1. Introduction
Vocabularies are linguistic resources that make it possible to access knowledge through words [
1]. In this regard, they can constitute, in their digital format, a mechanism to identify, describe, access, and explore all the digital resources with informational content (e.g., documents, websites, and educational software) pertaining to a specific knowledge domain [
2,
3]. Thus, they play a key role as systems for the representation and organization of knowledge in work environments in which information is created and used in a collaborative or free manner, as is the case in digital teaching and learning environments, e-learning environments, or the web [
4].
E-learning environments are spaces created on the Internet which integrate digital educational resources as a fundamental didactic component. E-learning environments currently constitute one of the basic elements in educational institutions and in professional training and updating services. By digital educational resources, also known as learning objects, we understand digital entities (files or file groups) which have at least one defined learning objective. Some examples of digital educational resources are video lessons, e-books, presentations, notes, exercises, and assessments. On the Internet, digital educational resources are usually located in educational digital repositories (also known as Learning Object Repositories). An educational digital repository is an online system to store, publish, retrieve, and reuse educational resources [
5]. Two good examples are MERLOT [
6] and ARIADNE [
7]. The main advantage of these repositories is that they facilitate to the maximum location and selection of the resources sought as well as their integration in e-learning environments, such as virtual courses in virtual campuses. To facilitate the location and selection of resources, mechanisms for identification and description are used—mainly metadata and e-vocabularies.
This review article focuses on one of the aforementioned mechanisms: e-vocabularies. The article describes, using a semasiological approach, what vocabularies are, how they are used, how they work, and what they contribute to retrieve digital educational resources. The final goal is to answer the main question—what is the position and purpose of e-vocabularies in the description, organization, and retrieval of digital educational resources used in e-learning environments?
To answer this question, a deductive–inductive method based on successive refinements has been applied. Starting from a theoretical core and a data sample, a double analysis is conducted going (1) from theory to the sample and (2) from the sample to the theory, comparing and trying to fit the theoretical proposals with the sample items. The theoretical core comprises the works presented in [
8,
9,
10], and the sample comprises the relevant examples of open educational repositories [
6,
7,
11,
12], picture [
13,
14,
15,
16], and vocabularies [
17,
18,
19,
20,
21,
22,
23,
24,
25,
26]).
When a fit is found, that is, when a theoretical proposal used in any of the sample items is found or vice versa, the answer is refined by searching in the literature for information that makes it possible to (a) go deeper into the theoretical proposal; and (b) verify that it has been applied to other relevant examples.
Finally, the results are presented in the article following the same deductive–inductive format as in the analysis: the theory and the actual examples that support it. The article is structured to answer the main question incrementally, by steps:
Section 2 provides a discussion of what a vocabulary is;
Section 3 discusses what a vocabulary is like;
Section 4 focuses on how vocabularies work in Information Retrieval;
Section 5 specializes
Section 4 to digital educative resources coming increasingly close to the main question: how vocabularies are used to describe and retrieve digital educational resources;
Section 6 answers how to describe digital educational resources albeit refining in each possible e-vocabulary type. Finally,
Section 7—the summary and conclusions—answers the main question and provides the view from the author about what the role of e-vocabularies in the description and retrieval of digital educational resources is.
2. What Is a Vocabulary?
The term
vocabulary is ambiguous, and its meaning depends on the discipline of which it is part and the context in which it is applied. For example, in the general knowledge domain of a language such as Spanish, “vocabulario” has seven meanings (
Figure 1): “(1) the set of words in a language; (2) a dictionary (book); (3) the set of words used in a region, a profession, a writer’s semantic field, etc.”, or simply “(4) the book in which they are included; …” [
27]. In more specialized domains, vocabularies have a more precise meaning, form, and application. In such domains, a word (or collection of words in several languages) designates a single concept which is called a
term and the set of terms is called a
terminology [
28,
29]. Although
vocabulary is not synonymous with
terminology,
vocabulary will be used in this article to cover not only words in generic language also but domain-specific words (e.g., the International Standardization Organization, ISO, uses the term
vocabulary to denote some of their terminology standards such as ISO 472:2013-Plastics—Vocabulary). Additionally, if vocabularies are built and used in electronic format, they are referred as
e-vocabularies. Since the majority of vocabularies are now built in electronic format, throughout the rest of the article “vocabularies” and “e-vocabularies” are used interchangeably.
In the domain of Library and Information Science, a vocabulary is called
term vocabulary and it is defined as a set of terms of conventional syntactic procedures used to represent the contents of a document in order to retrieve it [
30,
31]. They are also known as
documentary languages and provide a common, universal system for classification of bibliographic works and documents [
31].
This concept is also shared by the vocabularies used for Information Retrieval (hereinafter, IR). In this domain, vocabularies are used as components of the IR software systems to prevent linguistic ambiguity and polysemy [
8]. These are
controlled vocabularies that are defined as lists of terms, explicitly listed, unambiguous, and non-redundant which contribute a conceptual description and a pragmatic and empirical dimension to the information domain.
In the field of Computational Linguistics, Natural Language Processing, and Linguistic Technology, vocabularies are also called
computational lexicons or
lexical databases. They are conceived as databases and lexical knowledge bases designed for automatic processing of natural languages [
32]. In these vocabularies, lexical knowledge—at the phonetic and phonological, morphological, syntactic, semantic, pragmatic, discourse, and world levels—becomes explicit and is organized with formal data models that are suitable for automatic natural language processing [
33,
34,
35]. A widely used example of a computational lexicon is WordNet [
17]. Vocabularies constitute a basic component in the architecture of Natural Language Processing Systems: they are necessary for the development of linguistic applications such as spelling and style correctors, retrieval of textual information, and the indexing and description of documents and textual resources. Two sources of computational lexicon distribution are, for example, the European agency ELRA [
36] and the US consortium LDC [
37].
Finally, in the field of e-learning, vocabularies are a mechanism for semantic representation that allows human agents or software to locate, interpret, and retrieve educational content or to process it for didactic purposes. Vocabularies are currently mainly applied to solve two questions: (1) the representation and retrieval of digital educational resources; and (2) the interoperability between e-learning tools and content [
9,
10,
38]. In the former case, the main type of vocabularies used are taxonomies and thesauri [
10], that is, vocabularies of terms organized into categories and/or interconnected by hypernymy–hyponymy and other semantic relations. In the latter case, the type of vocabularies used are thesauri and ontologies that conceptually represent the dimensions of an e-learning system: the agents, tools, domain of knowledge, methodologies, and teaching models, etc. [
39]. In the following sections, vocabulary types and examples of each of these types will be seen.
3. What a Vocabulary Is Like
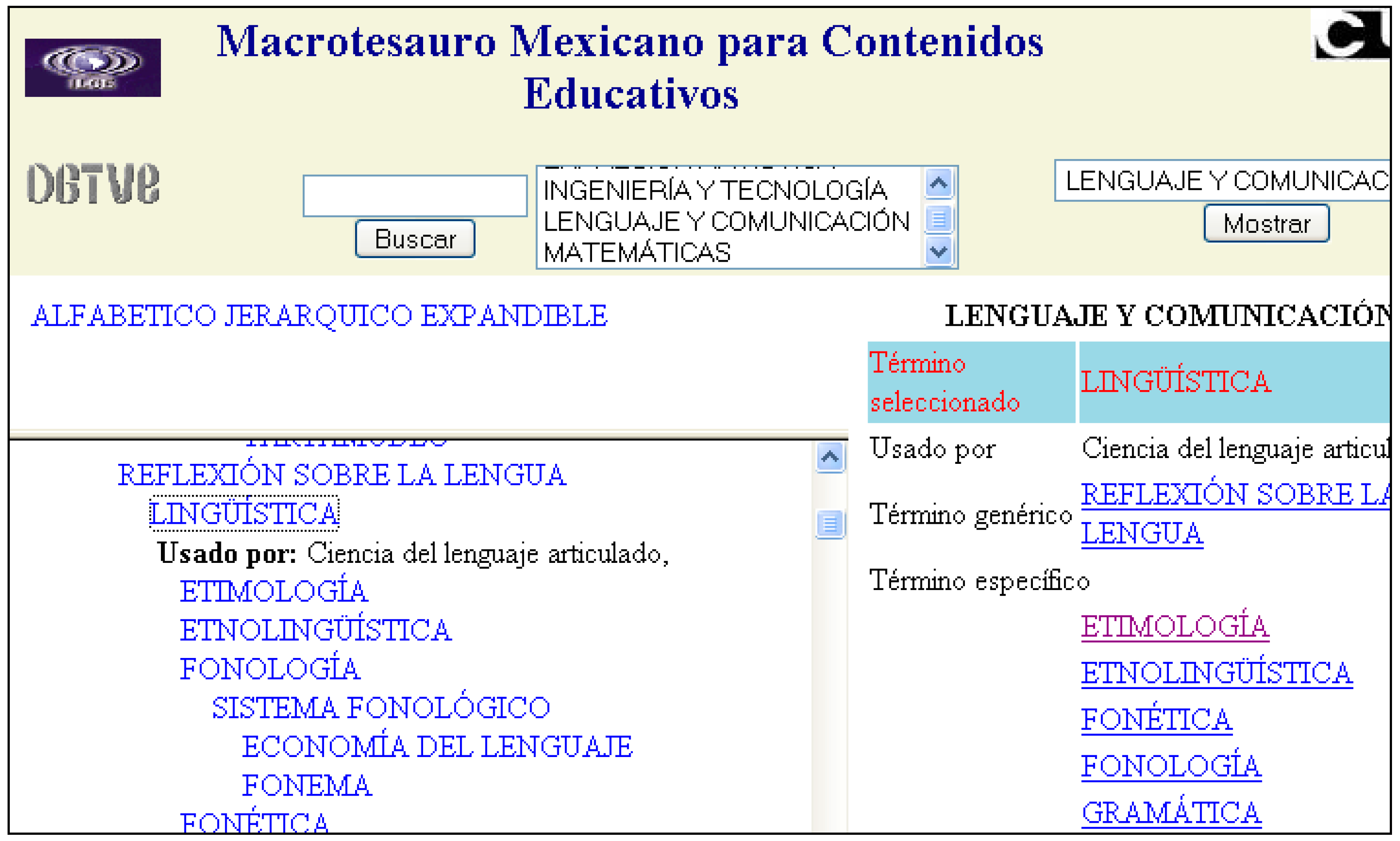
A vocabulary, in any of its interpretations, comprises at least a lexical unit which can be general or specific to a domain [
40]. The words or word groups that constitute it are presented in a standard form (i.e., canonical form) if they are inflected words and can be organized into classes or categories. The overall organization of the vocabulary is called its
macrostructure. The description of each word is given in what is known as an
entry (
Figure 1 and
Figure 2). The contents of entries, known as their
microstructure, depend on the purpose of the vocabulary [
41] but can include, in addition to their meanings, grammatical, usage, phonetic, and etymological information, and relations with other vocabulary terms.
Several types of vocabulary, on the one hand, can be distinguished concerning macrostructure and microstructure [
9]: (i) lists of terms; (ii) glossaries; (iii) classifications and taxonomies; (iv) thesauri; (v) ontologies; (vi) dictionaries; and (vii) lexicons [
10]. In
Section 6, the way in which each of these vocabulary types is configured will be shown in more detail, as well as some examples used in the retrieval of digital educational resources.
On the other hand, based on the procedural criterion of the output of a lookup strategy using vocabularies, two fundamental vocabulary types can be considered [
40]:
Semasiological vocabulary: the lookup key is the word (form) and the information required is semantic. Usually different meanings of a word can be considered as well as interrelations (mainly semantic) between words.
Onomasiological vocabulary: the lookup key is a concept and the information required is the word form or, more precisely, the term that designates the concept (and, if necessary, different terms correlated with it).
On that bases, this section and the rest of the article are mainly following a semasiological approach, although without ignoring the onomasiological angle. In this respect, the term “term” will be used to denote a word that is assigned to a concept used in special languages that occur “… in a domain or subject, and characterized by the use of specific linguistic means of expression…” [
42].
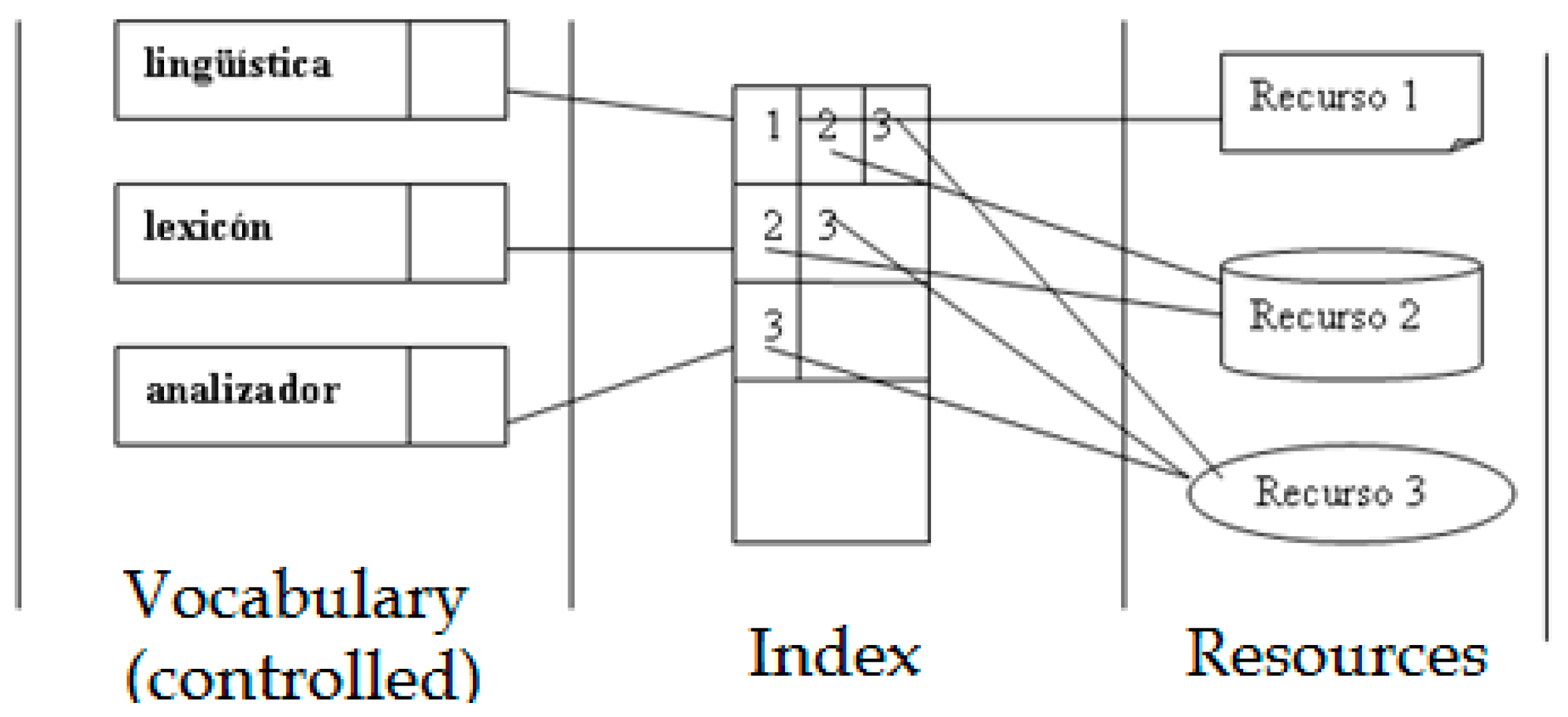
A vocabulary can also be conceived as an
index that establishes a correspondence between the orthographic form of a word and the information about that word [
40]. However, it may not be a one-to-one correspondence, as in those cases in which a word has different syntactic categories, in homographs, and in polysemy, a single word form can have different entries. This would be mainly the case of dictionaries and lexicons. In other cases, a biunivocal word-information correspondence is necessary, as in
controlled vocabularies for IR and retrieval of digital objects. Controlled vocabularies try to ensure a biunivocal correspondence by a control process that disambiguates homograph terms using qualifiers to specify, in the case of synonymy, a single term as the preferred term, also known as the descriptor (
Figure 3), and, in the case of polysemous terms, by restricting meaning through a domain note [
9].
