1. Introduction
Increased aircraft demand in air transportation is causing congestion at certain airports and airspace capacities [
1]. Moreover, this demand continues to grow year after year. EUROCONTROL has estimated that air traffic will grow by 1.9% per year until 2040 [
2]. This increase in aircraft demand creates capacity problems and associated delays, and these effects result in a drop in the efficiency of the air transport system [
3]. This situation is already of concern, but is expected to worsen in the coming years. Therefore, improving Air Traffic Management (ATM) efficiency is critical to cope with the increase in aircraft demand [
4].
To solve the problems due to the lack of capacity of the Air Traffic Control (ATC) system, the Air Traffic Flow Capacity Management (ATFCM) system arises. Its function is to try to balance the air traffic demand and the capacity of the ATC system at the strategic, pre-tactical, and tactical levels [
5]. The ATFCM system proposes short-term and long-term measures to address the effects of the lack of capacity and meteorological uncertainties, and the effectiveness of these measures will depend on the amount, accuracy, and timeliness of the information exchanged [
6]. Currently, the most typical ATFCM measure is to limit the entry of certain aircraft into airspace where there are capacity problems. These are the so-called ATFCM regulations. Regulations aim to reduce the workload of Air Traffic Controllers (ATCOs) [
7], but they carry associated ground delays concerning the initially planned time of certain aircraft [
8]. In recent years, around 50–60% of the total delay in Europe was caused by en-route airspace problems such as en-route capacity or weather [
9], reaching even more than 70% in 2018 and 2019 [
9]. This makes regulations analysis very relevant and a topic of interest for the industry.
Specifically, there are up to 14 types of regulations identified by EUROCONTROL [
10]. The most common regulations are those due to weather and lack of ATC capacity. The major cause of en-route ATFCM delay is the lack of ATC capacity or ATC staffing [
9], meaning that in a part of the airspace, the ATC system cannot cope with the air traffic demand [
11]. The weather is also a cause of regulation that causes significant delay. Due to the impact on airport and airspace capacity, and its strong influence on operations [
12], adverse weather conditions can lead to large demand-capacity mismatches [
13].
This great importance of regulations and their causes means that the study of ATFCM and regulations is arousing interest in the industry [
14,
15]. Related to this topic, the prediction of regulations due to lack of capacity has been set as the objective of this paper. Thanks to emerging digital technologies, such as [
16], the proposed methodology is expected to help improve the efficiency of the ATC system [
17]. In this regard, this paper is expected to help manage the ATC system’s capacities through prior knowledge of the regulations due to lack of capacity. This way, it is expected that the ATC system will be able to better organise its human and technological resources.
In this paper, our focus is to study only regulations due to capacity. Some studies raise the prediction of regulation during adverse weather conditions [
18] or propose solutions such as rescheduling during adverse weather conditions [
19]. However, the nature of weather is random and variable [
20], being of a different nature to the lack of capacity regulations. For this reason, this is not the subject of study of this paper.
As regulations often arise from imbalances between capacity and demand [
21], in this paper, it has been decided to try to predict these regulations. The specific objective is to develop a machine learning model based on historical ATFCM regulations and some information on how air traffic is structured in the sector. This machine learning is thus set to predict regulations due to a lack of capacity.
To achieve this objective, in
Section 2 a literature review is presented to see related research on the topic. Then, the methodology developed for the approach of this model is described in
Section 3. In addition, an example of the performance and explainability of the developed model under a real operating scenario is described in
Section 4. Finally,
Section 5 discusses the conclusions obtained after the development of the model and the future steps to be taken in this line of research.
2. Literature Review
In this section, a review of the literature related to the topic of ATFCM regulations and their prediction will be carried out. ATFCM regulations aim to adapt air traffic demand to the capacity of the ATC system. The regulations have their consequences on an operational tier, but also on an economic tier. In [
11], the adverse economic aspects of the regulations are analysed. It is estimated that the total cost can be very large due to the cost of extra fuel, crew cost, or compensation for the regulations themselves. Leading to this, the number of ATFCM regulations should be minimised.
As ATFCM regulations have to be minimised, the study of the causes of re-regulations becomes a priority. According to EUROCONTROL [
10], the different causes of these imbalances can be as many as 14. However, in practice, most regulations are caused by the same reasons. Specifically, based on historical data in European airspace in 2019, the distribution of causes of regulation was as stated in
Table 1:
Table 1 shows only those causes with a percentage higher than 1% of the total ATFCM regulations. These causes are mainly due to the lack of operational capacity or the weather. Therefore, although the EUROCONTROL studies estimate that there are many causes, there are two main causes that are responsible for ATFCM regulations: Lack of capacity and climate.
Climate is the most unpredictable factor. Some studies make analyses related to climate, such as [
20], where a model is developed to predict trajectories when there are weather uncertainties, or [
18], where a prediction of aircraft in the sector and regulations in adverse weather conditions is made. However, this variability makes weather regulations very difficult to analyse and estimate. In [
22], a study is carried out on the possibility of estimating weather regulations. In this reference, a machine learning model based on components such as wind, humidity, and temperature is used. Although the results seem to be positive, there is still a lot of work to be completed.
On the other hand, the study of capacity regulation is more widespread. There is a belief that it will be possible to estimate, and therefore anticipate, capacity regulations and their effects. For this reason, more studies are being carried out on this subject.
Some articles focus on studies of the influence of capacity regulation, such as [
23]. This paper develops a study of the applicability of machine learning models to predict the delay caused by capacity regulations. This research concludes that it is beneficial to use data-driven machine learning models to predict these delays, rather than using causal relationships.
Another article that focuses on the study of capacity regulations is [
14]. Here, a study is made of how capacity regulations can help reveal restorative mechanisms for tactical planning. A methodology for defining network states has been developed based on these capacity regulations.
In addition to the analysis of the capacity regulations themselves, there is also interest in their prediction by allowing the ATFCM service to anticipate their effects. This line of research is represented by [
24], where a machine learning model is developed that is capable of estimating capacity regulations using variables such as the capacity itself, the number of aircraft, or the expected workload of the controllers.
This research is currently gaining importance due to the development of machine learning models and the increasing imbalance between capacity and demand. Therefore, this paper is in this line. The aim of this paper is the same as the one of [
24]. Both papers attempt to predict capacity regulations. Therefore, the objective is different from the rest of the publications analysed:
The aim of this paper is different from that of [
14,
23], because in these two publications, regulations are analysed as a component, although the final target of analysis is the delays in [
23] and the definition of network states in [
14].
The aim of [
22] is to predict regulations by weather, so the model is different from the one in this paper, and the theoretical background will be different.
Therefore, from the publications analysed, the only one that shares this objective is [
24]. The main difference is the scope of the model, and thus the composition. The objective of [
24] is the prediction of regulations by capability but on a tactical or pre-tactical time horizon. In this publication, the scope is to predict regulations in a strategic horizon. This makes the theoretical background, and therefore the machine learning models developed, different, and even complementary.
After a review of the literature, one can also conclude the contributions of this paper to the prediction of regulations.
This paper aims at predicting regulations, as the other analysed papers. However, it tries to predict capacity regulations by means of a different and novel approach. Previous models are based solely or mainly on what the traffic is like at the time of prediction or what it is expected to be like. This is important, but the regulations will depend on many external aspects such as the situation of the ATC system. From an operational point of view, the time component is very important, as here, behaviour patterns can be found that do not depend solely on traffic.
In addition, the traffic flow distribution also allows for studying the influence of traffic without taking into account each individual aircraft. This will make it possible to find behavioural patterns in the traffic structure in general.
Finally, this model for predicting regulations will allow progress to be made in the study and prediction of their effects, which is what is really important. From an operational point of view, in a control room, 10-min time ranges can be used to evaluate the possible effect of the regulation, since the final real delay is always different from the ATFCM delay that an aircraft has, and this is seen in 10-min periods in order to have a margin to estimate this difference. Therefore, from an operational point of view, the 10-min window is used as the analysis parameter. Therefore, the approach followed has been based on real operational knowledge and will also bring these investigations closer to real operation.
3. Methodology
Once the motivation and objectives of this paper have been stated, the methodology in which the prediction of regulations in airspace is presented. This paper builds on some previous works, such as [
23], where the possibility of predicting delay in the presence of airspace capacity regulations in the airspace is discussed. However, in this paper, the aim is to go further, looking directly at the cause rather than the consequence.
In [
22], the authors also propose a prediction of ATFCM regulations, but this prediction is of weather-based regulations. Even so, part of the methodology is applicable. These same authors adapt this prediction of regulations to capacity regulations in [
24]. This model is based on predictions of capacity regulations, which are also based on the traffic situation and evolution in the sector, as well as on the controller’s workload. To complete the study of this work, it has been decided to use complementary variables to this study. Specifically, it has been decided to eliminate the variables related to the workload of the controllers, as this variable is subjective and subject to a certain model [
25]. In addition, it has been decided to structure the air traffic variables in the main traffic flows. Therefore, the model will have a limited number of variables, but the idea is that these variables will give a complete picture of how the traffic is structured.
