
Remaining Useful Life Prediction for Aero-Engines Based on Time-Series Decomposition Modeling and Similarity Comparisons

 , , ,
, , ,
Abstract
:1. Introduction
2. Preliminaries
2.1. Fuzzy C-Means (FCM)
2.1.1. Basic Principles
2.1.2. Computational Steps
- (1)
- Define clustering objects.
- (2)
- Data standardization.
- (3)
- Eablish fuzzy similarity matrix.
- (4)
- Clustering.
- (5)
- Determine the optimal threshold λ.
- ①
- Empirical method: The threshold is adjusted by several experienced experts according to the actual situation λ to select the appropriate classification number.
- ②
- F statistics: Assume that the threshold is λ when the number of classifications is r and the number of samples is n, the F statistic follows the F distribution with degrees of freedom of r−1 and n−r, and the formula of F statistic iswhere the molecule represents the distance between different classes; the denominator represents the distance between samples within the class. The larger the value of the F statistic, the smaller the difference within the class and the larger the difference between classes, that is, the better the classification effect. At the significant level α, if F > F α (r−1, n−r), according to the statistical principle, it is reasonable to classify under this significant level, therefore, the difference between different classes is significant.
2.2. Seasonal Trend Decomposition Procedure Based on LOESS (STL)
3. Proposed Methods
3.1. RUL Predictions Based on STL Modeling and Similarity Measurements
3.2. HI Construction Based on Fuzzy Clustering
3.3. Degradation Path Prediction Based on STL Decomposition
