1. Introduction
This paper focuses on fixed-
b inference of heteroskedasticity and autocorrelation (HAC) robust Wald statistics for testing for a structural break in a time series regression. We focus on kernel-based nonparametric HAC estimators which are commonly used to estimate the asymptotic variance. HAC estimators allow for arbitrary structure of the serial correlation and heteroskedasticity of weakly dependent time series and are consistent estimators of the long run variance under the assumption that the bandwidth (
M) is growing at a certain rate slower than the sample size (
T). Under consistency assumptions, the Wald statistics converge to the usual chi-square distributions. However, because the critical values from the chi-square distribution are based on a consistency approximation for the HAC estimator, the chi-square limit does not reflect the often substantial finite sample randomness of the HAC estimator. Furthermore, the chi-square approximation does not capture the impact of the choice of the kernel or the bandwidth on the Wald statistics. The sensitivity of the statistics to the finite sample bias and variability of the HAC estimator is well known in the literature; Kiefer and Vogelsang (2005) [
1] among others have illustrated by simulation that the traditional inference with a HAC estimator can have poor finite sample properties.
Departing from the traditional approach, Kiefer and Vogelsang [
1,
2,
3] obtain an alternative asymptotic approximation by assuming that the ratio of the bandwidth to the sample size,
, is held constant as the sample size increases. Under this alternative nesting of the bandwidth, they obtain pivotal asymptotic distributions for the test statistics which depend on the choice of kernel and bandwidth tuning parameter. Simulation results indicate that the resulting fixed-
b approximation has less size distortions in finite samples than the traditional approach, especially when the bandwidth is not small.
Theoretical explanations for the finite sample properties of the fixed-
b approach include the studies by Hashimzade and Vogelsang (2008) [
4], Jansson (2004) [
5], Sun, Phillips and Jin (2008, hereafter SPJ) [
6], Gonçalves and Vogelsang (2011) [
7] and Sun (2013) [
8]. Hashimzade and Vogelsang (2008) [
4] provides an explanation for the better performance of the fixed-
b asymptotics by analyzing the bias and variance of the HAC estimator. Gonçalves and Vogelsang (2011) [
7] provides a theoretical treatment of the asymptotic equivalence between the naive bootstrap distribution and the fixed-
b limit. Higher order theory is used by Jansson (2004) [
5], SPJ (2008) [
6] and Sun (2013) [
8] to show that the error in rejection probability using the fixed-
b approximation is more accurate than the traditional approximation. In a Gaussian location model, Jansson (2004) [
5] proves that for the Bartlett kernel with bandwidth equal to sample size (i.e.,
), the error in rejection probability of fixed-
b inference is
which is smaller than the usual rate of
. The results in SPJ (2008) [
6] complement Jansson’s result by extending the analysis for a larger class of kernels and focusing on smaller values of bandwidth ratio
b. In particular, they find that the error in rejection probability of the fixed-
b approximation is
around
. They also show that for positively autocorrelated series, which is typical for economic time series, the fixed-
b approximation has smaller error than the chi-square or standard normal approximation, even when
b is assumed to decrease to zero although the stochastic orders are same.
In this paper, fixed-
b asymptotics is applied to testing for structural change in a weakly dependent time series regression. The structural change literature is now enormous and no attempt will be made here to summarize the relevant literature. Some key references include Andrews (1993) [
9], Andrews and Ploberger (1994) [
10], and Bai and Perron (1998) [
11]. Andrews (1993) [
9] treats the issue of testing for a structural break in the generalized method of moments framework when the one-time break date is unknown and Andrews and Ploberger (1994) [
10] derive asymptotically optimal tests. Bai and Perron (1998) [
11] considers multiple structural change occurring at unknown dates and covers the issues of estimation of break dates, testing for the presence of structural change and testing for the number of breaks. For a comprehensive survey of the recent structural break literature see Perron (2006) [
12], Banerjee and Urga (2005) [
13], and Aue and Horváth (2013) [
14]. The fixed-
b analysis can be extended to the case of multiple breaks but the simulation of critical values will be computationally intensive. Therefore, we leave the case of multiple breaks for future research and we consider the case of a single break in this paper.
For testing the presence of break, the robust version of the Wald statistic is considered in this paper and a HAC estimator is used to construct the test statistic. The ways of constructing HAC estimators in the context of structural change tests are well described in Bai and Perron (2003) [
15] and Bai and Perron (1998) [
11]. We focus mainly on the HAC estimator documented in Bai and Perron (2003) (Section 4.1, [
15]) in which the usual “Newey-West-Andrews” approach is applied directly to the regression with regime dummies. Under the assumption of a fixed bandwidth ratio (fixed-
b assumption), the asymptotic limit of the test statistic is a nonstandard distribution but it is pivotal. As in standard fixed-
b theory, the impact of choice of bandwidth on the limiting distribution is substantial. In particular, the bandwidth interplays with the hypothesized break fraction so that the limit of the test statistic depends on both of them. For the unknown break date case, three existing test statistics (Sup-, Mean-, Exp-Wald) are considered and their fixed-
b critical values are tabulated. The finite sample performance is examined by simulation experiments with comparisons made to existing tests. For practitioners, we include results using a data-dependent bandwidth rule based on Andrews (1991) [
16]. This data-dependent bandwidth is calculated from the regression using the break fraction that yields the minimum sum of squared residuals (Bai and Perron, 1998 [
11]). One can calculate a bandwidth ratio
with this data-dependent bandwidth (
) and proceed to apply the fixed-
b critical values corresponding to this specific value of
.
