1. Introduction
Blockchain is expected to be applicable in various industries such as energy, health care, and finance [
1,
2,
3,
4,
5,
6,
7]. As expected, various blockchain business models are appearing today, especially cryptocurrency business models which are currently attracting the attention of many. The first form of cryptocurrency started with Bitcoin and was initially not popular due to the malicious use of cryptocurrency [
8], ICO (Initial Coin Offering) fraud [
9,
10], and volatility of values. However, recently, through DeFi (Decentralized Finance), CBDC (Central Bank Digital Currencies), and NFT (Non-Fungible Token), the value of cryptocurrency has been re-evaluated by interested individuals and entities. The interest in cryptocurrency can be observed through cryptocurrency exchanges such as CoinMarketCap [
11]. In addition, various studies related to cryptocurrency are currently in progress [
12,
13,
14,
15,
16,
17].
In order to bring true changes beyond expectations, developers must not only overcome the technical limitations of blockchain; but also need to comprehensively analyze the blockchain wallet. The blockchain wallet is an application that bridges the gap between blockchain networks and the real world. The blockchain wallet helps a user access personal digital assets in blockchain networks. For example, a user can send cryptocurrency to others using a blockchain wallet. Moreover, the blockchain wallet authenticates a blockchain user by checking possession of a private key. The private key of the blockchain is an object that identifies the user without additional authentication from other institutions [
18] and the private key can be generated and recovered through the blockchain wallet.
Mnemonic codes are the most commonly used technique to generate and recover a private key in the blockchain wallet. The mnemonic code technique used in blockchain uses the word list in BIP-0039 [
19]. A private key is generated by combining 12 to 24 words out of 2048 words of the BIP-0039 list as a seed. Despite the widespread use of blockchain key generation and recovery using the mnemonic code technique, the technique is inefficient in private key generation and recovery. For example, when a user tries to generate a private key, they are faced with the inconvenience of finding a word list that can be used as a mnemonic code or the user needs to employ a mnemonic code generator on the Internet. Furthermore, if a user tries to recover a private key but cannot recall or locate the mnemonic code, recovery becomes impossible. A 2017 survey found that four-million Bitcoins were inaccessible due to the user’s loss of a private key [
20]. In addition, a company went bankrupt after it failed to recover its lost private key [
21]. With these mentioned examples, accidents involving mnemonic code recovery failure continue to occur, suggesting that the mnemonic code technique does not consider usability in private key generation and recovery for users. Therefore, we propose a novel approach considering usability and security to improve the current private key generation and recovery process.
Various studies [
22,
23,
24,
25] to utilize a blockchain wallet are being conducted, as well as academic studies [
26,
27,
28,
29,
30,
31,
32] to improve the current private key generation and recovery process. The most common studies [
26,
27,
28,
29] allowed other users or external repositories to participate in the process of generating and recovering a private key. These studies suggested storing core information for recovering a private key to external users or external repositories. These studies ensured private key recovery by storing core information to other users and external repositories during a private key generation process. However, there is a limitation that if external users or repositories with core information are attacked, there is a high risk that a private key is recovered by another user. In other studies [
30,
31], authors suggested using unique biometric information such as fingerprints to generate and recover private keys. In these studies, the safety and usability of generating and recovering a private key were ensured by using biometric information possessed only by the user. However, there is the limitation of requiring special devices to collect biometric information. Another study [
32] suggested that a user includes information for recovering a private key when generating the private key. In this study, the safety and usability of private key generation and recovery were ensured by utilizing information generated by a user. However, the results were limited in effectiveness as it did not improve significantly from the mnemonic code technique.
In this paper, we propose a novel method to generate and recover a private key via a user’s recall of natural memories. Unlike the mnemonic code technique, which assigns words for the user to memorize for private key generation and recovery, our approach is novel in that it utilizes a user’s long-term memories to generate and recover a private key. In our approach, a user provides a specific number of pictures that can evoke natural memories. After that, the user inputs the location of each provided picture, and a user’s private key is generated based on the location provided by the user. When a user needs to recover the private key, they recall the location of the pictures they selected during the initial private key generation process. In addition, experiments are conducted on the basis of our approach and they show that our approach is sufficiently secure compared to the mnemonic code technique and takes into account usability. The contributions of this paper are as follows:
We propose a new approach that is based on a user’s long-term memory using distinctive pictures for generating and recovering a private key.
We conduct various experiments with at least 20 to 105 participants to assess the usability and security of the proposed approach.
We develop a real-world mobile wallet application to identify the development possibilities and feasibility of the proposed approach.
The remainder of this paper is organized as follows.
Section 2 presents background knowledge of blockchain and related work for private key generation and recovery.
Section 3 explains our approach and
Section 4 presents the experiments conducted to demonstrate the efficacy of our approach.
