
Towards Safe Visual Navigation of a Wheelchair Using Landmark Detection

 , ,
, ,  ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
3. Method Description
- An input image was masked at random locations at a high masking ratio, roughly 75%;
- An encoder (ViT) was applied on the visible parts of the image;
- The decoder operated on both the encoded paths and the masked tokens;
- Missing pixels were constructed.
4. Experimental Setup
4.1. Hardware
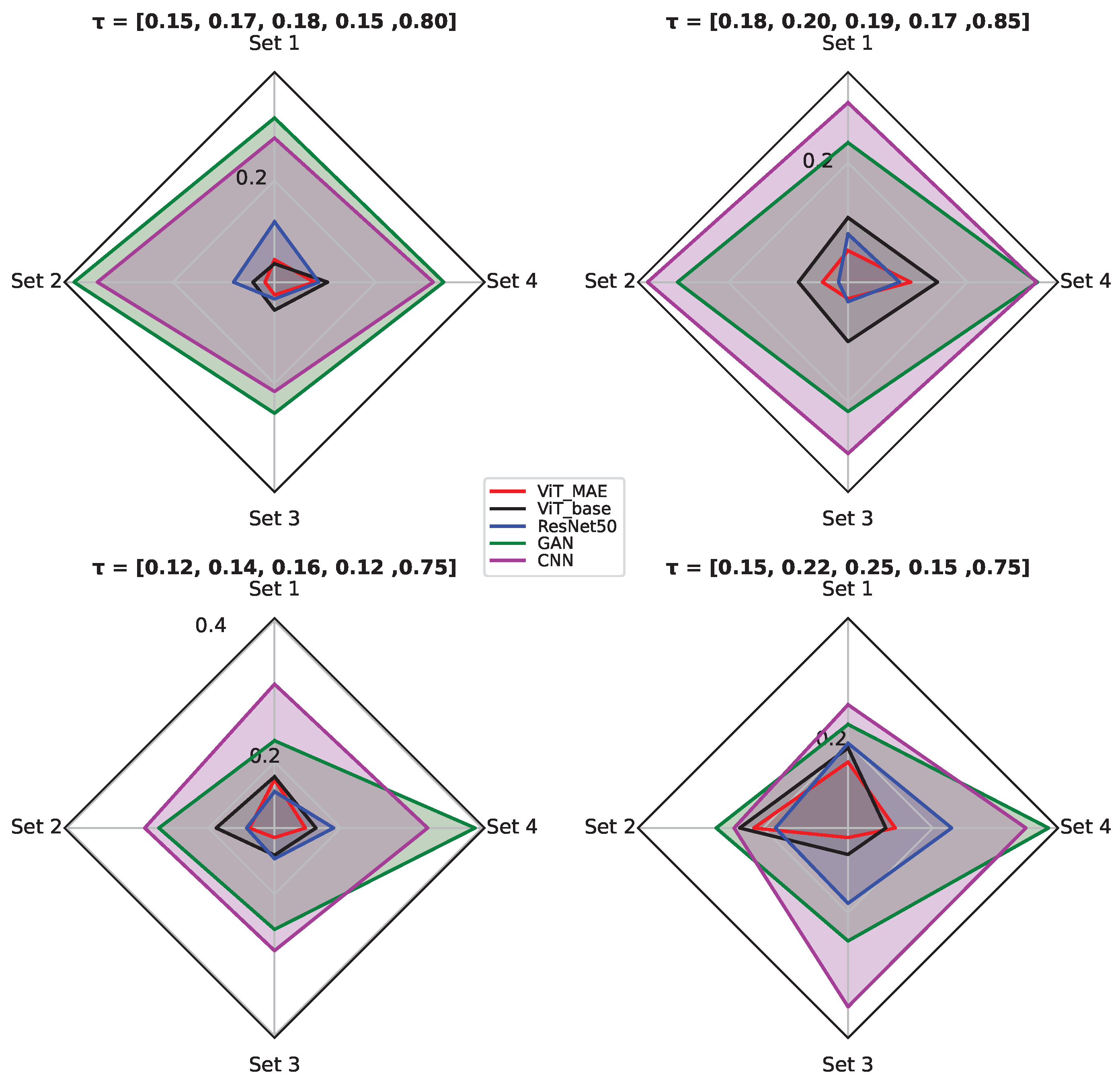
- Set 1: Hallway, desks, bright ambiance lighting, moving humans, wider staircases;
- Set 2: Hallway, desks/chairs, brick walls, static/moving humans, brighter ambiance lighting;
- Set 3: Normal ambiance lighting, moving humans, chairs/tables, narrower staircases;
- Set 4: Darker ambiance colors, bookshelves, conference room, desks.