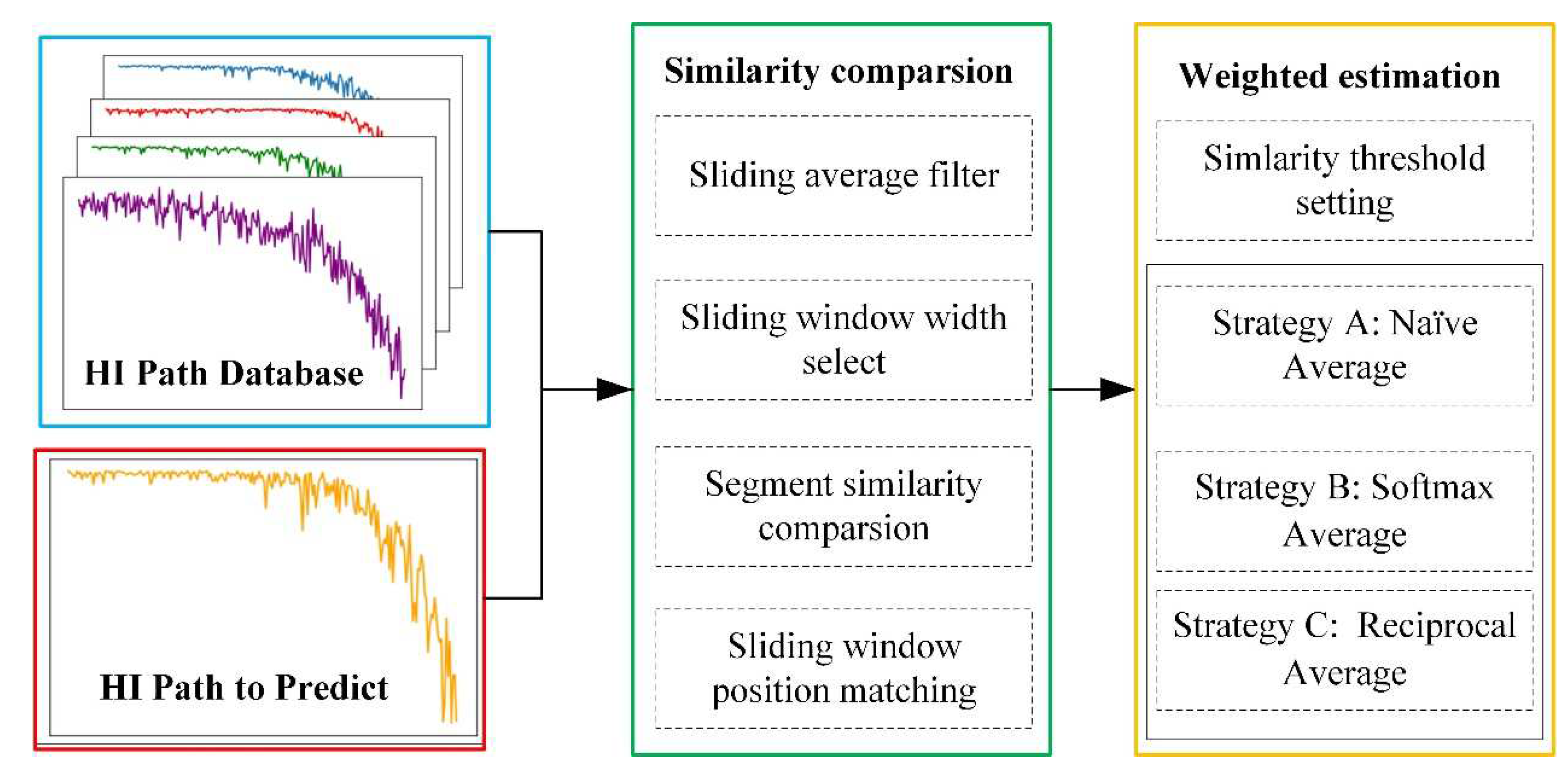
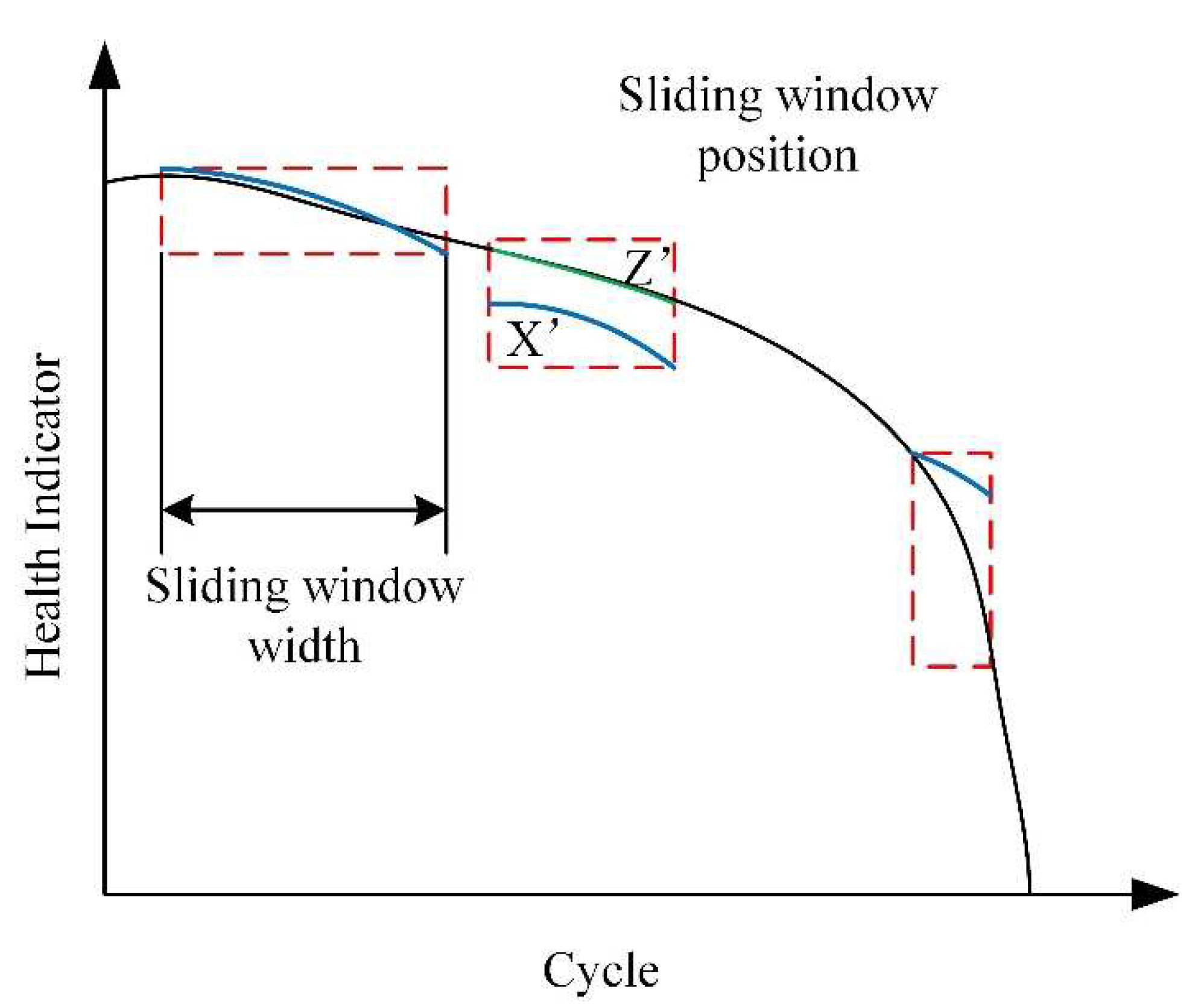
3.4. RUL Prediction Based on Similarity Comparison
4. Experiment and Analysis
4.1. Introduction of the Aero-Engine Dataset and Preprocessing
4.2. Experiment Results and Analysis
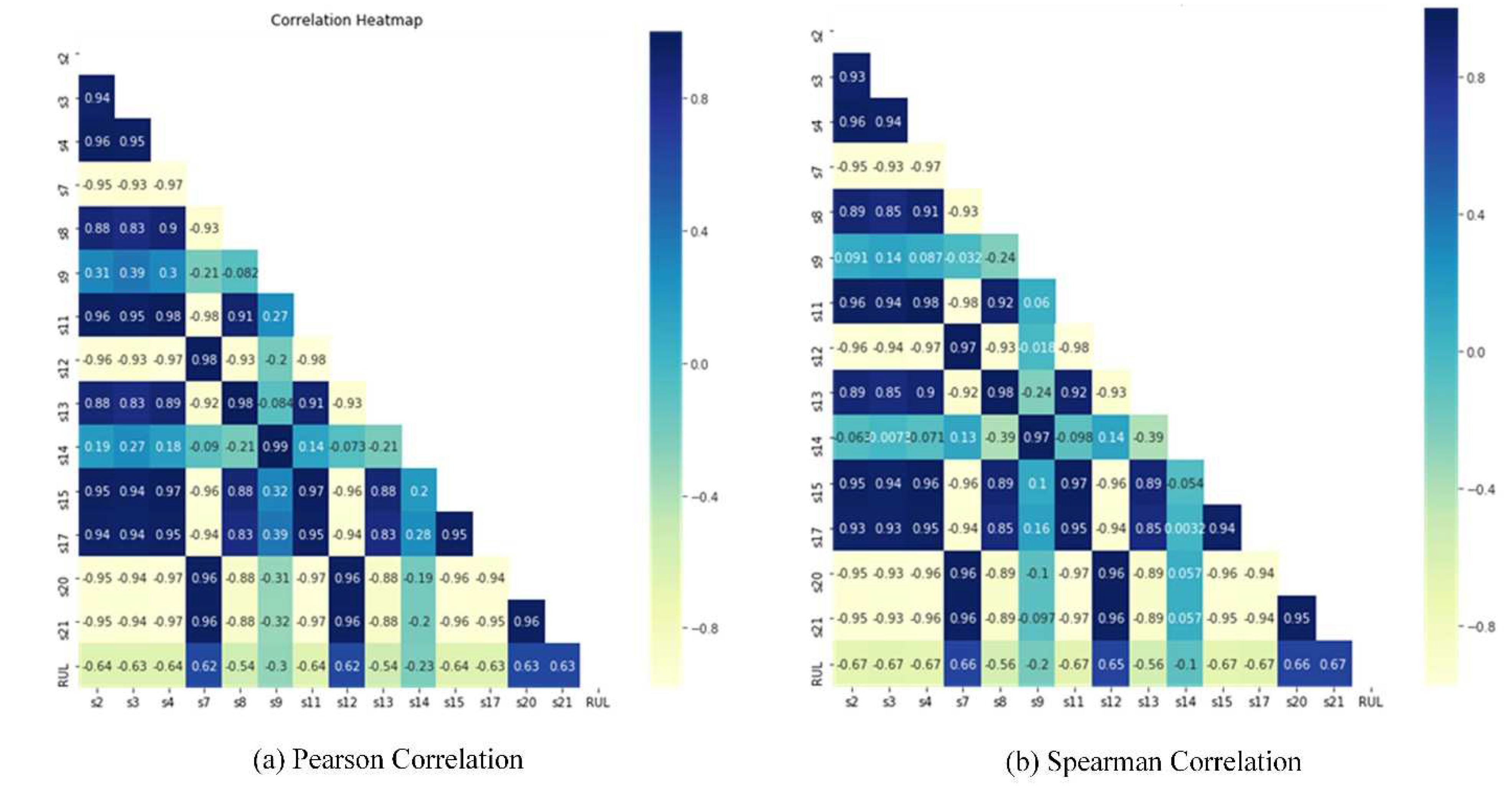
4.2.1. HI Construction Results and Analysis
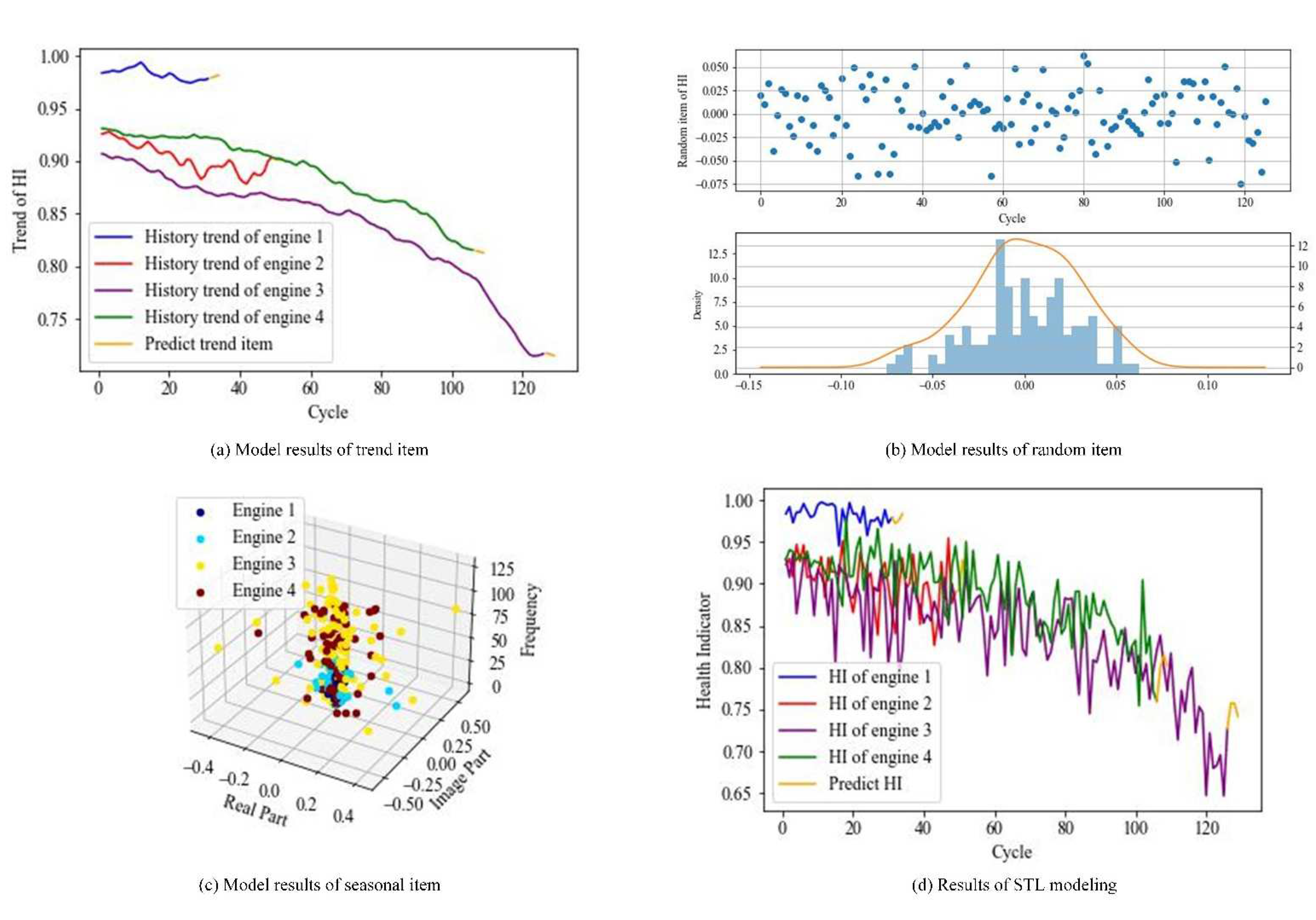
4.2.2. STL Modeling Results and Analysis
4.2.3. RUL Prediction Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nie, L.; Xu, S.; Zhang, L.; Yin, Y.; Dong, Z.; Zhou, X. Remaining Useful Life Prediction of Aeroengines Based on Multi-Head Attention Mechanism. Machines 2022, 10, 552. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Gontarz, S.; Lin, J.; Radkowski, S.; Dybala, J. A model-based method for remaining useful life prediction of machinery. IEEE Trans. Reliab. 2016, 65, 1314–1326. [Google Scholar] [CrossRef]
- El-Tawil, K.; Jaoude, A.A. Stochastic and nonlinear-based prognostic model. Syst. Sci. Control Eng. Open Access J. 2013, 1, 66–81. [Google Scholar] [CrossRef] [Green Version]
- Paroissin, C. Inference for the Wiener process with random initiation time. IEEE Trans. Reliab. 2015, 65, 147–157. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Li, N. A hybrid prognostics approach for estimating remaining useful life of rolling element bearings. IEEE Transac. Reliabil. 2018, 69, 401–412. [Google Scholar] [CrossRef]
- Li, H. Statistical Learning Methods; Tsinghua University Press: Beijing, China, 2012; pp. 1–2. [Google Scholar]
