
Analysis of the Factors Affecting Student Performance Using a Neuro-Fuzzy Approach


Abstract
:1. Introduction
2. Objectives and Scope of the Study
3. Related Work
3.1. Predicting Students’ Performance Using Machine Learning Methods
3.2. Predicting Students’ Performance Using Statistical Methods
3.3. Predictive Attributes for Student Performance
4. Research Methodology
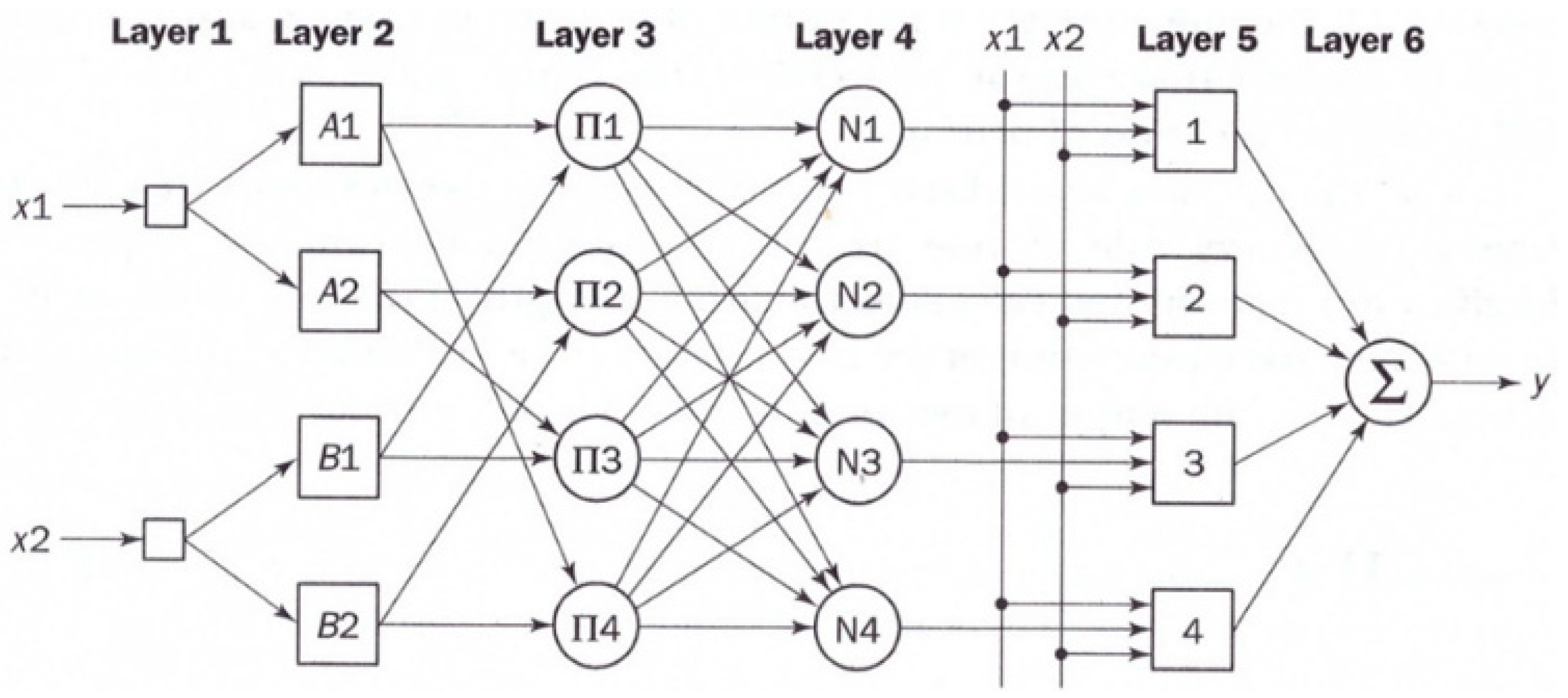
4.1. Adaptive Neuro-Fuzzy Inference System
4.2. Anfis Learning
4.3. Dataset
4.4. Predictive and Explanatory Model Performance
5. Results and Discussion
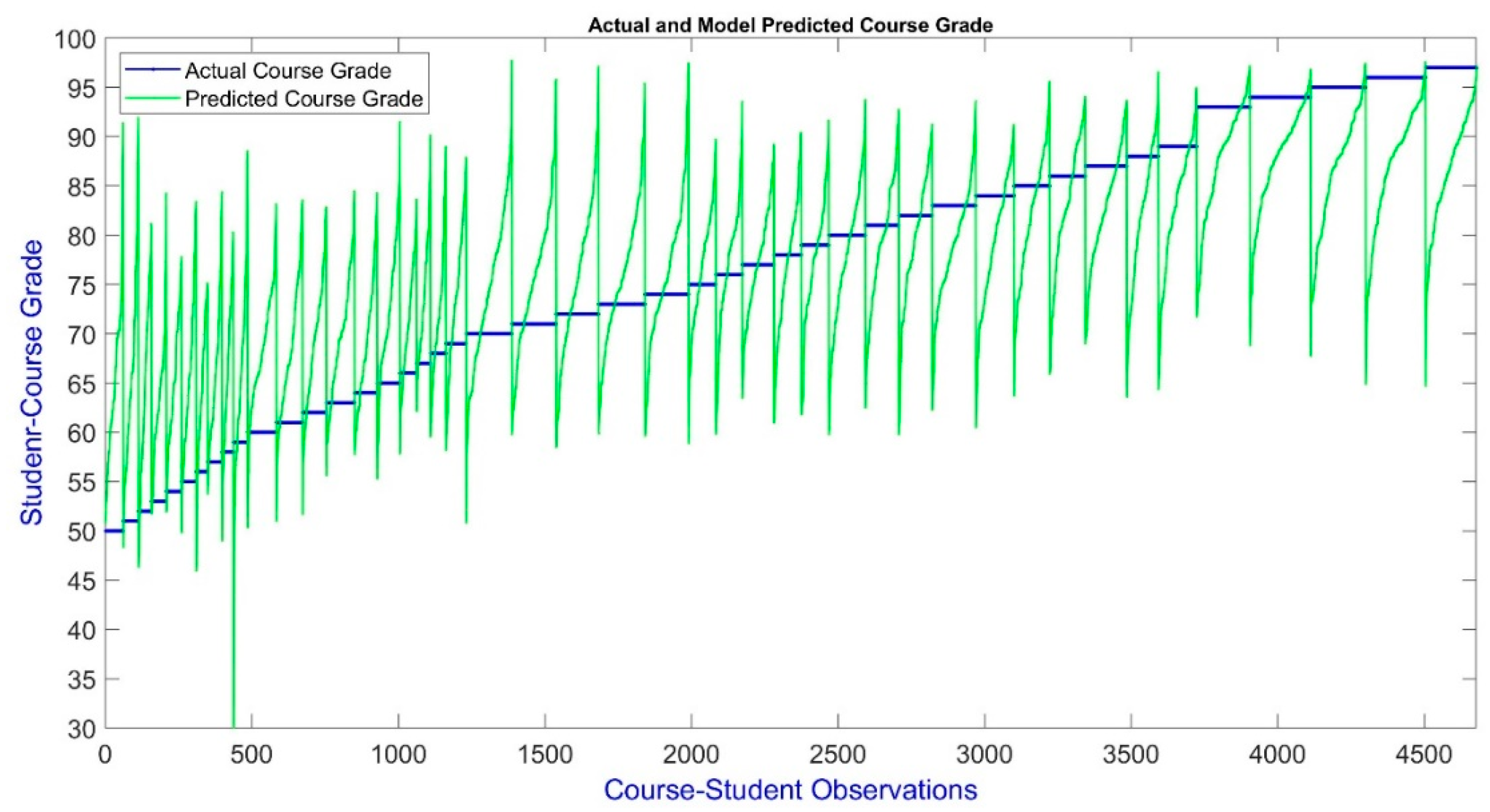
5.1. Model Performance
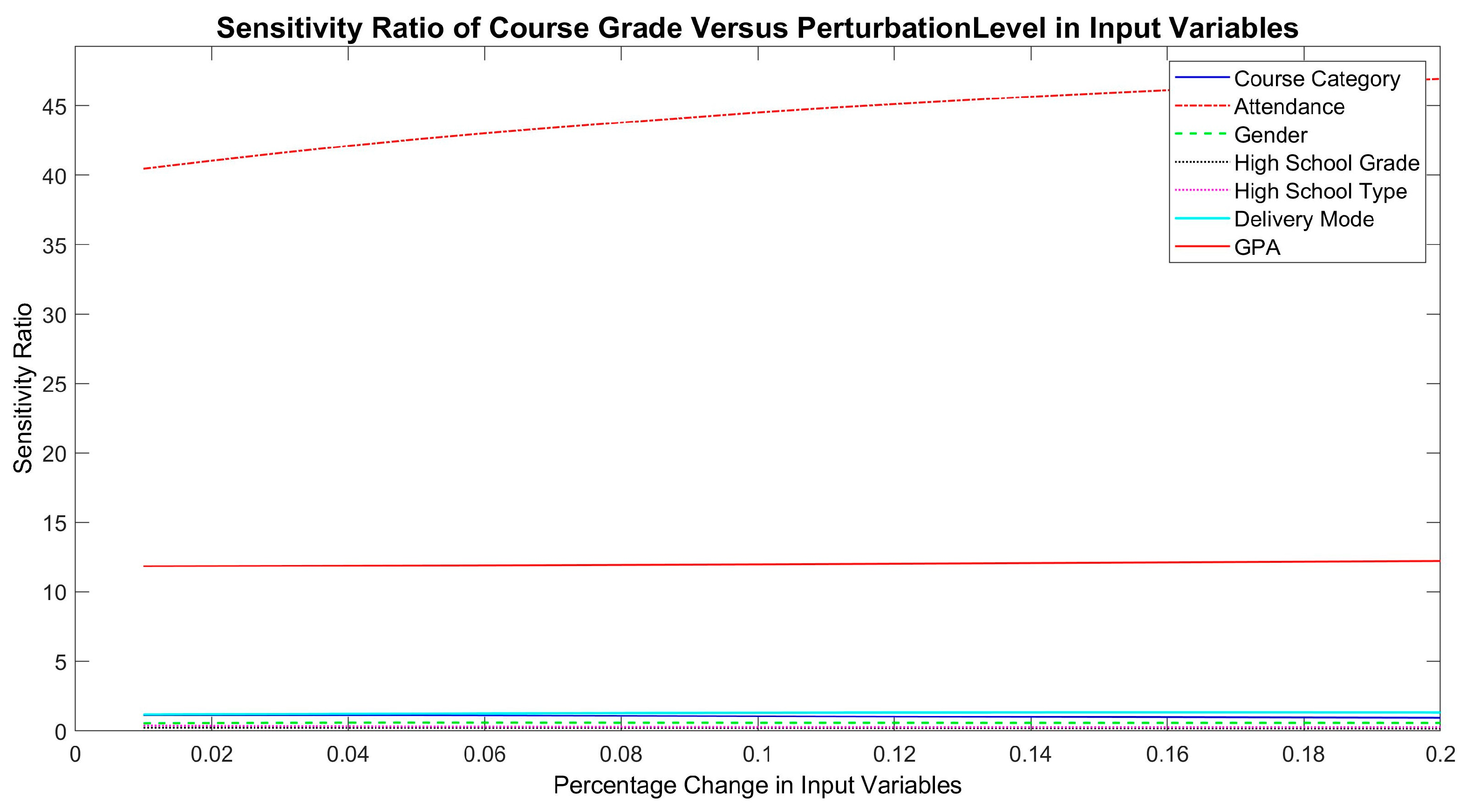
5.2. Predictive Importance of Input Variables
5.3. Model Explanatory Performance
5.4. Limitations and Model Validity
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Al Breiki, B.; Zaki, N.; Mohamed, E.A. Using educational data mining techniques to predict student performance. In Proceedings of the 2019 International Conference on Electrical and Computing Technologies and Applications (ICECTA), Ras Al Khaimah, United Arab Emirates, 19–21 November 2019; pp. 1–5. [Google Scholar]
