
Nonparametric Sieve Maximum Likelihood Estimation of Semi-Competing Risks Data



Abstract
:1. Introduction
2. Methodology
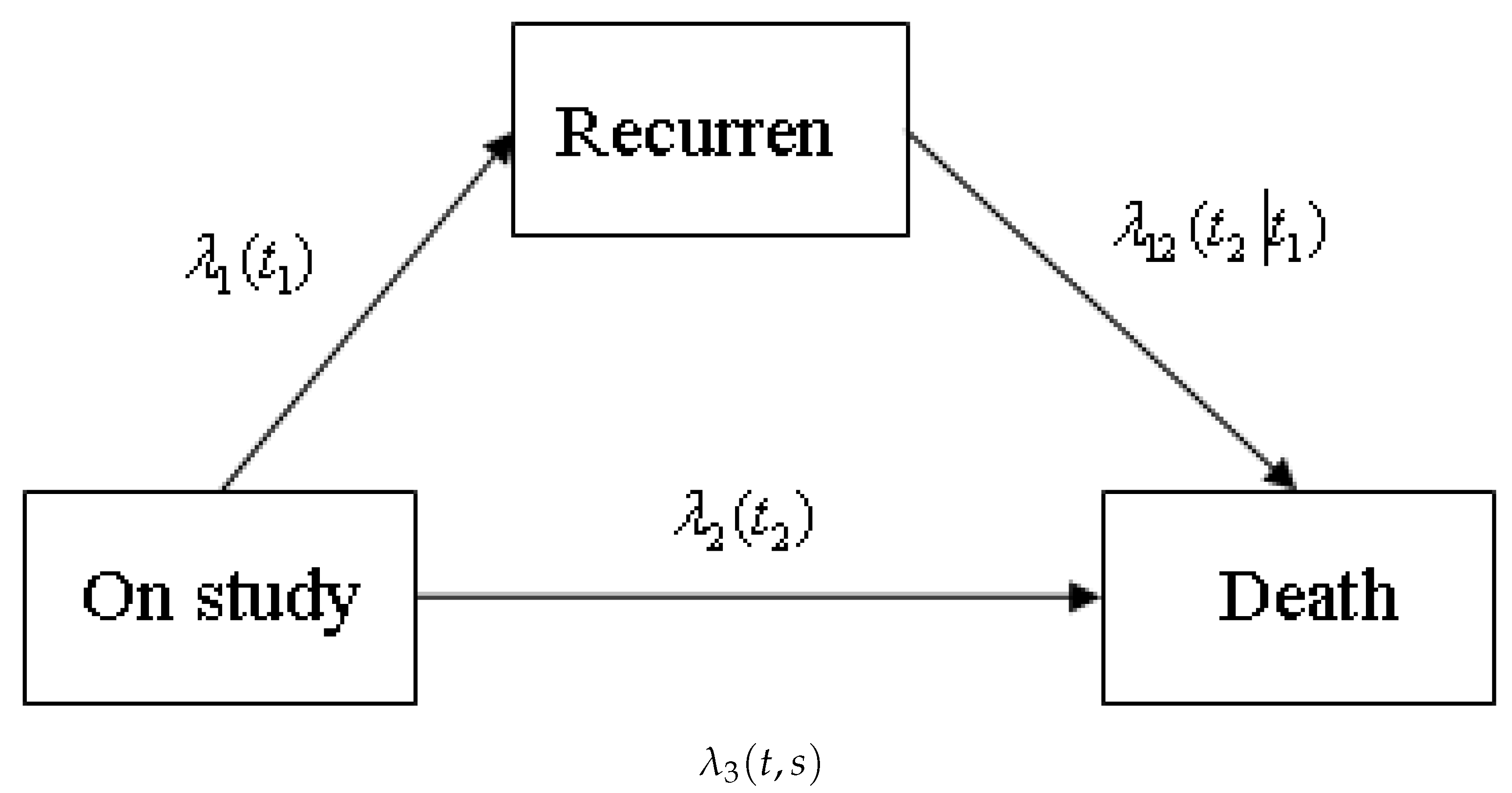
2.1. Model and Likelihood Function
2.2. Sieve Space for the Parameters
2.3. Maximization
3. Theoretical Properties
Assumptions
- (A1) and have compact supports (say ) and X has bounded support in where q is the dimension of Moreover, if there exists a constant and a constant vector such that almost surely, then and
- (A2) where is a compact set of with nonempty interior. and and
- (A3) where satisfies the restrictions
- (A4) where r is the measure of smoothness of in definitions of and
- (A5) for any is continuously differentiable in near and
4. Simulation Study
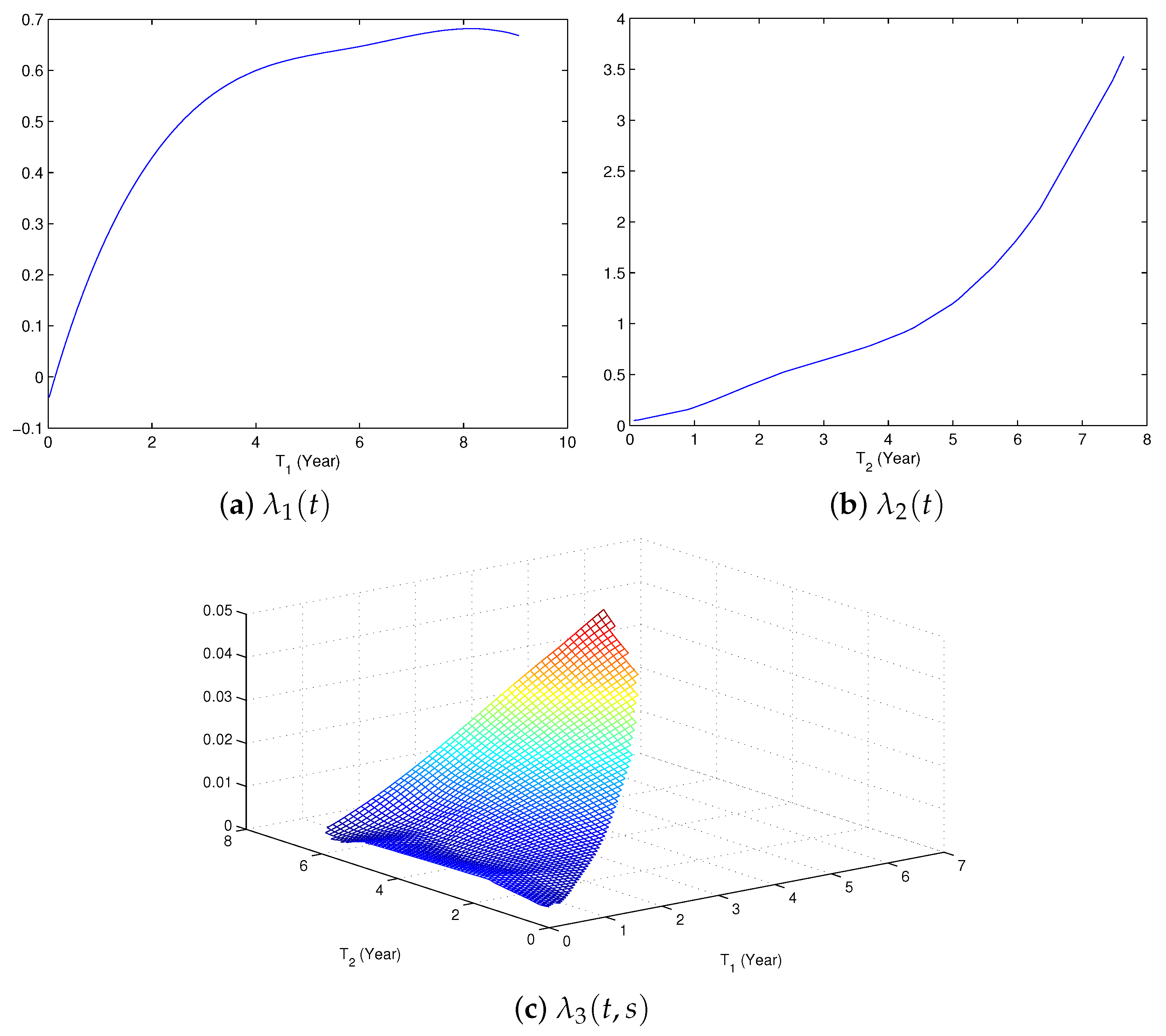
5. A Real Data Example
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Proofs of Theorem 1, Theorem 2, and Theorem 3
Appendix A.1. Proof of Theorem 1
Appendix A.2. Proof of Theorem 2
Appendix A.3. Proof of Theorem 3
References
- Fine, J.P.; Jiang, H.; Chappell, R. On semi-competing risks data. Biometrika 2001, 88, 907–919. [Google Scholar] [CrossRef]
- Wang, W. Estimating the association parameter for copula models under dependent censoring. J. R. Stat. Soc. Ser. Stat. Methodol. 2003, 65, 257–273. [Google Scholar] [CrossRef]
- Day, R.; Bryant, J.; Lefkopoulou, M. Adaptation of bivariate frailty models for prediction, with application to biological markers as prognostic indicators. Biometrika 1997, 84, 45–56. [Google Scholar] [CrossRef]
