
Safety Aspects of Supporting Apron Controllers with Automatic Speech Recognition and Understanding Integrated into an Advanced Surface Movement Guidance and Control System

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
1.2.1. Early Work on Speech Recognition in Air Traffic Control
1.2.2. Speech Recognition and Understanding Applications in Air Traffic Control
1.2.3. Related Work for Pre-Filling Flight Strips and Radar Labels
1.3. Paper Structure
2. Materials and Methods
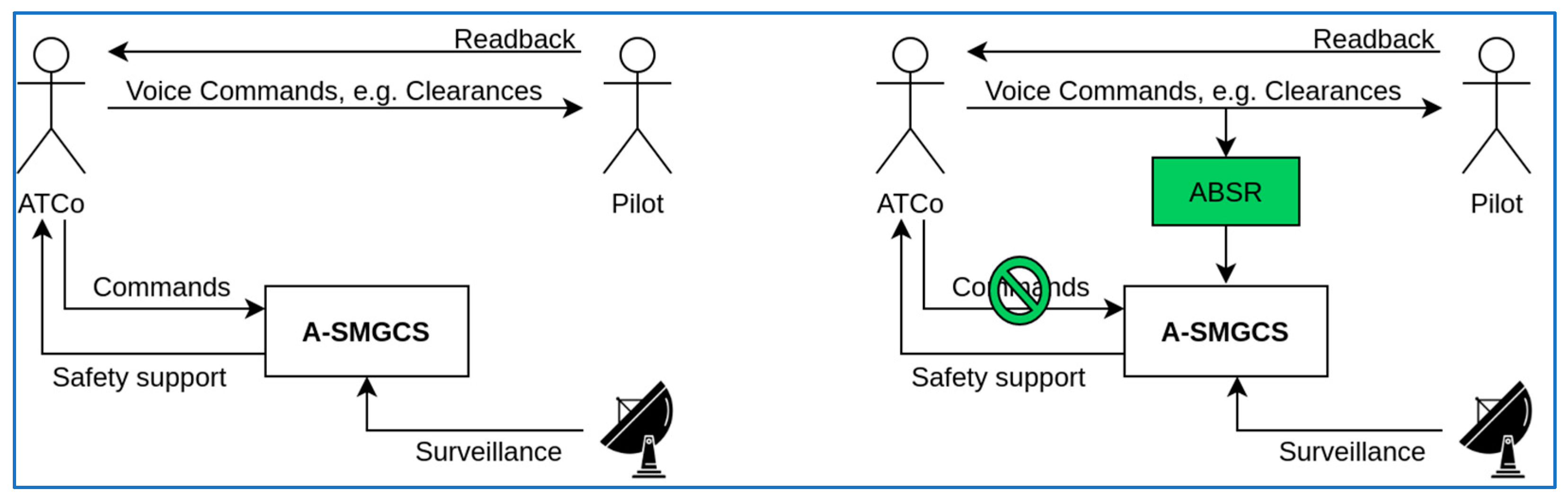
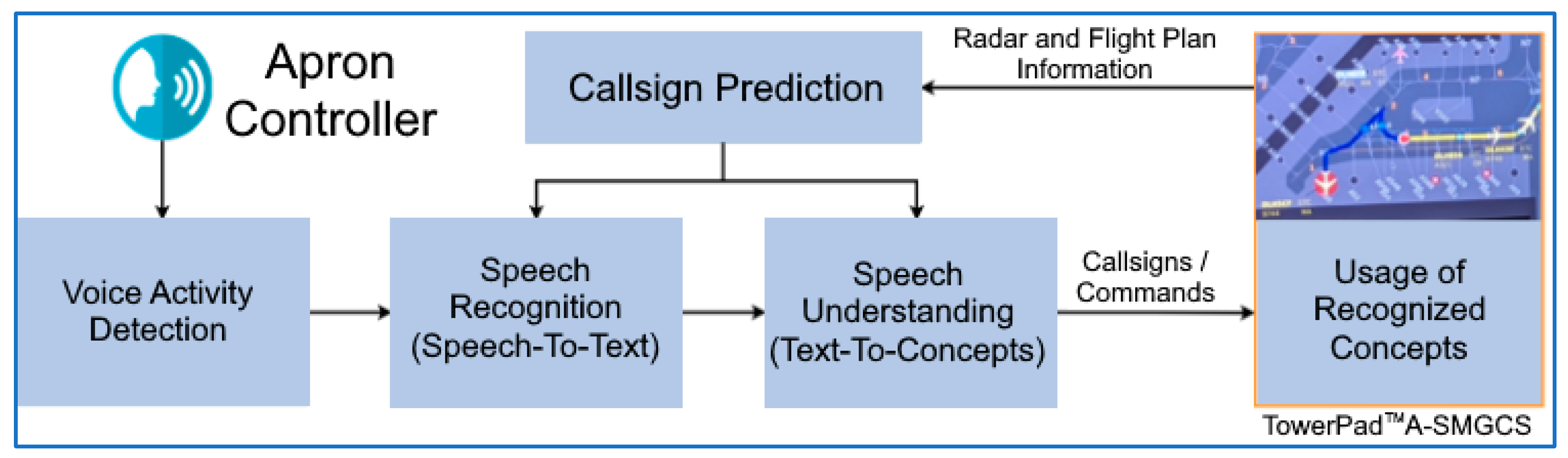
2.1. Application Use Case of Supporting Apron Controllers
- Commands given via voice by the controller to the pilot are recorded as an audio data stream (A/D conversion of utterances).
- The audio stream is divided into sections by detecting individual transmissions in the audio data.
- Speech-to-text (S2T) transformation is applied on the resulting audio sections. S2T is based on neural networks trained with freely available data as well as with domain-specific recorded audio data for the target environment.
- Relevant ATC concepts are automatically extracted from the S2T transcription using rule-based algorithms on a previously defined ontology and traffic data fed from the A-SMGCS.
- High-level system commands are generated from the extracted ATC instructions using rules algorithmically interpreted from operational necessities according to the current traffic situation and fed into the system.
- The changes to the system state resulting from the high-level system commands are presented to the human operators.
- Human operators can correct or undo the automatic inputs.
- The apron controller is continuously speaking to the pilots with some gaps in between, e.g., “… to seven five seven from the left… lufthansa four two two good morning behind opposite air france three twenty one continue november eight lima hold short lima six … austrian one foxtrot behind the passing”. The gaps occur either because no further action is required or due to the verbal response of the (simulation) pilot, which is not available to the ABSR.
- The audio stream sections are detected, and one continuous transmission could then be “lufthansa four two two good morning behind opposite air france three twenty one continue november eight lima hold short lima six”.
- Let us assume that the result of S2T contains some errors and results in the word sequence: “lufthansa four to two good morning behind opposite air frans three twenty one continue november eight lima holding short lima six” (errors marked in bold).
- The relevant ATC instruction, being extracted by ABSR even with the errors from S2T, would be:
- DLH422 GREETING;
- DLH422 GIVE_WAY AFR A321 OPPOSITE;
- DLH422 CONTINUE TAXI;
- DLH422 TAXI VIA N8 L;
- DLH422 HOLD_SHORT L6.
- The GREETING is ignored by the A-SMGCS. For the GIVE_WAY instruction the A-SMGCS may find out that the A321 from the opposite is the callsign AFR2AD. A symbol is generated in the human machine interface (HMI) of the apron controllers (and the simulation pilots), showing that DLH422 is waiting until the AFR2AD has passed. The continue statement is executed after the give way situation is resolved. The route along the taxiways N8 and L is shown. A hold short (stop) is displayed before taxiway L6.
- In summary, the following visual output is shown to the apron controller:
- The aircraft symbol of DLH422 is highlighted;
- A GIVE_WAY symbol between the two aircrafts;
- The taxi route via N8 and L;
- A HOLD_SHORT symbol (stop) at L6.
- The apron controller can accept or reject all three above options or can change some or all of them.
- The callsign addressed in the controller’s radio call is highlighted at the corresponding aircraft symbol in the A-SMGCS (DLH422 in the above example).
- Once the commands to the pilot are fully uttered, they are converted into corresponding system commands that would otherwise have to be manually entered, e.g., a taxi route.
- The result of the command input is displayed to the controller (and/or simulation pilot) in the A-SMGCS. Wherever possible, the visualization corresponds to the same visualization that would have resulted from a manual entry.
