
Individual Differences in Singing Behavior during Childhood Predicts Language Performance during Adulthood


Abstract
:1. Introduction
1.1. Measuring Language Perception and Production Ability
1.2. Measuring Music and Singing Ability
2. Materials and Methods
2.1. Participants
2.2. Educational and Musical Status
2.3. Language Perception
2.4. Language Production
2.5. Singing Measures
2.6. AMMA Test and Tone Frequency
2.7. Singing Behavior during Childhood
3. Results
3.1. Statistical Analysis
3.2. MANOVA
3.2.1. ANOVA: Language Pronunciation
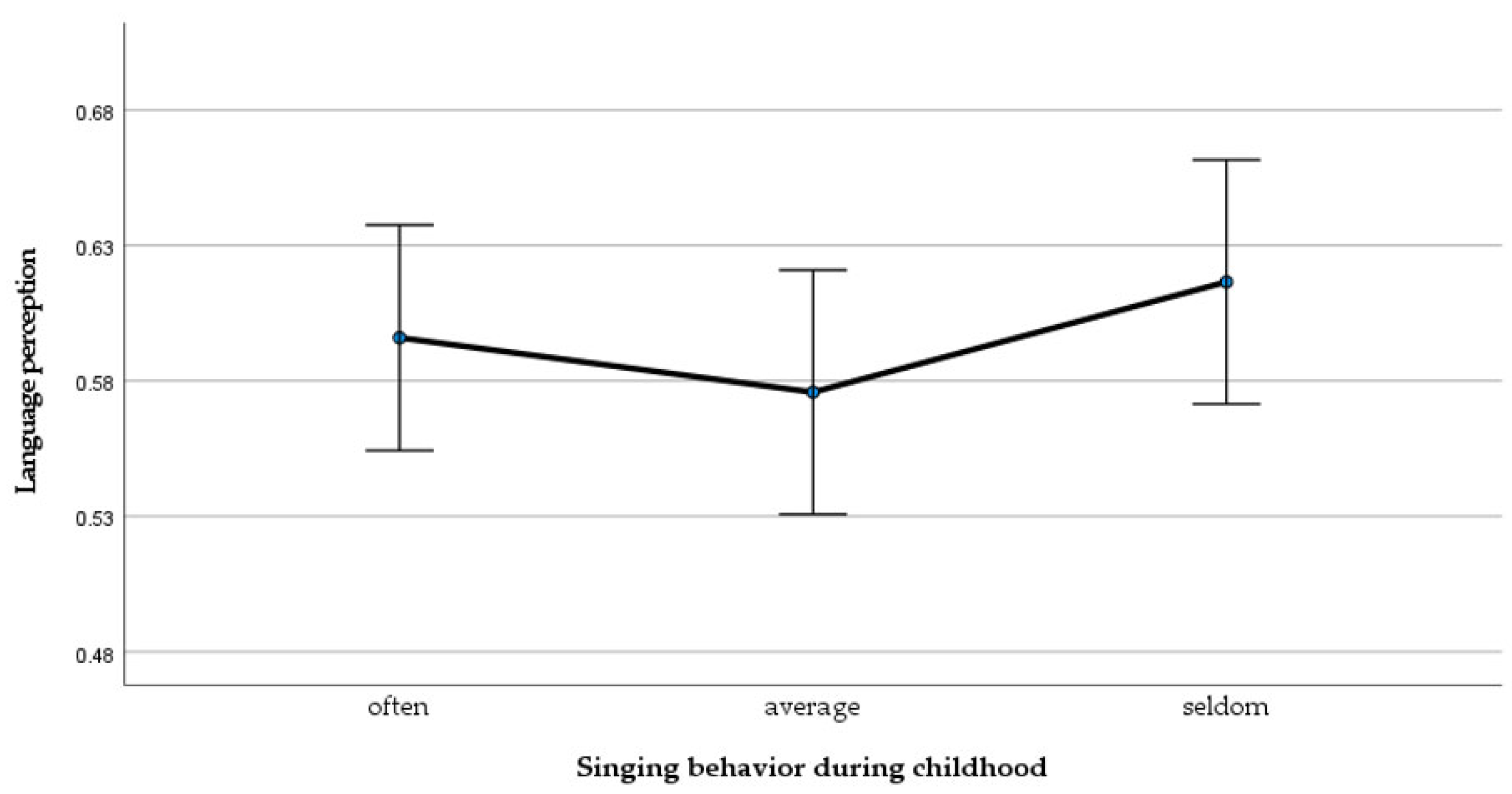
3.2.2. ANOVA: Language Perception
3.2.3. ANOVA: Singing Ability
3.2.4. ANOVA: AMMA Perception
3.2.5. ANOVA: Singing Hours per Week
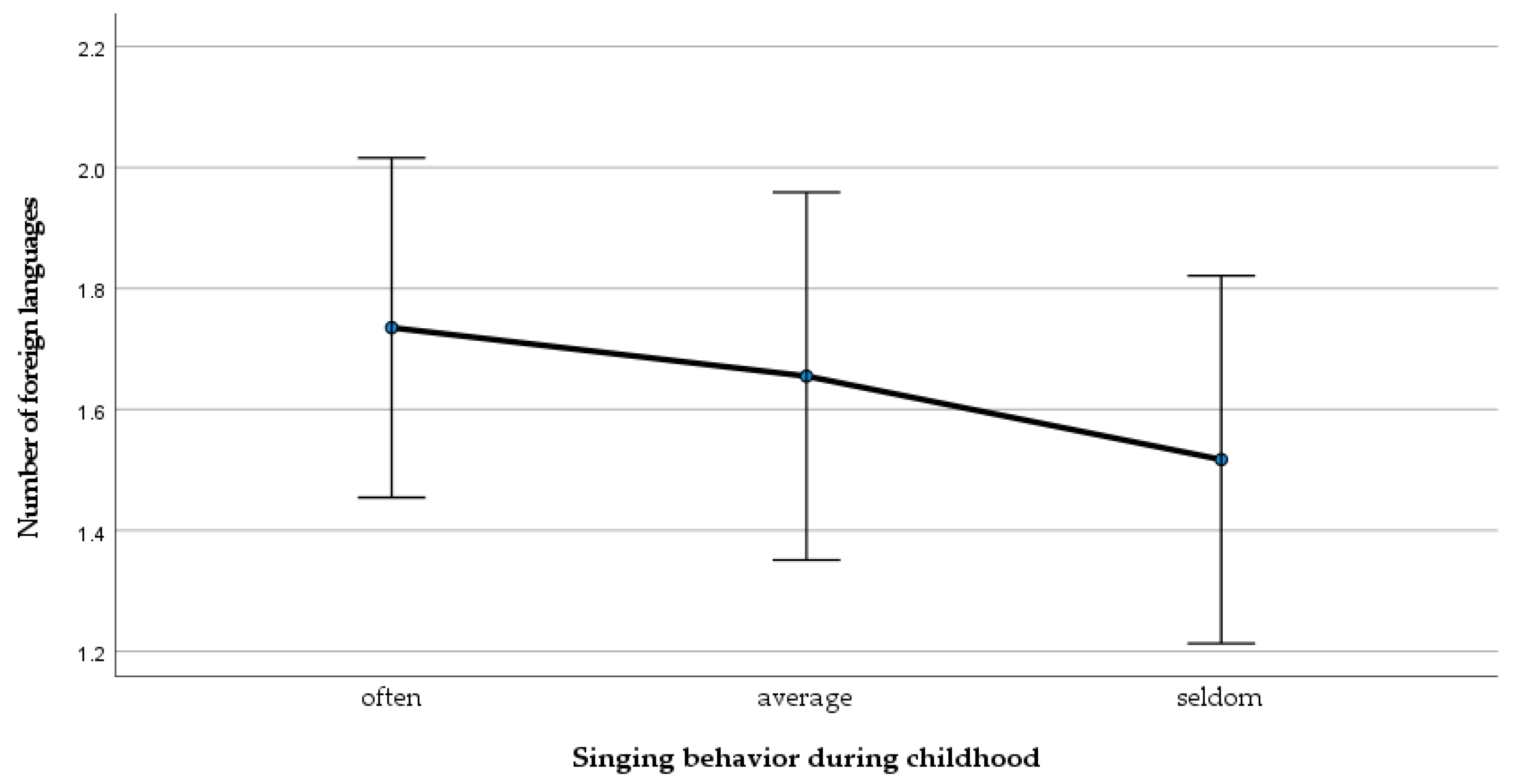
3.2.6. ANOVA: Number of Foreign Languages
3.2.7. ANOVA: Tone Frequency
3.3. Discriminant Analysis
3.4. Correlational Analysis
3.5. Regression Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Altenmüller, Eckart. 2008. Neurology of Musical Performance. Clinical Medicine 8: 410–13. [Google Scholar] [CrossRef] [PubMed]
- Anton, Ronald J. 1990. Combining Singing and Psychology. Hispania 73: 1166. [Google Scholar] [CrossRef]
- Ashtari, Manzar, Kelly L. Cervellione, Khader M. Hasan, Jinghui Wu, Carolyn McIlree, Hana Kester, Babak A. Ardekani, David Roofeh, Philip R. Szeszko, and Sanjiv Kumra. 2007. White Matter Development During Late Adolescence in Healthy Males: A Cross-Sectional Diffusion Tensor Imaging Study. NeuroImage 35: 501–10. [Google Scholar] [CrossRef]
- Bangert, Marc, Thomas Peschel, Gottfried Schlaug, Michael Rotte, Dieter Drescher, Hermann Hinrichs, Hans-Jochen Heinze, and Eckart Altenmüller. 2006. Shared Networks for Auditory and Motor Processing in Professional Pianists: Evidence from FMRI Conjunction. NeuroImage 30: 917–26. [Google Scholar] [CrossRef] [PubMed]
- Baumann, Simon, Susan Koeneke, Martin Meyer, Kai Lutz, and Lutz Jäncke. 2005. A Network for Sensory-Motor Integration: What Happens in the Auditory Cortex During Piano Playing Without Acoustic Feedback? Annals of the New York Academy of Sciences 1060: 186–88. [Google Scholar] [CrossRef]
- Berke, Gerald S., and Jennifer L. Long. 2010. Functions of the larynx and production of sounds. In Handbook of Mammalian Vocalization: An Integrative Neuroscience Approach (Handbook of Behavioral Neuroscience 19). London: Academic, vol. 19, pp. 419–26. [Google Scholar]
- Best, Catherine. 1995. A Direct Realist Perspective on Cross-Language Speech Perception. In Speech Perception and Linguistic Experience: Theoretical and Methodological Issues in Cross-Language Speech Research. Edited by Winifred Strange. Baltimore: York Press, pp. 171–204. [Google Scholar]