Section 5 concludes the paper and discusses future work.
3. Approach
We propose to generate and recover a private key using the distinctive picture-based personal memory for the blockchain wallet. Our Reminisce technique does not store core information that allows a private key to be directly recovered. The Reminisce technique also does not require special devices to generate and recover a private key and does not force the user to remember specific things. Our approach, Reminisce, is based on a phenomenon from neuronal science and cognitive psychology: (1) Long-term memory is held in a particular section of the brain, (2) special and emotional memory becomes long-term memory by hormone secretion, and (3) the picture superiority effect.
The case study of HM (Henry Molaison) [
40] is a famous case study for discovery of long-term memory being held in a particular section of the brain. Henry Molaison’s memory of the 11-year period before his surgery disappeared due to the surgeons removing the hippocampus. Based on this case, neuronal scientists discovered that short-term and long-term memories are classified in the human brain. Furthermore, a neuronal science study [
41] identified sections of the brain associated with long-term memory and short-term memory. Moreover, other neuronal science research works [
42,
43] assert that stimulating memory such as special or emotional memory is considered long-term memory via hormone secretion. In other words, although general long-term memory is created by repeating short-term memory learning, special or emotional memory is stored directly in a specific part of the human brain by hormones as long-term memory. In addition, according to Paivio and Caspo’s research [
44] on cognitive psychology, a person can recall picture-based memories easier than simple letters or words such as an alphabet, and this phenomenon is called the picture superiority effect. Based on this research, other cognitive psychology studies [
45,
46,
47] related to the picture superiority effect have been conducted.
The Reminisce uses pictures from the user to generate and recover a private key since the user’s distinctive pictures contain the special or emotional memory unique to that individual. Thus, the user can recall the information from pictures stored in their long-term memory. In addition, in the proposed approach, the pictures are specific objects that can be easily recalled by the user. When taking a picture with a cell phone, various metadata such as date, size, and location are stored in the picture. Among various metadata of a picture, the Reminisce technique uses location coordinates to generate and recover the private key.
3.1. Module Design
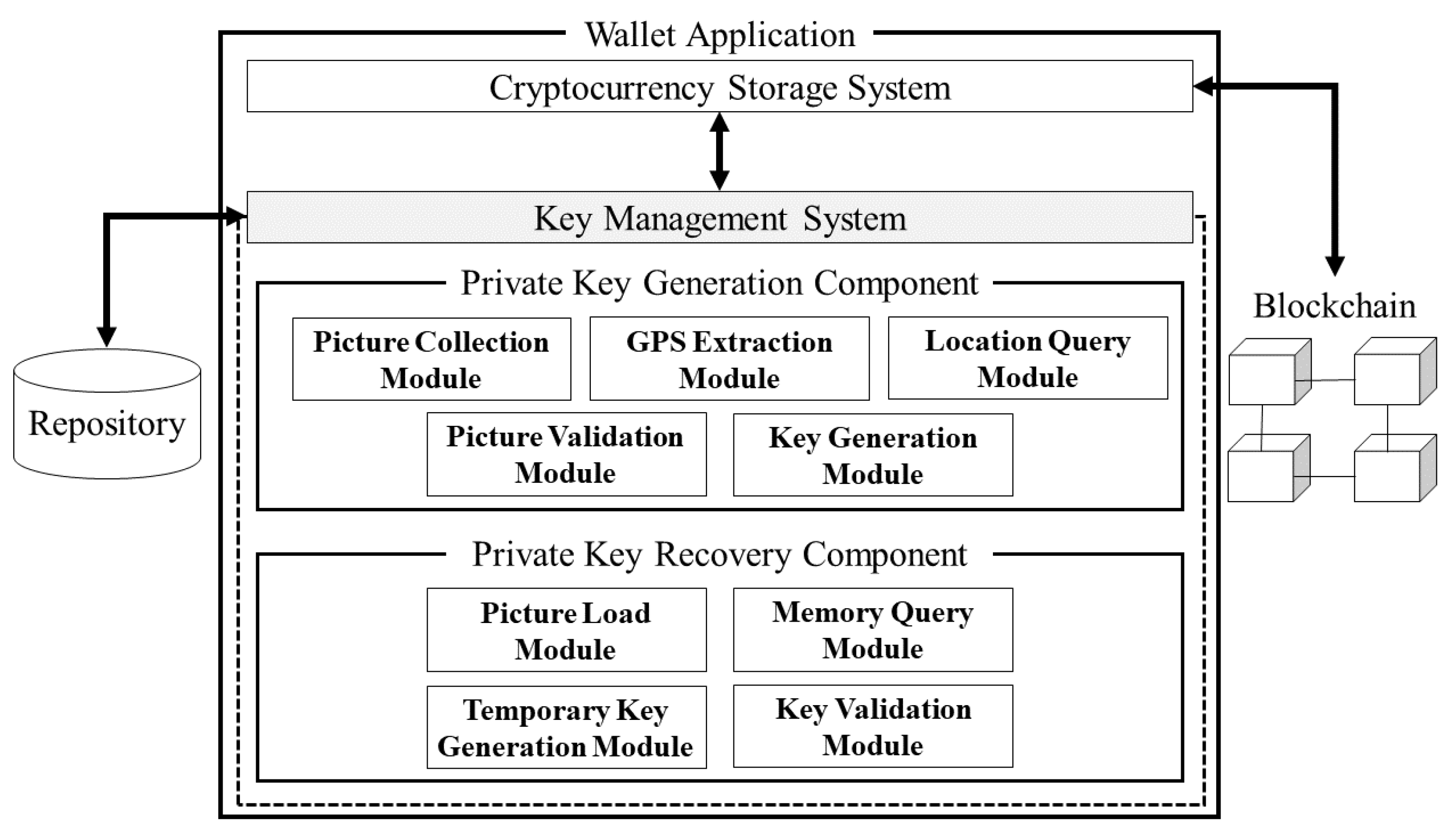
Before explaining the Reminisce technique process, it is worth mentioning the module design to explain how the Reminisce technique executes within a wallet application. The Reminisce technique is a part of a blockchain wallet application and it can be described in
Figure 1. The general blockchain wallet application can be largely divided into two main systems: cryptocurrency storage system and key management system. Each system is a basic system that should be included to perform a blockchain wallet application.
The cryptocurrency storage system is responsible for storing cryptocurrency in the wallet by connecting with blockchain platforms. The key management system helps a user generate and recover a private key. The Reminisce technique is applied as a part of the key management system. Furthermore, as shown in
Figure 1, the key management system of which the Reminisce technique consists of include: (a) private key generation component, and (b) private key recovery component. The key generation component consists of the following modules: (a) picture collection, (b) GPS extraction, (c) location query, (d) picture validation and (e) key generation. Similarly, the key recovery component consists of the following modules: (a) picture load, (b) memory query, (c) temporary key generation, and (d) key validation. The role of each module is briefly described below.
