In this section, the performance of ASRU is first presented. Secondly, the subjective feedback from questionnaires is explained and discussed. Finally, the section concludes with the objective results from performance measurements.
4.2. Subjective Results from ATCo Feedback
This section describes the results provided by the subjective ATCo feedback, which includes ISA, NASA-TLX, Bedford Workload Scale, SUS, CARS, and the three SHAPE questionnaires: (i) SASHA ATCo, (ii) SATI, and (iii) AIM, as described in the previous section.
4.2.1. Instantaneous Self-Assessment Measure
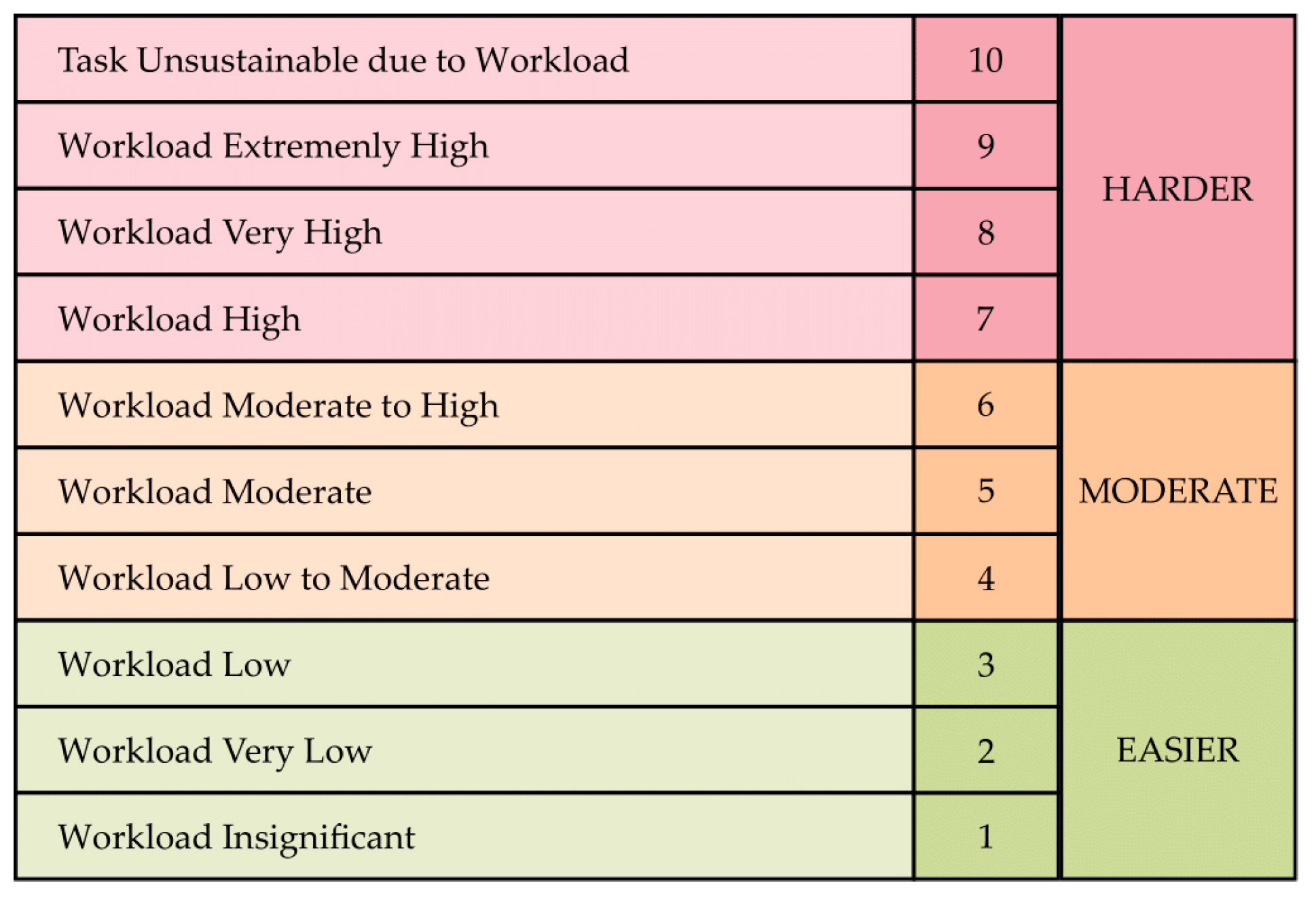
The results from ISA provide a retrospective self-assessment of the perceived mental workload by the ATCos.