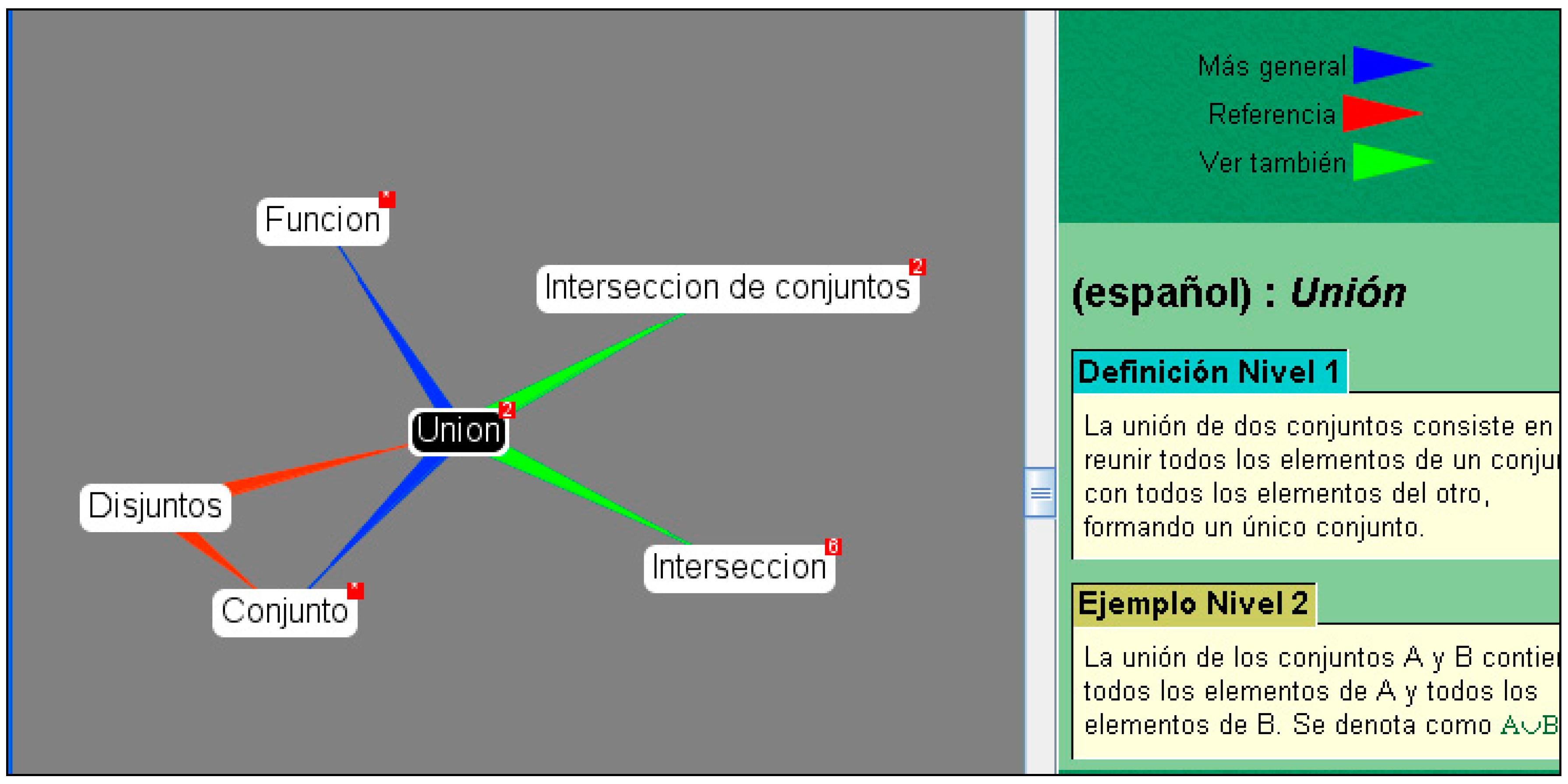
The meaning of a lexical entry is expressed in its
definition. A definition is “a descriptive representation of a concept which serves to differentiate it from related concepts” [
29]. The definition can take many forms, from a simple statement to references based on the establishment of semantic relations between the lexical units (or terms in specific languages) in the vocabulary. This latter approach—the definition of meaning based on semantic relations—is preferred in vocabularies aimed at information retrieval (IR) (
Figure 4).
Classic lexical
relations between word meanings are equivalence, opposition, inclusion, co-hyponymy, and part–all [
13]. The meaning equivalence relation is
synonymy. Two or more words are synonymous if they can be replaced in any context without changing meaning. This condition of equality in all the meanings of a word explains why absolute synonyms are scarce and, for practical purposes, a less strict definition is preferred, so that two or more words are synonymous with respect to a meaning if they can be exchanged in that specific context.
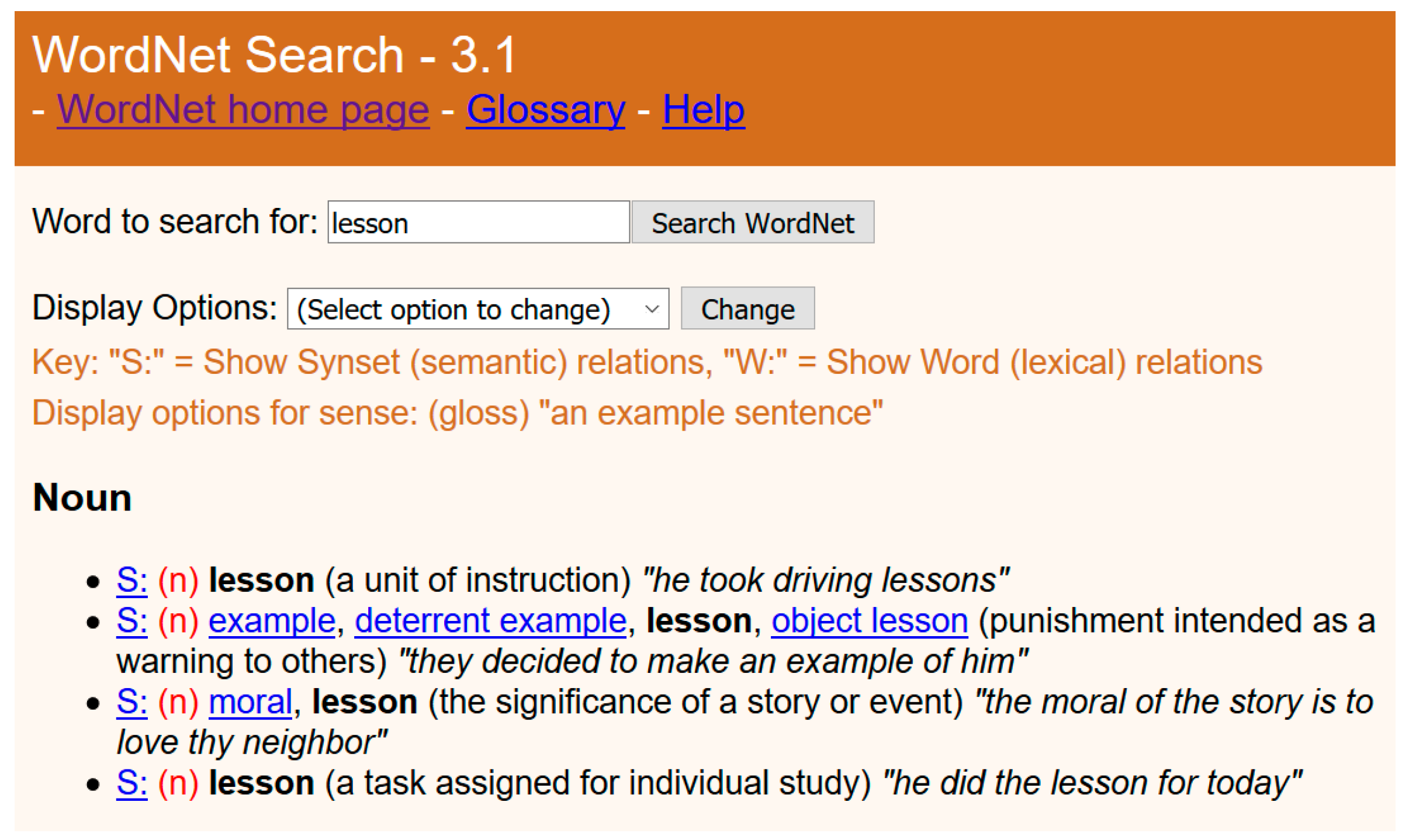
Figure 2 shows the synonym example, deterrent example, lesson, and object lesson with respect to the second meaning of a lesson.
The opposite relation to synonymy is
antonymy (
Figure 5). In the lexicographic tradition, antonyms are defined as words with opposite meanings and, as such, as opposed to synonyms. However, this definition of antonymy is too vague. In [
43], the notion is refined, taking into account the fact that antonymy entails similarity between the terms. Antonymous terms are always composed by common semes, i.e., semantic features: thus, brother and sister share the semes /human being/ and /born from the same parents/, and are opposed by the seme /pertaining to sex/. Consequently, the antonymy relation can be defined as the relation that binds two words in the same grammatical category that share part of their semes and that have an opposing counterpart. Antonymy is also composed of different types of oppositions, mainly binary ones. Three types of antonyms are usually distinguished: (1) Contradictory or complementary antonyms, which express an exclusive disjunction relation, that is, the negation of either one of the words implies the affirmation of the other one and the two terms cannot be simultaneously denied, e.g., man/woman, present/past. (2) Contrary or gradable antonyms, which define the poles in an implicit gradation scale and allow the existence of intermediate degrees. Big/small, heat/cold, love/hatred. (3) Reciprocal antonyms are those that force the replacement of one by the other in a given statement to preserve the relation, e.g., doctor/patient, parent/child.
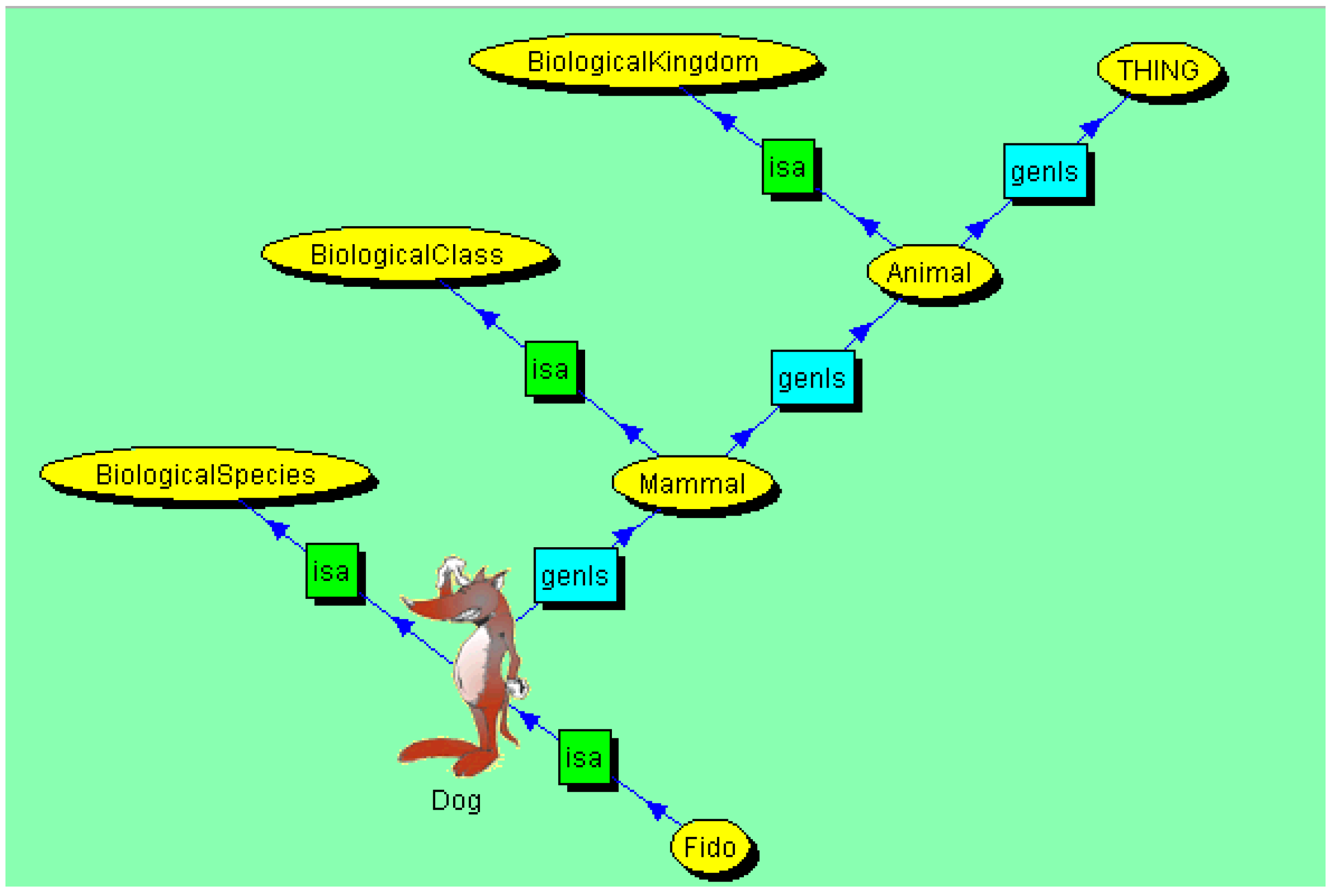
The main inclusion relation is generalization or
hypernymy, and its inverse relation is specialization or
hyponymy. An example of hypernymy–hyponymy relations is shown in
Figure 4. The hypernym appears marked as the Broader Term (BT), and the hyponyms are marked as Narrow Terms (NTs). Hypernymy–hyponymy relations are asymmetric and transitive so they “arrange” words into simple or multiple hierarchies from more general to more specific meanings. Structures are usually lattices, but the term hierarchy is used to emphasize the conceptual dependence of hyponyms on hypernyms.
