ParlAmI: A Multimodal Approach for Programming Intelligent Environments †


 ,
,  and
and
Abstract
:1. Introduction
2. Related Work
2.1. End-User Programming
2.2. End-User Programming Using Natural Language
2.3. Physical Conversational Agents and Intelligent Environments
2.4. Programming Intelligent Environments
3. The Infrastructure of the “Intelligent Home”
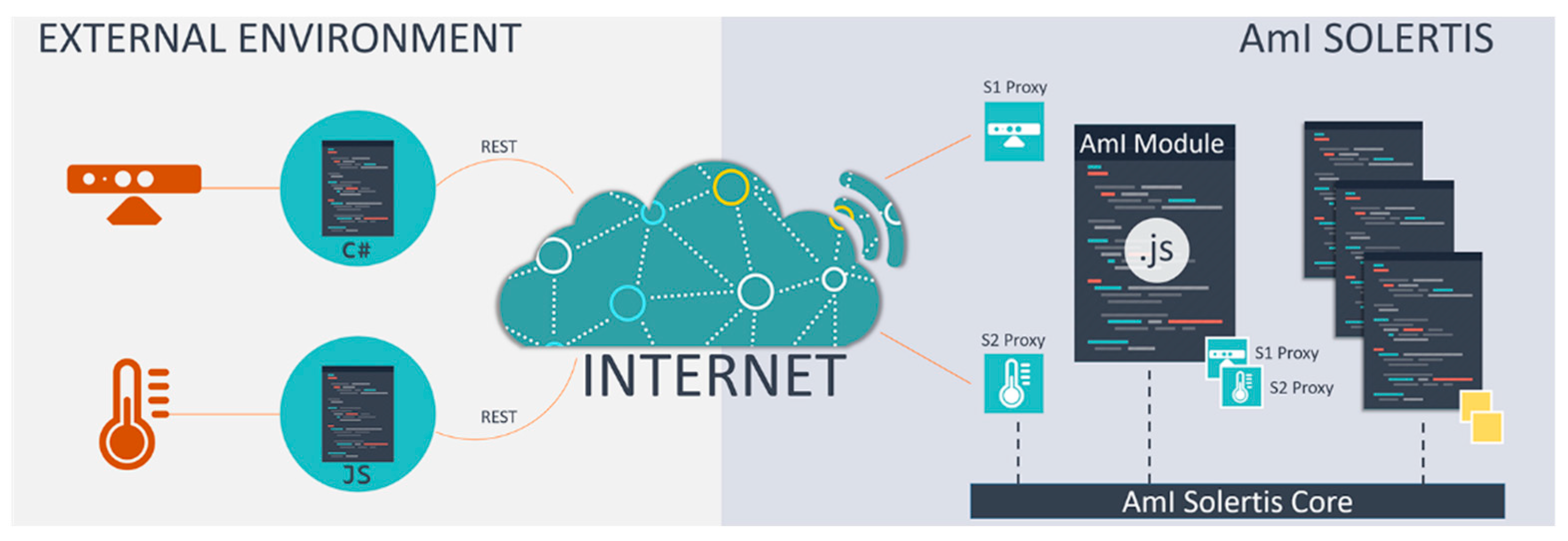
3.1. AmI-Solertis
3.2. LECTOR
- Rules that “model” a behavior5 based on physical context.3
- Rules that “model” the triggers6 based on the behavior5 of actors1 under domain specific context.4
- Rules that describe the conditions (triggers6 and domain specific context4) under which an intervention7 is initiated on a specific intervention host.2
- Actors are the (groups of) users or artifacts of the intelligent environment whose behavior needs to be monitored in order to decide whether an intervention is required.
- Intervention hosts can either launch an application with specific content or control the physical environment. They are: (i) common computing devices such as smartphones, tablets, and laptops, (ii) technologically augmented everyday physical objects (e.g., augmented coffee table), or (iii) custom made items (e.g., smart sofa).
- The physical context encapsulates information regarding physically observable phenomena via sensors (e.g., luminance, heart rate, sound levels, etc.).
- The domain specific context refers to any static or dynamic information that is provided through software components (e.g., user profile or agenda).
- Behavior is a model that represents the actions of an actor (e.g., a user is watching TV, cooking, sleeping).
- Trigger is the model of a high-level behavior that can initiate an intervention.
- Interventions are the system-guided actions that aim to help or support users during their daily activities.
3.3. The Intelligent Home
- Common domestic equipment such as the wide variety of commercial devices (e.g., Philips Hue Lights [98], blinds [99] Alexa [18], oil diffusers [100], and appliances (fridge, oven, coffee machine, air-conditioner) that can be controlled either via their own API or by using dedicated solutions to that matter (e.g., KNX bridge [101]).
- Technologically augmented objects of the living room (Figure 2):
- ○
- AmITV constitutes the main display of the “Intelligent Living Room”. It hosts a number of interactive applications that mostly aim to entertain and inform the user (e.g., ambient movie player, news reader, online radio, music player)
- ○
- AugmenTable is a stylish commercial coffee table made of wood with a smooth, non-reflective white finish that, in addition to its intended use for placing objects (e.g., cups, plates, books) on top of it, acts as a large projection area where secondary information can be presented. Through a Kinect sensor [102], AugmenTable becomes a touch-enabled surface that can recognize the physical objects placed on it as well.
- ○
- SurroundWall transforms the wall around the TV into a secondary non-interactive display that provides an enhanced viewing experience by augmenting—in a context-sensitive manner—the content presented on the AmITV artifact.
- ○
- SmartSofa is a commercial sofa equipped with various sensors aiming to detect user presence inside the room and provide information regarding the user’s posture while seated.
- Technologically augmented objects of the bedroom:
- ○
- The Hypnos framework aims to improve quality of sleep by providing sleep hygiene recommendations. To do so, it relies on the SleepCompanion (i.e., a bed that integrates various sensors like Withings Sleep Tracking Mat [103], Emfit QS Sleep Tracker [104]), and the inhabitants’ wearables (e.g., Nokia Steel HR [105], Fitbit Charge 3 [106]) to monitor their physical activity (e.g., movement, time in bed), physiological signals (e.g., respiration rate, heart rate, snoring) and various sleep-related parameters (e.g., time to fall asleep, time asleep, time awake, sleep cycles) while resting.
- ○
- SmartWardrobe is a custom-made closet equipped with various sensors (e.g., Radio Frequency Identification (RFID) readers, Passive Infrared (PIR) motion sensors, magnetic contacts) and a tablet that aims to provide outfit recommendations based on real-time weather prediction and the user’s daily schedule.