Table 9 shows the ISA results based on the paired
t-test from the validation trials. The ISA mean values were calculated for both scenarios (M and H) under conditions with and without ASRU support. Delta ISA and min α were calculated with and without considering sequence effects. A negative delta ISA value indicates that the mean ISA value was lower in the solution run compared to the baseline run.
It can be observed that all delta ISA values are negative, independent of whether sequence effects are considered. This indicates that solution runs received lower mean ISA values, suggesting that using ASRU support reduces the perceived mental workload of ATCos. Furthermore, the impact of considering sequence effects can be seen. The consideration influences the mean ISA value, reduces sigma, and improves the statistical significance. The minimal alpha value (α min) decreases from 0.7% to 0.3%. Examining the ISA mean values reveals that supporting ATCos with ASRU lowers the mean ISA value in both the M and H scenarios. However, the greatest impact can be seen for the H scenario. Here, the mean ISA value over all simulation runs was almost 15% lower. This result indicates that ASRU support is particularly effective in reducing the ATCos’ perceived mental workload during high traffic hours, corresponding to the H scenario.
4.2.2. NASA TLX
Table 10 shows the differences in the six NASA TLX question ratings, which was calculated as the mean solution value minus the mean baseline value. The last row provides a summary by displaying the arithmetic average of all six ratings. Weights between 1 (low workload) and 10 (high workload) were possible, as described in
Section 3.
The four columns labeled “
Medium” show the results of the performed
t-test for the medium traffic scenarios. The columns labeled “
Heavy” show the results for the heavy scenario, and the columns below “
Both” combine the “
Medium” and “
Heavy” columns. The six columns labeled “
Diff” show the average differences in the answers between the runs with and without ASRU support. Negative values indicate a lower workload in the solutions runs with ASRU support. The “
SE” columns contain the values before eliminating the sequence effects, while the “
NSE” columns show the values afterward elimination. The six columns under “
α” show the
p-value, which indicates the statistical significance or the probability of the null hypothesis (see
Section 3.3) being valid. In the following discussion, we will focus only on the values in the “
NSE” columns. However, we also include the values in the “
SE” columns to show the effectiveness of our SECT approach.
The differences in the “Diff” columns for the “Heavy” scenarios did not change when considering sequence effects. In the case of the medium traffic scenarios, the differences slightly vary because there were more solution runs as the first runs of the day compared to the baseline runs (with a ratio of seven to five). Therefore, the differences in columns “Both” also change.
In the majority of cases, the application of SECT led to an improvement in statistical significance, resulting in a decrease in the p-value. This shows the value of SECT in compensating for sequence effects. For the medium runs, statistically significant results (α < 5%) were obtained in two out of the six cases when the sequence effects were eliminated. Without eliminating the sequence effects, the results are not statistically significant. For the heavy traffic scenarios, the (color of the) statistical significance did not change, but in all cases, α decreased or did not change. For the combined scenarios, the statistical significance improved in five out of two cases, and in two cases, it “improves” to a different statistically significant range, transitioning from a yellow color code to light green or from light green to green.
Question “1” (MD) addresses the mental demand, which decreased by 0.5 units out of 10 in the heavy traffic scenarios, but with a high standard deviation. Question ”2” (PD) addresses the physical demand, which showed a statistically significant decrease in all runs. The same trend was observed for the related question (EF): “How hard did you have to work to accomplish your level of performance?”. The answers to (TD), “How hurried or rushed was the pace of the task”, did not exhibit statistically significant changes. The same applies to (FR) “discouraged, irritated, stressed” and (OP) “successfully accomplishing the task”. For the latter, there was even a tendency for the ATCos to subjectively believe that they performed better, at least in the heavy traffic runs without ASRU support. Later sections show that this was only a subjective feeling.
Question 4 (OP) “
How successful were you in accomplishing, what you were asked to do?” is the only question for which the answer “
low” corresponded to a poor performance. An explanation could be that some ATCos did not always recognize this when answering the questions. We mark these questions in the following tables in blue as the blue “OP” indicates in
Table 10. It should be pointed out again, that we have transformed the answers already before presenting them in the table, so that negative differences mean “better with ASRU”.
