
Tendency on the Application of Drill-Down Analysis in Scientific Studies: A Systematic Review

 ,
,  , and
, and 
Abstract
:1. Introduction
2. Theoretical Fundaments
2.1. DD Analysis
- To use a model more flexible than it should be, and
- To over-represent performance on a dataset.
- Early-stopping, which prevents the algorithm precision to stop improving after a certain point.
- Network-reduction, which is about reducing the noise amount when reducing the classification model size.
- Training-data expansion, which is to improve the training dataset quantity and quality, especially in supervised learning areas.
2.2. Deterministic Models
- Linear programming;
- Entire mixed linear programming;
- Algorithms.
3. Materials and Methods
3.1. Data Source
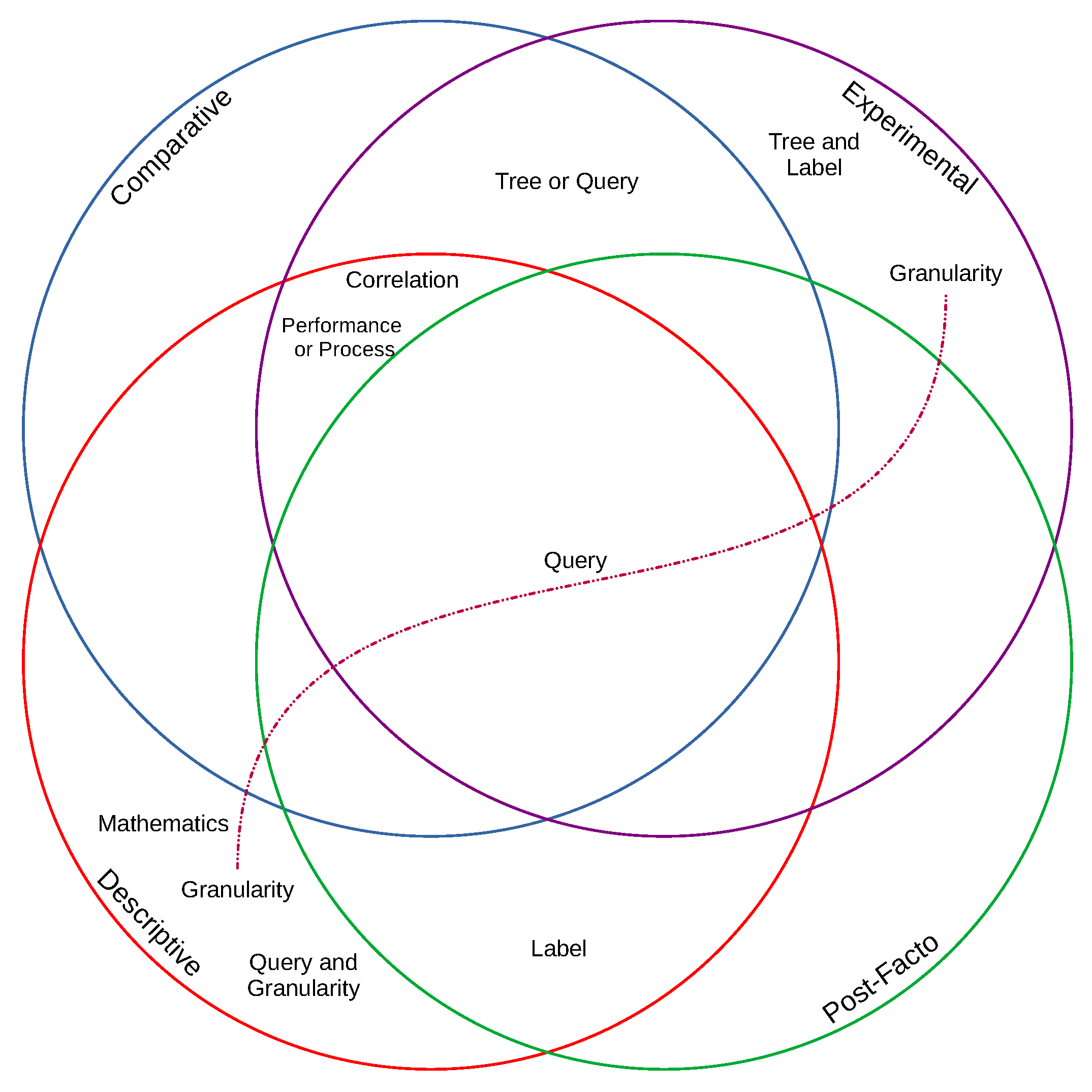
3.2. Works Clustered by Methodology
3.2.1. Tree
3.2.2. Query
3.2.3. Correlation
3.2.4. Granularity
3.3. Normalizing
3.4. Variable Definition
- The sum of works will establish the quantity of knowledge around the DD analysis on the scientific community. The denominator is the sum of time defined during the process [29].
- The modal will indicate the year the technique was more utilized and that it will be compared with the new knowledge stagnation or the absence of ANN techniques.
- Sum of problems solved and problems not solved will determine the proportionality of the successful method and the causes responsible for its no- usage in subsequent works. In set theory, this is represented by the method, which belongs to the objective searched.