- ○
- SmartDresser is a commercial dresser equipped with various sensors (e.g., RFID readers, load sensors) that is able to identify the location of the stored clothing items in order to help users find what there are looking for faster.
- ○
- A-mIrror is an intelligent mirror comprised of a vertical screen and a Kinect sensor that identifies the inhabitants via facial recognition and provides clothing advice and make up tips.
- Technologically augmented objects of the kitchen:
- ○
- AmICounterTop is a regular work surface that has been augmented with a (hidden) projector and a Kinect sensor that transforms it into an interactive display. By adding load sensors, it can double as a digital kitchen scale (which is useful while cooking).
- ○
- AmIBacksplash is a system adjacent to the countertop. The walls around the kitchen act as projection surfaces. Their position makes them ideal as secondary (non-interactive) displays to AmICounterTop, but they can also be used as primary displays if the user chooses so.
- Technologically augmented objects of the main entrance:
- ○
- SmartDoorBell is a system installed outside the main entrance of the house. The door is equipped with a smart lock [107], and a custom-made wooden case embedded in the wall houses a tablet device, a web-cam, an RFID reader, and a fingerprint reader. Through appropriate software, the SmartDoorBell delivers a sophisticated access control system for the residents and visitors of the home.
4. The ParlAmI System
4.1. Requirements
4.2. Architecture Overview
- Messaging web app (called MAI) is a service that hosts and controls a web-based chatbot user interface intended for end-users. MAI forwards all user written messages to the ParlAmI bridge and then waits for a response. The response directs MAI on how to reply to the user, especially in situations where the user has to provide additional input. To that end, it chooses between custom rich UI elements that can be used for different types of input, including controls that allow users to pick an action from a list, select a specific location, determine the smart artifacts to be controlled, set specific parameters (e.g., brightness), or answer polar questions (e.g., YES/NO). For example, if the user writes “I would like to turn on the lights”, the system will prompt her to choose which of the controllable lights/lamps currently available in the intelligent environment will be turned on.
- NAO manager (nAoMI) service is responsible for communicating with the bridge and for handling all robotic actions related to the current state of the conversation. NAO can be programmed using a Python software development kit (SDK) that gives high-level access to all robotic functions. In addition, there is a graphical editor for high-level robotic behaviors named Choregraphe [108] that allows the creation of simple scripts using functional boxes and connections between them.The speech recognition part of the conversation is implemented as a Choregraphe behavior while everything else is handled by a Python script called NAO manager. Whenever the robot is in listening mode, the speech recognition behavior is running. Since the system should be able to handle arbitrary input, it is not possible to use the built-in speech recognition that NAO offers, which can only listen to specific words or patterns. Instead, the robot records a voice clip that includes the user’s utterance, as it can understand when the user starts and stops a sentence. This clip is sent to an online speech-to-text service that returns either the text form of the user utterance or an error if nothing was recognized. In the latter case, the robot will kindly ask the user to repeat the last sentence. Finally, the recognized text is sent back to the NAO manager. The NAO manager forwards the texts it receives from the speech recognition behavior to the ParlAmI bridge for further processing.When a response is available from the bridge, the manager receives an encoded message with instructions on what to say and additional robotic actions that may be required according to the nature of the response. For example, when the response contains an object or concept that the robot can recognize or understand, it can point to the object or perform a relevant gesture to improve the quality of the conversation and make it seem more natural (e.g., when saying that the ceiling lights will turn on, the robot will point up towards their direction, or when greeting the user, the robot will make appropriate waving gestures).
- ParlAmI bridge provides an API that allows different conversational agent interfaces to be powered by the ParlAmI framework. It acts as a gateway to the ParlAmI framework where different embodied (e.g., humanoids) or disembodied (e.g., messaging web apps) agents can authenticate with and start conversations that result in the creation of new rules in the intelligent environment.After a connection is established with the ParlAmI bridge, any message received is forwarded to spaCy to initiate the analysis pipeline of ParlAmI. Upon receiving a response from ParlAmI, it forwards the message back to the corresponding conversational agent alongside the metadata regarding the meaning of the message; that way, the interface (visual or not) can be customized accordingly (e.g., location data are interpreted by the NAO manager in order to point to the specific object that the answer is referring to).
- spaCy is a library for advanced natural language processing in Python and Cython [109]. It includes various pre-trained statistical models and word vectors and currently supports tokenization for 30+ languages. It features a syntactic parser, convolutional neural network models for tagging, parsing, and named entity recognition, and easy deep learning integration. ParlAmI supports complex messages that can be composed of multiple triggers and/or actions. To that end, spaCy is used in order to tokenize a sentence to a syntactic tree. After the decomposition of the complex sentence, the tree is traversed in order to artificially generate the verbose equivalents of the separated sentences. The new utterances are then forwarded to Rasa for further processing to extract their meaning.
- Rasa is responsible for extracting structured data from a given sentence (such as user intents, i.e., what task the user aims to accomplish via the current dialogue, like “turn on the light”) and entities that have been successfully recognized and will be later translated into messages that will be forwarded to the services of the AmI-Solertis framework to execute the actual task (e.g., turn on the ceiling light and adjust its brightness to 65%). Rasa is being continuously trained with sentences provided by AmI-Solertis, which map directly to available services and their respective functions. To that end, service integrators are asked to supply indicative utterances while importing a new or updating an existing service via AmI-Solertis. The generated output is forwarded to the NLP core service for further processing.
- NLP core handles multiple key parts that enable ParlAmI to generate natural dialogues and to create rules affecting an actual intelligent environment. The service receives the data provided by Rasa and artificially aggregates them into a single sentence that can be interpreted by ChatScript. Alongside, as the dialog progresses, it collects the incoming data (e.g., intents, entities, parameters) that will compose the complete object to be forwarded to LECTOR as soon as all the pieces are recorded. For that to be achieved, it communicates with AmI-Solertis to retrieve, in a context-sensitive manner (i.e., based on the recognized intents/entities), information regarding the available actions (i.e., functions) and their parameters so as to provide appropriate hints to ChatScript on how to proceed with the conversation, store the data in a form that is recognizable by the Rule Builder Service, and invoke the appropriate services for building and deploying the aforementioned rule when ready. Moreover, the NLP core also handles user sessions, allowing concurrent conversations between multiple users and the ParlAmI.
