1. Introduction
When it comes to estimating the mean parameter of a multivariate normal distribution, the minimax technique has attracted the greatest attention and development in research thus far. Following Stein [
1], it is well-known that the maximum likelihood estimator (MLE) is minimax and admissible when the dimensions of the parameter space are less than or equal to two. On the other hand, the MLE maintains the minimax property but is no longer admissible when the dimension is greater than three. Therefore, enhancing estimators has been accomplished through the development of shrinkage estimators that minimize the risk associated with the quadratic loss function. The efficient outperformance of these shrinkage estimators, compared to the MLE, has been demonstrated in various studies; for example, see Baranchik [
2], Efron and Morris [
3,
4], Stein [
5], Casella and Whang [
6], Berger [
7], Arnold [
8], and Gruber [
9]. Stein [
1] and James and Stein [
10] have also provided specific suggestions for improvement. In this paper, we discuss adaptive shrinkage estimating strategies and show how they may be generated by shrinking a raw estimate. In addition, we report our investigation of the characteristics of several shrinkage estimators in the context of risk.
There have been various recent studies focused on shrinkage estimation, including those of Nourouzirad and Arashi [
11], Nimet and Selahettin [
12], Kashari et al. [
13], and Benkhaled and Hamdaoui [
14]. Shrinkage estimators for multivariate normal means in the Bayesian framework have been examined by Hamdaoui et al. [
15], in order to determine the minimaxity and limitations of their risk ratios. For the
model, the authors used the prior law
, in which the parameters
and
are known but the parameter
is unknown. They developed two modified Bayes estimators, a
and an empirical
. When the sample size
and the dimension of parameter space
are finite, they found that the estimators
and
are minimax under the quadratic loss. When
and
approach infinity, the risk ratios of these estimators were examined in terms of the MLE
.
Improvement of the estimators can also be achieved by incorporating a balanced loss function. Zellner [
16] presented a balanced loss function that is intended to represent two requirements; namely, quality of fit and accuracy of the estimate. We refer to Farsipour and Asgharzadeh [
17], Karamikabir et al. [
18], and Selahattin and Issam [
19] for further information on the use of this loss function. Using the generalized Bayes shrinkage estimators of location parameter for a spherical distribution subject to a balance-type loss, Karamikabir et al. [
20] determined the minimax and acceptable estimators of the location parameter.
In this paper, we use the model , in which the parameter is well known. Our main purpose was to estimate the unknown parameter , by using shrinkage estimators derived from the MLE to solve for . We utilized the risk associated with the balanced loss function to compare two estimators. With the incorporation of the balanced loss function, the risk function of the estimators was computed using , where the real constant may be dependent on , and is the typical norm in . In addition, we investigated the minimaxity characteristic of the estimators and concluded that the James–Stein estimator has the same feature. We also extended the work to study the limit of the risk ratios of the James–Stein estimator to the MLE when tends to infinity. We discuss the positive-part version of the James–Stein estimator and the asymptotic behavior of its risk ratios to the MLE in scenarios where the dimension of the parameter space is either finite or goes to infinity. We demonstrate that, when is finite, the positive-part version of the James–Stein estimator outperforms the James–Stein estimator.
The remainder of this paper is structured as follows: In
Section 2, we present our model and recall some published findings that are useful in proving the main results. In
Section 3, we show the minimaxity property and the limit of the risk ratios of the James–Stein estimator and its positive-part version, regarding the dimension of the parameter space. We end this paper with the results of a simulation study, which illustrate the performance of the considered estimators.
2. Model Presentations
In this section, we recall that, if is a multivariate Gaussian random variable in , then , where denotes the non-central chi-square distribution with degrees of freedom and non-centrality parameter .
Suppose that
is a random vector which follows a multivariate normal distribution
, where the parameter
is unknown. For any estimator
of the parameter
, the balanced squared error loss function of
can then be defined as
where
is the given estimator that is being compared to the target estimator
of
,
is the weight provided to the closeness of
to
, and
is the relative weight given to the precision of the estimator
to
. This means that the risk function associated with
is defined as follows:
Now, considering the model
, in which
is known, we focus on estimating the unknown mean parameter
using shrinkage estimators under the balanced loss function defined in Equation (1). For simplicity, we only consider the scenario
, as any model of the type
may be converted to a model
by a change of variables. Specifically, we investigate the estimation of the unknown parameter
when
. In this case, following Benkhaled et al. [
21], it is obvious that the MLE is
, and its risk function is
. Therefore, any estimator that dominates
is likewise minimax for
.
For the proof given in the next section, we needed to address the result of Lemma 1 given in Stein [
5], which states that
where
is a random variable that follows
,
is the derivative of
, and
.
3. Main Results
3.1. General Class of James–Stein Estimator
3.1.1. Risk Function and Minimaxity
Here, we study the minimaxity of estimators defined by
where
is a real parameter.
Proposition 1. Under the balanced loss functiongiven in Equation (1), the risk function of the estimator is
Proof of Proposition 1. From Equations (2) and (4), we have
Using Equation (3), we obtain
According to Equations (6) and (7), we obtain the desired result. □
Subsequently, from Equation (5), we can immediately deduce that a sufficient condition for the estimator
to dominate the MLE
is
Due to the convexity of the risk function
on
, the optimal value of
that minimizes this risk function is
By replacing
with
in Equation (4), we then obtain the James–Stein estimator that is defined as
Additionally, its risk function related to the balanced loss function
given in Equation (1) is given by
We can then deduce that the James–Stein estimator dominates the MLE; thus, is minimax.
3.1.2. Asymptotic Behavior of Risk Ratios of James–Stein Estimator
This section discusses the effectiveness of the James–Stein estimator, in terms of dominating the MLE under the balanced loss function when the dimension of the parameter space goes to infinity.
