In this section, we describe how we have developed a predictive model from a time series of data related to Calabria and how the model can be used to make future decisions. There are few examples of attempts to forecast the tourist flows based on regional data. Most focus on the factors affecting the choice of tourist destinations. These studies are mainly based on qualitative methods and focusing on short time periods, generally one or few years. In Calabria, the tourist flow is steadily growing.
2.1. Domain Definition
The development of a decision support system requires the correct definition of the factors that partially/totally influence the set of key performance indicators which have a direct impact on the objectives that the decision maker aims to optimize. The selection of indicators was carried out according to the indications reported by the European Tourism Indicator System (
European Commission (EC) 2014). The indicators have been divided into three overall categories: final goals, intermediate results and variables. “Final goals” are the three dimensions of sustainability: economic, social and environmental. The final goals cannot be directly measured. “Intermediate results” are intermediate objectives that can be directly measured and relate to the three dimensions of sustainability. Intermediate results have been linked to final goals through a procedure detailed in the following section. “Variables” are cause variables which have an impact on intermediate results and, through intermediate results, on the final goals. Some variables are under the control of the decision maker. They are the specific focus of our model. Others, like for example population and GDP, are contingent factors that must be taken into account but cannot be directly determined. See
Figure 1 for the details. We collected all the historical data available for Calabria to get a clear picture of the touristic impact on the economic, social and environmental goals. Then, in order to collect missing data we have consulted public databases of national institutions such as: Istat, Mibact, Sistan, Ispra, ACI, ANPA, Ateco, UNPLI, Arpacal, Eurostat, Banca D’Italia (the expanded name of the institutions is reported in the caption of the following table). Collaboration with the Regional Department of National and European Planning Funds, which we thank, allowed us to access the time series of European and Italian funds in the field of regional tourism. Other potentially relevant indicators were excluded from our analysis because their effect can be considered to a large extent included in the chosen indicators. For example, the effect of competition from alternative destinations is implicit in the number of tourists or in the average stay. The effect of macroeconomic factors such as the financial crisis is included in the GDP factor. This article proposes a procedure that can be applied using different indicators according to the needs of the subject conducting the analysis. In this first application we used indicators for which, without prejudice regarding their relevance, data were available. In future applications it will be possible to purposefully collect specific data according to refined indicators.
The data were grouped into “thematic” tables depending on the field of interest and the direct influence on the territory, subsequently selected as “variables” or “levers” as follows (
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5).
2.2. Time Delay Neural Networks
Accurate forecasts are crucial because of the unique nature of the tourism industry (
Frechtling 2012). These activities can be performed through qualitative and quantitative approaches (
Walle 1997). The first ones depend on substantial information and human experiences gained through the years.
Walle (
1997) criticized these techniques for their lack of generalizability. The second ones make use of mathematical functions to define the relationships of certain phenomena using numerical data. These models are then used to estimate future values based on past performance. The construction of an approximation model as a neural network has become a standard technique for many applications (
Specht 1991). However, the use of classical structures and training algorithms still present some shortcomings, being not satisfactory if the complexity or the dimension of the problem is increased. An alternative scheme of neural network architecture (NARX) is designed to model the non-linearity of the analyzed problem. NARX is one of the recurrent neural network schemes with a specific global feedback, considered as a time series forecasting network. It is particularly appropriate for dynamic system applications as it gives a fast and accurate training response, then describes a system as a linear combination of some input parameters, then past values up to a certain fixed time delay, and its own past values.