- ChatScript is the endpoint for the conversation between the user and ParlAmI from the framework’s stand point. ChatScript uses powerful pattern matching techniques that allow natural dialogues with end-users. Upon receiving a sentence from the NLP core, based on the context and the previous state of the conversation, it generates and reports back the appropriate answer.
- Rule Builder acts as a proxy from the ParlAmI environment to LECTOR. It transforms the extracted data from the conversation to a structured rule that can be interpreted by LECTOR. It then sends the data to LECTOR in order to create the appropriate actions, interventions, and triggers and finally generate the code that will then be deployed to the intelligent environment via AmI-Solertis.
- AmI-Solertis has two roles in ParlAmI. On the one hand, it feeds ParlAmI with rich information about the available programmable artifacts (i.e., service names, functions and their descriptions, parameters, expected values, example utterances) that can be used as training data. On the other hand, it is the backbone of LECTOR, providing an infrastructure that allows the deployment and execution of the created rule to the actual environment.
- LECTOR receives the rule that ParlAmI generates from a conversation with a user and transforms the appropriate triggers, interventions, and/or actions into AmI-Scripts. These scripts are finally forwarded to AmI-Solertis for deployment.
4.3. The Analysis Pipeline
5. The Two Faces of ParlAmI
5.1. HCI Aspects
- A.
- User intent identification: when speaking in natural language, different people might use different words/sentences when talking about the same thing (e.g., “YES” versus “SURE”). ParlAmI supports this diversity and permits users to express their directives in any way they desire without compromising the functionality of the system.
- B.
- Message decomposition: different users, depending on their preferences or experience, might build their rules step by step or define a rule in a single sentence (i.e., utterance). ParlAmI’s chatbot supports both options, and in case the user provides a complex message, it is able to decompose it into smaller sentences.
- ○
- Example B: consider a user creating the following rule: “when I come home, I would like the lights to turn on, the coffee machine to start, and the heater to turn on”.
- C.
- Confirmation mechanism: trying to cope with the fact that the chatbot might misunderstand the user’s intention, the need for a confirmation mechanism emerged. However, it would be tedious to continuously ask the user to (dis)approve every system action. To this end, the chatbot, before asking a new question, repeats the last acquired message, inviting the user to interrupt the conversation in case he/she identifies a wrong assumption.
- ○
- Example C: consider the vague user message “when we leave the house”; in that case, the chatbot assumes that “WE” refers to all family members but subtly prompts the user to confirm or reject that assumption.
- D.
- Error recovery: a user disapproving a system statement means that the chatbot misinterpreted their intention. To this end, it initiates an exploratory process to identify what the source of the problem was by explicitly asking the user what the mistake was (i.e., mimicking the reaction of a human in a similar real-life situation).
- ○
- Example D: consider the same vague user message “when we leave the house”, where instead of referring to all family members, the user implies only the adults of the family; in that case, the chatbot is mistaken if it assumes that “WE” refers to both adults and children and must be corrected.
- E.
- Exploitation of contextual information: ParlAmI’s chatbot relies heavily on contextual information so as to make the conversation appear more natural and alleviate the user from stating the obvious. Additionally, as the authors in [114] suggest, in case of failure to recognize the context, the chatbot initiates a dialogue with the user regarding the context of the statement. Consider the following example where the user provides an ambiguous message: “I want the lights to turn off automatically”. The system understands that the user wants to TURN OFF the lights; however, no information is given regarding the room of interest and the desired group of lights to control (e.g., ceiling lights, bedside lamps). In that case, the response of the system depends on the broader context:
- ○
- Example E1: if this action is part of a rule referring to “leaving the house” (i.e., a “house-oriented” rule), the chatbot assumes that the user wants to control ALL the lights of the HOUSE.
- ○
- Example E2: if this action is part of a rule referring to “when I watch a movie in the living room” (i.e., a “room-oriented” rule), the system assumes that the user wants to control ONLY the lights of the LIVING ROOM.
- F.
- Rule naming: regarding rule naming, when the user wants to create a rule, the system asks them how they want to name it. If, however, the user skips this step by immediately providing the condition and action of the rule in a single utterance, the system asks for a rule name at the end of the creation process.
- G.
- Hiding complexity: if the user provides a message that touches more than one of the available topics (i.e., behavior, trigger, intervention), the chatbot has the ability to implicitly complete any intermediate steps, hence avoiding burdening the user. For example, the user message “lock the doors when I get in bed at night” requires the creation of a trigger rule and an intervention rule. In that case, the following trigger rule is created implicitly: “during night, user getting into bed means TRIGGER_X”. As a next step, the intervention rule is formed as follows: “if TRIGGER_X, then lock the doors”. As shown, the outcome of the trigger rule gets an auto-generated name; however, if that specific trigger appears in multiple rules, after completing the conversation, the user is prompted to change the name so as to better reflect its meaning and thus promote its reusability in the future.
5.2. MAI: Messaging Application Interface
- User intent identification: as soon as a user types a message, before the pipeline processes it, typos and spelling mistakes are automatically corrected by a spellchecker, which ensures that every sentence is correct (at a lexical level).
- Message decomposition: in case the user provides a complex message, the chatbot decomposes it into smaller sentences and then MAI repeats them to the user one by one, permitting them to interrupt the conversation (i.e., selecting a response activates an appropriate control to mark it as incorrect) in case a misconception is identified (Figure 7a).
- Confirmation mechanism: in the case described in Example C, MAI, before asking the user about the desired action that this behavior should trigger, displays the following message: “so what do you want to happen when you, Eric, and the kids leave the house?”. That way, the user is immediately provided with feedback regarding what the system understood and can either intervene to correct the system or proceed with the remaining information that is required. Not interrupting the conversation signifies a confirmation, whereas if the user disagrees with the system, typing “no” or selecting the respective button from the GUI (Figure 7b) initiates the error recovery process.
- Error recovery: in the case described in Example D, the user can interrupt the system (e.g., “no, you did not understand correctly”) so as to correct the wrong assumption. Then, MAI displays a “text and buttons” type of message asking the user what the mistake was and then reactivates the respective dialogue so as to retrieve the correct information.
- Exploitation of contextual information: in the case described in Example E1 (where the user wants to control ALL the lights of the HOUSE), MAI displays an “image with text and buttons” message stating the parameters of the rule to be created (i.e., that all the lights of the house will turn off) and invites the user to agree or disagree (by selecting from the available “yes”/“no” buttons). If the user selects “no”, MAI initiates the error recovery process and asks the user “what do you want to do instead?”. Considering a different context (Example E2, where the user wants to control ONLY the lights of the LIVING ROOM), MAI offers the choices of the available groups of living room lights (e.g., ceiling lights, decorative lights, floor lamps, table lamps) in the form of “list of selectable images with text and buttons” so that the user can select which of the lights they wish to turn off (Figure 7d).
