
Søren Johansen and Katarina Juselius: A Bibliometric Analysis of Citations through Multivariate Bass Models


Abstract
:1. Introduction
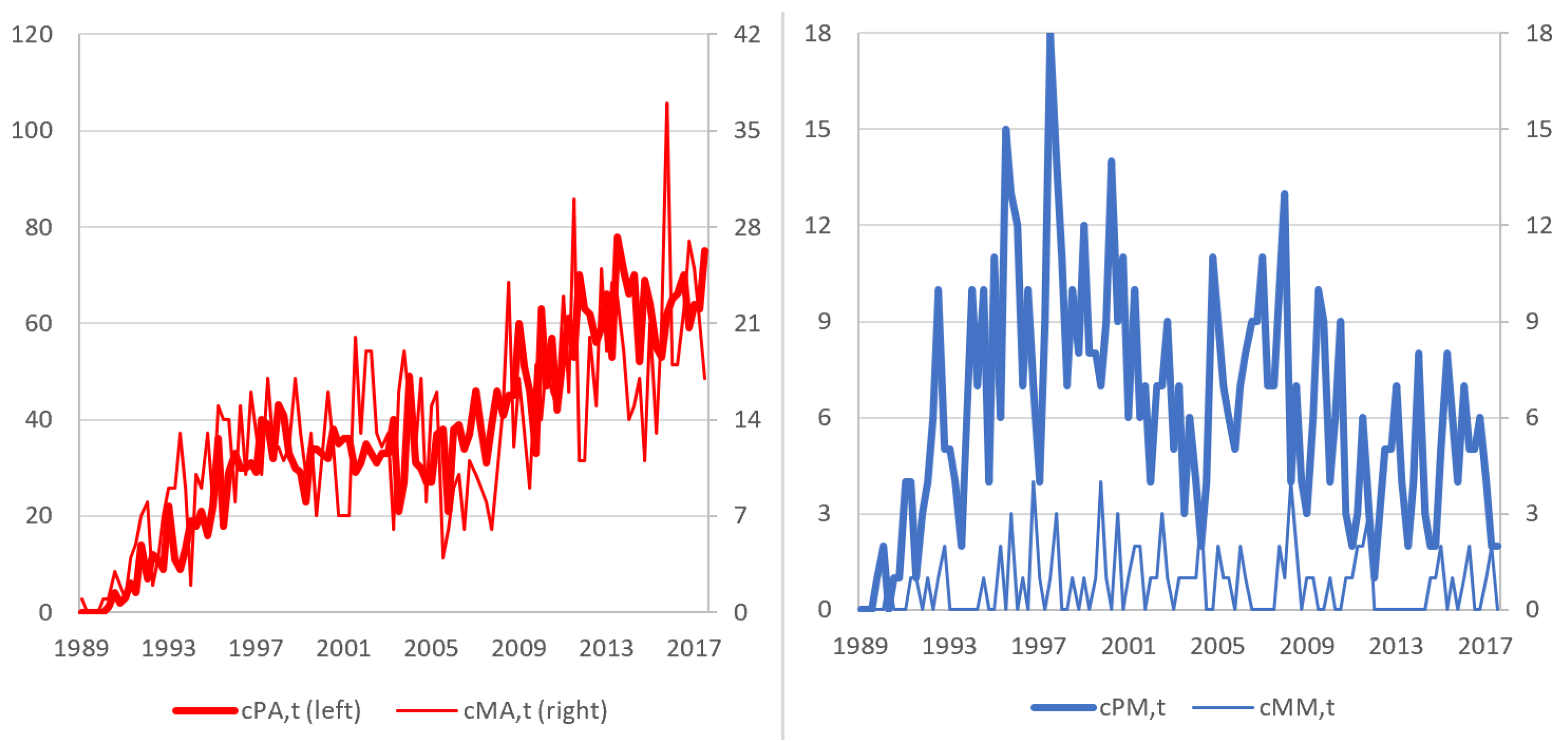
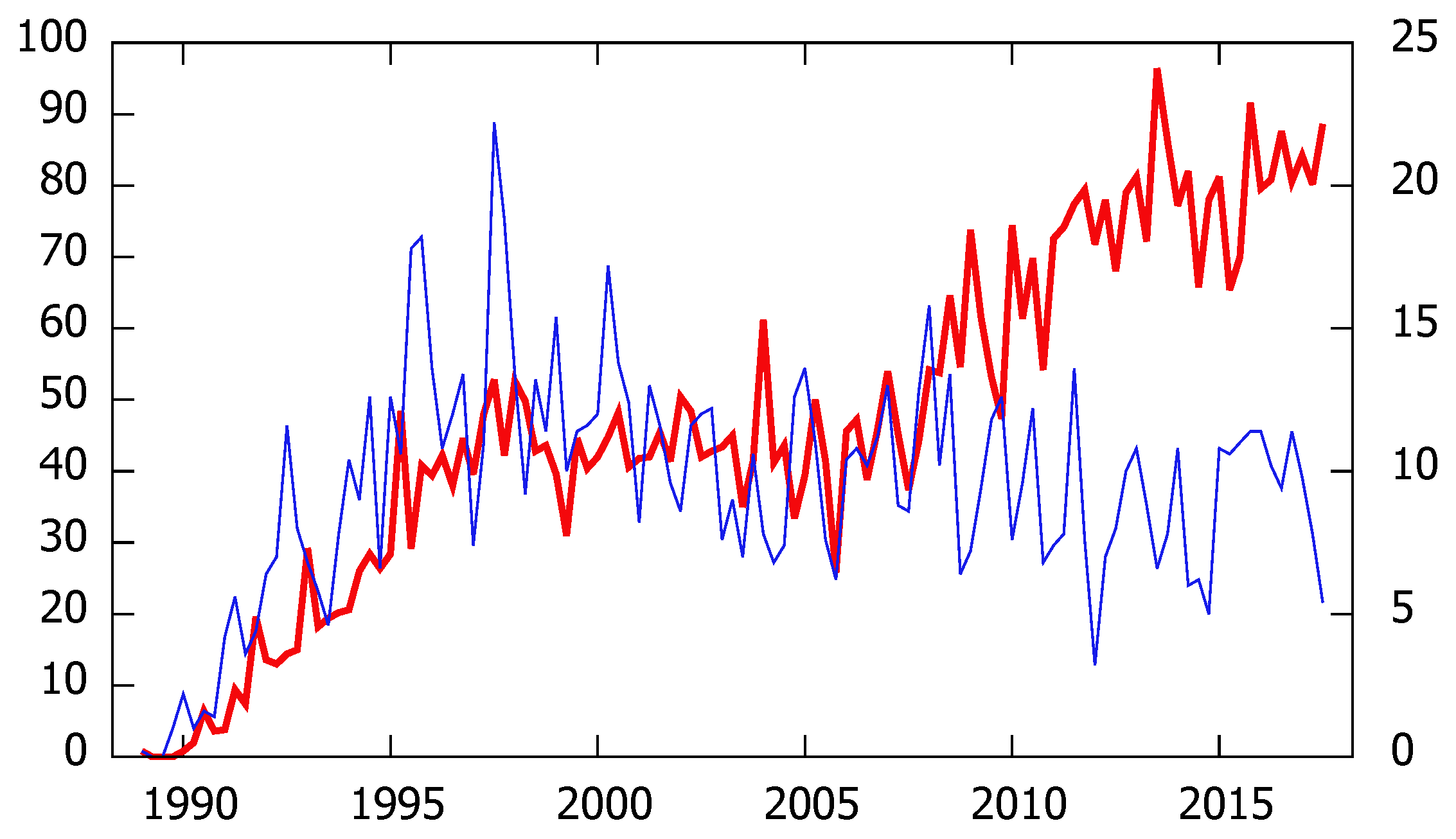
2. The Data
- Purely applied (PA) papers: the title refers to an application, with no reference to an econometric method, technique or issue. We have found such papers.
