1. Introduction
1.1. Idiom Representation and Processing in L1 Users
1.2. Direct Retrieval and Compositional Parsing in L1 Idiom Reading
One previous contribution examined multiple dimensions of idioms in one go and paved the way for the present study; thus, we detail it here.
Titone et al. (
2019) used eye-tracking during reading to assess how direct retrieval and compositional analysis interact in L1 idiom processing. Specifically, L1 speakers of English silently read English sentences containing idioms followed by a figurative context (Idiomatic–Idiomatic; e.g.,
Dolan spilled the beans when he mentioned the surprise party to his friend), idioms followed by a literal context (Idiomatic–Literal; e.g.,
Dolan spilled the beans when he tried to pour too many into the soup pot) and matched novel phrases followed by a literal disambiguating region (e.g.,
Dolan cooked the beans before he started adding vegetables to the soup pot) as their eye movements were recorded.
Focusing on reading times of the post-idiom disambiguating region, idioms followed by a literal continuation were disadvantaged compared to idioms followed by a figurative context, especially when familiarity was high and decomposability was low. This suggests that when idioms were more prone to direct retrieval and less compositionally analyzable, L1 readers were strongly committed to a figurative reading of the phrase and were thus garden-pathed when they encountered a literal continuation. However, when decomposability was higher, the processing cost of the Idiomatic–Literal condition was attenuated, as more decomposable idioms were less likely to be interpreted figuratively on the first pass. As further confirmation, at the level of idiom total reading time, higher familiarity made fully idiomatic sentences (Idiomatic–Idiomatic) faster to read than fully literal ones, in particular when decomposability was low (thus rendering the idioms more “word-like”). Overall, during later processing stages speakers appeared to engage in a word-by-word reanalysis of idioms’ internal semantics. This process was made harder by increased decomposability, which created greater ambiguity between a literal and a figurative interpretation of the phrase being processed (e.g., a highly decomposable idiom like get the message was harder to reanalyze than a low-decomposable idiom like have a lark).
To clarify which idiom component drove this
decomposability interference effect, in the same study,
Titone et al. (
2019) separately investigated the role of verb-related and noun-related decomposability (
Bortfeld 2003;
Keysar and Bly 1995;
Hamblin and Gibbs 1999;
Libben and Titone 2008).
Verb relatedness was expected to guide idiom comprehension
prospectively and can be exemplified by an idiom like
save your skin, where the verb
save independently contributes to the figurative phrasal meaning as compared to
kick in
kick the bucket. By the same token,
noun relatedness was expected to drive idioms’ semantic integration
retrospectively. This is exemplified by an idiom like
pop the question, where the noun
question shares more semantic features with the figurative meaning of the phrase than, for instance,
bucket in
kick the bucket. In
Titone et al. (
2019), L1 speakers’ comprehension was especially inhibited by increased prospective decomposability. This may have occurred because before reaching the idiom noun, participants presumably activated the literal meaning of the verb, but once they recognized the idiom at phrase offset, the contextually inappropriate literal meaning of the verb was more challenging to suppress when it was still partially related to the contextually appropriate figurative meaning of the phrase.
In sum, results from
Titone et al. (
2019) suggested that first-language speakers generally employ early-stage direct form retrieval when comprehending idioms in context, and reanalyze them compositionally later on. This leads to an interfering effect of decomposability, in that the word-by-word reanalysis of a decomposable idiom generates ambiguity between a literal and a figurative interpretation of the phrase.
Building from this study, an underexplored question that we will try to address in the present study is how idioms are read and comprehended in a second language, and which role direct retrieval and compositional parsing play in the process. Crucially, given that second-language speakers tend to be less familiar with idiom forms in their L2, they are expected to rely less on direct retrieval and to prefer a compositional strategy when encountering idioms in a sentence.
1.3. Previous Evidence on Idiom Reading in the L2
Focusing on reading data,
Underwood et al. (
2004) tracked the eye movements of L1 and L2 speakers of English while reading formulaic (including idioms) and non-formulaic sequences embedded into short paragraphs. While L1 speakers fixated on the terminal word of formulaic sequences for a shorter amount of time with respect to non-formulaic strings, the advantage registered for L2 speakers was only in terms of fixation count and not fixation duration. Eye-tracking evidence from
Siyanova-Chanturia et al. (
2011a) showed that, unlike L1 speakers, L2 speakers read idioms comparably to matched novel phrases, and that figurative meanings of idioms were harder to retrieve than literal ones. In Spanish-dominant bilinguals,
Cieślicka et al. (
2014) found that the reading of English idioms was facilitated when they were intended literally in a neutral context and intended figuratively in a figurative context. By contrast, in a self-paced reading task
Conklin and Schmitt (
2008) detected a processing advantage for idioms, used both figuratively and literally, over matched literals in both L1 English speakers and proficient L2 speakers.
