

Data-Driven Modeling of Air Traffic Controllers’ Policy to Resolve Conflicts



Abstract
:1. Introduction
1.1. Related Work
1.2. Contributions
- It specifies the problem of learning the ATCO policy as a supervised imitation learning task. Considering specific types of resolution actions that may be applied in the en route phase of flights at the tactical phase of operations, this results in a classification task.
- It studies alternative AI/ML methods to learn models of ATCOs’ behavior with respect to the formulation proposed.
- It evaluates the proposed AI/ML methods using real-world data, addressing the challenges to imitating ATCOs adequately.
2. Materials and Methods
2.1. Problem Specification
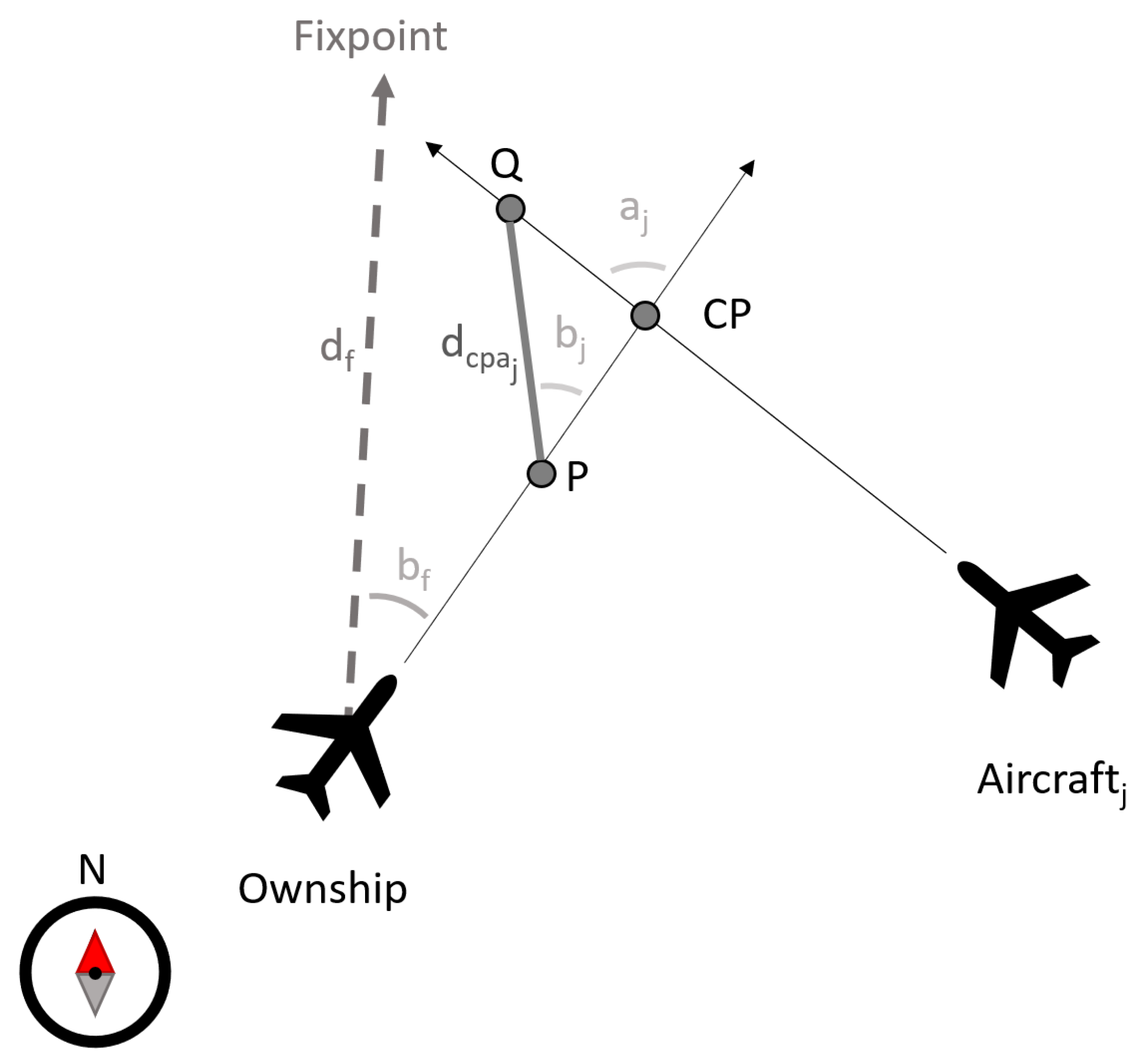
2.1.1. Definitions
- The aircraft have not crossed the crossing point;
- The tracks of the aircraft cross in less than minutes;
- The horizontal distance at the CPA is less than ;
- The time to the CPA is less than ;
- Aircraft altitude difference at the current time point is less than ft.
