
A Multi-Start Biased-Randomized Algorithm for the Capacitated Dispersion Problem

 ,
,  , , and
, , and 
Abstract
:1. Introduction
2. Related Work on Diversity Problems
- The Max-Min problem, whose objective is to maximize the minimum distance between any pair of elements in a solution.
- The Max-Sum problem, whose objective is to maximize the total distance among all elements in a solution.
- The Max-Mean problem, whose objective is to maximize the average dispersion of the elements, while the remaining problems in this list set a predefined number of elements, the Max-Mean problem does not require this constraint.
- The Max-MinSum problem, whose objective is to maximize the minimum aggregate dispersion of each element in a solution.
- The Min-Diff problem, whose objective is to minimize the difference between the maximum and the minimum aggregate dispersion of each element in a solution.
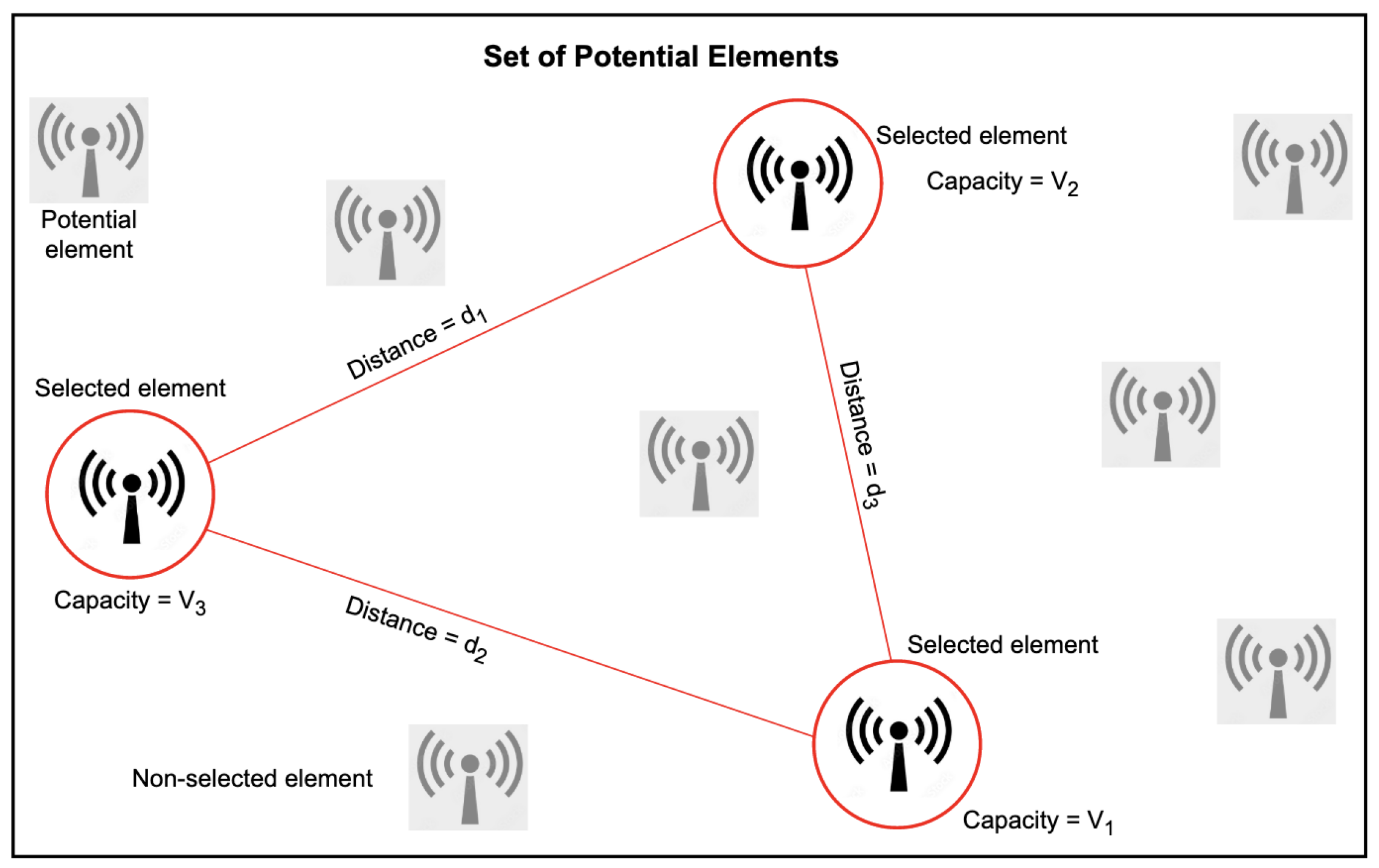
3. Problem Definition
4. Solution Approaches for the Capacitated Dispersion Problem
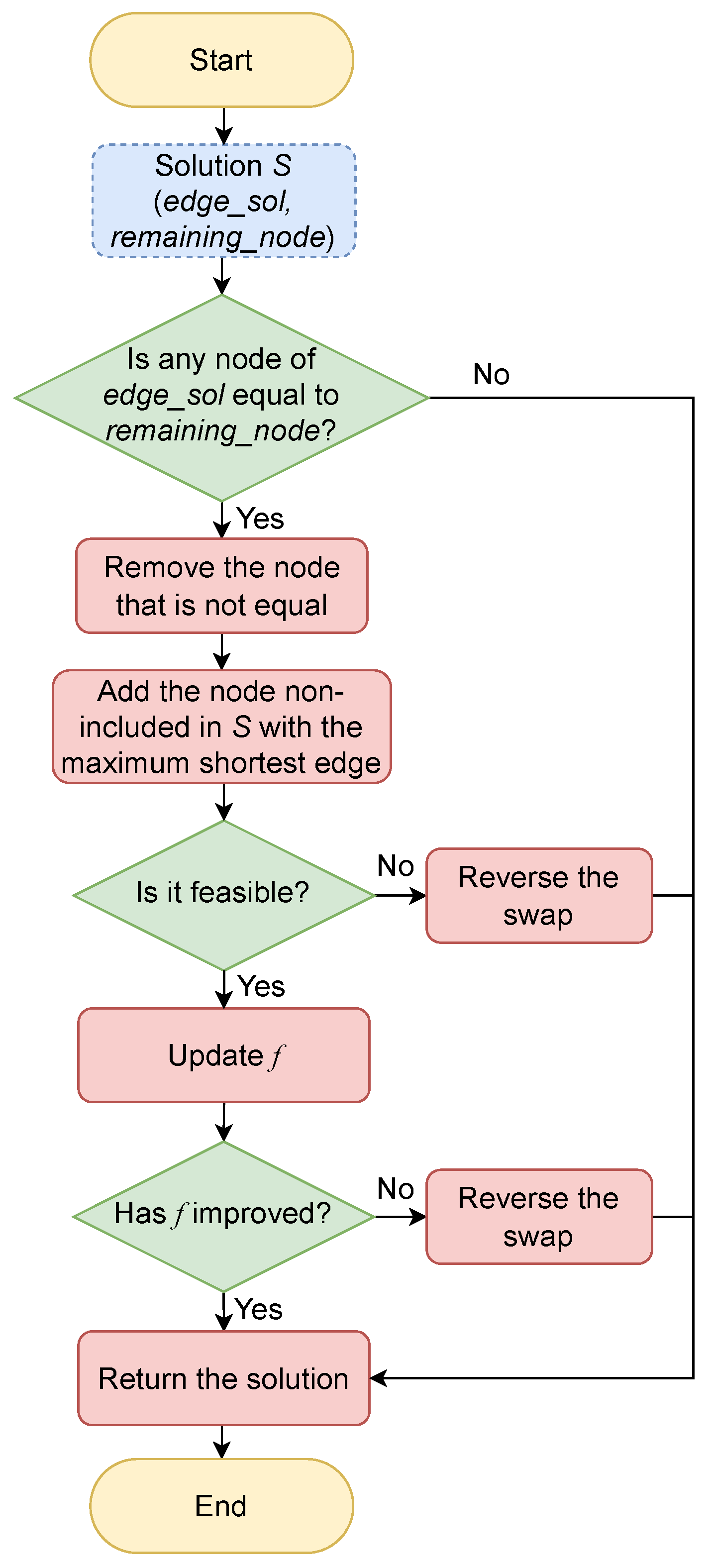
4.1. A Constructive Heuristic
| Algorithm 1: Constructive heuristic () |
