
Autonomous Shape Decision Making of Morphing Aircraft with Improved Reinforcement Learning


Abstract
:1. Introduction
2. Shape Decision Making of MA Based on the DDPGwTC Algorithm
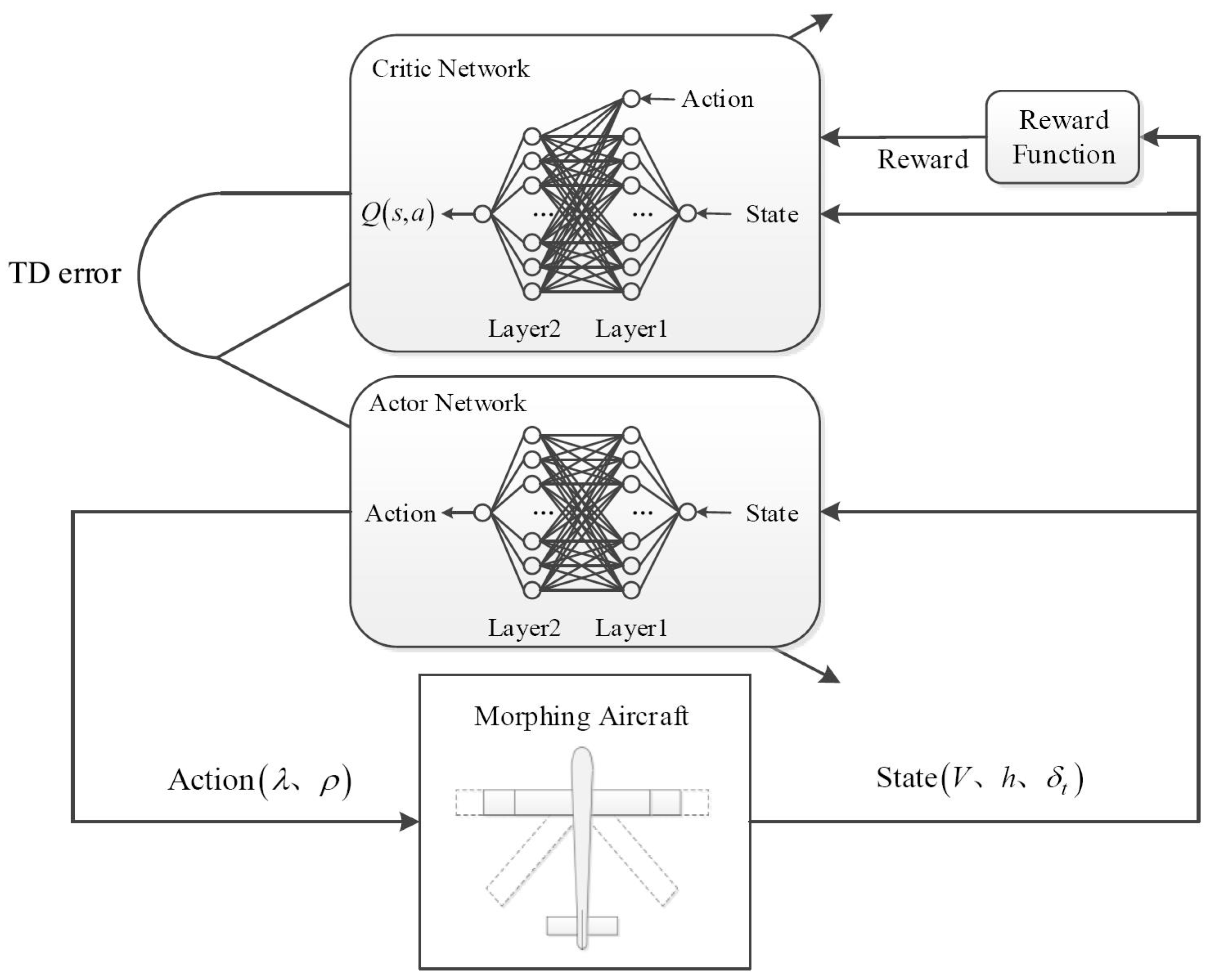
2.1. Principles of the DDPG Algorithm
2.2. Design of the DDPG Algorithm with Task Classifier
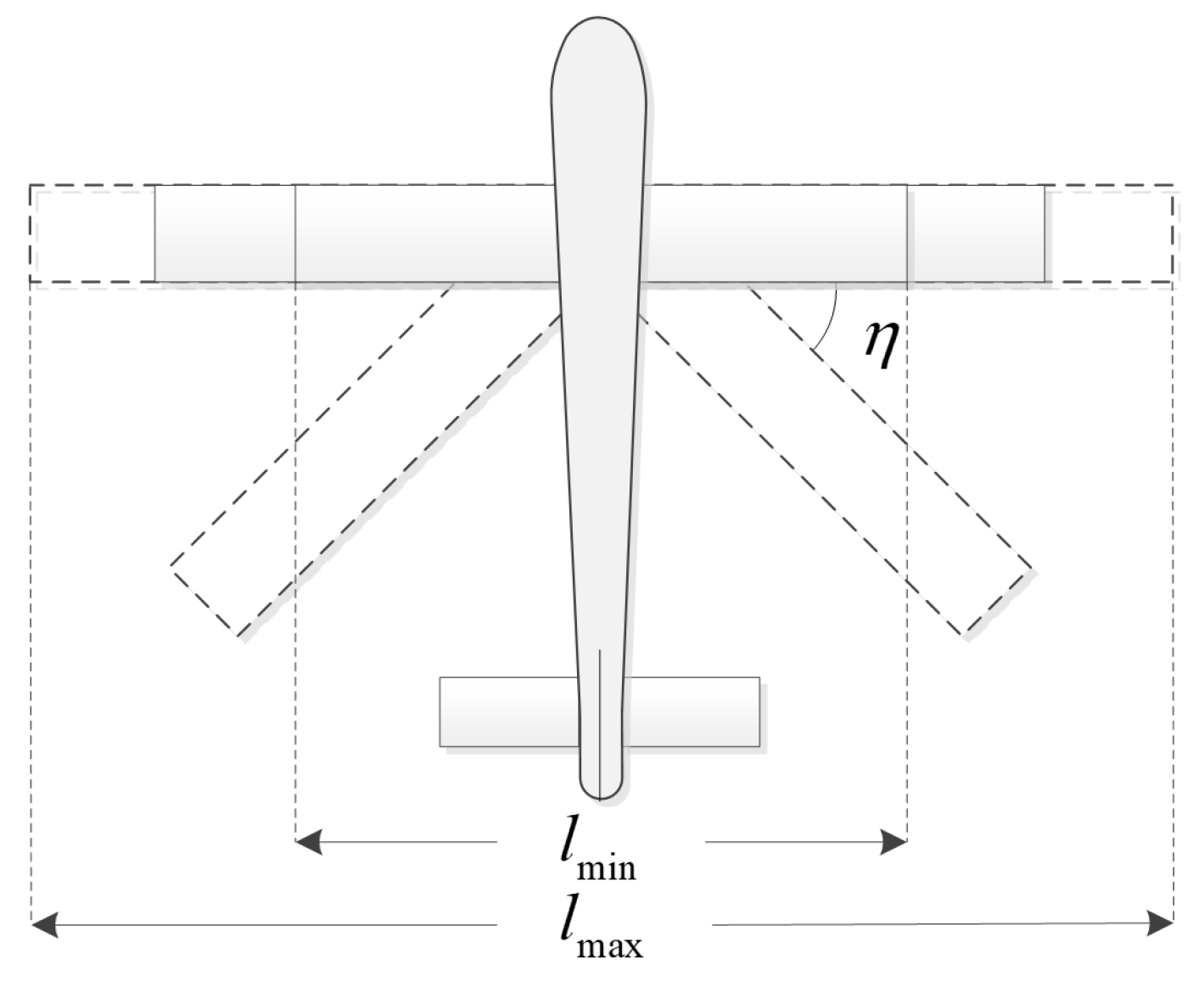
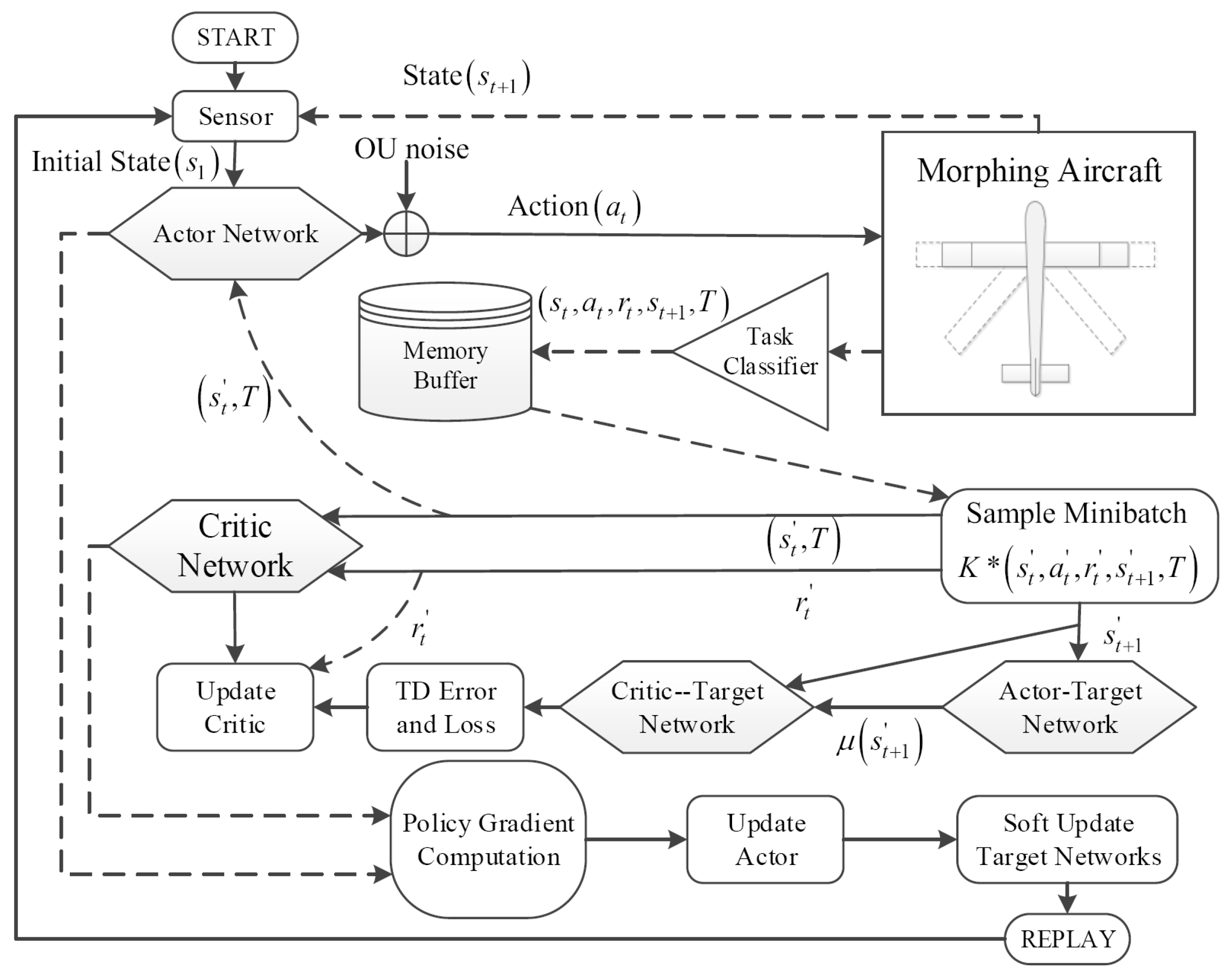
2.2.1. Framework of Shape Decision-Making Algorithm for MA
- (1)
- The aircraft fuselage is symmetrical about the longitudinal plane of the aircraft coordinate system, and the process of wing modification on both sides is synchronized. During the modification process, the center of mass of the aircraft moves along the x-axis of the aircraft, only considering the influence on longitudinal motion and not producing a component that affects lateral motion.
- (2)
- The aircraft adopts a single engine, ignoring the influence of the component generated by the engine installation angle on thrust and the influence of thrust on pitch torque.
- (3)
- Set the gravitational acceleration as a constant, ignoring changes in the mass of the aircraft.
- (4)
- Neglect the impact of unsteady aerodynamic forces generated during the variant process on the aircraft.