- Rule naming: regarding rule naming, MAI expects the users to provide a name for the new rule at the beginning of the creation process. However, if the user skips this step, MAI repeats the question in the end of the main conversation.
- Hiding complexity: ParlAmI is able to handle the implicit creation of behaviors, triggers, and interventions internally. However, if a recurrent use of the same behavior/trigger/intervention is identified, MAI asks the user to type in a friendly name after completing the conversation (Figure 7c).
5.3. nAoMI: Robot Interface
6. Results
- Introduction: during the introduction, the users were given a consent form for their voluntary participation in the experiment and were informed of the overall process. It was made clear that they were not the ones being evaluated, but rather the system, and that they could stop the experiment if they felt uncomfortable at any point. Subsequently, the concept of ParlAmI was explained to them, namely that they could interact with either a messaging application (through a smart phone) or a robot in order to create the rules that dictate the behavior of the “Intelligent Home” using natural language.
- The experiment itself: in this phase, the users were requested to follow a scenario (Appendix A) including the creation of two rules. The first one was relatively “easy”, including a simple trigger and a simple action (intervention) so that the user would grasp the “basics” of the rule making while also having their confidence boosted. The second one was more complicated since it was comprised of multiple actions (interventions). During the experiment, the users were encouraged to express their opinions and thoughts openly following the thinking-aloud protocol [117]. In order to make participants feel comfortable and ensure that the experiment progressed as planned, a facilitator was responsible for orchestrating the entire process, assisting the users when required, and managing any technical difficulties. Furthermore, two note-takers were present in order to record qualitative data (i.e., impressions, comments, and suggestions) along with a number of quantitative data (i.e., number of help requests and errors made).
- Debriefing: after completing the scenario, the users were handed a user experience questionnaire (UEQ) [118] to measure both classical usability aspects (efficiency, perspicuity, dependability) as well as user experience aspects (originality, stimulation). Afterwards, a debriefing session was held during which the participants were asked some questions regarding their opinion on the system (i.e., MAI or nAoMI), what they liked or disliked the most, and whether they had suggestions about its enhancement.
- Final interview: users were asked a small set of questions so as to be able to compare the two interaction paradigms—not necessarily to prove if one was better than the other but rather to understand the benefits that each provided, and the situations or conditions under which the users would prefer one interaction paradigm over the other (i.e., MAI versus nAoMI).
7. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| AmI | Ambient Intelligence |
| EUD | End User Development |
| TAP | Trigger Action Programming |
| GUI | Graphical User Interface |
| UI | User Interface |
| CI | Conversational Interface |
| DCA | Disembodied conversational agent |
| ECA | Embodied conversational agents |
| PBD | Programming by Demonstration |
| NLP | Natural Language Processing |
| CA | Conversational Agent |
| VR | Virtual Reality |
| AR | Augmented Reality |
| NLU | Natural Language Understanding |
| REST | Representation State Transfer |
| API | Application Programming Interface |
| DNS | Domain Name System |
| AI | Artificial Intelligence |
| AAL | Ambient Assisted Living |
| HCI | Human Computer Interaction |
| UX | User Experience |
| UEQ | User Experience Questionnaire |
Appendix A. Scenarios
Appendix A.1. Task 1
- Name: coming home
- Condition: you come home
- Actions: turn on the lights
Appendix A.2. Task 2
- Name: morning routine
- Condition: it is 8 in the morning
- Actions: alarm rings, lights turn on, coffee machine starts, turn on the TV on channel 5, your schedule is displayed on the wall
References
- Aarts, E.; Wichert, R. Ambient intelligence. In Technology Guide: Principles–Applications–Trends; Bullinger, H.-J., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 244–249. ISBN 978-3-540-88546-7. [Google Scholar]
- Xia, F.; Yang, L.T.; Wang, L.; Vinel, A. Internet of things. Int. J. Commun. Syst. 2012, 25, 1101. [Google Scholar] [CrossRef]
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing. Commun. ACM 2011, 53. [Google Scholar] [CrossRef]
- Stojkoska, B.L.R.; Trivodaliev, K.V. A review of Internet of Things for smart home: Challenges and solutions. J. Clean. Prod. 2017, 140, 1454–1464. [Google Scholar] [CrossRef]
- Dahl, Y.; Svendsen, R.-M. End-user composition interfaces for smart environments: A preliminary study of usability factors. In Proceedings of the 2011 International Conference of Design, User Experience, and Usability, Orlando, FL, USA, 9–14 July 2011; pp. 118–127. [Google Scholar]
- Davidoff, S.; Lee, M.K.; Yiu, C.; Zimmerman, J.; Dey, A.K. Principles of smart home control. In Proceedings of the 8th International Conference on Ubiquitous Computing, Orange County, CA, USA, 17–21 September 2006; pp. 19–34. [Google Scholar]
- Dey, A.K.; Sohn, T.; Streng, S.; Kodama, J. iCAP: Interactive prototyping of context-aware applications. In Proceedings of the International Conference on Pervasive Computing, Dublin, Ireland, 7–10 May 2006; pp. 254–271. [Google Scholar]
- Newman, M.W.; Elliott, A.; Smith, T.F. Providing an Integrated User Experience of Networked Media, Devices, and Services through End-User Composition. In Proceedings of the Pervasive Computing, Sydney, Australia, 19–22 May 2008; pp. 213–227. [Google Scholar]
- Truong, K.N.; Huang, E.M.; Abowd, G.D. CAMP: A magnetic poetry interface for end-user programming of capture applications for the home. In Proceedings of the International Conference on Ubiquitous Computing; Springer: Berlin/Heidelberg, Germany, 2004; pp. 143–160. [Google Scholar]
- Ur, B.; Pak Yong Ho, M.; Brawner, S.; Lee, J.; Mennicken, S.; Picard, N.; Schulze, D.; Littman, M.L. Trigger-Action Programming in the Wild: An Analysis of 200,000 IFTTT Recipes. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 3227–3231. [Google Scholar]
- Ur, B.; McManus, E.; Pak Yong Ho, M.; Littman, M.L. Practical Trigger-action Programming in the Smart Home. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 26 April–1 May 2014; pp. 803–812. [Google Scholar]
- Nacci, A.A.; Balaji, B.; Spoletini, P.; Gupta, R.; Sciuto, D.; Agarwal, Y. Buildingrules: A trigger-action based system to manage complex commercial buildings. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 381–384. [Google Scholar]
- Ghiani, G.; Manca, M.; Paternò, F. Authoring context-dependent cross-device user interfaces based on trigger/action rules. In Proceedings of the 14th International Conference on Mobile and Ubiquitous Multimedia, Linz, Austria, 30 November–2 December 2015; pp. 313–322. [Google Scholar]
- Ghiani, G.; Manca, M.; Paternò, F.; Santoro, C. Personalization of context-dependent applications through trigger-action rules. ACM Trans. Comput. Hum. Interact. (TOCHI) 2017, 24, 14. [Google Scholar] [CrossRef]
- IFTTT. Available online: https://ifttt.com/ (accessed on 5 October 2017).