The remainder of this paper is organized as follows. In
Section 2, the basic setup of the full/partial structural-change model is presented and preliminary results are provided.
Section 3 derives the fixed-
b limit of the Wald statistic and the fixed-
b critical values, for the case of unknown break dates, are tabulated in
Section 4.
Section 5 compares empirical null rejection probabilities and provides the size-adjusted power for tests based on the
data-dependent bandwidth ratio.
Section 6 concludes. Proofs and definitions are collected in
Appendix A.
2. Setup and Preliminary Results
Consider a weakly dependent time series regression model with a structural break given by
where
is
regressor vector,
is a break point, and
is the indicator function. Define
and
Recalling that
denotes the integer part of a real number,
x, notice that
for
and
for
For the time being, the potential break point (fraction)
λ is assumed to be known in order to develop the asymptotic theory for a test statistic and characterize its asymptotic limit. We will relax this assumption to deal with the empirically relevant case of an unknown break date. The regression model (
1) implies that coefficients of all explanatory variables are subject to potential structural change and this model is labeled the ‘full’ structural change model.
We are interested in testing the presence of a structural change in the regression parameters. Consider the null hypothesis of the form
where
and
is an
matrix with
Under the null hypothesis, we are testing that one or more linear relationships on the regression parameter(s) do not experience structural change before and after the break point. Tests of the null hypothesis of no structural change about a subset of the slope parameters are special cases. For example, we can test the null hypothesis that the slope parameter on the first regressor did not change by setting
. We can test the null hypothesis that none of the regression parameters have structural change by setting
. We focus on the OLS estimator of
β given by
In order to establish the asymptotic limits of the HAC estimators and the Wald statistics, two assumptions are sufficient. These assumptions imply that there is no heterogeneity in the regressors across the segments and the covariance structure of the errors is assumed to be the same across segments as well.
Assumption 1. uniformly in and exists.
Assumption 2. where is a standard Wiener process, and ⇒ denotes weak convergence.
For later use, we define a
nonsingular matrix
A such that
and
where
is
standard Wiener process. For a more detailed discussion about the regularity conditions under which Assumptions 1 and 2 hold, refer to Kiefer and Vogelsang (2002) [
3] and see Davidson (1994) [
17], Phillips and Durlauf (1986) [
18], Phillips and Solo (1992) [
19], and Wooldridge and White (1988) [
20] for more details.
The matrix
Q is the second moment matrix of
and is typically estimated using the quantity
. The matrix
is the asymptotic variance of
which is, for a covariance stationary series, given by
Consider the non-structural change regression equation where
and this coefficient parameter is estimated by OLS
. In this particular setup, the long run variance,
is commonly estimated by the kernel-based nonparametric HAC estimator given by
where
,
M is a bandwidth, and
is a kernel weighting function.
Under some regularity conditions (see Andrews (1991) [
16], DeJong and Davidson (2000) [
21], Hansen (1992) [
22], Jansson (2002) [
23] or Newey and West (1987) [
24]),
is a consistent estimator of Σ, i.e.,
. These regularity conditions include the necessary condition that
as
. This asymptotics is called “traditional” asymptotics throughout this paper.
In contrast to the traditional approach, fixed-
b asymptotics assumes
where
b is held constant as
T increases. Assumptions 1 and 2 are the only regularity conditions required to obtain a fixed-
b limit for
. Under the fixed-
b approach, for
, Kiefer and Vogelsang (2005) [
1] show that
where
is a
p-vector of standard Brownian bridges and the form of the random matrix
depends on the kernel. Following Kiefer and Vogelsang (2005) [
1], we consider three classes of kernels which give three forms of
. Let
denote a generic vector of stochastic processes.
denotes its transpose.
is defined in
Appendix A.
Getting back to our structural change regression model, fixed-
b results depend on the limiting behavior of the following partial sum process given by
Under Assumptions 1 and 2, the limiting behavior of
and the partial sum process
are given as follows.
Proposition 1. Let be given. Suppose the data generation process is given by (1) and let denote the integer part of where . Then, under Assumptions 1 and 2 as andwhereand It is easily seen that the asymptotic distributions of
and
are Gaussian and are independent of each other. Hence the asymptotic covariance of
and
is zero. The asymptotic variance of
is given by
where
In order to test the null hypothesis (
2), HAC robust Wald statistics are considered. These statistics are robust to heteroskedasticity and autocorrelation in the vector process,
The generic form of the robust Wald statistic is given by
where
and
is a HAC robust estimator of Ω.
We consider a particular way of constructing the HAC estimator. This estimator is the same one as in Bai and Perron (2003) [
15]. Denoted by
it is constructed using the residuals directly from the dummy regression (
1):
where
. We denote the components of
as
and
. Notice that
is the variance estimator one would be using if the usual “Newey-West-Andrews” approach is applied directly to the dummy regression (
1).
