2.1. Bird Activity Modelling and Characterization
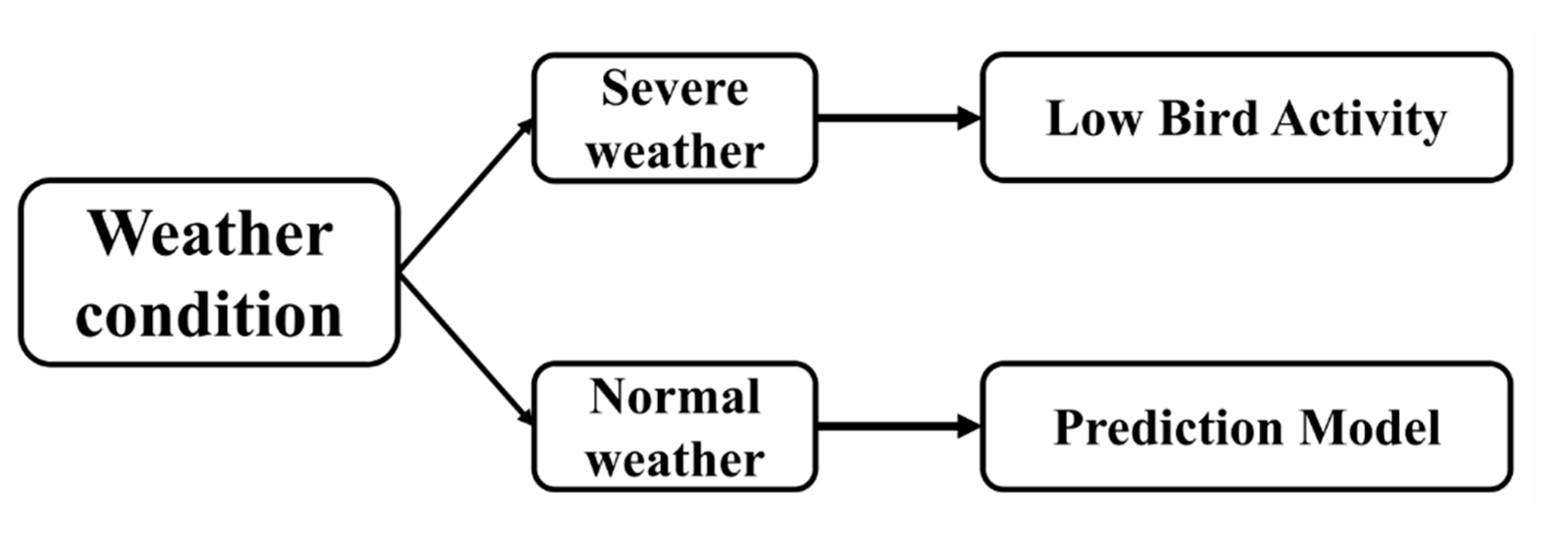
This paper presents a bird activity forecasting method using weather information based on machine learning techniques. The method is composed of two components. The first one is data selection. Existing experiments and analysis revealed a highly complicated relevance between bird activity and weather, and bird activity characters demonstrate remarkable differences in special weather conditions such as precipitation, gusts, fog, and hail. These could be denoted as adverse weather conditions since birds are usually inactive in these conditions. Therefore, it is more reasonable to exclude these adverse weather conditions and study bird activity relevance with normal and adverse weather conditions independently. According to this principle, there is a necessity to conduct a data filter by confining the weather information. Normal and adverse weather conditions are categorized through artificial or other simple methods automatically. A conditional parameter is defined as σ including weather and radar working conditions for data filtering. The dataset after filtering is denoted as . The symbol represents a track count at the date dk with the parameter σ.
The quantitative bird activity modeling is another fundamental component of the predicting method. The bird track count is the most straightforward and intuitive descriptor to interpret bird activity. The larger track count usually indicates more active bird behavior. However, the adoption of track count as an activity descriptor confronts many limitations: (1) Ground surveillance radar systems have inevitable blind zones, which make track counts inconsistent with real bird quantities. The ambiguity of a single or a flock in the radar viewpoint also constrains the track count accuracy. (2) The track count is a highly time-variable descriptor, which makes it suitable for short-term interpretation, and its numerical property also limits its integration with other track count information. (3) The relevance between bird track count and bird strike threats does not present a definite positive correlation. The reasonability of modeling the positive correlation between bird strike threats and track count is still controversial.
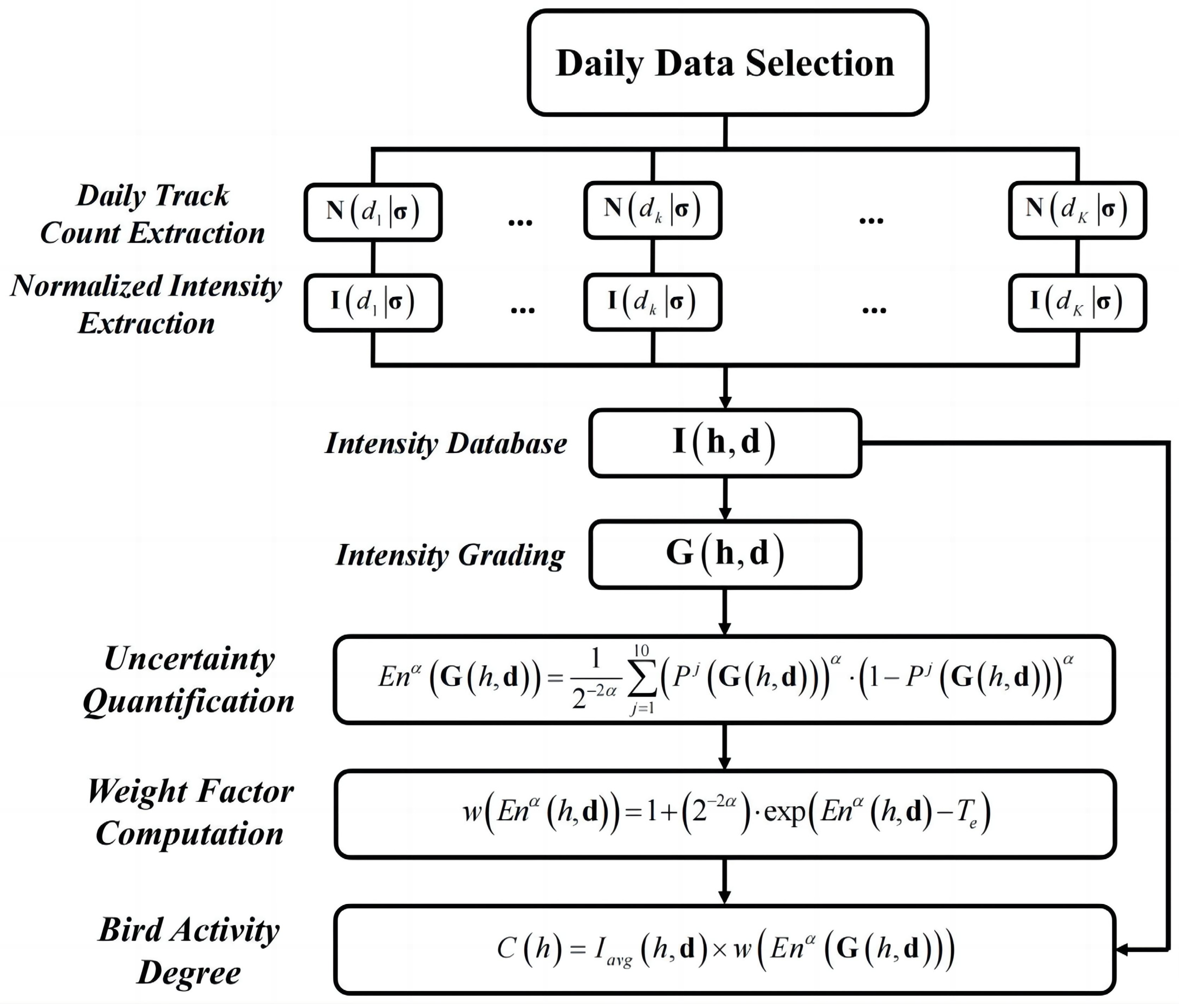
Due to the above limitations, a plausible and flexible quantitative descriptor is required for bird activity prediction. This paper introduces the activity degree as the solution. It is derived from the track count information and assumes the activity degree is an integration of intensity and uncertainty characters. The corresponding extraction procedure is composed of four steps:
STEP 1: Normalized intensity calculation. The normalized intensity is calculated from the hourly track counts. For date dk, the normalized intensity is denoted as . The term represents the intensity at the hourly interval between hours i-1 and i. The normalization range is between 20 and 100. The lower boundary is 20 instead of 0, as it is unreasonable to define the minimum track count as no bird activity.
