
Data-Driven Analysis of Forest–Climate Interactions in the Conterminous United States



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
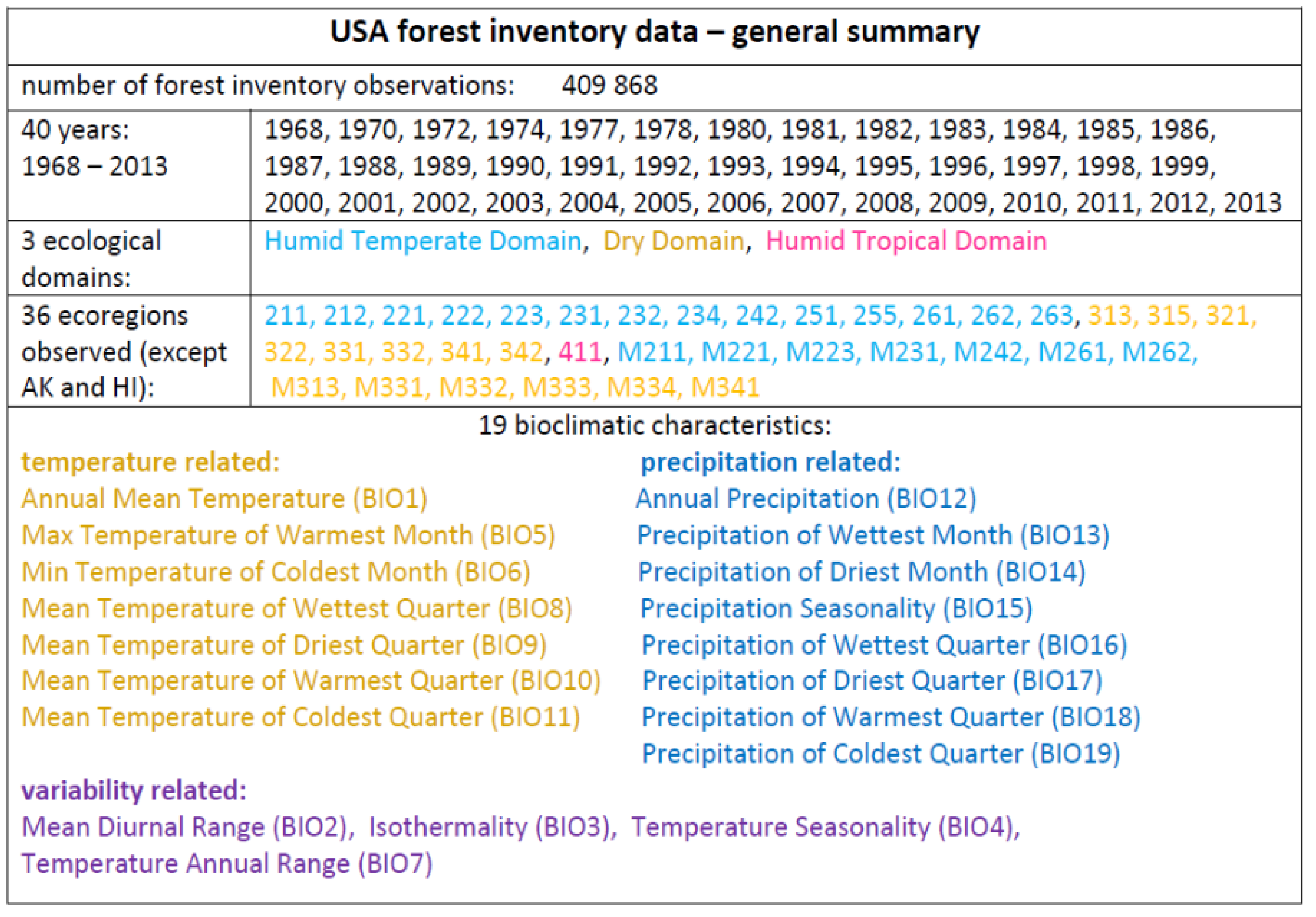
2. Materials and Methods
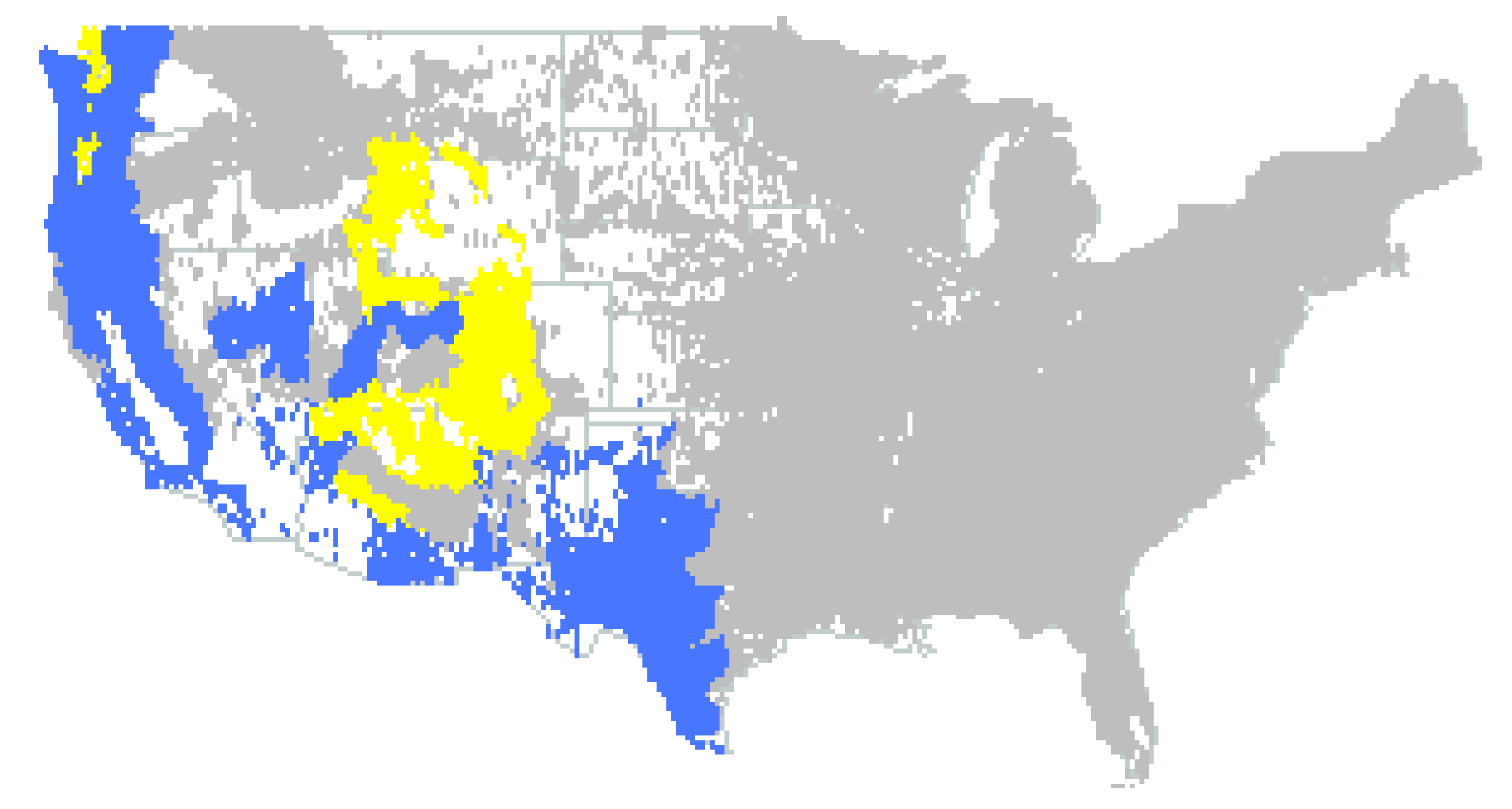
2.1. Data Mining
2.2. Data Analysis and Software
2.2.1. Stepwise Linear Regression
2.2.2. Random Forests
3. Results and Discussion
3.1. Stepwise Regression and Multivariate Statistical Analysis
3.1.1. Correlation Analysis
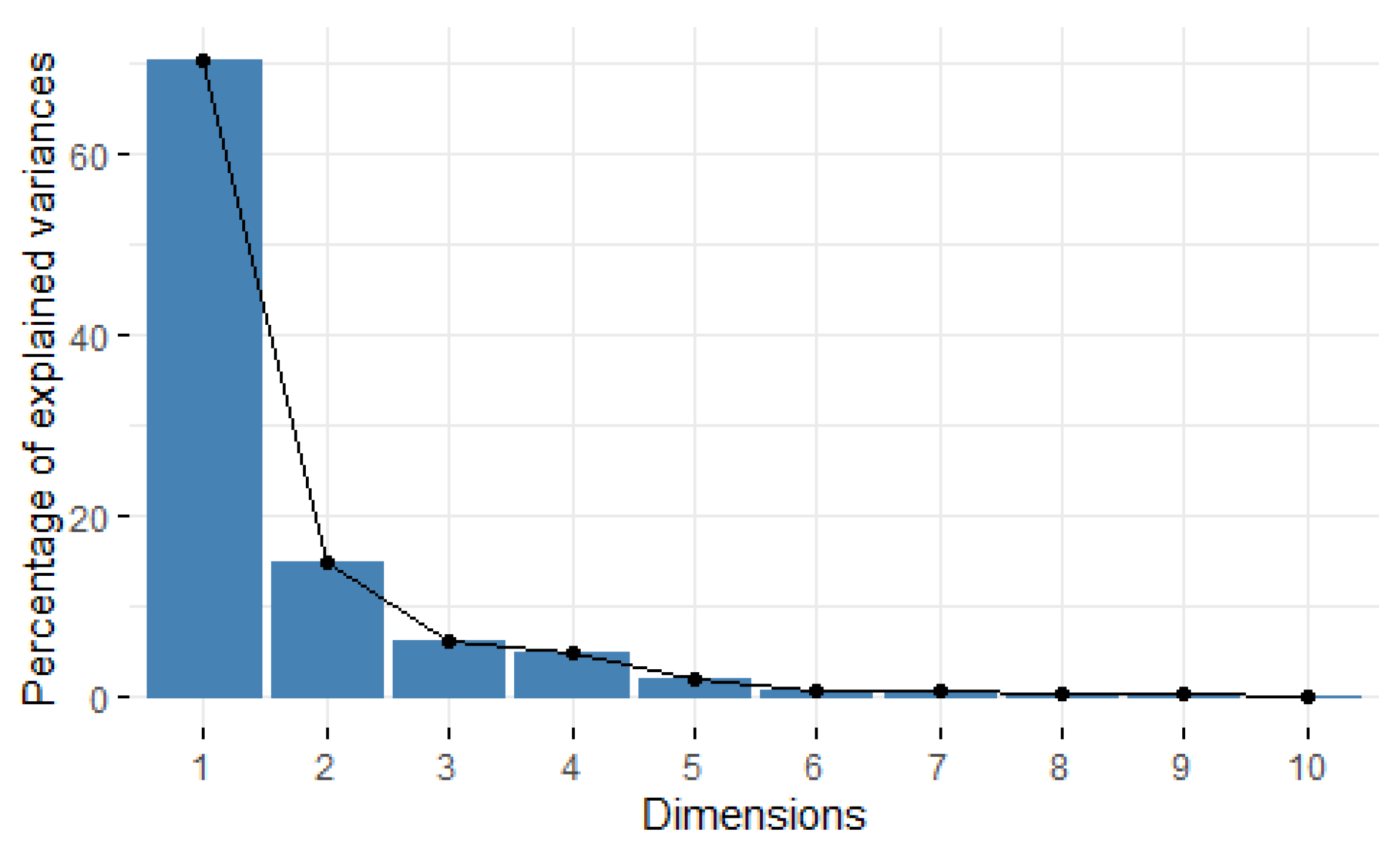
3.1.2. Principal Component Analysis
3.1.3. Stepwise Regression
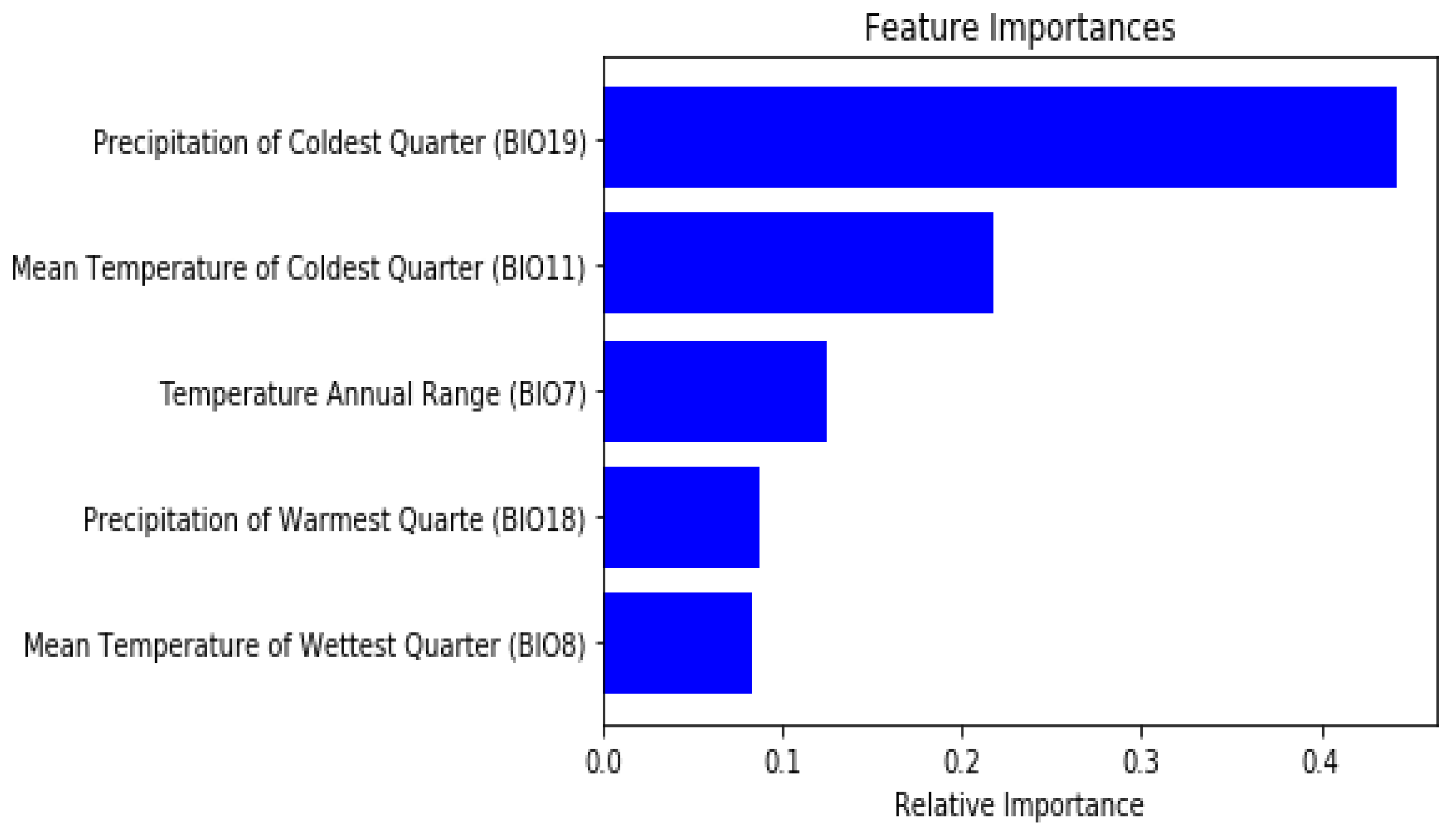
3.2. Random Forests
3.3. Stepwise Linear Regression Versus Random Forests
3.4. Summary
3.5. Future Research
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| USDA | United States Department of Agriculture |
| FIA | USDA Forest Service Forest Inventory and Analysis Program |
| GIS | Geographic Information Systems |
| PCA | Principal component analysis |
| RF | Random forests |
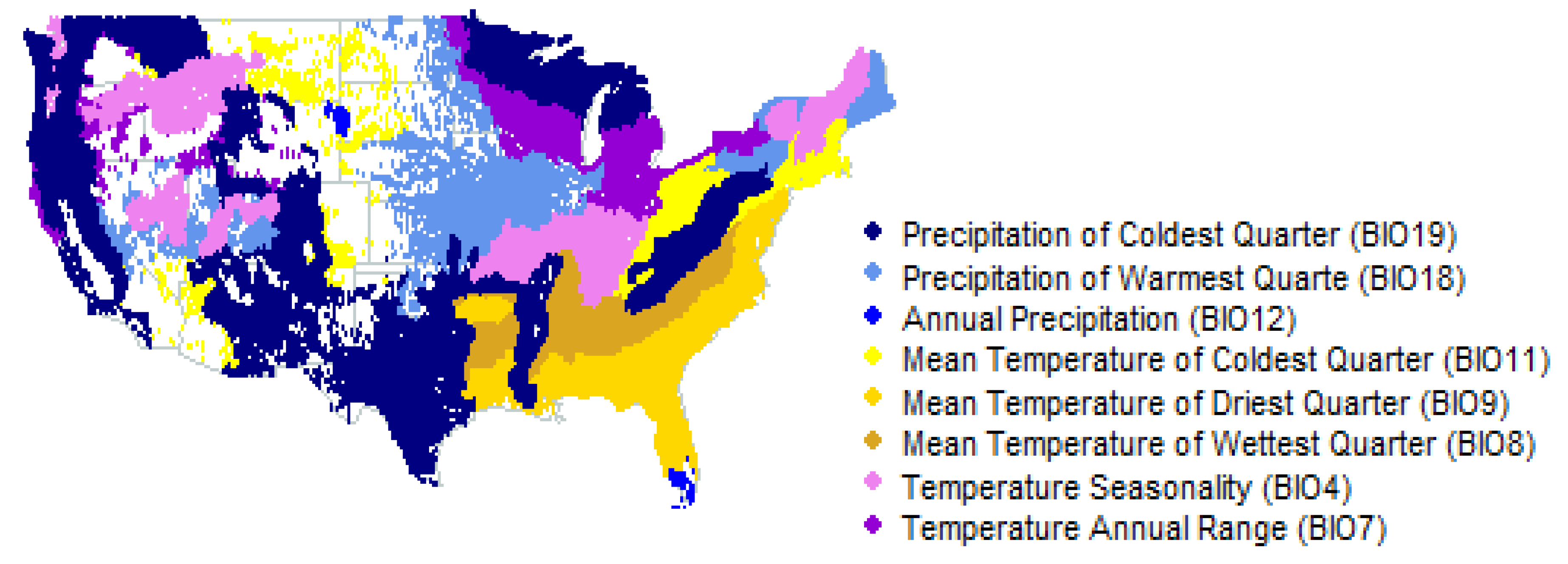
Appendix A. USA Ecological Subdivisions
- 211: Northeastern Mixed Forest Province
- 212: Laurentian Mixed Forest Province
- 221: Eastern Broadleaf Forest Province
- 222: Midwest Broadleaf Forest Province
- 223: Central Interior Broadleaf Forest Province
- 231: Southeastern Mixed Forest Province