Co-hyponymy within the same hierarchy is established between the words related to the same hyperonymy, e.g., in
Figure 4, “alternative school” and “boarding school” are co-hyponyms of “school”. Co-hyponyms are distinguished by one or more delimiting characteristics. A delimiting characteristic is a “necessary characteristic that distinguishes a concept from related concepts” [
29]. Unlike in antonymy based on a binary opposition, the negation of one of the co-hyponyms does not necessarily imply the affirmation of the other co-hyponym, but the choice remains open: if x is not an “alternative school”, it can be a “boarding school” or a “dancing school”. Co-hyponyms are mutually exclusive: a “school” is an “alternative school” or a “boarding school” or a “dancing school”, etc. Moreover, co-hyponyms can have synonymy or antonymy relations between each other. For example, “college” and “university” can be regarded as co-hyponyms of “school” and can pass for synonyms; contrariwise, “virtual learning” and “face-to-face learning”, co-hyponyms of “learning”, are antonymous [
43].
The part-all or
holonymy/meronymy relation is also a hierarchical, antisymmetric, and transitive relation in which one of the terms denotes a part and the other the whole pertaining to that part (
Figure 6). The difference with respect to the hyponymy–hypernymy relation is that it is a relation of belonging rather than inclusion, so meronyms do not inherit the homonyms’ attributes. Meronymic dependence relations are varied and complex: member/set (teacher/faculty), component/assembly (leg/chair), portion/mass (slice/cake), material/object (steel/bicycle) [
43]. In the WordNet vocabulary, three types of holonymic relations are used: member, substance, and part [
14].
In addition to “classic” lexical relations, vocabularies can include many other semantic associative relations, such as family (fire/fireman), agent (student/learning agent), instrument (exercise/practice instrument), or location (school/student location).
As will be seen in the following sections, semantic relations, particularly those of synonymy and hyponymy–hypernymy, are basic for building vocabularies for the classification and indexing of information and of digital educational resources.
4. How Vocabularies Work in Information Retrieval
Information retrieval (IR) is a field of Artificial Intelligence whose object is the search for information in documents, document search, the search for metadata that describe documents, and the search for data in databases, be it via the Internet, an intranet, for texts, images, sound, or other data, in a pertinent and relevant manner [
15]. Retrieval of digital educational resources is thus a particular case of IR. In this section, the basic IR mechanisms that are also shared by
retrieval of digital educational resources are reviewed.
In the context of IR, vocabularies are
information organization systems whose purpose is to increase the effectiveness of the processes of indexing, search, or navigation of collections of digital resources with informational content (hereinafter, simply resources). They constitute a “bridge” between information representation at a high level of abstraction and representation at the level of computer information system, as well as between the natural language in which people make a search query and the formal query languages used by machines [
8,
10,
16]. The idea is to use the terms to represent the contents of resources and relations between the terms in the vocabularies to improve the exhaustiveness and precision of the indexing results and the search for resources, as well as the usability of the user interface.
In this regard,
exhaustiveness in search processes improves if the terms employed by the user in their request (i.e., “dog”) are expanded by using all the possible terms related either orthographically (i.e., “dog”, “doggie”), in what is known as the form control, or else by their meaning, through synonym control (e.g., “pooch”, “canine”, “cur”), quasi-synonyms, hyponyms/hypernyms (e.g., “quadruped”, holonyms/meronyms (e.g., “pack”) and other associated terms. Regarding the improvement in
precision, vocabularies make it possible to combine terms to fine-tune the user’s query, what is known as coordination. They make it possible to distinguish between homographs, use definitions to disambiguate, restrict, or clarify the meanings of the query, and the frequency of use of the terms to statistically differentiate the most likely terms on the basis of use, context, or even user profile. Finally, as regards interface
usability, vocabularies offer users an alternative system for access to resources as a terminological-conceptual map of the resource collections (
Figure 7).
The functioning of vocabularies in the indexing, search, and navigation of resources are discussed in more detail in the next two subsections.
4.1. Vocabulary in Resource Indexing
The first process for IR is
resource indexing. In indexing, resources are represented by means of terms and the indices that link terms and resources are created (
Figure 8). A small, limited set of terms that represent the contents of the resource is selected and associated with this resource. The terms may come from a pre-existing controlled vocabulary, and it is then termed assignment indexing by assignation; otherwise, it can be extracted from within the resources themselves, what is known as extraction indexing [
8]. The index generated could be used, if so wished, as a terminological map for users to explore and retrieve the collection resources (
Figure 7).
Indexing is basically carried out in
three stages: (1) analysis of the domain (collection of resources), which entails the extraction of the key terms in each of the resources; (2) the selection of the most representative terms of a controlled vocabulary to describe the resources; and (3) the creation of data structures (called indices) to store the associations between resources and terms (
Figure 8).
The indexing process can be
manual, automatic, or
semiautomatic [
2]. In the first case, an expert (or expert committee) analyzes the contents, context, and structure of each resource and assigns to it the set of terms from a controlled vocabulary that best describes it (categorization by assignment). Another option in this first case is the extraction of the terms that are most representative of the resource or its metadata (categorization by extraction). Manual indexing has the advantage of having a high degree of precision in the description of resources, particularly in non-textual resources such as images or software applications. However, it is quite costly and in some cases lacks consistency in descriptions due to differences in criteria among indexers. The data provided in [
44] can serve as a sample: “…Yahoo uses 200 employees to index web pages in accordance with its 500,000-term taxonomy; MEDLINE (the national medical library) [
18] spends $2 million per year on the indexing of articles with the MeSH thesaurus…” [
19].
Automatic indexing, in the second case, uses algorithms that statistically analyze the words in the contents or metadata of the resources [
45]. Metadata are a set of properties and values that describe a resource (
Figure 9). In indexing by automatic extraction, patterns of word behavior are identified on the basis of such variables as frequency of use, placement, order, and proximity. In this way, the words and relations that best represent the contents of the resource are identified [
46]. In automatic indexing by assignment, the words extracted are compared to the terms of a controlled vocabulary to select those that are most similar as descriptors of the resource. The result are clusters of resources that show similar content patterns, tagged by means of the sequence of terms extracted from the controlled vocabularies or within the resources themselves , which best represent their contents [
8,
47]. As a sample of automatic indexing systems (see [
48,
49,
50]) and American Society for Indexing list of software [
51]. Automatic indexing is faster, less costly, and more consistent than manual indexing, but the level of accuracy of descriptions is lower and usually requires a certain degree of human involvement to correct the results obtained.
In the third case,
semiautomatic or
hybrid indexing systems combine human involvement to identify the potential meanings of the resources and the efficiency of automatic indexing [
47]. They are able to learn with experience, which makes them increasingly efficient. One example is the Verity documentary indexing systems used by Oracle [
52].
To
create indexing vocabularies, three points should be taken into account: firstly, in the design stage, it should be verified whether there are
standard reference vocabularies for the domain of knowledge of the collection of resources that can be used totally or partially before creating a new one ad hoc. The reason for this is twofold: not only does it reduce costs, but also facilitates interoperability between repositories and IR systems, for example, to transfer the vocabulary to potential new versions of the repository or to other information systems. If there are no such vocabularies and one must be created from scratch, the standard guidelines for the creation of vocabularies should be followed, to guarantee the interoperability of the vocabulary in every case [
9,
10,
53,
54,
55,
56].
Secondly, it should be taken into account whether the vocabulary will be used in
combination with metadata to describe the resources. This is a frequent option, which is described in
Section 5. Basically, it consists in using the terms of one or several vocabularies to assign values to the properties of the resource metadata.
Figure 9 shows use of the Universal Decimal Classification (UDC) to describe a resource in html format. The metadata model is Dublin Core [
57], which is probably the one most frequently used on the Internet.
Thirdly and finally, when creating new vocabularies, it should be borne in mind whether they will be also used in the IR system search, navigation, and personalization systems. This option has the advantages that not only are the costs of creation capitalized, but also the maintenance of the conceptual and designatory consistency of the collection resources is facilitated, which helps users to have a mental image of what the collection of resources is like, and thus locate more easily the resources sought.
4.2. Search and Navigation Vocabulary
To understand the
role of vocabularies in search and navigation, the following types of IR and online resource retrieval systems should be distinguished: browsing, searching, and filtering systems [
47].
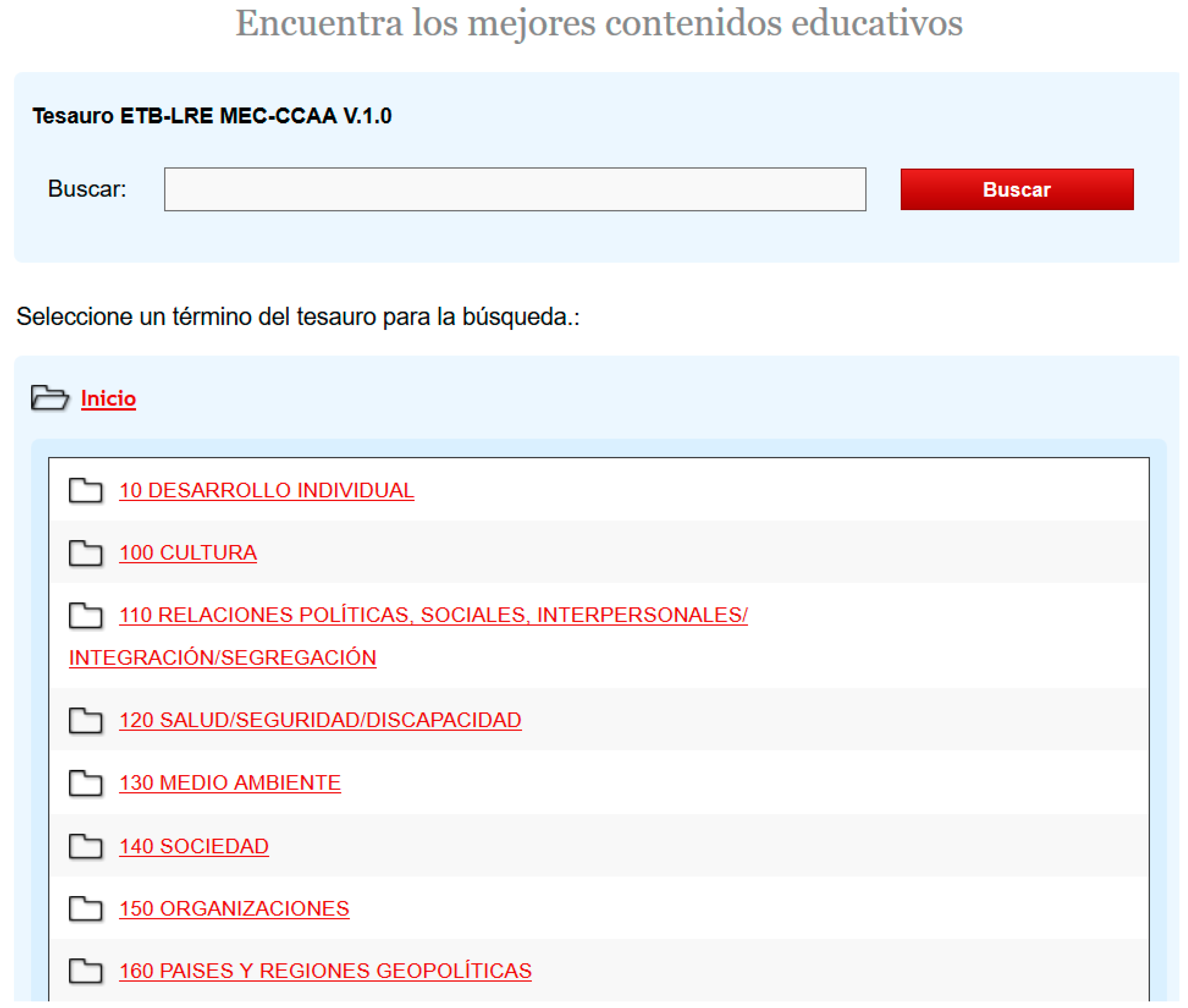
Browsing systems offer users an organized term structure, which is the vocabulary, which includes the information resources and a mechanism that allows users to browse the vocabulary to locate the resources sought. The way in which the vocabulary is presented ranges from simple navigation in an alphabetical list restricted to the vocabulary terms (
Figure 10) to hybrid systems that make it possible to select terms while browsing through the vocabulary to combine them in an expression that describes what is being sought [
58].
Search systems offer users the possibility of defining the resource(s) sought by entering the terms that describe said resource in a text box (
Figure 11). These systems are suitable if users are able to express in sufficient detail what they are looking for, that is, they know beforehand which information or resources they seek (and consequently do not need to “browse” as in the previous case). The vocabulary in this kind of system basically serves as a terminological reference system for users to use the same terms employed by the IR system to index the information or resources. In this way, better search results are guaranteed (recall and accuracy). In browsing and retrieval systems, users interact in real time with the IR search module.