STEP 2: Intensity grading. Normalized intensities compose the dataset
N. A normalized intensity array at hour
hk is formulated as
I(
hk,
d), with
d as all selected dates. Intensity fluctuations from track count variations might be misleading in activity modeling. To overcome this insufficiency, the intensity is transformed into 10 grades through a mapping in
Table 1. The new dataset after mapping is denoted as
G(
hk,
d).
STEP 3: Uncertainty quantification. The grade mapping reduces the intensity fluctuations to facilitate uncertainty evaluation. A large grade variation usually represents greater uncertainty, which elevates the difficulty of activity prediction. This mechanism is realized by the entropy concept. The α-quadratic entropy is taken to quantify activity uncertainty [
13]:
The term
indicates the probability of
G(h,
d) at grade
j. The uncertainty enlargement parameter α indicates entropy sensitivity to uncertainty [
14,
15]. The parameter α is selected as 0.7, but it is flexible to accommodate various scenarios with different bird activity complexity.
STEP 4: Activity degree calculation. Intensity and uncertainty information are integrated to model bird activities. Direct numerical integration is improper due to their independent physical meaning and dimensions. This paper develops a weighing strategy for uncertainty characters and applies it to intensity. An uncertainty weighing factor based on α-quadratic entropy is defined as [
16]:
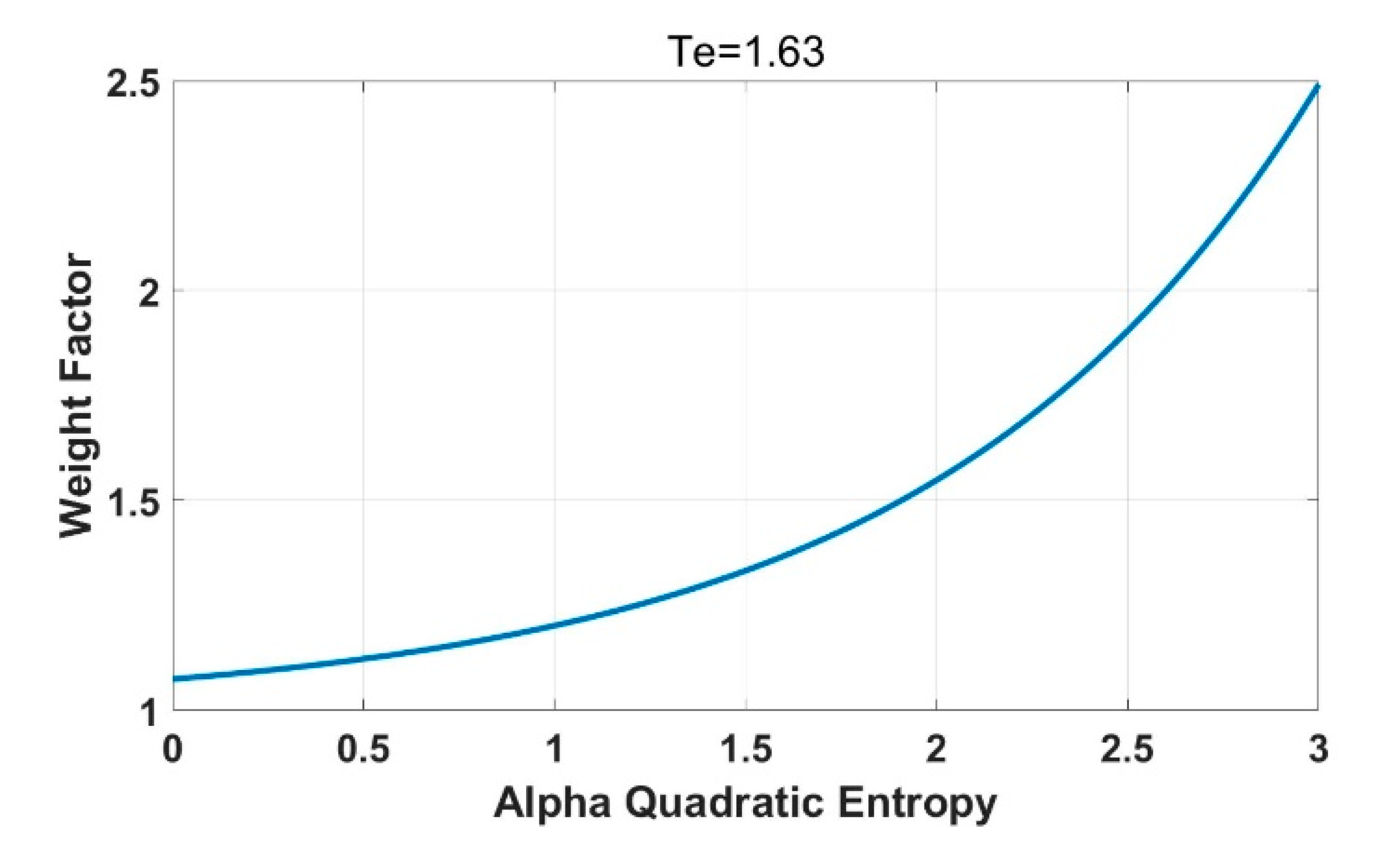
The weighing factor is larger than one to characterize its extra enlargement of intensity. The parameter Te is the entropy threshold. When the entropy is smaller than Te, the weighing factor provides a limited intensity enlargement. The weighing factor reflects a nonlinear increment to increase uncertainty contributions when the entropy is larger than the threshold.
Bird activities are manually categorized into large and small variations, and their entropy values are characterized in histogram forms for threshold determination. The selected threshold is a value minimizing overlapping probabilities between large and small variation histograms. The extracted threshold in this paper is 1.63.
Figure 1 demonstrates the weight factor distribution with entropy values in a remarkable exponential increment pattern.
The bird activity degree is the multiplication of intensity and weighing factor at hour
h:
The term
is the average value of
I.
Figure 2 presents the overall framework of activity degree extraction.
The proposed method is applicable for arbitrary hour spans to accommodate different problems. In this paper, the hour span indicates a time window with a specified start and end time, such as 05:00–08:00. The numerical and normalization properties of activity degree make it suitable for direct comparison and mutual verification. However, if the activity degree is taken as the prediction result, the system requires a robust regression capability, and its necessity is worthy of further discussion. The exact quantity of activity degree does not indicate a definite, accurate bird activity modeling due to its high fluctuation character. From the viewpoint and requirements of airport management, exact activity degree values possess little significance for wildlife management. A more reasonable activity categorization strategy might be more useful to facilitate bird strike risk evaluation and air traffic control. Therefore, modeling bird activity prediction as a regression problem would elevate the problem’s complexity and difficulty. This also deviates from the engineering application requirements. The solution proposed in this paper is mapping activity degrees into activity grades, as presented in
Table 2. This mapping transforms the prediction from a regression problem into a classification problem, which reduces the complexity while maintaining its application significance.
There is another concern that motivates the transformation from regression to classification. As the information source, the track count descriptor possesses inevitable uncertainty. Existing avian radar systems could not guarantee 100% detection accuracy; false alarms as well as clutter brought extra track count uncertainties. These factors have non-negligible impacts on data credibility. Even though the regression system could be well built to provide high accuracy, the predicted activity degree has a credibility problem as the data source is “polluted”. The transformation into a classification problem alleviates this adverse impact and simplifies the model to suit more complicated scenarios. Therefore, an activity prediction system with better robustness and intuitive feedback is preferred.
2.2. Bird Activity Relevance Study with Single Weather Parameter
According to historical radar data analysis and artificial field observation records, the avian radar systems adopted in this paper are categorized into two datasets. The first dataset consists of diurnal birds within the west side of the airport; most observed birds within this area present daily commuting or roosting activities. Their activity pattern and relevance to weather could be roughly estimated through artificial field observations. The source of the other dataset comes from the nocturnal birds in the southeast region of the airport. Existing observation records with both avian radar and optical equipment indicate most birds are engaged in migratory activities. Therefore, the nocturnal bird dataset mostly consists of migratory birds whose activity patterns reflect different weather relevance compared with diurnal residents. In the following analysis, weather relevance exploration and modeling are conducted on two datasets, respectively.