For this reason, in this paper, the aim is to make a prediction of capacity regulations based on objective data. The data which will be used in the machine learning model is:
The expected date. In other models, the time component is small or null. However, in air traffic, patterns of behaviour can be found. It is expected that patterns can also be found in the occurrence of capacity regulation in time. Given this hypothesis, the temporal analysis is considered fundamental in this paper.
Static traffic predictions. CRIDA organises traffic into main traffic flows based on flight plans. Therefore, the machine learning model will be adapted to be able to structure the air traffic into these flows and obtain a picture of the traffic at a given time.
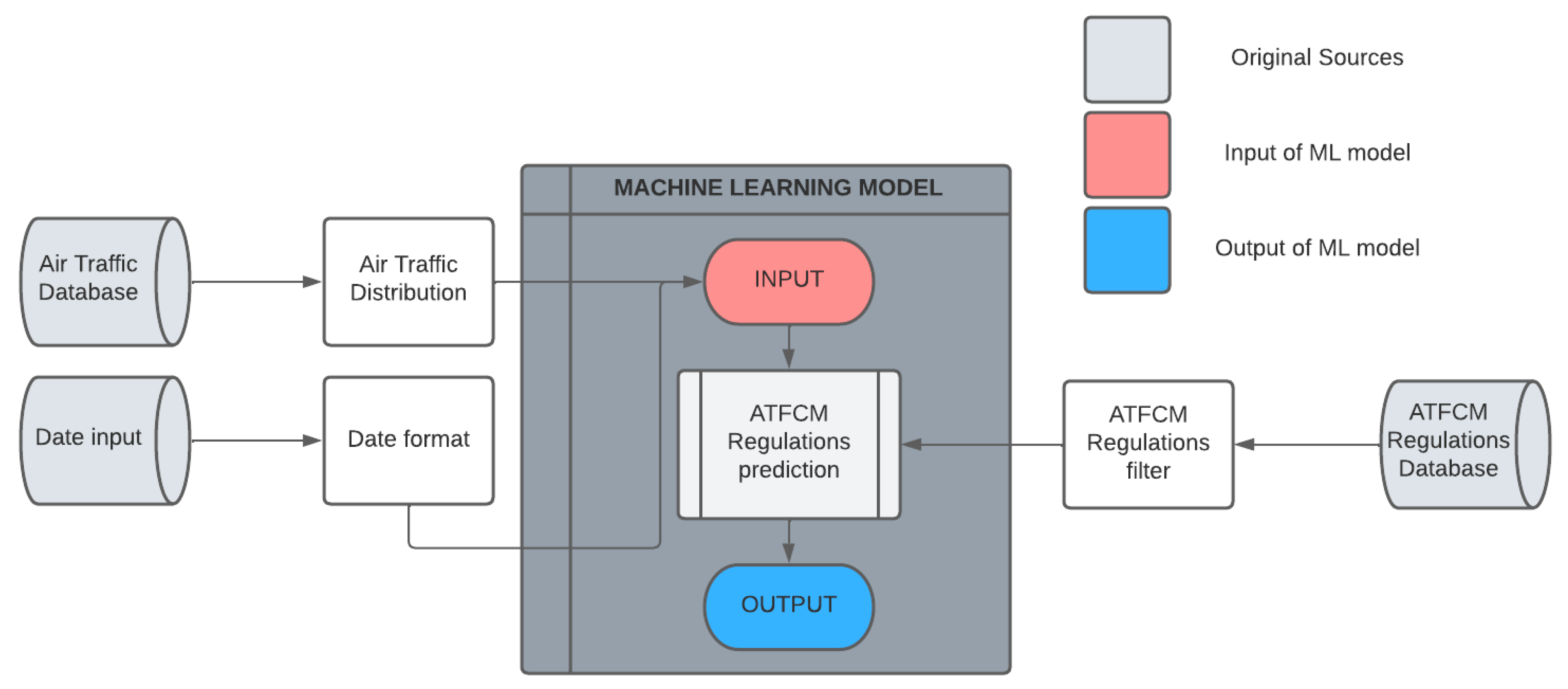
Therefore, the proposed methodology will be based on three main areas, and
Figure 1 shows the scheme that will be followed for the development of the machine learning model.
As schematised in
Figure 1, the model is based on three information inputs:
Air Traffic database: This database shall be composed of all aircraft flight plans. These flight plans are used to organise the traffic by its main air traffic flows, identifying each trajectory with a traffic flow.
Regulations database: This database will only be present for training, as it will be the result of the model prediction.
Date selection: Although it is not a database, the fundamental input to the model will be the date on which the prediction wants to be made.
In the following, it is detailed how each of the branches of the model is worked with and how they will be combined to form the complete machine learning model.
3.1. ATFCM Regulations Database
Firstly, the format of the output is explained, as the entire regulatory prediction model will depend on it. As the aim of this paper is to predict ATFCM regulations based on a strong temporal component, it is fundamental how these regulations are determined.
The first step is to filter the regulations to be predicted. In this paper, regulations based on the lack of ATC capacity will be predicted. Based on the causes proposed by [
10], the following causes shall be considered:
ATC Capacity
ATC Staff
Airport Capacity
These causes are related to the lack of capacity of the ATC system or of certain airports.
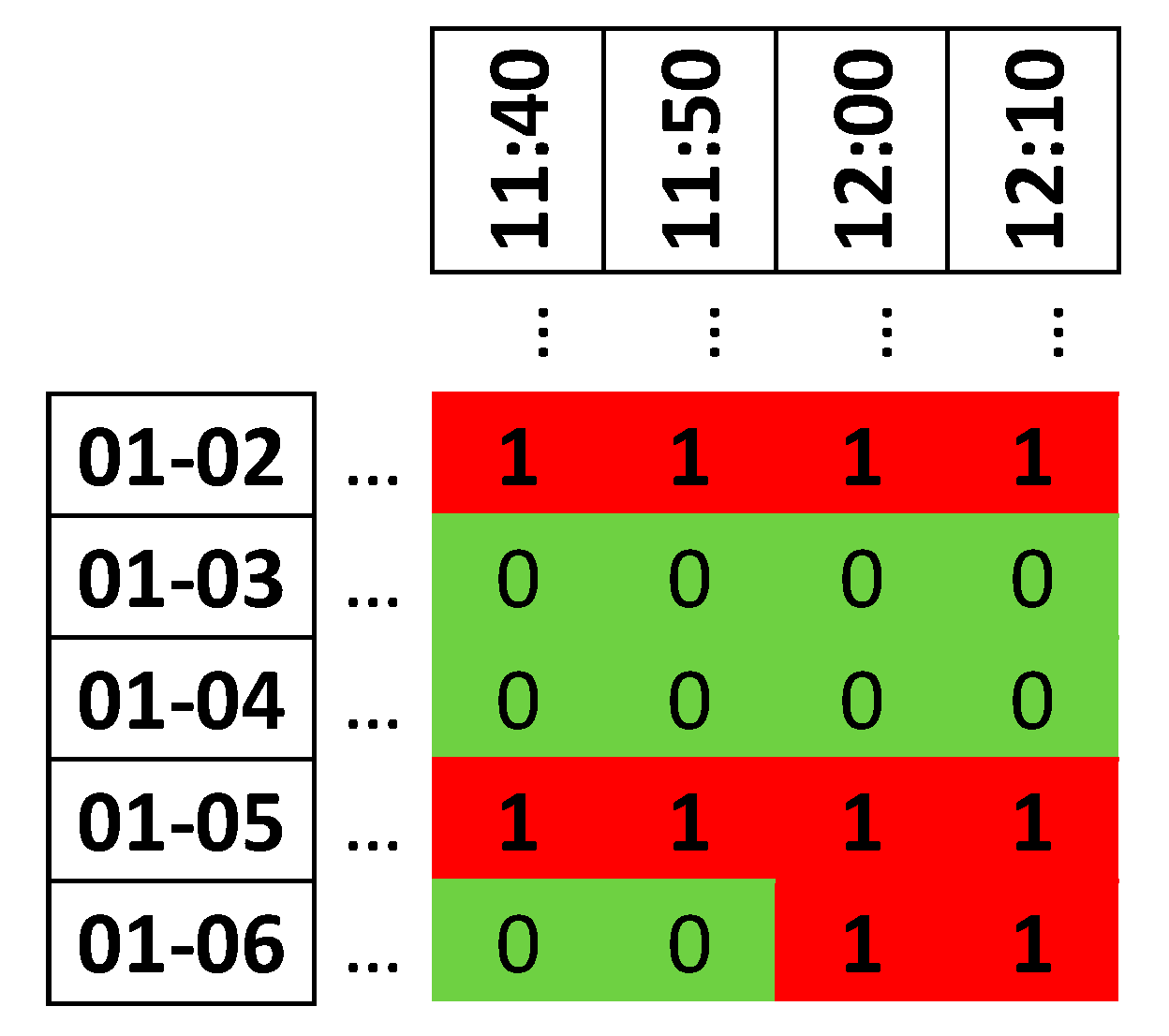
In addition, it has been decided to organise the ATFCM regulations in 10-min periods and in days of the year. In this way, all the time that the airspace was regulated will be arranged in a matrix as in
Figure 2. The rows of the matrix will be the day of the year under analysis, and the columns will be the 10-min period, with the start of the period marked as the column name.