- 232: Outer Coastal Plain Mixed Forest Province
- 234: Lower Mississippi Riverine Forest Province
- 242: Pacific Lowland Mixed Forest Province
- 251: Prairie Parkland (Temperate) Province
- 255: Prairie Parkland (Subtropical) Province
- 261: California Coastal Chaparral Forest and Shrub Province
- 262: California Dry Steppe Province
- 263: California Coastal Steppe, Mixed Forest, and Redwood Forest Province
- 313: Colorado Plateau Semidesert Province
- 315: Southwest Plateau and Plains Dry Steppe and Shrub Province
- 321: Chihuahuan Semidesert Province
- 322: American Semidesert and Desert Province
- 331: Great Plains Palouse Dry Steppe Province
- 332: Great Plains Steppe Province
- 341: Intermountain semidesert and Desert Province
- 342: Intermountain semidesert Province
- 411: Everglades Province
- M211: Adirondack New England Mixed Forest and Coniferous Forest, Alpine Meadow Province
- M221: Central Appalachian Broadleaf Forest Coniferous Forest Meadow Province
- M223: Ozark Broadleaf Forest Meadow Province
- M231: Ouachita Mixed Forest Meadow Province
- M242: Cascade Mixed Forest and Coniferous Forest Alpine Meadow Province
- M261: Sierran Steppe Mixed Forest and Coniferous Forest Alpine Meadow Province
- M262: California Coastal Range Open Woodland and Shrub Coniferous Forest Meadow Province