|
| Algorithm 2: Multi-start biased-randomized constructive heuristic () |
|
| Algorithm 3: Local Search (S) |
|
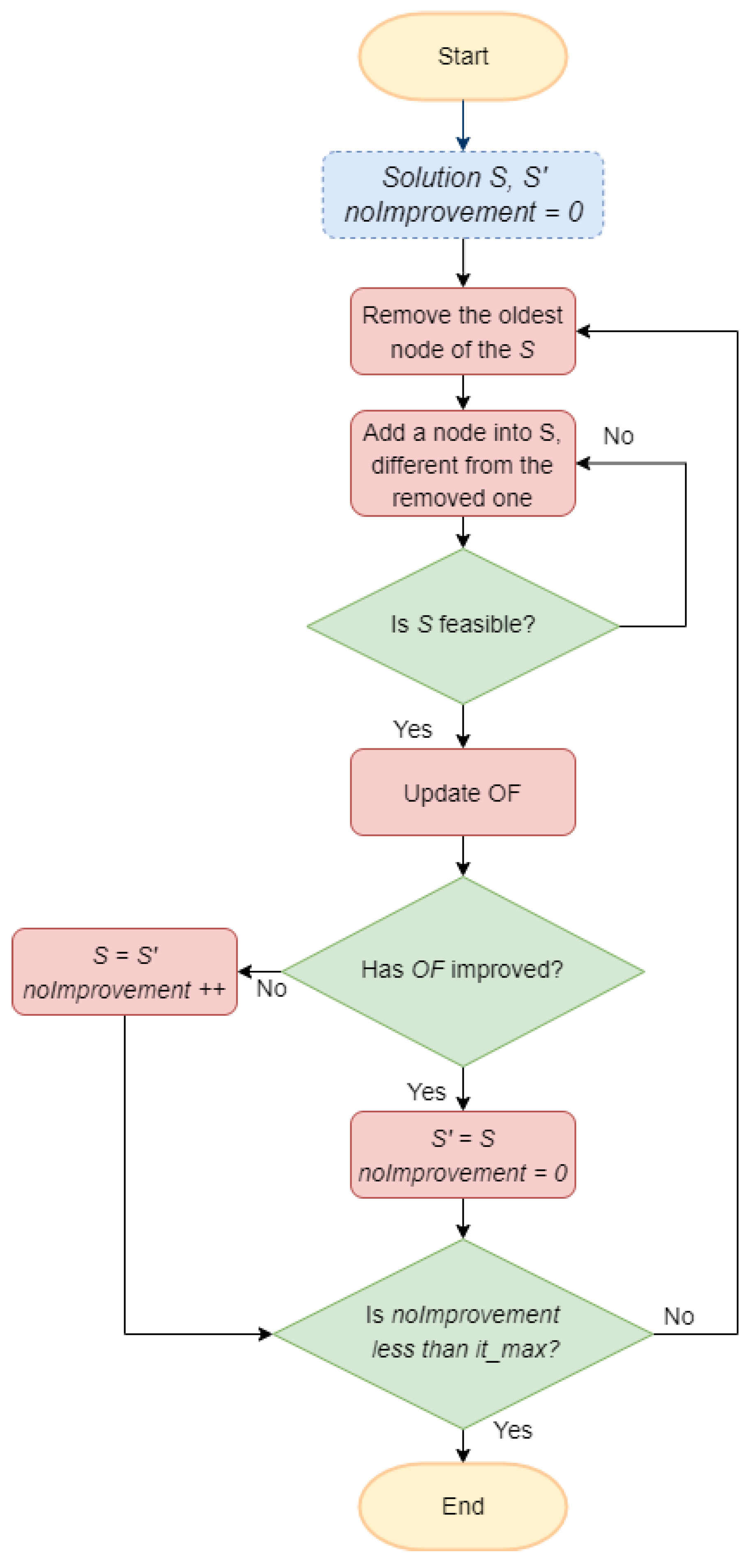
4.2. A Destructive Heuristic
| Algorithm 4: Destructive heuristic () |
|
| Algorithm 5: Multi-start biased-randomized destructive heuristic () |
|
5. Numerical Experiments and Results
5.1. Computational Environment
- SOM instances, which is a data set with random numbers between 0 and 9 from an integer Uniform distribution. The data set was proposed in Martí et al. [34]. These instances have 50 nodes.
- GKD instances, which is a data set built using Euclidean distances. Node coordinates were generated considering a Uniform distribution between 0 and 10. This data set was proposed in Martí et al. [34]. Two subsets were considered: the first one is called GKD-b and has instances with 50 and 150 nodes; and the second one is called GKD-c and has instances with 500 nodes.
- MDG instances, which is a data set with real numbers randomly selected between 0 and 1000 from a Uniform distribution. This data set was introduced by Duarte and Martí [27]. These instances have 500 nodes.