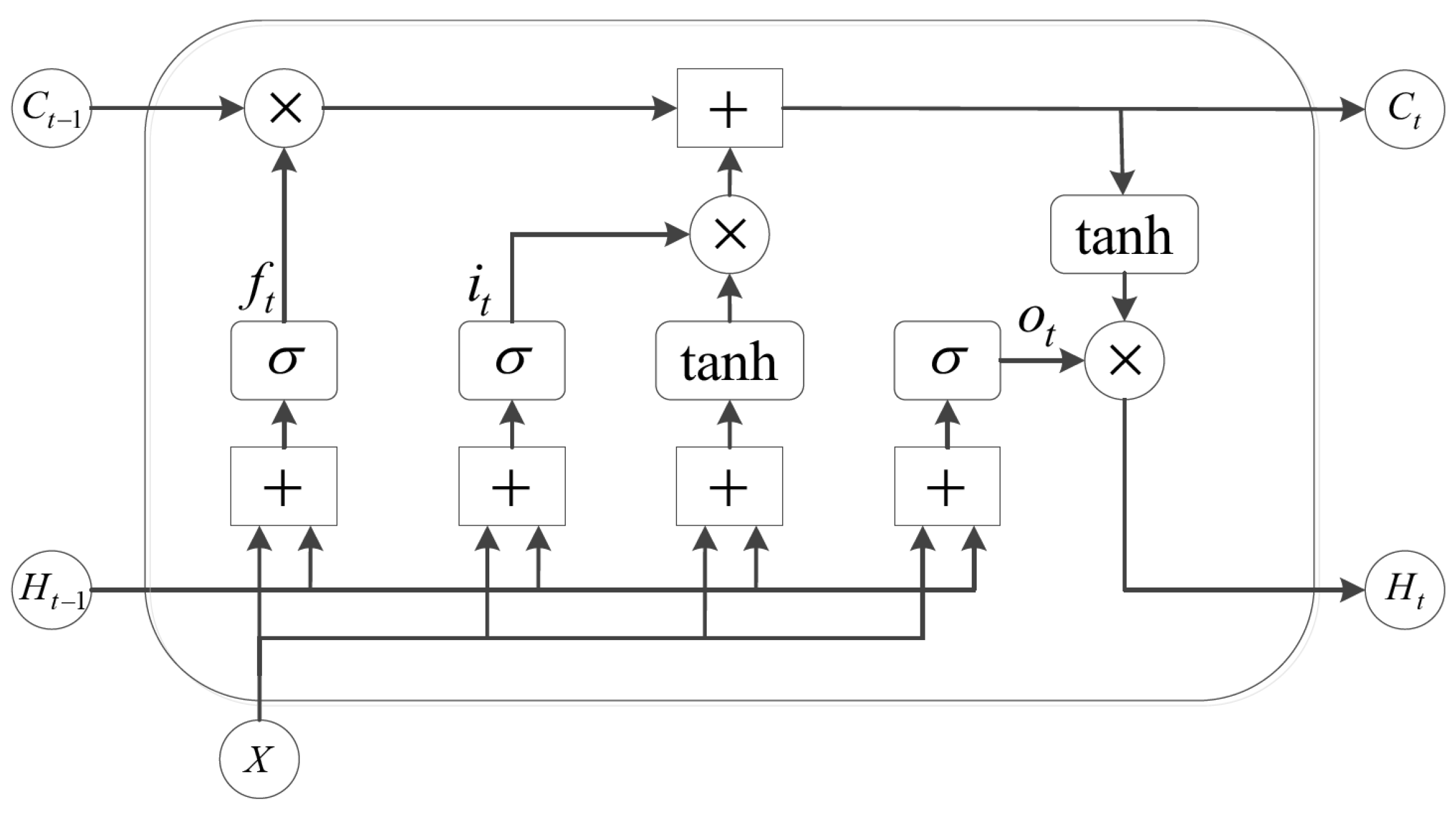
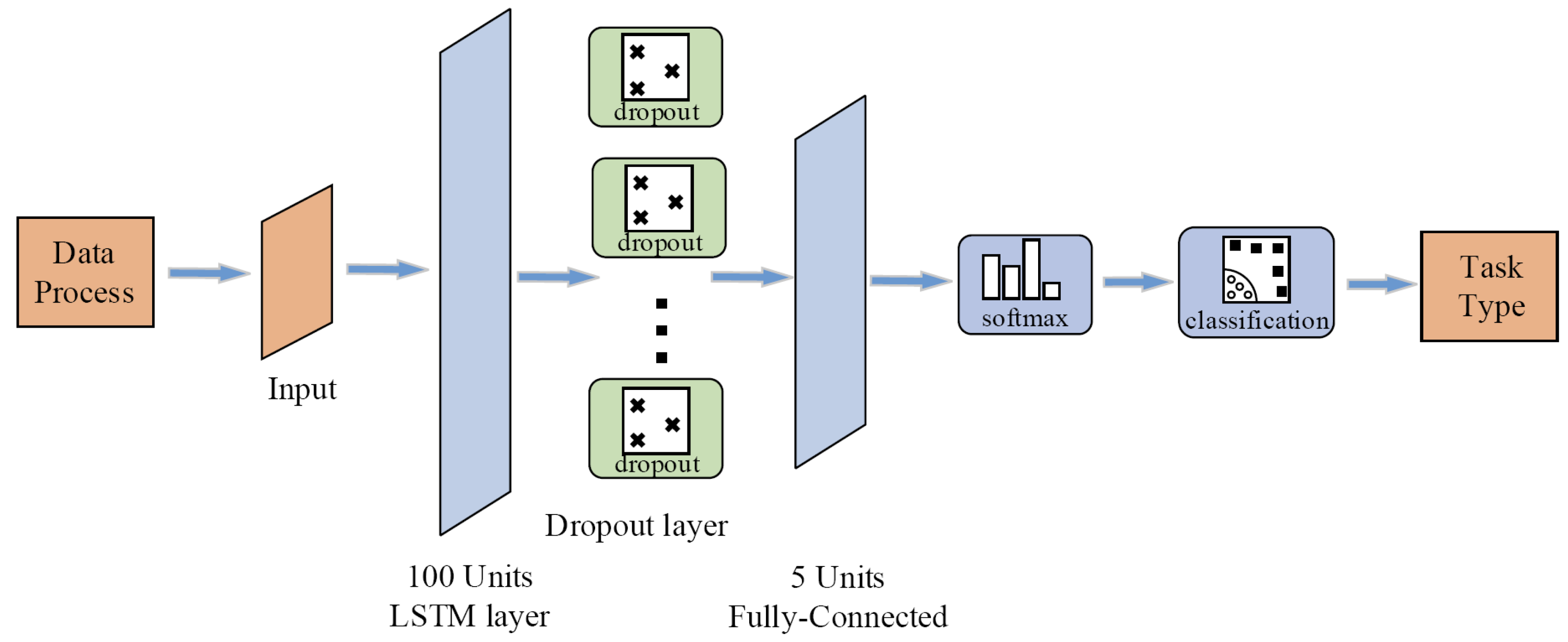
2.2.2. Task Classifier Design
2.2.3. Reward Function Design
2.2.4. The Process of the DDPGwTC Algorithm
| Algorithm 1 Deep deterministic policy gradient with task classifier (DDPGwTC) |
| 1: Randomly initialize critic and actor neural networks with weights and . |
| 2: Initialize target network and with weights , . |
| 3: Initialize replay buffer R. |
| 4: for episode= do |
| 5: Initialize a random process for action exploration. |
| 6: Receive initial observation state . |
| 7: for episode= do |
| 8: Select action according to the current policy and exploration noise. |
| 9: Execute action and observe new state . |
| 10: Classify to get the task signal T. |
| 11: Get reward according to T. |
| 12: Store transition in experience replay buffer R. |
| 13: Sample a random minibatch of K transitions from R. |
| 14: Set . |
| 15: Update critic by minimizing the loss L:
|
| 16: Update the actor policy using the sampled policy gradient:
|
| 17: Update target networks:
|
| 18: end for |
| 19: end for |
3. Network Training
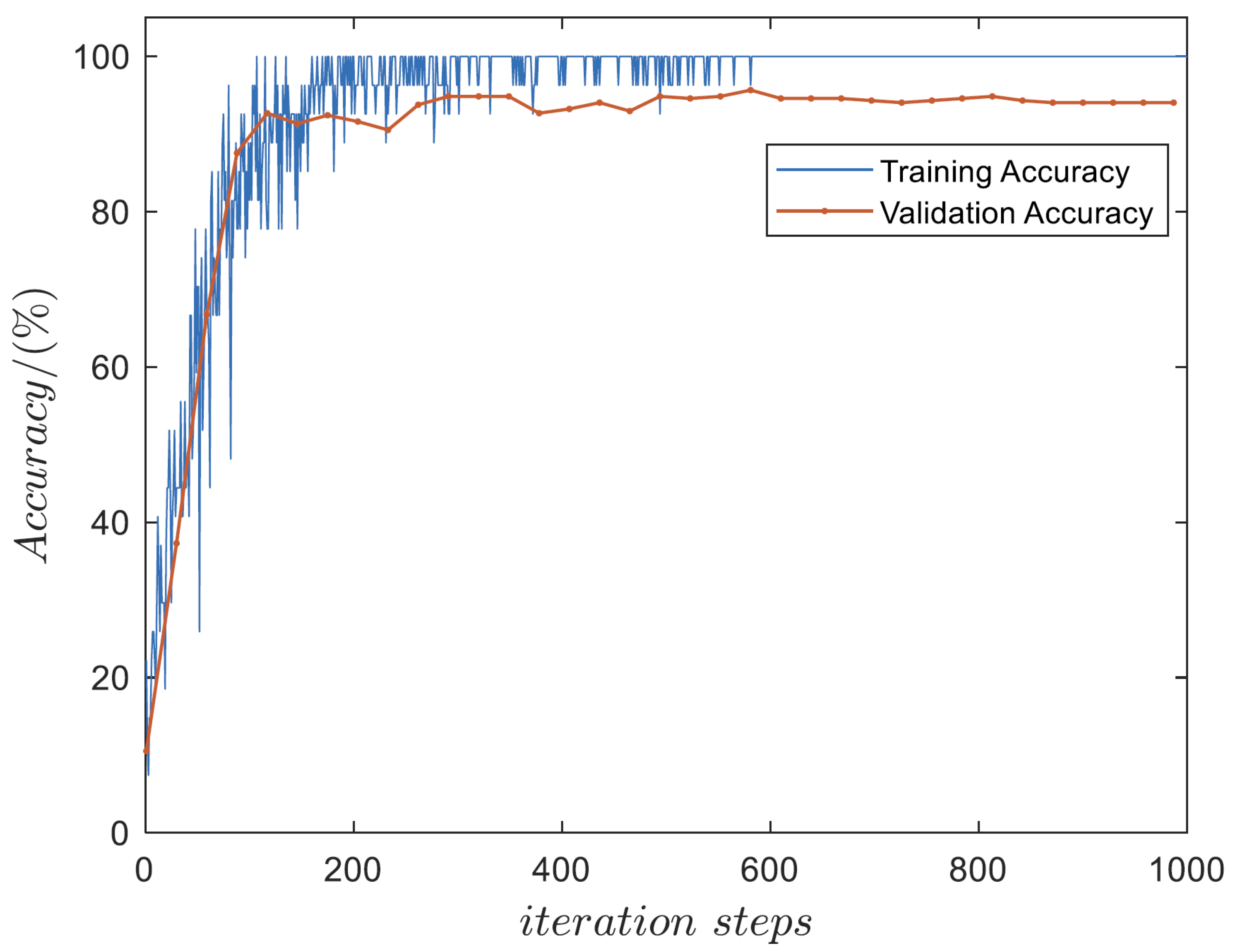
3.1. Task Classifier Network Training
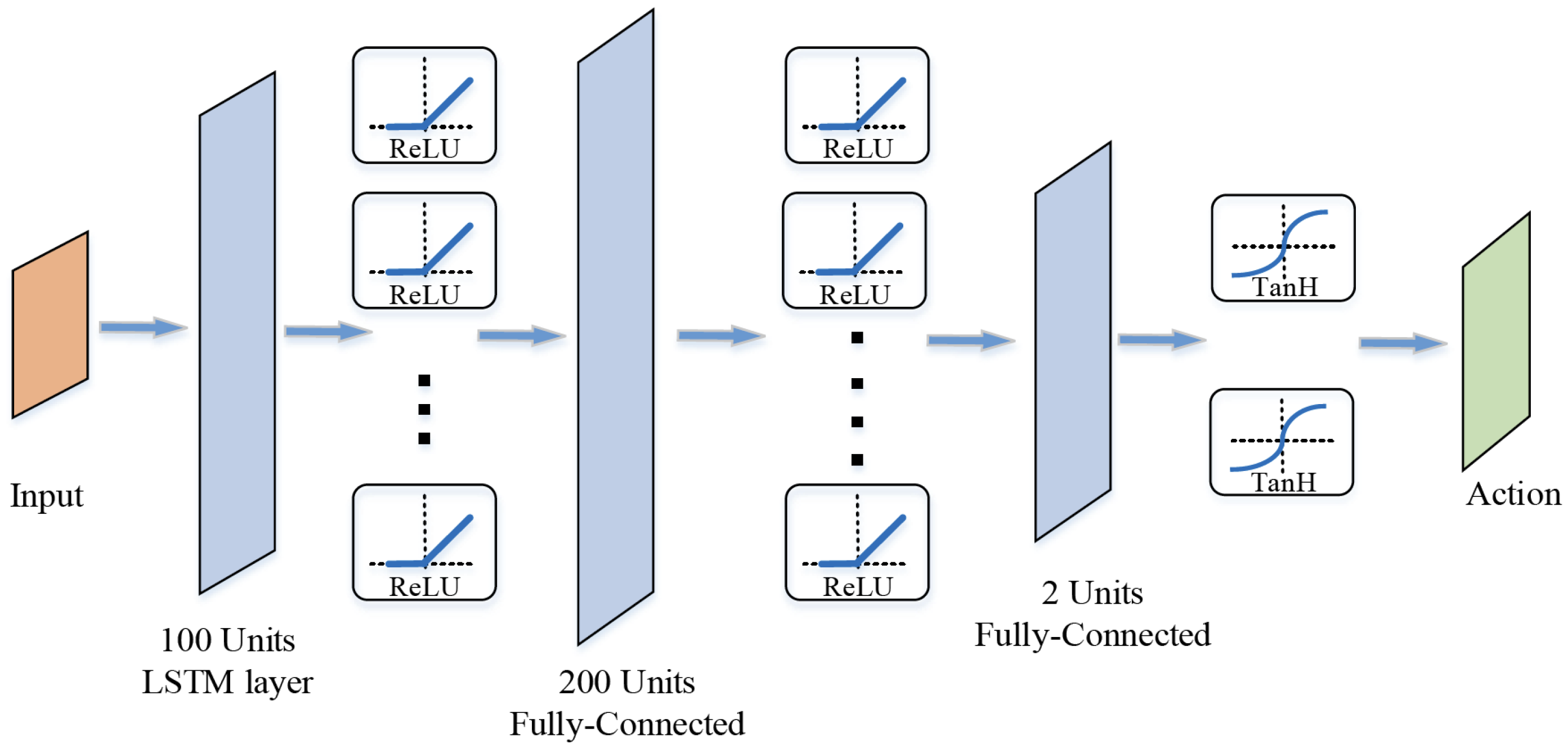