- Special case: If an error in the data processing causes the wrong command to be sent and therefore the wrong effects (or none) to be displayed, the human operator must manually correct the command or enter it into the system. Depending on the type of command, dedicated buttons are offered for this purpose.
2.2. Application Development
- Technical and operational requirements were determined;
- Software and interfaces were developed, implemented, and tested;
- Progress was validated by users in realistic operational scenarios in Fraport’s training simulator;
- Results were analyzed to derive new requirements.
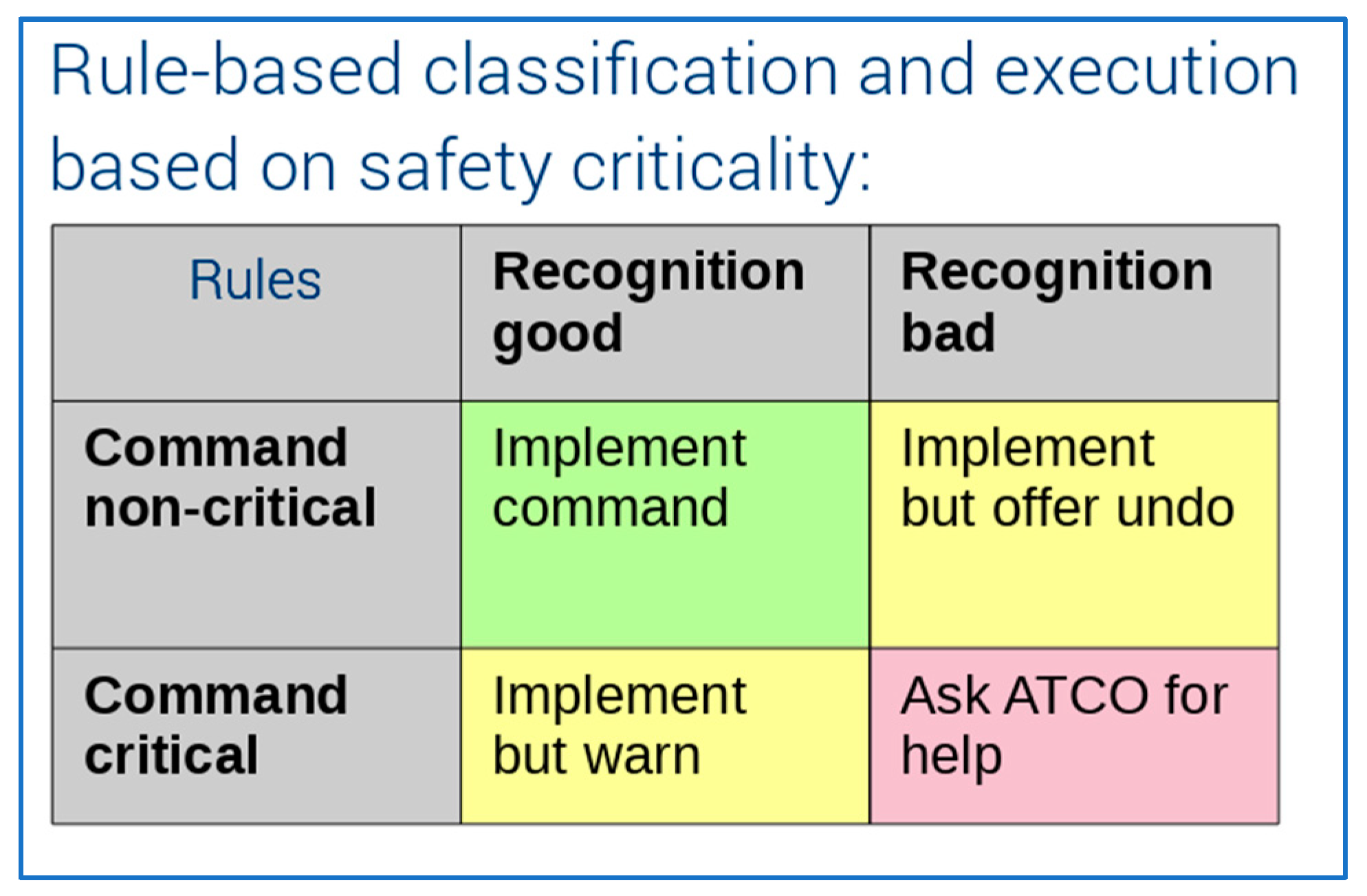
2.3. Safety Considerations
- Safety-criticality;
- Criticality for the work of the controller;
- Risk due to potential software development errors.
3. Description of Evaluation System
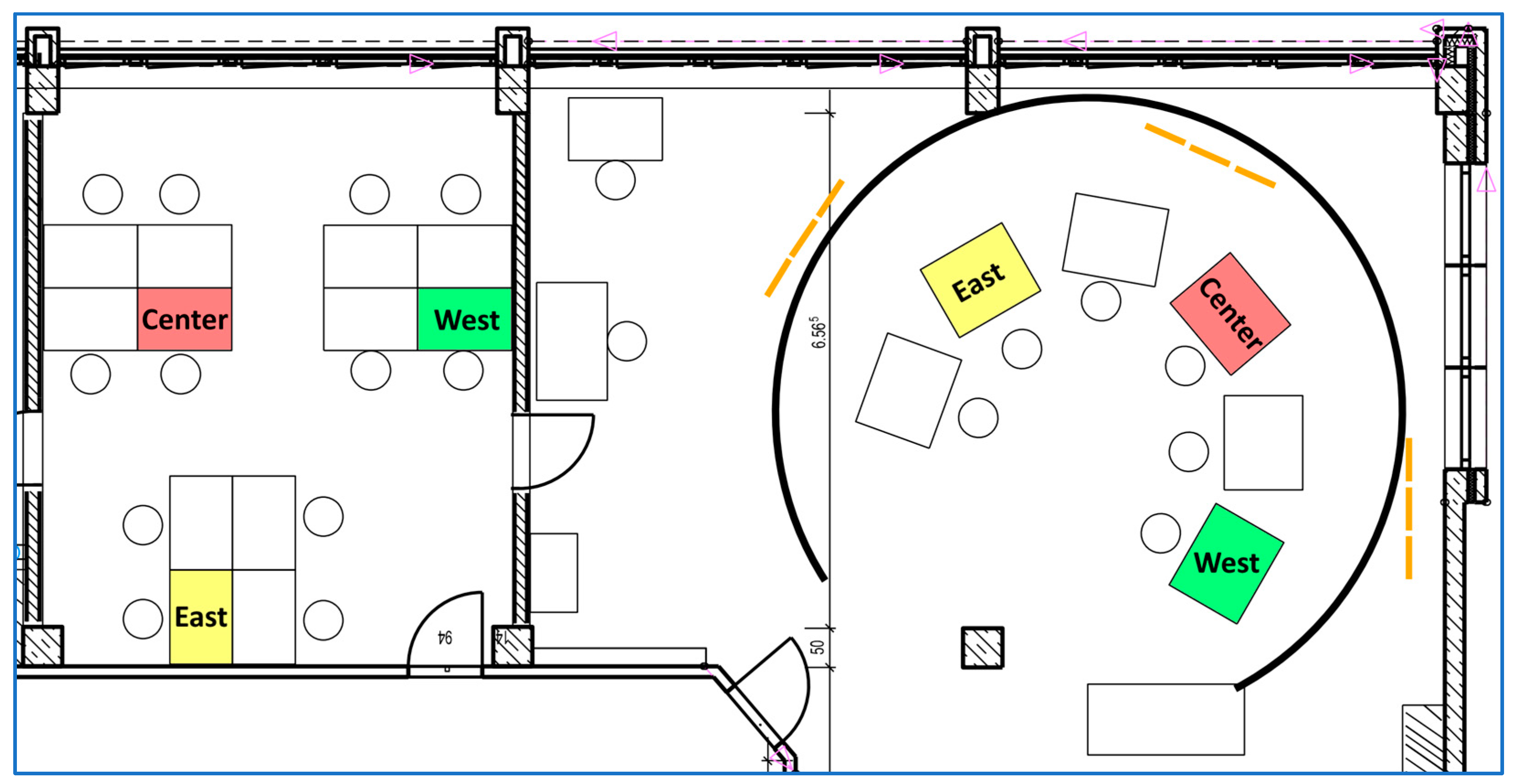
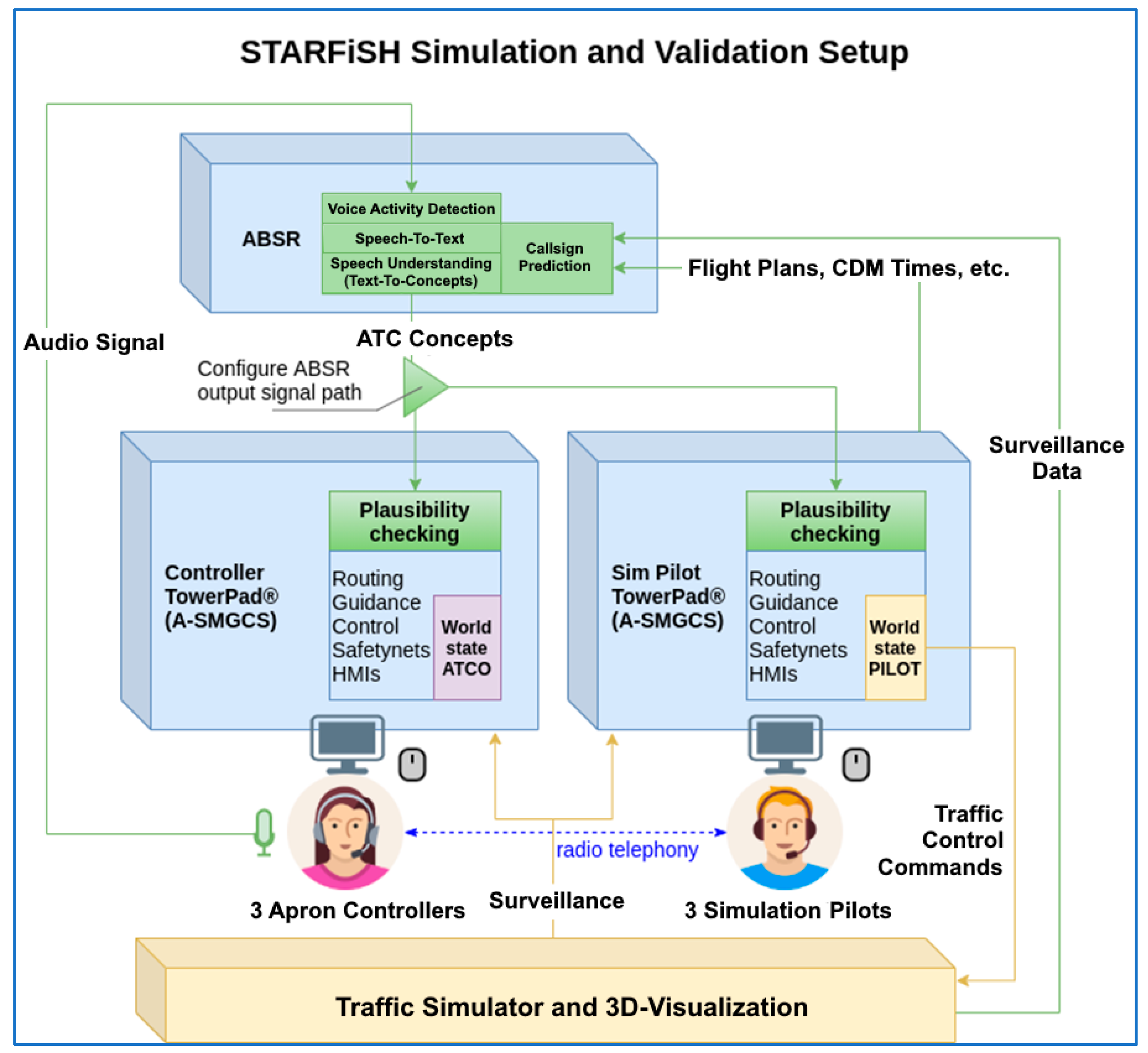
3.1. Technical Integration into the Simulator
3.2. Assistant-Based Speech Recognition
3.2.1. Voice Activity Detection
3.2.2. Speech Recognition, i.e., Speech-to-Text (Transcriptions)
“lufthansa three charlie foxtrot taxi alfa six two alfa via november one one november november eight at november eight give way to the company A three twenty from the right”.
- “lufthansa three charlie”;
- “lufthansa three charlie foxtrot taxi alfa six two alfa via”;
- “lufthansa three charlie foxtrot taxi alfa six two alfa via november one one november november eight”;
- “lufthansa three charlie foxtrot taxi alfa six two alfa via november one one november november eight at november eight give way to”;
- “lufthansa three charlie foxtrot taxi alfa six two alfa via november one one november november eight at november eight give way to the company A three twenty from the right”.
3.2.3. Speech Understanding
- DLH3CF TAXI TO A62A;
- DLH3CF TAXI VIA N11 N N8;
- DLH3CF GIVE_WAY DLH A320 RIGHT WHEN AT N8.
- It is logically not possible that an aircraft is instructed in a single radio transmission to taxi to two different target positions, e.g., a “TAXI TO” to two different parking positions, runways, or both in one transmission is impossible. Therefore, the module would automatically discard all “TAXI TO” commands within the transmission. Of course, with more information, it might be possible in some cases to determine which of the target positions is the correct one and only neglect one of the “TAXI TO” clearances, but that would require quite complex knowledge about the airport infrastructure to be implemented within the speech understanding component. The target application, on the other hand, which receives information from speech understanding, usually already has the required knowledge about the airport and therefore is more suitable to handle this task.
- A similar example would be a “TURN LEFT” and a “TURN RIGHT” command within one transmission and no other command in between, which is also impossible and would therefore be neglected for the same reasons.
- A less obvious example is the recognition of a “PUSHBACK” and a “TAXI TO” command in one transmission. Theoretically this might seem possible, but also these commands do not appear together and if they do, the error is usually a wrongly extracted “TAXI TO”. Therefore, the heuristic says to always neglect the “TAXI TO” in this case.