3.5. Dataset and Software
4. Results
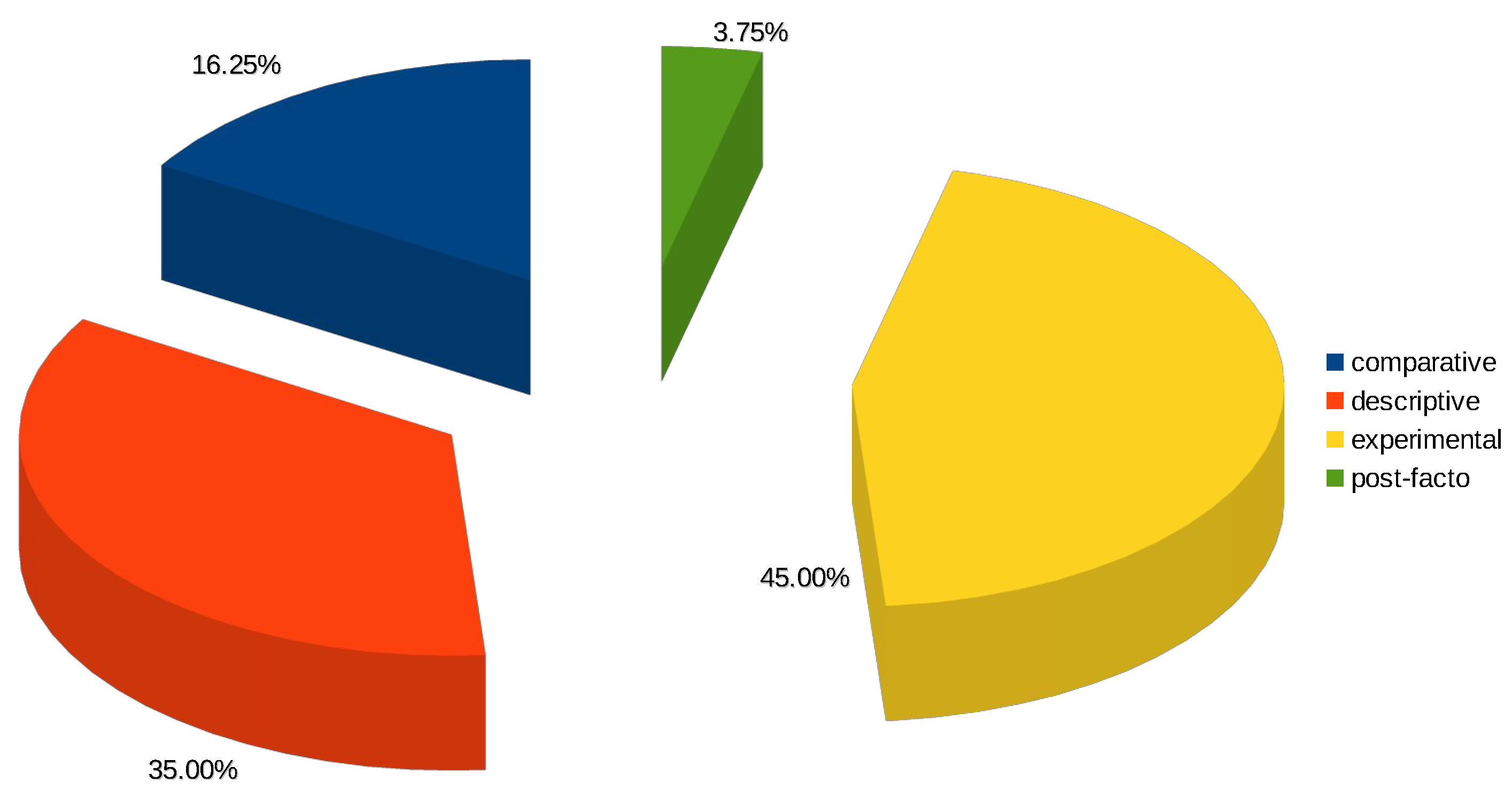
4.1. Data Distribution
4.1.1. Comparative
4.1.2. Descriptive
4.1.3. Experimental
4.1.4. Post Facto
4.2. Problems Solved
4.2.1. Comparative Methodology
4.2.2. Descriptive Methodology
4.2.3. Experimental Methodology
4.2.4. Post Facto Methodology
4.3. Problems Not Solved
4.3.1. Descriptive Methodology
4.3.2. Experimental Methodology
4.3.3. Post Facto Methodology
4.4. Methodologies Application
4.5. Perspective
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| DD | Drill-Down |
| DM | Data Mining |
| DW | Data Warehouse |
| ML | Machine Learning |
| OLAP | Online Analytical Processing |
References
- IBM. Breaking the Petaflop Barrier. Available online: https://www.ibm.com/ibm/history/ibm100/us/en/icons/petaflopbarrier/ (accessed on 1 July 2023).
- Frankenfeld, F. Trends in Computer Hardware and Software. Am. J. Hosp. Pharm. 1993, 50, 707–711. [Google Scholar] [CrossRef] [PubMed]
- Oracle. Introduction to Transparent Data Encryption. Available online: https://docs.oracle.com/en/database/oracle/oracle-database/19/asoag/introduction-to-transparent-data-encryption.html#GUID-62AA9447-FDCD-4A4C-B563-32DE04D55952 (accessed on 1 July 2023).
