
Theoretical Bounds on the Number of Tests in Noisy Threshold Group Testing Frameworks

{kind=link}
Abstract
:1. Introduction
2. Related Work
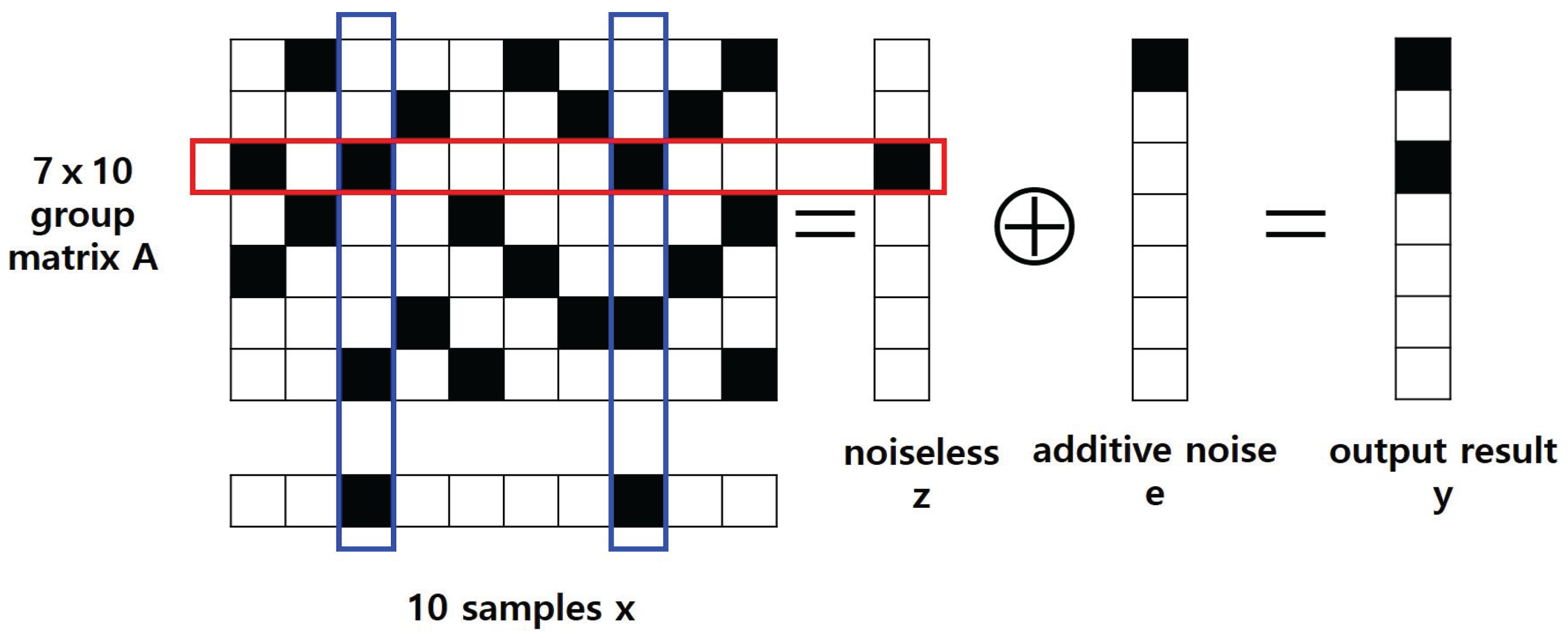
3. Noisy Threshold Group Testing Framework
3.1. Problem Statement
3.2. Decoding
3.3. Bounds for Group Testing Schemes
4. Necessary Condition for Complete Recovery
4.1. Lower Bound
4.2. Construction of Noisy Threshold Group Testing
5. Sufficient Condition for Average Performance
5.1. Upper Bound
5.2. Discussion for Necessary and Sufficient Conditions
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dorfman, R. The Detection of Defective Members of Large Populations. Ann. Math. Stat. 1943, 14, 436–440. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed Sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Du, D.-Z.; Hwang, F.-K. Pooling Designs and Nonadaptive Group Testing: Important Tools for DNA Sequencing; World Scientific: Singapore, 2006. [Google Scholar]
- Verdun, C.M.; Fuchs, T.; Harar, P.; Elbrächter, D.; Fischer, D.S.; Berner, J.; Grohs, P.; Theis, F.J.; Krahmer, F. Group Testing for SARS-CoV-2 Allows for Up to 10-Fold Efficiency Increas across Realistic Scenarios and Testing Strategies. Front. Public Health 2021, 9, 583377. [Google Scholar] [CrossRef] [PubMed]
- Mutesa, L.; Ndishimye, P.; Butera, Y.; Souopgui, J.; Uwineza, A.; Rutayisire, R.; Ndoricimpaye, E.L.; Musoni, E.; Rujeni, N.; Nyatanyi, T.; et al. A pooled testing strategy for identifying SARS-CoV-2 at low prevalence. Nature 2021, 589, 276–280. [Google Scholar] [CrossRef] [PubMed]
- Damaschke, P. Threshold group testing. Gen. Theory Inf. Transf. Comb. LNCS 2006, 4123, 707–718. [Google Scholar]
- Bui, T.V.; Kuribayashi, M.; Cheraghchi, M.; Echizen, I. Efficiently Decodable Non-Adaptive Threshold Group Testing. IEEE Trans. Inf. Theory 2019, 65, 5519–5528. [Google Scholar] [CrossRef] [Green Version]
- Seong, J.-T. Theoretical Bounds on Performance in Threshold Group Testing. Mathematics 2020, 8, 637. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Bonis, A.D. An almost optimal algorithm for generalized threshold group testing with inhibitors. J. Comput. Biol. 2011, 18, 851–864. [Google Scholar] [CrossRef] [PubMed]
- De Marco, G.; Jurdzinski, T.; Rozanski, M.; Stachowiak, G. Subquadratic non-adaptive threshold group testing. Fundam. Comput. Theory 2017, 111, 177–189. [Google Scholar]
- Sterrett, A. On the Detection of Defective Members of Large Populations. Ann. Math. Stat. 1957, 28, 1033–1036. [Google Scholar] [CrossRef]
- Sobel, M.; Groll, P.A. Group testing to eliminate efficiently all defectives in a binomial sample. Bell Syst. Tech. J. 1959, 38, 1179–1252. [Google Scholar] [CrossRef]
- Allemann, A. An Efficient Algorithm for Combinatorial Group Testing. In Information Theory, Combinatorics, and Search Theory; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7777. [Google Scholar]
- Srivastava, J.N. A Survey of Combinatorial Theory; North Holland Publishing Co.: Amsterdam, The Netherlands, 1973. [Google Scholar]
- Riccio, L.; Colbourn, C.J. Sharper bounds in adaptive group testing. Taiwan. J. Math. 2000, 4, 669–673. [Google Scholar] [CrossRef]