- Birdsong, David, and Jan Vanhove. 2016. Age of Second Language Acquisition: Critical Periods and Social Concerns. In Bilingualism Across the Lifespan: Factors Moderating Language Proficiency. Edited by Elena Nicoladis and Simona Montanari. Language and the Human Lifespan Series; Washington, DC: American Psychological Association, Berlin: Walter de Gruyter, pp. 163–81. [Google Scholar]
- Bongaerts, Theo. 1999. Ultimate Attainment in L2 Pronunciation: The Case of Very Advanced Late L2 Learners, in Second Language Acquisition and the Critical Period Hypothesis. In Second Language Acquisition and the Critical Period Hypothesis. Edited by David Birdsong. Second Language Acquisition Research. Mahwah: Erlbaum, pp. 133–59. [Google Scholar]
- Buchsbaum, Bradley R., Juliana Baldo, Kayoko Okada, Karen F. Berman, Nina Dronkers, Mark D’Esposito, and Gregory Hickok. 2011. Conduction Aphasia, Sensory-Motor Integration, and Phonological Short-Term Memory—An Aggregate Analysis of Lesion and FMRI Data. Brain and Language 119: 119–28. [Google Scholar] [CrossRef] [Green Version]
- Calì, Claudia. 2017. Creating Ties of Intimacy Through Music: The Case Study of a Family as a Community Music Experience. International Journal of Community Music 10: 305–16. [Google Scholar] [CrossRef]
- Carroll, John B. 1989. The Carroll Model: A 25-Year Retrospective and Prospective View. Educational Researcher 18: 26–31. [Google Scholar] [CrossRef]
- Chang, Soo-Eun, and David C. Zhu. 2013. Neural Network Connectivity Differences in Children Who Stutter. Brain a Journal of Neurology 136, Pt 12: 3709–26. [Google Scholar] [CrossRef] [Green Version]
- Chen, Joyce L., Virginia B. Penhune, and Robert J. Zatorre. 2008. Moving on Time: Brain Network for Auditory-Motor Synchronization Is Modulated by Rhythm Complexity and Musical Training. Journal of Cognitive Neuroscience 20: 226–39. [Google Scholar] [CrossRef]
- Christiner, Markus. 2013. Singing Performance and Language Aptitude: Behavioural Study on Singing Performance and Its Relation to the Pronunciation of a Second Language. Master’s Thesis, University of Vienna, Vienna, Austria. [Google Scholar]
- Christiner, Markus. 2018. Let the Music Speak: Examining the Relationship Between Music and Language Aptitude in Pre-School Children. In Exploring Language Aptitude: Views from Psychology, the Language Sciences, and Cognitive Neuroscience. Edited by Susanne M. Reiterer. English Language Education 16. Cham: Springer Nature, vol. 16, pp. 149–66. [Google Scholar]
- Christiner, Markus. 2020. Musicality and Second Language Acquisition: Singing and Phonetic Language Aptitude Phonetic Language Aptitude. Ph.D. thesis, Department of Linguistics, University of Vienna,, Vienna, Austria. [Google Scholar]