- Waubert de Puiseau, C.; Nanfack, D.T.; Tercan, H.; Löbbert-Plattfaut, J.; Meisen, T. Dynamic Storage Location Assignment in Warehouses Using Deep Reinforcement Learning. Technologies 2022, 10, 129. [Google Scholar] [CrossRef]
- Biagi, V.; Russo, A. Data Model Design to Support Data-Driven IT Governance Implementation. Technologies 2022, 10, 106. [Google Scholar] [CrossRef]
- Morfonios, K.; Konakas, S.; Ioannidis, Y.; Kotsis, N. ROLAP Implementations of the Data Cube. ACM Comput. Surv. 2007, 39, 12-es. [Google Scholar] [CrossRef]
- Li, X.; Xu, X.; Malik, T. Interactive provenance summaries for reproducible science. In Proceedings of the 2016 IEEE 12th International Conference on e-Science (e-Science), Baltimore, MD, USA, 23–27 October 2016; pp. 355–360. [Google Scholar] [CrossRef]
- Kim, M.; Zimmermann, T.; DeLine, R.; Begel, A. Data Scientists in Software Teams: State of the Art and Challenges. IEEE Trans. Softw. Eng. 2018, 44, 1024–1038. [Google Scholar] [CrossRef]
- Popescu, C.C. Improvements in business operations and customer experience through data science and Artificial Intelligence. Proc. Int. Conf. Bus. Excell. 2018, 12, 804–815. [Google Scholar] [CrossRef] [Green Version]
- Sunahara, A.S.; Perc, M.; Ribeiro, H.V. Association between productivity and journal impact across disciplines and career age. Phys. Rev. Res. 2021, 3, 033158. [Google Scholar] [CrossRef]
- Morris, A. Data Drilling Defined: Drill Down Analysis for Business; Oracle Netsuit: San Mateo, CA, USA, 2021. [Google Scholar]
- He, C.; Micallef, L.; He, L.; Peddinti, G.; Aittokallio, T.; Jacucci, G. Characterizing the Quality of Insight by Interactions: A Case Study. IEEE Trans. Vis. Comput. Graph. 2021, 27, 3410–3424. [Google Scholar] [CrossRef]
- Nemeth, M.; Borkin, D.; Nemethova, A.; Michalconok, G. Deep drill-down analysis for failures detection in the production line. In Proceedings of the 23rd International Conference on Process Control (PC), Strbske Pleso, Slovakia, 1–4 June 2021; pp. 325–330. [Google Scholar] [CrossRef]
- Lee, J.K.; Yang, H.; Park, K.H.; Lee, S.Y.; Choi, S.G. The flow-reduced malware detection system by controlling inactive/active timeout. In Proceedings of the 20th International Conference on Advanced Communication Technology (ICACT), Chuncheon, Republic of Korea, 11–14 February 2018; p. 1. [Google Scholar] [CrossRef]
- Lex, A.; Streit, M.; Partl, C.; Kashofer, K.; Schmalstieg, D. Comparative Analysis of Multidimensional, Quantitative Data. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1027–1035. [Google Scholar] [CrossRef]
- Cariou, V.; Cubillé, J.; Derquenne, C.; Goutier, S.; Guisnel, F.; Klajnmic, H. Embedded indicators to facilitate the exploration of a data cube. Int. J. Bus. Intell. Data Min. 2009, 4, 329–349. [Google Scholar] [CrossRef]
- Analytics Vidhya. Underfitting vs. Overfitting (vs. Best Fitting) in Machine Learning. Available online: https://www.analyticsvidhya.com/blog/2020/02/underfitting-overfitting-best-fitting-machine-learning/ (accessed on 1 July 2023).
- Hawkins, D.M. The Problem of Overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Ying, X. An Overview of Overfitting and its Solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Carabalí, G.J.; Rodríguez, S.J.; Cárdena, D.C. Herramientas cuantitativas para la planeación y programación de la producción: Estado del arte. Ing. Ind. Actual. Nuevas Tendencias 2017, 18, 99–114. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef] [PubMed]
- Khaldi, K. Quantitative, Qualitative or Mixed Research: Wich Research Paradigm Use? J. Educ. Soc. Res. 2017, 7, 15. [Google Scholar] [CrossRef] [Green Version]
- Wilkinson, L. Tree Structured Data Analysis: AID, CHAID and CART. Retrieved Febr. 1992, 1, 2008. [Google Scholar]
- Thakare, V.M. Selection of Materialized View Using Query Optimization in Database Management: An Efficient Methodology. Int. J. Manag. Syst. 2010, 2, 116–130. [Google Scholar] [CrossRef]
- Cloud Software Group. Correlation Analysis. Available online: https://docs.tibco.com/pub/sfire-dsc/6.5.0/doc/html/TIB_sfire-dsc_user-guide/GUID-E1BE59EB-9CDC-4C2C-9174-C86B1D71BFCA.html (accessed on 1 July 2023).
- Chen, G.; Zhong, N.; Yao, Y. A hypergraph model of granular computing. In Proceedings of the IEEE International Conference on Granular Computing, Hangzhou, China, 26–28 August 2008; pp. 130–135. [Google Scholar] [CrossRef]
- de Sá Sousa, H.P.; Nunes, V.T.; Cappelli, C.; Guizzardi, R.S.; do Prado Leite, J.C.S. Using Process Indicators to Help the Verification of Goal Fulfillment. ICEIS 2017, 3, 345–352. [Google Scholar]
- ISO 9000:2015 Quality Management Systems—Fundamentals and Vocabulary. Available online: https://www.iso.org/obp/ui/#iso:std:iso:9000:ed-4:v1:es (accessed on 1 July 2023).
- Mirón Canelo, J.A.; Alonso Sardón, M. Medidas de frecuencia, asociación e impacto en investigación aplicada. Med. Segur. Trab. 2008, 54, 93–102. [Google Scholar] [CrossRef] [Green Version]
- GitHub Silva-Blancas, V.H. Systematic Review Software. Available online: https://github.com/victorhugosilvablancas/systematic_review (accessed on 1 July 2023).