The picture collection module is responsible for collecting pictures from the user. The module checks that the user’s pictures contain location metadata and then interacts with the GPS extraction module. The GPS extraction module obtains GPS data from the metadata of the pictures and refines the GPS values. The location query module has a similar role to the GPS extraction module. The location query module obtains GPS data from the user’s answers and also refines the GPS values. The GPS extraction module and the location query module interact with the picture validation module. The picture validation module compares GPS data from the GPS extraction module and the location query module. The picture validation module checks whether the difference between the GPS extraction module and the location query module is below a predefined value. Moreover, the picture validation module deletes metadata of pictures. The key generation module generates a private key through GPS data that is from the picture validation module. After this, the key generation module sends a private key and a public key to the user. Furthermore, the module stores the metadata-deleted pictures and public key in a repository.
During the key recovery process, the four modules are executed. The picture load module brings an original public key and metadata-deleted pictures from the repository that matches the user who requested the private key recovery. The memory query module shows each of the pictures to a user and asks where the pictures are located. Based on the user’s answer, the temporary key generation module generates a temporary private key and a temporary public key. After this, the key validation module compares the temporary public key and the original public key. If the temporary public key and the original public key are the same, the key validation module determines that the private key recovery is successful.
3.2. Process Overview
This section explains the private key generation and recovery process. Furthermore, the Reminisce technique process can be described in
Figure 2. As shown in
Figure 2, the Reminisce technique is composed of two processes: private key generation process (Left part of
Figure 2), and private key recovery process (Right part of
Figure 2).
In the private key generation process, a user selects a picture whose location they can remember. Furthermore, the user provides the location of the provided picture. In step A-1, the provided picture is checked to see whether it contains metadata. If the picture contains metadata, the GPS data () of the picture are extracted in step A-2. The user’s answer of the location () is applied to a specific map application in step B-1. Based on , GPS data () are obtained from a map application in step B-2. After this, and are represented up to decimal places in step C.
In step D, and are compared to verify the location. If differences of and are greater than a specific value, the user has to select another picture. If the difference is less than or equal to the value of , the process is repeated until N pictures () are collected. When is collected, a seed is generated by multiple , and based on the seed, a private key is created in step E-1. Finally, the original private key (), and original public key () are generated and provided to the user. Moreover, the metadata for all pictures is deleted, and the metadata deleted pictures and are stored in a repository.
In the private key recovery process, based on , a temporary private key () is generated through steps A to C and this process is the same as steps B-1 to C of the private key generation process. After this, a temporary public key () is generated by and is compared with . If and are identical, the key recovery process is successful, and that is the same as is provided to the user. The next sections describe the Reminisce process with the module design in more detail.
