
Statistical Analysis and Modeling of the CO2 Series Emitted by Thirty European Countries


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Series
2.2. Methodology
2.2.1. Study the Time Series Recorded in Each Country
- (1)
- Test the hypothesis that the series is Gaussian against the hypothesis that it is not Gaussian by using the Anderson–Darling (AD) test [49].
- (2)
- (3)
- Perform the Mann–Kendall (MK) [52] to test the randomness hypothesis against the existence of a monotonic trend. If the null is rejected, the slope of a linear trend will be computed by Sen’s [53]. The following series were subject to this analysis:
- (a)
- The CO2 series recorded in each country (30 series);
- (b)
- The total CO2 emissions during 1990–2021.
- (4)
- Perform the Augmented Dickey–Fuller (ADF) test [54] to assess the existence of a unit root vs. the time series stationarity for the series from (3).
- (5)
- Perform the Kruskal–Wallis (K-W) test [55] to test whether the series in a group originates from the same distribution against the alternative that at least one comes from a different distribution. When the null hypothesis was rejected, the post-hoc Dunn’s test [56], with the adjustment proposed by Hochberg [57], was run.
- (6)
- Modeling the time series from (3) using the ARIMA technique.
2.2.2. Building RegS
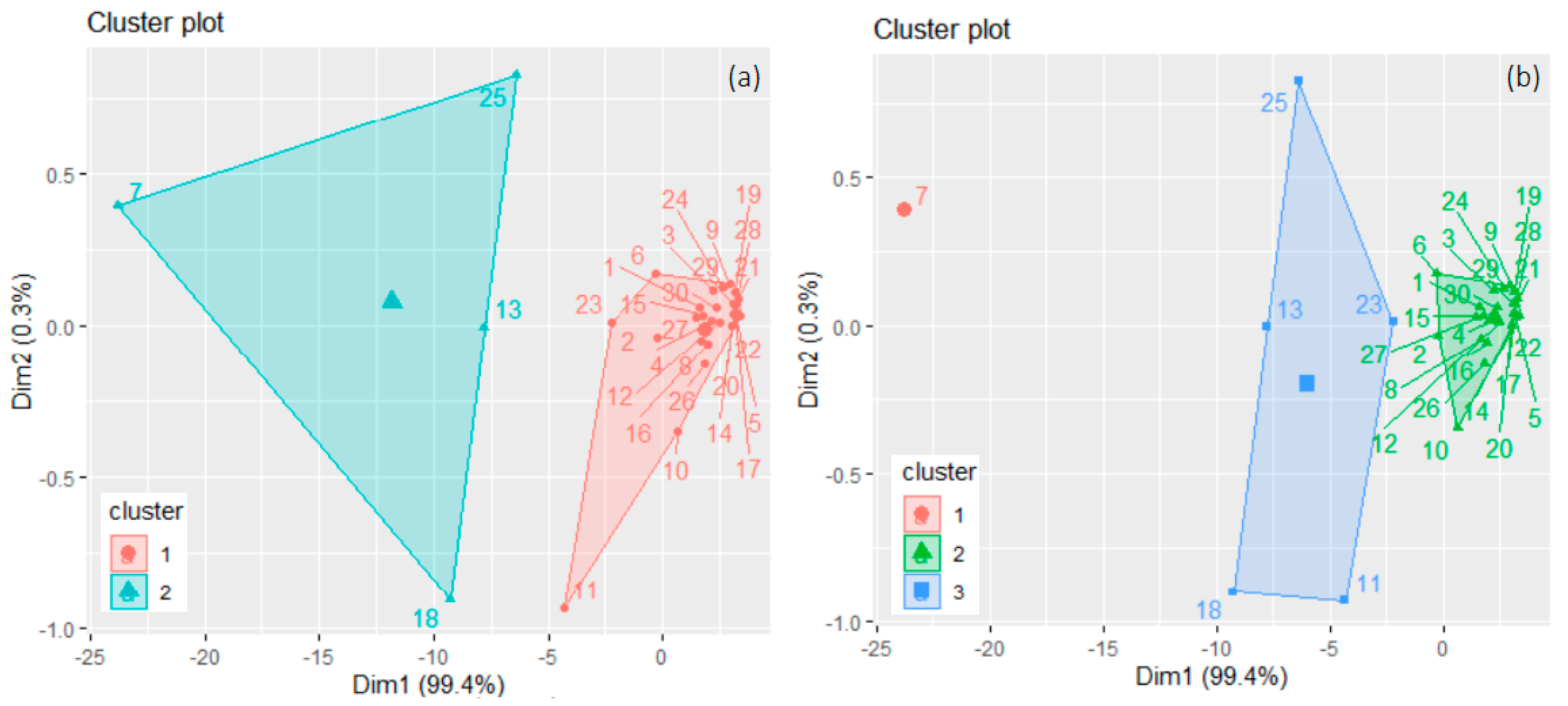
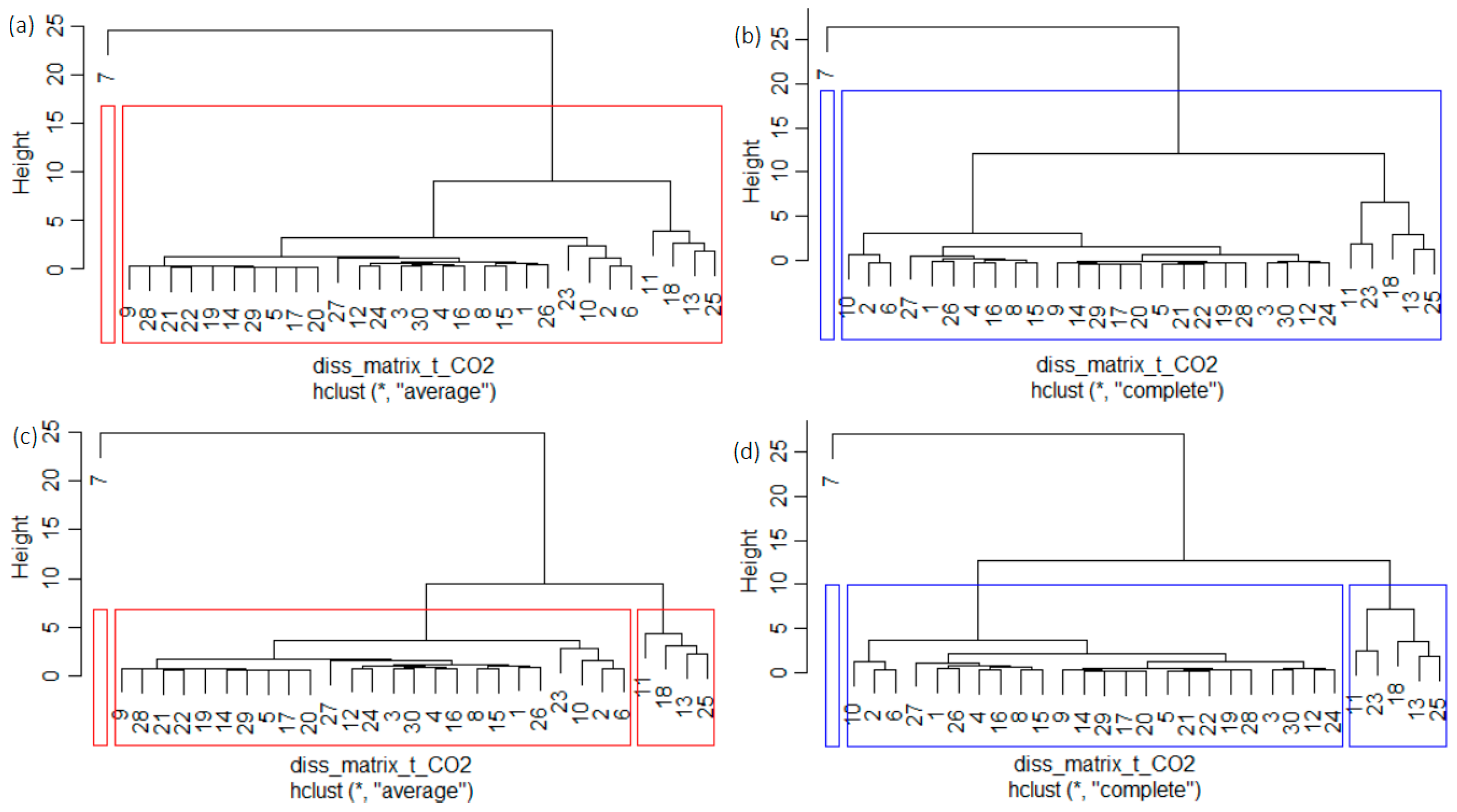
- 1.
- Determine the optimal number of clusters, k, perform the k-means and hierarchical clustering, and choose the best clustering.
- 2.
- Select the cluster with the highest number of elements, Clmax. When at least two clusters have this property, Clmax is the one with the smallest WSS.
- 3.
- Compute RegS, whose elements are the averages of the series from Clmax. More precisely, the value assigned to year j is the mean of values recorded in the same year in the countries from Clmax.
- 4.
- Evaluate the modeling errors for each series by subtracting the values of RegS from the recorded values.
- 5.
- Estimate the RegS’s goodness-of-fit of by computing the mean absolute percentage error (MAPE). MAPE was chosen because it is a non-dimensional index that can be utilized for comparing different models.
