Author Contributions
Conceptualization, B.L. and M.M.A.A.; methodology, B.L. and M.M.A.A.; software, B.L.; validation, B.L. and M.M.A.A.; formal analysis, B.L.; investigation, B.L. and M.M.A.A.; resources, B.L.; writing—original draft preparation, B.L.; writing—review and editing, B.L. and M.M.A.A.; supervision, M.M.A.A.; project administration, B.L. and M.M.A.A. All authors have read and agreed to the published version of the manuscript.
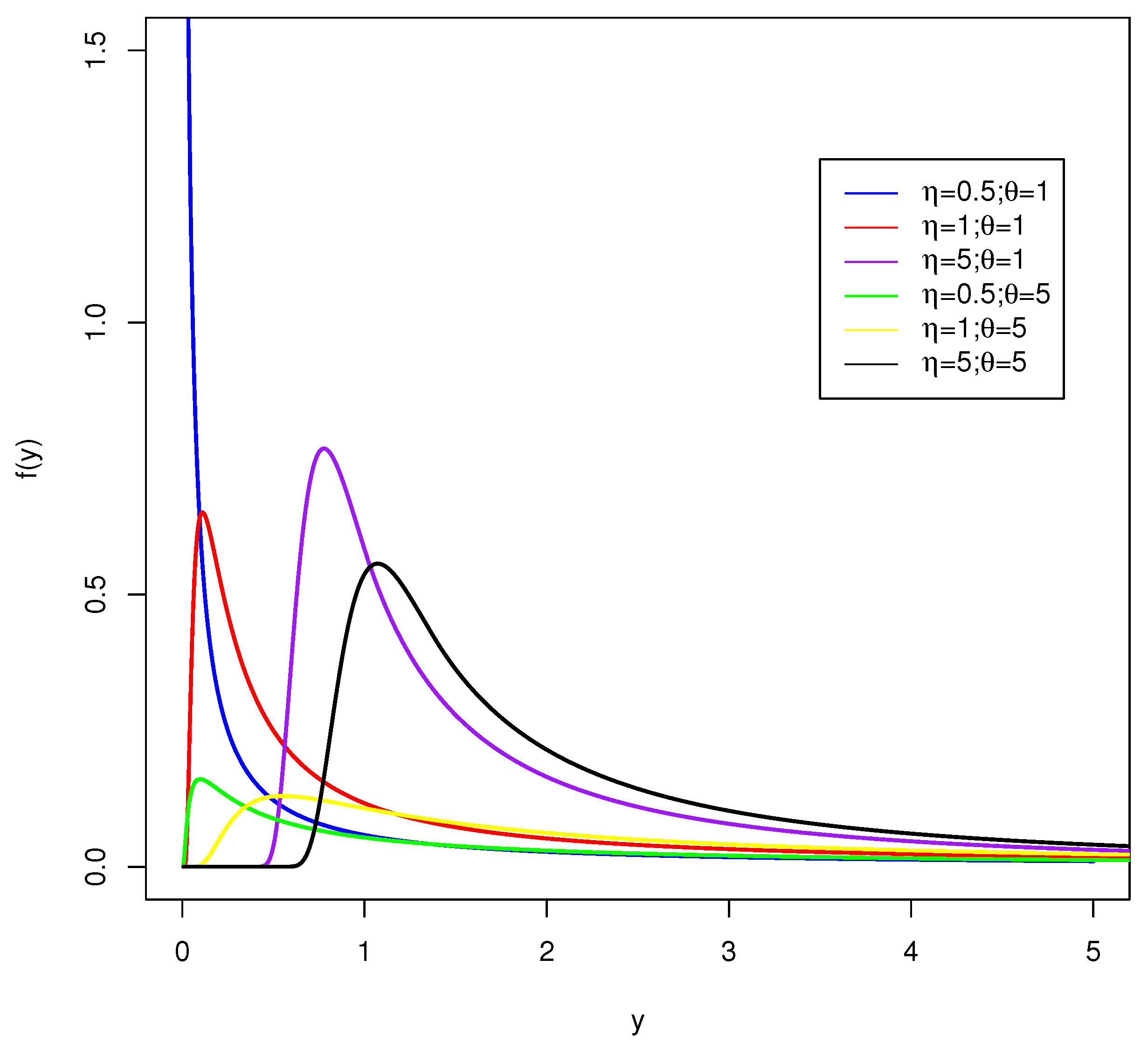
Figure 1.
Plots of the exponentiated IG-Pareto density function, for some parameter values.
Figure 1.
Plots of the exponentiated IG-Pareto density function, for some parameter values.
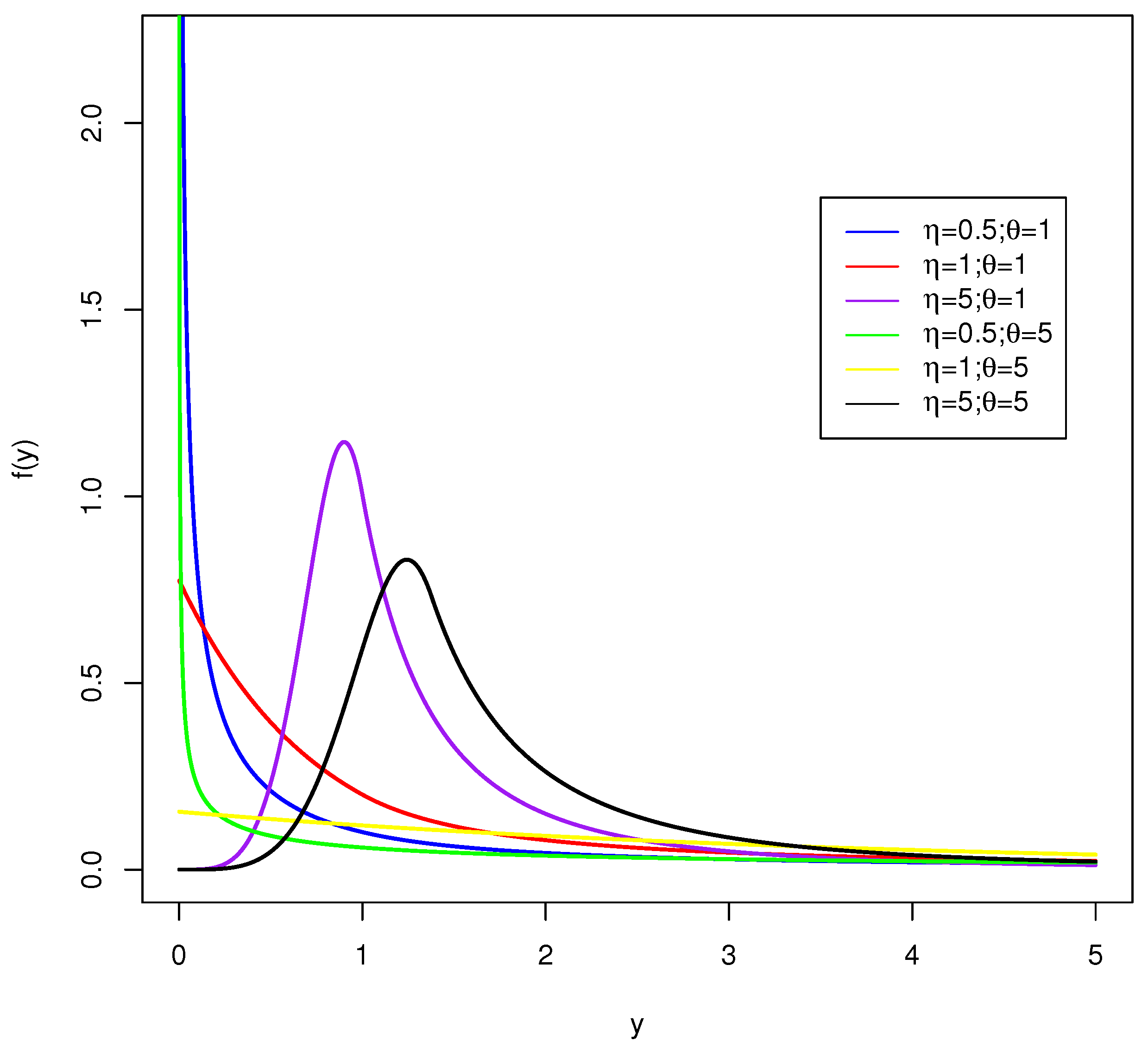
Figure 2.
