
Learning Analytics and Computerized Formative Assessments: An Application of Dijkstra’s Shortest Path Algorithm for Personalized Test Scheduling



Abstract
:1. Introduction
2. Intelligent Recommender System
2.1. Recommender Systems for Educational Assessments
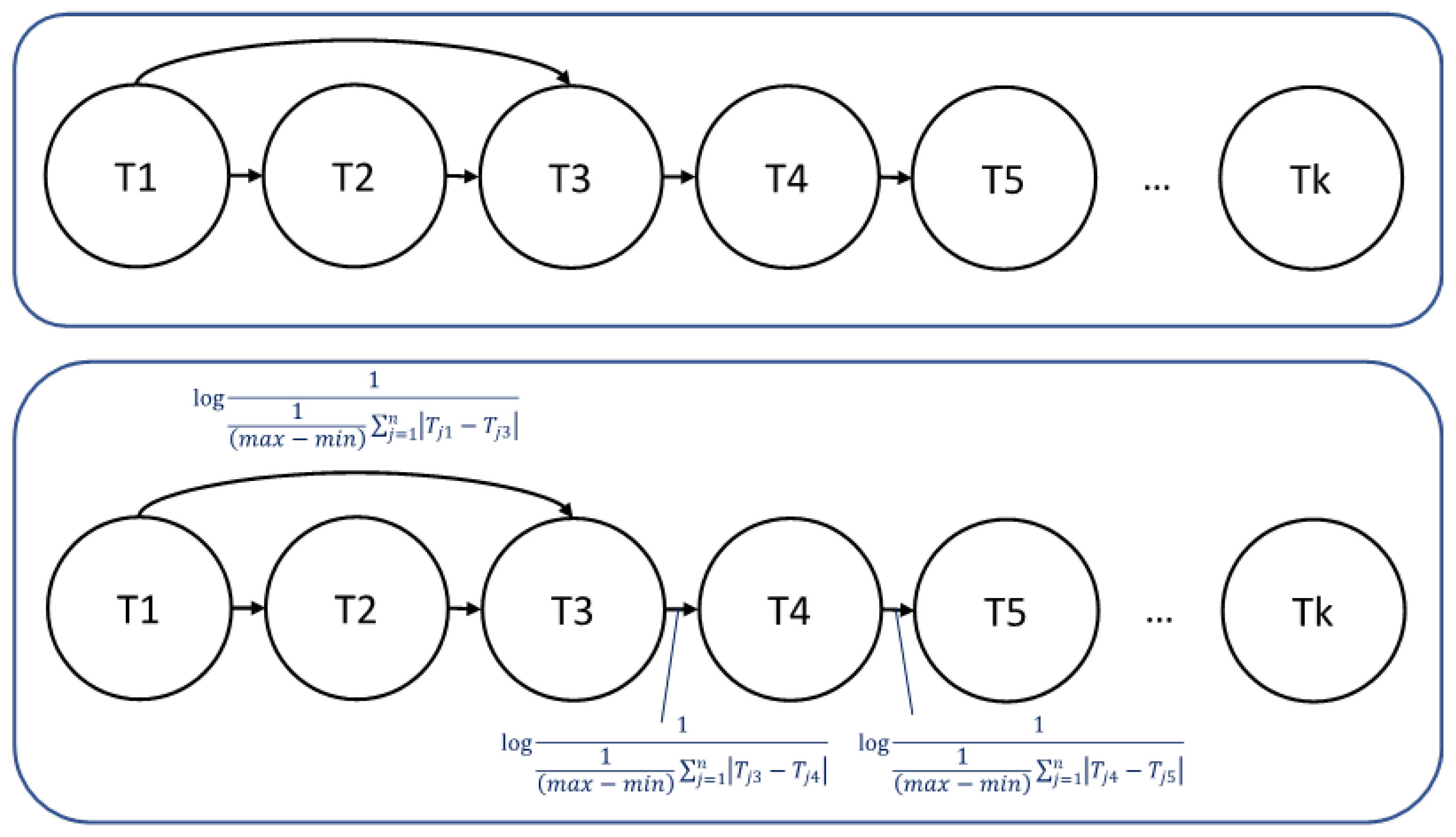
2.2. Directed Graph to Represent the Test Administration Sequence