Evidence from other methodologies, such as cross-modal or visual-visual priming, also suggests that L2 speakers adopt a slower literal and compositional strategy when processing idioms in comparison to L1 speakers (
Beck and Weber 2016a;
Cieślicka 2006;
Cieślicka et al. 2021; but see
van Ginkel and Dijkstra 2020). As stated above, speakers’ overall lower familiarity with idiomatic structures in their L2 prevents them from identifying idioms at first glance and retrieving them as a whole from the lexicon. Thus, they initially commit to a slower literal interpretation of the target phrase and revise it only later on when integrating its semantics with the sentential context.
1.4. Cross-Language Overlap as a Modulator of L2 Direct Retrieval
Although L2 speakers rely primarily on compositional processing when comprehending idioms, direct retrieval could potentially come into play at a later stage after speakers have identified the phrase as idiomatic. While familiarity mediates direct retrieval in the L1 (
Carrol and Littlemore 2020;
Cronk and Schweigert 1992;
Libben and Titone 2008;
Titone and Libben 2014;
Titone et al. 2019), it may not be as accurate a measure for second-language speakers, as it is likely correlated with factors such as comprehender proficiency and exposure. A more relevant determinant of bilingual idiom processing may instead be
cross-language overlap, which refers to whether an idiom possesses translational equivalents across the languages spoken by a subject. For example, a French–English bilingual speaker reading the idiom
play with fire in their L2-English might benefit from the availability of the congruent idiom
jouer avec le feu in their L1-French. Previous research has indeed shown facilitation for such “cognate” idioms that were dually represented across both languages spoken by participants in off-line comprehension and production (
Irujo 1986,
1993;
Laufer 2000;
Charteris-Black 2002), on-line production (
Liontas 2002) and on-line comprehension (
Carrol et al. 2016). For example,
Titone et al. (
2015) collected speeded meaningfulness judgments from English–French bilinguals for English idioms presented with their final noun intact (e.g.,
spill the beans) or switched to French (e.g.,
spill the fèves). Overlapping idioms were less disrupted by the presence of a phrase-final language switch, which generally penalized idioms over literals. Moreover,
Pritchett et al. (
2016) showed L2 idioms with an L1 counterpart to be more efficiently recalled from memory. These results dovetail nicely with cognate facilitation effects that have been replicated time and again at the single-word level in bilingual readers (e.g.,
Gullifer et al. 2013;
Libben and Titone 2009;
Pivneva et al. 2014;
Titone et al. 2011;
Van Hell and Dijkstra 2002), a point to which we later return in the General Discussion.
1.5. The Current Study
The goal of the current eye-tracking reading study was to extend the findings of
Titone et al. (
2019) to idiom reading in the L2. More specifically, the research questions pursued here concerned how L2 readers process idiomatic expressions during natural sentences reading, and to what extent the predictions of a hybrid model (
Libben and Titone 2008;
Titone and Libben 2014) apply to L2 idiom comprehension.
Following the methods of
Titone et al. (
2019), and using similar materials, French–English bilingual adults identifying French as their L1 silently read English sentences containing idioms used figuratively, idioms used literally and matched literal control phrases, while their eye movements were recorded. All idioms had a verb–determiner–noun structure (e.g.,
spill the beans). Literal controls were composed of the same idiom noun and a matched novel verb (e.g.,
cook the beans). Idiomatic and literal phrases were placed in sentence-initial position and followed by a disambiguating context.
According to a hybrid model (
Libben and Titone 2008;
Titone and Libben 2014), speakers use both direct retrieval and compositional analysis when making sense of idioms in context. Given that L2 readers benefit from early direct retrieval to a lesser extent, we predict they will engage in a preferential compositional mode when processing idioms. Given this, prospective and retrospective effects of decomposability may also play a differential role over time, with prospective verb relatedness guiding early-stage idiom identification and retrospective noun relatedness facilitating late-stage idiom integration. Given that direct retrieval should take place only after readers have correctly identified the phrase being read as idiomatic, we also hypothesized direct retrieval to play a secondary role in the form of a late facilitating effect of cross-language overlap.