- Mainly applied (MA) papers: the title refers both to an econometric method, technique or issue and an application, and the focus seems to be on the latter (e.g., “Does exchange-rate volatility affect import flows in G-7 countries? Evidence from cointegration models”). We have found such papers.
- Purely methodological (PM) papers: the title refers to an econometric method, technique or issue, with no reference at all to an application. We have found such papers.
- Mainly methodological (MM) papers: the title refers both to an econometric method, technique or issue and an application, and the focus seems on the first (e.g., “Robust cointegration testing in the presence of weak trends, with an application to the human origin of global warming”). We have found such papers.
3. The Bass Diffusion Model
3.1. Bass Discrete Time Model
3.2. Boswijk and Franses Model
- The assumption that is uncorrelated is at odds with the empirical evidence that deviations of the observed adoption path with respect to the ideal equilibrium path are persistent.
- The assumption that is homoskedastic is disputable since, at the beginning and at the end of the diffusion process, when is expected to be close to zero, the variance of is likely to be much smaller than around the peak; related to this, simulating (13) with an homoskedastic and Gaussian error is likely to produce negative values of in the initial and final phases of the diffusion.
3.3. Boswijk et al. Multivariate Model
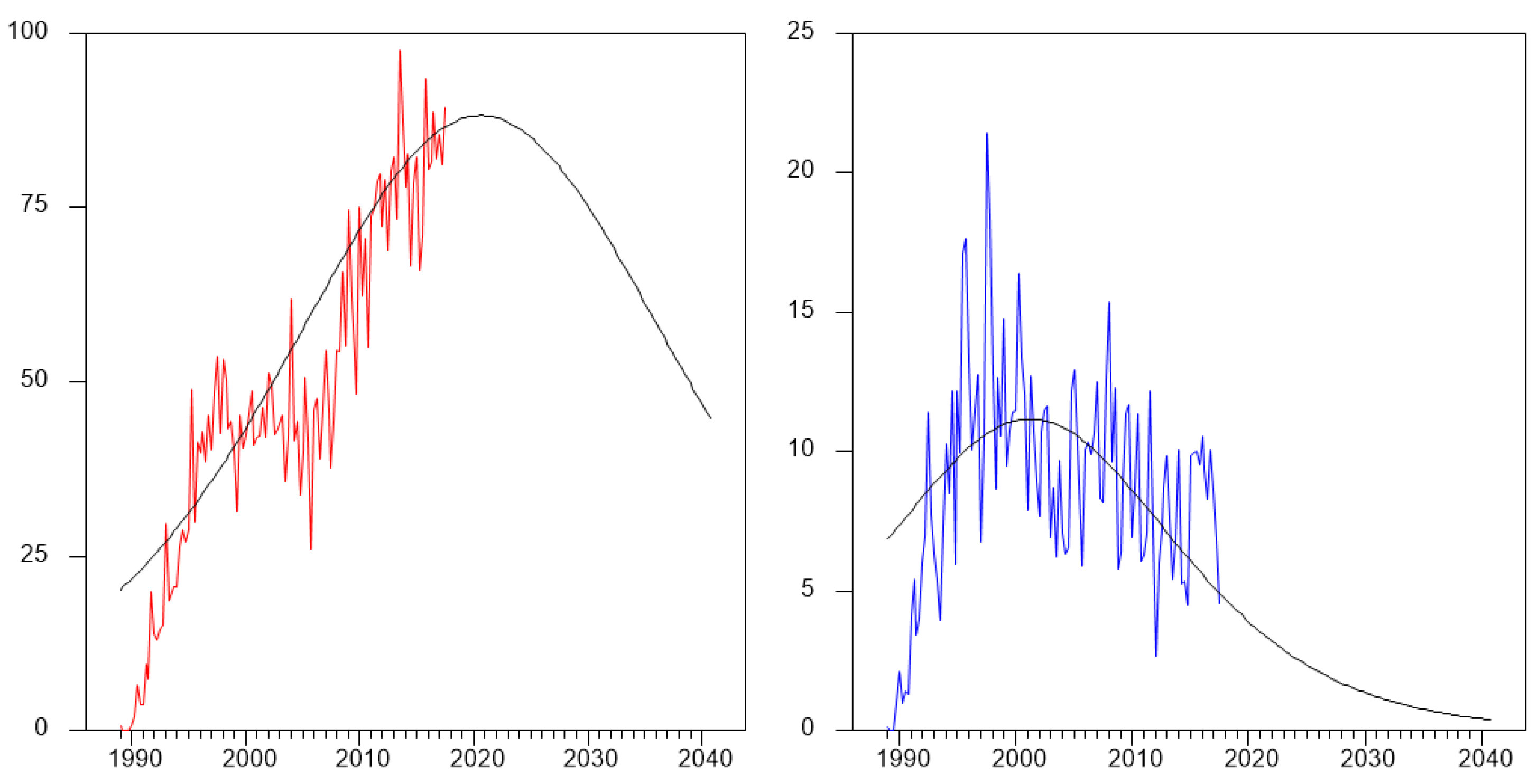
4. Results
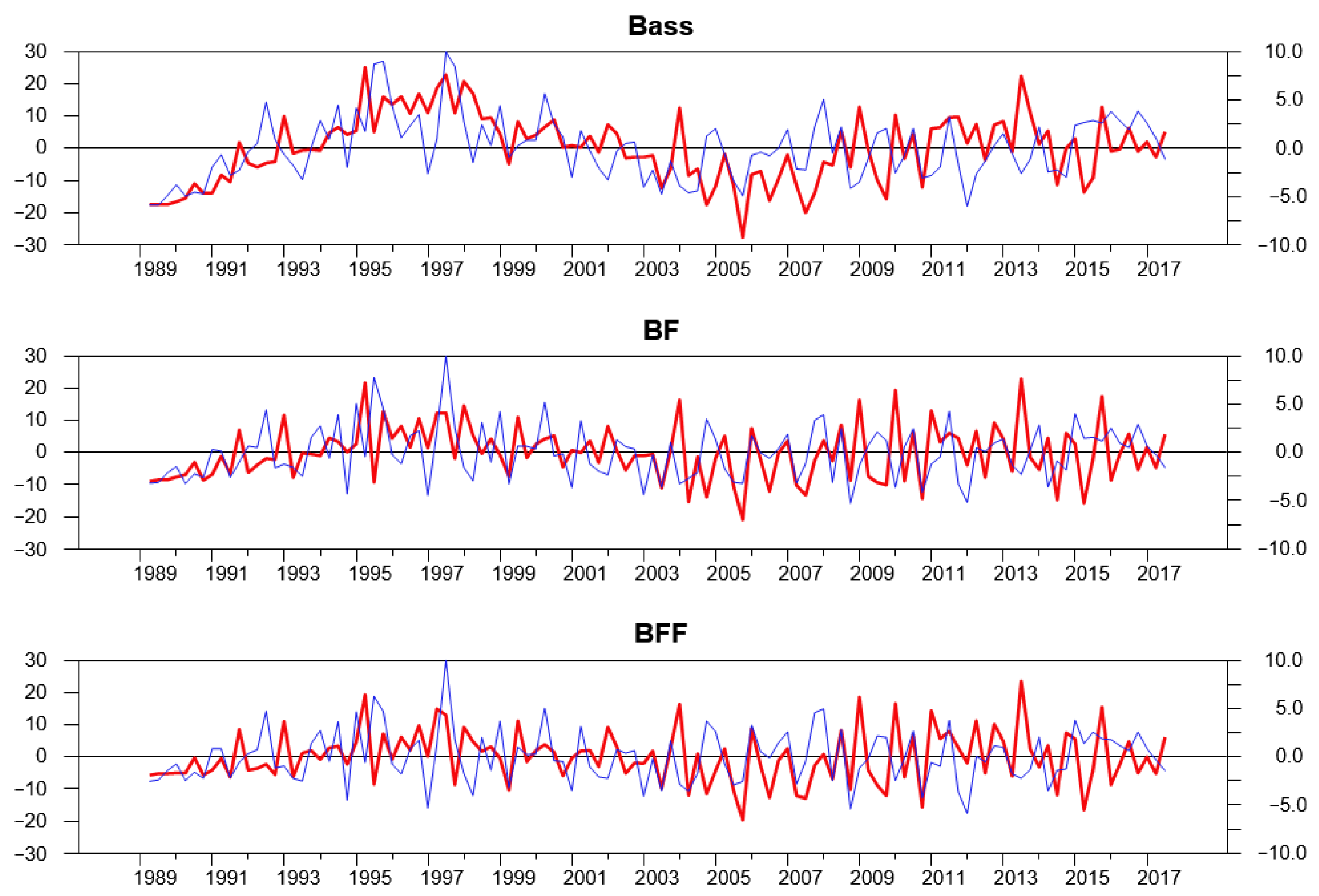