Casella and Whang [
6] have shown that the James–Stein estimator dominates the MLE under the quadratic loss function; that is, in the specific case of the balanced loss defined by Equation (1):
.
Theorem 1. Under the balanced loss functiondefined in Equation (1), if , we get
Proof of Theorem 1. From Lemma 1 of Casella and Whang [
6], and for
we have
Using Equations (9) and (10), we obtain
By passing to the limit—namely, when
tends to infinity and under the condition
we get
and then
Thus,
Therefore,
as
. This means that, even if
tends to infinity, the James–Stein estimator
is superior to the MLE
. As a result, the minimaxity feature of the James–Stein estimator
remains stable. □
3.2. The Positive-Part Version of the James–Stein Estimator
In this section, we study the superiority of the positive-part version of the James–Stein estimator to the James–Stein estimator, and the limit of the risk ratio of the positive-part version of the James–Stein estimator to the MLE when the dimension of the parameter space
tends to infinity. The positive-part version of James–Stein estimator is given by
where
, with
denoting the indicator function of the set
.
3.2.1. Comparison of Risk Functions of the Positive-Part Version of the James–Stein Estimator and the James–Stein Estimator
Proposition 2. Under the balanced loss functiondefined in Equation (1), the positive-part version of James–Stein estimator defined in Equation (11) dominates the James–Stein estimator given in Equation (8).
Proof of Proposition 2. We have
Baranchick [
2] has shown that, under the quadratic loss function (i.e., in the case where
),
If
the positive–part version of James–Stein estimator
then dominates the James–Stein estimator
Thus, using Equations (12) and (13), a sufficient condition for which
dominates
under the balanced loss function (i.e.,
is
Subsequently,
Thus,
dominates
for any
. □
3.2.2. Limit of Risk Ratio of the Positive-Part Version of the James–Stein Estimator to the MLE
Theorem 2. Under the balanced loss functiondefined in Equation (1), if , we get
Proof of Theorem 2. As dominates for any , then for any and for all and . Hence,
To ensure that
dominates the MLE as
tends to infinity, it suffices to show that
Using the same techniques as used in the proof of Lemma 5 in Benmansour and Hamdaoui [
22], based on Lemma 2.1 of Shao and Strawderman [
23], we obtain
As
where
is the chi-squared distribution with
degrees of freedom and non-centrality parameter