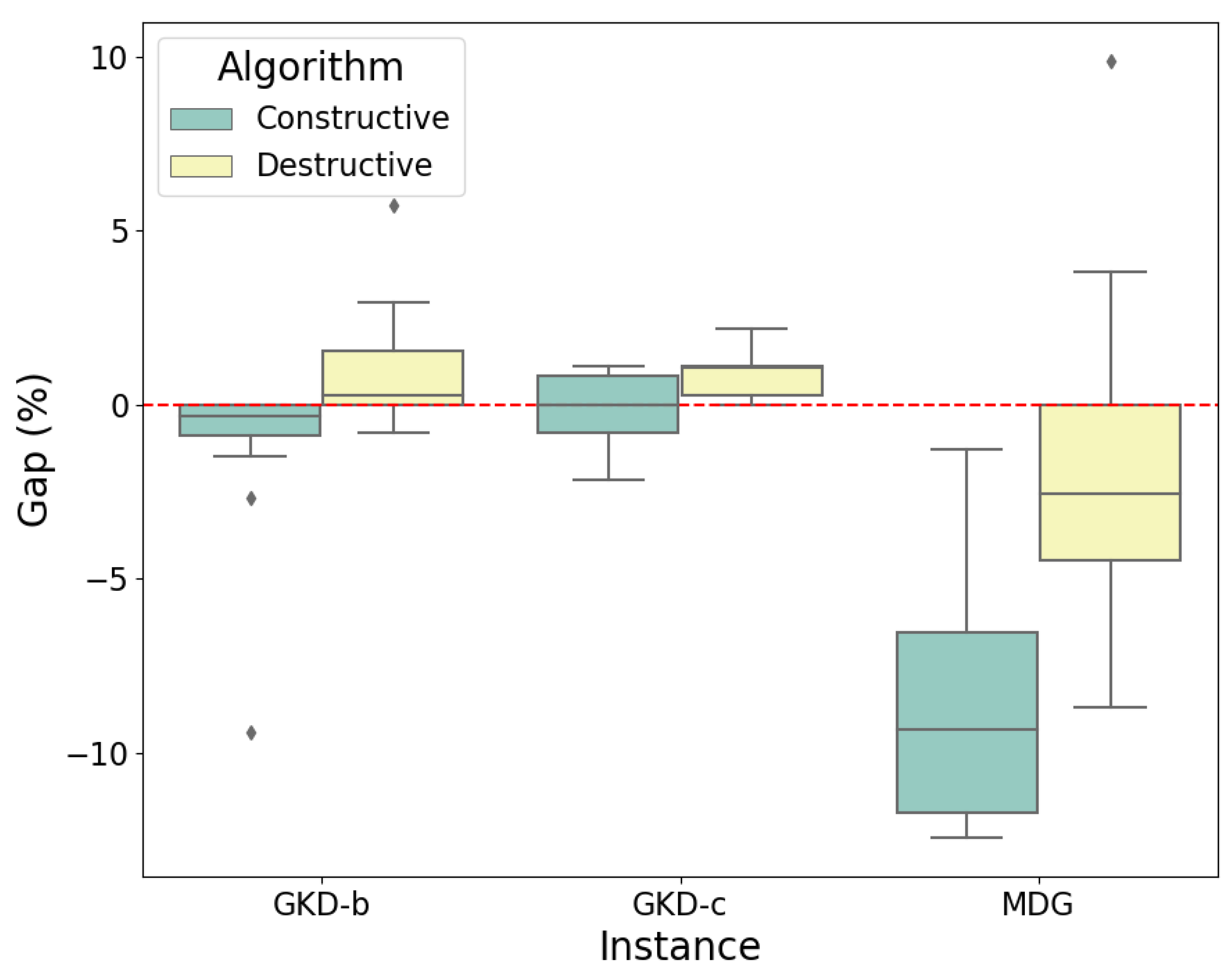
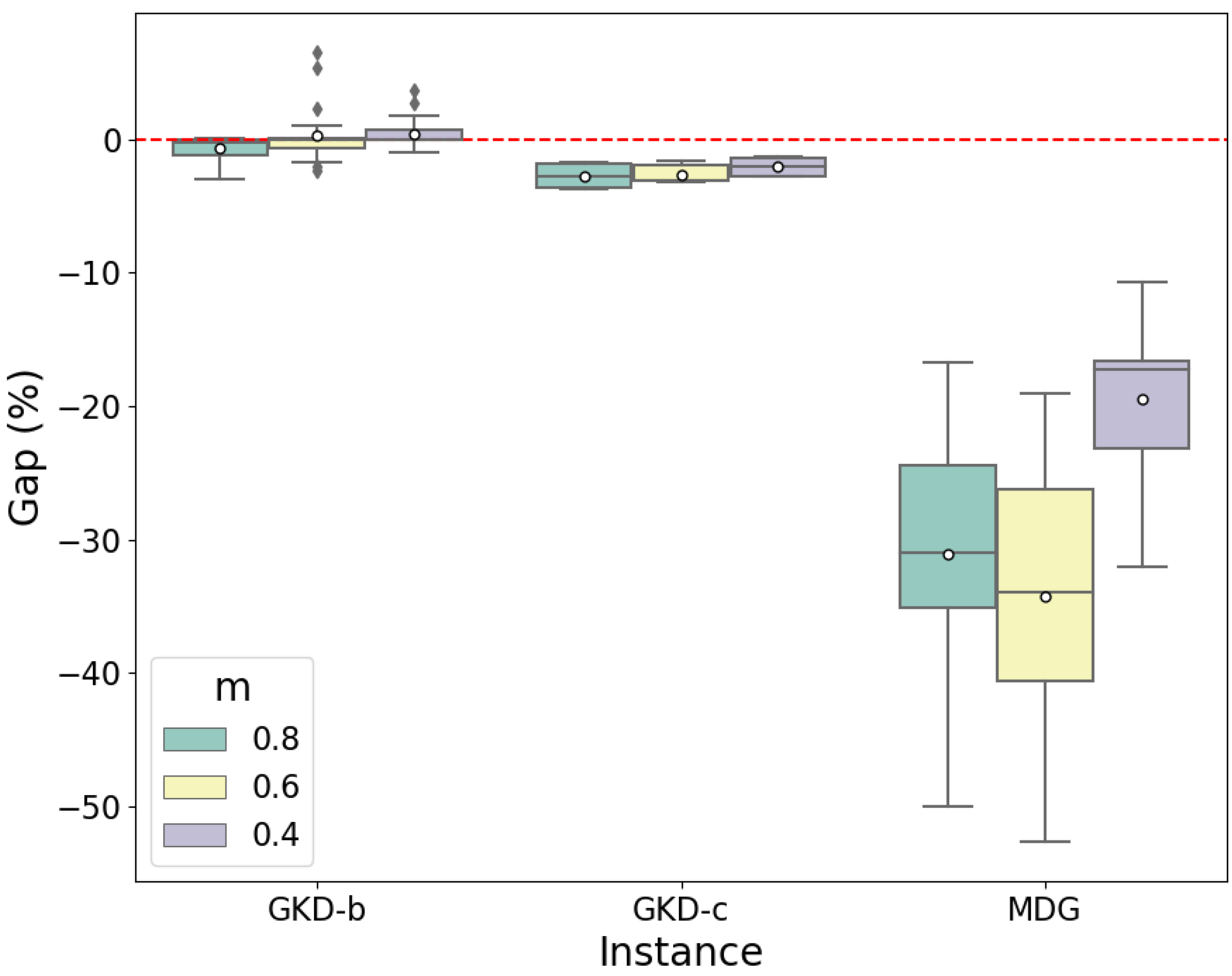
5.2. Analysis of Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Govindan, K.; Fattahi, M.; Keyvanshokooh, E. Supply chain network design under uncertainty: A comprehensive review and future research directions. Eur. J. Oper. Res. 2017, 263, 108–141. [Google Scholar] [CrossRef]
- Eskandarpour, M.; Dejax, P.; Miemczyk, J.; Péton, O. Sustainable supply chain network design: An optimization-oriented review. Omega 2015, 54, 11–32. [Google Scholar] [CrossRef]
- Correia, I.; Saldanha-da Gama, F. Facility location under uncertainty. In Location Science; Springer: Berlin/Heidelberg, Germany, 2015; pp. 185–213. [Google Scholar]
- Fernández, E.; Landete, M. Fixed-charge facility location problems. In Location Science; Springer: Berlin/Heidelberg, Germany, 2015; pp. 47–77. [Google Scholar]
- Dönmez, Z.; Kara, B.Y.; Karsu, Ö.; Saldanha-da Gama, F. Humanitarian facility location under uncertainty: Critical review and future prospects. Omega 2021, 102, 102393. [Google Scholar] [CrossRef]
- Ortiz-Astorquiza, C.; Contreras, I.; Laporte, G. Multi-level facility location problems. Eur. J. Oper. Res. 2018, 267, 791–805. [Google Scholar] [CrossRef] [Green Version]
- Boonmee, C.; Arimura, M.; Asada, T. Facility location optimization model for emergency humanitarian logistics. Int. J. Disaster Risk Reduct. 2017, 24, 485–498. [Google Scholar] [CrossRef]
- Ahmadi-Javid, A.; Seyedi, P.; Syam, S.S. A survey of healthcare facility location. Comput. Oper. Res. 2017, 79, 223–263. [Google Scholar] [CrossRef]
- Melo, M.T.; Nickel, S.; Saldanha-Da-Gama, F. Facility location and supply chain management—A review. Eur. J. Oper. Res. 2009, 196, 401–412. [Google Scholar] [CrossRef]
- Pagès-Bernaus, A.; Ramalhinho, H.; Juan, A.A.; Calvet, L. Designing e-commerce supply chains: A stochastic facility–location approach. Int. Trans. Oper. Res. 2019, 26, 507–528. [Google Scholar] [CrossRef]
- De Armas, J.; Juan, A.A.; Marquès, J.M.; Pedroso, J.P. Solving the deterministic and stochastic uncapacitated facility location problem: From a heuristic to a simheuristic. J. Oper. Res. Soc. 2017, 68, 1161–1176. [Google Scholar] [CrossRef]
- Fernandez, S.; Juan, A.A.; de Armas, J.; Silva, D.; Riera, D. Metaheuristics in telecommunication systems: Network design, routing, and allocation problems. IEEE Syst. J. 2018, 12, 3948–3957. [Google Scholar] [CrossRef]
- Martí, R.; Martínez-Gavara, A.; Pérez-Peló, S.; Sánchez-Oro, J. A review on discrete diversity and dispersion maximization from an OR perspective. Eur. J. Oper. Res. 2021, 299, 795–813. [Google Scholar] [CrossRef]
- Sandoya, F.; Martínez-Gavara, A.; Aceves, R.; Duarte, A.; Martí, R. Diversity and equity models. In Handbook of Heuristics; Springer: Berlin/Heidelberg, Germany, 2018; Volume 2, pp. 979–998. [Google Scholar]
- Glover, F.; Kuo, C.C.; Dhir, K.S. Heuristic algorithms for the maximum diversity problem. J. Inf. Optim. Sci. 1998, 19, 109–132. [Google Scholar] [CrossRef]
- Resende, M.G.; Martí, R.; Gallego, M.; Duarte, A. GRASP and path relinking for the max–min diversity problem. Comput. Oper. Res. 2010, 37, 498–508. [Google Scholar] [CrossRef]
- Correia, I.; Melo, T.; Saldanha-da Gama, F. Comparing classical performance measures for a multi-period, two-echelon supply chain network design problem with sizing decisions. Comput. Ind. Eng. 2013, 64, 366–380. [Google Scholar] [CrossRef] [Green Version]
- Tordecilla, R.D.; Copado-Méndez, P.J.; Panadero, J.; Quintero-Araujo, C.L.; Montoya-Torres, J.R.; Juan, A.A. Combining heuristics with simulation and fuzzy logic to solve a flexible-size location routing problem under uncertainty. Algorithms 2021, 14, 45. [Google Scholar] [CrossRef]