- Leu, M.-G. A note on the Hu–Hwang–Wang conjecture for group testing. ANZIAM J. 2008, 49, 561–571. [Google Scholar] [CrossRef] [Green Version]
- Chan, C.L.; Che, P.H.; Jaggi, S.; Saligrama, V. Non-adaptive probabilistic group testing with noisy measurements: Near-optimal bounds with efficient algorithms. In Proceedings of the 49th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 28–30 September 2011. [Google Scholar]
- Atia, G.K.; Saligrama, V. Boolean Compressed Sensing and Noisy Group Testing. IEEE Trans. Inf. Theory 2012, 58, 1880–1901. [Google Scholar] [CrossRef] [Green Version]
- Malyutov, M. The separating property of random matrices. Math. Notes Acad. Sci. USSR 1978, 23, 84–91. [Google Scholar] [CrossRef]
- Sejdinovic, D.; Johnson, O. Note on noisy group testing: Asymptotic bounds and belief propagation reconstruction. In Proceedings of the 48th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 29 September–1 October 2010. [Google Scholar]
- Malioutov, D.; Malyutov, M. Boolean compressed sensing: LP relaxation for group testing. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012. [Google Scholar]
- Bondorf, S.; Chen, B.; Scarlett, J.; Yu, H.; Zhao, Y. Sublinear-time non-adaptive group testing with O(k log n) tests via bit-mixing coding. IEEE Trans. Inf. Theory 2021, 67, 1559–1570. [Google Scholar] [CrossRef]
- Goodrich, M.T.; Atallah, M.J.; Tamassia, R. Indexing information for data forensics. In Proceedings of the Third International Conference on Applied Cryptography and Network Security, New York, NY, USA, 7–10 June 2005. [Google Scholar]
- Mistry, D.A.; Wang, J.Y.; Moeser, M.E.; Starkey, T.; Lee, L.Y. A systematic review of the sensitivity and specificity of lateral flow devices in the detection of SARS-CoV-2. BMC Infect. Dis. 2021, 21, 828. [Google Scholar] [CrossRef] [PubMed]
- Baldassini, L.; Johnson, O.; Aldridge, M. The capacity of adaptive group testing. In Proceedings of the IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013. [Google Scholar]
- Aldridge, M.; Baldassini, L.; Johnson, O. Group Testing Algorithms: Bounds and Simulations. IEEE Trans. Inf. Theory 2014, 60, 3671–3687. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar]
- Aldridge, M.; Johnson, O.; Scarlett, J. Group Testing: An Information Theory Perspective. Found. Trends Commun. Inf. Theory 2019, 15, 196–392. [Google Scholar] [CrossRef] [Green Version]
- Gallager, R. Information Theory and Reliable Communication; John Wiley and Sons: Hoboken, NJ, USA, 1968. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seong, J.-T. Theoretical Bounds on the Number of Tests in Noisy Threshold Group Testing Frameworks. Mathematics 2022, 10, 2508. https://doi.org/10.3390/math10142508
Seong J-T. Theoretical Bounds on the Number of Tests in Noisy Threshold Group Testing Frameworks. Mathematics. 2022; 10(14):2508. https://doi.org/10.3390/math10142508
Chicago/Turabian StyleSeong, Jin-Taek. 2022. "Theoretical Bounds on the Number of Tests in Noisy Threshold Group Testing Frameworks" Mathematics 10, no. 14: 2508. https://doi.org/10.3390/math10142508
APA StyleSeong, J. -T. (2022). Theoretical Bounds on the Number of Tests in Noisy Threshold Group Testing Frameworks. Mathematics, 10(14), 2508. https://doi.org/10.3390/math10142508