Immersive Virtual Reality as an Effective Tool for Second Language Vocabulary Learning


Abstract
:1. Introduction
1.1. L2 Learning Context Affects Learning Performance
1.2. Virtual Environments Can Provide Effective and Engaging Learning Experiences
1.3. Features of Virtual Environment Platforms That Support Learning
1.4. The Current Study
2. Methods
2.1. Participants
2.2. L2 Learning and Testing Materials
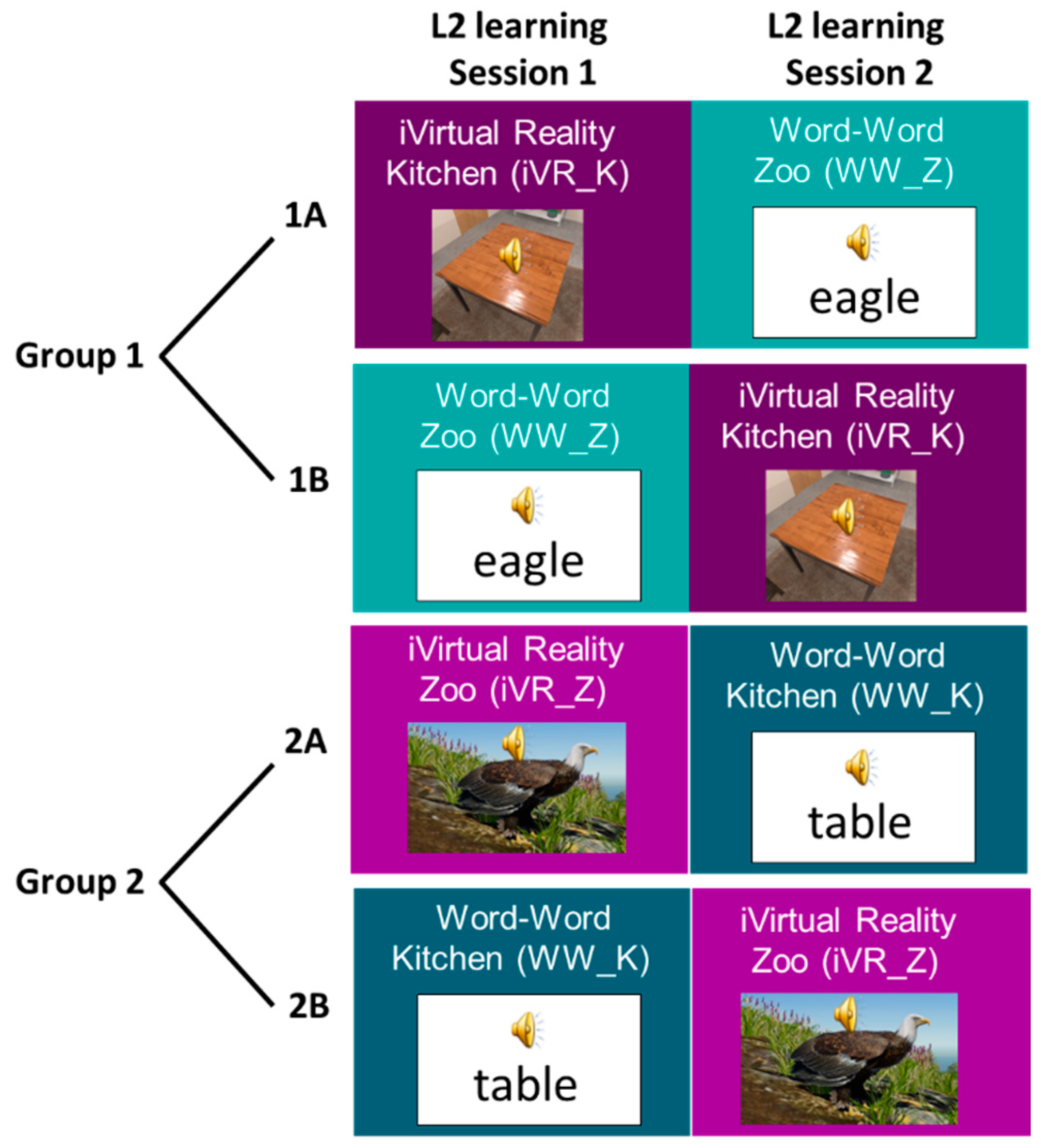
2.3. Procedure
2.3.1. Word–Word (WW) Association Learning
2.3.2. Immersive Virtual Reality (iVR) Learning
iVR Kitchen
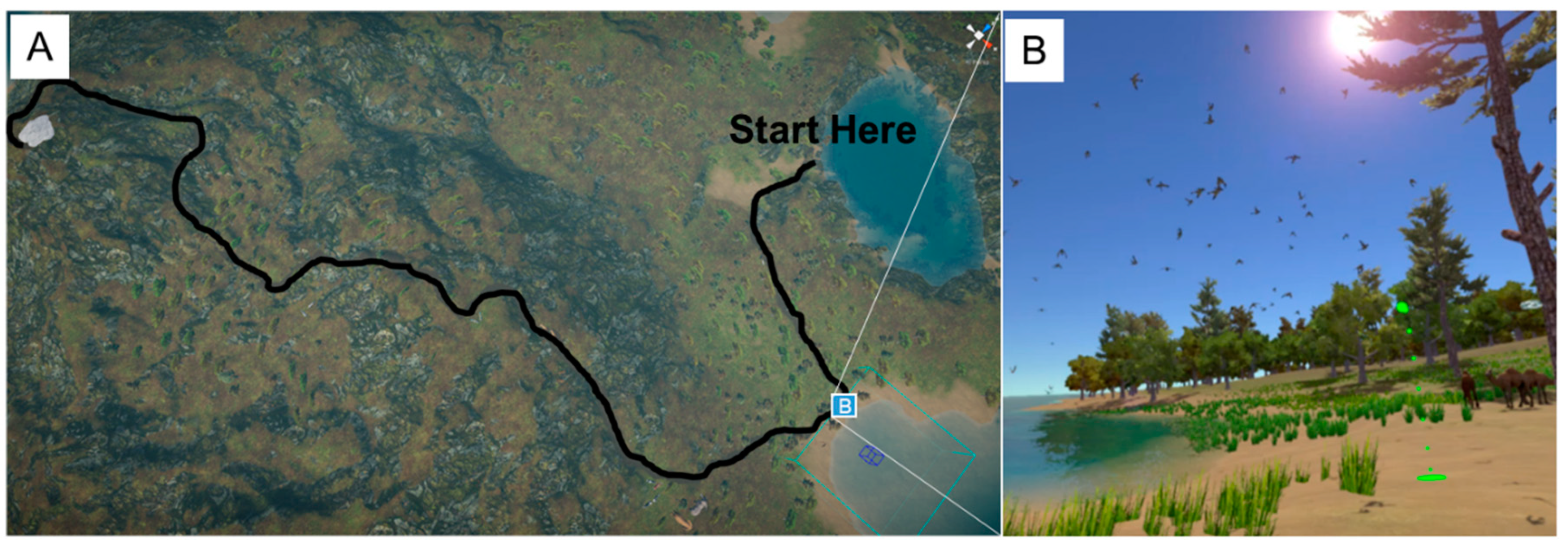
iVR Zoo
2.4. Cognitive Measures
2.4.1. Attentional Network/Flanker Task (ANT)
2.4.2. Language History Questionnaire (LHQ)
2.4.3. Letter Number Sequencing (LNS) Task
2.4.4. Peabody Picture Vocabulary Test 4 (PPVT-4)
2.4.5. Spatial Reasoning Instrument (SRI)
2.5. Data Analyses
3. Results
3.1. Effects of L2 Learning Context across All Participants
3.2. Cognitive Performance Associations with L2 Proficiency
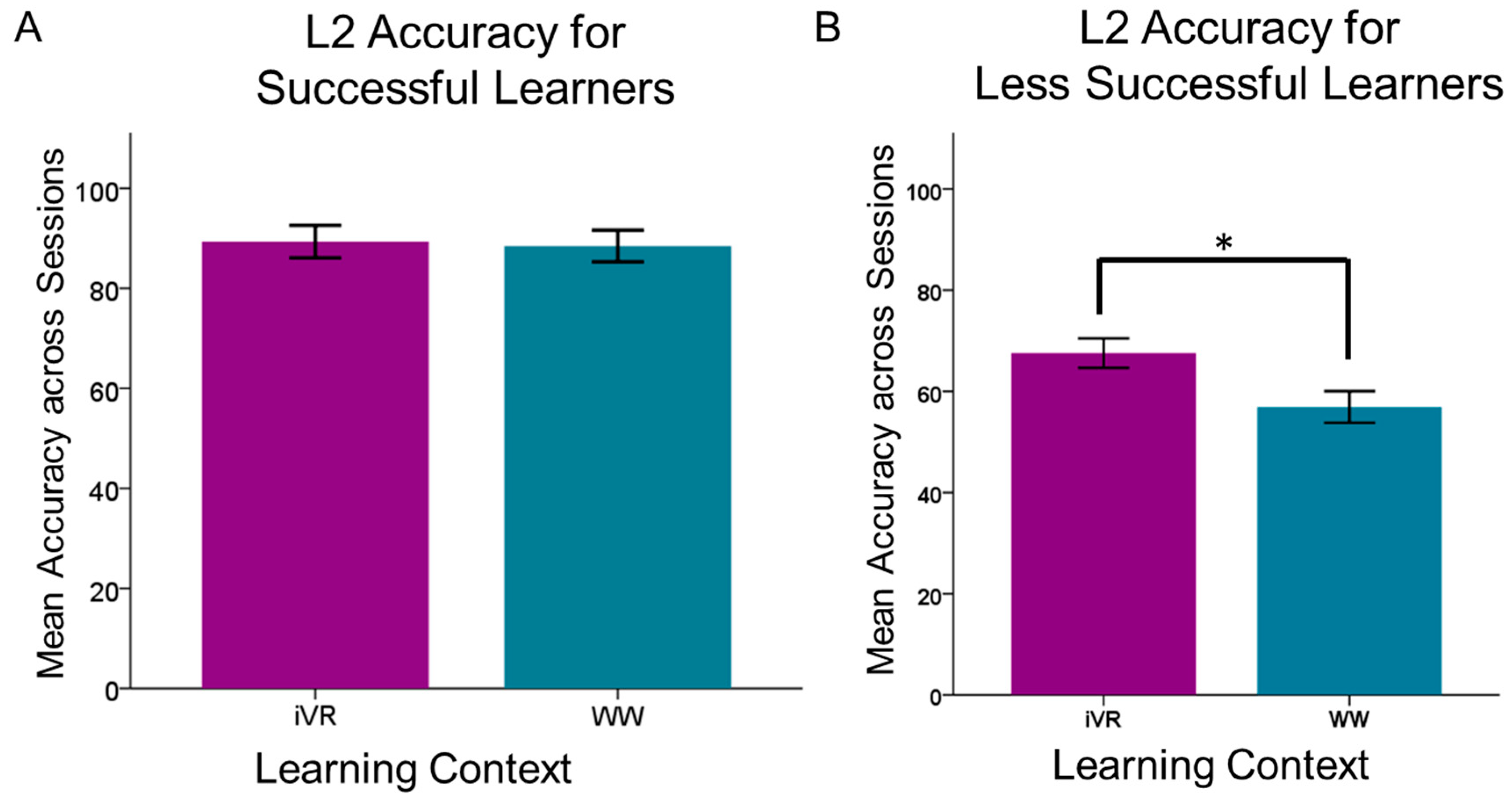
3.3. L2 Context Effects for Successful and Less Successful L2 Learners
4. Discussion
4.1. Virtual Reality Platforms Optimally Benefit Less Successful L2 Learners
4.2. Relationships between L2 Success and Individual Difference Measures
4.3. iVR Features in Learning that Affect L2 Learning and Cognitive Performance
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
| Bowl | 飯碗 | (fanwan) |
| Broom | 掃把 | (saoba) |
| Candle | 蠟燭 | (lazhu) |
| Chair | 椅子 | (yizi) |
| Chopsticks | 筷子 | (kuàizi) |
| Clock | 時鐘 | (shizhong) |
| Drainer | 濾網 | (luwang) |
| Drawer | 抽屜 | (chouti) |
| Funnel | 漏斗 | (loudou) |
| Jar | 罐子 | (guanzi) |
| Knife | 刀子 | (daozi) |
| Ladle | 湯勺 | (tangshao) |
| Lid | 鍋蓋 | (guogai) |
| Mitten | 手套 | (shoutao) |
| Oven | 烤箱 | (kaoxiang) |
| Plate | 盤子 | (panzi) |
| Refrigerator | 冰箱 | (bīngxiāng) |
| Scissor | 剪刀 | (jiandao) |
| Sink | 水槽 | (shuicao) |
| Spatula | 鏟子 | (chanzi) |
| Steel cup | 鋼杯 | (gangbei) |
| Stewpot | 燉鍋 | (dunguo) |
| Stool | 凳子 | (dengzi) |
| Stove | 電爐 | (dianlu) |
| Table | 餐桌 | (canzhuo) |
| Teacup | 茶杯 | (chabei) |
| Teapot | 茶壺 | (chahu) |
| Telephone | 電話 | (dianhua) |
| Vase | 花瓶 | (huaping) |
| Wineglass | 酒杯 | (jiubei) |
| Bear | 黑熊 | (heixiong) |
| Bird | 小鳥 | (xiaoniao) |
| Butterfly | 蝴蝶 | (hudie) |
| Camel | 駱駝 | (luotuo) |
| Cat | 小貓 | (xiaomao) |
| Cow | 黃牛 | (huangniu) |
| Crab | 螃蟹 | (pangxie) |
| Crocodile | 鱷魚 | (eyu) |
| Dog | 小狗 | (xiaogou) |
| Eagle | 老鷹 | (laoying) |
| Elephant | 大象 | (daxiang) |
| Fox | 狐狸 | (huli) |
| Frog | 青蛙 | (qingwa) |
| Goat | 山羊 | (shānyáng) |
| Kangaroo | 袋鼠 | (daishu) |
| Lion | 獅子 | (shizi) |
| Lizard | 蜥蜴 | (xiyi) |
| Monkey | 猴子 | (houzi) |
| Ostrich | 鴕鳥 | (tuoniao) |
| Panda | 熊貓 | (xiongmao) |
| Parrot | 鸚鵡 | (yingwu) |
| Peacock | 孔雀 | (kongque) |
| Penguin | 企鵝 | (qie) |
| Rabbit | 兔子 | (tuzi) |
| Rhinoceros | 犀牛 | (xiniu) |
| Rooster | 公雞 | (gongji) |
| Tiger | 老虎 | (laohu) |
| Turkey | 火雞 | (huoji) |
| Turtle | 烏龜 | (wugui) |
| Zebra | 斑馬 | (banma) |
Appendix B





References
- Abutalebi, Jubin, and David Green. 2007. Bilingual Language Production: The Neurocognition of Language Representation and Control. Journal of Neurolinguistics 20: 242–75. [Google Scholar] [CrossRef]
- Abutalebi, Jubin, Pasquale Anthony Della Rosa, David W. Green, Mireia Hernandez, Paola Scifo, Roland Keim, Stefano F. Cappa, and Albert Costa. 2012. Bilingualism Tunes the Anterior Cingulate Cortex for Conflict Monitoring. Cerebral Cortex 22: 2076–86. [Google Scholar] [CrossRef] [PubMed]