3.2.4. Callsign Prediction
3.2.5. Concept Interpretation
- Controller instructions via voice convey exactly the information that is necessary and sufficient for the addressed pilot in the current traffic situation. Globally, however, these instructions can be ambiguous. It is, therefore, necessary for an information technology system to unambiguously identify the addressed pilot and to make assumptions about his/her contextual knowledge in order to be able to exclude ambiguities from this perspective. A GIVE_WAY command from the right could identify several aircraft that approach from the right at the same time or consecutive taxiway crossings. The system has to determine the correct one that is implied from the traffic context.
- The extracted concepts may be erroneous. Either the controller has made a mistake, so that the verbal instruction does not correspond to what would be advised in the current traffic situation, or errors have occurred in the recording of the speech, the pause recognition, the conversion to text, or the speech understanding, so that the extracted concept is erroneous and should not be implemented.
- Preprocessing;
- Highlight the aircraft symbol on the basis of the recognized callsign;
- Trigger multiple actions based on a single command;
- Discard commands incompatible with the traffic situation;
- Correctly interpret context-dependent commands;
- Complete incomplete commands from the current traffic situation;
- Convert commands;
- Deal with detected errors;
- Deal with undetected errors and identify error sources.
3.3. Usability Considerations
3.3.1. Visualization of the Automation Actions (Feedback)
- Display the recognized transcriptions and the resulting annotations (ATC commands) on the side of the ABSR output log, in order to be able to compare the output of the ABSR system with the received data on the TowerPad™.
- Log data at the interfaces of the ABSR system and on the working position computers of the controllers and simulation pilots, in order to be able to analyze, after the simulation runs, whether the correct commands arrive in time.
- Log the commands provided by the ABSR system in chronological order on the working position computers to give users and researchers a way to observe and verify the results of the speech inputs independently of the implementation of the commands.
- Change a route;
- HOLD_SHORT command;
- GIVE_WAY command.
- Highlighting of the addressed aircraft symbols without disturbing user touch or mouse input, executed in parallel, additionally multi-highlighting when several commands are executed in quick succession.
- Feedback for changes, which are scarcely visible when executed manually, such as the transfer of an aircraft to another working position.
3.3.2. Manual Error Correction
4. Validation Trials
4.1. Pre-Simulations
4.2. Validation Plan
4.2.1. Validation Hypotheses
4.2.2. Independent Variables
- (IV-Input): Documentation on the controller’s HMI by ABSR vs. manual input (JC and CP vs. JP and NO).
