1. Introduction
The leverage effect in financial economics refers to the correlation between the driven system of an asset price and its volatility. It is widely accepted that the leverage effect is a common stylized fact of financial data, like the skewed distribution, volatility asymmetry, etc. Moreover, empirical analyses have provided evidence that the returns of equities are usually negatively correlated to the near future volatility. Ang and Chen [
1] found that volatility rises when stock prices go down and that volatility decreases if stock prices go up, see also Black [
2], Christie [
3].
The existence of the leverage effect is explained from an economic point of view, firstly. For example, Modigliani and Miller [
4] linked the leverage effect to the financial leverage of a firm, namely, the debt–equity ratio, which reflects a firm’s capital structure. Using the idea of leverage well demonstrates the negative leverage effect usually found in financial data. Precisely, with an increase in the stock price, the value of equity increases more than the value of debt because the claims of the debt holders are limited in a short time interval; thus, its leverage (debt to equity ratio) decreases; hence, the firm will be less risky, which results in a drop in the volatility. The same logic applies to falling stock prices, which should lead to an increase in future volatility. However, the financial leverage is not the only driver for the price-volatility relation, there is also evidence that the leverage effect observed in financial time series is not fully explained by a firm’s leverage. Modigliani and Miller [
4] found a strong leverage effect for falling stock prices but a very weak, even nonexistent, leverage effect for positive returns; Hens and Steude [
5] and Hasanhodzic and Lo [
6] found the leverage effect in many financial markets although the underlying asset did not exhibit any financial leverage at all.
The leverage effect characterizes the correlation between the latent process and the volatility process, since the volatility process is unobservable; hence, it has to be estimate with the observed data. For low-frequency data, it is hard to estimate unless assuming some stationary condition. However, for high-frequency data, it can be estimated more accurately. Therefore, the leverage effect can be more accurately measured in high-frequency data than low-frequency data. Recently, with help of widely available high-frequency financial data, the leverage effect can be quantitatively modelled and the statistical estimation of the leverage effect has been investigated. For example, Aït-Sahalia et al. [
7] found that an estimator of the leverage effect using high-frequency data yields a “zero” estimator whatever the true value of the leverage effect is, based on the Heston’s stochastic volatility model and they created a bias-corrected consistent estimator; Wang and Mykland [
8] considered the estimation of the leverage effect under the presence of microstructure noise; Aït-Sahalia et al. [
9] further theoretically split the leverage effect into two parts: the continuous leverage effect and discontinuous leverage effect, which are the quadratic co-variations of continuous diffusion parts and jump parts of a volatility process and underlying-price process, respectively. Both leverage effects have been consistently estimated. They also showed the empirical evidence of the existence of the two kinds of leverage effects; Kalnina and Xiu [
10] proposed a nonparametric model-free estimator for the leverage effect. The study provided two estimators for the leverage effect, the first one only uses the discretely observed stock-price data, as usual, while the second estimator also employs VIX data as the observation of the volatility process to improve estimation efficiency.
Despite the economic rationale and non-zero measure of the leverage effect in empirical analysis for most financial markets and equities, there is yet no theoretically valid test to tell whether it indeed exists under a given nominal level. If one wants to test the non-zero leverage effect, a natural way is to estimate the leverage effect first and then use the asymptotic normality (Studentized version) of the estimator to construct the confidence intervals. As the volatility is totally unobservable, we must estimate the volatility in advance, and then, based on these “estimated data” of the volatility and observed price data, we can compute the estimator of leverage effect, as stated in the above literature. This procedure, although theoretically feasible, must have a very slow convergence rate, which pays for the two estimation procedures ahead of the test statistic.
