
Identifying Historic Buildings over Time through Image Matching

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Motivation and Contribution
- Does time affect the identity of the building?
- To what extent is the validity of the identification affected?
3. Literature Analysis
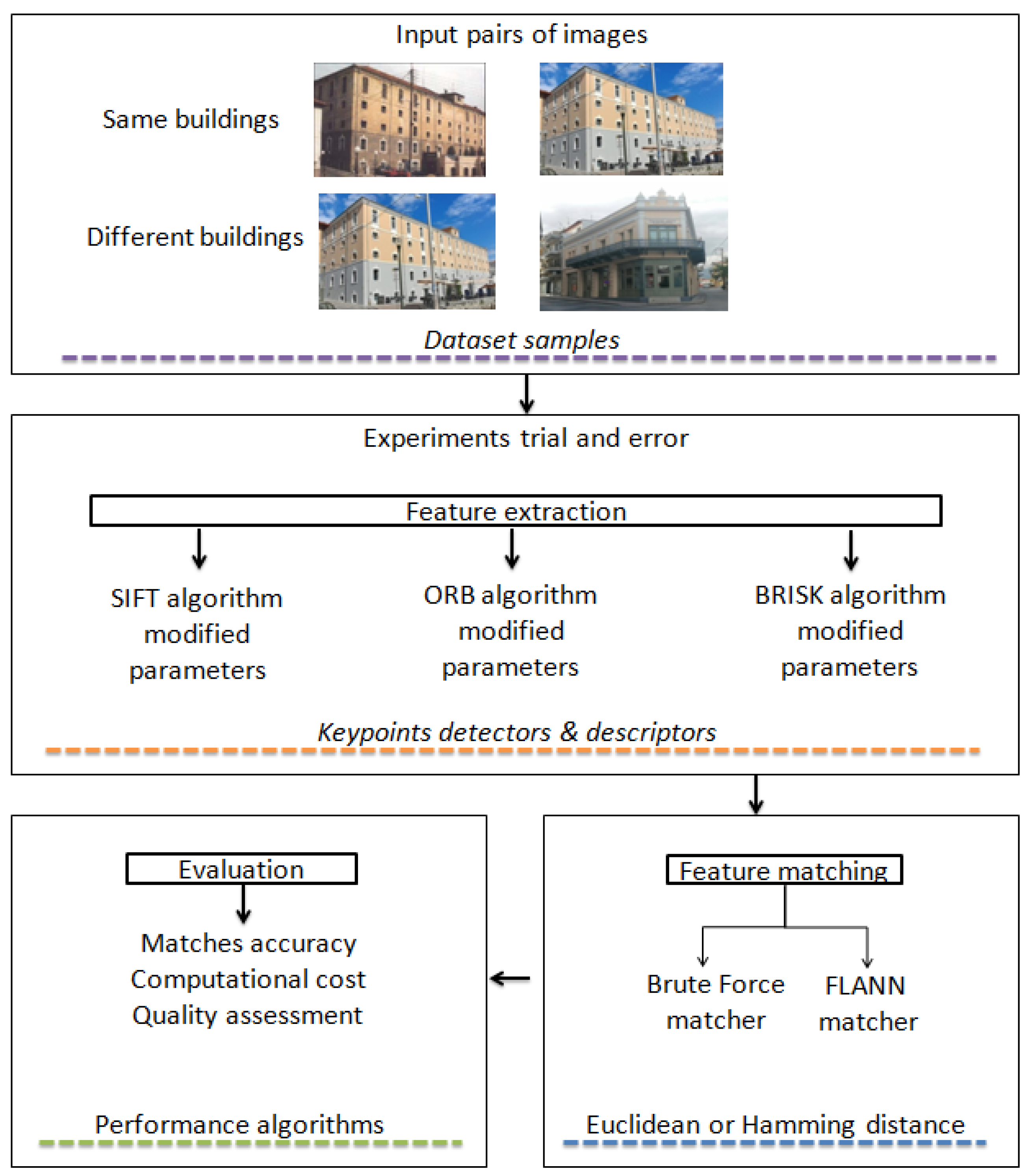
4. Materials and Methods
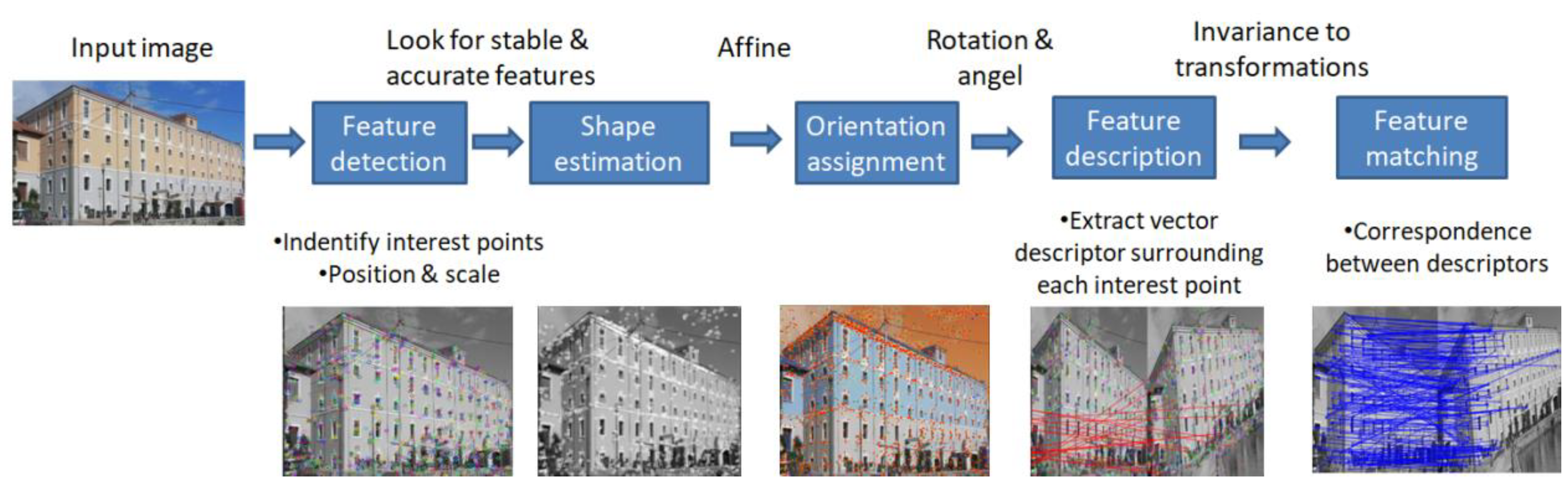
4.1. Correspondence Problem
4.2. Feature Detectors and Descriptors for Feature Matching
- Stability: the locations of the features detected should be independent of different geometric transformations, scaling, rotation, translation, photometric distortions, compression errors, and noise;
- Repeatability: detectors should be able to detect the same features of the same scene or object repeatedly under various viewing conditions;
- Generality: detectors should be able to detect features that can be used in different applications;
- Accuracy: the feature detection should be the same accuracy localized both in image location;
- Efficiency: fast detection to support applications in real time;
- Quantity: the number of detected features should be sufficiently large, such that a reasonable number of features are detected even on small objects.