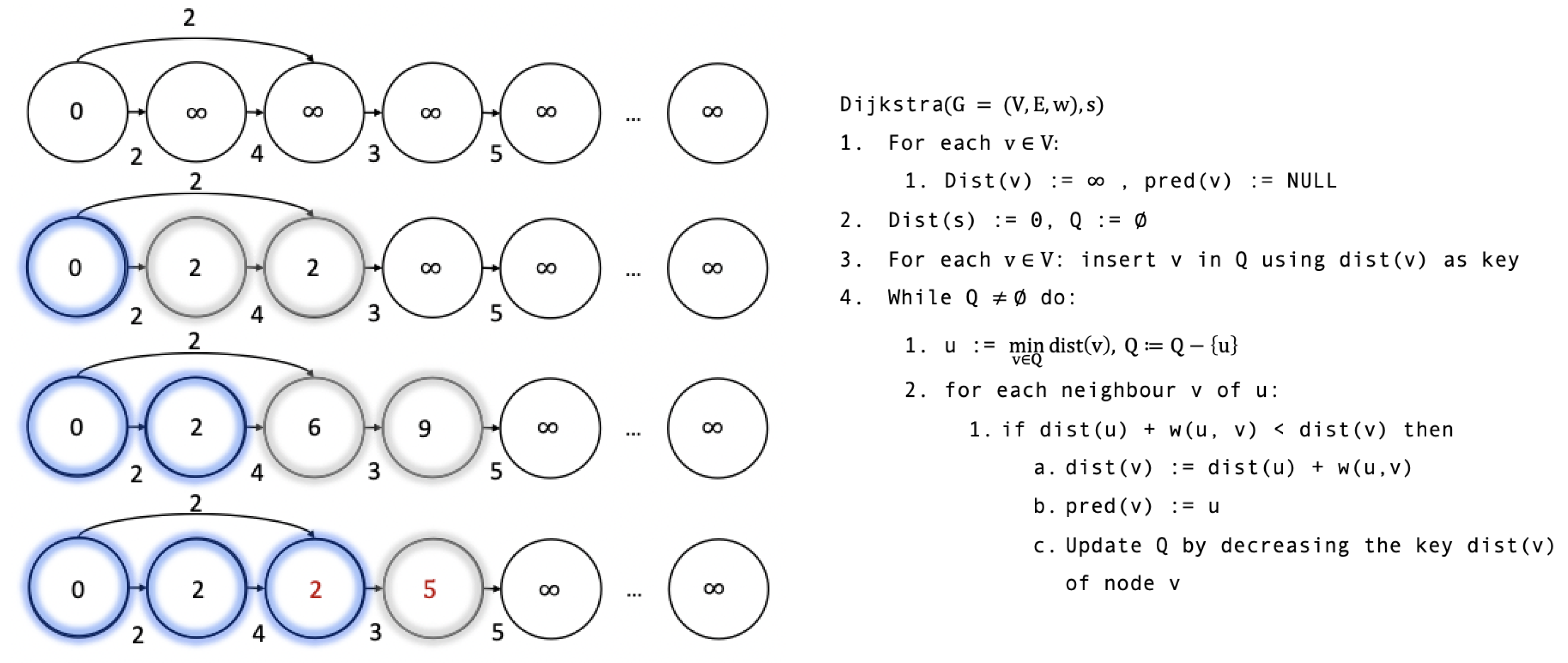
2.3. Shortest Path Similarity as Recommendations
- Does the IRS yield optimal test administration schedules with the minimum number of test administrations?
- Does the IRS produce robust recommendations for students with unusual growth trajectories (e.g., decreasing trajectory, flat growth trajectory)?