To the best of our knowledge, the interaction of semantic transparency and cross-language overlap in L2 idiom comprehension has so far only been addressed in an eye-tracking study by
Cieślicka and Heredia (
2017; for a related study on collocations, see
Yamashita 2018). There, English- and Spanish-dominant bilinguals read idiomatic sentences in English. Overlapping opaque idioms were processed more easily by Spanish-dominant bilinguals when used in their literal sense, while overlapping transparent idioms were read significantly slower when used literally. In contrast with their study, disambiguating contexts will be here placed only
after the idiomatic region, so that we can separately investigate how idiom phrases are processed on the first pass without any contextual support, and how they are re-analyzed after the biasing region has been read.
4. Discussion
The two eye-tracking experiments presented here investigated how L2 users read and processed idioms in a natural sentential context. In particular, we assessed to what extent the predictions of a hybrid model (
Libben and Titone 2008;
Titone and Libben 2014) extend to idiom processing in the L2, by analyzing the interplay of direct retrieval and compositional parsing during comprehension.
Experiment 1 drew upon the materials and methods of
Titone et al. (
2019) to test a sample of French–English bilingual adults, dominant in French, while they read English sentences containing idioms intended figuratively, idioms intended literally, and matched literal phrases followed by a disambiguating context. When testing L1 readers on the same materials,
Titone et al. (
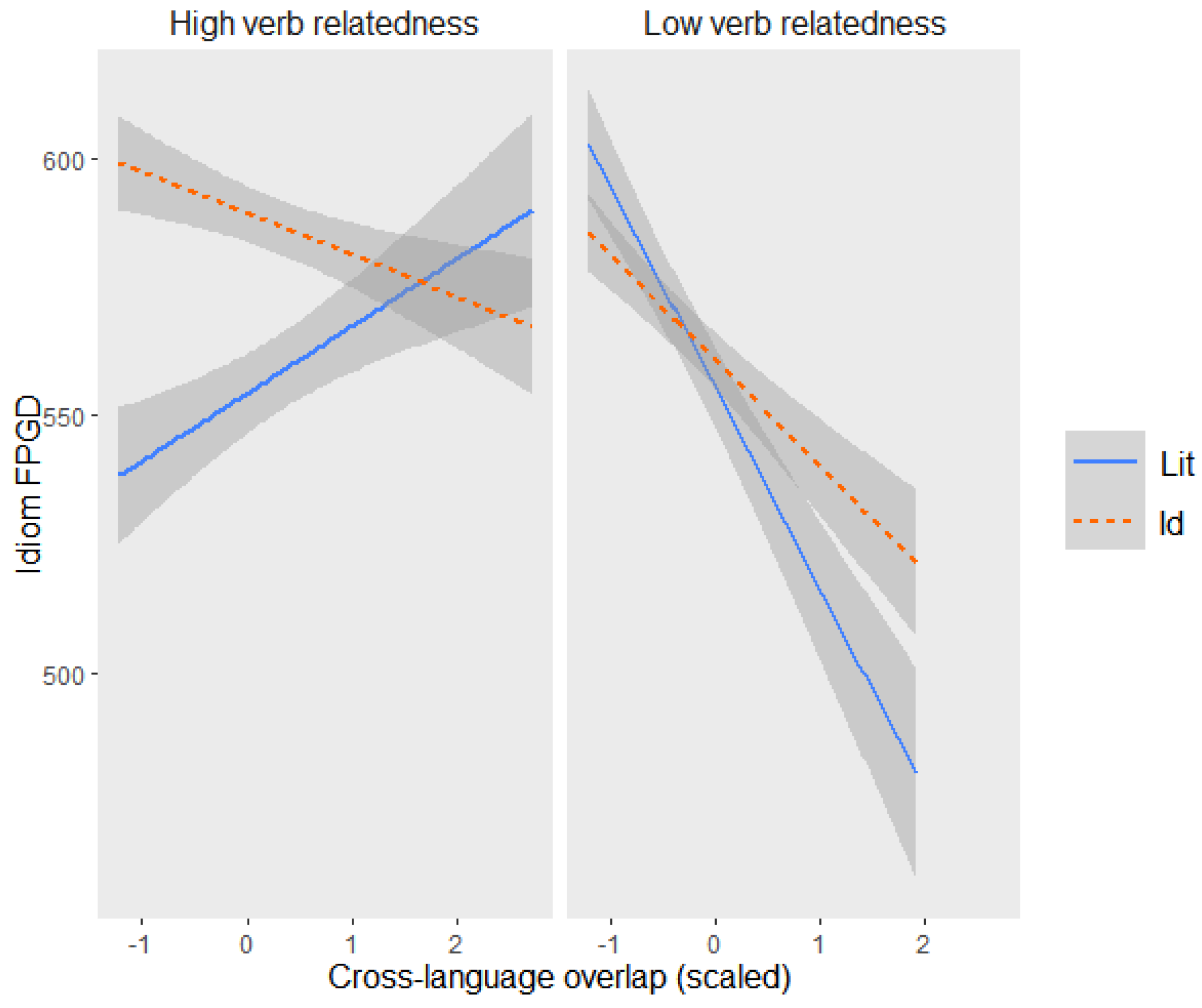
2019) detected a processing advantage for idioms over literal control sentences in early stages of comprehension, suggesting that L1 speakers readily identified idioms as familiar sequences and retrieved them directly from memory. In later comprehension stages, idioms appeared to be reanalyzed compositionally, with increased verb-related decomposability making idioms’ semantic integration more laborious. In this study, L2 readers did not process idioms differently from literal control sentences at an early stage, except when prospective verb relatedness was higher, and a congruent idiom “cognate” could not be retrieved from French or, vice versa, when verb relatedness was lower, and readers could rely on an equivalent French idiom. In the former case, high verb relatedness made interpretation of the phrase ambiguous between a figurative or a literal reading, and the idiomatic condition was read more slowly. In the latter case, when L2 users could not resort to verb-mediated decomposability to access the figurative meaning and identify the phrase as idiomatic, increased overlap with a congruent French idiom brought about a slight disadvantage of the idiomatic condition, signaling higher figurative priming. However, after readers encountered the disambiguating context, idiomatic sentences were facilitated in comparison to literal sentences by increased retrospective noun-related decomposability and by the availability of a translationally equivalent idiom in French.