- Xing, L.; Lesperance, M.L.; Zhang, X. Simultaneous prediction of multiple outcomes using revised stacking algorithms. Bioinformatics 2020, 36, 65–72. [Google Scholar] [CrossRef]
- Xu, J.; Kalbfleisch, J.D.; Tai, B. Statistical analysis of illness–death processes and semicompeting risks data. Biometrics 2010, 66, 716–725. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Andersen, P.K.; Borgan, O.; Gill, R.D.; Keiding, N. Statistical Models Based on Counting Processes; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Schumaker, L. Spline Functions: Basic Theory; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Stone, C.J. Optimal global rates of convergence for nonparametric regression. Ann. Stat. 1982, 10, 1040–1053. [Google Scholar] [CrossRef]
- Meira-Machado, L.; de Uña-Álvarez, J.; Cadarso-Suárez, C.; Andersen, P.K. Multi-state models for the analysis of time-to-event data. Stat. Methods Med. Res. 2009, 18, 195–222. [Google Scholar] [CrossRef] [Green Version]
- Wellner, J. Weak Convergence and Empirical Processes: With Applications to Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Pollard, D. Convergence of Stochastic Processes; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Bickel, P.J.; Kwon, J. Inference for semiparametric models: Some questions and an answer. Stat. Sin. 2001, 11, 863–886. [Google Scholar]



{kind=link}
{kind=link}
| BIAS | STD | ESE | CP | ||
|---|---|---|---|---|---|
| 0.021 | 0.233 | 0.219 | 0.953 | ||
| −0.016 | 0.230 | 0.263 | 0.954 | ||
| 0.026 | 0.281 | 0.219 | 0.986 | ||
| 0.017 | 0.166 | 0.159 | 0.963 | ||
| −0.013 | 0.167 | 0.164 | 0.960 | ||