3. Results and Discussion
3.1. Analysis of the CO2 Time Series
- -
- Column 2—the model type;
- -
- Column 3—the model’s coefficients (when a simple differentiation did not lead to the model) and the corresponding standard error (se) inside the brackets;
- -
- Column 4—the drift, if it exists, and the standard error (se) of its estimation inside the brackets;
- -
- The p-value computed in the Ljung–Box test applied to the model’s residual series;
- -
- The MAPE of the model.
3.2. Building RegS
- (a)
- Countries (HR, EE, FI, EL, IE, PT, SI, ES) for which the MK test did not reject H0 for both CO2 and GHG series, so no significant monotonic trend can be emphasized;
- (b)
- Countries for which H0 was rejected and both CO2 and GHG series have the same type of trend: negative (BE, BG, CH, CZ, DE, DK, FR, HU, IT, LT, LU, NL, PL, RO, SE, and SK) or positive (AT, CY, and IS);
- (c)
- Countries for which the CO2 series has a negative slope of the trend, but H0 was not rejected for the total GHGs series (MT).
- (d)
- Countries for which H0 was not rejected, but the GHGs series have a monotonic increasing (LV) or decreasing (NO) trend.
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- IPCC 2014. Contribution of Working Groups I, II and III to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change. Available online: https://www.ipcc.ch/report/ar5/syr/ (accessed on 14 September 2023).
- Inventory of U.S. Greenhouse Gas Emissions and Sinks. Available online: https://www.epa.gov/ghgemissions/inventory-us-greenhouse-gas-emissions-and-sinks (accessed on 16 November 2023).
- EU Economy Greenhouse Gas Emissions: −3% in Q1 2023. Available online: https://ec.europa.eu/eurostat/web/products-eurostat-news/w/ddn-20230816-1#:~:text=In%20the%20first%20quarter%20of,of%20CO2%2Deq (accessed on 14 September 2023).
- CO2 Emissions from Cars: Facts and Figures (Infographics). Available online: https://www.europarl.europa.eu/news/en/headlines/society/20190313STO31218/co2-emissions-from-cars-facts-and-figures-infographics (accessed on 7 August 2023).
- IEA. CO2 Emissions from Fuel Combustion; IEA: Paris, France, 2019. [Google Scholar] [CrossRef]
- Greenhouse Gas Emissions. Sources of Greenhouse Gas Emissions. Available online: https://www.epa.gov/ghgemissions/sources-greenhouse-gas-emissions (accessed on 7 July 2023).
- IPCC. Climate Change 2022: Mitigation of Climate Change; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar]
- Paris Agreement. In Report of the Conference of the Parties to the United Nations Framework Convention on Climate Change (21st Session, 2015: Paris); HeinOnline: Paris, France, 2015.
- Calotă, R.; Antonescu, N.N.; Stănescu, D.-P.; Năstase, I. The Direct Effect of Enriching the Gaseous Combustible with 23% Hydrogen in Condensing Boilers’ Operation. Energies 2022, 15, 9373. [Google Scholar] [CrossRef]
- Antonescu, N.N.; Stănescu, D.-P.; Calotă, R. CO2 Emissions Reduction through Increasing H2 Participation in Gaseous Combustible—Condensing Boilers Functional Response. Appl. Sci. 2022, 12, 3831. [Google Scholar] [CrossRef]
- Denman, K.L.; Brasseur, G.; Chidthaisong, A.; Ciais, P.; Cox, P.M.; Dickinson, R.E.; Hauglustaine, D.; Heinze, C.; Holland, E.; Jacob, D.; et al. Couplings Between Changes in the Climate System and Biogeochemistry. In Climate Change 2007: The Physical Science Basis. Contribution of Working Group I to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2007. [Google Scholar]
- Saini, M.; Saini, S.K. Identification of Major Sinks of Greenhouse Gases. In Greenhouse Gases: Sources, Sinks and Mitigation; Sonwani, S., Saxena, P., Eds.; Springer: Singapore, 2022; pp. 39–62. [Google Scholar]
- Greenhouse Gas Removal Methods and Their Potential UK Deployment. 2021. Available online: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/1026988/ggr-methods-potential-deployment.pdf (accessed on 14 September 2023).