These results suggest that L2 idiom comprehension is primarily compositional, with different idiom components individually contributing to their semantics over different time courses. As suggested by extant evidence on L1 idiom processing (
Cacciari and Tabossi 1988;
Carrol 2021;
Libben and Titone 2008;
Siyanova-Chanturia et al. 2011a;
Titone et al. 2019), L1 users’ greater exposure to idiomatic structures likely leads to the formation of automatized whole-phrase representations in memory that can be directly accessed during processing. In this regard, L2 speakers have comparably less experience with L2 idioms to form entrenched phrase-level representations that allow them to identify idioms at first glance in context. Consequently, when encountering an idiom in their L2, readers adopt (or continue) by default a literal and compositional strategy. Thus, at this point, every piece of semantic information that can cumulatively lead to the phrasal figurative meaning will be leveraged to successfully comprehend the idiom. Before the disambiguating region is reached, increased verb-mediated decomposability gives readers a clue that the intended phrasal meaning might be different from the preferred literal one, therefore slowing down the idiomatic condition. After the disambiguating region is read, idiom processing can be facilitated retrospectively if the meaning of the noun is closely related to the idiom’s phrasal meaning.
A facilitatory role of semantic decomposability ties in with previous work demonstrating that L2 users are more sensitive to the internal semantics of idioms, probably due to their analytical bias. In off-line rating tasks, L2 learners were found to judge idioms as more decomposable and transparent than L1 speakers (
Abel 2003;
Hubers et al. 2020), while
Steinel et al. (
2007) observed that both imageability and transparency facilitated L2 idioms in a paired-associate learning task. Similarly,
Skoufaki (
2008) found that advanced English learners defined the meanings of unknown idioms more consistently when they were highly transparent. By contrast, other studies found intuitions on decomposability and transparency to be dependent on L2 learners’ familiarity with the same meanings, rather than on specific properties of idioms’ constituents (
Keysar and Bly 1995;
Malt and Eiter 2004). Finally, neither
van Ginkel and Dijkstra’s (
2020) priming data nor
Beck and Weber’s (
2021) novel-phrase recall data revealed any transparency effects.
