
Cognitive Load Assessment of Air Traffic Controller Based on SCNN-TransE Network Using Speech Data

Abstract
:1. Introduction
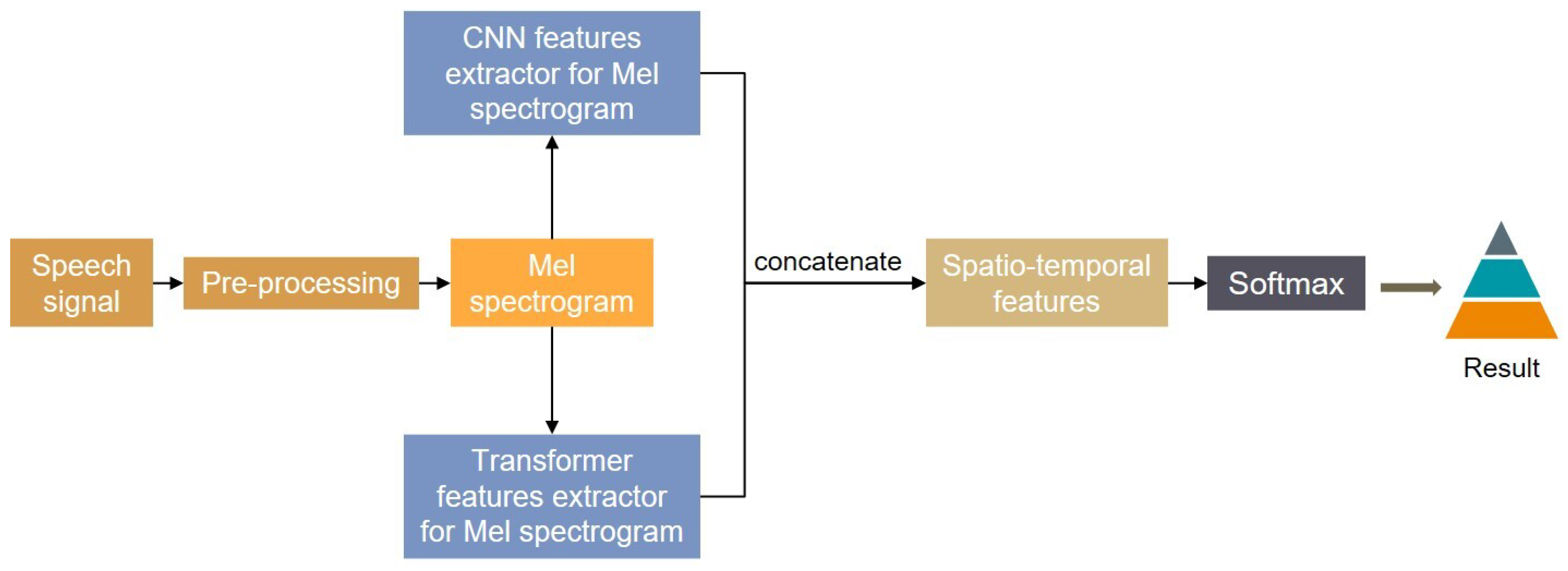
2. Architecture of Cognitive Load Assessment
- (1)
- Pre-processing of speech recordings: Endpoint recognition and segmentation are utilized to pre-process audio recordings.
- (2)
- Generation of Mel spectrogram: The dataset is obtained by further processing the audio signal, creating Mel spectrograms, and applying additive white Gaussian noise (AWGN) [51] enhanced data.
- (3)
- The CNN-TransE model is trained using the spatial features extracted by the CNN and the temporal features collected by the Transformers, which are concatenated into deep temporal features.
- (4)
- Classification: The stacked features are sent to the Softmax layer for identification.