Plots of the exponentiated exp-Pareto density function, for some parameter values.
Figure 2.
Plots of the exponentiated exp-Pareto density function, for some parameter values.
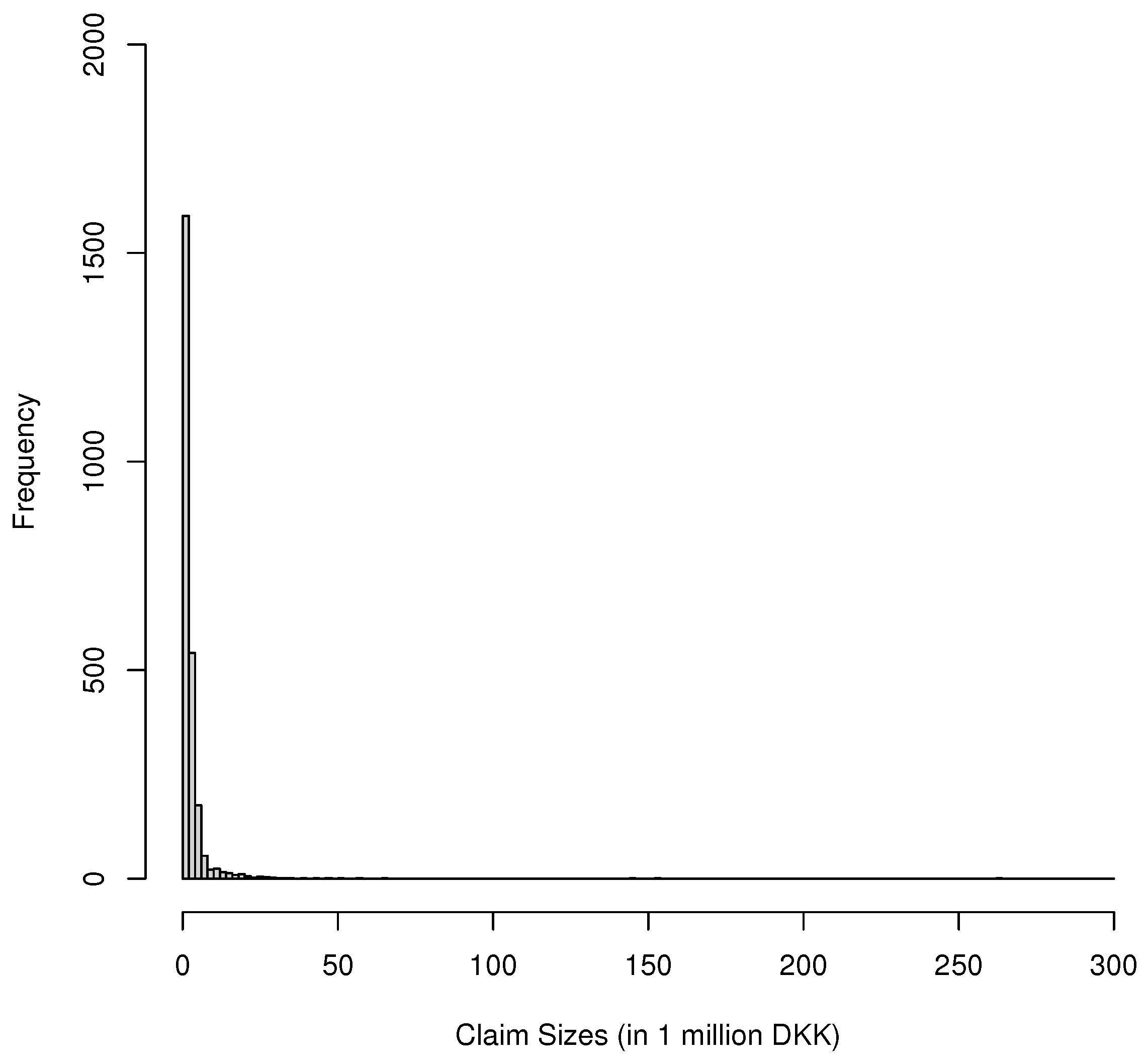