In this matrix, it will be noted in which periods and days when the sector will be regulated (1) and when it will not be regulated (0). With this format, a simple picture of when the sector will or will not be regulated emerges. Once the format of the output has been determined, the input variables, both the time and traffic databases, need to be adapted.
Furthermore, by arranging the data in this way, it can be established that the best-fitting machine learning model is a binary classification model. Classification problems are already widespread in the industry [
26,
27], and binary classification is the most widespread type of model. In a binary classification model, the training and test data are distributed into two labels, 0 (in this case, the sector is not regulated) and 1 (in this case, the sector is regulated). Therefore, by training the model with only two labels, the model will predict only the two labels. This type of model has the advantage of facilitating training by having fewer classes, and of being a model with simpler explainability than a model with a larger number of classes to classify.
This will facilitate the development and implementation of this model. In addition, a Random Forest model has been chosen to carry out this classification as it is an algorithm that works well in problems of a different nature and that allows a correct analysis of the explainability of the model [
28].
3.2. Date Input
The format of the model output has been determined, and consequently what type of machine learning model will be used. The next step is to determine the input variables and adapt them to the model output.
The most important part of the model is the time-based variables. The machine learning model will try to analyse patterns in the historical data to try to predict when a sector will be regulated, so it is essential to have a date-based input variable format. The input variables will be based on the information that can be extracted from the matrix in
Figure 2. In particular, the following information will be extracted.
Month: The date format indicated in the rows of the matrix will be mm-dd. Therefore, knowing the month to which any row belongs is straightforward. The month is a very useful variable, as the operation in certain sectors can be very seasonal, an example being the Balearic Islands [
29].
Day of the week: Like the month, the day of the week can be a very interesting variable for the search for patterns. This information can also be obtained relatively easily by formatting the rows of the matrix, knowing the year of operation, and with the help of a calendar.
Period of the day: The latest information will be obtained from the columns of the matrix in
Figure 2. This information is the period of the day. In the matrix in
Figure 2, there will be 144 rows, starting with the period 00:00–00:10 and ending with the period 23:50–00:00. Therefore, by numbering from 1 to 144, it is possible to identify in which period of the day the sector will be regulated or not. This variable is also considered interesting from an operational point of view as it will allow us to know if there are periods of the day in which the sector is more likely to be regulated.
Using this information, it is considered that a complete temporal analysis can be established and that the simplicity of the machine learning model is maintained.
3.3. Air Traffic Database
The last step in determining the input variables is to add to the temporal variables that allow the air traffic to be evaluated to the time variables. To do this, the first step is to structure the traffic according to its main traffic flows using the CRIDA methodology.
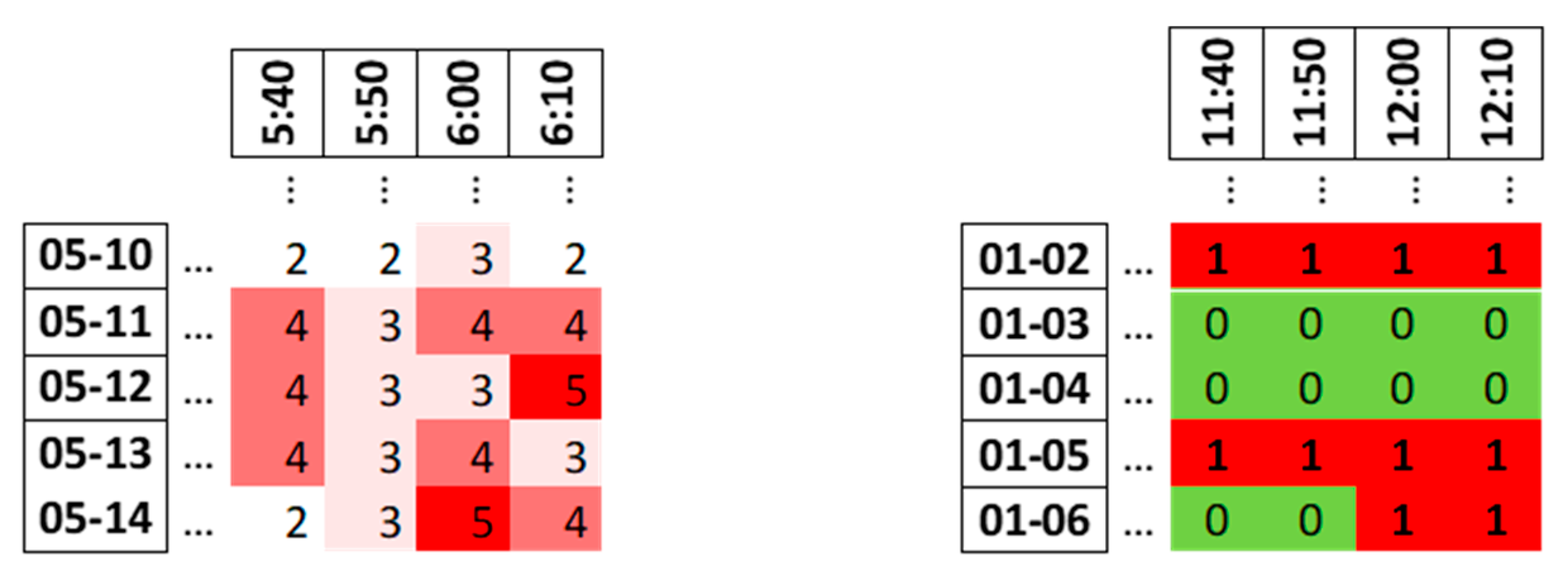
Once the traffic has been structured into flows, matrices will be filled in with information on this traffic, estimated before the operation. These matrices are presented in
Figure 3.
In matrices such as the one on the left, the following information shall be included:
Number of aircraft within the sector: Simply by using the traffic information, it is possible to estimate the number of aircraft that will be in the sector at a given time.
Number of flows containing aircraft: Through the allocation of flows made for each aircraft, it will also be possible to identify the number of flows that will be in the sector at the time of analysis.
Matrices such as the one on the right will include:
Which flows contain aircraft: In addition to knowing how many flows will contain aircraft, it is also possible to know what these flows will be. Specifically, a matrix such as the one on the left of
Figure 3 will be made for each flow, indicating when there will be aircraft in this flow and when there will not. In this way, it is intended to produce a map of the sector at the time of the prediction with previous information.
With all the information analysed, the input information of the model is completed. Therefore, the complete format of the model is presented in
Table 2 with the addition of an example use case. In this case, an example has been made in which the variables are aleatory. It does not represent a real case, but this example is used to observe the format of the data for the generation of the machine learning model. The values of the variables will vary depending on the actual operating scenario:
With Flow1, …, FlowN being the identifiers of the flows within the sector, and N is the total number of flows. It shall be identified with 0 when there are no aircraft within the sector and with 1 when there are aircraft. Similarly, 0 shall identify when the sector is not regulated and 1 when it is regulated.
3.4. Machine Learning Model Evaluation
With the machine learning model in place, part of the methodology is to determine which methods will best evaluate the performance of the model. Evaluating a machine learning model is a fundamental step. In machine learning applications in ATM, it is as important to correctly evaluate the model as it is to emphasise its explainability [
30]. The methods for evaluating and validating the model, based on a binary classification, are presented below.
The first method of evaluating the model will be Accuracy. This was the most important criterion for determining the performance of a classification algorithm, which showed the percentage of the proper classification of the total set of the experimental record [
31]. The Accuracy formula is:
In
Table 3, the meaning of
TP,
TN,
FP, and
FN is explained:
In this case, T and F are “True” and “False”. This classification is used in the literature to represent which elements of the training set are correctly (True) or not correctly (False) evaluated by the machine learning model or not. The terms “Negative” and “Positive” refer to whether the sector is not (Negative) or is (Positive) regulated.
This indicator will give a picture of the overall performance of the application. Based on applications of a similar nature, an Accuracy threshold of 0.85 out of 1 is set [
32]. As Accuracy is defined as correctly classified cases among total cases, the maximum Accuracy is 1 (corresponding to all the elements having been correctly classified). In the literature studied, a value that is considered to say that a machine learning model is good at classifying is that it classifies 85% of the cases correctly [
32]. However, since it is measured over one, this 85% corresponds to 0.85.
This limit is independent of the training of the model. The model is trained and tested independently. Subsequently, the Accuracy of the model is obtained and compared with the defined threshold. If the Accuracy of the model is greater than 0.85, the model is considered valid. If the Accuracy of the model is less than 0.85, the model is not valid and cannot be used in real applications.
To evaluate the two labels independently, the Recall, Precision, and F1-score parameters for each of the classes are added to the analysis for each of the classes [
33] (0 when the sector is not regulated and 1 when the sector is regulated). Recall indicates the ability of the algorithm to accurately detect when the sector will be regulated or not. The Precision indicates the ability of the algorithm to detect the categories. The F1-score is a harmonic mean of the Recall and the Precision [
31]. The formulae are [
34]:
In addition, to represent this information in a visual and summarised form, the confusion matrix is presented [
35].