3. Methods
3.1. Real Data Study
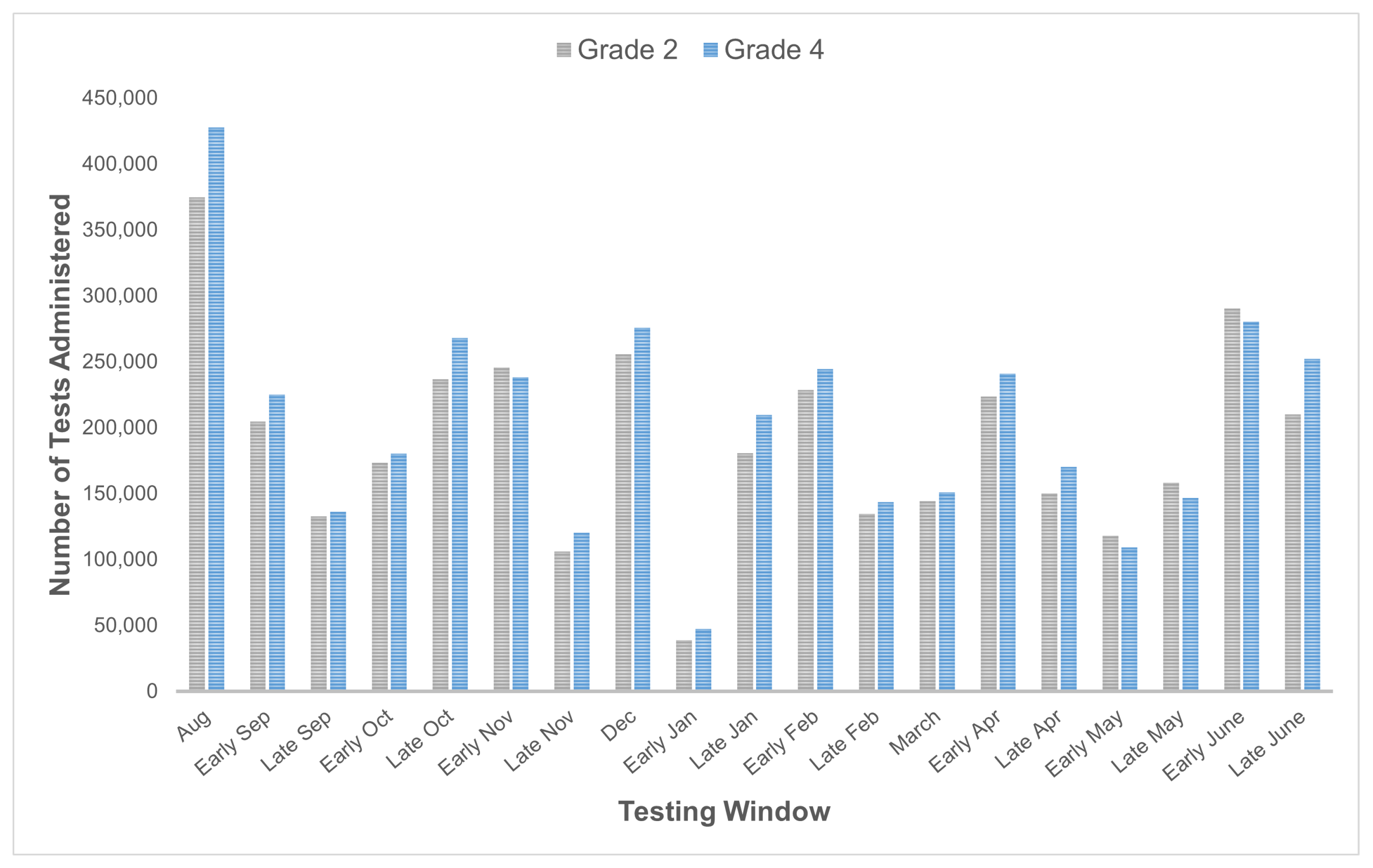
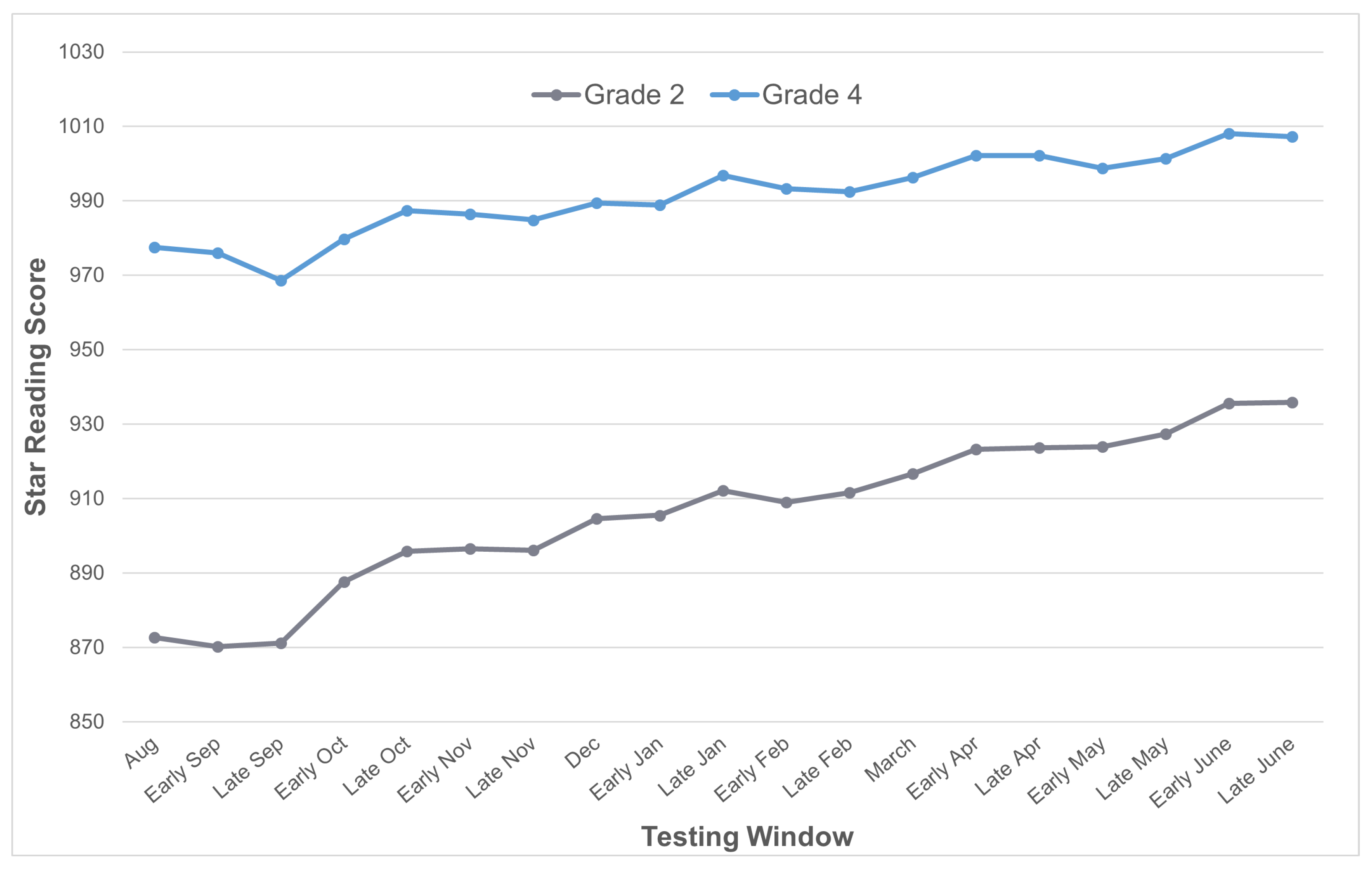
3.1.1. Sample and Instrument
3.1.2. Data Preprocessing
3.1.3. Data Analysis
3.2. Simulation Study
4. Results
4.1. Results of the Real-Data Study
4.2. Results of the Simulation Study
5. Discussion
5.1. Practical Implications
5.2. Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| EDM | Educational data mining |
| IRS | Intelligent recommender system |
| IRT | Item response theory |
| LA | Learning analytics |
| SPF | Shortest path first |
| TEL | Technology-enhanced learning |
References
- Black, P.; Harrison, C.; Lee, C.; Marshall, B.; Wiliam, D. Working inside the black box: Assessment for learning in the classroom. Phi Delta Kappan 2004, 86, 8–21. [Google Scholar] [CrossRef]
- McMillan, J.H.; Andrade, H.L.; Heritage, M. Using Formative Assessment to Enhance Learning, Achievement, and Academic Self-Regulation; Routledge: London, UK, 2017. [Google Scholar]
- Barana, A.; Conte, A.; Fissore, C.; Marchisio, M.; Rabellino, S. Learning analytics to improve formative assessment strategies. J. E-Learn. Knowl. Soc. 2019, 15, 75–88. [Google Scholar] [CrossRef]
- Siemens, G.; Gasevic, D. Guest editorial-learning and knowledge analytics. J. Educ. Technol. Soc. 2012, 15, 1–2. [Google Scholar]
- Admiraal, W.; Vermeulen, J.; Bulterman-Bos, J. Teaching with learning analytics: How to connect computer-based assessment data with classroom instruction? Technol. Pedagog. Educ. 2020, 29, 577–591. [Google Scholar] [CrossRef]
- Nouri, J.; Ebner, M.; Ifenthaler, D.; Sqr, M.; Malmberg, J.; Khalil, M.; Bruun, J.; Viberg, O.; González, M.Á.C.; Papamitsiou, Z.; et al. Efforts in Europe for data-driven improvement of education—A review of learning analytics research in six countries. Int. J. Learn. Anal. Artif. Intell. Educ. 2019, 1, 8–27. [Google Scholar] [CrossRef]
- Dawson, S.; Gašević, D.; Siemens, G.; Joksimovic, S. Current state and future trends: A citation network analysis of the learning analytics field. In Proceedings of the Fourth International Conference on Learning Analytics and Knowledge, Indianapolis, IN, USA, 24–28 March 2014; pp. 231–240. [Google Scholar] [CrossRef]
- Bulut, O.; Cormier, D.C. Validity evidence for progress monitoring with Star Reading: Slope estimates, administration frequency, and number of data points. Front. Educ. 2018, 3, 68. [Google Scholar] [CrossRef]
