
Speech GAU: A Single Head Attention for Mandarin Speech Recognition for Air Traffic Control

Abstract
:1. Introduction
2. Challenges and Related Work
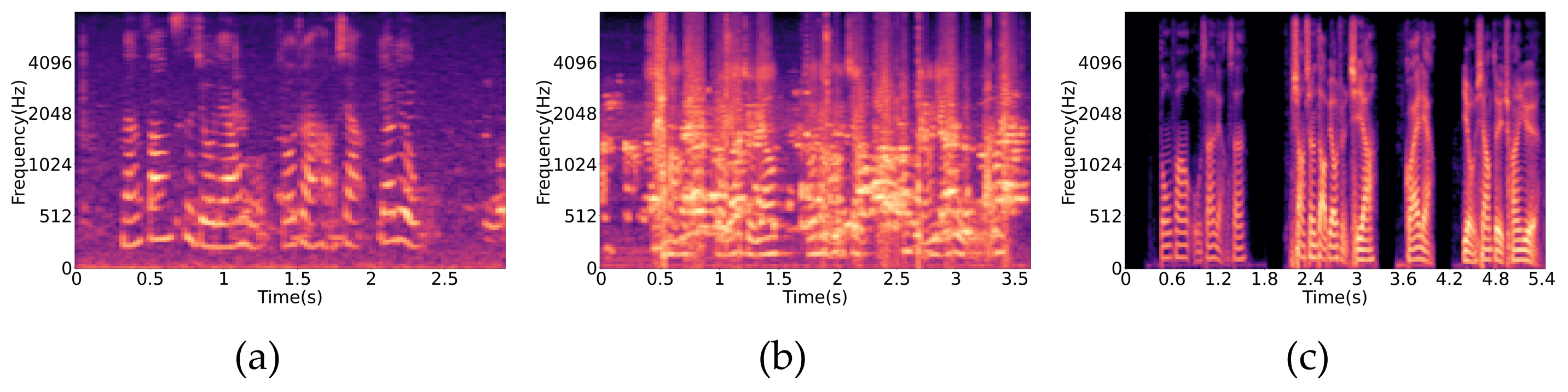
- Inferior speech quality: PCVCs use radio as the transmission vehicle for control command interaction. Generally, the pilot and the controller establish a two-way voice conversation through the transmitter and the receiver in the same designated very high frequency channel. Figure 1a–c shows the Mel spectrogram of several ATC utterances. Clearly, radio signals are inevitably subject to interference, distortion, deformation, and loss during propagation. Consequently, they are vulnerable to noise through direct or indirect coupling, which can result in issues such as degraded reception quality and communication jamming, which adversely affect speech recognition efficiency.
- Excessive speech rate: Since ATC officers have to provide pilots with control instructions, intelligence information, and provision of warning signals in a timely and effective manner, they often have to speak much faster than would occur in normal daily conversation. In busy airspace, with controllers interacting with multiple aircraft simultaneously, the speech rate can be as high as twice the normal rate. This is corroborated by the fact that the average speech rates in the open-source domain training set corpus and the target domain training set corpus we used in this study were 3.16 words/s and 4.75 words/s, respectively. High speech rates and varying accents can adversely affect model decoding.
- Scarcity of calibration data: Most E2E systems require large training sets that have speech data from the appropriate field with text annotations to achieve high accuracy. These training sets could range from hundreds of hours to hundreds of thousands of hours. In addition, the annotation of this large set of speech data requires specialized personnel. As a result, it is a significant challenge to obtain large-scale and high-quality, text-annotated, speech datasets relevant to civil aviation.
- Complications due to partial pronunciation: To avoid the ambiguity of terms leading to the asymmetry of information understanding between the transmitting and receiving ends in PCVCs, the Civil Aviation Administration of China has developed a set of guidelines titled “Radiotelephony Communications for Air Traffic Services”, based on the International Civil Aviation Organization guidelines, to standardize radio communication in China. The Mandarin speech communication standard integrates the control work experience and the daily speech habits. For example, the numbers 1 and 7 have a similar pronunciation. To avoid ambiguity, 1 (yi) is pronounced as yao, and 7 (qi) is pronounced as guai.