- Christiner, Markus, and Susanne M. Reiterer. 2013. Song and Speech: Examining the Link Between Singing Talent and Speech Imitation Ability. Frontiers in Psychology 4: 874. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christiner, Markus, and Susanne M. Reiterer. 2015. A Mozart Is Not a Pavarotti: Singers Outperform Instrumentalists on Foreign Accent Imitation. Frontiers in Human Neuroscience 9: 482. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christiner, Markus, and Susanne M. Reiterer. 2018. Early Influence of Musical Abilities and Working Memory on Speech Imitation Abilities: Study with Pre-School Children. Brain Sciences 8: 169. [Google Scholar] [CrossRef] [Green Version]
- Christiner, Markus, and Susanne Reiterer. 2019. Music, Song and Speech. Bilingual Processing and Acquisition 8. In The Internal Context of Bilingual Processing. Edited by John Truscott and Michael Sharwood Smith. Amsterdam: John Benjamins, vol. 3, pp. 131–56. [Google Scholar]
- Christiner, Markus, Stefanie Rüdegger, and Susanne M. Reiterer. 2018. Sing Chinese and Tap Tagalog? Predicting Individual Differences in Musical and Phonetic Aptitude Using Language Families Differing by Sound-Typology. International Journal of Multilingualism 15: 455–71. [Google Scholar] [CrossRef] [Green Version]
- Christiner, Markus, Christine Gross, Annemarie Seither-Preisler, and Peter Schneider. 2021. The Melody of Speech: What the Melodic Perception of Speech Reveals About Language Performance and Musical Abilities. Languages 6: 132. [Google Scholar] [CrossRef]
- Cohen, Annabel J. 2008. Advancing Interdisciplinary Research in Singing Through a Shared Digital Repository. Journal of the Acoustical Society of America 123: 3380. [Google Scholar] [CrossRef]
- Coumel, Marion, Markus Christiner, and Susanne M. Reiterer. 2019. Second Language Accent Faking Ability Depends on Musical Abilities, Not on Working Memory. Frontiers in Psychology 10: 257. [Google Scholar] [CrossRef] [PubMed]
- Crowder, Robert G., Mary Louise Serafine, and Bruno Repp. 1990. Physical Interaction and Association by Contiguity in Memory for the Words and Melodies of Songs. Memory & Cognition 18: 469–76. [Google Scholar] [CrossRef] [Green Version]
- Davies, Ann D. M., and Emlyn Roberts. 1975. Poor Pitch Singing: A Survey of Its Incidence in School Children. Psychology of Music 3: 24–36. [Google Scholar] [CrossRef]
- Deutsch, Diana, Trevor Henthorn, and Rachael Lapidis. 2011. Illusory Transformation from Speech to Song. Journal of the Acoustical Society of America 129: 2245–52. [Google Scholar] [CrossRef]
- Dörnyei, Zoltán, and Tatsuya Taguchi. 2010. Questionnaires in Second Language Research: Construction, Administration, and Processing, 2nd ed. Second Language Acquisition Research Series; New York: Routledge. [Google Scholar]
- Ekholm, Elizabeth, Georgios C. Papagiannis, and Françoise P. Chagnon. 1998. Relating Objective Measurements to Expert Evaluation Ofvoice Quality in Western Classical Singing: Critical Perceptual Parameters. Journal of Voice 12: 182–96. [Google Scholar] [CrossRef]
