Leader–Follower Synchronization of Uncertain Euler–Lagrange Dynamics with Input Constraints


Abstract
:1. Introduction
2. Preliminary Results
2.1. Euler–Lagrange Systems
2.2. Inverse Dynamic Based Control
2.3. Communication Graph
3. Adaptive Synchronization with Input Constraint
3.1. System Dynamics
3.2. Adaptive Synchronization of the Leader to the Reference Model
3.3. Adaptive Synchronization of the Follower to the Leader
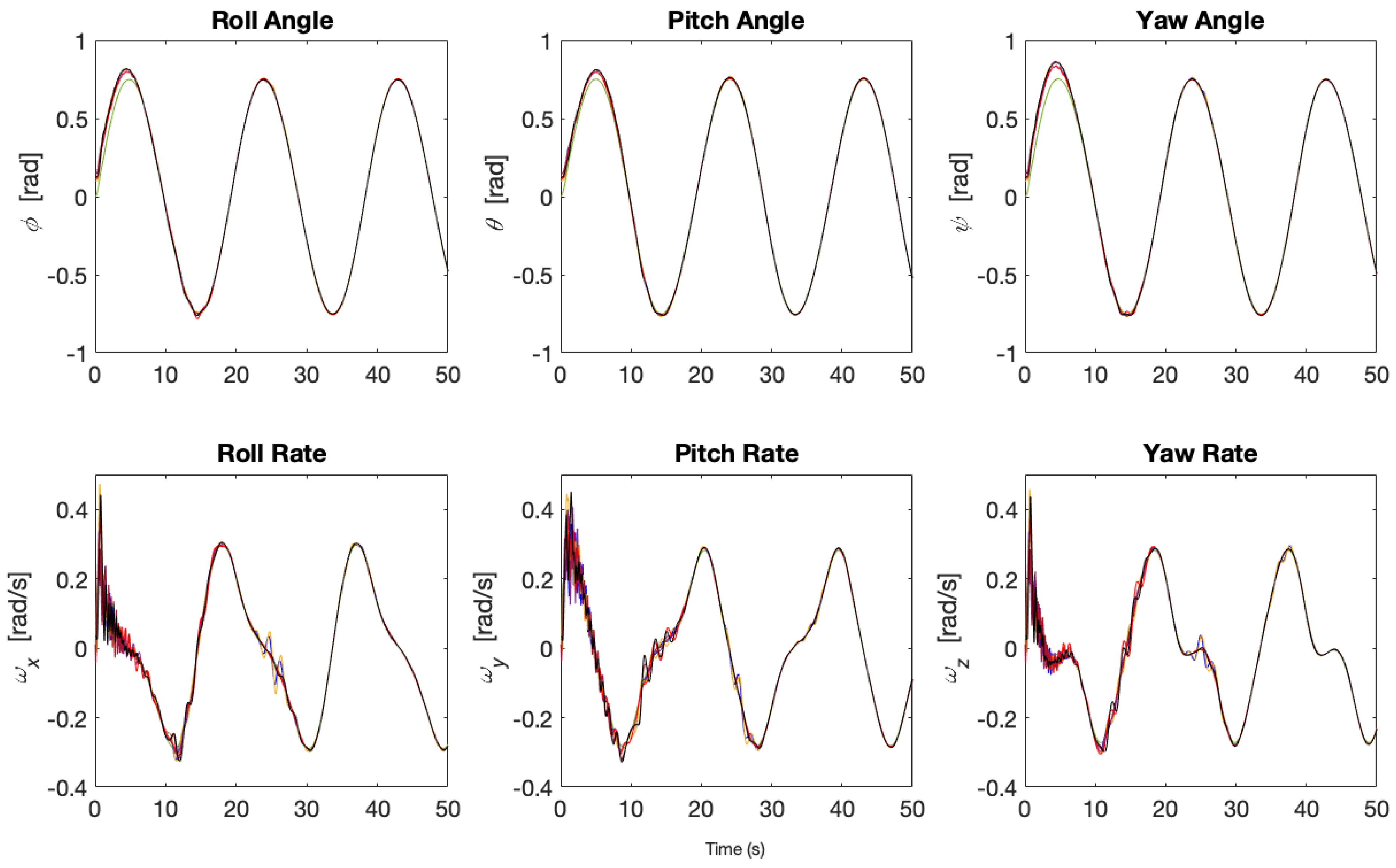
4. Spacecraft Test Case
5. Numerical Simulations
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Seyboth, G.S.; Ren, W.; Allgöwer, F. Cooperative control of linear multi-agent systems via distributed output regulation and transient synchronization. Automatica 2016, 68, 132–139. [Google Scholar] [CrossRef] [Green Version]
- Das, A.; Lewis, F.L. Distributed adaptive control for synchronization of unknown nonlinear networked systems. Automatica 2010, 46, 2014–2021. [Google Scholar] [CrossRef]
- Tang, Y.; Gao, H.; Zou, W.; Kurths, J. Distributed Synchronization in Networks of Agent Systems With Nonlinearities and Random Switchings. IEEE Trans. Cybern. 2013, 43, 358–370. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and Cooperation in Networked Multi-Agent Systems. Proc. IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef] [Green Version]
- Olfati-Saber, R.; Murray, R.M. Consensus problems in networks of agents with switching topology and time-delays. IEEE Trans. Autom. Control 2004, 49, 1520–1533. [Google Scholar] [CrossRef] [Green Version]
- Nazari, M.; Butcher, E.A.; Yucelen, T.; Sanyal, A.K. Decentralized Consensus Control of a Rigid-Body Spacecraft Formation with Communication Delay. J. Guid. Control Dyn. 2016, 39, 838–851. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Shi, P.; Su, H.; Chu, J. Exponential Synchronization of Neural Networks With Discrete and Distributed Delays Under Time-Varying Sampling. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1368–1376. [Google Scholar]
- Dong, H.; Wang, Z.; Gao, H. Distributed Filtering for a Class of Time-Varying Systems Over Sensor Networks With Quantization Errors and Successive Packet Dropouts. IEEE Trans. Signal Process. 2012, 60, 3164–3173. [Google Scholar] [CrossRef]
- Ren, W.; Beard, R.W.; Beard, A.W. Decentralized Scheme for Spacecraft Formation Flying via the Virtual Structure Approach. AIAA J. Guid. Control Dyn. 2003, 27, 73–82. [Google Scholar] [CrossRef]
- Lesser, V.; Tambe, M.; Ortiz, C.L. (Eds.) Distributed Sensor Networks: A Multiagent Perspective; Kluwer Academic Publishers: Norwell, MA, USA, 2003. [Google Scholar]
- Harfouch, Y.A.; Yuan, S.; Baldi, S. Adaptive control of interconnected networked systems with application to heterogeneous platooning. In Proceedings of the 2017 13th IEEE International Conference on Control Automation (ICCA), Ohrid, North Macedonia, 3–6 July 2017; pp. 212–217. [Google Scholar]