- Adamovich, Sergei V., Gerard G. Fluet, Eugene Tunik, and Alma S. Merians. 2009. Sensorimotor Training in Virtual Reality: A Review. NeuroRehabilitation 25: 29–44. [Google Scholar] [CrossRef] [PubMed]
- Aziz-Zadeh, Lisa, and Antonio Damasio. 2008. Embodied Semantics for Actions: Findings from Functional Brain Imaging. Journal of Physiology Paris 102: 35–39. [Google Scholar] [CrossRef] [PubMed]
- Barsalou, Lawrence W. 2008. Grounded Cognition. Annual Review of Psychology 59: 617–45. [Google Scholar] [CrossRef] [PubMed]
- Barsalou, Lawrence W., W. Kyle Simmons, Aron K. Barbey, and Christine D. Wilson. 2003. Grounding Conceptual Knowledge in Modality-Specific Systems. Trends in Cognitive Sciences 7: 84–91. [Google Scholar] [CrossRef]
- Berns, Anke, Antonio Gonzalez-Pardo, and David Camacho. 2013. Game-like Language Learning in 3-D Virtual Environments. Computers and Education 60: 210–20. [Google Scholar] [CrossRef]
- Blascovich, Jim, Jack Loomis, Andrew C. Beall, Kimberly R. Swinth, L. Crystal, Source Psychological Inquiry, and Jim Blascovich. 2002. Immersive Virtual Environment Technology as a Methodological Tool for Social Psychology. Psychological Inquiry 13: 103–24. [Google Scholar] [CrossRef]
- Brecht, Richard D., Dan Davidson, and Ralph B. Ginsberg. 1995. Predictors of Foreign Language Gain during Study Abroad. Second Language Acquisition in a Study Abroad Context 9: 53–82. [Google Scholar]
- Brooks, Barbara M., Jane E. McNeil, F. David Rose, Richard J. Greenwood, Elizabeth A. Attree, and Antony G. Leadbetter. 1999. Route Learning in a Case of Amnesia: A Preliminary Investigation into the Efficacy of Training in a Virtual Environment. Neuropsychological Rehabilitation 9: 63–76. [Google Scholar] [CrossRef]
- Casasanto, Daniel, and Kyle Jasmin. 2018. Virtual Reality. In Research Methods in Psycholinguistics and the Neurobiology of Language. Hoboken: John Wiley & Sons, pp. 174–90. [Google Scholar]
- Chen, Julian Cheng Chiang. 2016. The Crossroads of English Language Learners, Task-Based Instruction, and 3D Multi-User Virtual Learning in Second Life. Computers and Education 102: 152–71. [Google Scholar] [CrossRef]
- Collentine, J., and B. F. Freed. 2004. Learning context and its effects on second language acquisition: Introduction. Studies in Second Language Acquisition 26: 153–171. [Google Scholar]
- Costello, Patrick J. 1997. Health and Safety Issues Associated with Virtual Reality: A Review of Current Literature. Loughborough: Advisory Group on Computer Graphics. [Google Scholar]
- Cummins, Jim. 1991. Interdependence of First- and Second-Language Proficiency in Bilingual Children. In Language Processing in Bilingual Children. Cambridge: Cambridge University Press, pp. 70–89. [Google Scholar] [CrossRef]
- Dede, Chris. 2009. Immersive Interfaces for Engagement and Learning. Science 323: 66–99. [Google Scholar] [CrossRef] [PubMed]
- Dunn, Lloyd M., and Douglas M. Dunn. 2007. Peabody Picture Vocabulary Test. Minneapolis: Pearson. [Google Scholar] [CrossRef]
- Fan, Jin, Bruce D. McCandliss, Tobias Sommer, Amir Raz, and Michael I. Posner. 2002. Testing the Efficacy and Independence of Attentional Networks. Journal of Cognitive Neuroscience 14: 340–47. [Google Scholar] [CrossRef] [PubMed]
- Fischer, Martin H., and Rolf A. Zwaan. 2008. Embodied Language: A Review of the Role of the Motor System in Language Comprehension. Quarterly Journal of Experimental Psychology 61: 825–50. [Google Scholar] [CrossRef] [PubMed]