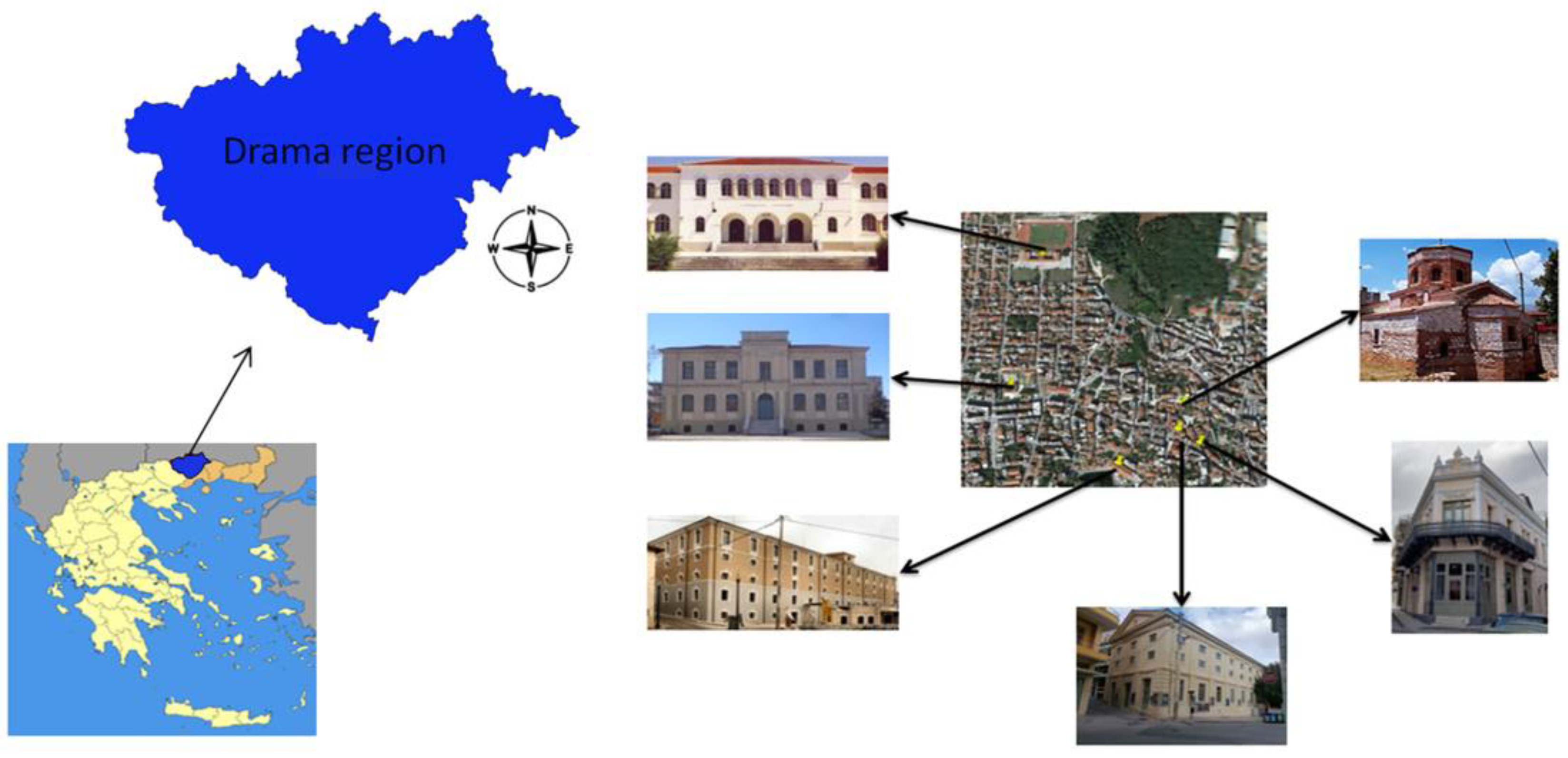
4.3. Study Area
4.4. Data Acquisition and Description
4.5. Experiments
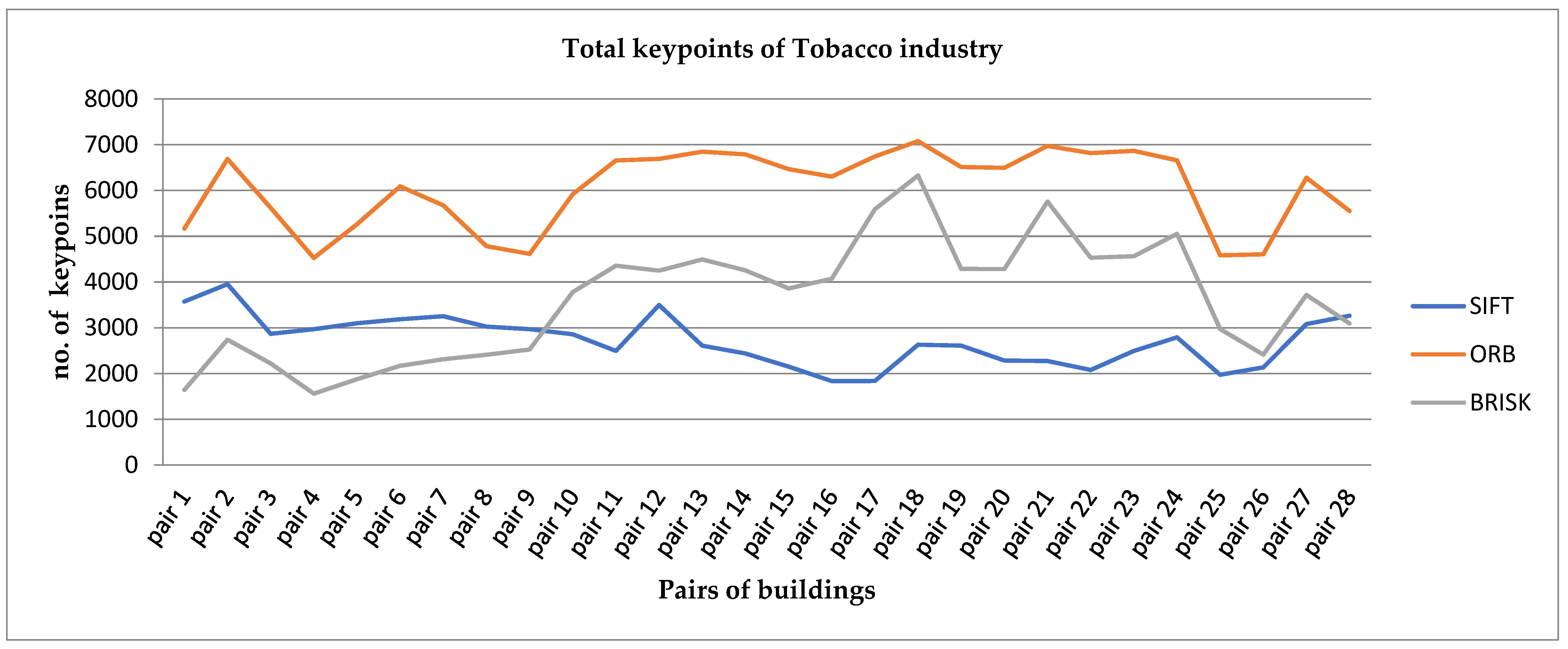
- The total number of keypoints from each pair of images.
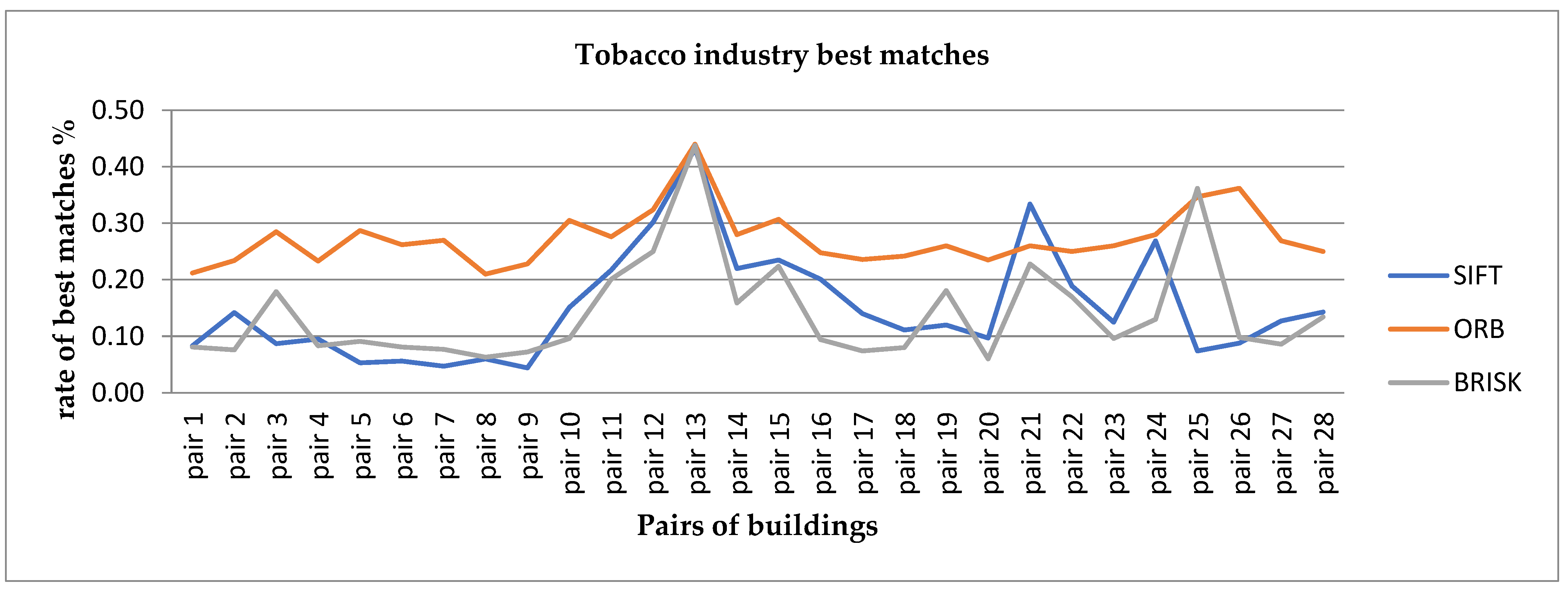
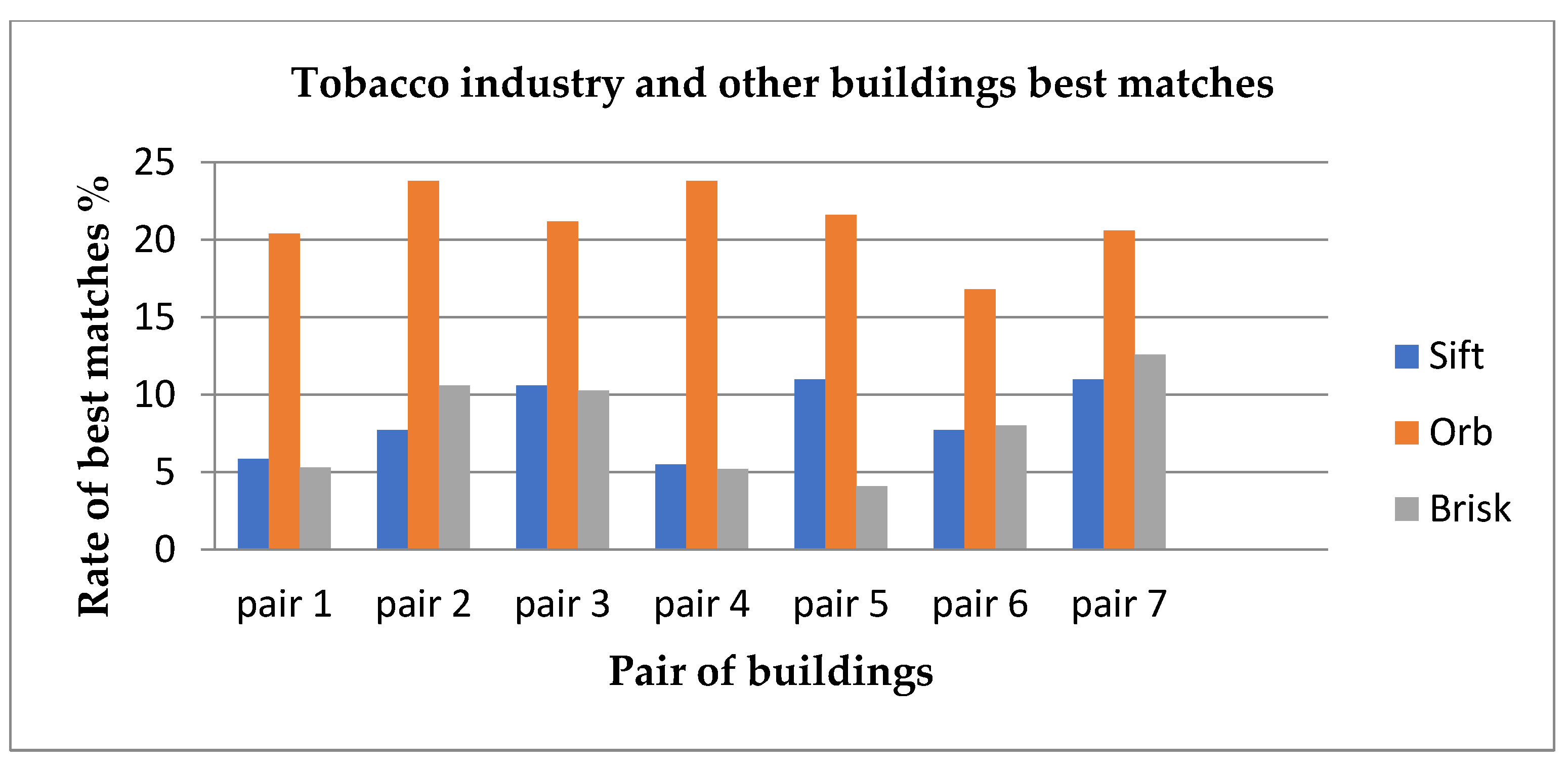
- The total number and the rate of the best matches (good matches). The percentage of best matches was calculated by dividing the best matches by the smallest number of keypoints extracted from the first or second image (good matches/min no, keypoints*100).