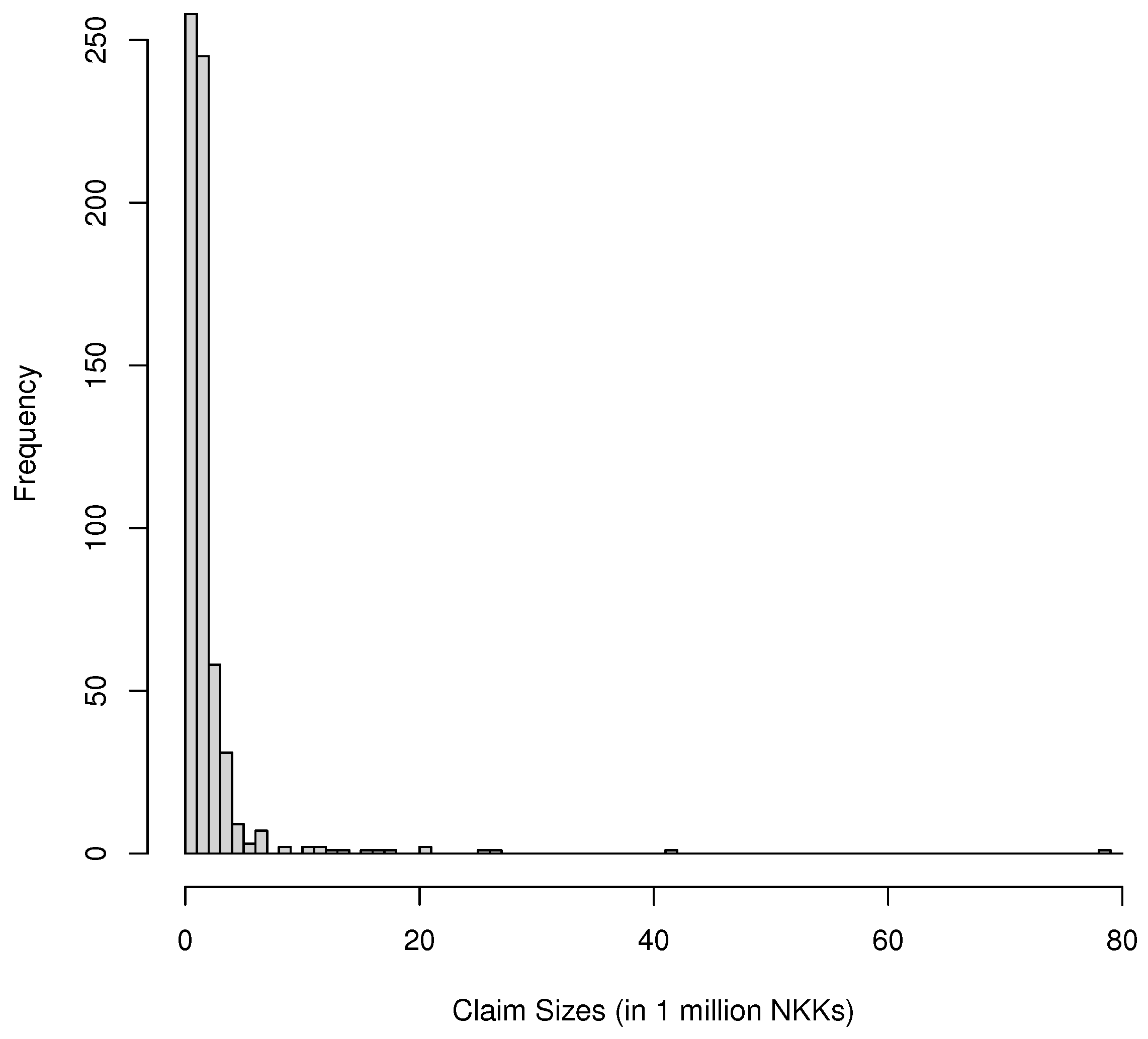
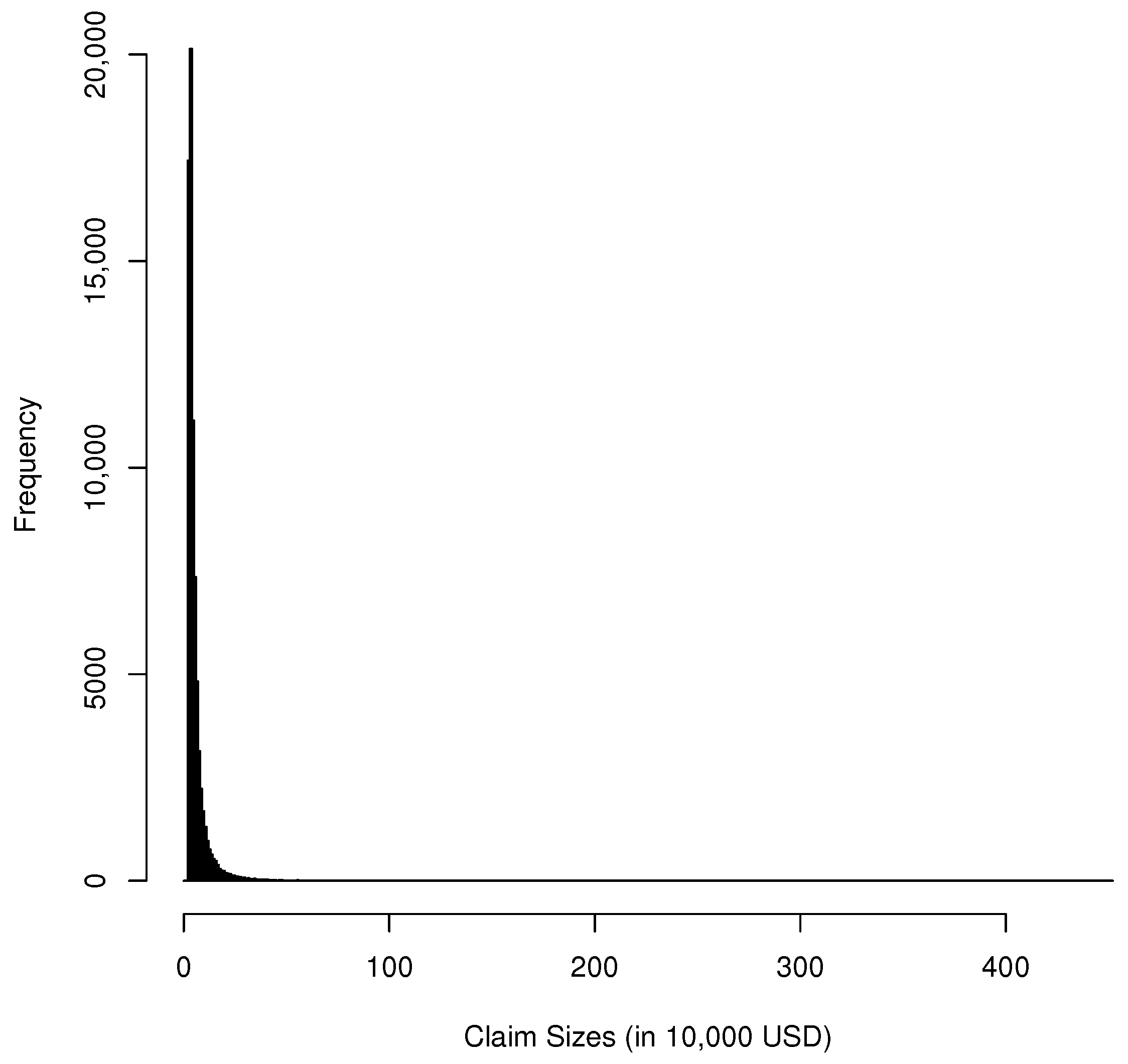
Figure 3.
Histogram of Danish fire insurance dataset.
Figure 3.
Histogram of Danish fire insurance dataset.