3.3. Private Key Generation Process
This section explains the private key generation process. The private key generation process works through a picture collection module, GPS extraction module, location query module, picture validation module, and key generation module. The private key generation process is represented in
Figure 3.
The picture collection module collects a user’s picture. If GPS is recorded in the metadata of the received picture (Step A-1), the module sends the picture to the GPS extraction module. If GPS is not recorded in the metadata of the received picture, the process is terminated or the module asks the user to select another picture.
After the picture collection module sends the user’s picture, the GPS extraction module extracts GPS data from the picture. The GPS extraction module obtains GPS data () expressed in latitude () and longitude () directly from the picture’s location metadata (Step A-2). Unlike the GPS extraction module, the location query module should work in conjunction with a user and a specific map application for obtaining GPS data. The module asks the user about the location of the picture and obtains the user’s answer (). After this, the module applies to a specific map application (Step B-1) to obtain GPS data that is (Step B-2).
After obtaining GPS data in both modules which are the GPS extraction module and the location query module, they separate the and values of and . Next, each separated and value is expressed to decimal places (Step A-3, B-3). The reason to express GPS data of and to decimal places is to facilitate the comparison of each GPS data.
In the case of , the location of the GPS recorded when taking a picture may record a place that is different from the user’s memory due to various factors such as device performance, GPS transmission location, or shadow fading. Furthermore, the value obtained by is extremely difficult to maintain the same level of accuracy as the recorded in the picture. For example, Google Maps which is a popular map application expresses GPS numbers up to six decimal places. However, it is difficult for users to respond to the exact location up to six decimal places. Thus, both modules express and of and to decimal places and send them to the picture validation module.
The picture validation module compares differences in GPS data between and (Step C). The reason and are compared is to ensure that the user actually remembers the location of the picture based on . The value is an allowable difference between and . If the value is too large, the module determines that the user remembers the location of the picture even if another location is entered, and if the value is too small, the user may have difficulty answering exactly where points to. If the difference between and is equal to or less than , the picture validation module determines that the user remembers the exact location and the module completes the process.
After a predefined amount of gathering is completed, the picture validation module checks the timestamp of each picture to check if pictures were taken on the same day. If provided pictures were taken on the same day, the module determines that the locations of the pictures have been duplicated and subsequently terminates the process. If the timestamp of the pictures indicate a different date, the module deletes metadata of all provided pictures.
Following this, the picture validation module generates a seed and sends the seed with the pictures to the key generation module. The key generation module generates a private key (Step D) using the seed created by multiple from the picture validation module. The module generates a private key (), and public key (), respectively. The pictures that have deleted metadata and are stored in a repository. When the whole process is complete, the module sends , and to the user.
3.4. Private Key Recovery Process
This section explains the private key recovery process. The private key recovery process works through picture load module, memory query module, temporary key generation module, and key validation module. The private key recovery process represents in
Figure 4. The private key recovery process starts with bringing pictures and
from a repository by the picture load module. In this paper, we do not consider repository techniques such as the form of storing pictures and
, security of repository, or authentication technique.
When a user requests the private key recovery in a wallet application, the wallet application sends the user’s basic information to the picture load module. Based on the user’s information, the picture load module brings pictures and that are related to the user from the repository. After this, the picture load module sends pictures to the memory query module. Similar to the location query module in the private key generation process, the memory query module works in conjunction with the user and the specific map application (Step A). The memory query module asks the user about the location of the picture. The module collects GPS data until and the module expresses GPS data to decimal places (Step B). Based on GPS data, the memory query module creates a temporary seed and sends the temporary seed to the temporary key generation module.
The temporary key generation module generates , by the temporary seed (Step C). After the generation is complete, the temporary key generation module sends , , and to the key validation module.
After the key validation module is received , from the temporary key generation module, the key validation module brings from the picture load module. Next, the key validation module verifies has been completed in the same way as (Step D). If the user responds to each picture correctly in the memory query module, the seed used in the temporary key generation and the key generation module have the same value. Eventually, and will be the same, and and generated through and will be the same. If and are the same, the module determines that the private key recovery process is completed and provides the value of to the user (Step E-1). If and are different, the key validation module terminates the process (Step E-2) because the user responded incorrectly in the memory query module.
4. Experiment
In this section, we describe the different experiments conducted to solve several research questions related to our approach.
4.1. Preliminary Study
In this section, we conduct experiments to obtain the three variables mentioned in the approach before answering the research questions (RQ1, RQ2). There are three variables defined in our approach: (1) decimal places in GPS data (α), (2) allowable difference value (δ), and (3) number of pictures for generating a private key (). Deciding upon the three variables should be undertaken carefully because these variables directly affect security and usability. If high security is applied to our approach through the variables, usability is decreased. On the contrary, increased usability reduces security. We experimented to determine applicable values for each of these variables. The experiments conducted are described in subsections.