3. Methodology
3.1. Optimization Measures
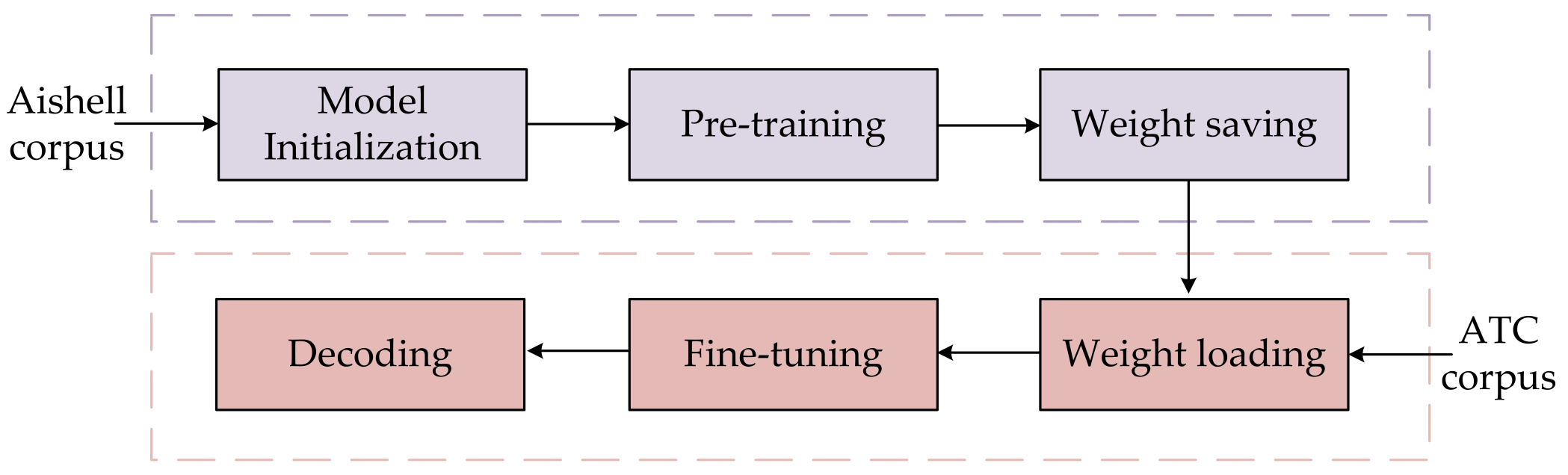
3.1.1. Transfer Learning
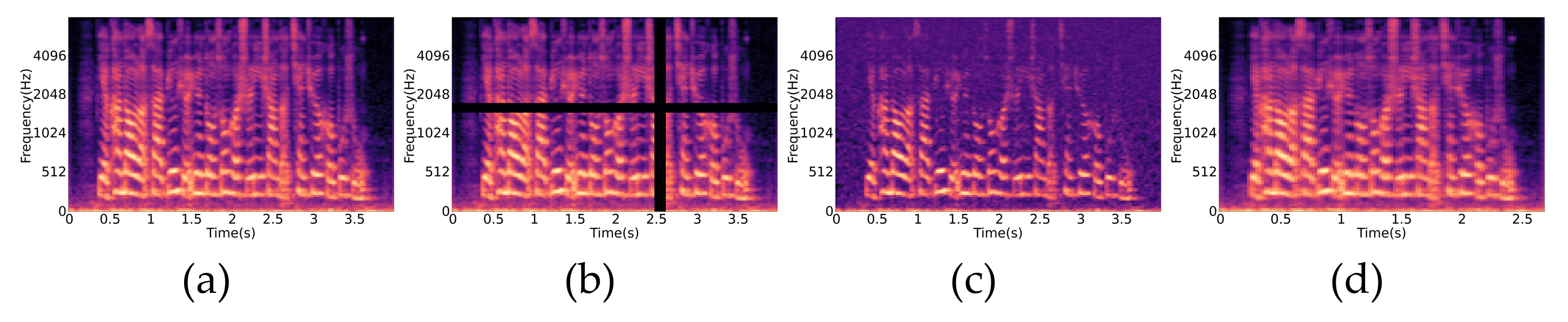
3.1.2. Data Augmentation
3.2. GAU Module
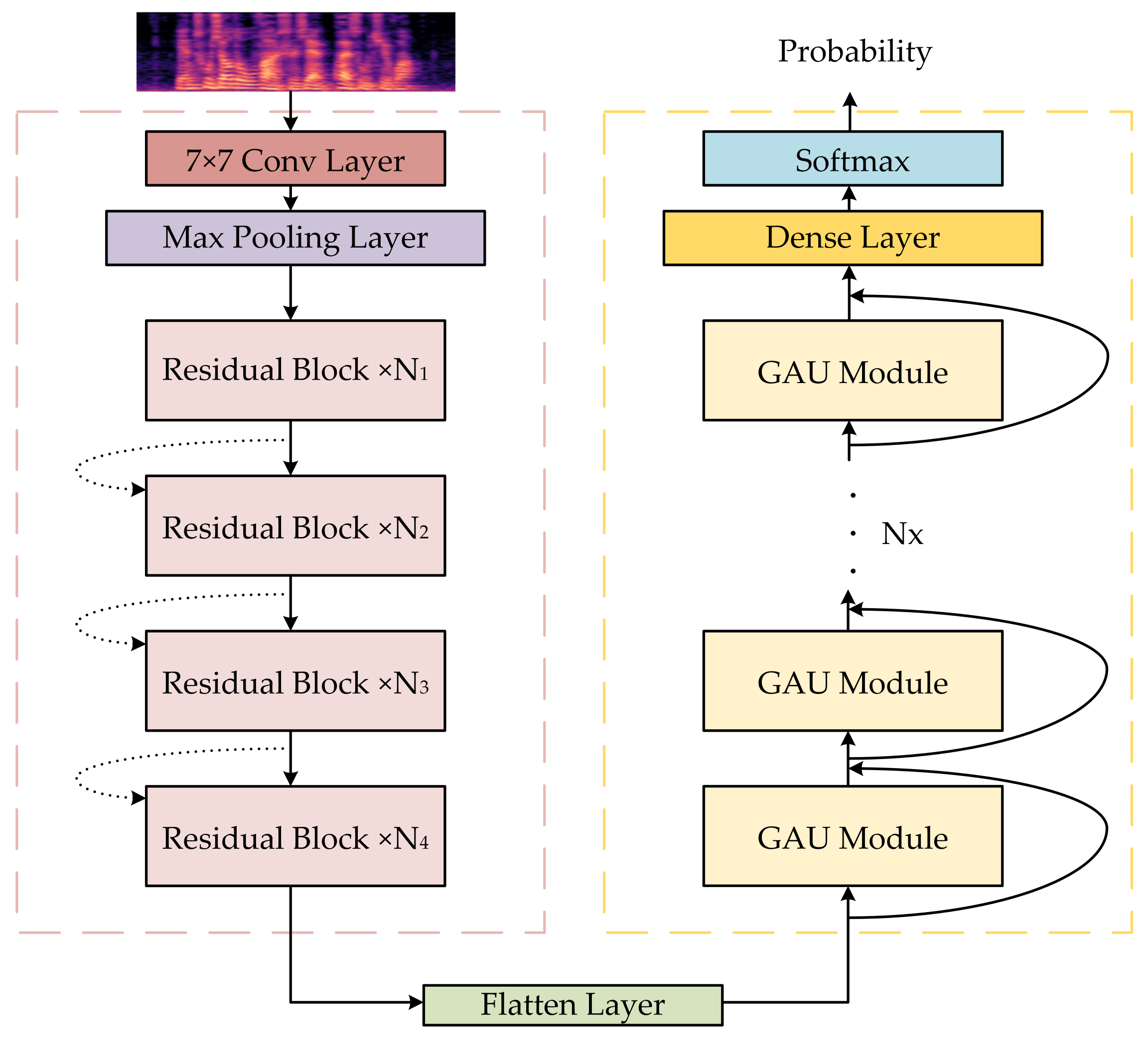
3.3. Overall Architecture of the Model
3.4. Training and Decoding
4. Experiments
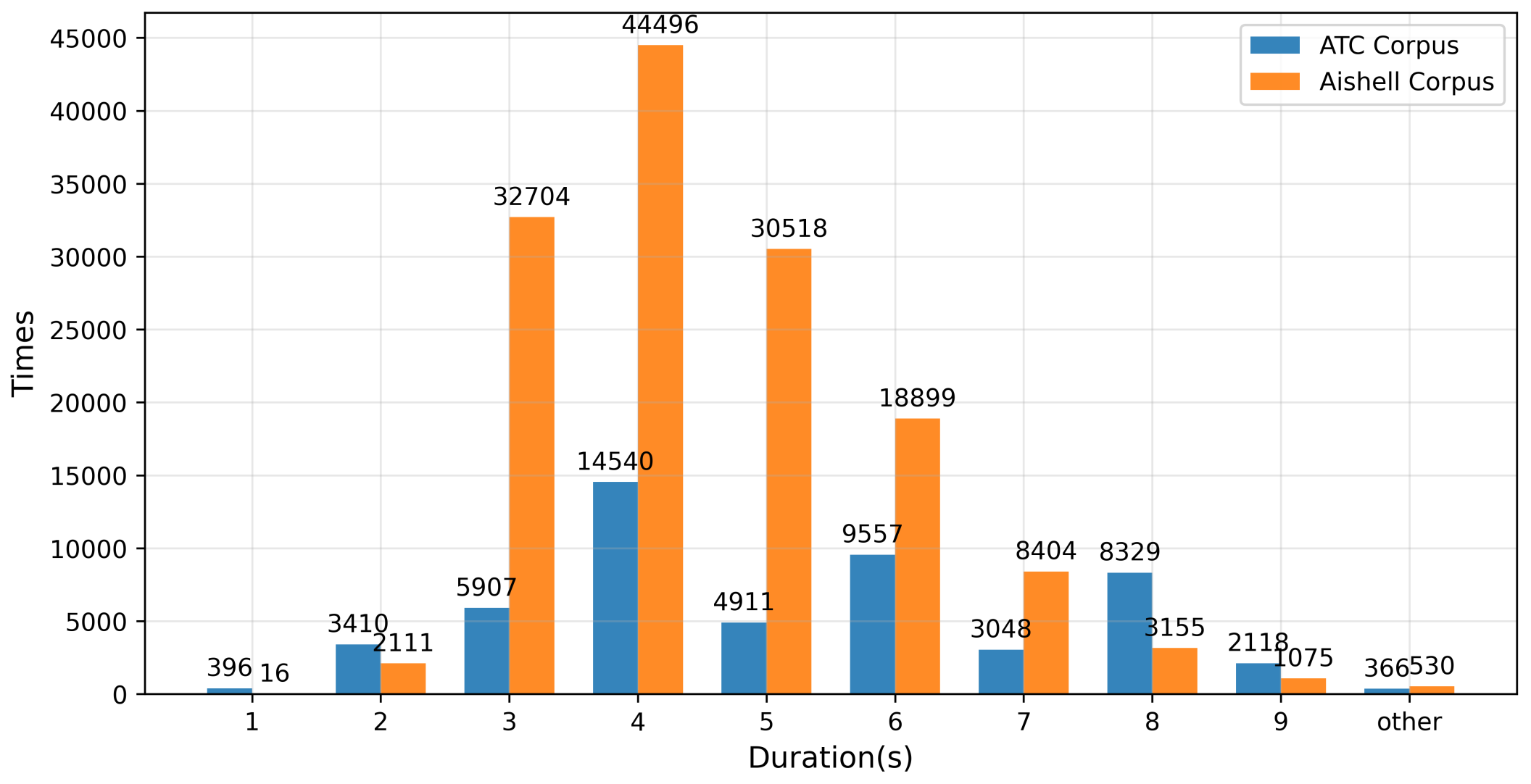
4.1. Experimental Data
4.2. Experimental Platform
4.3. Experimental Analysis
4.3.1. Pre-Training Results of Different Models in the Expanded Aishell Corpus
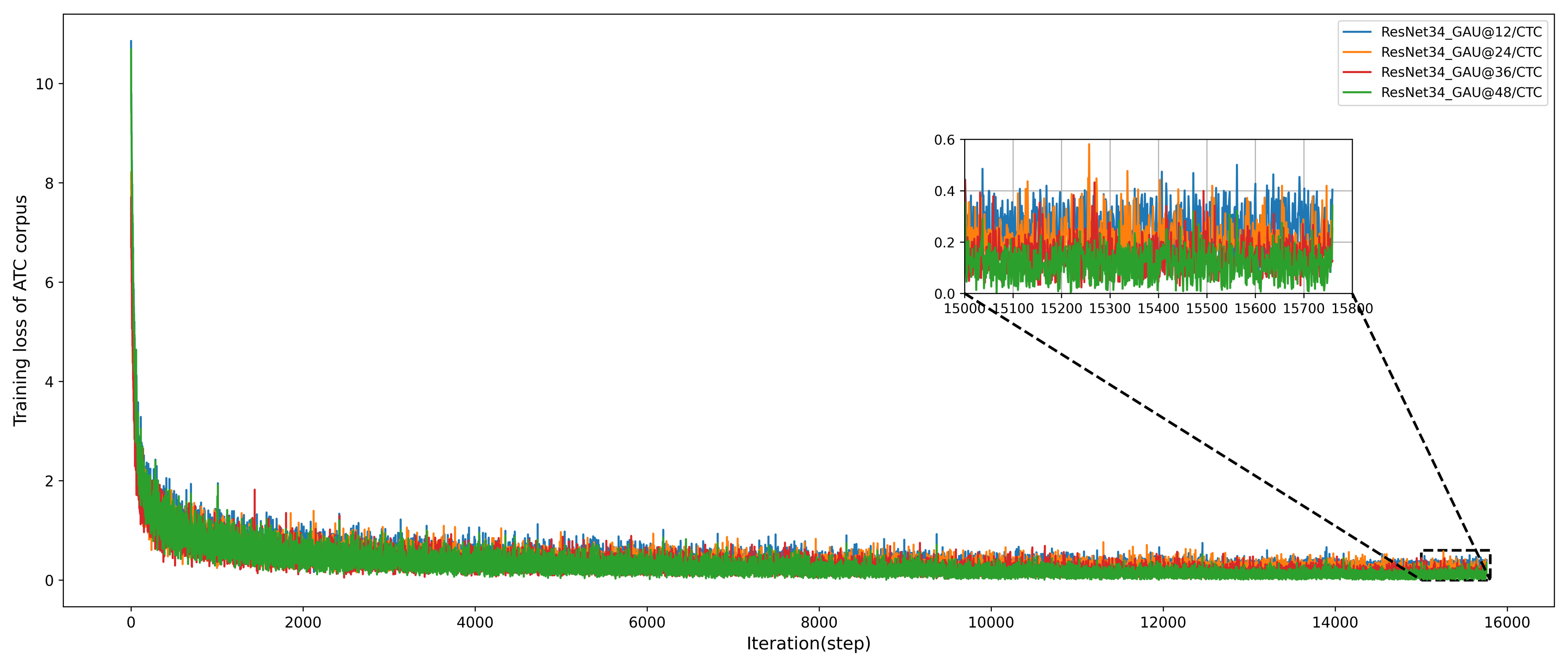
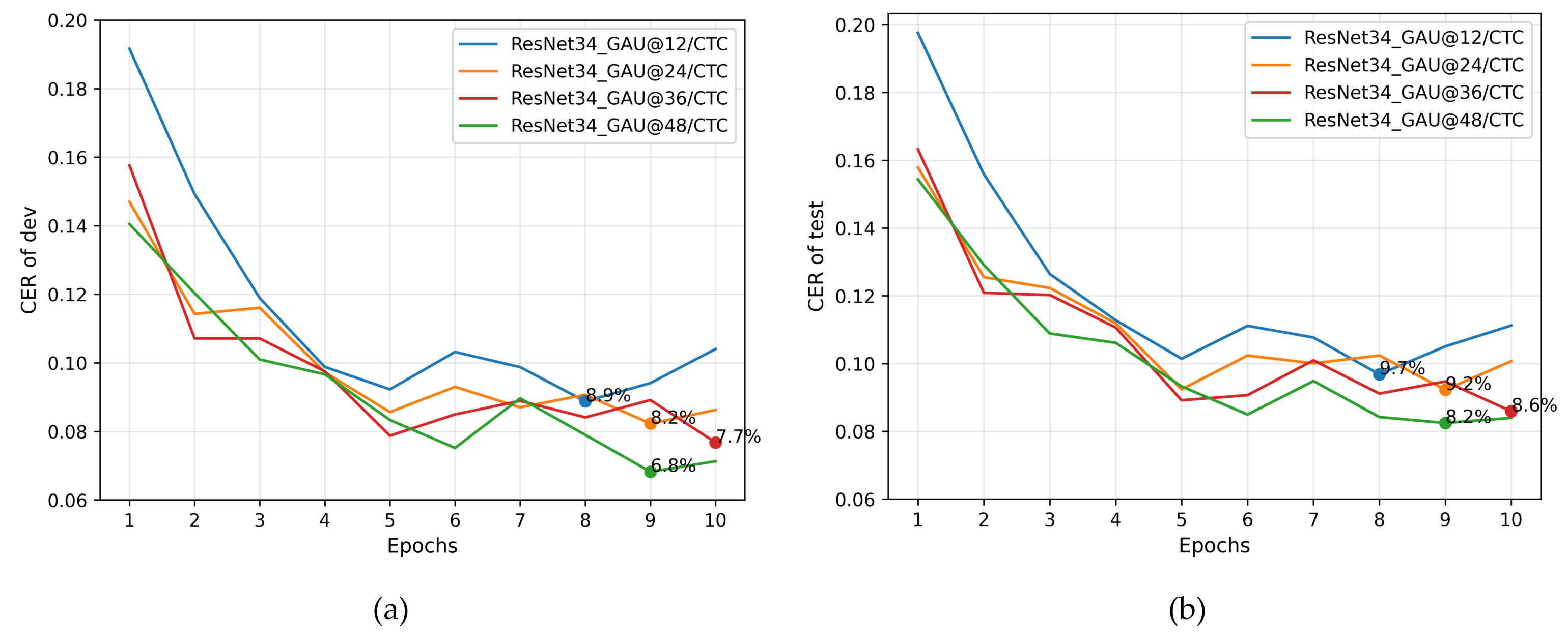
4.3.2. Experimental Results of GAU Module with Different Number of Layers in the ATC Corpus
4.3.3. Experimental Results of Different Convolutional Architectures in the ATC Corpus
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| E2E | End-to-End |
| ATC | Air Traffic Control |
| ResNet | Residual Network |
| CNN | Convolutional Neural Network |
| GAU | Gated Attention Unit |
| CTC | Connectionist Temporal Classification |
| CER | Character Error Rate |
| PCVCs | Pilot-Controller Voice Communications |
| ASR | Automated Speech Recognition |
| HMM | Hidden Markov Model |
| GMM | Gaussian Mixture Model |
| DNN | Deep Neural Network |
| AM | Acoustic Model |
| PM | Pronunciation Model |
| LM | Language Model |
| RNNs | Recurrent Neural Networks |
| LSTM | Long Short-Term Memory |