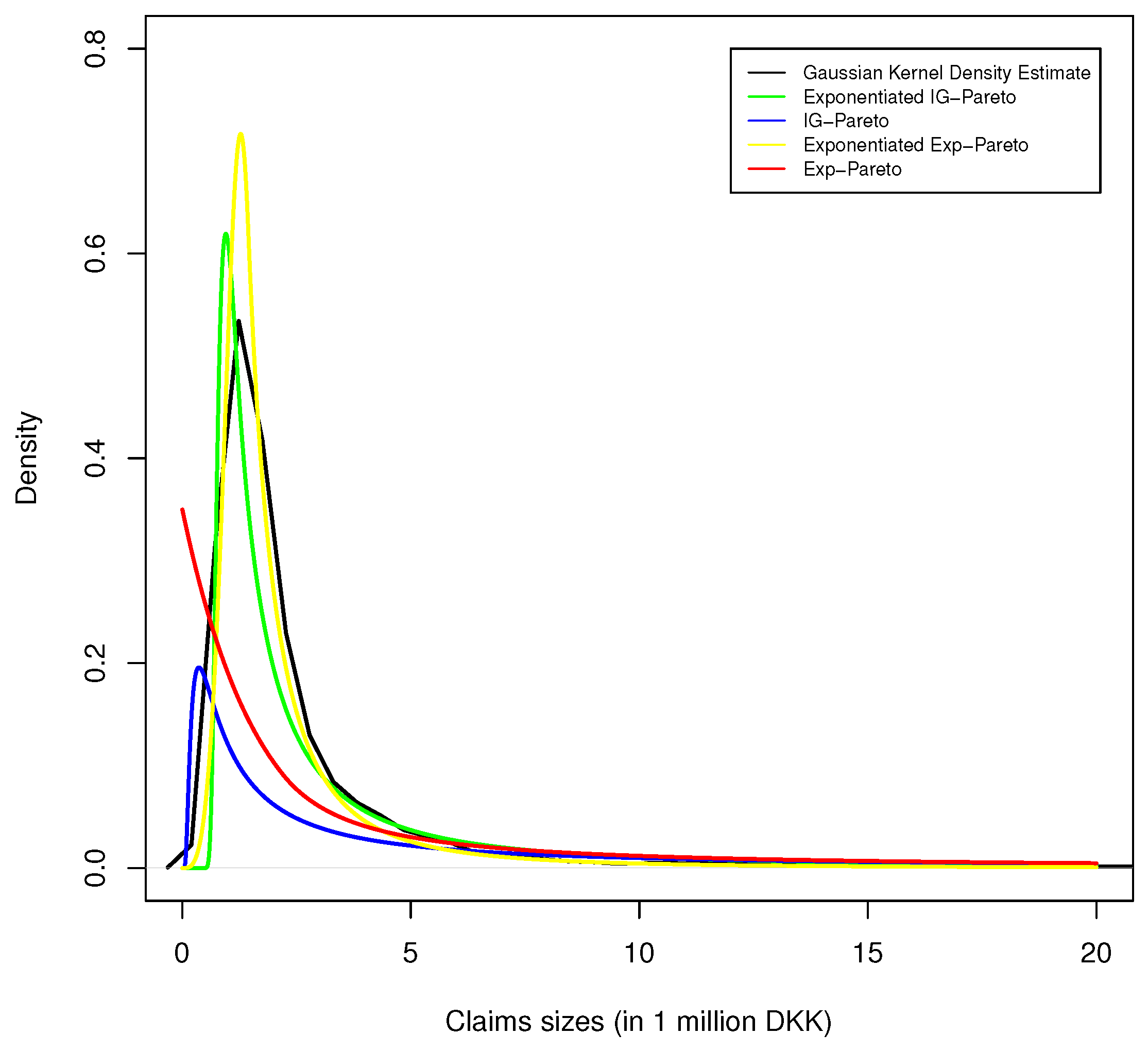
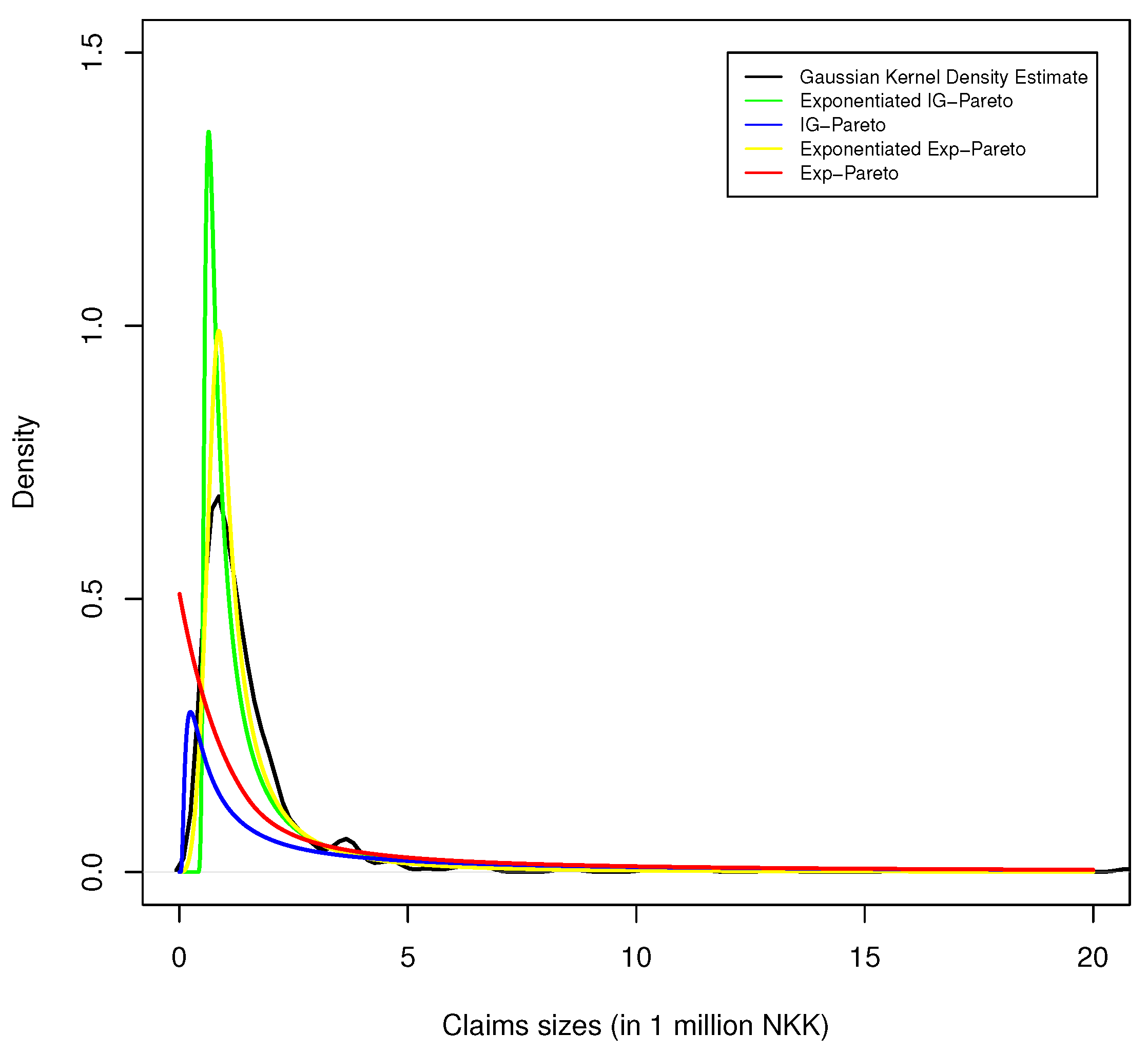
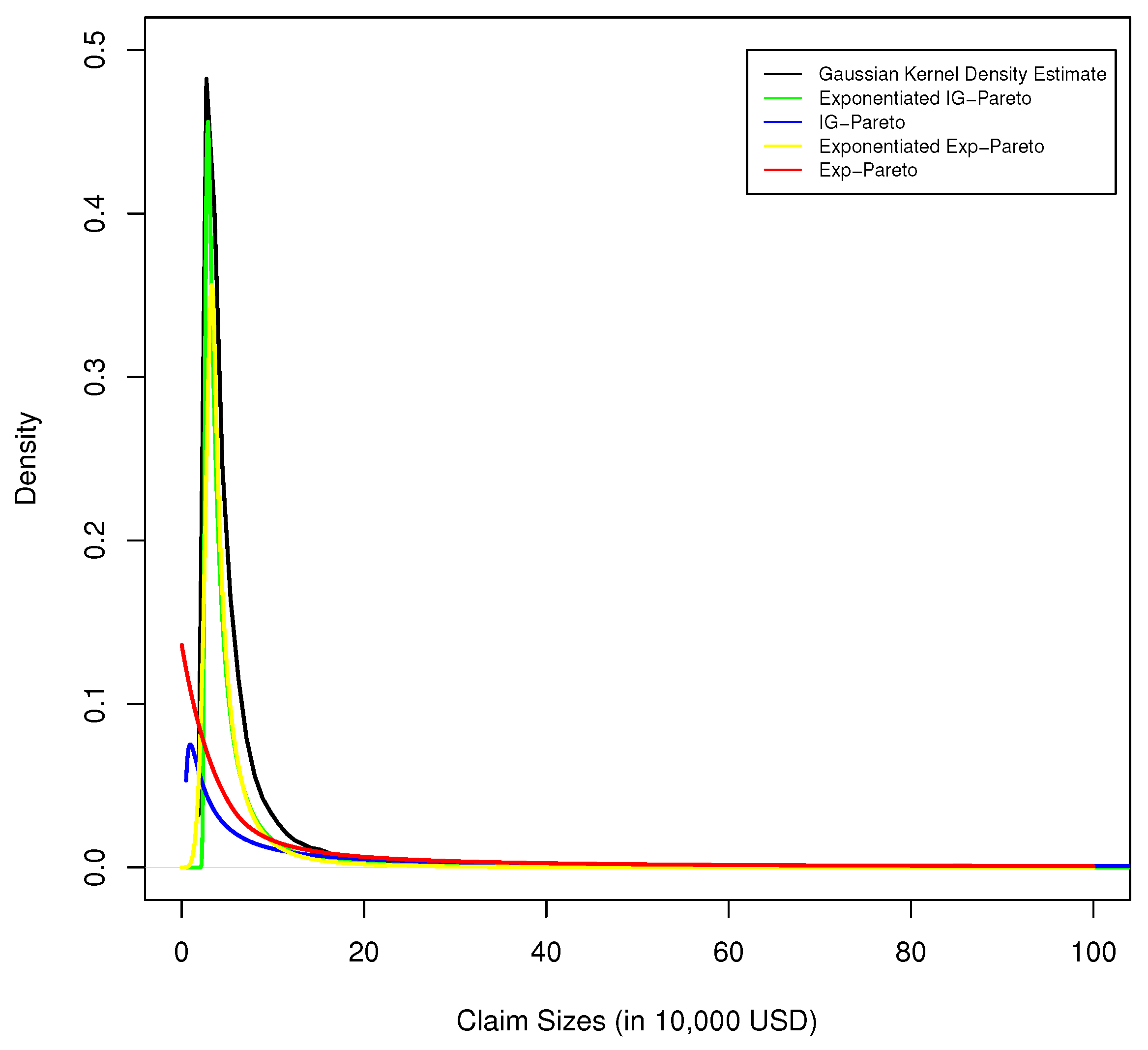
Figure 4.
Kernel density estimate of Danish fire insurance data, with corresponding exponentiated exp-Pareto, exp-Pareto, exponentiated IG-Pareto, and IG-Pareto fit.
Figure 4.
Kernel density estimate of Danish fire insurance data, with corresponding exponentiated exp-Pareto, exp-Pareto, exponentiated IG-Pareto, and IG-Pareto fit.