4.1. Analysis of the Reduced Form—Comparing Bass, BF, BFF
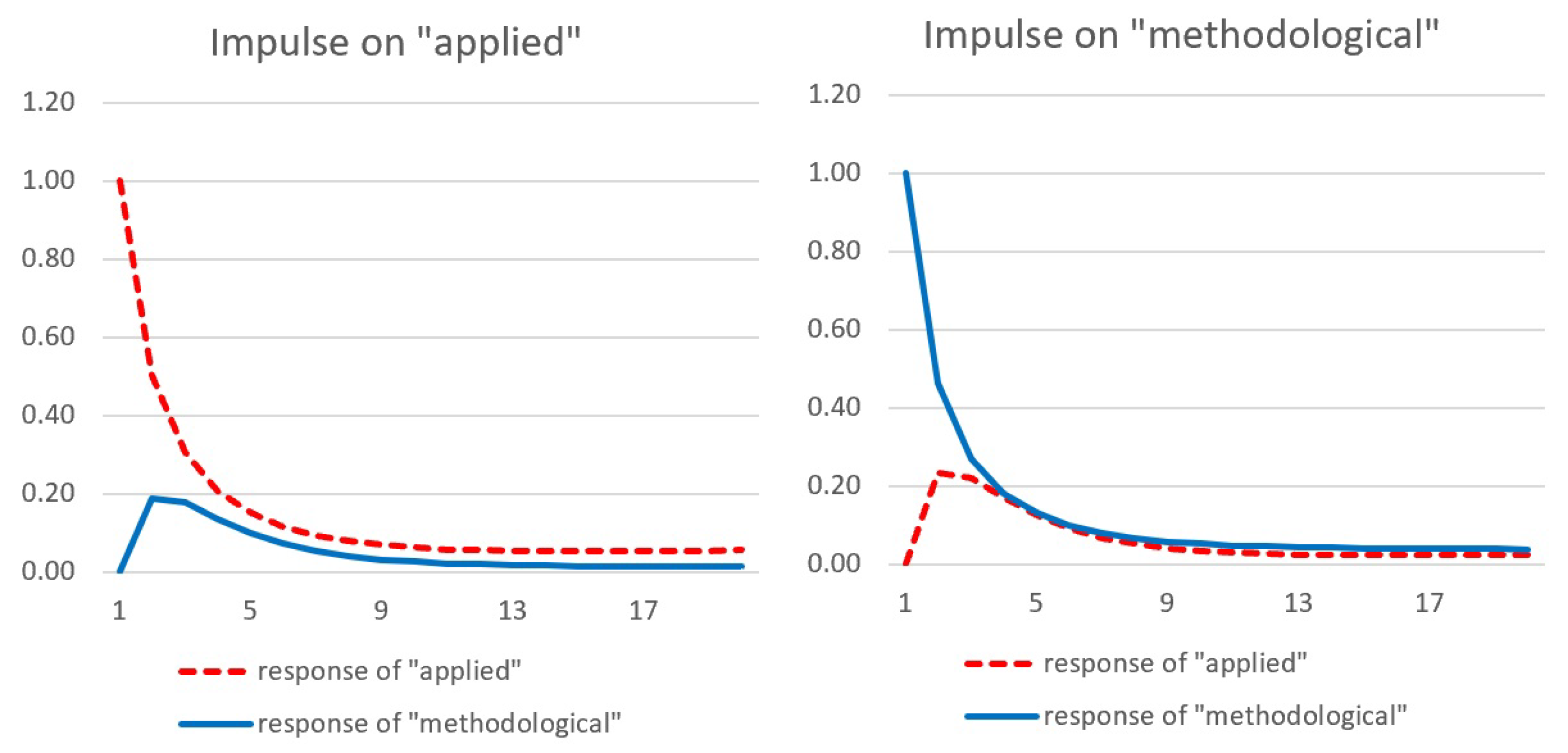
4.2. Analysis of the Structural Form
5. Conclusions and Suggestions for Further Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
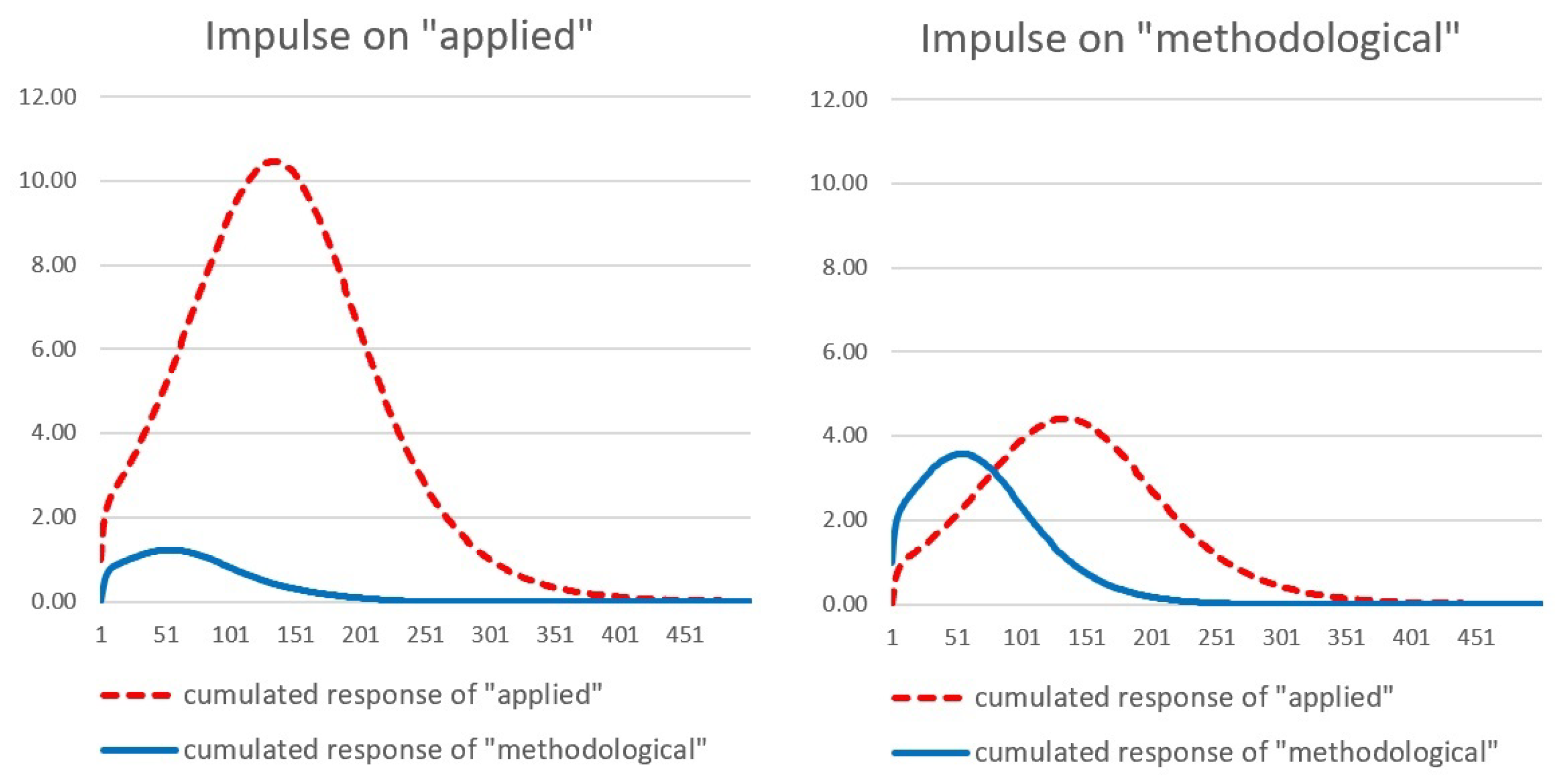
Appendix A. Bass vs. Autoregressive Models
- If , , and , then and the model collapses into a standard stationary AR(1) with unconditional expectation m.
- If , and , then so that initially the system behaves like an explosive AR(1) with a positive drift . When , then so that the system locally behaves like a random walk with drift. When , then so that the system starts adjusting. An illustrative example, based on the estimated parameters for the methodological index, is given in Figure A1.

