1. Introduction
In aircraft, system identification can be thought of as estimating aerodynamic parameters or defining a mathematical model of the system. Three methods have been proposed in the literature for the estimation of aerodynamic parameters of parachute landing systems [
1]. The first of these covers analytical methods based on computational fluid dynamics. Others are wind tunnel tests and flight tests. In this study, we focused on the methods used in flight tests.
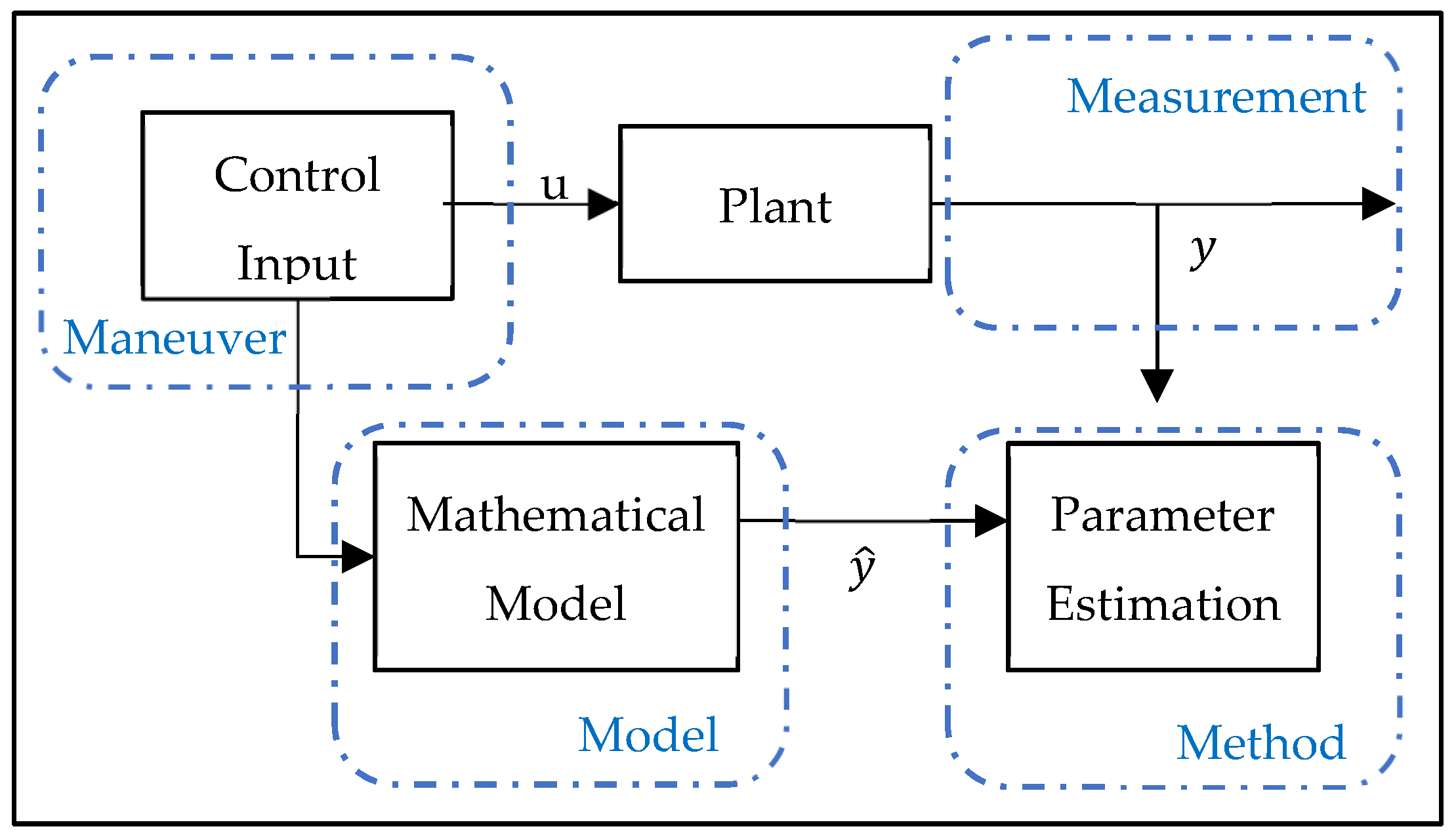
The purpose of system definition is to obtain a mathematical model according to the inputs and outputs obtained from the flight tests. Hamel and Jategaonkar proposed the 4M (maneuver, measurement, method, model—see
Figure 1) requirements for successful system identification [
2], arguing that:
Control inputs should be created to cover extreme points;
High-resolution measurements should be used;
The possible mathematical model of the vehicle should be defined; and
The most suitable method for the data should be chosen.
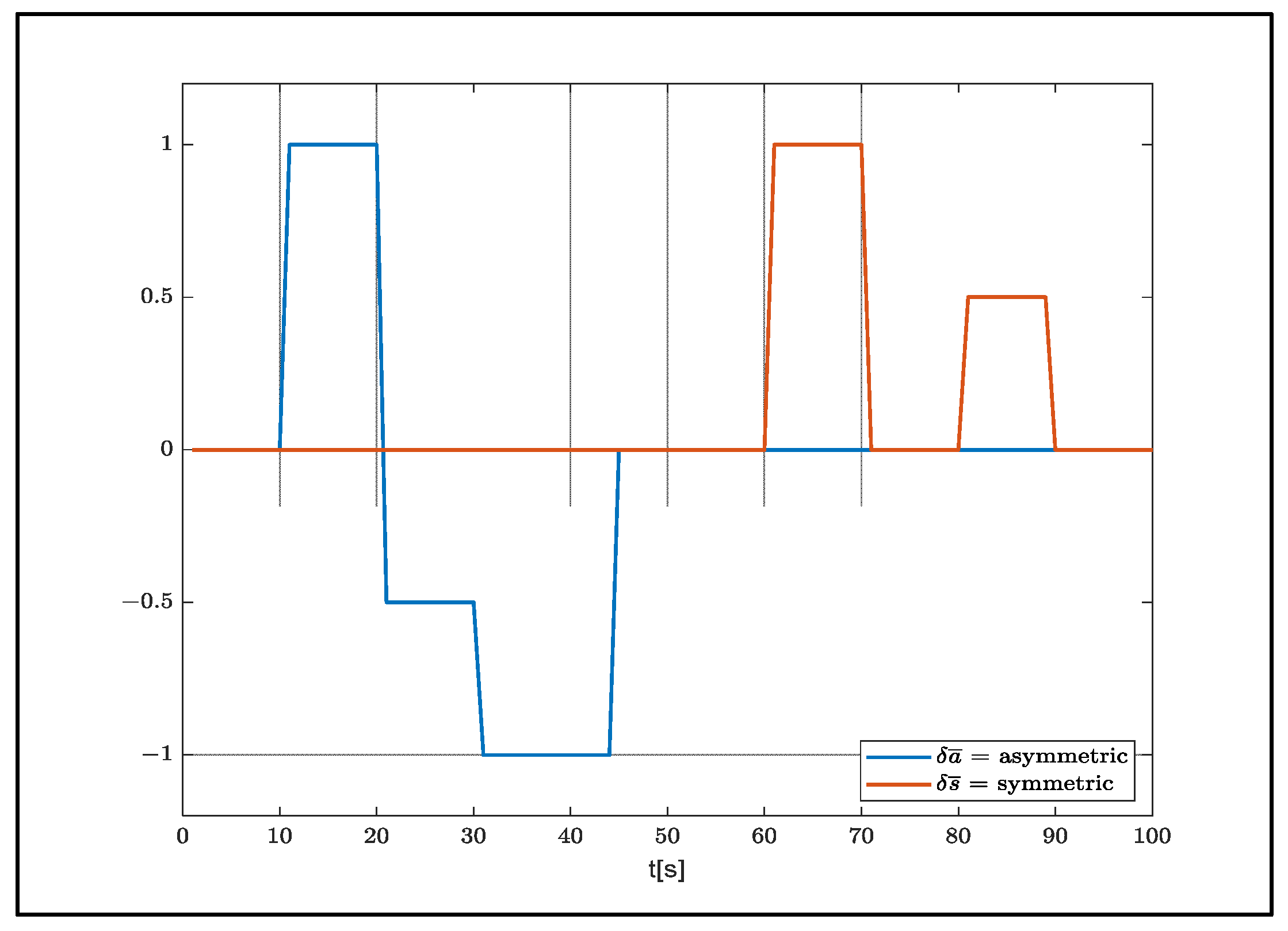
Jann and Strickert suggested separating the symmetric and asymmetric maneuvers that need to be carried out in the formation of data to be used in the definition process [
3] (
Figure 2).