- Maier, U.; Wolf, N.; Randler, C. Effects of a computer-assisted formative assessment intervention based on multiple-tier diagnostic items and different feedback types. Comput. Educ. 2016, 95, 85–98. [Google Scholar] [CrossRef]
- Bulut, O.; Cormier, D.C.; Shin, J. An intelligent recommender system for personalized test administration scheduling with computerized formative assessments. Front. Educ. 2020, 5, 182. [Google Scholar] [CrossRef]
- Shin, J.; Bulut, O. Building an intelligent recommendation system for personalized test scheduling in computerized assessments: A reinforcement learning approach. Behav. Res. Methods 2022, 54, 216–232. [Google Scholar] [CrossRef]
- January, S.A.A.; Van Norman, E.R.; Christ, T.J.; Ardoin, S.P.; Eckert, T.L.; White, M.J. Progress monitoring in reading: Comparison of weekly, bimonthly, and monthly assessments for students at risk for reading difficulties in grades 2–4. Sch. Psychol. Rev. 2018, 47, 83–94. [Google Scholar] [CrossRef] [Green Version]
- January, S.A.A.; Van Norman, E.R.; Christ, T.J.; Ardoin, S.P.; Eckert, T.L.; White, M.J. Evaluation of schedule frequency and density when monitoring progress with curriculum-based measurement. Sch. Psychol. 2019, 34, 119. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. (Eds.) Recommender Systems: Introduction and Challenges. In Recommender Systems Handbook; Springer: Boston, MA, USA, 2015; pp. 1–34. [Google Scholar] [CrossRef]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- Zaiane, O. Building a recommender agent for e-learning systems. In Proceedings of the International Conference on Computers in Education, Auckland, New Zealand, 3–6 December 2002; pp. 55–59. [Google Scholar] [CrossRef]
- Manouselis, N.; Drachsler, H.; Verbert, K.; Santos, O.C. (Eds.) Recommender Systems for Technology Enhanced Learning: Research Trends and Applications; Springer Science & Business Media: New York, NY, USA, 2014. [Google Scholar]
- Thai-Nghe, N.; Drumond, L.; Krohn-Grimberghe, A.; Schmidt-Thieme, L. Recommender system for predicting student performance. Procedia Comput. Sci. 2010, 1, 2811–2819. [Google Scholar] [CrossRef] [Green Version]
- Leite, W.; Roy, S.; Chakraborty, N.; Michailidis, G.; Huggins-Manley, A.C.; D’Mello, S.; Shirani Faradonbeh, M.K.; Jensen, E.; Kuang, H.; Jing, Z. A novel video recommendation system for algebra: An effectiveness evaluation study. In Proceedings of the LAK22: 12th International Learning Analytics and Knowledge Conference, Newport Beach, CA, USA, 21–25 March 2022; pp. 294–303. [Google Scholar]