Appendix B. Sensitivity to ω

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 4969.5 | 5445.2 | 5649 | |
| 1487.5 | 1011.8 | 808 | |
| 0.543 | 0.253 | 0.048 |
| Estimate | t-Ratio | Estimate | t-Ratio | Estimate | t-Ratio | ||
|---|---|---|---|---|---|---|---|
| APP | −0.620 | −7.17 | −0.508 | −6.26 | −0.459 | −5.92 | |
| 0.782 | 4.00 | 0.715 | 2.81 | 0.624 | 2.33 | ||
| 16.95 | 4.58 | 19.81 | 4.78 | 21.11 | 4.88 | ||
| 0.0209 | 5.13 | 0.0190 | 4.61 | 0.0180 | 4.33 | ||
| −1.86×10 | −2.06 | −1.32×10 | −1.60 | −1.06×10 | −1.33 | ||
| 7.46 | 8.15 | 8.62 | |||||
| MET | 0.0902 | 2.25 | 0.0635 | 2.34 | 0.0590 | 2.38 | |
| −0.545 | −6.12 | −0.547 | −6.44 | −0.596 | −7.04 | ||
| 8.87 | 4.81 | 6.74 | 4.65 | 5.64 | 4.42 | ||
| 0.0161 | 2.66 | 0.0187 | 2.73 | 0.0223 | 2.96 | ||
| −9.54×10 | −2.23 | −1.97×10 | −2.86 | −3.15×10 | −3.39 | ||
| 3.46 | 2.72 | 2.71 | |||||
| 0.253 | 0.161 | 0.034 | |||||
| Coefficient | Estimate | Std.err. | Estimate | Std.err. | Estimate | Std.err. | |
|---|---|---|---|---|---|---|---|
| APP | 11,994.6 | 3644.9 | 15,350.6 | 6396.2 | 18,058.0 | 9516.0 | |
| 0.00141 | 3.94×10 | 0.00129 | 4.65×10 | 0.00117 | 5.31×10 | ||
| 0.0224 | 0.00425 | 0.0203 | 0.00442 | 0.0192 | 0.00456 | ||
| 2018:1 | 22.6 | 2020:4 | 32.4 | 2023:2 | 42.4 | ||
| 76 | 10.3 | 88 | 18.4 | 98 | 28.0 | ||
| 5618 | 1719.8 | 7188 | 3050.6 | 8479 | 4578.2 | ||
| MET | 2129.1 | 351.5 | 1227.7 | 119.7 | 907.1 | 62.3 | |
| 0.00416 | 8.77×10 | 0.00549 | 4.91×10 | 0.00622 | 0.00133 | ||
| 0.0203 | 0.00604 | 0.0242 | 0.00643 | 0.0285 | 0.00682 | ||
| 2005:1 | 11.7 | 2001:2 | 8.4 | 1999:4 | 7.2 | ||
| 16 | 1.2 | 11 | 1.0 | 10 | 0.8 | ||
| 846 | 122.6 | 475 | 49.9 | 355 | 34.2 | ||
| 1 | Many thanks for the provision of the initial Web of Science data to Evi Sachini, Antonis Kardasis and Penny Nikolaidou of the National Documentation Centre/N.H.R.F. based in Athens, Greece. |
| 2 | Around the same time Google Scholar (GS) reported more than 50,000 citations for the same 10 papers. We opted for WoS instead of GS because, to avoid double counting, the analysis carried on in this paper is based on the citing papers instead of the citations, and working out the citing papers from GS is not easy. Admittedly, one drawback with using WoS instead of GS is that books cannot be considered; we think however that this would not substantially change the picture. In fact, according to GS, the book Johansen (1995) would rank 4th in terms of citations, the book Juselius (2006) would rank 6th, and adding both books the total citations count would be about 15% higher; however, since many papers citing one of the books will cite also some of the older papers, the impact of the books on the citing papers is likely to be way less than 10%. |
| 3 | Among the “super-citing” papers, there are also 14 papers with six citations and 53 papers with five citations. We remark that 40 of the 6457 papers (i.e., 0.62%) are authored or coauthored by SJ and/or KJ: given the small share we did not correct for self-citations. |
| 4 | An alternative way of measuring the influence of a paper could be based on counting the authors instead of the papers. We could then consider the number of authors citing KJ or SJ in each quarter, or preferably the number of “new authors”, i.e., the number of authors citing KJ or SJ for the first time in each quarter, who never cited them before (this would avoid double counting, and would be a more precise measure of “contagion”). We do not explore this alternative in the present paper, leaving it for future research. |
| 5 | Classifying an econometric paper as “methodological” or “applied” is clearly arbitrary to some extent. A general discussion, although related to the ‘delineation of scientific areas’ may be found in Zitt (2006); he states that fields may be defined at various levels (e.g., institutional setting of academic actors; shared topics and possibly shared journals; shared terminology; close connections of collaboration or citation, etc.) and concludes that “… natural borders, generally speaking, are an illusion” (Zitt 2006, p. 6). In fact, a more scientific-bibliometric related methodological approach could be the analysis based on networks, as for instance in Vieira and Teixeira (2010), although this is outside the scope of the present paper. |
| 6 | When unsure regarding the screening, we proceeded following Katsaliaki and Mustafee (2011, p. 1434): “The two authors independently and critically reviewed all the abstracts of the (…) papers and read the full text when necessary.” Notice that an alternative classification scheme could be based on the publishing journal since some journals are more oriented toward applications, while others are more methodological. As discussed below, we believe that our approach provides a more accurate measure. |
| 7 | The title of the MA paper by Baillie and Bollerslev is "Common stochastic trends in a system of exchange rates", while the title of the PM paper by Gilbert is "Economic theory and econometric models" |
| 8 | Actually, at the individual level, the term “innovator” associated to a constant hazard is somewhat misleading, and not exactly a synonym of “early adopter”. In fact, an individual with constant hazard rate might well be a laggard, especially if his/her individual hazard rate is low. The parameter p is hardly interpretable in epidemiology, where the notion of “innovator” is essentially limited to the “patient zero”. |
| 9 | We remark that that the solution is not unique. The formulae in (15) are the ones giving positive values of m, p and q with our estimated ’s. |
| 10 | Maintaining the assumption that is i.i.d. normal, an alternative estimation strategy could be based on Non Linear Least Squares (NLLS). Estimates of m, p and q would be based on the following:
The advantage of NLLS is that it provides directly the estimates of the parameters of interest (m, p and q) and the corresponding standard error, without having to resort to the delta method. The disadvantage is that convergence of the numerical optimization routines is sometimes not easy: this is partly due to the strong collinearity, and partly to the fact that the optimization problem has two solutions. In the following, we opt for OLS and the delta method. |