- Blaabjerg, F.; Teodorescu, R.; Liserre, M.; Timbus, A.V. Overview of Control and Grid Synchronization for Distributed Power Generation Systems. IEEE Trans. Ind. Electron. 2006, 53, 1398–1409. [Google Scholar] [CrossRef] [Green Version]
- Jun, M.; D’Andrea, R. Path Planning for Unmanned Aerial Vehicles in Uncertain and Adversarial Environments. In Cooperative Control: Models, Applications and Algorithms; Springer: Boston, MA, USA, 2003; pp. 95–110. [Google Scholar]
- Yucelen, T.; Johnson, E.N. Control of multivehicle systems in the presence of uncertain dynamics. Int. J. Control 2013, 86, 1540–1553. [Google Scholar] [CrossRef]
- Popa, D.O.; Sanderson, A.C.; Komerska, R.J.; Mupparapu, S.S.; Blidberg, D.R.; Chappel, S.G. Adaptive sampling algorithms for multiple autonomous underwater vehicles. In Proceedings of the 2004 IEEE/OES Autonomous Underwater Vehicles, Sebasco, ME, USA, 17–18 June 2004; pp. 108–118. [Google Scholar]
- Jin, X.; Haddad, W.M.; Yucelen, T. An Adaptive Control Architecture for Mitigating Sensor and Actuator Attacks in Cyber-Physical Systems. IEEE Trans. Autom. Control 2017, 62, 6058–6064. [Google Scholar] [CrossRef]
- Fax, J.A.; Murray, R.M. Information flow and cooperative control of vehicle formations. IEEE Trans. Autom. Control 2004, 49, 1465–1476. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Wei, B. A review on model reference adaptive control of robotic manipulators. Annu. Rev. Control 2017, 43, 188–198. [Google Scholar] [CrossRef]
- Baldi, S.; Frasca, P. Adaptive synchronization of unknown heterogeneous agents: An adaptive virtual model reference approach. J. Frankl. Inst. 2019, 356, 935–955. [Google Scholar] [CrossRef] [Green Version]
- Rosa, M.R. Adaptive Synchronization for Heterogeneous Multi-Agent Systems with Switching Topologies. Machines 2018, 6, 7. [Google Scholar] [CrossRef] [Green Version]
- Baldi, S.; Rosa, M.R.; Frasca, P. Adaptive state-feedback synchronization with distributed input: The cyclic case. In Proceedings of the 7th IFAC Workshop on Distributed Estimation and Control in Networked Systems (NecSys18), Groningen, The Netherlands, 27–28 August 2018. [Google Scholar]
- Rosa, M.R.; Baldi, S.; Wang, X.; Lv, M.; Yu, W. Adaptive hierarchical formation control for uncertain Euler–Lagrange systems using distributed inverse dynamics. Eur. J. Control 2019, 48, 52–65. [Google Scholar] [CrossRef]
- Abdessameud, A.; Polushin, I.G.; Tayebi, A. Synchronization of Heterogeneous Euler–Lagrange Systems with Time Delays and Intermittent Information Exchange. IFAC Proc. Vol. 2014, 47, 1971–1976. [Google Scholar] [CrossRef] [Green Version]
- Abdessameud, A.; Tayebi, A.; Polushin, I.G. On the leader–follower synchronization of Euler–Lagrange systems. In Proceedings of the 2015 54th IEEE Conference on Decision and Control (CDC), Osaka, Japan, 15–18 December 2015; pp. 1054–1059. [Google Scholar]