- Peiró, J.; Jiménez, I.; Laguardia, J.; Martí, R. Heuristics for the capacitated dispersion problem. Int. Trans. Oper. Res. 2021, 28, 119–141. [Google Scholar] [CrossRef]
- Erkut, E.; Neuman, S. Analytical models for locating undesirable facilities. Eur. J. Oper. Res. 1989, 40, 275–291. [Google Scholar] [CrossRef]
- Martínez-Gavara, A.; Corberán, T.; Martí, R. GRASP and Tabu Search for the Generalized Dispersion Problem. Expert Syst. Appl. 2021, 173, 114703. [Google Scholar] [CrossRef]
- Daskin, M.S. Network and Discrete Location: Models, Algorithms, and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Lozano-Osorio, I.; Martínez-Gavara, A.; Martí, R.; Duarte, A. Max–min dispersion with capacity and cost for a practical location problem. Expert Syst. Appl. 2022, 200, 116899. [Google Scholar] [CrossRef]
- Rosenkrantz, D.J.; Tayi, G.K.; Ravi, S.S. Facility Dispersion Problems under Capacity and Cost Constraints. J. Comb. Optim. 2000, 4, 7–33. [Google Scholar] [CrossRef]
- Belloso, J.; Juan, A.A.; Faulin, J. An iterative biased-randomized heuristic for the fleet size and mix vehicle-routing problem with backhauls. Int. Trans. Oper. Res. 2019, 26, 289–301. [Google Scholar] [CrossRef] [Green Version]
- Ferone, D.; Hatami, S.; González-Neira, E.M.; Juan, A.A.; Festa, P. A biased-randomized iterated local search for the distributed assembly permutation flow-shop problem. Int. Trans. Oper. Res. 2020, 27, 1368–1391. [Google Scholar] [CrossRef]
- Duarte, A.; Martí, R. Tabu search and GRASP for the maximum diversity problem. Eur. J. Oper. Res. 2007, 178, 71–84. [Google Scholar] [CrossRef]
- Chandrasekaran, R.; Daughety, A. Location on Tree Networks: P-Centre and n-Dispersion Problems. Math. Oper. Res. 1981, 6, 50–57. [Google Scholar] [CrossRef] [Green Version]
- Kuo, C.C.; Glover, F.; Dhir, K.S. Analyzing and Modeling the Maximum Diversity Problem by Zero-One Programming. Decis. Sci. 1993, 24, 1171–1185. [Google Scholar] [CrossRef]
- Ghosh, J.B. Computational aspects of the maximum diversity problem. Oper. Res. Lett. 1996, 19, 175–181. [Google Scholar] [CrossRef] [Green Version]
- Prokopyev, O.A.; Kong, N.; Martinez-Torres, D.L. The equitable dispersion problem. Eur. J. Oper. Res. 2009, 197, 59–67. [Google Scholar] [CrossRef]
- Parreño, F.; Álvarez-Valdés, R.; Martí, R. Measuring diversity. A review and an empirical analysis. Eur. J. Oper. Res. 2021, 289, 515–532. [Google Scholar] [CrossRef]
- Martí, R.; Gallego, M.; Duarte, A.; Pardo, E.G. Heuristics and metaheuristics for the maximum diversity problem. J. Heuristics 2013, 19, 591–615. [Google Scholar] [CrossRef]
- Martí, R.; Gallego, M.; Duarte, A. A branch and bound algorithm for the maximum diversity problem. Eur. J. Oper. Res. 2010, 200, 36–44. [Google Scholar] [CrossRef]
- Lozano, M.; Molina, D.; García-Martínez, C. Iterated greedy for the maximum diversity problem. Eur. J. Oper. Res. 2011, 214, 31–38. [Google Scholar] [CrossRef]
- Zhou, Y.; Hao, J.K.; Duval, B. Opposition-based memetic search for the maximum diversity problem. IEEE Trans. Evol. Comput. 2017, 21, 731–745. [Google Scholar] [CrossRef] [Green Version]
- Aringhieri, R.; Cordone, R. Comparing local search metaheuristics for the maximum diversity problem. J. Oper. Res. Soc. 2011, 62, 266–280. [Google Scholar] [CrossRef]
- Mladenović, N.; Todosijević, R.; Urošević, D. Less is more: Basic variable neighborhood search for minimum differential dispersion problem. Inf. Sci. 2016, 326, 160–171. [Google Scholar] [CrossRef]
- Duarte, A.; Sánchez-Oro, J.; Resende, M.G.; Glover, F.; Martí, R. Greedy randomized adaptive search procedure with exterior path relinking for differential dispersion minimization. Inf. Sci. 2015, 296, 46–60. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, Q.; Glover, F. Effective metaheuristic algorithms for the minimum differential dispersion problem. Eur. J. Oper. Res. 2017, 258, 829–843. [Google Scholar] [CrossRef]