| GRU | Gate Recurrent Unit |
| MHSA | Multi-Head Self-Attention |
| GLU | Gated Linear Unit |
| NLP | Natural Language Processing |
| ReLU | Rectified Linear Unit |
| SiLU | Sigmoid Linear Unit |
| RTF | Real-time Factor |
| VGG | Visual Geometry Group |
References
- Juang, B.H.; Rabiner, L.R. Hidden Markov Models for speech recognition. Technometrics 2012, 33, 251–272. [Google Scholar] [CrossRef]
- Zweig, G.; Russell, S. Speech recognition with Dynamic Bayesian Networks. In Proceedings of the AAAI-98: Fifteenth National Conference on Artificial Intelligence, Madison, WI, USA, 26–30 July 1998. [Google Scholar]
- Liu, X.; Gales, M. Automatic model complexity control using marginalized discriminative growth functions. IEEE Workshop Autom. Speech Recognit. Underst. 2007, 15, 1414–1424. [Google Scholar] [CrossRef]
- Abe, A.; Kazumasa, Y.; Seiichi, N. Robust speech recognition using DNN-HMM acoustic model combining noise-aware training with spectral subtraction. In Proceedings of the 16th Annual Conference of the International-Speech-Communication-Association (INTERSPEECH 2015), Dresden, Germany, 10 June 2015. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Kingsbury, B. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Mohamed, A.; Dahl, G.E.; Hinton, G. Acoustic modeling using Deep Belief Networks. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 14–22. [Google Scholar] [CrossRef]