- Abdessameud, A.; Tayebi, A.; Polushin, I.G. Leader–Follower Synchronization of Euler–Lagrange Systems With Time-Varying Leader Trajectory and Constrained Discrete-Time Communication. IEEE Trans. Autom. Control 2017, 62, 2539–2545. [Google Scholar] [CrossRef]
- Baldi, S.; Rosa, M.R.; Frasca, P.; Kosmatopoulos, E.B. Platooning merging maneuvers in the presence of parametric uncertainty. In Proceedings of the 7th IFAC Workshop on Distributed Estimation and Control in Networked Systems (NecSys18), Groningen, The Netherlands, 27–28 August 2018. [Google Scholar]
- Karason, S.P.; Annaswamy, A.M. Adaptive control in the presence of input constraints. IEEE Trans. Autom. Control 1994, 39, 2325–2330. [Google Scholar] [CrossRef]
- Wen, C.; Zhou, J.; Liu, Z.; Su, H. Robust Adaptive Control of Uncertain Nonlinear Systems in the Presence of Input Saturation and External Disturbance. IEEE Trans. Autom. Control 2011, 56, 1672–1678. [Google Scholar] [CrossRef]
- Lavretsky, E.; Hovakimyan, N. Stable adaptation in the presence of input constraints. Syst. Control Lett. 2007, 56, 722–729. [Google Scholar] [CrossRef]
- Baldi, S.; Liu, D.; Jain, V.; Yu, W. Establishing Platoons of Bidirectional Cooperative Vehicles With Engine Limits and Uncertain Dynamics. IEEE Trans. Intell. Transp. Syst. 2020, 1–13. [Google Scholar] [CrossRef]
- Ortega, R.; Spong, M.W. Adaptive motion control of rigid robots: A tutorial. Automatica 1989, 25, 877–888. [Google Scholar] [CrossRef]
- Mei, J.; Ren, W.; Ma, G. Distributed Coordinated Tracking With a Dynamic Leader for Multiple Euler-Lagrange Systems. IEEE Trans. Autom. Control 2011, 56, 1415–1421. [Google Scholar] [CrossRef]
- Nuno, E.; Ortega, R.; Basanez, L.; Hill, D. Synchronization of Networks of Nonidentical Euler-Lagrange Systems With Uncertain Parameters and Communication Delays. IEEE Trans. Autom. Control 2011, 56, 935–941. [Google Scholar] [CrossRef]
- Chen, F.; Feng, G.; Liu, L.; Ren, W. Distributed Average Tracking of Networked Euler-Lagrange Systems. IEEE Trans. Autom. Control 2015, 60, 547–552. [Google Scholar] [CrossRef]
- Klotz, J.R.; Kan, Z.; Shea, J.M.; Pasiliao, E.L.; Dixon, W.E. Asymptotic Synchronization of a Leader–Follower Network of Uncertain Euler-Lagrange Systems. IEEE Trans. Control Netw. Syst. 2015, 2, 174–182. [Google Scholar] [CrossRef]
- Roy, S.; Roy, S.B.; Kar, I.N. Adaptive–Robust Control of Euler–Lagrange Systems With Linearly Parametrizable Uncertainty Bound. IEEE Trans. Control Syst. Technol. 2018, 26, 1842–1850. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.; Kar, I.N.; Lee, J.; Jin, M. Adaptive-Robust Time-Delay Control for a Class of Uncertain Euler–Lagrange Systems. IEEE Trans. Ind. Electron. 2017, 64, 7109–7119. [Google Scholar] [CrossRef]