- Ming, T.; de Richter, R.; Oeste, F.D.; Tulip, R.; Caillol, S. A nature-based negative emissions technology able to remove atmospheric methane and other greenhouse gases. Atmos. Pollut. Res. 2021, 12, 101035. [Google Scholar] [CrossRef]
- Naiyer, S.; Abbas, S.S. Effect of Greenhouse Gases on Human Health. In Greenhouse Gases: Sources, Sinks and Mitigation; Sonwani, S., Saxena, P., Eds.; Springer: Singapore, 2022; pp. 85–106. [Google Scholar]
- Hajtar, L.; Herczeg, L. Influence of carbon-dioxide concentration on human well-being and intensity of mental work. Időjárás 2012, 116, 145–169. [Google Scholar]
- Satish, U.; Mendell, M.J.; Shekhar, K.; Hotchi, T.; Sullivan, D.; Strufert, S.; Fisk, W.J. Is CO2 an indoor pollutant? Direct effects of low-to-moderate CO2 concentrations on human decision-making performance. Environ. Health Perspect. 2012, 120, 1671–1677. [Google Scholar] [CrossRef] [PubMed]
- Allen, J.G.; MacNaughton, P.; Satish, U.; Santanam, S.; Vallarino, J.; Spengler, J.D. Associations of cognitive function scores with carbon dioxide, ventilation, and volatile organic compound exposures in office workers: A controlled exposure study of green and conventional office environment. Environ. Health Perspect. 2016, 124, 805–812. [Google Scholar] [CrossRef] [PubMed]
- Snow, S.; Boyson, A.S.; Paas, K.H.W.; Gough, H.; King, M.-F.; Barlow, J.; Noakes, C.J.; Schraefel, M.C. Exploring the physiological, neurophysiological and cognitive performance effects of elevated carbon dioxide concentrations indoors. Build. Environ. 2019, 156, 243–252. [Google Scholar] [CrossRef]
- Jacobson, T.A.; Kler, J.S.; Hernke, M.T.; Braun, R.K.; Meyer, K.C.; Funk, W.E. Direct human health risks of increased atmospheric carbon dioxide. Nat. Sustain. 2019, 2, 691–701. [Google Scholar] [CrossRef]
- Smith, D. Is Carbon Dioxide Harmful to People? Available online: https://learn.kaiterra.com/en/air-academy/is-carbon-dioxide-harmful-to-people (accessed on 15 September 2023).
- Hunter, P. The impact of CO2. The global rise in the levels of CO2 is good for trees, bad for grasses and terrible for corals. EMBO Rep. 2007, 8, 1104–1106. [Google Scholar] [CrossRef] [PubMed]
- Ehleringer, J.R.; Cerling, T.; Dearing, M.D. A History of Atmospheric CO2 and Its Effects on Plants, Animals, and Ecosystems; Ecological Studies 177; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Hadipoor, M.; Keivanimehr, F.; Baghban, A.; Reza Ganjali, M.; Habibzadeh, S. Chapter 24—Carbon dioxide as a main source of air pollution: Prospective and current trends to control. In Sorbents Materials for Controlling Environmental Pollution; Núñez-Delgado, A., Ed.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 623–688. [Google Scholar]
- Wang, T.; Chen, Y.; Zeng, L. Spatial-Temporal Evolution Analysis of Carbon Emissions Embodied in Inter-Provincial Trade in China. Int. J. Environ. Res. Public Health 2022, 19, 6794. [Google Scholar] [CrossRef]
- Li, Y.L.; Chen, B.; Chen, G.Q. Carbon network embodied in international trade: Global structural evolution and its policy implications. Energy Policy 2020, 139, 11131. [Google Scholar] [CrossRef]
- Chiritescu, R.-V.; Luca, E.; Iorga, G. Observational study of major air pollutants over urban Romania in 2020 in comparison with 2019. Rom. Rep. Phys. 2024, 76, 702. [Google Scholar]
- Dumitru, A.; Olaru, E.-A.; Dumitru, M.; Iorga, G. Assessment of air pollution by aerosols over a coal open-mine influenced region in southwestern Romania. Rom. J. Phys. 2024, 69, 801. [Google Scholar]
- Bărbulescu, A.; Dumitriu, C.S.; Popescu-Bodorin, N. On the aerosol optical depth series in the Arabian Gulf region. Rom. J. Phys. 2022, 67, 814. [Google Scholar]
- Bărbulescu, A.; Dumitriu, C.S.; Popescu-Bodorin, N. Assessing atmospheric pollution and its impact on the human health. Atmosphere 2022, 13, 938. [Google Scholar] [CrossRef]