- Graves, A.; Fernandez, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning (ICML’06), New York, NY, USA, 25 June 2006. [Google Scholar]
- Graves, A.; Jaitly, N. Towards end-to-end speech recognition with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Bejing, China, 22–24 June 2014. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.H.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Zhang, Y.; Lu, X. A speech recognition acoustic model based on LSTM -CTC. In Proceedings of the 2018 IEEE 18th International Conference on Communication Technology (ICCT), Chongqing, China, 1 October 2018. [Google Scholar]
- Shi, Y.Y.; Hwang, M.-Y.; Liu, X. End-To-End speech recognition using a high rank LSTM-CTC based model. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12 March 2019. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Zhu, Z. Deep Speech 2: End-to-End Speech Recognition in English and Mandarin. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Wang, D.; Wang, X.D.; Lv, S.H. End-to-end mandarin speech recognition combining CNN and BLSTM. Symmetry 2019, 11, 644. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zhang, Q.; Lu, H.; Sak, H.; Tripathi, A.; McDermott, E.; Koo, S.; Kumar, S. Transformer Transducer: A streamable speech recognition model with transformer encoders and RNN-T loss. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 8 April 2020. [Google Scholar]
- Shazeer, N. GLU Variants Improve Transformer. arXiv 2020, arXiv:2002.05202. [Google Scholar]
- Du, N.; Huang, Y.P.; Andrew, M.D. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts. arXiv 2021, arXiv:2112.06905. [Google Scholar]
- Romal, T.; Daniel, D.F.; Jamie, H. Lamda: Language Models for Dialog Applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 30 June 2016. [Google Scholar]
- Hua, W.; Dai, Z.; Liu, H.; Le, Q.V. Transformer Quality in Linear Time. arXiv 2022, arXiv:2202.10447. [Google Scholar]
- Holone, H. Possibilities, Challenges and the State of the Art of Automatic Speech Recognition in Air Traffic Control. Int. J. Comput. Inf. Eng. 2015, 9, 1933–1942. [Google Scholar]
- Wang, J.; Liu, S.H.; Yang, Q. Transfer learning for air traffic control LVCSR system. In Proceedings of the 2017 Second International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 10 December 2017. [Google Scholar]
- Lin, Y.; Li, Q.; Yang, B. Improving speech recognition models with small samples for air traffic control systems. Neurocomputing 2021, 445, 287–297. [Google Scholar] [CrossRef]
- Midl, L.; Vec, J.; Praak, A.; Trmal, J. Semi-supervised training of DNN-based acoustic model for ATC speech recognition. In Proceedings of the 20th International Conference, SPECOM 2018, Leipzig, Germany, 18–22 September 2018. [Google Scholar]