| 11 | We decided to adopt slightly different symbols with respect to BF. In particular our has opposite sign with respect to theirs. |
| 12 | |
| 13 | Actually, Boswijk et al. (2009) propose an heteroskedastic version of the model, where , with and fixed to either or 1. In this paper we only briefly discuss the heteroskedastic BFF model, since in our application suitable heteroskedasticity tests seem to accept the hypothesis of homoskedasticity. |
| 14 | Precisely,
|
| 15 | A diagonal corresponds to . As already observed, in this case ML would not correspond to equation by equation OLS, due to the correlation of the error terms. One might maximize the likelihood either by iterated SUR as illustrated in Section 3.2, or equivalently using the algorithm illustrated here. |
| 16 | Minor modifications are needed if instead we assume heteroskedasticity of the type postulated in Boswijk et al. (2009), where , with ( is assumed to be known) and . Notice that, premultiplying (30), left and right, by , using the properties of the operator, one obtains either the following:
The first equation allows to estimate by GLS when and are known, while the second allows to estimate by GLS when and are known. A "switching" iterative algorithm similar to Hansen (2003) is therefore possible also in this case. Of course, linear restrictions on or are easily dealt with also in this case. |
| 17 | |
| 18 | We also considered different values of k, from 4 to 20, and the results remain essentially unchanged. Regarding the number of degrees of freedom, as illustrated in Appendix A, the standard Bass model can be seen as an AR(1) with state dependent parameters, while the BF and BFF models can be seen as AR(2): therefore we considered heuristically degrees of freedom in the Q test, with for the standard Bass model and for BF and BFF models. |
| 19 | Actually, the slope in the auxiliary regression is negative in some cases, which is exactly the opposite of BF intuition. We think that the result might reflect the neglected autocorrelation rather than heteroskedasticity: the ample swings in the residuals clearly visible in Figure 3 are misinterpreted by the test as heteroskedasticity. |
| 20 | Alternative initializations are possible: this point is further discussed in footnote 25. |
| 21 | For simplicity, we do not “orthogonalize” the shocks by assuming some direction for the simultaneous relationship: we believe that this is justified in this case, given the modest correlation between the residuals (16.1%). As a robustness check we also tried to orthogonalize in either direction, and to apply the “ordering invariant” method proposed in Pesaran and Shin (1998) but, as expected given the low correlation, the results are essentially unchanged. For a discussion of the simultaneous correlation, see also Appendix B. |
| 22 | It is important to remark that, given the nonlinear dynamics implied by (29), the impulse responses will change according to the initial conditions. We also considered alternative initializations, starting in different points of the diffusion path: we observed that when the impulse is given further ahead along the diffusion path, the shape of the responses changes in a rather intuitive way: the peak of the cumulative IRs occurs earlier, and the intensity becomes weaker. This can be explained in the light of the discussion presented in Appendix A: in the initial stages of the process, when both and are close to zero and much lower than and , respectively, the processes behave as explosive AR(2), and therefore, the shocks are initially amplified; however, as and grow, the processes become less and less explosive, until eventually they start adjusting and the cumulative impact of the shock is driven down to zero. However, some characteristics of the cumulative IRs do not change, even when the initial conditions are modified: the cumulative cross impact seems to be relatively stronger from the methodological to the applied literature than vice versa. |
| 23 | The variance-covariance matrix for is then obtained as the following:
|
| 24 | |
| 25 | Similarly, when , the 92 MM papers are entirely treated as methodological, whereas, when , only half of them (46) are treated as methodological, while the other half is treated as applied. Given the small number of MM papers, their influence on the indices is negligible, and that is why in our discussion we emphasize the role of the MA papers. |
References
- Bass, Frank M. 1969. A new product growth for model consumer durables. Management Science 15: 215–27. [Google Scholar] [CrossRef]
- Bjork, Samuel, Avner Offer, and Gabriel Söderberg. 2014. Time series citation data: The nobel prize in economics. Scientometrics 98: 185–96. [Google Scholar] [CrossRef]
- Boswijk, H. Peter, Dennis Fok, and Philip Hans Franses. 2009. A New Multivariate Product Growth Model. Amsterdam: University of Amsterdam, Technical Report, Econometrics Discussion Paper 2009/07. [Google Scholar]
- Boswijk, H. Peter, and Philip Hans Franses. 2005. On the econometrics of the bass diffusion model. Journal of Business & Economic Statistics 23: 255–68. [Google Scholar] [CrossRef] [Green Version]
- Boswijk, H. Peter, Philip Hans Franses, and Dick van Dijk. 2010. Cointegration in a historical perspective. Journal of Econometrics 158: 156–59. [Google Scholar] [CrossRef] [Green Version]
- Chandrasekaran, Deepa, and Gerard J. Tellis. 2018. A Summary and Review of New Product Diffusion Models and Key Findings. chapter 14. Cheltenham: Edward Elgar Publishing, pp. 291–312. [Google Scholar] [CrossRef]
- Coupé, Tom. 2003. Revealed performances: Worldwide rankings of economists and economics departments, 1990–2000. Journal of the European Economic Association 1: 1309–45. [Google Scholar] [CrossRef]
- Engle, Robert F., and Clive W. J. Granger. 1987. Co-integration and error correction: Representation, estimation, and testing. Econometrica 55: 251–71. [Google Scholar] [CrossRef]
- Eryarsoy, Enes, Dursun Delen, Behrooz Davazdahemami, and Kazim Topuz. 2021. A novel diffusion-based model for estimating cases, and fatalities in epidemics: The case of covid-19. Journal of Business Research 124: 163–87. [Google Scholar] [CrossRef]