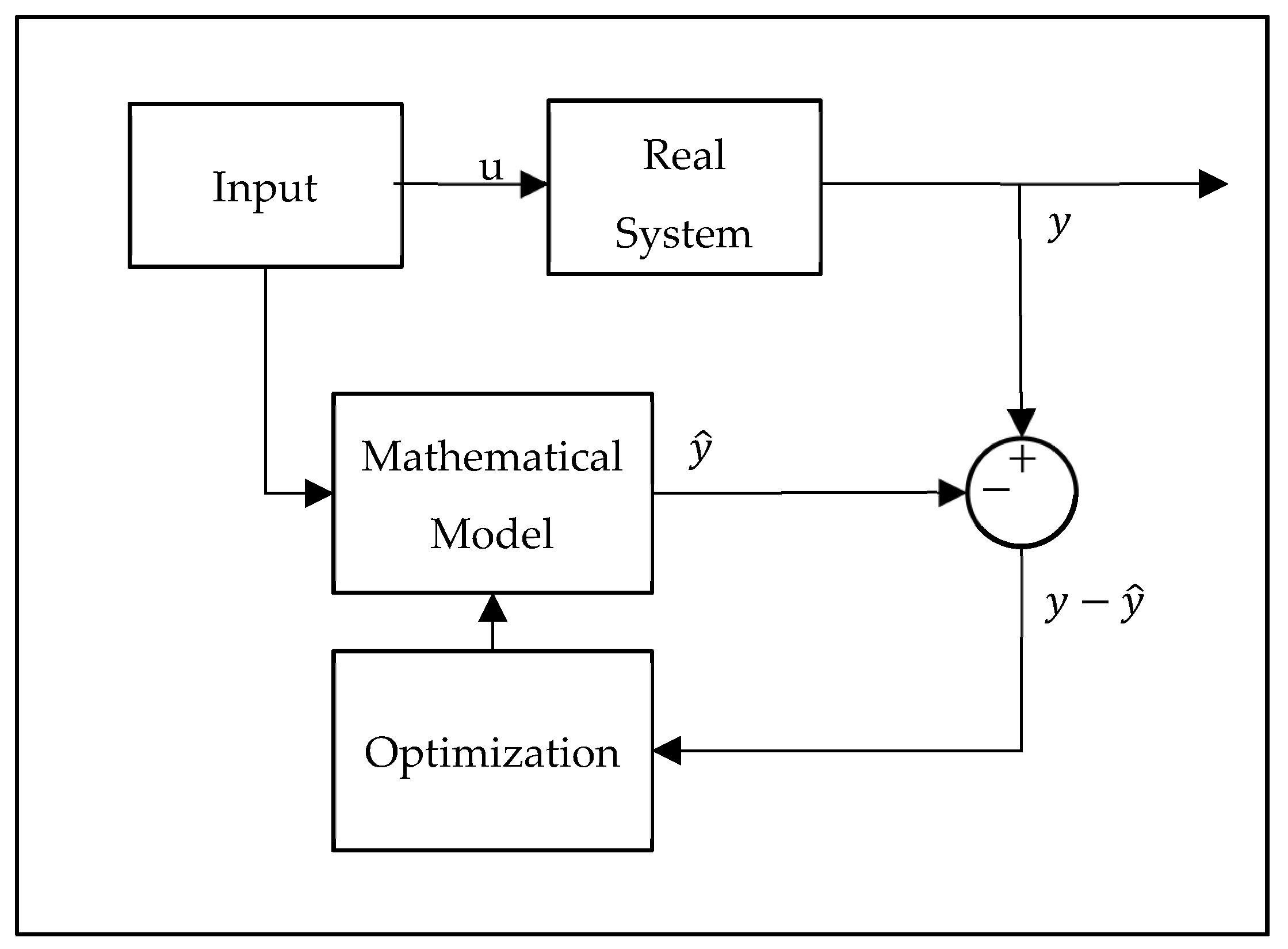
The methods used in parameter estimation can be listed as the Equation-error, output-error, and filter-error methods. The question of which method to choose can be decided according to the measurement and the noise present in the process [
2] (
Figure 3). If disruptive factors can be ignored in both, the fastest method, the equality-error method, is preferred. If the disturbing factors are only assumed in the measurements, the output-error method is recommended, and if both are present, the filter-error method is recommended.
The output-error method is the most widely preferred method for parameter estimation in the literature. In his study, Grauer calculated a dynamic model of an aircraft during flight by adapting the output-error method, which is usually carried out using post-flight data, to real-time flight data [
4]. In another study using the output-error method, Jann estimated the state variables of a parachute landing system called ALEX via sensor inputs (GPS, Magnetometers, Gyros, Accelerometers) [
5]. On the other hand, Jaiswal, Prakash, and Chaturvedi estimated the aerodynamic coefficients of a parachute landing system using the maximum likelihood method and the output-error method [
6].
In addition to statistical methods, machine learning techniques, which are increasing in popularity day by day, have also been successfully used in solving system identification problems. In the literature, artificial neural networks have been used in modeling aircraft dynamics [
7,
8,
9,
10,
11], estimating aerodynamic forces and moments [
12,
13,
14,
15], and in controller designs [
16,
17]. Both feed-forward neural networks [
14,
18] and recurrent neural networks have been widely used in these studies [
19]. Roudbari and Saghafi proposed a new method for describing the dynamics of highly maneuverable aircraft. In the model they developed, they modeled the flight dynamics with artificial neural networks. The difference between their approach and those of traditional methods is that they did not use aerodynamic information during the training process [
20]. Bagherzadeh supported a model with flight dynamics in order to increase the performance of the artificial neural network model [
21].
The development of deep learning methods has enabled these methods to be used frequently in system identification problems. The residual neural network approach, which is one type of deep neural network, is one of the methods used to solve these problems. Goyal and Benner developed a special architecture for dynamic systems called LQResNET [
22]. The method they proposed allowed for the use of observations in the modeling of dynamical systems. Their model was based on the principle that the rate of a variable depends on the linear and quadratic forms of the variable. Chen and Xiu suggested the framework called gResNet. They defined the residual as the estimation error of the prior model. They also used a DNN to model the residual [
23].
In this study, a NARX Network with a serial-parallel structure was used to identify an unknown aerial delivery system with a ram-air parachute. The dataset was created using the software-in-the-loop method (software in the loop). Gazebo was used as the simulator and PX4 was used as the autopilot software. The performance of the NARX network differed according to parameters used, such as the selected training algorithm, the input and output delays, the hidden layer, and the number of neurons. Within the scope of this study, each parameter was examined independently. Models were trained using MATLAB 2020a.
2. Mathematical Model
In this study, a 6-degree-of-freedom model developed for a parachute landing system was used [
24]. The Equations of motion of the vehicle can be written as:
where
m is the mass,
I is the inertia matrix, [
u,
v w] are linear velocities, [
p,
q r] are the angular velocities in the body frame,
S(
ω) is a skew-symmetric matrix consisting of linear velocity vectors,
F is the force, and
M is moment.
Due to the xz-symmetry plane of the parachute landing system, the inertial matrices consist of 4 unique components.
The forces and moments affecting the parachute are caused by gravity and aerodynamic forces. The gravitational force can be written according to the body (b) axis.
The aerodynamic forces acting on the system are written using the relevant aerodynamic coefficients (
,
,
,
,
,
), according to the body axis.
In this Equation,
S represents the parachute surface area,
represents symmetric trailing edge deflection, and (
) is the rotation matrix from the aerodynamic coordinate system to the body axis.
The angle of attack and slip angle are obtained from the velocity vector in the body axis.
The velocity vector in the body axis consists of the global velocity and the wind effect.
is the rotation matrix from the coordinate system on the North-East-Down-axis which has its origin in the center of mass of the parachute to the body axis. Euler angles (roll, pitch, yaw) are used in this notation.
Aerodynamic moments affecting the parachute can also be written using the relevant coefficients (
,
,
,
,
,
,
,
,
,
). These are roll, pitch, and yaw moments, respectively [
2].
here,
ρ is air density,
represents mean aerodynamic chord,
is asymmetric trailing-edge deflection, and
S is the canopy reference area.