Mathematically speaking, we consider a continuous-time semi-martingale:
where
W is a standard Brownian motion defined on an appropriate probability space, and
b and
are two processes satisfying some regular conditions (specified later), so that the stochastic differential equation is well-defined. The quantity of interest is the correlation between the two processes
and
X, precisely, the quadratic co-variation
In this paper, we provide a simple and easy-ito-mplement testing procedure in which we do not need to estimate the leverage effect. Precisely, we assume that the volatility process further follows a continuous semi-martingale:
where
W is the driven Brownian motion of
X and
B is another standard Brownian motion, independent of
W. Under this framework, we can see that
indicates the absence of the leverage effect. Therefore, it is necessary to find statistics whose limit is an explicit function of
L. For instance, we can firstly estimate it by the method in either Wang and Mykland [
8] or Aït-Sahalia et al. [
9], and then create the test statistics from a related central limit theorem. Here, instead of estimating first and testing afterwards, we create a direct test procedure. Kinnebrock and Podolskij [
11] derived the following limiting result for the cubic variation of semi-martingale:
From this limiting result, if
(under the null hypothesis), the limit on the right-hand side is a conditional normal random variable. Moreover, the “conditional mean”
can be consistently estimated, and the conditional variance can be consistently estimated as well. That is, after Studentization, it would result in a standard normal distribution asymptotically. Our analysis shows that this de-biased and Studentized statistic, although it indeed yields a satisfactory performance under the null hypothesis as expected, it does not provide a unit power under the alternative hypothesis. To improve the power, we consider the high-frequency data of a long time period—
, for instance—and then implement and replicate the procedure in each time interval
for
, to obtain a sequence of asymptotically independent standard normal random variables. The final test statistic is constructed globally based on these independent standard normal random variables. We can show that this overall test procedure provides a unit power under the alternative hypothesis; the
T is large. We establish the related asymptotic theory under both null and alternative hypotheses. The simulation studies assess the finite sample performance of the proposed test and show that the test provides satisfactory finite sample size and power. Finally, we also implement the procedure to test the presence of the leverage effect in modelling the SP500 index. The high-frequency dataset consists of the daily SP500 index in years 2000–2019, a total of 240 months. We consider the null hypothesis of the absence of the monthly leverage effect. The results show that the null hypothesis of zero monthly leverage effect is rejected for most of months. This supports the claim that the leverage effect is a necessary component in modelling high-frequency data.
The remainder of this paper is organized as follows.
Section 2 contains the model setup and assumptions. In
Section 3, we introduce some statistics and derive the related central limit theorem, based on which the test procedure is presented.
Section 4 is the simulation studies and
Section 5 is the application to a real high-frequency dataset. All the technical proofs are put into the
Appendix A.
3. Test
Over the time interval
, we assume that the process
X is observed discretely on the time points
,
, where
. Let
. We start from an auxiliary result from Kinnebrock and Podolskij [
11], which gives the asymptotic behaviour of the cubic power variation of
X:
where
is a standard Brownian motion defined on an extension of the original probability space independent of
W and
B and
denotes the stable convergence. (A sequence of random variables,
, is said to converge stably in law to
, which is defined on an appropriate extension of the origin probability space
if, for any
measurable, bounded random variable
and any bounded continuous function
f, we have the convergence
where
is the expectation defined on the extended probability space. The stable convergence is slightly stronger than the weak convergence (let
); we write the stable convergence as
. We refer to Renyi [
19] and Aldous and Eagleson [
20] for the more detailed discussion on stable convergence. The extension of stable convergence to stochastic processes has been discussed in Jacod and Shiryayev [
21] (Chap. IX.7).) The first two terms in the limit are from the process
X. Under
, the first term vanishes; if we could consistently estimate the second term, then only a mixed normal variable remains in the limit. We now illustrate this standardization procedure.
In the following, denotes the convergence in distribution if the limit is a random variable and denotes the weak convergence if the limit is a distribution, and denotes the convergence in probability.
Observing the convergence in (
20), under the null hypothesis
, namely,
, we have
If we have a consistent estimator for the “bias” term
, then the quantity on the left-hand side will behave asymptotically as a mixed normal random variable. This idea results in the following proposition. We define the local volatility estimator as
where we take
for some
.
