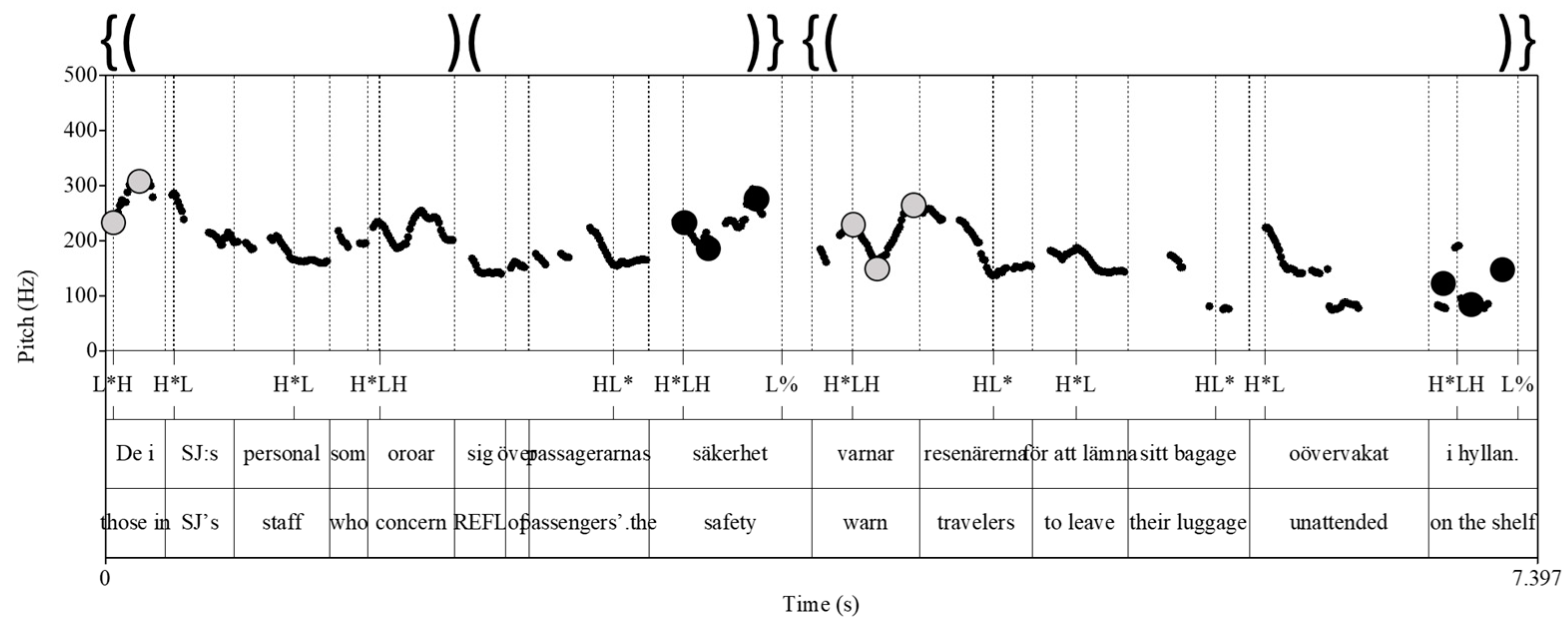
4.3. An Alternative Account to the Asymmetry Problem in Japanese
In what follows, we attempt to suggest an alternative account, although it is still of a preliminary nature and providing a full-fledged account of the Japanese example lies beyond the scope of the current article. The key point of the analysis is the similarity between the Asymmetry Problem in Stockholm Swedish and that in Japanese: both in Swedish and in Japanese, the prosodic edge that is associated with a prosodic head requires a stronger correlation with syntax than the other edge.