3. Speech Data Processing
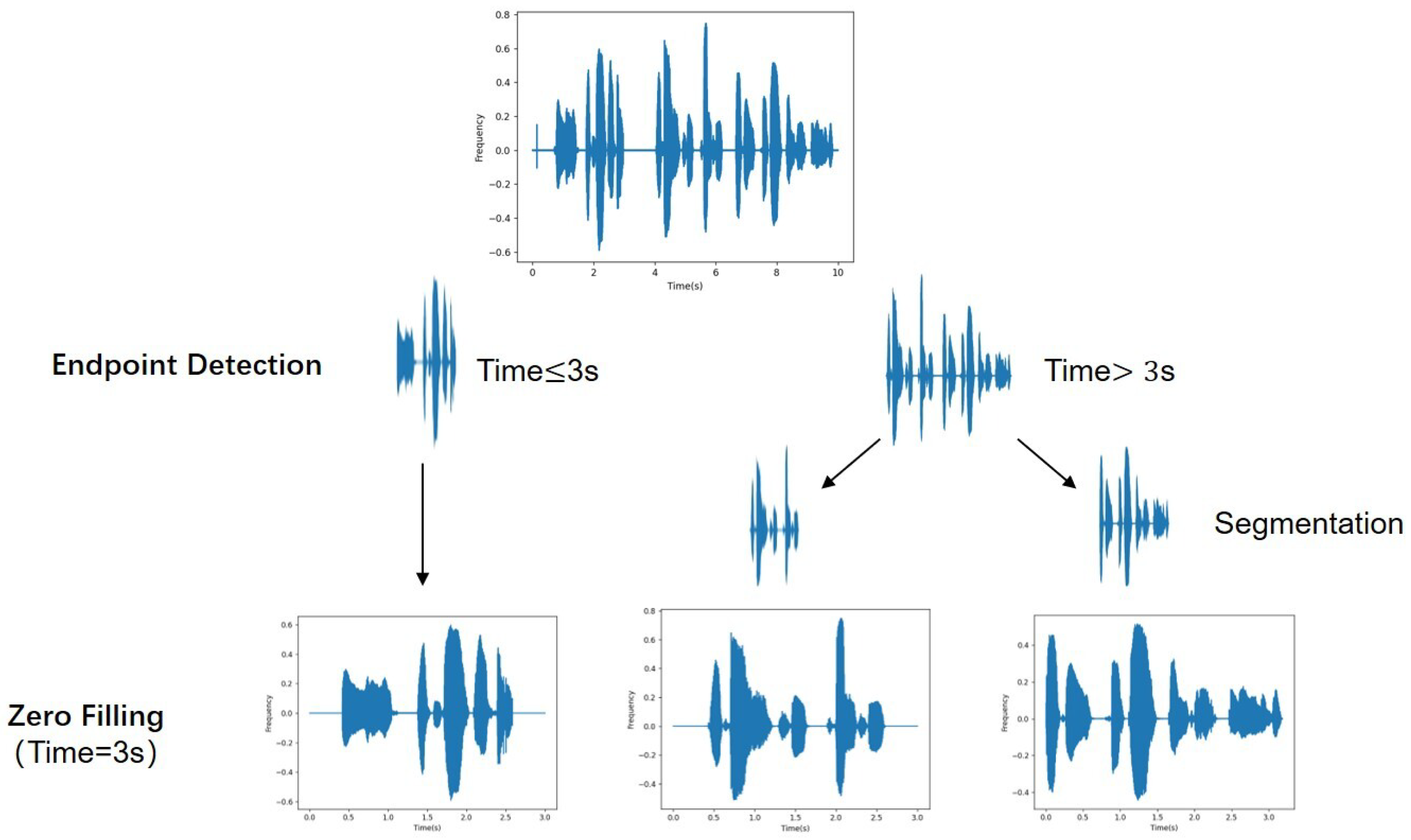
3.1. Endpoint Detection and Segmentation
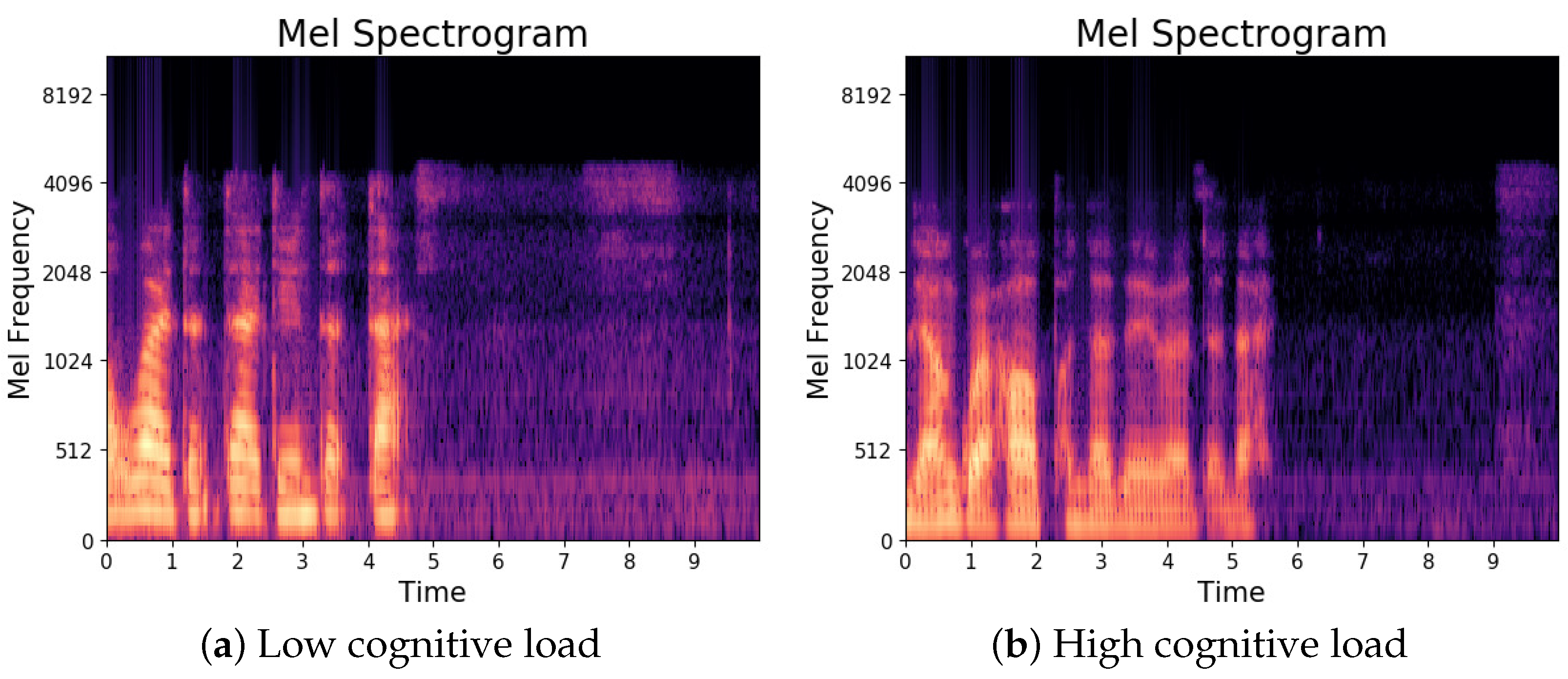
3.2. Generate Mel Spectrogram
- Pre-emphasis: Generally, the intensity of the high-frequency components in an audio signal is lower than that of the low-frequency components [54]. The purpose of signal pre-emphasis is to pass the signal through a high-pass filter, which can prevent a large difference in the intensity between the high-frequency and low-frequency components of the signal. The pre-emphasis filter plays a role in balancing the spectrum and improving the signal-to-noise ratio (SNR). In the time domain, perform the following with the signal :where represents the pre-weighted factor, usually in the range of 0.9∼1. and indicate the speech signal at time t and , respectively.