- Wang, M.; Iyer, B. Efficient roll-up and drill-down analysis in relational database. In Proceedings of the Workshop on Research Issues on Data Mining and Knowledge Discover, Newport Beach, CA, USA, 14–17 August 1997. [Google Scholar]
- Feng, Y.; Agrawal, D.; Abbadi, A.E.; Metwally, A. Range cube: Efficient cube computation by exploiting data correlation. In Proceedings of the 20th International Conference on Data Engineering, Boston, MA, USA, 2 April 2004; pp. 658–669. [Google Scholar] [CrossRef]
- McGuffin, M.J.; Davison, G.; Balakrishnan, R. Expand-Ahead: A Space-Filling Strategy for Browsing Trees. In Proceedings of the IEEE Symposium on Information Visualization, Austin, TX, USA, 10–12 October 2004; pp. 119–126. [Google Scholar] [CrossRef]
- Wang, H.B.; Wang, C.B.; Liu, K.; Meng, B.; Zhou, D.R. VisDM-PC: A visual data mining tool based on parallel coordinate. In Proceedings of the 2004 International Conference on Machine Learning and Cybernetics, Shanghai, China, 26–29 August 2004; pp. 1244–1248. [Google Scholar] [CrossRef]
- Vieira, M.R.; Chino, F.J.; Traina, C., Jr.; Traina, A.J. A visual framework to understand similarity queries and explore data in Metric Access Methods. Int. J. Bus. Intell. Data Min. 2010, 5, 370–397. [Google Scholar] [CrossRef] [Green Version]
- Geymayer, T.; Lex, A.; Streit, M.; Schmalstieg, D. Visualizing the Effects of Logically Combined Filters. In Proceedings of the 15th International Conference on Information Visualisation, London, UK, 13–15 July 2011; pp. 47–52. [Google Scholar] [CrossRef] [Green Version]
- Psiuk, M.; Bujok, T.; Zieliński, K. Enterprise Service Bus Monitoring Framework for SOA Systems. IEEE Trans. Serv. Comput. 2012, 5, 450–466. [Google Scholar] [CrossRef]
- Nemeth, M.; Michalconok, G. The initial analysis of failures emerging in production process for further data mining analysis. In Proceedings of the 21st International Conference on Process Control, Strbske Pleso, Slovakia, 6–9 June 2017; pp. 210–215. [Google Scholar] [CrossRef]
- Meshjal, R.K. A Hybrid Data Warehouse Model to Improve Mining Algorithms. J. Kufa Math. Comput. 2017, 4, 21–30. [Google Scholar]
- Lee, D.J.L.; Dev, H.; Hu, H.; Elmeleegy, H.; Parameswaran, A. Avoiding drill-down fallacies with VisPilot. In Proceedings of the 24th International Conference on Intelligent User Interfaces, Marina del Ray, CA, USA, 16–20 March 2019; pp. 186–196. [Google Scholar] [CrossRef]
- Sitanggang, I.; Trisminingsih, R.; Khotimah, H.; Syukur, M. Usability testing of SOLAP for Indonesia agricultural commodity. IOP Conf. Ser. Earth Environ. Sci. 2019, 299, 012054. [Google Scholar] [CrossRef]
- Yunita, A.; Santoso, H.; Hasibuan, Z. Research Review on Big Data Usage for Learning Analytics and Educational Data Mining: A Way Forward to Develop an Intelligent Automation System. J. Phys. Conf. Ser. 2021, 1898, 012044. [Google Scholar] [CrossRef]
- Johansson, J.; Treloar, R.; Jern, M. Integration of unsupervised clustering, interaction and parallel coordinates for the exploration of large multivariate data. In Proceedings of the Eighth International Conference on Information Visualisation, London, UK, 16–16 July 2004; pp. 52–57. [Google Scholar] [CrossRef]
- Angryk, R.A.; Petry, F.E. Mining Multi-Level Associations with Fuzzy Hierarchies. In Proceedings of the 14th IEEE International Conference on Fuzzy Systems, Reno, NV, USA, 25 May 2005; pp. 785–790. [Google Scholar] [CrossRef]
- Chang, C.; Chen, R.; Zhuo, Y. The case study for building a data warehouse in semiconductor manufacturing. Int. J. Comput. Appl. Technol. 2005, 24, 195–202. [Google Scholar] [CrossRef]
- Zhang, D.; Tang, S.; Yang, D.; Jiang, L. An Effective Drill-Down Paths Pruning Method in OLAP. In Proceedings of the Fuzzy Systems and Knowledge Discovery, Fourth International Conference, Haikou, China, 24–27 August 2007; pp. 649–653. [Google Scholar] [CrossRef]
- Adler, Y.; Farchi, E.; Klausner, M.; Pelleg, D.; Raz, O.; Shochat, M.; Ur, S.; Zlotnick, A. Automated substring hole analysis. In Proceedings of the 31st International Conference on Software Engineering, Vancouver, BC, Canada, 16–24 May 2009; pp. 203–206. [Google Scholar] [CrossRef] [Green Version]
- Wetzstein, B.; Leitner, P.; Rosenberg, F.; Brandic, I.; Dustdar, S.; Leymann, F. Monitoring and Analyzing Influential Factors of Business Process Performance. In Proceedings of the IEEE International Enterprise Distributed Object Computing Conference, Auckland, New Zealand, 1–4 September 2009; pp. 141–150. [Google Scholar] [CrossRef]
- Robinson, A.J.; Rahayu, W.J.; Dillon, T. WAD Workflow System: Data-Centric Workflow System. In Proceedings of the Australian Software Engineering Conference, Gold Coast, QLD, Australia, 14–17 April 2009; pp. 337–344. [Google Scholar] [CrossRef]