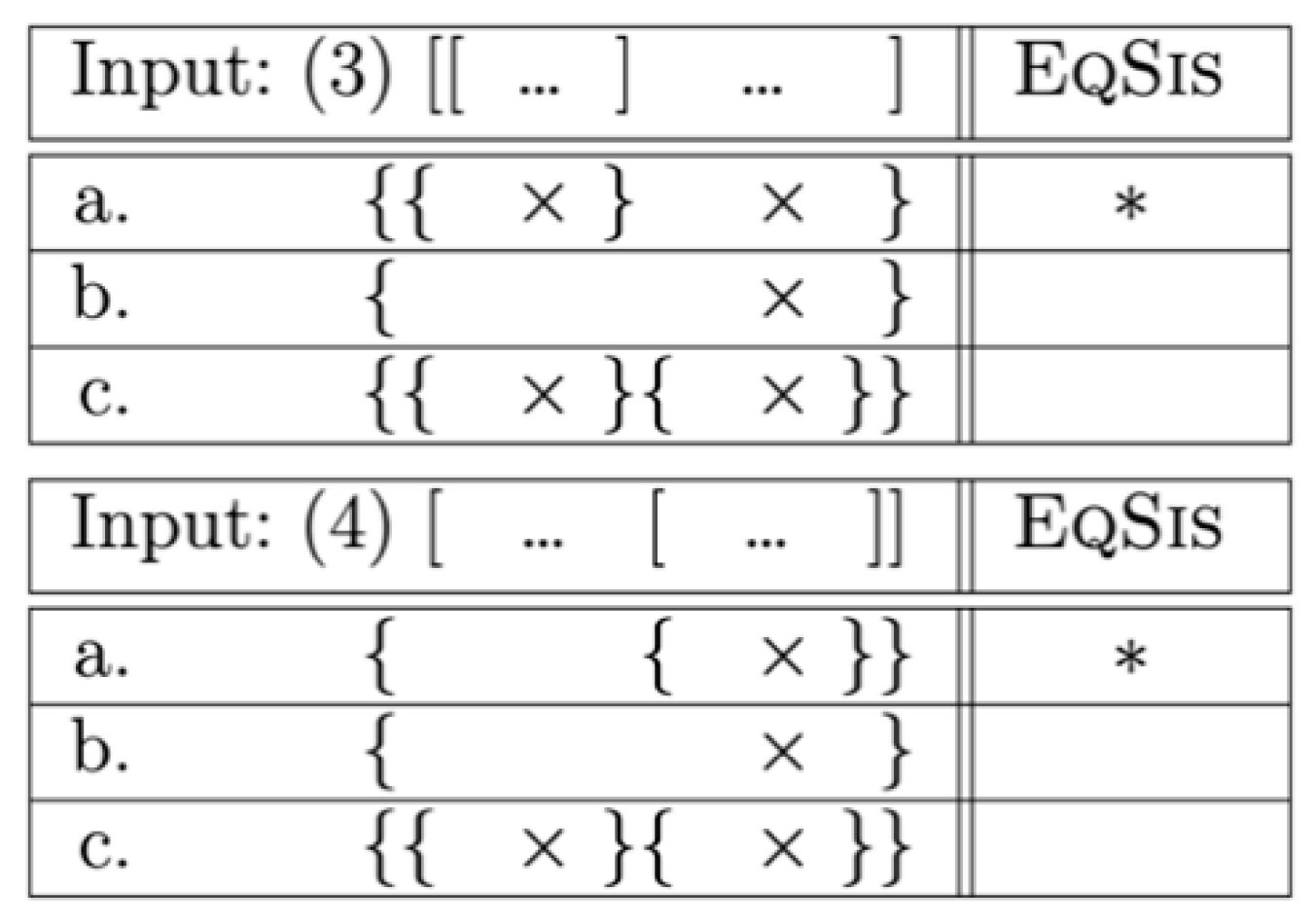
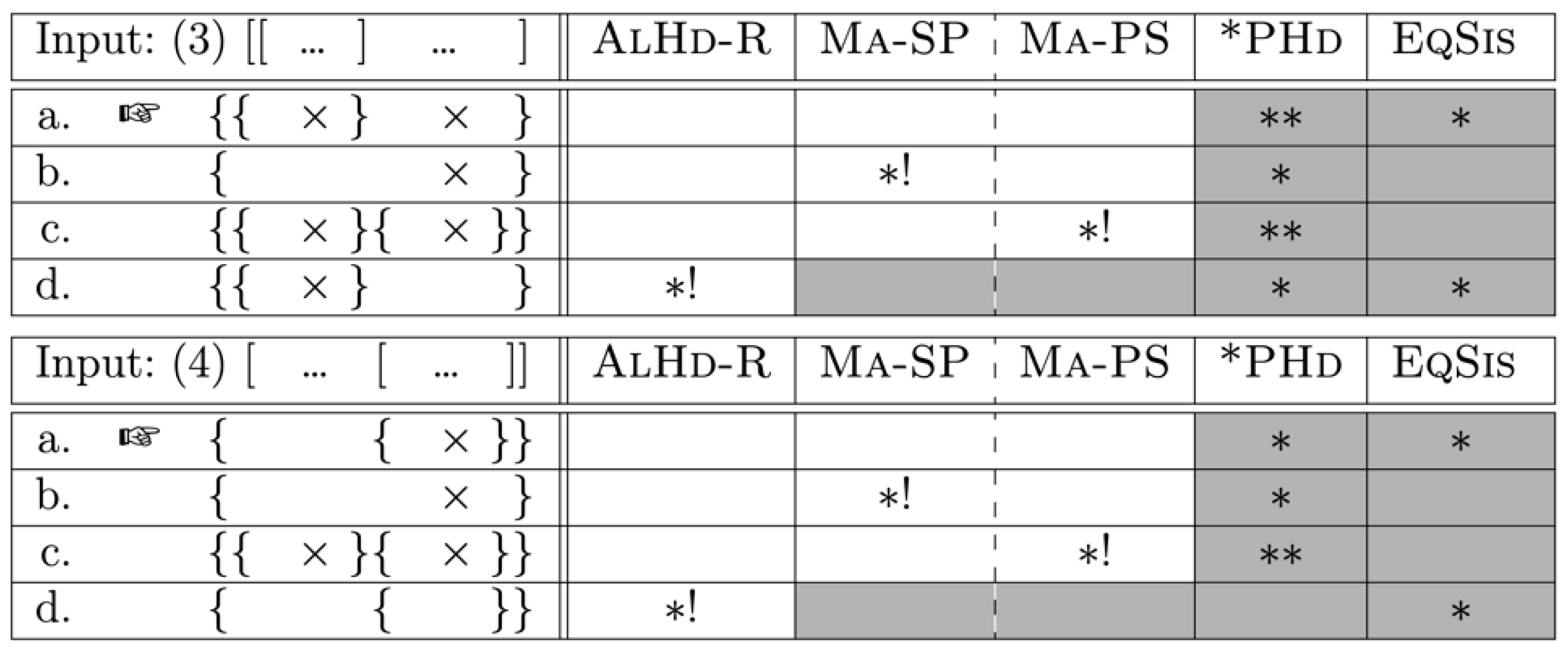
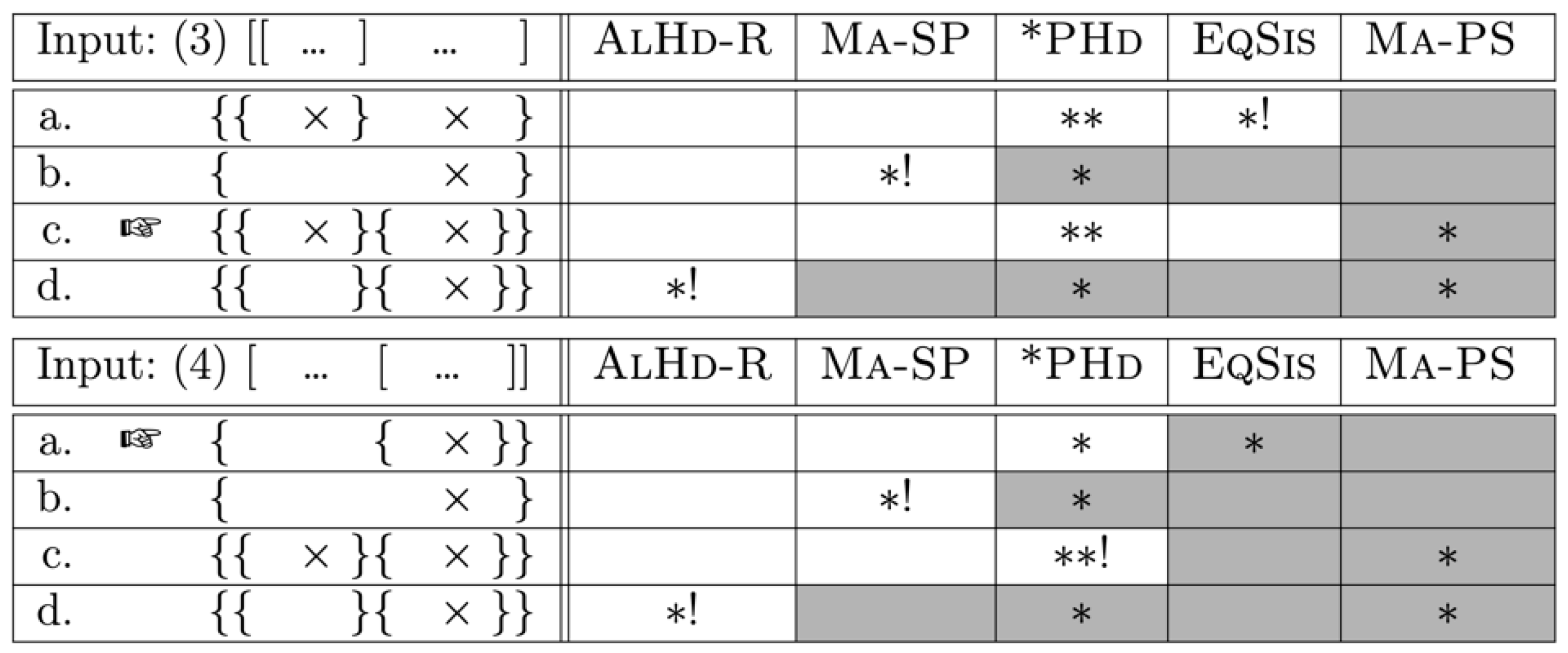
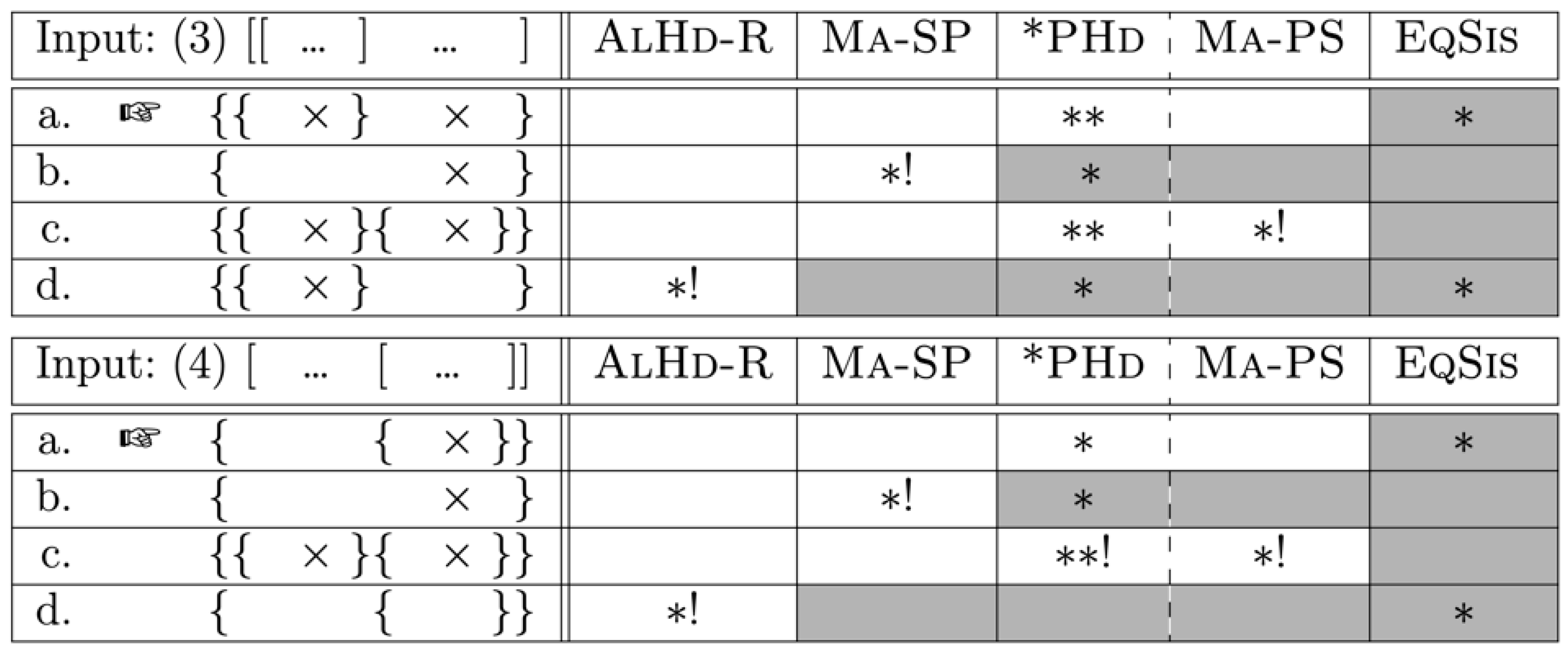
The Asymmetry Problem in Stockholm Swedish discussed in this article shows that right edges of ιs (i.e., the edges associated with ι-heads) have a stronger correlation with syntax than left edges. This stronger correlation is visible by the fact that it is easier to insert a prosodic left edge that has no corresponding edge in syntax (3c) than to insert a prosodic right edge without a corresponding syntactic edge (4c).