4.2. Data Collection and Processing
4.3. Fine-Tuning
5. Ablation Study
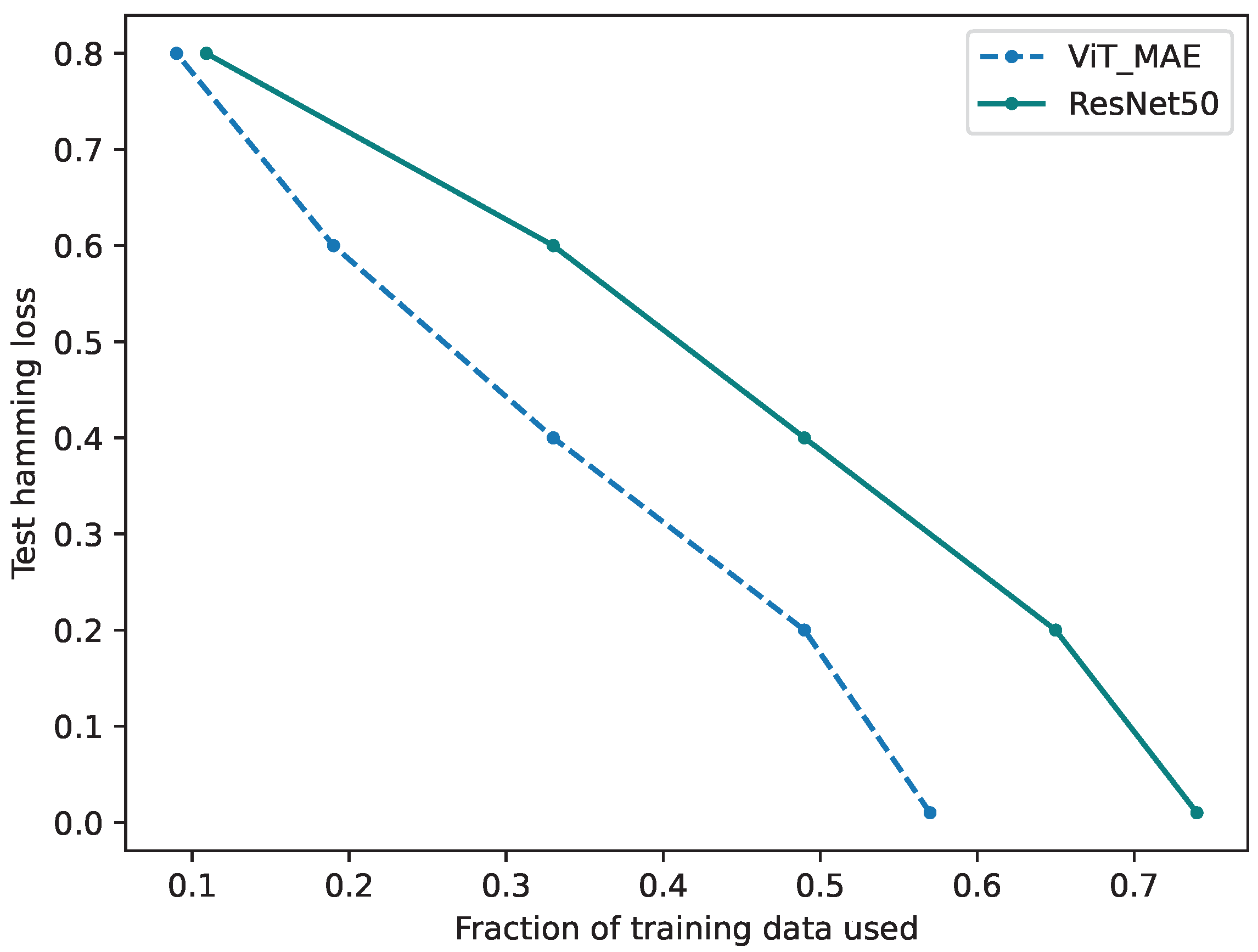
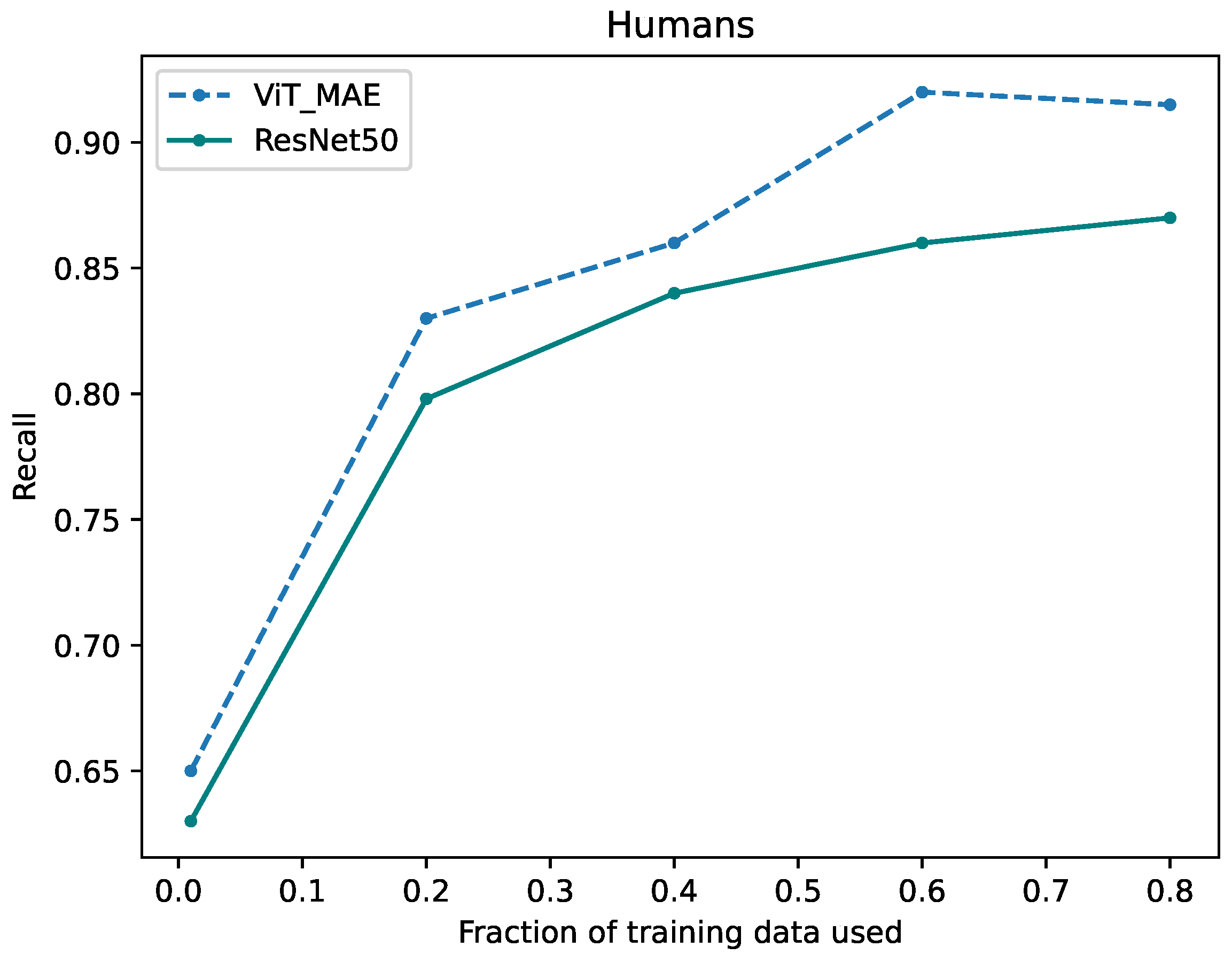
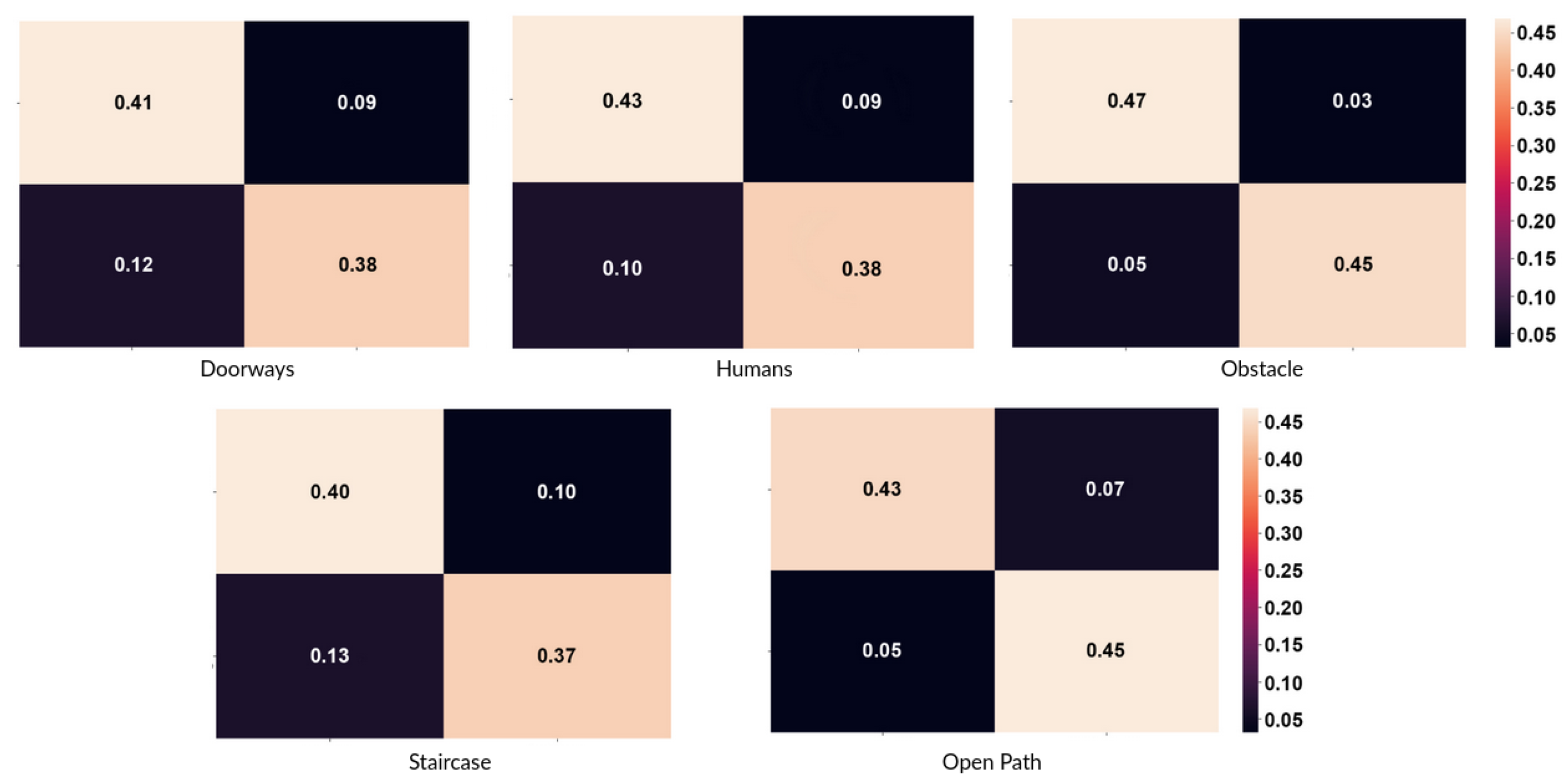
6. Results
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sevastopoulos, C.; Konstantopoulos, S. A survey of traversability estimation for mobile robots. IEEE Access 2022, 10, 96331–96347. [Google Scholar] [CrossRef]
- Leaman, J.; La, H.M. A comprehensive review of smart wheelchairs: Past, present, and future. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 486–499. [Google Scholar] [CrossRef]
- Podobnik, J.; Rejc, J.; Slajpah, S.; Munih, M.; Mihelj, M. All-terrain wheelchair: Increasing personal mobility with a powered wheel-track hybrid wheelchair. IEEE Robot. Autom. Mag. 2017, 24, 26–36. [Google Scholar] [CrossRef]
- Pasteau, F.; Narayanan, V.K.; Babel, M.; Chaumette, F. A visual servoing approach for autonomous corridor following and doorway passing in a wheelchair. Robot. Auton. Syst. 2016, 75, 28–40. [Google Scholar] [CrossRef]
- Delmerico, J.A.; Baran, D.; David, P.; Ryde, J.; Corso, J.J. Ascending stairway modeling from dense depth imagery for traversability analysis. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 2283–2290. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Trahanias, P.E.; Lourakis, M.I.; Argyros, S.; Orphanoudakis, S.C. Navigational support for robotic wheelchair platforms: An approach that combines vision and range sensors. In Proceedings of the International Conference on Robotics and Automation, Albuquerque, NM, USA, 25 April 1997; Volume 2, pp. 1265–1270. [Google Scholar]
- Horn, O.; Kreutner, M. Smart wheelchair perception using odometry, ultrasound sensors, and camera. Robotica 2009, 27, 303–310. [Google Scholar] [CrossRef]