4.2.3. Bedford Workload Scale
Table 11 displays the results from the Bedford Workload Scale after performing the
t-test, as described previously.
Medium,
Heavy, and
Both represent the corresponding results for the scenarios used during the validation trials. Columns indicated by
SE show the results with sequence effects. Columns with
NSE show the results after compensating for the sequence effects.
The average and peak workload change for ATCos in the M scenario ranged from [−0.33 to −0.49]. Thus, the average and peak workloads were lower with ASRU support. In the H scenario, the differences ranged from [−0.17 to −0.33]. The highest value for the difference was calculated for the average workload. The statistical significance for the H scenario remained largely unchanged with or without considering sequence effects, ranging from 16.2% to 34.1%. For both scenarios together, the differences between with and without ASRU support fall within the interval of [−0.25 to −0.41], indicating an overall improved perceived workload (lower) when using ASRU support. Statistical significance mostly improved after compensating for sequence effects. The results for the peak workload are not statistically significant, because the α values are still greater than 10%.
Overall, the results from the Bedford Workload Scale demonstrate that applying ASRU support for ATCos improved the results by lowering the perceived workload. Greater effects were recorded for the M scenario compared to the H scenario. Nevertheless, the relative change was minor. Compensating for the sequence effects significantly improved the statistical significance in all cases. In addition to the results from the Bedford Workload Scale, direct feedback was also gathered from ATCos. This feedback is summarized below.
There are three areas of feedback regarding the factors contributing to high workload for ATCos: (1) HMI aspects that were related to ASRU, (2) HMI aspects that were not related to ASRU, and (3) simulation aspects such as the amount of traffic, the simulation-pilots, and the requirement to enter all clearances into the system.
Regarding “HMI aspects that were related to ASRU”, the ATCos identified areas for improvement in the radar label interaction, such as reduced scrolling, using drop-down menus for inputs, and addressing issues with incorrect system inputs, especially if the callsign was wrongly recognized. However, some ATCos also acknowledged the potential usefulness of ASRU if they were more familiar with the new HMI. The aspect of “getting used to the HMI” was also the main criticism for the second feedback area, “HMI aspects that were not related to ASRU”. The differences between the TopSky system used in Vienna and the prototypic CWP in Braunschweig caused some difficulties, such as the unavailability of distance measuring or the number of required clicks for system input. Most of the feedback concerned the third area of simulation aspects, where ATCos faced a high traffic load in the high-density traffic scenario. This included radio frequency congestion due to many transmissions, different speed handling, sometimes uncommon flight profiles, a few inaccurate simulation-pilot inputs, and more traffic than they were accustomed to handling alone. The main difference may have been the requirement to enter all instructed commands into the ATC system, which the ATCos do not need to do in their usual system.
4.2.4. System Usability Scale (SUS)
Table 12 displays the results of the SUS after performing a
t-test, as described previously.
Medium,
Heavy, and
Both represent the corresponding results for the scenarios used during the validation trials. Columns indicated by
SE show the results with the sequence effects. Columns with
NSE show the results after compensating for the sequence effects.
The results from the SUS assessment show the highest changes in the M runs when comparing runs with and without ASRU support, which range between 0.22 and −1.46. Thus, in most reported cases, the ASRU support enabled a better usability of the system. Statistical significance (p-value) ranged between 3 × 10−8% and −50%. For the M runs, in three cases, a p-value larger than |20%| was reported (bold framed cells) after compensating for the sequence effects, which indicates no statistical significance. For the H scenario, the differences ranged from [−1.4 to 0.70]. In one case (question 4), the p-value of −1.8% indicated that the results were statistically significance and indicate a better performance without ASRU support. Row 4 indicates that “I think that I would need the support of a technical person to be able to use this system”. The same effect can be seen for that question, when analyzing the results of the t-tests for both scenarios combined, since the experience with the given system was relatively low compared to their general working experience with the TopSky system. However, when all 10 questions (row “summary”) were combined, the results indicated that the overall system had a higher usability while using the ASRU support during the common ATC task. The statistical significance was very high, with an average value of 8 × 10−5.
4.2.5. Controller Acceptance Rating Scale (CARS)
Table 13 shows the results of the CARS analysis.
Medium,
Heavy, and
Both represent the corresponding results for the scenarios used during the validation trials. Columns indicated by
SE show the results with sequence effects. Columns with
NSE show the results after compensating the sequence effects.