- Buccafurri, F.; Lax, G. Approximating sliding windows by cyclic tree-like histograms for efficient range queries? Data Knowl. Eng. 2010, 69, 979–997. [Google Scholar] [CrossRef]
- Egenland, R.; Wildish, T.; Huang, C. PhEDEx Data Service. J. Phys. Conf. Ser. 2010, 219, 062010. [Google Scholar] [CrossRef]
- Fung, C.C.; Thanadechteemapat, W. Discover Information and Knowledge from Websites Using an Integrated Summarization and Visualization Framework. In Proceedings of the Third International Conference on Knowledge Discovery and Data Mining, Phuket, Thailand, 9–10 January 2010; pp. 232–235. [Google Scholar] [CrossRef] [Green Version]
- Prat, N.; Comyn-Wattiau, I.; Akoka, J. Combining objects with rules to represent aggregation knowledge in data warehouse and OLAP systems. Data Knowl. Eng. 2011, 70, 732–752. [Google Scholar] [CrossRef] [Green Version]
- Klimentov, A.; Nevski, P.; Potekhin, M.; Wenaus, T. The ATLAS PanDA Monitoring System and its Evolution. J. Phys. Conf. Ser. 2011, 331, 072058. [Google Scholar] [CrossRef]
- Guimares, R.V.; Soares, A.G.M.; Carneiro, N.J.S.; Meiguins, A.S.; Meiguins, B.S. Design Considerations for Drill-down Charts. In Proceedings of the 15th International Conference on Information Visualisation, London, UK, 13–15 July 2011; pp. 73–79. [Google Scholar] [CrossRef]
- Kim, J.-h.; Yoon, S.-H.; Kim, M.-S. Study on traffic classification taxonomy for multilateral and hierarchical traffic classification. In Proceedings of the 14th Asia-Pacific Network Operations and Management Symposium (APNOMS), Seoul, Republic of Korea, 25–27 September 2012; pp. 1–4. [Google Scholar] [CrossRef]
- Xie, S.; Hu, Q.; Zhang, J.; Yu, P.S. An effective and economic bi-level approach to ranking and rating spam detection. In Proceedings of the IEEE International Conference on Data Science and Advanced Analytics, Paris, France, 19–21 October 2015; pp. 1–10. [Google Scholar] [CrossRef]
- Yin, J.; Zhang, Q.; Karunanithi, M. Unsupervised daily routine and activity discovery in smart homes. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Milan, Italy, 25–29 August 2015; pp. 5497–5500. [Google Scholar] [CrossRef]
- de Carvalho, M.B.; Meiguins, B.S.; de Morais, J.M. Temporal Data Visualization Technique Based on Treemap. In Proceedings of the 20th International Conference Information Visualisation (IV), Lisbon, Portugal, 19–22 July 2016; pp. 399–403. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, B.; Wang, W. NetFlowMatrix: A visual approach for analysing large NetFlow data. Int. J. Secur. Netw. 2017, 12, 215–229. [Google Scholar] [CrossRef]
- Jiménez-Vargas, W. Data Mining Techniques for the Integrated Postsecondary Data System. Available online: https://prcrepository.org/bitstream/handle/20.500.12475/254/WI-18_Articulo%20Final_Wilfredo%20Jimenez.pdf?sequence=1&isAllowed=y (accessed on 1 July 2023).
- Franciscus, N.; Ren, X.; Stantic, B. Precomputing architecture for flexible and efficient big data analytics. Vietnam J. Comput. Sci. 2018, 5, 133–142. [Google Scholar] [CrossRef] [Green Version]
- Joglekar, M.; Garcia-Molina, H.; Parameswaran, A. Interactive Data Exploration with Smart Drill-Down. IEEE Trans. Knowl. Data Eng. 2019, 31, 46–60. [Google Scholar] [CrossRef]
- Putra, A.B.; Mukaromah, S.; Lusiarini, Y.; Rizky, M.I.; Bestari, P.Y. Design and Development Executive Information System Application with Drilldown and What-If Analysis features. J. Phys. Conf. Ser. 2019, 1569, 022050. [Google Scholar] [CrossRef]
- Zou, B.; You, J.; Ding, J.; Sun, H. TAVO: A Tree-like Analytical View for OLAP. In Proceedings of the IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, Victoria, BC, Canada, 21–23 August 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Shabaninejad, S.; Khosravi, H.; Indulska, M.; Bakharia, A.; Isaias, P. Automated insightful drill-down recommendations for learning analytics dashboards. In Proceedings of the Tenth International Conference on Learning Analytics & Knowledge, Frankfurt, Germany, 23–27 March 2020; pp. 41–46. [Google Scholar] [CrossRef] [Green Version]
- Rocha, T.D.M.E.S.; Silva, R.R.; Carneiro, T.G.D.S.; Lima, J.D.C. Spatial data cubes based on shared dimensions and neighbourhood relationship concepts. Int. J. Bus. Inf. Syst. 2021, 37, 308–335. [Google Scholar] [CrossRef]
- Splechtna, R.; Gračanin, D.; Todorović, G.; Goja, S.; Bedić, B.; Hauser, H.; Matković, K. Interactive Visual Analysis of Structure-borne Noise Data. IEEE Trans. Vis. Comput. Graph. 2023, 29, 778–787. [Google Scholar] [CrossRef]