- M313: Arizona-New Mexico Mountains Semidesert and Open Woodland Coniferous Forest Alpine Meadow Province
- M331: Southern Rocky Mountain Steppe and Open Woodland Coniferous Forest Alpine Meadow Province
- M332: Middle Rocky Mountain Steppe and Coniferous Forest Alpine Meadow Province
- M333: Northern Rocky Mountain Forest and Steppe Coniferous Forest Alpine Meadow Province
- M334: Black Hills Coniferous Forest Province
- M341: Nevada-Utah Mountains Semidesert and Coniferous Forest Alpine Meadow Province

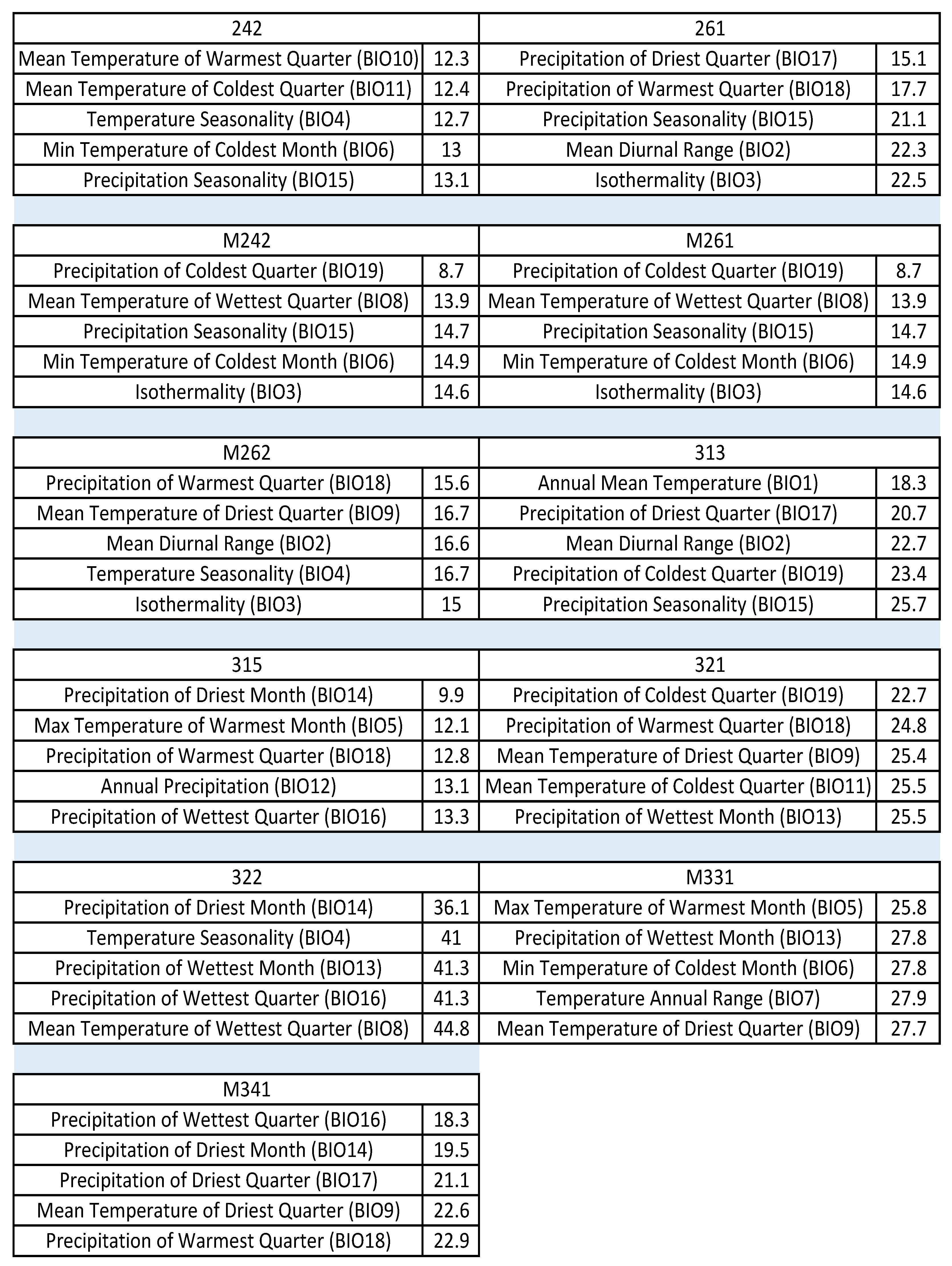
Appendix B. Supplementary Statistical Results




References
- Whittaker, R. Communities and Ecosystems; Current Concepts in Biology; Macmillan: New York, NY, USA, 1970. [Google Scholar]
- Woodward, F. Climate and Plant Distribution; Cambridge Studies in Ecology; Cambridge University Press: Cambridge, UK, 1987. [Google Scholar]
- von Humboldt, A.; Bonpland, A. Essai sur la Géographie des Plantes; Chez Levrault, Schoell et Compagnie: Paris, France, 1805. [Google Scholar]
- Köppen, W. Die Wärmezonen der Erde, nach der Dauer der heissen, gemässigten und kalten Zeit und nach der Wirkung der Wärme auf die organische Welt betrachtet (The thermal zones of the Earth according to the duration of hot, moderate and cold periods and of the impact of heat on the organic world). Meteorol. Z. 1884, 1, 215–226. [Google Scholar]
