
The Use of Machine Learning for the Prediction of the Uniformity of the Degree of Cure of a Composite in an Autoclave

Abstract
:1. Introduction
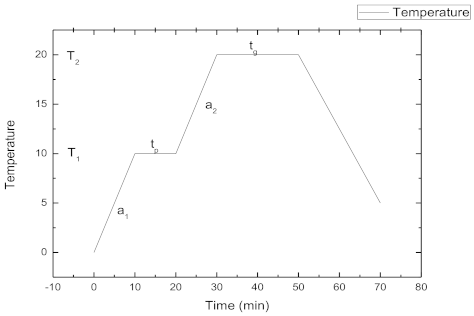
2. Material Description
3. Estimation Model
3.1. Data Processing
3.2. FCNN
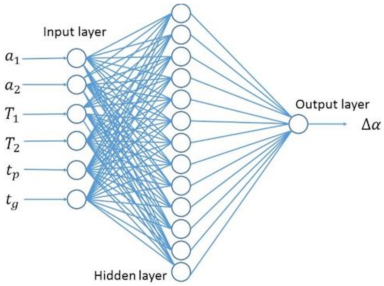
3.2.1. Fully Connected Neural Network
3.2.2. The Establishment of a Fully Connected Neural Network
3.3. DNN
3.3.1. Deep Neural Network
3.3.2. The Establishment of a DNN
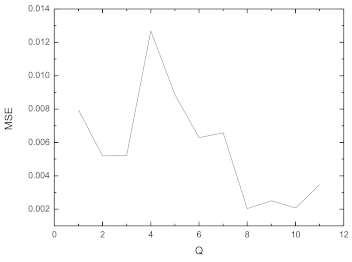
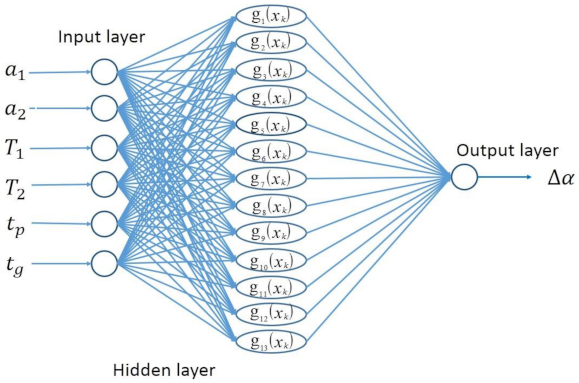
3.4. RBF Neural Network
3.5. SVR Model
3.6. KNN Regression Model
4. Results and Discussion
5. Conclusions
- The models based on machine learning for the prediction of the uniformity of the degree of cure of the composite in an autoclave had a small error margin and high efficiency, greatly saving manpower and time. These models provided a new and effective method for the estimation of the maximum ∆α of a composite in autoclave forming.
- Based on the estimated maximum curing degree difference, we could quickly find the curing process parameter group with the smaller maximum ∆α so as to reduce the residual stress in the composite molded parts and provide convenience for the optimization of the composite molding process.
- In the five machine learning prediction models including a fully connected (FC) neural network model, a deep neural network (DNN) model, a radial basis function (RBF) neural network model, a support vector regression (SVR) model and a K-nearest neighbors (KNN) model, the prediction effect of the RBF neural network model was the best, the prediction effect of the SVR model was the worst and the prediction effects of the KNN model and the DNN model were better when predicting the maximum ∆α.
- Compared with the experimental test method, the machine learning prediction models had the advantages of low cost and high speed but the method had certain errors. If sufficient data cannot be provided, the calculation result will be inconsistent with the true value. The accuracy of the result also depends on the training data. Compared with a numerical simulation, this method also had the advantages of low cost and high speed but this method could only obtain the final numerical results and could not dynamically reflect the reaction process. Therefore, the specific method to be used must be analyzed in conjunction with the actual situation.
