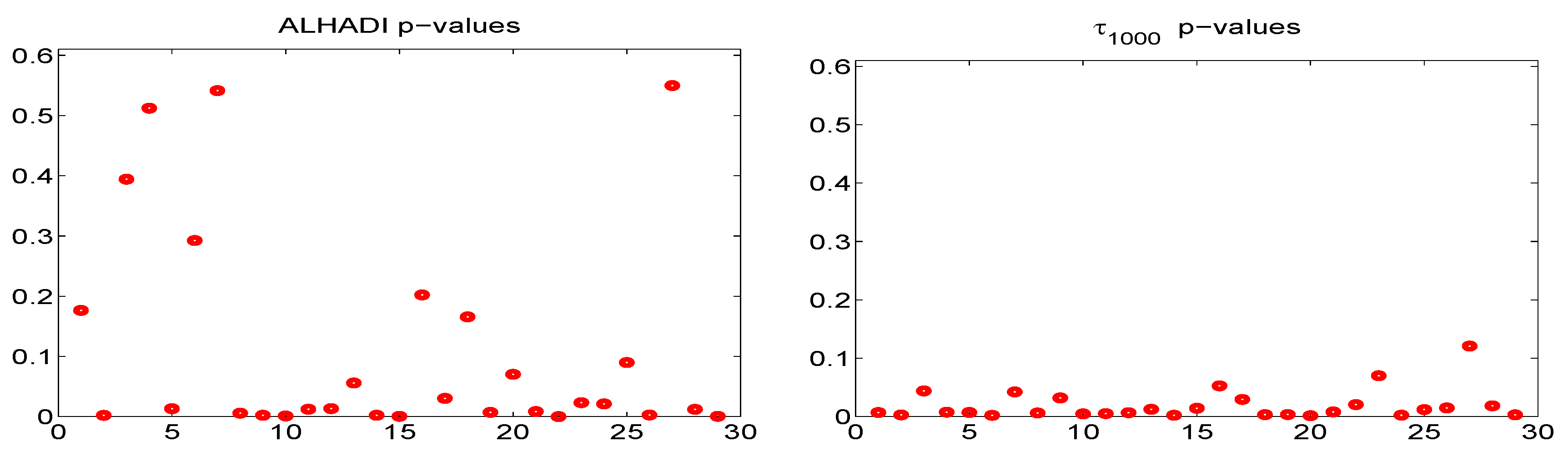
Next,
Figure 13 shows the ALHADI and
p-values computed on all 29 stocks, using the entire time series of
daily returns, and using
for the
test to ensure near-uniqueness of its values. About 2/3 of the series have ALHADI
p-values below 0.10, while 28 of the 29
p-values for the
test are below 0.10, with five close to or above 0.05. This would suggest strong evidence against the stable assumption, but the value of this exercise is somewhat questionable because, as previously mentioned, it assumes that the data generating process is constant throughout the entire time span, and it being a
-APARCH process, with constant parameters. For shorter windows, this might indeed be a very reasonable approximation to reality, but for nearly 14 years of daily data, this is highly unlikely, and the resulting sequence of filtered innovations is surely “less close” to being i.i.d. than those corresponding to shorter windows of data.
Finally, we consider the results of the LRT, when applied to the filtered innovation sequence of the fitted
-APARCH process applied to the 348 windows of length
, this having been estimated by joint maximum likelihood of all seven model parameters, using the spline approximation of the asymmetric stable density provided in Nolan’s toolbox and the method detailed in Krause and Paolella [
55] and Paolella [
34] for fast estimation of the location-scale NCT. The results of the LRT test are binary, with one indicating rejection at the 5% level. The resulting average rejection rate is 0.47,
i.e., for about half of the 348 time series, the stable hypothesis is rejected at the 5% level. This rate is higher than that of
, which was 0.39. One reason is that the LRT is more powerful than
. Another reason is that, possibly, it is also more sensitive to deviations from i.i.d.. Only extensive simulation evidence could shed some partial light on this, but as any GARCH-type model will be misspecified to some extent, particularly as the sample size grows, it is not clear how to definitively address this issue.
Remark:
Throughout the above analysis, we used the method in (16), such that the APARCH parameters, the location term
(based on the trimmed mean method), and two shape parameters of the stable distribution (the latter based on table lookup) are estimated. It is of interest to consider the behavior of the
p-values when we fix the APARCH coefficients, as described in (18) (but still estimating
and the two stable shape parameters as before). The mean number of rejections at the nominal level of 0.05 are 0.18, 0.19, 0.26, for the
, ALHADI, and
tests, respectively. These are very close to the previously obtained numbers but such that the rejection rates for the latter two tests are a bit lower. A possible explanation of this is that the fixed APARCH parametrization is mildly better specified, as argued in Krause and Paolella [
55], so that the resulting filtered innovation sequence is “a bit closer to i.i.d.” than its APARCH-fitted counterpart. As the tests assume i.i.d., deviations from this assumption might affect their performance such that the probability of rejection of the null (of i.i.d. stable) is higher when the model is “more misspecified”.