- Fok, Dennis, and Philip Hans Franses. 2007. Modeling the diffusion of scientific publications. Journal of Econometrics 139: 376–90. [Google Scholar] [CrossRef] [Green Version]
- Franses, Philip Hans. 2003. The diffusion of scientific publications: The case of econometrica, 1987. Scientometrics 56: 29–42. [Google Scholar] [CrossRef]
- Garfield, Eugene, Morton V. Malin, and Henry Small. 1978. Citation data as science indicators. In Toward a Metric of Science: The Advent of Science Indicators. Edited by Yehuda Elkana, Joshua Lederberg, Robert K. Merton, Arnold Thackray and Harriet Zuckerman. New York: John Wiley & Sons, pp. 179–207. [Google Scholar]
- Guseo, Renato, and Mariangela Guidolin. 2008. Cellular automata and riccati equation models for diffusion of innovations. Statistical Methods and Applications 17: 291–308. [Google Scholar] [CrossRef]
- Hansen, Peter Reinhard. 2003. Structural changes in the cointegrated vector autoregressive model. Journal of Econometrics 114: 261–95. [Google Scholar] [CrossRef] [Green Version]
- Heeler, Roger M., and Thomas P. Hustad. 1980. Problems in predicting new product growth for consumer durables. Management Science 26: 1007–20. [Google Scholar] [CrossRef]
- Hendry, David, and Katarina Juselius. 2001. Explaining cointegration analysis. part ii. The Energy Journal 22: 75–120. [Google Scholar] [CrossRef] [Green Version]
- Hyman, Michael R. 1988. The timeliness problem in the application of bass-type new product-growth models to durable sales forecasting. Journal of Business Research 16: 31–47. [Google Scholar] [CrossRef]
- Johansen, Søren. 1988. Statistical analysis of cointegration vectors. Journal of Economic Dynamics and Control 12: 231–54. [Google Scholar] [CrossRef]
- Johansen, Søren. 1991. Estimation and hypothesis testing of cointegration vectors in gaussian vector autoregressive models. Econometrica 59: 1551–80. [Google Scholar] [CrossRef]
- Johansen, Søren. 1992a. Cointegration in partial systems and the efficiency of single-equation analysis. Journal of Econometrics 52: 389–402. [Google Scholar] [CrossRef]
- Johansen, Søren. 1992b. Determination of cointegration rank in the presence of a linear trend. Oxford Bulletin of Economics and Statistics 54: 383–97. [Google Scholar] [CrossRef]
- Johansen, Søren. 1992c. Testing weak exogeneity and the order of cointegration in uk money demand data. Journal of Policy Modeling 14: 313–34. [Google Scholar] [CrossRef]
- Johansen, Søren. 1995. Likelihood-Based Inference in Cointegrated Vector Autoregressive Models. Oxford: Oxford University Press. [Google Scholar] [CrossRef]
- Johansen, Søren. 2006. Statistical analysis of hypotheses on the cointegrating relations in the i(2) model. Journal of Econometrics 132: 81–115. [Google Scholar] [CrossRef]
- Johansen, Søren, and Katarina Juselius. 1990. Maximum likelihood estimation and inference on cointegration—With applications to the demand for money. Oxford Bulletin of Economics and Statistics 52: 169–210. [Google Scholar] [CrossRef]
- Johansen, Søren, and Katarina Juselius. 1992. Testing structural hypotheses in a multivariate cointegration analysis of the ppp and the uip for uk. Journal of Econometrics 53: 211–44. [Google Scholar] [CrossRef]
- Johansen, Søren, and Katarina Juselius. 1994. Identification of the long-run and the short-run structure an application to the islm model. Journal of Econometrics 63: 7–36. [Google Scholar] [CrossRef]
- Johansen, Søren, Rocco Mosconi, and Bent Nielsen. 2000. Cointegration analysis in the presence of structural breaks in the deterministic trend. The Econometrics Journal 3: 216–49. [Google Scholar] [CrossRef] [Green Version]
- Juselius, Katarina. 2006. The Cointegrated VAR Model: Methodology and Applications. Oxford: Oxford University Press. [Google Scholar]
- Juselius, Katarina. 2021. Searching for a theory that fits the data: A personal research odyssey. Econometrics 9: 5. [Google Scholar] [CrossRef]
- Kalaitzidakis, Pantelis, Theofanis P. Mamuneas, and Thanasis Stengos. 1999. European economics: An analysis based on publications in the core journals. European Economic Review 43: 1150–68. [Google Scholar] [CrossRef]
- Kalaitzidakis, Pantelis, Theofanis P. Mamuneas, and Thanasis Stengos. 2003. Rankings of academic journals and institutions in economics. Journal of the European Economic Association 1: 1346–66. [Google Scholar] [CrossRef] [Green Version]
- Katsaliaki, Korina, and Navonil Mustafee. 2011. Applications of simulation within the healthcare context. Journal of the Operational Research Society 62: 1431–51. [Google Scholar] [CrossRef]
- Koop, Gary, M. Hashem Pesaran, and Simon M. Potter. 1996. Impulse response analysis in nonlinear multivariate models. Journal of Econometrics 74: 119–47. [Google Scholar] [CrossRef]
- Kuc-Czarnecka, Marta, Samuele Lo Piano, and Saltelli Andrea. 2020. Quantitative storytelling in the making of a composite indicator. Social Indicators Research 1: 775–802. [Google Scholar] [CrossRef] [Green Version]
- Lütkepohl, Helmut. 2016. Impulse Response Function. London: Palgrave Macmillan UK, pp. 1–5. [Google Scholar] [CrossRef]
- Min, Chao, Ying Ding, Jiang Li, Yi Bu, Lei Pei, and Jianjun Sun. 2018. Innovation or imitation: The diffusion of citations. Journal of the Association for Information Science and Technology 69: 1271–82. [Google Scholar] [CrossRef]
- Nardo, Michela, Michaela Saisana, Andrea Saltelli, Stefano Tarantola, Anders Hoffmann, and Enrico Giovannini. 2008. Handbook on Constructing Composite Indicators: Methodology and User Guide. Paris: OECD Publishing. [Google Scholar]
- Pesaran, H. Hashem, and Yongcheol Shin. 1998. Generalized impulse response analysis in linear multivariate models. Economics Letters 58: 17–29. [Google Scholar] [CrossRef]
- Potter, Simon M. 2000. Nonlinear impulse response functions. Journal of Economic Dynamics and Control 24: 1425–46. [Google Scholar] [CrossRef] [Green Version]
- Redner, Sidney. 1998. How popular is your paper? An empirical study of the citation distribution. The European Physical Journal B-Condensed Matter and Complex Systems 4: 131–34. [Google Scholar] [CrossRef]
- Satoh, Daisuke. 2001. A discrete bass model and its parameter estimation. Journal of the Operations Research Society of Japan 44: 1–18. [Google Scholar] [CrossRef] [Green Version]
