
Building News Measures from Textual Data and an Application to Volatility Forecasting



Abstract
:1. Introduction
2. Literature Review
2.1. Mixture of Distributions Hypothesis
2.2. Macroeconomic News
2.3. Firm-Specific News and Sentiment
2.4. Google Trends
3. Database Construction
3.1. Dataset
- StreetAccount news stories: firm-specific news stories released by StreetAccount
- Thomson Reuters news stories: firm-specific news stories released by Thomson Reuters
- Earnings announcements: firm-specific EPS earnings per share (announcement and forecast) released by StreetAccount
- Macro-announcements: ten macroeconomic indicators (announcement and forecast) released by Thomson Reuters
- Google Trends: firm-specific relative indicators of internet search volume available from Google
3.2. Topics and Importance for News Classification
3.3. News stories’ Summary Stats and Provider Comparison
4. Sentiment Detection
- single words: no, not, none, never, nothing, nobody, nowhere, neither, nor, hardly, scarcely, seldom, barely, few, little, rarely, instead, can’t, cannot, don’t, doesn’t, didn’t, mustn’t, won’t, despite, overly, too, less
- two-word sequences: can not, do not, did not, short of, not every, not all, not much, not many, not always, not so, instead of, far from, not to, never to, no way, out of, not very, not enough, too few, too little, no big, not big, no significant, not significant
- three-word sequences: not at all, by no means, in no way, in place of, in spite of, in lieu of
- Positive words are given a value of 1 and negative words a value of ; the value is inverted in case of negation.
- The values of all words with a sentiment are summed to get the sentiment sum (Sent_Sum):where i is the word index, N is the number of words with a sentiment in a text, and is the sentiment of the word indexed by i.
- Sent_Sum is divided by the number of words with a sentiment to obtain a standardized quantity that we call relative sentiment (Rel_Sent) and that is between −1 and 1 by construction:
- If Rel_Sent is larger than 0.05 or smaller than , we associate a positive (1) or a negative sentiment () to the news, respectively; otherwise a neutral sentiment (0) is given. News sentiment is therefore neutral when a significant number of positive and negative words are detected and their proportion is roughly the same:
5. Creating News Measures
5.1. Concepts for Variables Related to News Stories
- Standard measures: number of news stories, number of words, sentiment. Number of news stories and number of words are proxies for the amount of information.
- Abnormal quantity: number of news stories above a certain threshold. Investors’ reaction could be triggered by the release of an unusual amount of information.
- Uncertainty: occurrence of news stories with opposite sentiments during the reference period. Information is released, but investors are likely unable to detect whether it is good or bad.
- News burst index: a measure of the amount of information released during the reference period that takes into account the possibility that a sudden, abnormal burst of information can affect market activity differently from the same information released gradually. Developed from the notion of realized volatility of an asset’s intraday returns, the news burst index is computed as the sum of the k-th power of the number of news stories (or words) disclosed over a series of time intervals:where t is the time period over which the measure is computed, M is the number of subintervals into which t can be split, and is the number of news stories disclosed within (t-1 + (j-1)/M) and (t-1 + j/M)—that is, in each subinterval. t can range from few minutes to a day or a series of days. If t is a day, it will be split in a series of intraday intervals, such as five minutes, ten minutes, or fifteen minutes. If t is a longer period—say, a week or a month—it is reasonable to divide it into a series of days, such as one-day, two-day, or five-day intervals.
- Quantity variation: variation across periods of the quantity of news stories (or words). This concept takes into account the chance that investors’ reactions are triggered not only by the release of information, but more generally by increases in the quantity of information. The market can become accustomed to news releases such that it perceives them as informative only when they are released at a higher (lower) rate than usual, in which case they wait for the rate of information arrival to increase (decrease) before making a decision.
- News persistence/interaction: when the quantity of news is above a threshold in each of two consecutive periods. Since providers do not supply redundant news9, this event denotes persistence in the release of news stories that are related in each period to a different issue.
- Sentiment inversion: when the sentiment of the reference period is opposite to that of previous periods.
- Quantity variation conditional on sentiment: positive quantity variation conditional on the sentiment of the reference period and negative quantity variation conditional on the sentiment of the previous period. The sentiment of the period with a higher quantity of information is likely to have the greater influence on investors’ attention.
- Sentiment conditional on quantity: sentiment of the reference period conditional on the quantity of information released during the same and during longer periods. Investors may base their decisions on the sentiment of the reference period, but their attention may depend on the quantity of information that is released during periods of the same duration or during longer periods.
5.2. Standardized Surprises of Earnings and Macro-Announcements
5.3. Google Search Index
- The set of daily series for each month (121 series, one for each month from February 2005 to February 2015, with the observations in each series equaling the number of days in the month), where for each series the observations are relative to the maximum of 100 during the month. Therefore, observations are not comparable across different months.
- The monthly-aggregated series for the whole sample (one series having 121 observations), where the observations are relative to the maximum of 100.
- Compute the relative contribution of day d to the search volume of month m , by dividing the daily observation of day d (relative to the maximum of month m) by the sum of all the daily observations of that month:11where is the number of days of month m.
- Compute the daily observations relative to the whole sample , by multiplying the relative contribution of day d to the search volume of month m by the monthly observation of month m :
- Find by dividing by the maximum and multiplying by 100:where is the max of over the series.
5.4. Proposed Measures Based on Various Time Horizons
- Overnight: information from the market closing time of day t-1 to the market opening time of day t
- Weekly: the most recent five trading days
- Monthly: the most recent twenty-two trading days
6. Application: News Measures and Volatility Forecasting
6.1. Methodology: Realized Volatility Modelling with News
6.2. Uncovering News Impact on RV
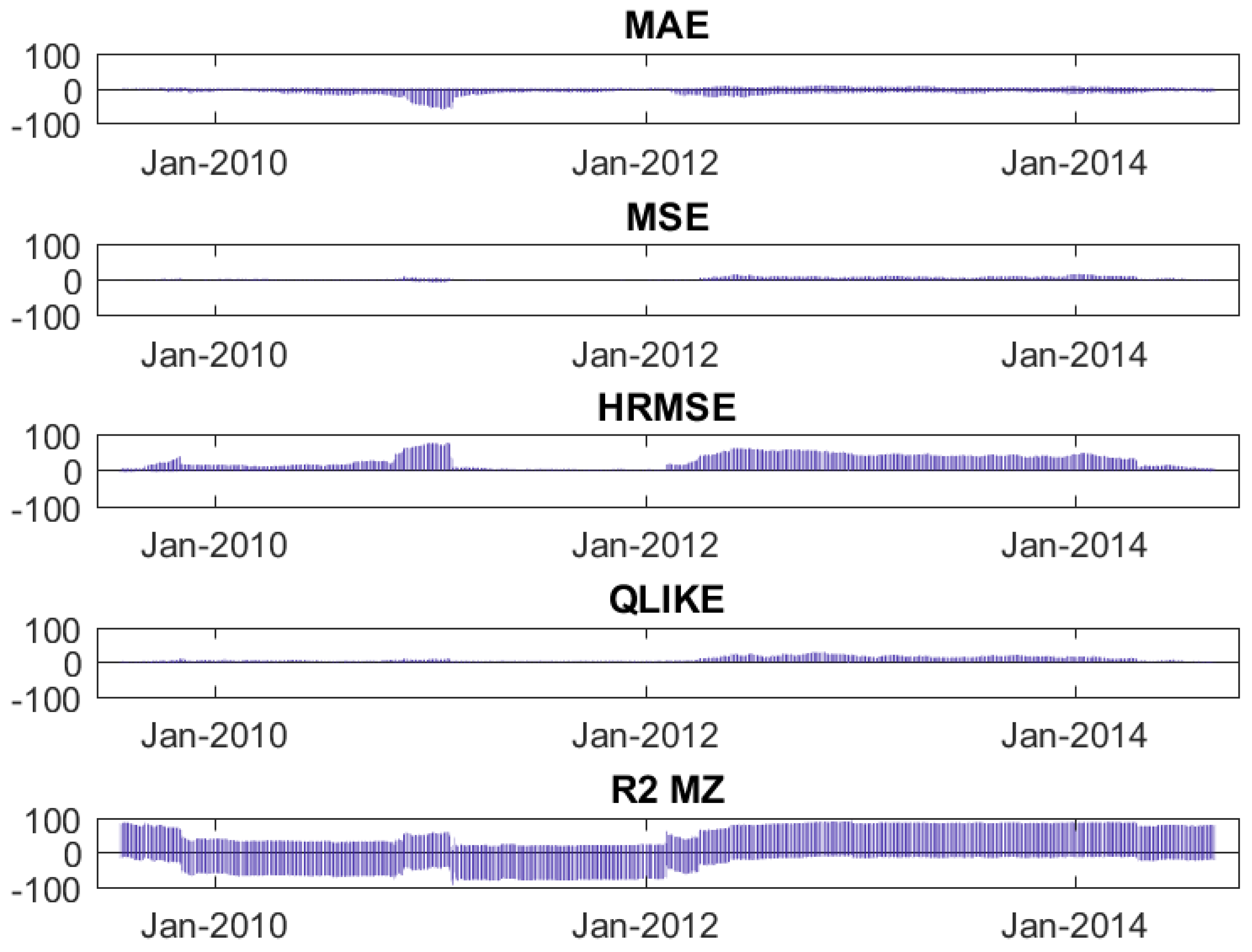
6.3. Evaluating the Improvement in Forecasting Performance
- The MAE mean absolute error:where is the ex-post value of realized variance, and is the forecast.