- Trujillo-León, A.; Vidal-Verdú, F. Driving interface based on tactile sensors for electric wheelchairs or trolleys. Sensors 2014, 14, 2644–2662. [Google Scholar] [CrossRef]
- Kurata, J.; Grattan, K.T.; Uchiyama, H. Navigation system for a mobile robot with a visual sensor using a fish-eye lens. Rev. Sci. Instrum. 1998, 69, 585–590. [Google Scholar] [CrossRef]
- Ha, V.K.L.; Chai, R.; Nguyen, H.T. A telepresence wheelchair with 360-degree vision using WebRTC. Appl. Sci. 2020, 10, 369. [Google Scholar] [CrossRef]
- Delmas, S.; Morbidi, F.; Caron, G.; Albrand, J.; Jeanne-Rose, M.; Devigne, L.; Babel, M. SpheriCol: A Driving Assistance System for Power Wheelchairs Based on Spherical Vision and Range Measurements. In Proceedings of the 2021 IEEE/SICE International Symposium on System Integration (SII), Iwaki, Japan, 11–14 January 2021; pp. 505–510. [Google Scholar]
- Lecrosnier, L.; Khemmar, R.; Ragot, N.; Decoux, B.; Rossi, R.; Kefi, N.; Ertaud, J.Y. Deep learning-based object detection, localisation and tracking for smart wheelchair healthcare mobility. Int. J. Environ. Res. Public Health 2021, 18, 91. [Google Scholar] [CrossRef]
- Duan, Z.; Tezcan, O.; Nakamura, H.; Ishwar, P.; Konrad, J. RAPiD: Rotation-aware people detection in overhead fisheye images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 636–637. [Google Scholar]
- Hirose, N.; Sadeghian, A.; Vázquez, M.; Goebel, P.; Savarese, S. Gonet: A semi-supervised deep learning approach for traversability estimation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3044–3051. [Google Scholar]
- Caruso, D.; Engel, J.; Cremers, D. Large-scale direct slam for omnidirectional cameras. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–3 October 2015; pp. 141–148. [Google Scholar]