- De Oliveira, M.G.; Marques Ciarelli, P.; Oliveira, E. Recommendation of programming activities by multi-label classification for a formative assessment of students. Expert Syst. Appl. 2013, 40, 6641–6651. [Google Scholar] [CrossRef]
- Baylari, A.; Montazer, G.A. Design a personalized e-learning system based on item response theory and artificial neural network approach. Expert Syst. Appl. 2009, 36, 8013–8021. [Google Scholar] [CrossRef]
- Chen, C.M.; Lee, H.M.; Chen, Y.H. Personalized e-learning system using item response theory. Comput. Educ. 2005, 44, 237–255. [Google Scholar] [CrossRef]
- De Schipper, E.; Feskens, R.; Keuning, J. Personalized and automated feedback in summative assessment using recommender systems. Front. Educ. 2021, 6, 652070. [Google Scholar] [CrossRef]
- Kundu, S.S.; Sarkar, D.; Jana, P.; Kole, D.K. Personalization in Education Using Recommendation System: An Overview. In Computational Intelligence in Digital Pedagogy; Springer: Berlin/Heidelberg, Germany, 2021; pp. 85–111. [Google Scholar]
- Chen, M.; Chowdhury, R.A.; Ramachandran, V.; Roche, D.L.; Tong, L. Priority Queues and Dijkstra’s Algorithm; Computer Science Department, University of Texas at Austin: Austin, TX, USA, 2007. [Google Scholar]
- Renaissance. Star Assessments™ for Reading Technical Manual; Technical Report; Renaissance: Wisconsin Rapids, WI, USA, 2018. [Google Scholar]
- Vannest, K.J.; Parker, R.I.; Davis, J.L.; Soares, D.A.; Smith, S.L. The Theil–Sen slope for high-stakes decisions from progress monitoring. Behav. Disord. 2012, 37, 271–280. [Google Scholar] [CrossRef] [Green Version]
- Van Rossum, G.; Drake, F.L. Python 3 Reference Manual; CreateSpace: Scotts Valley, CA, USA, 2009. [Google Scholar]
- Komsta, L. Mblm: Median-Based Linear Models. R Package Version 0.12.1. 2019. Available online: https://cran.r-project.org/web/packages/mblm/ (accessed on 30 May 2022).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Hoogland, I.; Schildkamp, K.; Van der Kleij, F.; Heitink, M.; Kippers, W.; Veldkamp, B.; Dijkstra, A.M. Prerequisites for data-based decision making in the classroom: Research evidence and practical illustrations. Teach. Teach. Educ. 2016, 60, 377–386. [Google Scholar] [CrossRef]
- Kaufman, T.E.; Graham, C.R.; Picciano, A.G.; Popham, J.A.; Wiley, D. Data-driven decision making in the K-12 classroom. In Handbook of Research on Educational Communications and Technology; Springer: Berlin/Heidelberg, Germany, 2014; pp. 337–346. [Google Scholar] [CrossRef]