- Ullah, I.; Ali, S.; Shah, M.H.; Yasim, F.; Rehman, A.; Al-Ghazali, B.M. Linkages between Trade, CO2 Emissions and Healthcare Spending in China. Int. J. Environ. Res. Public Health 2019, 16, 4298. [Google Scholar] [CrossRef] [PubMed]
- Jakob, M.; Marschinski, R. Interpreting trade-related CO2 emission transfers. Nat. Clim. Chang. 2013, 3, 19–23. [Google Scholar] [CrossRef]
- Slechten, A.; Verardi, V. Assessing the Effectiveness of Global Air-Pollution Treaties on CO2 Emissions; Working Papers 64981625; Lancaster University Management School, Economics Department: Lancaster, UK, 2014. [Google Scholar]
- Lindenmaier, R.; Dubey, M.K.; Henderson, B.G.; Butterfield, Z.T.; Herman, J.R.; Rahn, T.; Lee, S. Multiscale observations of CO2, and pollutants at Four Corners for emission verification and attribution. Proc. Nat. Acad. Sci. USA 2014, 111, 8386–8391. [Google Scholar] [CrossRef] [PubMed]
- Budiono, R.; Juahir, H.; Mamat, M.; Sukono; Supian, S.; Nurzaman, M. Modeling and analysis of CO2 emissions in million tons of sectoral greenhouse gases in Indonesia. IOP Conf. Ser. Mat. Sci. Eng. 2019, 621, 012020. [Google Scholar] [CrossRef]
- Debone, D.; Pazini Leite, V.; Georges El Khouri Miraglia, S. Modelling approach for carbon emissions, energy consumption and economic growth: A systematic review. Urban Clim. 2021, 37, 100849. [Google Scholar] [CrossRef]
- Yousefi-Sahzabi, A.; Sasaki, K.; Djamaluddin, I.; Yousefi, H.; Sugai, Y. GIS modeling of CO2 emission sources and storage possibilities. Energy Proceed. 2011, 4, 2831–2838. [Google Scholar] [CrossRef]
- Bâki iz, H. The evolution of large-scale variations in globally averaged atmospheric CO2 concentrations since 1830. All Earth 2022, 34, 16–26. [Google Scholar]
- Hansen, J.; Sato, M.; Kharecha, P.; Beerling, D.; Berner, R.; Masson-Delmotte, V.; Pagani, M.; Raymo, M.; Royer, D.L.; Zachos, J.C. Target Atmospheric CO2: Where Should Humanity Aim? Available online: https://arxiv.org/ftp/arxiv/papers/0804/0804.1126.pdf (accessed on 15 September 2023).
- Rahman, A.; Mahmudul Hasan, M.M. Modeling and Forecasting of Carbon Dioxide Emissions in Bangladesh Using Autoregressive Integrated Moving Average (ARIMA) Models. Open J. Stat. 2017, 7, 560–566. [Google Scholar] [CrossRef]
- Tawiah, K.; Daniyal, M.; Qureshi, M. Pakistan CO2 Emission Modelling and Forecasting: A Linear and Nonlinear Time Series Approach. J. Environ. Public Health 2023, 2023, 5903362. [Google Scholar] [CrossRef] [PubMed]
- Chang, S.C.; Lee, C.T. Evaluation of the temporal variations of air quality in Taipei City, Taiwan, from 1994 to 2003. J. Environ. Manag. 2008, 86, 627–635. [Google Scholar] [CrossRef] [PubMed]
- Kuttippurath, J.; Peter, R.; Singh, A.; Raj, S. The increasing atmospheric CO2 over India: Comparison to global trends. iScience 2022, 25, 104863. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Zhang, J.; Hu, S. Regression analysis and driving force model building of CO2 emissions in China. Sci. Rep. 2021, 11, 6715. [Google Scholar] [CrossRef]
- Jiang, P.; Gong, X.; Yang, Y.; Tang, K.; Zhao, Y.; Liu, S.; Liu, L. Research on spatial and temporal differences of carbon emissions and influencing factors in eight economic regions of China based on LMDI model. Sci. Rep. 2023, 13, 7965. [Google Scholar] [CrossRef]
- Bărbulescu, A.; Nazzal, Y.; Howari, F. Statistical analysis and estimation of the regional trend of aerosol size over the Arabian Gulf Region during 2002–2016. Sci. Rep. 2018, 8, 9571. [Google Scholar] [CrossRef]
- Bărbulescu, A.; Postolache, F. New approaches for modeling the regional pollution in Europe. Sci. Total Environ. 2021, 753, 141993. [Google Scholar] [CrossRef]
- EEA Greenhouse Gases—Data Viewer. Available online: https://www.eea.europa.eu/data-and-maps/data/data-viewers/greenhouse-gases-viewer (accessed on 15 June 2023).