The CARS results show that for each scenario (M and H) as well as when combining both scenarios (Both), the differences were between −1.12 (Heavy) and −1.36 (Both) on the 10-point scale after compensating for sequence effects. This suggests that the ATCo acceptance increased with the usage of ASRU support compared to simulation runs without ASRU support. The p-values for all three cases were below 5%, indicating that the null hypothesis is invalid and there is statistical significance with the usage of ASRU support.
4.2.6. Situation Awareness for SHAPE (SASHA)
Table 14 shows the results of the SASHA analysis. SASHA is the first of three assessments from the SHAPE questionnaire, which analyses the situational awareness of ATCos.
Medium,
Heavy, and
Both represent the corresponding results for the scenarios used during the validation trials. Columns indicated by
SE show the results with sequence effects. Columns with
NSE show the results after compensating for the sequence effects.
The SASHA results show that for the M, H, and Both scenarios, the average differences were between −0.17 (Medium) and −0.33 (Heavy) after compensating for the sequence effects. This suggests that the situational awareness of the ATCos slightly increased across all scenarios when using the ASRU support during the simulation runs. The greatest positive impact on the ATCos’ situational awareness was recorded during the H scenario. The p-values after compensating for the sequence effects reduce for the Both scenarios combined (α = 1.8%) to below 5%. This indicates that the null hypothesis was invalid and the statistical significance improved with the use of the ASRU support. For the M scenario, the p-value after compensating for sequence effects was 8.6%, and for the H scenario, it was 5.3%. Here, the statistical significance was slightly improved with SECT. One possible explanation is that during the M scenarios, the ATCos had more time to verify their current planning process (situational awareness) and thus did not feel the need for any support system. However, during the H scenario, there was less time between different verbal ATC instructions to check their own planning process. In this case, the spare time obtained through the ASRU radar label input was valued even more, which improved the ATCos’ situational awareness.
4.2.7. SHAPE Automation Trust Index (SATI)
Table 15 shows the results of the SATI analysis. SATI was the second of three assessments from the SHAPE questionnaire, which analyzed the ATCos’ trust in the automated functions or systems.
Medium,
Heavy, and
Both represent the corresponding results for the scenarios used during the validation trials. Columns indicated by
SE show the results with sequence effects. Columns with
NSE show the results after compensating for the sequence effects.
The SATI results show that for the M scenario, H scenario, and the combined Both scenarios, the average difference ranged from −0.48 (Medium) to −1.12 (Heavy) after compensating for sequence effects. This suggests that he ATCos’ trust in the system increased when using the ASRU support compared to the simulation runs without ASRU support. The highest average difference was recorded during the H scenario. The p-value ranged below 5% for the H scenario (α = 0.2%) and Both scenarios (α = 0.5%), indicating that the null hypothesis was invalid and the usage of ASRU support increased the statistical significance. For the M scenario, the average p-value was greater than 10% (α = 17.0%), which indicates that no increase in trust could be achieved by using ASRU support. This applies before and after compensating for sequence effects. During the M scenario, the ATCos might have had enough time to explore the system and were not dependent on ASRU support. This effect could have decreased the statistical significance compared to the H scenario, where there was less time to create doubts and the system had to be used as implemented.
4.2.8. Assessing the Impact on Mental Workload (AIM)
Table 16 shows the results of the AIM analysis. AIM was the third of three assessments from the SHAPE questionnaire used in this study, which analyzed the ATCos’ mental workload experienced.
Medium,
Heavy, and
Both represent the corresponding results for the scenarios used during the validation trials. Columns indicated by
SE show the results with sequence effects. Columns with
NSE show the results after compensating for the sequence effects.
The AIM results show that for the M scenario, the average difference was 0.19 after compensating for sequence effects (row “Summary”, column “NSE”). This suggests that using the ASRU support increased the mental workload. For the H scenario and when combining both scenarios, the average difference ranged from −0.10 (Both) to −0.38 (Heavy) after compensating for sequence effects. These results indicate that the mental workload decreased during the simulation runs when using the ASRU support compared to the simulation runs without ASRU support.
The average p-value results for the M scenario (α = −27%) and when combining Both scenarios (α = 30%) were greater than |10%|. This indicates that no statistical significance could be achieved when using the ASRU support. For the H scenario, the average p-value was 2.5% after compensating for sequence effects. This indicates that for the H scenario, the null hypothesis was invalid and the mental workload was improved by using the ASRU support.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}