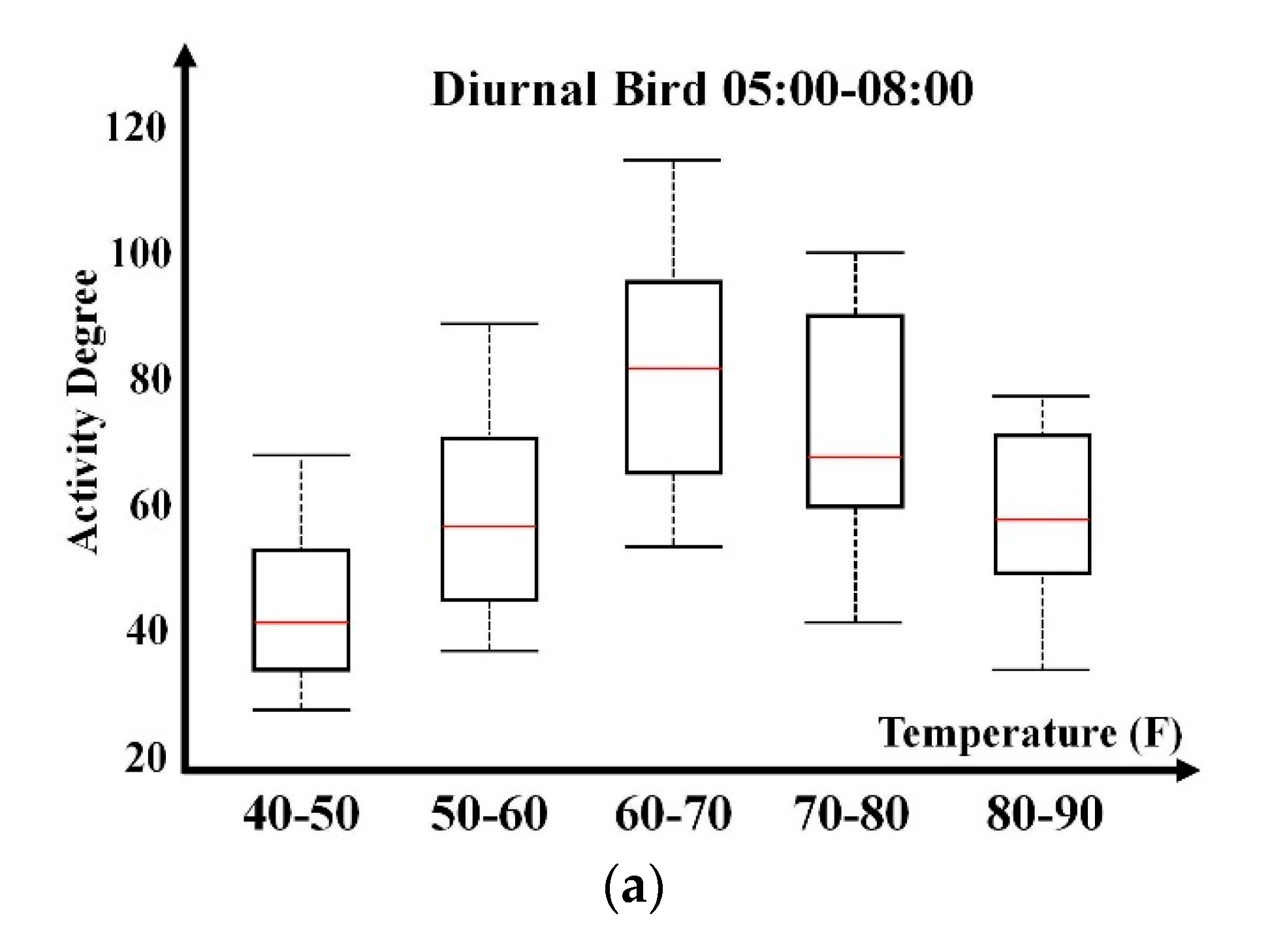
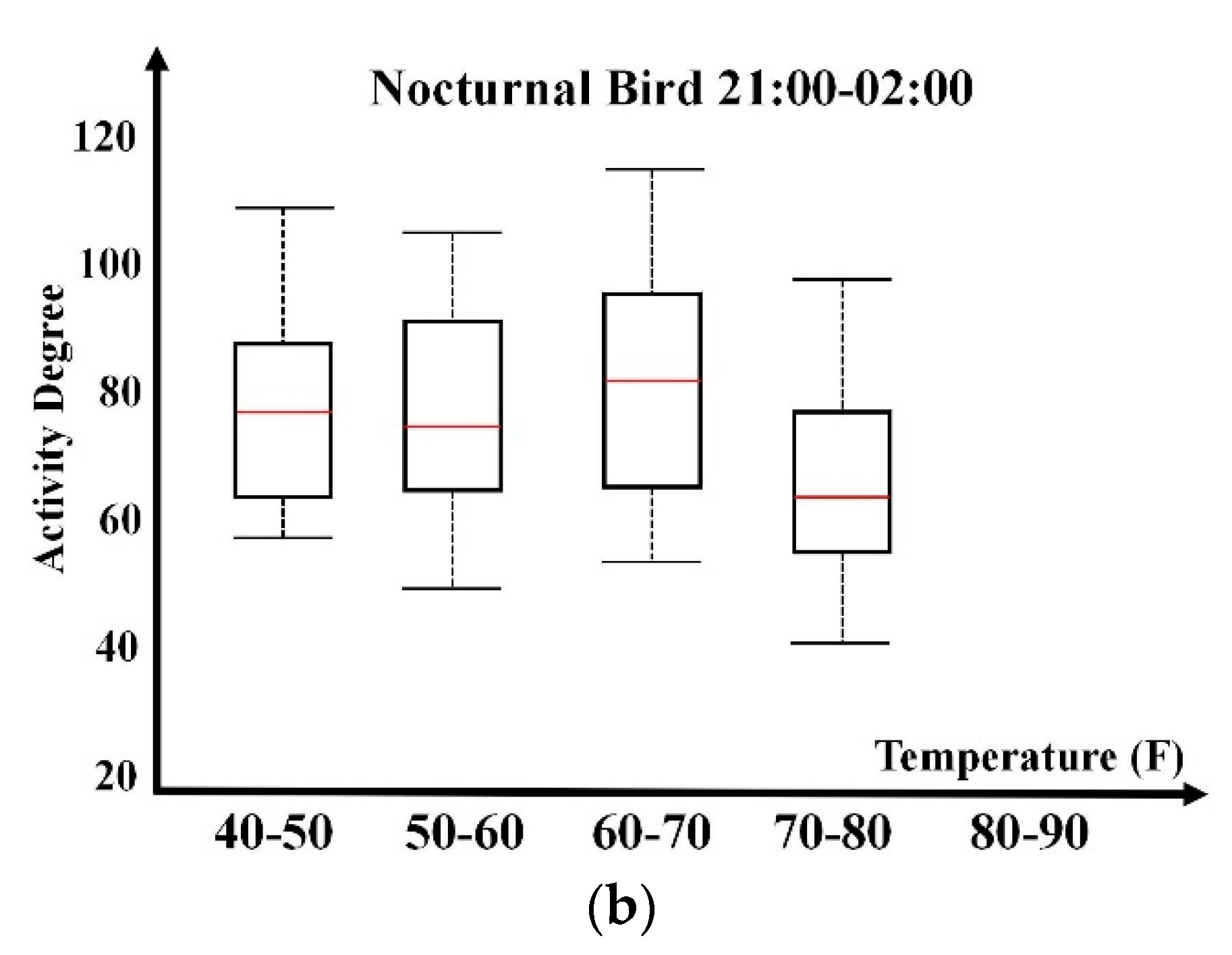
The preliminary study of bird activity relevance with a single weather parameter is presented in this section to support the necessity of bird activity association with weather parameters. Based on existing analysis and understandings, temperature, humidity, wind speed, and wind direction are selected to construct a multivariable weather feature vector. For a specific hour, such as 08:00–09:00, weather information and bird activity degree information are collected from local weather records and radar observation data. This paper adopts the box plot to present activity dependence on a single weather parameter in a statistical manner. Temperature, humidity, and wind speed parameters possess numerical properties; their value spans are constructed for box plot generation. The wind direction possesses discrete property by categorizing it into eight directions (north, northeast, east, southeast, south, southwest, west, and northwest). Box plots are generated for each direction.
2.4. Humidity
Humidity is another comfort indicator of bird activity.