- Framing: After applying pre-emphasis, the signal needs to be segmented into short-term frames for the subsequent Fourier transform. The application of the Fourier transform necessitates input signal stability; however, the frequency of the speech signal varies with time. Consequently, the computation of the Fourier transform for the entire speech signal is meaningless. The speech signal is characterized as a short-time stationary signal where the frequency remains relatively stable over short time intervals. Therefore, it is essential to divide the speech signal into short-term frames and perform a Fourier transform on each frame individually to obtain a reliable estimation of the signal’s frequency distribution. The framing process is shown in Figure 3. An overlapping region should be established to reduce unnecessary changes in both the consecutive frames.
- Add windows: After dividing the signal into frames, to strengthen the continuity of neighboring frames and to minimize spectrum leakage, each frame is multiplied by a window function. The Hamming window is used in this paper, as follows:where , N is the window length. The constant parameter a offers distinct hamming windows with variations observed across different a values typically set at 0.46.
- FFT: Because it is often hard to figure out the properties of a signal in the time domain, the FFT of the signal can be used to convert it to the energy distribution in the frequency domain. Various energy distributions reflect various traits of speech [55]. Perform an N-point FFT to compute the frequency spectrum over each frame after windowing:where is the input speech signal; i symbolizes the number of time-domain frames; , N represents the number of points of the Fourier transform, and the value of N is usually 256 or 512. The power spectrum can be obtained by taking the magnitude squared and divided by the corresponding number of FFT points.
- Extract the Mel spectrogram by the Mel filter bank: Trigonometric filters can be employed to extract bands from the power spectrum using a predefined set of Mel scales. The combination of these frequency bands forms the Mel spectrogram. The Mel scale offers better discrimination at lower frequencies and is designed to imitate the non-linear sense of sound by the human ear [56]. Given the center frequency of each filter, the corresponding frequency response of each filter can be explicitly expressed as follows:
3.3. Additive White Gaussian Noise
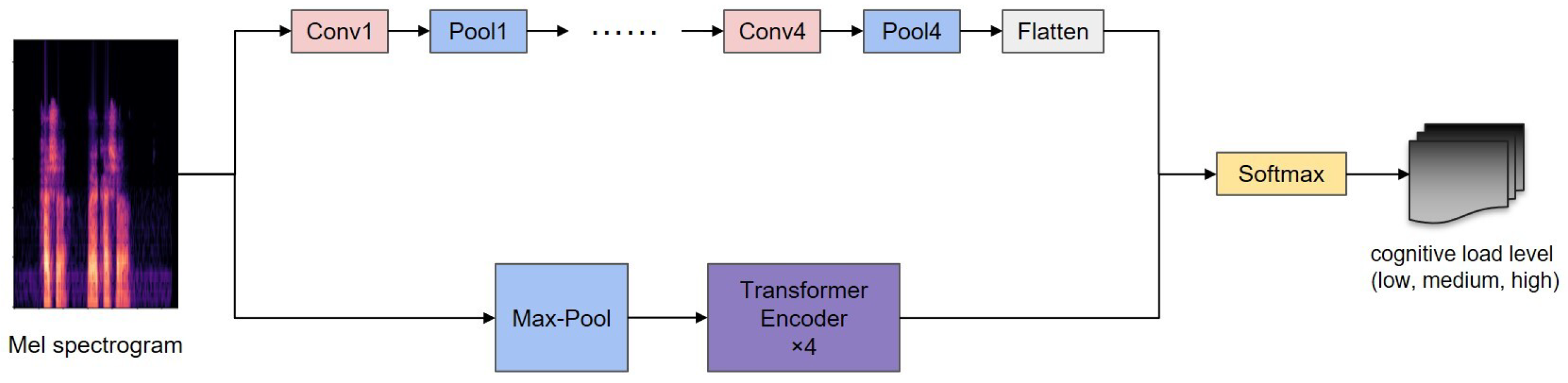
4. SCNN-TransE Network
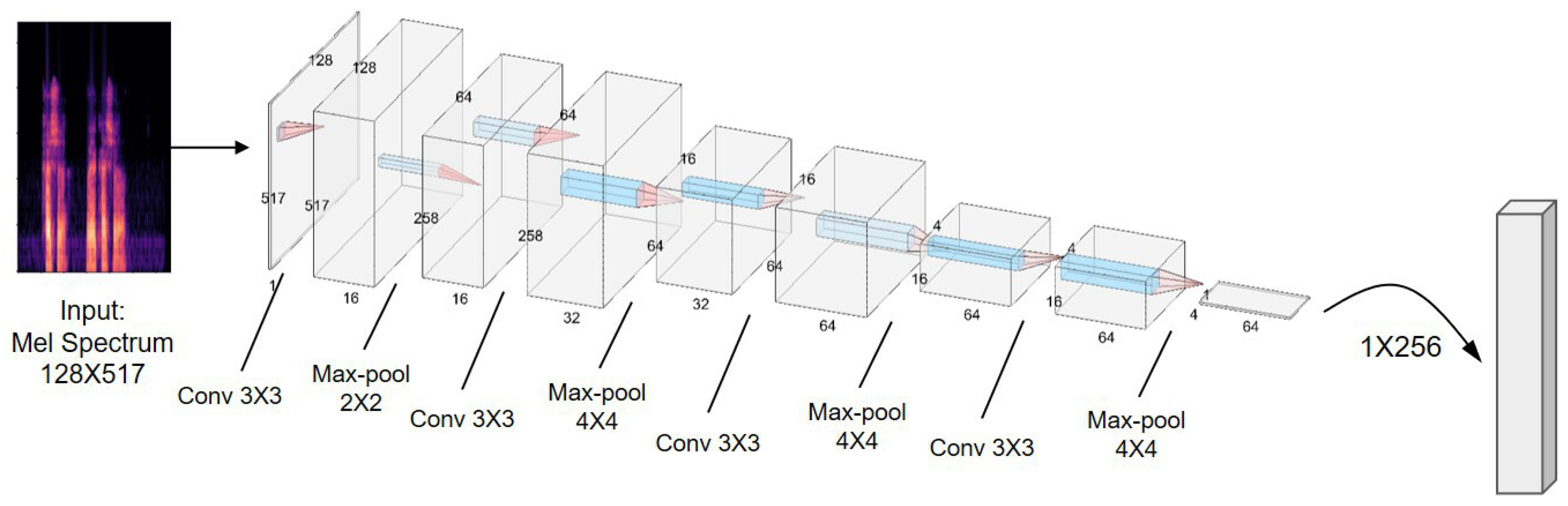
4.1. Stacked Convolutional Neural Network
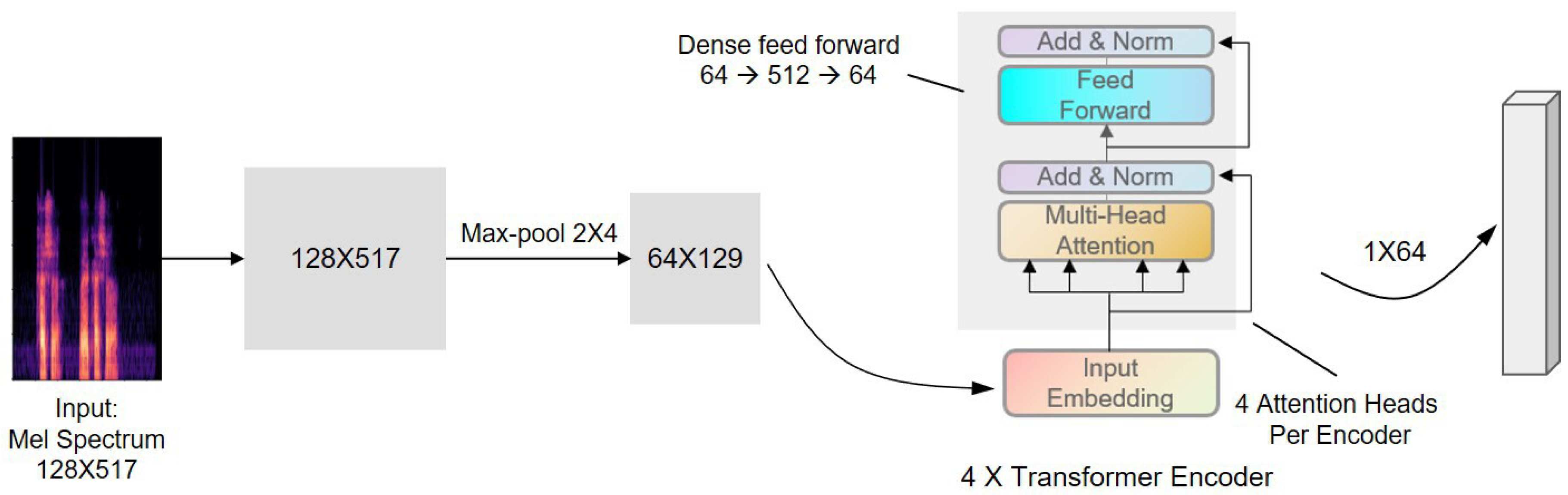
4.2. Transformer Encoder
5. Experiments and Results
5.1. Experiments Data
5.2. Parameter Setting
5.3. Evaluation Indexes
5.4. Result and Analysis
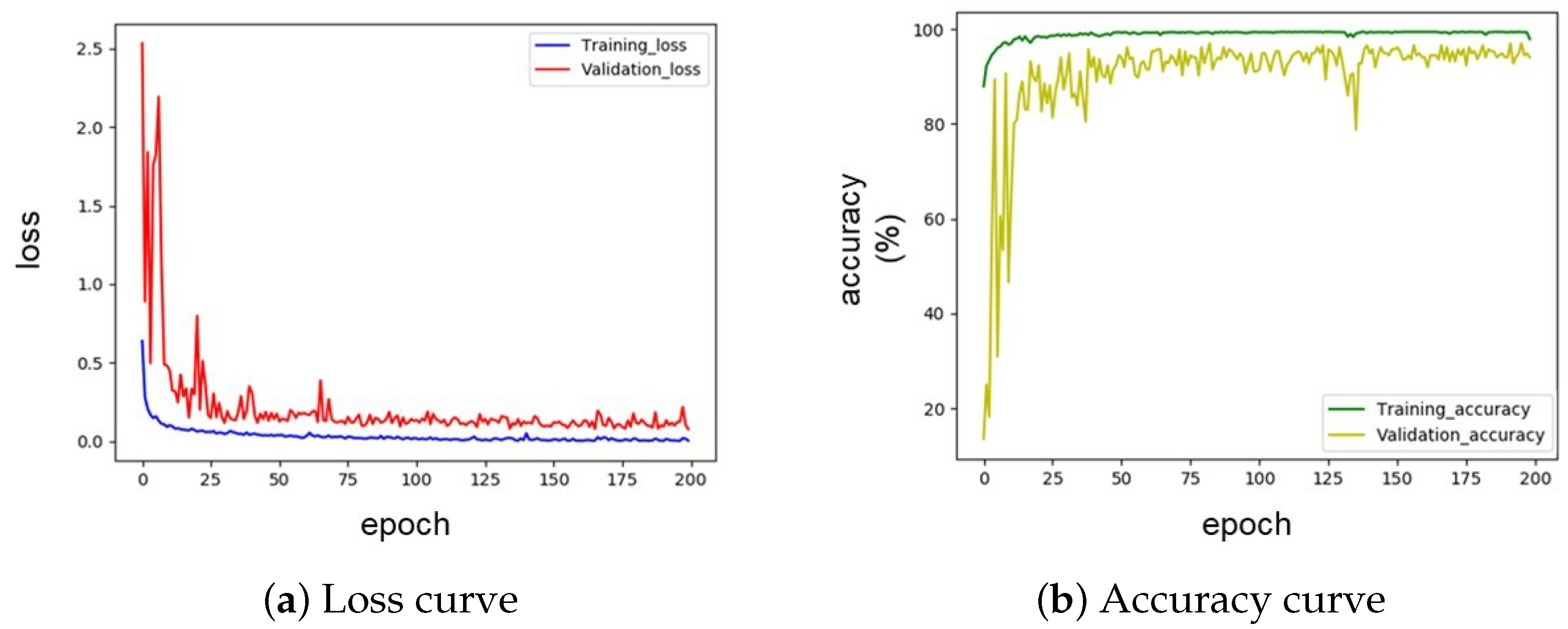
5.4.1. Algorithm Verification
5.4.2. Assessment of Cognitive Load
6. Conclusions
7. Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- de Sant, D.A.L.M.; de Hilal, A.V.G. The impact of human factors on pilots’ safety behavior in offshore aviation companies: A brazilian case. Saf. Sci. 2021, 140, 105272. [Google Scholar]