- Zhou, Y.; Hao, J.K. An iterated local search algorithm for the minimum differential dispersion problem. Knowl.-Based Syst. 2017, 125, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Lai, X.; Hao, J.K.; Glover, F.; Yue, D. Intensification-driven tabu search for the minimum differential dispersion problem. Knowl.-Based Syst. 2019, 167, 68–86. [Google Scholar] [CrossRef]
- Martí, R.; Sandoya, F. GRASP and path relinking for the equitable dispersion problem. Comput. Oper. Res. 2013, 40, 3091–3099. [Google Scholar] [CrossRef]
- Lai, X.; Hao, J.K. A tabu search based memetic algorithm for the max-mean dispersion problem. Comput. Oper. Res. 2016, 72, 118–127. [Google Scholar] [CrossRef] [Green Version]
- Carrasco, R.; Pham, A.; Gallego, M.; Gortázar, F.; Martí, R.; Duarte, A. Tabu search for the Max-Mean Dispersion Problem. Knowl.-Based Syst. 2015, 85, 256–264. [Google Scholar] [CrossRef]
- Brimberg, J.; Mladenović, N.; Todosijević, R.; Urošević, D. Less is more: Solving the Max-Mean diversity problem with variable neighborhood search. Inf. Sci. 2017, 382–383, 179–200. [Google Scholar] [CrossRef]
- Lai, X.; Yue, D.; Hao, J.K.; Glover, F. Solution-based tabu search for the maximum min-sum dispersion problem. Inf. Sci. 2018, 441, 79–94. [Google Scholar] [CrossRef]
- Amirgaliyeva, Z.; Mladenović, N.; Todosijević, R.; Urošević, D. Solving the maximum min-sum dispersion by alternating formulations of two different problems. Eur. J. Oper. Res. 2017, 260, 444–459. [Google Scholar] [CrossRef]
- Martínez-Gavara, A.; Campos, V.; Laguna, M.; Martí, R. Heuristic solution approaches for the maximum minsum dispersion problem. J. Glob. Optim. 2017, 67, 671–686. [Google Scholar] [CrossRef]
- Lai, X.; Fu, Z.H. A tabu search approach with dynamical neighborhood size for solving the maximum min-sum dispersion problem. IEEE Access 2019, 7, 181357–181368. [Google Scholar] [CrossRef]
- Martí, R.; Martínez-Gavara, A.; Sánchez-Oro, J. The capacitated dispersion problem: An optimization model and a memetic algorithm. Memetic Comput. 2021, 13, 131–146. [Google Scholar] [CrossRef]
- Sayyady, F.; Fathi, Y. An integer programming approach for solving the p-dispersion problem. Eur. J. Oper. Res. 2016, 253, 216–225. [Google Scholar] [CrossRef]
- Juan, A.A.; Corlu, C.G.; Tordecilla, R.D.; de la Torre, R.; Ferrer, A. On the use of biased-randomized algorithms for solving non-smooth optimization problems. Algorithms 2020, 13, 8. [Google Scholar] [CrossRef] [Green Version]
- Grasas, A.; Juan, A.A.; Faulin, J.; De Armas, J.; Ramalhinho, H. Biased randomization of heuristics using skewed probability distributions: A survey and some applications. Comput. Ind. Eng. 2017, 110, 216–228. [Google Scholar] [CrossRef]
- Juan, A.A.; Faulin, J.; Ferrer, A.; Lourenço, H.R.; Barrios, B. MIRHA: Multi-start biased randomization of heuristics with adaptive local search for solving non-smooth routing problems. TOP 2013, 21, 109–132. [Google Scholar] [CrossRef]
- Ferrer, A.; Guimarans, D.; Ramalhinho, H.; Juan, A.A. A BRILS metaheuristic for non-smooth flow-shop problems with failure-risk costs. Expert Syst. Appl. 2016, 44, 177–186. [Google Scholar] [CrossRef] [Green Version]
- Dominguez, O.; Juan, A.A.; De La Nuez, I.; Ouelhadj, D. An ILS-biased randomization algorithm for the two-dimensional loading HFVRP with sequential loading and items rotation. J. Oper. Res. Soc. 2016, 67, 37–53. [Google Scholar] [CrossRef] [Green Version]
- Estrada-Moreno, A.; Savelsbergh, M.; Juan, A.A.; Panadero, J. Biased-randomized iterated local search for a multiperiod vehicle routing problem with price discounts for delivery flexibility. Int. Trans. Oper. Res. 2019, 26, 1293–1314. [Google Scholar] [CrossRef]