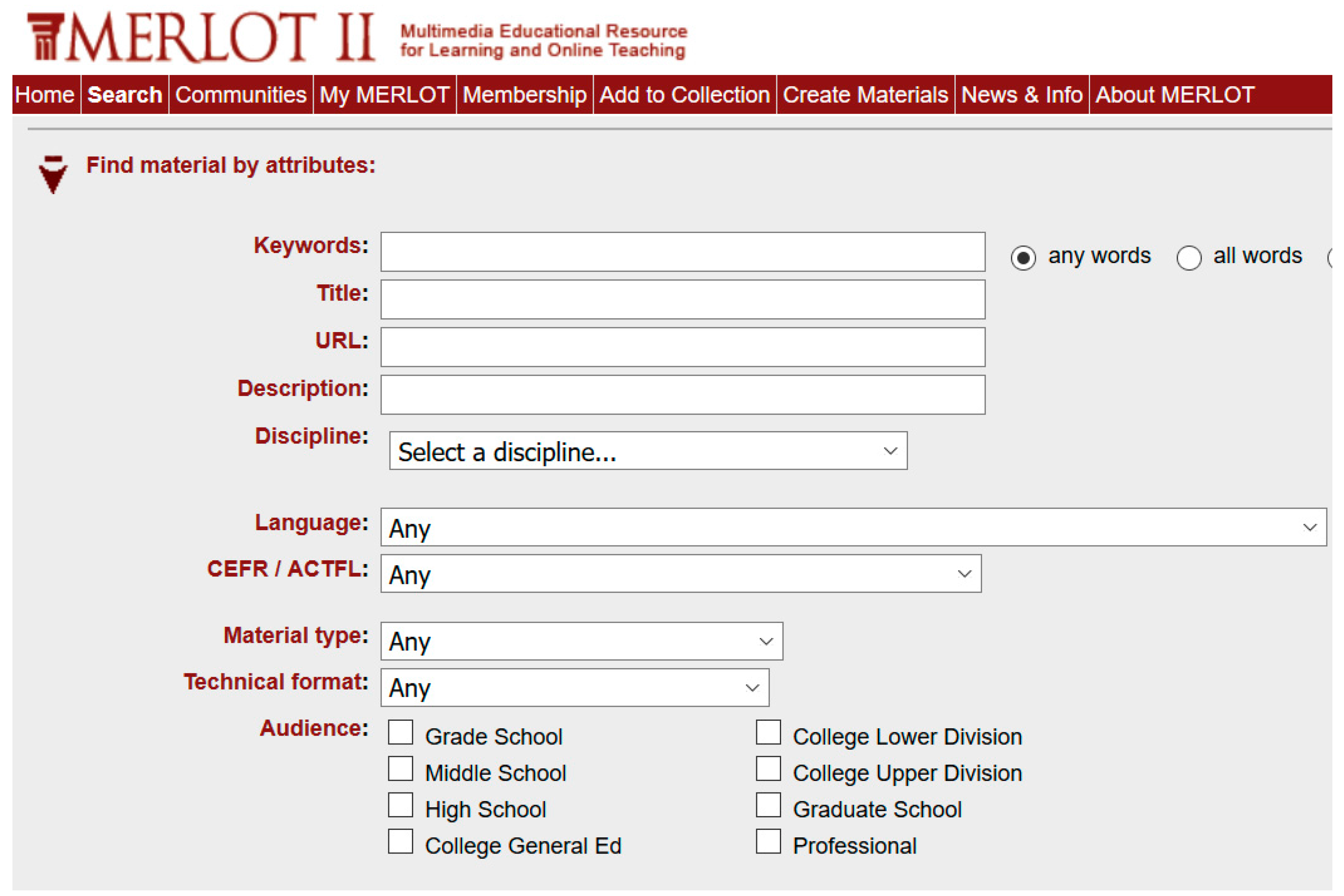
Filtering systems allow users to define their content preferences in their profile. These preferences (e.g., Spanish Literature) are used by the IR system to filter the resources and offer users only those resources in which they are interested. In this kind of system, the vocabulary allows users to select the terms that define their preferences, which are the same terms used by the IR system to index the resources. One example of use of this system is the “My MERLOT” option in the MERLOT educational repository (
Figure 12).
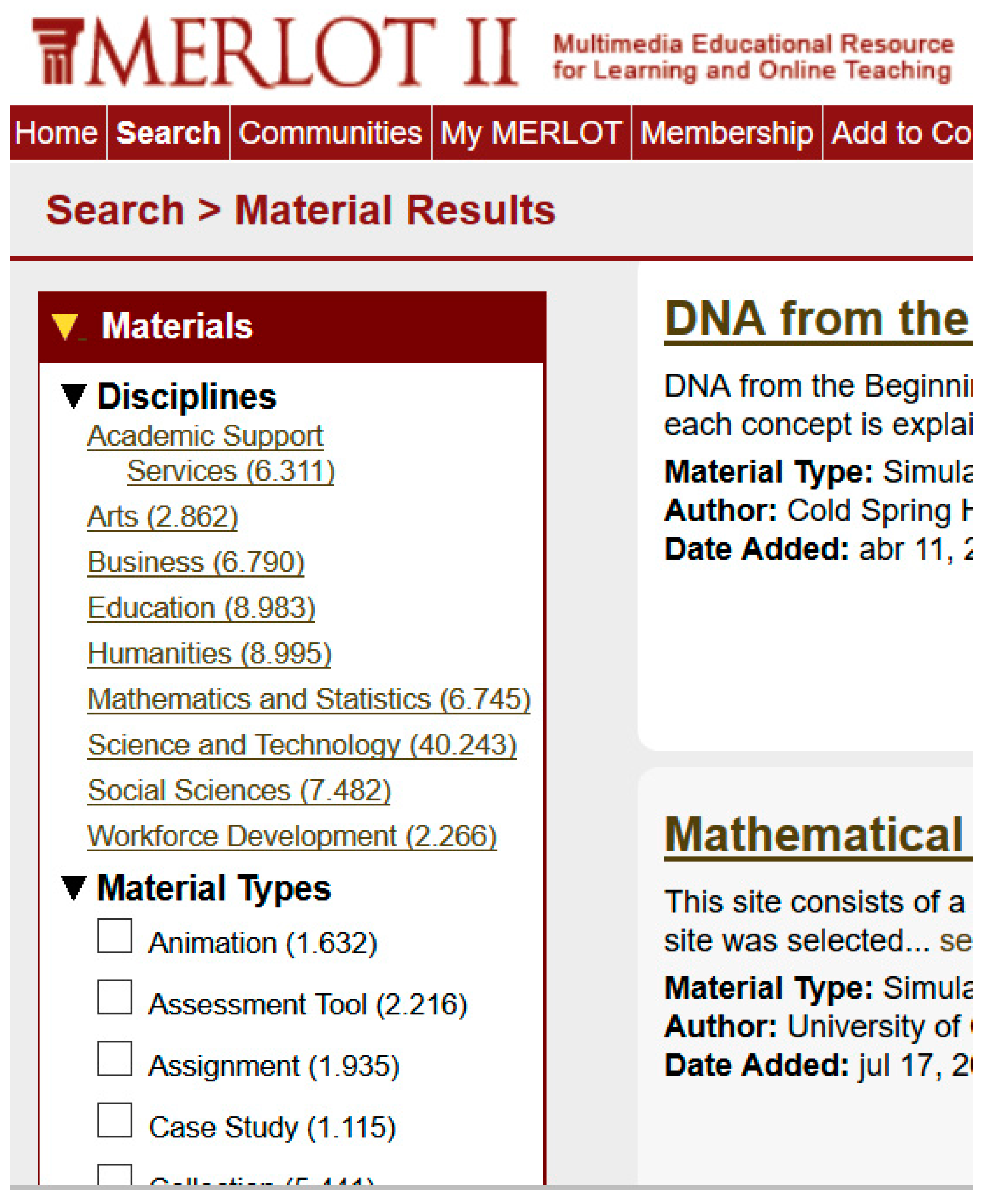
To conclude, vocabularies for resource searches play two basic roles in IR: (i) serving as the language of reference to make queries and index the resources; and (ii) guiding users, or the system, in the search by offering them all the potential options for information and resource retrieval through a map of related terms.
In this respect, the key issue solved by vocabularies is that of making the users’ query language correspond to the indexing language in the IR system. Thus, two operations are carried out in the search process: analysis of the user’s query, and its translation into the resource indexing language. If users make their query the same language that is employed for indexing, the search process is simplified and results are optimized, as the analysis of the query only involves checking that the terms used by the user belong to the IR system vocabulary, and the translation is limited to an adjustment between the terms of the query and the terms of resource indexing.
Despite the effectiveness of this solution, there are, however, two drawbacks that restrict it: users are obligated to express what they are searching for using a limited vocabulary that is not always capable of expressing what they really need [
8], and users also need to be familiar with that vocabulary. Two approaches have been put forward to solve these drawbacks: (i) expressing the query in natural language that is as close as possible to users, and analyzing the query using natural language processing techniques to translate it into the IR system indexing language. The second approach (ii) consists in dynamically adapting the vocabulary, automatically or manually, so that it approaches the user’s vocabulary. This approach entails applying an update methodology that includes the criteria to accept new terms and relations without losing the vocabulary’s consistency [
2].
Finally, to understand the role of vocabularies in IR, it is also necessary to know
when and why vocabularies fail as “intermediaries” between users and IR systems. The two main sources of failures that can be attributed to vocabularies are the specificity of the vocabulary and spurious relations [
8].
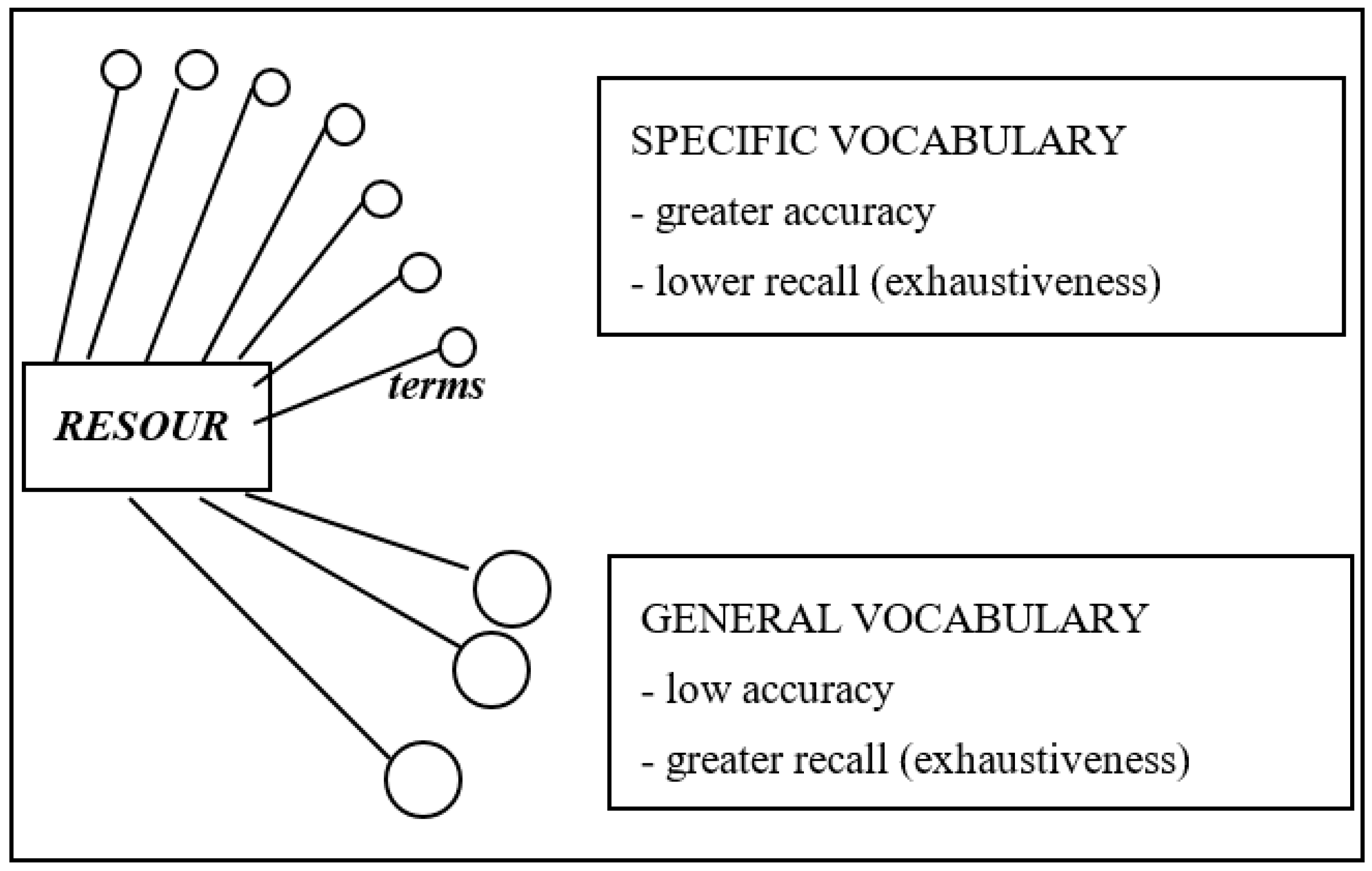
Specificity is probably the factor that has the greatest impact on search effectiveness. When a vocabulary is very specific, it makes it possible to describe a resource by means of many terms or small categories; this means greater indexing accuracy but also complicates resource location, as users must have in-depth knowledge of the vocabulary to express the query with sufficient accuracy. By contrast, if the vocabulary is general, users are more likely to find the resource(s) sought, using concepts with a broad meaning, but the results obtain will be irrelevant in a high percentage (
Figure 13). The goal is thus to achieve a compromise between generality and specificity in such a way that the vocabulary terms are sufficiently specific to make it possible to retrieve the information or resources in a sufficiently fast and accurate manner (with the minimum number of undesired results), but the vocabulary should also contain sufficiently general terms to respond to the queries of users that are not experts in the domain of knowledge—e.g., learning students—or in the IR system vocabulary.
The second source of failure in IR vocabularies is uncontrolled synonymy relations and ambiguous relations between terms. Synonymy control is necessary to make the IR system indexing language coincide with the user’s query language. For example, if a user searches for information about “car” engines, they should also receive information that is indexed as “automobile” engines. The ambiguity of relations appears in systems that index resources by using multiple terms but do not coordinate, that is, do not take syntax into account. They give rise to such failures as false term coordination or incorrect relations. False coordination takes place, for example, when a document on “engines for clean nuclear fusion” is ambiguously indexed under the terms “engine”, “fusion”, “nuclear”, and “cleaning” when it should be indexed under the coordination “nuclear fusion engine”. If the query searches for documents about “engine cleaning”, the false coordination between “engine” and “cleaning” in the indexed document will include it as an erroneous search result.
To summarize, vocabularies play the role of the language of reference in IR systems to ensure effective communication between users and the system. However, this role is not free of problems which should be taken into account to make it effective. The first problem is that the vocabulary used by the IR system and the vocabulary used by users to make queries are often not the same. The second problem arises if coordination (combination of terms) is not properly performed when retrieving information or resources. Consequently, a vocabulary will be effective in an IR system if it is close to the users’ vocabulary and if coordination of the indexing and query terms is properly performed.
5. How Vocabularies Are Used to Describe and Retrieve Digital Educational Resources
Retrieval of digitalized resources from the Internet and from large repositories is a specific case of IR, so use of vocabularies is basically the same but with distinct characteristics which should be taken into account to improve its effectiveness in the specific context of educational resources.
As an IR system, vocabularies for the retrieval of digital educational resources are used as a reference system
to describe and retrieve those resources. The resource repository or storage system uses these descriptions to index and then find them. Three approaches can be taken to describe and retrieve digital resources: metadata, vocabularies, or metadata with vocabularies. Metadata are a set of properties and values that describe a resource from multiple points of view—content, authorship, format, intellectual property, purpose, etc. (
Figure 14).