- Wu, Q.K.; Yao, D.K.; Zhao, G.H.; Zhu, T.T. Safety Analysis of Lateral Interval between Military Training Airspace and Civil Route. In Proceedings of the 2016 4th International Conference on Machinery, Materials and Information Technology Applications, Xi’an, China, 10–11 December 2016; pp. 1021–1028. [Google Scholar]
- Leso, V.; Fontana, L.; Caturano, A.; Vetrani, I.; Fedele, M.; Iavicoli, I. Impact of shift work and long working hours on worker cognitive functions: Current evidence and future research needs. Int. J. Environ. Res. Public Health 2021, 18, 6540. [Google Scholar] [CrossRef] [PubMed]
- Sandoval, C.; Stolar, M.N.; Hosking, S.G.; Jia, D.; Lech, M. Real-Time Team Performance and Workload Prediction from Voice Communications. IEEE Access 2022, 10, 78484–78492. [Google Scholar] [CrossRef]
- Sweller, J. Cognitive load theory, learning difficulty, and instructional design. Learn. Instr. 1994, 4, 295–312. [Google Scholar] [CrossRef]
- O’Donnell, R.D. Workload assessment methodology. Cogn. Process. Perform. 1986, 2, 1–49. [Google Scholar]
- Cain, B. A Review of the Mental Workload Literature; Defense Technical Information Center: Toronto, ON, Canada, 2007. [Google Scholar]
- Galy, E.; Cariou, M.; Mélan, C. What is the relationship between mental workload factors and cognitive load types? Int. J. Psychophysiol. 2012, 83, 269–275. [Google Scholar] [CrossRef]
- Icao, D. 9426-AN/924 Air Traffic Services Planning Manual. Int. Civ. Aviat. Organ. 1984, 2, 126–128. [Google Scholar]
- Pawlak, W.; Goel, V.; Rothenberg, D.; Brinton, C. Comparison of algorithms for the dynamic resectorization of airspace. In Proceedings of the Guidance, Navigation, and Control Conference and Exhibit, Boston, MA, USA, 10–12 August 1998; p. 4106. [Google Scholar]
- Laudeman, I.V.; Shelden, S.G.; Branstrom, R.; Brasil, C. Dynamic Density: An Air Traffic Management Metric; Technical Report; NASA: Washington, DC, USA, 1998. [Google Scholar]
- Zrnic, D.S. Estimation of spectral moments for weather echoes. IEEE Trans. Geosci. Electron. 1979, 17, 113–128. [Google Scholar] [CrossRef]
- Reid, G.B.; Nygren, T.E. The subjective workload assessment technique: A scaling procedure for measuring mental workload. In Advances in Psychology; Elsevier: Amsterdam, The Netherlands, 1988; Volume 52, pp. 185–218. [Google Scholar]
- Manning, C.A.; Mills, S.H.; Fox, C.; Pfleider, E.; Mogilka, H.J. Investigating the Validity of Performance and Objective Workload Evaluation Research (POWER); Technical Report; FAA: Oklahoma, OK, USA, 2001. [Google Scholar]
- Manning, C.A.; Mills, S.H.; Fox, C.M.; Pfleiderer, E.M.; Mogilka, H.J. Using Air Traffic Control Taskload Measures and Communication Events to Predict Subjective Workload; Technical Report; FAA: Oklahoma, OK, USA, 2002. [Google Scholar]
- Paas, F.; Renkl, A.; Sweller, J. Cognitive load theory and instructional design: Recent developments. Educ. Psychol. 2003, 38, 1–4. [Google Scholar] [CrossRef]
- Tsai, Y.F.; Viirre, E.; Strychacz, C.; Chase, B.; Jung, T.P. Task performance and eye activity: Predicting behavior relating to cognitive workload. Aviat. Space Environ. Med. 2007, 78, B176–B185. [Google Scholar]