- Srinivasan, V., and Charlotte H. Mason. 1986. Nonlinear least squares estimation of new product diffusion models. Marketing Science 5: 169–78. [Google Scholar] [CrossRef] [Green Version]
- Stigler, Stephen M. 1994. Citation patterns in the journals of statistics and probability. Statistical Science 9: 94–108. [Google Scholar] [CrossRef]
- Stokes, Donald E. 1997. Pasteur’s Quadrant: Basic Science and Technological Innovation. Washington: Brookings Institution Press. [Google Scholar]
- Van den Bulte, Christophe, and Gary L. Lilien. 1997. Bias and systematic change in the parameter estimates of macro-level diffusion models. Marketing Science 16: 338–53. [Google Scholar] [CrossRef]
- Vieira, Pedro, and Aurora Teixeira. 2010. Are finance, management, and marketing autonomous fields of scientific research? An analysis based on journal citations. Scientometrics 85: 627–46. [Google Scholar] [CrossRef] [Green Version]
- Zitt, Michel. 2006. Scientometric indicators: A few challenges. data mine-clearing; knowledge flows measurements; diversity issues. Invited plenary talk. Paper presented at the International Workshop on Webometrics, Informetrics and Scientometrics & Seventh COLLNET Meeting, Nancy, France, December 12–15. [Google Scholar]







| Order (Time) | Paper | Citations (WoS) | New Citations (WoS) |
|---|---|---|---|
| 1 | Johansen (1988) | 4008 | 4008 |
| 2 | Johansen and Juselius (1990) | 2567 | 1060 |
| 3 | Johansen (1991) | 2256 | 997 |
| 4 | Johansen (1992c) | 170 | 45 |
| 5 | Johansen and Juselius (1992) | 477 | 90 |
| 6 | Johansen (1992b) | 249 | 40 |
| 7 | Johansen (1992a) | 251 | 69 |
| 8 | Johansen and Juselius (1994) | 196 | 32 |
| 9 | Johansen et al. (2000) | 167 | 60 |
| 10 | Hendry and Juselius (2001) | 112 | 56 |
| 10,453 | 6457 |
| Author(s) | Quarter | |||||||
|---|---|---|---|---|---|---|---|---|
| Baillie-Bollerslev | 1989:Q1 | 1 | 0 | 1 | 0 | 0 | 0.85 | 0.15 |
| 1989:Q2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 1989:Q3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Gilbert | 1989:Q4 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| Rank | Journal | |||
|---|---|---|---|---|
| 1 | APPLIED ECONOMICS | 539 | 92.0% | 8.0% |
| 2 | APPLIED ECONOMICS LETTERS | 254 | 89.2% | 10.8% |
| 3 | ENERGY ECONOMICS | 208 | 94.9% | 5.1% |
| 4 | ECONOMIC MODELLING | 204 | 92.7% | 7.3% |
| 5 | ENERGY POLICY | 172 | 95.1% | 4.9% |
| 6 | JOURNAL OF ECONOMETRICS | 154 | 2.9% | 97.1% |
| 7 | J. OF INTERNATIONAL MONEY & FINANCE | 135 | 95.7% | 4.3% |
| 8 | JOURNAL OF POLICY MODELING | 121 | 96.4% | 3.7% |
| 9 | ECONOMICS LETTERS | 104 | 62.0% | 38.0% |
| 10 | JOURNAL OF MACROECONOMICS | 96 | 92.0% | 8.0% |
| 11 | OXFORD BULLETIN OF ECON. & STAT. | 92 | 46.5% | 53.5% |
| 12 | ECONOMETRIC THEORY | 86 | 0.2% | 99.8% |
| 13 | EMPIRICAL ECONOMICS | 81 | 88.6% | 11.4% |
| 14 | JOURNAL OF FUTURES MARKETS | 70 | 96.1% | 3.9% |
| 15 | JOURNAL OF APPLIED ECONOMETRICS | 68 | 54.7% | 45.3% |
| 16 | MANCHESTER SCHOOL | 66 | 94.6% | 5.4% |
| 17 | ENERGY | 61 | 92.5% | 7.5% |
| 18 | JOURNAL OF BANKING & FINANCE | 58 | 94.8% | 5.2% |
| 19 | JOURNAL OF BUSINESS & ECON. STAT. | 55 | 38.4% | 61.6% |
| 20 | JOURNAL OF FORECASTING | 52 | 51.4% | 48.6% |
| All Journals | 6457 | 84.4% | 15.6% |
| Model (18) | Model (27) | Model (29) | |||||
|---|---|---|---|---|---|---|---|
| Estimate | t-Ratio | Estimate | t-Ratio | Estimate | t-Ratio | ||
| APP | −1 | −0.435 | −5.74 | −0.508 | −6.26 | ||
| 0 | 0 | 0.715 | 2.81 | ||||
| 17.55 | 9.00 | 19.40 | 5.28 | 19.81 | 4.78 | ||
| 0.0196 | 9.62 | 0.0183 | 4.76 | 0.0190 | 4.61 | ||
| −1.33×10 | −3.22 | −1.054×10 | −1.35 | −1.32×10 | −1.60 | ||
| 10.40 | 8.42 | 8.15 | |||||
| MET | 0 | 0 | 0.0635 | 2.34 | |||
| −1 | −0.492 | −6.28 | −0.547 | −6.44 | |||
| 5.90 | 8.28 | 6.27 | 5.05 | 6.74 | 4.65 | ||
| 0.0205 | 5.77 | 0.0199 | 3.21 | 0.0187 | 2.73 | ||
| −2.06×10 | −5.71 | −2.07×10 | −3.29 | −1.97×10 | −2.86 | ||
| 3.30 | 2.79 | 2.72 | |||||
| 0.416 | 0.140 | 0.161 | |||||
| −715.81 | −682.06 | −675.26 | |||||
| Model (18) | Model (27) | Model (29) | |||||
|---|---|---|---|---|---|---|---|
| Test | p-Value | Test | p-Value | Test | p-Value | ||
| 247.3 | 0.000 | 32.64 | 0.013 | 31.74 | 0.016 | ||
| APP | 3.96 | 0.047 | 0.88 | 0.348 | 2.79 | 0.095 | |
| 3.86 | 0.047 | 0.33 | 0.566 | 1.27 | 0.260 | ||
| 101.1 | 0.000 | 27.48 | 0.051 | 26.31 | 0.069 | ||
| MET | 1.41 | 0.235 | 1.77 | 0.184 | 2.96 | 0.085 | |
| 6.30 | 0.012 | 0.91 | 0.340 | 1.46 | 0.226 | ||
| Model (12) | Model (19) | Model (28) | |||||
|---|---|---|---|---|---|---|---|
| Coefficient | Estimate | Std.err. | Estimate | Std.err. | Estimate | Std.err. | |
| APP | 15,619.7 | 3289.6 | 18,332.5 | 9687.4 | 15,350.6 | 6396.2 | |
| 0.00112 | 1.98×10 | 0.00106 | 4.79×10 | 0.00129 | 4.65×10 | ||
| 0.0207 | 0.00216 | 0.0193 | 0.00421 | 0.0203 | 0.00442 | ||
| 2022:2 | 16.2 | 2024:3 | 42.1 | 2020:4 | 32.4 | ||
| 89 | 9.9 | 99 | 30.0 | 88 | 18.4 | ||
| 7386 | 1578.9 | 8664 | 4688.9 | 7188 | 3050.6 | ||
| MET | 1229.3 | 61.3 | 1212.2 | 100.7 | 1227.7 | 119.7 | |
| 0.00480 | 5.38×10 | 0.00517 | 9.50×10 | 0.00549 | 4.91×10 | ||
| 0.0253 | 0.00333 | 0.0251 | 0.00580 | 0.0242 | 0.00643 | ||
| 2002:4 | 4.4 | 2002:1 | 7.2 | 2001:2 | 8.4 | ||
| 11 | 0.5 | 11 | 0.8 | 11 | 1.0 | ||
| 498 | 23.7 | 481 | 40.2 | 475 | 49.9 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Archontakis, F.; Mosconi, R. Søren Johansen and Katarina Juselius: A Bibliometric Analysis of Citations through Multivariate Bass Models. Econometrics 2021, 9, 30. https://doi.org/10.3390/econometrics9030030
Archontakis F, Mosconi R. Søren Johansen and Katarina Juselius: A Bibliometric Analysis of Citations through Multivariate Bass Models. Econometrics. 2021; 9(3):30. https://doi.org/10.3390/econometrics9030030
Chicago/Turabian StyleArchontakis, Fragiskos, and Rocco Mosconi. 2021. "Søren Johansen and Katarina Juselius: A Bibliometric Analysis of Citations through Multivariate Bass Models" Econometrics 9, no. 3: 30. https://doi.org/10.3390/econometrics9030030
APA StyleArchontakis, F., & Mosconi, R. (2021). Søren Johansen and Katarina Juselius: A Bibliometric Analysis of Citations through Multivariate Bass Models. Econometrics, 9(3), 30. https://doi.org/10.3390/econometrics9030030