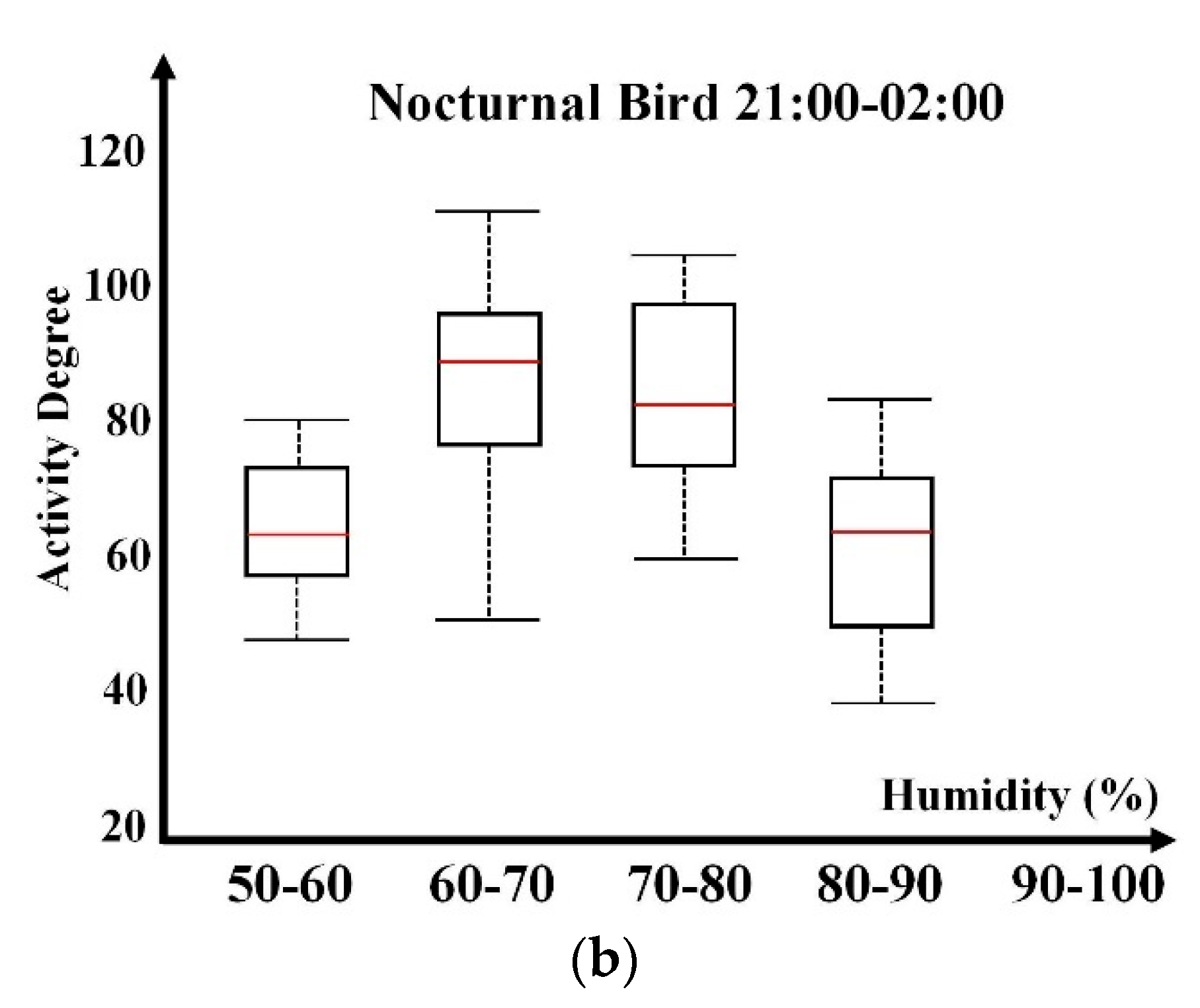
Figure 4 presents box plots for diurnal and nocturnal birds under different humidity spans in the unit of %. Diurnal bird activities are remarkable within [70, 80]%. The longer box within this span indicates greater activity variability. Excessively dry or wet environments are not favored by birds, and corresponding box lengths are shorter with less sample support. The humidity within [90, 100]% is usually accompanied by fog, which obviously restrains bird activity.
Nocturnal bird activities present weaker relevance with humidity. The principal active span is [60, 70]%. There is no humidity record within [90, 100]%. Compared with diurnal birds, the box length of nocturnal birds is shorter, indicating smaller variability. This is reasonable, as nocturnal bird activities usually present more prominent regularity and periodicity. Similar to the temperature study, the relevance credibility is also influenced by the humidity information deviation, as in the temperature case.
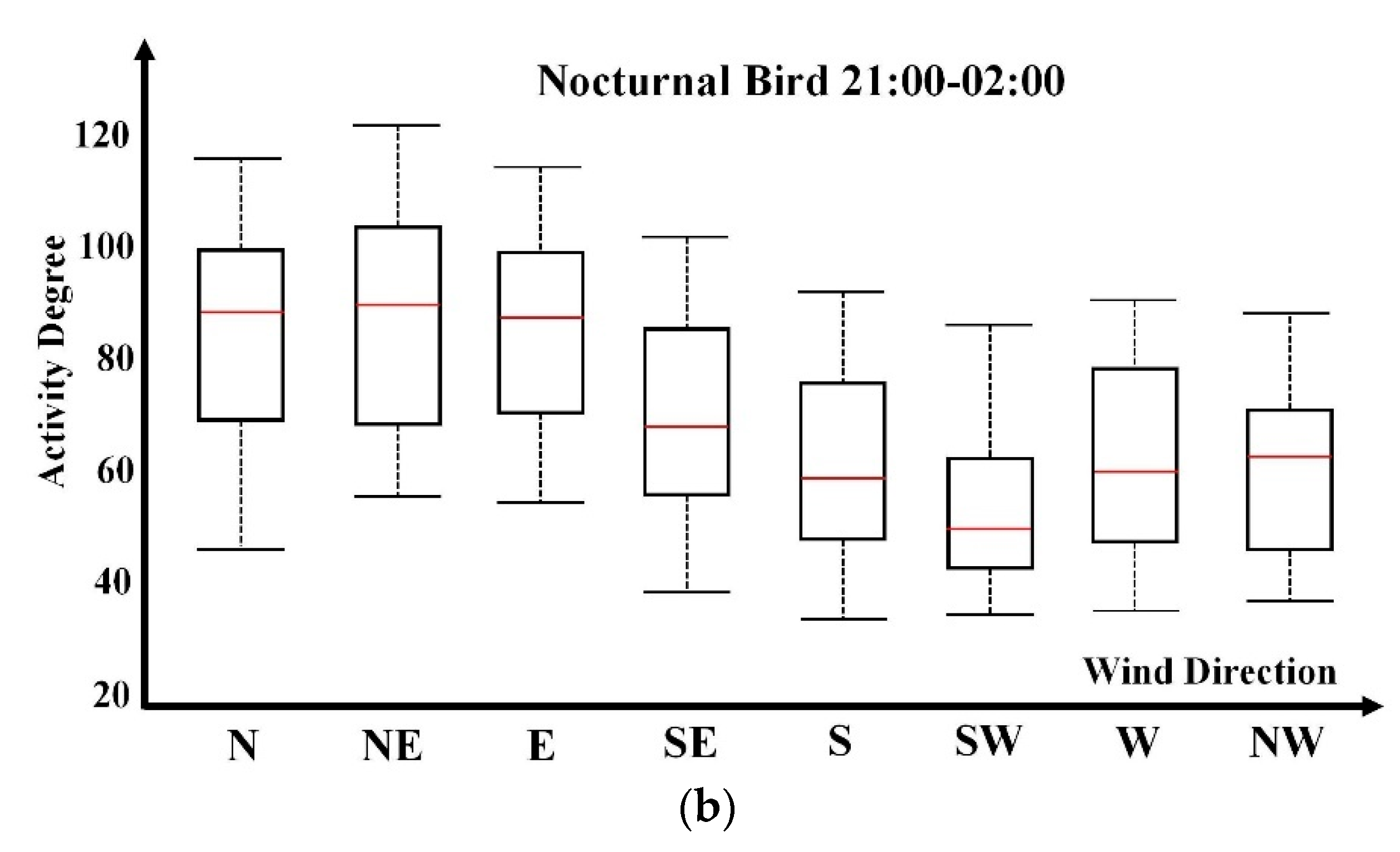
2.6. Wind Direction
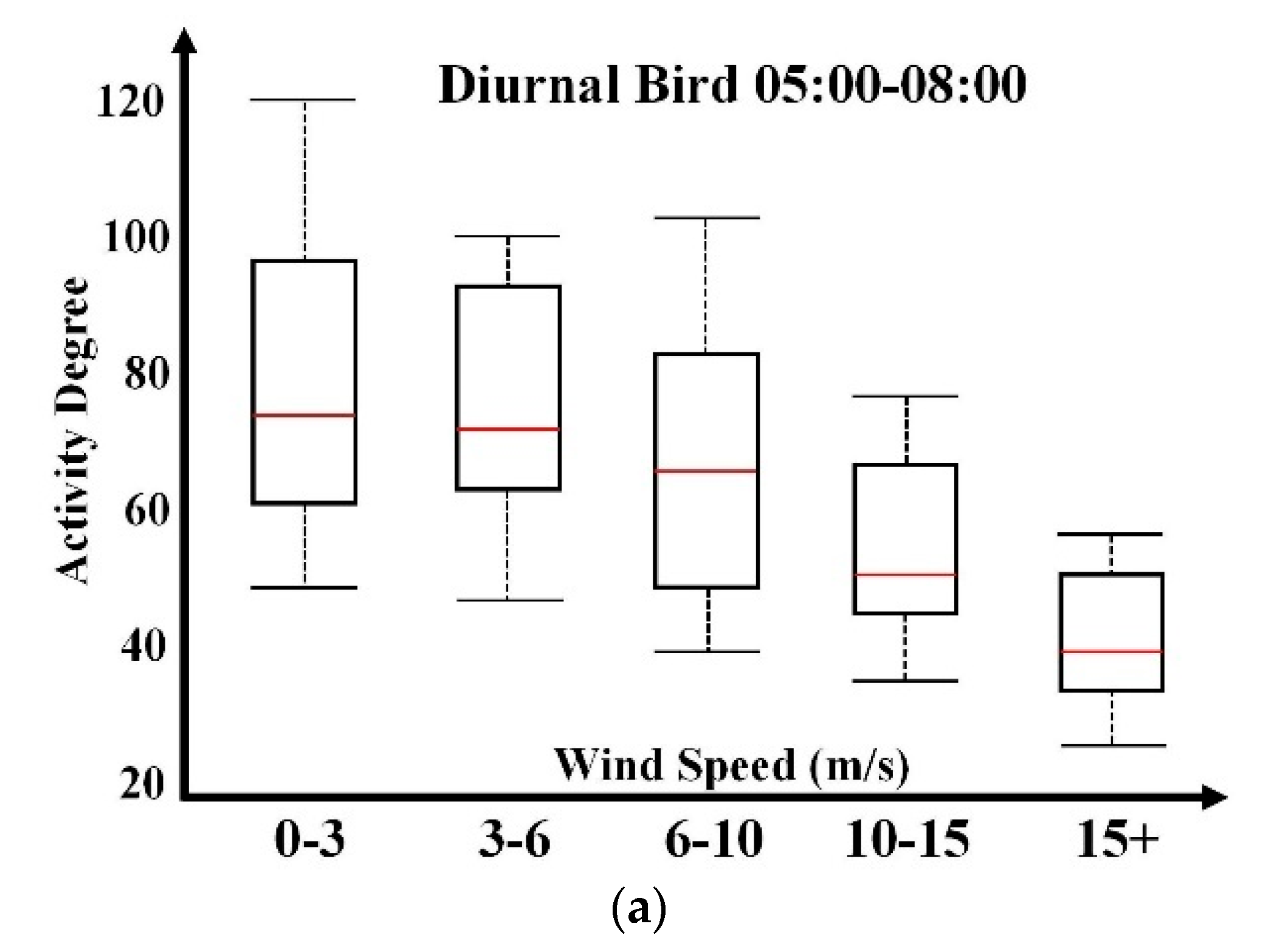
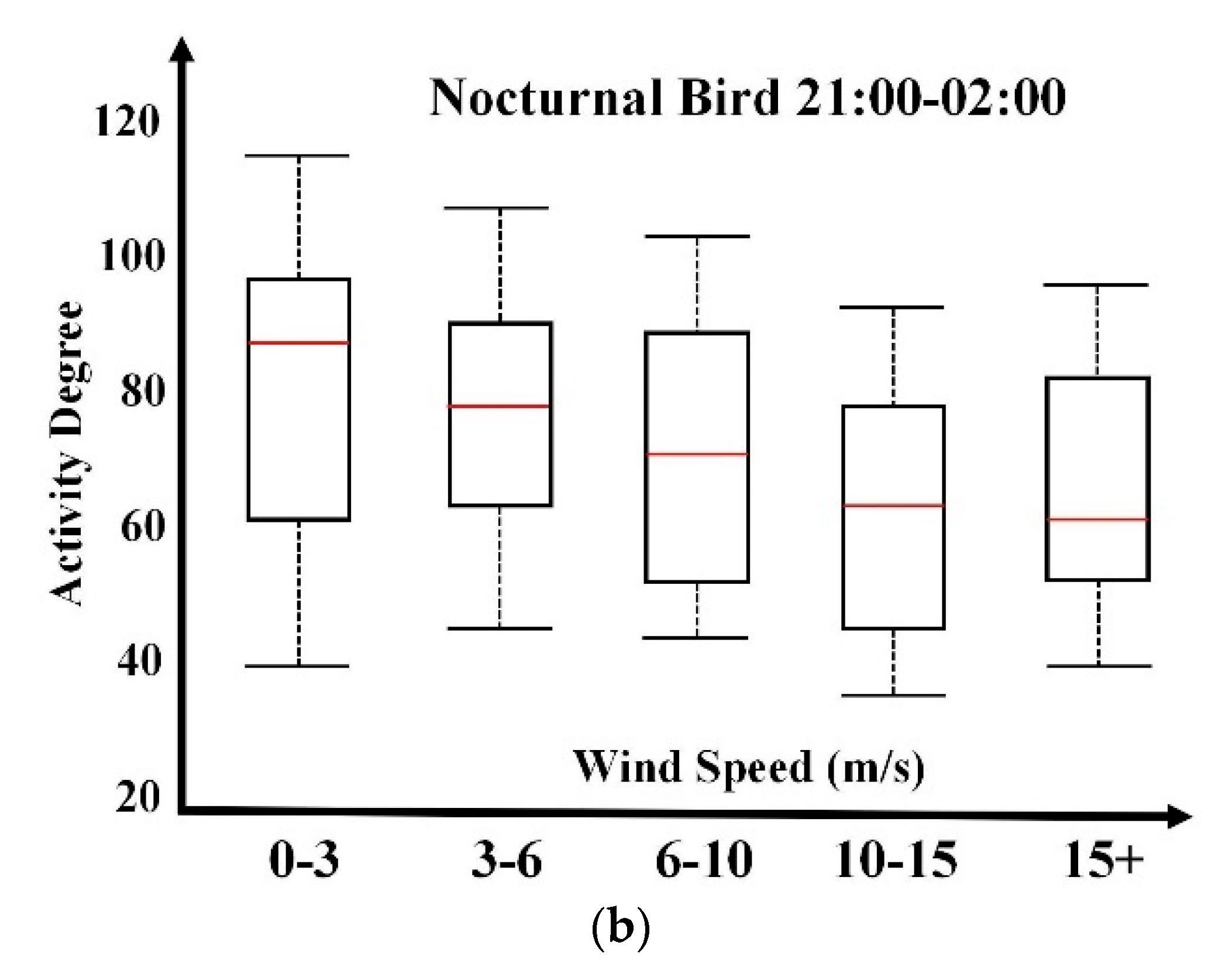
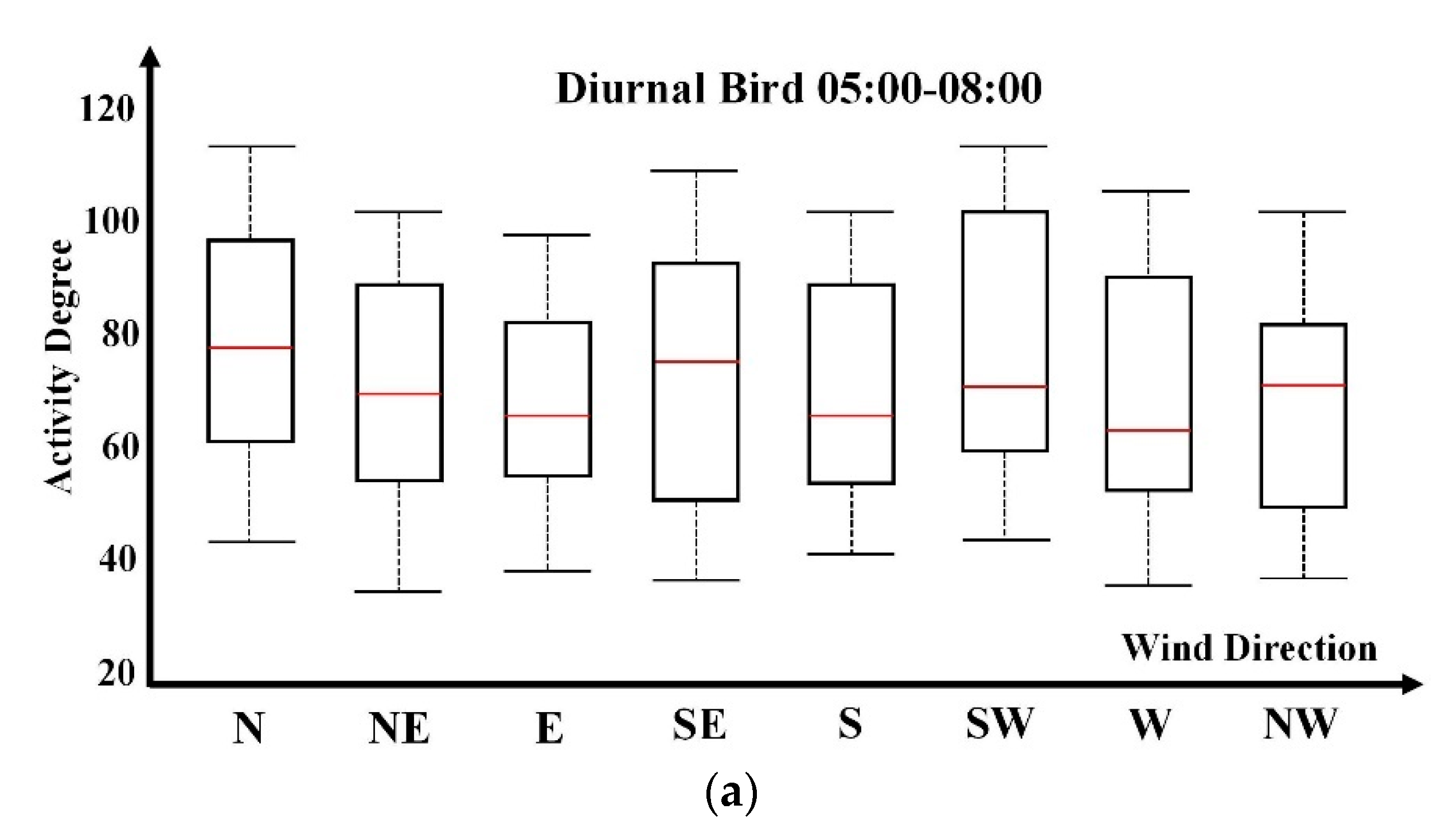
Diurnal bird activities are usually not sensitive to wind directions. As illustrated in