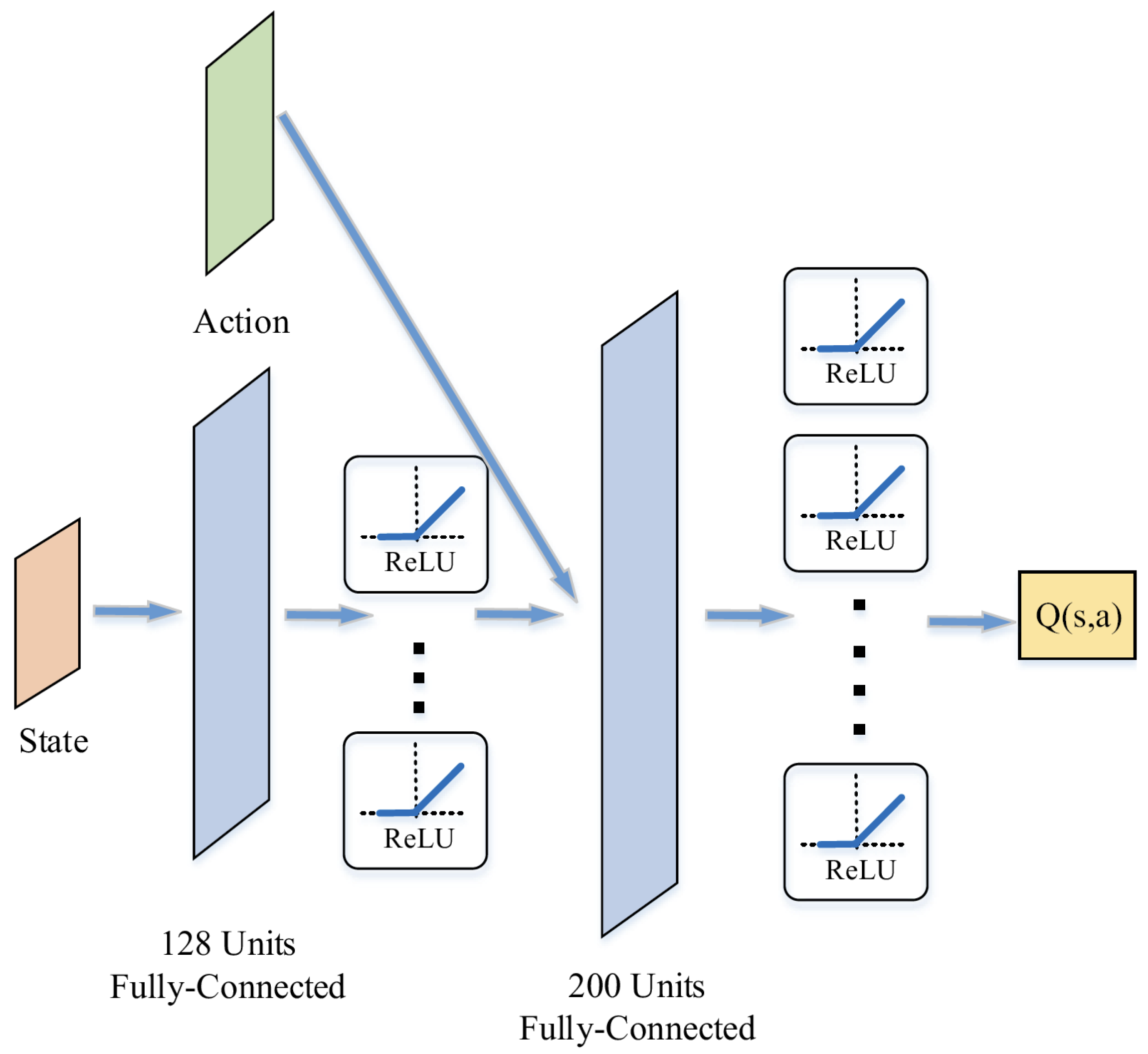
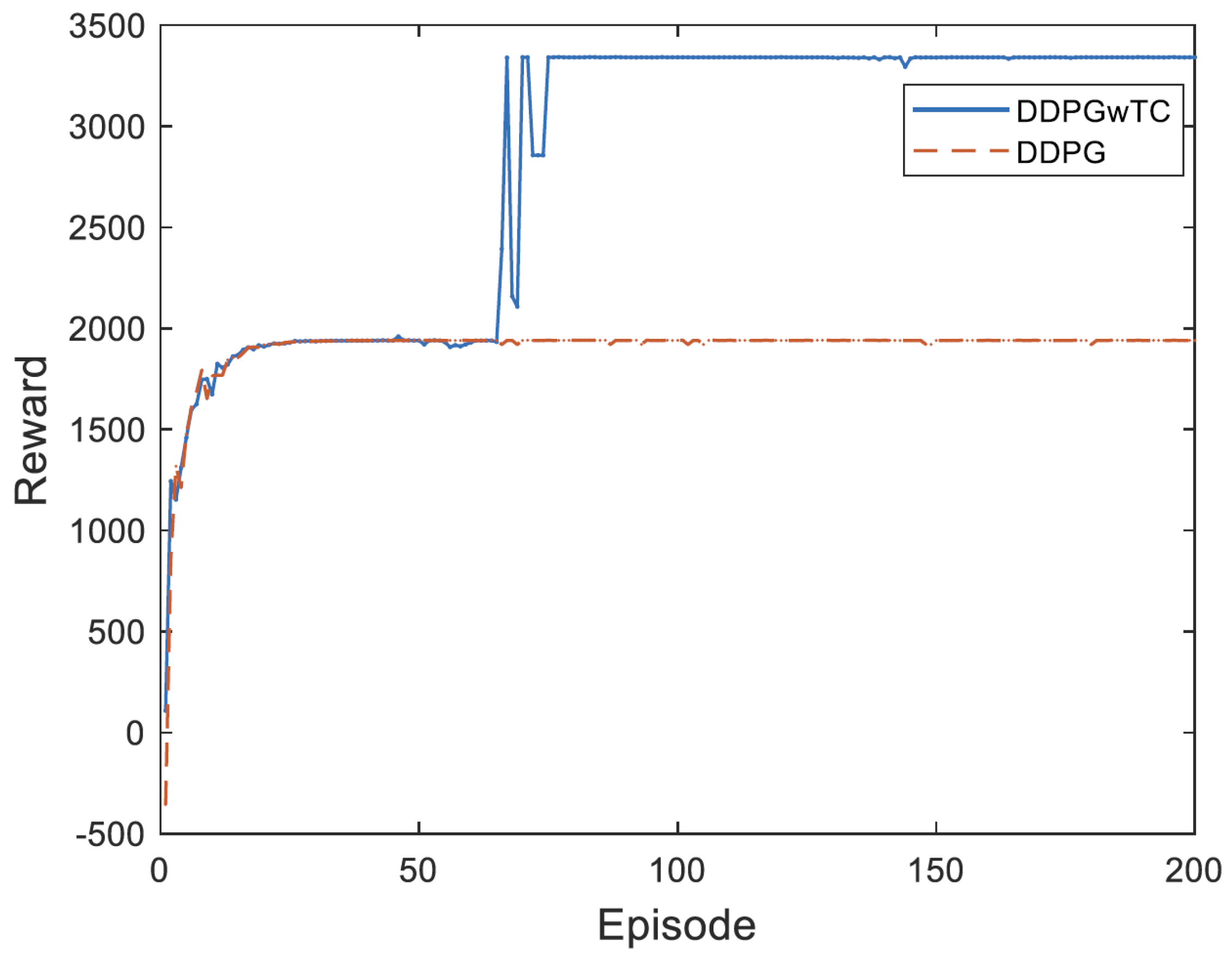
3.2. DDPGwTC Algorithm Training
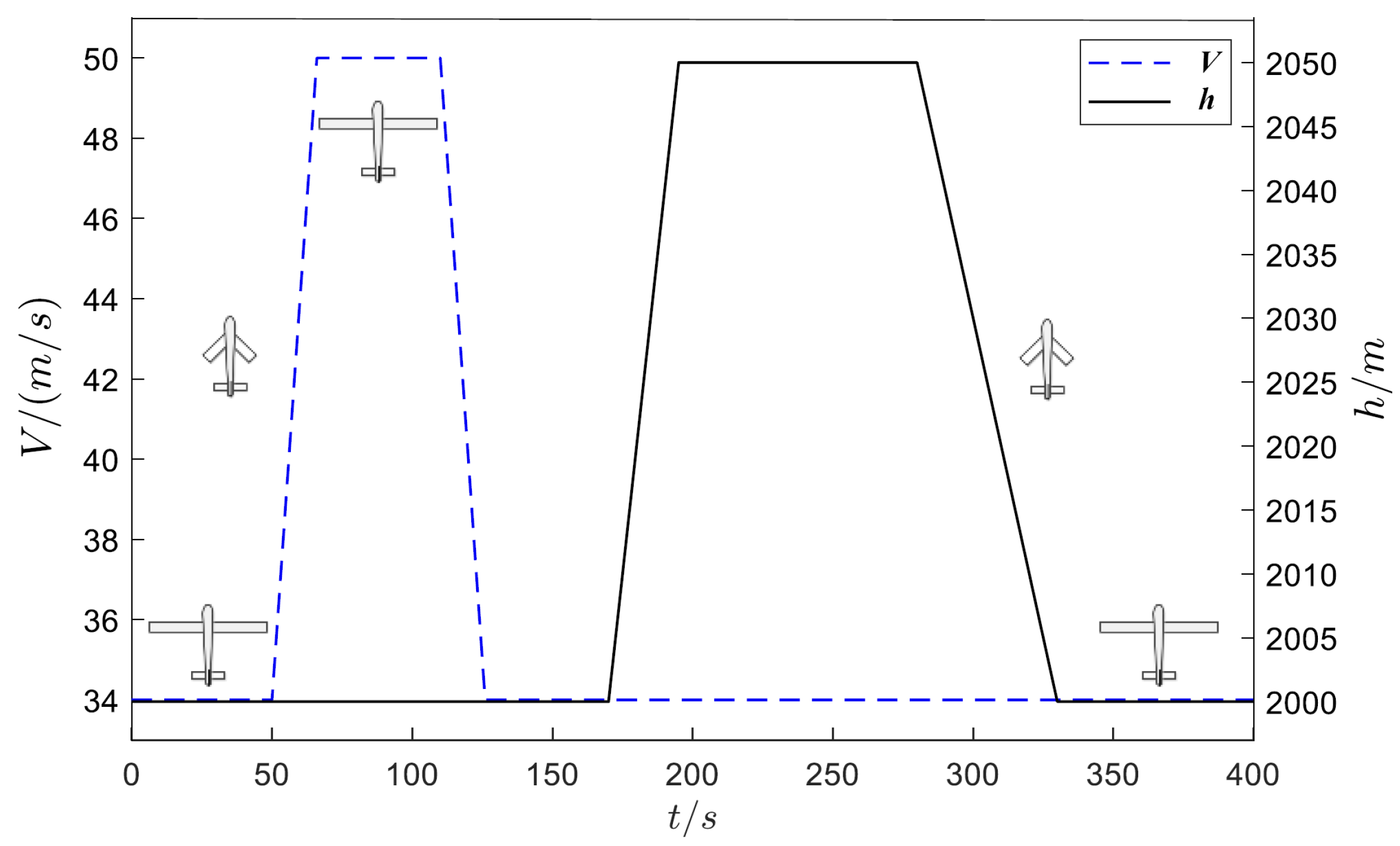
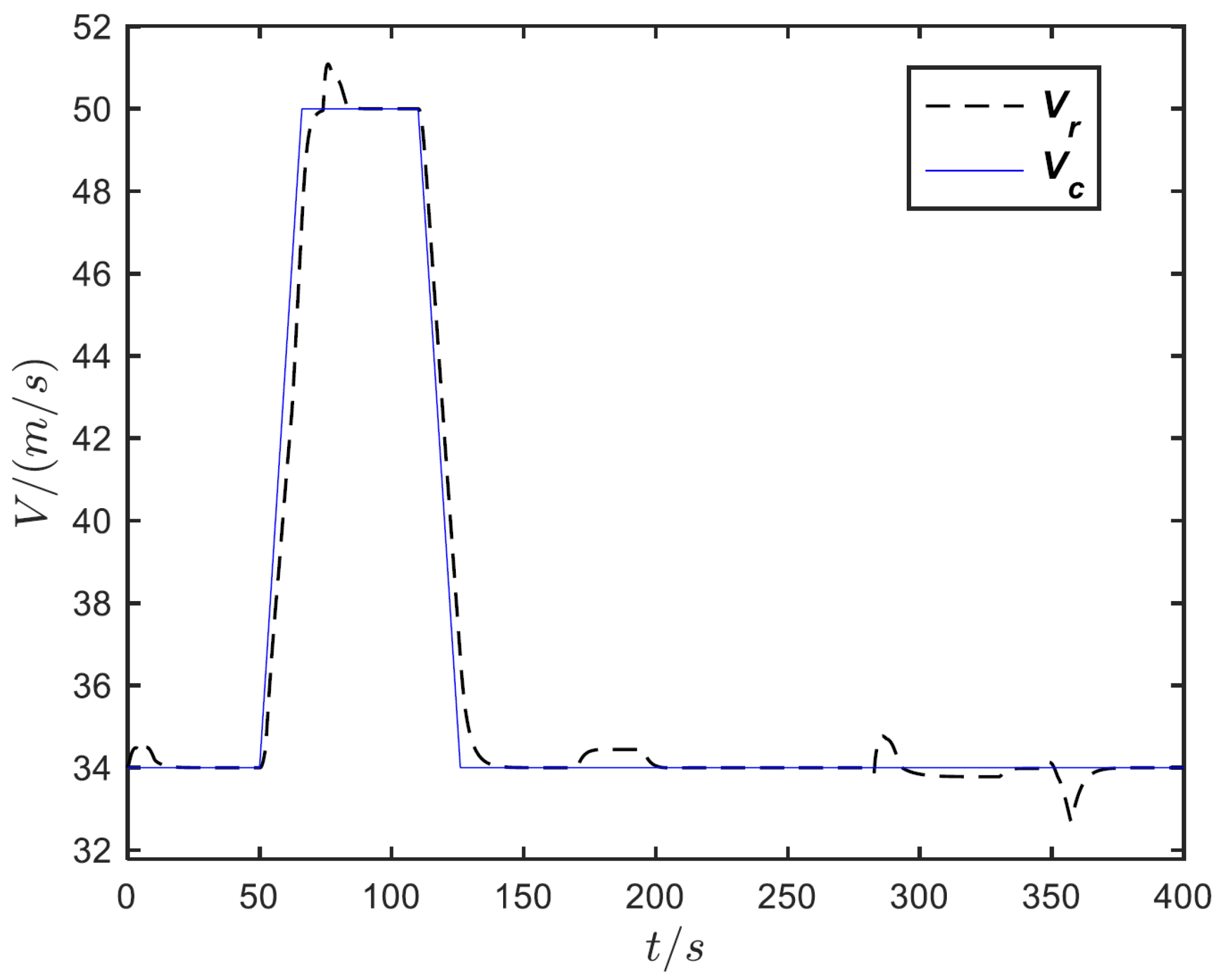
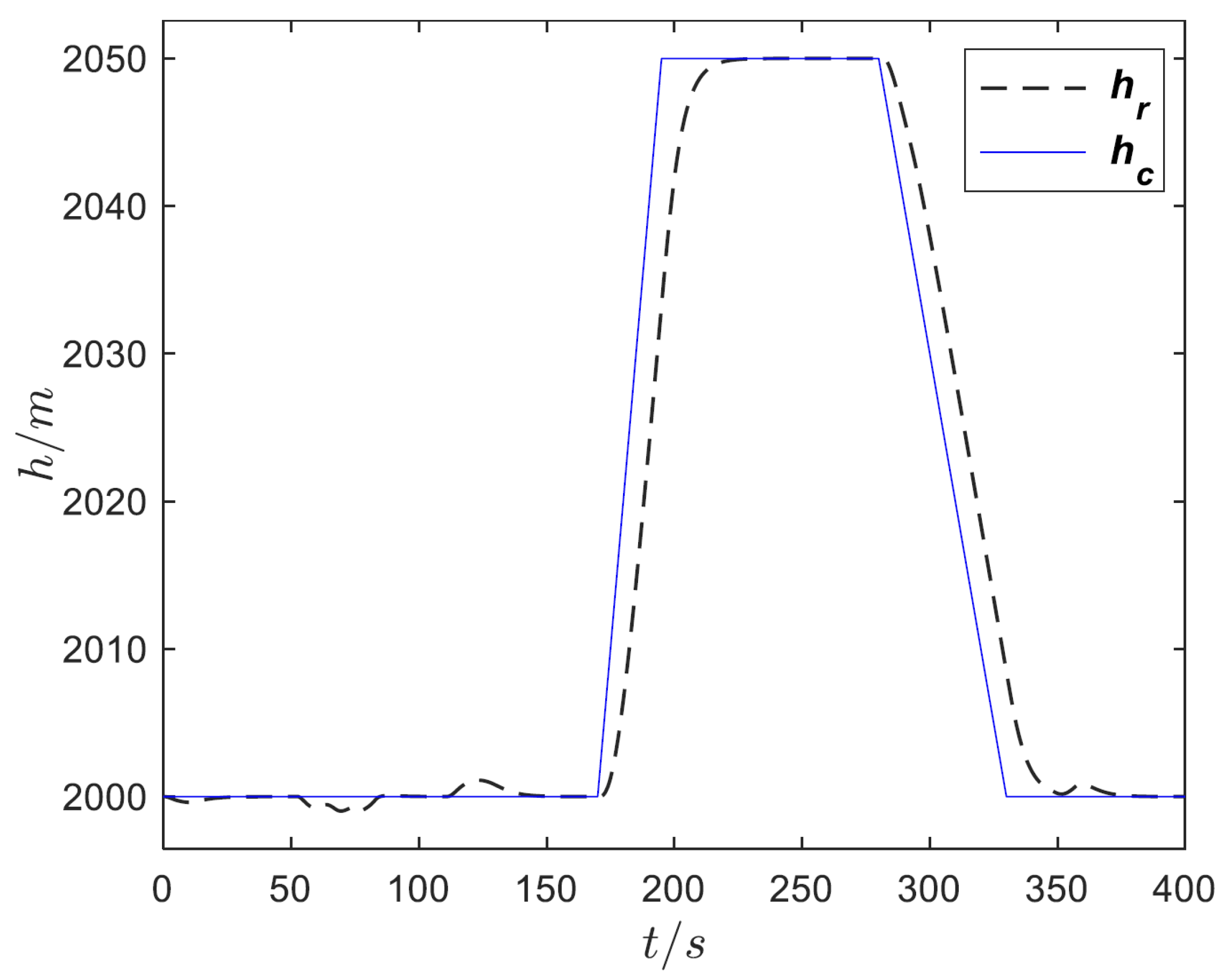
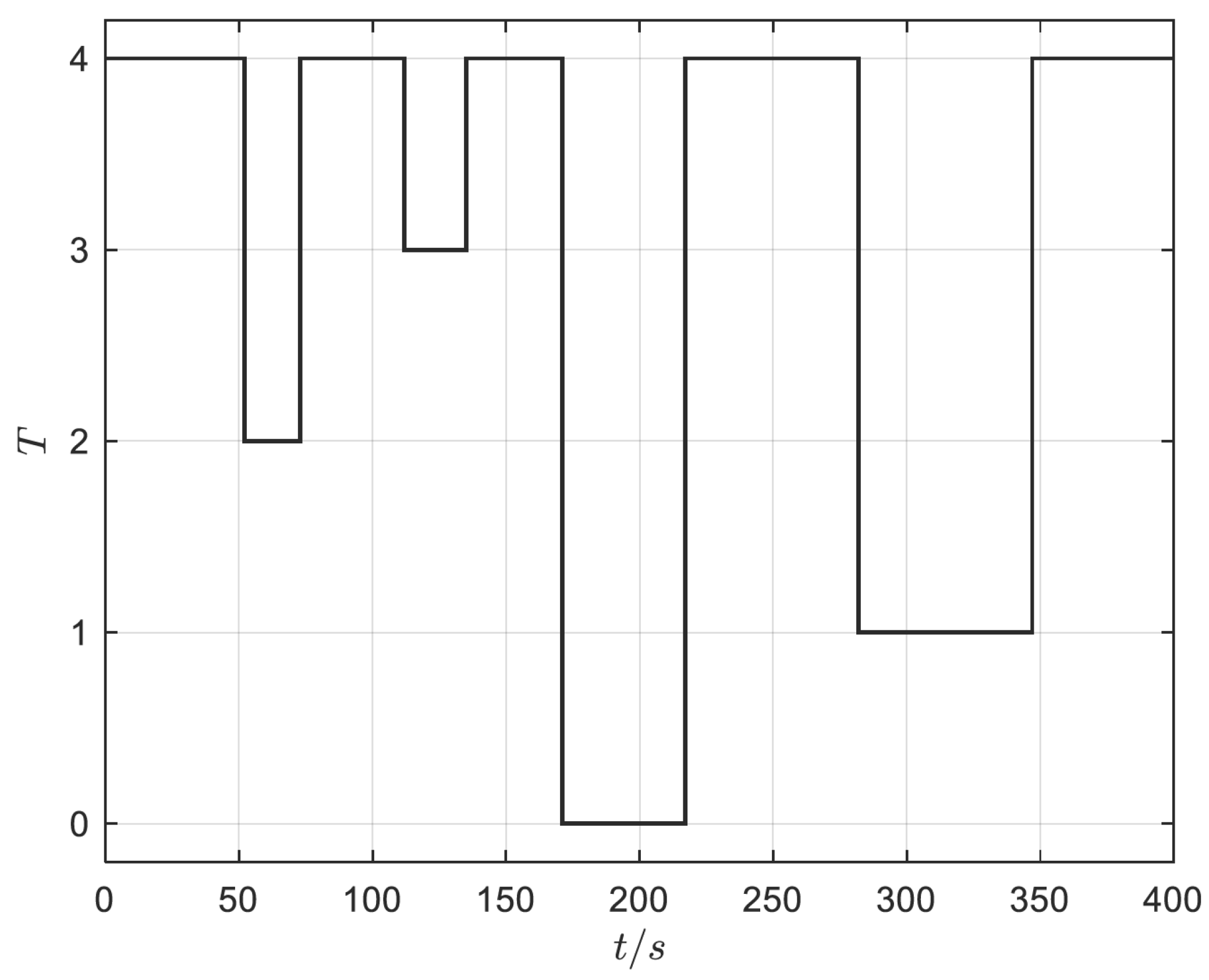
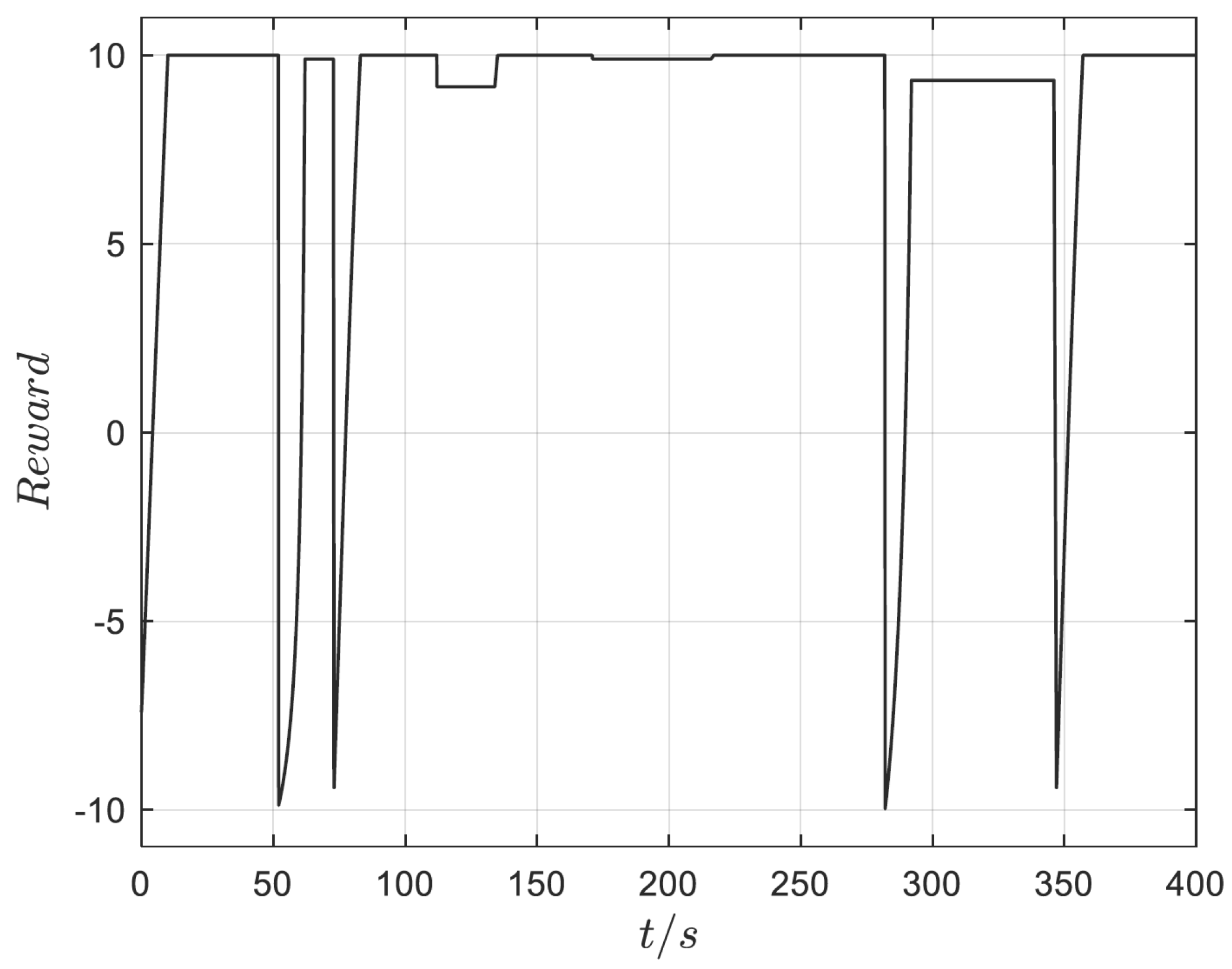
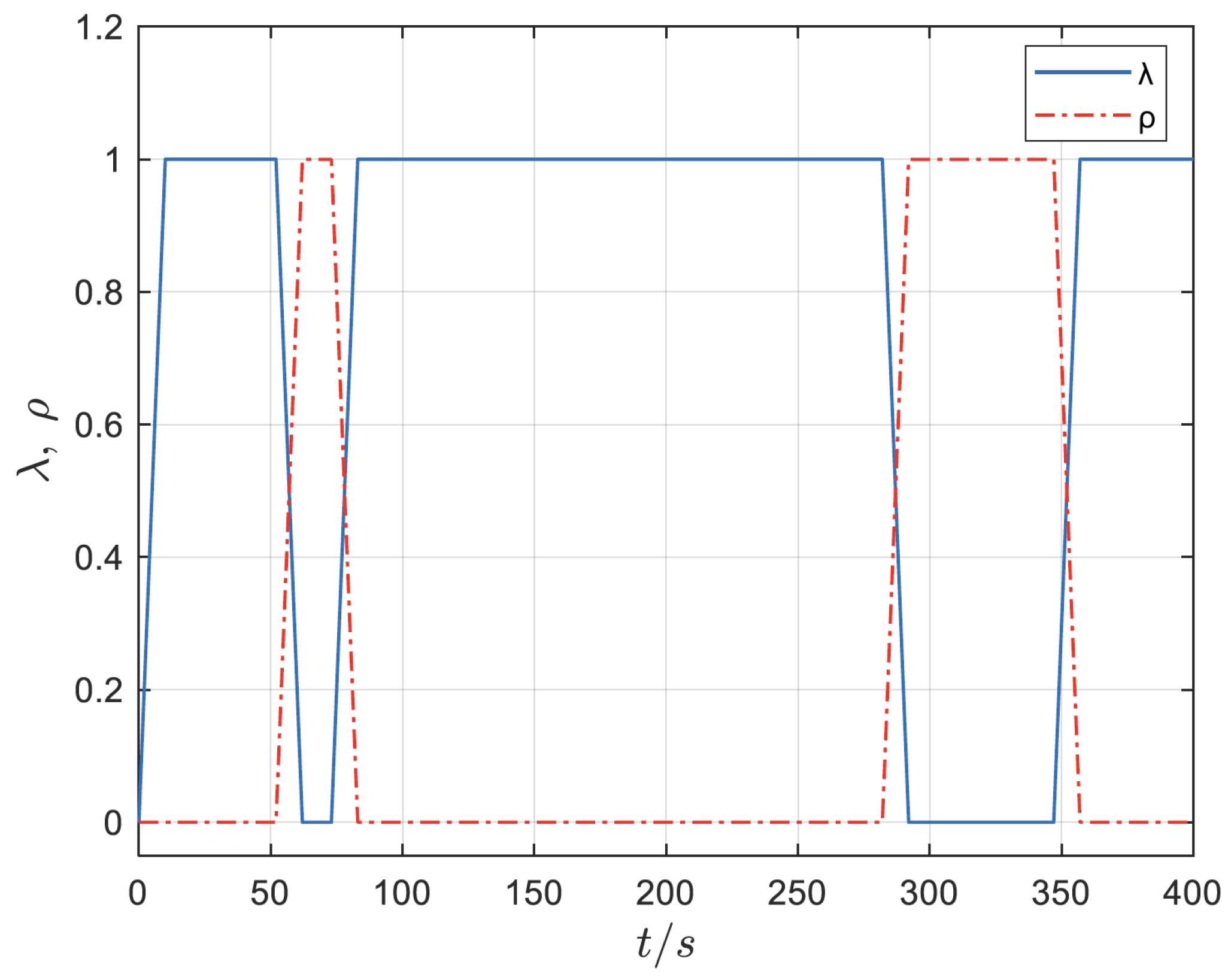
4. Simulation Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Weisshaar, T.A. Morphing aircraft systems: Historical perspectives and future challenges. J. Aircraft 2013, 50, 337–353. [Google Scholar] [CrossRef]
- Ajaj, R.M.; Parancheerivilakkathil, M.S.; Amoozgar, M.; Friswell, M.I.; Cantwell, W.J. Recent developments in the aeroelasticity of morphing aircraft. Prog. Aerosp. Sci. 2021, 120, 100682. [Google Scholar] [CrossRef]
- Wang, Q.; Gong, L.; Dong, C.; Zhong, K. Morphing aircraft control based on switched nonlinear systems and adaptive dynamic programming. Aerosp. Sci. Technol. 2019, 93, 105325. [Google Scholar] [CrossRef]
- Li, W.; Wang, W.; Huang, W. Morphing aircraft systems: Historical perspectives and future challenges. Appl. Sci. 2021, 11, 2505. [Google Scholar]