Proposition 1. Assumption 1 holds. If , then we havewhere Z is a standard normal variable. Here, we take an appropriate Studentization to obtain the standard normal, which is necessary for a valid test procedure. The denominator is just the standard deviation of the normal variable in the numerator.
Remark 2. The asymptotic result above provides a guarantee on the first type error. However, it is not a consistent text statistic. We see that, under the alternative hypothesis , we haveHere, the limit on the right-hand side is a mixed normal random variable with conditional meanTherefore, the asymptotic power for this test is not 1. The reason is that we only use the data from a fixed period ; the bias under the alternative is not big enough to guarantee the asymptotic power is 1. Therefore, one natural way to increase the power is to use the data from a long time period, . Following this idea, we may overcome the issue of power by considering the data from a long time span (
). We denote
as the sample size of one period for some
, and define
for
with
.
Theorem 1. X and σ satisfy Assumption 1. If , and if as , for a continuous function g with finite first order derivative , and , then we havewhere Z defines a standard normal variable. Now, under the alternative hypothesis, since the new test statistic gathers non-central normal random variables (conditionally independent), it would tend to infinity with . This is demonstrated by the following corollary.
Corollary 1. Assumption 1 holds. Denote with the α-quantile of standard normal distribution. g is a continuous function with finite first order derivative , and . If as , then we have Under the null, the limiting null distribution of coincides with that of the zero-mean normal random variable with unit variance while, under the alternative, the test statistic diverges in probability, thus delivering a unit power.
Remark 3. Some possible choices of g are given in the following:
:
:
:
: where = and .
We can also use the extreme value distribution to construct the test. That is, we havewhere is the Gumbel distribution with cumulative distribution function . Remark 4. From the conditions of Theorem 1, () is required to obtain the desired asymptotic results. Due to the restriction, therefore, (or T) cannot be too large. For example, if we consider the daily trading set (6.5 hours) with frequency one minute, then we have ; hence, a reasonable choice for will be 10–20. This may yield a low power, although the test is asymptotically consistent. To obtain a larger sample size , we can consider a shorter local time span, namely, for . It is easy to see that the asymptotic results keep true for this case as long as ϑ is fixed. For instance, if we consider the half-day trading set, will be doubled. Moreover, we may consider the extreme case of (but ). However, the asymptotic behaviour will be totally different to that obtained in the current setting, and it would be investigated in a future work.
4. Simulation
In this section, we conduct simulation studies to assess the finite sample performance of our proposed test statistics. We generate the high-frequency data from the following one-factor stochastic volatility model (see Andersen et al. [
22]):
where,
W and
B are two standard Brownian motions, independent of each other, and
represents the level of the leverage effect. The parameters of the model are calibrated to real financial data. The parameter values used in the generating process under the null and alternative hypotheses are displayed in
Table 1, where
represents monthly interest rate, corresponding to an annual interest of about 8%.
The observation scheme is similar to that of our empirical application. We set , , and , which corresponds to sampling every 5 min in a 6.5 h trading day. In the estimation of the local volatility, we let . We tested for presence of the leverage effect on an interval from length of (day), to (one quarter), by summing the test statistics over the T days. For the choice of function g (which is used in the Theorem 1), we selected the following functions:
, which corresponds to the test statistic ;
, which corresponds to the test statistic ;
, which corresponds to the test statistic ;
, which corresponds to the test statistic ;
These four functions are all have bounded derivatives and, therefore, satisfy the condition of Theorem 1. From the first to the last, the derivative becomes gradually smaller.