- Precision is a performance measure of the best matches (best matches/total matches), while then, we evaluated optically the best matches, aiming to find the false positive matches.
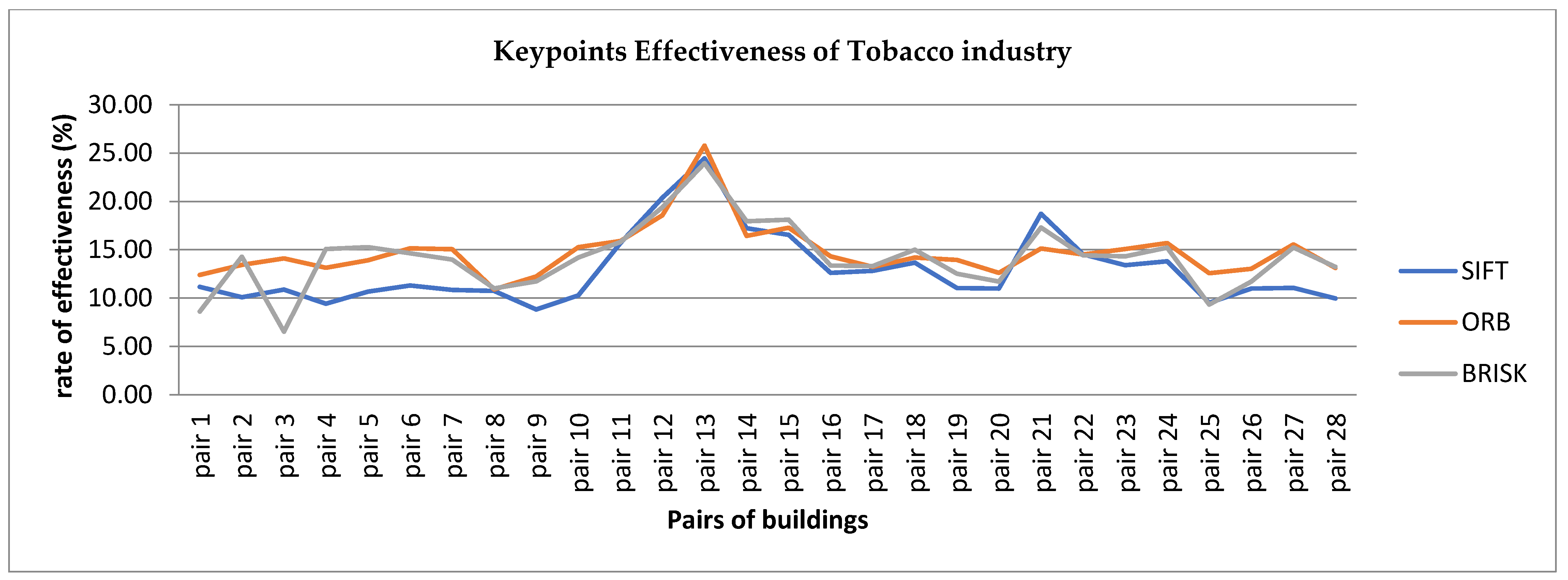
- Effectiveness (%) measure (total matches/total keypoints) to evaluate the actual number of keypoints used for matching.
4.6. SIFT, ORB, BRISK Trial and Error Methods
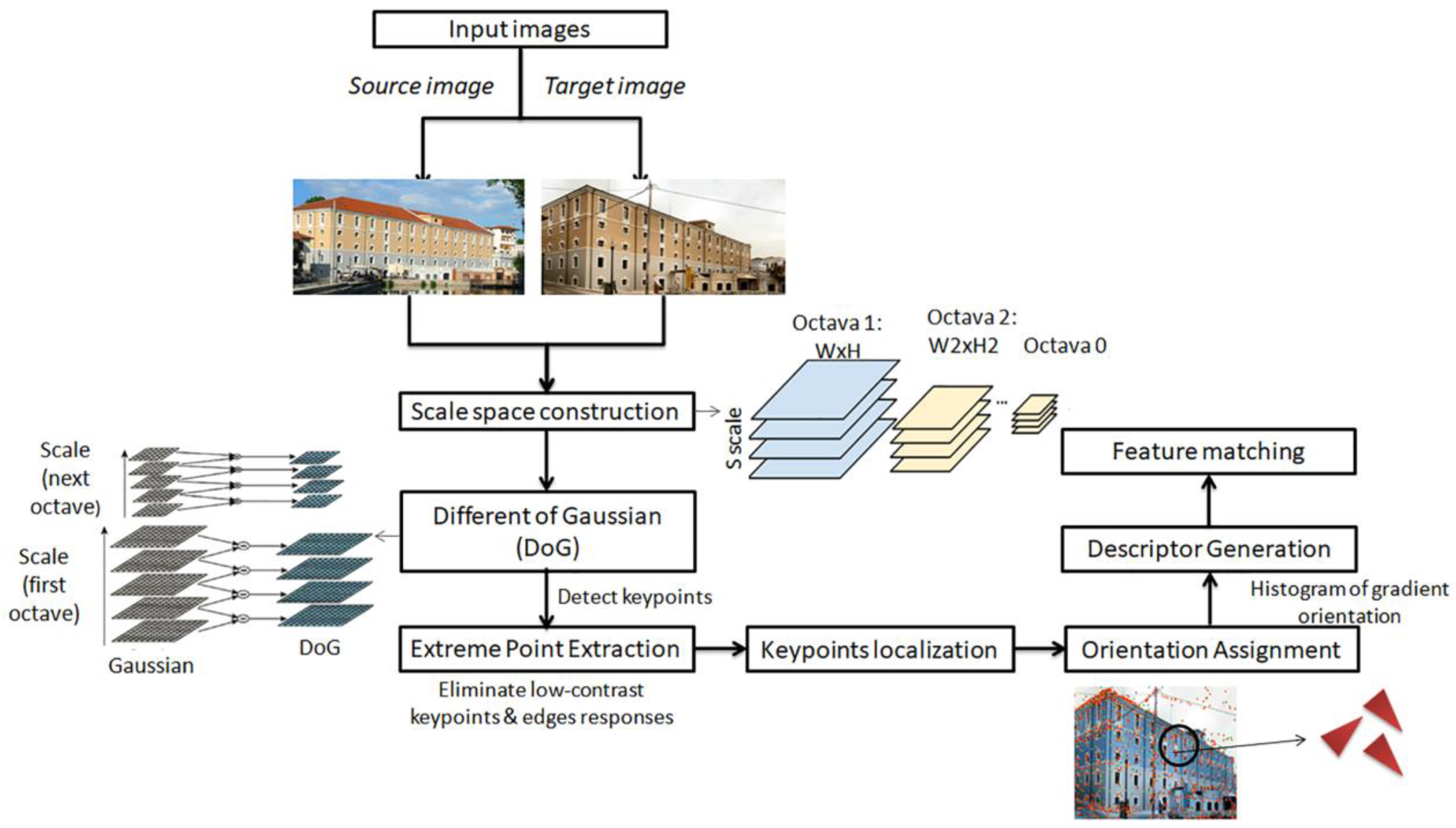
4.6.1. SIFT Algorithm
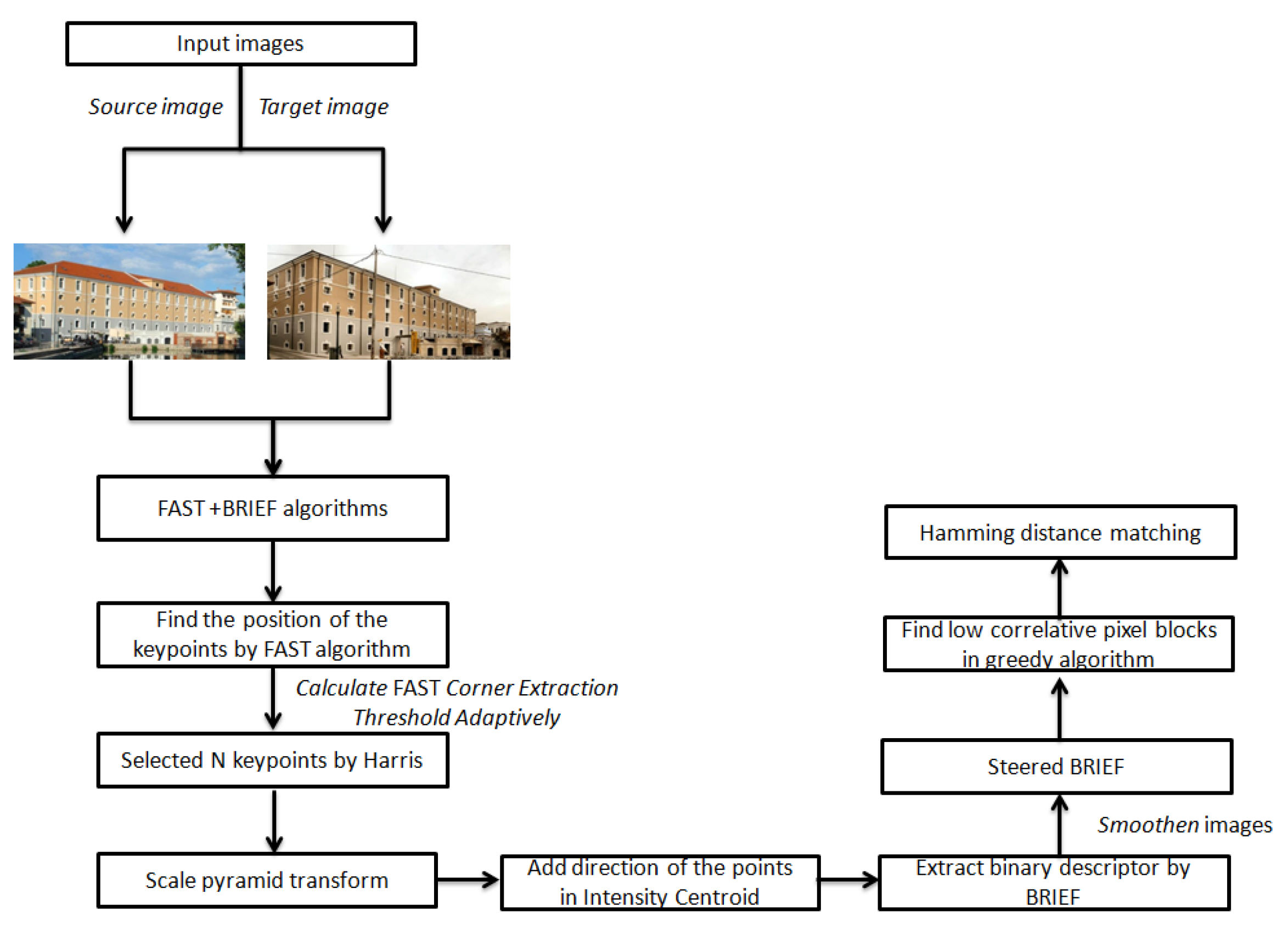