3. Materials and Methods
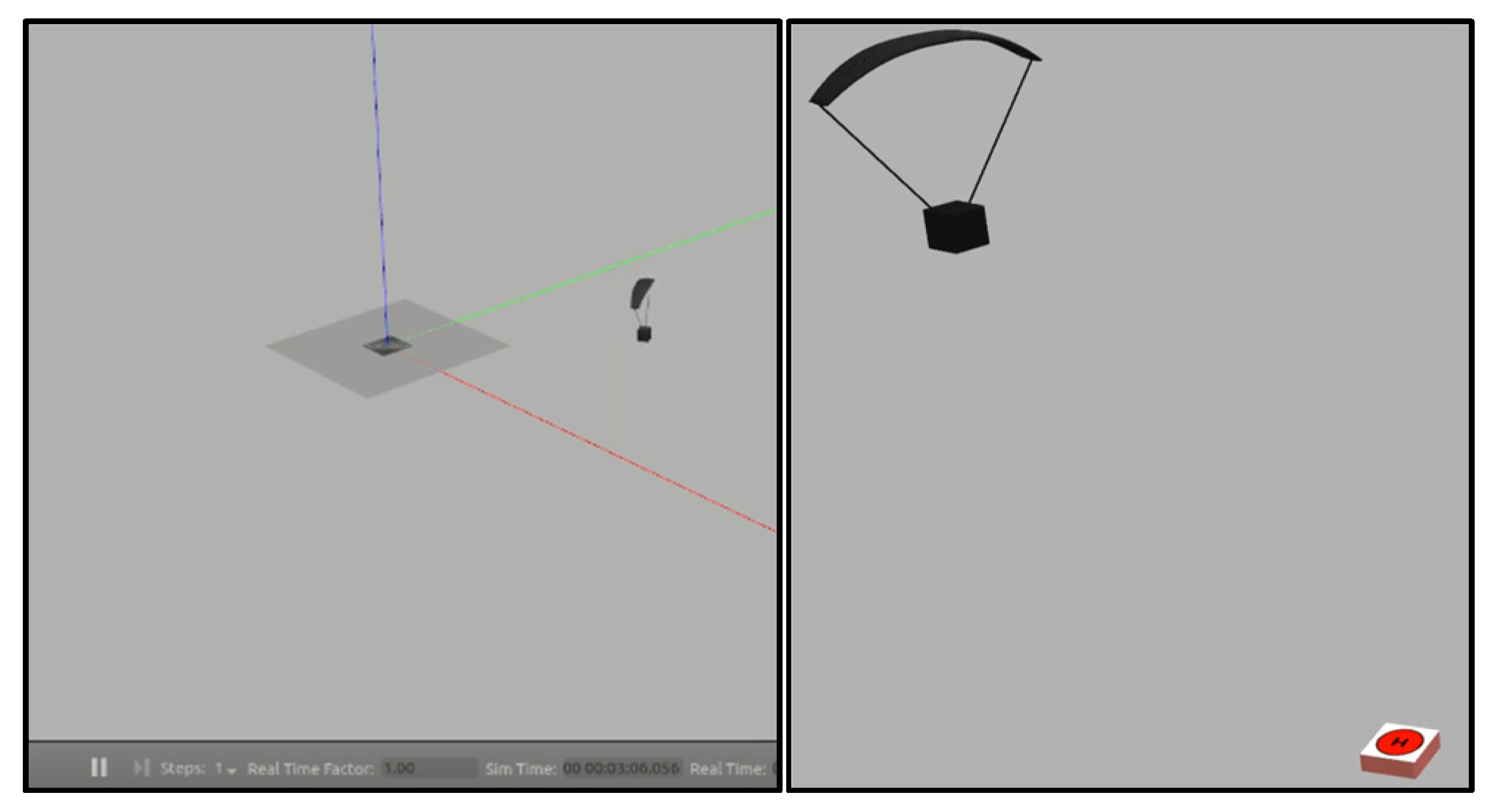
The dataset was created using the software-in-the-loop method (software in the loop). Gazebo was used as the simulator and PX4 was used as the autopilot software. A virtual flight was performed in the Gazebo environment (
Figure 4).
The parameters required for the simulation were used considering the autonomous landing system with a parachute model named Snowflake (
Table 1) [
3].
Gazebo compatible sensor models were used to obtain the flight data for the vehicle in the simulation environment. These consisted of a gyroscope, magnetometer, accelerometer, barometer, and GPS. The estimation of the state variables of the vehicle was carried out with PX4 software, using the extended Kalman filter.
PX4 has a state estimation module called EKF2 which uses the EKF algorithm. It uses IMU data in the state prediction phase. To correct these values, a GPS and barometer are used in the state correction phase [
24].
Simplified models of the sensors used can be shown similarly [
25]:
where
is the measured value;
is the real value; and
,
, and
represent bias and Gaussian noise, respectively. The sensor parameters can also be expressed using this notation. The sensor parameters used in the simulation are given in
Table 2.
The simulation was carried out in a windless environment and the air density was 1.225 kg/m
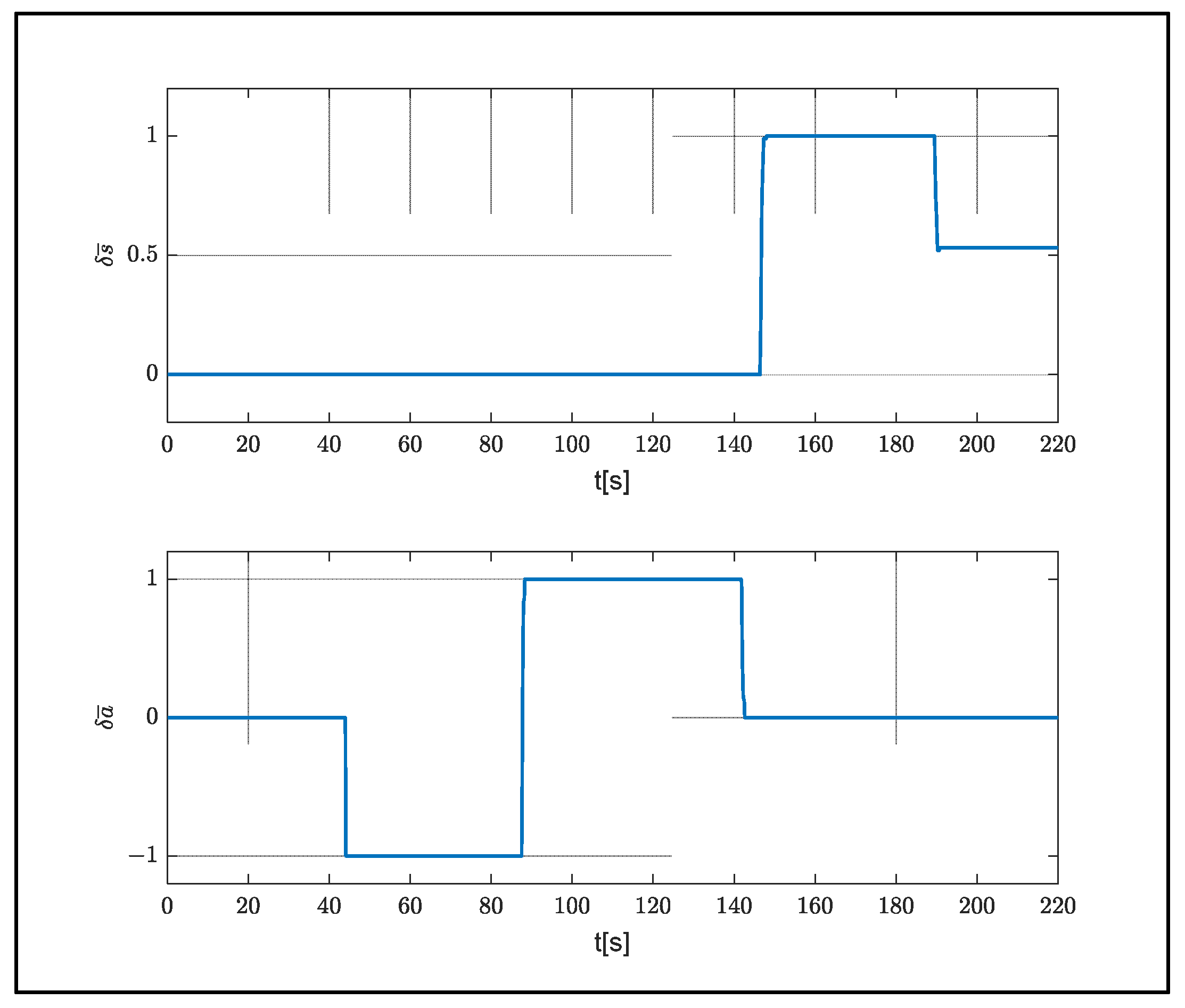
3. In the simulation, the system was released from a height of 500 m. Dropping occurred in 30 s. Control inputs
and
are given as full right and full left (
Figure 5).
The flight data received from the system were arranged and the input vector
x and the output vector y were created.