- Estis, Julie M., Joana K. Coblentz, and Robert E. Moore. 2009. Effects of Increasing Time Delays on Pitch-Matching Accuracy in Trained Singers and Untrained Individuals. Journal of Voice 23: 439–45. [Google Scholar] [CrossRef] [PubMed]
- Falk, Simone, Ramona Schreier, and Frank A. 2020. Russo. Singing and Stuttering. In The Routledge Companion to Interdisciplinary Studies in Singing: Volume III: Wellbeing. Edited by Rachel Heydon, Daisy Fancourt and Annabel J. Cohen. New York: Routledge, pp. 50–60. [Google Scholar]
- Franco, Fabia, Chiara Suttora, Maria Spinelli, Iryna Kozar, and Mirco Fasolo. 2021. Singing to Infants Matters: Early Singing Interactions Affect Musical Preferences and Facilitate Vocabulary Building. Journal of Child Language, 1–26. Available online: https://www.cambridge.org/core/article/singing-to-infants-matters-early-singing-interactions-affect-musical-preferences-and-facilitate-vocabulary-building/103D68368DDDCB6B80D2939C5667FD7F (accessed on 27 December 2021). [CrossRef] [PubMed]
- Fritz, Thomas, Sebastian Jentschke, Nathalie Gosselin, Daniela Sammler, Isabelle Peretz, Robert Turner, Angela D. Friederici, and Stefan Koelsch. 2009. Universal Recognition of Three Basic Emotions in Music. Current Biology 19: 573–76. [Google Scholar] [CrossRef] [Green Version]
- García-López, Isabel, and Javier Gavilán Bouzas. 2010. La voz cantada. [The Singing Voice] Acta Otorrinolaringologica Espanola 61: 441–51. [Google Scholar] [CrossRef]
- Gathercole, Susan E. 2006. Nonword Repetition and Word Learning: The Nature of the Relationship. Applied Psycholinguistics 27: 513–43. [Google Scholar] [CrossRef]
- Gathercole, Susan E., and Alan David Baddeley. 1990. The Role of Phonological Memory in Vocabulary Acquisition: A Study of Young Children Learning New Names. British Journal of Psychology 81: 439–54. [Google Scholar] [CrossRef]
- Gathercole, Susan E., Graham J. Hitch, Elisabet Service, and Amanda J. Martin. 1997. Phonological Short-Term Memory and New Word Learning in Children. Developmental Psychology 33: 966–79. [Google Scholar] [CrossRef]
- Goetze, Mary, Nancy Cooper, and Carol J. Brown. 1990. Recent Research on Singing in the General Music Classroom. Bulletin of the Council for Research in Music Education 104: 16–37. [Google Scholar]
- Golestani, Narly, and Christophe Pallier. 2007. Anatomical Correlates of Foreign Speech Sound Production. Cerebral Cortex 17: 929–34. [Google Scholar] [CrossRef]
- Gordon, Edwin. 1965. Musical Aptitude Profile Manual. Boston: Houghton Mifflin. [Google Scholar]
- Gordon, Edwin. 1979. Primary Measures of Music Audiation. Chicago: GIA. [Google Scholar]
- Gordon, Edwin. 1982. Intermediate Measures of Music Audiation. Chicago: GIA. [Google Scholar]
- Gordon, Edwin. 1989. Advanced Measures of Music Audiation. Chicago: GIA. [Google Scholar]
- Gordon, Edwin E. 2013. Music Learning Theory for Newborn and Young Children. Chicago: GIA. [Google Scholar]