- Anderson, T.W.; Darling, D.A. Asymptotic theory of certain “goodness of fit” criteria based on stochastic processes. Ann. Math. Stat. 1952, 23, 193–212. [Google Scholar] [CrossRef]
- Fligner, M.A.; Killeen, T.J. Distribution-free two-sample tests for scale. J. Am. Stat. Assoc. 1976, 71, 210–213. [Google Scholar] [CrossRef]
- Conover, W.J.; Johnson, M.E.; Johnson, M.M. A comparative study of tests for homogeneity of variances, with applications to the outer continental shelf biding data. Technometrics 1981, 23, 351–361. [Google Scholar] [CrossRef]
- Kendall, M.G. Rank Correlation Methods, 4th ed.; Charles Griffin: London, UK, 1975. [Google Scholar]
- Sen, P.K. Estimates of the regression coefficient based on Kendall’s tau. J. Am. Stat. Assoc. 1968, 63, 1379–1389. [Google Scholar] [CrossRef]
- Fuller, W.A. Introduction to Statistical Time Series; John Wiley and Sons: New York, NY, USA, 1976. [Google Scholar]
- Kruskal, W.H.; Wallis, W.A. Use of ranks in one-criterion variance analysis. J. Am. Stat. Assoc. 1952, 47, 583–621. [Google Scholar] [CrossRef]
- Dunn, O.J. Multiple comparisons using rank sums. Technometrics 1964, 6, 241–252. [Google Scholar] [CrossRef]
- Hochberg, Y. A sharper Bonferroni procedure for multiple tests of significance. Biometrika 1988, 75, 800–802. [Google Scholar] [CrossRef]
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Akaike, H. Time series analysis and control through parametric models. In Applied Time Series Analysis; Findley, D.F., Ed.; Academic Press: New York, NY, USA, 1978. [Google Scholar]
- Ljung, G.M.; Box, G.E.P. On a Measure of a Lack of Fit in Time Series Models. Biometrika 1978, 65, 297–303. [Google Scholar] [CrossRef]
- Bărbulescu, A.; Postolache, F.; Dumitriu, C.Ș. Estimating the precipitation amount at regional scale using a new tool, Climate Analyzer. Hidrology 2021, 8, 125. [Google Scholar] [CrossRef]
- Bărbulescu, A. On the Regional Temperature Series Evolution in the South-Eastern Part of Romania. Appl. Sci. 2023, 13, 3904. [Google Scholar] [CrossRef]
- K-Mean: Getting the Optimal Number of Clusters. Available online: https://www.analyticsvidhya.com/blog/2021/05/k-mean-getting-the-optimal-number-of-clusters/ (accessed on 16 June 2023).
- Hierarchical Clustering in, R. Available online: https://www.datacamp.com/tutorial/hierarchical-clustering-R (accessed on 18 June 2023).
- Kassambara, A. Practical Guide to Cluster Analysis in R. Unsupervised Machine Learning. Available online: https://www.datanovia.com/en/product/practical-guide-to-cluster-analysis-in-r/ (accessed on 10 May 2023).
- Daburra, I. K-Means Clustering: Algorithm, Applications, Evaluation Methods, and Drawbacks. Available online: https://towardsdatascience.com/k-means-clustering-algorithm-applications-evaluation-methods-and-drawbacks-aa03e644b48a (accessed on 18 June 2023).
- Rousseeuw, P. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Thorndike, R.L. Who belongs in the family? Psychometrika 1953, 18, 267–276. [Google Scholar] [CrossRef]
- Löhr, T. K-Means Clustering and the Gap-Statistics. Available online: https://towardsdatascience.com/k-means-clustering-and-the-gap-statistics-4c5d414acd29 (accessed on 16 June 2023).
- Madsen, B.E.; Browning, S.R. A Groupwise Association Test for Rare Mutations Using a Weighted Sum Statistic. PLoS Genet. 2009, 5, e1000384. [Google Scholar] [CrossRef]
- Sokal, R.R.; Rohlf, F.J. The comparison of dendrograms by objective methods. Taxon 1962, 11, 33–40. [Google Scholar] [CrossRef]
- Farris, J.S. On the cophenetic correlation coefficient. System. Zool. 1969, 18, 279–285. [Google Scholar] [CrossRef]
- Myrphy, P. Clustering Data in R. Available online: https://rstudio-pubs-static.s3.amazonaws.com/599072_93cf94954aa64fc7a4b99ca524e5371c.html (accessed on 30 June 2023).