- Bernhardt, K.A.; Poltavski, D.; Petros, T.; Ferraro, F.R.; Jorgenson, T.; Carlson, C.; Drechsel, P.; Iseminger, C. The effects of dynamic workload and experience on commercially available EEG cognitive state metrics in a high-fidelity air traffic control environment. Appl. Ergon. 2019, 77, 83–91. [Google Scholar] [CrossRef]
- Vukovic, M.; Sethu, V.; Parker, J.; Cavedon, L.; Lech, M.; Thangarajah, J. Estimating cognitive load from speech gathered in a complex real-life training exercise. Int. J. Hum. Comput. Stud. 2019, 124, 116–133. [Google Scholar] [CrossRef]
- Radüntz, T.; Fürstenau, N.; Mühlhausen, T.; Meffert, B. Indexing mental workload during simulated air traffic control tasks by means of dual frequency head maps. Front. Physiol. 2020, 11, 300. [Google Scholar] [CrossRef] [Green Version]
- Radüntz, T.; Mühlhausen, T.; Freyer, M.; Fürstenau, N.; Meffert, B. Cardiovascular biomarkers’ inherent timescales in mental workload assessment during simulated air traffic control tasks. Appl. Psychophysiol. Biofeedback 2021, 46, 43–59. [Google Scholar] [CrossRef]
- Abur, D.; MacPherson, M.K.; Shembel, A.C.; Stepp, C.E. Acoustic measures of voice and physiologic measures of autonomic arousal during speech as a function of cognitive load in older adults. J. Voice 2021, 31, 504-e1. [Google Scholar] [CrossRef]
- Zhang, J.; Hua, Y.; Gu, J.; Chen, Y.; Yin, Z. Dynamic hierarchical learning of temporal-spatial-spectral EEG features with transformers for cognitive workload estimation. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Heifei, China, 25–27 July 2022; pp. 7112–7117. [Google Scholar]
- Magnusdottir, E.H.; Johannsdottir, K.R.; Majumdar, A.; Gudnason, J. Assessing Cognitive Workload Using Cardiovascular Measures and Voice. Sensors 2022, 22, 6894. [Google Scholar] [CrossRef]
- Wu, N.; Sun, J. Fatigue Detection of Air Traffic Controllers Based on Radiotelephony Communications and Self-Adaption Quantum Genetic Algorithm Optimization Ensemble Learning. Appl. Sci. 2022, 12, 10252. [Google Scholar] [CrossRef]
- Gallardo Antolín, A.; Montero Martínez, J.M. A saliency-based attention LSTM model for cognitive load classification from speech. In Proceedings of the 20th Annual Conference of the International Speech Communication Association (ISCA 2019), Graz, Austria, 15–19 September 2019; pp. 216–220. [Google Scholar]
- Mijić, I.; Šarlija, M.; Petrinović, D. MMOD-COG: A database for multimodal cognitive load classification. In Proceedings of the 2019 11th International Symposium on Image and Signal Processing and Analysis (ISPA), Dubrovnik, Croatia, 23–25 September 2019; pp. 15–20. [Google Scholar]
- Lee, J. Task complexity, cognitive load, and L1 speech. Appl. Linguist. 2019, 40, 506–539. [Google Scholar] [CrossRef]
- Larmuseau, C.; Cornelis, J.; Lancieri, L.; Desmet, P.; Depaepe, F. Multimodal learning analytics to investigate cognitive load during online problem solving. Br. J. Educ. Technol. 2020, 51, 1548–1562. [Google Scholar] [CrossRef]
- Ramakrishnan, P.; Balasingam, B.; Biondi, F. Cognitive load estimation for adaptive human–machine system automation. In Learning Control; Elsevier: Amsterdam, The Netherlands, 2021; pp. 35–58. [Google Scholar]
- Biondi, F.N.; Saberi, B.; Graf, F.; Cort, J.; Pillai, P.; Balasingam, B. Distracted worker: Using pupil size and blink rate to detect cognitive load during manufacturing tasks. Appl. Ergon. 2023, 106, 103867. [Google Scholar] [CrossRef]