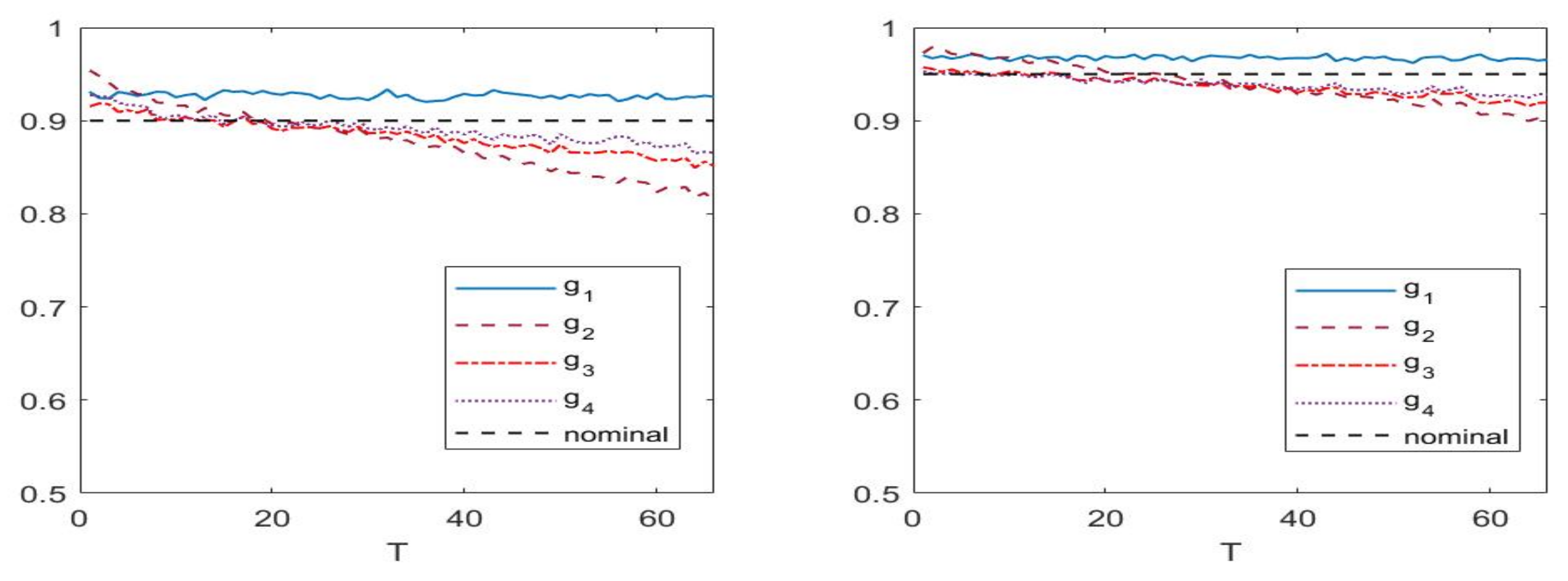
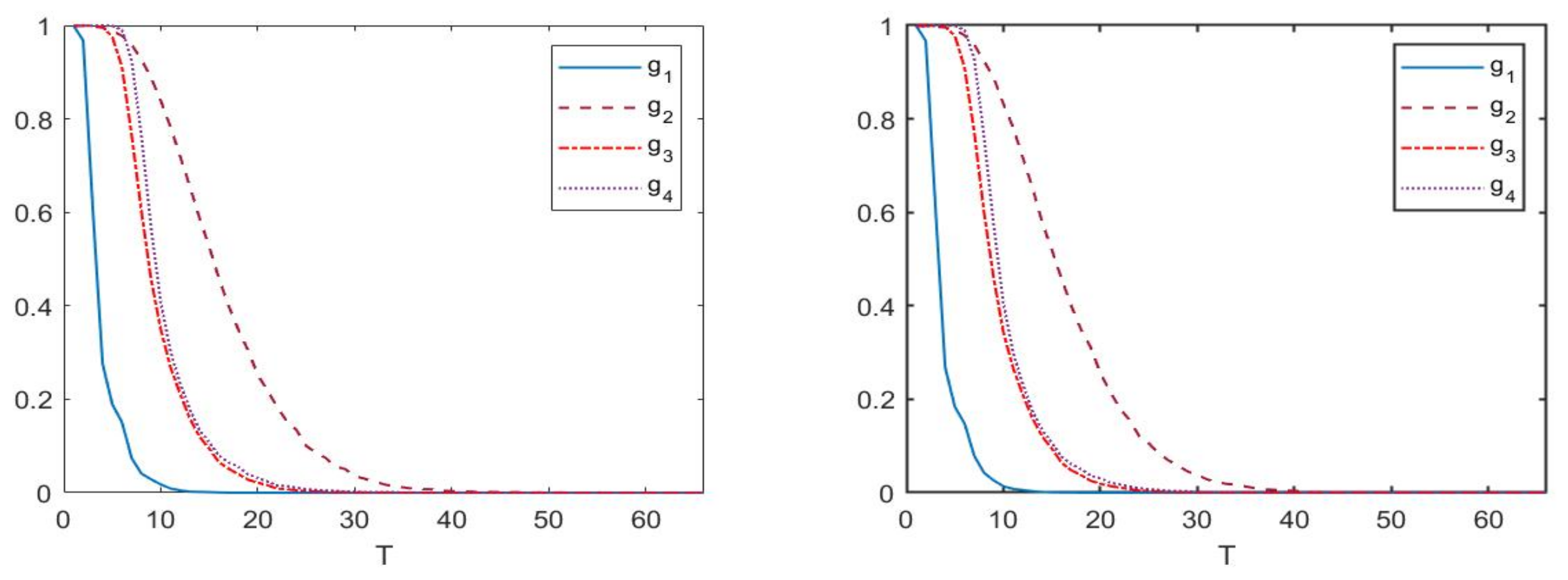
We computed the finite sample size and power for all cases. The results from the Monte Carlo, which is based on 10,000 replications, are reported in two tables (
Table 2 and
Table 3) and two figures (
Figure 1 and
Figure 2).
Table 2 and
Figure 1 display the finite sample size and
Table 3 and
Figure 2 exhibit the finite sample power, respectively.
From
Table 2, we see that the test statistic
performs stably relatively, with the length of time interval,
T. The coverage rates of other three test statistics tend to decrease more clearly when
T increases.
Figure 1 shows the same results pictorially. This is consistent with our theoretical results, noting that Theorem 1 and Corollary 1 indicate that
(hence
T) cannot be too large, to guarantee a valid converge rate under the null hypothesis
.
Table 3 shows that all four test statistics tend to perform better uniformly when the time interval becomes longer under the alternative hypothesis
, which is also consistent with our theoretical result. In fact, the only condition to assure the test statistics tending to infinity under alternative hypothesis
is letting
. Therefore, an ideal choice for the length of the test period should be determined via a tradeoff between the size and power. To perform this, we computed the averaged errors of sizes and powers, namely, the difference between finite sample coverage rate and asymptotic coverage rate, of the four test statistics. The simulation results indicate that, for the high-frequency data with sampling frequency of five minutes, the best choice for the time interval of the test is between a month and two months.
5. Real Data Analysis
In this section, we implement the proposed test procedures to a real high-frequency financial dataset. The dataset consists of 5-minute close prices of the SP500 index from 1997 to 2000. To clear the data, we firstly removed the largest 3% returns to avoid the possible presence of jumps and no further adjustment was conducted for the data set. Finally, we obtained a total of 250,669 data points. We computed the test statistics with several periods, namely, a day, a week, a month, a quarter, half a year and a year, respectively. More precisely, for example, for the daily test, we took
(
n = 390, 1716, 5418, 10,296 and 20,592 for the weekly test, monthly test, quarterly test, semiannual test and annual test, respectively.) and
, using the following statistic with
:
where we used the similar test function
g used in the simulation.
Table 4 displays the values of the test statistics and related rejection rates of the tests based on these six different time spans.
From
Table 4, for the time period longer than a day, all four test statistics reject the null hypothesis of the absence of the leverage effect. For the daily test, we see that
shows the highest rejection rate for all kinds of time periods, followed by
and
;
has a lowest rejection rate. This is same as the order of empirical powers in the simulation study; hence, we may conclude that the leverage effect is a necessary component in modelling the high-frequency data of the SP500 index.





{kind=link}
{kind=link}