- Köppen, W. Versuch einer Klassifikation der Klimate, vorzugsweise nach ihren Beziehungen zur Pflanzenwelt. Geogr. Z. 1900, 6, 593–611. [Google Scholar]
- Koppen, W. Klassifikation der Klima nach Temperatur, Niederschlag und Jahreslauf. Petermanns Geogr. Mitteilungen 1918, 64, 193–203. [Google Scholar]
- Kottek, M.; Grieser, J.; Beck, C.; Rudolf, B.; Rubel, F. World map of the Köppen-Geiger climate classification updated. Meteorol. Z. 2006, 15, 259–263. [Google Scholar] [CrossRef]
- Peel, M.C.; Finlayson, B.L.; Mcmahon, T.A. Updated world map of the Köppen-Geiger climate classification. Hydrol. Earth Syst. Sci. Discuss. 2007, 4, 439–473. [Google Scholar]
- Rohli, R.V.; Joyner, T.A.; Reynolds, S.J.; Ballinger, T.J. Overlap of global Köppen–Geiger climates, biomes, and soil orders. Phys. Geogr. 2015, 36, 158–175. [Google Scholar] [CrossRef]
- Rubel, F.; Kottek, M. Observed and projected climate shifts 1901–2100 depicted by world maps of the Köppen-Geiger climate classification. Meteorol. Z. 2010, 19, 135–141. [Google Scholar] [CrossRef] [Green Version]
- Geiger, R.; Pohl, W. Eine neue Wandkarte der Klimagebiete der Erde nach W. Köppens Klassifikation (A New Wall Map of the Climatic Regions of the World According to W. Köppen’s Classification). Erdkunde 1954, 8, 58–61. [Google Scholar]