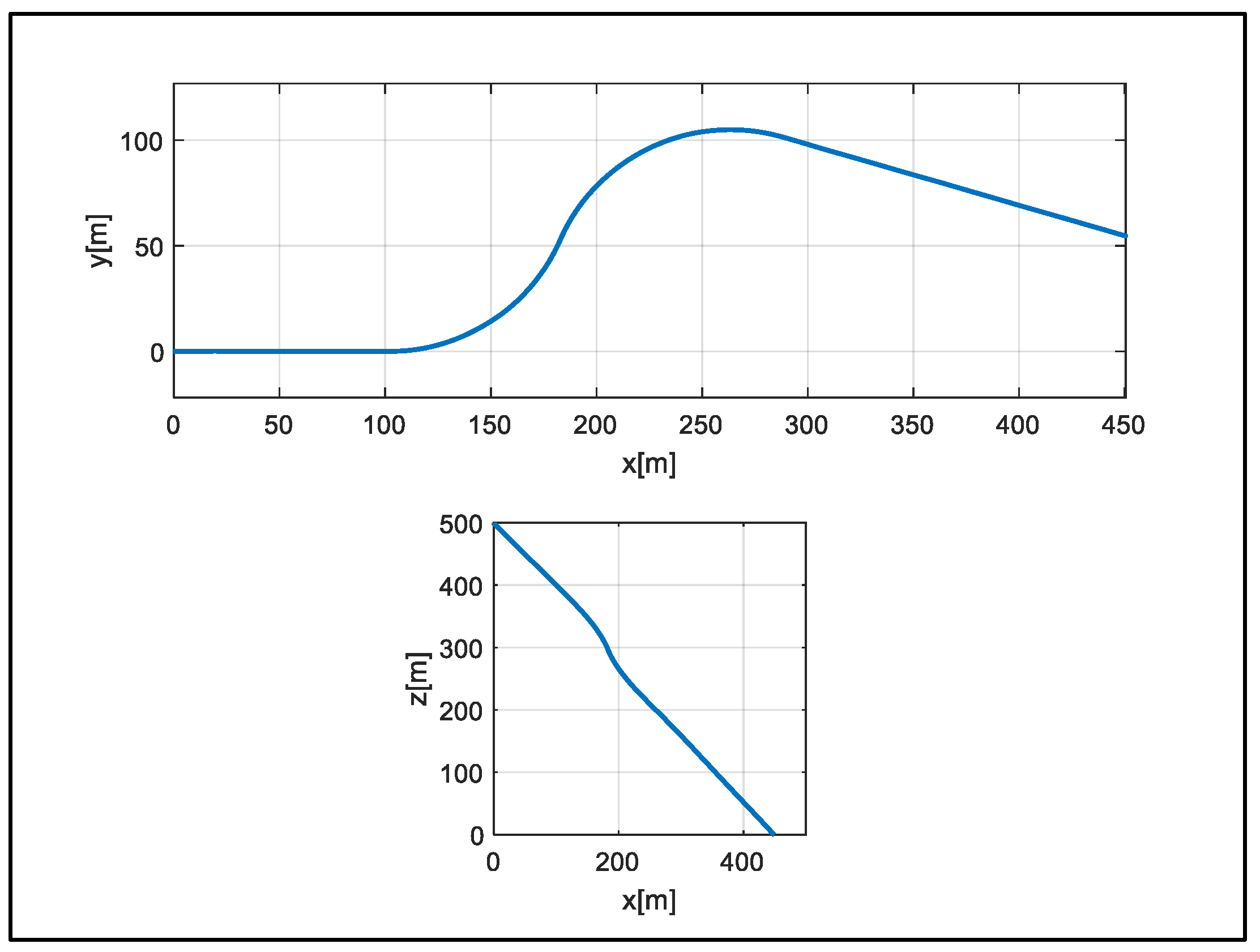
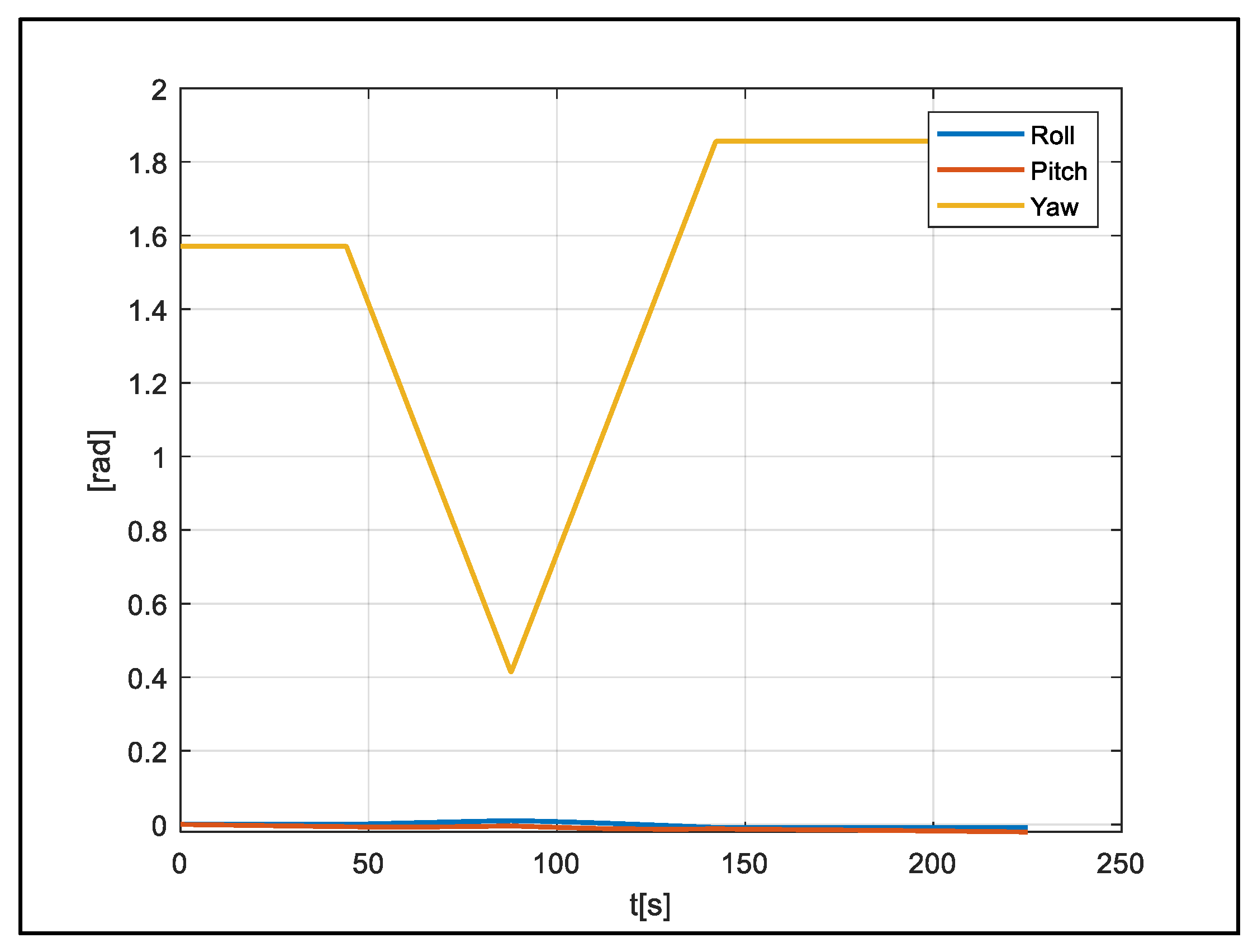
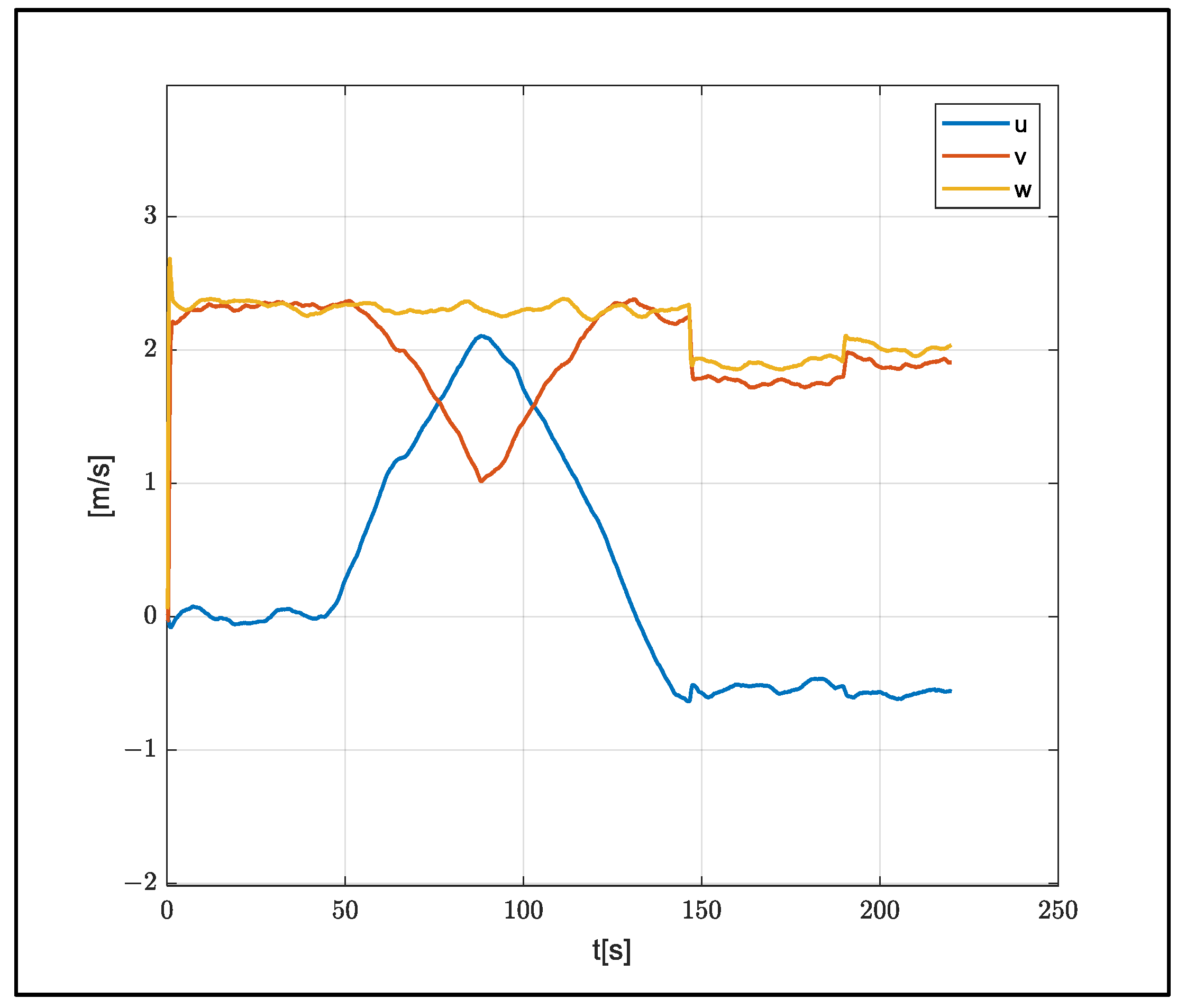
A total of 270 s of data were reduced to 225 s to cover the flight section, and 2250 pieces of data were produced using a 10 Hz measurement. The position and velocity of the vehicle in the flight data used are shown in
Figure 6,
Figure 7 and
Figure 8.
In order to improve the performance of the model, 70% of the flight was used for training and the remaining 30% was used in the testing process. Since the landing position is the most important phase, the first phase of the flight was selected as the training data.