- Zhang, B.; Zheng, K.; Huang, Q.; Feng, S.; Zhou, S.; Zhang, Y. Aircraft engine prognostics based on informative sensor selection and adaptive degradation modeling with functional principal component analysis. Sensors 2020, 20, 920. [Google Scholar] [CrossRef] [Green Version]
- Zaidan, M.A.; Mills, A.R.; Harrison, R.F.; Fleming, P.J. Gas turbine engine prognostics using Bayesian hierarchical models: A variational approach. Mech. Syst. Signal Process. 2016, 70, 120–140. [Google Scholar] [CrossRef]
- Liu, K.; Huang, S. Integration of data fusion methodology and degradation modeling process to improve prognostics. IEEE Trans. Autom. Sci. Eng. 2014, 13, 344–354. [Google Scholar] [CrossRef]
- Song, C.; Liu, K. Statistical degradation modeling and prognostics of multiple sensor signals via data fusion: A composite health index approach. IISE Trans. 2018, 50, 853–867. [Google Scholar] [CrossRef]
- Cui, L.-F.; Zhang, Q.-Z.; Shi, Y.; Yang, L.-M.; Wang, J.-L.; Bai, C.-G. A method for satellite time series anomaly detection based on fast-DTW and improved-KNN. Chin. J. Aeronaut. 2022, in press. [Google Scholar] [CrossRef]
- Kim, M.; Song, C.; Liu, K. A generic health index approach for multisensor degradation modeling and sensor selection. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1426–1437. [Google Scholar] [CrossRef]
- Zhang, J.; Dong, Z.; Shi, H. Real-time remaining useful life prediction based on adaptive kernel window width density. Meas. Sci. Technol. 2022, 33, 105122. [Google Scholar] [CrossRef]
- Deutsch, J.; He, D. Using deep learning-based approach to predict remaining useful life of rotating components. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 11–20. [Google Scholar] [CrossRef]