- Srinivasamurthy, A.; Motlice, P.; Himawan, I. Semi-supervised learning with semantic knowledge extraction for improved speech recognition in air traffic control. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Zhou, K.; Yang, Q.; Sun, X.S.; Liu, S.H.; Lu, J.J. Improved CTC-Attention Based End-to-End Speech Recognition on Air Traffic Control. In Proceedings of the 9th International Conference on Intelligence Science and Big Data Engineering (IScIDE), Nanjing, China, 17–20 October 2019. [Google Scholar]
- Lin, Y.; Guo, D.; Zhang, J.; Chen, Z.; Yang, B. A Unified Framework for Multilingual Speech Recognition in Air Traffic Control Systems. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3608–3620. [Google Scholar] [CrossRef] [PubMed]
- Bu, H.; Du, J.Y.; Na, X.Y.; Wu, B.G.; Zheng, H. AISHELL-1: An open-source Mandarin speech corpus and a speech recognition baseline. In Proceedings of the 20th Conference of the Oriental-Chapter-of-the-International-Coordinating-Committee-on-Speech-Databases-and-Speech-I/O-Systems-and-Assessment (O-COCOSDA), Seoul, Korea, 1–3 November 2017. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- So, D.R.; Manke, W.; Liu, H.; Dai, Z.; Shazeer, N.; Le, Q.V. Primer: Searching for Efficient Transformers for Language Modeling. arXiv 2021, arXiv:2109.08668. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Thomas, H.; Charles, E.; Ronald, L. Introduction to Algorithms, 3rd ed.; The MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Utterances | Total Time (h) | Average Rate (Characters/s) |
|---|---|---|---|
| Aishell corpus | 141,600 | 178 | 3.16 |
| ATC corpus | 50,902 | 67 | 4.75 |
| Structural Order | Output Size | Parameters Setup |
|---|---|---|
| Conv layer | ||
| Max pooling layer | ||
| Residual block | and | |
| Residual block | and | |
| Residual block | and | |
| Residual block | and | |
| Permute | ||
| Flatten layer | ||
| GAU module | for U, for V, for , for O | |
| Dense layer |
| Model | CER (%) | RTF | Params | Run Time | Training Time | |
|---|---|---|---|---|---|---|
| dev | Test | |||||
| ResNet34_BiLSTM@4 | 15.4 | 17.6 | 0.24 | 46.9 M | 15.7 h | 1.51 s/step |
| ResNet34_BiGRU@4 | 15.7 | 17.4 | 0.23 | 41.2 M | 14.2 h | 1.36 s/step |
| ResNet34_MHSA-GLU@24 | 11.0 | 12.5 | 0.20 | 93.2 M | 13.9 h | 1.33 s/step |
| ResNet34_GAU@24 (ours) | 10.2 | 11.1 | 0.18 | 63.3 M | 12.7 h | 1.22 s/step |
| Model | CER (%) | RTF | Params | Run Time | Training Time | |
|---|---|---|---|---|---|---|
| dev | Test | |||||
| ResNet34_GAU@12 | 8.9 | 9.7 | 0.16 | 43.6 M | 1.6 h | 0.74 s/step |
| ResNet34_GAU@24 | 8.2 | 9.2 | 0.18 | 63.3 M | 2.3 h | 1.03 s/step |
| ResNet34_GAU@36 | 7.7 | 8.6 | 0.21 | 83.0 M | 3.0 h | 1.36 s/step |