, and by applying Equation (1.3) in Casella and Hwang [
6], we have
From Equations (16)–(18), we obtain
Using Equation (3.4) from Casella and Hwang [
6], we have
Subsequently, under the condition
, we obtain
According to Equations (14) and (19), we can deduce that
namely, the positive-part version of James–Stein estimator
dominates the MLE, even if
tends to infinity. Thus, there is a stability of the minimaxity property of the positive-part version of the James–Stein estimator
when the dimension of parameter space
is in the neighborhood of infinity. □
4. Simulation Results
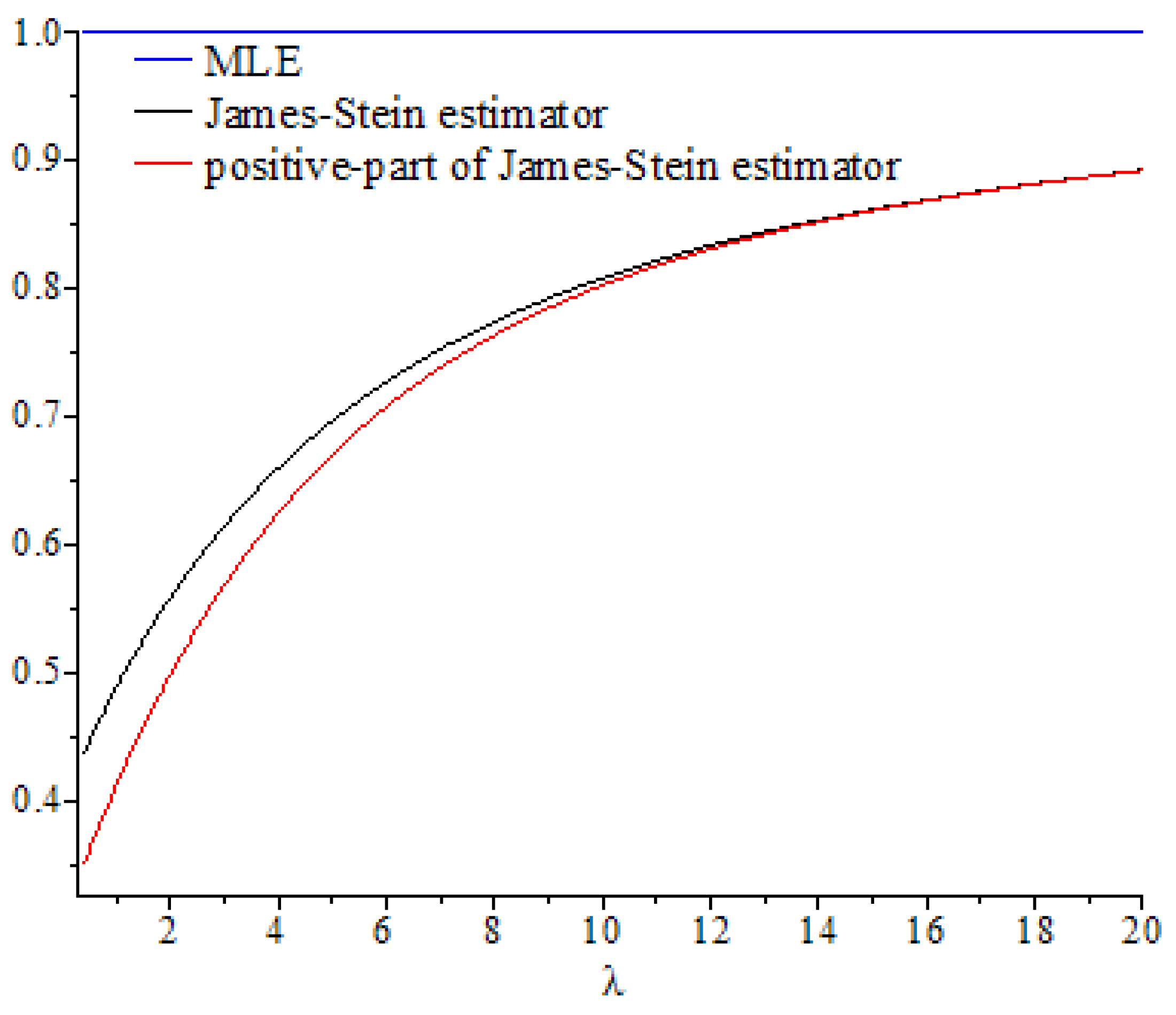
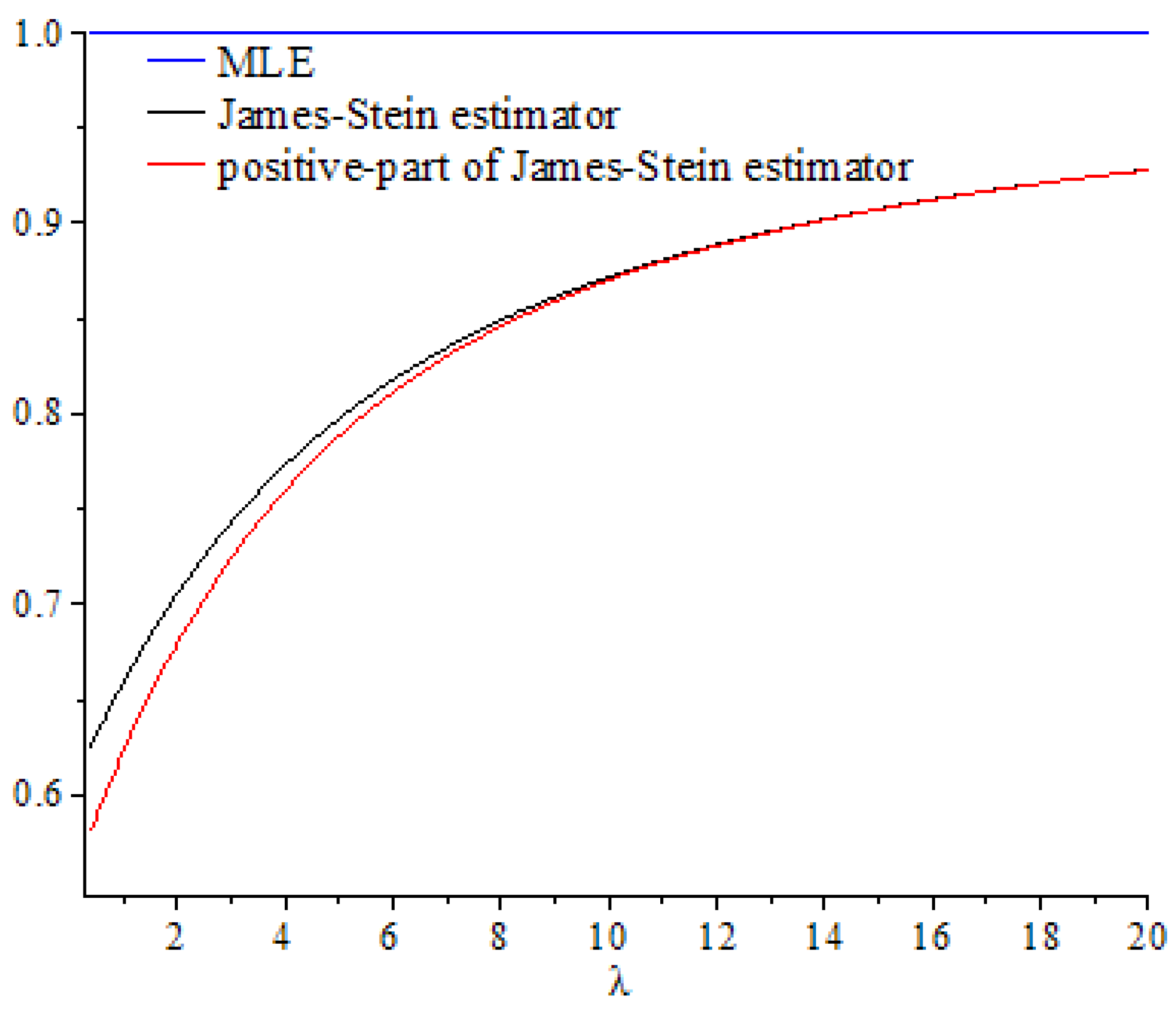
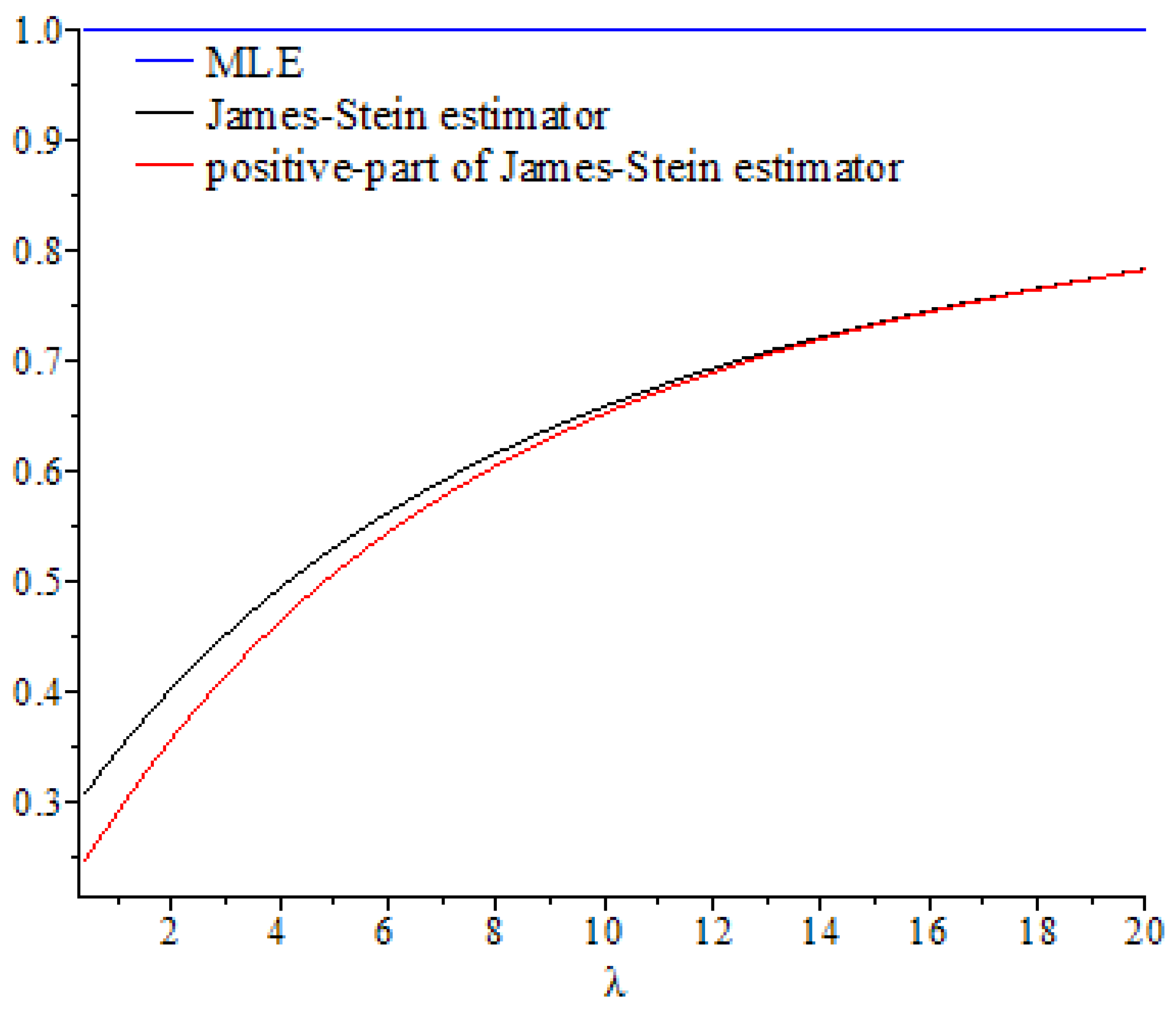
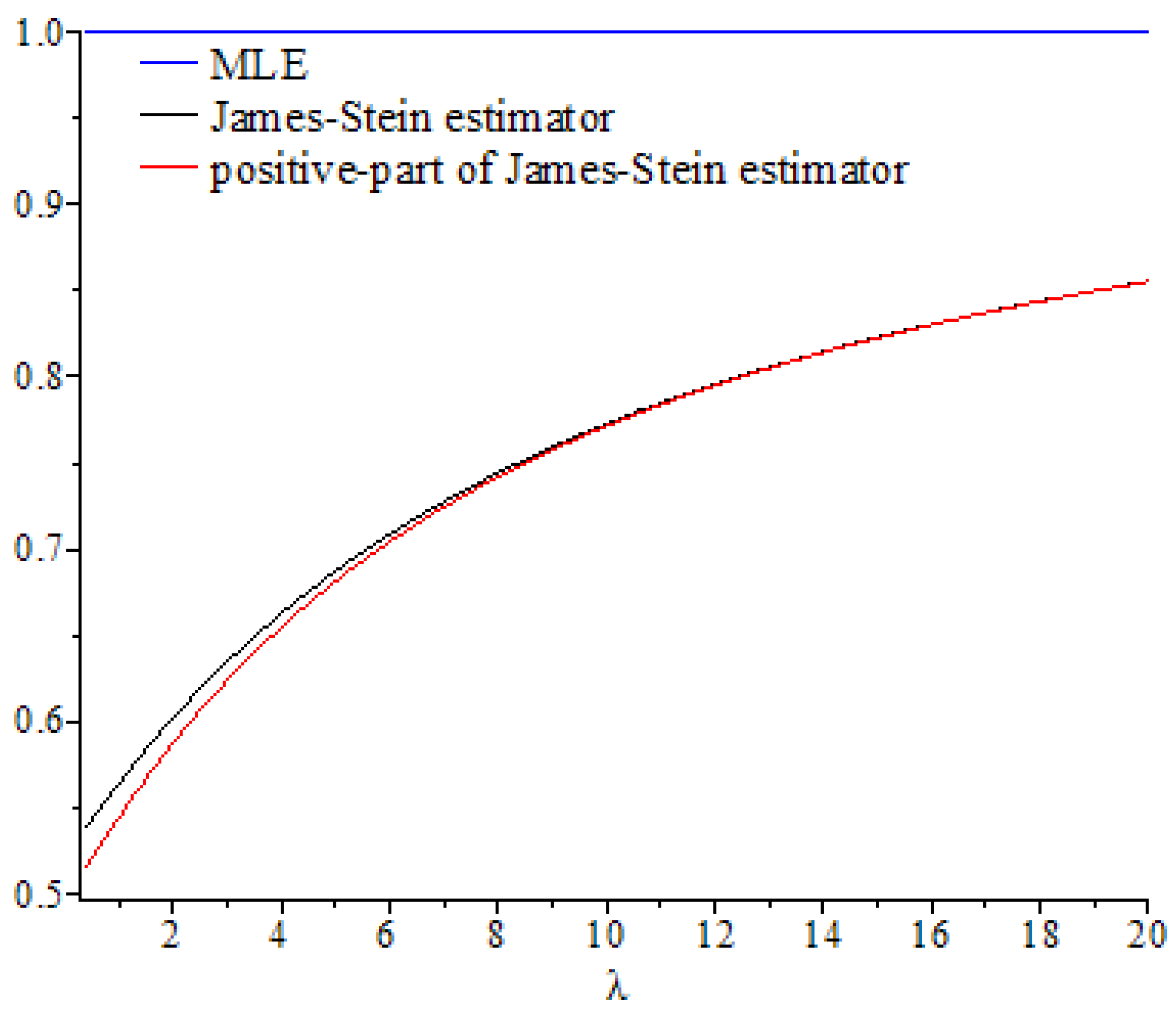
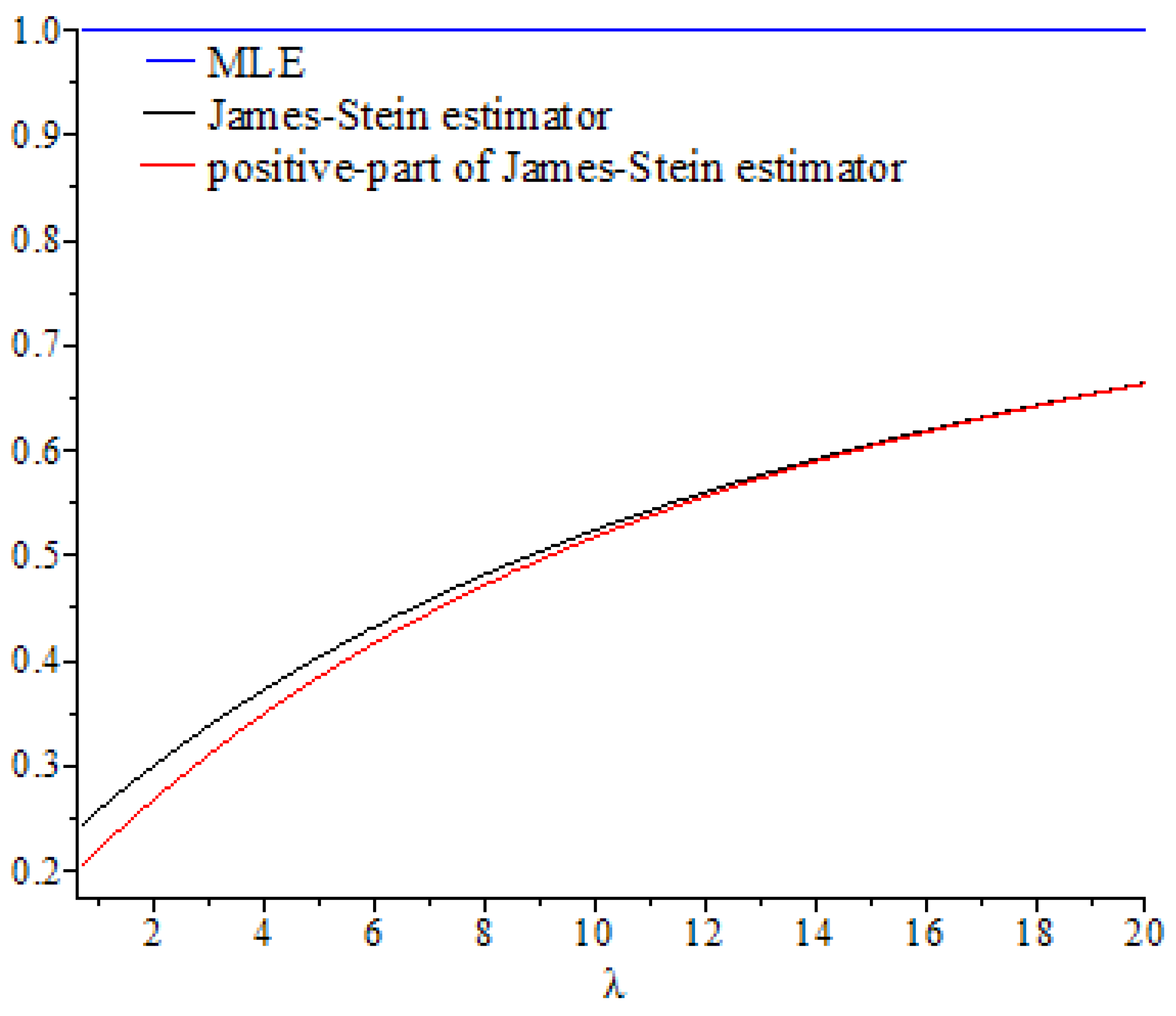
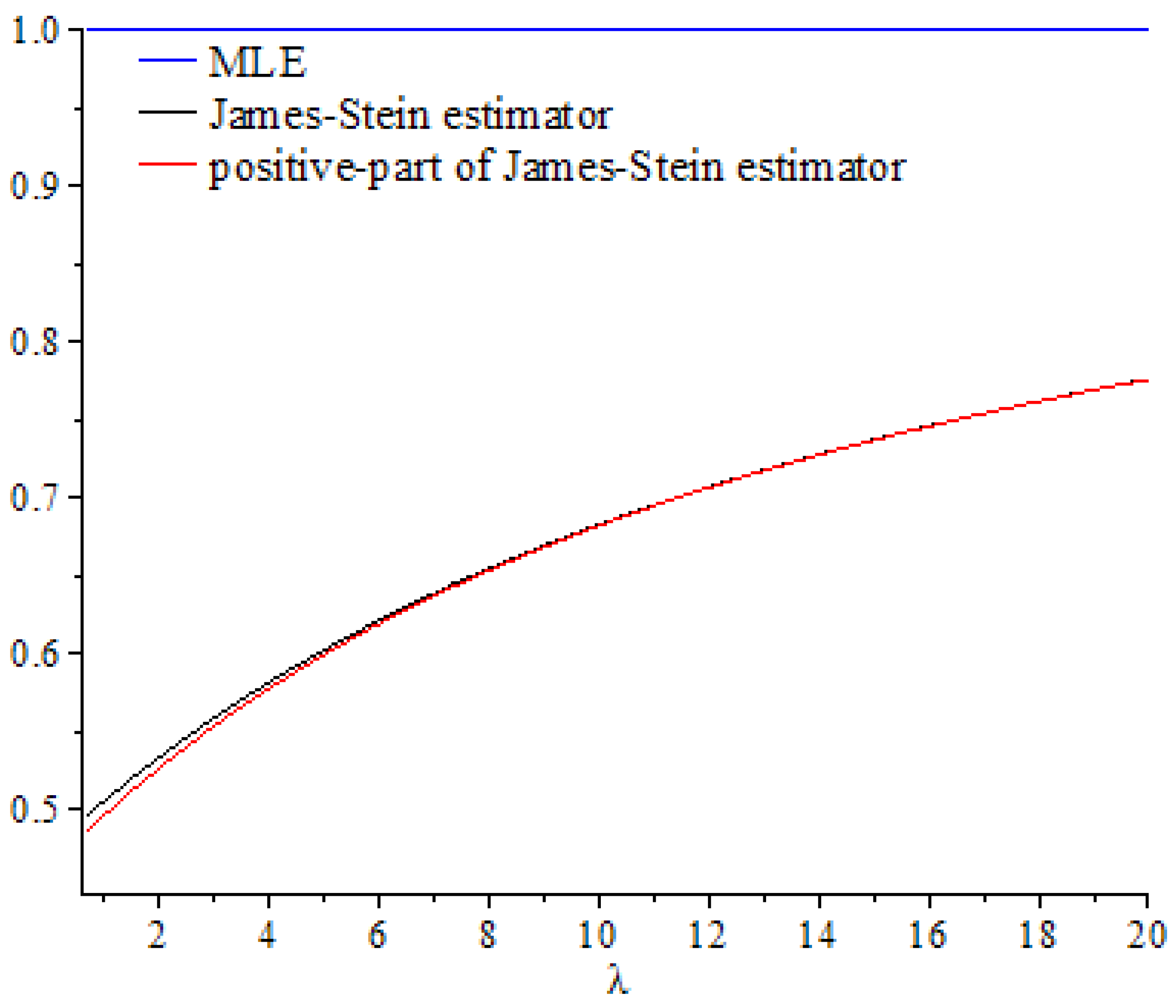
In this section, we discuss the values of the risk ratios of the James–Stein estimator defined in Equation (8), for which the risk function under the balanced loss function is given by Equation (9), and the positive-part version of James–Stein estimator defined by Equation (11), for which the risk function related to the balanced loss function is given by Equation (15), with respect to the MLE. We denote these risk