2.1.2. Modeling the ATCOs Policy
- Predicting at any trajectory point whether the ATCOs would issue a resolution action;
- Representing the ATCO policy, predicting the resolution action the ATCOs would decide, if any.
2.2. Learning the ATCOs Policy
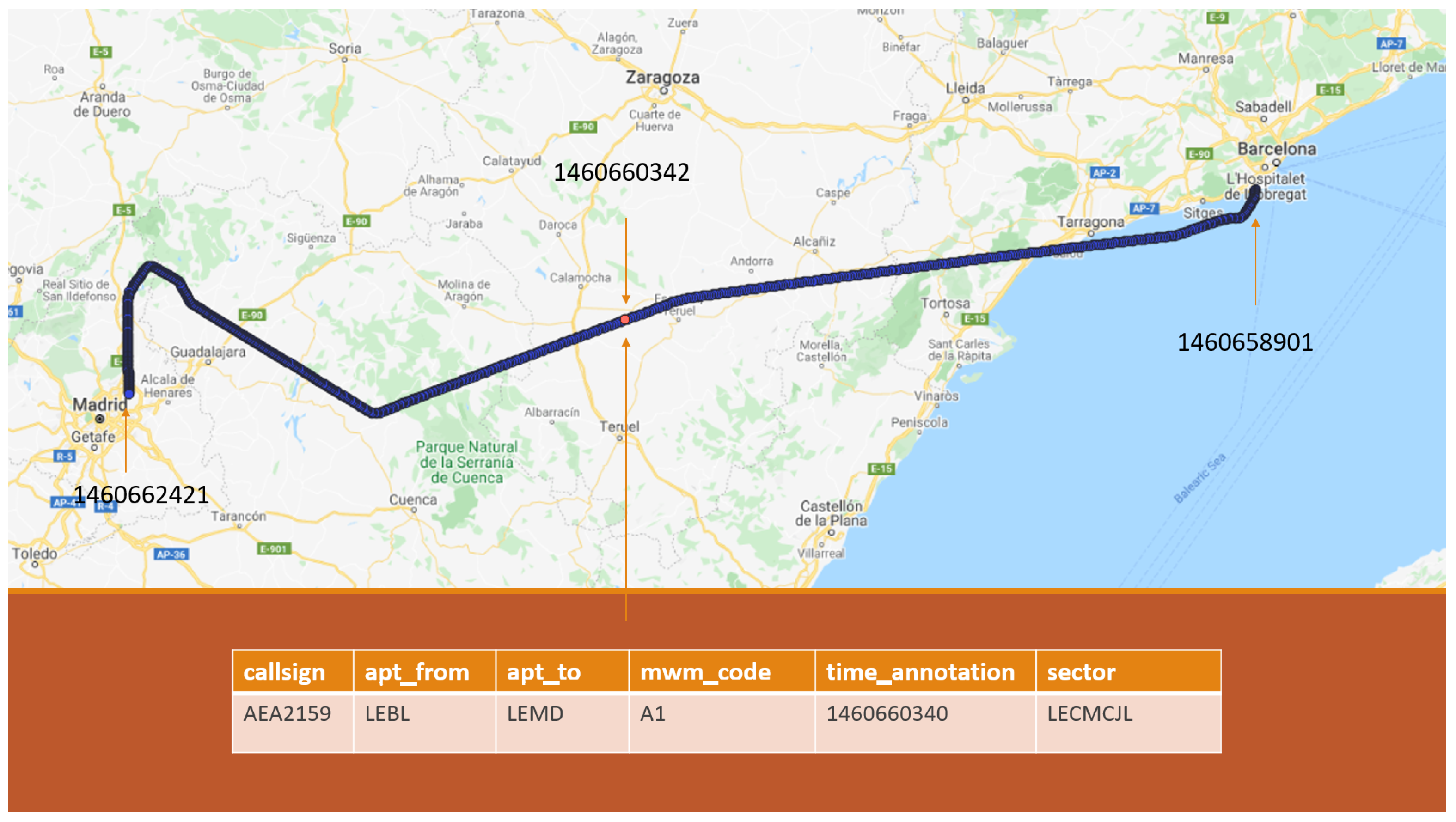
2.2.1. Data Sources
- .callsign = T.callsign
- .departure_airport = T.departure_airport
- .destination_airport = T.destination_airport
- Timestamp of the first T point ≤ timestamp of ≤ timestamp of the last T point.
2.2.2. Detection of Conflicts, States, and ATCOs’ Resolution Actions

- -
- : “Speed change resolution action”
- -