- (IV-Control): Control of the simulation by ABSR for the controller’s utterances vs. full manual input (JP and CP vs. JC and NO).
4.2.3. Dependent Variables
4.3. Execution of the Final Validation Trials
4.4. Objective Workload Measurement by a Secondary Task
5. Validation Results
5.1. Speech Recognition and Understanding Performance
5.1.1. Speech-to-Text Accuracy (Speech Recognition)
5.1.2. Text-to-Concept Accuracy (Speech Understanding)
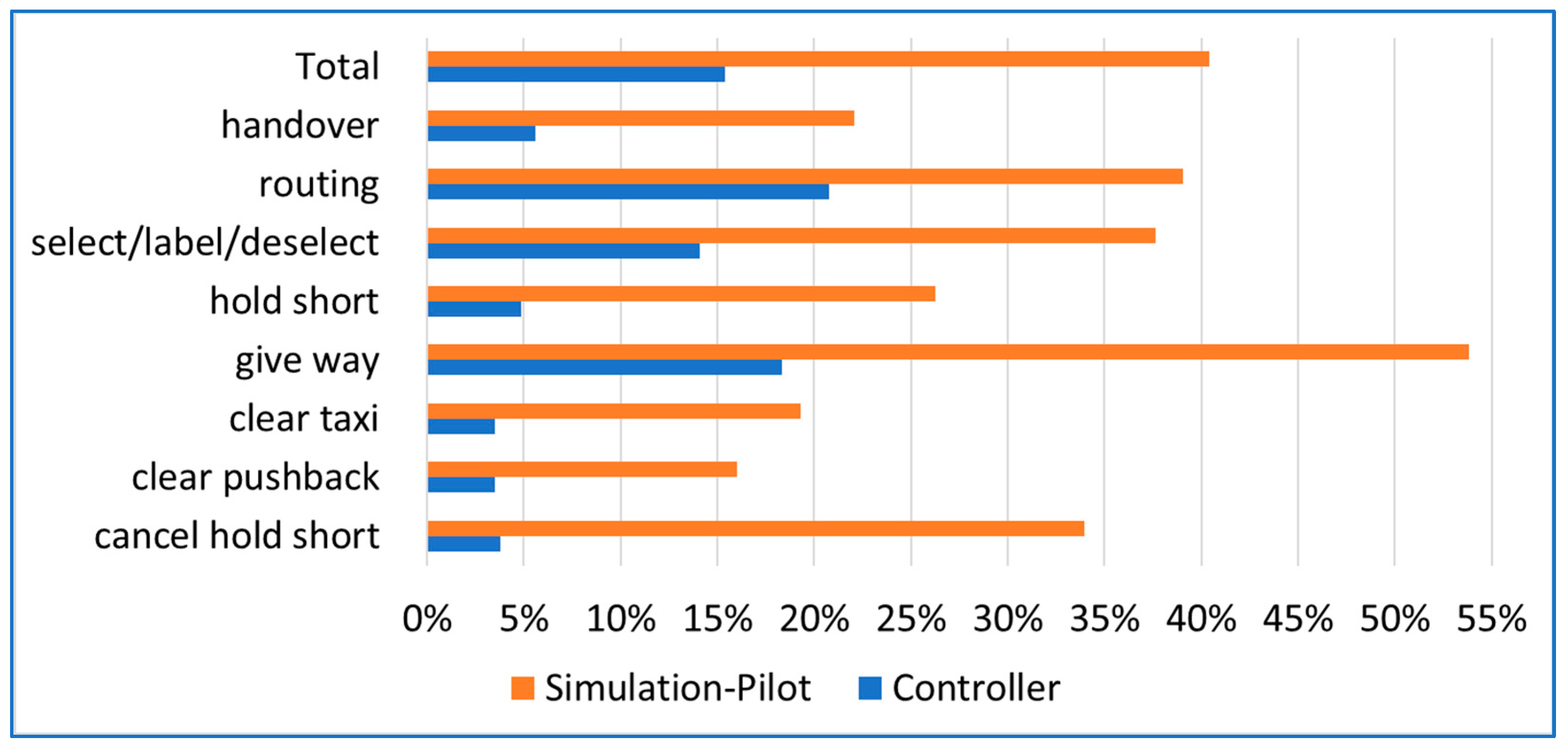
5.2. Interaction Count
5.3. Workload, NASA TLX
- Mental Demand: How mentally demanding was the task?
- Physical Demand: How physically demanding was the task?
- Temporal Demand: How hurried or rushed was the pace of the task?
- Performance: How successful were you in accomplishing what you were asked to do?
- Effort: How hard did you have to work to accomplish your level of performance?
- Frustration: How insecure, discouraged, irritated, stressed, and annoyed were you?
5.4. Evaluation of Stroop Tests as Secondary Task
- “If the Stroop tasks are done while R/T [radio telephony] must be done, selecting the correct button takes longer.”
- “More complicated routes increase the error rate [in Stroop tasks].”
5.5. Situational Awareness, Shape-SASHA
- In the previous working period(s), …
- ○
- I was ahead of the traffic.
- ○
- I started to focus on a single problem or a specific area of the sector.*
- ○
- There was the risk of forgetting something important […].*
- ○
- I was able to plan and to organize my work as I wanted.
- ○
- I was surprised by an event I did not expect […].*
- ○
- I had to search for an item of information.*
5.6. Confidence in Automation, Shape-SATI
- In the previous working period(s), I felt that …
- ○
- The system was useful.
- ○
- The system was reliable.
- ○
- The system worked accurately.
- ○
- The system was understandable.
- ○
- The system worked robustly (in difficult situations, with invalid inputs, etc.).
- ○
- I was confident when working with the system.
5.7. Results with Respect to Safety
5.7.1. Software Failure Modes, Effects, and Criticality Analysis (SFMECA)
- Indirect impact due to automation errors (too many disruptive errors, either due to a lack of recognition or incorrect recognition);
- Lack of visibility of the automation result (a loss of “situational awareness”);
- Lack of flexibility (no possibility of correction or override by the user and therefore a loss of control);
- Overconfidence/complacency.
- Achieve sufficient recognition rates and sufficiently low recognition error rates to prevent potential overload from occurring in the first place.
- Make the results visible enough for users to retain situational awareness at all times.
- Allow human operators to make corrections to automation errors in order to remain in control.
- Assessments of risk by overconfidence through safety considerations: what can happen if automation errors are not corrected?
5.7.2. Feedback from the Test Subjects on Safety
- Since the speech recognizer still makes mistakes and you have to check if everything is correct whenever you are spoken to, you are less free in your timing. One also expects that, e.g., the callsign is highlighted. If that doesn’t happen, you’re wondering why it didn’t work.
- You could always see if there were errors or not.
- The delay is fine. You can already talk to the next pilot or you get the indication during the readback. That’s sufficient.
- The errors were very few. They couldn’t put us in critical situations.
- Here, the aircraft are controlled very directly because the simulator directly implements commands [with voice recognition enabled] [including errors]. A pilot would not do that. That’s why it [emerging situations] would be less critical in real life.
- If something takes too long, you leave it out.—If the pilot executes it correctly, it’s okay.—If incorrectly detected, the worst thing that can happen is false alarms.
5.7.3. Summary of All Feedback Collected
5.8. Results with Respect to Validation Hypotheses
5.8.1. Hypotheses with Respect to “Number of Manual Inputs”
5.8.2. Hypothesis with Respect to “Free Cognitive Resources of Apron Controller”
5.8.3. Hypothesis with Respect to “Apron Controller Workload Reduction”
5.8.4. Hypothesis with Respect to “Apron Controller’s Situational Awareness”
5.8.5. Hypotheses with Respect to “Apron Controller’s Confidence”
5.8.6. Hypotheses with Respect to “Automatic Speech Understanding for Complete Commands”
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. DV-Input: Number of Manual Inputs for Control by Controllers/Simulation Pilots
- DV-Input-H-C-less_input (ABSR for the controllers reduces the number of manual inputs).
- DV-Input-H-P-less_input (ABSR for the simulation pilots reduces the number of manual inputs).
Appendix A.2. DV-Cog-Res: Measurement of Cognitive Resources by Secondary Task
- DV-Cog-Res-H-C-more_cog_res (more free cognitive resources of the controller due to ABSR).
Appendix A.3. DV-Workload Scoring by NASA TLX
- DV-Workload-H-C-less_workload (less controller workload due to ABSR).
