
Creating a Machine Learning Tool to Predict Acute Kidney Injury in African American Hospitalized Patients


Abstract
:1. Introduction
2. Materials and Methods
2.1. AKI Definition
2.2. Participant Selection
2.3. Data Extraction
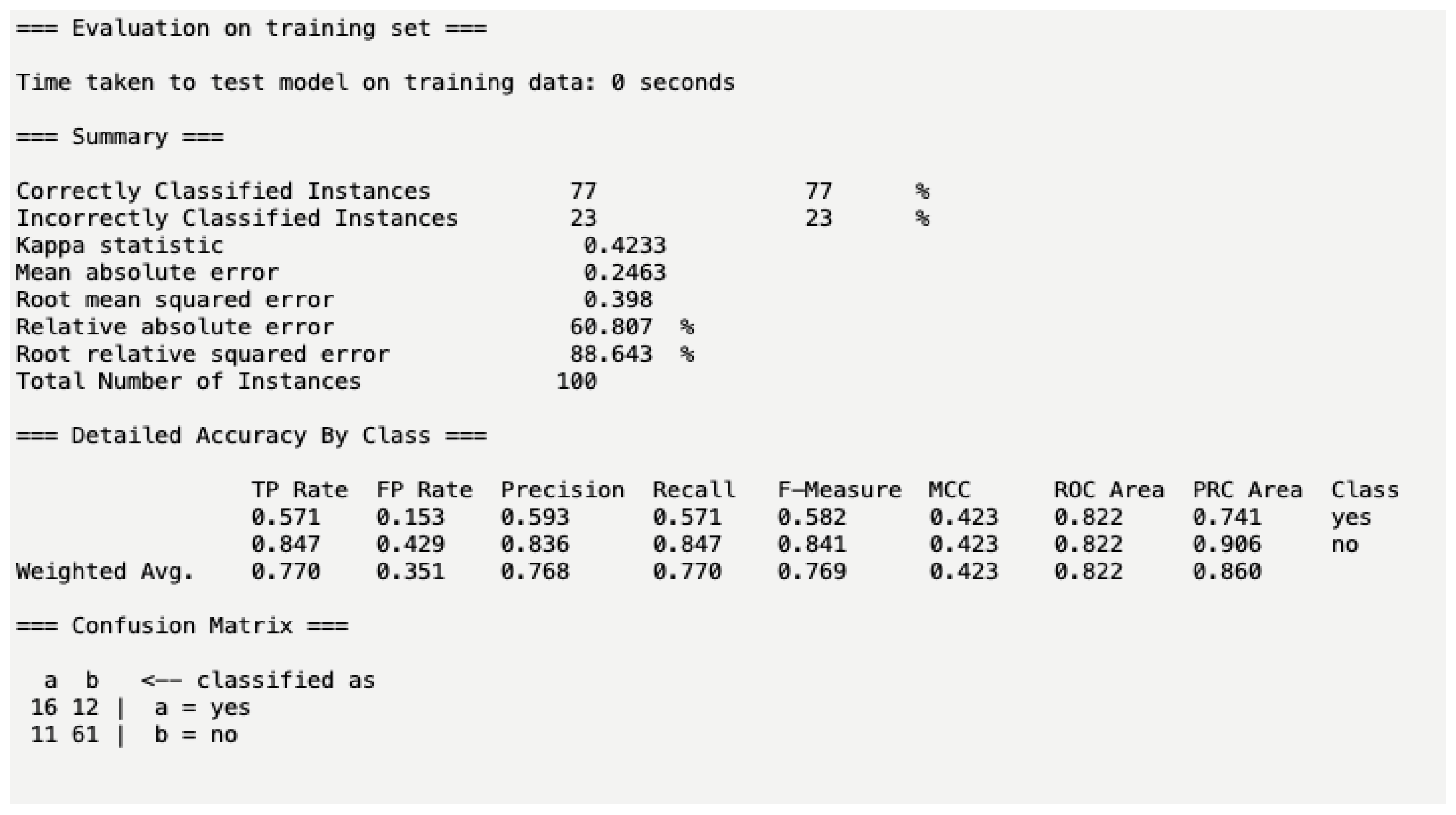
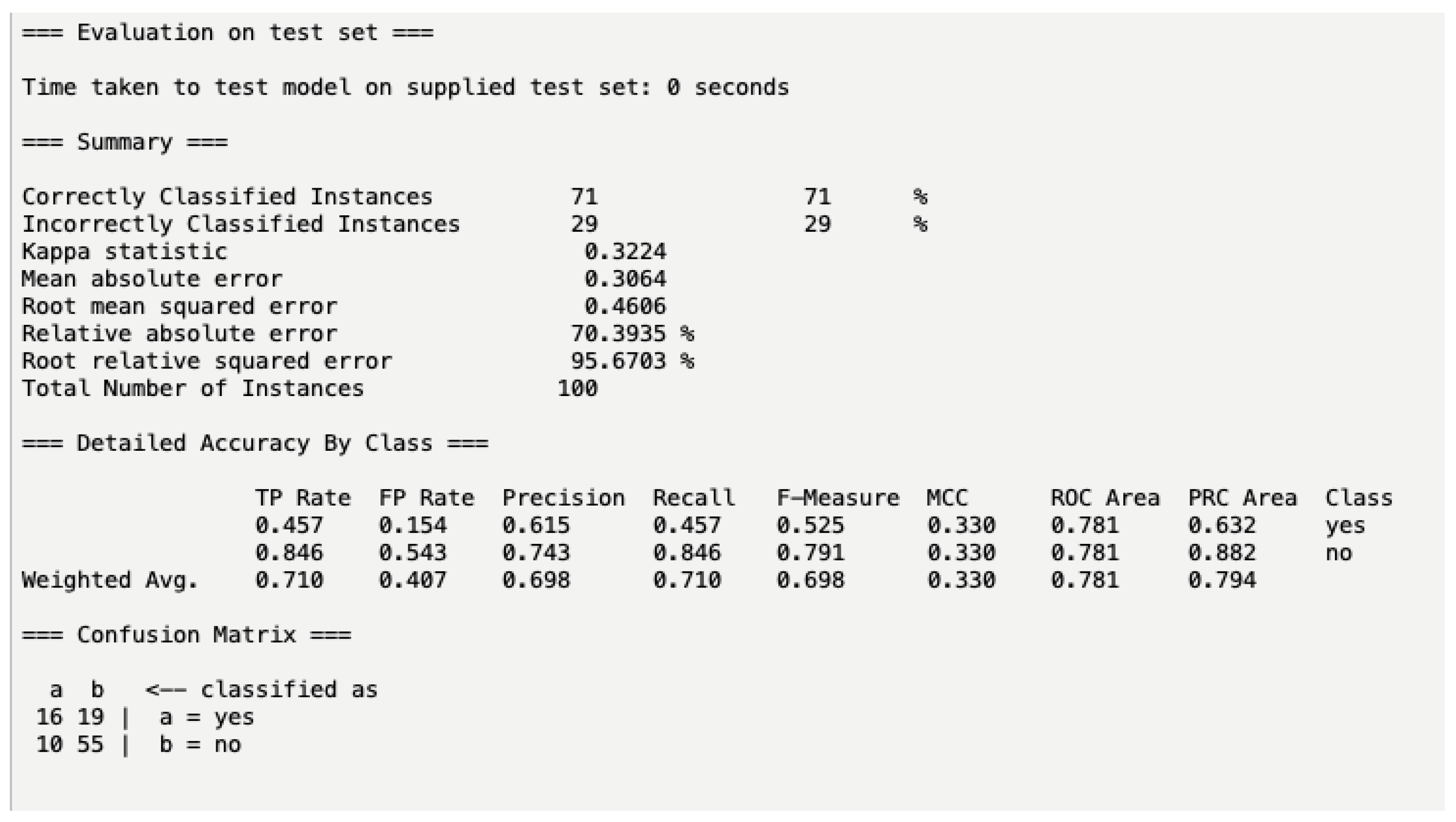
2.4. Statistical Analysis and Machine Learning Creation