- : “Direct to waypoint resolution action”
- -
- : “Radar vectoring resolution action”
2.2.3. Learning the ATCO Policy
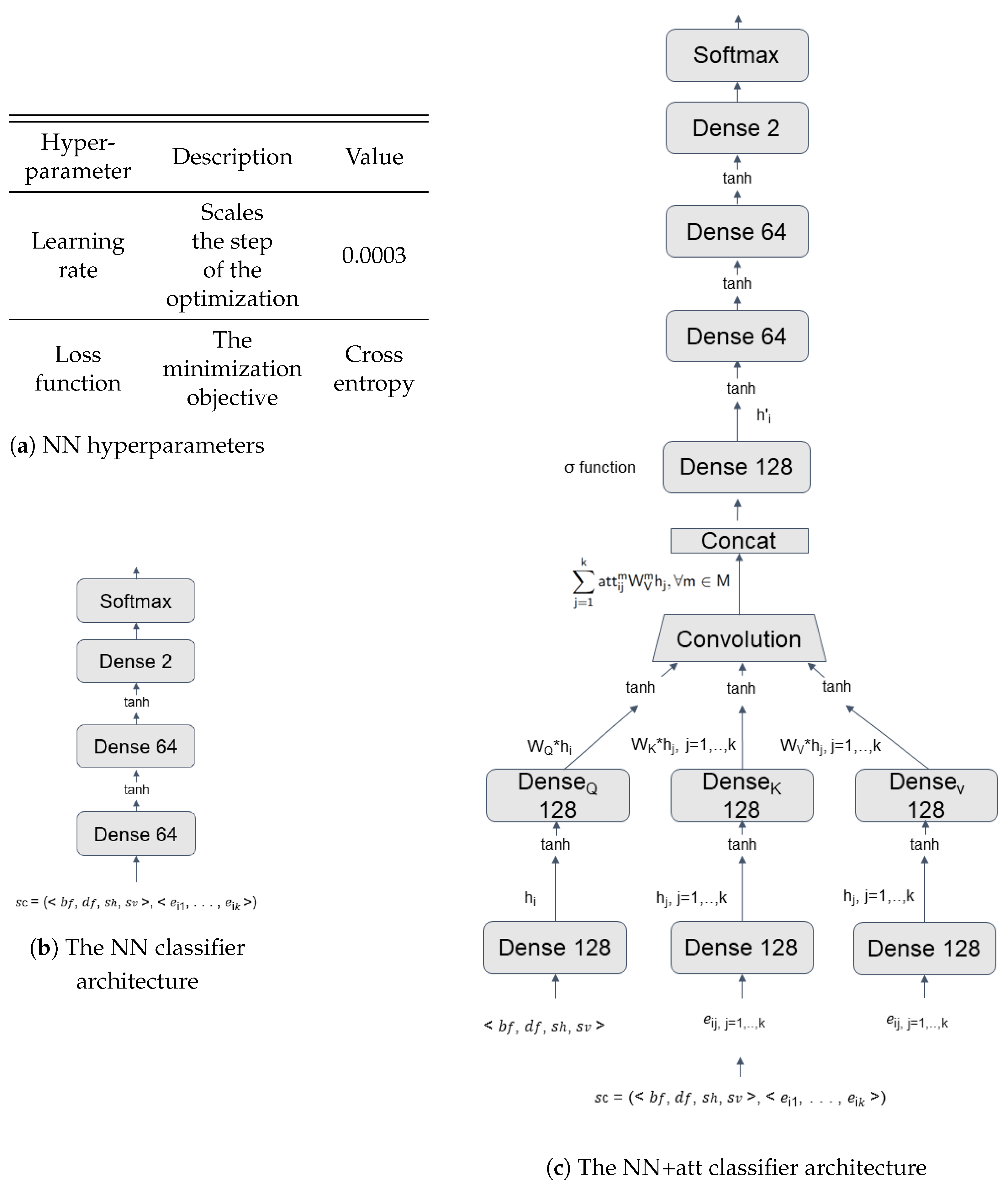
Neural Networks
Random Forest and Gradient Tree Boosting
3. Results
3.1. Experimental Setting
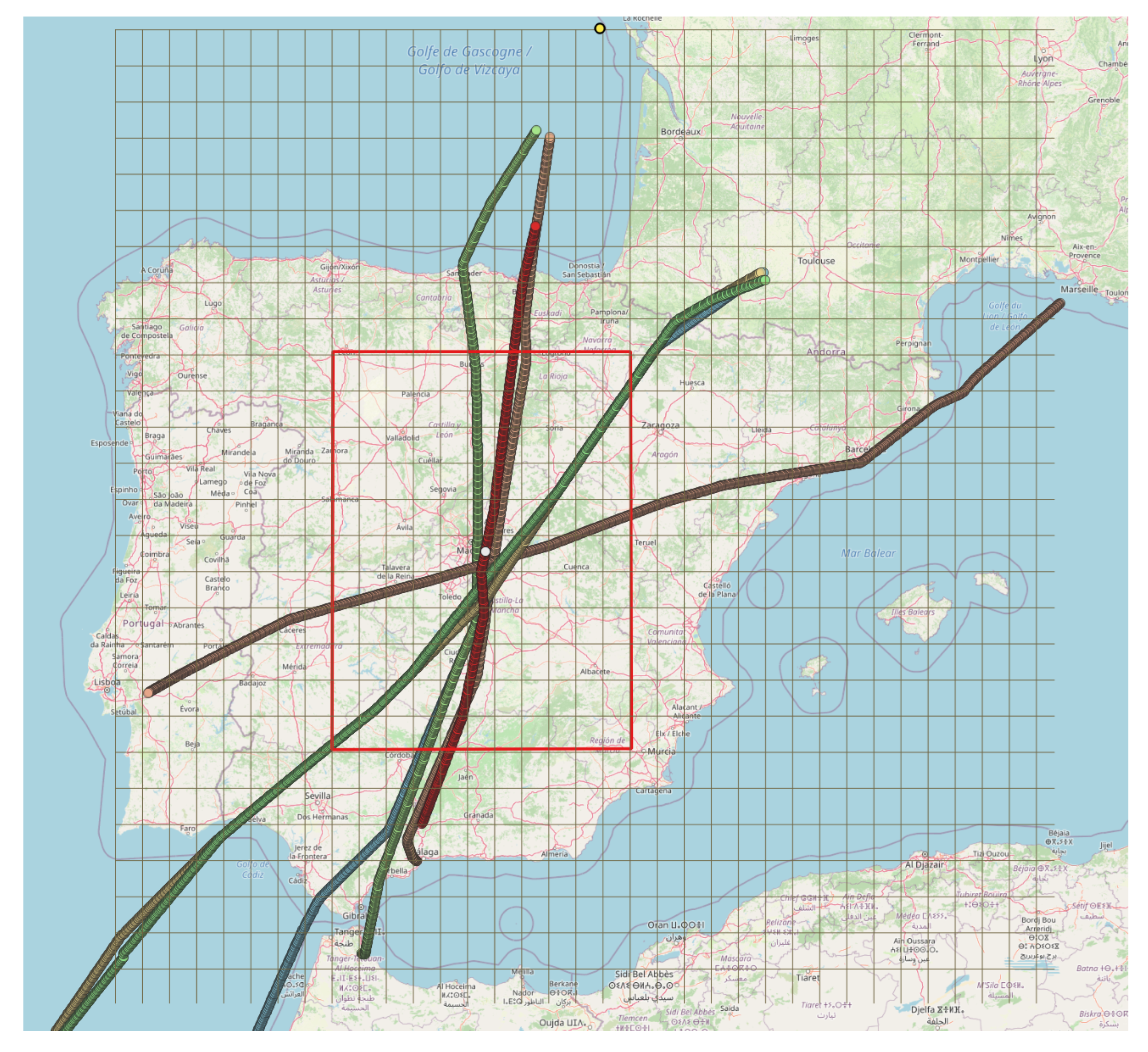
3.2. Datasets and Pre-Processing
3.3. Experimental Results
4. Discussion
- All methods have difficulty in predicting the resolution action type accurately.
- The number of samples might be small, especially for training NN models.
- As discussed in Section 2.2.3, we deal with historical data that do not demonstrate the conflicts occurred; thus, it