- Freed, Barbara F., Norman Segalowitz, and Dan P. Dewey. 2004. Context of Learning and Second Language Fluency in French: Comparing Regular Classroom, Study Abroad, and Intensive Domestic Immersion Programs. Studies in Second Language Acquisition 26: 275–301. [Google Scholar] [CrossRef]
- Glenberg, Arthur, Marc Sato, Luigi Cattaneo, Lucia Riggio, Daniele Palumbo, and Giovanni Buccino. 2008. Processing Abstract Language Modulates Motor System Activity. Quarterly Journal of Experimental Psychology 61: 905–19. [Google Scholar] [CrossRef] [PubMed]
- Hernandez, Arturo, and Ping Li. 2007. Age of Acquisition: Its Neural and Computational Mechanisms. Psychological Bulletin 133: 638–50. [Google Scholar] [CrossRef] [PubMed]
- Hernandez, Arturo, Ping Li, and Brian MacWhinney. 2005. The Emergence of Competing Modules in Bilingualism. Trends in Cognitive Sciences 9: 220–25. [Google Scholar] [CrossRef] [PubMed]
- Hsiao, Indy Y. T., Yu-Ju Lan, Chia-Ling Kao, and Ping Li. 2017. Visualization Analytics for Second Language Vocabulary Learning in Virtual Worlds. Journal of Educational Technology & Society 20: 161–75. [Google Scholar]
- Ibáñez, María Blanca, José Jesús García, Sergio Galán, David Maroto, and Diego Morillo. 2011. Design and Implementation of a 3D Multi-User Virtual World for Language Learning. Educational Technology & Society 14: 2–10. [Google Scholar]
- Jarmon, Leslie, Tomoko Traphagan, Michael Mayrath, and Avani Trivedi. 2009. Virtual World Teaching, Experiential Learning, and Assessment: An Interdisciplinary Communication Course in Second Life. Computers and Education 53: 169–82. [Google Scholar] [CrossRef]
- Jerald, Jason. 2016. The VR book: Human-Centered Design for Virtual Reality. New York: ACM Books, San Rafael: Morgan & Claypool. [Google Scholar]
- Jeong, Hyeonjeong, Motoaki Sugiura, Yuko Sassa, Keisuke Wakusawa, Kaoru Horie, Shigeru Sato, and Ryuta Kawashima. 2010. Learning Second Language Vocabulary: Neural Dissociation of Situation-Based Learning and Text-Based Learning. NeuroImage 50: 802–9. [Google Scholar] [CrossRef] [PubMed]
- Johnson-Glenberg, Mina C., David A. Birchfield, Lisa Tolentino, and Tatyana Koziupa. 2014. Collaborative Embodied Learning in Mixed Reality Motion-Capture Environments: Two Science Studies. Journal of Educational Psychology 106: 86–104. [Google Scholar] [CrossRef]
- Johnson, Jacqueline S., and Elissa L. Newport. 1989. Critical Period Effects in Second Language Learning: The Influence of Maturational State on the Acquisition of English as a Second Language. Cognitive Psychology 21: 60–99. [Google Scholar] [CrossRef]
- Lafford, Barbara A. 1995. Getting into, through, and out of a Survival Situation: A Comparison of Communicative Strategies Used by Students Studying Spanish-Abroad and ‘at Home’. Second Language Acquisition in a Study Abroad Context 9: 97–121. [Google Scholar]
- Lan, Yu-Ju, Nian-Shing Chen, Ping Li, and Scott Grant. 2015. Embodied Cognition and Language Learning in Virtual Environments. Educational Technology Research and Development 63: 639–44. [Google Scholar] [CrossRef]
- Lan, Yu-Ju, Shin-Yi Fang, Jennifer Legault, and Ping Li. 2014. Second Language Acquisition of Mandarin Chinese Vocabulary: Context of Learning Effects. Educational Technology Research and Development 63: 671–90. [Google Scholar] [CrossRef]
- Lee, Elinda Ai-lim, and Kok Wai Wong. 2008. A Review of Using Virtual Reality for Learning. In Transactions on Edutainment I. Berlin/Heidelberg: Springer, pp. 231–41. [Google Scholar] [CrossRef]