Appendix A.4. DV-Sit-Aw Scoring According to SHAPE-SASHA
- DV-Sit-Aw-H-C-sit_aw_ok (situational awareness of the controller).
Appendix A.5. DV-Trust: Scoring According to SHAPE-SATI
- DV-Trust-H-C-conf (automation trust of the controller).
- DV-Trust-H-P-conf (automation trust of the simulation pilot).
Appendix A.6. DV-CmdRR: Command Extraction Rate
- DV-CmdRR-H-E-CmdRR (comparable command extraction rate as in the approach environment).
Appendix A.7. DV-CmdER: Command Extraction Error Rate
- DV-CmdER-H-E-CmdRR (comparable command extraction error rate as in the approach environment).
Appendix A.8. DV-CsgRR: Callsign Extraction Rate
- DV-CsgRR-H-E-CsgRR (comparable callsign extraction rate as in the approach environment).
Appendix A.9. DV-CsgER: Callsign Extraction Error Rate
- DV-CsgER-H-E-CsgER (comparable callsign extraction error rate as in the approach environment).
Appendix B
Appendix B.1. Preprocessing
Appendix B.2. Highlighting the Aircraft Symbol on the Basis of the Recognized Callsign
Appendix B.3. Checking and Interpretation
Appendix B.3.1. Triggering Multiple Actions Based on a Single Command
Appendix B.3.2. Discarding Commands Incompatible with the Traffic Situation
Appendix B.3.3. Correctly Interpret Context-Dependent Commands
Appendix B.3.4. Completing Incomplete Commands from Current Traffic Situation
Appendix B.3.5. Conversion of Commands
Appendix B.3.6. Dealing with Detected Errors
Appendix B.3.7. Undetected Errors and Identification of Error Sources
References
- Kleinert, M.; Shetty, S.; Helmke, H.; Ohneiser, O.; Wiese, H.; Maier, M.; Schacht, S.; Nigmatulina, I.; Sarfjoo, S.S.; Motlicek, P. Apron Controller Support by Integration of Automatic Speech Recognition with an Advanced Surface Movement Guidance and Control System. In Proceedings of the 12th SESAR Innovation Days, Budapest, Hungary, 5–8 December 2022. [Google Scholar]
- International Civil Aviation Organization (ICAO). Advanced Surface Movement Control and Guidance Systems (ASMGCS) Manual, Doc 9830 AN/452, 1st ed.; International Civil Aviation Organization (ICAO): Montréal, QC, Canada, 2004. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Mühlhausen, T.; Wies, M. Reducing Controller Workload with Automatic Speech Recognition. In Proceedings of the 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016. [Google Scholar]
- Helmke, H.; Ohneiser, O.; Buxbaum, J.; Kern, C. Increasing ATM Efficiency with Assistant Based Speech Recognition. In Proceedings of the 12th USA/Europe Air Traffic Management Research and Development Seminar (ATM2017), Seattle, WA, USA, 26–30 June 2017. [Google Scholar]
- European Commission. L 36/10; Commission Implementing Regulation (EU) 2021/116 of 1 February 2021 on the Establishment of the Common Project One Supporting the Implementation of the European Air Traffic Management Master Plan Provided for in Regulation (EC) No 550/2004 of the European Parliament and of the Council, Amending Commission Implementing Regulation (EU) No 409/2013 and Repealing Commission Implementing Regulation (EU) No 716/2014. Official Journal of the European Union: Luxembourg, 1 February 2021.
- Helmke, H.; Rataj, J.; Mühlhausen, T.; Ohneiser, O.; Ehr, H.; Kleinert, M.; Oualil, Y.; Schulder, M. Assistant-Based Speech Recognition for ATM Applications. In Proceedings of the 11th USA/Europe Air Traffic Management Research and Development Seminar (ATM2015), Lisbon, Portugal, 23–26 June 2015. [Google Scholar]
- Davis, K.H.; Biddulph, R.; Balashek, S. Automatic recognition of spoken digits. J. Acoust. Soc. Am. 1952, 24, 637–642. [Google Scholar] [CrossRef]
- Juang, B.H.; Rabiner, L.R. Automatic speech recognition–a brief history of the technology development. Ga. Inst. Technol. Atlanta Rutgers Univ. Univ. Calif. St. Barbar. 2005, 1, 67. [Google Scholar]
- Connolly, D.W. Voice Data Entry in Air Traffic Control; Report N93-72621; National Aviation Facilities Experimental Center: Atlantic City, NJ, USA, 1977. [Google Scholar]
- Hamel, C.; Kotick, D.; Layton, M. Microcomputer System Integration for Air Control Training; Special Report SR89-01; Naval Training Systems Center: Orlando, FL, USA, 1989. [Google Scholar]
- FAA. National Aviation Research Plan (NARP); FAA: Washington, DC, USA, 2012. [Google Scholar]
- Updegrove, J.A.; Jafer, S. Optimization of Air Traffic Control Training at the Federal Aviation Administration Academy. Aerospace 2017, 4, 50. [Google Scholar] [CrossRef] [Green Version]
- Schäfer, D. Context-Sensitive Speech Recognition in the Air Traffic Control Simulation. Eurocontrol EEC Note No. 02/2001. Ph.D. Thesis, University of Armed Forces, Munich, Germany, 2001. [Google Scholar]
- Tarakan, R.; Baldwin, K.; Rozen, R. An automated simulation pilot capability to support advanced air traffic controller training. In Proceedings of the 26th Congress of the International Council of the Aeronautical Sciences, Anchorage, Alaska, 14–19 September 2008. [Google Scholar]
- Ciupka, S. Siris big sister captures DFS (original German title: Siris große Schwester erobert die DFS). Transmission 2012, 1. [Google Scholar]
- Doc 4444 ATM/501; ATM (Air Traffic Management): Procedures for Air Navigation Services. International Civil Aviation Organization (ICAO): Montréal, QC, Canada, 2007.
- Cordero, J.M.; Dorado, M.; de Pablo, J.M. Automated speech recognition in ATC environment. In Proceedings of the 2nd International Conference on Application and Theory of Automation in Command and Control Systems (ATACCS’12), London, UK, 29–31 May 2012; IRIT Press: Toulouse, France, 2012; pp. 46–53. [Google Scholar]
- Cordero, J.M.; Rodríguez, N.; de Pablo, J.M.; Dorado, M. Automated Speech Recognition in Controller Communications applied to Workload Measurement. In Proceedings of the 3rd SESAR Innovation Days, Stockholm, Sweden, 26–28 November 2013. [Google Scholar]
- Nguyen, V.N.; Holone, H. N-best list re-ranking using syntactic score: A solution for improving speech recognition accuracy in Air Traffic Control. In Proceedings of the 2016 16th International Conference on Control, Automation and Systems (ICCAS), Gyeongju, Republic of Korea, 16–19 October 2016; pp. 1309–1314. [Google Scholar]