- Deutsch, J.; He, M.; He, D. Remaining useful life prediction of hybrid ceramic bearings using an integrated deep learning and particle filter approach. Appl. Sci. 2017, 7, 649. [Google Scholar] [CrossRef] [Green Version]
- Zhao, G.; Zhang, G.; Liu, Y.; Zhang, B.; Hu, C. Lithium-ion battery remaining useful life prediction with deep belief network and relevance vector machine. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), IEEE, Dallas, TX, USA, 19–21 June 2017; pp. 7–13. [Google Scholar]
- Liu, R.; Yang, B.; Hauptmann, A.G. Simultaneous bearing fault recognition and remaining useful life prediction using joint-loss convolutional neural network. IEEE Trans. Ind. Inform. 2019, 16, 87–96. [Google Scholar] [CrossRef]
- Jiao, R.; Peng, K.; Dong, J. Remaining useful life prediction for a roller in a hot strip mill based on deep recurrent neural networks. IEEE/CAA J. Autom. Sin. 2021, 8, 1345–1354. [Google Scholar] [CrossRef]
- Fu, B.; Yuan, W.; Cui, X.; Yu, T.; Zhao, X.; Li, C. Correlation analysis and augmentation of samples for a bidirectional gate recurrent unit network for the remaining useful life prediction of bearings. IEEE Sens. J. 2020, 21, 7989–8001. [Google Scholar] [CrossRef]
- Cui, L.-F.; Zhang, Q.-Z.; Yang, L.-M.; Bai, C.-G. A Performance Prediction Method Based on Sliding Window Grey Neural Network for Inertial Platform. Remote Sens. 2021, 12, 4864. [Google Scholar] [CrossRef]
- Han, X.-X.; Xiang, G.; Cui, L.-F.; Wang, J.-L.; Zhang, Q.-Z.; Lin, R.-S.; Jin, Y.; Liu, H.-D. Online Transfer Learning-based Method for Predicting Remaining Useful Life of Aero-engines. In Proceedings of the 2022 7th International Conference on Intelligent Computing and Signal Processing, Virtual, 15–17 April 2022. [Google Scholar]