| ResNet34_GAU@48 | 6.8 | 8.2 | 0.23 | 102.7 M | 3.9 h | 1.76 s/step |
| Model | CER (%) | RTF | Params | Run Time | Training Time | |
|---|---|---|---|---|---|---|
| dev | Test | |||||
| VGG16_GAU@48 | 7.1 | 8.3 | 0.23 | 102.4 M | 4.1 h | 1.88 s/step |
| VGG19_GAU@48 | 6.9 | 8.2 | 0.25 | 107.8 M | 5.0 h | 2.31 s/step |
| ResNet34_GAU@48 | 6.8 | 8.2 | 0.23 | 102.7 M | 3.9 h | 1.76 s/step |
| ResNet50_GAU@48 | 6.8 | 8.0 | 0.24 | 106.0 M | 4.4 h | 2.01 s/step |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Kong, J.; Chen, C.; Li, Y.; Liang, H. Speech GAU: A Single Head Attention for Mandarin Speech Recognition for Air Traffic Control. Aerospace 2022, 9, 395. https://doi.org/10.3390/aerospace9080395
Zhang S, Kong J, Chen C, Li Y, Liang H. Speech GAU: A Single Head Attention for Mandarin Speech Recognition for Air Traffic Control. Aerospace. 2022; 9(8):395. https://doi.org/10.3390/aerospace9080395
Chicago/Turabian StyleZhang, Shiyu, Jianguo Kong, Chao Chen, Yabin Li, and Haijun Liang. 2022. "Speech GAU: A Single Head Attention for Mandarin Speech Recognition for Air Traffic Control" Aerospace 9, no. 8: 395. https://doi.org/10.3390/aerospace9080395
APA StyleZhang, S., Kong, J., Chen, C., Li, Y., & Liang, H. (2022). Speech GAU: A Single Head Attention for Mandarin Speech Recognition for Air Traffic Control. Aerospace, 9(8), 395. https://doi.org/10.3390/aerospace9080395