- Miller, M.; Holley, S.; Mrusek, B.; Weiland, L. Assessing cognitive processing and human factors challenges in NextGen air traffic control tower team operations. In Proceedings of the Advances in Human Factors and Systems Interaction: AHFE 2020 Virtual Conference on Human Factors and Systems Interaction, San Diego, CA, USA, 16–20 July 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 289–295. [Google Scholar]
- Sloboda, J.; Lammert, A.; Williamson, J.; Smalt, C.; Mehta, D.D.; Curry, C.; Quatieri, T. Vocal biomarkers for cognitive performance estimation in a working memory task. Proc. Interspeech 2018, 5, 1756–1760. [Google Scholar]
- Herms, D.I.R. Effective Speech Features for Cognitive Load Assessment: Classification and Regression; Technische Universität: Chemnitz, Germany, 2019. [Google Scholar]
- Zhao, Z.; Li, Q.; Cummins, N.; Liu, B.; Wang, H.; Tao, J.; Schuller, B. Hybrid Network Feature Extraction for Depression Assessment from Speech. In Proceedings of the Interspeech 2020, ISCA-INST Speech Communication Association, Shanghai, China, 25–29 October 2020; pp. 4956–4960. [Google Scholar]
- Bhattacharjee, M.; Prasanna, S.M.; Guha, P. Speech/music classification using features from spectral peaks. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1549–1559. [Google Scholar] [CrossRef]
- Vukovic, M.; Stolar, M.; Lech, M. Cognitive load estimation from speech commands to simulated aircraft. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1011–1022. [Google Scholar] [CrossRef]
- Li, J.; Zhang, X.; Huang, L.; Li, F.; Duan, S.; Sun, Y. Speech Emotion Recognition Using a Dual-Channel Complementary Spectrogram and the CNN-SSAE Neutral Network. Appl. Sci. 2022, 12, 9518. [Google Scholar] [CrossRef]
- Borwankar, S.; Verma, J.P.; Jain, R.; Nayyar, A. Improvise approach for respiratory pathologies classification with multilayer convolutional neural networks. Multimed. Tools Appl. 2022, 81, 39185–39205. [Google Scholar] [CrossRef]
- Liu, H.; Wang, X.; Wei, Y.; Shao, W.; Liono, J.; Salim, F.D.; Deng, B.; Du, J. ProMETheus: An intelligent mobile voice meeting minutes system. In Proceedings of the 15th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, New York, NY, USA, 5–7 November 2018; pp. 392–401. [Google Scholar]
- Shewalkar, A.; Nyavanandi, D.; Ludwig, S.A. Performance evaluation of deep neural networks applied to speech recognition: RNN, LSTM and GRU. J. Artif. Intell. Soft Comput. Res. 2019, 9, 235–245. [Google Scholar] [CrossRef] [Green Version]
- Gallardo-Antolín, A.; Montero, J.M. External attention LSTM models for cognitive load classification from speech. In Proceedings of the Statistical Language and Speech Processing: 7th International Conference, SLSP 2019, Ljubljana, Slovenia, 14–16 October 2019; pp. 139–150. [Google Scholar]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control. 2019, 47, 312–323. [Google Scholar]
- Yu, Y.; Kim, Y.J. Attention-LSTM-attention model for speech emotion recognition and analysis of IEMOCAP database. Electronics 2020, 9, 713. [Google Scholar] [CrossRef]