- Trewartha, G.; Horn, L. An Introduction to Climate, 5th ed.; McGraw-Hill Book Co.: New York, NY, USA, 1980. [Google Scholar]
- Belda, M.; Holtanová, E.; Halenka, T.; Kalvová, J. Climate classification revisited: From Köppen to Trewartha. Clim. Res. 2014, 59, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Bailey, R.G. Ecosystem Geography: From Ecoregions to Sites; Springer Science & Business Media: Berlin, Germany, 2009. [Google Scholar]
- Holdridge, L.R. Determination of world plant formations from simple climatic data. Science 1947, 105, 367–368. [Google Scholar] [CrossRef]
- Holdridge, L.R. Life Zone Ecology; Tropical Science Center: Monteverde, Costa Rica, 1967. [Google Scholar]
- Lugo, A.E.; Brown, S.L.; Dodson, R.; Smith, T.S.; Shugart, H.H. The Holdridge life zones of the conterminous United States in relation to ecosystem mapping. J. Biogeogr. 1999, 26, 1025–1038. [Google Scholar] [CrossRef]
- Talluto, M.V.; Boulangeat, I.; Ameztegui, A.; Aubin, I.; Berteaux, D.; Butler, A.; Doyon, F.; Drever, C.R.; Fortin, M.J.; Franceschini, T.; et al. Cross-scale integration of knowledge for predicting species ranges: A metamodelling framework. Glob. Ecol. Biogeogr. 2016, 25, 238–249. [Google Scholar] [CrossRef] [Green Version]