Using
we can write
as
Three important observations are in order. First, the main component of the two diagonal blocks are within regime HAC estimators of Σ, the long run variance of
However, one should see that the “effective” bandwidth ratio being applied to
is not
b but
which is bigger than
b since
Similarly, the effective bandwidth ratio for
is
. As documented in fixed-
b literature (e.g., Kiefer and Vogelsang (2005) [
1]), the bias in HAC estimators not accounted by traditional inference increases as the bandwidth ratio gets bigger. So, when the HAC estimator is constructed as in (
8), traditional inference might be often exposed to size distortion—more than expected—due to this mechanism of determining effective bandwidths. The second issue is that the above estimator has non-zero off-diagonal blocks. So, the methodology based on partial samples such as in Andrews (1993) [
9] does not exactly cover this case because the off-diagonal blocks in Andrews (1993) [
9] are assumed to be zero, matching the zero asymptotic covariance of the OLS estimators of the slope coefficients between pre- and post-regimes. It is presumable that the influence of having non-zero off diagonal terms might be small since the off-diagonal blocks converge to zero under the traditional assumption
as sample size grows (see a proof in Cho (2014) [
25] for the Bartlett kernel) but it might still negatively affect the performance of tests in finite samples and we need to develop an alternative asymptotic theory to explicitly reflect the presence of these components. Third, there is another issue when a researcher uses a data-dependent bandwidth as in Andrews (1991) [
16]. For a given hypothesized break fraction, a data-dependent bandwidth can be calculated based on the pooled series of
and
This method would result in an optimal bandwidth which minimizes the MSE in estimating Σ but the presence of non-zero off-diagonal terms are not taken into account in this procedure. Moreover, when the break date is treated as unknown, a sequence of data-dependent bandwidth across potential break dates will be generated. In this case, the fixed-
b limits are not useful approximations because the sequence of the data-dependent bandwidth is random by nature so the limiting distributions of corresponding test statistics cannot be characterized by a single particular value of
Denote by
, the Wald statistic given by (
6) using the break date
with
used for
. Tests for a potential structural break with an unknown break date are well studied in Andrews (1993) [
9], Andrews and Ploberger (1994) [
10], and Bai and Perron (1998) [
11]. Andrews (1993) [
9] considers several tests based on the supremum across breakpoints of Wald and Largrange multiplier statistics and shows that they are asymptotically equivalent. Andrews and Ploberger (1994) [
10] derives tests that maximize average power across potential breakpoints.
As argued by Andrews (1993) [
9] and Andrews and Ploberger (1994) [
10], break dates close to the end points of the sample cannot be used and so some trimming is needed. To that end, define
with
to be the set of admissible break dates. The tuning parameter,
ϵ, denotes the amount of trimming of potential break dates. We consider the three statistics following Andrews (1993) [
9]
1 and Andrews and Ploberger (1994) [
10]
2 defined as
The next section provides asymptotic results for the robust Wald statistics under the fixed-b asymptotics.
5. Finite Sample Properties
In this section, we report the results of a finite sample simulation study that illustrates the performance of fixed-
b critical values relative to traditional critical values. The data generating process (DGP) is given by (
1) with
where
is a scalar time series,
, and
. We use the break point
. The regressor
and the regression error
are generated as
and
where
and
are independent of each other with
i.i.d.
. We use the parameter values:
and
(see
Table 2):
The value of
θ measures the persistence of the time varying regressor
The parameters
ρ and
φ jointly determine the serial correlation structure of the error term
. Bigger values of these three parameters lead to higher persistence of the series
except for specification A where bigger values of
θ would not increase persistence in
. We set
,
and
,
. Under the null hypothesis of no structural change,
, whereas for
there is structural change in both the intercept and slope parameters. We report results for sample sizes
and 1000 and the number of replications is 2500. The nominal level of all tests is 5%. We compute the
/
/
-
statistics for testing the joint null hypothesis of no structural change in both the intercept and slope parameters. The frequency of rejections for the case of
measures the empirical type-I error.
4We report empirical rejection frequencies for traditional inference and for fixed-
b inference. In traditional inference, we select the bandwidth following Andrews (1991) [
16] for each hypothesized break date using the AR(1) plug-in formula. For fixed-
b inference, we report results for different values of
b to show how the null rejection probability varies with the choice of
We also give results for another test in which a single data-dependent bandwidth ratio, denoted by
is used across all hypothetical break dates and a fixed-
b critical value is applied. The data-dependent bandwidth ratio,
is computed as follows. We find the break date which minimizes the sum of squared residuals; we use that break date to select Andrews (1991) [
16] data-dependent bandwidth (
) with the AR(1) plug-in formula and calculate the implied bandwidth ratio (
); we implement the test using the fixed-
b critical values for
The rationale behind
is as follows. If a different bandwidth is used for each potential break point within the trimming range, then the fixed-
b limits of the sup/mean/exp statistics will be functions of those bandwidth ratios and tabulation of fixed-
b critical values will be computationally prohibitive. To provide practitioners with a data-dependent bandwidth approach that can be implemented with fixed-
b critical values, we need a single data-dependent bandwidth to be used for all potential break points in which case the tabulated critical values can be used. Given the nice properties of the least squares estimator of the break point under the alternative of structural change (see Bai and Perron (1998) [
11]), it is natural to use the least squares estimator of the break point to generate residuals needed to implement the Andrews (1991) [
16] plug-in formula. Under the null of no structural change, any break point, including the least squares break point, will generate useful residuals for the Andrews (1991) [
16] plug-in formula. Crainiceanu and Vogelsang (2007) [
28] also considered using the least squares estimator of the break point to deal with the nonmonotonic power of the CUSUM test.