- Soetewey, A. Stats and R. The Complete Guide to Clustering Analysis: K-Means and Hierarchical Clustering by Hand and in R. Available online: https://statsandr.com/blog/clustering-analysis-k-means-and-hierarchical-clustering-by-hand-and-in-r/ (accessed on 20 June 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Country | AT | BE | BG | CH | CY | CZ | DE | DK | EE | EL |
| MK p−val | 0.000 (+) | 0.000 (−) | 0.007 (−) | 0.002 (−) | 0.001 (+) | 0.000 (−) | 0.000 (−) | 0.000 (−) | 0.5703 | 0.116 |
| Country | ES | FI | FR | HR | HU | IE | IS | IT | LT | LU |
| p−val | 0.783 | 0.212 | 0.000 (−) | 0.250 | 0.000 (−) | 0.446 | 0.000 (+) | 0.001 (−) | 0.003 (−) | 0.034 (−) |
| Country | LV | MT | NL | NO | PL | PT | RO | SE | SI | SK |
| p−val | 0.570 | 0.043 (−) | 0.001 (−) | 0.884 | 0.017 (−) | 0.910 | 0.000 (−) | 0.000 (−) | 0.062 | 0.000 (−) |
| Model | Coefficient (se) | Drift (se) | Ljung–Box | MAPE | |
|---|---|---|---|---|---|
| AT | ARIMA (0,1,0) | 0.068 | 9.540 | ||
| BE | ARIMA (1,1,0) | ar1 = −0.5379 (0.1541) | −823,323.2 (434,892.5) | 0.585 | 2.528 |
| BG | ARIMA (0,1,0) | 0.696 | 10.242 | ||
| CH | ARIMA (0,1,0) | 0.163 | 3.565 | ||
| CY | ARIMA (1,2,0) | ar1 = −0.4796 (0.1660) | 0.872 | 3.118 | |
| CZ | ARIMA (0,1,0) | −1,672,886.6 (912,138.5) | 0.721 | 3.382 | |
| DE | ARIMA (0,1,0) | −13,175,314 (5,529,230) | 0.663 | 2.801 | |
| DK | ARIMA (0,1,1) | ma1 = −0.3653 (0.1724) | −1,071,914.1 (530,997.1) | 0.863 | 5.936 |
| EE | ARIMA (1,0,0),mean = 18,424,007 (5,355,966) | ar1 = 0.9194 (0.0809) | 0.978 | 15.576 | |
| EL | ARIMA (0,2,1) | ma1 = −0.7087 (0.1233) | 0.578 | 3.755 | |
| ES | ARIMA (0,0,0), mean = 240,898,858 (7,123,938) | 0.000 | 13.679 | ||
| FI | ARIMA (0,0,1) with mean = 30,004,148 (1,645,259) | ma1 = 0.4819 (0.2230) | 0.662 | 19.416 | |
| FR | ARIMA (0,1,1) | ma1 = −0.4832 (0.1950) | −3,180,106 (1,285,215) | 0.575 | 2.903 |
| HR | ARIMA (1,0,0), mean = 12,922,689 (1,229,364) | ar1 = 0.7948 (0.0809) | 0.889 | 8.736 | |
| HU | ARIMA (0,1,0) | −923,762.9 (441,331.6) | 0.429 | 3.588 | |
| IE | ARIMA (1,0,2) with mean = 44,879,052 (2,889,765) | ar1 = 0.8256 (0.0983) ma1 = 0.2435 (0.1239) ma2 = 0.6980 (0.1712) | 0.997 | 2.913 | |
| IS | ARIMA (0,1,0) | 37689.71 (24201.84) | 0.501 | 1.227 | |
| IT | ARIMA (0,1,0) | 0.956 | 3.974 | ||
| LT | ARIMA (0,1,0) | 0.256 | 27.837 | ||
| LU | ARIMA (2,0,0) with mean = 9,754,522.1 (622,592.4) | ar1 = 1.1611 (0.1629) ma1 = −0.3443 (0.1769) | 0.626 | 5.342 | |
| LV | ARIMA (0,0,1) with mean = 4,189,224.4 (525,627.8) | ma1 = 0.5705 (0.1333) | 0.586 | 258.177 | |
| MT | ARIMA (0,1,0) | 0.934 | 6.524 | ||
| NL | ARIMA (1,2,1) | ar1 = −0.2340 (0.1926) ma1 = 0.8333 (0.1073) | 0.567 | 2.651 | |
| NO | ARIMA (1,0,0), mean = 24,099,466 (1,405,598) | ar1 = 0.6871 (0.1205) | 9.482 | ||
| PL | ARIMA (0,1,0) | 0.795 | 3.040 | ||
| PT | ARIMA (1,0,0), mean = 49,480,302 (3,843,606) | ar1 = 0.6729 (0.1330) | 0.945 | 10.135 | |
| RO | ARIMA (0,1,1) | ma1 = 0.5272 (0.1465) | −4,199,933 (2,188,561) | 0.569 | 10.766 |
| SE | ARIMA (0,1,0) | 0.714 | 55.183 | ||
| SI | ARIMA (0,1,0) | 0.356 | 7.363 | ||
| SK | ARIMA (0,1,0) | −793,429.1 (483,098) | 0.783 | 6.182 |
| k = 2 | k = 3 | ||||
|---|---|---|---|---|---|
| Clusters | AvgJaccard | Instability | Clusters | AvgJaccard | Instability |
| 1 | 0.7507 | 0.343 | 1 | 0.6445 | 0.361 |
| 2 | 0.9568 | 0.000 | 2 | 0.9061 | 0.007 |