- Wang, B.; Lei, Y.; Yan, T.; Li, N.; Guo, L. Recurrent convolutional neural network: A new framework for remaining useful life prediction of machinery. Neurocomputing 2020, 379, 117–129. [Google Scholar] [CrossRef]
- Liu, J.; Li, Q.; Chen, W.; Yan, Y.; Qiu, Y.; Cao, T. Remaining useful life prediction of PEMFC based on long short-term memory recurrent neural networks. Int. J. Hydrogen Energy 2019, 44, 5470–5480. [Google Scholar] [CrossRef]
- Xiao, L.; Zhang, L.; Niu, F.; Su, X.; Song, W. Remaining Useful Life Prediction of Wind Turbine Generator Based on 1D-CNN and Bi-LSTM. Int. J. Fatigue 2022, 163, 107051. [Google Scholar] [CrossRef]
- Li, C.; Zhang, H.; Wang, C.; Li, X.; Lu, Y.; Qian, C. An Efficient Yinyang k-Means Clustering Algorithm. J. Jilin Univ. Sci. Ed. 2021, 59, 1455–1460. [Google Scholar]
- Wu, C.; Qi, S. Adaptive weighted K-nearest neighbor fingerprint location algorithm based on improved K-means clustering. J. Chongqing Univ. Posts Telecommun. (Nat. Sci. Ed.) 2021, 33, 946–954. [Google Scholar]
- Liu, Y.; Zhang, Y.; Zheng, W. Optimization research of denoised hierarchical mapping analysis for multidimensional cluster analysis. J. Sichuan Univ. (Nat. Sci. Ed.) 2022, 59, 84–92. [Google Scholar]
- Saxena, A.; Prasad, M.; Gupta, A.; Bharill, N.; Patel, O.P.; Tiwari, A.; Er, M.J.; Ding, W.; Lin, C.T. A review of clustering techniques and developments. Neurocomputing 2017, 267, 664–681. [Google Scholar] [CrossRef] [Green Version]