- Legault, Jennifer, Shin-Yi Fang, Yu-Ju Lan, and Ping Li. 2018. Structural brain changes as a function of second language vocabulary training: Effects of learning context. Brain and Cognition. [Google Scholar] [CrossRef] [PubMed]
- Lenneberg, Eric H. 1967. The Biological Foundations of Language. New York: Wiley. [Google Scholar] [CrossRef]
- Levak, Natasha, and Jeong Bae Son. 2017. Facilitating Second Language Learners’ Listening Comprehension with Second Life and Skype. ReCALL 29: 200–218. [Google Scholar] [CrossRef]
- Li, Ping, Fan Zhang, Anya Yu, and Xiaowei Zhao. 2019. Language History Questionnaire (LHQ3): An enhanced tool for assessing multilingual experience. Bilingualism: Language and Cognition. in press. [Google Scholar]
- Linck, Jared A., Judith F. Kroll, and Gretchen Sunderman. 2009. Losing access to the native language while immersed in a second language: Evidence for the role of inhibition in second language learning. Psychological Science 20: 12, 1507–1515. [Google Scholar] [CrossRef] [PubMed]
- Linck, Jared A., Peter Osthus, Joel T. Koeth, and Michael F. Bunting. 2014. Working Memory and Second Language Comprehension and Production: A Meta-Analysis. Psychonomic Bulletin & Review 21: 861–83. [Google Scholar] [CrossRef]
- Lohse, Keith R., Courtney G.E. Hilderman, Katharine L. Cheung, Sandy Tatla, and H. F. Machiel Van Der Loos. 2014. Virtual Reality Therapy for Adults Post-Stroke: A Systematic Review and Meta-Analysis Exploring Virtual Environments and Commercial Games in Therapy. PLoS ONE 9: e93318. [Google Scholar] [CrossRef] [PubMed]
- Lövdén, Martin, Elisabeth Wenger, Johan Mårtensson, Ulman Lindenberger, and Lars Bäckman. 2013. Structural Brain Plasticity in Adult Learning and Development. Neuroscience and Biobehavioral Reviews 37: 2296–310. [Google Scholar] [CrossRef] [PubMed]
- MacWhinney, Brian. 2012. The Logic of the Unified Model. In Handbook of Second Language Acquisition. London: Routledge, pp. 211–27. [Google Scholar]
- Mahon, Bradford Z., and Alfonso Caramazza. 2008. A Critical Look at the Embodied Cognition Hypothesis and a New Proposal for Grounding Conceptual Content. Journal of Physiology Paris 102: 59–70. [Google Scholar] [CrossRef] [PubMed]
- Martin, Alex, Cheri L. Wiggs, Leslie G. Ungerleider, and James V. Haxby. 1996. Neural Correlates of Category-Specific Knowledge. Nature 379: 649. [Google Scholar] [CrossRef] [PubMed]
- McNamara, Adam, Giovanni Buccino, Mareike M. Menz, Jan Gläscher, Thomas Wolbers, Annette Baumgärtner, and Ferdinand Binkofski. 2008. Neural dynamics of learning sound—action associations. PLoS ONE 3: e3845. [Google Scholar] [CrossRef] [PubMed]
- Milgram, Paul, and Fumio Kishino. 1994. A Taxonomy of Mixed Reality Visual-Displays. Ieice Transactions on Information and Systems 77: 1321–29. [Google Scholar]
- Milton, James, and Paul Meara. 1995. How Periods Abroad Affect Vocabulary Growth in a Foreign Language. International Journal of Applied Linguistics 107–108: 17–34. [Google Scholar] [CrossRef]
- Miyake, Akira, and Naomi P Friedman. 1998. Individual Differences in Second Language Proficiency: Working Memory as Language Aptitude. Foreign Language Learning Psycholinguistic Studies on Training and Retention, 339–64. [Google Scholar]
- Ramful, Ajay, Thomas Lowrie, and Tracy Logan. 2017. Measurement of Spatial Ability: Construction and Validation of the Spatial Reasoning Instrument for Middle School Students. Journal of Psychoeducational Assessment 35: 709–27. [Google Scholar] [CrossRef]