4.1.1. Decimal Places in the GPS Data ()
As discussed in
Section 3.3, the reason to express GPS data of
and
to
decimal places is to facilitate comparison because decimal places in the GPS data can be changed easily by external factors, and the user. Decimal places in GPS data influence the number of elements in the GPS set (
). The
is a collection of GPS data that can express from a combination of
and
. In other words, the
is the number of cases that a user can have by
. If the
contains a large number of GPS data, the security can be increased because of the lower risk of private key overlapping. Furthermore, a large number of GPS data can decrease the hacking probability of a brute-force attack. On the contrary, a small number of GPS data increases the risk of private key duplication and a brute-force attack.
Table 2 shows the number of GPS data in
depending on
. The first column indicates decimal places in the GPS data. The GPS data can be expressed up to eight decimal places (
= 8). However, because Google Maps, the most commonly used GPS application, expresses GPS values up to six decimal places (
= 6), the first column represents only
= 0 to
= 6. The second column indicates the number of GPS data that can occur from a combination of
and
. Since 70% of the Earth’s surface is water, 30% of the places where users can take pictures are presented as the
Number of GPS data on land in the last column.
As shown in
Table 2, increasing the decimal places of GPS data increases the number of elements in
. For security concerns, choosing
= 6 may seem the right choice because a large
value can prevent overlapping a private key and the potential of a brute-force attack. However, the proposed approach requires consideration of how many decimal places users can perceive through
. For example, when
= 6, if a user cannot recognize the difference of place between 0.000001 and 0.000002 on GPS data,
= 6 is exceptionally difficult to apply even if it is more secure.
The decimal places of GPS data are used to accurately represent a location, and a numerical change of a specific digit means a change in the place of distance. In addition, the changes in distance value are different depending on and . The 1 is always expressed at 111 km (40,075,161.2 m/360) because the circumference of the Earth is 40,075,161.2 m (2 × 6,378,106 m) and the consists of a total of 360.
The
of 1
is characterized by varying distance depending on the
because the Earth is not perfectly spherical. The
can be obtained by a formula of 2
× 6,378,106 ×
and it can be arranged as shown in
Table 3. According to
Table 3, when
0
, change of
by 1
means a change of 111 km. Furthermore, when
10
, a change in
by 1
indicates a change of 109 km. In this paper, to simplify the calculation, it is assumed that
and
have the same distance change (second row in
Table 3).
If the GPS data are expressed with six decimal places ( = 6), a unit change in GPS data at the 6th decimal place represents a change in distance of 11.1cm. Similarly, a unit change in other decimal places are as follows: = 5 means a change in distance of 1.11 m, = 4 is 11.1 m, = 3 is 111 m, = 2 is 1.11 km = 1 is 11.1 km.
If decimal places of GPS data are expressed as values between = 4 and = 6, it means that the user should recognize in distance smaller than a tennis court (length: 23.77 m, width: 10.97 m). For example, when = 4 is applied to the proposed approach, a user should separate positions at the opposing ends of a tennis court for answering the location of a picture. Case of = 3 also means that a user should be aware of the change in location within a range less than an American football field (length: 109.7 m, width: 48.4 m) or soccer field (length: 150 m, width: 68 m).
As a result, choosing a value for = 3∼6 may increase the security of the approach due to the number of GPS data in being large, but it may pose difficulties to the user in terms of usability. In other words, the value of should be defined as less than three ( < 3) for a user to answer location information. Since the highest number of GPS data among the three values ( = 0∼2), the case of = 2 can be considered as an applicable value for the proposed approach.
4.1.2. Allowable Difference in GPS Data ()
The previous section established that expressing GPS data in second decimal places ( = 2) is the best option for a user to indicate the location of a picture. However, even if the GPS data is expressed in second decimal places, the user’s response may differ from the actual GPS value recorded in the picture. For example, when a user identifies the location of a picture taken in front of Niagara Falls, a user can give a detailed answer such as a street address but another user can give an ambiguous answer such as Buffalo. Through an experiment, we tried to find out how users tend to answer the location question for a picture and how great is the difference from the actual value.
An experiment was conducted with a total of 51 participants. Each participant provided 10 pictures of their own and answered the locations of each picture. Based on the participant’s answer (
),
was obtained through Google Maps. If
was not immediately specified on Google Maps because
was ambiguous, participants selected a location by themselves. Afterwards, the
and
were compared to measure differences Because of the large amount of raw data, the raw data of this experiment are shared on Github (
https://github.com/jungwonrs/experiment_rawdata/blob/main/mppm_raw_data.md), accessed on 2 May 2022. The results are as below:
The smallest difference value of is 0.00002 and is 0.000004.