- Li, R.; Wang, Q.; Dong, C. Morphing Strategy Design for UAV based on Prioritized Sweeping Reinforcement Learning. In Proceedings of the IECON 2020 The 46th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 18–21 October 2020; pp. 2786–2791. [Google Scholar]
- Zhang, J.; Shaw, A. Aeroelastic model and analysis of an active camber morphing wing. Aerosp. Sci. Technol. 2021, 111, 106534. [Google Scholar] [CrossRef]
- Grigorie, T.L.; Botez, R.M. A Self–Tuning Intelligent Controller for a Smart Actuation Mechanism of a Morphing Wing Based on Shape Memory Alloys. Actuators 2023, 12, 350. [Google Scholar] [CrossRef]
- Huang, J.; Fu, X.; Jing, Z. Singular dynamics for morphing aircraft switching on the velocity boundary. Commun. Nonlinear Sci. Numer. Simul. 2021, 95, 105625. [Google Scholar] [CrossRef]
- Burdette, D.A.; Martins, J.R.R.A. Design of a transonic wing with an adaptive morphing trailing edge via aerostructural optimization. Aerosp. Sci. Technol. 2018, 81, 192–203. [Google Scholar] [CrossRef]
- Li, W.; Wang, W.; Huang, X.; Zhang, S.; Li, C. Roll Control of Morphing Aircraft with Synthetic Jet Actuators at a High Angle of Attack. Appl. Sci. 2021, 11, 505. [Google Scholar] [CrossRef]
- Yan, B.; Dai, P.; Liu, R. Adaptive super-twisting sliding mode control of variable sweep morphing aircraft. Aerosp. Sci. Technol. 2019, 92, 198–210. [Google Scholar] [CrossRef]