ratios as and , respectively. First, we discuss the performance of both estimators as functions of , and then compare their performance to the MLE based on selected values of the parameters and . We then explain their performance based on various values of, , and
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 show the curves of
and
as functions of
, based on selected values of the parameters
and
. These curves were also compared to the gold standard curve of the risk ratio of the MLE (a constant function equal to 1). We noted that the values of the risk ratios
and
were less than 1 for all selected values of
and
This indicates that the James–Stein estimator
and the positive-part version of the James–Stein estimator
are minimax. Furthermore, the estimators
and
represented a significant improvement over the MLE, especially when the values of
were close to zero and the dimension of the parameter space
was high. Moreover, we noted a better performance of
, compared to
, for the same values of
and
By looking at the curves of both risk ratios, it can be seen that the risk ratio
was obviously lower than that of
for most values of
. The difference between these curves was significant for small values of
and negligible for larger values. This indicates that the improvement of
over
was slight for large values of
, and the curves of their risk ratios were almost identical once
exceeded a certain value. All results discussed through these figures can be confirmed by the values of risk ratios
and
provided in
Table 1,
Table 2 and
Table 3 for different set values of
,
, and
. The first entry of each cell in these tables is the ratio
, while the second entry is the ratio
.
The superiority of the James–Stein estimator and the positive-part version of the James–Stein estimator over the MLE were observed under small values of both and . This improvement tended to decrease and approached zero as and increased. We also observed that the improvement of both estimators and the dimension of the parameter space d were positively correlated under fixed values of . We also noted that, for each value of , the values of the risk ratios and tended to be identical for large values of .
Hence, these results indicate the minimaxity of James–Stein estimator and the positive-part version of the James–Stein estimator, as well as the superiority of the positive-part version of the James–Stein estimator to the James–Stein estimator for different values of and .