- Ruspini, E.H.; Bezdek, J.C.; Keller, J.M. Fuzzy clustering: A historical perspective. IEEE Comput. Intell. Mag. 2019, 14, 45–55. [Google Scholar] [CrossRef]
- Pu, X.; Huang, J.; Qi, N.; Song, C. Application of K-Means Algorithm Based on Density Information Entropy in Customer Segmentation. J. Jilin Univ. Sci. Ed. 2021, 59, 1245–1251. [Google Scholar]
- Wang, H.; Cui, W.; Xu, P.; Li, C. Optimization of Canopy on K Selection in Partition Clustering Algorithm. J. Jilin Univ. (Sci. Ed.) 2020, 58, 634–638. [Google Scholar]
- Cleveland, R.B.; Cleveland, W.S.; Terpenning, I. STL: A Seasonal-Trend Decomposition Procedure Based on Loess. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Zhang, Q.-Z.; Zhang, Q.-Q.; Cui, L.-F.; Han, X.-X.; Jin, Y.; Xiang, G.; Shi, Y. A method for measuring similarity of time series based on series decomposition and dynamic time warping. Appl. Intell. 2022, 6. [Google Scholar] [CrossRef]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage propagation modeling for aircraft engine run-to-failure simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, IEEE, Denver, CO, USA, 6–9 October 2008; pp. 1–9. [Google Scholar]
- Cui, L.-F.; Wang, L.; Xiang, G.; Zhang, Q.-Z.; Bai, C.-G.; Yang, G.-B. A Method Based on Correlation Analysis of the Assembly Process and Neural Network for Precision Prediction of the Inertial Platform. In Proceedings of the ICCBDC 2021–2021 5th International Conference on Cloud and Big Data Computing, New York, NY, USA, 20–22 August 2021. [Google Scholar]
- Zhang, C.; Lim, P.; Qin, A.K.; Tan, K.C. Multiobjective deep belief networks ensemble for remaining useful life estimation in prognostics. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2306–2318. [Google Scholar] [CrossRef] [PubMed]