- The MSE mean square error:
- The QLIKE loss function:
- the R of Mincer-Zarnowitz forecasting regressions.
7. Concluding Remarks
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Assets, News Topics and News Summary Stats

{kind=link}
{kind=link}
| Ticker | Name | Sector |
|---|---|---|
| AAPL | Apple | Consumer Goods |
| ABT | Abbott Laboratories | Healthcare |
| ACN | Accenture plc | Technology |
| AEP | American Electric Power Co., Inc. | Utilities |
| AIG | American International Group, Inc. | Financial |
| ALL | The Allstate Corporation | Financial |
| AMGN | Amgen Inc. | Healthcare |
| AMZN | Amazon.com, Inc. | Services |
| APA | Apache Corp. | Basic Materials |
| APC | Anadarko Petroleum Corporation | Basic Materials |
| AXP | American Express Company | Financial |
| BA | The Boeing Company | Industrial Goods |
| BAX | Baxter International Inc. | Healthcare |
| BHI | Baker Hughes Incorporated | Basic Materials |
| BIIB | Biogen Inc. | Healthcare |
| BK | The Bank of New York Mellon Corporation | Financial |
| BMY | Bristol-Myers Squibb Company | Healthcare |
| BRK.B | Berkshire Hathaway Inc. | Financial |
| C | Citigroup Inc. | Financial |
| CAT | Caterpillar Inc. | Industrial Goods |
| CELG | Celgene Corporation | Healthcare |
| CL | Colgate-Palmolive Co. | Consumer Goods |
| CMCSA | Comcast Corporation | Services |
| COF | Capital One Financial Corporation | Financial |
| COP | ConocoPhillips | Basic Materials |
| COST | Costco Wholesale Corporation | Services |
| CSCO | Cisco Systems, Inc. | Technology |
| CVS | CVS Health Corporation | Healthcare |
| CVX | Chevron Corporation | Basic Materials |
| DD | E. I. du Pont de Nemours and Company | Basic Materials |
| DIS | The Walt Disney Company | Services |
| DOW | The Dow Chemical Company | Basic Materials |
| EBAY | eBay Inc. | Services |
| EMC | EMC Corporation | Technology |
| EMR | Emerson Electric Co. | Industrial Goods |
| EXC | Exelon Corporation | Utilities |
| FCX | Freeport-McMoRan Inc. | Basic Materials |
| FDX | FedEx Corporation | Services |
| GD | General Dynamics Corporation | Industrial Goods |
| GE | General Electric Company | Industrial Goods |
| GILD | Gilead Sciences Inc. | Healthcare |
| GS | The Goldman Sachs Group, Inc. | Financial |
| HAL | Halliburton Company | Basic Materials |
| HD | The Home Depot, Inc. | Services |
| HON | Honeywell International Inc. | Industrial Goods |
| HPQ | HP Inc. | Technology |
| IBM | International Business Machines Corporation | Technology |
| INTC | Intel Corporation | Technology |
| JNJ | Johnson & Johnson | Healthcare |
| JPM | JPMorgan Chase & Co. | Financial |
| KO | The Coca-Cola Company | Consumer Goods |
| LLY | Eli Lilly and Company | Healthcare |
| LMT | Lockheed Martin Corporation | Industrial Goods |
| LOW | Lowe’s Companies, Inc. | Services |
| MCD | McDonald’s Corp. | Services |
| MDLZ | Mondelez International, Inc. | Consumer Goods |
| MDT | Medtronic plc | Healthcare |
| MET | MetLife, Inc. | Financial |
| MMM | 3M Company | Industrial Goods |
| MO | Altria Group, Inc. | Consumer Goods |
| MON | Monsanto Company | Basic Materials |
| MRK | Merck & Co. Inc. | Healthcare |
| MSFT | Microsoft Corporation | Technology |
| NKE | NIKE, Inc. | Consumer Goods |
| NSC | Norfolk Southern Corporation | Services |
| ORCL | Oracle Corporation | Technology |
| OXY | Occidental Petroleum Corporation | Basic Materials |
| PEP | Pepsico, Inc. | Consumer Goods |
| PFE | Pfizer Inc. | Healthcare |
| PG | The Procter & Gamble Company | Consumer Goods |
| QCOM | QUALCOMM Incorporated | Technology |
| RTN | Raytheon Company | Industrial Goods |
| SBUX | Starbucks Corporation | Services |
| SLB | Schlumberger Limited | Basic Materials |
| SO | Southern Company | Utilities |
| SPG | Simon Property Group Inc. | Financial |
| T | AT&T, Inc. | Technology |
| TGT | Target Corp. | Services |
| TXN | Texas Instruments Inc. | Technology |
| UNH | UnitedHealth Group Incorporated | Healthcare |
| UNP | Union Pacific Corporation | Services |
| UPS | United Parcel Service, Inc. | Services |
| USB | U.S. Bancorp | Financial |
| UTX | United Technologies Corporation | Industrial Goods |
| WBA | Walgreens Boots Alliance, Inc. | Services |
| WFC | Wells Fargo & Company | Financial |
| WMB | Williams Companies, Inc. | Basic Materials |
| WMT | Wal-Mart Stores Inc. | Services |
| XOM | Exxon Mobil Corporation | Basic Materials |
| StreetAccount | Thomson Reuters | ||
|---|---|---|---|
| 1. | Conjecture | 1. | General Products |
| 2. | Corporate Actions | 2. | Production Guidance |
| 3. | Earnings | 3. | Business Deals |
| 4. | Guidance | 4. | M & A |
| 5. | Litigation | 5. | Officer Changes |
| 6. | M & A | 6. | Divestitures |
| 7. | Management Changes | 7. | Spin-Offs |
| 8. | News | 8. | New Business/Units/Subsidiary |
| 9. | Regulatory | 9. | New Markets |
| 10. | Syndicate | 10. | Equity Investments |
| 11. | Up/Downgrades | 11. | Share Repurchases |
| 12. | General Reorganization | ||
| 13. | Layoffs | ||
| 14. | Labor Issues | ||
| 15. | Class Action Lawsuit | ||
| 16. | Bankruptcy / Related | ||
| 17. | Initial Public Offerings | ||
| 18. | Equity Financing / Related | ||
| 19. | Debt Financing / Related | ||
| 20. | Indices Changes | ||
| 21. | Exchange Changes | ||
| 22. | Name Changes | ||
| 23. | Other Accounting | ||
| 24. | Restatements | ||
| 25. | Delinquent Filings | ||
| 26. | Change in Accounting Method/Policy | ||
| 27. | Corporate Litigation | ||
| 28. | Earnings Announcements | ||
| 29. | Negative Earnings Pre-Announcement | ||
| 30. | Positive Earnings Pre-Announcement | ||
| 31. | Other Pre-Announcement | ||
| 32. | Strategic Combinations | ||
| 33. | Regulatory/Company Investigation | ||
| 34. | Dividends | ||
| 35. | Debt Ratings | ||
| 36. | Special Events | ||
Appendix B. Realized Volatility Measurement and Jump Testing
| Min | Max | Mean | Median | |
|---|---|---|---|---|
| Jump days (%) | 1.57 | 4.82 | 3.02 | 2.90 |

Appendix C. Most Selected Regressors in the LHAR-CJN Model by Subsample
| Past Volatility Components and Leverage | % Selected | % Pos | % Neg | ||||||
|---|---|---|---|---|---|---|---|---|---|
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 53.93 | 53.93 | 0.00 | ||||||
| log | 0.00 | 0.00 | 0.00 | ||||||
| log | 0.00 | 0.00 | 0.00 | ||||||
| log | 1.12 | 1.12 | 0.00 | ||||||
| 30.34 | 0.00 | 30.34 | |||||||
| 8.99 | 0.00 | 8.99 | |||||||
| 16.85 | 0.00 | 16.85 | |||||||
| Macro | Firm-Specific | News | Importance | Topic | Time Aggregation | Measure | % Selected | % Pos | % Neg |
| X | EPS | day | flag for announcement | 13.48 | 13.48 | 0.00 | |||
| X | TR news | low | earnings | flow: day-to-day | flag if n. news stories | 10.11 | 10.11 | 0.00 | |
| X | SA news | earnings | flow: day-to-day | flag if n. news stories | 10.11 | 10.11 | 0.00 | ||
| X | EPS | day | flag if surp | 8.99 | 8.99 | 0.00 | |||
| X | JOBLESS | overnight | flag if surp | 7.87 | 7.87 | 0.00 | |||
| X | SA news | earnings | flow: day-to-day | flag if n. words | 7.87 | 7.87 | 0.00 | ||
| X | SA news | earnings | flow: day-to-day | flag if n. news stories | 7.87 | 7.87 | 0.00 | ||