3.1. NARX Network
A nonlinear autoregressive exogenous (NARX) network is a nonlinear model representation used in time series models. In this notation, the model’s outputs depend on the past output values, the inputs, and the past values of the inputs. Its mathematical expression is given as follows:
where
y denotes outputs,
u denotes inputs, and
f represents a nonlinear function. The structure in which f is modeled as a neural network is named the NARX neural network (NARX network) [
26]. This model has been used for modeling conventional fixed-wing [
27,
28] and rotary-wing [
29,
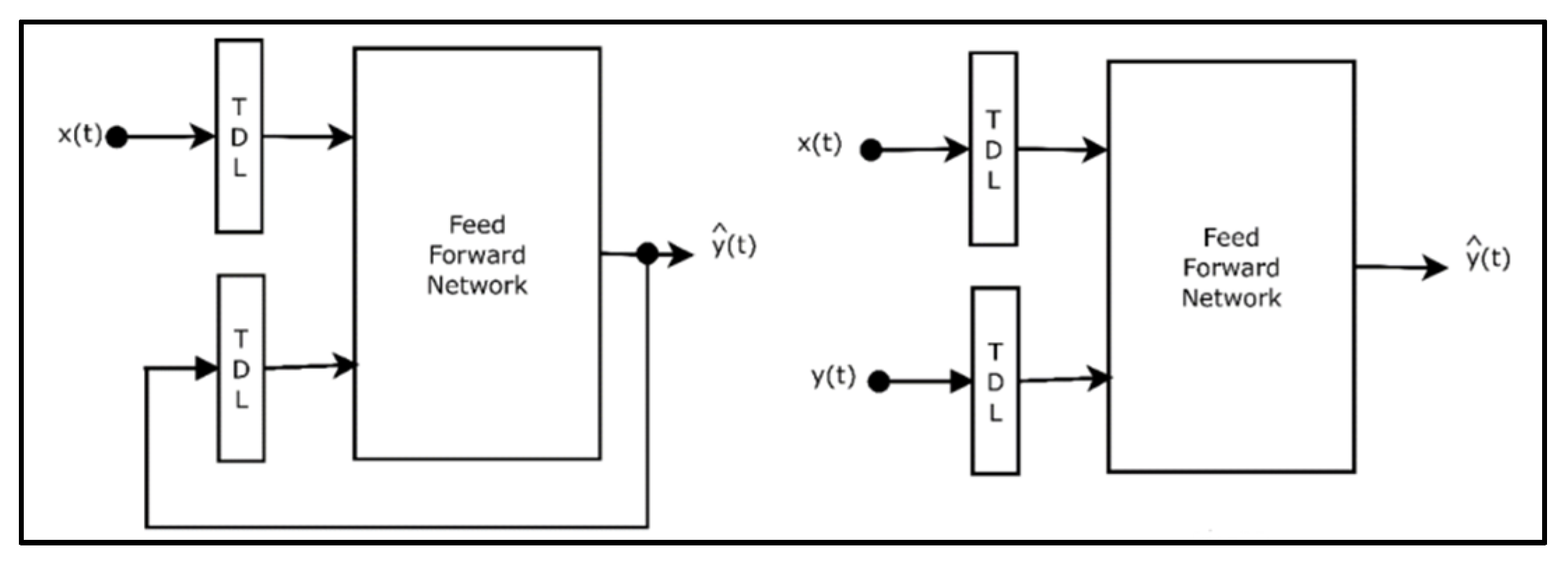
30] aircraft. A NARX neural network can be modeled using two types of models: parallel and serial-parallel (
Figure 9). In the parallel model, the estimated output values are fed back into the system.
In the serial-parallel model, only real system outputs are used:
where
represents the estimated output value time
t.
Since the data set used in this study included real system outputs, the serial-parallel structure was preferred. The feed-forward network block shown in
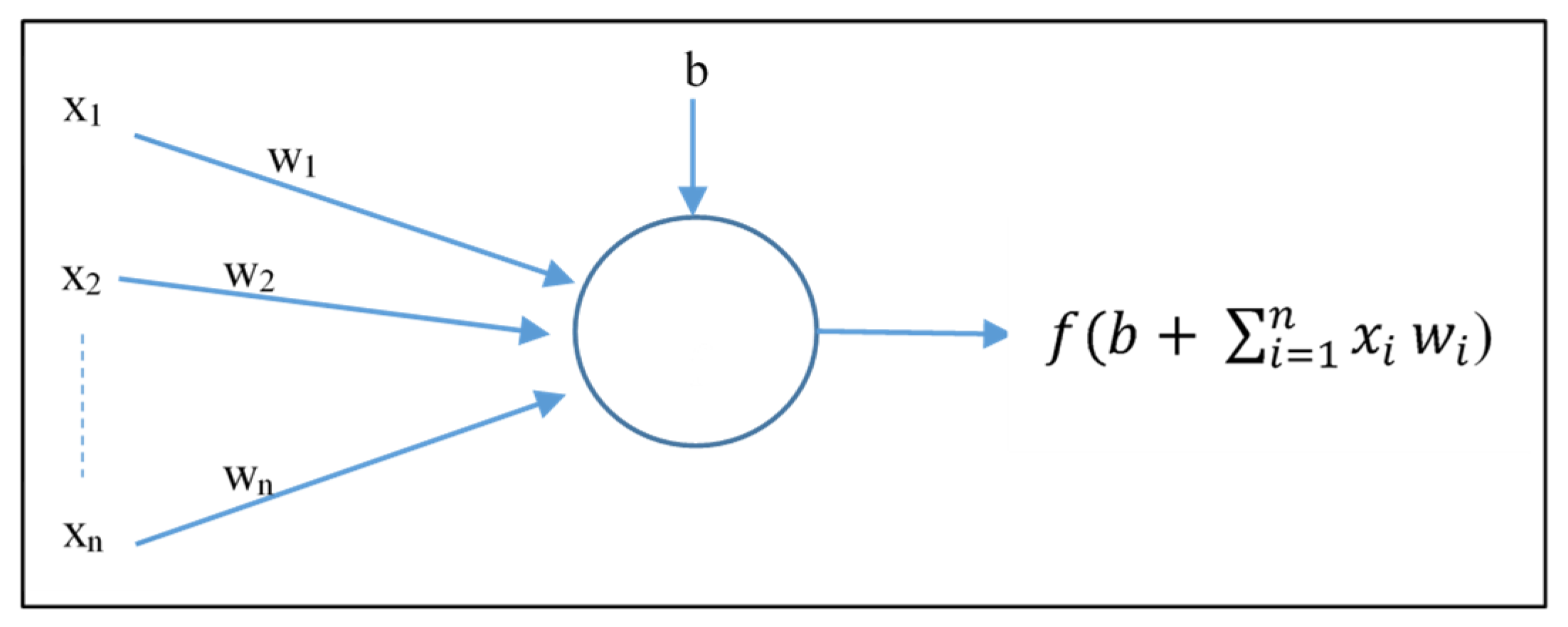
Figure 9 consisted of multilayer feedforward neural networks, which consisted of at least one hidden layer and neurons. Each neuron calculated the outputs with the help of the activation function, determined using the inputs and their weights, as shown in
Figure 10, where,
,
,
b, and
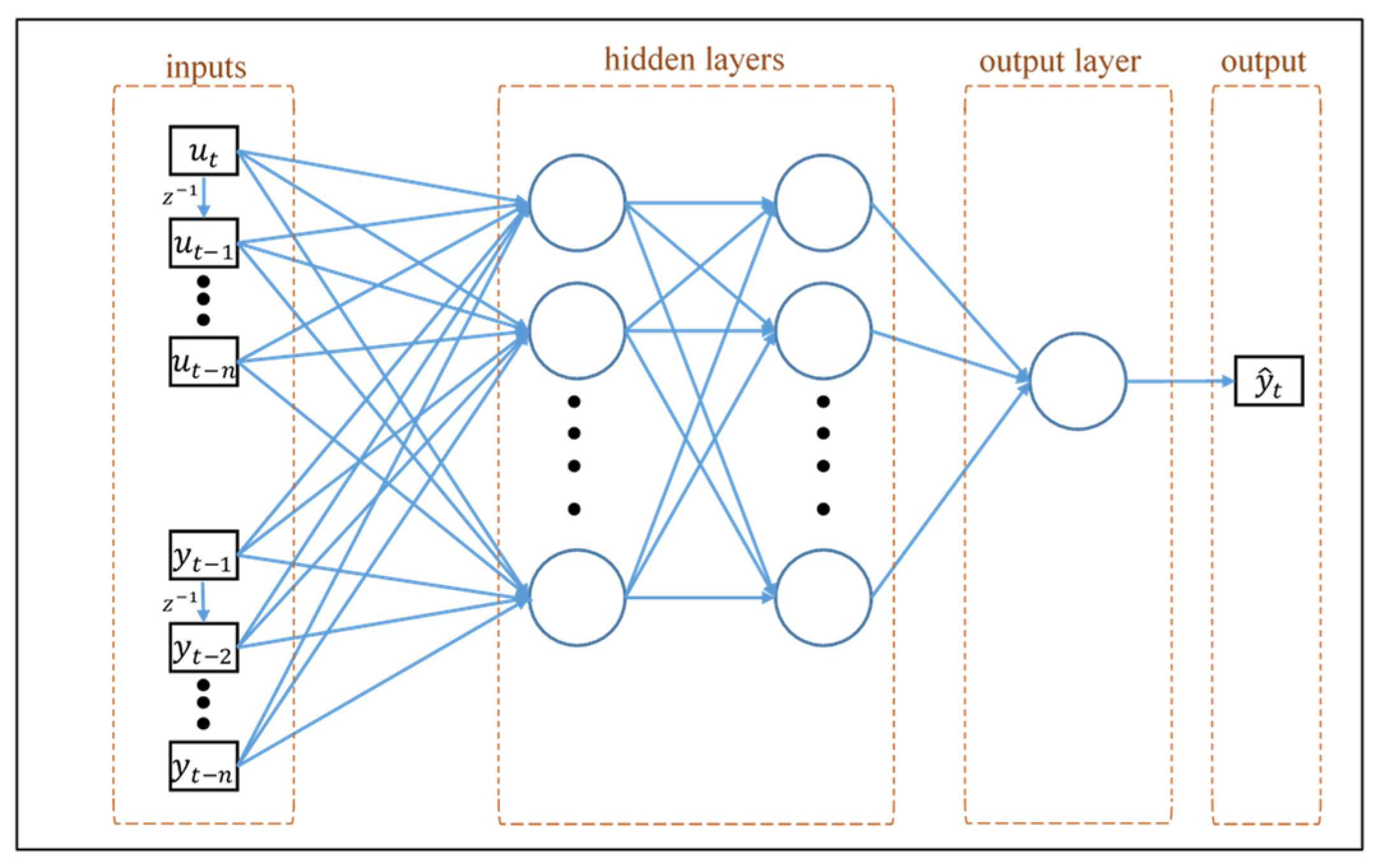
f represent inputs, weights, bias, and the activation function, respectively. The architecture of the NARX neural network with a serial-parallel structure is shown in
Figure 11.