Given a default compositional approach of L2 readers when making sense of idioms in context, direct retrieval exerted only a secondary role in early comprehension when compositional parsing was impeded, and took on a more general facilitating effect in later stages, after the disambiguating context made the idiomatic interpretation of the phrase explicit. More specifically, readers were facilitated in integrating idioms’ semantics at the sentence level by the possibility to retrieve a corresponding idiom form from their L1 (e.g.,
briser la glace for
break the ice). This “cognate” effect for idioms coheres with past research showing facilitating effects of cross-language overlap on the processing of L2 idioms (
Carrol et al. 2016;
Charteris-Black 2002;
Irujo 1986,
1993;
Laufer 2000;
Liontas 2002;
Pritchett et al. 2016;
Titone et al. 2015) and single-word cognates (
Gullifer et al. 2013;
Libben and Titone 2009;
Pivneva et al. 2014;
Titone et al. 2011;
Van Hell and Dijkstra 2002). Nonetheless, as noted by
Titone et al. (
2015), the concept of cross-language overlap (i.e., “cognate” status) involves an abstract and structural mapping that goes beyond orthography or phonology when it comes to idioms. In this regard,
Beck and Weber (
2016a) teased apart
lexical level idioms, which have word-for-word translational counterparts, and
post-lexical level idioms, which point to the same idiomatic concepts but do not share the same lexemes across languages, finding no processing difference between the two.
Interestingly, while some scholars have interpreted this general advantage of congruent “cognate” idioms as an indication that the bilingual lexicon might be integrated also beyond the single-word level (
Zeng et al. 2020), a few studies have found that even L1-unique idioms enjoy some form of processing advantage when encountered as word-for-word translations in the comprehender’s L2 (
Carrol and Conklin 2014,
2017;
Carrol et al. 2016;
Carrol et al. 2018). Woven together, the evidence accumulated thus far suggests that comprehenders can generally leverage their L1 knowledge when required to identify multiword representations in the L2 (see also
Conklin and Carrol 2018).
In Experiment 2, a language-switching manipulation was added to the same conditions of the previous experiment. Idioms and literals thus appeared either in their canonical form or with their nouns translated into French (e.g.,
spill the fèves,
cook the fèves). Participants were once again French–English bilingual adults identifying French as their L1. The purpose of this follow-up experiment was to confirm the secondary role of direct retrieval in L2 idiom reading by testing a formal manipulation that intentionally undermined it. Previous research similarly addressed the impact of canonical form disruption on idiom processing, focusing mostly on L1 speakers (
Geeraert et al. 2018;
Gibbs et al. 1989;
Haeuser et al. 2021;
Kyriacou et al. 2020,
2021;
McGlone et al. 1994;
Smolka and Eulitz 2020). In this study, inserting a momentary language shift on idiom-final nouns would push readers into a compositional parsing mode, therefore hindering direct retrieval. Therefore, a specific disadvantage incurred by switched idioms over switched literals would confirm that a failed attempt at direct retrieval had taken place in the idiom condition. Vice versa, if idioms and literals were equally impacted by language switching, this would suggest that a compositional strategy had been adopted in both conditions.
When
Senaldi et al. (
n.d.) tested the same manipulation on L1 readers, language switching inhibited idioms more than literals in early processing stages. Parallel findings were obtained by
Titone et al. (
2015) with speeded meaningfulness judgments. While a general switching cost is consistent with previous experimental literature (
Altarriba et al. 1996;
Bultena et al. 2015;
Gullifer and Titone 2019;
Guzzardo Tamargo et al. 2016;
Litcofsky and Van Hell 2017), this specific idiom disadvantage confirmed a disruption in direct retrieval during early stage L1 idiom recognition. In the present study, L2 idioms and literals were not differentially impacted by the presence of a language switch in early measures; however, switched idioms in a figurative context (Idiomatic–Idiomatic) incurred greater processing costs with respect to idioms with a literal continuation (Idiomatic–Literal) in total reading time. Hence, evidence from Experiment 2 confirms that direct form retrieval characterizes only late-stage L2 idiom processing, after comprehenders read the entire idiom phrase and entered the disambiguating region.