| X | SA news | earnings | day | log n. words | 6.74 | 6.74 | 0.00 | ||
| X | TR news | medium | earnings | flow: day-to-day | flag if n. news stories | 5.62 | 5.62 | 0.00 | |
| X | TR news | low | earnings | flow: day-to-day | flag if n. words | 5.62 | 5.62 | 0.00 | |
| X | TR news | low | earnings | flow: day-to-day | flag if n. news stories | 5.62 | 5.62 | 0.00 | |
| X | SA news | earnings | day | flag if n. news stories | 5.62 | 5.62 | 0.00 | ||
| X | TR news | low | earnings | day | sqrt n. words | 4.49 | 4.49 | 0.00 | |
| X | TR news | low | earnings | day | sqrt n. news stories | 4.49 | 4.49 | 0.00 | |
| X | TR news | low | earnings | day | flag if n. news stories | 4.49 | 4.49 | 0.00 | |
| X | TR news | low | earnings | day | n. news stories | 4.49 | 4.49 | 0.00 | |
| X | SA news | earnings | day | sqrt n. words | 4.49 | 4.49 | 0.00 | ||
| X | TR news | medium | earnings | flow: day-to-day | flag if n. words | 3.37 | 3.37 | 0.00 | |
| X | TR news | medium | earnings | flow: day-to-day | flag if n. news stories | 3.37 | 3.37 | 0.00 | |
| X | TR news | medium | earnings | day | sqrt n. words | 3.37 | 3.37 | 0.00 | |
| X | TR news | medium | all | day | sqrt n. words | 3.37 | 3.37 | 0.00 | |
| X | TR news | low | earnings | flow: day-to-day | flag if n. words | 3.37 | 3.37 | 0.00 | |
| X | TR news | low | earnings | day | log n. words | 3.37 | 3.37 | 0.00 | |
| X | TR news | low | earnings | day | log n. news stories | 3.37 | 3.37 | 0.00 | |
| X | SA news | earnings | flow: day-to-day | flag if n. words | 3.37 | 3.37 | 0.00 | ||
| X | SA news | earnings | day | flag if n. news stories | 3.37 | 3.37 | 0.00 | ||
| X | SA news | earnings | day | n. news stories | 3.37 | 3.37 | 0.00 | ||
| X | SA news | all | flow: day-to-day | n. news stories | 3.37 | 0.00 | 3.37 | ||
| X | SA news | all | day | flag if n. news stories | 3.37 | 3.37 | 0.00 | ||
| X | SA news | all | day | square n. news stories | 3.37 | 3.37 | 0.00 | ||
| Past Volatility Components and Leverage | % Selected | % Pos | % Neg | ||||||
|---|---|---|---|---|---|---|---|---|---|
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 33.71 | 33.71 | 0.00 | ||||||
| log | 0.00 | 0.00 | 0.00 | ||||||
| log | 0.00 | 0.00 | 0.00 | ||||||
| log | 1.12 | 1.12 | 0.00 | ||||||
| 19.10 | 0.00 | 19.10 | |||||||
| 11.24 | 0.00 | 11.24 | |||||||
| 37.08 | 0.00 | 37.08 | |||||||
| Macro | Firm-Specific | News | Importance | Topic | Time Aggregation | Measure | % Selected | % Pos | % Neg |
| Google Trends | week | log GSI | 2.25 | 2.25 | 0.00 | ||||
| X | SA news | M&A | month | sentiment | 2.25 | 0.00 | 2.25 | ||
| X | SA news | M&A | month | flag if n. news stories | 2.25 | 2.25 | 0.00 | ||
| Google Trends | month | sqrt GSI | 1.12 | 1.12 | 0.00 | ||||
| Google Trends | month | GSI | 1.12 | 1.12 | 0.00 | ||||
| Google Trends | week | square GSI | 1.12 | 1.12 | 0.00 | ||||
| Google Trends | week | sqrt GSI | 1.12 | 1.12 | 0.00 | ||||
| Google Trends | week | GSI | 1.12 | 1.12 | 0.00 | ||||
| Google Trends | day | log GSI | 1.12 | 1.12 | 0.00 | ||||
| Google Trends | day | sqrt GSI | 1.12 | 1.12 | 0.00 | ||||
| X | RSALES | week | sqrt surp | 1.12 | 0.00 | 1.12 | |||
| X | NFP | month | surp | 1.12 | 0.00 | 1.12 | |||
| X | CPI | week | flag if surp | 1.12 | 1.12 | 0.00 | |||
| X | TR news | high | M&A | flow: day-to-day | flag if n. words | 1.12 | 1.12 | 0.00 | |
| X | TR news | high | M&A | month | flag if sentiment | 1.12 | 1.12 | 0.00 | |
| X | TR news | high | earnings | flow: day-to-day | flag if n. news stories | 1.12 | 1.12 | 0.00 | |
| X | TR news | high | all | flow: day-to-day | flag if n. news stories | 1.12 | 1.12 | 0.00 | |
| X | TR news | high | all | month | news burst index (M = 78, k = 2) | 1.12 | 1.12 | 0.00 | |
| X | TR news | high | all | month | sentiment | 1.12 | 0.00 | 1.12 | |
| X | TR news | high | all | month | square n. words | 1.12 | 1.12 | 0.00 | |
| X | TR news | high | all | month | n. words | 1.12 | 1.12 | 0.00 | |
| X | TR news | high | all | week | n. news | 1.12 | 1.12 | 0.00 | |
| X | TR news | medium | earnings | day | square n. words | 1.12 | 1.12 | 0.00 | |
| X | TR news | medium | all | month | sentiment | 1.12 | 0.00 | 1.12 | |
| X | TR news | low | regulatory | flow: month-to-day | flag if n. words | 1.12 | 1.12 | 0.00 | |
| X | TR news | low | regulatory | flow: month-to-day | flag if n. news stories | 1.12 | 1.12 | 0.00 | |
| X | TR news | low | M&A | month | sentiment | 1.12 | 0.00 | 1.12 | |
| X | TR news | low | litigation | month | words burst index (M = 78, k = 4) | 1.12 | 1.12 | 0.00 | |
| X | TR news | low | financial | month | news burst index (M = 78, k = 4) | 1.12 | 1.12 | 0.00 | |
| X | TR news | low | earnings | flow: day-to-day | flag if n. words | 1.12 | 1.12 | 0.00 | |
| Past Volatility Components and Leverage | % Selected | % Pos | % Neg | ||||||
|---|---|---|---|---|---|---|---|---|---|
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 0.00 | 0.00 | 0.00 | ||||||
| log | 0.00 | 0.00 | 0.00 | ||||||
| log | 0.00 | 0.00 | 0.00 | ||||||
| 76.40 | 0.00 | 76.40 | |||||||
| 52.81 | 0.00 | 52.81 | |||||||
| 3.37 | 0.00 | 3.37 | |||||||
| Macro | Firm-Specific | News | Importance | Topic | Time Aggregation | Measure | % Selected | % Pos | % Neg |
| X | EPS | day | flag for announcement | 49.44 | 49.44 | 0.00 | |||
| X | SA news | all | day | n. news stories | 32.58 | 32.58 | 0.00 | ||
| X | SA news | earnings | flow: day-to-day | flag if n. news stories | 20.22 | 20.22 | 0.00 | ||
| X | EPS | day | flag if surp | 17.98 | 17.98 | 0.00 | |||
| X | SA news | earnings | flow: day-to-day | flag if n. words | 16.85 | 16.85 | 0.00 | ||
| X | SA news | earnings | day | flag if n. news stories | 16.85 | 16.85 | 0.00 | ||
| X | SA news | earnings | day | log n. news stories | 15.73 | 15.73 | 0.00 | ||
| X | TR news | low | earnings | flow: day-to-day | flag if n. news stories | 14.61 | 14.61 | 0.00 | |
| X | TR news | low | earnings | flow: day-to-day | flag if n. news stories | 13.48 | 13.48 | 0.00 | |
| X | SA news | earnings | flow: day-to-day | flag if n. words | 12.36 | 12.36 | 0.00 | ||
| X | SA news | earnings | day | n. news stories | 12.36 | 12.36 | 0.00 | ||
| X | TR news | low | earnings | flow: day-to-day | flag if n. words | 11.24 | 11.24 | 0.00 | |
| X | TR news | low | earnings | day | n. news stories | 11.24 | 11.24 | 0.00 | |
| X | SA news | earnings | day | sqrt n. words | 11.24 | 11.24 | 0.00 | ||
| X | SA news | earnings | day | flag if n. news stories | 11.24 | 11.24 | 0.00 | ||
| X | SA news | all | flow: day-to-day | flag if n. words | 11.24 | 11.24 | 0.00 | ||
| X | SA news | all | day | n. words | 11.24 | 11.24 | 0.00 | ||
| X | SA news | all | day | square n. news stories | 11.24 | 11.24 | 0.00 | ||
| X | TR news | low | earnings | flow: day-to-day | flag if n. words | 10.11 | 10.11 | 0.00 | |
| X | SA news | earnings | flow: day-to-day | flag if n. news stories | 10.11 | 10.11 | 0.00 | ||
| X | SA news | earnings | day | log n. words | 10.11 | 10.11 | 0.00 | ||
| Google Trends | month | GSI | 8.99 | 5.62 | 3.37 | ||||
| X | TR news | low | earnings | day | flag if n. news stories | 8.99 | 8.99 | 0.00 | |