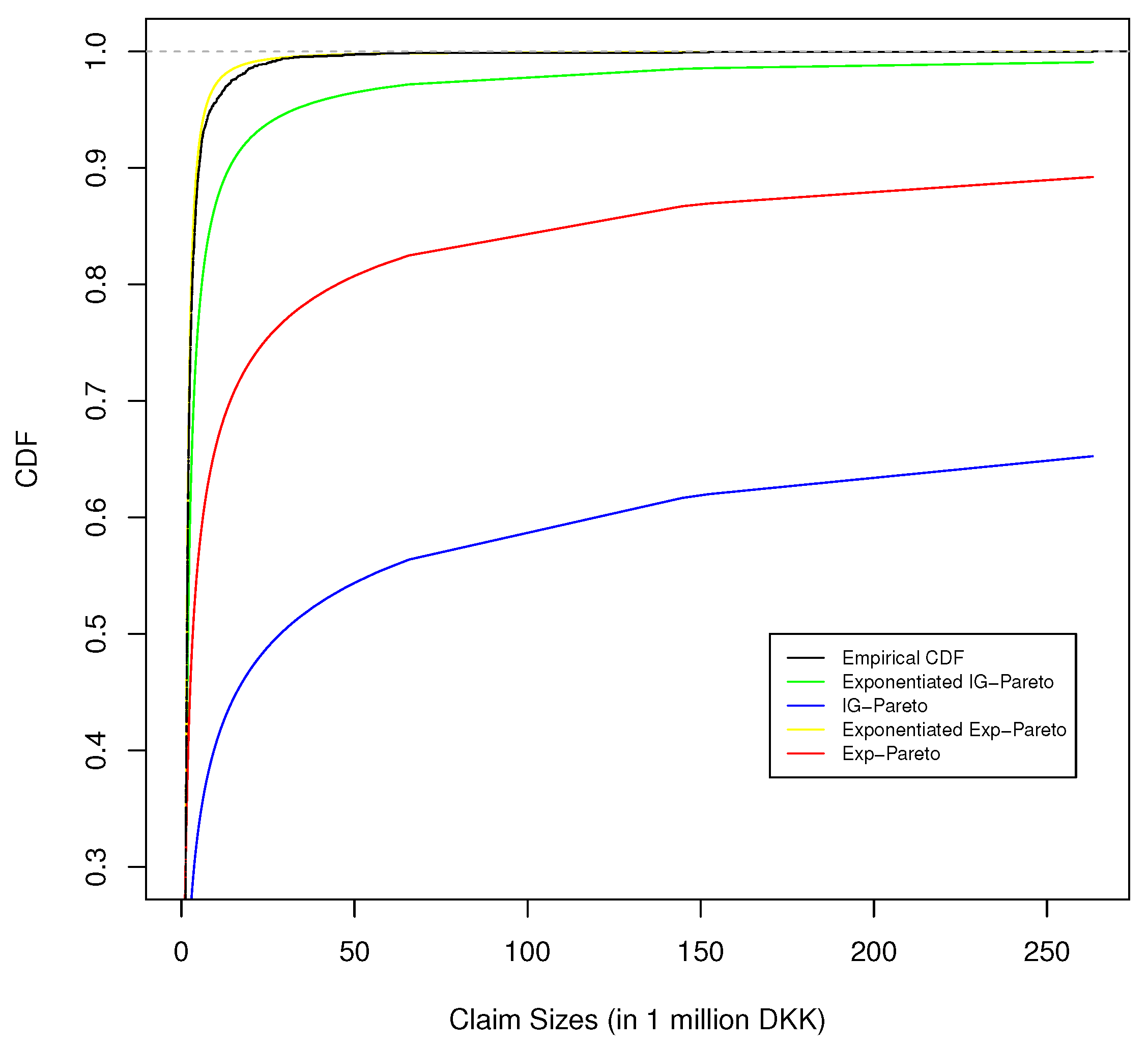
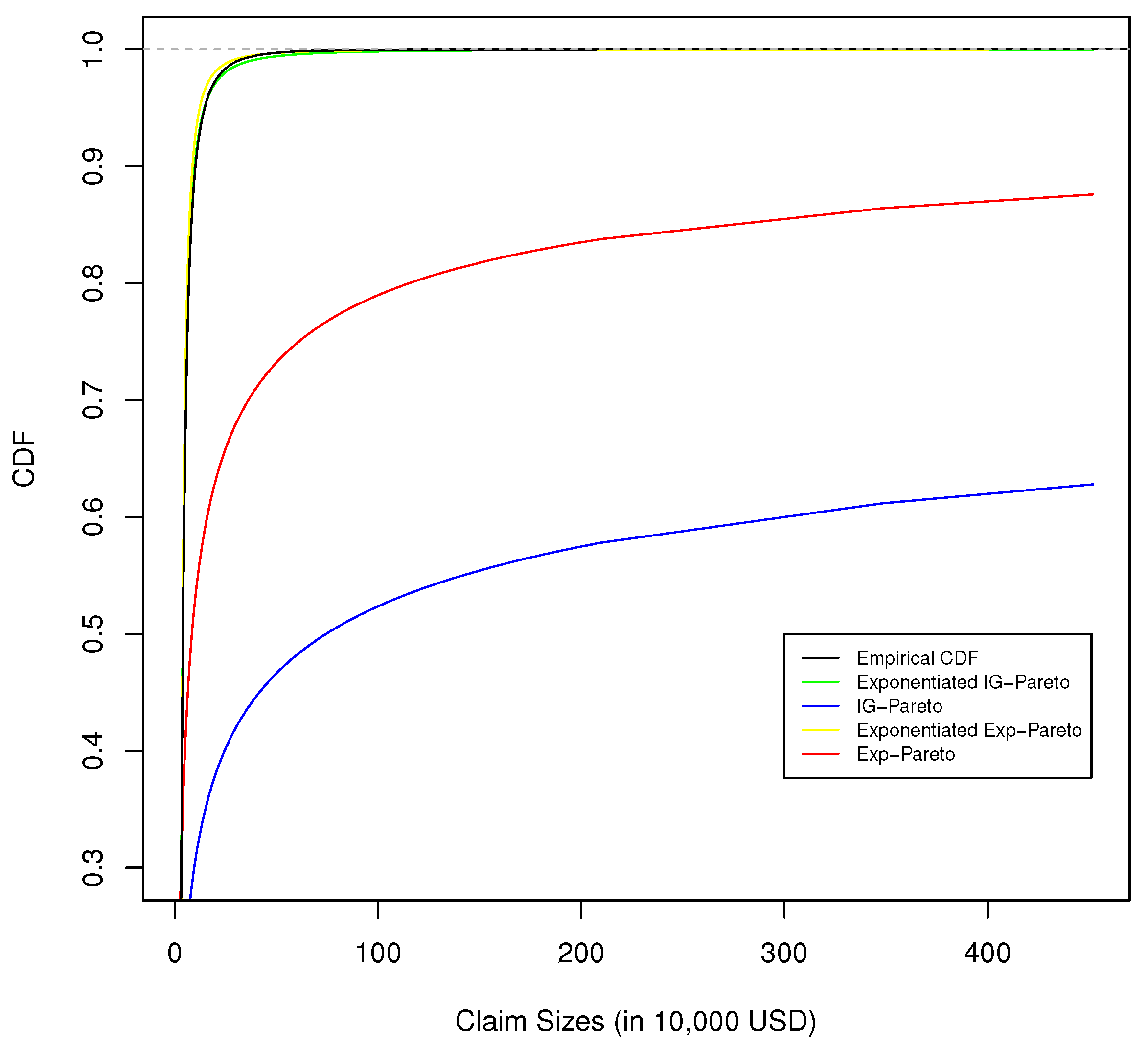
Figure 5.
The empirical CDF of Danish fire insurance data and the fitted CDF, of corresponding exponentiated IG-Pareto, IG-Pareto, exponentiated exp-Pareto, and exp-Pareto model fit.
Figure 5.
The empirical CDF of Danish fire insurance data and the fitted CDF, of corresponding exponentiated IG-Pareto, IG-Pareto, exponentiated exp-Pareto, and exp-Pareto model fit.
Figure 6.
Histogram of Norwegian fire insurance data for 1990.
Figure 6.
Histogram of Norwegian fire insurance data for 1990.
Figure 7.
Kernel density estimate of Norwegian fire insurance data, for 1990, with corresponding exponentiated exp-Pareto, exp-Pareto, exponentiated IG-Pareto, and IG-Pareto fit.
Figure 7.
Kernel density estimate of Norwegian fire insurance data, for 1990, with corresponding exponentiated exp-Pareto, exp-Pareto, exponentiated IG-Pareto, and IG-Pareto fit.