The largest difference value of is 0.291382 and is 0.182889.
The average difference value of is 0.009597341 and the standard deviation is 0.027383761.
The average difference value of is 0.009685855 and the standard deviation is 0.023168967.
As a result of this experiment, most participants preferred to refer to the town rather than the street address. The difference between and was about 0.01. Based on this experiment, we can conclude that the location identified by the participants and the actual location are the same when the difference in GPS data is less than 0.01, and hence, a value of 0.01 can be set as the threshold for allowable difference ( = 0.01).
4.1.3. Number of Pictures for Generating a Private Key ()
Pictures are the most important element of our approach and should be provided by a user. Because pictures can expose a user’s privacy, the user may not want to provide pictures even if pictures help to generate and recover the user’s private key. Thus, we wanted to know whether a user is willing to provide their pictures for generating and recovering a private key. We used a Google Survey form where we provided a brief description of our approach and asked the participants how many pictures they would be willing to provide. A total of 105 participants answered the survey and the results of the survey are shown in
Figure 5 and below:
11 participants responded that they were not willing to provide a single picture because of privacy concerns (Orange).
44 participants responded that they were willing to provide 10 pictures (Yellow).
9 participants responded that they were willing to provide more than 10 pictures (Green).
2 participants did not respond properly and they are expressed as N.P (Purple)
Figure 5.
Survey results for .
Figure 5.
Survey results for .
As shown in
Figure 5, participants who were willing to provide 10 pictures comprise 41.9% of the total responses. Based on the survey, we concluded that requiring a minimum of 10 pictures would not be excessively burdensome for a user who wants to use key generation and recovery and, hence
value can be set as more than 10 (
≥ 10) for our approach. Moreover, using a minimum of 10 pictures means that our approach has at least as many cases as
to generate a private key when
.
4.2. Security of the Proposed Approach
This section describes the experiment we conducted to answer the first research question, (RQ1) How secure is the proposed approach when variables indicate in the preliminary study are applied? The security of the proposed approach should be considered with respect to two aspects: (1) Risk of overlapping a private key, and (2) risk of private key recovery by others. Security was evaluated by applying = 2, = 0.01, and ≥ 10 in the experiments conducted for the two aforementioned scenarios.
4.2.1. Risk of Overlapping Private Key
The risk of overlapping a private key refers to the overlap of seeds used to generate a private key between users. In this section, the risk of the overlapping private key is considered in view of two aspects: (A) Entropy, and (B) Probability.
A. Entropy
We conducted several experiments to calculate disorder through entropy and compared it with the mnemonic code to identify the risk of private key duplication. Entropy can generally express how disordered a particular set is. Entropy is also used by applying it to password generation, and password entropy is the measure of the quality of a password [
48]. Furthermore, high entropy indicates difficulty in inferring and overlapping passwords due to the high disorder.
A private key is generated by a seed and the private key is used for identifying a blockchain user. Thus, a private key can be considered the same as a password. This section uses password entropy to compare the entropy between the mnemonic code technique and the proposed approach. The entropy is calculated using Equation (1), from [
49,
50].
where
S refers to the size of a set in which a seed can be generated.
L indicates the number of elements used from the set.
Table 4 shows Equation 1 applied to the mnemonic code and the proposed approach.
Mnemonic code requires a user to select from 12 words to 24 words from BIP-0039 for generating a private key, and the BIP-0039 consists of 2048 words [
19]. Because the mnemonic code does not allow duplication to select words,
S can be calculated with the
formula.
N is a pool of word size which is 2048 words, and
K is the number of selected words which is the same as
L. For example, if a user wants to create a private key using the mnemonic code of 12 words,
, and
L = 12.
For Reminisce,
S can be calculated with
because our approach does not consider the duplication of GPS data, and
N can be obtained depending on
from
Table 2. So, if a user wants to create a private key using the proposed approach of 10 pictures,
and
L = 10.
As shown in
Table 4, when a user uses 10 pictures to create a private key in our approach, the entropy is higher than using the mnemonic code of 18 words. In addition, the maximum entropy of the mnemonic code is 4434.412 bits by using 24 words and it is smaller than the proposed approach by using 13 pictures. Furthermore, although the mnemonic code has a maximum limit of 24 words, the entropy of the proposed approach may continue to increase depending on the user’s choice because our approach has no maximum limit. As a result, the proposed approach is more disordered than mnemonic codes and which means that overlapping a private key is more difficult and unlikelt to occur than using a mnemonic code.
B. Probability
In this section, we experimented to find out the probability of private key overlapping. A seed is created by
based on
and the number of seeds available for private key generation in a single picture is shown in
Table 2.