- Doniņa, A.; Svētiņa, K.; Svētiņš, K. Class Attendance As a Factor Affecting Academic Performance. In Proceedings of the International Scientific Conference, Rezekne, Latvia, 20 May 2020; Volume 6, pp. 578–594. [Google Scholar]
- Etemadpour, R.; Zhu, Y.; Zhao, Q.; Hu, Y.; Chen, B.; Sharier, M.A.; Zheng, S.; SPaiva, J.G. Role of absence in academic success: An analysis using visualization tools. Smart Learn. Environ. 2020, 7, 2. [Google Scholar] [CrossRef] [Green Version]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Multi-split optimized bagging ensemble model selection for multi-class educational data mining. Appl. Intell. 2020, 50, 4506–4528. [Google Scholar] [CrossRef]
- Livieris, I.E.; Drakopoulou, K.; Tampakas, V.T.; Mikropoulos, T.A.; Pintelas, P. Predicting secondary school students’ performance utilizing a semi-supervised learning approach. J. Educ. Comput. Res. 2019, 57, 448–470. [Google Scholar] [CrossRef]
- Amrieh, E.A.; Hamtini, T.; Aljarah, I. Mining educational data to predict student’s academic performance using ensemble methods. Int. J. Database Theory Appl. 2016, 9, 119–136. [Google Scholar] [CrossRef]
- El-Halees, A. Mining students data to analyze learning behavior: A case study. In Proceedings of the 2008 International Arab Conference of Information Technology (ACIT2008)—Conference Proceedings, Hammamet, Tunisia, 16–18 December 2008; p. 137. [Google Scholar]
- Ayesha, S.; Mustafa, T.; Sattar, A.; Khan, I. Data mining model for higher education system. Eur. J. Sci. Res. 2018, 43, 24–29. [Google Scholar]
- Karnik, A.; Kishore, P.; Meraj, M. Examining the linkage between class attendance at university and academic performance in an International Branch Campus setting. Res. Comp. Int. Educ. 2020, 15, 371–390. [Google Scholar] [CrossRef]
- Jang, J.S. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Negnevitsky, M.; Intelligence, A. A guide to intelligent systems. In Artificial Intelligence; Prentice Hall: Harlow, UK, 2017. [Google Scholar]
- Rutkowski, L. Fuzzy Inference Systems. In Flexible Neuro-Fuzzy Systems: Structures, Learning and Performance Evaluation, The International Series in Engineering and Computer Science; Springer: Boston, MA, USA, 2004; Volume 771, pp. 27–50. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining Concepts and Techniques, 3rd ed.; University of Illinois at Urbana-Champaign Micheline Kamber Jian Pei Simon Fraser University: Burnaby, BC, Canada, 2012. [Google Scholar]
- Du, X.; Yang, J.; Hung, J.L.; Shelton, B. Educational data mining: A systematic review of research and emerging trends. Inf. Discov. Deliv. 2020, 48, 225–236. [Google Scholar] [CrossRef]
- Anjewierden, A.A.; Kolloffel, B.; Hulshof, C. Towards educational data mining. Using data mining methods for automated chat analysis and support inquiry learning processes. In Proceedings of the International Workshop on Applying Data Mining in e-Learning, Crete, Greece, 17–18 September 2007; Available online: https://core.ac.uk/display/20962888 (accessed on 16 August 2021).