- Groß, Christine, Bettina L. Serrallach, Eva Möhler, Jachin E. Pousson, Peter Schneider, Markus Christiner, and Valdis Bernhofs. 2022. Musical Performance in Adolescents with ADHD, ADD and Dyslexia—Behavioral and Neurophysiological Aspects. Brain Sciences 12: 127. [Google Scholar] [CrossRef] [PubMed]
- Gupta, Chitralekha, Haizhou Li, and Ye Wang. 2018. A Technical Framework for Automatic Perceptual Evaluation of Singing Quality. APSIPA Transactions on Signal and Information Processing 7: 1. [Google Scholar] [CrossRef] [Green Version]
- Halwani, Gus F., Psyche Loui, Theodor Rüber, and Gottfried Schlaug. 2011. Effects of Practice and Experience on the Arcuate Fasciculus: Comparing Singers, Instrumentalists, and Non-Musicians. Frontiers in Psychology 2: 156. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hernandez, Arturo E., and Ping Li. 2007. Age of Acquisition: Its Neural and Computational Mechanisms. Psychological Bulletin 133: 638–50. [Google Scholar] [CrossRef]
- Hutchins, Sean, and Sylvain Moreno. 2013. The Linked Dual Representation Model of Vocal Perception and Production. Frontiers in Psychology 4: 825. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hutchins, Sean Michael, and Isabelle Peretz. 2012. A Frog in Your Throat or in Your Ear? Searching for the Causes of Poor Singing. Journal of Experimental Psychology 141: 76–97. [Google Scholar] [CrossRef] [Green Version]
- Hutchins, Sean, Pauline Larrouy-Maestri, and Isabelle Peretz. 2014. Singing Ability Is Rooted in Vocal-Motor Control of Pitch. Attention Perception & Psychophysics 76: 2522–30. [Google Scholar] [CrossRef] [Green Version]
- Iverson, Jana M. 2010. Developing Language in a Developing Body: The Relationship Between Motor Development and Language Development. Journal of Child Language 37: 229–61. [Google Scholar] [CrossRef]
- Jepsen, Morten L., Stephan D. Ewert, and Torsten Dau. 2008. A computational model of human auditory signal processing and perception. Journal of the Acoustical Society of America 124: 422–38. [Google Scholar] [CrossRef] [Green Version]
- Kleber, Boris, Ralf Veit, Niels Birbaumer, John Gruzelier, and Martin Lotze. 2010. The Brain of Opera Singers: Experience-Dependent Changes in Functional Activation. Cerebral Cortex 20: 1144–52. [Google Scholar] [CrossRef] [Green Version]
- Koelsch, Stefan, Thomas C. Gunter, Matthias Wittfoth, and Daniela Sammler. 2005. Interaction Between Syntax Processing in Language and in Music: An ERP Study. Journal of Cognitive Neuroscience 17: 1565–77. [Google Scholar] [CrossRef]
- Larrouy-Maestri, Pauline, Yohana Lévêque, Daniele Schön, Antoine Giovanni, and Dominique Morsomme. 2013. The Evaluation of Singing Voice Accuracy: A Comparison Between Subjective and Objective Methods. Journal of Voice 27: 259.e1–259.e5. [Google Scholar] [CrossRef] [PubMed]