- Zapier. Available online: https://zapier.com/ (accessed on 7 October 2017).
- Liu, X.; Wu, D. From Natural Language to Programming Language. In Innovative Methods, User-Friendly Tools, Coding, and Design Approaches in People-Oriented Programming; IGI Global: Hershey, PA, USA, 2018; pp. 110–130. [Google Scholar]
- Amazon Alexa. Available online: https://developer.amazon.com/alexa (accessed on 5 November 2018).
- McTear, M.; Callejas, Z.; Griol, D. The Conversational Interface: Talking to Smart Devices; Springer: Berlin, Germany, 2016; ISBN 3-319-32967-7. [Google Scholar]
- Serrano, J.; Gonzalez, F.; Zalewski, J. CleverNAO: The intelligent conversational humanoid robot. In Proceedings of the 2015 IEEE 8th International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Warsaw, Poland, 24–26 September 2015; Volume 2, pp. 887–892. [Google Scholar]
- Ruttkay, Z.; Pelachaud, C. From Brows to Trust: Evaluating Embodied Conversational Agents; Springer Science & Business Media: Berlin, Germany, 2006; Volume 7, ISBN 1-4020-2730-3. [Google Scholar]
- King, W.J.; Ohya, J. The representation of agents: Anthropomorphism, agency, and intelligence. In Proceedings of the Conference Companion on Human Factors in Computing Systems, Vancouver, BC, Canada, 13–18 April 1996; pp. 289–290. [Google Scholar]
- Araujo, T. Living up to the chatbot hype: The influence of anthropomorphic design cues and communicative agency framing on conversational agent and company perceptions. Comput. Hum. Behav. 2018, 85, 183–189. [Google Scholar] [CrossRef]
- Stefanidi, E.; Korozi, M.; Leonidis, A.; Antona, M. Programming Intelligent Environments in Natural Language: An Extensible Interactive Approach. In Proceedings of the 11th PErvasive Technologies Related to Assistive Environments Conference, Corfu, Greece, 26–29 June 2018; pp. 50–57. [Google Scholar]
- Nao (robot). Available online: https://en.wikipedia.org/wiki/Nao_(robot) (accessed on 10 December 2018).
- Korozi, M.; Leonidis, A.; Antona, M.; Stephanidis, C. LECTOR: Towards Reengaging Students in the Educational Process Inside Smart Classrooms. In Proceedings of the International Conference on Intelligent Human Computer Interaction, Evry, France, 11–13 December 2017; pp. 137–149. [Google Scholar]
- Lieberman, H.; Paternò, F.; Klann, M.; Wulf, V. End-User Development: An Emerging Paradigm. In End User Development; Lieberman, H., Paternò, F., Wulf, V., Eds.; Human-Computer Interaction Series; Springer Netherlands: Dordrecht, The Netherlands, 2006; pp. 1–8. ISBN 978-1-4020-5386-3. [Google Scholar]
- Dertouzos, M.L.; Dertrouzos, M.L.; Foreword By-Gates, B. What Will Be: How the New World of Information Will Change Our Lives; HarperCollins Publishers: New York, NY, USA, 1998; ISBN 0-06-251540-3. [Google Scholar]
- MacLean, A.; Carter, K.; Lövstrand, L.; Moran, T. User-tailorable systems: Pressing the issues with buttons. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Seattle, WA, USA, 1–5 April 1990; pp. 175–182. [Google Scholar]
- Wulf, V.; Golombek, B. Direct activation: A concept to encourage tailoring activities. Behav. Inf. Technol. 2001, 20, 249–263. [Google Scholar] [CrossRef] [Green Version]
- Won, M.; Stiemerling, O.; Wulf, V. Component-based approaches to tailorable systems. In End User Development; Springer: Berlin, Germany, 2006; pp. 115–141. [Google Scholar]
- Quirk, C.; Mooney, R.J.; Galley, M. Language to Code: Learning Semantic Parsers for If-This-Then-That Recipes. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL-15), Beijing, China, July 2015; pp. 878–888. [Google Scholar]
- You Don’t Need to Be a Coder. Available online: https://bubble.is/ (accessed on 6 December 2018).
- Resnick, M.; Maloney, J.; Monroy-Hernández, A.; Rusk, N.; Eastmond, E.; Brennan, K.; Millner, A.; Rosenbaum, E.; Silver, J.; Silverman, B. Scratch: Programming for all. Commun. ACM 2009, 52, 60–67. [Google Scholar] [CrossRef]
- Cooper, S.; Dann, W.; Pausch, R. Alice: A 3-D tool for introductory programming concepts. In Proceedings of the Fifth Annual CCSC Northeastern Conference on the Journal of Computing in Small Colleges, Mahwah, NJ, USA, 28–29 April 2000; Volume 15, pp. 107–116. [Google Scholar]
- Snap! Build Your Own Blocks 4.2.2.9. Available online: https://snap.berkeley.edu/snapsource/snap.html (accessed on 6 December 2018).