- Yan, H.; Zuo, H.; Sun, J.; Zhou, D.; Wang, H. Two-Stage Degradation Assessment and Prediction Method for Aircraft Engine Based on Data Fusion. Int. J. Aerosp. Eng. 2021, 1–16. [Google Scholar] [CrossRef]
- Miao, H.; Li, B.; Sun, C.; Liu, J. Joint learning of degradation assessment and RUL prediction for aeroengines via dual-task deep LSTM networks. IEEE Trans. Ind. Inform. 2019, 15, 5023–5032. [Google Scholar] [CrossRef]
- Li, H.; Li, Y.; Wang, Z.; Li, Z. Remaining Useful Life Prediction of Aero-Engine Based on PCA-LSTM. In Proceedings of the 2021 7th International Conference on Condition Monitoring of Machinery in Non-Stationary Operations (CMMNO), IEEE, Guangzhou, China, 11–13 June 2021; pp. 63–66. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Part Name | Monitoring Parameters Characterize Failure | |
|---|---|---|
| 1 | Aero-engine blade | Fan speed, fan inlet pressure, temperature, etc. |
| 2 | Aero-engine main bearing | Rotor speed, gas path pressure, turbine flow, etc. |
| 3 | Connecting bolt of the aero-engine rotor | Rotor speed, gas path pressure, temperature, etc. |
| Parameters | Variance | Parameters | Variance |
|---|---|---|---|
| s1 | 0.005532 | s12 | 0.157257 |
| s2 | 0.150615 | s13 | 0.105761 |
| s3 | 0.133660 | s14 | 0.098440 |
| s4 | 0.151931 | s15 | 0.144302 |
| s5 | 0.005215 | s16 | 0.007783 |
| s6 | 0.010709 | s17 | 0.129060 |
| s7 | 0.142523 | s18 | 0.005741 |
| s8 | 0.107551 | s19 | 0.006879 |
| s9 | 0.099086 | s20 | 0.140110 |
| s10 | 0.015037 | s21 | 0.149473 |
| s11 | 0.158977 |