- Lee, J.; Grossman, D.; Frieder, O.; McCabe, M.C. Integrating structured data and text: A multi-dimensional approach. In Proceedings of the International Conference on Information Technology: Coding and Computing, Las Vegas, NV, USA, 27–29 March 2000; pp. 264–269. [Google Scholar] [CrossRef]
- Conklin, N.; Prabhakar, S.; North, C. Multiple foci drill-down through tuple and attribute aggregation polyarchies in tabular data. In Proceedings of the IEEE Symposium on Information Visualization, Boston, MA, USA, 28–29 October 2002; pp. 131–134. [Google Scholar] [CrossRef]
- Palza, E.; Fuhrman, C.; Abran, A. Establishing a generic and multidimensional measurement repository in CMMI context. In Proceedings of the 28th Annual NASA Goddard Software Engineering Workshop, Greenbelt, MD, USA, 3–4 December 2003; pp. 12–20. [Google Scholar] [CrossRef]
- Shi, K.; Irani, P.; Li, B. An evaluation of content browsing techniques for hierarchical space-filling visualizations. In Proceedings of the IEEE Symposium on Information Visualization, Minneapolis, MN, USA, 23–25 October 2005; pp. 81–88. [Google Scholar] [CrossRef] [Green Version]
- Tang, S.; Yang, J.; Liu, Y.; Wu, Z.; Chen, B. An Energy Efficient Design of Multi-resolution Storage for Ubiquitous Data Management. In Proceedings of the IFIP International Conference on Network and Parallel Computing Workshops, Dalian, China, 18–21 September 2007; pp. 263–268. [Google Scholar] [CrossRef]
- Chen, J.; Long, T.; Deng, K. The Consistency of Materialized View Maintenance and Drill-Down in a Warehousing Environment. In Proceedings of the 9th International Conference for Young Computer Scientists, Hunan, China, 18–21 November 2008; pp. 1169–1174. [Google Scholar] [CrossRef]
- You, J.; Xi, J.; Zhang, P.; Chen, H. A Parallel Algorithm for Closed Cube Computation. In Proceedings of the Seventh IEEE/ACIS International Conference on Computer and Information Science, Portland, OR, USA, 14–16 May 2008; pp. 95–99. [Google Scholar] [CrossRef]
- Ziegler, C.N.; Skubacz, M.; Viermetz, M. Mining and Exploring Unstructured Customer Feedback Data Using Language Models and Treemap Visualizations. In Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology, Sydney, NSW, Australia, 9–12 December 2008; pp. 932–937. [Google Scholar] [CrossRef] [Green Version]
- Sen, S.; Chaki, N.; Cortesi, A. Optimal Space and Time Complexity Analysis on the Lattice of Cuboids Using Galois Connections for Data Warehousing. In Proceedings of the Fourth International Conference on Computer Sciences and Convergence Information Technology, Seoul, Republic of Korea, 24–26 November 2009; pp. 1271–1275. [Google Scholar] [CrossRef]
- Pourabbas, E.; Shoshani, A. Improving estimation accuracy of aggregate queries on data cubes. Data Knowl. Eng. 2010, 69, 50–72. [Google Scholar] [CrossRef] [Green Version]
- Sen, S.; Chaki, N. Efficient Traversal in Data Warehouse Based on Concept Hierarchy Using Galois Connections. In Proceedings of the Second International Conference on Emerging Applications of Information Technology, Kolkata, India, 19–20 February 2011; pp. 335–339. [Google Scholar] [CrossRef]
- Ikeda, R.; Cho, J.; Fang, C.; Salihoglu, S.; Torikai, S.; Widom, J. Provenance-Based Debugging and Drill-Down in Data-Oriented Workflows. In Proceedings of the IEEE 28th International Conference on Data Engineering, Arlington, VA, USA, 1–5 April 2012; pp. 1249–1252. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Qin, H.; Liu, K.; Wu, T. System composition and multidimensional analysis tools of the Multidimensional Hyperspectral Database for Rocks and Minerals. In Proceedings of the 4th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing, Shanghai, China, 4–7 June 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Soulis, K.; Varlamis, I.; Giannakoulopoulos, A.; Charatsev, F. A tool for the visualisation of public opinion. Int. J. Electron. Gov. 2013, 6, 218–231. [Google Scholar] [CrossRef]
- Baltzer, O.; Dehne, F.; Rau-Chaplin, A. OLAP for moving object data. Int. J. Intell. Inf. Database Syst. 2013, 7, 79–112. [Google Scholar] [CrossRef]
- Baresi, L.; Guinea, S. Event-Based Multi-level Service Monitoring. In Proceedings of the IEEE 20th International Conference on Web Services, Santa Clara, CA, USA, 28 June–3 July 2013; pp. 83–90. [Google Scholar] [CrossRef]
- Bianchi, R.G.; Hatano, G.Y.; Siqueira, T.L.L. On the performance and use of spatial OLAP tools. In Proceedings of the XXXIX Latin American Computing Conference, Caracas, Venezuela, 7–11 October 2013; pp. 1–12. [Google Scholar] [CrossRef]
- Kotamsetty, R.; Govindarasu, M. Adaptive Latency-Aware Query Processing on Encrypted Data for the Internet of Things. In Proceedings of the 25th International Conference on Computer Communication and Networks (ICCCN), Waikoloa, HI, USA, 1–4 August 2016; pp. 1–7. [Google Scholar] [CrossRef]