5. Conclusions
In this paper, we considered the estimation of the mean of a multivariate normal distribution . We assessed the risk associated with the balanced loss function for comparing any two estimators. First, we established the minimaxity of the estimators defined by , where is a real parameter related to the dimension of the parameter space, , and deduced the minimaxity of James–Stein estimator . When the value of was in the neighborhood of infinity, we studied the asymptotic behavior of risk ratios of the James–Stein estimator to the MLE. We then showed that, under the condition the limit of the risk ratio tended to the value ; in other words, the James–Stein estimator dominates the MLE, even when tends to infinity. Thus, the minimaxity property of the James–Stein estimator remains stable, even if is in the neighborhood of infinity. Second, following the same steps as in the first part, we examined the minimaxity of the positive-part version of the James–Stein estimator , in the case when is finite. When was infinite, we obtained the same results as reported previously; namely, we showed that, under the condition the limit of the risk ratio tended to . Thus, we observed the stability of the minimaxity property of the positive-part version of the James–Stein estimator, , when the dimension of parameter space is in the neighborhood of infinity.
For further work, we plan to examine the general multivariate normal distribution where is an arbitrary unknown positive matrix. This work can also be explored in the Bayesian framework as well as in the general case where the model has a symmetrical spherical distribution.
Author Contributions
Conceptualization, A.H., W.A., M.T. and A.B.; methodology, A.H., W.A., M.T. and A.B.; formal analysis, A.H., W.A., M.T. and A.B.; writing—review and editing, A.H., W.A., M.T. and A.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The corresponding author can provide the data sets utilized in this work upon reasonable request.
Acknowledgments
The authors are very grateful to the editor and the anonymous referees for their valuable suggestions and comments.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Stein, C. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In Proceedings of the 3rd Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1956; pp. 197–206. [Google Scholar]
- Baranchik, A.J. Multiple Regression and Estimation of the Mean of a Multivariate Normal Distribution; Technical Report No. 51; Stanford University: Stanford, CA, USA, 1964. [Google Scholar]
- Efron, B.; Morris, C.N. Stein’s estimation rule and its competitors: An empirical Bayes approach. J. Am. Stat. Assoc. 1973, 68, 117–130. [Google Scholar]
- Efron, B.; Morris, C.N. Data analysis using Stein’s estimator and its generalizations. J. Am. Stat. Assoc. 1975, 70, 311–319. [Google Scholar] [CrossRef]
- Stein, C. Estimation of the mean of a multivariate normal Distribution. Ann. Stat. 1981, 9, 1135–1151. [Google Scholar] [CrossRef]
- Casella, G.; Hwang, J.T. Limit expressions for the risk of James-Stein estimator. Can. J. Stat. 1982, 10, 305–309. [Google Scholar] [CrossRef] [Green Version]
- Berger, J.O.; Strawderman, W.E. Choice of hierarchical priors: Admissibility in estimation of normal means. Ann. Stat. 1996, 24, 931–951. [Google Scholar] [CrossRef]
- Arnold, F.S. The Theory of Linear Models and Multivariate Analysis; John Wiley and Sons: New York, NY, USA, 1981; pp. 159–179. [Google Scholar]
- Gruber, H.G.M. Improving efficiency by shrinkage, Statistics: The James-Stein and Ridge Regression Estimators. In Statistics, Textbooks, and Monographs, 1st ed.; Rochester Institute of Technology: Rochester, NY, USA, 1998; pp. 71–370. [Google Scholar]
- James, W.; Stein, C. Estimation with quadratic loss. In Proceedings of the 4th Berkeley Symposium on Mathematical Statistics and Probability, Los Angeles, CA, USA, 20 June–30 July 1960; pp. 361–379. [Google Scholar]
- Norouzirad, M.; Arashi, M. Preliminary test and Stein-type shrinkage ridge estimators in robust regression. Stat. Pap. 2019, 60, 1849–1882. [Google Scholar] [CrossRef]
- Özbay, N.; Kaçıranlar, S. Risk performance of some shrinkage estimators. Commun. Stat. Simul. Comput. 2019, 50, 323–342. [Google Scholar] [CrossRef]
- Kashani, M.; Rabiei, M.R.; Arashi, M. An integrated shrinkage strategy for improving efficiency in fuzzy regression modeling. Soft Comput. 2021, 25, 8095–8107. [Google Scholar] [CrossRef]
- Benkhaled, A.; Hamdaoui, A. General classes of shrinkage estimators for the multivariate normal mean with unknown variancee: Minimaxity and limit of risks ratios. Kragujev. J. Math. 2019, 46, 193–213. [Google Scholar]
- Hamdaoui, A.; Benkhaled, A.; Mezouar, N. Minimaxity and limits of risks ratios of shrinkage estimators of a multivariate normal mean in the Bayesian case. Stat. Optim. Inf. Comput. 2020, 8, 507–520. [Google Scholar] [CrossRef]
- Zellner, A. Bayesian and non-Bayesian estimation using balanced loss functions. In Statistical Decision Theory and Methods; Berger, J.O., Gupta, S.S., Eds.; Springer: New York, NY, USA, 1994; pp. 337–390. [Google Scholar]
- Farsipour, N.S.; Asgharzadeh, A. Estimation of a normal mean relative to balanced loss functions. Stat. Pap. 2004, 45, 279–286. [Google Scholar] [CrossRef]
- Karamikabir, H.; Afshari, M.; Arashi, M. Shrinkage estimation of non-negative mean vector with unknown covariance under balance loss. J. Inequal. Appl. 2018, 1, 331. [Google Scholar] [CrossRef] [PubMed]
- Selahattin, K.; Issam, D. The optimal extended balanced loss function estimators. J. Comput. Appl. Math. 2019, 345, 86–98. [Google Scholar] [CrossRef]
- Karamikabir, H.; Afshari, M. Generalized Bayesian shrinkage and wavelet estimation of location parameter for spherical distribution under balanced-type loss: Minimaxity and admissibility. J. Multivar. Anal. 2020, 177, 110–120. [Google Scholar] [CrossRef]
- Benkhaled, A.; Terbeche, M.; Hamdaoui, A. Polynomials shrinkage estimators of a multivariate normal mean. Stat. Optim. Inf. Comput. 2021. [Google Scholar] [CrossRef]
- Benmansour, D.; Hamdaoui, A. Limit of the ratio of risks of James-Stein estimators with unknown variance. Far East J. Stat. 2011, 36, 31–53. [Google Scholar]
- Shao, P.; Strawderman, W.E. Improving on the James-Stein positive-part. Ann. Stat. 1994, 22, 1517–1539. [Google Scholar] [CrossRef]
Figure 1.