In the first approach, resources are described and indexed using a common
metadata scheme. The metadata schemes used are generally standard to facilitate interoperability between repositories [
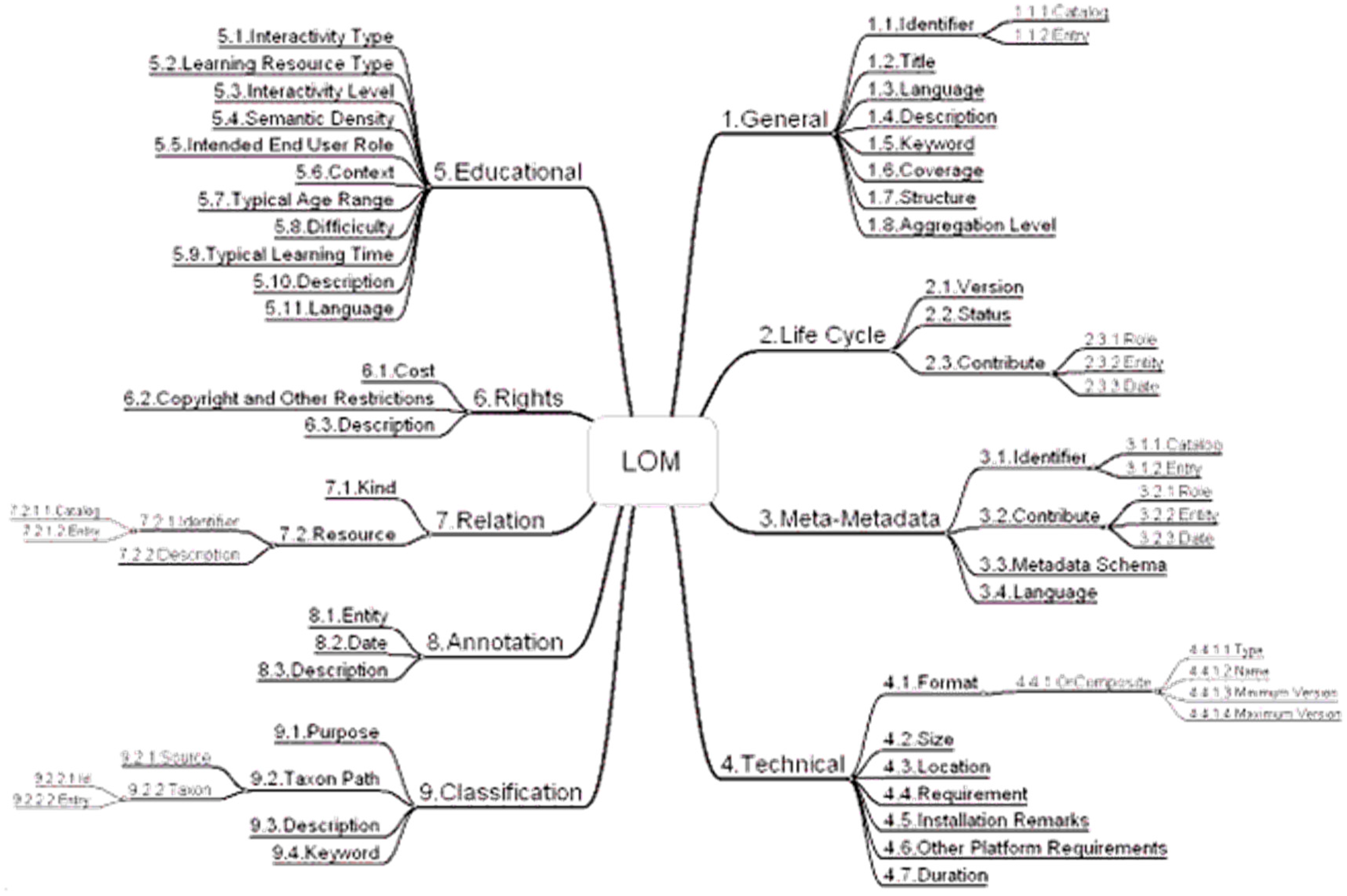
59]. Interoperability is the ability to take resources from a repository or e-learning space and use them in another location with another set of tools or platforms. The standard schemes most frequently used for the description of educational resources are Dublin Core [
60] (
Figure 14) and Learning Object Metadata (LOM) [
61] (
Figure 15).
Retrieval of the educational resources in a repository is carried out on the basis of the properties and values of its metadata. To do so, search forms (
Figure 16) or navigation menus (
Figure 17) are used which show the properties (also known as attributes) of the metadata for users to select the values sought.
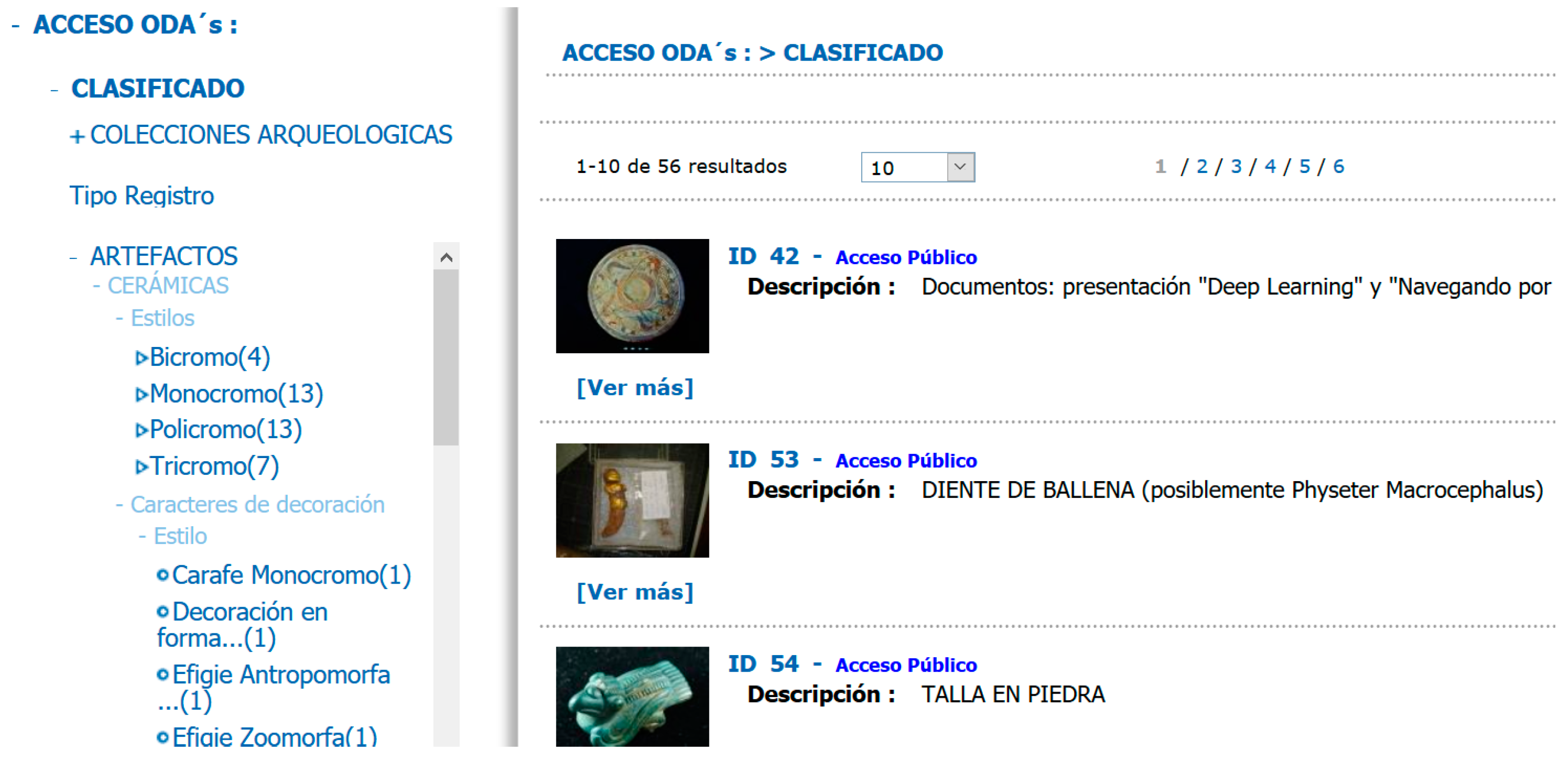
Metadata-based retrieval is very effective but not flexible. Indexers and users must follow the repository’s metadata scheme or storage system, which can be a problem for two reasons: (i) in highly specialized disciplines (e.g., pre-Columbian archeology in
Figure 7), the properties and values of metadata schemes are too general and cannot describe the resources; and (ii) the values used for properties (e.g., the subject property in the Dublin Core scheme) may be not fixed, so users can employ values that are not those used in indexing. This has a negative impact on the effectiveness of retrieval.
The second option is based on use of
indexing languages [
62]. As described in the previous section, an indexing language is a vocabulary, and in some cases a set of syntactic rules that standardize the combination of terms in resource indexing. Two types of indexing languages can be established: (a) those that use terms from controlled vocabularies; and (b) those that use the symbols of bibliographic classifications and formal knowledge representation systems, such as ontologies [
63]. In both cases, indexing languages provide a shared vocabulary to express the indexing and search terms and to create navigation menus.
The limitation of indexing languages as opposed to metadata is that they only make it possible to describe one property or aspect of the resource collection, usually the topic, and no other properties or attributes are used that could help refine the search, such as key words, language, type of material, technical format, etc. (
Figure 16). Moreover, they pose the problems, mentioned in the previous section, of differences between the indexing terminology and the user’s terminology, and a lack of accuracy in coordination, which have an impact on effectiveness of retrieval.
A third option is
joint use of metadata and indexing languages. The idea is to describe educational resources using metadata schemes in which certain properties take as their values the terms of one or several vocabularies set or recommended in the metadata scheme. If the metadata and vocabularies are standard, they also solve the problem of the interoperability and compatibility between repositories and e-learning platforms, allowing the exchange, shared use, and integration of resource collections. In this regard, it is worth pointing out the role currently played by vocabularies as “mediators” (software modules that employ the encoded knowledge to create information at higher level than the applications that they integrate and connect) in the sharing and exchange of resources between people and computer systems (e.g., repositories and e-learning platforms) [
64]. MERLOT [
6], EUROPEANA [
11], and ARIADNE [
7] are examples of repositories that use standard metadata and controlled vocabularies.
The vocabularies used with standard metadata meet a number of requirements: authority (i.e., they are evaluated by a committee or recognized authority), stability (i.e., they do not disappear or change frequently), maintenance (i.e., there is someone responsible for their being operative on a permanent basis), dissemination, coverage, multilingualism, adaptation to users’ needs, degree of compliance with standards, and specifications such as those of [
10] and [
61]. In this respect, it is important to point out that no ad hoc vocabularies are allowed, nor is using folksonomies, which are categorization systems that describe a resource domain by means of tags created collaboratively: for example, the categorizations of
del.icio.us websites, which categorize favourite links and pictures on
Flickr. The vocabularies recommended for metadata include the DDC [
20] and LCSH [
58] general classification systems, the vocabularies of specific scientific area such as the Medical Subjects Heading [
19], the NASA Thesaurus [
22], the ACM taxonomy [
23], or general vocabularies such as Cyc [
24], WordNet [
17], the UNESCO thesaurus [
25], and the ARIADNE thesaurus [
65] (
Figure 18).
These recommendations are meant to ensure the interoperability and reusability of the metadata schemes and vocabularies. However, as for IR vocabularies and standard metadata, the vocabularies recommended for metadata have two drawbacks: (i) they require an effort on the part of the authors, the indexers, and the users of educational resources repositories to learn the vocabulary; and (ii) it is not guaranteed that the vocabulary will be able to accurately describe all the educational resources [
66,
67,
68], particularly in highly specialized academic contexts [
69]. These drawbacks can be solved, as described in the previous section, by adapting the standard vocabulary to the knowledge domain of the educational resources, but this has a significant cost, as it requires (i) being fully familiar with the vocabulary (its terms, expansion rules, and technology); (ii) knowledge of the specialized vocabulary, and (iii) having sufficient technical resources and staff to make the adaptation. This cost frequently accounts for the fact that new vocabularies are created, which specifically target the knowledge domain of the collection of educational resources and the educational community that uses them [
10,
66,
69].
Finally, it is important to highlight
three characteristics of use of vocabularies to retrieve digital educational resources. The first one is that, despite the recommended standards, the vocabularies used are frequently
non-standard and
highly specialized in the knowledge domain of the resources described, targeting the educational communities that use them. This, however, is not the case with other contexts for retrieval of digital resources, such as digital libraries [
10,
67,
69]. One of the reasons that may account for this non-standard use is, as was previously stated, that the authors, indexers, and users of the educational resources cannot spend the time and effort required to learn the recommended standard vocabularies, or do not wish to spend it because they are not certain that they adequately represent their educational resources.
Secondly, retrieval vocabularies are frequently used as a
conceptual representation system for the knowledge domain to which the collections of educational resources belong. These representations or conceptual maps are useful not only to find what is sought but also to support and reinforce the learning of the domain terms and concepts [
70,
71].
Thirdly, it is important to point out that the vocabularies for the retrieval of digital educational resources are often created in an
inductive and
collaborative manner by the groups of teachers and students that use them, by means of virtual learning environments [
72,
73].
To summarize, vocabularies are used in the retrieval of educational resources as in IR, but embedded in the standard educational metadata that document resources. The vocabularies pertaining to the contents of the resources or their teaching use are often created as needed and collaboratively by the educational community that uses them. They are non-standard, highly specialized vocabularies, adapted to the educational community that creates them. Thus, the vocabulary, in addition to a communication language with the repository retrieval system, is in itself an educational resource that helps students to create a conceptual map of the knowledge domain and learn its terminology. Despite the specific nature of these vocabularies, their joint use with standard metadata provides sufficient interoperability to ensure that the educational resources will be enduring from the technological point of view.