- Broll, B.; Lédeczi, Á.; Zare, H.; Do, D.N.; Sallai, J.; Völgyesi, P.; Maróti, M.; Brown, L.; Vanags, C. A visual programming environment for introducing distributed computing to secondary education. J. Parallel Distrib. Comput. 2018, 118, 189–200. [Google Scholar] [CrossRef]
- Myers, B.A. Creating User Interfaces by Demonstration; Academic Press Professional: San Diego, CA, USA, 1987. [Google Scholar]
- Myers, B.A.; McDaniel, R.G.; Kosbie, D.S. Marquise: Creating complete user interfaces by demonstration. In Proceedings of the INTERACT’93 and CHI’93 Conference on Human Factors in Computing Systems, Amsterdam, The Netherlands, 24–29 April 1993; pp. 293–300. [Google Scholar]
- Cypher, A.; Smith, D.C. KidSim: End user programming of simulations. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 7–11 May 1995; pp. 27–34. [Google Scholar]
- Little, G.; Lau, T.A.; Cypher, A.; Lin, J.; Haber, E.M.; Kandogan, E. Koala: Capture, share, automate, personalize business processes on the web. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 28 April–3 May 2007; pp. 943–946. [Google Scholar]
- Leshed, G.; Haber, E.M.; Matthews, T.; Lau, T. CoScripter: Automating & sharing how-to knowledge in the enterprise. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Florence, Italy, 5–10 April 2008; pp. 1719–1728. [Google Scholar]
- Dey, A.K.; Hamid, R.; Beckmann, C.; Li, I.; Hsu, D. A CAPpella: Programming by demonstration of context-aware applications. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vienna, Austria, 24–29 April 2004; pp. 33–40. [Google Scholar]
- Tasker for Android. Available online: https://tasker.joaoapps.com/ (accessed on 6 December 2018).
- Automate-Apps on Google Play. Available online: https://play.google.com/store/apps/details?id=com.llamalab.automate&hl=en (accessed on 6 December 2018).
- Sammet, J.E. The use of English as a programming language. Commun. ACM 1966, 9, 228–230. [Google Scholar] [CrossRef]
- Heidorn, G.E. Automatic programming through natural language dialogue: A survey. IBM J. Res. Dev. 1976, 20, 302–313. [Google Scholar] [CrossRef]
- Miller, L.A. Natural language programming: Styles, strategies, and contrasts. IBM Syst. J. 1981, 20, 184–215. [Google Scholar] [CrossRef]
- Ballard, B.W. Semantic and Procedural Processing for a Natural Language Programming System. Ph.D. Thesis, Duke University, Durham, NC, USA, 1980. [Google Scholar]
- Ballard, B.W.; Biermann, A.W. Programming in natural language: “NLC” as a prototype. In Proceedings of the 1979 Annual Conference, New York, NY, USA, 16–17 August 1979; pp. 228–237. [Google Scholar]
- Biermann, A.W.; Ballard, B.W. Toward natural language computation. Comput. Linguist. 1980, 6, 71–86. [Google Scholar]
- Jain, A.; Kulkarni, G.; Shah, V. Natural language processing. Int. J. Comput. Sci. Eng. 2018, 6, 161–167. [Google Scholar] [CrossRef]
- Stenmark, M.; Nugues, P. Natural language programming of industrial robots. In Proceedings of the 2013 44th International Symposium on Robotics (ISR), Seoul, Korea, 24–26 October 2013; pp. 1–5. [Google Scholar]
- Lauria, S.; Bugmann, G.; Kyriacou, T.; Klein, E. Mobile robot programming using natural language. Robot. Auton. Syst. 2002, 38, 171–181. [Google Scholar] [CrossRef]
- Williams, T.; Scheutz, M. The state-of-the-art in autonomous wheelchairs controlled through natural language: A survey. Robot. Auton. Syst. 2017, 96, 171–183. [Google Scholar] [CrossRef]
- Good, J.; Howland, K. Programming language, natural language? Supporting the diverse computational activities of novice programmers. J. Vis. Lang. Comput. 2017, 39, 78–92. [Google Scholar] [CrossRef]
- Liu, H.; Lieberman, H. Metafor: Visualizing stories as code. In Proceedings of the 10th international conference on Intelligent user interfaces, San Diego, CA, USA, 10–13 January 2005; pp. 305–307. [Google Scholar]
- Liu, H.; Lieberman, H. Programmatic semantics for natural language interfaces. In Proceedings of the CHI’05 Extended Abstracts on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; pp. 1597–1600. [Google Scholar]
- Lieberman, H.; Ahmad, M. Knowing what you’re talking about: Natural language programming of a multi-player online game. In No Code Required; Elsevier: New York, NY, USA, 2010; pp. 331–343. [Google Scholar]
- Nelson, G. Natural language, semantic analysis, and interactive fiction. IF Theory Reader 2006, 141, 99–104. [Google Scholar]
- Nelson, G. Afterword: Five years later. In IF Theory Reader; Jackson-Mead, K., Wheeler, J.R., Eds.; Transcript On Press: Norman, OK, USA, 2011; pp. 189–202. [Google Scholar]
- McTear, M.; Callejas, Z.; Griol, D. Introducing the Conversational Interface. In The Conversational Interface; Springer: Berlin, Germany, 2016; pp. 1–7. [Google Scholar]
- Huang, T.-H.K.; Azaria, A.; Bigham, J.P. Instructablecrowd: Creating if-then rules via conversations with the crowd. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 1555–1562. [Google Scholar]
- Thórisson, K.R. Gandalf: An embodied humanoid capable of real-time multimodal dialogue with people. In Proceedings of the First International Conference on Autonomous Agents, Marina del Rey, CA, USA, 5–8 February 1997; pp. 536–537. [Google Scholar]
- Cassell, J.; Thorisson, K.R. The power of a nod and a glance: Envelope vs. emotional feedback in animated conversational agents. Appl. Artif. Intell. 1999, 13, 519–538. [Google Scholar] [CrossRef]
- Cassell, J.; Bickmore, T.; Vilhjálmsson, H.; Yan, H. More than just a pretty face: Affordances of embodiment. In Proceedings of the 5th International Conference on Intelligent User Interfaces, New Orleans, LA, USA, 9–12 January 2000; pp. 52–59. [Google Scholar]
- Kim, K.; Boelling, L.; Haesler, S.; Bailenson, J.N.; Bruder, G.; Welch, G. Does a Digital Assistant Need a Body? The Influence of Visual Embodiment and Social Behavior on the Perception of Intelligent Virtual Agents in AR. In Proceedings of the IEEE International Symposium on Mixed and Augmented Reality, Munich, Germany, 16–20 October 2018. [Google Scholar]