- Nguyen, V.N.; Holone, H. N-best list re-ranking using syntactic relatedness and syntactic score: An approach for improving speech recognition accuracy in Air Traffic Control. In Proceedings of the 2016 16th International Conference on Control, Automation and Systems (ICCAS 2016), Gyeongju, Republic of Korea, 16–19 October 2016; pp. 1315–1319. [Google Scholar]
- Helmke, H.; Kleinert, M.; Shetty, S.; Ohneiser, O.; Ehr, H.; Arilíusson, H.; Simiganoschi, T.S.; Prasad, A.; Motlicek, P.; Veselý, K.; et al. Readback Error Detection by Automatic Speech Recognition to Increase ATM Safety. In Proceedings of the 14th USA/Europe Air Traffic Management Research and Development Seminar (ATM2021), Virtual, 20–24 September 2021. [Google Scholar]
- Ohneiser, O.; Helmke, H.; Shetty, S.; Kleinert, M.; Ehr, H.; Murauskas, Š.; Pagirys, T.; Balogh, G.; Tønnesen, A.; Kis-Pál, G.; et al. Understanding Tower Controller Communication for Support in Air Traffic Control Displays. In Proceedings of the 12th SESAR Innovation Days, Budapest, Hungary, 5–8 December 2022. [Google Scholar]
- Helmke, H.; Kleinert, M.; Ahrenhold, N.; Ehr, H.; Mühlhausen, T.; Ohneiser, O.; Motlicek, P.; Prasad, A.; Zuluaga-Gomez, J. Automatic Speech Recognition and Understanding for Radar Label Maintenance Support Increases Safety and Reduces Air Traffic Controllers’ Workload. In Proceedings of the 15th USA/Europe Air Traffic Management Research and Development Seminar (ATM2023), Savannah, GA, USA, 5–9 June 2023. [Google Scholar]
- García, R.; Albarrán, J.; Fabio, A.; Celorrio, F.; de Oliveira, C.P.; Bárcena, C. Automatic Flight Callsign Identification on a Controller Working Position: Real-Time Simulation and Analysis of Operational Recordings. Aerospace 2023, 10, 433. [Google Scholar] [CrossRef]
- Chen, S.; Kopald, H.D.; Elessawy, A.; Levonian, Z.; Tarakan, R.M. Speech inputs to surface safety logic systems. In Proceedings of the IEEE/AIAA 34th Digital Avionics Systems Conference (DASC), Prague, Czech Republic, 13–17 September 2015. [Google Scholar]
- Chen, S.; Kopald, H.D.; Chong, R.; Wei, Y.; Levonian, Z. Read back error detection using automatic speech recognition. In Proceedings of the 12th USA/Europe Air Traffic Management Research and Development Seminar (ATM2017), Seattle, WA, USA, 26–30 June 2017. [Google Scholar]
- Helmke, H.; Ondřej, K.; Shetty, S.; Arilíusson, H.; Simiganoschi, T.S.; Kleinert, M.; Ohneiser, O.; Ehr, H.; Zuluaga-Gomez, J.-P.; Smrz, P. Readback Error Detection by Automatic Speech Recognition and Understanding—Results of HAAWAII project for Isavia’s Enroute Airspace. In Proceedings of the 12th SESAR Innovation Days, Budapest, Hungary, 5–8 December 2022. [Google Scholar]
- Zuluaga-Gomez, J.-P.; Sarfjoo, S.S.; Prasad, A.; Nigmatulina, I.; Motlicek, P.; Ondřej, K.; Ohneiser, O.; Helmke, H. BERTRAFFIC: BERT-based joint Speaker Role and Speaker Change Detection for Air Traffic Control Communications. In Proceedings of the 2022 IEEE Spoken Language Workshop Technology Workshop (SLT 2022), Doha, Qatar, 9–12 January 2023. [Google Scholar]
- Helmke, H.; Slotty, M.; Poiger, M.; Herrer, D.F.; Ohneiser, O.; Vink, N.; Cerna, A.; Hartikainen, P.; Josefsson, B.; Langr, D.; et al. Ontology for transcription of ATC speech commands of SESAR 2020 solution PJ.16-04. In Proceedings of the IEEE/AIAA 37th Digital Avionics Systems Conference (DASC), London, UK, 23–27 September 2018. [Google Scholar]
- Kleinert, M.; Helmke, H.; Moos, S.; Hlousek, P.; Windisch, C.; Ohneiser, O.; Ehr, H.; Labreuil, A. Reducing Controller Workload by Automatic Speech Recognition Assisted Radar Label Maintenance. In Proceedings of the 9th SESAR Innovation Days, Athens, Greece, 2–6 December 2019. [Google Scholar]
- Lin, Y. Spoken Instruction Understanding in Air Traffic Control: Challenge, Technique, and Application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Ohneiser, O.; Helmke, H.; Kleinert, M.; Siol, G.; Ehr, H.; Hobein, S.; Predescu, A.-V.; Bauer, J. Tower Controller Command Prediction for Future Speech Recognition Applications. In Proceedings of the 9th SESAR Innovation Days, Athens, Greece, 2–5 December 2019. [Google Scholar]
- Ohneiser, O.; Sarfjoo, S.; Helmke, H.; Shetty, S.; Motlicek, P.; Kleinert, M.; Ehr, H.; Murauskas, Š. Robust Command Recognition for Lithuanian Air Traffic Control Tower Utterances. In Proceedings of the InterSpeech 2021, Brno, Czech Republic, 30 August–3 September 2021. [Google Scholar]
- Boehm, B. A Spiral Model of Software Development and Enhancement. IEEE Comput. 1988, 21, 61–72. [Google Scholar] [CrossRef]
- Neufelder, A.M. Effective Application of Software Failure Modes Effects Analysis; Quanterion Solutions, Incorporated: New York, NY, USA, 2017. [Google Scholar]
- Povey, D. Online Endpoint Recognition. 2013. Available online: https://github.com/kaldi-asr/kaldi/blob/master/src/online2/online-endpoint.h (accessed on 15 May 2023).
- Povey, D.; Peddinti, V.; Galvez, D.; Ghahremani, P.; Manohar, P.; Na, X.; Wang, Y.; Khudanpur, S. Purely sequence-trained neural networks for ASR based on lattice-free MMI. Interspeech 2016, 2016, 2751–2755. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi Speech Recognition Toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, IEEE Signal Processing Society, Waikoloa, Big Island, HI, USA, 11–15 December 2011. [Google Scholar]
- Kleinert, M.; Helmke, H.; Shetty, S.; Ohneiser, O.; Ehr, H.; Prasad, A.; Motlicek, P.; Harfmann, J. Automated Interpretation of Air Traffic Control Communication: The Journey from Spoken Words to a Deeper Understanding of the Meaning. In Proceedings of the IEEE/AIAA 40th Digital Avionics Systems Conference (DASC), Virtual, 3–7 October 2021. [Google Scholar]
- Nigmatulina, I.; Zuluaga-Gomez, J.; Prasad, A.; Sarfjoo, S.S.; Motlicek, P. A two-step approach to leverage contextual data: Speech recognition in air-traffic communications. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022. [Google Scholar]
- Zuluaga-Gomez, J.; Nigmatulina, I.; Prasad, A.; Motlicek, P.; Vesely, K.; Kocour, M.; Szöke, I. Contextual Semi-Supervised Learning: An Approach to Leverage Air-Surveillance and Untranscribed ATC Data in ASR Systems. Interspeech 2021, 2021, 3296–3300. [Google Scholar]
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Stroop, J.R. Studies of interference in serial verbal reactions. J. Exp. Psychol. 1935, 18, 643–662. [Google Scholar] [CrossRef]
- Maier, M. Workload-Gauge. Available online: https://github.com/MathiasMaier/workload-gauge (accessed on 15 May 2023).