is likely that the labels (in our case, historical ATCO resolution action types) of revealed conflicts are noisy.
5. Conclusions
- It specifies a formulation of learning the ATCO policy problem as a classification task;
- It studies enhanced AI/ML methods to learn models of ATCO policy from real-world historical datasets;
- It evaluates the proposed AI/ML methods using real-world data.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- NextGen. Available online: https://www.faa.gov/nextgen (accessed on 2 June 2023).
- SESAR Joint Undertaking. Available online: https://www.sesarju.eu/ (accessed on 2 June 2023).
- International Civil Aviation Organization. Annex 11—Air Traffic Services; International Civil Aviation Organization: Montreal, QC, Canada, 2001. [Google Scholar]
- International Civil Aviation Organization. Air Traffic Management-Procedures for Air Navigation Services (Doc 4444); International Civil Aviation Organization: Montreal, QC, Canada, 2007. [Google Scholar]
- Rodríguez, R.; Olbés, A. D2.1 TAPAS Use Cases Description, TAPAS SESAR-ER4-01-2019 Project, Edition 00.01.01. 2020. Available online: https://tapas-atm.eu/wp-content/uploads/2021/06/D2.1_TAPAS-Use-Cases-Description_Ed_00.01.01.pdf (accessed on 2 June 2023).