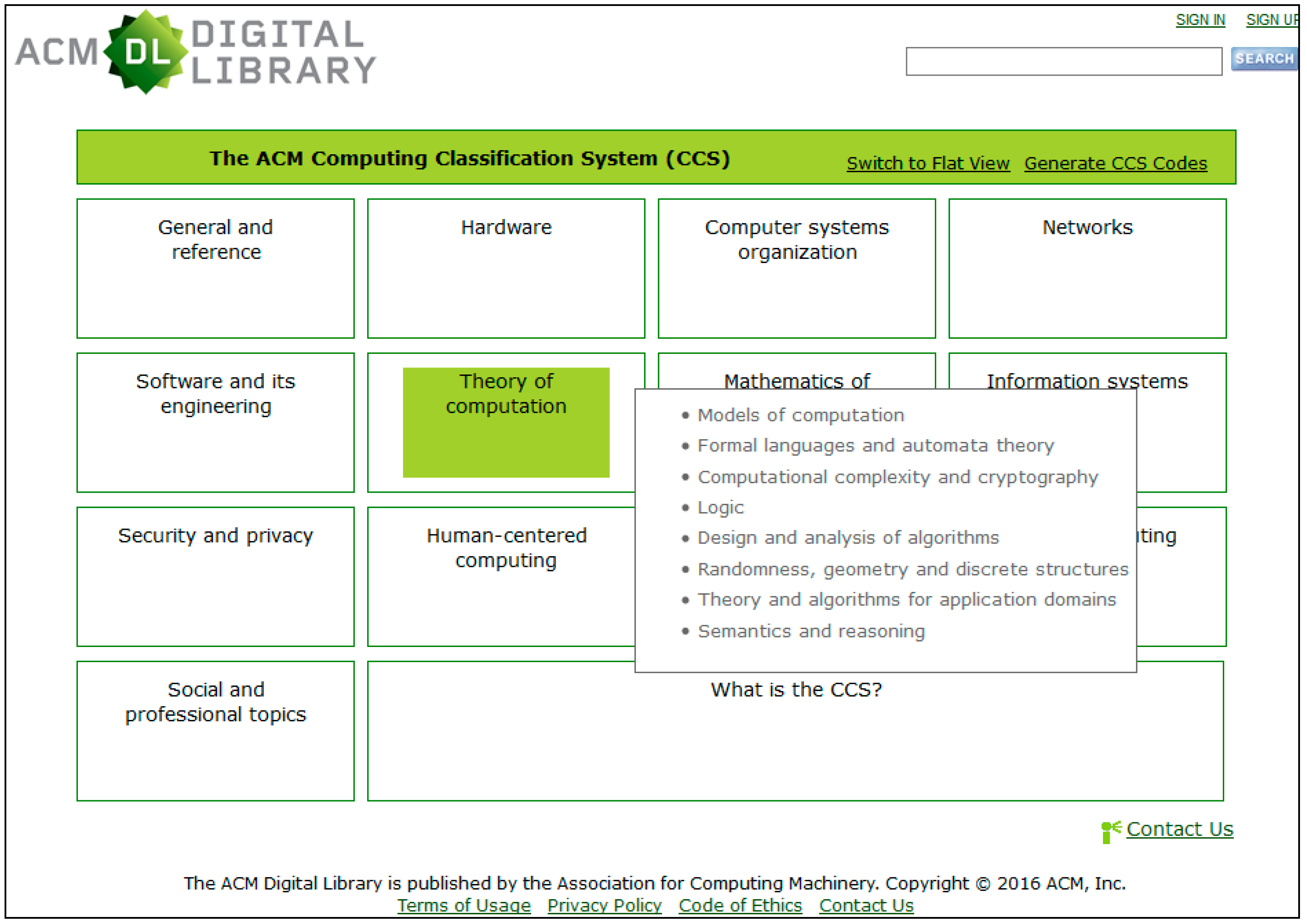
In the following section, the last aspect of vocabularies is described, namely their type. There are five types of vocabularies: lists, classifications and taxonomies, thesauri, ontologies, and dictionaries and glossaries. Each type plays a specific role in the retrieval of digital educational resources.
6. Types of Vocabularies for Retrieval of Digital Educational Resources
The types of vocabularies distinguished in this section are based on the ANSI/NISO Z39.19 [
9] standard for the creation of monolingual vocabularies and on the recommendations for use of vocabularies for the description of “learning objects” made by the European Commission for Standards [
10]. There are five types:
- 1)
Simple vocabularies or lists of values;
- 2)
Classifications and taxonomies;
- 3)
Thesauri;
- 4)
Ontologies;
- 5)
Dictionaries and glossaries.
The selection of a specific type for retrieval of educational resources depends on (i) the specific role to be played; (ii) the users targeted; (iii) compatibility with the information system where it is integrated; (iv) the resources (financial, personal, and time) for their creation and maintenance; (v) the coverage; (vi) the size; (vii) the nature of the educational resources; and (viii) the type of queries, searches, and user profiles [
2]. The types of vocabulary and their use experience complete the review made in this paper of the role of vocabularies in the retrieval of digital educational resources.
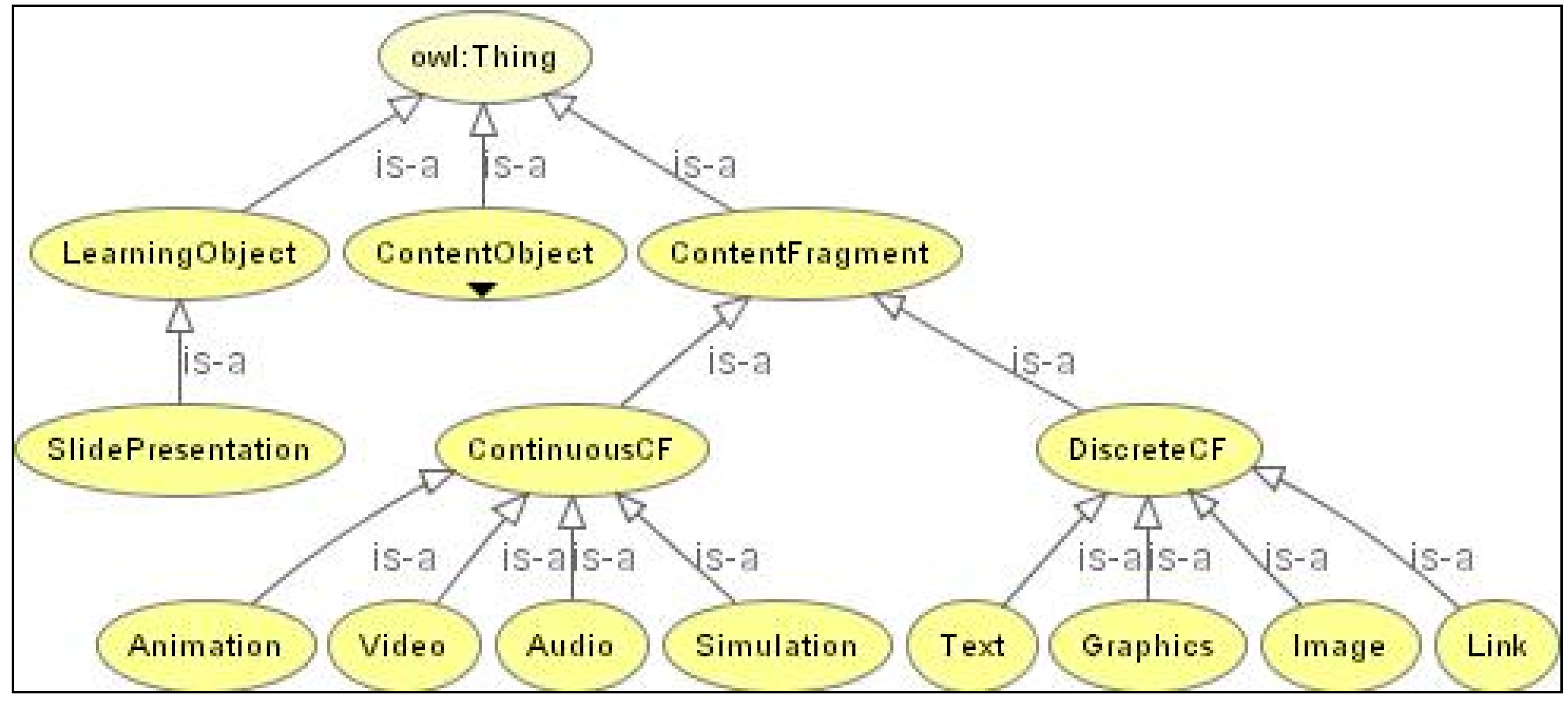
6.1. Simple Vocabulary or List of Values
The simplest form of vocabulary is a list of terms (
Figure 19). They can be accompanied by unique alphanumerical identifier and some other types of very simple associated information, but they do not contain definitions or semantic relations with other terms. Their structure is flat: completely linear and in alphabetical order when viewed.
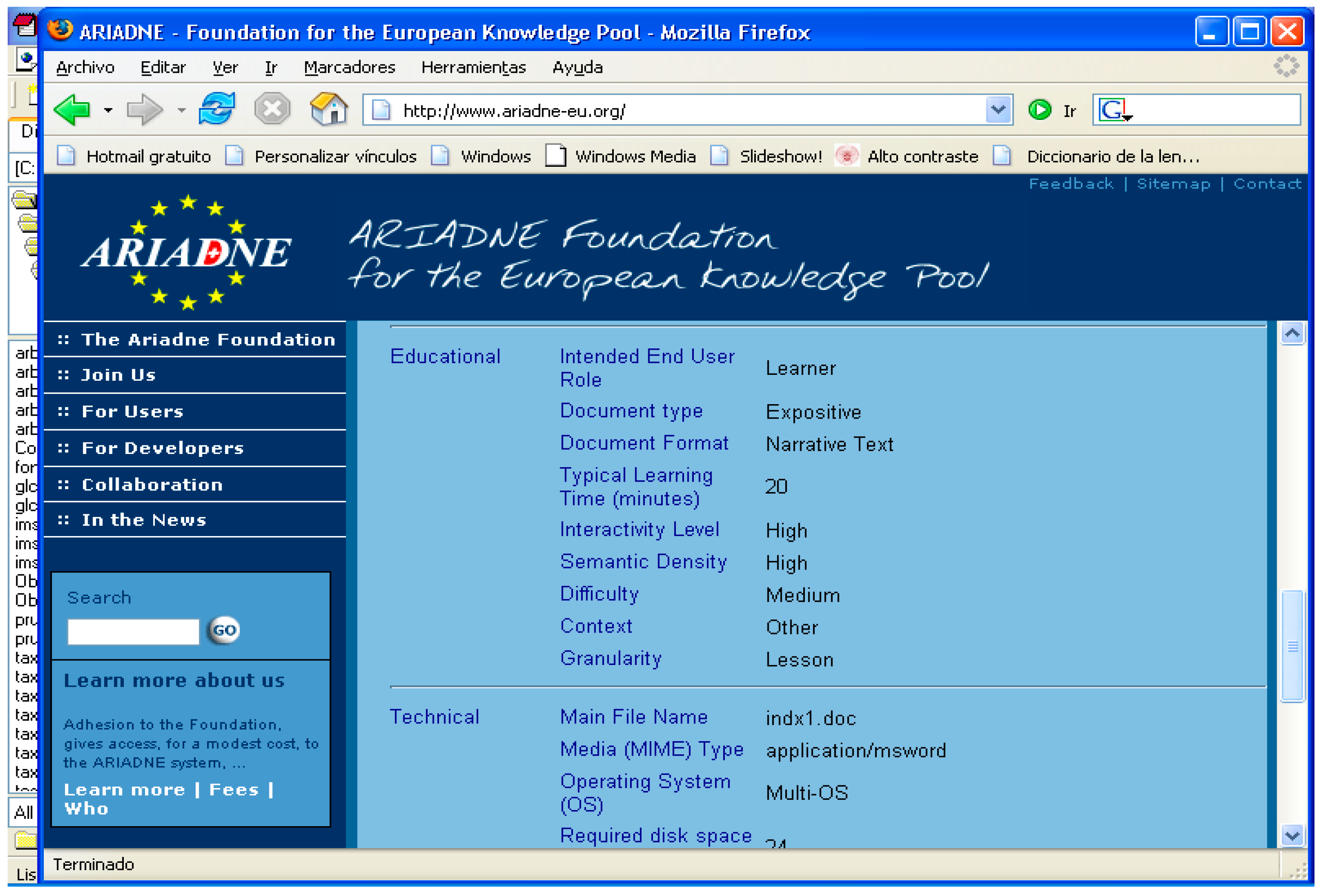
Simple vocabularies are suitable for providing values for certain properties (also known as attributes) of the digital resource metadata. For example,
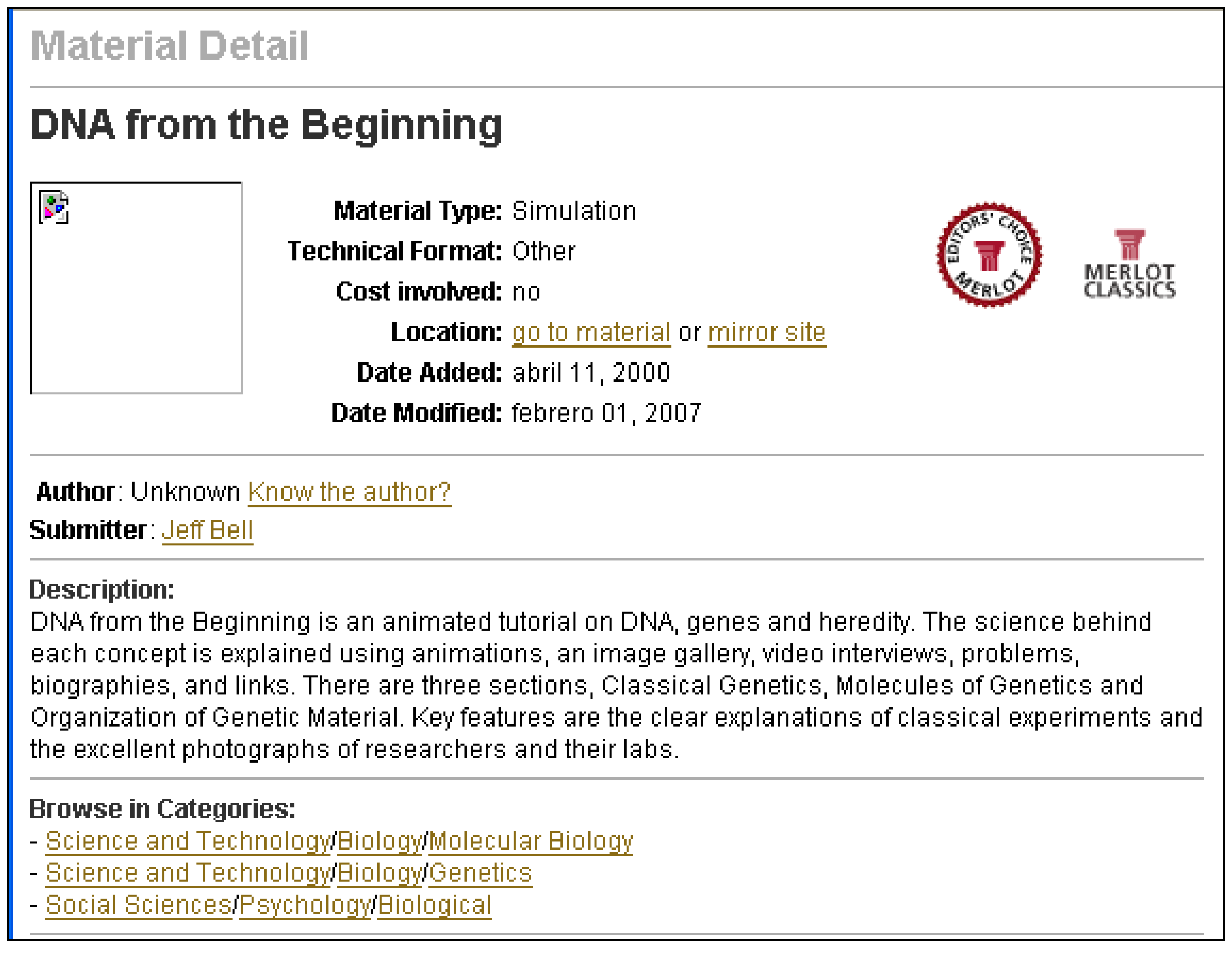
Figure 20 shows an excerpt of the metadata of an educational resource in the former ARIADNE European repository [
7]. The properties Educational, Media (MIME), Type, and Operating System (OS) take their values from simple vocabularies.
Figure 21 shows use of the ISO 3166 vocabulary [
74] in
Figure 19 to describe the property “language” in an XML document.