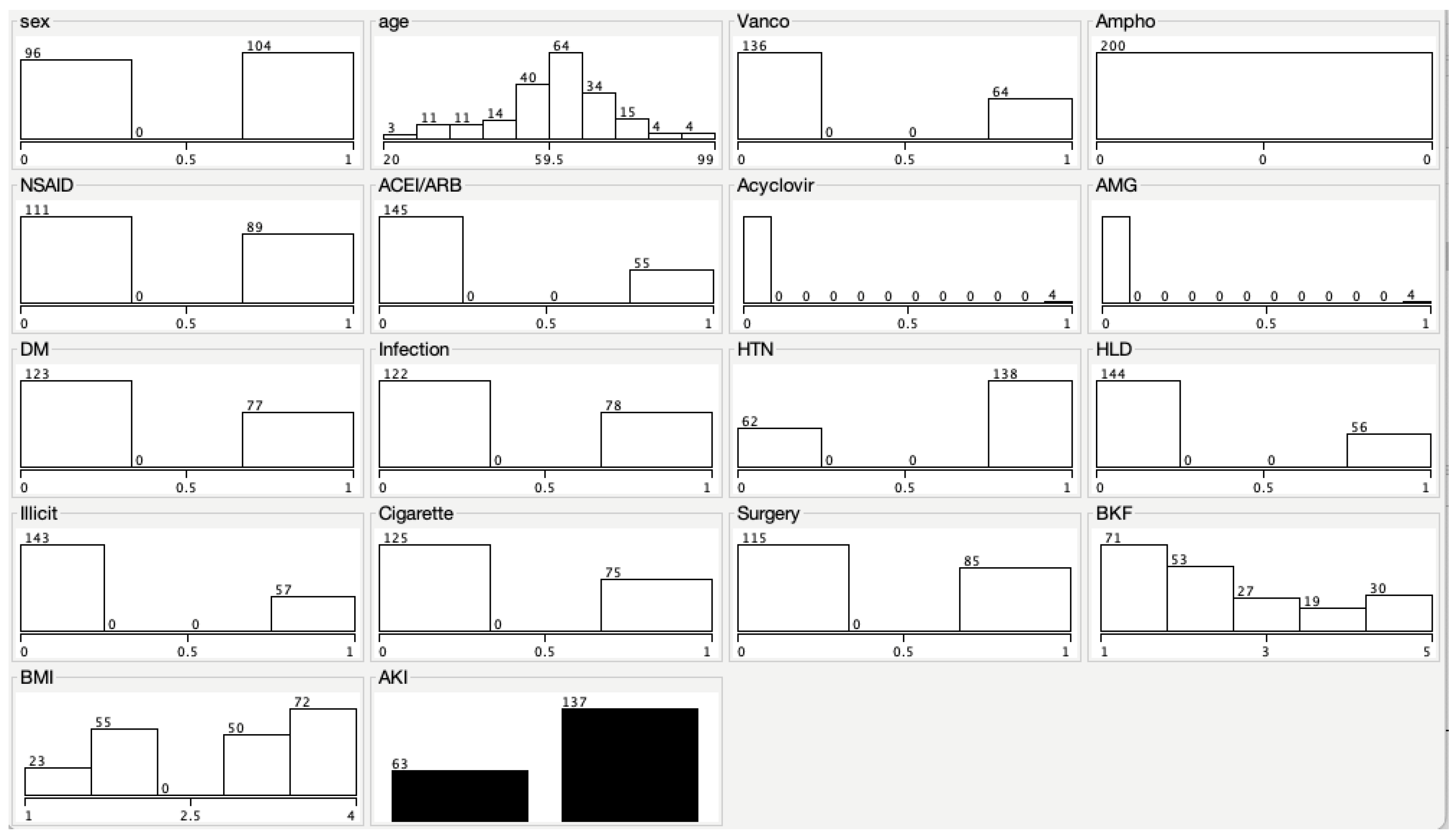
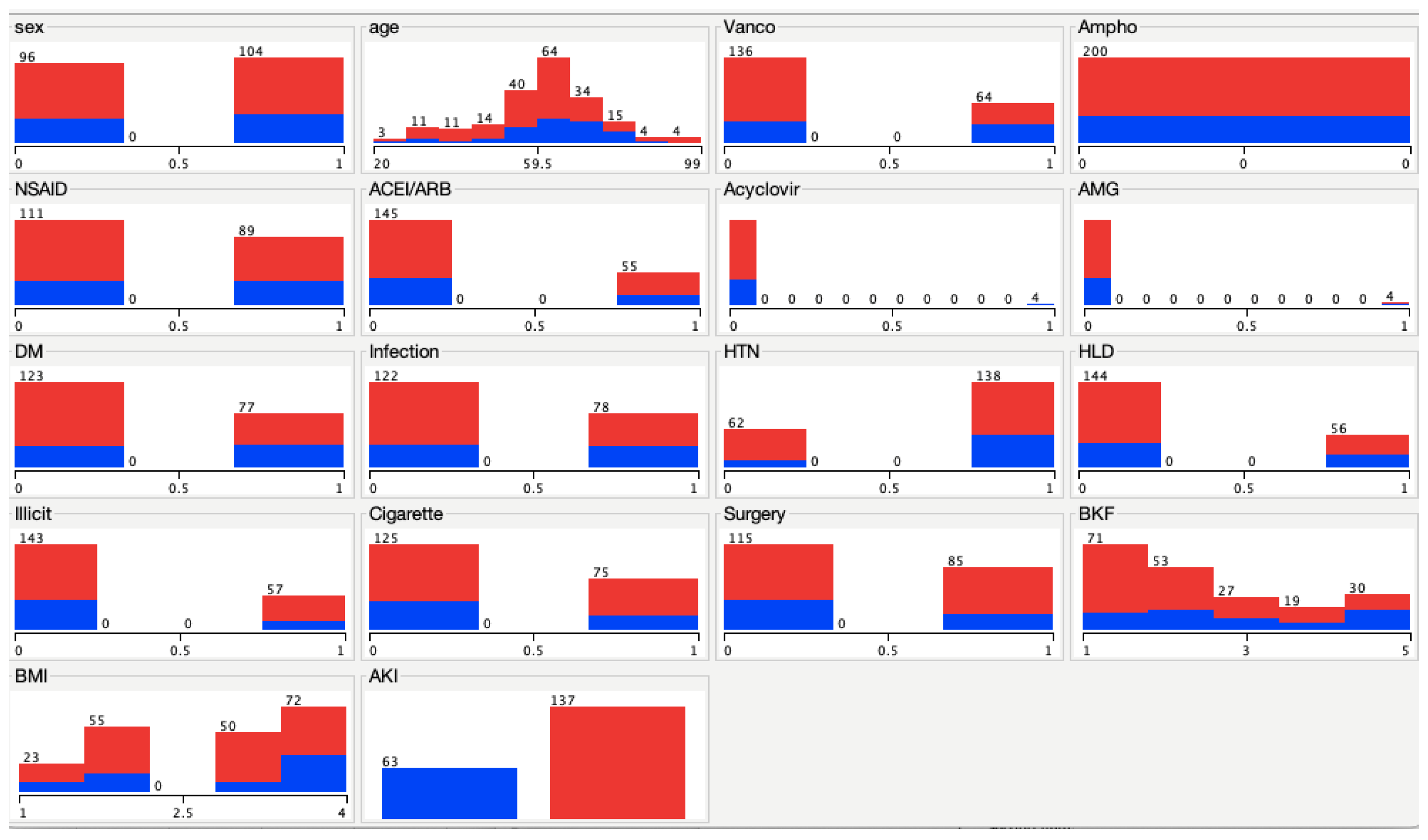
3. Results
Baseline Characteristics
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Wang, H.E.; Muntner, P.; Chertow, G.M.; Warnock, D.G. Acute kidney injury and mortality in hospitalized patients. Am. J. Nephrol. 2012, 35, 349–355. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dummer, P.D.; Limou, S.; Rosenberg, A.Z.; Heymann, J.; Nelson, G.; Winkler, C.A.; Kopp, J.B. APOL1 kidney disease risk variants: An evolving landscape. Semin Nephrol. 2015, 35, 222–236. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Laster, M.; Shen, J.I.; Norris, K.C. Kidney disease among African Americans: A population perspective. Am. J. Kidney Dis. 2018, 72 (Suppl. 1), S3–S7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kolata, G. Targeting the uneven burden of kidney disease on black Americans. The New York Times. Published 17 May 2022. Available online: https://www.nytimes.com/2022/05/17/health/kidney-disease-black-americans.html (accessed on 30 May 2022).