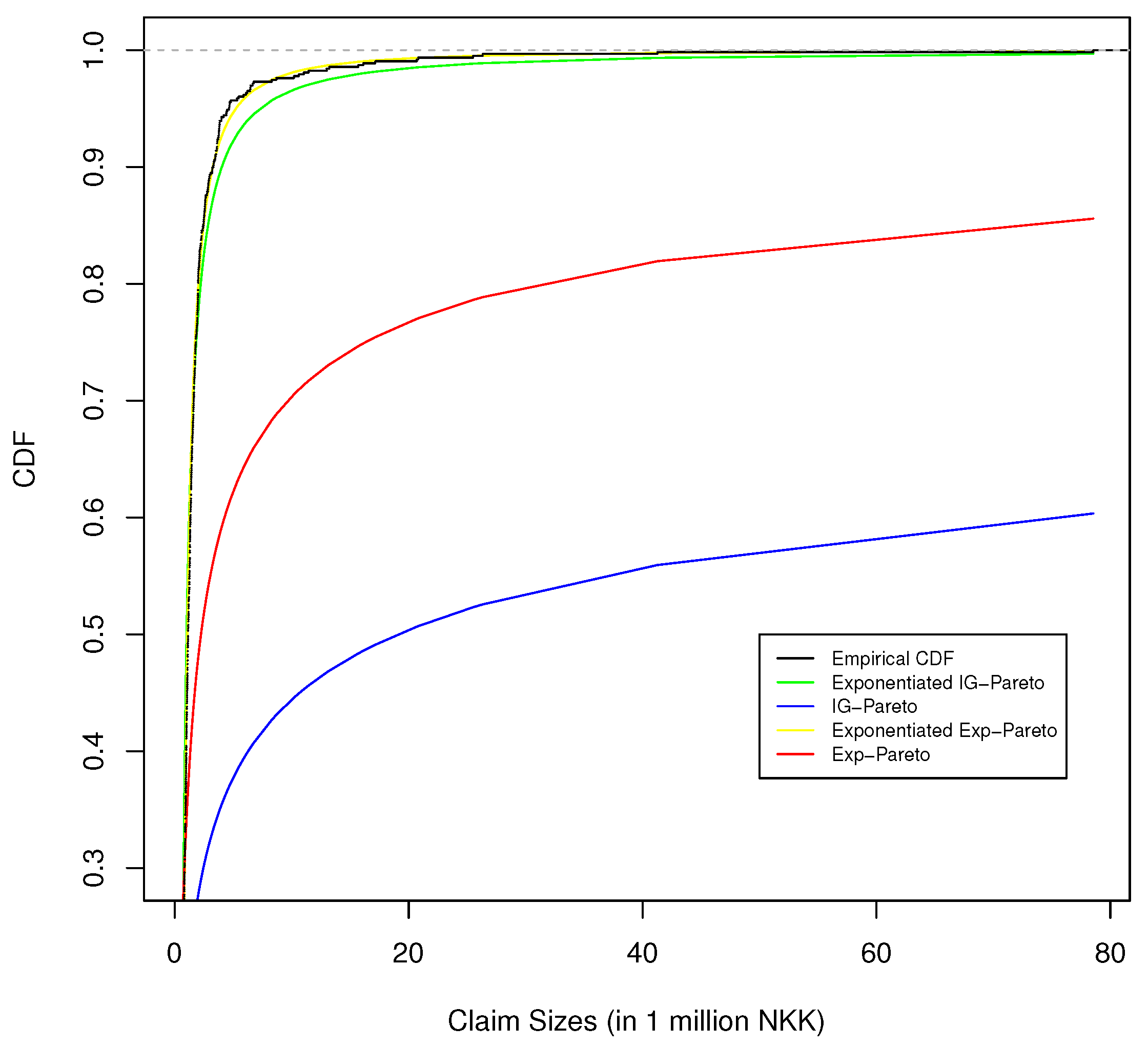
Figure 8.
The empirical CDF of Norwegian fire insurance data and the fitted CDF of corresponding exponentiated IG-Pareto, IG-Pareto, exponentiated exp-Pareto, and exp-Pareto model fit.
Figure 8.
The empirical CDF of Norwegian fire insurance data and the fitted CDF of corresponding exponentiated IG-Pareto, IG-Pareto, exponentiated exp-Pareto, and exp-Pareto model fit.
Figure 9.
Histogram of SOA group medical insurance claims data, for 1991.
Figure 9.
Histogram of SOA group medical insurance claims data, for 1991.
Figure 10.
Kernel density estimate of SOA group medical claims data, with corresponding exponentiated exp-Pareto, exp-Pareto, exponentiated IG-Pareto, and IG-Pareto fit.
Figure 10.
Kernel density estimate of SOA group medical claims data, with corresponding exponentiated exp-Pareto, exp-Pareto, exponentiated IG-Pareto, and IG-Pareto fit.
Figure 11.
The empirical CDF of SOA group medical claims data and the fitted CDF of corresponding exponentiated IG-Pareto, IG-Pareto, exponentiated exp-Pareto, and exp-Pareto model fit.
Figure 11.
The empirical CDF of SOA group medical claims data and the fitted CDF of corresponding exponentiated IG-Pareto, IG-Pareto, exponentiated exp-Pareto, and exp-Pareto model fit.
Table 1.
Simulation results for the parameter estimation of the exponentiated exp-Pareto distributions.
Table 1.
Simulation results for the parameter estimation of the exponentiated exp-Pareto distributions.
| Scenarios | | | | | |
|---|
| | Par.1 | Mean | SD | SE | Mean | SD | SE | Mean | SD | SE | Mean | SD | SE |
| 0.8 | 1 | | 0.828 | 0.119 | 0.113 | 0.811 | 0.080 | 0.078 | 0.807 | 0.055 | 0.055 | 0.803 | 0.034 | 0.035 |
| | | | 1.046 | 0.354 | 0.328 | 1.017 | 0.235 | 0.225 | 1.000 | 0.153 | 0.156 | 1.005 | 0.098 | 0.099 |
| 5 | 1 | | 5.158 | 0.749 | 0.702 | 5.077 | 0.506 | 0.489 | 5.042 | 0.354 | 0.343 | 5.011 | 0.210 | 0.216 |
| | | | 1.046 | 0.347 | 0.326 | 1.018 | 0.242 | 0.226 | 1.007 | 0.158 | 0.157 | 1.002 | 0.099 | 0.099 |
| 0.8 | 5 | | 0.828 | 0.117 | 0.113 | 0.815 | 0.078 | 0.078 | 0.807 | 0.054 | 0.055 | 0.803 | 0.035 | 0.035 |
| | | | 5.551 | 2.043 | 1.882 | 5.234 | 1.269 | 1.226 | 5.135 | 0.850 | 0.841 | 5.058 | 0.532 | 0.521 |
| 5 | 5 | | 5.140 | 0.714 | 0.700 | 5.072 | 0.505 | 0.488 | 5.047 | 0.351 | 0.343 | 5.023 | 0.208 | 0.216 |
| | | | 5.503 | 1.997 | 1.860 | 5.259 | 1.289 | 1.230 | 5.125 | 0.859 | 0.840 | 5.064 | 0.517 | 0.522 |
| 10 | 5 | | 10.312 | 1.461 | 1.404 | 10.174 | 1.004 | 0.979 | 10.068 | 0.682 | 0.685 | 10.029 | 0.433 | 0.432 |
| | | | 5.527 | 2.006 | 1.873 | 5.231 | 1.287 | 1.225 | 5.113 | 0.844 | 0.838 | 5.049 | 0.532 | 0.520 |
| 10 | 20 | | 10.324 | 1.406 | 1.406 | 10.158 | 0.990 | 0.978 | 10.119 | 0.703 | 0.689 | 10.023 | 0.430 | 0.431 |
| | | | 24.183 | 13.175 | 11.360 | 21.995 | 7.403 | 7.021 | 21.112 | 4.896 | 4.684 | 20.261 | 2.848 | 2.801 |
| 0.4 | 2 | | 0.414 | 0.058 | 0.056 | 0.408 | 0.040 | 0.039 | 0.404 | 0.028 | 0.027 | 0.401 | 0.017 | 0.017 |
| | | | 2.112 | 0.670 | 0.638 | 2.048 | 0.459 | 0.437 | 2.030 | 0.316 | 0.304 | 2.011 | 0.189 | 0.190 |
| 0.4 | 1 | | 0.415 | 0.059 | 0.057 | 0.407 | 0.041 | 0.039 | 0.402 | 0.028 | 0.027 | 0.402 | 0.018 | 0.017 |
| | | | 1.033 | 0.353 | 0.325 | 1.018 | 0.231 | 0.225 | 1.009 | 0.159 | 0.158 | 1.001 | 0.097 | 0.099 |
| 4 | 5 | | 4.141 | 0.578 | 0.564 | 4.060 | 0.400 | 0.391 | 4.029 | 0.267 | 0.274 | 4.012 | 0.173 | 0.173 |
| | | | 5.515 | 2.080 | 1.864 | 5.206 | 1.292 | 1.218 | 5.100 | 0.839 | 0.835 | 5.038 | 0.530 | 0.519 |
| 4 | 1 | | 4.125 | 0.576 | 0.562 | 4.052 | 0.381 | 0.390 | 4.035 | 0.277 | 0.275 | 4.016 | 0.171 | 0.173 |
| | | | 1.042 | 0.339 | 0.326 | 1.021 | 0.233 | 0.226 | 1.012 | 0.159 | 0.158 | 1.000 | 0.098 | 0.099 |
Table 2.