Moreover, emphasis will be placed on the explainability of the model. This analysis will provide insight into the learning and prediction process of the developed model. In this case, the analysis of explainability was carried out with graphs made in the Shapley Additive exPlanations (SHAP) library. This library is used for the explainability of machine learning models and its use is widespread in the industry [
36,
37].
4. Results
Once the methodology used to develop the machine learning model has been explained, the model is tested in a real application case. For its testing, it has been decided to choose the data of the LECMPAU sector in the year 2019. Specifically, the machine learning models have been trained with the matrix developed for 2019. In this matrix, there are 144 columns and 365 rows. With this, 52,560 data have been obtained to train and test the model. Specifically, 80%, 42,048 data, have been used to train the model. The rest has been used for model testing.
The operational data have been obtained based on ENAIRE radar traces and have been provided to the authors after processing and validation by the company CRIDA. The company CRIDA has also provided the data to the authors with the necessary regulatory data, after proper processing and validation.
4.1. Analysis of LECMPAU Air Traffic and ATFCM Regulations
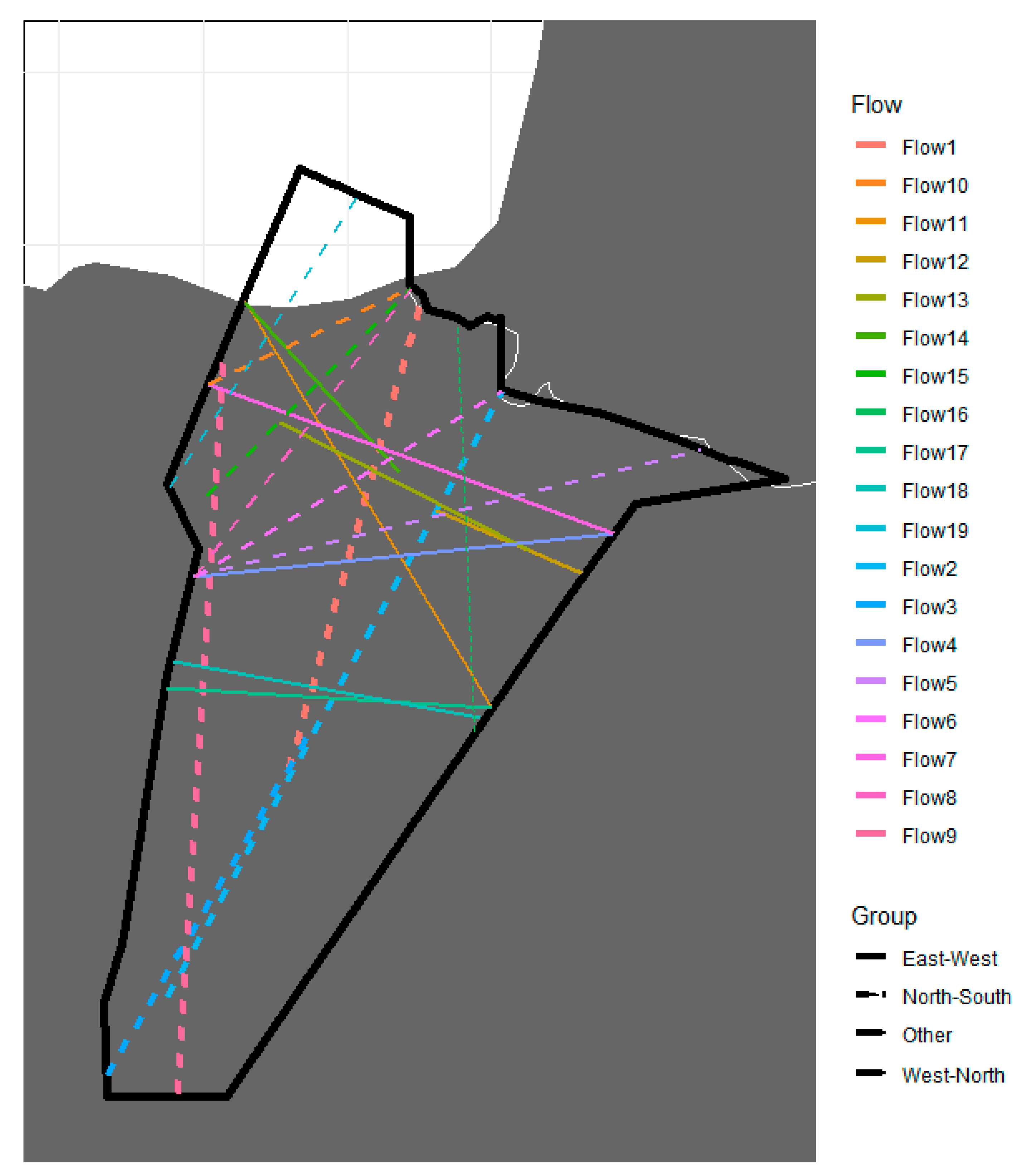
Before starting to test the model and analyse its explainability, it is important to understand the operation in the Pamplona Upper (LECMPAU) sector, as well as the behaviour of the regulations in the sector. To study traffic behaviour, the methodology developed by CRIDA has been used to organise traffic into flows. The flows obtained from the methodology are presented in this paper as part of the input variables of the machine learning model will be whether there are aircraft in each flow or not. The flows are presented in
Figure 4.
The air traffic flows identified have been divided into four main groups. The flows that cross the sector from north to south are of great importance in the operation of the sector, as they contain flights that normally depart from or go to the Madrid-Barajas airport. Other flows of great interest are those crossing the sector from east to west, as these will normally be associated with flights departing from or going to Barcelona-El Prat. With this, it can also be said that LECMPAU is a sector whose operation is very complex, as it includes operations around the two largest airports in Spain, making it a sector of great interest.
Additionally, there is another group of flows that cross the sector diagonally from the west of the sector to the north or vice versa. Flights belonging to these flows are more variable and difficult to classify into a single flight type.
With these air traffic flows, an attempt to characterise the traffic in the sector simply is made, taking into account the different trajectories that can be flown. In addition, it is important to characterise the regulations in the LECMPAU sector, as it will be possible to see certain patterns in the appearance of these regulations that can be used to validate the results of the machine learning model.
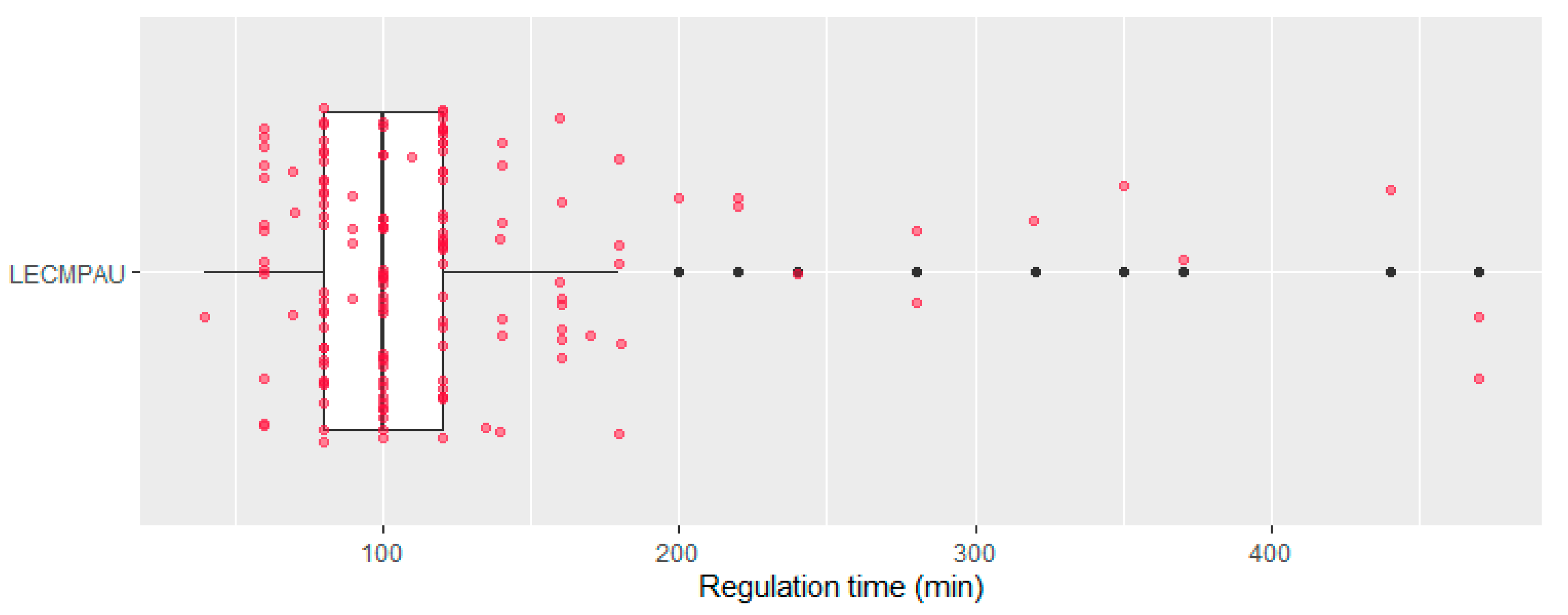
Overall, there were 150 regulations in LECMPAU in 2019. These regulations had a mean regulation time of 121.9 min, and a standard deviation of 71.16. To be more specific, the boxplot of the regulation time is presented in
Figure 5.