- Beddiar, D.R.; Jahan, M.S.; Oussalah, M. Data expansion using back translation and paraphrasing for hate speech detection. Online Soc. Netw. Media 2021, 24, 100153. [Google Scholar] [CrossRef]
- Gaballah, A.; Tiwari, A.; Narayanan, S.; Falk, T.H. Context-aware speech stress detection in hospital workers using Bi-LSTM classifiers. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 8348–8352. [Google Scholar]
- Sharma, Y.; Singh, B.K. One-dimensional convolutional neural network and hybrid deep-learning paradigm for classification of specific language impaired children using their speech. Comput. Methods Programs Biomed. 2022, 213, 106487. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A.; Epps, J.; Eyben, F.; Ringeval, F.; Marchi, E.; Zhang, Y. The interspeech 2014 computational paralinguistics challenge: Cognitive & physical load, multitasking. In Proceedings of the INTERSPEECH 2014, 15th Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Liao, J.; Li, H.; Feng, A.; Wu, X.; Luo, Y.; Duan, X.; Ni, M.; Li, J. Domestic pig sound classification based on TransformerCNN. Appl. Intell. 2022, 53, 4907–4923. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, G.; Xu, Y.; Li, J.; Zhao, Z. Learning Mutual Correlation in Multimodal Transformer for Speech Emotion Recognition. In Proceedings of the Interspeech, Brno, Czechia, 30 August–3 September 2021; pp. 4518–4522. [Google Scholar]
- Delon, J.; Desolneux, A. A patch-based approach for removing impulse or mixed Gaussian-impulse noise. SIAM J. Imaging Sci. 2013, 6, 1140–1174. [Google Scholar] [CrossRef]
- Jalil, M.; Butt, F.A.; Malik, A. Short-time energy, magnitude, zero crossing rate and autocorrelation measurement for discriminating voiced and unvoiced segments of speech signals. In Proceedings of the 2013 The International Conference on Technological Advances in Electrical, Electronics and Computer Engineering (TAEECE), Konya, Turkey, 9–11 May 2013; pp. 208–212. [Google Scholar]
- Guo, Q.; Li, N.; Ji, G. A improved dual-threshold speech endpoint detection algorithm. In Proceedings of the 2nd International Conference on Computer and Automation Engineering (ICCAE), Singapore, 26–28 February 2010; Volume 2, pp. 123–126. [Google Scholar]
- Von Helversen, D.; Von Helversen, O. Recognition of sex in the acoustic communication of the grasshopper Chorthippus biguttulus (Orthoptera, Acrididae). J. Comp. Physiol. A 1997, 180, 373–386. [Google Scholar] [CrossRef]
- Kamiloğlu, R.G.; Fischer, A.H.; Sauter, D.A. Good vibrations: A review of vocal expressions of positive emotions. Psychon. Bull. Rev. 2020, 27, 237–265. [Google Scholar] [CrossRef] [Green Version]
- Hidaka, S.; Lee, Y.; Wakamiya, K.; Nakagawa, T.; Kaburagi, T. Automatic Estimation of Pathological Voice Quality Based on Recurrent Neural Network Using Amplitude and Phase Spectrogram. In Proceedings of the INTERSPEECH, 2020, Shanghai, China, 25–29 October 2020; pp. 3880–3884. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Michel, P.; Levy, O.; Neubig, G. Are sixteen heads really better than one? Adv. Neural Inf. Process. Syst. 2019, 32, 14037–14047. [Google Scholar]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [Green Version]