4.6.2. ORB Algorithm
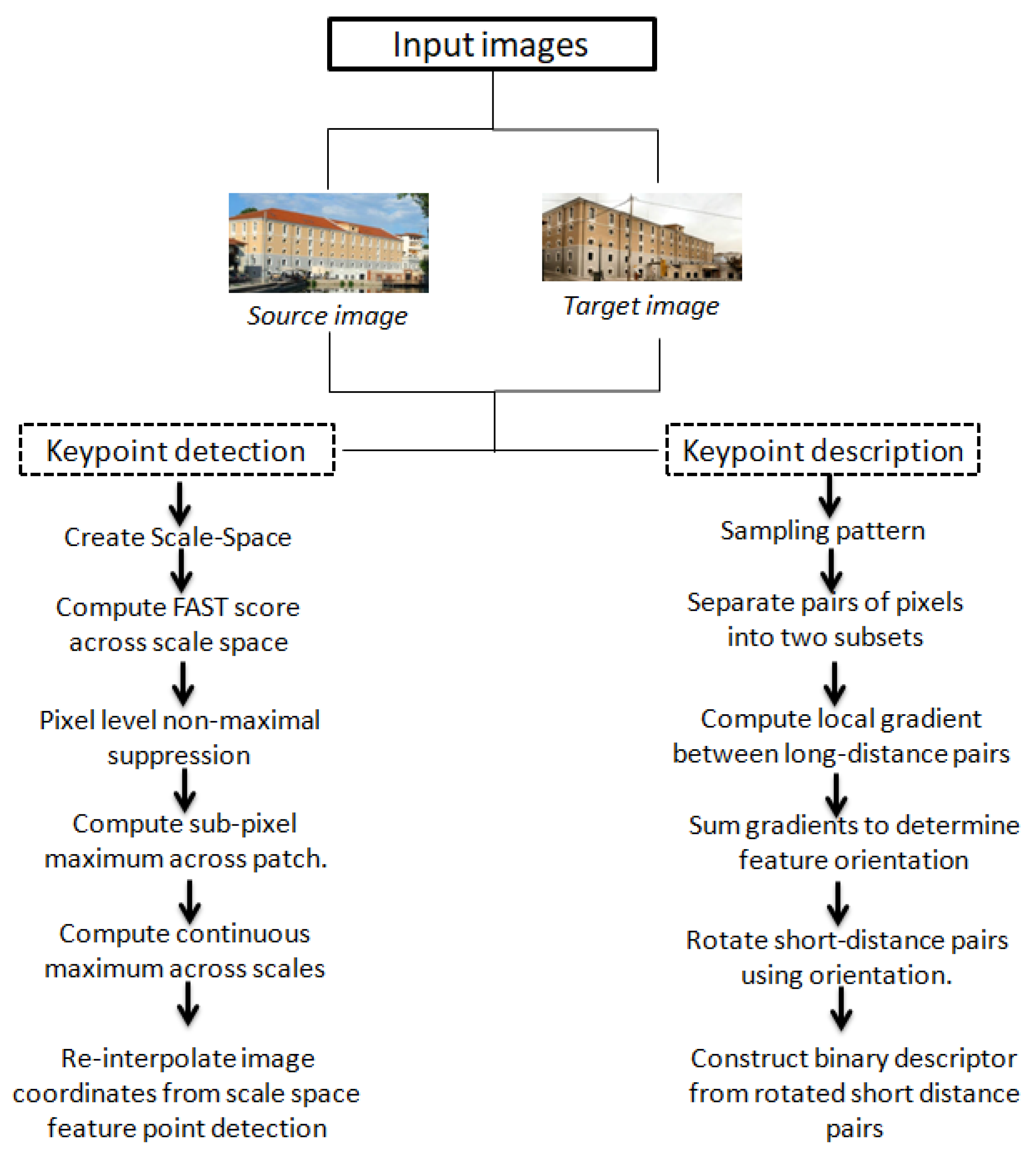
4.6.3. BRISK Algorithm
- At least nine consecutive pixels within the 16-pixel circle centered on the test point must be sufficiently brighter or darker than the test point;
- The test point needs to fulfill the maximum condition with respect to its eight neighboring FAST scores S in the same octave;
- The score of the test point must be larger than the scores of corresponding pixels in the above and below layers [77].