- Bertozzi, M.; Castangia, L.; Cattani, S.; Prioletti, A.; Versari, P. 360 detection and tracking algorithm of both pedestrian and vehicle using fisheye images. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (iv), Seoul, Republic of Korea, 28 June–1 July 2015; pp. 132–137. [Google Scholar]
- Yogamani, S.; Hughes, C.; Horgan, J.; Sistu, G.; Varley, P.; O’Dea, D.; Uricár, M.; Milz, S.; Simon, M.; Amende, K.; et al. Woodscape: A multi-task, multi-camera fisheye dataset for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9308–9318. [Google Scholar]
- Yoon, H.Y.; Kim, J.H.; Jeong, J.W. Classification of the Sidewalk Condition Using Self-Supervised Transfer Learning for Wheelchair Safety Driving. Sensors 2022, 22, 380. [Google Scholar] [CrossRef] [PubMed]
- Goh, E.; Chen, J.; Wilson, B. Mars Terrain Segmentation with Less Labels. arXiv 2022, arXiv:2202.00791. [Google Scholar]
- Gao, B.; Hu, S.; Zhao, X.; Zhao, H. Fine-grained off-road semantic segmentation and mapping via contrastive learning. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 5950–5957. [Google Scholar]
- Shah, D.; Levine, S. Viking: Vision-based kilometer-scale navigation with geographic hints. arXiv 2022, arXiv:2202.11271. [Google Scholar]
- Wang, W.; Wang, N.; Wu, X.; You, S.; Neumann, U. Self-paced cross-modality transfer learning for efficient road segmentation. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1394–1401. [Google Scholar]
- Huh, M.; Agrawal, P.; Efros, A.A. What makes ImageNet good for transfer learning? arXiv 2016, arXiv:1608.08614. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27, 3320–3328. [Google Scholar] [CrossRef]