- Richardson, Fiona M., and Cathy J. Price. 2009. Structural MRI studies of language function in the undamaged brain. Brain Structure and Function 213: 511–23. [Google Scholar] [CrossRef] [PubMed]
- Schubert, Thomas, Frank Friedmann, and Holger Regenbrecht. 1999. Embodied Presence in Virtual Environments. In Visual Representations and Interpretations. London: Springer, pp. 269–78. [Google Scholar] [CrossRef]
- Schwienhorst, Klaus. 2002. Why Virtual, Why Environments? Implementing Virtual Reality Concepts in Computer-Assisted Language Learning. Simulation and Gaming 33: 196–209. [Google Scholar] [CrossRef]
- Schneider, Walter, Amy Eschman, and Anthony Zuccolotto. 2002. E-Prime: User’s Guide. Pittsburgh: Psychology Software Incorporated. [Google Scholar]
- Si, Mei. 2015. A Virtual Space for Children to Meet and Practice Chinese. International Journal of Artificial Intelligence in Education 25: 271–90. [Google Scholar] [CrossRef]
- Snyder, Peter J., and Lauren Julius Harris. 1993. Handedness, Sex, Familial Sinistrality Effects on Spatial Tasks. Cortex 29: 115–34. [Google Scholar] [CrossRef]
- Stein, Maria, Carmen Winkler, Anelis Kaiser, and Thomas Dierks. 2014. Structural brain changes related to bilingualism: Does immersion make a difference? Frontiers in Psychology 5: 1116. [Google Scholar] [CrossRef] [PubMed]
- Wang, Yi Fei, Stephen Petrina, and Francis Feng. 2017. VILLAGE—Virtual Immersive Language Learning and Gaming Environment: Immersion and Presence. British Journal of Educational Technology 48: 431–50. [Google Scholar] [CrossRef]
- Wechsler, David. 1997. Wechsler Adult Intelligence Scale III. San Antonio: The Psychological Corporation. [Google Scholar] [CrossRef]
- Willems, Roel M., and Daniel Casasanto. 2011. Flexibility in Embodied Language Understanding. Frontiers in Psychology 2: 1–11. [Google Scholar] [CrossRef]
| 1 | If the split was based solely on the mean accuracy (which was 74.7), there would have been 36 participants in the successful learner group and 28 in the less successful learner group, which would not have been as comparable. |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Participants | L2 Training Methods | VE Immersion | VE Interaction | Main Behavioral Findings |
|---|---|---|---|---|---|
| Berns et al. (2013) | 85 Spanish speakers who had learned German for 8 months prior to VE training | L2 Training across five sessions for a total of 60–95 min. L2 testing: Vocabulary pre-test and multiple choice post-test |
|
|
|
| Chen (2016) | 9 participants aged between 21 and 55 from across Europe, Asia, and Africa learning English as a foreign language | L2 training across five weeks consisting of ten 90-min sessions. L2 testing: learning journal and interview questions on VE efficacy |
|
| VE: promoted collaboration and L2 communication skills. Effective VE features:
|
| Ibáñez et al. (2011) | 12 non-native Spanish learners and six foreign language teachers | Spanish learners and teachers were grouped in six different VEs. L2 testing: interview questions on VE efficacy. |
|
| VE: engaging L2 platform. Effective VE features: natural chatting via NPCs and chatbots led to effective communication skills. |
| Jeong et al. (2010) | 31 Native Japanese speakers learning Korean (mean age: 21.6) | One 3-h session to learn 12 items via situation-based videos and 12 items via text-based videos. L2 testing: situation-based and text-based contexts. |
|
| Situation-based items were remembered more flexibly than text-based items.