5. Experimental Results
5.1. Algorithms Parameters Trial and Error
5.2. Features Detection and Matching
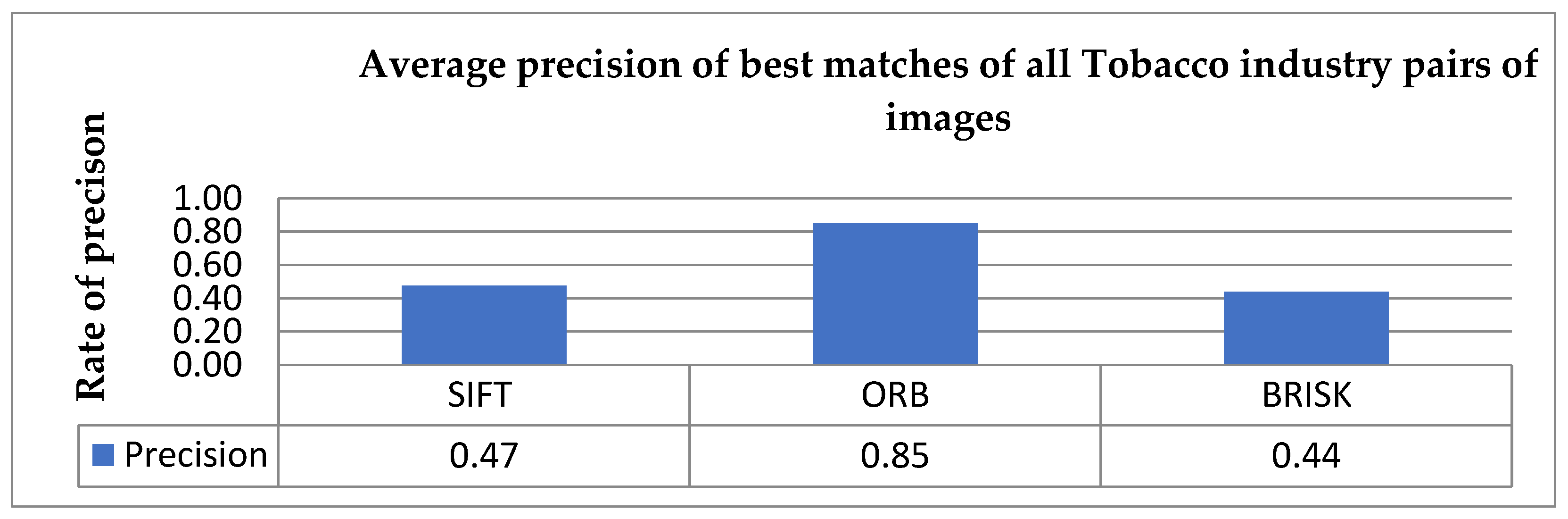
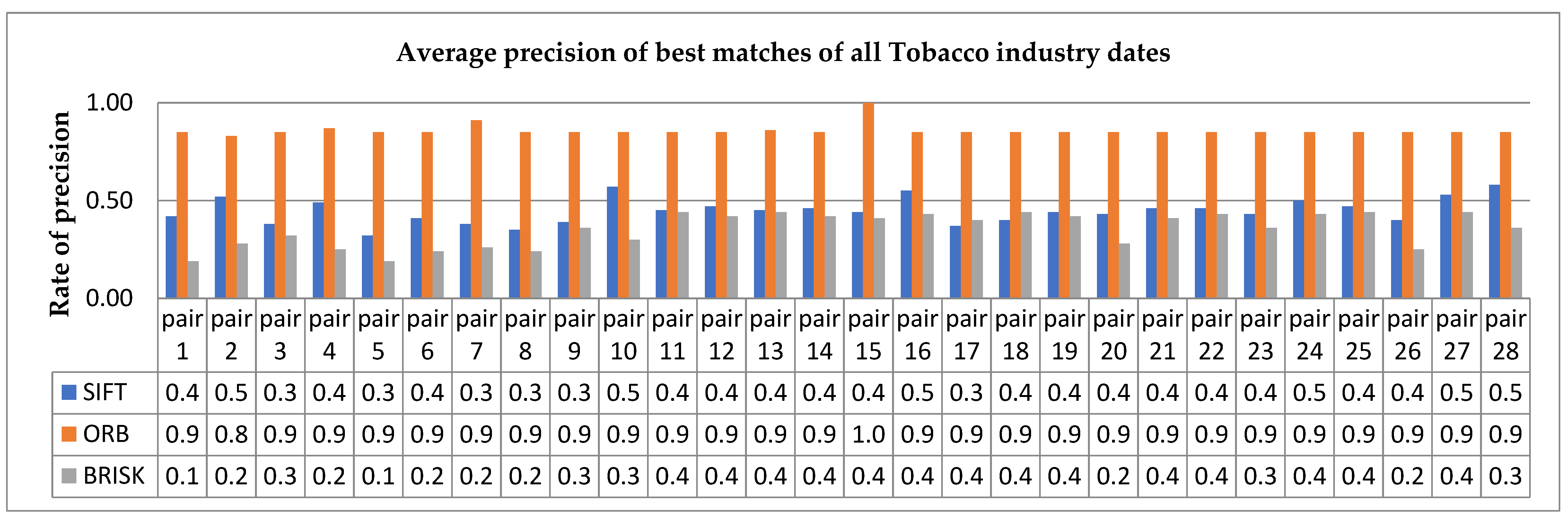
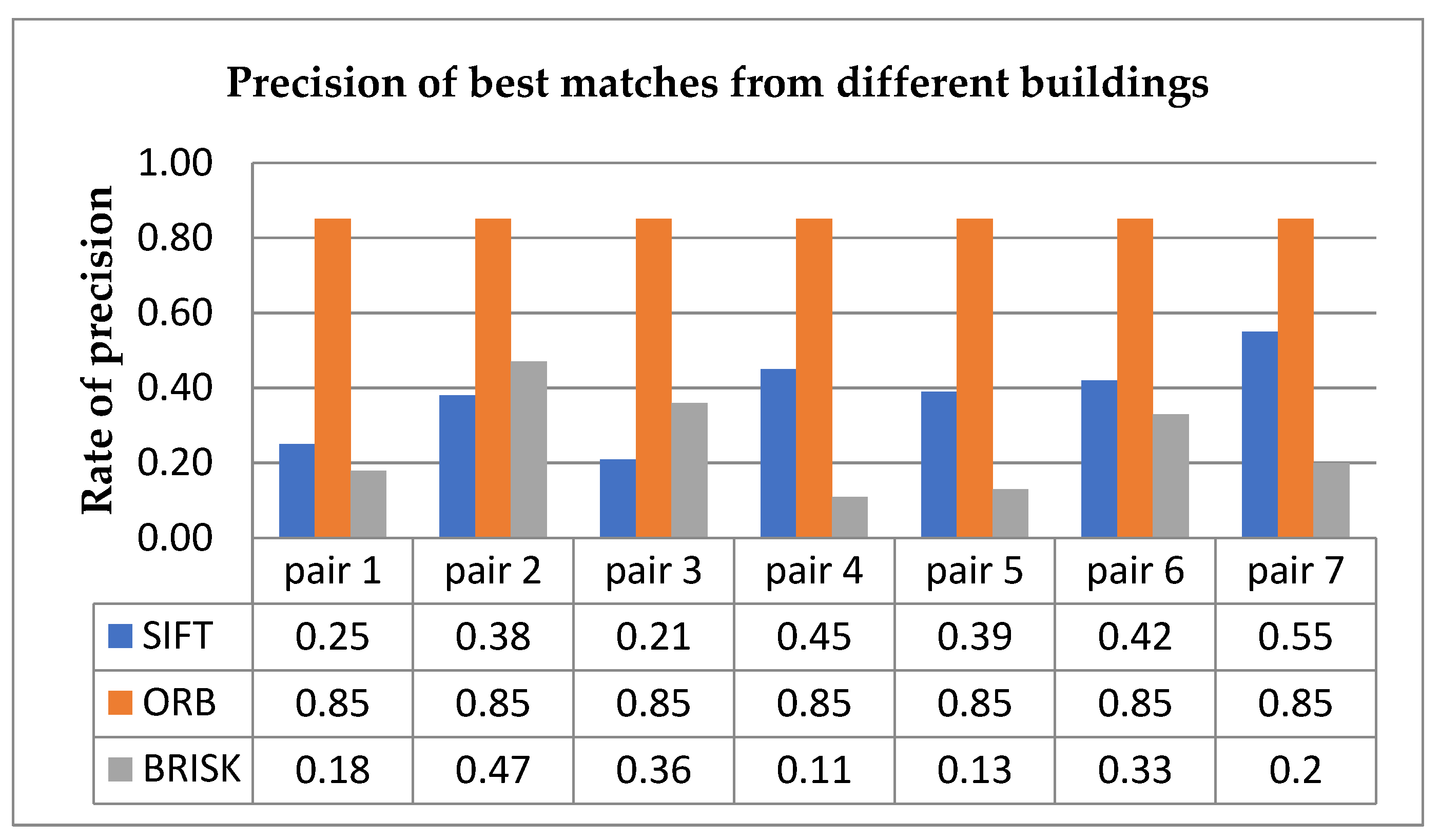
5.3. Feature Performance Evaluation
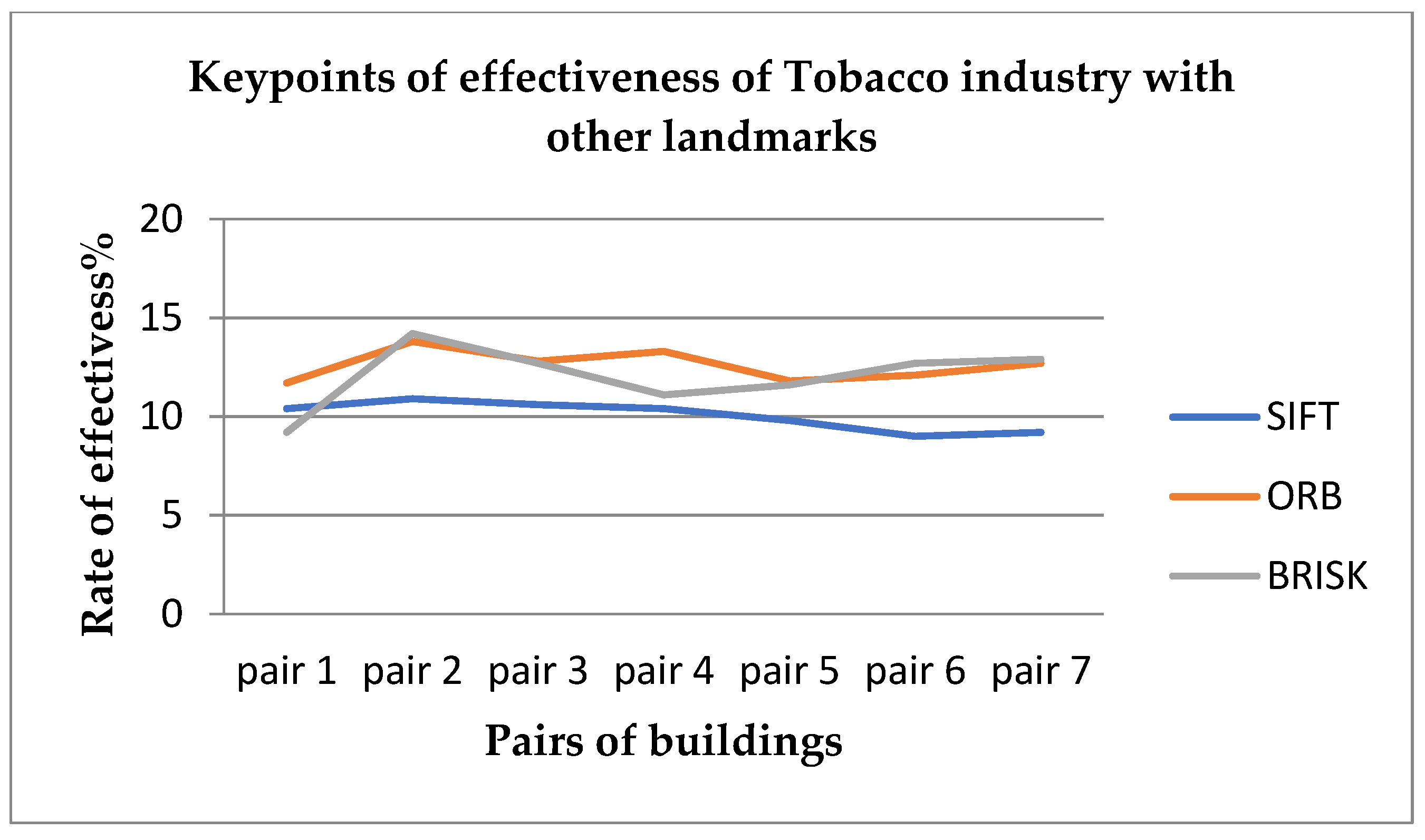
5.4. Efficient Keypoints Matching
Image Matching Accuracy
6. Discussion—Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Whitehead, A.; Opp, J. Timescapes: Putting History in Your Hip Pocket. In Proceedings of the Computers and Their Applications Conference CATA, Honolulu, HI, USA, 4–6 March 2013; pp. 261–266. [Google Scholar]
- Kabir, S.R.; Akhtaruzzaman, M.; Haque, R. Performance Analysis of Different Feature Detection Techniques for Modern and Old Buildings. In Proceedings of the 3rd International Conference on Recent Trends and Applications in Computer Science and Information Technology, Tiranë, Albania, 23 November 2018; pp. 120–127. [Google Scholar]
- Rebec, K.M.; Deanovič, B.; Oostwegel, L. Old Buildings Need New Ideas: Holistic Integration of Conservation-Restoration Process Data Using Heritage Building Information Modelling. J. Cult. Herit. 2022, 55, 30–42. [Google Scholar] [CrossRef]
- Mahinda, M.C.P.; Udhyani, H.P.A.J.; Alahakoon, P.M.K.; Kumara, W.G.C.W.; Hinas, M.N.A.; Thamboo, J.A. Development of An Effective 3D Mapping Technique for Heritage Structures. In Proceedings of the 2021 3rd International Conference on Electrical Engineering (EECon), Colombo, Sri Lanka, 24 September 2021; pp. 92–99. [Google Scholar] [CrossRef]
- Tuytelaars, T.; Mikolajczyk, K. Local Invariant Feature Detectors: A Survey. FNT Comput. Graph. Vis. 2007, 3, 177–280. [Google Scholar] [CrossRef] [Green Version]
- Santosh, D.; Achar, S.; Jawahar, C.V. Autonomous Image-Based Exploration for Mobile Robot Navigation. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation, Pasadena, CA, USA, 19–23 May 2008; pp. 2717–2722. [Google Scholar] [CrossRef]
- Milford, M.; McKinnon, D.; Warren, M.; Wyeth, G. Feature-based Visual Odometry and Featureless Place Recognition for SLAM in 2.5 D Environments. In Proceedings of the Australasian Conference on Robotics and Automation (ACRA 2011), Melbourne Australia, 7–9 December 2011; pp. 1–8. [Google Scholar]
- Sminchisescu, C.; Bo, L.; Ionescu, C.; Kanaujia, A. Feature-Based Pose Estimation. In Visual Analysis of Humans; Moeslund, T.B., Hilton, A., Krüger, V., Sigal, L., Eds.; Springer: London, UK, 2011; pp. 225–251. [Google Scholar] [CrossRef]
- Hu, Y. Research on a Three-Dimensional Reconstruction Method Based on the Feature Matching Algorithm of a Scale-Invariant Feature Transform. Math. Comput. Model. 2011, 54, 919–923. [Google Scholar] [CrossRef]
- Nixon, M.S.; Aguado, A.S. Feature Extraction and Image Processing, 1st ed.; Newnes: Oxford, UK; Boston, MA, USA, 2002. [Google Scholar]
- Amiri, M.; Rabiee, H.R. RASIM: A Novel Rotation and Scale Invariant Matching of Local Image Interest Points. IEEE Trans. Image Process. 2011, 20, 3580–3591. [Google Scholar] [CrossRef]
- Weng, D.; Wang, Y.; Gong, M.; Tao, D.; Wei, H.; Huang, D. DERF: Distinctive Efficient Robust Features From the Biological Modeling of the P Ganglion Cells. IEEE Trans. Image Process. 2015, 24, 2287–2302. [Google Scholar] [CrossRef]