- Silver, S.A.; Chertow, G.M. The economic consequences of acute kidney injury. Nephron 2017, 137, 297–301. [Google Scholar] [CrossRef] [PubMed]
- Amazon.com. Available online: https://aws.amazon.com/machine-learning/ (accessed on 30 May 2022).
- Khwaja, A. KDIGO clinical practice guidelines for acute kidney injury. Nephron Clin. Pract. 2012, 120, c179–c184. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. SIGKDD Explor. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Gandhi, R. Naive Bayes classifier. Towards Data Science. Published 5 May 2018. Available online: https://towardsdatascience.com/naive-bayes-classifier-81d512f50a7c (accessed on 30 May 2022).
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Mean Absolute Error. C3 AI. Published 28 October 2020. Available online: https://c3.ai/glossary/data-science/mean-absolute-error/ (accessed on 30 May 2022).
- Coding Prof. 3 Ways to Calculate the Root Relative Squared Error (RRSE) in R. CodingProf.com. Published 3 January 2022. Available online: https://www.codingprof.com/3-ways-to-calculate-the-root-relative-squared-error-rrse-in-r/ (accessed on 30 May 2022).
- RMSE: Root Mean Square Error. Statistics How To. Published 12 May 2020. Available online: https://www.statisticshowto.com/probability-and-statistics/regression-analysis/rmse-root-mean-square-error/ (accessed on 30 May 2022).
- Koehrsen, W. When Accuracy Isn’t Enough, Use Precision and Recall to Evaluate Your Classification Model. Built in. Published 3 August 2021. Available online: https://builtin.com/data-science/precision-and-recall (accessed on 30 May 2022).
- Precision, Recall and Correctly Classified Instances. Stack Overflow. Available online: https://stackoverflow.com/questions/25349841/precision-recall-and-correctly-classified-instances (accessed on 30 May 2022).
- Get Your Guide. What is a Good F1 Score?—Inside Get Your Guide. Published 13 October 2020. Available online: https://inside.getyourguide.com/blog/2020/9/30/what-makes-a-good-f1-score (accessed on 30 May 2022).
- Towardsdatascience.com. Available online: https://towardsdatascience.com/the-best-classification-metric-youve-never-heard-of-the-matthews-correlation-coefficient-3bf50a2f3e9 (accessed on 30 May 2022).
- Mandrekar, J.N. Receiver operating characteristic curve in diagnostic test assessment. J. Thorac. Oncol. 2010, 5, 1315–1316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Precision-Recall Curves—What are They and How are They Used? Acutecaretesting.org. Available online: https://acutecaretesting.org/en/articles/precision-recall-curves-what-are-they-and-how-are-they-used (accessed on 30 May 2022).