- Helmke, H.; Shetty, S.; Kleinert, M.; Ohneiser, O.; Prasad, A.; Motlicek, P.; Cerna, A.; Windisch, C. Measuring Speech Recognition Understanding Performance in Air Traffic Control Domain Beyond Word Error Rates. In Proceedings of the 11th SESAR Innovation Days, Virtual, 7–9 December 2021. [Google Scholar]
- Hart, S.G. NASA-TASK LOAD INDEX (NASA-TLX); 20 years later. In Proceedings of the Human Factors and Ergonomics Society, San Francisco, CA, USA, 16–20 October 2006; Volume 50, pp. 904–908. [Google Scholar]
- Dehn, D.M. Assessing the Impact of Automation on the Air Traffic Controller: The SHAPE Questionnaires. Air Traffic Control Q. 2008, 16, 127–146. [Google Scholar] [CrossRef]
- Di Nardo, M.; Murino, T.; Osteria, G.; Santillo, L.C. A New Hybrid Dynamic FMECA with Decision-Making Methodology: A Case Study in an Agri-Food Company. Appl. Syst. Innov. 2022, 5, 45. [Google Scholar] [CrossRef]
- Mihalache, S.; Burileanu, D. Using Voice Activity Detection and Deep Neural Networks with Hybrid Speech Feature Extraction for Deceptive Speech Detection. Sensors 2022, 22, 1228. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zuluaga-Gomez, J.; Vesely, K.; Szöke, I.; Motlicek, P.; Kocour, M.; Rigault, M.; Choukri, K.; Prasad, A.; Sarfjoo, S.S.; Nigmatulina, I.; et al. ATCO2 corpus: A Large-Scale Dataset for Research on Automatic Speech Recognition and Natural Language Understanding of Air Traffic Control Communications. arXiv 2022, arXiv:2211.04054. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition Name | Operational Conditions |
|---|---|
| NO | No ABSR support; manual input, i.e., the baseline scenario. The controllers manually enter the spoken commands via mouse into the controller’s HMI of the TowerPad™. Simulation pilots control taxi traffic at their working positions by manual input via mouse and keyboard. This corresponds to the established mode of operation without ABSR. |
| JC | Use of ABSR support just for controllers, i.e., automatic command recognition support for controllers plus manual correction, if ABSR fails. Commands spoken by the controller are processed by the ABSR system and transmitted to the controller’s working position, where they are automatically entered for the controller. The controller receives feedback on the recognized commands via the controller’s HMI and can correct errors via a mouse. No support by ABSR for the simulation pilots. |
| JP | Use of ABSR support just for simulation pilots, i.e., automatic command recognition and control for pilots. The commands spoken by the controllers are processed by the ABSR system, transmitted to the working position of the responsible simulation pilot, and automatically executed as control commands for the simulation pilot. The simulation pilot receives feedback on the recognized commands via the simulation pilot’s HMI and can correct errors via a mouse and keyboard. No support by ABSR for the controllers. |
| CP | Use of ABSR support for both controllers and simulation pilots, as described individually for JC and JP conditions. |
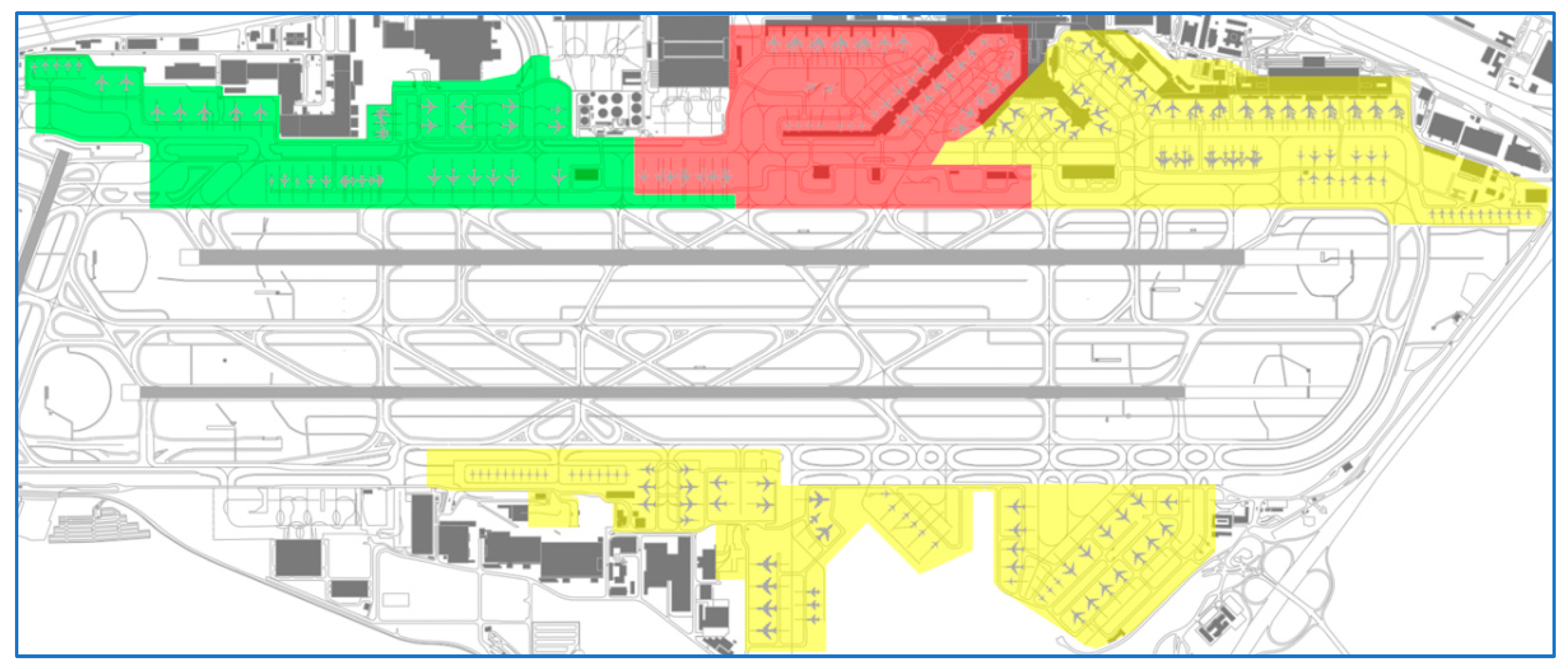
| Traffic Scenario | # Aircraft | # Arriving Aircraft | # Departing Aircraft | # Expected Aircraft East | # Expected Aircraft Center | # Expected Aircraft West |
|---|---|---|---|---|---|---|
| OD25 | 106 | 46 | 60 | 59 | 61 | 63 |
| OD07 | 106 | 46 | 60 | 57 | 45 | 59 |
| # Cmds | % of All | # Utterances | % of All | |
|---|---|---|---|---|
| Center | 5858 | 38% | 2437 | 38% |
| West | 4376 | 28% | 1654 | 26% |
| East | 5235 | 34% | 2262 | 36% |
| Simulation Run Name with OD | Operational Conditions and Traffic Scenario |
|---|---|
| T | Training of fully manual input and ABSR-supported input with manual corrections at controllers’ and simulation pilots’ working positions. |
| CP25 | ABSR support for controllers and simulation pilots. |
| JC25 | ABSR support just for controllers. |
| JP25 | ABSR support just for simulation pilots. |
| NO25 | No ABSR support. |
| CP07 | ABSR support for controllers and simulation pilots. |
| JP07 | ABSR support just for simulation pilots. |
| Team 1 | Team 2 | Team 3 | Team 4 | Team 5 |
|---|---|---|---|---|
| Day 1 | Day 2 | Day 3 | Day 4 | Day 5 |
| T | T | T | T | T |
| NO25 | CP25 | JP25 | JP25 | JP07 |
| JC25 | JP25 | NO25 | CP25 | CP07 |
| JP25 | JC25 | CP25 | JP07 | CP25 |
| CP25 | NO25 | JC25 | CP07 | JP25 |
| JP07 | CP07 | JP07 | NO25 | JC25 |
| CP07 | JP07 | CP07 | JC25 | NO25 |
| Recognition Mode | WER | |
|---|---|---|