- Latif, S.; Qayyum, A.; Usman, M.; Qadir, J. Cross lingual speech emotion recognition: Urdu vs. western languages. In Proceedings of the 2018 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 17–19 December 2018; pp. 88–93. [Google Scholar]
- Pichora-Fuller, M.K.; Dupuis, K. Toronto emotional speech set (TESS). Sch. Portal Dataverse 2020, 1, 2020. [Google Scholar]
- Ahmed, M.R.; Islam, S.; Islam, A.M.; Shatabda, S. An ensemble 1D-CNN-LSTM-GRU model with data augmentation for speech emotion recognition. Expert Syst. Appl. 2023, 218, 119633. [Google Scholar]
- Krishnan, P.T.; Joseph Raj, A.N.; Rajangam, V. Emotion classification from speech signal based on empirical mode decomposition and non-linear features: Speech emotion recognition. Complex Intell. Syst. 2021, 7, 1919–1934. [Google Scholar] [CrossRef]
- Chatterjee, R.; Mazumdar, S.; Sherratt, R.S.; Halder, R.; Maitra, T.; Giri, D. Real-time speech emotion analysis for smart home assistants. IEEE Trans. Consum. Electron. 2021, 67, 68–76. [Google Scholar] [CrossRef]
- Patel, N.; Patel, S.; Mankad, S.H. Impact of autoencoder based compact representation on emotion detection from audio. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 1–19. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotion | Anger | Happy | Neutral | Sad | Disgust | Surprise | Fearful | Calm | Average |
|---|---|---|---|---|---|---|---|---|---|
| Ravdess | 73.68 | 84.21 | 80.00 | 68.42 | 89.47 | 78.95 | 63.16 | 84.21 | 77.62 |
| URDU | 90.00 | 80.00 | 80.00 | 100.00 | - | - | - | - | 87.50 |
| TESS | 100.00 | 100.00 | 100.00 | 100.00 | 97.50 | 97.50 | 100.00 | - | 99.29 |
| Literature | Years | Features | Classifier | Accuracy |
|---|---|---|---|---|
| Krishnan et al. [67] | 2021 | entropy feature | SVM | 81.67% |
| Krishnan et al. [67] | 2021 | entropy feature | LDA | 93.30% |
| Chatterjee et al. [68] | 2021 | MFCC | CNN | 95.79% |
| Patel et al. [69] | 2022 | MFCC | Autoencoder + CNN | 96.00% |
| Ahmed et al. [66] | 2023 | MFCC, Mel spectrogram, ZCR and chromagram | CNN + LSTM + Gated recurrent unit | 99.46% |
| Our Method | - | Mel spectrogram | CNN + Transformer encoder | 99.29% |
| Method | KNN | AdaBoost | RF | SVM | SCNN-LSTM-Attention | SCNN-TransE |
|---|---|---|---|---|---|---|
| Accuracy (%) | 73.11 | 75.63 | 84.03 | 91.60 | 94.96 | 97.48 |
| Macro-F1 (%) | 55.82 | 67.62 | 75.00 | 88.32 | 93.810 | 97.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Yang, H.; Wu, Z.; Wu, X. Cognitive Load Assessment of Air Traffic Controller Based on SCNN-TransE Network Using Speech Data. Aerospace 2023, 10, 584. https://doi.org/10.3390/aerospace10070584
Yang J, Yang H, Wu Z, Wu X. Cognitive Load Assessment of Air Traffic Controller Based on SCNN-TransE Network Using Speech Data. Aerospace. 2023; 10(7):584. https://doi.org/10.3390/aerospace10070584
Chicago/Turabian StyleYang, Jing, Hongyu Yang, Zhengyuan Wu, and Xiping Wu. 2023. "Cognitive Load Assessment of Air Traffic Controller Based on SCNN-TransE Network Using Speech Data" Aerospace 10, no. 7: 584. https://doi.org/10.3390/aerospace10070584
APA StyleYang, J., Yang, H., Wu, Z., & Wu, X. (2023). Cognitive Load Assessment of Air Traffic Controller Based on SCNN-TransE Network Using Speech Data. Aerospace, 10(7), 584. https://doi.org/10.3390/aerospace10070584