Summary statistics, for Danish fire insurance data (in 1 million DKKs).
Table 2.
Summary statistics, for Danish fire insurance data (in 1 million DKKs).
| Sample Size | Mean | SD | Minimum | Q1 | Q2 | Q3 | Maximum |
|---|
| 2492 | 3.06 | 7.98 | 0.31 | 1.16 | 1.63 | 2.65 | 263.25 |
Table 3.
Comparisons of different models, with the Danish fire insurance data.
Table 3.
Comparisons of different models, with the Danish fire insurance data.
| Model | k1 | NLL | AIC | BIC | KS | | |
|---|
| Empirical Estimate | | | | | | 5.08 | 8.41 |
| IG-Pareto (One-Parameter) | 1 | 6983.8 | 13,969.6 | 13,975.5 | 0.575 | | |
| Exponentiated IG-Pareto | 2 | 4287.7 | 8591.0 | 8590.0 | 0.136 | 13.82 | 32.48 |
| exp-Pareto (One-Parameter) | 1 | 5878.0 | 11,758.0 | 11,763.8 | 0.333 | 325.62 | 2359.69 |
| Exponentiated exp-Pareto | 2 | 3961.0 | 7926.0 | 7937.7 | 0.057 | 4.42 | 6.89 |
| Weibull-Inverse Weibull 2 | 4 | 3820.0 | 7648.0 | 7671.3 | 0.021 | 5.08 | 8.02 |
| Weibull | 2 | 5270.5 | 10,545.0 | 10,556.6 | 0.409 | 4.57 | 5.98 |
| IG | 2 | 4097.9 | 8199.8 | 8211.4 | 0.358 | 4.67 | 6.41 |
Table 4.
Summary statistics for Norwegian fire insurance claims, during 1990 (in 1 million NOKs).
Table 4.
Summary statistics for Norwegian fire insurance claims, during 1990 (in 1 million NOKs).
| Sample Size | Mean | SD | Minimum | Q1 | Q2 | Q3 | Maximum |
|---|
| 628 | 1.97 | 4.26 | 0.50 | 0.79 | 1.15 | 1.81 | 78.54 |
Table 5.
Comparisons of different models with the Norwegian fire insurance data, for 1990.
Table 5.
Comparisons of different models with the Norwegian fire insurance data, for 1990.
| Model | k1 | NLL | AIC | BIC | KS | | |
|---|
| Empirical Estimate | | | | | | 3.25 | 4.59 |
| IG-Pareto (One-Parameter) | 1 | 1503.7 | 3009.4 | 2013.9 | 0.591 | | |
| Exponentiated IG-Pareto | 2 | 755.6 | 1515.1 | 1524.0 | 0.097 | 4.02 | 7.28 |
| exp-Pareto (One-Parameter) | 1 | 1225.6 | 2453.3 | 2457.7 | 0.355 | 223.64 | 1620.64 |
| Exponentiated exp-Pareto | 2 | 772.2 | 1548.4 | 1557.3 | 0.053 | 3.26 | 5.23 |
| Weibull-Inverse Weibull 2 | 4 | 751.0 | 1509.9 | 1527.7 | 0.038 | 3.02 | 4.36 |
| Weibull | 2 | 1054.4 | 2112.8 | 2121.7 | 0.232 | 4.57 | 5.98 |
| IG | 2 | 773.9 | 1551.7 | 1560.6 | 0.049 | 3.09 | 4.24 |
Table 6.
Summary statistics for SOA group medical insurance claims, for 1991 (in 10,000 USD).
Table 6.
Summary statistics for SOA group medical insurance claims, for 1991 (in 10,000 USD).
| Sample Size | Mean | SD | Minimum | Q1 | Q2 | Q3 | Maximum |
|---|
| 75,789 | 5.84 | 6.60 | 2.50 | 3.05 | 4.02 | 6.13 | 451.84 |
Table 7.
Comparisons of different models, with the SOA group medical claims insurance data, for 1991.
Table 7.
Comparisons of different models, with the SOA group medical claims insurance data, for 1991.
| Model | k1 | NLL | AIC | BIC | KS | | |
|---|
| Empirical Estimate | | | | | | 10.18 | 14.76 |
| IG-Pareto (One-Parameter) | 1 | 277,440.9 | 347,243.2 | 347,261.7 | 0.602 | | |
| Exponentiated IG-Pareto | 2 | 160,836.6 | 321,677.2 | 321,695.7 | 0.035 | 9.77 | 14.54 |
| exp-Pareto (One-Parameter) | 1 | 242,318.1 | 484,638.2 | 484,647.4 | 0.369 | 835.46 | 6054.35 |
| Exponentiated exp-Pareto | 2 | 168,683.5 | 337,371.0 | 337,389.5 | 0.085 | 8.69 | 12.29 |
| Weibull-Inverse Weibull 2 | 4 | 167,745.8 | 335,499.6 | 335,536.5 | 0.070 | 8.67 | 11.40 |
| Weibull | 2 | 204,223.9 | 408,451.8 | 408,470.3 | 0.256 | 12.24 | 15.01 |
| IG | 2 | 173,619.6 | 554,883.8 | 554,893.0 | 0.099 | 9.29 | 11.78 |
Table 8.
The parameter estimates and estimated standard error of the exponentiated-composite models, when fitted to the three datasets.
Table 8.
The parameter estimates and estimated standard error of the exponentiated-composite models, when fitted to the three datasets.
| Dataset | Estimated Parameters | Exponentiated IG-Pareto (se) | Exponentiated Exp-Pareto (se) |
|---|
| Danish Fire Insurance Data | | 2.81 (0.15) | 5.22 (0.24) |
| | | 4.95 (0.07) | 4.47 (0.09) |
| Norwegian Fire Insurance Data | | 0.13 (0.02) | 0.96 (0.09) |
| | | 7.13 (0.27) | 4.19 (0.16) |
| SOA Group Medical Claims Data | | 216,610 (8131.23) | 1596.72 (38.98) |
| | | 10.64 (0.04) | 5.72 (0.02) |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}