The selection of the activation functions plays an important role in the model design. The functions used in the hidden layers and the functions used in the output layer vary. Differentiable functions are preferred in hidden layers. These functions, which are preferred over linear functions during training, enable the models to perform successfully with more complex problems. In the literature, functions that are frequently used in hidden layers are ReLU (Rectified Linear Activation), sigmoid (logistic), and Tanh (hyperbolic tangent) functions. The function used in the output layer differs according to the type of problem. Linear functions are used in regression problems, whereas softmax or sigmoid functions are used in classification problems. This concept is illustrated in detail in
Table 3.
The process of calculating and updating the weights is called training. The aim here is to minimize the targeted error function for model performance. In the neural network model, this function can be written as the sum of the squares of the errors:
where
e is the error and
n is the number of data.
The training algorithm used in feed-forward neural network methods is known as the back-propagation algorithm [
31]. Since the convergence rate of the steepest descent method, which is used as a standard in the back-propagation algorithm, is slow, many learning algorithms have been developed for neural network training. The main ones are the Levenberg–Marquardt algorithm [
32], the Bayesian regularization algorithm [
33], and the scaled conjugate gradient algorithm [
34].
3.2. Levenberg–Marquardt
The Levenberg–Marquardt algorithm is a second-order training algorithm used in solving nonlinear optimization problems. According to the weight values that need to be updated, the Jacobian of the error function shown in Equation (23) can be calculated as follows:
where
m is the number of weights in the network. After finding the Jacobian matrix, the gradient vector (
g) and the Hessian matrix (
H) can also be calculated.
The weights are updated based on the Jacobian matrix.
where
is the learning coefficient and
is the unit matrix. A theoretical analysis can be found in [
35].
3.3. Bayesian Regularization
The error function is rearranged using the regularization method to generalize the neural network [
36]:
where
μ and
ν are the regularization parameters and
is the sum of the squared weights. The Bayesian regularization method is used for the optimization of the editing parameters. Considering the weight values as random variables, it aims to calculate the weight values that will maximize the posterior probability distribution of the weights in the given data set. The posterior distribution can be expressed according to the Bayes rule:
where
D represents the dataset and
N represents the neural network model.
expresses the likelihood function,
is the prior density, and
is the normalization factor. It can be said that the noise in the dataset and in the weights has a Gaussian distribution. Thus, the likelihood function and antecedent intensity values can be calculated.
Here,
and
. By rearranging these equations, the posterior distribution to the weights can be rewritten.
Regularization parameters are effective in the
N model. The Bayes rule can be applied for the optimization of these parameters.
As can be seen in Equation (34), the function
is directly proportional to
. Therefore, the maximum value of the function
must be calculated. Adjustment parameters can be calculated using the Taylor expansion of Equation (29). A theoretical analysis can be found in [
37].
3.4. Scaled Conjugate Gradient
In the steepest descent algorithm implemented in the standard back-propagation algorithm, a search is made in the opposite direction of the gradient vector while updating the weights. Although the error function decreases rapidly in this direction, the same cannot be said for the convergence rate. Conjugate gradient algorithms search using the direction with the fastest convergence. This direction is called the conjugate direction. In this method, the search first starts in the reverse of the gradient vector, similarly to the steepest descent algorithm. It differs from the second iteration as follows.
Different algorithms have been developed according to the way in which the
coefficient is calculated. Moller, on the other hand, combined the LM algorithm and the conjugate gradient algorithm for the calculation of the number of steps in the algorithm he developed. This algorithm is called the scaled conjugate gradient algorithm [
35]. In this algorithm, which is based on calculating the approximate value of the Hessian matrix, the design parameters change in each iteration and are independent of the user. This is the most important factor affecting the success of the algorithm.
4. Results and Discussion
The performance of the NARX network differs according to parameters used, such as the selected training algorithm, the input and output delays, the hidden layer, and the number of neurons. Within the scope of this study, each parameter was examined independently. Models were trained using MATLAB 2020a. The root-mean-square error (RMSE) and mean absolute error (MAE) values were used to evaluate model performance. The metrics used are presented in
Table 4.
First, the performance of the training algorithms (Bayes arrangement, Levenberg–Marquardt, scaled conjugate gradient) in a model consisting of a single hidden layer and 15 neurons was compared. The input and output delay vectors were determined as in [
12]. A hyperbolic tangent was used as the activation function in the hidden layer and a linear function was used in the output layer. The errors according to the training algorithms are shown in
Table 5.
Despite the fast training time, SCG performed worse than LM and BR. At this stage, the hidden layer and the number of neurons within it were changed and the results were examined and shown in
Table 6. BR was used as the training algorithm.
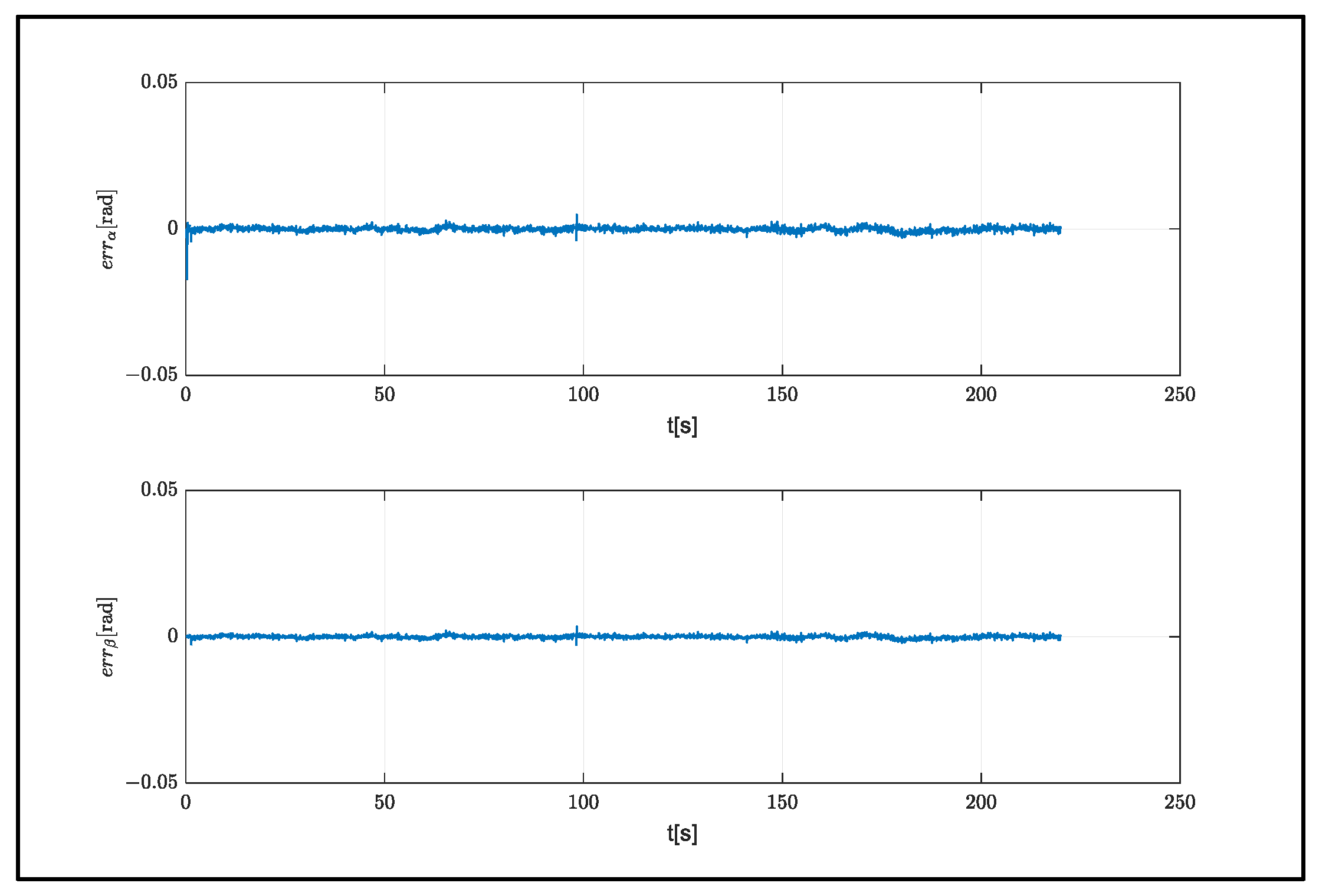
According to the angle of attack and the slip angle, it can be seen that model 4, which consisted of a single hidden layer and five neurons, showed the best performance. A comparison of the model results with the real system is shown in
Figure 12.