In the boxplot, it can be seen that most of the regulations have a regulation time between 50 and 200 min. There are cases of outliers due to both deficit and excess. With this data, only 18,285 min in the whole year will be regulated. This is 3.5% of the total time analysed. As the model will tell whether the sector is regulated or not, there is likely an imbalance in the sample to be analysed, as LECMPAU is much longer unregulated than regulated.
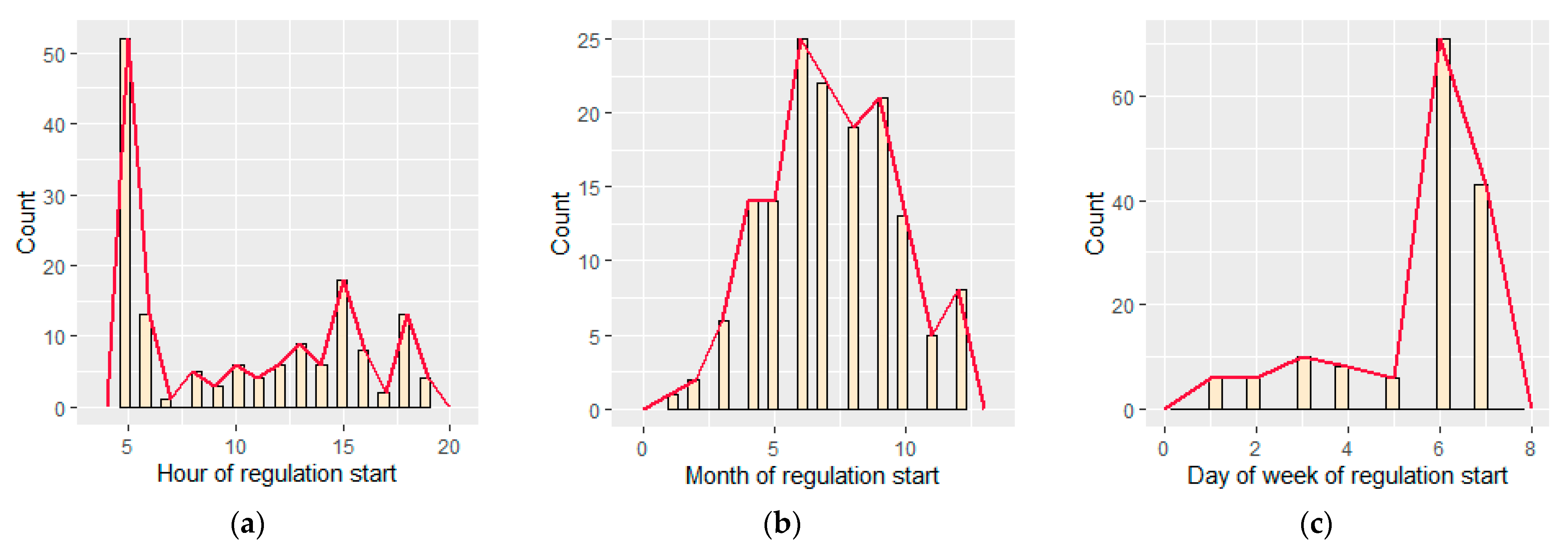
Rather than the duration of these regulations, it is of interest to know how they are distributed over time. This information is presented in
Figure 6, which shows histograms of the regulations according to their month (a), day of the week (b), and start time (c).
The temporal analysis indicates that most of the regulations will occur in summer. This is normal, as Barcelona and Mallorca are common holiday destinations, and flights from the US to these airports will pass through LECMPAU via flows crossing the sector from east to west. This increase in traffic will lead to more capacity regulations. As for the day of the week, most of the regulations will occur on weekends, mainly on Saturdays. This is also natural, as weekend traffic will be higher than Monday to Friday. Finally, the hourly analysis indicates that regulation will be centred at 05:00, with three secondary peaks of regulation at 06:00, 15:00, and 18:00. These are the most common times for business and holiday flights.
With this information, it is possible to find patterns in the behaviour of regulations in 2019, so it is possible that the machine learning algorithm, which is mainly based on temporal variables, will find these patterns and manage to act satisfactorily. The results of the model are presented below.
4.2. Machine Learning Model Evaluation
Once how both traffic and regulations behave in LECMPAU in 2019 has been studied, the machine learning model that will attempt to predict when the sector will be regulated is evaluated. For this model, the total dataset has been divided into 80% for training and 20% for testing. This ratio is often used by machine learning models developed for different academic fields [
38]. Firstly, the Accuracy of the model is shown to test the model in general.
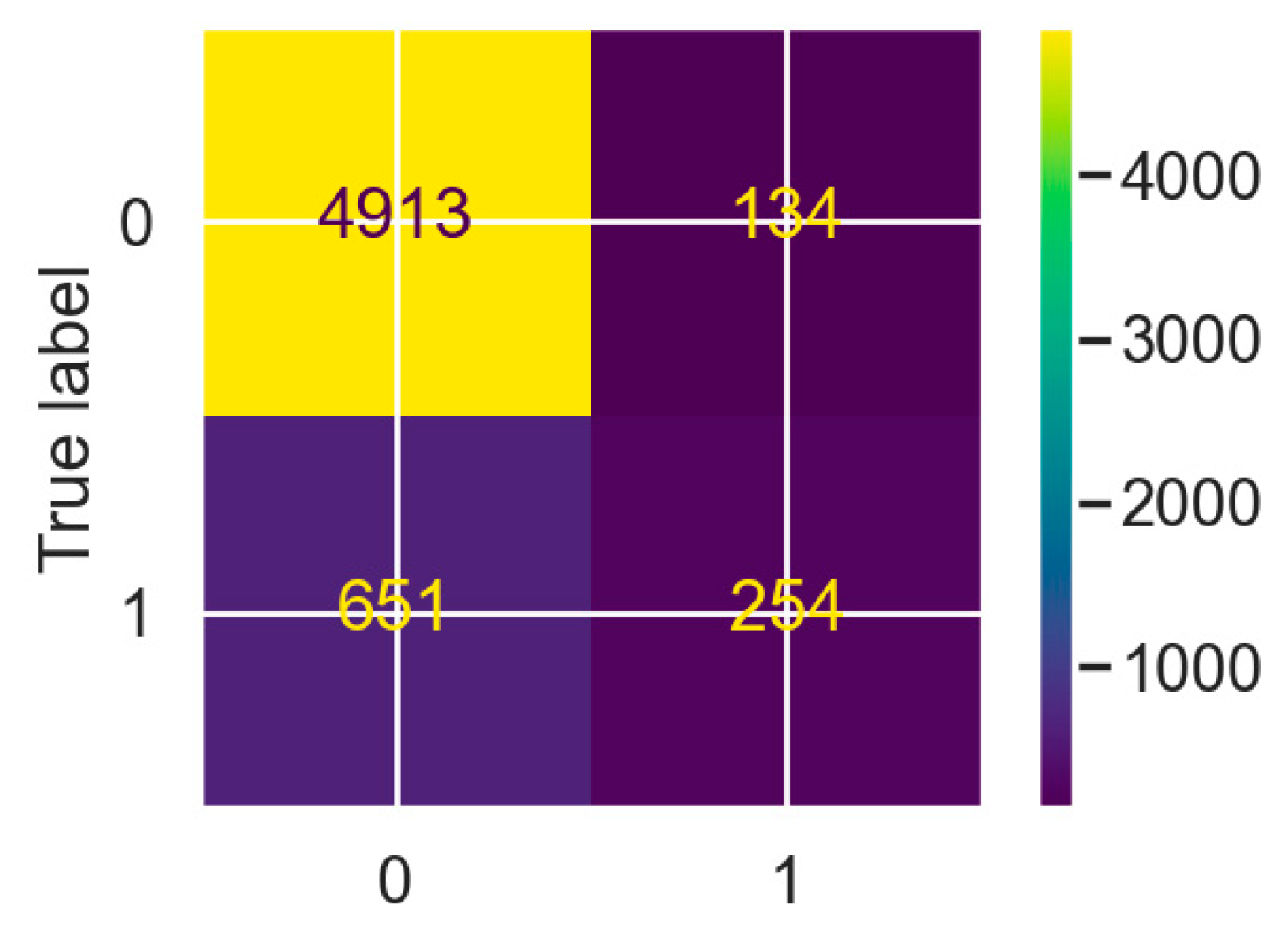
The Accuracy is above 0.85, so the model seems to work correctly according to the established standards. However, to evaluate the model more specifically, the Confusion Matrix is presented in
Figure 7 and the indicators related to the Confusion Matrix are in
Table 4. The confusion matrix is a visual indicator that simply indicates the number of cases where the model predicts whether the sector is regulated (1) or not (0) and compares it with the actual labels. This indicator is complementary to those defined in
Section 3.4 and presents the same information visually.