- Levine, M.D. Feature Extraction: A Survey. Proc. IEEE 1969, 57, 1391–1407. [Google Scholar] [CrossRef]
- Ha, Y.-S.; Lee, J.; Kim, Y.-T. Performance Evaluation of Feature Matching Techniques for Detecting Reinforced Soil Retaining Wall Displacement. Remote Sens. 2022, 14, 1697. [Google Scholar] [CrossRef]
- Viola, P.; Wells III, W.M. Alignment by maximization of mutual information. Int. J. Comput. Vis. 1997, 24, 137–154. [Google Scholar] [CrossRef]
- Myronenko, A.; Song, X. Intensity-Based Image Registration by Minimizing Residual Complexity. IEEE Trans. Med. Imaging 2010, 29, 1882–1891. [Google Scholar] [CrossRef]
- Liu, X.; Tian, Z.; Ding, M. A Novel Adaptive Weights Proximity Matrix for Image Registration Based on R-SIFT. AEU-Int. J. Electron. Commun. 2011, 65, 1040–1049. [Google Scholar] [CrossRef]
- Leng, C.; Xiao, J.; Li, M.; Zhang, H. Robust Adaptive Principal Component Analysis Based on Intergraph Matrix for Medical Image Registration. Comput. Intell. Neurosci. 2015, 2015, 829528. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Friedrichs, K.; Münster, S.; Kröber, C.; Bruschke, J. Creating Suitable Tools for Art and Architectural Research with Historic Media Repositories. In Digital Research and Education in Architectural Heritage; Münster, S., Friedrichs, K., Niebling, F., Seidel-Grzesińska, A., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 817, pp. 117–138. [Google Scholar] [CrossRef]
- Ali, H.; Whitehead, A. Subset Selection for Landmark Modern and Historic Images. In Proceedings of the 2nd International Conference on Signal and Image Processing, Geneva, Switzerland, 21–22 March 2015; pp. 69–79. [Google Scholar] [CrossRef]
- Ali Heider, K.; Whitehead, A. Modern to Historic Image Matching: ORB/SURF an Effective Matching Technique. In Proceedings of the Computers and Their Applications, Las Vegas, NV, USA, 24–26 March 2014. [Google Scholar]
- Becker, A.-K.; Vornberger, O. Evaluation of Feature Detectors, Descriptors and Match Filtering Approaches for Historic Repeat Photography. In Image Analysis; Felsberg, M., Forssén, P.-E., Sintorn, I.-M., Unger, J., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 11482, pp. 374–386. [Google Scholar] [CrossRef]
- Anderson-Bell, J.; Schillaci, C.; Lipani, A. Predicting non-residential building fire risk using geospatial information and convolutional neural networks. Remote Sens. Appl. Soc. Environ. 2021, 21, 100470. [Google Scholar] [CrossRef]
- Agarwal, S.; Snavely, N.; Simon, I.; Seitz, S.M.; Szeliski, R. Building Rome in a Day. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 72–79. [Google Scholar] [CrossRef]
- Uttama, P.L.; Delalandre, Μ.; Ogier, J.M. Segmentation and Retrieval of Ancient Graphic Documents. In Graphics Recognition. Ten Years Review and Future Perspectives; Springer: Cham, Switzerland, 2006; pp. 88–98. [Google Scholar]
- Ali, H.; Whitehead, A. Feature Matching for Aligning Historical and Modern Images. Int. J. Comput. Appl. 2014, 21, 188–201. [Google Scholar]
- Wolfe, R. Modern to Historical Image Feature Matching. 2015. Available online: http://robbiewolfe.ca/programming/honoursproject/report.pdf (accessed on 3 February 2023).