- Mokrenko, V.; Yu, H.; Raychoudhury, V.; Edinger, J.; Smith, R.O.; Gani, M.O. A Transfer Learning Approach to Surface Detection for Accessible Routing for Wheelchair Users. In Proceedings of the 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 12–16 July 2021; pp. 794–803. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Bednarek, M.; Łysakowski, M.; Bednarek, J.; Nowicki, M.R.; Walas, K. Fast haptic terrain classification for legged robots using transformer. In Proceedings of the 2021 European Conference on Mobile Robots (ECMR), Bonn, Germany, 31 August–3 September 2021; pp. 1–7. [Google Scholar]
- Chen, K.; Chen, J.K.; Chuang, J.; Vázquez, M.; Savarese, S. Topological planning with transformers for vision-and-language navigation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11276–11286. [Google Scholar]
- Wang, R.; Shen, Y.; Zuo, W.; Zhou, S.; Zheng, N. TransVPR: Transformer-based place recognition with multi-level attention aggregation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13648–13657. [Google Scholar]
- Dutta, P.; Sistu, G.; Yogamani, S.; Galván, E.; McDonald, J. ViT-BEVSeg: A Hierarchical Transformer Network for Monocular Birds-Eye-View Segmentation. arXiv 2022, arXiv:2205.15667. [Google Scholar]
- Antonazzi, M.; Luperto, M.; Basilico, N.; Borghese, N.A. Enhancing Door Detection for Autonomous Mobile Robots with Environment-Specific Data Collection. arXiv 2022, arXiv:2203.03959. [Google Scholar]
- Bhojanapalli, S.; Chakrabarti, A.; Glasner, D.; Li, D.; Unterthiner, T.; Veit, A. Understanding robustness of transformers for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10231–10241. [Google Scholar]
- Chen, C.F.R.; Fan, Q.; Panda, R. Crossvit: Cross-attention multi-scale vision transformer for image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 357–366. [Google Scholar]