- Alvarez, S.; Ferone, D.; Juan, A.A.; Silva, D.; de Armas, J. A 2-stage biased-randomized iterated local search for the uncapacitated single allocation p-hub median problem. Trans. Emerg. Telecommun. Technol. 2018, 29, e3418. [Google Scholar] [CrossRef]
- Alvarez, S.; Ferone, D.; Juan, A.; Tarchi, D. A simheuristic algorithm for video streaming flows optimisation with QoS threshold modelled as a stochastic single-allocation p-hub median problem. J. Simul. 2021. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance | Solution Approach | Gaps (%) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Gurobi (UB) [1] | Martí et al. [51] BKS [2] | GRASP [3] | Constructive Avg [4] | Constructive Best [5] | Destructive Avg [6] | Destructive Best [7] | [1]–[5] | [1]–[7] | [2]–[5] | [2]–[7] | [3]–[5] | [3]–[7] | [5]–[7] | |
| SOM-a_11_n50_m5 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SOM-a_12_n50_m5 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SOM-a_13_n50_m5 | 5.0 | 5.0 | 5.0 | 5.0 | 5.0 | 5.0 | 5.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SOM-a_14_n50_m5 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SOM-a_15_n50_m5 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SOM-a_16_n50_m15 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SOM-a_17_n50_m15 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SOM-a_18_n50_m15 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SOM-a_19_n50_m15 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| SOM-a_20_n50_m15 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 4.0 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| GKD-b_11_n50_b02 | 147.2 | 147.2 | 147.2 | 135.1 | 147.2 | 146.6 | 146.6 | 0.0% | 0.4% | 0.0% | 0.4% | 0.0% | 0.4% | 0.4% |
| GKD-b_12_n50_b02 | 178.1 | 178.1 | 178.1 | 164.9 | 178.1 | 178.1 | 178.1 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| GKD-b_13_n50_b02 | 96.1 | 93.6 | 96.1 | 83.6 | 96.1 | 92.2 | 92.2 | 0.0% | 4.1% | −2.7% | 1.5% | 0.0% | 4.1% | 4.1% |
| GKD-b_14_n50_b02 | 84.6 | 84.6 | 84.6 | 73.3 | 84.6 | 84.6 | 84.6 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| GKD-b_15_n50_b02 | 154.9 | 154.9 | 154.9 | 140.7 | 154.9 | 154.9 | 154.9 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| GKD-b_16_n50_b02 | 77.7 | 77.7 | 77.7 | 65.8 | 77.7 | 77.7 | 77.7 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| GKD-b_17_n50_b02 | 41.8 | 38.2 | 41.8 | 33.2 | 41.8 | 38.4 | 38.4 | 0.0% | 8.1% | −9.4% | −0.5% | 0.0% | 8.1% | 8.1% |
| GKD-b_18_n50_b02 | 108.5 | 108.5 | 108.5 | 97.6 | 108.5 | 105.9 | 106.6 | 0.0% | 1.8% | 0.0% | 1.8% | 0.0% | 1.8% | 1.8% |
| GKD-b_19_n50_b02 | 119.1 | 119.1 | 119.1 | 106.1 | 119.1 | 119.1 | 119.1 | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| GKD-b_20_n50_b02 | 115.3 | 115.3 | 115.3 | 103.5 | 115.3 | 108.7 | 108.7 | 0.0% | 5.7% | 0.0% | 5.7% | 0.0% | 5.7% | 5.7% |
| GKD-b_41_n150_b02 | 164.2 | 161.8 | 161.7 | 152.7 | 164.2 | 157.5 | 158.7 | 0.0% | 3.3% | −1.5% | 1.9% | −1.5% | 1.9% | 3.3% |
| GKD-b_42_n150_b02 | 84.3 | 84.1 | 84.0 | 74.6 | 84.1 | 82.9 | 84.0 | 0.2% | 0.4% | 0.0% | 0.1% | −0.1% | 0.0% | 0.1% |
| GKD-b_43_n150_b02 | 63.3 | 62.0 | 62.0 | 54.4 | 62.7 | 61.5 | 62.5 | 0.9% | 1.3% | −1.1% | −0.8% | −1.1% | −0.8% | 0.3% |
| GKD-b_44_n150_b02 | 103.3 | 101.6 | 102.2 | 91.4 | 102.2 | 98.1 | 98.6 | 1.1% | 4.5% | −0.6% | 3.0% | 0.0% | 3.5% | 3.5% |
| GKD-b_45_n150_b02 | 106.6 | 105.8 | 104.9 | 96.0 | 106.6 | 104.4 | 104.4 | 0.0% | 2.1% | −0.8% | 1.3% | −1.6% | 0.5% | 2.1% |
| GKD-b_46_n150_b02 | 124.5 | 123.8 | 124.4 | 113.2 | 124.5 | 123.2 | 123.2 | 0.0% | 1.0% | −0.6% | 0.5% | −0.1% | 1.0% | 1.0% |
| GKD-b_47_n150_b02 | 163.4 | 162.6 | 163.0 | 153.2 | 162.9 | 162.3 | 162.5 | 0.3% | 0.6% | −0.2% | 0.1% | 0.1% | 0.3% | 0.2% |