Figure 6a, box plot distribution on wind directions does not reflect clear and interpretable relevance. This is consistent with ornithologists’ understandings. Compared with
Figure 5, wind speed has a more remarkable influence on diurnal bird activity degrees. In contrast, nocturnal bird activity’s dependence on wind direction is more distinctive, as presented in
Figure 6b. North, northeast, and east directions are preferable. Track flight direction analysis over historical data indicates the principal nocturnal migration direction in the fall season is the southwest direction. Therefore, the wind direction dependency analysis indicates that birds in this area are inclined to fly along the wind’s blowing direction for energy savings. Predominant bird activities reflect longer box plots, indicating greater variability. According to discussions with ornithologists, the box plot length has the potential to deduce bird species composition within a specific spatial and temporal window according to prior knowledge.
Preliminary experiments presented in this section indicate the reasonability of associating bird activities with weather parameters. It is observed that weather parameters present their respective relevance patterns. Even with measurement deviations, it is still plausible to predict bird activities with weather information. Since bird activities are influenced by multiple weather parameters in a joint manner, the extension of the multivariable weather dependence study is necessary.
2.7. Multivariable Weather Relevance Modelling and Analysis
The mapping in
Table 2 categorizes bird activities into labels A, B, C, and D, which models bird activity prediction as a supervised learning problem. The multivariable weather feature vector is constructed as
F = [
t,
h,
s,
w], which represents temperature, humidity, wind speed, and wind direction, respectively. Weather parameters have different dimensions and value ranges; a normalization procedure is necessary to reduce feather space distortion. Wind directions do not possess numerical properties; eight wind directions are labeled from 1 to 8. To guarantee numerical consistency, other weather parameters are normalized within the numerical range of [1, 8]. The feature vector
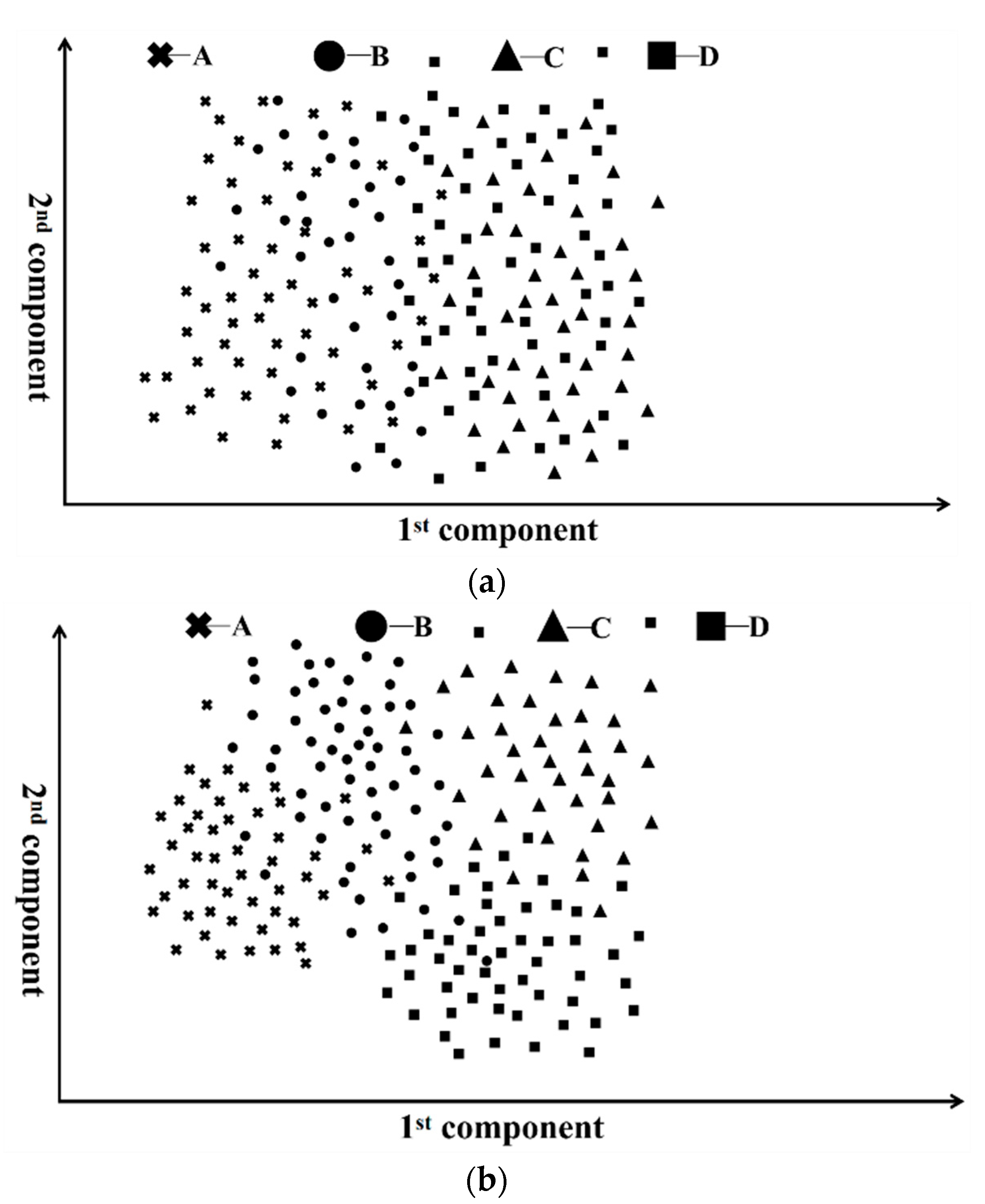
F is the input of the classification model. The output is the labeled activity grade {A,B,C,D}. This paper chooses two sets of machine learning techniques to verify the feasibility of the prediction model.