- Westin, C.; Borst, C.; Kampen, E.J.; Nunes, T.M.M.; Boonsong, S.; Hilburn, B.; Cocchioni, M.; Bonelli, S. Personalized and Transparent AI Support for ATC Conflict Detection and Resolution: An Empirical Study. In Proceedings of the 12th SESAR Innovation Days, Budapest, Hungary, 5–8 December 2022. [Google Scholar]
- Bastas, A.; Vouros, G. Data-driven prediction of Air Traffic Controllers reactions to resolving conflicts. Inf. Sci. 2022, 613, 763–785. [Google Scholar] [CrossRef]
- Ribeiro, M.; Ellerbroek, J.; Hoekstra, J. Review of conflict resolution methods for manned and unmanned aviation. Aerospace 2020, 7, 79. [Google Scholar] [CrossRef]
- Islami, A.; Chaimatanan, S.; Delahaye, D. Large-Scale 4D Trajectory Planning. In Air Traffic Management and Systems II: Selected Papers of the 4th ENRI International Workshop, 2015; Institute, Electronic Navigation Research, Ed.; Springer: Tokyo, Japan, 2017; pp. 27–47. [Google Scholar] [CrossRef]
- Dougui, N.; Delahaye, D.; Puechmorel, S.; Mongeau, M. A light-propagation model for aircraft trajectory planning. J. Glob. Optim. 2013, 56, 873–895. [Google Scholar] [CrossRef] [Green Version]
- Durand, N.; Gotteland, J.B. Genetic Algorithms Applied to Air Traffic Management. In Metaheuristics for Hard Optimization: Simulated Annealing, Tabu Search, Evolutionary and Genetic Algorithms, Ant Colonies,… Methods and Case Studies; Springer: Berlin/Heidelberg, Germany, 2006; pp. 277–306. [Google Scholar] [CrossRef]
- Srivatsa, M.; Ganti, R.; Chu, L.; Christiansson, M.; Nilsson, J.; Rydell, S.; Josefsson, B. Towards AI-based Air Traffic Control. In Proceedings of the ATM Seminar 2021, Virtual Event, 20–23 September 2021. [Google Scholar]
- Ayhan, S.; Costas, P.; Samet, H. Prescriptive analytics system for long-range aircraft conflict detection and resolution. In Proceedings of the 26th ACM SIGSPATIAL, Seattle, WA, USA, 6–9 November 2018; pp. 239–248. [Google Scholar] [CrossRef]
- Pham, D.T.; Tran, N.P.; Goh, S.K.; Alam, S.; Duong, V. Reinforcement learning for two-aircraft conflict resolution in the presence of uncertainty. In Proceedings of the 2019 IEEE-RIVF, Danang, Vietnam, 20–22 March 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Pham, D.T.; Tran, N.P.; Alam, S.; Duong, V.; Delahaye, D. A machine learning approach for conflict resolution in dense traffic scenarios with uncertainties. In Proceedings of the ATM Seminar 2019, Vienna, Austria, 17–21 June 2019. [Google Scholar]
- Dalmau, R.; Allard, E. Air Traffic Control using message passing neural networks and multi-agent reinforcement learning. In Proceedings of the 10th SESAR Innovation Days, Virtual Event, 7–10 December 2020; pp. 7–10. [Google Scholar]
- Ghosh, S.; Laguna, S.; Lim, S.H.; Wynter, L.; Poonawala, H. A deep ensemble multi-agent reinforcement learning approach for air traffic control. arXiv 2020, arXiv:2004.01387. [Google Scholar] [CrossRef]
- Isufaj, R.; Sebastia, D.A.; Piera, M.A. Towards Conflict Resolution with Deep Multi-Agent Reinforcement Learning. In Proceedings of the ATM Seminar 2021, Virtual Event, 20–23 September 2021. [Google Scholar]
- Calvo-Fernández, E.; Perez-Sanz, L.; Cordero-García, J.M.; Arnaldo-Valdés, R.M. Conflict-free trajectory planning based on a data-driven conflict-resolution model. J. Guid. Control. Dyn. 2017, 40, 615–627. [Google Scholar] [CrossRef]
- Tran, N.P.; Pham, D.T.; Goh, S.K.; Alam, S.; Duong, V. An Intelligent Interactive Conflict Solver Incorporating Air Traffic Controllers’ Preferences Using Reinforcement Learning. In Proceedings of the IEEE Integrated Communications, Navigation and Surveillance Conference, Herndon, VA, USA, 9–11 April 2019; pp. 1–8. [Google Scholar] [CrossRef]
- van Rooijen, S.J.; Ellerbroek, J.; Borst, C.; van Kampen, E. Toward Individual-Sensitive Automation for Air Traffic Control Using Convolutional Neural Networks. J. Air Transp. 2020, 28, 105–113. [Google Scholar] [CrossRef]