Table 3 provides empirical null rejection frequencies for the traditional tests. For each hypothetical break date, the HAC estimator is constructed using the data-dependent bandwidth. For DGP A with zero persistence, all tests using
are subject to severe size distortions when the sample size is 100. Having more data or using more trimming helps reduce the size distortions. The null rejections decrease towards the 5% nominal level for all statistics when T is 500 and
Under the DGP B, as the sample size increases from 100 to 500, the null rejection probabilities drop to 0.194 from 0.594 for the supremum test with
and the QS kernel being used. The T = 500 rejection rate is still far from the nominal level. Size distortions get worse under more persistent data (DGP C). The mean test, which has the least size distortion of the three statistics, only attains a null rejection of 0.368 with the larger trimming value and T = 500. While traditional inference provides tests with reasonable size under DGPs with zero or mild persistence, as the DGP becomes more persistent, over-rejections can be substantial.
Table 4,
Table 5 and
Table 6 present simulation results for fixed-
b inference. A single bandwidth ratio,
is applied across all hypothetical break dates in constructing HAC estimators. We report results for
and
These tables also contain the null rejection probability when the traditional critical values in Andrews (1993) [
9] or Andrews and Ploberger (1994) [
10] are used. The traditional critical values are not designed to work well with relatively large bandwidths and this can be clearly seen in the tables. In general, as the bandwidth ratio gets bigger, the tendency to over-reject becomes more and more pronounced because using more lags generates a systematic downward bias in the HAC estimator and pushes up the value of test statistic. The traditional critical values do not take this impact of lag-choice into account. Because the effective bandwidths play important roles for the behavior of the HAC estimator (
8), the impact of using large values of
b is greater than for HAC estimators in non-structural change settings.
For fixed-
b inference, several patterns stand out in
Table 4 for the supremum test. Rejections using fixed-