- Jiang, W.; Wu, K.; Wang, Z. Gain-scheduled control for morphing aircraft via switching polytopic linear parameter-varying systems. Aerosp. Sci. Technol. 2020, 107, 106242. [Google Scholar] [CrossRef]
- Cheng, L.; Li, Y.; Yuan, J.; Ai, J.; Dong, Y. L1 Adaptive Control Based on Dynamic Inversion for Morphing Aircraft. Aerospace 2023, 10, 786. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Wang, Z.; Schaul, T.; Hessel, M. Dueling network architectures for deep reinforcement learning. Int. Conf. Mach. Learn. 2016, 48, 1995–2003. [Google Scholar]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable MDPs. In Proceedings of the Association for the Advancement of Artificial Intelligence Presented the 2015 Fall Symposium Series, Arlington, VA, USA, 12–14 November 2015; Volume 1507, p. 06527. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P. Policy gradient methods for reinforcement learning with function approximation. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N. Deterministic policy gradient algorithms. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 22–24 June 2014; pp. 387–395. [Google Scholar]
- Valasek, J.; Tandale, M.D.; Rong, J. A reinforcement learning - adaptive control architecture for morphing. J. Aerosp. Comput. Inf. Commun. 2005, 2, 174–195. [Google Scholar] [CrossRef]
- Valasek, J.; Doebbler, J.; Tandale, M.D. Improved adaptive-reinforcement learning control for morphing unmanned air vehicles. IEEE Trans. Syst. Man, Cybern. Part B (Cybern.) 2008, 38, 1014–1020. [Google Scholar] [CrossRef] [PubMed]
- Lampton, A.; Niksch, A.; Valasek, J. Morphing airfoils with four morphing parameters. In Proceedings of the AIAA Guidance, Navigation and Control Conference and Exhibit, Honolulu, HI, USA, 18–21 August 2008; pp. 72–82. [Google Scholar]
- Lampton, A.; Niksch, A.; Valasek, J. Reinforcement learning of a morphing airfoil-policy and discrete learning analysis. J. Aerosp. Comput. Inf. Commun. 2010, 7, 241–260. [Google Scholar] [CrossRef]
- Lampton, A.; Niksch, A.; Valasek, J. Reinforcement learning of morphing airfoils with aerodynamic and structural effects. J. Aerosp. Comput. Inf. Commun. 2015, 6, 30–50. [Google Scholar] [CrossRef]
- Yan, B.; Li, Y.; Dai, P. Adaptive wing morphing strategy and flight control method of a morphing aircraft based on reinforcement learning. J. Northwest. Polytech. Univ. 2019, 37, 656–663. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Wen, N.; Liu, Z.; Zhu, L. Deep reinforcement learning and its application on autonomous shape optimization for morphing. J. Astronaut. 2017, 38, 1153–1159. [Google Scholar]
- Goecks, V.G.; Leal, P.B.; White, T. Control of morphing wing shapes with deep reinforcement learning. In Proceedings of the 2018 AIAA Information Systems—AIAA Infotech@ Aerospace, Kissimmee, FL, USA, 8–12 January 2018; p. 2139. [Google Scholar]
- Xu, D.; Hui, Z.; Liu, Y.; Chen, G. Morphing control of a new bionic morphing UAV with deep reinforcement learning. Aerosp. Sci. Technol. 2019, 92, 232–243. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, King’s College, London, UK, 1989. [Google Scholar]
- Jiang, W.; Wu, K.; Bao, C.; Xi, T. T-S Fuzzy Modeling and Tracking Control of Morphing Aircraft. Lect. Notes Electr. Eng. 2022, 644, 2869–2881. [Google Scholar]
- Shen, X.; Dong, C.; Jiang, W. Longitudinal control of morphing aircraft based on T-S fuzzy model. In Proceedings of the IEEE Chinese Guidance, Navigation and Control Conference, Yantai, China, 8–10 August 2014. [Google Scholar]
- Seigler, T.M. Dynamics and Control of Morphing Aircraft. Ph.D. Thesis, Virginia Polytechnic Institute and State University, Blacksburg, VA, USA, 2005. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Target Update Factor / | 0.001 |