| GKD-b_48_n150_b02 | 100.2 | 98.7 | 98.5 | 89.3 | 100.0 | 98.1 | 98.1 | 0.2% | 2.1% | −1.3% | 0.6% | −1.5% | 0.4% | 1.9% |
| GKD-b_49_n150_b02 | 166.3 | 165.5 | 166.3 | 156.0 | 166.3 | 166.0 | 166.3 | 0.0% | 0.0% | −0.5% | −0.5% | 0.0% | 0.0% | 0.0% |
| GKD-b_50_n150_b02 | 111.2 | 110.3 | 110.1 | 100.0 | 111.2 | 107.3 | 108.1 | 0.0% | 2.8% | −0.8% | 2.0% | −1.0% | 1.8% | 2.8% |
| GKD-c_01_n500_b02 | 9.4 | 9.2 | 9.1 | 8.3 | 9.1 | 9.1 | 9.1 | 3.2% | 3.2% | 1.1% | 1.1% | 0.0% | 0.0% | 0.0% |
| GKD-c_02_n500_b02 | 9.5 | 9.3 | 9.2 | 8.4 | 9.4 | 9.2 | 9.2 | 1.1% | 3.2% | −1.1% | 1.1% | −2.2% | 0.0% | 2.1% |
| GKD-c_03_n500_b02 | 9.4 | 9.2 | 9.1 | 8.3 | 9.2 | 8.9 | 9.0 | 2.1% | 4.3% | 0.0% | 2.2% | −1.1% | 1.1% | 2.2% |
| GKD-c_04_n500_b02 | 9.3 | 9.1 | 9.0 | 8.2 | 9.1 | 9.0 | 9.1 | 2.2% | 2.2% | 0.0% | 0.0% | −1.1% | −1.1% | 0.0% |
| GKD-c_05_n500_b02 | 9.3 | 9.1 | 9.0 | 8.2 | 9.1 | 8.9 | 9.0 | 2.2% | 3.2% | 0.0% | 1.1% | −1.1% | 0.0% | 1.1% |
| GKD-c_06_n500_b02 | 9.4 | 9.0 | 8.9 | 8.2 | 9.1 | 8.9 | 8.9 | 3.2% | 5.3% | −1.1% | 1.1% | −2.2% | 0.0% | 2.2% |
| GKD-c_07_n500_b02 | 9.3 | 9.1 | 9.1 | 8.3 | 9.1 | 9.0 | 9.1 | 2.2% | 2.2% | 0.0% | 0.0% | 0.0% | 0.0% | 0.0% |
| GKD-c_08_n500_b02 | 9.6 | 9.3 | 9.3 | 8.5 | 9.5 | 9.2 | 9.3 | 1.0% | 3.1% | −2.2% | 0.0% | −2.2% | 0.0% | 2.1% |
| GKD-c_09_n500_b02 | 9.3 | 9.1 | 9.1 | 8.2 | 9.0 | 9.0 | 9.0 | 3.2% | 3.2% | 1.1% | 1.1% | 1.1% | 1.1% | 0.0% |
| GKD-c_10_n500_b02 | 9.5 | 9.3 | 9.1 | 8.3 | 9.2 | 9.1 | 9.2 | 3.2% | 3.2% | 1.1% | 1.1% | −1.1% | −1.1% | 0.0% |
| MDG-b_01_n500_b02 | 125.0 | 50.6 | 51.1 | 37.5 | 56.9 | 51.7 | 54.5 | - | - | −12.5% | −7.7% | −11.4% | −6.7% | 4.2% |
| MDG-b_02_n500_b02 | 125.0 | 46.0 | 46.6 | 33.4 | 50.9 | 44.8 | 50.0 | - | - | −10.7% | −8.7% | −9.2% | −7.3% | 1.8% |
| MDG-b_03_n500_b02 | 125.0 | 45.8 | 45.3 | 33.8 | 51.4 | 43.6 | 45.8 | - | - | −12.2% | 0.0% | −13.5% | −1.1% | 10.9% |
| MDG-b_04_n500_b02 | 125.0 | 47.6 | 49.6 | 34.7 | 53.0 | 41.5 | 42.9 | - | - | −11.3% | 9.9% | −6.9% | 13.5% | 19.1% |
| MDG-b_05_n500_b02 | 125.0 | 49.1 | 48.1 | 34.9 | 50.7 | 46.7 | 49.1 | - | - | −3.3% | 0.0% | −5.4% | −2.1% | 3.2% |
| MDG-b_06_n500_b02 | 125.0 | 46.6 | 45.4 | 33.7 | 49.9 | 44.6 | 48.7 | - | - | −7.1% | −4.5% | −9.9% | −7.3% | 2.4% |
| MDG-b_07_n500_b02 | 125.0 | 47.3 | 44.9 | 33.1 | 47.9 | 43.4 | 45.5 | - | - | −1.3% | 3.8% | −6.7% | −1.3% | 5.0% |
| MDG-b_08_n500_b02 | 125.0 | 48.7 | 45.2 | 34.0 | 51.8 | 48.1 | 50.1 | - | - | −6.4% | −2.9% | −14.6% | −10.8% | 3.3% |
| MDG-b_09_n500_b02 | 125.0 | 48.8 | 47.8 | 35.9 | 52.7 | 46.7 | 49.9 | - | - | −8.0% | −2.3% | −10.3% | −4.4% | 5.3% |
| MDG-b_10_n500_b02 | 125.0 | 50.5 | 47.5 | 34.9 | 56.5 | 47.5 | 52.7 | - | - | −11.9% | −4.4% | −18.9% | −10.9% | 6.7% |
| Average | 73.9 | 58.1 | 58.1 | 51.1 | 59.3 | 57.1 | 57.9 | 0.7% | 1.8% | % | 0.2% | % | % | 2.1% |
| Instance | Minimum Aggregate Capacity m | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0.8 | 0.6 | 0.4 | |||||||
| Constructive | Destructive | Gap | Constructive | Destructive | Gap | Constructive | Destructive | Gap | |
| GKD-b_11_n50_b02 | 95.3 | 95.3 | 0.0% | 107.8 | 107.8 | 0.0% | 122.4 | 122.4 | 0.0% |
| GKD−b_12_n50_b02 | 117.7 | 117.7 | 0.0% | 136.1 | 136.1 | 0.0% | 148.7 | 146.1 | 1.7% |
| GKD−b_13_n50_b02 | 43.0 | 43.0 | 0.0% | 55.1 | 55.1 | 0.0% | 70.9 | 70.9 | 0.0% |
| GKD−b_14_n50_b02 | 39.7 | 39.7 | 0.0% | 47.9 | 47.9 | 0.0% | 62.5 | 62.5 | 0.0% |
| GKD−b_15_n50_b02 | 93.0 | 92.9 | 0.1% | 111.1 | 109.9 | 1.1% | 129.2 | 129.2 | 0.0% |
| GKD−b_16_n50_b02 | 22.2 | 22.2 | 0.0% | 39.0 | 39.0 | 0.0% | 49.1 | 49.1 | 0.0% |
| GKD−b_17_n50_b02 | 6.5 | 6.5 | 0.0% | 13.8 | 12.9 | 6.5% | 22.5 | 21.9 | 2.7% |
| GKD−b_18_n50_b02 | 54.8 | 54.8 | 0.0% | 74.4 | 72.7 | 2.3% | 88.0 | 84.8 | 3.6% |