| Engine ID | Model | Log Likelihood | AIC | BIC | HQIC |
|---|---|---|---|---|---|
| 1 | SARIMAX(0, 2, 0) | 143.074 | −284.149 | −282.781 | −283.721 |
| 2 | SARIMAX(0, 1, 1) | 216.029 | −428.057 | −424.315 | −426.643 |
| 3 | SARIMAX(1, 1, 1) | 673.926 | −1339.852 | −1328.539 | −1335.256 |
| 4 | SARIMAX(0, 1, 3) | 564.176 | −1118.351 | −1105.081 | −1112.974 |
| MSE | Score | |
|---|---|---|
| Prediction without the STL model | 570 | 1401 |
| Prediction with the STL model | 528 | 1280 |
| Improved degree | 8.0% | 9.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Wang, H.; Cui, L.; Xiang, G.; Han, X.; Zhang, Q.; Chen, J. Remaining Useful Life Prediction for Aero-Engines Based on Time-Series Decomposition Modeling and Similarity Comparisons. Aerospace 2022, 9, 609. https://doi.org/10.3390/aerospace9100609
Wang M, Wang H, Cui L, Xiang G, Han X, Zhang Q, Chen J. Remaining Useful Life Prediction for Aero-Engines Based on Time-Series Decomposition Modeling and Similarity Comparisons. Aerospace. 2022; 9(10):609. https://doi.org/10.3390/aerospace9100609
Chicago/Turabian StyleWang, Mingxian, Hongyan Wang, Langfu Cui, Gang Xiang, Xiaoxuan Han, Qingzhen Zhang, and Juan Chen. 2022. "Remaining Useful Life Prediction for Aero-Engines Based on Time-Series Decomposition Modeling and Similarity Comparisons" Aerospace 9, no. 10: 609. https://doi.org/10.3390/aerospace9100609
APA StyleWang, M., Wang, H., Cui, L., Xiang, G., Han, X., Zhang, Q., & Chen, J. (2022). Remaining Useful Life Prediction for Aero-Engines Based on Time-Series Decomposition Modeling and Similarity Comparisons. Aerospace, 9(10), 609. https://doi.org/10.3390/aerospace9100609