- Altujjar, Y.; Altamimi, W.; Al-Turaiki, I.; Al-Razgan, M. Predicting critical courses affecting students performance: A case study. Procedia Comput. Sci. 2016, 82, 65–71. [Google Scholar] [CrossRef] [Green Version]
- Yağcı, M. Educational data mining: Prediction of students’ academic performance using machine learning algorithms. Smart Learn. Environ. 2022, 9, 11. [Google Scholar] [CrossRef]
- Rodríguez-Hernández, C.F.; Musso, M.; Kyndt, E.; Cascallar, E. Artificial neural networks in academic performance prediction: Systematic implementation and predictor evaluation. Comput. Educ. Artif. Intell. 2021, 2, 100018. [Google Scholar] [CrossRef]
- Baashar, Y.; Alkawsi, G.; Mustafa, A.; Alkahtani, A.A.; Alsariera, Y.A.; Ali, A.Q.; Hashim, W.; Tiong, S.K. Toward predicting student’s academic performance using artificial neural networks (ANNs). Appl. Sci. 2022, 12, 1289. [Google Scholar] [CrossRef]
- Liu, C.; Wang, H.; Yuan, Z. A Method for Predicting the Academic Performances of College Students Based on Education System Data. Mathematics 2022, 10, 3737. [Google Scholar] [CrossRef]
- Cazarez, R.L. Accuracy comparison between statistical and computational classifiers applied for predicting student performance in online higher education. Educ. Inf. Technol. 2022, 27, 11565–11590. [Google Scholar] [CrossRef]
- Chaka, C. Educational Data Mining, Student Academic Performance Prediction, Prediction Methods, Algorithms and Tools: An Overview of Reviews. Available online: https://www.preprints.org/manuscript/202108.0345/v1 (accessed on 16 August 2021).
- Hasan, R.; Palaniappan, S.; Raziff, A.R.; Mahmood, S.; Sarker, K.U. Student academic performance prediction by using decision tree algorithm. In Proceedings of the 2018 4th International Conference on Computer and Information Sciences (ICCOINS), Kuala Lumpur, Malaysia, 13 August 2018; pp. 1–5. [Google Scholar]
- Díaz-Uriarte, R.; Alvarez de Andrés, S. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4 August 2001; Volume 3, pp. 41–46. [Google Scholar]
- Zhang, Z. Introduction to machine learning: K-nearest neighbors. Ann. Transl. Med. 2016, 4, 218. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beyer, K.; Goldstein, J.; Ramakrishnan, R.; Shaft, U. When is “nearest neighbor” meaningful? In Proceedings of the International Conference on Database Theory, Jerusalem, Israel, 10 January 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 217–235. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Balogh, Z.; Kuchárik, M. Predicting student grades based on their usage of LMS moodle using Petri nets. Appl. Sci. 2019, 9, 4211. [Google Scholar] [CrossRef] [Green Version]
- Atanassov, K.; Sotirova, E.; Andonov, V. Generalized net model of multicriteria decision making procedure using intercriteria analysis. In Advances in Fuzzy Logic and Technology 2017: Proceedings of: EUSFLAT-2017–The 10th Conference of the European Society for Fuzzy Logic and Technology, September 11–15, 2017, Warsaw, Poland IWIFSGN’2017–The Sixteenth International Workshop on Intuitionistic Fuzzy Sets and Generalized Nets, September 13–15, 2017, Warsaw, Poland, Volume 1 10; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 99–111. [Google Scholar]
- Kassarnig, V.; Bjerre-Nielsen, A.; Mones, E.; Lehmann, S.; Lassen, D.D. Class attendance, peer similarity, and academic performance in a large field study. PLoS ONE 2017, 12, e0187078. [Google Scholar] [CrossRef] [Green Version]
- Imran, M.; Latif, S.; Mehmood, D.; Shah, M. Student academic performance prediction using supervised learning techniques. Int. J. Emerg. Technol. Learn. 2019, 14, 92–104. [Google Scholar] [CrossRef] [Green Version]
- Zeineddine, H.; Braendle, U.; Farah, A. Enhancing prediction of student success: Automated machine learning approach. Comput. Electr. Eng. 2021, 89, 106903. [Google Scholar] [CrossRef]