| Offline (PTT signal simulated) | 3.1% | Male: 3.3% Female: 2.6% |
| Online (voice activity detection) | 5.0% | Male: 5.5% Female: 3.7% |
| Actual Commands | Recognized Commands | Contribution to Metric |
|---|---|---|
| DLH695 TURN RIGHT | DLH695 TURN LEFT | ⊖ |
| DLH695 TAXI VIA N10 N | DLH695 TAXI VIA N10 N | ⊕ |
| DLH695 TAXI TO V162 | ⊖ | |
| AUA1F PUSHBACK | AUA1F NO_CONCEPT | ○ |
| CCA644 NO_CONCEPT | CCA644 NO_CONCEPT | ⊕ |
| Recognition Rate (⊕) = 2/4 = 50% | Error Rate (⊖) = 2/4 = 50% | Rejection Rate (○) = 1/4 = 25% |
| Recognition Mode | # Utterances | # Commands | Cmds [%] | Csgn [%] | ||||
|---|---|---|---|---|---|---|---|---|
| RecR | ErrR | RejR | RecR | ErrR | RejR | |||
| Offline (PTT signal simulated) | 5495 | 13,251 | 91.8 | 3.2 | 5.4 | 97.4 | 1.3 | 1.3 |
| Online (voice activity detection) | 5432 | 13,168 | 88.7 | 4.3 | 7.5 | 95.2 | 2.3 | 2.4 |
| Offline (no callsign prediction used) | 76.3 | 10.5 | 13.7 | 81.1 | 9.6 | 9.3 | ||
| Delta to context | 15.5 | −7.3 | −8.3 | 16.3 | −8.3 | −8.0 | ||
| Command Type | # Cmds | RecR | ErrR | RejR |
|---|---|---|---|---|
| TAXI VIA | 2922 | 86.9 | 3.9 | 9.1 |
| HOLD_SHORT | 1837 | 89.3 | 0.8 | 9.9 |
| TAXI TO | 1406 | 89.0 | 1.1 | 9.9 |
| CONTACT_FREQUENCY | 1387 | 95.7 | 0.7 | 3.6 |
| CONTINUE TAXI | 1102 | 95.4 | 0.0 | 4.6 |
| GIVE_WAY | 728 | 69.6 | 10.2 | 20.3 |
| CONTACT | 672 | 98.4 | 0.3 | 1.3 |
| PUSHBACK | 663 | 92.3 | 1.2 | 6.5 |
| TURN | 359 | 89.2 | 3.9 | 6.9 |
| HOLD_POSITION | 223 | 93.4 | 0.0 | 6.6 |
| West | Center | East | All | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Workload | Base | Sol | α | Base | Sol | α | Base | Sol | α | Base | Sol | α |
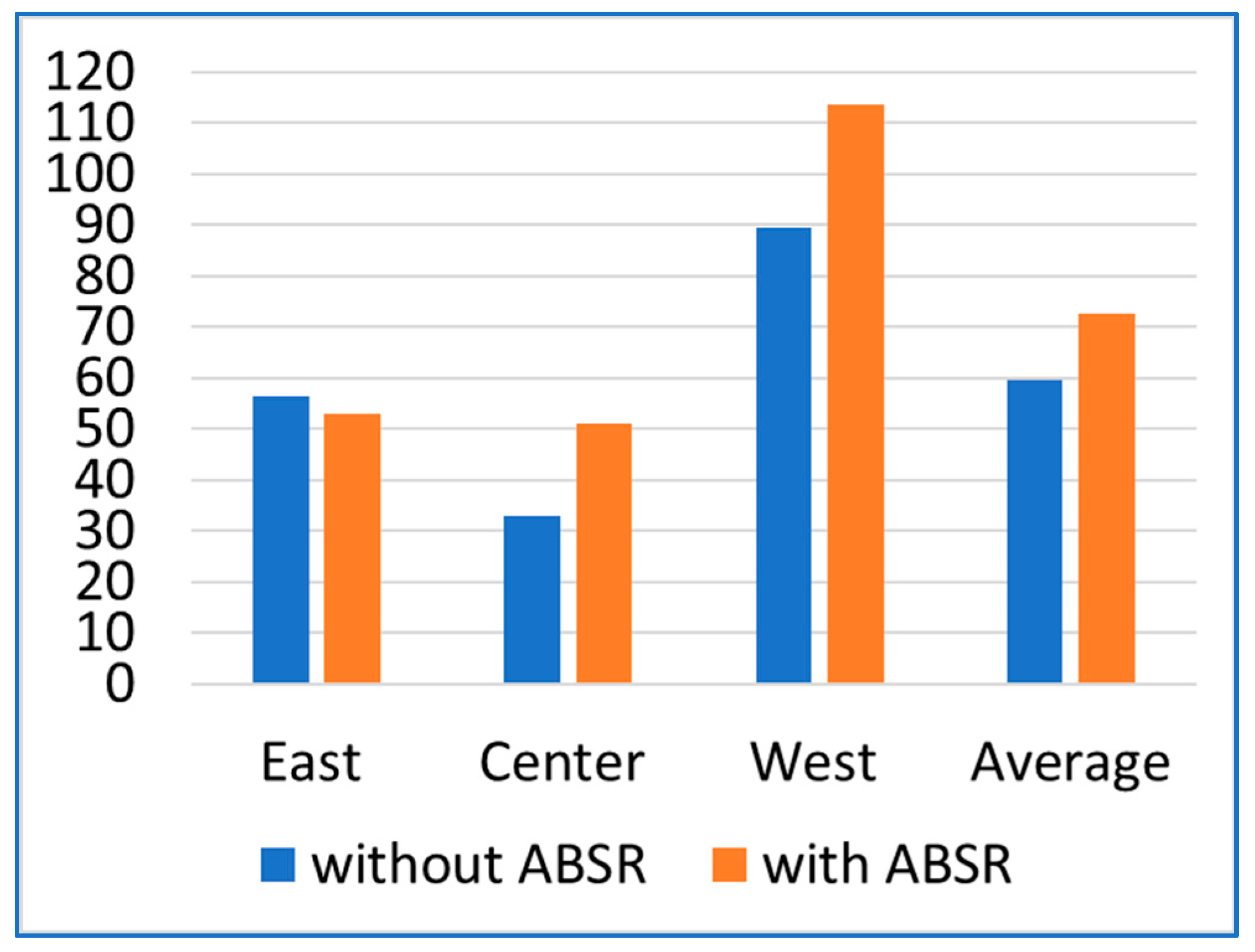
| Mental Demand [MD] | 7.9 | 6.4 | 14.5% | 14.4 | 12.4 | 1.1% | 14.7 | 13.8 | 10.3% | 12.3 | 10.8 | 1.3% |
| Physical Demand [PD] | 7.6 | 3.3 | 0.4% | 9.4 | 5.6 | 0.3% | 10.6 | 7.9 | 2.5% | 9.2 | 5.6 | 3 × 10−4 |
| Temporal Demand [TD] | 8.1 | 5.9 | 4.4% | 12.8 | 10.7 | 2.4% | 14.1 | 13.1 | 6.2% | 11.7 | 9.9 | 0.3% |
| Effort [EF] | 8.6 | 5.5 | 2.1% | 12.6 | 10.5 | 1.3% | 14.5 | 12.4 | 1.6% | 11.9 | 9.5 | 1 × 10−3 |
| Frustration [FR] | 4.0 | 3.4 | 23.9% | 6.8 | 3.5 | 1.0% | 7.2 | 5.0 | 6.1% | 6.0 | 4.0 | 0.2% |
| ALL | 7.2 | 4.9 | 2.5% | 11.2 | 8.5 | 0.2% | 12.2 | 10.4 | 1.4% | 10.2 | 8.0 | 6 × 10−4 |
| Situational Awareness | without ABSR (W/C/E) | with ABSR (W/C/E) |
|---|---|---|
| ahead of traffic | 4.4 (5.2/4.0/4.0) | 4.7 (5.4/4.2/4.6) |
| focus single problem | 4.3 (4.9/3.9/4.2) | 4.3 (4.2/4.3/4.5) |
| risk of forgetting | 3.9 (4.8/3.5/3.4) | 4.4 (4.9/4.1/4.3) |
| able to plan | 4.1 (4.7/3.9/3.6) | 4.6 (4.9/4.6/4.3) |
| surprised by event | 4.5 (5.1/4.5/4.0) | 4.9 (5.4/4.7/4.7) |
| search information | 3.9 (4.1/3.8/3.9) | 4.4 (4.5/4.7/4.0) |
| ALL | 4.2 (4.8/3.9/3.8) | 4.6 (4.9/4.4/4.4) |
| Automation Trust | Controllers (15) | Simulation Pilots (6) |
|---|---|---|
| useful | 5.1 | 4.6 |
| reliable | 4.5 | 4.2 |
| accurate | 4.3 | 4.2 |
| understandable | 4.9 | 5.3 |
| robust | 4.2 | 4.2 |
| confident | 4.8 | 4.3 |
| ALL | 4.6 | 4.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kleinert, M.; Ohneiser, O.; Helmke, H.; Shetty, S.; Ehr, H.; Maier, M.; Schacht, S.; Wiese, H. Safety Aspects of Supporting Apron Controllers with Automatic Speech Recognition and Understanding Integrated into an Advanced Surface Movement Guidance and Control System. Aerospace 2023, 10, 596. https://doi.org/10.3390/aerospace10070596
Kleinert M, Ohneiser O, Helmke H, Shetty S, Ehr H, Maier M, Schacht S, Wiese H. Safety Aspects of Supporting Apron Controllers with Automatic Speech Recognition and Understanding Integrated into an Advanced Surface Movement Guidance and Control System. Aerospace. 2023; 10(7):596. https://doi.org/10.3390/aerospace10070596
Chicago/Turabian StyleKleinert, Matthias, Oliver Ohneiser, Hartmut Helmke, Shruthi Shetty, Heiko Ehr, Mathias Maier, Susanne Schacht, and Hanno Wiese. 2023. "Safety Aspects of Supporting Apron Controllers with Automatic Speech Recognition and Understanding Integrated into an Advanced Surface Movement Guidance and Control System" Aerospace 10, no. 7: 596. https://doi.org/10.3390/aerospace10070596
APA StyleKleinert, M., Ohneiser, O., Helmke, H., Shetty, S., Ehr, H., Maier, M., Schacht, S., & Wiese, H. (2023). Safety Aspects of Supporting Apron Controllers with Automatic Speech Recognition and Understanding Integrated into an Advanced Surface Movement Guidance and Control System. Aerospace, 10(7), 596. https://doi.org/10.3390/aerospace10070596