- Hartono, W.S.; Widyantoro, D.H. Fisheye zoom and semantic zoom on citation network visualization. In Proceedings of the 2016 International Conference on Data and Software Engineering (ICoDSE), Denpasar, Indonesia, 26–27 October 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Chavalier, M.; Malki, M.E.; Kopliku, A.; Teste, O.; Tournier, R. Document-oriented data warehouses: Models and extended cuboids, extended cuboids in oriented document. In Proceedings of the IEEE Tenth International Conference on Research Challenges in Information Science, Grenoble, France, 1–3 June 2016; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Kritzinger, L.M.; Krismayer, T.; Vierhauser, M.; Rabiser, R.; Grünbacher, P. Visualization support for requirements monitoring in systems of systems. In Proceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering, Urbana, IL, USA, 30 October–3 November 2017; pp. 889–894. [Google Scholar] [CrossRef]
- Augustine, V.; Hudepohl, J.; Marcinczak, P.; Snipes, W. Deploying Software Team Analytics in a Multinational Organization. IEEE Softw. 2018, 35, 72–76. [Google Scholar] [CrossRef]
- Basat, R.B.; Shahout, R.; Friedman, R. Frequent elements on query defined ranges. In Proceedings of the IEEE Conference on Computer Communications Workshops, Honolulu, HI, USA, 15–19 April 2018; pp. 1–2. [Google Scholar] [CrossRef]
- Vassiliadis, P.; Marcel, P.; Rizzi, S. Beyond roll-up s and drill-down s: An intentional analytics model to reinvent OLAP. Data Knowl. Eng. 2019, 85, 68–91. [Google Scholar] [CrossRef]
- Chen, Q.; Li, Z.; Pong, T.C.; Qu, H. Designing Narrative Slideshows for Learning Analytics. In Proceedings of the IEEE Pacific Visualization Symposium, Bangkok, Thailand, 23–26 April 2019; pp. 237–246. [Google Scholar] [CrossRef]
- Afzal, S.; Ghani, S.; Jenkins-Smith, H.C.; Ebert, D.S.; Hadwiger, M.; Hoteit, I. A Visual Analytics Based Decision Making Environment for COVID-19 Modeling and Visualization. In Proceedings of the IEEE Visualization Conference, Salt Lake City, UT, USA, 25–30 October 2020; pp. 86–90. [Google Scholar] [CrossRef]
- Ragavi, V.; Geetha, N. A drill down analysis of the pandemic COVID-19 cases in India using PDE. Mater. Today Proc. 2021, 37, 592–595. [Google Scholar] [CrossRef]
- Mathrani, S. Critical business intelligence practices to create meta-knowledge. Int. J. Bus. Inf. Syst. 2021, 36, 1–164. [Google Scholar] [CrossRef]
- Khosravi, H.; Shabaninejad, S.; Bakharia, A.; Sadiq, S.; Indulska, M.; Gasevic, D. Intelligent Learning Analytics Dashboards: Automated Drill-Down Recommendations to Support Teacher Data Exploration. J. Learn. Anal. 2021, 8, 133–154. [Google Scholar] [CrossRef]
- Agrawal, K.; Mehta, V.; Renganathan, S.; Acharyya, S.; Padmanabhan, V.; Kotipalli, C.; Zhao, L. Monitoring Cloud Service Unreachability at Scale. In Proceedings of the IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Franklin, P. Solving Problems with Rapid Data Discovery. In Proceedings of the Annual Reliability and Maintainability Symposium, Orlando, FL, USA, 24–27 May 2021; pp. 1–3. [Google Scholar] [CrossRef]
- Ilyas, Q.M.; Ahmad, M.; Zaman, N.; Alshamari, M.A.; Ahmed, I. Localized Text-Free User Interfaces. IEEE Access 2022, 10, 2357–2371. [Google Scholar] [CrossRef]
- Santra, A.; Komar, K.; Bhowmick, B.; Chakravarthy, S. From base data to knowledge discovery—A life cycle approach—Using multilayer networks. Data Knowl. Eng. 2022, 141, 102058. [Google Scholar] [CrossRef]
- Odoni, F.; Kuntschik, P.; Braşoveanu, A.M.; Weichselbraun, A. On the Importance of Drill-Down Analysis for Assessing Gold Standards and Named Entity Linking Performance. Procedia Comput. Sci. 2018, 137, 33–42. [Google Scholar] [CrossRef]
- Grabot, B. Rule mining in maintenance: Analysing large knowledge bases. Comput. Ind. Eng. 2020, 139, 105501. [Google Scholar] [CrossRef]
- Lechner, C.; Rumpler, M.; Dorley, M.C.; Li, Y.; Ingram, A.; Fryman, H. Developing an Online Dashboard to Visualize Performance Data-Tennessee Newborn Screening Experience. Int. J. Neonatal Screen. 2022, 8, 49. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
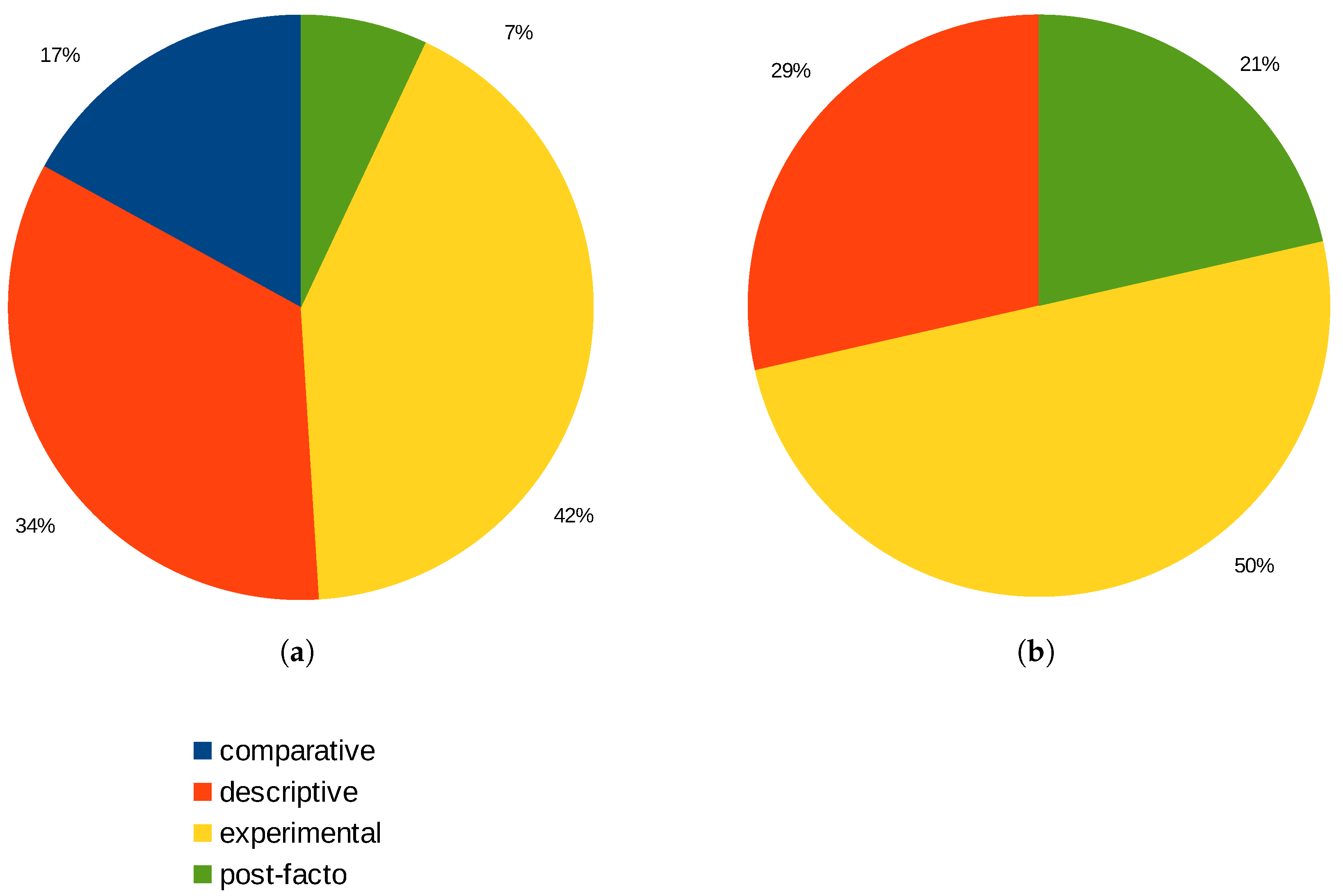{kind=link}
| Work | Methodology | Problem Solved | Problem Unsolved |
|---|---|---|---|
| The research work | Applied methodology | The problem or problems solved | The problem or problems not solved (when researchers have reported) |
| Year | Category | Type | Solved | Unsolved |
|---|---|---|---|---|
| Publication year | For method categorization | For type of categorization | Quantity of problems solved by work | Quantity of problems not solved when authors had manifested them |
| Independent Variable | Affect on | Dependent Variable | Performance Indicator |