- Fateh ALLAH, A.Q. Using Machine Learning to Support Students’ Academic Decisions. Ph.D. Thesis, The British University in Dubai (BUiD)), Dubai, United Arab Emirates, 2019. [Google Scholar]
- Mengash, H.A. Using data mining techniques to predict student performance to support decision-making in university admission systems. IEEE Access 2020, 8, 55462–55470. [Google Scholar] [CrossRef]
- Berens, J.; Schneider, K.; Görtz, S.; Oster, S.; Burghoff, J. Early Detection of Students at Risk—Predicting Student Dropouts Using Administrative Student Data and Machine Learning Methods. CESifo Working Paper No. 7259. 2018. Available online: https://ssrn.com/abstract=3275433 (accessed on 16 August 2021). [CrossRef]
- Kemper, L.; Vorhoff, G.; Wigger, B.U. Predicting student dropout: A machine learning approach. Eur. J. High. Educ. 2020, 10, 28–47. [Google Scholar] [CrossRef]
- Xu, J.; Moon, K.H.; Mvd, S. A machine learning approach for tracking and predicting student performance in degree programs. IEEE J. Sel. Top. Signal. Process. 2017, 11, 742–753. [Google Scholar] [CrossRef]
- Nabil, A.; Seyam, M.; Abou-Elfetouh, A. Prediction of students’ academic performance based on courses’ grades using deep neural networks. IEEE Access 2021, 9, 140731–140746. [Google Scholar] [CrossRef]
- Poudyal, S.; Mohammadi-Aragh, M.J.; Ball, J.E. Prediction of Student Academic Performance Using a Hybrid 2D CNN Model. Electronics 2022, 11, 1005. [Google Scholar] [CrossRef]
- Mehdi, R.; Nachouki, M. A neuro-fuzzy model for predicting and analyzing student graduation performance in computing programs. Educ. Inform. Technol. 2022, 28, 1–30. [Google Scholar] [CrossRef]
- Nachouki, M.; Abou Naaj, M. Predicting Student Performance to Improve Academic Advising Using the Random Forest Algorithm. Int. J. Distance Educ. Technol. (IJDET) 2022, 20, 1–7. [Google Scholar] [CrossRef]
- Vermunt, J.D. Relations between student learning patterns and personal and contextual factors and academic performance. High. Educ. 2005, 49, 205–234. [Google Scholar] [CrossRef]
- Azhar, M.; Nadeem, S.; Naz, F.; Perveen, F.; Sameen, A. Impact of parental education and socioeconomic status on academic achievements of university students. Eur. J. Psychol. Res. 2014, 1, 1–9. [Google Scholar]
- Tsinidou, M.; Gerogiannis, V.; Fitsilis, P. Evaluation of the factors that determine quality in higher education: An empirical study. Qual. Assur. Educ. 2010, 18, 227–244. [Google Scholar] [CrossRef] [Green Version]
- You, J.W. Testing the three-way interaction effect of academic stress, academic self-efficacy, and task value on persistence in learning among Korean college students. High. Educ. 2018, 76, 921–935. [Google Scholar] [CrossRef]
- Musaddiq, M.H.; Sarfraz, M.S.; Shafi, N.; Maqsood, R.; Azam, A.; Ahmad, M. Predicting the Impact of Academic Key Factors and Spatial Behaviors on Students’ Performance. Appl. Sci. 2022, 12, 10112. [Google Scholar] [CrossRef]
- Diseth, Å.; Pallesen, S.; Brunborg, G.S.; Larsen, S. Academic achievement among first semester undergraduate psychology students: The role of course experience, effort, motives and learning strategies. High. Educ. 2010, 59, 335–352. [Google Scholar] [CrossRef]
- Pal, M.; Bharati, P. Introduction to correlation and linear regression analysis. In Applications of Regression Techniques; Springer: Singapore, 2019; pp. 1–18. [Google Scholar]
- Tanaka KSugeno, M. Introduction to fuzzy modelling. In Fuzzy Systems: Modeling and Control; Nguyen, H.T., Sugeno, M., Eds.; Kluwer: New York, NY, USA, 1998; pp. 63–89. [Google Scholar]
- Subhedar, M.; Birajdar, G. Comparison of mamdani and sugeno inference systems for dynamic spectrum allocation in cognitive radio networks. Wirel. Pers. Commun. 2013, 71, 805–819. [Google Scholar] [CrossRef]