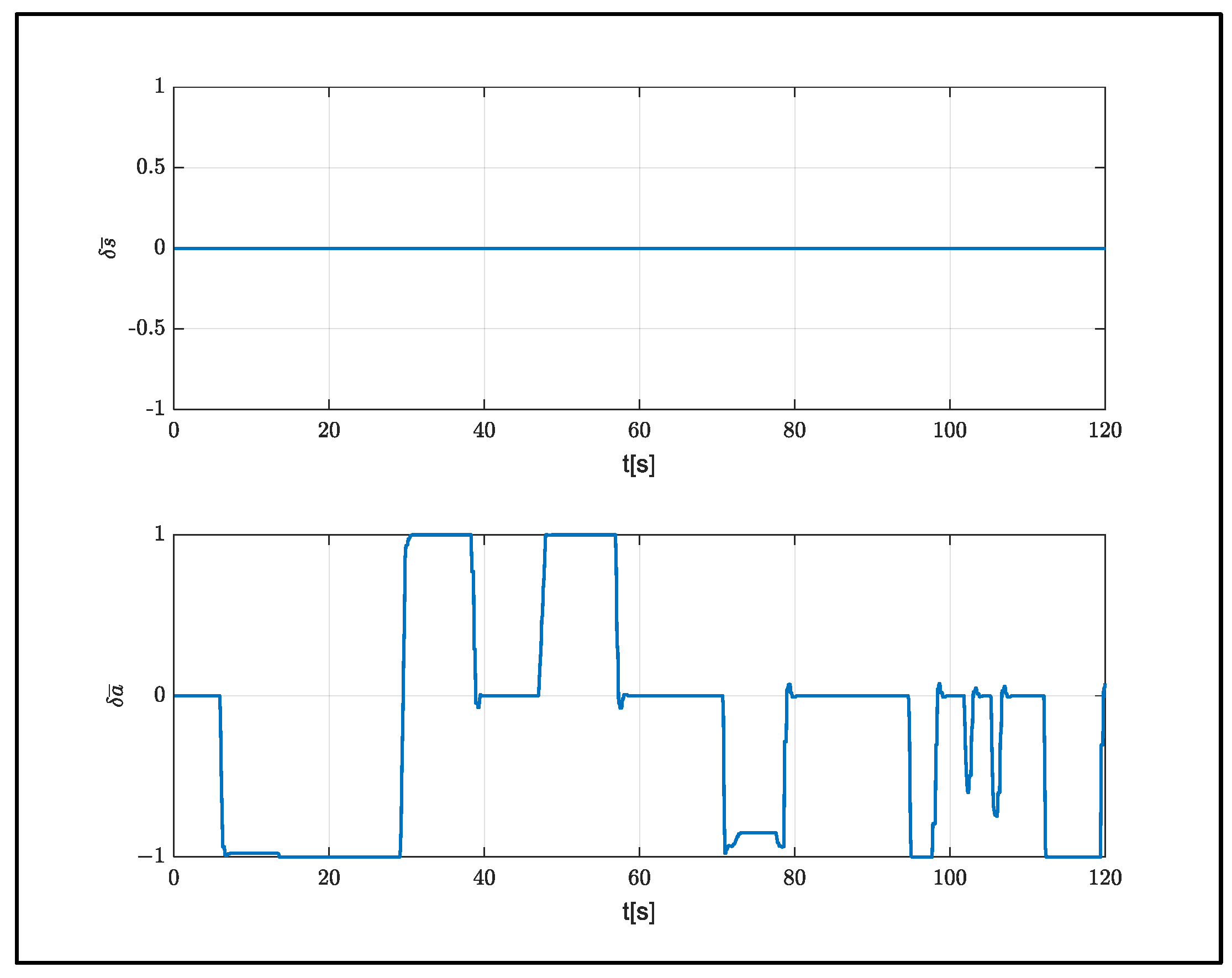
In order to observe the performance of the models with the same aerodynamic characteristics and different weights, the system weight was increased to 10 kg and a flight was carried out from an altitude of 1000 m. Control inputs produced during the flight are shown in
Figure 13.
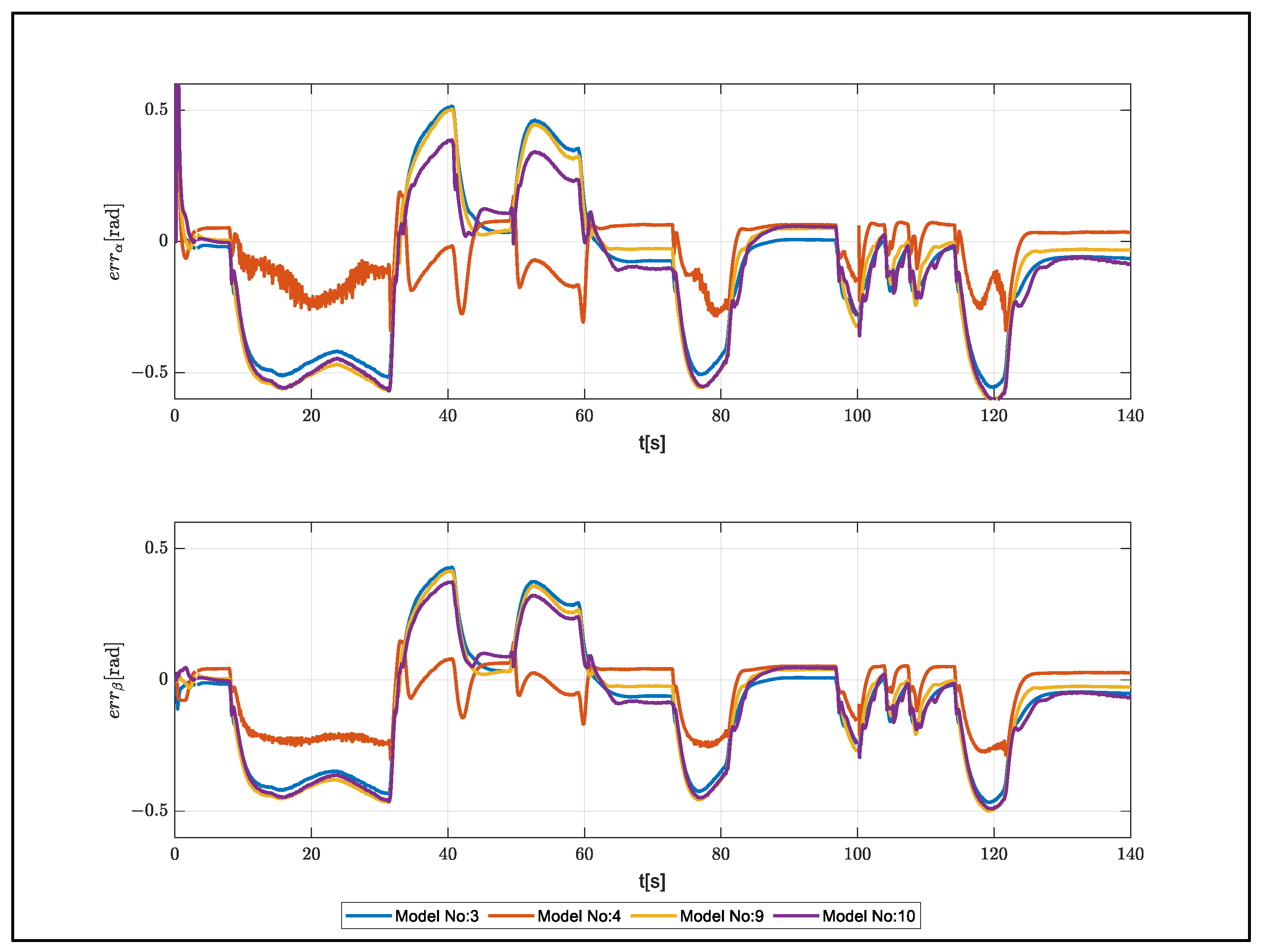
The model performances for a 120 s flight were compared using error metrics and computational costs measures. As can be seen in
Table 7, increasing the number of hidden layers and neurons increased the computation time. Considering the model performances, model number 4 exhibited the best performance.
The estimation errors for increased weight are shown in
Figure 14. The increase in the number of hidden layers increased the overshoot values, although it did not result in any significant changes in model performance. Finally, the performance of the developed models was examined in a system with different aerodynamic properties. An aerial delivery system called ALEX was used to determine the necessary parameters (
Table 8) [
3].