- Liénard, J.; Harrison, J.; Strigul, N. US forest response to projected climate-related stress: A tolerance perspective. Glob. Chang. Biol. 2016, 22, 2875–2886. [Google Scholar] [CrossRef] [PubMed]
- Levin, S.A. Ecosystems and the Biosphere as Complex Adaptive Systems. Ecosystems 1998, 1, 431–436. [Google Scholar] [CrossRef]
- Levin, S.A. Complex adaptive systems: Exploring the known, the unknown and the unknowable. Am. Math. Soc. 2003, 40, 3–19. [Google Scholar] [CrossRef] [Green Version]
- Snyder, C.W.; Mastrandrea, M.D.; Schneider, S.H. The Complex Dynamics of the Climate System: Constraints on our Knowledge, Policy Implications and the Necessity of Systems Thinking. In Philosophy of Complex Systems; Handbook of the Philosophy of Science; Hooker, C., Ed.; North-Holland: Amsterdam, The Netherlands, 2011; Volume 10, pp. 467–505. [Google Scholar]
- Mihailović, D.T.; Mimić, G.; Arsenić, I. Climate predictions: The chaos and complexity in climate models. Adv. Meteorol. 2014, 2014, 878249. [Google Scholar] [CrossRef]
- Strigul, N.; Florescu, I.; Welden, A.R.; Michalczewski, F. Modelling of forest stand dynamics using Markov chains. Environ. Model. Softw. 2012, 31, 64–75. [Google Scholar] [CrossRef]
- Strigul, N. Individual-based models and scaling methods for ecological forestry: Implications of tree phenotypic plasticity. In Sustainable Forest Management; Garcia, J., Casero, J., Eds.; InTech: Rijeka, Croatia, 2012; pp. 359–384. [Google Scholar] [CrossRef] [Green Version]