- In future work, in order to improve the accuracy of the prediction model, an ensemble learning of five machine learning models will be constructed to obtain excellent generalization performance. the integration method may be boosting, bagging or random forest.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Loos, A.C.; Springer, G.S. Curing of Epoxy Matrix Composites. J. Compos. Mater. 1983, 17, 135–169. [Google Scholar] [CrossRef] [Green Version]
- Hojjati, M.; Hoa, S. Curing simulation of thick thermosetting composites. Compos. Manuf. 1994, 5, 159–169. [Google Scholar] [CrossRef]
- Johnston, A.A. An integrated model of the development of process-induced deformation in autoclave processing of composite structures. Ph.D. Thesis, The University of British Columbia, Ann Arbor, MI, Canada, July 1998. [Google Scholar]
- Hoa, S.V. Design and manufacturing of composites. In An Investigation of Autoclave Convective Heat Transfer, 2nd ed.; Johnston, A., Hubert, P., Vaziri, R., Poursartip, A., Eds.; Technomic Pub.: Lancaster, PA, USA, 1998. [Google Scholar]
- Dolkun, D.; Zhu, W.D.; Xu, Q.; Yinglin, K.E. Optimization of cure profile for thick composite parts based on finite element analysis and genetic algorithm. J. Compos. Mater. 2018, 52, 155–181. [Google Scholar] [CrossRef]
- Blest, D.C.; Duffy, B.R.; McKee, S.; Zulkifle, A.K. Curing simulation of thermoset composites. Compos. Part A 1999, 30, 1289–1309. [Google Scholar] [CrossRef]
- Khan, A.; Kim, N.; Shin, J.K. Damage assessment of smart composite structures via machine learning: A review. JMST Adv. 2019, 1, 107–124. [Google Scholar] [CrossRef] [Green Version]
- Cheung, A.; Yu, Y.; Pochiraju, K. Three-dimensional finite element simulation of curing of polymer composites. Finite Elem. Anal. Des. 2004, 40, 895–912. [Google Scholar] [CrossRef]
- Kim, Y.K.; White, S.R. VISCOELASTIC ANALYSIS OF PROCESSING-INDUCED RESIDUAL STRESSES IN THICK COMPOSITE LAMINATES. Mech. Adv. Mater. Struct. 1997, 4, 361–387. [Google Scholar] [CrossRef]
- Kempner, E.A.; Hahn, H.T.; Huh, H. The effect of the aged materials on the autoclave cure of thick composites. In Proceedings of the International Conference of Composite Materials/11, Gold Coast, QLD, Australia, 14–18 July 1997; pp. 422–431. [Google Scholar]
- Gao, T.L. Simulation and Control Methods of Curing Deformation of Thermosetting Resin Matrix Composites; Northwestern Polytechnical University: Xi’an, China, 2018. [Google Scholar]
- Liu, X.T. Study on Data Normalization in BP Neural Network. Mech. Eng. Autom. 2010, 6, 122–126. [Google Scholar]
- Jiao, L.C. Theory of Neural Network System; Xidian University Press: Xi’an, China, 1990. [Google Scholar]
- WU, J.T.; Wang, J.H. Neural Network Technology and Its Application; Harbin Engineering University Press: Harbin, China, 1998. [Google Scholar]
- Zhang, D.F.; Ding, W.X.; Lei, X.P. Matlab Programming and Comprehensive Application; Tsinghua University Press: Beijing, China, 2012; pp. 1–3. [Google Scholar]
- Lin, S.G.; Ou, Y.X. Research of the Optimization of the Learning Parameters in BP Neural Network; Microcomputer Information: Guangzhou, China, 2010. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. Theory of the Backpropagation Neural Network—Based on “nonindent”. In Proceedings of the International Joint Conference on Neural Networks, Hoffman Estates, IL, USA, 18–22 June 1989; Harry Wechsler. Elsevier: Amsterdam, The Netherlands, 1992; pp. 65–93. [Google Scholar]
- Jiang, J.X.; Wang, B.; Wang, M.; Cai, S.G.; Ni, T.; Ao, Y.F.; Liu, Y. Study on Natural Lighting Design for CDUT Library Based on BIM and BP Neural Network. J. Inf. Technol. Civ. Eng. Archit. 2020, 12, 30–38. [Google Scholar] [CrossRef]
- Robert, H.N. Kolmogorov’s Mapping Neural Network Existence Theorem. In Proceedings of the International Conference on Neural Networks, San Diego, CA, USA, 21–24 June 1987; Volume 3, pp. 11–13. [Google Scholar]