| 3 | 0.8511 | 0.087 | |||
| k = 2 | k = 3 | |||||
|---|---|---|---|---|---|---|
| Clusters | AvgJaccard | Instability | Clusters | AvgJaccard | Instability | |
| 1 | 0.9453 | 0.000 | 1 | 0.9685 | 0.003 | |
| Average | 2 | 0.6320 | 0.368 | 2 | 0.6330 | 0.367 |
| 3 | 0.8607 | 0.100 | ||||
| 1 | 0.9479 | 0.000 | 1 | 0.9567 | 0.002 | |
| Complete | 2 | 0.6500 | 0.350 | 2 | 0.6520 | 0.348 |
| 3 | 0.7994 | 0.161 | ||||
| Country | AT(II) | BE(II) | BG(II) | CH(II) | CY(II) | CZ(II) | DE(I) | DK(II) | EE(II) | EL(II) |
| MAPE_c | 31.37 | 67.32 | 10.48 | 8.98 | 461.98 | 68.09 | 95.61 | 29.29 | 162.05 | 56.28 |
| MAPE_av | 22.45 | 62.46 | 17.15 | 7.32 | 544.39 | 63.33 | 94.96 | 20.99 | 201.15 | 49.78 |
| Country | ES(III) | FI(II) | FR(III) | HR(II) | HU(II) | IE(II) | IS(II) | IT(III) | LT(II) | LU(II) |
| MAPE_c | 84.30 | 35.67 | 89.35 | 206.68 | 27.70 | 20.23 | 322.71 | 90.55 | 460.03 | 286.51 |
| MAPE_av | 81.98 | 53.32 | 87.76 | 252.04 | 16.87 | 13.55 | 384.98 | 89.14 | 545.67 | 343.94 |
| Country | LV(II) | MT(II) | NL * | NO(II) | PL(III) | PT(II) | RO(II) | SE(II) | SI(II) | SK(II) |
| MAPE_c | 3479.83 | 1515.61 | 78.73 | 59.12 | 87.70 | 24.26 | 37.91 | 790.94 | 267.03 | 13.25 |
| MAPE_av | 3989.87 | 1756.43 | 75.58 | 82.63 | 85.88 | 16.69 | 36.49 | 926.02 | 321.11 | 29.31 |
| Country | AT(II) | BE(II) | BG(II) | CH(II) | CY(II) | CZ(II) | DE(I) | DK(II) | EE(II) | EL(II) |
| MAPE_DE | 1470.27 | 645.88 | 2185.87 | 1999.82 | 12,765.59 | 628.38 | 0 | 1514.20 | 5862.92 | 899.55 |
| MAPE_c_III | 495.42 | 183.73 | 773.61 | 698.86 | 4755.16 | 177.69 | 61.84 | 515.07 | 2191.58 | 279.10 |
| MAPE_av_III | 440.63 | 157.82 | 693.56 | 625.74 | 4308.59 | 152.34 | 65.33 | 459.30 | 1981.18 | 244.53 |
| Country | ES(III) | FI(II) | FR(III) | HR(II) | HU(II) | IE(II) | IS(II) | IT(III) | LT(II) | LU(II) |
| MAPE_DE | 259.42 | 2948.87 | 143.00 | 6927.44 | 1550.89 | 1771.96 | 9549.77 | 116.04 | 12,757.89 | 81,008.29 |
| MAPE_c_III | 35.95 | 1054.96 | 7.64 | 2560.80 | 529.14 | 608.88 | 3564.49 | 17.93 | 4820.68 | 3261.18 |
| MAPE_av_III | 23.53 | 948.93 | 15.94 | 2316.76 | 471.88 | 543.93 | 3227.47 | 25.40 | 4376.74 | 2953.39 |
| Country | LV(II) | MT(II) | NL * | NO(II) | PL(III) | PT(II) | RO(II) | SE(II) | SI(II) | SK(II) |
| MAPE_DE | 36,791.50 | 385.23 | 3523.23 | 180.29 | 1632.33 | 1504.66 | 19,918.22 | 8266.20 | 2465.86 | 36,791.50 |
| MAPE_c_III | 31,259.28 | 13,915.38 | 84.61 | 1283.56 | 10.63 | 557.26 | 511.89 | 7706.14 | 3090.75 | 878.89 |
| MAPE_av_III | 28,253.60 | 12,639.55 | 67.68 | 1156.23 | 10.35 | 497.13 | 457.15 | 6998.47 | 2796.41 | 789.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bărbulescu, A. Statistical Analysis and Modeling of the CO2 Series Emitted by Thirty European Countries. Climate 2024, 12, 34. https://doi.org/10.3390/cli12030034
Bărbulescu A. Statistical Analysis and Modeling of the CO2 Series Emitted by Thirty European Countries. Climate. 2024; 12(3):34. https://doi.org/10.3390/cli12030034
Chicago/Turabian StyleBărbulescu, Alina. 2024. "Statistical Analysis and Modeling of the CO2 Series Emitted by Thirty European Countries" Climate 12, no. 3: 34. https://doi.org/10.3390/cli12030034
APA StyleBărbulescu, A. (2024). Statistical Analysis and Modeling of the CO2 Series Emitted by Thirty European Countries. Climate, 12(3), 34. https://doi.org/10.3390/cli12030034