| X | SA news | earnings | day | sqrt n. news stories | 8.99 | 8.99 | 0.00 | ||
| X | SA news | all | day | flag if n. news stories | 8.99 | 8.99 | 0.00 | ||
| X | SA news | all | day | sqrt n. words | 8.99 | 8.99 | 0.00 | ||
| Google Trends | week | log GSI | 7.87 | 7.87 | 0.00 | ||||
| Google Trends | week | sqrt GSI | 7.87 | 7.87 | 0.00 | ||||
| Google Trends | week | GSI | 7.87 | 6.74 | 1.12 | ||||
| X | TR news | medium | earnings | flow: day-to-day | flag if n. news stories | 7.87 | 7.87 | 0.00 | |
Appendix D. Outliers Adjustment for the LHAR-CJN Model
| Condition | |
|---|---|
References
- Allen, David E., Michael J. McAleer, and Abhay K. Singh. 2015a. Daily Market News Sentiment and Stock Prices. Tinbergen Institute Discussion Papers 15-090/III. Amsterdam, The Netherlands: Tinbergen Institute. [Google Scholar]
- Allen, David E., Michael J. McAleer, and Abhay K. Singh. 2015b. Machine News and Volatility: The Dow Jones Industrial Average and the TRNA Real-Time Sentiment Series. In The Handbook of High Frequency Trading. Edited by Greg N. Gregoriou. Amsterdam, The Netherlands: Elsevier, pp. 327–44. [Google Scholar]
- Allen, David E., Michael J. McAleer, and Abhay K. Singh. 2017. An Entropy-Based Analysis of the Relationship between the DOW JONES Index and the TRNA Sentiment Series. Applied Economics 49: 677–92. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, Francis X. Diebold, and Paul Labys. 2003. Modeling and Forecasting Realized Volatility. Econometrica 71: 579–625. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, and Francis X. Diebold. 2007. Roughing It Up: Including Jump Components in the Measurement, Modeling, and Forecasting of Return Volatility. The Review of Economics and Statistics 89: 701–20. [Google Scholar] [CrossRef]
- Andrei, Daniel, and Michael Hasler. 2015. Investor Attention and Stock Market Volatility. The Review of Financial Studies 28: 33–72. [Google Scholar] [CrossRef]
- Antweiler, Werner, and Murray Z. Frank. 2004. Is All That Talk Just Noise? The Information Content of Internet Stock Message Boards. The Journal of Finance 59: 1259–94. [Google Scholar] [CrossRef]
- Audrino, Francesco, and Simon D. Knaus. 2016. Lassoing the HAR Model: A Model Selection Perspective on Realized Volatility Dynamics. Economet Reviews 35: 1485–521. [Google Scholar] [CrossRef]
- Bajgrowicz, Pierre, Olivier Scaillet, and Adrien Treccani. 2016. Jumps in High-Frequency Data: Spurious Detections, Dynamics, and News. Management Science 62: 2198–217. [Google Scholar] [CrossRef]
- Baker, Scott, and Andry Fradkin. 2011. What Drives Job Search? Evidence from Google Search Data. Discussion Papers. Stanford, CA, USA: Stanford Instititute for Economic Policy Research. [Google Scholar]
- Baklaci, Hasan F., Gokce Tunc, Berna Aydogan, and Gulin Vardar. 2011. The Impact of Firm-Specific Public News on Intraday Market Dynamics: Evidence from the Turkish Stock Market. Emerging Markets Finance and Trade 47: 99–119. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, Ole E., and Neil Shephard. 2004. Power and Bipower Variation with Stochastic Volatility and Jumps. Journal of Financial Econometrics 2: 1–37. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, Ole E., and Neil Shephard. 2006. Econometrics of Testing for Jumps in Financial Economics Using Bipower Variation. Journal of Financial Econometrics 4: 1–30. [Google Scholar] [CrossRef]
- Berry, Thomas D., and Keith M. Howe. 1994. Public Information Arrival. The Journal of Finance 49: 1331–46. [Google Scholar] [CrossRef]
- Bergmeir, Christoph, and José M. Benitez. 2012. On the Use of Cross-validation for Time Series Predictor Evaluation. Information Sciences 191: 192–213. [Google Scholar] [CrossRef]
- Berk, Kenneth N. 1978. Comparing Subset Regression Procedures. Technometrics 20: 1–6. [Google Scholar] [CrossRef]
- Birz, Gene, and John R. Lott. 2011. The Effect of Macroeconomic News on Stock Returns: New Evidence from Newspaper Coverage. Journal of Banking & Finance 35: 2791–800. [Google Scholar]
- Bollerslev, Tim. 1986. Generalized Autoregressive Conditional Heteroskedasticity. Journal of Econometrics 31: 307–27. [Google Scholar] [CrossRef]
- Bollerslev, Tim, and Eric Ghysels. 1996. Periodic Autoregressive Conditional Heteroscedasticity. Journal of Business & Economic Statistics 14: 139–51. [Google Scholar]
- Bomfim, Antulio N. 2003. Pre-announcement Effects, News Effects, and Volatility: Monetary Policy and the Stock Market. Journal of Banking & Finance 27: 133–51. [Google Scholar]
- Borovkova, Svetlana, and Diego Mahakena. 2015. News, Volatility and Jumps: the Case of Natural Gas Futures. Quantitative Finance 15: 1217–42. [Google Scholar] [CrossRef]
- Brailsford, Timothy J. 1996. The Empirical Relationship between Trading Volume, Returns and Volatility. Accounting & Finance 36: 89–111. [Google Scholar]
- Brenner, Menachem, Paolo Pasquariello, and Marti Subrahmanyam. 2009. On the Volatility and Comovement of U.S. Financial Markets around Macroeconomic News Announcements. Journal of Financial and Quantitative Analysis 44: 1265–89. [Google Scholar] [CrossRef]
- Burman, Prabir, Edmond Chow, and Deborah Nolan. 1994. A Cross-validatory Method for Dependent Data. Biometrika 81: 351–58. [Google Scholar] [CrossRef]
- Busse, Jeffrey A., and T. Clifton Green. 2002. Market Efficiency in Real Time. Journal of Financial Economics 65: 415–37. [Google Scholar] [CrossRef]
- Castle, Jennifer L., Jurgen A. Doornik, and David F. Hendry. 2011. Evaluating Automatic Model Selection. Journal of Time Series Econometrics 3: 1–33. [Google Scholar] [CrossRef]
- Clark, Peter K. 1973. A Subordinated Stochastic Process Model with Finite Variance for Speculative Prices. Econometrica 41: 135–55. [Google Scholar] [CrossRef]
- Corsi, Fulvio. 2009. A Simple Approximate Long-Memory Model of Realized Volatility. Journal of Financial Econometrics 7: 174–96. [Google Scholar] [CrossRef]
- Corsi, Fulvio, Davide Pirino, and Roberto Reno. 2010. Threshold Bipower Variation and the Impact of Jumps on Volatility Forecasting. Journal of Econometrics 159: 276–88. [Google Scholar] [CrossRef]
- Corsi, Fulvio, and Roberto Renò. 2012. Discrete-Time Volatility Forecasting With Persistent Leverage Effect and the Link With Continuous-Time Volatility Modeling. Journal of Business & Economic Statistics 30: 368–80. [Google Scholar]
- Cutler, David M., James M. Poterba, and Lawrence H. Summers. 1989. What Moves Stock Prices? The Journal of Portfolio Management 15: 4–12. [Google Scholar] [CrossRef]
- Da, Zhi, Joseph Engelberg, and Pengjie Gao. 2011. In Search of Attention. The Journal of Finance 66: 1461–99. [Google Scholar] [CrossRef]
- Da, Zhi, Joseph Engelberg, and Pengjie Gao. 2015. The Sum of All FEARS Investor Sentiment and Asset Prices. The Review of Financial Studies 28: 1–32. [Google Scholar] [CrossRef]
- D’Amuri, Francesco, and Juri Marcucci. 2012. The Predictive Power of Google Searches in Forecasting Unemployment. Banca D’Italia Working Papers n. 891. Roma, Italy: Bank of Italy. [Google Scholar]
- Diebold, Francis X., and Robert S. Mariano. 1995. Comparing Predictive Accuracy. Journal of Business & Economic Statistics 13: 253–63. [Google Scholar]