- Lai, M.K.; Schildkamp, K. Data-based Decision Making: An Overview. In Data-Based Decision Making in Education: Challenges and Opportunities; Springer: Dordrecht, The Netherlands, 2013; pp. 9–21. [Google Scholar] [CrossRef]
- Marsh, J.A.; Pane, J.F.; Hamilton, L.S. Making Sense of Data-Driven Decision Making in Education: Evidence from Recent RAND Research; RAND Corporation: Santa Monica, CA, USA, 2006. [Google Scholar] [CrossRef]
- Ferguson, R. Learning analytics: Drivers, developments and challenges. Int. J. Technol. Enhanc. Learn. 2012, 4, 304–317. [Google Scholar] [CrossRef]
- Baker, R.S.; Yacef, K. The state of educational data mining in 2009: A review and future visions. J. Educ. Data Min. 2009, 1, 3–17. [Google Scholar] [CrossRef]
- Baepler, P.; Murdoch, C.J. Academic analytics and data mining in higher education. Int. J. Scholarsh. Teach. Learn. 2010, 4, 1–9. [Google Scholar] [CrossRef]
- Vatrapu, R.; Teplovs, C.; Fujita, N.; Bull, S. Towards visual analytics for teachers’ dynamic diagnostic pedagogical decision-making. In Proceedings of the 1st International Conference on Learning Analytics and Knowledge, LAK ’11, Banff, AB, Canada, 27 February–1 March 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 93–98. [Google Scholar]
- Tempelaar, D.T.; Rienties, B.; Giesbers, B. In search for the most informative data for feedback generation: Learning analytics in a data-rich context. Comput. Hum. Behav. 2015, 47, 157–167. [Google Scholar] [CrossRef] [Green Version]
- Christ, T.J.; Zopluoglu, C.; Long, J.D.; Monaghen, B.D. Curriculum-based measurement of oral reading: Quality of progress monitoring outcomes. Except. Child. 2012, 78, 356–373. [Google Scholar] [CrossRef]
- Baker, R.S.; Koedinger, K.R. Towards demonstrating the value of learning analytics for K-12 education. In Learning Analytics in Education; Niemi, D., Pea, R.D., Saxberg, B., Clark, R.E., Eds.; Information Age Publishing: Charlotte, NC, USA, 2018; Chapter 2; pp. 49–62. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Slope Type | Sparse Data | Full Data | Sample Size | |||
|---|---|---|---|---|---|---|
| Slope Range | Number of Tests * | Slope Range | Number of Tests | |||
| Negative Slope | Linear | (−1.1, 0) | 5.86 | (−0.6, −0.3) | 20 | 1000 |
| Quadratic | (−1.1, 0) | 5.80 | (−0.6, −0.4) | 20 | 1000 | |
| Minimal Change | Zero slope | (−0.01, 0.0) | 5.09 | (−0.01, 0.0) | 20 | 1000 |
| Plateau | After 14 | (−0.1, 0.1) | 9.32 | (−0.1, 0.1) | 20 | 1000 |