These indicators show that the model only predicts well when the sector is not regulated. Since the sample is so unbalanced, and most of the time the sector is not regulated, the model normally predicts that the sector will not be regulated. In doing so, the model is mostly correct, giving an Accuracy above the minimum. However, the model is influenced by the imbalance of the sample and the indicators of when the sector is regulated are well below what is considered correct.
As the sample is highly unbalanced, it has been decided to balance it with Synthetic Minority Oversampling TEchnique (SMOTE) to generate minority class samples [
39]. This model creates samples of the minoritarian class based on the behaviour of contiguous elements (neighbours). In particular, the creators of the method state: “synthetic samples are generated in the following way: Take the difference between the sample under consideration and its nearest neighbor. Multiply this difference by a random number between 0 and 1 and add it to the feature vector under consideration. [
40]”.
With this sample balancing, the Accuracy of the model is:
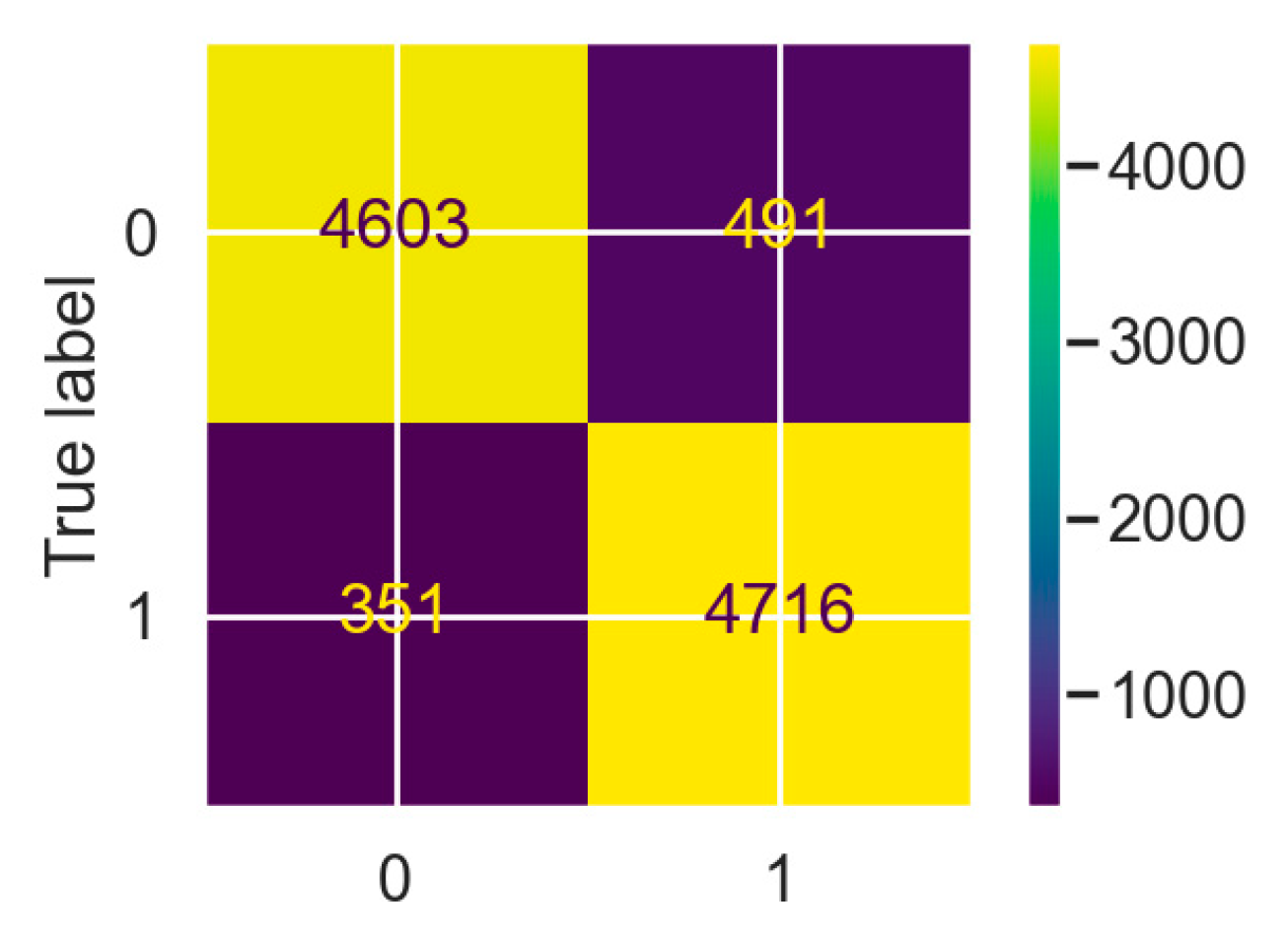
Accuracy has increased by 6%. This, in advance, makes the model better beforehand. However, it is necessary to check that the model acts correctly when predicting for each of the classes. For this purpose,
Figure 8 shows the Confusion Matrix, and
Table 5 the Classification report.
These indicators are all above 0.9, exceeding the 0.85 set, so the performance of the model is very good both in predicting that the sector will be regulated and in predicting that it will not be regulated.
The balanced machine learning model seems to have found behavioural patterns in seasonality or air traffic and correctly predicts when the sector will be regulated. Therefore, with these results obtained, this model can be validated for the case of the LECMPAU sector.
4.3. Explainability of Machine Learning Model
Once the model has been validated and the indicators are found to be above the preset minimum, a study of the model’s explainability is carried out.
The explainability of the model makes it possible to learn what the learning process of the machine learning model is like. It also shows the behavioural patterns found in the data and how it arrives at the predictions it makes. The Python SHAP library is used to perform this explainability analysis, which allows us to obtain graphs of explainability graphs. This method of describing the explainability of a machine learning model was introduced in [
41] and is explained as “SHAP values attribute to each feature the change in the expected model prediction when conditioning on that feature. They explain how to get from the base value E[f(z)] that would be predicted if we did not know any features to the current output f(x) [
41]“ by the creators of this algorithm.
The first graph obtained is the influence of the temporal parameters on the prediction of the model. The SHAP algorithm starts from an initial expected value and adjusts the actual value of the prediction according to the labels of the input variables. Therefore, it is possible to analyse what effect the input variables will have, whether they will make the sector regulated (adding to the estimated initial value) or will make it unregulated (subtracting from the estimated initial value).
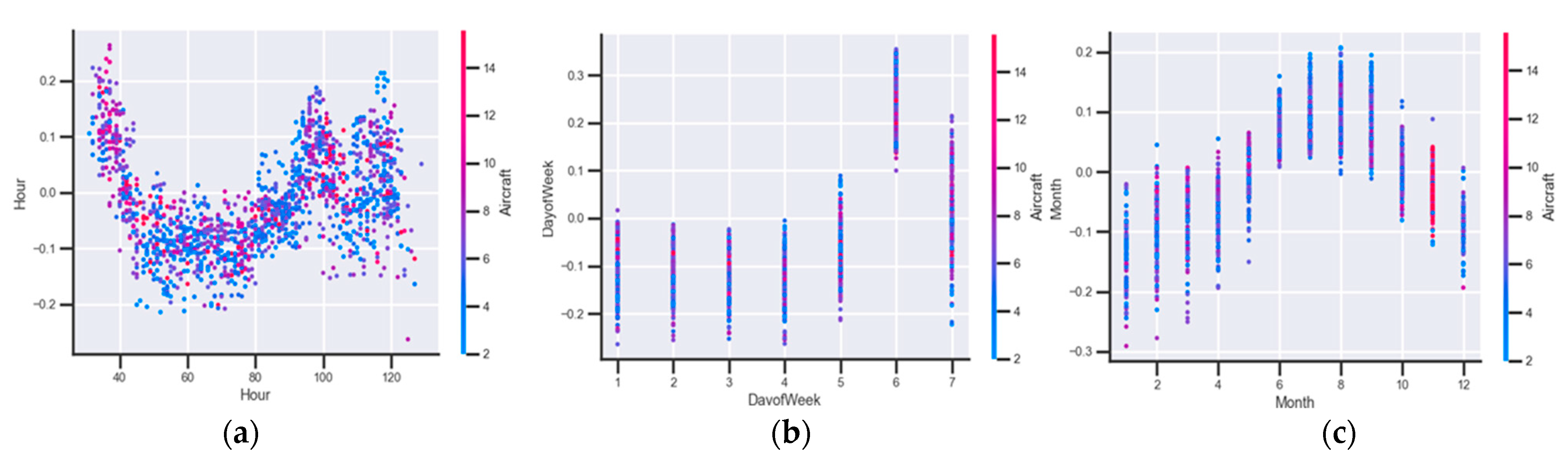
Figure 9 presents the effect of the period of the day (a), the day of the week (b), and the month of the year (c) on the final prediction.
It can be seen how
Figure 9 is very similar to the histograms shown in
Figure 6.
Figure 9 represents the influence of each of the training sample data, so the distribution of the training sample will be adjusted as seen above. Regarding the period of the day, approximately up to about period 40 of the day (06:30), this variable allows predicting the sector as regulated. On the other hand, from period 90 to 120 (15:00–20:00), there are two peaks where this variable helps the sector to be regulated. This presents an analogy with
Figure 6c where at 15:00 and 18:00 there are two peaks in the time of occurrence of regulation.