- Wu, G.; Wang, Z.; Li, J.; Yu, Z.; Qiao, B. Contour-Based Historical Building Image Matching. In Proceedings of the 2nd International Symposium on Image Computing and Digital Medicine—ISICDM, Chengdu, China, 13–15 October 2018; ACM Press: Chengdu, China, 2018; pp. 32–36. [Google Scholar] [CrossRef]
- Hasan, M.S.; Ali, M.; Rahman, M.; Arju, H.A.; Alam, M.M.; Uddin, M.S.; Allayear, S.M. Heritage Building Era Detection Using CNN. IOP Conf. Ser. Mater. Sci. Eng. 2019, 617, 012016. [Google Scholar] [CrossRef]
- Maiwald, F.; Schneider, D.; Henze, F.; Münster, S.; Niebling, F. Feature matching of historical images based on geometry of quadrilaterals. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2018, XLII-2, 643–650. [Google Scholar] [CrossRef] [Green Version]
- Yue, L.; Li, H.; Zheng, X. Distorted Building Image Matching with Automatic Viewpoint Rectification and Fusion. Sensors 2019, 19, 5205. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Si, L.; Hu, X.; Liu, B. Image Matching Algorithm Based on the Pattern Recognition Genetic Algorithm. Comput. Intell. Neurosci. 2022, 2022, 7760437. [Google Scholar] [CrossRef]
- Edward, J.; Yang, G.-Z. RANSAC with 2D Geometric Cliques for Image Retrieval and Place Recognition. In Proceedings of the CVPR Workshop, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Avrithis, Y.; Tolias, G. Hough Pyramid Matching: Speeded-Up Geometry Re-Ranking for Large Scale Image Retrieval. Int. J. Comput Vis. 2014, 107, 1–19. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An Efficient Alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar] [CrossRef]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust Invariant Scalable Keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar] [CrossRef] [Green Version]
- Smith, S.M.; Brady, J.M. Susan-a new approach to low level image processing. Int. J. Comput. Vis. 1997, 23, 45–78. [Google Scholar] [CrossRef]
- Nixon, M.; Aguado, A. Feature Extraction & Image Processing for Computer Vision; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar] [CrossRef]
- Tsafrir, D.; Tsafrir, I.; Ein-Dor, L.; Zuk, O.; Notterman, D.A.; Domany, E. Sorting Points into Neighborhoods (SPIN): Data Analysis and Visualization by Ordering Distance Matrices. Bioinformatics 2005, 21, 2301–2308. [Google Scholar] [CrossRef] [Green Version]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference 1988; Alvey Vision Club: Manchester, UK, 1988; pp. 23.1–23.6. [Google Scholar] [CrossRef]
- Shi, F.; Huang, X.; Duan, Y. Robust Harris-Laplace Detector by Scale Multiplication. In Advances in Visual Computing; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Kuno, Y., Wang, J., Wang, J., Wang, J., Pajarola, R., Lindstrom, P., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5875, pp. 265–274. [Google Scholar] [CrossRef]
- Sarangi, S.; Sahidullah, M.; Saha, G. Optimization of Data-Driven Filterbank for Automatic Speaker Verification. Digit. Signal Process. 2020, 104, 102795. [Google Scholar] [CrossRef]
- Mutlag, W.K.; Ali, S.K.; Aydam, Z.M.; Taher, B.H. Feature Extraction Methods: A Review. J. Phys. Conf. Ser. 2020, 1591, 012028. [Google Scholar] [CrossRef]
- Kumar, G.; Bhatia, P.K. A Detailed Review of Feature Extraction in Image Processing Systems. In Proceedings of the 2014 Fourth International Conference on Advanced Computing & Communication Technologies, Rohtak, India, 8–9 February 2014; pp. 5–12. [Google Scholar] [CrossRef]
- Wang, X.; Jabri, A.; Efros, A.A. Learning Correspondence from the Cycle-Consistency of Time. Comput. Vis. Pattern Recognit. 2019, 2566–2576. [Google Scholar] [CrossRef]
- Muhammad, U.; Tanvir, M.; Khurshid, K. Feature Based Correspondence: A Comparative Study on Image Matching Algorithms. Int. J. Adv. Comput. Sci. Appl. 2016, 7. [Google Scholar] [CrossRef] [Green Version]
- Zhao, C.; Cao, Z.; Yang, J.; Xian, K.; Li, X. Image Feature Correspondence Selection: A Comparative Study and a New Contribution. IEEE Trans. Image Process. 2020, 29, 3506–3519. [Google Scholar] [CrossRef]
- Howe, P.D.; Livingstone, M.S. Binocular Vision and the Correspondence Problem. J. Vis. 2005, 5, 800. [Google Scholar] [CrossRef]
- Torresani, L.; Kolmogorov, V.; Rother, C. Feature Correspondence Via Graph Matching: Models and Global Optimization. In Computer Vision—ECCV 2008; Forsyth, D., Torr, P., Zisserman, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5303, pp. 596–609. [Google Scholar] [CrossRef]
- Kolmogorov, V.; Zabih, R. Computing Visual Correspondence with Occlusions Using Graph Cuts. In Proceedings of the Eighth IEEE International Conference on Computer Vision. ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 508–515. [Google Scholar] [CrossRef] [Green Version]
- Kabbai, L.; Abdellaoui, M.; Douik, A. Image Classification by Combining Local and Global Features. Vis. Comput. 2019, 35, 679–693. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Mikolajczyk, K. Scale & Affine Invariant Interest Point Detectors. Int. J. Comput. Vis. 2004, 60, 63–86. [Google Scholar] [CrossRef]
- Keyvanpour, M.R.; Vahidian, S.; Ramezani, M. HMR-Vid: A Comparative Analytical Survey on Human Motion Recognition in Video Data. Multimed. Tools Appl. 2020, 79, 31819–31863. [Google Scholar] [CrossRef]
- Chen, L.; Rottensteiner, F.; Heipke, C. Feature Detection and Description for Image Matching: From Hand-Crafted Design to Deep Learning. Geo-Spat. Inf. Sci. 2021, 24, 58–74. [Google Scholar] [CrossRef]
- Krig, S. Interest Point Detector and Feature Descriptor Survey. In Computer Vision Metrics; Springer International Publishing: Cham, Switzerland, 2016; pp. 187–246. [Google Scholar] [CrossRef]
- Hassaballah, M.; Abdelmgeid, A.A.; Alshazly, H.A. Image Features Detection, Description and Matching. In Image Feature Detectors and Descriptors; Awad, A.I., Hassaballah, M., Eds.; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2016; Volume 630, pp. 11–45. [Google Scholar] [CrossRef]
- Leng, C.; Zhang, H.; Li, B.; Cai, G.; Pei, Z.; He, L. Local Feature Descriptor for Image Matching: A Survey. IEEE Access 2019, 7, 6424–6434. [Google Scholar] [CrossRef]
- González-Aguilera, D.; Ruiz de Oña, E.; López-Fernandez, L.; Farella, E.; Stathopoulou, E.K.; Toschi, I.; Remondino, F.; Rodríguez-Gonzálvez, P.; Hernández-López, D.; Fusiello, A.; et al. Photomatch: An open-source multi-view and multi-modal feature matching tool for photogrammetric applications. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2020, XLIII-B5-2020, 213–219. [Google Scholar] [CrossRef]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-Free Local Feature Matching with Transformers. Comput. Vis. Pattern Recognit. 2021, 8922–8931. [Google Scholar] [CrossRef]
- Zitová, B.; Flusser, J. Image Registration Methods: A Survey. Image and Vision Computing 2003, 21, 977–1000. [Google Scholar] [CrossRef] [Green Version]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Flusser, J.; Suk, T. A Moment-Based Approach to Registration of Images with Affine Geometric Distortion. IEEE Trans. Geosci. Remote Sens. 1994, 32, 382–387. [Google Scholar] [CrossRef]
- Goshtasby, A.; Stockman, G.; Page, C. A Region-Based Approach to Digital Image Registration with Subpixel Accuracy. IEEE Trans. Geosci. Remote Sens. 1986, GE-24, 390–399. [Google Scholar] [CrossRef]
- Hsieh, Y.C.; McKeown, D.M.; Perlant, F.P. Performance Evaluation of Scene Registration and Stereo Matching for Cartographic Feature Extraction. IEEE Trans. Pattern Anal. Machine Intell. 1992, 14, 214–238. [Google Scholar] [CrossRef] [Green Version]
- Hellier, P.; Barillot, C. Coupling Dense and Landmark-Based Approaches for Nonrigid Registration. IEEE Trans. Med. Imaging 2003, 22, 217–227. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. A Performance Evaluation of Local Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Noble, F.K. Comparison of OpenCV’s Feature Detectors and Feature Matchers. In Proceedings of the 2016 23rd International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Nanjing, China, 28–30 November 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Dhana Lakshmi, M.; Mirunalini, P.; Priyadharsini, R.; Mirnalinee, T.T. Review of Feature Extraction and Matching Methods for Drone Image Stitching. In Proceedings of the International Conference on ISMAC in Computational Vision and Bio-Engineering 2018 (ISMAC-CVB), Palladam, India, 16–17 May 2018; Pandian, D., Fernando, X., Baig, Z., Shi, F., Eds.; Lecture Notes in Computational Vision and Biomechanics; Springer International Publishing: Cham, Switzerland, 2019; Volume 30, pp. 595–602. [Google Scholar] [CrossRef]
- Spasova, V.G. Experimental evaluation of keypoints detector and descriptor algorithms for indoors person localization. Annu. J. Electron. 2014, 8, 85–87. [Google Scholar]
- Vijayan, V.; Kp, P. FLANN Based Matching with SIFT Descriptors for Drowsy Features Extraction. In Proceedings of the 2019 Fifth International Conference on Image Information Processing (ICIIP), Shimla, India, 15–17 November 2019; pp. 600–605. [Google Scholar] [CrossRef]