In the case of Japanese, it is left edges of φ that are expected to have a stronger correlation with syntax, as the φ in Japanese is prosodically left-headed. In fact, the data in (18)/(19) seem to suggest that this is the case, although the stronger correlation is realized in a different manner from the Swedish data. In the Japanese example, it appears that failing to reflect a syntactic left edge in prosody is a more serious violation than failing to reflect a right edge in prosody. What is happening in the left-branching structure in (18a), where the rephrasing takes place, can be described as ignoring the XP right edge between C and D, i.e., not mapping that XP right edge as a φ right edge. Note that the corresponding rephrasing option is not available in the right-branching structure in (18b), i.e., the left edge between A and B cannot be ignored. Put differently, a syntactic left edge must be realized as a φ left edge, while a syntactic right edge may or may not be realized as a φ right edge in Japanese.
This is precisely what Align-XP in Bellik et al.’s analysis (namely AlignLeft(XP, φ)) empirically captures. However, this syntax–prosody mapping constraint might arguably be concealing the real source of the asymmetry, namely the directionality of prosodic headedness. If our account of the Asymmetry Problem in Swedish is on the right track, and if it can be extended to the Asymmetry Problem in Japanese as well, the reason why Japanese XP left edges exhibit a stronger correlation to φ left edges might be related to the fact that the φ in Japanese is prosodically left-headed. As prosodic headedness is a property of prosodic constituents rather than syntactic constituents, it seems more appropriate to express headedness-related asymmetries as prosodic well-formedness constraints instead of syntax–prosody mapping constraints.
In order to incorporate this insight into the account, a new model of the syntax–prosody interface proposed by
Kratzer and Selkirk (
2020) is adopted. The model, which they call the MSO-PI-PO model, strictly separates influences of syntax on prosody, which are usually expressed as syntax–prosody mapping constraints such as
Align-XP and Match constraints
9 from purely phonological effects, which are usually expressed as prosodic well-formedness constraints. This separation is made possible by adopting a grammatical architecture similar to the serial OT model (
Kiparsky 2000), which involves two independent computational processes, as illustrated in (20).
| 20. | Kratzer and Selkirk’s (2020) MSO-PI-PO model. |
| | Morpho-Syntactic Output Representation (MSO) |
| | | ↓ Spellout (gives phonological expression to MSO) |
| | Phonological Input Representation (PI) |
| | | ↓ Phonology (determines optimal PO on basis of PI) |
| | Phonological Output Representation (PO) |
| | | ↓ |
| | | Phonetic Interpretation |
The first process in (20) is Spellout, i.e. the mapping of the morpho-syntactic output (MSO) representation onto the phonological input (PI) representation, which is regulated by requirements from the syntax–prosody mapping. The next process takes place within phonology proper, in which the phonological input (PI) representation is subject to the mapping process that results in the phonological output (PO) representation that optimally satisfies prosodic well-formedness conditions. The PO representation will then be interpreted phonetically for actual articulation.