yj(
t) and
xi(
t) represent, respectively, the input and output vectors at time step
t,
ny and
nui are the input and output time delays, while the function
f is a non-linear mapping function. The non-linear mapping
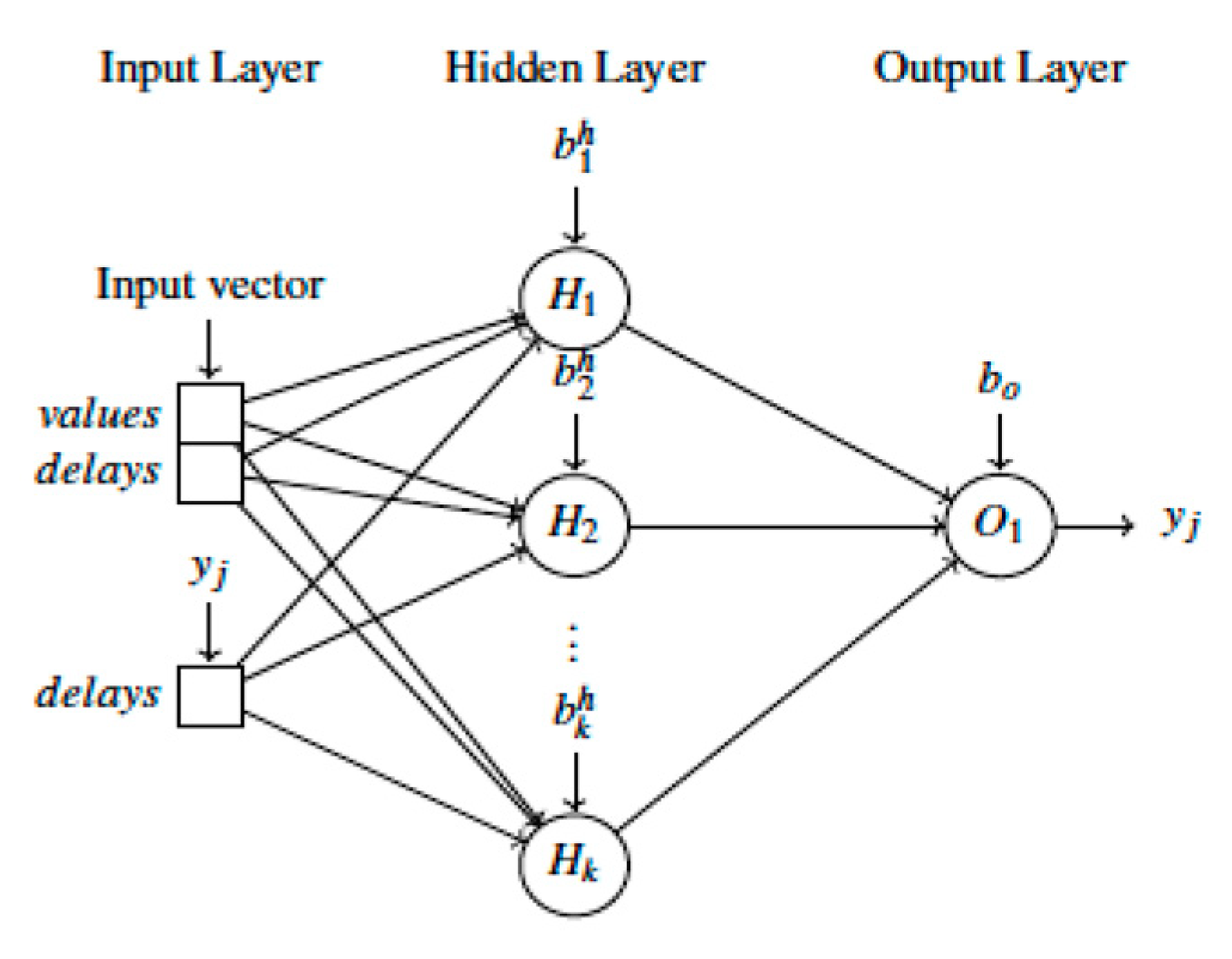
f in (1) is generally unknown but can be approximated, using a standard multilayer perceptron network with a combination of different activation functions (e.g., RELU, sigmoid, linear). For illustration purposes, the architecture of the NARX network is shown in
Figure 2.
The first layer of the network is composed by the input information used to predict the value of
. For the particular application, the layer contains a subset of the decision variables of tourism development goals reported in
Table 1 and previous recorded values of
. The subset of relevant information can be detected by using a trial and error approach or through statistical techniques (e.g., Analysis of Variance). The values stored in the input layers are then manipulated through a structure of weighted connections and hidden units. An example of a network composed of three layers is shown in
Figure 2. The value of a generic hidden unit in the second layer
is given by the following equation:
where
is a sigmoid function and
are weight coefficients. Finally, in a similar way the predicted output value
yj(
t) is modeled as:
It is worth noting that Equations (2) and (3) apply to a three-layer network. If the NARX architecture is made by more than one hidden layer, additional intermediate transformations are required.
Backpropagation through time (BPTT) is the most used algorithm for training recurrent neural networks. The aim of the BPTT algorithm is to minimize the error of the network outputs. The general algorithm is:
fix an initial set of weights;
present the input data and propagate it through the network to get the estimated output;
compare the predicted output to the expected output and calculate the error;
calculate the derivates of the error with respect to the network weights and adjust the weights so that the error is minimized.
The error
E to be minimized is:
where
is the estimated output value at time
t. The new weights are iteratively updated computing the error propagation term by proceeding backward through
t =
T, …, 1 for each time
t and unit activation
xi(
t),
y(
t). The performance of the NARX network in terms of complexity and accuracy is largely dependent on internal components, such as the number of hidden neurons and the activation functions, and training algorithm parameters, such as the learning rate and the momentum. The process of selecting an adequate value of these parameters is still a controversial issue even if several approaches have been proposed in recent years. In this work, a procedure based on the use of a genetic algorithm illustrated in
Ciancio et al. (
2016) has been used to determine a suitable network architecture. The first step of this method is to encode the features of the neural network into specific chromosomes. A chromosome is a sequence of bits with value 0 or 1. Genetic algorithm undertakes to evolve the solution, during its execution, according to the following basic pattern:
- (1)
random generation of the first population of solutions;
- (2)
application of a fitness function to the solutions belonging to the current population;
- (3)
selection of the best solutions based on the value of the fitness function;
- (4)
generation of new solutions using crossover and mutation;
- (5)
repetition of steps 2, 3 and 4 for k iterations;
- (6)
selection of the best found solution.
One of the disadvantages of BPTT is that when the number of time steps increases, the computation also increases, making the overall model noisy. The high cost of single parameter updates makes the BPTT impossible to use for a large number of iterations. For this reason, it is important to consider only the relevant input parameters and time delays. The ANOVA technique was used to determine which decision variables significantly affect the selected criteria (
Rajput et al. 2011). A
p-Value threshold of 0.05 was used to determine the relevant features. The 26 data related to the period 1990–2015 were split in two sets. The first set, 1990–2013, was used to train and validate the regression model, while the last two data sets were used for validation purposes.
Table 3 reports the accuracy of the estimated input–output relationships both in absolute and percentage terms.
In order to test the prediction accuracy, we compared the real KPI values measured in 2014 and 2015 with the predicted responses obtained by imposing the strategic decisions adopted in those two years as input values. The results are reported in
Table 6 and
Table 7.






{kind=link}
{kind=link}