|---|---|---|---|
| Works | Production | Technique knowledge | |
| Modal | Frequency | Problematic impact | |
| Applied | Effectivity | Problems solved | |
| methodologies | Effectivity | Problems not solved |
| Year | Work | Type |
|---|---|---|
| 2004 | [32] | correlation |
| [33] | performance|process | |
| [34] | query | |
| 2010 | [15] | correlation |
| [35] | performance|process | |
| 2011 | [36] | correlation |
| 2012 | [37] | performance|process |
| 2017 | [38] | performance|process |
| [39] | tree|query | |
| 2019 | [40] | query |
| [41] | query | |
| 2021 | [13] | correlation |
| [42] | query |
| Year | Work | Type |
|---|---|---|
| 2004 | [43] | performance|process |
| 2005 | [44] | correlation |
| [45] | performance|process | |
| 2007 | [46] | performance|process |
| 2009 | [16] | correlation |
| [47] | correlation | |
| [48] | correlation | |
| [49] | performance|process | |
| 2010 | [50] | correlation |
| [51] | performance|process | |
| [52] | performance|process | |
| 2011 | [53] | label |
| [54] | performance|process | |
| [55] | query | |
| 2012 | [56] | correlation |
| 2015 | [57] | correlation |
| [58] | correlation | |
| 2016 | [59] | performance|process |
| [7] | performance|process | |
| 2017 | [60] | correlation |
| 2018 | [61] | granularity |
| [62] | query|granularity | |
| 2019 | [63] | mathematics |
| [64] | performance|process | |
| [65] | performance|process | |
| 2020 | [66] | query |
| 2021 | [67] | performance|process |
| 2023 | [68] | performance|process |
| Year | Work | Type |
|---|---|---|
| 1997 | [31] | tree|label |
| 2000 | [69] | performance|process |
| 2002 | [70] | query |
| 2003 | [71] | performance|process |
| 2005 | [72] | tree|label |
| 2007 | [73] | performance|process |
| 2008 | [74] | performance|process |
| [75] | performance|process | |
| [76] | tree|label | |
| 2009 | [77] | correlation |
| 2010 | [78] | correlation |
| 2011 | [79] | tree|query |
| 2012 | [80] | query |
| [81] | query | |
| 2013 | [82] | correlation |
| [83] | granularity | |
| [84] | performance|process | |
| [85] | performance|process | |
| 2016 | [86] | performance|process |
| [87] | query | |
| [88] | query | |
| 2017 | [89] | performance|process |
| 2018 | [90] | correlation |
| [14] | performance|process | |
| [91] | query | |
| 2019 | [92] | query |
| [93] | query | |
| 2020 | [94] | performance|process |
| 2021 | [95] | correlation |
| [96] | correlation | |
| [12] | correlation | |
| [97] | performance|process | |
| [98] | performance|process | |
| [99] | performance|process | |
| 2022 | [100] | tree|label |
| [101] | tree|query |
| Variable Type | Observation | Value | Unit |
|---|---|---|---|
| Independent | Applied studies | 80 | Works |
| Independent | Modal | 2021 (9) | Modal |
| Independent | Applied Methodologies | experimental (36) | Predominant |
| Dependent | Problems Solved | 100 | Works |
| Dependent | Problems Not Solved | 14 | Works |
| Category | Sum |
|---|---|
| comparative | 13 |
| descriptive | 28 |
| experimental | 36 |
| post facto | 3 |
| Category | Type | Works |
|---|---|---|
| Comparative | correlation | 4 |
| performance|process | 4 | |
| query | 4 | |
| tree|query | 1 | |
| Descriptive | correlation | 9 |
| granularity | 1 | |
| label | 1 | |
| mathematics | 1 | |
| performance|process | 13 | |
| query | 2 | |
| query|granularity | 1 | |
| Experimental | correlation | 7 |
| granularity | 1 | |
| performance|process | 14 | |
| query | 8 | |
| tree|label | 4 | |
| tree|query | 2 | |
| Post facto | label | 1 |
| query | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva-Blancas, V.H.; Álvarez-Alvarado, J.M.; Herrera-Navarro, A.M.; Rodríguez-Reséndiz, J. Tendency on the Application of Drill-Down Analysis in Scientific Studies: A Systematic Review. Technologies 2023, 11, 112. https://doi.org/10.3390/technologies11040112
Silva-Blancas VH, Álvarez-Alvarado JM, Herrera-Navarro AM, Rodríguez-Reséndiz J. Tendency on the Application of Drill-Down Analysis in Scientific Studies: A Systematic Review. Technologies. 2023; 11(4):112. https://doi.org/10.3390/technologies11040112
Chicago/Turabian StyleSilva-Blancas, Victor Hugo, José Manuel Álvarez-Alvarado, Ana Marcela Herrera-Navarro, and Juvenal Rodríguez-Reséndiz. 2023. "Tendency on the Application of Drill-Down Analysis in Scientific Studies: A Systematic Review" Technologies 11, no. 4: 112. https://doi.org/10.3390/technologies11040112
APA StyleSilva-Blancas, V. H., Álvarez-Alvarado, J. M., Herrera-Navarro, A. M., & Rodríguez-Reséndiz, J. (2023). Tendency on the Application of Drill-Down Analysis in Scientific Studies: A Systematic Review. Technologies, 11(4), 112. https://doi.org/10.3390/technologies11040112