- Law, Lily N. C., and Marcel Zentner. 2012. Assessing Musical Abilities Objectively: Construction and Validation of the Profile of Music Perception Skills. PLoS ONE 7: e52508. [Google Scholar] [CrossRef] [Green Version]
- Liberman, Alvin M., and Ignatius G. Mattingly. 1985. The Motor Theory of Speech Perception Revised. Cognition 21: 1–36. [Google Scholar] [CrossRef]
- Ludke, Karen M., Fernanda Ferreira, and Katie Overy. 2014. Singing Can Facilitate Foreign Language Learning. Memory & Cognition 42: 41–52. [Google Scholar] [CrossRef]
- Margulis, Elizabeth H., Rhimmon Simchy-Gross, and Justin L. Black. 2015. Pronunciation Difficulty, Temporal Regularity, and the Speech-to-Song Illusion. Frontiers in Psychology 6: 48. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McClellan, Josef William. 2011. Comparative Analysis of Speech Level Singing and Traditional Vocal Training in the United States. Ph.D. Thesis, University of Memphis, Memphis, TN, USA. [Google Scholar]
- McClelland, James L., and Jeffrey L. Elman. 1986. The TRACE Model of Speech Perception. Cognitive Psychology 18: 1–86. [Google Scholar] [CrossRef]
- McMullen, Erin, and Jenny R. Saffran. 2004. Music and Language: A Developmental Comparison. Music Perception 21: 289–311. [Google Scholar] [CrossRef]
- Meara, Paul. 2005. LLAMA Language Aptitude Tests. Swansea: Lognostics. [Google Scholar]
- Mithen, Steven. 2007. The Singing Neanderthals: The Origins of Music, Language, Mind and Body. 1, Harvard University Press Paperback ed. Cambridge: Harvard University Press. [Google Scholar]
- Nasir, Sazzad M., and David J. Ostry. 2009. Auditory plasticity and speech motor learning. Proceedings of the National Academy of Sciences USA 106: 20470–75. [Google Scholar] [CrossRef] [Green Version]
- Nathani, Suneeti, David J. Ertmer, and Rachel E. Stark. 2006. Assessing Vocal Development in Infants and Toddlers. Clinical Linguistics & Phonetics 20: 351–69. [Google Scholar] [CrossRef]
- Norton, Andrea, Lauryn Zipse, Sarah Marchina, and Gottfried Schlaug. 2009. Melodic Intonation Therapy: Shared Insights on How It Is Done and Why It Might Help. Annals of the New York Academy of Sciences 1169: 431–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ocklenburg, Sebastian, and Onur Güntürkün. 2018. Structural Hemispheric Asymmetries. In The Lateralized Brain: The Neuroscience and Evolution of Hemispheric Asymmetries. Edited by Sebastian Ocklenburg and Onur Güntürkün. London: Elsevier Academic Press, pp. 239–62. [Google Scholar]
- Papagno, Costanza, and G. Vallar. 1995. Verbal Short-Term Memory and Vocabulary Learning in Polyglots. Quarterly Journal of Experimental Psychology Section A 48: 98–107. [Google Scholar] [CrossRef] [PubMed]
- Patel, Aniruddh D. 2007. Music, Language, and the Brain. Oxford: Oxford University Press, Available online: http://gbv.eblib.com/patron/FullRecord.aspx?p=415568 (accessed on 23 October 2020).