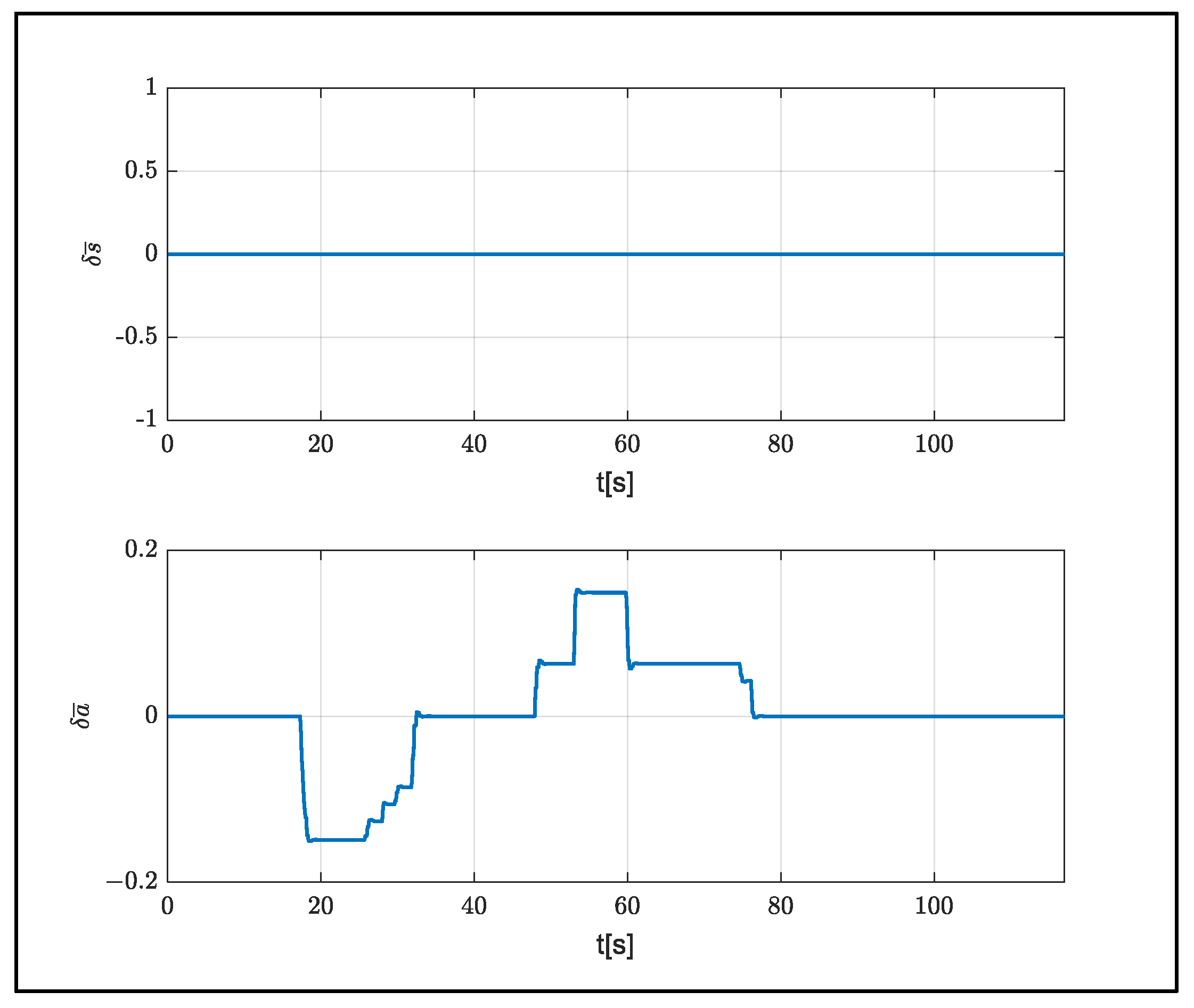
The control inputs used in this flight, starting from a 200 m altitude, are shown in
Figure 15.
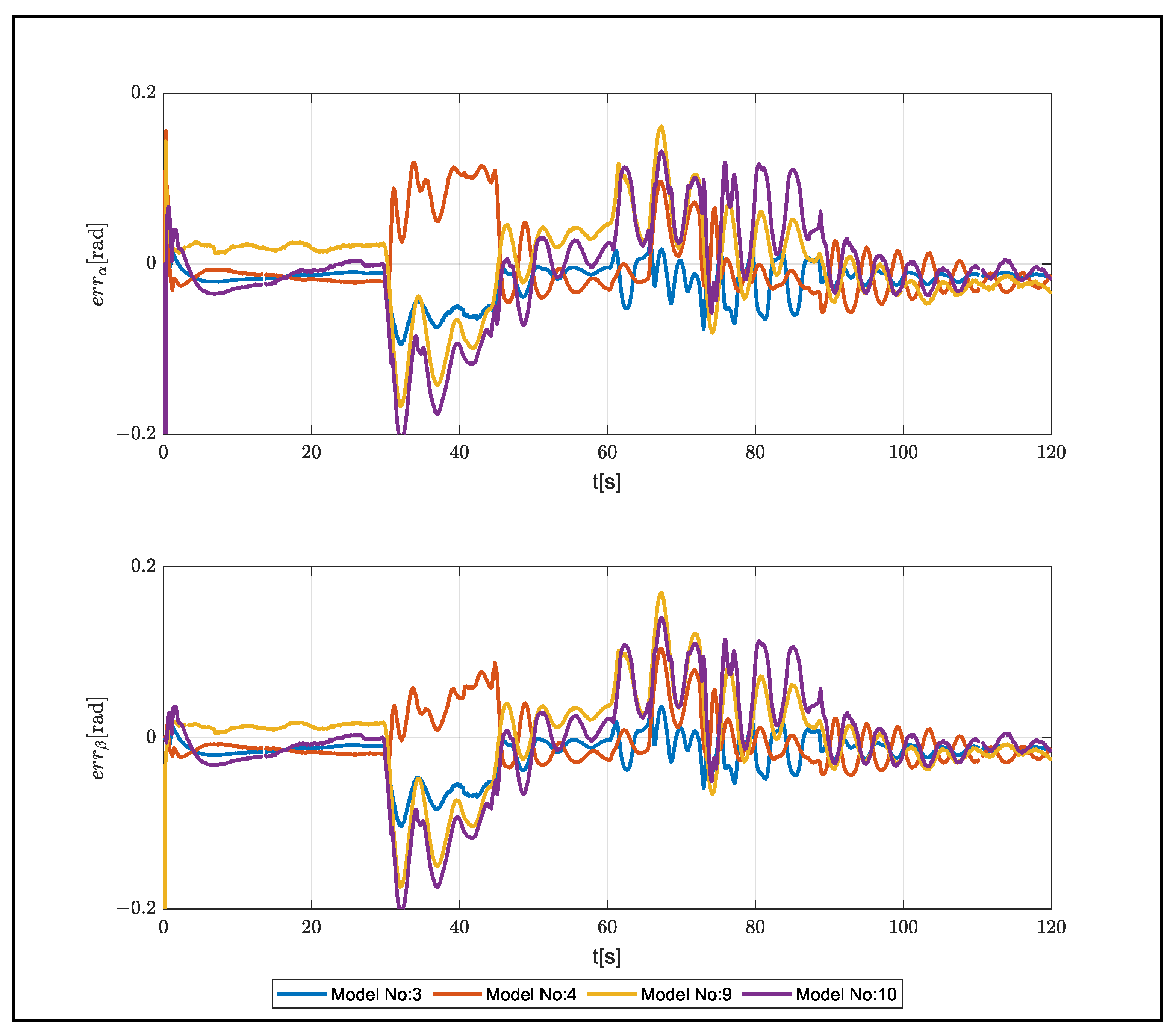
The performances of the models are shown in
Table 9 and
Figure 16. Model 1, which was found to have the best performance, consisted of a single hidden layer and 10 neurons.
In order to determine the limits of the developed models, the effects of weight and aerodynamic coefficients on the models were observed. The aerodynamic coefficients that determined the effects of control inputs on force and moment were chosen. Error rates were observed by changing the selected parameters by ±10%. RMSE was used as the error metric. As can be seen in
Table 10, model 4, which consisted of a single hidden layer and five neurons, demonstrated the best performance.
Considering the maximum error of five degrees, the limits of the models could be determined approximately, according to the parameters, via interpolation. The results are shown in
Table 11.
5. Conclusions
In this study, a simulation environment was designed for a parachute landing system in the Gazebo/ROS environment. By implementing an aerial delivery system in PX4 autopilot software, the necessary infrastructure for a software-in-the-loop system was created. Flights were performed in the simulation environment and flight data were collected. Using these data for the description of the system, an NARX network model was trained, and a dynamic model was used to estimate the system. During the training process, different training algorithms were used (LM, BR, and SCG) and the effects of the numbers of hidden layers and neurons were observed. The effects of weight and aerodynamic coefficients on the models were also examined and the model limits were determined. As a result of the examinations, the model consisting of a single hidden layer and five neurons outperformed the other models evaluated. As the rates of different model parameters increase, the model which has the best performance may change. Therefore, errors in models can be improved by means of online training methods.
In future studies, pre-trained models will be updated using online training methods. Furthermore, the trained model will be tested using real flight data. After the model is verified, controller studies will be carried out and autonomous landing of the landing system will be carried out at the desired target location.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