In the model summarized in (20), the syntax–prosody correspondence is accounted for exclusively by the Match constraints that regulate the Spellout process (i.e., MSO-to-PI). No reference to morpho-syntactic categories can be made in the PI-to-PO process. In that sense, it strictly follows the MIH proposed above.
If we adopt this MSO-PI-PO model, it is possible to capture the insight suggested here and explain the Japanese data in (19) without
Align-XP. First, at the point of Spellout, syntactic structures are mapped to input phonological representation based on
Match (S-P faithfulness) constraints in (8a). Unless other morpho-syntactic factors (such as focus and givenness) are involved,
10 syntactic XP boundaries are mapped to φ’s without any mismatch. (21) is the MSO-PI mapping of the left- and right-branching structures discussed in (18). For expository purposes, XPs and corresponding φs are indexed with numbers.
| 21. | MSO → PI |
| | a. | Left-branching structure: |
| | | [XP1 [XP2 [XP3 A B] C] D] → (φ1 (φ2 (φ3 A B) C) D) |
| | b. | Right-branching structure: |
| | | [XP1 A [XP2 B [XP3 C D]]] → (φ1 A (φ2 B (φ3 C D))) |
Note that the PI representations (i.e., the representation to the right of the arrows in (21)) no longer contain syntactic information. They instead contain information about prosodic constituents. With this PI representation as inputs, optimal phonological output representations (POs) will be chosen as a result of interactions of faithfulness and markedness constraints.
Markedness constraints (prosodic well-formedness constraints) include, among other things, constraints on prosodic heads, such as
HeadProminence-in-φ (
Kratzer and Selkirk 2020, p. 24) in (22), which requires one and only one head per φ, and head-alignment constraints (
Truckenbrodt 1995, for Japanese;
Féry and Samek-Lodovici 2006), which require any prosodic head to be either right- or left-aligned. In the case of Japanese, φ-heads are left-aligned, which means that
Align(φ, Left, Head(φ), Left), shown in (23), is active. Note that
Align(φ, Left, Head(φ), Left) is a purely phonological (markedness) constraint, i.e., a prosodic well-formedness constraint, as it does not refer to any syntactic information.
| 22. | HeadProminence-in-φ (HdProm-in-φ) (Kratzer and Selkirk 2020, p. 24) |
| | Every φ has exactly one prominent daughter, its head. |
| 23. | Align(φ, Left, Head(φ), Left)—Align-φ-Left (adapted from Féry and Samek-Lodovici 2006) |
| | Align the left boundary of every φ with its head(s). |
It is assumed here, for expository purposes, that (22) and (23) are undominated in Japanese. We therefore do not consider any candidate that violates these constraints. In addition to that, we assume, contrary to the original proposal by Kratzer and Selkirk, that PI representations contain default prosodic heads, as predicted from the constraints in (22) and (23), as in (24), where heads are marked with boldface. The leftmost (prosodic) word in each φ in the PI is the head of that φ. In the left-branching structure in (24a), A is the head of all three φs (φ1, φ2 and φ3), while in the right-branching structure in (24b), A, B and C are the heads of φ1, φ2 and φ3, respectively.
| 24. | PIs with prosodic heads: |
| | a. | Left-branching structure: |
| | | (φ1 (φ2 (φ3 A1,2,3 | B) | C) | D) |
| | b. | Right-branching structure: No rephrasing |
| | | (φ1 A1 | (φ2 B2 | (φ3 C3 | D))) |
These phonological input representations then undergo the PI-to-PO mapping process, which results in a phonological output (PO) representation that optimally satisfies relevant markedness and faithfulness constraints. This process is illustrated in (25).
| 25. | PI → PO (Phonetic outputs): |
| | a. | Left-branching structure: |
| | | (φ1 (φ2 (φ3 A B ) C ) D ) | → | (φ1 (φ3 A B ) (φ4 C D )) | (Rephrasing due to binarity) |
| | b. | Right-branching structure: No rephrasing |
| | | (φ1 A (φ2 B (φ3 C D ))) | → | (φ1 A (φ2 B (φ3 C D ))) | (No effect of binarity) |
In the left-branching structure (25a), φ2 in the phonological input (PI) is removed in the phonological output (PO), while in the right-branching structure (25b), φ2 in the PI is maintained in the PO. In Bellik et al.’s account, the removal of φ2 is triggered by
BinMax(φ,ω), as in (26).