- Luo, Z.; Zhou, L.; Bai, X.; Chen, H.; Zhang, J.; Yao, Y.; Li, S.; Fang, T.; Quan, L. ASLFeat: Learning Local Features of Accurate Shape and Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In Computer Vision—ECCV 2006; Leonardis, A., Bischof, H., Pinz, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 430–443. [Google Scholar] [CrossRef]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Computer Vision—ECCV 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6314, pp. 778–792. [Google Scholar] [CrossRef] [Green Version]
- Martin, K.A.C. A BRIEF History of the “Feature Detector”. Cereb Cortex 1994, 4, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Tareen, S.A.K.; Saleem, Z. A Comparative Analysis of SIFT, SURF, KAZE, AKAZE, ORB, and BRISK. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018; pp. 1–10. [Google Scholar] [CrossRef]
- Azimi, E.; Behrad, A.; Ghaznavi-Ghoushchi, M.B.; Shanbehzadeh, J. A Fully Pipelined and Parallel Hardware Architecture for Real-Time BRISK Salient Point Extraction. J. Real-Time Image Proc. 2019, 16, 1859–1879. [Google Scholar] [CrossRef]
- Awad, A.I.; Hassaballah, M. (Eds.) Image Feature Detectors and Descriptors: Foundations and Applications. In Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2016; Volume 630. [Google Scholar] [CrossRef]
- Chen, J.; Shan, S.; He, C.; Zhao, G.; Pietikäinen, M.; Chen, X.; Gao, W. WLD: A Robust Local Image Descriptor. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1705–1720. [Google Scholar] [CrossRef]
- Zhang, H.; Wohlfeil, J.; Grießbach, D. Extension and evaluation of the AGAST feature detector. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2016, III–4, 133–137. [Google Scholar] [CrossRef] [Green Version]
- Xiong, X.; Choi, B.-J. Comparative Analysis of Detection Algorithms for Corner and Blob Features in Image Processing. Int. J. Fuzzy Log. Intell. Syst. 2013, 13, 284–290. [Google Scholar] [CrossRef] [Green Version]
- Ghafoor, A.; Iqbal, R.N.; Khan, S. Robust Image Matching Algorithm. In Proceedings of the 4th EURASIP Conference focused on Video/Image Processing and Multimedia Communications (IEEE Cat. No.03EX667), Zagreb, Croatia, 2–5 July 2003; Volume 1, pp. 155–160. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Jakubovic, A.; Velagic, J. Image Feature Matching and Object Detection Using Brute-Force Matchers. In Proceedings of the 2018 International Symposium ELMAR, Zadar, Croatia, 16–19 September 2018; pp. 83–86. [Google Scholar] [CrossRef]
- Norouzi, M.; Fleet, D.J.; Salakhutdinov, R.R. Hamming distance metric learning. In Proceedings of the Neural Information Processing Systems (NeurIPS 2012), Lake Tahoe, NV, USA, 3–8 December 2012; Volume 25, pp. 1061–1069. [Google Scholar]
- Lu, Y.; Liu, A.-A.; Su, Y.-T. Detection in Biomedical Images. In Computer Vision for Microscopy Image Analysis; Elsevier: Amsterdam, The Netherlands, 2021; pp. 131–157. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Properties | SIFT (2004) | ORB (2011) | BRISK (2011) |
|---|---|---|---|
| Operators | (a) Detecting keypoints from the multi-scale image space, presented by difference-of-Gaussians (DoG) operator (i.e., approximation of Laplacian-of-Gaussian (LoG)), (b) Keypoint point localization by removing low-contrast and those on edge, (c) assigning orientations to each keypoint based on an orientation histogram, weighted by gradient magnitude and Gaussian-weighted circular window, and (d) providing a unique and robust keypoint descriptor by considering the neighborhood around the keypoint and its orientation histogram [33] | It is a combination of modified FAST (Features from Accelerated Segment Test) which detects corner objects as candidate points, and the Harris Corner score is then utilized to refine them from low-quality points. [73], detection and BRIEF (binary robust independent elementary features) descriptor [74] | It first extracts corners as feature point candidates using the AGAST algorithm [74] and then refines them with the FAST corner score in each scale-space pyramid layer. The illumination robust and rotation invariant descriptor has been generated based on each feature’s characteristic direction and simple brightness tests [37] |
| Keypoints | DoG [57,78] | FAST [79] | AGAST [80] |
| Detectors type | Blob [81] | Corner [82] | Corner [82] |
| Descriptors |  |  |  |
| Descriptors type and length | Integer vector 128 bytes [35] | Binary string 256 bits [36] | Binary string 64 bytes [37] |
| Encode information | Gradient-based descriptor [83,84] | Intensity-based descriptor [16] | Intensity-based descriptor [16] |
| Scale invariant | Yes | Yes (achievable via an image pyramid) | Yes |
| Rotation invariant | Yes | Yes (achievable via intensity centroid) | Yes |
| Distance matching | Euclidean [85] | Hamming [86] | Hamming [86] |
| Constraints | Limited affine changes, high computational cost | Limited affine changes | Limited affine changes, error rate does not exist |
| Strong points | Robust to illumination fluctuations, noise, Partial occlusion, and minor viewpoint changes in the images [87] | Very Fast, Reduce sensitivity to noise | Robust to noise and affine performance |
| Algorithms | Default Parameters | Modified Parameters Trial and Error |
|---|---|---|
| SIFT | nfeatures = 0, nOctaveLayers = 3, contrastThreshold = 0.04, edgeThreshold = 10, sigma = 1.6, ratio = 0.7 | nfeatures = 0, nOctaveLayers = 4, contrastThreshold = 0.05, edgeThreshold = 8, sigma = 1.5, ratio = 0.85 |
| ORB | nfeatures = 500, scaleFactor = 1.2, nlevels = 8, scoreType = cv.ORB_HARRIS_SCORE, edgeThreshold = 31, firstlevel = 0, scoreType:Harris_score, patchsize = 31, WTA_K = 2, FastThreshold = 20, ratio = 0.7 | nfeatures = 5000, scaleFactor = 1.5, nlevels = 8, scoreType = cv.ORB_HARRIS_SCORE, edgeThreshold = 31, firstLevel = 0, WTA_K = 2, patchSize = 31, FastThreshold = 20, ratio = 0.85 |
| BRISK | threshold = 30, octaves = 3, patternScale = 1.0, ratio = 0.7 | thresh = 40, octaves = 2, patternScale = 1.0, ratio = 0.85 |
| Algorithms | Total Keypoints | Total Matches | Runtime (s) |
|---|---|---|---|
| SIFT | 76,192 | 25,246 | 44.18 |
| ORB | 169,233 | 21,017 | 31.64 |
| BRISK | 101,074 | 14,881 | 10.93 |
| Buildings | Algorithms | Keypoints | Total Matches | Runtime (s) | |
|---|---|---|---|---|---|
| Image 1 | Image 2 | ||||
| Pair 1 | SIFT | 1428 | 900 | 297 | 2.00 |
| ORB | 2011 | 3672 | 606 | 2.70 | |
| BRISK | 1242 | 2824 | 375 | 0.72 | |
| Pair 2 | SIFT | 1586 | 1345 | 320 | 3.16 |
| ORB | 2514 | 1978 | 623 | 2.10 | |
| BRISK | 1282 | 586 | 265 | 0.43 | |
| Pair 3 | SIFT | 2532 | 1497 | 177 | 2.34 |
| ORB | 3424 | 2462 | 754 | 1.93 | |
| BRISK | 1329 | 894 | 282 | 0.91 | |
| Pair 4 | SIFT | 1579 | 2000 | 372 | 1.78 |
| ORB | 3096 | 3527 | 880 | 1.54 | |
| BRISK | 1126 | 3382 | 502 | 0.75 | |
| Pair 5 | SIFT | 1586 | 1158 | 268 | 1.40 |
| ORB | 2514 | 3184 | 674 | 1.76 | |
| BRISK | 1282 | 2958 | 492 | 0.65 | |
| Pair 6 | SIFT | 1042 | 1010 | 183 | 1.12 |
| ORB | 1743 | 1824 | 434 | 1.93 | |
| BRISK | 309 | 549 | 109 | 0.42 | |
| Pair 7 | SIFT | 1586 | 1010 | 240 | 1.22 |
| ORB | 2514 | 1824 | 553 | 1.75 | |
| BRISK | 1282 | 549 | 236 | 0.85 | |
| Buildings | SIFT | ORB | BRISK |
|---|---|---|---|
| Pair 1 | 97.67 | 51.47 | 68.00 |
| Pair 2 | 100.00 | 58.58 | 100.00 |
| Pair 3 | 93.55 | 74.74 | 93.00 |
| Pair 4 | 100.00 | 96.63 | 100.00 |
| Pair 5 | 100.00 | 97.75 | 97.06 |
| Pair 6 | 98.88 | 99.23 | 92.90 |
| Pair 7 | 94.74 | 82.05 | 26.14 |
| Pair 8 | 100.00 | 91.63 | 100.00 |
| Pair 9 | 100.00 | 99.17 | 100.00 |
| Pair 9 | 84.90 | 55.41 | 86.99 |
| Pair 11 | 21.80 | 42.16 | 33.86 |
| Pair 12 | 7.57 | 20.95 | 44.14 |
| Pair 13 | 10.18 | 18.21 | 37.59 |
| Pair 14 | 15.48 | 10.77 | 35.01 |
| Pair 15 | 24.90 | 10.33 | 51.67 |
| Pair 16 | 47.44 | 52.35 | 77.30 |
| Pair 17 | 71.56 | 40.37 | 79.19 |
| Pair 18 | 53.39 | 11.48 | 39.09 |
| Pair 19 | 62.90 | 44.23 | 38.36 |
| Pair 20 | 68.32 | 67.82 | 94.52 |
| Pair 21 | 25.51 | 12.96 | 34.48 |
| Pair 22 | 27.69 | 8.57 | 24.28 |
| Pair 23 | 32.06 | 39.25 | 70.62 |
| Pair 24 | 23.62 | 13.85 | 64.47 |
| Pair 25 | 100.00 | 85.89 | 98.71 |
| Pair 26 | 94.12 | 71.76 | 92.06 |
| Pair 27 | 41.45 | 60.92 | 96.08 |
| Pair 28 | 90.86 | 95.95 | 90.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tychola, K.A.; Chatzistamatis, S.; Vrochidou, E.; Tsekouras, G.E.; Papakostas, G.A. Identifying Historic Buildings over Time through Image Matching. Technologies 2023, 11, 32. https://doi.org/10.3390/technologies11010032
Tychola KA, Chatzistamatis S, Vrochidou E, Tsekouras GE, Papakostas GA. Identifying Historic Buildings over Time through Image Matching. Technologies. 2023; 11(1):32. https://doi.org/10.3390/technologies11010032
Chicago/Turabian StyleTychola, Kyriaki A., Stamatis Chatzistamatis, Eleni Vrochidou, George E. Tsekouras, and George A. Papakostas. 2023. "Identifying Historic Buildings over Time through Image Matching" Technologies 11, no. 1: 32. https://doi.org/10.3390/technologies11010032
APA StyleTychola, K. A., Chatzistamatis, S., Vrochidou, E., Tsekouras, G. E., & Papakostas, G. A. (2023). Identifying Historic Buildings over Time through Image Matching. Technologies, 11(1), 32. https://doi.org/10.3390/technologies11010032