- Dimpfl, Thomas, and Stephan Jank. 2016. Can Internet Search Queries Help to Predict Stock Market Volatility? European Financial Management 22: 171–92. [Google Scholar] [CrossRef]
- Dougal, Casey, Joseph Engelberg, Diego García, and Christopher A. Parsons. 2012. Journalists and the Stock Market. The Review of Financial Studies 25: 639–79. [Google Scholar] [CrossRef]
- Efron, Bradley, Trevor Hastie, Iain Johnstone, and Robert Tibshirani. 2004. Least Angle Regression. The Annals of statistics 32: 407–51. [Google Scholar]
- Engle, Robert F. 1982. Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation. Econometrica 50: 987–1007. [Google Scholar] [CrossRef]
- Engle, Robert F., and Jose Gonzalo Rangel. 2008. The Spline-GARCH Model for Low-Frequency Volatility and Its Global Macroeconomic Causes. The Review of Financial Studies 21: 1187–222. [Google Scholar] [CrossRef]
- Epps, Thomas W., and Mary Lee Epps. 1976. The Stochastic Dependence of Security Price Changes and Transaction Volumes: Implications for the Mixture-of-Distributions Hypothesis. Econometrica 44: 305–21. [Google Scholar] [CrossRef]
- Fan, Jianqing, and Runze Li. 2001. Variable Selection via Nonconcave Penalized Likelihood and its Oracle Properties. Journal of the American statistical Association 96: 1348–60. [Google Scholar] [CrossRef]
- Fang, Lily, and Joel Peress. 2009. Media Coverage and the Cross-section of Stock Returns. The Journal of Finance 64: 2023–52. [Google Scholar] [CrossRef]
- Feig, Douglas G. 1978. Ridge Regression: When Biased Estimation is Better. Social Science Quarterly 58: 708–16. [Google Scholar]
- Flannery, Mark J., and Aris A. Protopapadakis. 2002. Macroeconomic Factors do Influence Aggregate Stock Returns. The review of financial studies 15: 751–82. [Google Scholar] [CrossRef]
- Gallo, Giampiero M., and Barbara Pacini. 2000. The Effects of Trading Activity on Market Volatility. The European Journal of Finance 6: 163–75. [Google Scholar] [CrossRef]
- García, Diego. 2013. Sentiment during Recessions. The Journal of Finance 68: 1267–300. [Google Scholar] [CrossRef]
- Ginsberg, Jeremy, Matthew H. Mohebbi, Rajan S. Patel, Lynnette Brammer, Mark S. Smolinski, and Larry Brilliant. 2009. Detecting Influenza Epidemics Using Search Engine Query Data. Nature 457: 1012–14. [Google Scholar] [CrossRef] [PubMed]
- Gloß-Klußmann, Axel, and Nikolaus Hautsch. 2011. When Machines Read the News: Using Automated Text Analytics to Quantify High Frequency News-Implied Market Reactions. Journal of Empirical Finance 18: 321–40. [Google Scholar] [CrossRef]
- Goddard, Arben, and Qingwei Wang. 2015. Investor Attention and FX Market Volatility. Journal of International Financial Markets, Institutions & Money 38: 79–96. [Google Scholar]
- Guo, Jian-Feng, and Qiang Ji. 2013. How does Market Concern Derived from the Internet Affect Oil Prices? Applied Energy 112: 1536–43. [Google Scholar] [CrossRef]
- Hamid, Alain, and Moritz Heiden. 2015. Forecasting Volatility with Empirical Similarity and Google Trends. Journal of Economic Behavior & Organization 117: 62–81. [Google Scholar]
- Hautsch, Nikolaus, Dieter Hess, and David Veredas. 2011. The Impact of Macroeconomic News on Quote Adjustments, Noise, and Informational Volatility. Journal of Banking & Finance 35: 2733–46. [Google Scholar]
- Ho, Kin-Yip, Yanlin Shi, and Zhaoyong Zhang. 2013. How Does News Sentiment Impact Asset Volatility? Evidence from Long Memory and Regime-Switching Approaches. The North American Journal of Economics and Finance 26: 436–56. [Google Scholar] [CrossRef]
- Holm, Sture. 1979. A Simple Sequentially Rejective Multiple Test Procedure. Scandinavian Journal of Statistics 6: 65–70. [Google Scholar]
- James, Gareth, Daniela Witten, Trevor Hastie, and Robert Tibshirani. 2013. An Introduction to Statistical Learning. New York: Springer-Verlag. [Google Scholar]
- Janssen, Gust. 2004. Public Information Arrival and Volatility Persistence in Financial Markets. The European Journal of Finance 10: 177–97. [Google Scholar] [CrossRef]
- Jones, Charles M., Owen Lamont, and Robin L. Lumsdaine. 1998. Macroeconomic News and Bond Market Volatility. Journal of Financial Economics 47: 315–37. [Google Scholar] [CrossRef]
- Kalev, Petko S., Wai-Man Liu, Peter K. Pham, and Elvis Jarnecic. 2004. Public Information Arrival and Volatility of Intraday Stock Returns. Journal of Banking & Finance 28: 1441–67. [Google Scholar]
- Kim, Dongcheol, and Stanley J. Kon. 1994. Alternative Models for the Conditional Heteroscedasticity of Stock Returns. Journal of Business 67: 563–98. [Google Scholar] [CrossRef]
- Kraussl, Roman, and Elizaveta Mirgorodskaya. 2016. Media, Sentiment and Market Performance in the Long Run. The European Journal of Finance 22: 1–24. [Google Scholar] [CrossRef]
- Lamoureux, Christopher G., and William D. Lastrapes. 1990. Heteroskedasticity in Stock Return Data: Volume versus GARCH Effects. The Journal of Finance 45: 221–29. [Google Scholar] [CrossRef]
- Li, Li, and R.F. Engle. 1998. Macroeconomic Announcements and Volatility of Treasury Futures. Discussion Paper. San Diego, CA, USA: University of California. [Google Scholar]
- Loughran, Tim, and Bill McDonald. 2011. When is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks. The Journal of Finance 66: 35–65. [Google Scholar] [CrossRef]
- Martens, Martin, Dick van Dijk, and Michiel de Pooter. 2009. Forecasting S&P 500 Volatility: Long Memory, Level Shifts, Leverage Effects, Day-of-the-Week Seasonality, and Macroeconomic Announcements. International Journal of Forecasting 25: 282–303. [Google Scholar]
- McMillan, David G., and Raquel Quiroga García. 2013. Does Information Help Intra-Day Volatility Forecasts? Journal of Forecasting 32: 1–9. [Google Scholar] [CrossRef]
- Mitchell, Mark L., and J. Harold Mulherin. 1994. The Impact of Public Information on the Stock Market. Journal of Forecasting 49: 923–50. [Google Scholar] [CrossRef]
- Mitra, Gautam, and Leela Mitra. 2011. The Handbook of News Analytics in Finance. Hoboken: John Wiley and Sons. [Google Scholar]
- Mitra, Gautam, and Xiang Yu. 2016. The Handbook of Sentiment Analysis in Finance. New York: Albury Books. [Google Scholar]
- Omran, M.F., and E. McKenzie. 2000. Heteroscedasticity in Stock Returns Data Revisited: Volume versus GARCH Effects. Applied Financial Economics 10: 553–60. [Google Scholar] [CrossRef]
- Pavlou, Menelaos, Gareth Ambler, Shaun Seaman, Maria De Iorio, and Rumana Z. Omar. 2016. Review and Evaluation of Penalised Regression Methods for Risk Prediction in Low-Dimensional Data with Few Events. Statistics in Medicine 35: 1159–77. [Google Scholar] [CrossRef] [PubMed]
- Preis, Tobias, Daniel Reith, and H. Eugene Stanley. 2010. Complex Dynamics of our Economic Life on Different Scales: Insights from Search Engine Query Data. Philosophical Transactions of the Royal Society A 368: 5707–19. [Google Scholar] [CrossRef] [PubMed]
- Racine, Jeff. 2000. Consistent Cross-validatory Model-selection for Dependent Data: hv-block Cross-validation. Journal of Econometrics 99: 39–61. [Google Scholar] [CrossRef]
- Rangel, José Gonzalo. 2011. Macroeconomic News, Announcements, and Stock Market Jump Intensity Dynamics. Journal of Banking & Finance 35: 1263–76. [Google Scholar]