11| 26. | BinMax(φ,ω) (Bellik et al. 2022, p. 463) |
| | Assign one violation for every node of category φ in the prosodic tree that dominates more than two nodes of category ω. |
φ1 and φ2 in the input representations (24a)/(24b) violate BinMax(φ,ω), as they both contain more than two ωs. Just like in the discussion of (18)/(19) (see note 8), however, it is assumed here that φ1, the outermost φ, is never affected by BinMax. The relevant fact that needs to be accounted for is that while φ2 is removed in the PO in the left-branching structure (25a) in order to satisfy BinMax, φ2 is kept in the PO in the right-branching structure in (25b), even though it violates BinMax.
With the assumption that the head-alignment constraint (
Align-φ-
Left in (23)) is undominated, the difference between (25a) and (25b) can now be derived as a result of the ranking of
BinMax(φ, ω) and the faithfulness constraints on prosodic heads in (27):
| 27. | Faithfulness constraints on prosodic heads: |
| | a. | Max(φ-head)—do not delete any φ-head |
| | b. | Dep(φ-head)—do not add any φ-head |
The ranking to derive the asymmetry in Japanese is as follows:
| 28. | Max(φ-head) >> BinMax(φ,ω) >> Dep(φ-head) |
The result is shown in
Figure 11. Each φ is indexed to show the correspondence between the φs in the input and φs in the output. The heads of φs are indicated by boldface and are coindexed with corresponding phrases. Prosodic heads are already indicated in the input by assuming that the head-prominence and head-alignment constraints in (22) and (23) are unboundedly ranked.
In the left-branching structure (top of
Figure 11), A is the prosodic head of all three φs (φ1, φ2 and φ3). Candidate a maintains the input structure and hence violates
BinMax twice, while it satisfies both faithfulness constraints. In candidate b, φ2 is removed to avoid
BinMax violation, and a new phrase, φ4, is added instead.
12 As a result, this candidate violates
BinMax only once, while it violates
Dep(φ-head), which is ranked lower than
BinMax.
In the right-branching structure, by contrast, candidate b violates Max(φ-head), because the head of φ2 in the input (i.e., B2) is no longer a prosodic head in the output. This violation causes candidate a, which is the matching output, to be chosen as the winning candidate.
This analysis captures the insight that the Asymmetry Problem should be reduced to the directionality of prosodic headedness. The MSO-PI-PO model provides an input prosodic structure that carries prosodic heads either on the left or right edges of each φ (depending on the prosodic headedness of the language), and faithfulness constraints would prefer to maintain these prosodic heads in the PO representations. The effect originally expressed by Align-XP can therefore be replaced by these faithfulness constraints together with the Alignment constraints that expresses the prosodic headedness (Align-φ-Left in (23) in the case of Japanese).
The reason why the standard (single-cycle) OT account requires Align-XP to explain the Japanese data is that the input representation is a syntactic structure, which, obviously, contains neither prosodic heads nor edges. With a syntactic structure as input, it is not possible to apply prosodic well-formedness constraints on prosodic heads, such as HeadProminence-in-φ in (22) and Align(φ, Left, Head(φ), Left) in (23).
In the MSO-PI-PO model, by contrast, the syntax-to-prosody mapping takes place at Spellout, producing a Match-compliant prosodic structure as the phonological input (PI) representation. With a prosodic structure as input, prosodic head-related constraints can correctly derive an optimal output representation that maintain the head-associated prosodic edges in the phonological output (PO) representation, which allows us to maintain the insight that prosodic asymmetry is caused by prosodic headedness.
In Alignment-based analyses, the main effect of Align-XP is to (implicitly) associate a syntactic left/right edge in the input to a prosodic head (that is not visible, or existent, in a syntactic representation) that needs to be realized in the phonological output. This implies, however, that Alignment-based mapping constraints such as Align-XP are inherently “contaminated” by effects of prosodic headedness, which should ideally be formulated as prosodic well-formedness constraints that regulate the distribution of prosodic heads. In that sense, only Match constraints allow strict separation of syntax–prosody mapping effects and prosodic well-formedness effects.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