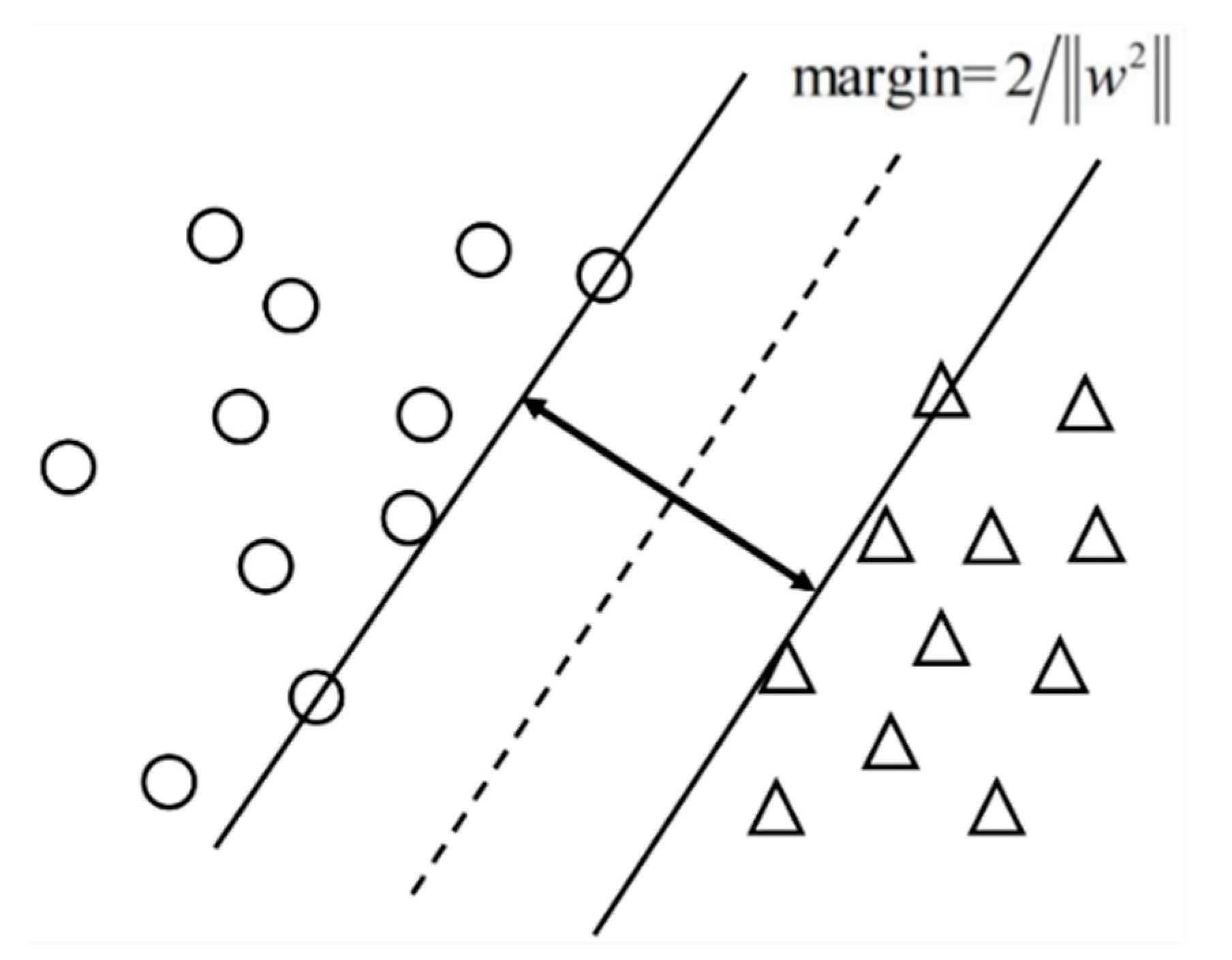
The first technique routine is the Support Vector Machine (SVM) [
17,
18,
19] classifier with the Linear Discrimination Algorithm (LDA) [
20,
21,
22] for feature extraction. SVM is a representative learning machine based on the risk minimization criteria in statistical learning theory. It is widely adopted in various machine learning problems due to its solid theoretical support and robustness in sample variations. SVM usually constructs the optimal hyperplane in a kernel-projected higher-dimensional feature space according to the maximum margin strategy. Its principle is graphically demonstrated in
Figure 7. This paper adopts the Gaussian kernel function to project the feature space into higher-dimensional space. SVM has demonstrated its outstanding performance in many supervised classification and regression problems with the assistance of feature extraction techniques. Feature extraction methods are usually adopted as a preprocessing block to reduce feature dimension or enhance sample separability. LDA is a representative feature extraction technique to reshape sample distribution patterns for separability enhancement. It constructs the projection matrix by maximizing the ratio of between-class and within-class scatterers. Projected samples are applied to the learning machine for training and unknown sample classification. The composition of SVM and LDA reflects good performances in many problems, such as radar target recognition using target range profiles [
23]. For the problem in this paper, this integration is challenged by inconsistent feature dimensions and numerical properties, which generate a highly distorted feature space. Moreover, due to the non-numerical property of wind direction, its numerical formulation results in feature space inconsistency in the wind direction dimension. This inconsistency might lead to non-negligible adverse impacts on the classification’s performance.
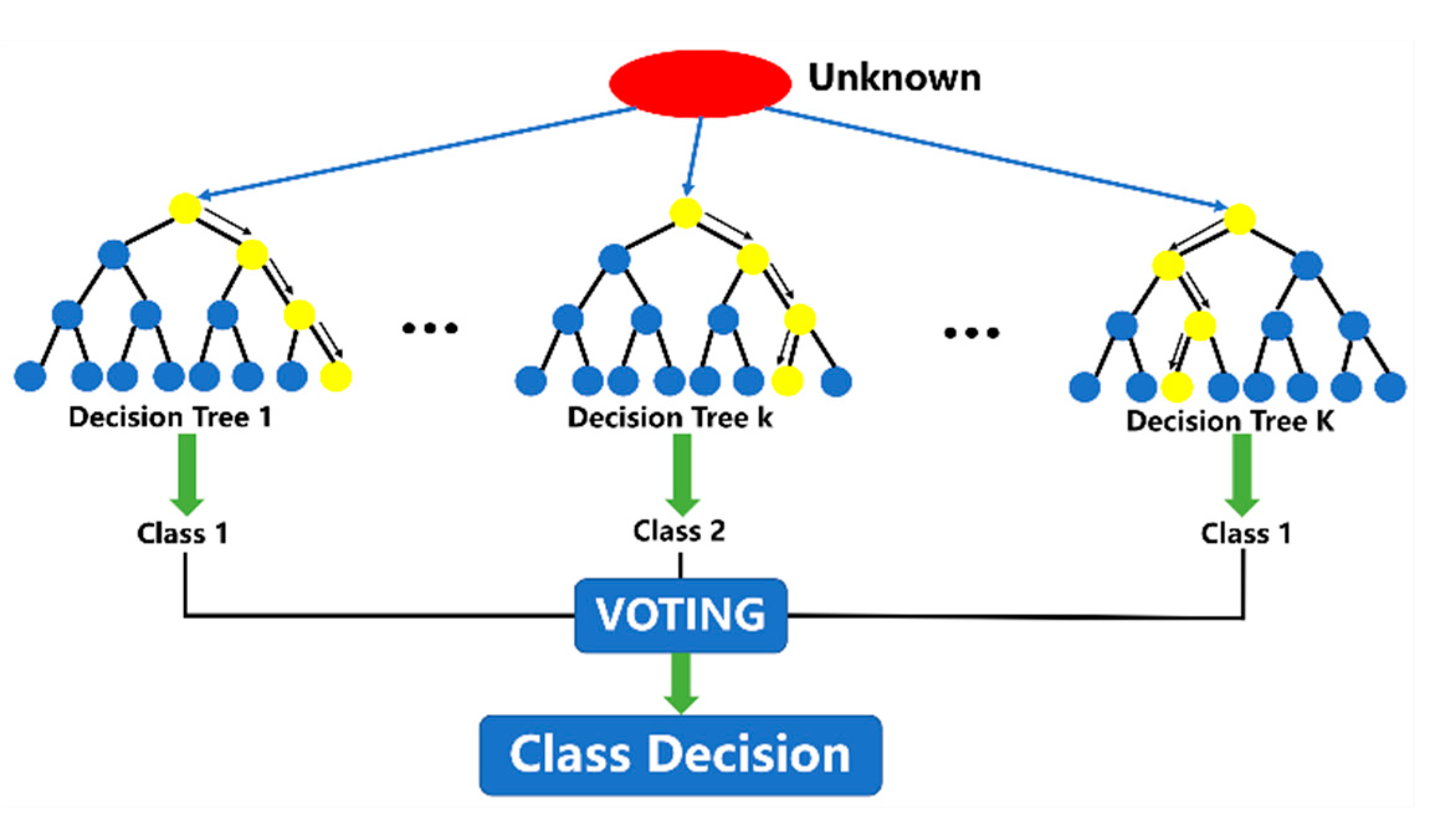
The other technique is utilizing the random forest model for classification. Random forest is an ensemble classification model [
24,
25] that models multiple decision trees. The basic principle of a random forest is to build multiple decision trees by randomly selecting partial features from the feature space. The decision procedures of trees are independent, and the final decision is made through the weighted integration of all trees. Its principle is graphically demonstrated in
Figure 8.