| 0.018 | 0.122 | 0.141 | 0.965 |
| BIAS | STD | ESE | CP | ||
|---|---|---|---|---|---|
| = −1 | −0.015 | 0.244 | 0.225 | 0.956 | |
| = −1 | 0.019 | 0.232 | 0.239 | 0.962 | |
| = −1 | −0.014 | 0.269 | 0.284 | 0.961 | |
| = −1 | −0.013 | 0.144 | 0.165 | 0.961 | |
| = −1 | 0.014 | 0.158 | 0.164 | 0.945 | |
| = −1 | −0.013 | 0.197 | 0.185 | 0.980 |
| BIAS | STD | ESE | CP | ||
|---|---|---|---|---|---|
| 0.017 | 0.230 | 0.205 | 0.966 | ||
| −0.013 | 0.221 | 0.219 | 0.965 | ||
| 0.016 | 0.182 | 0.218 | 0.945 | ||
| 0.008 | 0.172 | 0.155 | 0.941 | ||
| −0.011 | 0.132 | 0.152 | 0.954 | ||
| 0.012 | 0.125 | 0.157 | 0.938 |
| Transition | Parameters | Estimate | Standard Error | p-Value |
|---|---|---|---|---|
| 12 | −0.513 | 0.119 | 1.6 × 10 | |
| 13 | −0.028 | 0.379 | 0.469 | |
| 23 | 0.738 | 0.130 | 7.0 × 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Xu, J. Nonparametric Sieve Maximum Likelihood Estimation of Semi-Competing Risks Data. Mathematics 2022, 10, 2248. https://doi.org/10.3390/math10132248
Huang X, Xu J. Nonparametric Sieve Maximum Likelihood Estimation of Semi-Competing Risks Data. Mathematics. 2022; 10(13):2248. https://doi.org/10.3390/math10132248
Chicago/Turabian StyleHuang, Xifen, and Jinfeng Xu. 2022. "Nonparametric Sieve Maximum Likelihood Estimation of Semi-Competing Risks Data" Mathematics 10, no. 13: 2248. https://doi.org/10.3390/math10132248
APA StyleHuang, X., & Xu, J. (2022). Nonparametric Sieve Maximum Likelihood Estimation of Semi-Competing Risks Data. Mathematics, 10(13), 2248. https://doi.org/10.3390/math10132248