- Pfordresher, Peter Q., and James T. Mantell. 2014. Singing with Yourself: Evidence for an Inverse Modeling Account of Poor-Pitch Singing. Cognitive Psychology 70: 31–57. [Google Scholar] [CrossRef] [PubMed]
- Pimsleur, Paul. 1966. Pimsleur Language Aptitude Battery. New York: Harcourt Brace Javanovich. [Google Scholar]
- Reiterer, Susanne Maria, Xiaochen Hu, Michael Erb, Giuseppina Rota, Davide Nardo, Wolfgang Grodd, Susanne Winkler, and Hermann Ackermann. 2011. Individual Differences in Audio-Vocal Speech Imitation Aptitude in Late Bilinguals: Functional Neuro-Imaging and Brain Morphology. Frontiers in Psychology 2: 271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rutkowski, Joanne. 1996. The Effectiveness of Individual/small-Group Singing Activities on Kindergartners’ Use of Singing Voice and Developmental Music Aptitude. Journal of Research in Music Education 44: 353–68. [Google Scholar] [CrossRef]
- Salvador, Karen. 2010. How Can Elementary Teachers Measure Singing Voice Achievement? A Critical Review of Assessments, 1994–2009. Update: Applications of Research in Music Education 29: 40–47. [Google Scholar] [CrossRef]
- Sergeant, Desmond, and Graham Frederick Welch. 2008. Age-Related Changes in Long-Term Average Spectra of Children’s Voices. Journal of Voice 22: 658–70. [Google Scholar] [CrossRef]
- Skehan, Peter. 2012. Language Aptitude. In The Routledge Handbook of Second Language Acquisition. Edited by Susan Gass and Alison Mackay. Routledge Handbooks in Applied Linguistics. Milton Park, Abingdon, Oxon and New York: Routledge, pp. 381–95. [Google Scholar]
- Sloboda, John. 2005. Exploring the Musical Mind: Cognition, Emotion, Ability, Function. Oxford: Oxford University Press. [Google Scholar]
- Snow, David, and Heather L. Balog. 2002. Do Children Produce the Melody Before the Words? A Review of Developmental Intonation Research. Lingua 112: 1025–58. [Google Scholar] [CrossRef]
- Stadler Elmer, Stefanie. 2020. From Canonical Babbling to Early Singing and Its Relation to the Beginnings of Speech. In The Routledge Companion to Interdisciplinary Studies in Singing: Volume I: Development. Edited by Frank A. Russo, Beatriz Ilari and Annabel J. Cohen. Routledge Companion to Interdisciplinary Studies in Singing. New York and London: Routledge. [Google Scholar]
- Stager, Sheila V., Keith J. Jeffries, and Allen R. Braun. 2003. Common Features of Fluency-Evoking Conditions Studied in Stuttering Subjects and Controls: An H215O PET Study. Journal of Fluency Disorders 28: 319–36. [Google Scholar] [CrossRef]
- Sundberg, Johan. 1988. The Science of the Singing Voice. Dekalb: Northern Illinois University. [Google Scholar]
- Sundberg, Johan. 1999. The Perception of Singing. In The Psychology of Music, 2nd ed. Edited by Diana Deutsch. Academic Press Series in Cognition and Perception. San Diego: Academic Press, pp. 171–212. [Google Scholar]
- Thiessen, Erik D., and Jenny R. Saffran. 2009. How the Melody Facilitates the Message and Vice Versa in Infant Learning and Memory. Annals of the New York Academy of Sciences 1169: 225–33. [Google Scholar] [CrossRef]
- Tillmann, Barbara, Katrin Schulze, and Jessica M. Foxton. 2009. Congenital Amusia: A Short-Term Memory Deficit for Non-Verbal, but Not Verbal Sounds. Brain and Cognition 71: 259–64. [Google Scholar] [CrossRef] [PubMed]
- Tremblay-Champoux, Alexandra, Simone Dalla Bella, Jessica Phillips-Silver, Marie-Andrée Lebrun, and Isabelle Peretz. 2010. Singing Proficiency in Congenital Amusia: Imitation Helps. Cognitive Neuropsychology 27: 463–76. [Google Scholar] [CrossRef] [PubMed]
- Tsang, Christine D., Rayna H. Friendly, and Laurel J. Trainor. 2011. Singing Development as a Sensorimotor Interaction Problem. Psychomusicology 21: 31–44. [Google Scholar] [CrossRef]
- Turker, Sabrina, Sabine Sommer-Lolei, and Markus Christiner. 2018. Sprachtalent Und Musikgenie—Zwei Seiten Einer Münze? Zusammenspiel Musikalischer Und Sprachlicher Fähigkeiten Durch Umsetzungsnahe Ideen Im Schulischen Und Familiären Bereich. Journal für Begabtenförderung 2: 53–60. [Google Scholar]
- Wallentin, Mikkel, Andreas Højlund Nielsen, Morten Friis-Olivarius, Christian Vuust, and Peter Vuust. 2010. The Musical Ear Test, a New Reliable Test for Measuring Musical Competence. Learning and Individual Differences 20: 188–96. [Google Scholar] [CrossRef] [Green Version]