- Roy, S.; Kar, I.N.; Lee, J.; Tsagarakis, N.G.; Caldwell, D.G. Adaptive-Robust Control of a Class of EL Systems With Parametric Variations Using Artificially Delayed Input and Position Feedback. IEEE Trans. Control Syst. Technol. 2019, 27, 603–615. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.; Kar, I.N.; Lee, J. Toward Position-Only Time-Delayed Control for Uncertain Euler–Lagrange Systems: Experiments on Wheeled Mobile Robots. IEEE Robot. Autom. Lett. 2017, 2, 1925–1932. [Google Scholar] [CrossRef]
- Johansen, T.A.; Fossen, T.I. Control allocation—A survey. Automatica 2013, 49, 1087–1103. [Google Scholar] [CrossRef] [Green Version]
- Ioannou, P.; Fidan, B. Adaptive Control Tutorial (Advances in Design and Control); Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2006. [Google Scholar]
- Tao, G. Adaptive Control Design and Analysis (Adaptive and Learning Systems for Signal Processing, Communications and Control Series); John Wiley & Sons, Inc.: New York, NY, USA, 2003. [Google Scholar]
- Leonessa, A.; Haddad, W.M.; Hayakawa, T.; Morel, Y. Adaptive control for nonlinear uncertain systems with actuator amplitude and rate saturation constraints. Int. J. Adapt. Control Signal Process. 2009, 23, 73–96. [Google Scholar] [CrossRef] [Green Version]
- Romdlony, M.Z.; Jayawardhana, B. Stabilization with guaranteed safety using Control Lyapunov–Barrier Function. Automatica 2016, 66, 39–47. [Google Scholar] [CrossRef]
- Yucelen, T.; Haddad, W.M. Low-Frequency Learning and Fast Adaptation in Model Reference Adaptive Control. IEEE Trans. Autom. Control 2013, 58, 1080–1085. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial Cond. []’ (0) | Initial Cond. []’ (0) | Moment of Inertia (kg m) | |
|---|---|---|---|
| Agent 0 (Trajectory Generator) | [0, 0, 0]’ | [0, 0, 0]’ | |
| Agent 1 (Leader 1) | [0.1, 0.1, 0.1]’ | [0.1, 0.1, 0.1]’ | |
| Agent 1 (Leader 2) | [0.3, 0.3, 0.3]’ | [−0.2, −0.2, −0.2]’ | |
| Agent 1 (Leader 3) | [−0.3, −0.3, −0.3]’ | [0.2, 0.2, 0.2]’ | |
| Agent 4 (Follower 1) | [0.2, 0.2, 0.2]’ | [−0.1, −0.1, −0.1]’ | |
| Agent 5 (Follower 2) | [−0.2, −0.2, −0.2]’ | [0.2, 0.2, 0.2]’ | |
| Agent 6 (Follower 3) | [0.4, 0.4, 0.4]’ | [0.1, 0.1, 0.1]’ |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rosa, M.R. Leader–Follower Synchronization of Uncertain Euler–Lagrange Dynamics with Input Constraints. Aerospace 2020, 7, 127. https://doi.org/10.3390/aerospace7090127
Rosa MR. Leader–Follower Synchronization of Uncertain Euler–Lagrange Dynamics with Input Constraints. Aerospace. 2020; 7(9):127. https://doi.org/10.3390/aerospace7090127
Chicago/Turabian StyleRosa, Muhammad Ridho. 2020. "Leader–Follower Synchronization of Uncertain Euler–Lagrange Dynamics with Input Constraints" Aerospace 7, no. 9: 127. https://doi.org/10.3390/aerospace7090127
APA StyleRosa, M. R. (2020). Leader–Follower Synchronization of Uncertain Euler–Lagrange Dynamics with Input Constraints. Aerospace, 7(9), 127. https://doi.org/10.3390/aerospace7090127