- Ian, G.; Yoshua, B.; Aaron, C. Deep Learning: Adaptive Computation and Machine Learning Series; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Stefaniak, D.; Kappel, E.; Spröwitz, T.; Hühne, C. Experimental identification of process parameters inducing warpage of autoclave-processed CFRP parts. Compos. Part A Appl. Sci. Manuf. 2012, 43, 1081–1091. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1578 | 1578 | 0.4135 | 12.83 | 198.6 × 103 | |
| 2.102 × 109 | 2.014 × 109 | 1.960 × 105 | 8.07 × 104 | 7.78 × 104 | 5.66 × 104 |
| Range | [1, 5] | [1, 5] | [115, 155] | [175, 215] | [0, 100] | [0, 150] |
| Δα | ||||||
|---|---|---|---|---|---|---|
| 4 | 2 | 135 | 212 | 133 | 15 | 0.013438 |
| 3 | 1 | 134 | 198 | 5 | 98 | 0.006745 |
| 3 | 4 | 135 | 212 | 129 | 15 | 0.010842 |
| 4 | 2 | 127 | 204 | 133 | 14 | 0.018056 |
| 3 | 3 | 120 | 180 | 120 | 60 | 0.007668 |
| 3 | 1 | 115 | 194 | 122 | 24 | 0.00391 |
| 4 | 3 | 147 | 199 | 22 | 82 | 0.00553 |
| 1 | 3 | 146 | 198 | 84 | 10 | 0.011303 |
| 1 | 4 | 141 | 190 | 87 | 46 | 0.007735 |
| 5 | 2 | 116 | 201 | 8 | 35 | 0.00844 |
| Models | FCNN | DNN | RBF | SVR | KNN |
|---|---|---|---|---|---|
| MSE | 0.00203 | 0.000722 | 0.000115 | 0.005769 | 0.000122 |
| Group | Actual Value | ||||||
|---|---|---|---|---|---|---|---|
| 1 | 3 | 3 | 120 | 181 | 120 | 60 | 0.008564 |
| 2 | 2 | 1 | 119 | 178 | 120 | 60 | 0.003828 |
| 3 | 1 | 1 | 119 | 178 | 120 | 60 | 0.003957 |
| 4 | 1 | 1 | 117 | 177 | 111 | 66 | 0.003597 |
| 5 | 1 | 1 | 116 | 176 | 105 | 70 | 0.003512 |
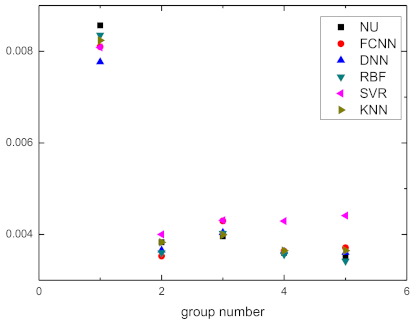
| Group | Actual Value | FC Predicted Value | DNN Predicted Value | RBF Predicted Value | SVR Predicted Value | KNN Predicted Value |
|---|---|---|---|---|---|---|
| 1 | 0.008564 | 0.007715 | 0.007767 | 0.008355 | 0.008082 | 0.008237 |
| 2 | 0.003828 | 0.003707 | 0.003657 | 0.003602 | 0.004 | 0.003828 |
| 3 | 0.003957 | 0.004324 | 0.004044 | 0.004027 | 0.004311 | 0.003995 |
| 4 | 0.003597 | 0.003797 | 0.003625 | 0.003561 | 0.004291 | 0.003645 |
| 5 | 0.003512 | 0.003823 | 0.003609 | 0.003417 | 0.00441 | 0.003645 |
| Group | FC | DNN | RBF | SVR | KNN |
|---|---|---|---|---|---|
| 1 | −0.00031 | −0.0008 | −0.00021 | −0.00048 | −0.00033 |
| 2 | −0.00051 | −0.00017 | −0.00023 | 0.000171 | 2.49 × 10−11 |
| 3 | −2.7 × 10−5 | 8.68 × 10−5 | 6.97 × 10−5 | 0.000354 | 3.8 × 10−5 |
| 4 | −0.00017 | 2.82 × 10−5 | −3.6 × 10−5 | 0.000693 | 4.73 × 10−5 |
| 5 | −3.7 × 10−5 | 9.68 × 10−5 | −9.5 × 10−5 | 0.000898 | 0.000132 |
| Group | FC | DNN | RBF | SVR | KNN |
|---|---|---|---|---|---|
| 1 | −0.03655 | −0.09301 | −0.02434 | −0.05625 | −0.03816 |
| 2 | −0.13318 | −0.04485 | −0.05916 | 0.044781 | 6.51 × 10−9 |
| 3 | −0.00677 | 0.021937 | 0.017619 | 0.089503 | 0.009611 |
| 4 | −0.0465 | 0.007825 | −0.01004 | 0.192761 | 0.013157 |
| 5 | −0.01056 | 0.027568 | −0.02696 | 0.255647 | 0.037712 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Guan, Z. The Use of Machine Learning for the Prediction of the Uniformity of the Degree of Cure of a Composite in an Autoclave. Aerospace 2021, 8, 130. https://doi.org/10.3390/aerospace8050130
Lin Y, Guan Z. The Use of Machine Learning for the Prediction of the Uniformity of the Degree of Cure of a Composite in an Autoclave. Aerospace. 2021; 8(5):130. https://doi.org/10.3390/aerospace8050130
Chicago/Turabian StyleLin, Yuan, and Zhidong Guan. 2021. "The Use of Machine Learning for the Prediction of the Uniformity of the Degree of Cure of a Composite in an Autoclave" Aerospace 8, no. 5: 130. https://doi.org/10.3390/aerospace8050130
APA StyleLin, Y., & Guan, Z. (2021). The Use of Machine Learning for the Prediction of the Uniformity of the Degree of Cure of a Composite in an Autoclave. Aerospace, 8(5), 130. https://doi.org/10.3390/aerospace8050130