- Bailenson, J.N.; Blascovich, J.; Beall, A.C.; Loomis, J.M. Equilibrium theory revisited: Mutual gaze and personal space in virtual environments. Presence Teleoper. Virtual Environ. 2001, 10, 583–598. [Google Scholar] [CrossRef]
- Bailenson, J.N.; Blascovich, J.; Beall, A.C.; Loomis, J.M. Interpersonal distance in immersive virtual environments. Personal. Soc. Psychol. Bull. 2003, 29, 819–833. [Google Scholar] [CrossRef] [PubMed]
- Mutlu, B.; Forlizzi, J.; Hodgins, J. A storytelling robot: Modeling and evaluation of human-like gaze behavior. In Proceedings of the 2006 6th IEEE-RAS International Conference on Humanoid Robots, Genova, Italy, 4–6 December 2006; pp. 518–523. [Google Scholar]
- Wainer, J.; Feil-Seifer, D.J.; Shell, D.A.; Mataric, M.J. The role of physical embodiment in human-robot interaction. In Proceedings of the ROMAN 2006-The 15th IEEE International Symposium on Robot and Human Interactive Communication, Hatfield, UK, 6–8 September 2006; pp. 117–122. [Google Scholar]
- Heerink, M.; Krose, B.; Evers, V.; Wielinga, B. Observing conversational expressiveness of elderly users interacting with a robot and screen agent. In Proceedings of the 2007 IEEE 10th International Conference on Rehabilitation Robotics, Noordwijk, The Netherlands, 13–15 June 2007; pp. 751–756. [Google Scholar]
- Pereira, A.; Martinho, C.; Leite, I.; Paiva, A. iCat, the chess player: The influence of embodiment in the enjoyment of a game. In Proceedings of the 7th International Joint Conference on Autonomous Agents and Multiagent Systems-Volume 3, Estoril, Portugal, 12–16 May 2008; pp. 1253–1256. [Google Scholar]
- Li, J. The benefit of being physically present: A survey of experimental works comparing copresent robots, telepresent robots and virtual agents. Int. J. Hum. Comput. Stud. 2015, 77, 23–37. [Google Scholar] [CrossRef]
- Amft, O.; Novais, P.; Tobe, Y.; Chatzigiannakis, I. Intelligent Environments 2018: Workshop Proceedings of the 14th International Conference on Intelligent Environments; IOS Press: Amsterdam, The Netherlands, 2018. [Google Scholar]
- García-Herranz, M.; Haya, P.A.; Alamán, X. Towards a Ubiquitous End-User Programming System for Smart Spaces. J. UCS 2010, 16, 1633–1649. [Google Scholar]
- Heun, V.; Hobin, J.; Maes, P. Reality editor: Programming smarter objects. In Proceedings of the 2013 ACM Conference on Pervasive and Ubiquitous Computing Adjunct Publication, Zurich, Switzerland, 8–12 September 2013; pp. 307–310. [Google Scholar]
- Heun, V.; Kasahara, S.; Maes, P. Smarter objects: Using AR technology to program physical objects and their interactions. In Proceedings of the CHI’13 Extended Abstracts on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 961–966. [Google Scholar]
- Ens, B.; Anderson, F.; Grossman, T.; Annett, M.; Irani, P.; Fitzmaurice, G. Ivy: Exploring spatially situated visual programming for authoring and understanding intelligent environments. In Proceedings of the 43rd Graphics Interface Conference, Edmonton, AB, Canada, 16–19 May 2017; pp. 156–162. [Google Scholar]
- Lee, G.A.; Nelles, C.; Billinghurst, M.; Kim, G.J. Immersive authoring of tangible augmented reality applications. In Proceedings of the 3rd IEEE/ACM International Symposium on Mixed and Augmented Reality, Arlington, VA, USA, 5 November 2004; pp. 172–181. [Google Scholar]
- Sandor, C.; Olwal, A.; Bell, B.; Feiner, S. Immersive mixed-reality configuration of hybrid user interfaces. In Proceedings of the Fourth IEEE and ACM International Symposium on Mixed and Augmented Reality (ISMAR’05), Vienna, Austria, 5–8 October 2005; pp. 110–113. [Google Scholar]
- Steed, A.; Slater, M. A dataflow representation for defining behaviours within virtual environments. In Proceedings of the Virtual Reality Annual International Symposium, Santa Clara, CA, USA, 30 March–03 April 1996; pp. 163–167. [Google Scholar]
- Desolda, G.; Ardito, C.; Matera, M. Empowering end users to customize their smart environments: Model, composition paradigms, and domain-specific tools. ACM Trans. Comput. Hum. Interact. (TOCHI) 2017, 24, 12. [Google Scholar] [CrossRef]
- Walch, M.; Rietzler, M.; Greim, J.; Schaub, F.; Wiedersheim, B.; Weber, M. homeBLOX: Making home automation usable. In Proceedings of the 2013 ACM conference on Pervasive and ubiquitous computing adjunct publication, Zurich, Switzerland, 8–12 September 2013; pp. 295–298. [Google Scholar]
- Zipato. Available online: https://www.zipato.com/ (accessed on 7 October 2017).
- Supermechanical: Twine. Listen to Your World. Talk to the Web. Available online: http://supermechanical.com/twine/technical.html (accessed on 6 October 2017).
- WigWag. Available online: https://www.wigwag.com/ (accessed on 6 October 2017).
- AI, R. Resonance|Predicting Human Behaviours. Available online: https://www.resonance-ai.com/ (accessed on 7 October 2017).
- De Ruyter, B.; Van De Sluis, R. Challenges for End-User Development in Intelligent Environments. In End User Development; Lieberman, H., Paternò, F., Wulf, V., Eds.; Springer Netherlands: Dordrecht, The Netherlands, 2006; pp. 243–250. ISBN 978-1-4020-5386-3. [Google Scholar]
- Leonidis, A.; Arampatzis, D.; Louloudakis, N.; Stephanidis, C. The AmI-Solertis System: Creating User Experiences in Smart Environments. In Proceedings of the 13th IEEE International Conference on Wireless and Mobile Computing, Networking and Communications, Rome, Italy, 9–11 October 2017. [Google Scholar]
- Preuveneers, D.; Van den Bergh, J.; Wagelaar, D.; Georges, A.; Rigole, P.; Clerckx, T.; Berbers, Y.; Coninx, K.; Jonckers, V.; De Bosschere, K. Towards an extensible context ontology for ambient intelligence. In Proceedings of the European Symposium on Ambient Intelligence, Eindhoven, The Netherlands, 8–11 November 2004; pp. 148–159. [Google Scholar]
- Hohpe, G.; Woolf, B. Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions; Addison-Wesley: Boston, MA, USA, 2004; ISBN 0-321-20068-3. [Google Scholar]
- Menge, F. Enterprise Service Bus; O’Reilly Media, Inc.: Newton, MA, USA, 2007; Volume 2, pp. 1–6. [Google Scholar]
- OpenAPI Specification|Swagger. Available online: https://swagger.io/specification/ (accessed on 9 December 2018).