Of note, in the idiom literature, another variable that is frequently examined as a modulator of direct retrieval is familiarity (
Cronk and Schweigert 1992;
Libben and Titone 2008;
Titone and Libben 2014). In the present work, familiarity ratings had been collected from participants to confirm that they were familiar overall with the items used in the study. Average familiarity scores for Experiment 1 (1.99 out of 3) and Experiment (4.29 out of 7) suggest that this was the case. However, as noted in
Section 1.3, we believe that familiarity might be less reliable a predictor when it comes to L2 processing, in that it might be influenced by a host of related factors like subjects’ exposure to the L2 and overall proficiency. For this reason, we have rather focused on the role of cross-language overlap, which could be conceived of as L2 readers’ familiarity with equivalent idiom forms in their L1. As a confirmation of this, cross-language overlap and familiarity appeared to be overall correlated both in Experiment 1 (ρ = 0.79) and Experiment 2 (ρ = 0.65). To ensure that this did not impact our interpretation of the results, we re-ran all the models in Experiments 1 and 2, adding scaled average self-reported familiarity as a control variable. Likelihood ratio tests indicated that adding familiarity as a control variable did not significantly change models’ fit for Experiment 1. For Experiment 2, inserting familiarity in the models significantly changed fit except in models predicting idiom first pass gaze duration with noun relatedness. Most importantly, in all the models, for both experiments, predictors’ significance did not change after controlling for this measure.
Also of note, one of the control variables included in both experiments was literal plausibility (or ambiguity), in order to check if the possibility to interpret a given idiom literally (e.g., scratch your head vs. give your word) could represent a potential confound. Overall, we selected idioms with a high degree of literal plausibility to make the Idiomatic–Literal condition possible and natural for all items. Therefore, since our chosen idioms do not cover the full spectrum of literal plausibility, exploring its interaction with the other main experimental variables (condition, cross-language overlap and verb/noun relatedness) would not be an ideal indicator of the impact of this variable.
Another related variable to examine in future research on L2 idiom reading is meaning dominance, which builds on the notion of literal plausibility to measure how often an ambiguous idiom string is employed in the figurative versus literal sense in language use (
Milburn and Warren 2019). While meaning dominance can give a more nuanced picture of the effects of idioms’ semantic ambiguity on L2 reading, there might be a chance that it is less informative a predictor than with L1 speakers. While a second-language speaker could easily label an idiom like
scratch your head as potentially literal, knowing in which proportion it occurs in each of its two senses would require extensive exposure to its use in the L2, which might not be the case for all L2 learners. Moreover, making a meaning dominance judgment could be challenging in the case of highly decomposable idioms, where the literal and the figurative meaning can be quite similar and hard to disentangle.
Taken together, the heavier reliance of L2 users on compositional parsing that emerged in both experiments is also consistent with usage-based and constructionist views (
Bybee 2006;
Goldberg 2006;
Tomasello 2003;
Wulff 2008), which conceive of the lexicon as a network of linguistic structures of varying complexity, from single words to idioms and abstract syntactic patterns. Since this framework predicts language experience to be a major determinant of constructions’ entrenchment in the mind, ambient exposure of L2 users to idiomatic and multiword language would not suffice to form entrenched and automatized representations that can be retrieved directly in processing. On a related note, the L2 acquisition framework put forth by
Wray (
2000,
2002) postulates a dynamic balance between holistic memory-based and analytic composition-based processes, depending on how late the second language is acquired. In accordance with this model, late bilinguals lean towards the analytical end of the spectrum, which could explain the literal/compositional bias exhibited during idiom processing.
The emphasis of the present work was specifically on the cognitive underpinnings of bilingual idiom reading; however, converging findings of a slower literal and compositional processing of L2 idioms also come from other experimental paradigms.