- Wapnick, Joel, and Elizabeth Ekholm. 1997. Expert Consensus in Solo Voice Performance Evaluation. Journal of Voice 11: 429–36. [Google Scholar] [CrossRef]
- Warner, Rebecca M. 2013. Applied Statistics: From Bivariate Through Multivariate Techniques, 2nd ed. Los Angeles: Sage. [Google Scholar]
- Welch, Graham F. 2006. Singing and Vocal Development. In The Child as Musician: A Handbook of Musical Development. Edited by Gary McPherson. Oxford and New York: Oxford University Press, pp. 311–30. [Google Scholar]
- Welch, Graham F. 2007. Singing as Communication. In Musical Communication. Edited by Dorothy M. Repr. Oxford: Oxford University Press, pp. 239–60. [Google Scholar]
- Welch, Graham F., Evangelos Himonides, Jo Saunders, Ioulia Papageorgi, Tiija Rinta, Costanza Preti, Claire Stewart, Jennifer Lani, and Joy Hill. 2011. Researching the First Year of the National Singing Programme Sing up in England: An Initial Impact Evaluation. Psychomusicology 21: 83–97. [Google Scholar] [CrossRef]
- Werker, Janet F., and Richard C. Tees. 2005. Speech Perception as a Window for Understanding Plasticity and Commitment in Language Systems of the Brain. Developmental Psychobiology 46: 233–51. [Google Scholar] [CrossRef]
- Zarate, Jean Mary. 2013. The Neural Control of Singing. Frontiers in Human Neuroscience 7: 237. [Google Scholar] [CrossRef] [Green Version]
- Zatorre, Robert J., Joyce L. Chen, and Virginia B. Penhune. 2007. When the Brain Plays Music: Auditory-Motor Interactions in Music Perception and Production. Nature Reviews. Neuroscience 8: 547–58. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Mean (M) | Standard Deviation (SD) | Minimum | Maximum |
|---|---|---|---|---|
| AMMA total | 54.54 | 8.36 | 35 | 72 |
| Language perception | 0.63 | 0.12 | 0.36 | 0.91 |
| Language pronunciation | 2.95 | 0.91 | 1.18 | 5.83 |
| Singing ability | 5.89 | 1.17 | 3.58 | 8.91 |
| Singing behavior during childhood | 3.26 | 1.82 | 1.13 | 5.88 |
| Number of foreign languages | 1.64 | 0.82 | 0 | 3 |
| Singing hpw | 1.41 | 2.04 | 0 | 8 |
| Tone frequency | 24.53 | 13.80 | 4.60 | 62.50 |
| Singing Hpw | Singing Ability | Singing Behavior during Childhood | AMMA Total | Language Perception | Number of Foreign Lanuages | Tone Frequency | |
|---|---|---|---|---|---|---|---|
| Language pronunciation | 0.042 | 0.513 ** | 0.497 ** | 0.280 ** | 0.133 | 0.420 ** | −0.035 |
| Singing hpw | 0.284 ** | 0.318 ** | 0.062 | 0.031 | 0.074 | 0.006 | |
| Singing ability | 0.593 ** | 0.286 ** | 0.117 | 0.127 | −0.158 | ||
| Singing behavior during childhood | 0.022 | −0.114 | 0.205 * | 0.064 | |||
| AMMA total | 0.265 * | 0.164 | −0.330 ** | ||||
| Language perception | 0.054 | −0.252 * | |||||
| Number of foreign languages | −0.232 * |
| Predictor | Partial Correlation (pr) | p-Value |
|---|---|---|
| Dependent variable: Language pronunciation | ||
| R = 0.51, F(1, 90) = 32.23, p < 0.001 | ||
| Singing ability | 0.51 | <0.001 |
| Dependent variable: Language pronunciation | ||
| R = 0.63, F(1, 89) = 18.71, p < 0.001 | ||
| Singing ability | 0.51 | <0.001 |
| Number of foreign languages | 0.41 | <0.001 |
| Dependent variable: Language pronunciation | ||
| R = 0.65, F(1, 88) = 5.13, p = 0.026 | ||
| Singing ability | 0.34 | <0.001 |
| Number of foreign languages | 0.39 | <0.001 |
| Singing behavior during childhood | 0.24 | 0.026 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Christiner, M.; Bernhofs, V.; Groß, C. Individual Differences in Singing Behavior during Childhood Predicts Language Performance during Adulthood. Languages 2022, 7, 72. https://doi.org/10.3390/languages7020072
Christiner M, Bernhofs V, Groß C. Individual Differences in Singing Behavior during Childhood Predicts Language Performance during Adulthood. Languages. 2022; 7(2):72. https://doi.org/10.3390/languages7020072
Chicago/Turabian StyleChristiner, Markus, Valdis Bernhofs, and Christine Groß. 2022. "Individual Differences in Singing Behavior during Childhood Predicts Language Performance during Adulthood" Languages 7, no. 2: 72. https://doi.org/10.3390/languages7020072
APA StyleChristiner, M., Bernhofs, V., & Groß, C. (2022). Individual Differences in Singing Behavior during Childhood Predicts Language Performance during Adulthood. Languages, 7(2), 72. https://doi.org/10.3390/languages7020072