- Yue, S.; Li, S.; Huang, X.; Liu, J.; Hou, X.; Zhao, Y.; Niu, D.; Wang, Y.; Tan, W.; Wu, J. Machine learning for the prediction of acute kidney injury in patients with sepsis. J. Transl. Med. 2022, 20, 215. [Google Scholar] [CrossRef] [PubMed]
- Deng, Y.H.; Luo, X.Q.; Yan, P.; Zhang, N.Y.; Liu, Y.; Duan, S.B. Outcome prediction for acute kidney injury among hospitalized children via eXtreme Gradient Boosting algorithm. Sci. Rep. 2022, 12, 8956. [Google Scholar] [CrossRef] [PubMed]
- Mathioudakis, N.N.; Giles, M.; Yeh, H.C.; Haywood, C., Jr.; Greer, R.C.; Golden, S.H. Racial differences in acute kidney injury of hospitalized adults with diabetes. J. Diabetes Complicat. 2016, 30, 1129–1136. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Melvin, R.L. Sample Size in Machine Learning and Artificial Intelligence. Uab.edu. Available online: https://sites.uab.edu/periop-datascience/2021/06/28/sample-size-in-machine-learning-and-artificial-intelligence/ (accessed on 30 May 2022).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | N = 200 (%) | AKI (% per Characteristic) | No AKI (% per Characteristic) |
|---|---|---|---|
| Gender | Male: 104 (52%) Female: 96 (48%) | Male: 34 (32.7%) Female: 29 (30.2%) | Male: 70 (67.3%) Female: 67 (69.8%) |
| Age | Mean: 60.94 years | - | - |
| BMI | Mean range: 18.5–24.9 kg/m2 | - | - |
| Baseline kidney Function | Mean GFR: 45–89 mL/min/1.73 m2 | - | - |
| Presence of infection | 78 (39.0%) | 31 (39.7%) | 47 (60.3%) |
| Hypertension | 138 (69.0%) | 52 (37.7%) | 86 (62.3%) |
| Hyperlipidemia | 56 (28.0%) | 22 (39.3%) | 34 (60.7%) |
| T2DM | 77 (38.5%) | 32 (41.6%) | 45 (58.4%) |
| Vancomycin | 64 (32%) | 29 (45.3%) | 35 (54.7%) |
| NSAID | 89 (44.5%) | 31 (34.8%) | 58 (65.2%) |
| ACEI/ARB | 55 (27.5%) | 17 (30.9%) | 38 (69.1%) |
| Acyclovir | 4 (2.0%) | 3 (75.0%) | 1 (25.0%) |
| Aminoglycoside | 4 (2.0%) | 2 (50.0%) | 1 (25.0%) |
| Amphotericin B | 0 (0%) | 0 (0%) | 0 (0%) |
| Illicit drug use | 57 (28.5%) | 14 (24.6%) | 43 (75.4%) |
| Cigarette use | 75 (37.5%) | 21 (28.0%) | 54 (72.0%) |
| Surgery | 85 (42.5%) | 22 (25.9%) | 63 (74.1%) |
| AKI | 63 (31.5%) | - | 137 (68.5%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pierre-Paul, S.; Wang, X.S.; Mere, C.; Rungkitwattanakul, D. Creating a Machine Learning Tool to Predict Acute Kidney Injury in African American Hospitalized Patients. Pharmacy 2022, 10, 68. https://doi.org/10.3390/pharmacy10040068
Pierre-Paul S, Wang XS, Mere C, Rungkitwattanakul D. Creating a Machine Learning Tool to Predict Acute Kidney Injury in African American Hospitalized Patients. Pharmacy. 2022; 10(4):68. https://doi.org/10.3390/pharmacy10040068
Chicago/Turabian StylePierre-Paul, Sasha, Xiang S. Wang, Constance Mere, and Dhakrit Rungkitwattanakul. 2022. "Creating a Machine Learning Tool to Predict Acute Kidney Injury in African American Hospitalized Patients" Pharmacy 10, no. 4: 68. https://doi.org/10.3390/pharmacy10040068
APA StylePierre-Paul, S., Wang, X. S., Mere, C., & Rungkitwattanakul, D. (2022). Creating a Machine Learning Tool to Predict Acute Kidney Injury in African American Hospitalized Patients. Pharmacy, 10(4), 68. https://doi.org/10.3390/pharmacy10040068