b critical values are similar to the rejections in traditional inference when a small bandwidth ratio is used. However, as the bandwidth increases, rejections using fixed-
b critical values systematically decrease towards the nominal level of 0.05. Under DGP B, the null rejections decrease as 0.131→0.096→0.083→0.086 over the range of
b with T = 500 and the Bartlett kernel and
being used. Even under DGP C, the null rejections approach the nominal level as
b increases for all sample sizes when the QS kernel and the trimming value of 0.2 are used.
Table 7 gives null rejection probabilities when using the data-dependent bandwidth ratio
. Columns on the left give rejections using fixed-
b critical values whereas columns on the right give rejections using traditional critical values. Patterns in
Table 7 are similar to patterns in
Table 4,
Table 5 and
Table 6. Over-rejections are often large when traditional critical values are used. Over-rejections are systematically smaller when fixed-
b critical values are used and
works reasonably well if the sample size is large enough relative to the strength of the persistence in the data. This is particularly true when the QS kernel is used with 0.2 trimming for the mean statistic and 0.05 trimming for the supremum and exponential statistics.
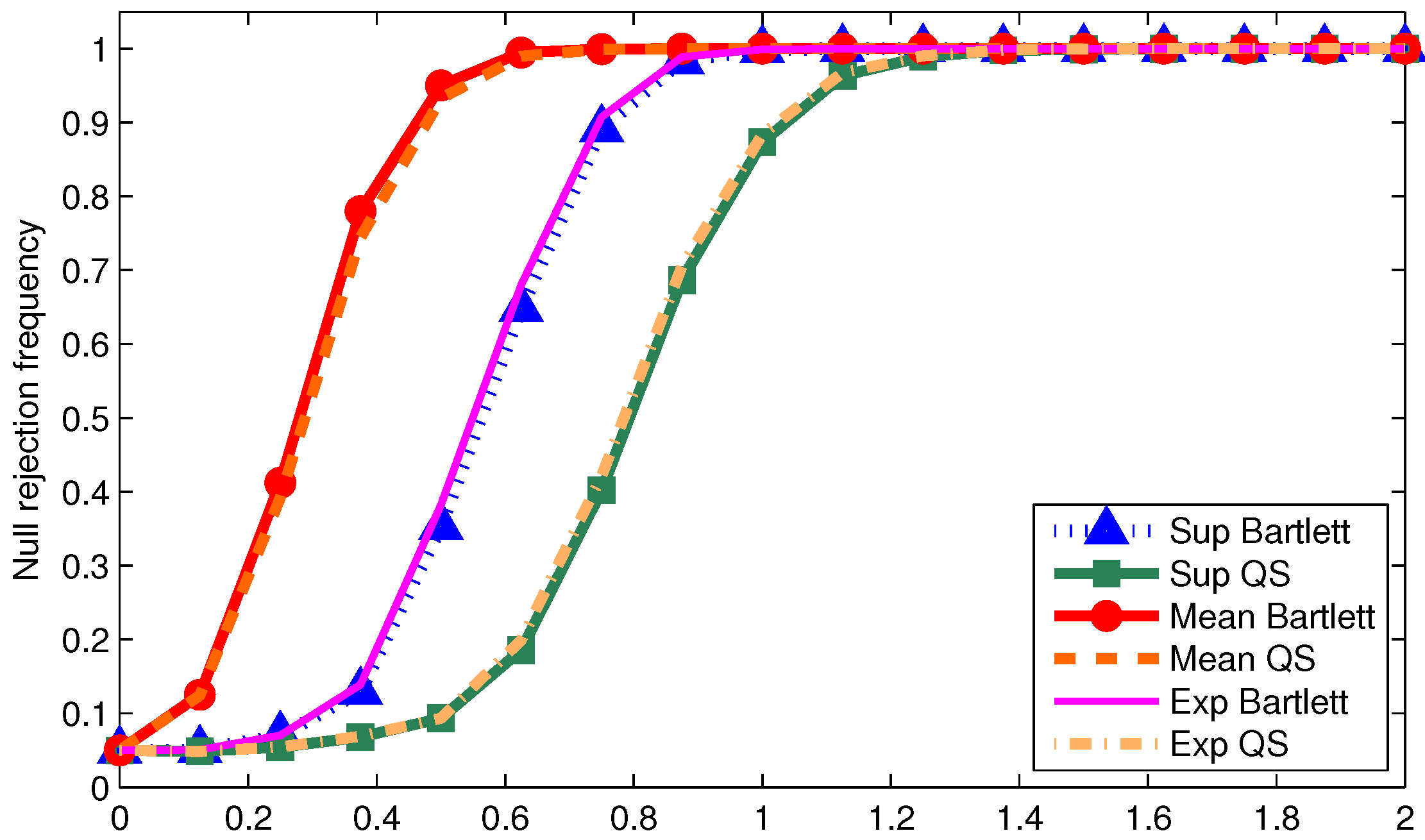
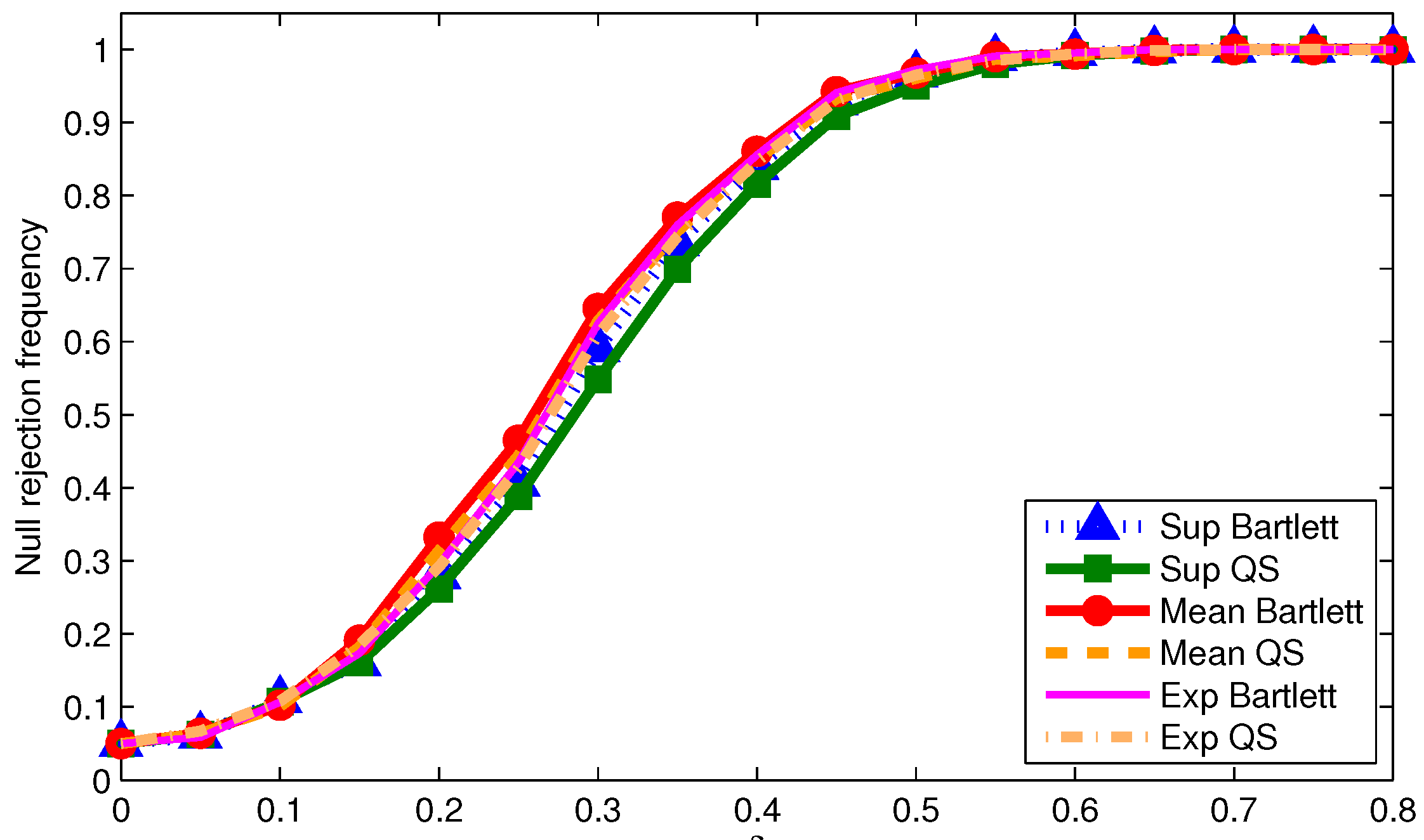
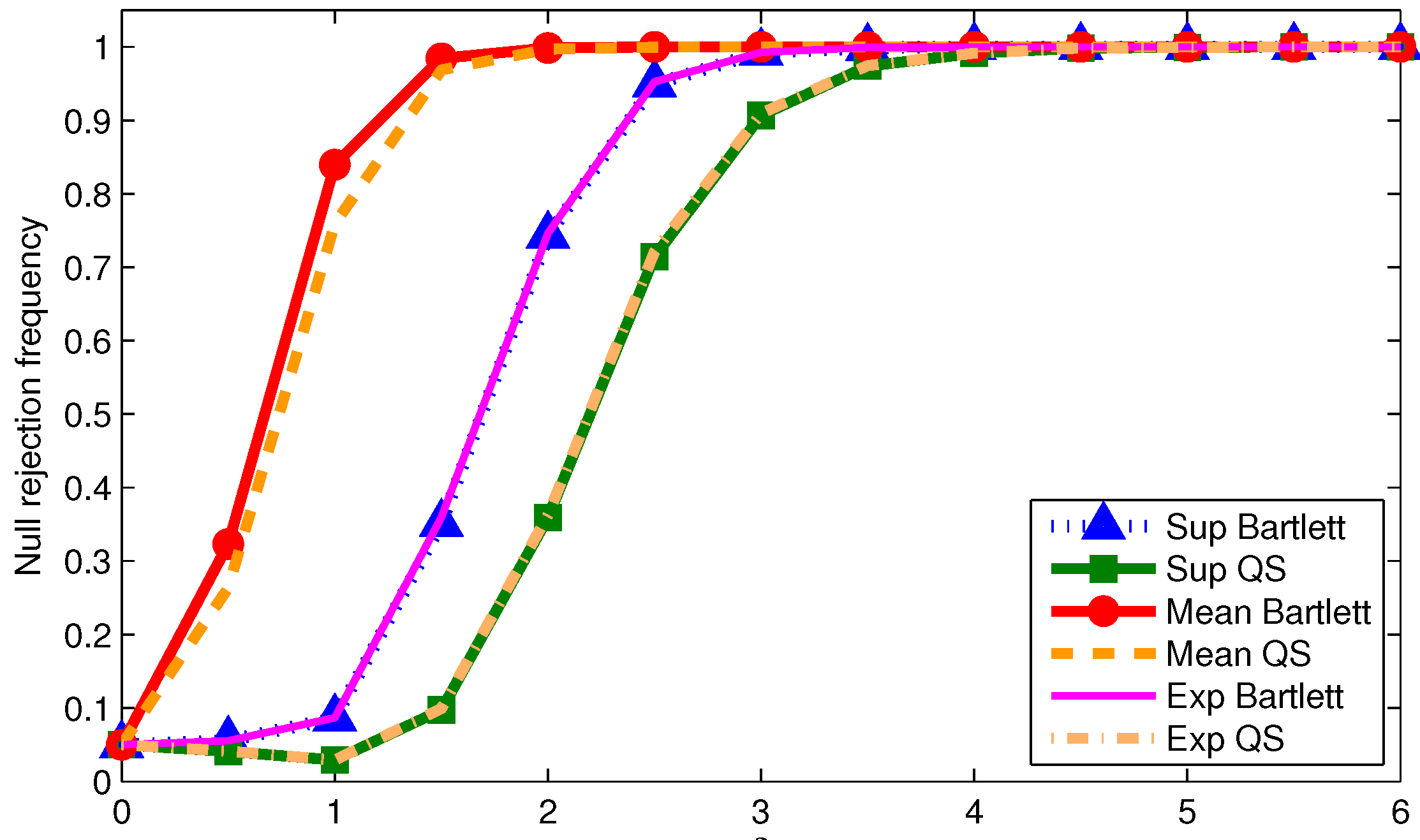
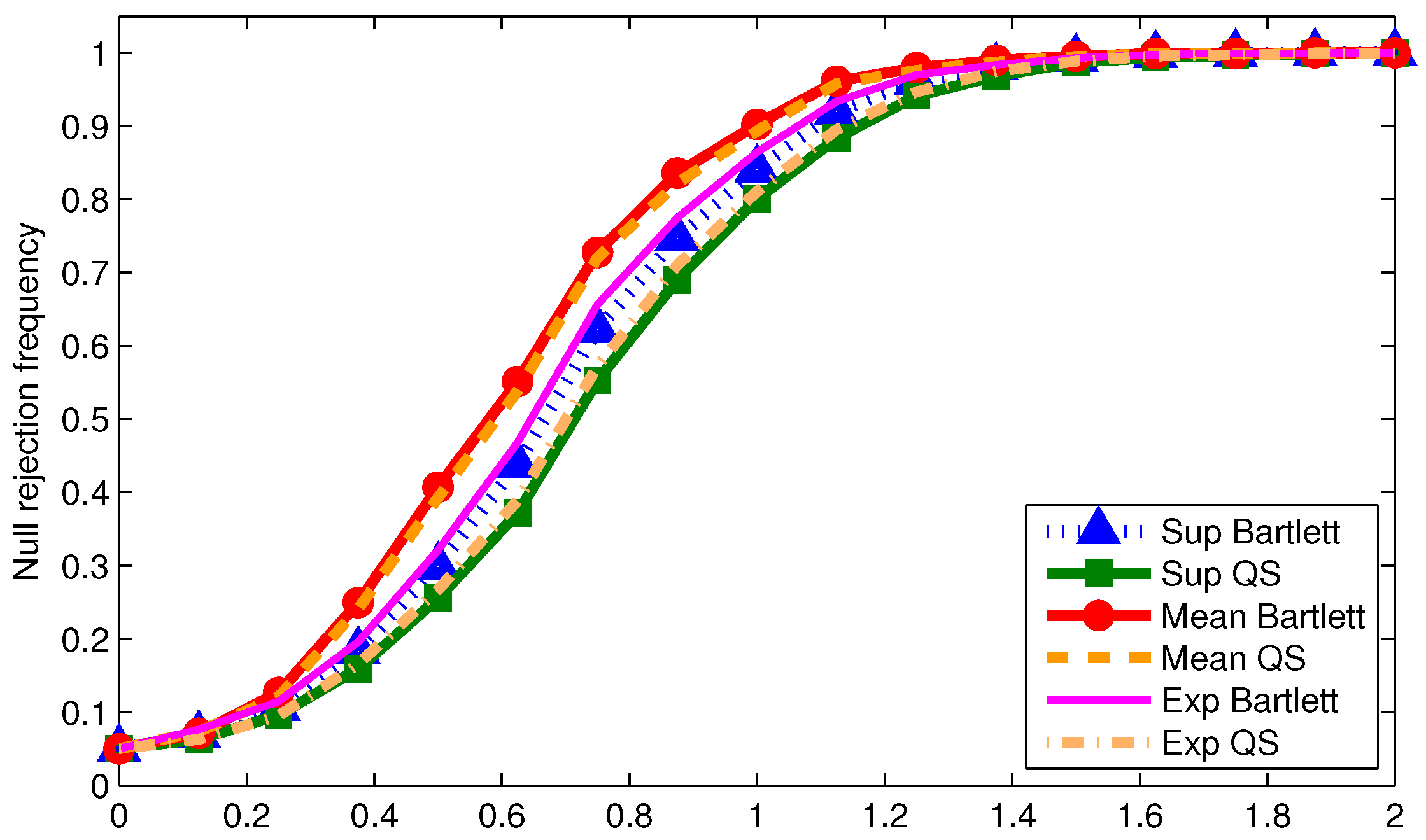
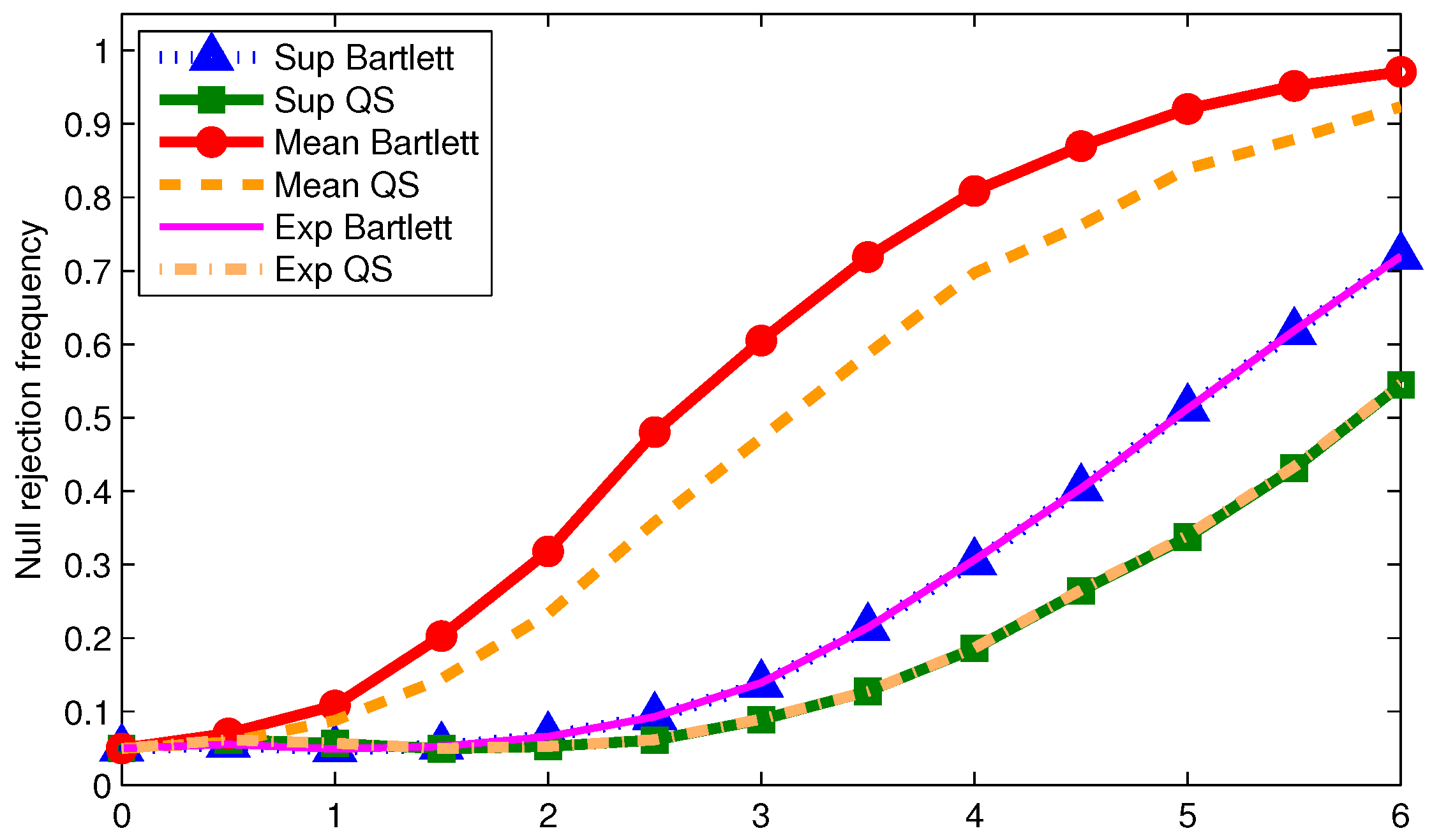
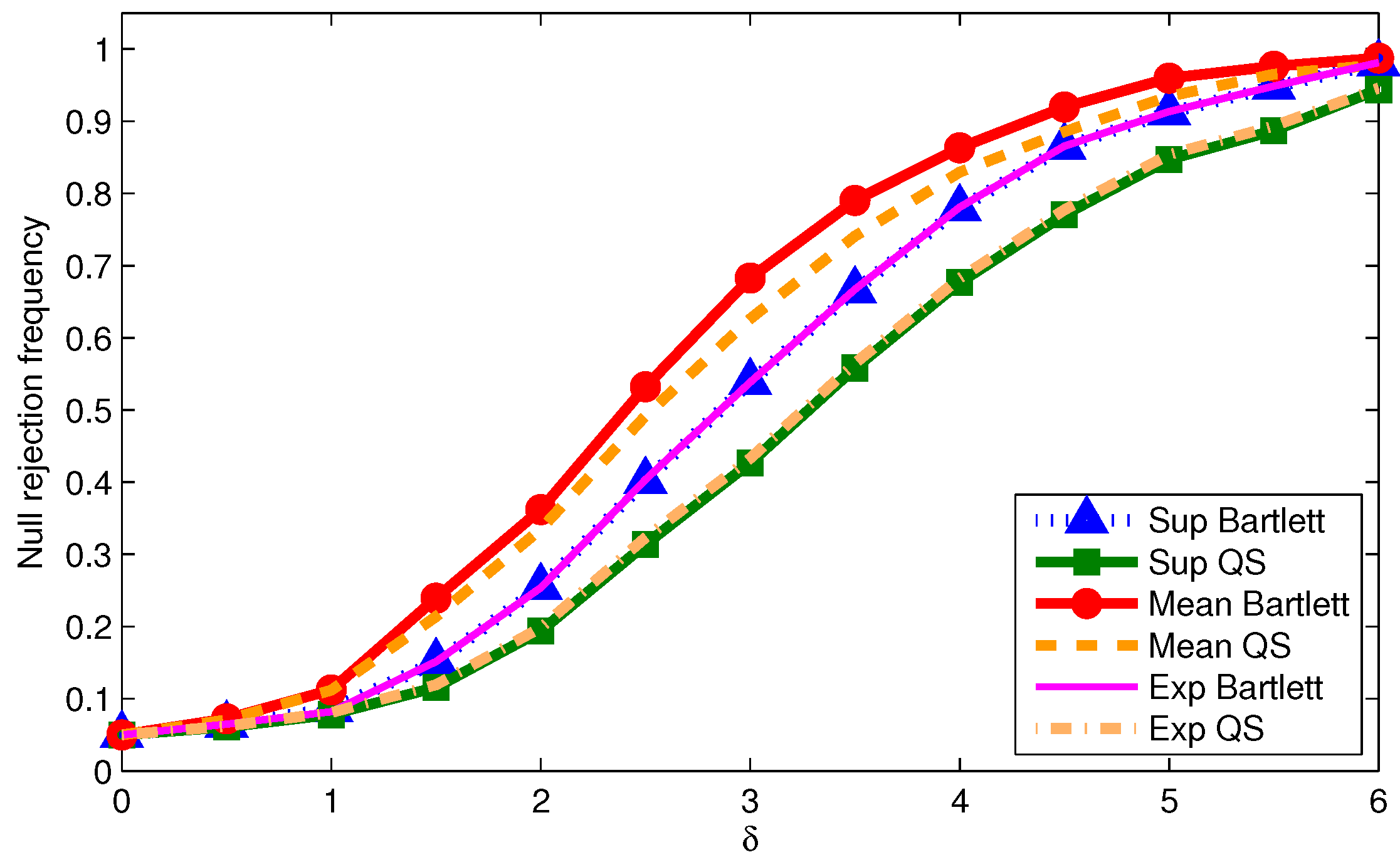
We now examine the power of the tests when using
We report size-adjusted power for T = 200 in
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6. Recall the break point under the alternative is
Odd (even) numbered figures give results with 0.05 (0.2) trimming. Results are given for the three DGPs used for the tables. First note that more trimming leads to higher power in all cases as one would expect. Second, the mean statistic tends to have the highest power regardless of the DGP or kernel. This is not surprising given the power optimality properties of the mean statistic derived by Andrews and Ploberger (1994) [
10] using traditional asymptotics. Third, for a given kernel, the supremum and exponential statistics have almost the same power across DGPs and trimming. This is somewhat surprising given that under traditional asymptotics, the exponential statistic is in the class of power optimal tests but the supremum statistic is not. This finding could be driven by values of
being far away from zero in which case the traditional asymptotics might not be accurately reflecting finite sample power. Finally, the Bartlett kernel tends to give tests with higher power than the QS kernel; a similar finding was made by Kiefer and Vogelsang (2005) [
1] in models without structural change.
The size and power results for the statistics implemented with point to the typical size-power tradeoff when using HAC variance estimators. Configurations that give the least size distortions also tend to have low power. As long as the data is not too persistent relative to the sample size, a reasonable approach for practice that balances size distortions and power is to use the mean statistic with 0.2 trimming implemented with the QS kernel with and fixed-b critical values.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}