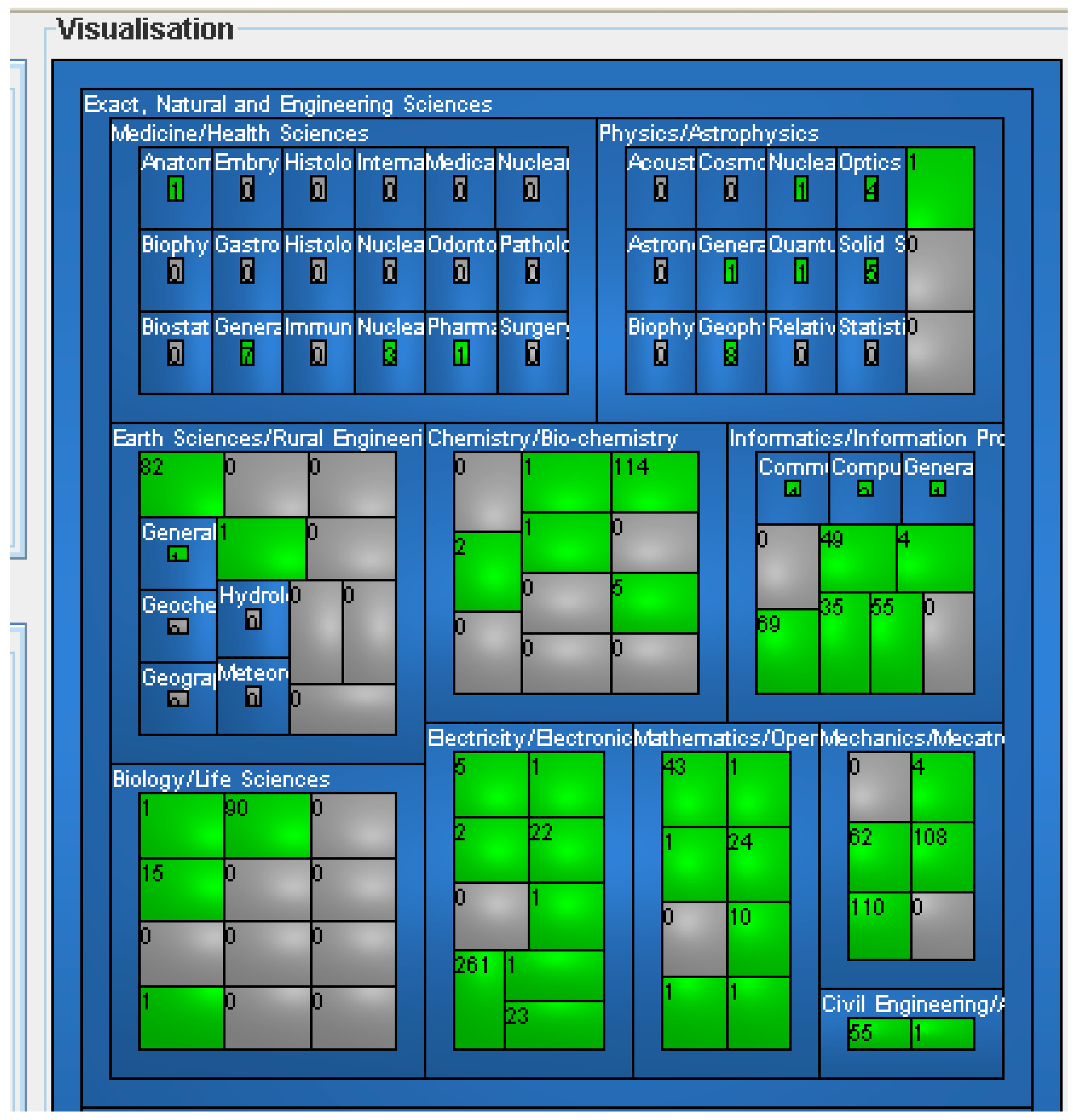
6.2. Classifications and Taxonomies
A
classification is a vocabulary comprising categories. Categories are usually presented in alphabetical order (
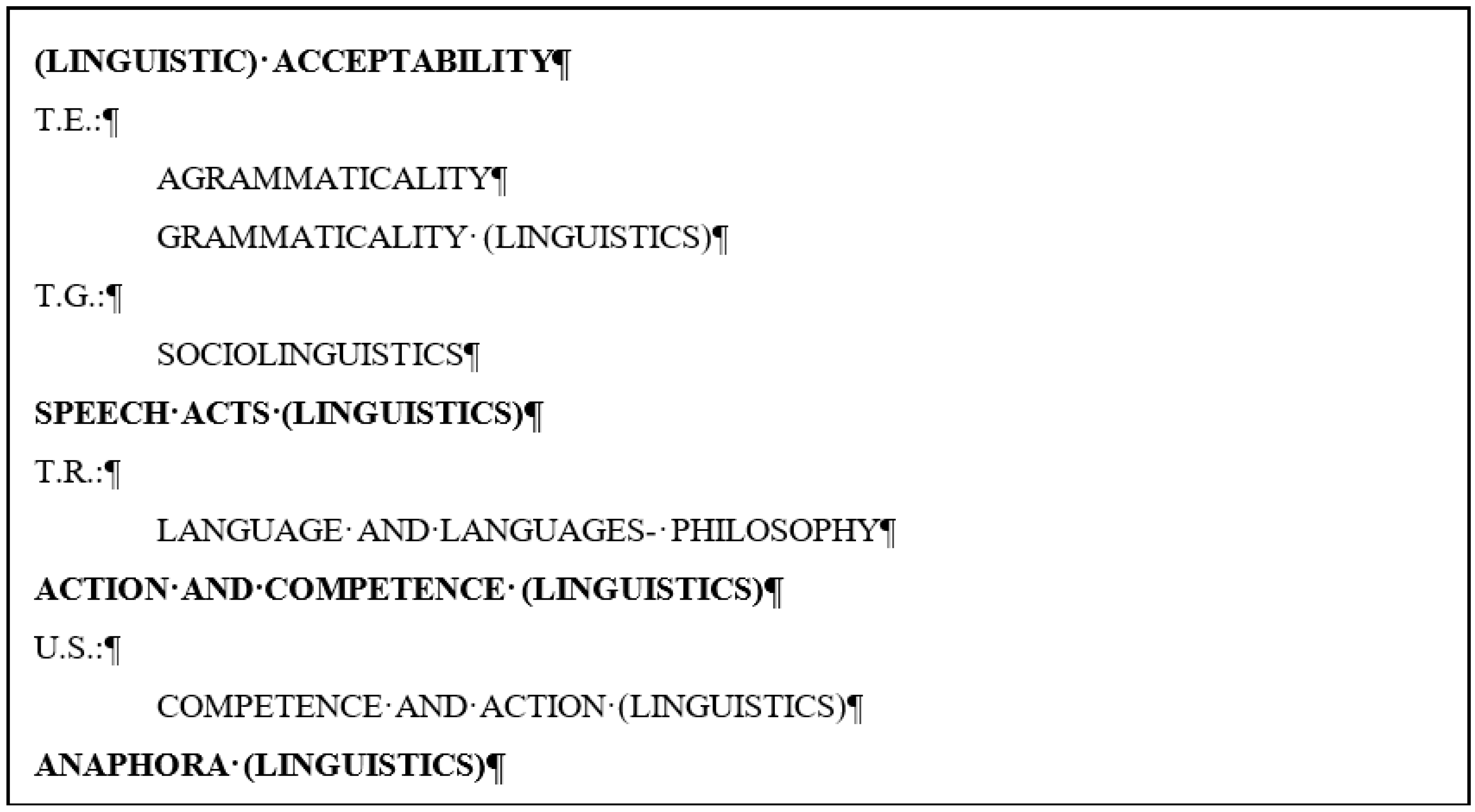
Figure 22) or hierarchically if they are linked by hypernymy–hyponymy or generalization–specialization relations. For example,
Figure 23 shows the “Language. Linguistics. Literature” category, the “Linguistics and language” subcategory, and the subcategories within this subcategory in the Decimal Universal Classification.
A
taxonomy is a classification for a speciality, discipline, or specific thematic area [
10]. It constitute specialized representation of a specific knowledge domain. The structure of a taxonomy is hierarchy. Categories or general descriptors are located at the top level. The successive hierarchy levels refine the top-level categories or descriptors (
Figure 24). Descriptors can also have an alphanumerical ID. They are frequently integrated in more general vocabularies. For example, the Cyc ontology includes the Mesh medical taxonomy and the Open Directory topic taxonomy [
75].
This difference between classification and taxonomy is very subtle and in practice both terms are frequently used as synonyms. For example,
Figure 24 shows the ACM taxonomy for the Computer Science domain, and yet it is called as “classification system”.
In any case, use of classifications and taxonomies to conceptually describe digital educational resources consists in associating each resource with the suitable category or categories. The semantic description of the resource is a set of terms, called taxonomic paths, from the terminal categories, called “leaf”, which include them, to the top or “root” categories in the classification or taxonomy (
Figure 25). The indexing tools and the tools for search by concept and topic in the educational resource repositories are based, for the most part, in categories and taxonomies (
Figure 26).
6.3. Thesauri
A
thesaurus is a limited vocabulary, usually of specialized terms, including their semantic correspondence, selected to represent the notions that appear in a given context for use in computing and in the establishment of indices [
76]. The concept of thesaurus has been adapted to new Information and Communications Technologies uses. Thus, later definitions are oriented towards IR: Aitchison defines a thesaurus as “the vocabulary of a controlled indexing language, formally organized so as to make relations between concepts explicit beforehand” [
2], and the ANSI/NISO Z39.19 standard as “a controlled vocabulary that is organized and structured in a known form, where relations between equivalent terms, homographs, hierarchical and associative relations are clearly viewed by means of standard and reciprocal markers” [
9].
The difference between a thesaurus and other types of vocabularies lies in the fact that its priority is formally representing semantic relations between concepts using natural language terms. Simple vocabularies do not contain semantic relations: classifications and taxonomies implicitly represent the generalization/specialization relation only. Dictionaries and glossaries, as will later be seen, contain natural language descriptions of works in which relations between words are not always explicit (
Figure 27). Finally, ontologies represent concepts (not words) and their relations at a language-independent level.
Thesauri explicitly define the standard semantic relations of associativity, equivalence, and hierarchy and other potential relations pertaining to the speciality domain, for each of the terms that constitute it. They can also organize terms by aspect (i.e., separate categories) or by category (i.e., categories that are not necessarily separate), including information to specify the definition of the concept designated by the term.
Figure 28,
Figure 29 and
Figure 30 show three examples of thesauri used to describe digital educational resources.
One of the main applications of thesauri is currently the retrieval of digital educational resources, but it is not the only one. Other uses include support in general understanding of a knowledge area, providing conceptual maps and conceptual schemes that show the interrelations between concepts and entities (e.g., resources), the search for alternative terms in text writing or reading, the learning of the terms in a discipline, and the generation of keyword lists [
2].
Regarding the retrieval of educational resources, thesauri are used for exploration and search in digital repositories. Resources are associated with one or several terms in the thesaurus (
Figure 31), and during the search all the combinations of the query terms that are related in the thesaurus are calculated to specify and complete the query, thus reducing the number of unwanted results or the likelihood of obtaining no results (
Figure 32) [
10].
For exploration, the thesaurus can be visually presented as a conceptual map through which users can browse. While browsing, users can interactively discard those thesaurus terms that do not meet their request so as to specify the results. Results can also be expanded by finding new resources from the terms related to the search term(s).
Figure 33 and
Figure 34 show two examples.
Thesauri are systems for the representation and retrieval of educational resources that are easy to use by people as they contain natural language terms or speciality terms to represent the contents of the educational resources, avoiding the ambiguity intrinsic to natural language. However, strictly speaking thesauri cannot be regarded as a conceptual representation of the knowledge domain or as a natural-language description. Rather, they constitute an intermediate system between conceptual representations and natural language.
6.4. Ontologies
The term
ontology is taken from Philosophy and has been adapted to Computer Science and to Library and Information Science to handle the representation, management, and exchange of knowledge. From a computer point of view, ontology is defined as the specification of a conceptualization [
78], or, more specifically, the
formal specification of a shared conceptualization [
79]. A conceptualization is an abstract, simplified view of the world to be represented (known as the domain model); it is shared because it is agreed, and it is formal because it is precise and non-ambiguous, which makes it automatic processing possible (
Figure 35). Ontologies provide a shared, agreed understanding of a knowledge domain which can be used by people and by computer systems [
80]. In this regard, they are a models for knowledge representation, exchanging knowledge by reusing and incorporating it from different sources [
35].
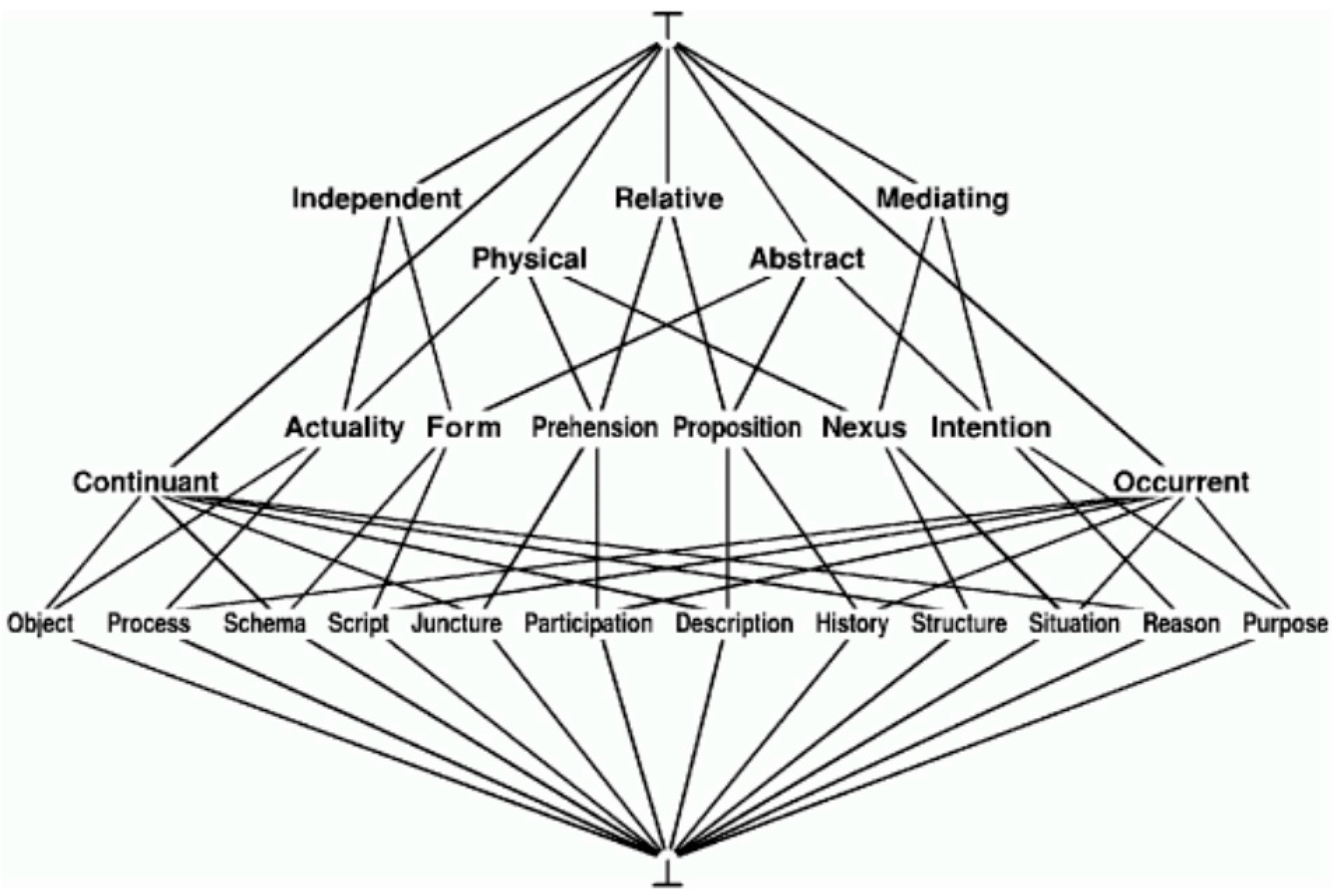
Ontologies comprise a set of entities or concepts, relations and instances of entities and relations. They define the structure of a domain and use a shared vocabulary and semantics (
Figure 35 and
Figure 36). They are usually structured by generality levels: a top level, which represents knowledge of the world in general and provides basic notions and abstract concepts (
Figure 35), and specific level, corresponding to specific domains or knowledge areas.