The number of seeds available for private key generation is affected by the value of
and
. The value of
was fixed as 2 (
= 2) as discussed in
Section 4.1.1 which lets the user specify as many as 648,054,001 GPS data as a seed in a single picture but the actual number of GPS data available for a seed is 194,416,200 (Number of GPS data on land).
A user needs to use a minimum of 10 pictures ( ≥ 10) for generating a private key in our approach. If the user uses 10 pictures, the number of GPS data available for a seed is 194,146,200 ≈ 7.71 × 10, and probability of overlapping a single seed is 1.296 × 10 which is smaller than 8.636 × 10 ≈ (known as SHA-256 hash algorithm collision probability). Furthermore, 1.296 × 10 is smaller than 2.398 × 10 ≈ the probability of overlapping a private key when generating a private key with 24 words as seeds in the mnemonic code. As a result, a seed that is used to generate a private key in the situation = 2, ≥ 10 has a small risk of overlap.
4.2.2. Risk of Overlapping Private Key
To steal a user’s private key, a hacker must attack the repository where pictures are safely stored for accessing a specific user’s pictures and public key. Even if the repository hacking is successful, the hacker can only obtain the number of pictures that have been used to generate a private key. In this section, two attack scenarios are described, assuming that the hacker obtained 10 pictures of users.
A. Brute-Force Attack
A brute-force attack is an attack where hackers substitute all possible values to identify a particular value. In the proposed approach, a hacker can try the brute-force attack by combining all GPS data to create a seed. In this section, we describe an experiment that was conducted to see whether the theft of a private key was practically possible.
We experimented to find out how much time would be required to generate a private key. The hardware specifications of the computer used had an Intel i7-8700 CPU with 64GB RAM and Windows 10 OS installed. We continued generating GPS data for 10 locations as a seed and based on the seed, private and public keys were generated. The experiment measured how many private and public keys could be generated over an hour, and the same process was repeated 300 times.
As a result of the experiment, the number of private keys generated in an hour, on average was 42,934,122 and the public keys, 28,662,193. Based on this result, if the hacker somehow knows = 2, the hacker must spend 2.68995 × 10 hours (≈) to complete public key generation through 10 random GPS combinations. The time of 2.68995 × 10 hours is much larger than 4.03223 × 10 hours (≈ ((4.603 × 10 years) × 8760)), which equates to the age of the Sun. In conclusion, the brute-force attack may not be possible because it may take longer than the age of the Sun.
B. Random guessing attack
In the proposed approach, the random guessing attack can be executed by guessing GPS data where a hacker guesses a location by analyzing pictures stored in a repository. In order for the attack to succeed, a hacker needs to find a target that contains pictures with landmarks or topographic features.
Furthermore, assuming the hacker finds the target, the target has to contain less than three pictures, the locations of which are unknown to the hacker. For example, when = 10, the hacker knows the location of seven pictures, and the hacker then tries to find the location of the remaining pictures. Because the hacker cannot guess the three pictures, the hacker should use a brute-force attack on the three pictures to obtain the GPS data. In this case, it takes 2.56 × 10 h (≈) to make a seed by combining the GPS data of the three pictures with the seven pictures again. The time of 2.56 × 10 h is less than 2.68995 × 10 h but is still larger than 4.03223 × 10 h, which is the age of the Sun.
Furthermore, in order to find out how many pictures users provide containing landmarks or topographic features, we analyzed 510 pictures that were previously provided by 51 participants and used in
Section 4.1.2. We identified what was captured in the picture and classified it into six categories: animals, landscapes, food, people, undefined, and landmarks.
Figure 6 shows examples of pictures classified in each category. Each picture shown in
Figure 6 is numbered in the upper left corner. The pictures in
Figure 6 represent animals, landscapes, food, and people in numerical order, respectively. The undefined category included pictures such as accessories, posters, and cell phones, while the landmark category included pictures that could infer places by signboards or famous places such as Torre Di Pisa.
Table 5 shows the results of classifying 510 pictures and indicates the category and the number of pictures in each category.
As a result of classification, only 11.4% of the pictures can infer specific locations. Additionally, we classified pictures to see how many landmark pictures a person provides in a set that contains 10 pictures given by one person, and the results are in
Table 6.
As shown in
Table 6, the maximum number of landmark pictures in one set is four, and sets including four landmark pictures is two. Furthermore, most sets are classified as containing only one landmark picture. As a result of classifying 510 pictures, we observed that when people provide pictures, they do not consciously provide pictures that are inherently easy to remember such as places with landmarks, but instead provide pictures randomly based on their own choices.
In addition, for a successful random guessing attack to occur, a hacker not only needs the ability to attack the repository, but the hacker is likely to succeed only when there are fewer than two pictures that cannot be inferred from targets. In the proposed approach, the picture validation module prevents the use of multiple pictures taken on the same day. Thus, it is safe from the random guessing attack unless the user intentionally provides pictures of the landmark taken at the same place on different days.