- Erzberger, H. Automated conflict resolution for air traffic control. In Proceedings of the 25th International Congress of the Aeronautical Sciences, Hamburg, Germany, 3–8 September 2006; National Aeronautics and Space Administration, Ames Research Center: Mountain View, CA, USA, 2006. [Google Scholar]
- Bishop, C.M. Neural networks and their applications. Rev. Sci. Instrum. 1994, 65, 1803–1832. [Google Scholar] [CrossRef] [Green Version]
- Codevilla, F.; Santana, E.; López, A.M.; Gaidon, A. Exploring the limitations of behavior cloning for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9329–9338. [Google Scholar]
- Pomerleau, D.A. Alvinn: An autonomous land vehicle in a neural network. Adv. Neural Inf. Process. Syst. 1988, 1, 305–313. [Google Scholar]
- Amari, S.i. Backpropagation and stochastic gradient descent method. Neurocomputing 1993, 5, 185–196. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Bishop, C.M. Regularization and Complexity Control in Feed-Forward Networks; Aston University (General): Birmingham, UK, 1995. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 12 June 2023).
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Han, B.; Yao, J.; Niu, G.; Zhou, M.; Tsang, I.; Zhang, Y.; Sugiyama, M. Masking: A new perspective of noisy supervision. Adv. Neural Inf. Process. Syst. 2018, 31, 5836–5846. [Google Scholar]
- Xia, X.; Liu, T.; Han, B.; Gong, C.; Wang, N.; Ge, Z.; Chang, Y. Robust early learning: Hindering the memorization of noisy labels. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Ma, X.; Huang, H.; Wang, Y.; Romano, S.; Erfani, S.; Bailey, J. Normalized loss functions for deep learning with noisy labels. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 12–18 July 2020; pp. 6543–6553. [Google Scholar]
- Chen, P.; Ye, J.; Chen, G.; Zhao, J.; Heng, P.A. Beyond class-conditional assumption: A primary attempt to combat instance-dependent label noise. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 11442–11450. [Google Scholar]
- Nguyen, D.T.; Mummadi, C.K.; Ngo, T.P.N.; Nguyen, T.H.P.; Beggel, L.; Brox, T. Self: Learning to filter noisy labels with self-ensembling. arXiv 2019, arXiv:1910.01842. [Google Scholar]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Liaw, A.; Breiman, L. Using Random Forest to Learn Imbalanced Data; University of California: Berkeley, CA, USA, 2004; Volume 110, p. 24. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Value |
|---|---|---|
| The crossing time threshold. | 20 min | |
| Time to closest point of approach (CPA) threshold | 20 min | |
| The horizontal distance threshold between aircraft at the CPA. | 15 NM | |
| The vertical distance threshold. | 1000 ft below flight level (FL) 420, 2000 ft else |
| Hyperparameter | Description | RF Value | GTB Value |
|---|---|---|---|
| criterion | The function to measure the quality of a split. | gini | friedman mse |
| max_depth | The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure (containing one class only) or until all leaves contain less than min_samples_split samples. | None | 3 |
| min_samples_split | The minimum number of samples required to split an internal node. | 2 | 2 |
| min_samples_leaf | The minimum number of samples required to be at a leaf node. | 1 | 2 |
| min_weight_fraction_leaf | The minimum weighted fraction of the sum total of weights (of all the input samples) required to be at a leaf node. | 0 | 0 |
| max_features | The number of features to consider when looking for the best split. If “sqrt”, then max_features is equal to the square root of the total number of features. If None, then max_features is equal to the number of total features. | sqrt | None |
| max_leaf_nodes | Trees grown with max_leaf_nodes in best-first fashion. Best nodes are defined as a relative reduction in impurity. If None then unlimited number of leaf nodes. | None | None |