|
| Lan et al. (2015b) | 36 Native English speakers learning Chinese:
| Seven 1-h training sessions on 90 vocabulary words. L2 testing: four alternative-forced choice (4AFC) recognition of all items. |
|
| VE: more effective than PW learning.
|
| Levak and Son (2017) | 35 students (Age: 18–30)
| L2 course—supplement sessions contained eight communication-based tasks. English and Croatian participants were paired together. L2 testing: listening comprehension |
|
| Participants benefited from both Skype and VE sessions. Effective VE features:
|
| Si (2015) | 20 Native English children between the ages of 6 and 8 learning Mandarin Chinese. | One month of VE training, with two 30-min sessions per week using a desktop computer game and Kinect motion sensors |
|
| VE: increased engagement, L2 vocabulary, and speaking skills Effective VE features:
|
| Wang et al. (2017) | 80 Native Chinese speakers learning English
| Participants communicated with other characters. L2 testing: Igroup Presence Questionnaire and Immersive Tendencies Questionnaire |
|
| The participants using the combined VE + chatbox and time machine functions for L2 learning scored significantly higher in perception of immersion and presence as compared to other L2 learning contexts. |
| Learning Condition | L2 Accuracy Mean (SD) | L2 Correct RT Mean (SD) | Number of Exposures Mean (SD) |
|---|---|---|---|
| iVR Kitchen | 81.15 (11.87) | 3638.67 (671.70) | 505.69 (118.61) |
| iVR Zoo | 74.38 (19.09) | 4061.82 (720.95) | 269.31 (87.19) |
| WW Kitchen | 75.10 (20.59) | 3734.41 (644.75) | 329.03 (137.08) |
| WW Zoo | 68.23 (24.97) | 3948.93 (1323.47) | 292 (120.79) |
| Fixed Effects and Coefficients | |||||||
|---|---|---|---|---|---|---|---|
| Source | F | df1 | df2 | Model Coefficient | Standard Error | t | Sig. * |
| Corrected Model | 23.634 | 2 | 3836 | 0.000 | |||
| Intercept | 0.864 | 0.1181 | 0.550 | 0.000 | |||
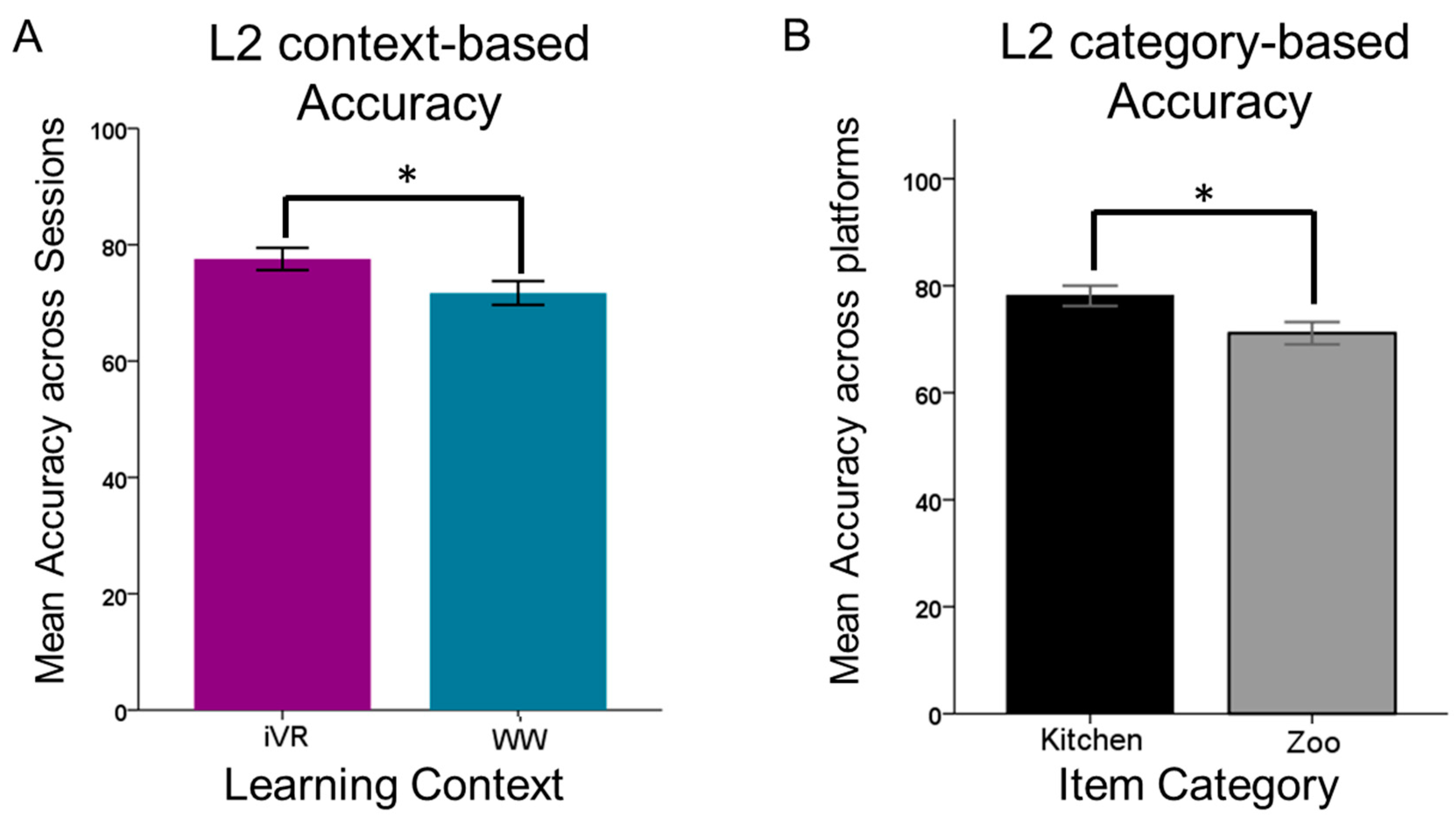
| Learning context | 19.869 | 1 | 3836 | 0.358 | 0.0951 | 4.827 | 0.000 * |
| Item category | 28.331 | 1 | 3836 | 0.428 | 0.0951 | 5.021 | 0.000 * |