- Lienard, J.F.; Gravel, D.; Strigul, N.S. Data-intensive modeling of forest dynamics. Environ. Model. Softw. 2015, 67, 138–148. [Google Scholar] [CrossRef]
- Easterling, D.R.; Meehl, G.A.; Parmesan, C.; Changnon, S.A.; Karl, T.R.; Mearns, L.O. Climate extremes: Observations, modeling, and impacts. Science 2000, 289, 2068–2074. [Google Scholar] [CrossRef] [Green Version]
- Kelling, S.; Hochachka, W.; Fink, D.; Riedewald, M.; Caruana, R.; Ballard, G.; Hooker, G. Data-intensive Science: A New Paradigm for Biodiversity Studies. BioScience 2009, 59, 613–620. [Google Scholar] [CrossRef]
- Michener, W.K.; Jones, M.B. Ecoinformatics: Supporting ecology as a data-intensive science. Trends Ecol. Evol. 2012, 27, 85–93. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hargrove, W.W.; Hoffman, F.M. Potential of multivariate quantitative methods for delineation and visualization of ecoregions. Environ. Manag. 2004, 34, S39–S60. [Google Scholar] [CrossRef]
- Bailey, R.G. Identifying Ecoregion Boundaries. Environ. Manag. 2004, 34, S14–S26. [Google Scholar] [CrossRef]
- Bailey, R.G. Description of the Ecoregions of the United States, 2nd ed.; Number 1391; US Department of Agriculture, Forest Service: Washington, DC, USA, 1995.