- Riordan, Ryan, Andreas Storkenmaier, Martin Wagener, and S. Sarah Zhang. 2013. Public Information Arrival: Price Discovery and Liquidity in Electronic Limit Order Markets. Journal of Banking & Finance 37: 1148–59. [Google Scholar]
- Roll, Richard. 1988. R2. The Journal of Finance 43: 541–66. [Google Scholar] [CrossRef]
- Savor, Pavel, and Mungo Wilson. 2013. How Much Do Investors Care About Macroeconomic Risk? Evidence from Scheduled Economic Announcements. Journal of Financial and Quantitative Analysis 48: 343–75. [Google Scholar] [CrossRef]
- Schwert, G. William. 1989. Why Does Stock Market Volatility Change over Time? The Journal of Finance 44: 1115–53. [Google Scholar] [CrossRef]
- Smales, Lee A. 2015. Time-Variation in the Impact of News Sentiment. International Review of Financial Analysis Journal 37: 40–50. [Google Scholar] [CrossRef]
- Smith, Geoffrey Peter. 2012. Google Internet Search Activity and Volatility Prediction in the Market for Foreign Currency. Finance Research Letters 9: 103–10. [Google Scholar] [CrossRef]
- Solomon, David H., Eugene Soltes, and Denis Sosyura. 2014. Winners in the Spotlight: Media Coverage of Fund Holdings as a Driver of Flows. Journal of Financial Economics 113: 53–72. [Google Scholar] [CrossRef]
- Tauchen, George E., and Mark Pitts. 1983. The Price Variability-Volume Relationship on Speculative Markets. Econometrica 51: 485–505. [Google Scholar] [CrossRef]
- Tetlock, Paul C. 2007. Giving Content to Investor Sentiment: The Role of Media in the Stock Market. The Journal of Finance 62: 1139–68. [Google Scholar] [CrossRef]
- Tetlock, Paul C., Maytal Saar-Tsechansky, and Sofus Macskassy. 2008. More than Words: Quantifying Language to Measure Firms’ Fundamentals. The Journal of Finance 63: 1437–67. [Google Scholar] [CrossRef]
- Tibshirani, Robert. 1996. Regression Shrinkage and Selection via the Lasso. Journal of the Royal Statistical Society B 58: 267–88. [Google Scholar]
- Tibshirani, Robert, Michael Saunders, Saharon Rosset, Ji Zhu, and Keith Knight. 2005. Sparsity and Smoothness via the Fused Lasso. Journal of the Royal Statistical Society B 67: 91–108. [Google Scholar] [CrossRef]
- Vlastakis, Nikolaos, and Raphael N. Markellos. 2012. Information Demand and Stock Market Volatility. Journal of Banking & Finance 36: 1808–21. [Google Scholar]
- Vozlyublennaia, Nadia. 2014. Investor Attention, Index Performance, and Return Predictability. Journal of Banking & Finance 41: 17–35. [Google Scholar]
- Vrugt, Evert B. 2009. U.S. and Japanese Macroeconomic News and Stock Market Volatility in Asia-Pacific. Pacific-Basin Finance Journal 17: 611–27. [Google Scholar] [CrossRef]
- Yuan, Ming, and Yi Lin. 2006. Model Selection and Estimation in Regression with Grouped Variables. Journal of the Royal Statistical Society B 68: 49–67. [Google Scholar] [CrossRef]
- Zhang, Ying, Peggy E. Swanson, and Wikrom Prombutr. 2012. Measuring Effects on Stock Returns of Sentiment Indexes Created from Stock Message Boards. Journal of Financial Research 35: 79–114. [Google Scholar] [CrossRef]
- Zhang, Yongjie, Lina Feng, Xi Jin, Dehua Shen, Xiong Xiong, and Wei Zhang. 2014. Internet Information Arrival and Volatility of SME PRICE INDEX. Physica A 399: 70–74. [Google Scholar] [CrossRef]
- Zou, Hui. 2006. The Adaptive Lasso and its Oracle Properties. Journal of the American Statistical Association 101: 1418–29. [Google Scholar] [CrossRef]
- Zou, Hui, and Trevor Hastie. 2005. Regularization and Variable Selection via the Elastic Net. Journal of the Royal Statistical Society B 67: 301–20. [Google Scholar] [CrossRef]
| 1. | Google Trends is a public web facility of Google Inc. based on Google Search that shows how often a particular search-term is entered relative to the total search volume across various regions of the world and in various languages. |
| 2. | Baidu News is a service of the Chinese web services company Baidu. Baidu News provides links to a selection of local, national, and international news, and presents news stories in a searchable format within minutes of their publication on the web. |
| 3. | the SME Price Index functions as the market indicator of China’s small and medium-size enterprises listed on the SME Board. |
| 4. | Reuters NewsScope Sentiment Engine and Thomson Reuters News Analytics are tools that provide sentiment and linguistic analytics, such as novelty and relevance indicators, for each news article. The indicators are produced based on automated linguistic pattern recognition of news texts. |
| 5. | RavenPack News Analytics is a service of RavenPack.com, a provider of news analytics and machine-readable content, that provides event and sentiment information to financial services clients. |
| 6. | A Form 10-K is an annual report required by the U.S. Securities and Exchange Commission (SEC), that gives a comprehensive summary of a company’s financial performance. |
| 7. | From the pioneering works of Tetlock (2007) and Tetlock et al. (2008) to the more recent studies of, for example, (Birz and Lott 2011; Dougal et al. 2012; García 2013; Solomon et al. 2014; and Kraussl and Mirgorodskaya 2016), authors have employed general economic or company-specific news articles from newspapers or specific sections/columns to explain asset price dynamics but have not made selections based on articles’ relevance or novelty. |
| 8. | Guidance news is almost coincident with earnings-related news; conjecture news describes possible and uncertain events and are presumably perceived as not important; corporate actions news is about companies’ internal events, which usually have minor relevance to investors; management changes and syndicate news stories are rare and even non-existent for some stocks. |
| 9. | News providers claim to supply only novel news stories, so we expect them not to report the same information more than once. |
| 10. | The term “Google Search Index” is consistent with the recent literature. |
| 11. | refers to the daily observations being divided by their sum over the month in such a way that their sum over each month is equal to 1. |
| 12. | t, t-1, and so on refer to trading days only, so information released during holidays and weekends is considered part of the daily information of the first following trading day, as well as part of its overnight information. |
| 13. | The variables, as in Corsi and Renò (2012), are specified in logs. As Andersen et al. (2003) point out, while the distributions of realized volatilities are clearly right-skewed, the distributions of realized volatilities’ logarithms are approximately Gaussian. Andersen et al. (2003) also use the logarithmic transformation to model and forecast the realized volatilities. The model can also be specified directly for and for , as in Andersen et al. (2007) and Corsi et al. (2010). |