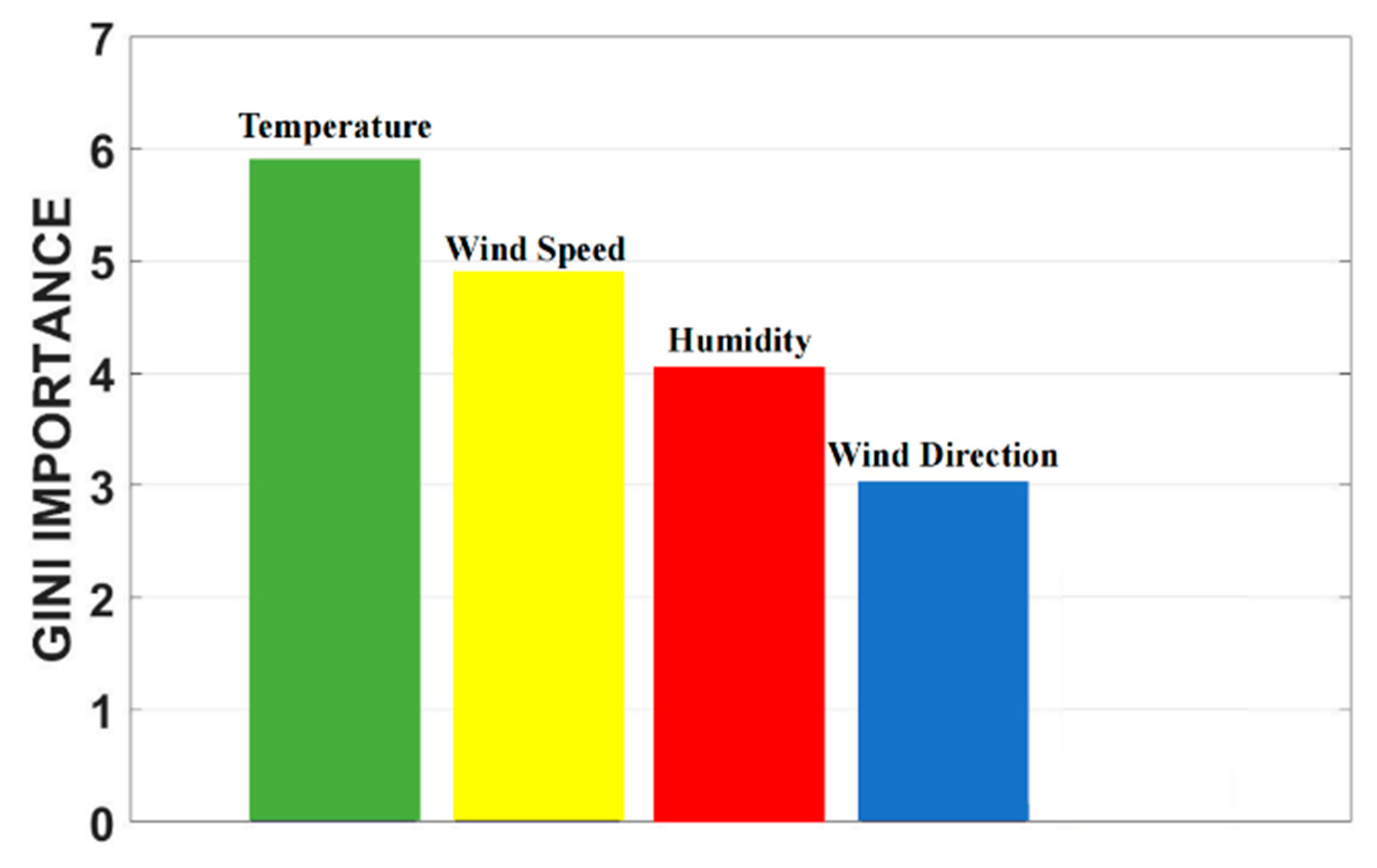
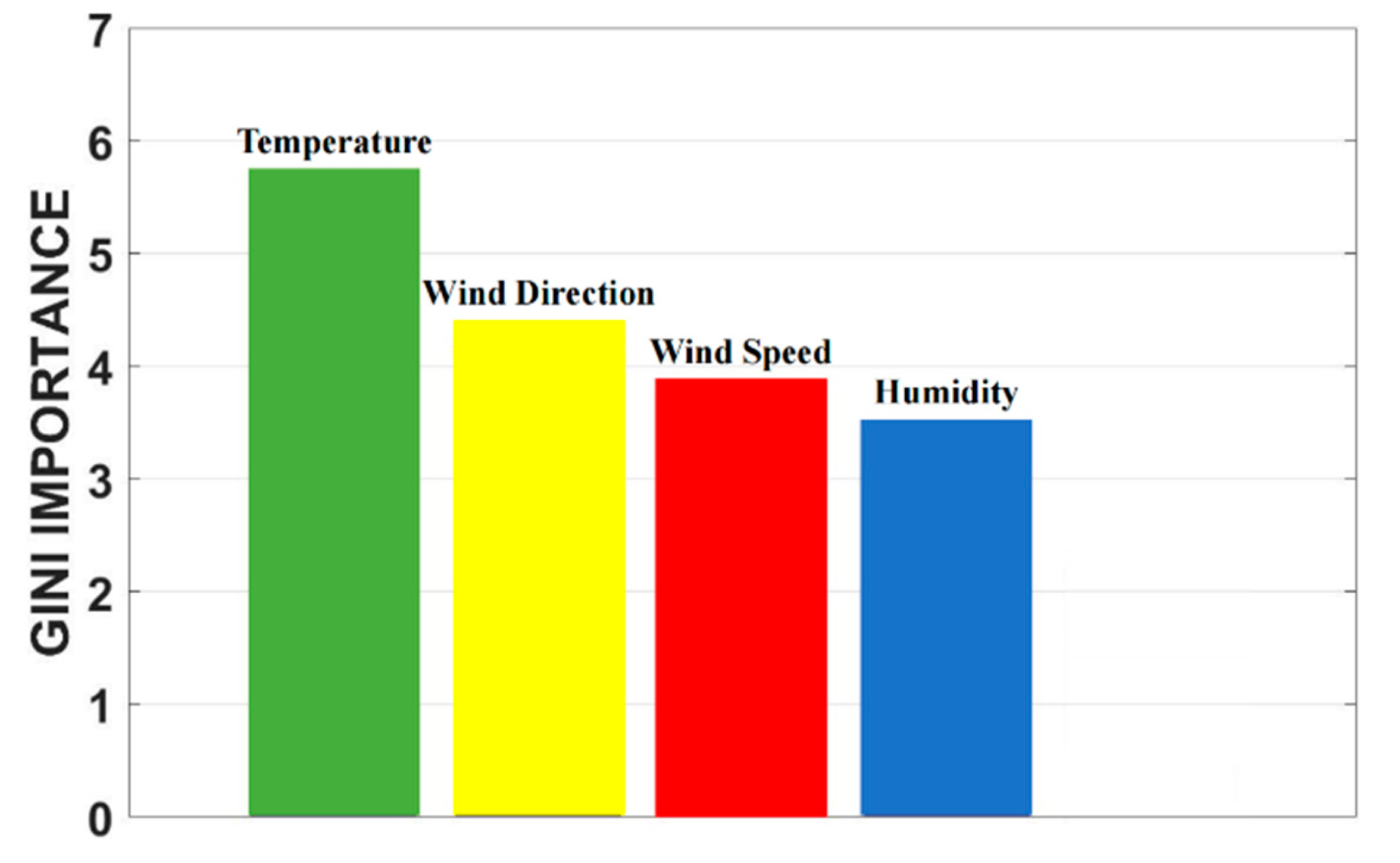
One benefit of the decision tree and random forest models is their adaptability to both numerical and non-numerical features. The dimension inconsistency is not problematic for the random forest classifier. Feature extraction techniques such as LDA are not applicable for random forests since their projected feature space does not have a clear physical meaning. The other advantage of random forests is their feature importance evaluation capability using the Gini index [
26]. This property is helpful for feature selection in the case of ambiguous features in a specific classification or regression problem. The ensemble classification structure of the random forest model makes it possess intrinsic sampling and feature robustness in many complicated classification problems.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}