Graph of the risk ratios and as functions of for .
Figure 1.
Graph of the risk ratios and as functions of for .
Figure 2.
Graph of the risk ratios and as functions of for .
Figure 2.
Graph of the risk ratios and as functions of for .
Figure 3.
Graph of the risk ratios and as functions of for .
Figure 3.
Graph of the risk ratios and as functions of for .
Figure 4.
Graph of the risk ratios and as functions of for .
Figure 4.
Graph of the risk ratios and as functions of for .
Figure 5.
Graph of the risk ratios and as functions of for .
Figure 5.
Graph of the risk ratios and as functions of for .
Figure 6.
Graph of the risk ratios and as functions of for .
Figure 6.
Graph of the risk ratios and as functions of for .
Table 1.
Values of the risk ratios and for and at different values of .
Table 1.
Values of the risk ratios and for and at different values of .
| | | | | |
|---|
| 1.2418 | 0.6648 | 0.7020 | 0.8138 | 0.8882 | 0.9627 |
| 0.5826 | 0.6326 | 0.7809 | 0.8748 | 0.9611 |
| 1.6712 | 0.6950 | 0.7289 | 0.8305 | 0.8983 | 0.9661 |
| 0.6229 | 0.6686 | 0.8028 | 0.8872 | 0.9647 |
| 3.7523 | 0.7969 | 0.8194 | 0.8871 | 0.9323 | 0.9774 |
| 0.7601 | 0.7898 | 0.8750 | 0.9278 | 0.9769 |
| 5.0019 | 0.8348 | 0.8532 | 0.9082 | 0.9449 | 0.9816 |
| 0.8108 | 0.8342 | 0.9009 | 0.9423 | 0.9814 |
| 10.4310 | 0.9142 | 0.9237 | 0.9523 | 0.9714 | 0.9905 |
| 0.9108 | 0.9212 | 0.9515 | 0.9712 | 0.9904 |
| 20.0000 | 0.9550 | 0.9237 | 0.9523 | 0.9714 | 0.9905 |
| 0.9549 | 0.9212 | 0.9515 | 0.9712 | 0.9904 |
Table 2.
Values of the risk ratios and for and at different values of .
Table 2.
Values of the risk ratios and for and at different values of .
| | | | | |
|---|
| 1.2418 | 0.3609 | 0.4319 | 0.6449 | 0.7870 | 0.9290 |
| 0.3083 | 0.3914 | 0.6349 | 0.7855 | 0.9290 |
| 1.6712 | 0.3854 | 0.4567 | 0.6585 | 0.7951 | 0.9317 |
| 0.3368 | 0.4169 | 0.6498 | 0.7939 | 0.9317 |
| 3.7523 | 0.4839 | 0.5413 | 0.7133 | 0.8280 | 0.9427 |
| 0.4525 | 0.5190 | 0.7089 | 0.8274 | 0.9426 |
| 5.0019 | 0.5306 | 0.5827 | 0.7392 | 0.8435 | 0.9478 |
| 0.5070 | 0.5666 | 0.7364 | 0.8432 | 0.9478 |
| 10.4310 | 0.6668 | 0.7039 | 0.8149 | 0.8889 | 0.9630 |
| 0.6610 | 0.7003 | 0.8145 | 0.8889 | 0.9630 |
| 20.0000 | 0.7828 | 0.8070 | 0.8793 | 0.9276 | 0.9759 |
| 0.7825 | 0.8068 | 0.8793 | 0.9276 | 0.9759 |
Table 3.
Values of the risk ratios and for and at different values of .
Table 3.
Values of the risk ratios and for and at different values of .
| | | | | |
|---|
| 1.6712 | 0.2529 | 0.3359 | 0.5849 | 0.7509 | 0.9170 |
| 0.2245 | 0.3169 | 0.5831 | 0.7508 | 0.9169 |
| 2.4948 | 0.2807 | 0.3606 | 0.6004 | 0.7602 | 0.9201 |
| 0.2558 | 0.3445 | 0.5991 | 0.7602 | 0.9201 |
| 3.7523 | 0.3196 | 0.3952 | 0.6220 | 0.7732 | 0.9244 |
| 0.2991 | 0.3826 | 0.6211 | 0.7732 | 0.9244 |
| 5.0019 | 0.3545 | 0.4263 | 0.6414 | 0.7848 | 0.9283 |
| 0.3380 | 0.4165 | 0.6408 | 0.7848 | 0.9283 |
| 10.4310 | 0.4739 | 0.5323 | 0.7077 | 0.8246 | 0.9415 |
| 0.4681 | 0.5295 | 0.7076 | 0.8246 | 0.9415 |
| 20.0000 | 0.6054 | 0.6492 | 0.7808 | 0.8684 | 0.9561 |
| 0.6047 | 0.6490 | 0.7807 | 0.8684 | 0.9561 |
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}