4.3. Usability of the Real-World Application
In this section, we describe the experiment with real-world application of our proposed approach in order to answer the second research question,
(RQ2) What is the usability of the real-world application of our approach by users? We used the variables obtained from
Section 4.1 for this usability experiment. We asked the participants who provided 10 pictures in response to the survey to participate in this experiment and a total of 20 participants agreed to join the experiment.
Figure 7 shows the user interface (UI) of the application. The shaded boxes do not appear in the real application and they are inserted in this paper only to hide the information of pictures. The left screen shows the UI of the user choosing 10 pictures, and allows the user to select only pictures that contain GPS data for the picture selection. The right UI is the process of validating the picture one by one that has been selected from the left UI. The right UI is the same used in the process of generating and recovering a private key. On the right screen, the user can enter a location for a picture and press the enter button to search on the map application. If a searched location is correct, the user can press the verification button, and if a searched location is different from a location they thought, they can move the map to select the desired location. A picture verification is complete if the difference between
and
is equal to or less than 0.01 (
= 0.01).
We worked with 20 participants one by one and showed them how to use the application and generate a private key using their own pictures Each participant joined the experiment by downloading the wallet application called COLET from Apple App Store (
https://apps.apple.com/kr/app/colet/id1503144673, accessed on 2 May 2022) or Google Play Store (
https://play.google.com/store/apps/details?id=com.colet accessed on 2 May 2022). All participants demonstrated no difficulties in generating a private key and a month later, the private key recovery experiment was conducted.
All participants were able to recover their own private keys without difficulty after a month. Of the 20 participants, 18 succeeded in recovering their private keys in their first attempt, 1 (
P) required two attempts, and the other (
K) was successful in recovering after four attempts. The results of this experiment are shown in
Table 7.
The Index column represents the participants and the attempt column represents the number of attempts. The last column shows the time taken to recover a private key when participants succeeded in the private key recovery. As shown in
Table 7, participants successfully performed private key recovery after a month but private key recovery time varied from person to person.
The fastest recovery recorded was 1.10 min, while the slowest was 8.29 min. The average amount of time spent recovering a private key is 2.56 min. According to this experiment, depending on which pictures were used to generate the private key, the time to recall the locations of pictures differed for each participant. Participants who were quick to recover their private keys had used pictures of their favorite or frequently visited places in the private key generation process. Those who were slower to recover their private keys consumed time recalling overseas locations which were less familiar locations.
4.4. Threats to Validity
(
Threat to construct validity) The results of entropy calculations in
Section 4.2.1 may be affected by using different formulas. Since the private key is used to identify a user such as the password technique, the formula for measuring password entropy was used in the entropy measurement of the private key seed. However, the password entropy continues to be studied and if the new password entropy formula is applied to
Section 4.2.1, the results of the entropy calculations may be affected. Moreover, if there is a direct way to measure the entropy of a private key seed, the entropy calculation results in
Section 4.2.1 also may be affected.
(Threats to statistical conclusion validity) The results of and may be influenced by the number of participants. We experimented with 51 participants and used 510 pictures to define . Furthermore, is defined by 105 participant surveys. In order to avoid bias from participants, we tried to organize recruitment diverse as possible by age, and nationality. However, if the number of participants is increased, the value of the defined variables could be affected.
(
Threats to external validity) In
Section 4.3, the 20 participants had experience using blockchain wallets and were between the ages of 20 and 40. In other words, the participants in the experiment were already familiar to some extent in using blockchain wallet applications. However, if participants have never used a blockchain wallet application and are unfamiliar with mobile applications, the results in
Section 4.3 may be affected.
5. Conclusions
Cryptocurrency is expected to spark new innovations and be highly valuable for not only individual trade but also in various other industries. The blockchain wallet is an application that bridges the gap between blockchain networks and the real world. The mnemonic code technique is the most widely used method to generate and recover a private key in the blockchain wallet. However, the mnemonic code technique does not consider usability to generate and recover a private key for users. Our approach is based on the idea that a user can hold long-term memory from personal pictures.
When generating a private key, a user provides distinctive pictures to a wallet application. Based on the provided pictures, the user can generate a private key. Furthermore, it is possible for the user to recover a private key through the pictures that were used in the private key generation process. In order to demonstrate the security and usability of our approach, we have considered various perspectives from participants and used mathematical methods. Through our experimentation, we have demonstrated that our approach is usable and secure.
This study only considers applying fixed variables to all the pictures. Thus, we plan to utilize dynamic variables and apply different parameters to each picture in our future work. Furthermore, additional research is needed to process personal information such as faces and landmarks that can be used to infer the location of each picture and at the same time protect the privacy of individuals in the pictures.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}