- Mitra, S.; Hayashi, Y. Neuro-fuzzy rule generation: Survey in soft computing framework. IEEE Trans. Neural Netw. 2000, 11, 748–768. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geisser, S. Predictive Inference: An Introduction; Chapman and Hall/CRC: New York, NY, USA, 2017. [Google Scholar]
- Shmueli, G. To explain or to predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Geisser, S. The predictive sample reuse method with applications. J. Am. Stat. Assoc. 1975, 70, 320–328. [Google Scholar] [CrossRef]
- Mosteller FTukey, J.W. Data Analysis and Regression; Addison-Wesley: Reading, MA, USA, 1977. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef] [Green Version]
- Cao, M.; Alkayem, N.F.; Pan, L.; Novák, D.; Rosa, J.L. Advanced methods in neural networks-based sensitivity analysis with their applications in civil engineering. In Artificial Neural Networks-Models and Applications; IntechOpen: London, UK, 2016; pp. 335–353. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Jones, P.; Partridge, D. Assessing the impact of input features in a feedforward neural network. Neural Comput. Appl. 2000, 9, 101–112. [Google Scholar] [CrossRef]
- Cheng, A.Y.; Yeung, D.S. Sensitivity analysis of neocognitron. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 1999, 29, 238–249. [Google Scholar] [CrossRef]
- Lamy, D. Modelling and sensitivity analysis of neural network. Math. Comput. Simul. 1996, 40, 535–548. [Google Scholar] [CrossRef]
- Tomkin, J.H.; West, M.; Herman, G.L. An improved grade point average, with applications to C.S. undergraduate education analytics. ACM Trans. Comput. Educ. (TOCE) 2018, 18, 1–6. [Google Scholar] [CrossRef]
- e Silva, I.H.; Pacheco, O.; Tavares, J. Effects of curriculum adjustments on first-year programming courses: Students performance and achievement. In Proceedings of the Frontiers in Education Conference, Boulder, CO, USA, 5–8 November 2003; Volume 1, p. T4C-10. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categorical Input | Values |
|---|---|
| course category | Programming, Mathematics, Core Information Technology, Advanced Information Technology, Advanced Information Systems Courses, Engineering, General Education, and Business Courses |
| gender | Male, Female |
| school type | National High School Certificate, American High School Certificate or equivalent, British GCE High School Certificate or equivalent, Pakistani/Indian High School Certificate, and African/Iranian High School Certificate |
| delivery mode | Face-to-face, online, hybrid |
| Delivery Mode | Mean Course Grade | Standard Deviation | Sample Size |
|---|---|---|---|
| Face-to-face | 75.28 | 14.17 | 5815 |
| Fully online | 76.85 | 12.73 | 3636 |
| Hybrid | 78.84 | 12.28 | 6145 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abou Naaj, M.; Mehdi, R.; Mohamed, E.A.; Nachouki, M. Analysis of the Factors Affecting Student Performance Using a Neuro-Fuzzy Approach. Educ. Sci. 2023, 13, 313. https://doi.org/10.3390/educsci13030313
Abou Naaj M, Mehdi R, Mohamed EA, Nachouki M. Analysis of the Factors Affecting Student Performance Using a Neuro-Fuzzy Approach. Education Sciences. 2023; 13(3):313. https://doi.org/10.3390/educsci13030313
Chicago/Turabian StyleAbou Naaj, Mahmoud, Riyadh Mehdi, Elfadil A. Mohamed, and Mirna Nachouki. 2023. "Analysis of the Factors Affecting Student Performance Using a Neuro-Fuzzy Approach" Education Sciences 13, no. 3: 313. https://doi.org/10.3390/educsci13030313
APA StyleAbou Naaj, M., Mehdi, R., Mohamed, E. A., & Nachouki, M. (2023). Analysis of the Factors Affecting Student Performance Using a Neuro-Fuzzy Approach. Education Sciences, 13(3), 313. https://doi.org/10.3390/educsci13030313