| Actor Learning Rate | 0.0005 |
| Critic Learning Rate | 0.001 |
| Experience Replay Buffer Capacity | |
| Minibatch Size | 128 |
| Discount Factor / | 0.99 |
| Maximum Number of Scenes | 200 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Zheng, C.; Hou, D.; Wu, K.; Wang, Y. Autonomous Shape Decision Making of Morphing Aircraft with Improved Reinforcement Learning. Aerospace 2024, 11, 74. https://doi.org/10.3390/aerospace11010074
Jiang W, Zheng C, Hou D, Wu K, Wang Y. Autonomous Shape Decision Making of Morphing Aircraft with Improved Reinforcement Learning. Aerospace. 2024; 11(1):74. https://doi.org/10.3390/aerospace11010074
Chicago/Turabian StyleJiang, Weilai, Chenghong Zheng, Delong Hou, Kangsheng Wu, and Yaonan Wang. 2024. "Autonomous Shape Decision Making of Morphing Aircraft with Improved Reinforcement Learning" Aerospace 11, no. 1: 74. https://doi.org/10.3390/aerospace11010074
APA StyleJiang, W., Zheng, C., Hou, D., Wu, K., & Wang, Y. (2024). Autonomous Shape Decision Making of Morphing Aircraft with Improved Reinforcement Learning. Aerospace, 11(1), 74. https://doi.org/10.3390/aerospace11010074