- Toledo, M.; Poorter, L.; Peña-Claros, M. Climate is a stronger driver of tree and forest growth rates than soil and disturbance. J. Ecol. 2011, 99, 254–264. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, Y.; Zhou, G.; Xiao, C. Composition and Structure of Pinus koraiensis Mixed Forest Respond to Spatial Climatic Changes. PLoS ONE 2014, 10, e0097192. [Google Scholar] [CrossRef]
- Khan, D.; Muneer, M.A.; Zaib-Un-Nisa. Effect of Climatic Factors on Stem Biomass and Carbon Stock of Larix gmelinii and Betula platyphylla in Daxing’anling Mountain of Inner Mongolia, China. Adv. Meteorol. 2019, 2019, 5692574. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Hijmans, R.J.; Cameron, S.E.; Parra, J.L.; Jones, P.G.; Jarvis, A. Very high resolution interpolated climate surfaces for global land areas. Int. J. Climatol. A J. R. Meteorol. Soc. 2005, 25, 1965–1978. [Google Scholar] [CrossRef]
- Liénard, J.F.; Strigul, N.S. Modelling of hardwood forest in Quebec under dynamic disturbance regimes: A time-inhomogeneous Markov chain approach. J. Ecol. 2016, 104, 806–816. [Google Scholar] [CrossRef] [Green Version]
- Liénard, J.; Florescu, I.; Strigul, N. An Appraisal of the Classic Forest Succession Paradigm with the Shade Tolerance Index. PLoS ONE 2015, 10, e0117138. [Google Scholar] [CrossRef] [Green Version]
- Gaal, M.; Moriondo, M. Modelling the impact of climate change on the Hungarian wine regions using Random Forest. Appl. Ecol. Environ. Res. 2012, 10, 121–140. [Google Scholar] [CrossRef]
- Garzón, M.B.; Sánchez de Dios, R. Effects of climate change on the distribution of Iberian tree species. Appl. Veg. Sci. 2008, 11, 169–178. [Google Scholar] [CrossRef]
- Guo, F.T.; Guangyu, W. What drives forest fire in Fujian, China? Evidence from logistic regression and Random Forests. Int. J. Wildland Fire 2016, 25, 505–519. [Google Scholar] [CrossRef]
- Evans, J.S.; Murphy, M.A. Modeling Species Distribution and Change Using Random Forest. In Predictive Species and Habitat Modeling in Landscape Ecology; Springer: Berlin, Germany, 2016; pp. 139–159. [Google Scholar]
- Iverson, L.; Prasad, A. New machine learning tools for predictive vegetation mapping after climate change: Bagging and Random Forest perform better than Regression Tree Analysis. In Landscape Ecology of Trees and Forests; IALE: Manchester, UK, 2004; p. 317. [Google Scholar]
- Hashimoto, H.; Wang, W.; Melton, F.S. High-resolution mapping of daily climate variables by aggregating multiple spatial data sets with the random forest algorithm over the conterminous United States. Int. J. Climatol. 2019, 39, 2964–2983. [Google Scholar] [CrossRef]
- Mutanga, O.; Elhadi, A.; Azong Cho, M. High density biomass estimation for wetland vegetation using WorldView-2 imagery and random forest regression algorithm. Int. J. Appl. Earth Obs. Geoinf. 2012, 18, 399–406. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, X.; Zhu, X. Estimation of biomass in wheat using random forest regression algorithm and remote sensing data. Crop J. 2016, 4, 212–219. [Google Scholar] [CrossRef] [Green Version]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rumyantseva, O.; Strigul, N. Data-Driven Analysis of Forest–Climate Interactions in the Conterminous United States. Climate 2021, 9, 108. https://doi.org/10.3390/cli9070108
Rumyantseva O, Strigul N. Data-Driven Analysis of Forest–Climate Interactions in the Conterminous United States. Climate. 2021; 9(7):108. https://doi.org/10.3390/cli9070108
Chicago/Turabian StyleRumyantseva, Olga, and Nikolay Strigul. 2021. "Data-Driven Analysis of Forest–Climate Interactions in the Conterminous United States" Climate 9, no. 7: 108. https://doi.org/10.3390/cli9070108
APA StyleRumyantseva, O., & Strigul, N. (2021). Data-Driven Analysis of Forest–Climate Interactions in the Conterminous United States. Climate, 9(7), 108. https://doi.org/10.3390/cli9070108