- Hoareau, D.; Mahéo, Y. Middleware support for the deployment of ubiquitous software components. Pers. Ubiquitous Comput. 2008, 12, 167–178. [Google Scholar] [CrossRef]
- Dawson, M.R.W. Minds and Machines: Connectionism and Psychological Modeling; John Wiley & Sons: Hoboken, NJ, USA, 2008; ISBN 978-0-470-75298-2. [Google Scholar]
- Siegel, M. The sense-think-act paradigm revisited. In Proceedings of the 1st International Workshop on Robotic Sensing, 2003. ROSE’ 03, Orebo, Sweden, 5–6 June 2003; p. 5. [Google Scholar]
- Wireless and Smart Lighting by Philips|Meet Hue. Available online: http://www2.meethue.com/en-us (accessed on 19 January 2018).
- Motorized Blinds, Shades, Awnings and Curtains with Somfy. Available online: https://www.somfysystems.com (accessed on 27 November 2018).
- RENPHO Essential Oil Diffuser WiFi Smart Humidifier Works with Alexa, Google Assistant and APP, 120ml Ultrasonic Aromatherapy Diffuser for Home Office, Adjustable Cool Mist, Waterless Auto Shut-off. Available online: https://renpho.com/Health/essential-oil-diffusers/product-950.html (accessed on 6 December 2018).
- Merz, H.; Hansemann, T.; Hübner, C. Building Automation: Communication Systems with EIB/KNX, LON and BACnet; Springer Science & Business Media: Berlin, Germany, 2009. [Google Scholar]
- Kinect-Windows App Development. Available online: https://developer.microsoft.com/en-us/windows/kinect (accessed on 9 December 2018).
- Withings Sleep. Available online: /uk/en/sleep (accessed on 6 December 2018).
- EMFIT Sleep Tracking & Monitoring with Heart-Rate-Variability. Available online: https://www.emfit.com (accessed on 9 December 2018).
- Hybrid Smartwatch|Steel HR-Withings. Available online: /ca/en/steel-hr (accessed on 6 December 2018).
- Fitbit Charge 3|Advanced Health and Fitness Tracker. Available online: https://www.fitbit.com/eu/charge3 (accessed on 6 December 2018).
- Smart Lock-Keyless Electronic Door Lock for Smart Access. Available online: https://nuki.io/en/ (accessed on 27 November 2018).
- What is Choregraphe?|SoftBank Robotics Community. Available online: https://community.ald.softbankrobotics.com/en/resources/faq/developer/what-choregraphe (accessed on 6 December 2018).
- Cython: C-Extensions for Python. Available online: https://cython.org/ (accessed on 10 December 2018).
- Wilcox, B. Chatscript. Available online: http://meta-guide.com/bots/chatbots/chatscript (accessed on 10 December 2018).
- Bocklisch, T.; Faulker, J.; Pawlowski, N.; Nichol, A. Rasa: Open Source Language Understanding and Dialogue Management. arXiv, 2017; arXiv:1712.05181. [Google Scholar]
- Language Understanding with Rasa NLU—Rasa NLU 0.10.5 Documentation. Available online: https://rasa-nlu.readthedocs.io/en/latest/index.html# (accessed on 22 December 2017).
- spaCy-Industrial-Strength Natural Language Processing in Python. Available online: https://spacy.io/index (accessed on 22 December 2017).
- Lieberman, H.; Liu, H. Feasibility studies for programming in natural language. In End User Development; Springer: Berlin, Germany, 2006; pp. 459–473. [Google Scholar]
- Brinck, T.; Gergle, D.; Wood, S.D. Usability for the Web: Designing Web Sites that Work; Morgan Kaufmann: Burlington, MA, USA, 2001; ISBN 0-08-052031-6. [Google Scholar]
- Mavridis, N. A review of verbal and non-verbal human–robot interactive communication. Robot. Auton. Syst. 2015, 63, 22–35. [Google Scholar] [CrossRef] [Green Version]
- Thinking Aloud: The #1 Usability Tool. Available online: https://www.nngroup.com/articles/thinking-aloud-the-1-usability-tool/ (accessed on 31 October 2017).
- User Experience Questionnaire (UEQ). Available online: https://www.ueq-online.org/ (accessed on 6 December 2018).
- Cloud Speech-to-Text-Speech Recognition|Cloud Speech-to-Text API. Available online: https://cloud.google.com/speech-to-text/ (accessed on 9 December 2018).
- Stephanidis, C. The Universal Access Handbook; CRC Press: Boca Raton, FL, USA, 2009; ISBN 1-4200-6499-1. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Expertise Level | Users | MAI | nAoMI | ||||
|---|---|---|---|---|---|---|---|
| Avg. Time | Errors | Help | Avg. Time | Errors | Help | ||
| 1 | 4 | 6:25 | 2 | 1 | 6.31 | 5 | 1 |
| 2 | 7 | 7:29 | 7 | 1 | 7:46 | 10 | 8 |
| 3 | 4 | 9:44 | 6 | 3 | 7:22 | 1 | 2 |
| 4 | 1 | 14:19 | 0 | 0 | 12:30 | 2 | 0 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stefanidi, E.; Foukarakis, M.; Arampatzis, D.; Korozi, M.; Leonidis, A.; Antona, M. ParlAmI: A Multimodal Approach for Programming Intelligent Environments. Technologies 2019, 7, 11. https://doi.org/10.3390/technologies7010011
Stefanidi E, Foukarakis M, Arampatzis D, Korozi M, Leonidis A, Antona M. ParlAmI: A Multimodal Approach for Programming Intelligent Environments. Technologies. 2019; 7(1):11. https://doi.org/10.3390/technologies7010011
Chicago/Turabian StyleStefanidi, Evropi, Michalis Foukarakis, Dimitrios Arampatzis, Maria Korozi, Asterios Leonidis, and Margherita Antona. 2019. "ParlAmI: A Multimodal Approach for Programming Intelligent Environments" Technologies 7, no. 1: 11. https://doi.org/10.3390/technologies7010011
APA StyleStefanidi, E., Foukarakis, M., Arampatzis, D., Korozi, M., Leonidis, A., & Antona, M. (2019). ParlAmI: A Multimodal Approach for Programming Intelligent Environments. Technologies, 7(1), 11. https://doi.org/10.3390/technologies7010011