Multiple models and types have been put forward to build ontology, depending on the purpose or the domain to be modeled [
81,
82,
83,
84]. More specifically, in [
82], four types of ontology are put forward: formal, terminological, prototypes, and mixed.
In
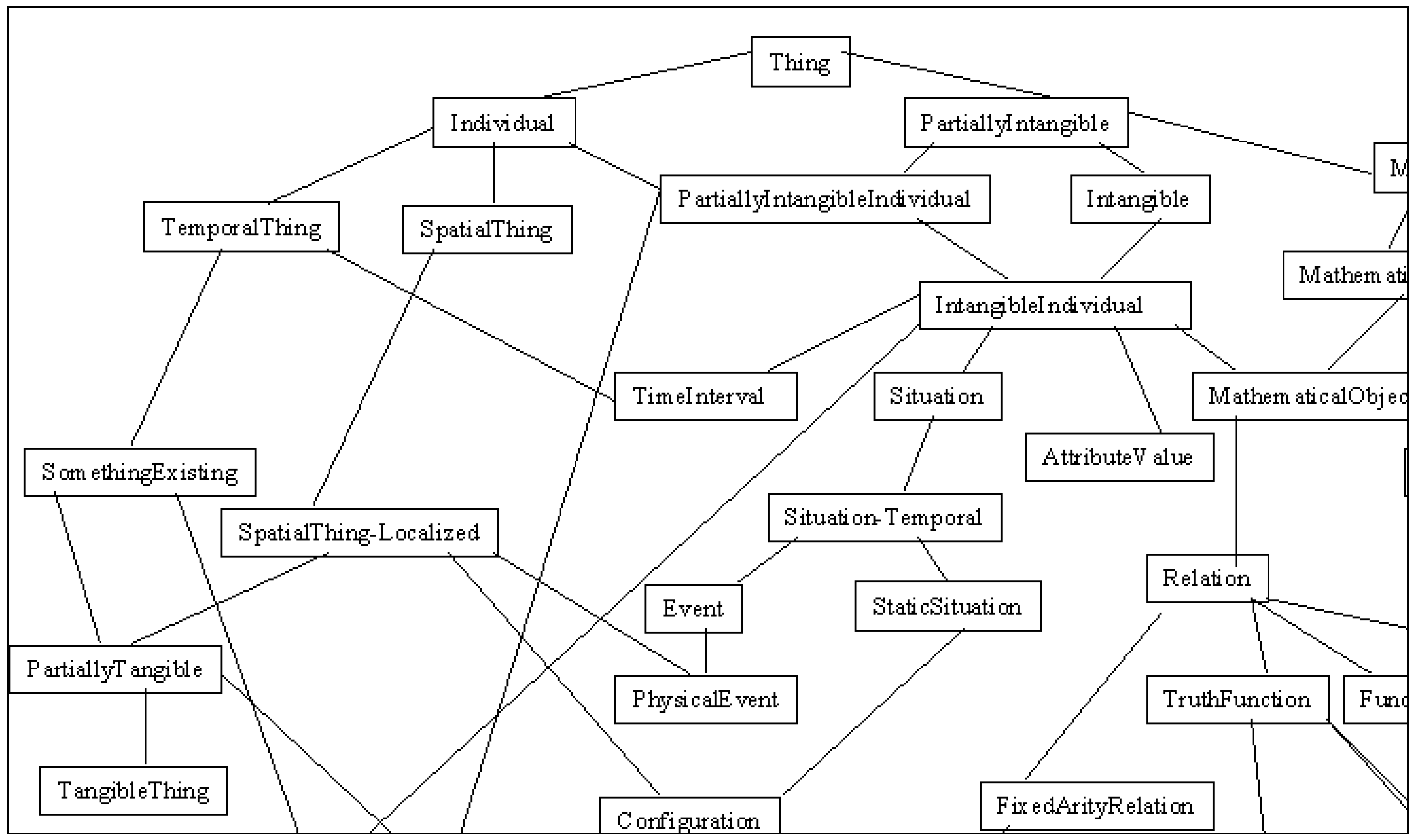
formal ontologies, concepts are defined by means of axioms and definitions in logic or in some programming language that can be automatically translated into logic (
Figure 37 and
Figure 38). These ontologies have the greatest expressive power, as they make it possible to make queries not only regarding the knowledge explicitly stored but also regarding implicit knowledge by means of the application of inference rules and automatic reasoning. Their drawback is that they are costly to build and hard to maintain.
Terminological ontologies express concepts by means of natural-language terms and semantic relations [
82]. A standard example is WordNet [
17], which calls concepts “Synsets”, represents them by means of one or several language terms, and links them by means of semantic relations that depend on the grammatical category of each term. For example, the basis semantic relations for nouns are hyponymy–hypernymy and part–whole (
Figure 39).
Prototype ontologies define concepts by means of categories that are defined by the instances that contain them. Thus, for every category (or concept) “c” of the ontology, there must exist a prototype or instance “p”, and a semantic distance function “d(p,x,c)” which measures the similarity or difference between “p” and the other “x” instances in the ontologies. The new instances in the ontology are "placed” in categories that contain similar instances, that is, with small semantic differences with respect to it. The prototype theory has its philosophical roots in Wittgenstein’s famous “family resemblance theory”, which states that objects (or instances) covered by a term often share a family resemblance [
85]. Thus, prototype categories are constructed on the basis of experientially perceived similarities among members, and these similarities may involve one or more dimensions, or characteristics.
Finally, mixed ontologies contain concepts defined as in formal ontologies in the top, more abstract levels, and concepts defined by means of prototypes or instances at the more specialized levels. They are a “mix” of formal and prototype ontologies.
Regardless of their type, ontologies have a complex structure, as they are networks of organized concepts with partial order relations, such as subtype–type (i.e., hyponymy–hypernymy) or part–whole (meronymy–holonymy). The resulting structure is called a lattice in mathematics, and one or several types of hierarchies can be distinguished within it. The operations and properties defined in lattices can be programmed to automatically manage the knowledge that they contain.
In the context of e-learning, ontologies are applied to describe the components of Learning Management Systems (applications to build virtual e-learning spaces), such as user types, academic organization and administration, courses, activities, and resources. These semantic descriptions for each component make it possible to create applications to personalize and adapt teaching and learning to each student’s needs, facilitating collaborative learning in a distributed environment, exchange and reuse of information and knowledge, and management of and access to digital educational resource repositories [
10,
39,
72,
86,
87].
Regarding the role of ontologies in management of and access to digital educational resource repositories, these are basically used as indexes to index resources with respect to their contents. One example is the ALOCoM ontology, which defines a
content model to describe the Learning Objects in the ARIADNE European repository (ARIADNE Learning Objects Content Model) [
88]. Ontologies also serve to interpret users’ queries by using concept-based search strategies [
89]. Finally, they are also used as conceptual maps and schemes of the domain, like thesauri, through which teachers and students can browse to locate resources that have related content, topics, or concepts (for example, [
90]) (
Figure 40).
In practice, the distinction between ontologies and thesauri is not always clear. In the bibliography cited in this paper we find many examples of thesauri called ontologies, particularly in the case of terminological ontologies that model specific knowledge domains. For example, in the ontology classification given in [
84], vocabularies—lists, glossaries, and thesauri—are regarded as a type of ontology.
However, other authors such as Sowa [
26,
40] clearly establish the differences between vocabularies understood as lexicons—lists, taxonomies, thesauri, dictionaries, and glossaries—and ontologies. They believe that ontologies have three clear characteristics with respect to other vocabularies: (1) they constitute the conceptual representations of the knowledge domain at an abstract semantic level; (2) they must be representations that are independent from natural languages even though their notation must be close so as to be legible (for which reason they have been used as interlanguage modules in multilingual systems [
91]); and (3) they can include inferential knowledge (rules) that make it possible to reason on the basis of the knowledge explicitly stored. Sowa [
92] rightly defined the role of the lexicon with respect to the role of ontologies in the knowledge representation as follows: “the lexicon is the bridge between language and the knowledge expressed with that language”.
In any case, ontologies are preferred as systems for the description of computer applications because they facilitate interoperability between said applications, while thesauri are preferred as mechanisms for the indexing, search, and browsing through information and digitalized resource collections as they facilitate operability for people.
6.5. Glossaries and Dictionaries
Glossaries and dictionaries are vocabularies organized and written for human use even if they are presented in an electronic format, among other reasons because the information which they contain is not always explicit, it is semi-structured, and its interpretation depends on the user’s linguistic competence and knowledge of the world [
93].
Generally speaking, when information is semi-structured, the structure of the content elements (such as the lemma, the definition, and the examples) is embedded in the text and is recognized because a convention or simple syntax is used [
94]. Thus, the preamble of dictionaries describes the conventions to recognize each information item, such as the convention to present the structural element “lemma” shown in
Figure 41 [
27].
A
dictionary is a “repertoire in the form of a book on paper or on an electronic support which brings together, in a given order, the words or idioms of one or more languages or of a specific subject, together with their definition, equivalence, or explanation” (
Figure 42) [
27]. As for a
glossary, it is a “catalogue of words of one subject, field of study, work, etc., defined or discussed” [
27]. The difference between them lies in their coverage, complexity, and purpose. Glossaries have a limited number of entries and more specific content than dictionaries. Their purpose is to accurately define the specific terms of a given text, work (
Figure 43), or subject (
Figure 44) to help readers to understand the material [
95].
Use of glossaries and dictionaries in the
retrieval of digital resources is very limited. In the case of dictionaries, they are used as a source of lexical knowledge to create other types of vocabularies that are suitable for retrieval (classifications and taxonomies, thesauri, ontologies, and lexical databases) [
97]. Glossaries, by contrast, have been directly used as a tool to access digital resources, both to expand search mechanisms [
98] and to organize and explore digital information, content, and resources [
99].
Glossaries are used in the retrieval of educational digital resources, not only to delimit the set of natural-language terms used to index and describe the stored resources, as in the case of lists or classifications and taxonomies, but also to provide the definition of the sense in which said terms are used. In this way, users can compare whether what is sought for corresponds to what was indexed and stored in the system, which also helps them to understand and grasp the concepts in the knowledge domain that encompasses the educational resource repository.
7. Summary and Conclusions
To understand the role of vocabularies in the retrieval of digitalized educational resources, we have reviewed (i) their nature, which depends on the vocabulary type; (ii) their role in IR systems; and in particular (iii) their role in the retrieval of educational resources, taking the vocabulary type also into account. The conclusions of this review are the following:
Firstly, in the context of retrieval of educational resources in electronic environments, the vocabulary constitutes a linguistic, computer, and educational resource that brings together and formalizes the lexical knowledge of a knowledge domain in order to describe and index the resources of said domain so that they can be easily located by people or computer systems.
Secondly, regarding the nature of the vocabularies for retrieval, a vocabulary usually comprises a set of terms that can be associated and described. When terms have a single meaning, the vocabulary is regarded as being controlled and suitable for IR, and in particular for the retrieval of educational resources. Associations between terms and descriptions depend on the vocabulary type. Thus, (i) lists do not contain associations or descriptions; (ii) taxonomies, thesauri, and ontologies only contain semantic associations between terms, basically hyponymy–hypernymy in classifications and taxonomies, synonymy, hyponymy–hypernymy and related terms in thesauri, and hyponymy–hypernymy and varied typology in ontologies; (iii) glossaries and dictionaries contain natural-language descriptions that implicitly and explicitly contain relations with other words. From the point of view of the retrieval of digital educational resources, the most effective systems are classifications, taxonomies, and thesauri.
Thirdly, regarding the role of vocabularies in IR systems, they provide a precise language to describe and guide the search for the information that is the object of a query. They are used in indexing and queries. Vocabularies are IR-effective if they are able to represent the resources in indexing in the same way as users make searches in their queries. For this reason, a vocabulary that is effective in an IR context is not always effective in a different IR context within the same knowledge domain. Consider, for example, the educational context of a university, where teachers, researchers, and students are usually the authors, indexers, and users of the information generated. In this context, vocabularies of reference such as the Universal Decimal Classification, which is widely used for IR in libraries and documentation centers, seem not to be effective in educational repositories, and, if possible, new vocabularies closer to the speciality language shared by the creators and users of the knowledge domain are created.
Fourthly and finally, regarding the role of vocabularies in the retrieval of digital educational resources, they provide a precise, shared language to index, describe, and locate the resources. They are usually employed with metadata as they benefit from the features of metadata, which are simpler to process and, if standard, provide a minimum level of interoperability, as well as from the benefits of vocabularies, which provide a language for metadata values that is suited to users’ knowledge and needs (teachers and students).
To conclude, experience in use of vocabularies for the retrieval of the digitalized educational resources reviewed indicates that vocabularies constitute the language for the retrieval of educational resources and are usually employed to add value to metadata properties. Vocabularies could be more effective if: (i) they are adapted to the knowledge domain of the collection resources and the teaching and speciality language of the teachers who are the main users and in many cases the authors of the resources; (ii) they provide mechanisms that facilitate the collaborative and inductive creation of these vocabularies in a framework that is as standardized as possible; and (iii) they can be used as an educational resource in themselves to learn the speciality language for the subject(s) which they encompass.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











