- Chen, X.; Hsieh, C.J.; Gong, B. When vision transformers outperform ResNets without pre-training or strong data augmentations. arXiv 2021, arXiv:2106.01548. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Beer, J.M.; Fisk, A.D.; Rogers, W.A. Toward a framework for levels of robot autonomy in human-robot interaction. J. Hum.-Robot Interact. 2014, 3, 74. [Google Scholar] [PubMed]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16000–16009. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tsoumakas, G.; Katakis, I. Multi-label classification: An overview. Int. J. Data Warehous. Min. (IJDWM) 2007, 3, 1–13. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sevastopoulos, C.; Zadeh, M.Z.; Theofanidis, M.; Acharya, S.; Patel, N.; Makedon, F. Towards Safe Visual Navigation of a Wheelchair Using Landmark Detection. Technologies 2023, 11, 64. https://doi.org/10.3390/technologies11030064
Sevastopoulos C, Zadeh MZ, Theofanidis M, Acharya S, Patel N, Makedon F. Towards Safe Visual Navigation of a Wheelchair Using Landmark Detection. Technologies. 2023; 11(3):64. https://doi.org/10.3390/technologies11030064
Chicago/Turabian StyleSevastopoulos, Christos, Mohammad Zaki Zadeh, Michail Theofanidis, Sneh Acharya, Nishi Patel, and Fillia Makedon. 2023. "Towards Safe Visual Navigation of a Wheelchair Using Landmark Detection" Technologies 11, no. 3: 64. https://doi.org/10.3390/technologies11030064
APA StyleSevastopoulos, C., Zadeh, M. Z., Theofanidis, M., Acharya, S., Patel, N., & Makedon, F. (2023). Towards Safe Visual Navigation of a Wheelchair Using Landmark Detection. Technologies, 11(3), 64. https://doi.org/10.3390/technologies11030064