| min_impurity_decrease | A node will be split if this split induces a decrease in the impurity greater than or equal to this value. | 0 | 0 |
| ccp_alpha | Complexity parameter used for minimal cost-complexity pruning. The subtree with the largest cost complexity that is smaller than ccp_alpha will be chosen. When 0, no pruning is performed. | 0 | 0 |
| Hyperparameter | Description | Value |
|---|---|---|
| n_estimators | The number of trees in the ensemble. | 100 |
| bootstrap | Whether bootstrap samples are used when building trees. If False, the whole dataset is used to build each tree. | True |
| oob_score | Whether to use out-of-bag samples (samples that have not been used when bootstrapping) to estimate the generalization score. | False |
| class_weight | Weights associated with classes. If None, all classes are supposed to have weight one. | None |
| max_samples | If bootstrap is True, draw a number of samples from the training set to train each base estimator. If None, then draw a number of samples equal to the size of the training set. | None |
| random_state | Controls both the randomness of the bootstrapping of the samples used when building trees (if bootstrap=True) and the sampling of the features to consider when looking for the best split at each node (if max_features < total number of features). | None |
| Hyperparameter | Description | Value |
|---|---|---|
| n_estimators | The number of trees in the ensemble. | 100 |
| loss | The loss function to be optimized. | log_loss |
| learning rate | Shrinks the contribution of each tree. | 0.1 |
| subsample | The fraction of samples to be used for fitting the individual base learners. | 1 |
| init | An estimator that is used to compute the initial predictions. If None, the initial estimator predicts the classes’ priors. | None |
| validation_fraction | The proportion of training data to set aside as the validation set for early stopping. Only used if n_iter_no_change is set to an integer. | Not used |
| n_iter_no_change | Used to decide if early stopping will be used to terminate training when the validation score does not improve. If None, early stopping is disabled. | None |
| random_state | Controls the random seed given to each Tree estimator at each boosting iteration. In addition, it controls the random permutation of the features at each split. | None |
| tol | Tolerance for early stopping. When the loss is not improving by at least tol for n_iter_no_change iterations (if set to a number), the training stops. | 1 × 10−4 |
| Method | Dataset | Precision | Recall | f1-Score | MCC | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NN | train | ||||||||||
| test | |||||||||||
| NN+att | train | ||||||||||
| test | |||||||||||
| RF | train | ||||||||||
| test | |||||||||||
| GTB | train | ||||||||||
| test | |||||||||||
| Method | Dataset | Precision | Recall | f1-Score | MCC | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Balanced RF | train | ||||||||||
| test | |||||||||||
| NN+att+AP loss+augm | train | ||||||||||
| test | |||||||||||
| NN+att+SEAL+augm | train | ||||||||||
| test | |||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bastas, A.; Vouros, G.A. Data-Driven Modeling of Air Traffic Controllers’ Policy to Resolve Conflicts. Aerospace 2023, 10, 557. https://doi.org/10.3390/aerospace10060557
Bastas A, Vouros GA. Data-Driven Modeling of Air Traffic Controllers’ Policy to Resolve Conflicts. Aerospace. 2023; 10(6):557. https://doi.org/10.3390/aerospace10060557
Chicago/Turabian StyleBastas, Alevizos, and George A. Vouros. 2023. "Data-Driven Modeling of Air Traffic Controllers’ Policy to Resolve Conflicts" Aerospace 10, no. 6: 557. https://doi.org/10.3390/aerospace10060557
APA StyleBastas, A., & Vouros, G. A. (2023). Data-Driven Modeling of Air Traffic Controllers’ Policy to Resolve Conflicts. Aerospace, 10(6), 557. https://doi.org/10.3390/aerospace10060557