Furthermore, the day of the week will only serve for the sector to be regulated sometimes on Fridays and Sundays, and always on Saturdays. This also represents a clear analogy with
Figure 6b, where it can be seen that most of the regulations in LECMPAU appear on Saturday and Sunday.
As for the months of the year, the trend is also similar to the histogram results in
Figure 6a. The months from June to September will be those in which the model tends to regulate the sector, while during the rest of the year, the model will tend not to regulate the sector.
Based on these results, it can be said that the model has been able to analyse time trends and make a personalised prediction based on the time data. The result allows us to verify that the approach of the model, mainly focused on an analysis of temporal patterns, seems to be correct. Furthermore,
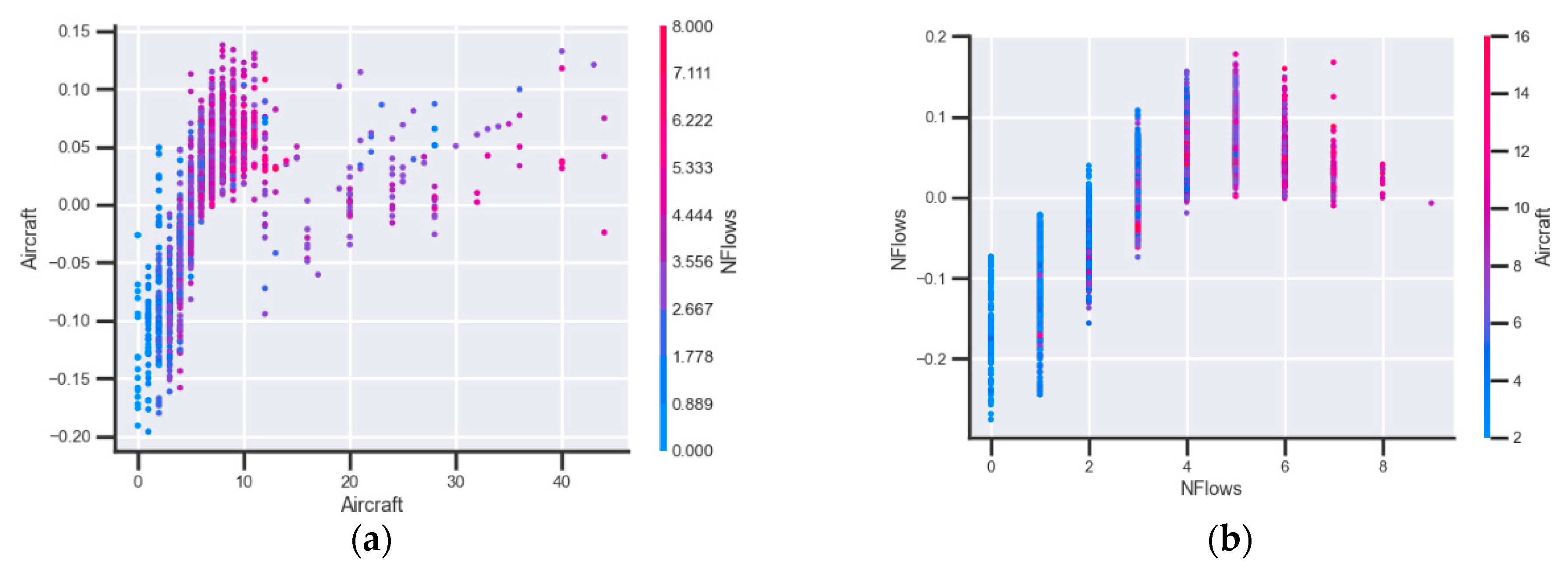
Figure 10 shows the same type of graphs, but in this case for the number of aircraft (a) and the number of flows (b) in the sector. This analysis is executed to check whether the model has also been able to find patterns in the traffic data of the sector.
These variables representing air traffic behaviour also seem to behave quite intuitively. As for the number of aircraft, it is observed that when there are hardly any aircraft in the sector (from 0 to 5), the model helps to predict that the sector will not be regulated, whereas from five aircraft upwards, the model tends to predict that the sector will be regulated. This makes a lot of sense from an operational point of view, as the sector is most likely to be regulated when there is a considerable amount of traffic. The number of flows has a similar trend, with the frontier at four flows. From here, this variable will help the prediction that the sector is regulated.
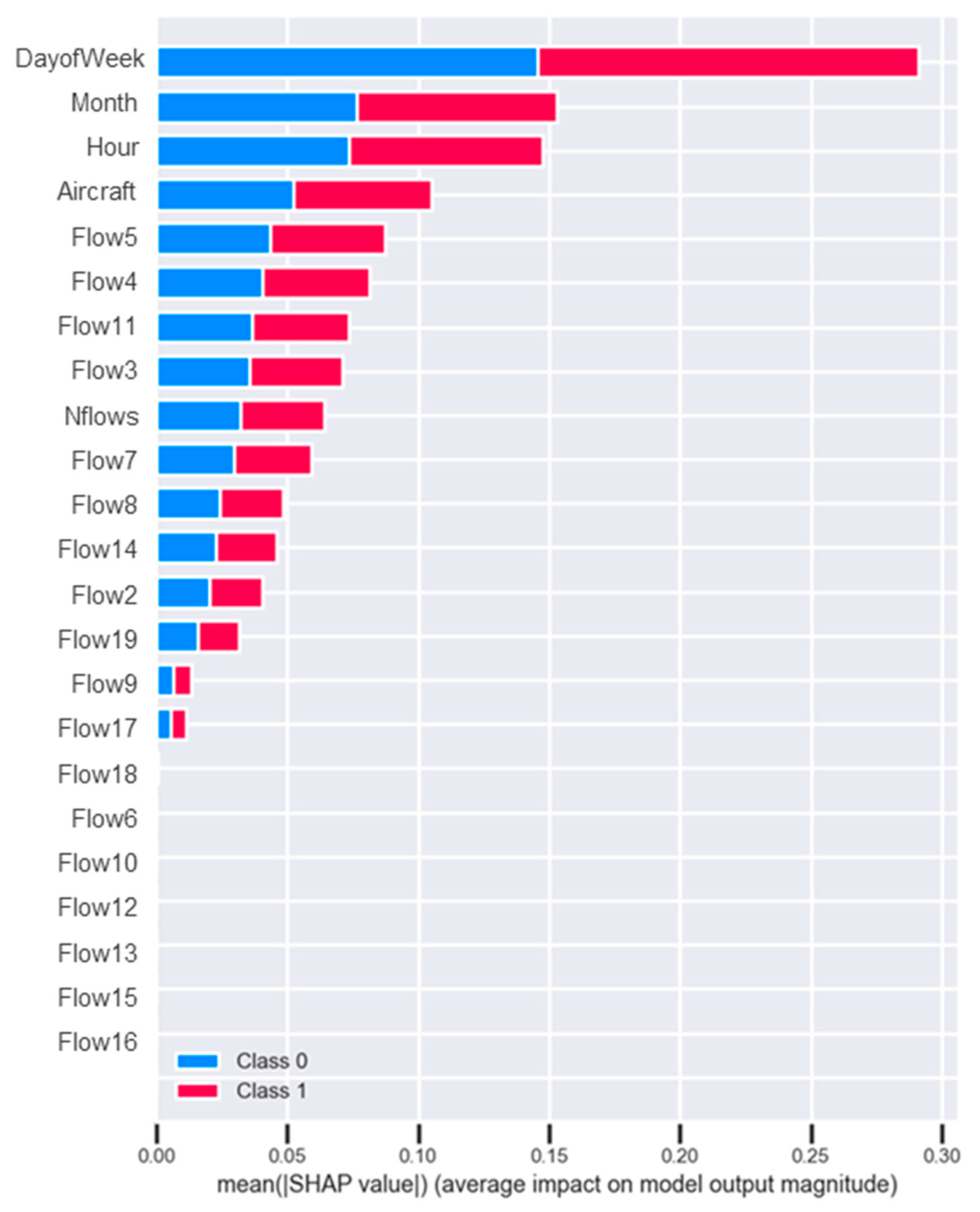
In addition, the relative importance of the model is presented in this explanatory study. The SHAP algorithm can also identify which variables will be most important in the prediction of both classes. The graph is presented in
Figure 11.
The main variables of the algorithm are time variables. The greatest relative importance is that of the timing variables. This leads to the conclusion that the model is based on time-based components, and that it is possible to predict when the sector will be regulated or unregulated based on the date of analysis. The following variable is the number of aircraft in the sector and the presence of various traffic flows. In particular:
Flow5: Flow across the sector from the west to the northeast.
Flow4: Flow across the sector from west to east
Flow1: Flow across the sector from north to south.
Flow3: Flow across the sector from north to south.
Among the flows, there are the main flows of each of the previously classified groups. There are two representatives of the flows that cross the sector from north to south, as traffic from Madrid-Barajas is the most influential in terms of traffic in LECMPAU.