7.3. Summary of p-Values from 100 S&P500 Stocks
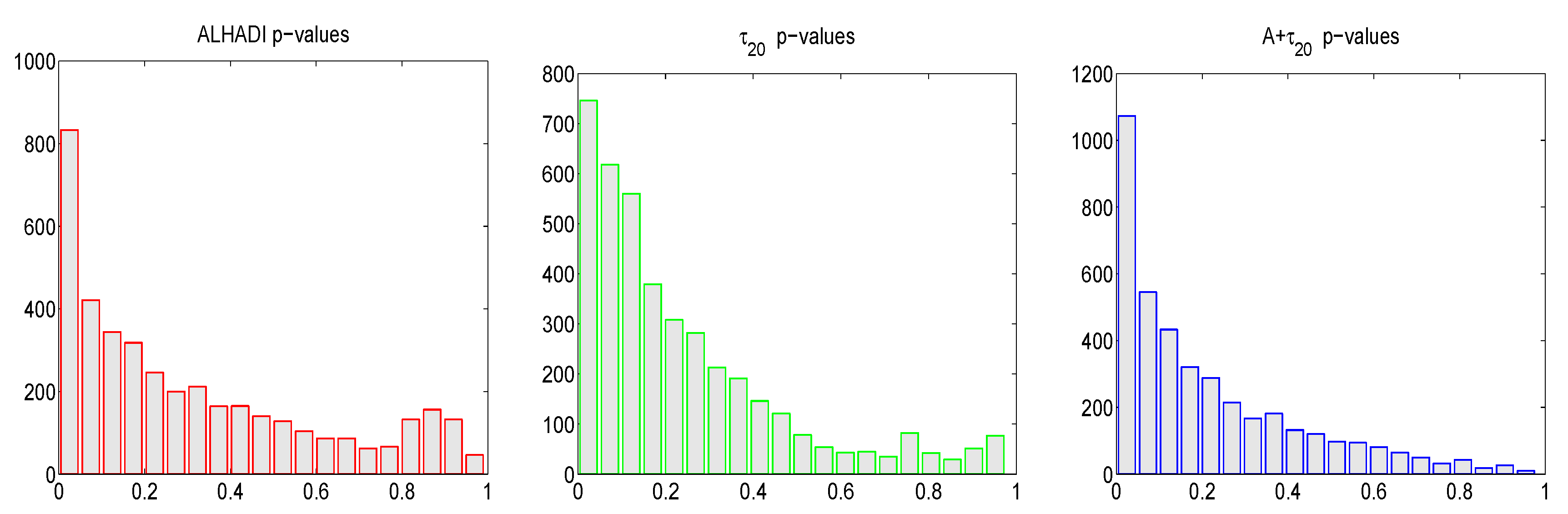
Here we consider a larger data set, using the daily percentage log returns from the top 100 market-cap corporations of the S&P500 index (obtained from CRSP), from 3rd January 1997 until 31st December 2014. The results are shown in
Figure 14, which is similar to
Figure 12, but based on the resulting 4100
p-values, from the 100 stocks and 41 windows of length
incremented by 100 days. We observe a similar phenomenon as with the DJIA stocks, namely, that the
p-values for all the tests are not uniform on
, but rather indicative that the stable assumption can be rejected for some stocks and time periods. The mean number of rejections at the nominal level of 0.05 are 0.19, 0.21, 0.27, for the
, ALHADI, and
tests, respectively. Again notice that the latter has the highest rejection rate, as it is the most powerful of the three tests.
When conducting this same analysis using moving windows of length in increments of 250 (resulting in 1500 time series), the resulting mean number of rejections are 0.36, 0.32, and 0.48. The LRT test, applied to the same windows, yields an average rejection rate of 0.50, i.e., for half of the 1500 time series, the stable assumption is rejected at the 5% level. Observe that the rejection rate using the LRT is the highest among all the tests considered, while that of the combined was very close, being 0.48.
8. Conclusions
A fast new method for estimating the parameters of the -APARCH is developed, and this is used to obtain the filtered innovation sequences when the model is applied to daily financial asset returns data. These are, in turn, subject to several new tests for stability. Application of the tests to the components of the DJIA-30 index and the top 100 market-cap corporations of the S&P500 index suggests that, for most stocks and some segments of time, the assumption of the innovation process driving a GARCH-type process being i.i.d. stable Paretian cannot be rejected, though overall, based on the rejection rates, there is evidence against it.
One should differentiate in this context between the use of formal testing procedures for a distributional assumption, and the appropriateness, or lack thereof, of using that distribution. In particular, the successful use of the stable distribution in conjunction with GARCH-type models for risk prediction and asset allocation lends evidence that, at least from a purely practical point of view, the model has merit. This point is also made in Nolan [
101]. Moreover, a very large number of empirical studies exist that use a GARCH model with Student’s
t or generalized exponential (GED) innovations, these being available in many software packages, but rarely, if ever, is the distributional assumption questioned or addressed in a formal way. Instead, some studies will compare the forecasting performance of several models, usually finding that the use of a GARCH-type model that allows for asymmetric shocks to volatility, in conjunction with a leptokurtic, asymmetric distribution, delivers competitive risk forecasts.
All models and distributions employed for modeling non-trivial real data are nothing but approximations and are necessarily wrong; and without an infinite amount of data, tail measurements will always be inaccurate. As such, at least in finance, while distributional testing is an important diagnostic, a crucial measure of the utility of a model is in the application to forecasting, such as downside risk, or portfolio optimization—for which different (non-Gaussian) models can be compared and ranked.
Both in-sample and out-of-sample diagnostics and testing procedures have value for assessing the appropriateness of a model, but the purpose of the model must always be considered. For example, if tomorrow’s VaR is required on 100,000 portfolios, then speed, numeric reliability, and practicality will play a prominent role. In the complicated game of financial risk forecasting and asset allocation, it is highly unlikely that a single model will be found to consistently outperform all others, but the appropriate use of distributional testing, out-of-sample performance diagnostics, and common sense can lead to a model that reliably fulfils its purpose.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