| Cognitive Measure | Group 1: iVR Kitchen and WW Zoo Mean (SD) | Group 2: iVR Zoo and WW Kitchen Mean (SD) |
|---|---|---|
| n | 32 | 32 |
| Gender | 25 female 7 male | 24 female 8 male |
| Age | 18.9 (0.78) | 19.2 (0.90) |
| PPVT | 190.44 (12.47) | 192.97 (10.64) |
| ANT CE T1 | 119.65 (70.33) | 111.89 (66.50) |
| ANT CE T2 | 94.95 (47.20) | 85.14 (48.55) |
| LNS T1 | 0.52 (0.14) | 0.55 (0.15) |
| LNS T2 | 0.58 (0.13) | 0.62 (0.13) |
| SRI Total T1 | 0.68 (0.18) | 0.68 (0.12) |
| SRI Total T2 | 0.65 (0.18) | 0.68 (0.15) |
| SRI SO T1 | 0.90 (0.14) | 0.91 (0.12) |
| SRI SO T2 | 0.79 (0.19) | 0.91 (0.12) |
| Fixed Effects and Coefficients | |||||||
|---|---|---|---|---|---|---|---|
| Source | F | df1 | df2 | Model Coefficient | Standard Error | t | Sig. * |
| Corrected Model | 6.191 | 9 | 3641 | 0.000 | |||
| Intercept | −7.335 | 2.2815 | −3.215 | 0.001 | |||
| LNS 1 | 0.131 | 1 | 3641 | 0.378 | 0.363 | 0.717 | 0.717 |
| LNS 2 | 0.002 | 1 | 3641 | −0.046 | −0.042 | 0.967 | 0.967 |
| PPVT | 9.068 | 1 | 3641 | 0.039 | 3.011 | 0.003 | 0.003 * |
| SRI_S1 | 0.024 | 1 | 3641 | 0.161 | 0.155 | 0.877 | 0.877 |
| SRI_S2 | 0.334 | 1 | 3641 | 0.663 | 0.578 | 0.563 | 0.563 |
| Conflict effect 1 | 0.293 | 1 | 3641 | −0.001 | −0.542 | 0.588 | 0.588 |
| Conflict effect 2 | 0.634 | 1 | 3641 | 0.003 | 0.796 | 0.426 | 0.426 |
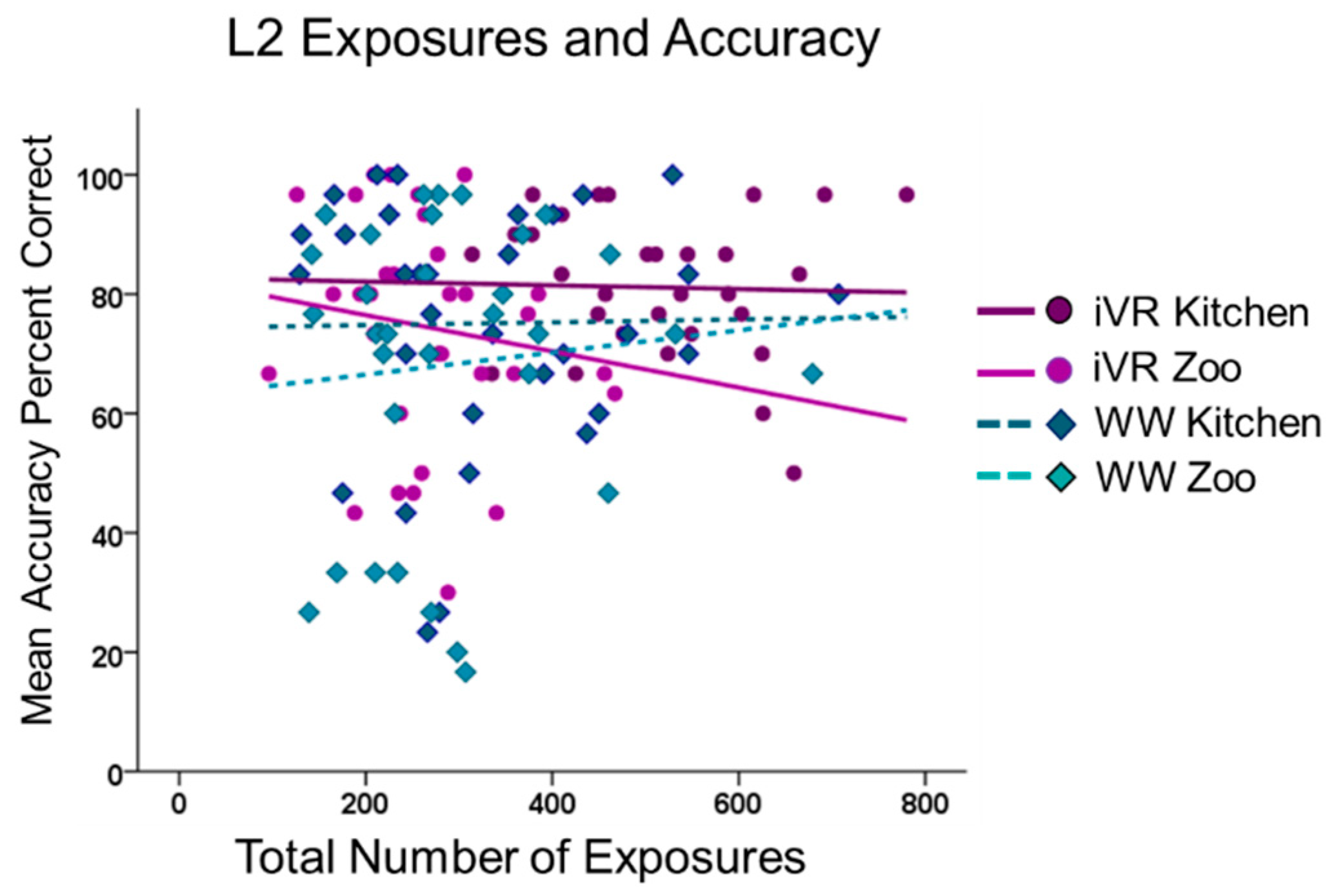
| Learning exposures | 10.655 | 1 | 3641 | 0.011 | 1.160 | 0.246 | 0.246 |
| Learning exposures x L2 context | 19.714 | 1 | 3641 | 0.030 | 4.440 | 0.000 | 0.000 * |
| Fixed Effects and Coefficients for High-Accuracy L2 Learners | |||||||
|---|---|---|---|---|---|---|---|
| Source | F | df1 | df2 | Model Coefficient | Standard Error | t | Sig. * |
| Corrected Model | 1.433 | 2 | 1797 | 1.938 | 0.1500 | 12.921 | 0.239 |
| Intercept | 1.938 | 0.1500 | 12.921 | 0.000 | |||
| Learning context | 0.183 | 1 | 1797 | 0.064 | 0.1503 | 0.428 | 0.669 |
| Item category | 2.779 | 1 | 1797 | 0.251 | 0.1506 | 1.667 | 0.096 |
| Fixed Effects and Coefficients for Low-Accuracy L2 Learners | |||||||
|---|---|---|---|---|---|---|---|
| Source | F | df1 | df2 | Model Coefficient | Standard Error | t | Sig. * |