| After 15 | (−0.1, 0.1) | 7.58 | (−0.1, 0.1) | 20 | 1000 | |
| After 17 | (−0.1, 0.1) | 7.07 | (−0.1, 0.1) | 20 | 1000 | |
| Evaluation Criteria | Grade 2 | Grade 4 | ||
|---|---|---|---|---|
| SP | IRS | SP | IRS | |
| Average number of tests | 5.42 | 3.51 | 5.37 | 3.84 |
| Average positive score change | 8.32 | 12.25 | 3.49 | 4.63 |
| Minimum number of test administrations * | 1 | 1 | 1 | 1 |
| Maximum number of test administrations * | 17 | 5 | 17 | 6 |
| Slope Type | Simulated Data | IRS | |||
|---|---|---|---|---|---|
| Number of Tests * | Test Score Change | Number of Tests | Test Score Change | ||
| Negative Slope | Linear | 5.86 | −44.66 | 3.75 | −55.41 |
| Quadratic | 5.80 | −52.87 | 3.50 | −71.99 | |
| Minimal Change | Zero slope | 5.09 | −3.22 | 3.90 | −4.14 |
| Plateau | After 14 | 9.32 | −0.65 | 3.26 | −1.92 |
| After 15 | 7.58 | −0.54 | 3.23 | −1.29 | |
| After 17 | 7.07 | −0.68 | 3.20 | −1.38 | |
| Slope Type | Simulated Data | IRS | |||
|---|---|---|---|---|---|
| Number of Tests | Test Score Change | Number of Tests | Test Score Change | ||
| Negative Slope | Linear | 18 | −14.59 | 4.65 | −55.41 |
| Quadratic | 18 | −17.57 | 3.55 | −78.24 | |
| Minimal Change | Zero slope | 18 | −1.41 | 4.30 | −4.68 |
| Plateau | After 14 | 18 | −0.38 | 5.01 | −1.36 |
| After 15 | 18 | −0.28 | 4.98 | −1.01 | |
| After 17 | 18 | −0.27 | 4.87 | −0.97 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bulut, O.; Shin, J.; Cormier, D.C. Learning Analytics and Computerized Formative Assessments: An Application of Dijkstra’s Shortest Path Algorithm for Personalized Test Scheduling. Mathematics 2022, 10, 2230. https://doi.org/10.3390/math10132230
Bulut O, Shin J, Cormier DC. Learning Analytics and Computerized Formative Assessments: An Application of Dijkstra’s Shortest Path Algorithm for Personalized Test Scheduling. Mathematics. 2022; 10(13):2230. https://doi.org/10.3390/math10132230
Chicago/Turabian StyleBulut, Okan, Jinnie Shin, and Damien C. Cormier. 2022. "Learning Analytics and Computerized Formative Assessments: An Application of Dijkstra’s Shortest Path Algorithm for Personalized Test Scheduling" Mathematics 10, no. 13: 2230. https://doi.org/10.3390/math10132230
APA StyleBulut, O., Shin, J., & Cormier, D. C. (2022). Learning Analytics and Computerized Formative Assessments: An Application of Dijkstra’s Shortest Path Algorithm for Personalized Test Scheduling. Mathematics, 10(13), 2230. https://doi.org/10.3390/math10132230