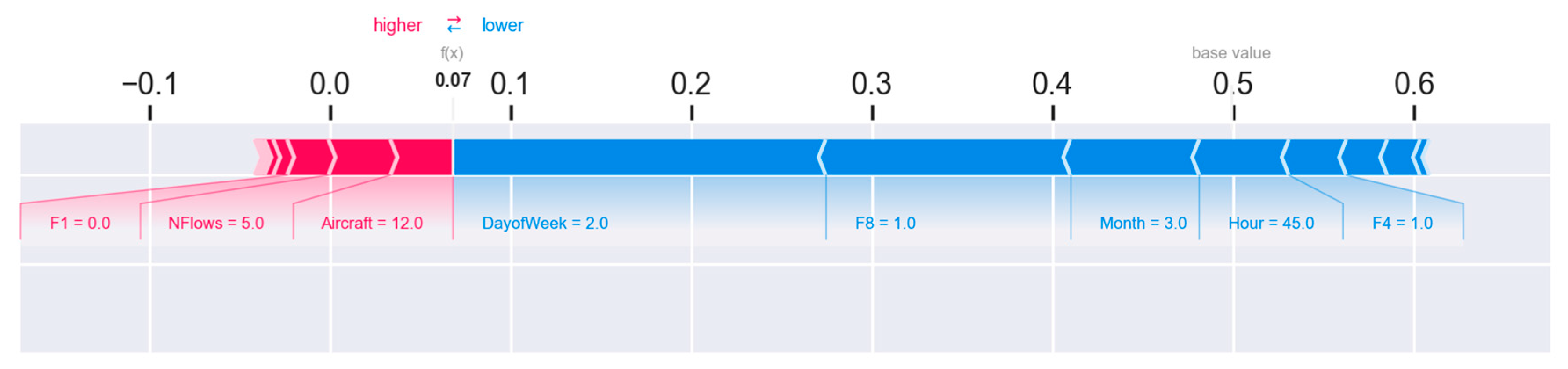
To conclude the explanatory analysis, two examples of predictions and how they are influenced by different variables are presented.
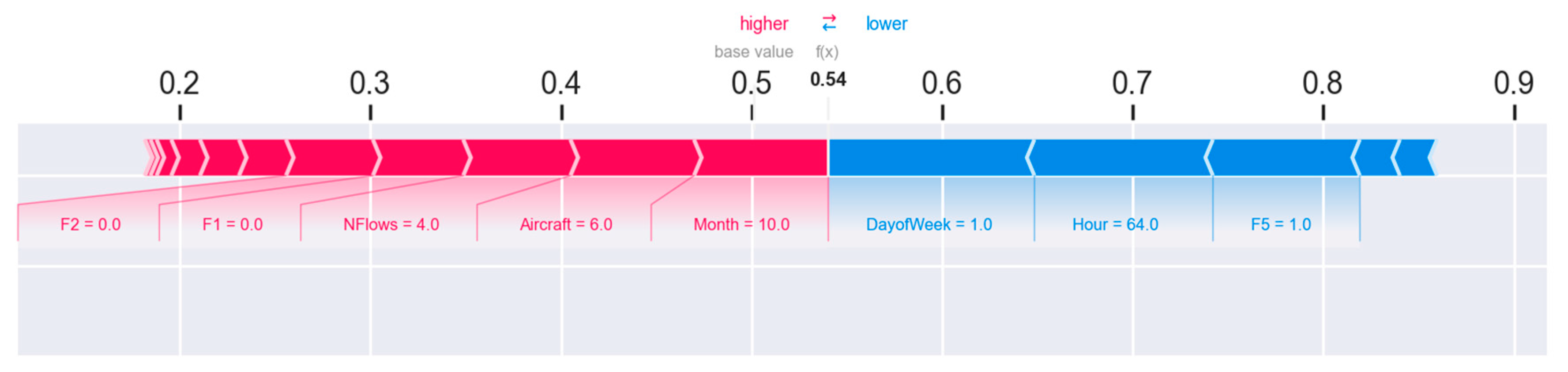
Figure 12 shows an example where the sector will not be regulated, and
Figure 13 shows an example where it will be regulated.
The variables that cause the sector to be regulated are shown in red, and those that cause the sector to be not regulated are shown in blue. In the first example, on a Tuesday in March, even though there are 12 aircraft in 5 flows in the sector, the time component has too much influence on the prediction. On the other hand, in the second example, it can be seen how a flight on a Monday in October is regulated. In this case, the time component is more complex. The period of the day and the day of the week tend not to regulate the sector, but the month of the year compensates for this tendency. The latter variable, with the help of the traffic component of the sector, means that the sector is expected to be regulated.
This explainability analysis gives an idea of how the algorithm behaves and on which variables it bases its predictions on. Thanks to this analysis, it is possible to validate the model and the methodology developed from an operational point of view. This, together with the results obtained, which are above the established standards, means that the methodology is considered a success in LECMPAU.
4.4. Comparison with Other Machine Learning Models
This section compares the results of this model with the results of other models with the same objective. Following a literature review, it is concluded that [
24] is the closest reference to the model being used in this paper. Firstly, the indicators of the model are presented to compare the overall performance. In
Table 6, the maximum and minimum values are presented. This may allow a comparison of evaluation results for models with the same objective.
This indicates that the two models have a very similar tier of performance. In
Table 6, the minimum and maximum are presented, because in [
24] several algorithms are tested.
In terms of explainability, this model is mainly influenced by the time components. In the model of [
24], the main variable is the timestamp. In this respect, the two models coincide. The next most important variables are the Entry Count for the next 60 min, the capacity, and the Entry Count for the next 20 min. From this point on, workload and traffic distribution variables start to appear. The Entry Count is analogous to the number of aircraft, and the traffic distribution variables would be similar to the flow distribution in this model.
With these two comparisons, although with different approaches, the two models arrive at similar results. This allows us to conclude that the model developed in this paper is correct, having been tested against a robust model with prestige within academia.
5. Conclusions and Future Work
Once the machine learning model has been validated, it can be concluded that the results are satisfactory and that it is indeed possible to predict when a sector will or will not be regulated based on mainly temporal components. This model will not decrease the number of regulations directly, as it simply evaluates and predicts based on the situation within the sector and the time of year. The realisation of this model can present advantages in the management of the technological and human resources of the ATC system. By applying this model before the actual operation, the ATC system will be able to see which sectors will be regulated at which time and be able to dedicate more or fewer resources to the more or less regulated areas, allowing the ATC system to be more efficient in its labour.
Several conclusions can be drawn from the design of the model and its application.
The fact that the model is based on a modular methodology is a great advantage. By having three modules independent of each other, variations are possible. Modules could be added, or the existing ones could be changed. This gives the model great flexibility and makes the developed methodology robust.
The model has been able to predict when the regulations will appear in the sector, mainly based on the temporal analysis. This fulfils the objective of the development of this work.
The model explainability analysis of the model is very useful. In an aviation application, it is not enough to have a model whose test results are correct, it is also necessary that the learning process is correct, and this learning process has been validated thanks to the explainability analysis.
The number of total flows is a fixed parameter. The NFlows parameter indicates the number of flows in which there are aircraft within the total number of flows. In situations where there are a large number of flows, the model will depend on a number of other parameters that will have more influence. This is the ninth most important (
Figure 11). For this reason, the analysis of the model when there are a large number of flows, which could be interesting from an operational point of view, may lead to unrepresentative and misleading results, as the model relies mainly on other variables.
10-min windows have been chosen because this is enough time for regulations to appear or not to appear in the airspace. Smaller time windows would introduce noise into the sample by not allowing time for the model labels to change. Furthermore, the aim of the regulation study is to see, in future studies, the effects that these regulations may have, and from an operational point of view, in a control room, this range is used to evaluate the possible effect of the regulation. With larger time windows, insufficient granularity would be achieved.
In addition to the general conclusions of the model, the computational time allows conclusions to be drawn about the feasibility of the model, and the possibility of its implementation in a real case study. This model has been trained and tested in a time of 4 min, having been developed on a general computer. This time is practically immediate for such a large volume of data. When running a new application of the model, the prediction of a full day (144 elements) has been completed in just 2 s. These application times mean that the model can be implemented in a real tool. Moreover, although the results obtained have been good, there is interest in continuing this line of research. Future lines of research that would be interesting for the full development of the model are set out below.
Application to more ATC sectors. This model has been successfully validated in a single ATC sector, with very specific traffic conditions and patterns at the onset of regulations. An application to other sectors could allow the validation of this methodology and model in different circumstances.
Study of additional variables. Although the traffic study is a complement to the model, based mainly on the time component, it is necessary to take it into account. Therefore, adding or considering variables other than those from the study may be of interest, as it would allow a broader view.
Application of the model to specific air traffic flows. At present, regulations affecting an entire sector are being studied. However, regulations may only affect air traffic flows within the sector. It would be interesting to develop a model based on the current one that is able to predict whether an air traffic flow will be regulated or not.
In general, in order to have an operational validation of the methodology, more comparative studies will be needed. Such studies will be pursued in the future when more data is available to apply the methodology in different sectors, or when another methodology is available to compare the results with.




 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}