| Corrected Model | 24.756 | 2 | 2036 | 0.000 | |||
| Intercept | 0.065 | 0.1181 | 0.550 | 0.582 | |||
| Learning context | 25.214 | 1 | 2036 | 0.459 | 0.0951 | 4.827 | 0.000 * |
| Item category | 23.304 | 1 | 2036 | 0.478 | 0.0951 | 5.021 | 0.000 * |
| Fixed Effects and Coefficients for Low-Accuracy L2 Learners | |||||||
|---|---|---|---|---|---|---|---|
| Source | F | df1 | df2 | Model Coefficient | Standard Error | t | Sig. * |
| Corrected Model | 6.191 | 9 | 3641 | 0.000 | |||
| Intercept | −4.631 | 1.7089 | −2.710 | 0.007 | |||
| LNS 1 | 0.617 | 1 | 1904 | 0.804 | 1.0234 | 0.786 | 0.432 |
| LNS 2 | 0.163 | 1 | 1904 | −0.345 | 0.8547 | −0.404 | 0.686 |
| PPVT | 5.280 | 1 | 1904 | 0.022 | 0.0095 | 2.298 | 0.022 |
| SRI_S1 | 0.029 | 1 | 1904 | 0.133 | 0.7873 | 0.169 | 0.866 |
| SRI_S2 | 0.024 | 1 | 1904 | 0.137 | 0.8779 | 0.155 | 0.876 |
| Conflict effect 1 | 0.072 | 1 | 1904 | 0.000 | 0.0018 | −0.269 | 0.788 |
| Conflict effect 2 | 0.935 | 1 | 1904 | 0.002 | 0.0023 | 0.967 | 0.334 |
| Learning_exposures | 14.551 | 1 | 1904 | 0.019 | 0.0110 | 1.714 | 0.087 |
| Learning exposures %#xD7; L2 context | 17.472 | 1 | 1904 | 0.033 | 0.0079 | 4.180 | 0.000 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Legault, J.; Zhao, J.; Chi, Y.-A.; Chen, W.; Klippel, A.; Li, P. Immersive Virtual Reality as an Effective Tool for Second Language Vocabulary Learning. Languages 2019, 4, 13. https://doi.org/10.3390/languages4010013
Legault J, Zhao J, Chi Y-A, Chen W, Klippel A, Li P. Immersive Virtual Reality as an Effective Tool for Second Language Vocabulary Learning. Languages. 2019; 4(1):13. https://doi.org/10.3390/languages4010013
Chicago/Turabian StyleLegault, Jennifer, Jiayan Zhao, Ying-An Chi, Weitao Chen, Alexander Klippel, and Ping Li. 2019. "Immersive Virtual Reality as an Effective Tool for Second Language Vocabulary Learning" Languages 4, no. 1: 13. https://doi.org/10.3390/languages4010013
APA StyleLegault, J., Zhao, J., Chi, Y. -A., Chen, W., Klippel, A., & Li, P. (2019). Immersive Virtual Reality as an Effective Tool for Second Language Vocabulary Learning. Languages, 4(1), 13. https://doi.org/10.3390/languages4010013