| GKD−b_19_n50_b02 | 64.6 | 64.6 | 0.0% | 81.0 | 76.7 | 5.3% | 96.3 | 96.1 | 0.2% |
| GKD−b_20_n50_b02 | 65.1 | 65.1 | 0.0% | 77.9 | 77.9 | 0.0% | 90.1 | 90.1 | 0.0% |
| GKD−b_41_n150_b02 | 117.4 | 118.8 | −1.2% | 129.5 | 130.3 | −0.6% | 145.2 | 143.5 | 1.2% |
| GKD−b_42_n150_b02 | 43.5 | 43.9 | −0.9% | 52.8 | 53.3 | −0.9% | 64.7 | 64.9 | −0.3% |
| GKD−b_43_n150_b02 | 27.6 | 28.3 | −2.5% | 37.4 | 38.0 | −1.6% | 44.2 | 44.6 | −0.9% |
| GKD−b_44_n150_b02 | 56.6 | 58.3 | −3.0% | 69.4 | 69.5 | −0.1% | 79.5 | 78.8 | 0.9% |
| GKD−b_45_n150_b02 | 65.9 | 66.5 | −0.9% | 75.3 | 76.6 | −1.7% | 87.7 | 88.6 | −1.0% |
| GKD−b_46_n150_b02 | 76.3 | 76.8 | −0.7% | 88.1 | 89.9 | −2.0% | 102.2 | 102.2 | 0.0% |
| GKD−b_47_n150_b02 | 119.1 | 120.6 | −1.3% | 131.1 | 131.6 | −0.4% | 143.0 | 143.5 | −0.3% |
| GKD−b_48_n150_b02 | 57.7 | 58.6 | −1.6% | 66.9 | 68.5 | −2.4% | 78.2 | 77.7 | 0.6% |
| GKD−b_49_n150_b02 | 120.6 | 121.2 | −0.5% | 133.8 | 133.3 | 0.4% | 147.1 | 147.1 | 0.0% |
| GKD−b_50_n150_b02 | 66.1 | 67.0 | −1.4% | 77.2 | 77.3 | −0.1% | 90.1 | 89.9 | 0.2% |
| GKD−c_01_n500_b02 | 5.5 | 5.7 | −3.6% | 6.4 | 6.6 | −3.1% | 7.3 | 7.5 | −2.7% |
| GKD−c_02_n500_b02 | 5.7 | 5.8 | −1.8% | 6.4 | 6.6 | −3.1% | 7.5 | 7.6 | −1.3% |
| GKD−c_03_n500_b02 | 5.5 | 5.7 | −3.6% | 6.3 | 6.4 | −1.6% | 7.3 | 7.5 | −2.7% |
| GKD−c_04_n500_b02 | 5.4 | 5.5 | −1.9% | 6.3 | 6.5 | −3.2% | 7.3 | 7.5 | −2.7% |
| GKD−c_05_n500_b02 | 5.5 | 5.6 | −1.8% | 6.3 | 6.5 | −3.2% | 7.4 | 7.5 | −1.4% |
| GKD−c_06_n500_b02 | 5.4 | 5.6 | −3.7% | 6.4 | 6.6 | −3.1% | 7.3 | 7.4 | −1.4% |
| GKD−c_07_n500_b02 | 5.5 | 5.7 | −3.6% | 6.4 | 6.6 | −3.1% | 7.2 | 7.4 | −2.8% |
| GKD−c_08_n500_b02 | 5.4 | 5.5 | −1.9% | 6.4 | 6.6 | −3.1% | 7.5 | 7.6 | −1.3% |
| GKD−c_09_n500_b02 | 5.6 | 5.7 | −1.8% | 6.4 | 6.5 | −1.6% | 7.3 | 7.4 | −1.4% |
| GKD−c_10_n500_b02 | 5.5 | 5.7 | −3.6% | 6.4 | 6.5 | −1.6% | 7.4 | 7.6 | −2.7% |
| MDG−b_01_n500_b02 | 1.4 | 1.9 | −35.7% | 4.0 | 5.0 | −25.0% | 11.5 | 14.5 | −26.1% |
| MDG−b_02_n500_b02 | 1.2 | 1.6 | −33.3% | 4.2 | 5.5 | −31.0% | 12.2 | 13.5 | −10.7% |
| MDG−b_03_n500_b02 | 1.2 | 1.4 | −16.7% | 3.7 | 5.2 | −40.5% | 10.4 | 12.3 | −18.3% |
| MDG−b_04_n500_b02 | 1.2 | 1.6 | −33.3% | 3.5 | 5.1 | −45.7% | 9.6 | 11.0 | −14.6% |
| MDG−b_05_n500_b02 | 1.2 | 1.7 | −41.7% | 3.7 | 4.8 | −29.7% | 10.5 | 13.1 | −24.8% |
| MDG−b_06_n500_b02 | 1.3 | 1.6 | −23.1% | 3.7 | 5.2 | −40.5% | 11.2 | 13.1 | −17.0% |
| MDG−b_07_n500_b02 | 1.5 | 1.8 | −20.0% | 4.2 | 5.0 | −19.0% | 10.6 | 14.0 | −32.1% |
| MDG−b_08_n500_b02 | 1.4 | 1.8 | −28.6% | 4.7 | 5.7 | −21.3% | 13.8 | 16.2 | −17.4% |
| MDG−b_09_n500_b02 | 1.4 | 1.8 | −28.6% | 3.8 | 5.8 | −52.6% | 12.7 | 14.8 | −16.5% |
| MDG−b_10_n500_b02 | 1.2 | 1.8 | −50.0% | 3.8 | 5.2 | −36.8% | 11.4 | 13.4 | −17.1% |
| Average | 35.5 | 35.9 | −8.8% | 42.7 | 43.1 | −9.1% | 51.2 | 51.6 | −5.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gomez, J.F.; Panadero, J.; Tordecilla, R.D.; Castaneda, J.; Juan, A.A. A Multi-Start Biased-Randomized Algorithm for the Capacitated Dispersion Problem. Mathematics 2022, 10, 2405. https://doi.org/10.3390/math10142405
Gomez JF, Panadero J, Tordecilla RD, Castaneda J, Juan AA. A Multi-Start Biased-Randomized Algorithm for the Capacitated Dispersion Problem. Mathematics. 2022; 10(14):2405. https://doi.org/10.3390/math10142405
Chicago/Turabian StyleGomez, Juan F., Javier Panadero, Rafael D. Tordecilla, Juliana Castaneda, and Angel A. Juan. 2022. "A Multi-Start Biased-Randomized Algorithm for the Capacitated Dispersion Problem" Mathematics 10, no. 14: 2405. https://doi.org/10.3390/math10142405
APA StyleGomez, J. F., Panadero, J., Tordecilla, R. D., Castaneda, J., & Juan, A. A. (2022). A Multi-Start Biased-Randomized Algorithm for the Capacitated Dispersion Problem. Mathematics, 10(14), 2405. https://doi.org/10.3390/math10142405