| 14. | When validation data are randomly selected for cross-validation from the entire time domain, training and validation data from nearby locations will be dependent. Consequently, if the objective is to project outside the structure of the training data, error estimates from random cross-validations will be overly optimistic (overfitting). To address this, blocks of contiguous time can be designed to better ensure independence between cross-validation folds and to achieve more reliable error estimates and higher forecasting performance (Burman et al. 1994; Racine 2000; Bergmeir and Benitez 2012). We apply 10-fold cross-validation on data that is not partitioned randomly, but sequentially into ten sets. So, the problem of dependent values is resolved (except for some values at the borders of the blocks). |
| 15. | See Section 3.1 for the selection criteria. |
| 16. | Hereafter, “surprise” refers to standardized surprise, and “log,” “square root,” and “square” refer to sign-preserving transformations. In brackets, the percentage of assets for which the measure is selected. |
| 17. | News’ estimated coefficients are not reported here, as the focus is on the variation of the estimated coefficients of volatility and leverage after the inclusion of news, and on the significance of news coefficients. News coefficients estimated with LASSO are described in Table 15. |
| 18. | In a few cases, the LHAR-CJN model provides extremely low or extremely high forecasts of realized volatility, which are not reliable. We apply an adjustment procedure, detailed in Appendix D. |
| 19. | We have four null hypotheses to test and we want to control the familywise error rate, that is the probability that we will identify at least one significant result, when in fact all of the null hypotheses are true. We apply the sequential Bonferroni correction proposed by Holm (1979) to each asset. In Holm’s sequential procedure, the tests are first performed in order to obtain their p-values. The tests are then ordered from the one with the smallest p-value to the one with the largest p-value. The test with the lowest probability is tested first with a Bonferroni correction involving all tests (which consists in multiplying the p-value by the total number of tests performed, in our case four). The second test is tested with a Bonferroni correction involving one less test and so on for the remaining tests. The procedure stops when the first non-significant test is obtained or when all the tests have been performed. |
| 20. | At each iteration we apply the sequential Bonferroni correction to each asset. |

| Abbreviation | Complete Name |
|---|---|
| CCONF | Consumer Confidence |
| CPI | Consumer Price Index |
| FOMC | FOMC Rate Decisions |
| GDP | Gross Domestic Product |
| INDPROD | Industrial Production |
| BOP | Balance of Payments |
| JOBLESS | Jobless Claims |
| NFP | Non-Farm Payrolls |
| PPI | Producer Price Index |
| RSALES | Retail Sales |
| StreetAccount | Thomson Reuters |
|---|---|
| all | all |
| earnings related | earnings pre-announcements |
| M&A | M&A |
| litigation | litigation |
| regulatory | regulatory/company investigation |
| newspapers | financial |
| up/downgrades |
| Measure | Min | Quant 5% | Median | Quant 95% | Max | Mean | Std Dev |
|---|---|---|---|---|---|---|---|
| StreetAcc. n. news stories per day | 0.00 | 0.00 | 0.00 | 1.00 | 7.00 | 0.23 | 0.60 |
| T. Reuters n. news stories per day | 0.00 | 0.00 | 0.00 | 1.00 | 3.00 | 0.10 | 0.33 |
| StreetAcc. n. words per day | 0.00 | 0.00 | 0.00 | 102.00 | 1079.00 | 18.18 | 66.68 |
| T. Reuters n. words per day | 0.00 | 0.00 | 0.00 | 68.90 | 390.00 | 8.23 | 31.80 |
| Topic | Coincident/Total Ratio | % SA News Days | % TR News Days |
|---|---|---|---|
| all | 26.27 | 19.95 | 13.14 |
| earnings | 34.72 | 3.55 | 1.46 |
| litigation | 13.38 | 0.86 | 0.84 |
| M&A | 22.83 | 2.25 | 1.65 |
| regulatory | 3.90 | 1.27 | 0.28 |
| Transformation | Formula |
|---|---|
| original measure | x |
| flag if 0 | |
| flag if | |
| flag if | |
| signed square root(x) | |
| signed log(x) | |
| signed square(x) |
| Variable | N. Transf. |
|---|---|
| STANDARD | |
| n. news stories | 5 |
| n. words | 4 |
| sentiment | 3 |
| ABNORMAL QUANTITY | |
| n. news stories ≥ 2 | 1 |
| UNCERTAINTY | |
| pos and neg news in same day | 1 |
| NEWS BURST INDEX | |
| news burst index (n. news) × | 6 |
| news burst index (n. words) × | 6 |
| SENTIMENT COND. ON QUANTITY | |
| pos sent & n. news stories ≥ 2 | 1 |
| neg sent & n. news stories ≥ 2 | 1 |
| total for each topic | 28 |
| grand total (28 × 31e) | 868 |
| Variable | N. Transf. |
|---|---|
| STANDARD | |
| n. news stories | 5 |
| n. words | 4 |
| sentiment | 3 |
| ABNORMAL QUANTITY | |
| n. news stories ≥ 2 | 1 |
| UNCERTAINTY | |
| pos and neg news in same day | 1 |
| SENTIMENT COND. ON QUANTITY | |
| pos sent & n. news stories ≥ 2 | 1 |
| neg sent & n. news stories ≥ 2 | 1 |
| total for each topic | 16 |
| grand total (16 × 31) | 496 |
| Variable | N. Transf. |
|---|---|
| STANDARD | |
| av. n. news stories | 5 |
| av. n. words | 4 |
| sentiment | 3 |
| ABNORMAL QUANTITY | |
| av. n. news stories ≥ 1 | 1 |
| NEWS BURST INDEX | |
| news burst index (n. news) × | 2 |
| news burst index (n. words) × | 2 |
| SENTIMENT CONDITIONAL ON QUANTITY | |
| pos sent & av. n. news stories ≥ 1 | 1 |
| neg sent & av. n. news stories ≥ 1 | 1 |
| total for each topic | 19 |
| grand total (19 × 31) | 589 |
| Variable | N. Transf. |
|---|---|
| STANDARD | |
| av. n. news stories | 5 |
| av. n. words | 4 |
| sentiment | 3 |
| ABNORMAL QUANTITY | |
| av. n. news stories ≥ 1 | 1 |
| NEWS BURST INDEX | |
| news burst index (n. news) x | 2 |
| news burst index (n. words) x | 2 |
| SENTIMENT CONDITIONAL ON QUANTITY | |
| pos sent & av. n. news stories ≥ 1 | 1 |
| neg sent & av. n. news stories ≥ 1 | 1 |
| total for each topic | 19 |
| grand total (19 x 31) | 589 |
| Variable | N. Transf. |
|---|---|
| QUANTITY VARIATION | |
| day-to-day n. news stories | 7 |
| week-to-day n. news stories | 7 |
| month-to-day n. news stories | 7 |
| day-to-day n. words | 7 |
| week-to-day n. words | 7 |
| month-to-day n. words | 7 |
| NEWS PERSISTENCE/INTERACTION | |
| n. news stories today ≥ 2 & n. news stories day before ≥ 2 | 1 |
| n. news stories today ≥ 2 & av. n. news stories week before ≥ 1 | 1 |
| n. news stories today ≥ 2 & av. n. news stories month before ≥ 1 | 1 |
| SENTIMENT INVERSION | |
| day-to-day sent inv | 1 |
| day-to-day sent inv, neg to pos | 1 |
| day-to-day sent inv, pos to neg | 1 |
| week-to-day sent inv | 1 |
| week-to-day sent inv, neg to pos | 1 |
| week-to-day sent inv, pos to neg | 1 |
| month-to-day sent inv | 1 |
| month-to-day sent inv, neg to pos | 1 |
| month-to-day sent inv, pos to neg | 1 |
| Variable | N. Transf. |
|---|---|
| QUANTITY VARIATION COND. ON SENTIMENT | |
| day-to-day n. news stories > 0 & pos sent today | 1 |
| day-to-day n. news stories > 0 & neg sent today | 1 |
| day-to-day n. news stories < 0 & pos sent day before | 1 |
| day-to-day n. news stories < 0 & neg sent day before | 1 |
| week-to-day n. news stories > 0 & pos sent today | 1 |
| week-to-day n. news stories > 0 & neg sent today | 1 |
| week-to-day n. news stories < 0 & pos sent week before | 1 |
| week-to-day n. news stories < 0 & neg sent week before | 1 |
| month-to-day n. news stories > 0 & pos sent today | 1 |
| month-to-day n. news stories > 0 & neg sent today | 1 |