Van Lancker Sidtis (
2003) found that L2 speakers performed worse at distinguishing idiomatic and literal meanings of aurally presented sentences; however, in a cross-modal priming by
Cieślicka (
2006), L2 speakers exhibited increased priming for literal rather than idiomatic targets. Building on the
graded salience hypothesis (
Giora 1997,
1999,
2003), which predicted a processing advantage for the phrasal meaning (literal or figurative) that is more salient (i.e., frequent, familiar and/or conventional) in the speakers’ lexicon,
Cieślicka (
2006,
2010) put forth a
literal salience resonant model for L2 idiom processing. Accordingly, literal meanings of L2 idioms enjoy a more salient status, even after L2 idioms are incorporated into the learners’ lexicon, since learners are likely to use and come across literal meanings more often. A hybrid, multidetermined model would say that this more salient status arises mechanistically from the fact that holistic idiomatic representations are less entrenched in the minds of L2 speakers (e.g.,
Titone et al. 2015). Other cross-modal and visual priming studies found facilitation for both literally and figuratively related targets over unrelated targets in both L1 and L2 speakers (
Beck and Weber 2016a;
van Ginkel and Dijkstra 2020), although L2 speakers in
Beck and Weber (
2016a) exhibited a figurative disadvantage compared to literal phrases. Figurative attunement, i.e., incremental facilitation for figurative targets, seems nonetheless achievable in L2 speakers by increasing the proportion of idiomatic sentences in the experimental list (
Beck and Weber 2016b). Increased late-stage attunement to L2 idioms’ figurative reading was also observed by
Cieślicka et al. (
2021) when L2 speakers processed an anaphoric referent placed downstream from an idiomatic phrase, which is supposed to suppress a contextually inappropriate literal reading (e.g.,
I always miss the boat when it comes to jokes, and that makes it nearly impossible for me to attend comedy shows).
5. Conclusions
In Experiment 1, we showed that idiom comprehension in an L2 is mostly driven by compositional processes, with prospective verb-related decomposability and retrospective noun-related decomposability jointly guiding readers towards a bottom-up access to the figurative meaning. Unlike L1 idiom processing, direct retrieval plays a later role in comprehension, and it is mediated by the availability of a translationally congruent “cognate” idiom in the comprehenders’ L1. Additional support for these findings emerged in Experiment 2 using language-switched idioms. Here, idioms whose direct retrieval was disrupted by a language shift appeared to be penalized only in later processing stages, while in earlier stages they were processed akin to switched literal phrases.
Of note, the present study examined L2 readers as one monolithic group because of the complexity already present in the design. Therefore, further research is necessary to shed light on how individual differences in L2 proficiency affect readers’ propensity for a holistic versus incremental comprehension route. While more proficient L2 readers are expected to behave more similarly to L1 readers, preliminary findings from
Milburn et al. (
2021) suggest that, after overcoming an initial literal bias, even more advanced L2 learners might go through a temporary phase where they overapply a figurative direct-retrieval strategy also to literal contexts. This intriguing result deserves additional empirical follow-up work. The differential impact of individual bilingual experiences on idiom processing emerged also in previous work by
López and Vaid (
2018). Here, bilingual speakers with more extensive brokering (i.e., informal translation) experience were facilitated in making semantic relatedness judgments on idioms across language boundaries. These findings could have interesting implications for the role of cross-language overlap in bilingual speakers with different individual experiences.
Finally, idioms in this study were placed in sentence-initial position with no prior semantic context; however, putting them after a disambiguating context might facilitate L2 readers in interpreting them figuratively right from the start. Whether this would translate to enhanced decomposability effects, more direct access to idiom forms, or both, is fodder for future investigations.
Taken together, this study, in combination with prior work using similar materials and procedures for L1 readers, suggests that the cognitive mechanisms of idiom processing involve different concentrations of idiom form retrieval and compositional processes over time, calibrated by readers’ current state of L1 and L2 knowledge, and how idiom representations overlap across an L1 and L2. Indeed, this mechanistic account is the central core of a hybrid multidetermined model (
Libben and Titone 2008;
Titone and Libben 2014;
Titone et al. 2019). Notably, an advantage of this mechanistic account is that it is not restricted to the comprehension of literary idioms of the type studied here, but is also more general, and can be applied to other forms of figurative and non-figurative language (e.g., metaphor as in
Columbus et al. 2015; and also multiword expressions that are not typically thought of as “idioms” but function cognitively within the same processing space as detailed by
Wray 2002,
2013), and may underlie dominant assumptions about how language generally is understood. In this way, a hybrid, multidetermined account, supported empirically here and in past work, may be seen as an extension of general language processing operations. Similarly, the comprehension of idiomatic or other multiword expressions may be seen as a natural and fundamental, core part of “language” proper, as cogently advanced by usage-based models of language (
Bybee 2006;
Goldberg 2006;
Tomasello 2003;
Wulff 2008).




{kind=link}
{kind=link}
{kind=link}