| month-to-day n. news stories < 0 & pos sent month before | 1 |
| month-to-day n. news stories < 0 & neg sent month before | 1 |
| SENTIMENT COND. ON PAST QUANTITY | |
| pos sent today & n. news stories day before ≥ 2 | 1 |
| neg sent today & n. news stories day before ≥ 2 | 1 |
| pos sent today & av. n. news stories week before ≥ 1 | 1 |
| neg sent today & av. n. news stories week before ≥ 1 | 1 |
| pos sent today & av. n. news stories month before ≥ 1 | 1 |
| neg sent today & av. n. news stories month before ≥ 1 | 1 |
| total for each topic | 72 |
| grand total (72 x 31) | 2232 |
| Variable | N. Transf. |
|---|---|
| daily SUE | 8 |
| overnight SUE | 8 |
| weekly SUE | 8 |
| monthly SUE | 8 |
| grand total | 32 |
| Variable | N. Transf. |
|---|---|
| daily Std_CCONF | 8 |
| daily Std_CPI | 8 |
| daily Std_FOMC | 8 |
| daily Std_GDP | 8 |
| daily Std_INDPROD | 8 |
| daily Std_BOP | 8 |
| daily Std_JOB | 8 |
| daily Std_NFP | 8 |
| daily Std_PPI | 8 |
| daily Std_RSALES | 8 |
| overnight Std_Macro | 8 × 10 |
| weekly Std_Macro | 8 × 10 |
| monthly Std_Macro | 8 × 10 |
| grand total | 320 |
| Variable | N. Transf. |
|---|---|
| daily GSI | 4 |
| weekly av. GSI | 4 |
| monthly av. GSI | 4 |
| day-to-day GSI | 7 |
| week-to-day GSI | 7 |
| month-to-day GSI | 7 |
| grand total | 33 |
| Past Volatility Components and Leverage | % Selected | % Pos | % Neg | ||||||
|---|---|---|---|---|---|---|---|---|---|
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 100.00 | 100.00 | 0.00 | ||||||
| log | 0.00 | 0.00 | 0.00 | ||||||
| log | 0.00 | 0.00 | 0.00 | ||||||
| log | 3.37 | 3.37 | 0.00 | ||||||
| 91.01 | 0.00 | 91.01 | |||||||
| 70.79 | 0.00 | 70.79 | |||||||
| 33.71 | 0.00 | 33.71 | |||||||
| Macro | Firm-Specific | News | Importance | Topic | Time Aggregation | Measure | % Selected | % Pos | % Neg |
| X | EPS | day | flag for announcement | 58.43 | 58.43 | 0.00 | |||
| X | SA news | earnings | flow: day-to-day | flag if n. words | 28.09 | 28.09 | 0.00 | ||
| X | SA news | all | day | n. news stories | 24.72 | 24.72 | 0.00 | ||
| X | TR news | low | earnings | flow: day-to-day | flag if n. news stories | 23.60 | 23.60 | 0.00 | |
| X | NFP | month | surp | 22.47 | 0.00 | 22.47 | |||
| X | SA news | earnings | flow: day-to-day | flag if n. news stories | 20.22 | 20.22 | 0.00 | ||
| X | TR news | low | earnings | flow: day-to-day | flag if n. news stories | 17.98 | 17.98 | 0.00 | |
| X | TR news | low | earnings | flow: day-to-day | flag if n. words | 16.85 | 16.85 | 0.00 | |
| X | SA news | earnings | flow: day-to-day | flag if n. words | 15.73 | 15.73 | 0.00 | ||
| X | SA news | earnings | day | sqrt n. words | 15.73 | 15.73 | 0.00 | ||
| X | SA news | earnings | day | flag if n. news stories | 14.61 | 14.61 | 0.00 | ||
| X | EPS | day | flag if surp | 13.48 | 13.48 | 0.00 | |||
| X | SA news | earnings | flow: day-to-day | flag if n. news stories | 13.48 | 13.48 | 0.00 | ||
| X | SA news | earnings | day | n. news stories | 12.36 | 12.36 | 0.00 | ||
| X | TR news | medium | earnings | flow: day-to-day | flag if n. news stories | 11.24 | 11.24 | 0.00 | |
| X | SA news | earnings | day | log n. news stories | 11.24 | 11.24 | 0.00 | ||
| X | SA news | earnings | day | sqrt n. news stories | 11.24 | 11.24 | 0.00 | ||
| X | SA news | earnings | day | flag if n. news stories | 11.24 | 11.24 | 0.00 | ||
| X | TR news | medium | earnings | flow: day-to-day | flag if n. words | 10.11 | 10.11 | 0.00 | |
| Google Trends | week | log GSI | 8.99 | 8.99 | 0.00 | ||||
| X | TR news | high | earnings | flow: day-to-day | flag if n. news stories | 8.99 | 8.99 | 0.00 | |
| X | TR news | medium | earnings | flow: day-to-day | flag if n. words | 8.99 | 8.99 | 0.00 | |
| X | TR news | medium | earnings | flow: day-to-day | flag if n. news stories | 8.99 | 8.99 | 0.00 | |
| X | TR news | low | earnings | flow: day-to-day | flag if n. words | 8.99 | 8.99 | 0.00 | |
| X | SA news | all | flow: day-to-day | flag if n. words | 8.99 | 8.99 | 0.00 | ||
| X | TR news | high | earnings | flow: day-to-day | flag if n. news stories | 7.87 | 7.87 | 0.00 | |
| X | TR news | low | earnings | day | log n. words | 7.87 | 7.87 | 0.00 | |
| X | NFP | month | log surp | 6.74 | 0.00 | 6.74 | |||
| X | TR news | low | all | flow: day-to-day | flag if n. words | 6.74 | 6.74 | 0.00 | |
| X | SA news | up/downgrades | flow: day-to-day | flag if n. words | 6.74 | 6.74 | 0.00 | ||
| (a) 2005–2015 | (b) 2005–2007 | |||||
| LHAR-CJ | LHAR-CJN | LHAR-CJ | LHAR-CJN | |||
| () | () | 0.01 | () | () | 0.00 | |
| 0.31 (11.31) | 0.29 (10.77) | 0.25 (5.24) | 0.23 (5.11) | |||
| 0.30 (7.22) | 0.29 (7.24) | 0.30 (3.80) | 0.28 (3.64) | |||
| 0.28 (8.00) | 0.29 (8.12) | 0.01 | 0.21 (2.77) | 0.21 (2.88) | 0.00 | |
| 0.14 (1.91) | 0.12 (1.68) | 0.11 (0.85) | 0.10 (0.81) | |||
| (−0.25) | () | 0.00 | 0.02 (0.27) | 0.02 (0.28) | 0.00 | |
| 0.01 (0.57) | 0.01 (0.57) | 0.00 | 0.01 (0.22) | 0.01 (0.19) | 0.00 | |
| () | () | 0.00 | () | () | 0.00 | |
| (−2.29 ) | () | () | () | 0.00 | ||
| 0.09 () | 0.09 () | 0.00 | () | () | ||
| R | 0.69 | 0.71 | 0.39 | 0.43 | ||
| F-test % rejection hyp. news not significant (sign. level = 5 %) | 97.75% | 64.04% | ||||
| (c) 2007–2009 | (d) 2009–2015 | |||||
| LHAR-CJ | LHAR-CJN | LHAR-CJ | LHAR-CJN | |||
| 0.15 | 0.18 | 0.03 | 0.00 | |||
| (1.90) | (2.18) | () | () | |||
| 0.36 | 0.36 | 0.00 | 0.30 | 0.27 | ||
| (5.71) | (5.62) | (8.23) | (7.71) | |||
| 0.32 | 0.31 | 0.27 | 0.26 | |||
| (3.57) | (3.51) | (4.86) | (4.93) | |||
| 0.15 | 0.15 | 0.00 | 0.27 | 0.28 | 0.01 | |
| (1.92) | (1.88) | (5.55) | (5.61) | |||
| 0.14 | 0.13 | −0.01 | 0.22 | 0.19 | ||
| (1.23) | (1.17) | (1.81) | (1.69) | |||
| 0.00 | 0.00 | |||||
| () | () | () | () | |||
| 0.00 | 0.00 | 0.00 | 0.02 | 0.02 | 0.00 | |
| () | () | (0.50) | (0.52) | |||
| 0.00 | 0.00 | |||||
| () | () | () | () | |||
| 0.00 | ||||||
| () | () | (-2.05) | (-2.29) | |||
| 0.00 | ||||||
| () | () | () | () | |||
| R | 0.70 | 0.71 | 0.53 | 0.58 | ||
| F-test % rejection hyp. news not significant (sign. level = 5 %) | 20.22% | 98.88% | ||||
| LHAR-CJ | LHAR-CJN | |
|---|---|---|
| MAE | 0.99 (8.99%) | 0.97 (1.12%) |
| MSE | 65.73 (3.37%) | 37.11 (0.00%) |
| HRMSE | 0.90 (0.00%) | 0.83 (48.31%) |
| QLIKE | 1.45 (1.12%) | 1.44 (32.58%) |
| R MZ | 0.49 (25.84%) | 0.51 (74.16%) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Caporin, M.; Poli, F. Building News Measures from Textual Data and an Application to Volatility Forecasting. Econometrics 2017, 5, 35. https://doi.org/10.3390/econometrics5030035
Caporin M, Poli F. Building News Measures from Textual Data and an Application to Volatility Forecasting. Econometrics. 2017; 5(3):35. https://doi.org/10.3390/econometrics5030035
Chicago/Turabian StyleCaporin, Massimiliano, and Francesco Poli. 2017. "Building News Measures from Textual Data and an Application to Volatility Forecasting" Econometrics 5, no. 3: 35. https://doi.org/10.3390/econometrics5030035
APA StyleCaporin, M., & Poli, F. (2017). Building News Measures from Textual Data and an Application to Volatility Forecasting. Econometrics, 5(3), 35. https://doi.org/10.3390/econometrics5030035